Region Based CNN for Foreign Object Debris Detection on Airfield Pavement


 ,
,
Abstract
:1. Introduction
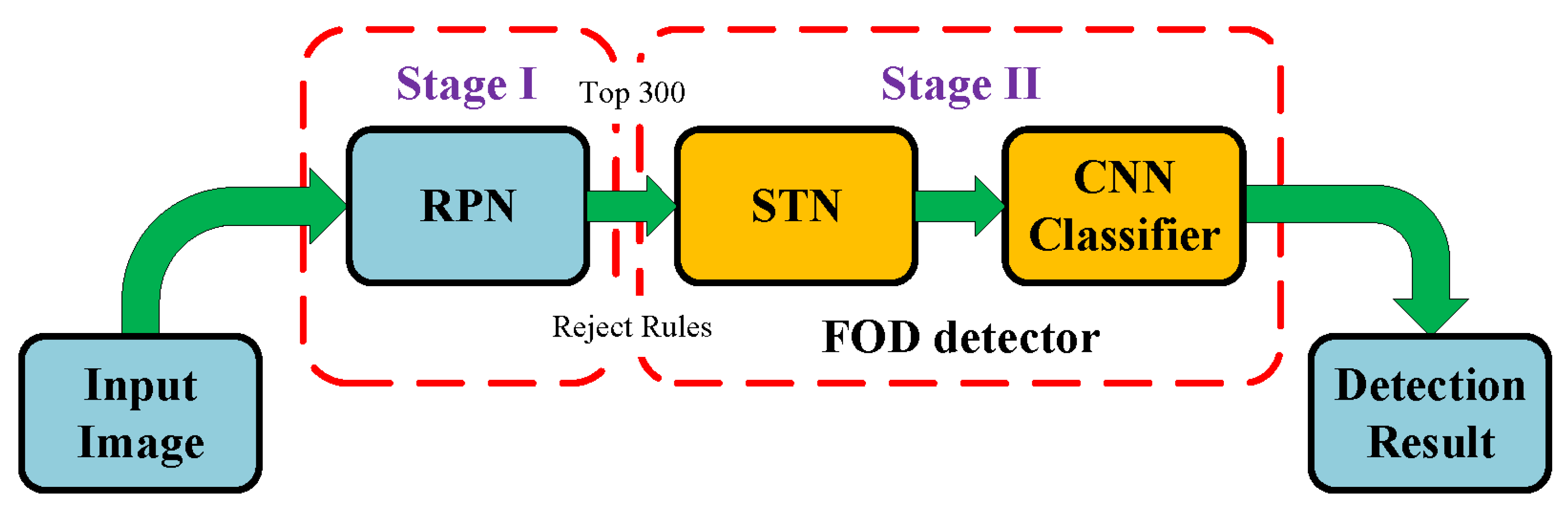
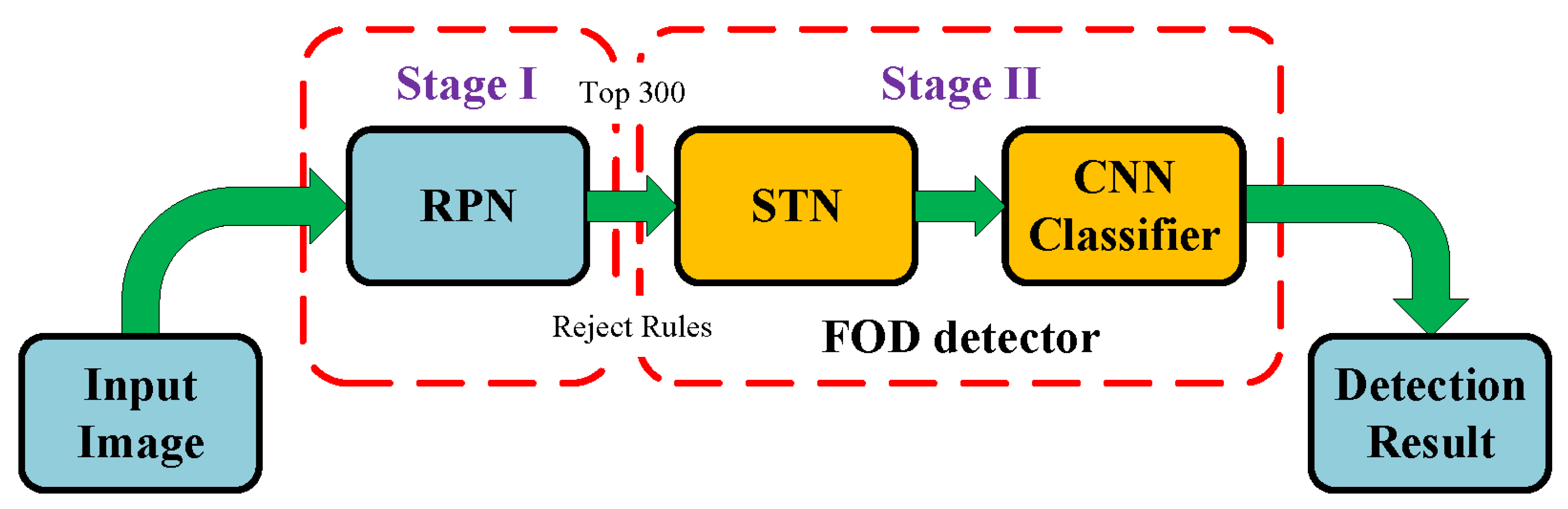
- A new FOD detection framework based on CNN models for FOD detection is proposed with improved region proposal network and spatial transformer network.
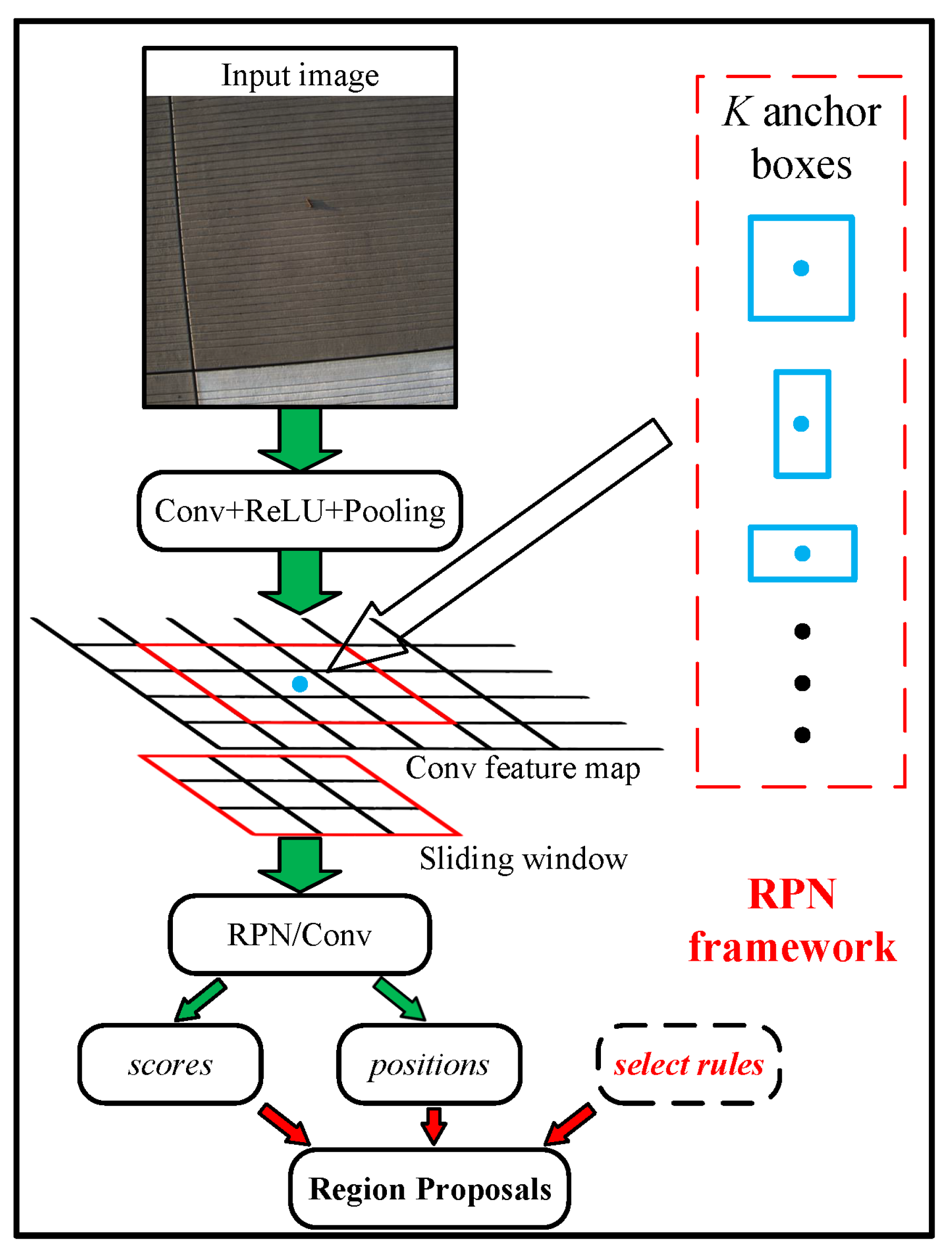
- RPN is firstly introduced and improved to generate high quality region proposals for FOD detection on airfield pavement. In addition, some candidate select rules are designed to reduce quantity and improve quality of region proposals.
- The vehicular imaging system, including DGPS, cameras, alarm, FOD management system and remote query system, is presented and discussed in detail.
2. Related Work
3. Algorithm
3.1. Locate FOD Candidates with Improved RPN
3.2. Spatial Transformer Network
3.2.1. Localization Network
3.2.2. Grid Generator
3.2.3. Sampler
3.3. FOD Classification with Convolutional Neural Network
4. Experiments
4.1. The Dataset and Training
4.2. The Experiments of Location
4.3. The Experiments of Classification
4.4. Comparison with Other Algorithms
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Ojala, T.; Pietikäinen, M.; Mäenpää, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances In Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Kim, K.W.; Hong, H.G.; Nam, G.P.; Park, K.R. A Study of Deep CNN-Based Classification of Open and Closed Eyes Using a Visible Light Camera Sensor. Sensors 2017, 17, 1534. [Google Scholar] [CrossRef] [PubMed]
- Satat, G.; Tancik, M.; Gupta, O.; Heshmat, B.; Raskar, R. Object classification through scattering media with deep learning on time resolved measurement. Opt. Express 2017, 25, 17466–17479. [Google Scholar] [CrossRef] [PubMed]
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. Deepface: Closing the gap to human-level performance In face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar]
- Sun, Y.; Liang, D.; Wang, X.; Tang, X. Deepid3: Face recognition with very deep neural networks. arXiv, 2015; arXiv:1502.00873. [Google Scholar]
- Chen, J.; Patel, V.M.; Chellappa, R. Unconstrained face verification using deep cnn features. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Lake Placid, NY, USA, 7–9 March 2016; pp. 1–9. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Liu, Z.; Li, X.; Luo, P.; Loy, C.; Tang, X. Semantic image segmentation via deep parsing network. In Proceedings of the IEEE International Conference on Computer Vision (2015), Los Alamitos, CA, USA, 7–13 December 2015; pp. 1377–1385. [Google Scholar]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2016. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, T.; Bui, V.; Lam, V.; Raub, C.B.; Chang, L.C.; Nehmetallah, G. Automatic phase aberration compensation for digital holographic microscopy based on deep learning background detection. Opt. Express 2017, 25, 15043–15057. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Jiao, J.; Li, F.; Deng, Z.; Ma, W. A Smartphone Camera-Based Indoor Positioning Algorithm of Crowded Scenarios with the Assistance of Deep CNN. Sensors 2017, 17, 704. [Google Scholar] [CrossRef] [PubMed]
- Wu, F.; Wang, Z.; Zhang, Z.; Yang, Y.; Luo, J.; Zhu, W.; Zhuang, Y. Weakly semi-supervised deep learning for multi-label image annotation. IEEE Trans. Big Data 2015, 1, 109–122. [Google Scholar] [CrossRef]
- Lev, G.; Sadeh, G.; Klein, B.; Wolf, L. RNN fisher vectors for action recognition and image annotation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 833–850. [Google Scholar]
- Murthy, V.N.; Maji, S.; Manmatha, R. Automatic image annotation using deep learning representations. In Proceedings of the 5th ACM on International Conference on Multimedia Retrieval, Shanghai, China, 23–26 June 2015; pp. 603–606. [Google Scholar]
- Yao, Y.; Tian, B.; Wang, F. Coupled Multivehicle Detection and Classification WithPrior Objectness Measure. IEEE Trans. Veh. Technol. 2017, 66, 1975–1984. [Google Scholar] [CrossRef]
- Li, X.; Li, L.; Flohr, F.; Wang, J.; Xiong, H.; Bernhard, M.; Pan, S.; Gavrila, D.M.; Li, K. A unified framework for concurrent pedestrian and cyclist detection. IEEE Trans. Intell. Transp. Syst. 2017, 18, 269–281. [Google Scholar] [CrossRef]
- Chen, L.; Hu, X.; Xu, T.; Kuang, H.; Li, Q. Turn Signal Detection During Nighttime by CNN Detector and Perceptual Hashing Tracking. IEEE Trans. Intell. Transp. Syst. 2017, 99, 1–12. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Everingham, M.; Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. Thepascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Lin, T.; Maire, M.; Belongie, S.J.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects In Context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances In Neural Information Processing Systems, Montreal, QC, Canada, 11–12 December 2015; pp. 91–99. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial transformer networks. In Proceedings of the Advances In Neural Information Processing Systems, Montreal, QC, Canada, 11–12 December 2015; pp. 2017–2025. [Google Scholar]
- Cao, X.; Gong, G.; Liu, M.; Qi, J. Foreign Object Debris Detection on Airfield Pavement Using Region Based Convolution Neural Network. In Proceedings of the International Conference on Digital Image Computing: Techniques and Applications, Cold Coast, Australia, 30 November–2 December 2016; pp. 1–6. [Google Scholar]
- Mund, J.; Zouhar, A.; Meyer, L.; Fricke, H.; Rother, C. Performance evaluation of LiDAR point clouds towards automated FOD detection on airport aprons. In Proceedings of the 5th International Conference on Application and Theory of Automation In Command and Control Systems, Toulouse, France, 30 September–2 October 2015; pp. 85–94. [Google Scholar]
- Li, Y.; Xiao, G. A new FOD recognition algorithm based on multi-source information fusion and experiment analysis. Proc. SPIE 2011. [Google Scholar] [CrossRef]
- Li, J.; Deng, G.; Luo, C.; Lin, Q.; Yan, Q.; Ming, Z. A Hybrid Path Planning Method In Unmanned Air/Ground Vehicle (UAV/UGV) Cooperative Systems. IEEE Trans. Veh. Technol. 2016, 65, 9585–9596. [Google Scholar] [CrossRef]
- Ölzen, B.; Baykut, S.; Tulgar, O.; Belgül, A.U.; Yalçin, İ.K.; Şahinkaya, D.S.A. Foreign object detection on airport runways by mm-wave FMCW radar. In Proceedings of the 25th IEEE Signal Processing and Communications Applications Conference, Antalya, Turkey, 15–18 May 2017; pp. 1–4. [Google Scholar]
- Futatsumori, S.; Morioka, K.; Kohmura, A.; Okada, K.; Yonemoto, N. Detection characteristic evaluations of optically-connected wideband 96 GHz millimeter-wave radar for airport surface foreign object debris detection. In Proceedings of the 41st International Conference on Infrared, Millimeter, and Terahertz waves, Copenhagen, Denmark, 25–30 September 2016; pp. 1–2. [Google Scholar]
- Zeitler, A.; Lanteri, J.; Pichot, C.; Migliaccio, C.; Feil, P.; Menzel, W. Folded reflectarrays with shaped beam pattern for foreign object debris detection on runways. IEEE Trans. Antennas Propag. 2010, 58, 3065–3068. [Google Scholar] [CrossRef]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. In Proceedings of the Conference on Neural Information Processing Systems, Barcelona, Spain, 5–6 December 2016; pp. 379–387. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R.B. Mask r-cnn. arXiv, 2017; arXiv:1703.06870. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. arXiv, 2016; arXiv:1612.08242. [Google Scholar]
- Girshick, R.B.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R.B. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Los Alamitos, CA, USA, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.B.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Bottou, L. Large-scale machine learning with stochastic gradient descent. In Proceedings of the COMPSTAT’2010, Paris, France, 22–27 August 2010; pp. 177–186. [Google Scholar]
- Uijlings, J.R.; Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Proceedings of the European Conference on Computer Vision, Portland, OR, USA, 23–28 June 2013; pp. 818–833. [Google Scholar]
- Bai, X.; Zhou, F. Analysis of new top-hat transformation and the application for infrared dim small target detection. Pattern Recognit. 2010, 43, 2145–2156. [Google Scholar] [CrossRef]
- Bi, Y.; Bai, X.; Jin, T.; Guo, S. Multiple Feature Analysis for Infrared Small Target Detection. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1333–1337. [Google Scholar] [CrossRef]
- Bai, X.; Bi, Y. Derivative Entropy-Based Contrast Measure for Infrared Small-Target Detection. IEEE Trans. Geosci. Remote Sens. 2018. [Google Scholar] [CrossRef]
- Li, Z.; Xie, J.; Tu, D.; Choi, Y.-J. Sparse Signal Recovery by Stepwise Subspace Pursuit In Compressed Sensing. Int. J. Distrib. Sens. Netw. 2013, 1, 945–948. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | IoU | Recall Num | Total Num | Recall Rate | Average Num |
|---|---|---|---|---|---|
| Selective Search | IoU > 0.5 | 2108 | 2469 | 85.37% | 800 |
| IoU > 0.6 | 1875 | 2469 | 75.94% | 800 | |
| Region Proposal Network (RPN) | IoU > 0.5 | 2263 | 2469 | 91.65% | Top5 |
| IoU > 0.6 | 2253 | 2469 | 91.25% | Top5 | |
| IoU > 0.5 | 2399 | 2469 | 97.16% | Top10 | |
| IoU > 0.6 | 2394 | 2469 | 96.96% | Top10 | |
| IoU > 0.5 | 2462 | 2469 | 99.72% | Top20 | |
| IoU > 0.6 | 2461 | 2469 | 99.60% | Top20 |
| FOD Detector | Recall Rate |
|---|---|
| FOD classification (no fine-tune) | 94.52% |
| STN + FOD classification (no fine-tune) | 96.31% |
| FOD classification + fine-tune | 96.45% |
| STN + FOD classification + fine-tune | 97.67% |
| Methods | FAR |
|---|---|
| faster R-CNN | 11.02% |
| SSD | 8.19% |
| Selective Search + FOD Detector | 1.21% |
| RPN + FOD Detector | 0.66% |
| Methods | Screw RR | Stone RR |
|---|---|---|
| faster R-CNN | 83.51% | 93.84% |
| SSD | 87.72% | 88.63% |
| Selective Search + FOD Detector | 80.63% | 81.46% |
| RPN + FOD Detector | 96.90% | 96.40% |
| Methods | mAP |
|---|---|
| faster R-CNN | 89.43% |
| SSD | 89.92% |
| Selective Search + FOD Detector | 96.65% |
| RPN + FOD Detector | 98.41% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, X.; Wang, P.; Meng, C.; Bai, X.; Gong, G.; Liu, M.; Qi, J. Region Based CNN for Foreign Object Debris Detection on Airfield Pavement. Sensors 2018, 18, 737. https://doi.org/10.3390/s18030737
Cao X, Wang P, Meng C, Bai X, Gong G, Liu M, Qi J. Region Based CNN for Foreign Object Debris Detection on Airfield Pavement. Sensors. 2018; 18(3):737. https://doi.org/10.3390/s18030737
Chicago/Turabian StyleCao, Xiaoguang, Peng Wang, Cai Meng, Xiangzhi Bai, Guoping Gong, Miaoming Liu, and Jun Qi. 2018. "Region Based CNN for Foreign Object Debris Detection on Airfield Pavement" Sensors 18, no. 3: 737. https://doi.org/10.3390/s18030737
APA StyleCao, X., Wang, P., Meng, C., Bai, X., Gong, G., Liu, M., & Qi, J. (2018). Region Based CNN for Foreign Object Debris Detection on Airfield Pavement. Sensors, 18(3), 737. https://doi.org/10.3390/s18030737