UISTD: A Trust-Aware Model for Diverse Item Personalization in Social Sensing with Lower Privacy Intrusion


Abstract
:1. Introduction
2. Related Work
3. Models for Recommendation
3.1. Factored Similarity Models with Trust
3.1.1. Item Similarity Model
3.1.2. Model of Both User and Item Similarities
3.1.3. Ranking with Trust
3.2. Our UISTD Model for Diverse Items
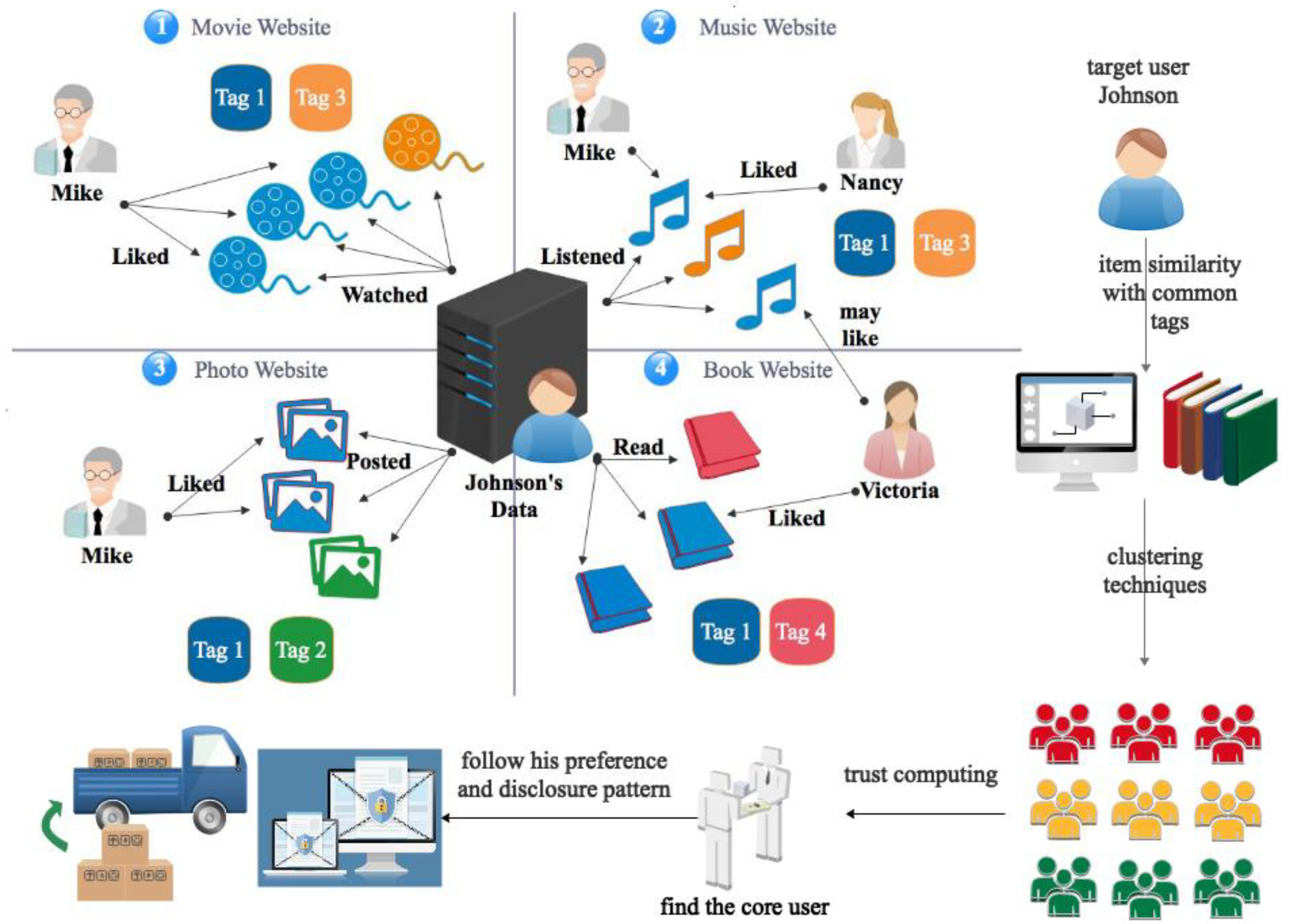
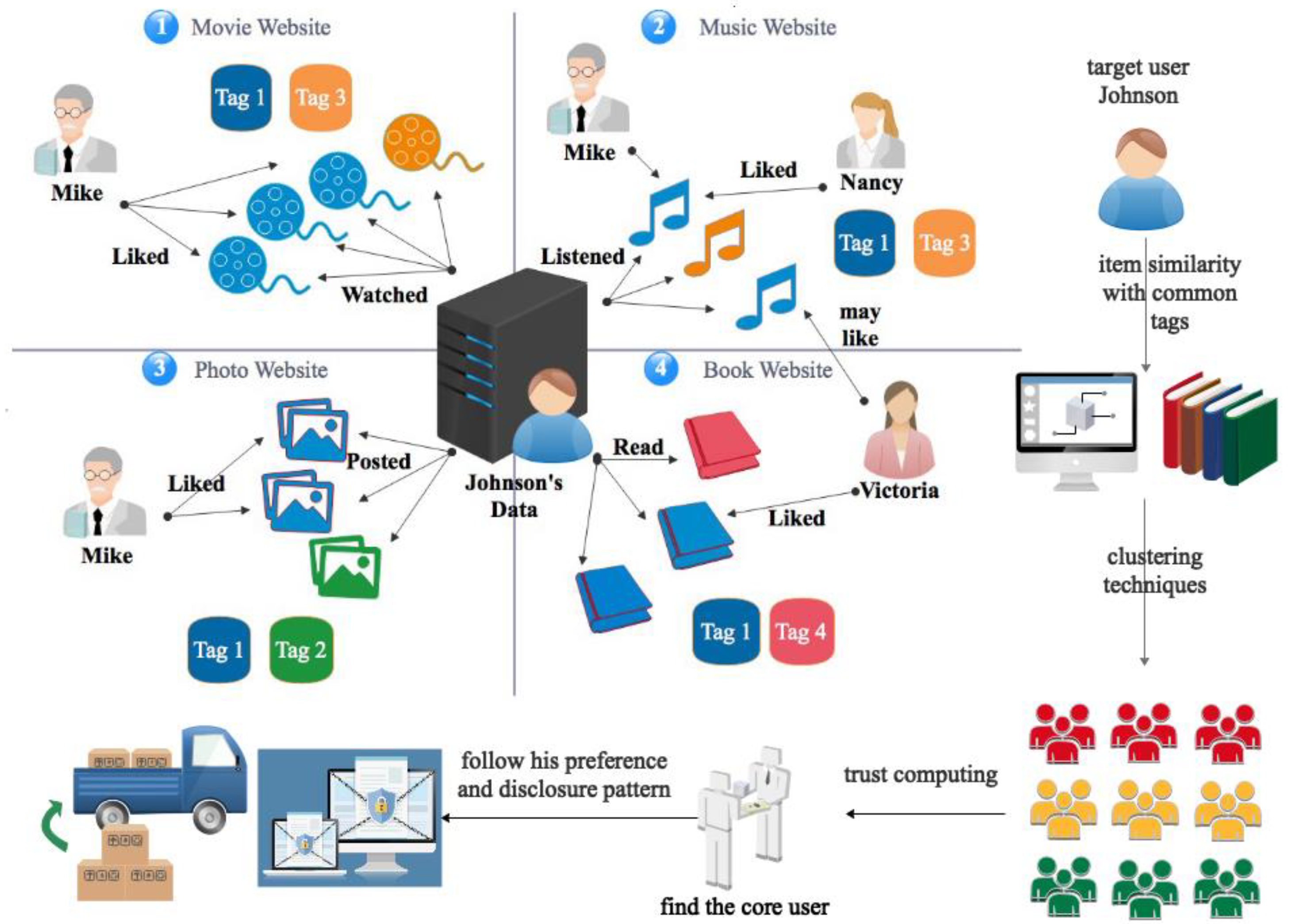
3.2.1. Basic Data Structure
3.2.2. Personalization Engine
3.2.3. Clustering and Core User
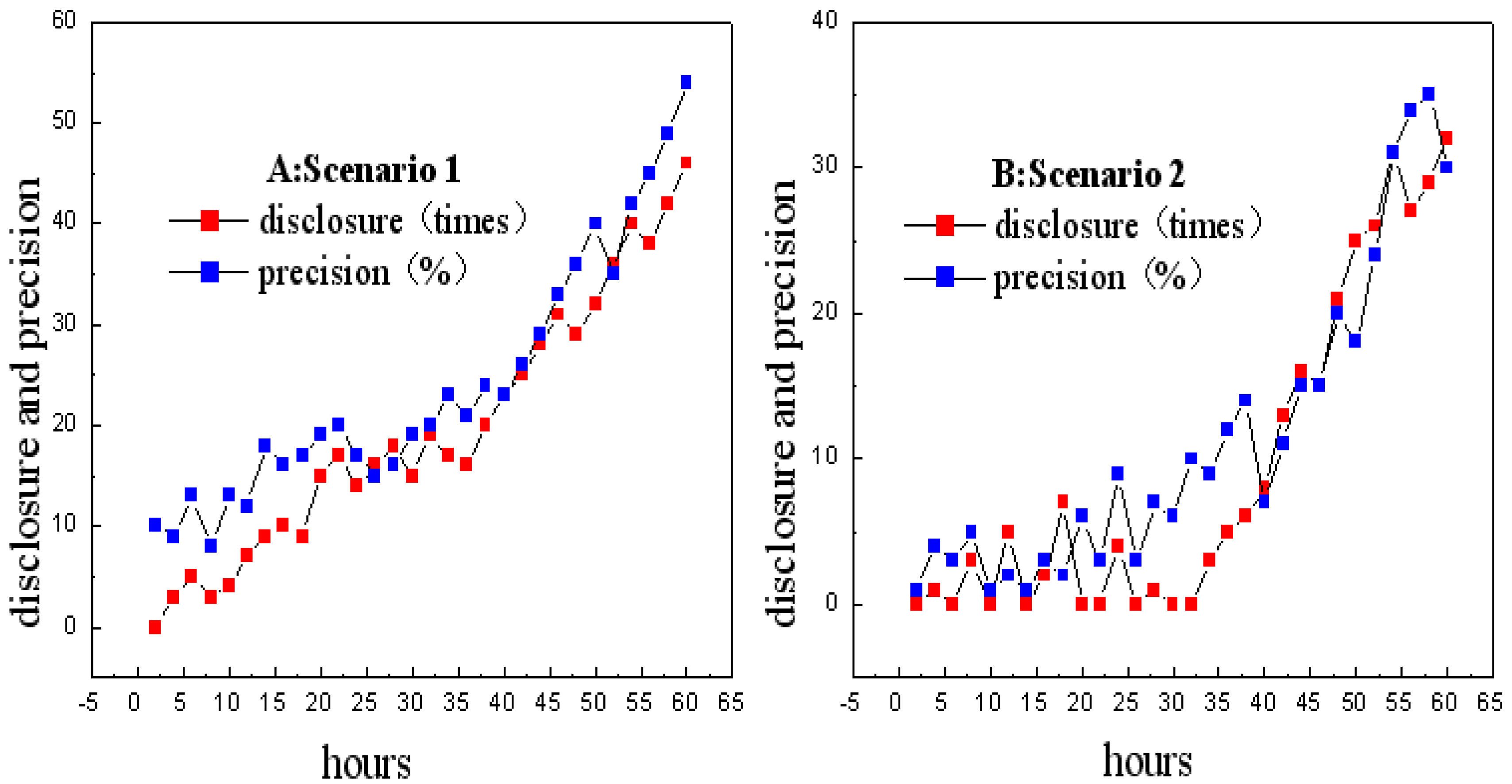
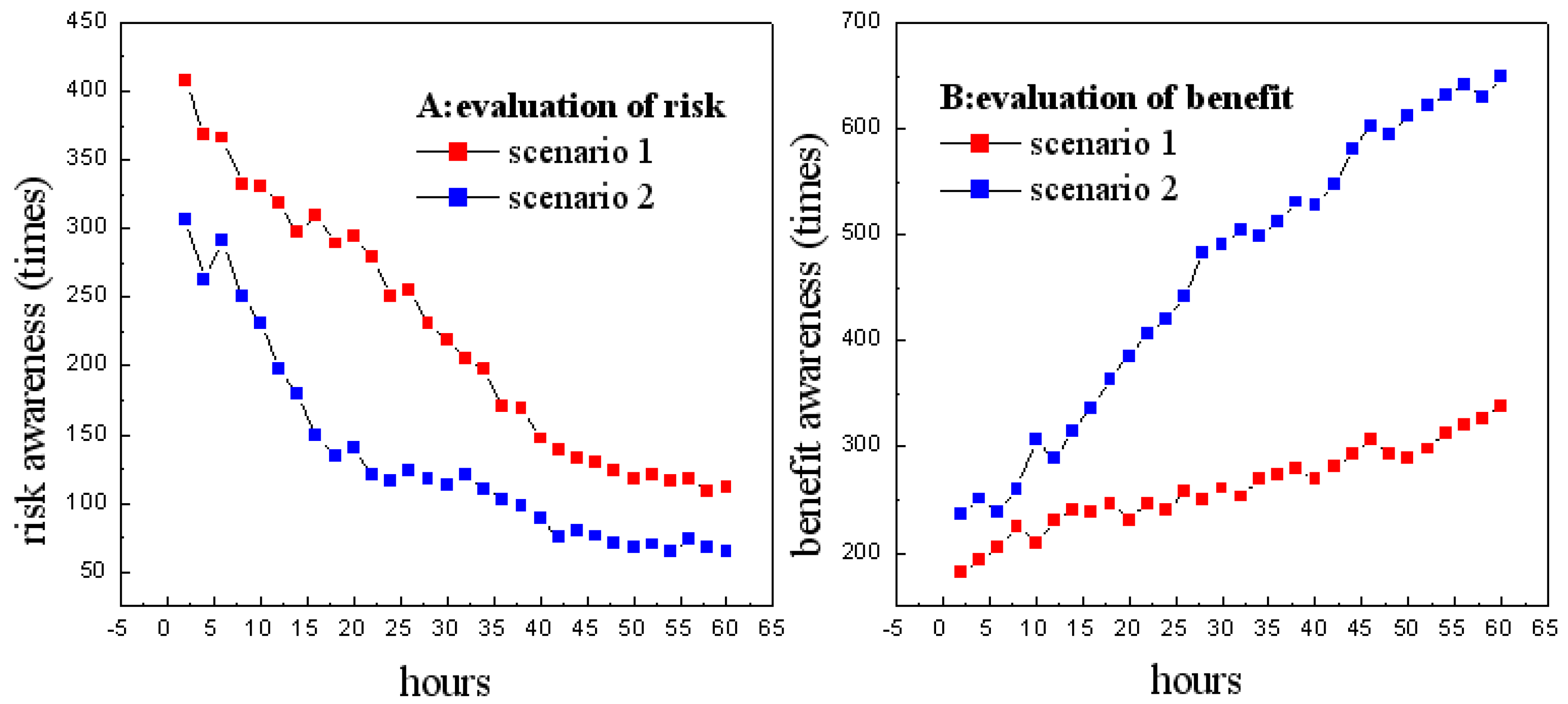
3.2.4. Privacy Disclosure Solution
4. Experiments
4.1. Data Sets
4.2. Evaluation Metrics
4.3. Comparison with Other Methods
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Alsaffar, A.A.; Pham, H.P.; Hong, C.S.; Huh, E.N.; Aazam, M. An architecture of IoT service delegation and resource allocation based on collaboration between fog and cloud computing. Mob. Inf. Syst. 2016, 2016, 6123234. [Google Scholar] [CrossRef]
- Gomez-Uribe, C.A.; Hunt, N. The netflix recommender system: Algorithms, business value, and innovation. ACM Trans. Manag. Inf. Syst. 2016, 6, 13. [Google Scholar] [CrossRef]
- Zhang, Y. GroRec: A group-centric intelligent recommender system integrating social, mobile and big data technologies. IEEE Trans. Serv. Comput. 2016, 9, 786–795. [Google Scholar] [CrossRef]
- Mirbakhsh, N.; Ling, C.X. Improving top-N recommendation for cold-start users via cross-domain information. ACM Trans. Knowl. Discov. Data (TKDD) 2015, 9, 33. [Google Scholar] [CrossRef]
- Christakopoulou, E.; Karypis, G. Local item-to-item models for top-n recommendation. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016. [Google Scholar]
- Cai, Y.; Leung, H.F.; Li, Q.; Min, H.; Tang, J.; Li, J. Typicality-based collaborative filtering recommendation. IEEE Trans. Knowl. Data Eng. 2014, 26, 766–779. [Google Scholar] [CrossRef]
- Yu, X.; Lin, Y.; Jiang, F.; Du, J.; Han, J. A Cross-Domain Collaborative Filtering Algorithm Based on Feature Construction and Locally Weighted Linear Regression. Comput. Intell. Neurosci. 2018, 2018, 1425365. [Google Scholar] [CrossRef] [PubMed]
- An, X.; Lin, F.; Xu, S.; Miao, L.; Gong, C. A Novel Differential Game Model-Based Intrusion Response Strategy in Fog Computing. Secur. Commun. Netw. 2018, 2018, 1821804. [Google Scholar] [CrossRef]
- Yan, Z.; Zhang, P.; Vasilakos, A.V. A survey on trust management for Internet of Things. J. Netw. Comput. Appl. 2014, 42, 120–134. [Google Scholar] [CrossRef]
- Zhang, F.; Lee, V.E.; Jin, R.; Garg, S.; Choo, K.K.R.; Maasberg, M.; Dong, L.; Cheng, C. Privacy-aware smart city: A case study in collaborative filtering recommender systems. J. Parallel Distrib. Comput. 2018. [Google Scholar] [CrossRef]
- Sendra, S.; Granell, E.; Lloret, J.; Rodrigues, J.J. Smart collaborative system using the sensors of mobile devices for monitoring disabled and elderly people. In Proceedings of the 2012 IEEE International Conference on Communications (ICC), Ottawa, ON, Canada, 10–15 June 2012; pp. 6479–6483. [Google Scholar]
- Wang, C.; Bi, Z.; Da Xu, L. IoT and cloud computing in automation of assembly modeling systems. IEEE Trans. Ind. Inf. 2014, 10, 1426–1434. [Google Scholar] [CrossRef]
- Colombo-Mendoza, L.O.; Valencia-García, R.; Rodríguez-González, A.; Alor-Hernández, G.; Samper-Zapater, J.J. RecomMetz: A context-aware knowledge-based mobile recommender system for movie showtimes. Expert Syst. Appl. 2015, 42, 1202–1222. [Google Scholar] [CrossRef]
- Garcin, F.; Faltings, B.; Donatsch, O.; Alazzawi, A.; Bruttin, C.; Huber, A. Offline and online evaluation of news recommender systems at swissinfo.ch. In Proceedings of the 8th ACM Conference on Recommender Systems, Foster City, CA, USA, 6–10 October 2014. [Google Scholar]
- Protasiewicz, J.; Pedrycz, W.; Kozłowski, M.; Dadas, S.; Stanisławek, T.; Kopacz, A.; Gałężewska, M. A recommender system of reviewers and experts in reviewing problems. Knowl. Based Syst. 2016, 106, 164–178. [Google Scholar] [CrossRef]
- Wang, Z.; Liao, J.; Cao, Q.; Qi, H.; Wang, Z. Friendbook: A semantic-based friend recommendation system for social networks. IEEE Trans. Mob. Comput. 2015, 14, 538–551. [Google Scholar] [CrossRef]
- Adomavicius, G.; Tuzhilin, A. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions. IEEE Trans. Knowl. Data Eng. 2005, 17, 734–749. [Google Scholar] [CrossRef]
- Kang, Z.; Peng, C.; Cheng, Q. Top-N Recommender System via Matrix Completion. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence (AAAI-16), Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Guo, G.; Zhang, J.; Thalmann, D. Merging trust in collaborative filtering to alleviate data sparsity and cold start. Knowl. Based Syst. 2014, 57, 57–68. [Google Scholar] [CrossRef]
- Golbeck, J. Generating Predictive Movie Recommendations from Trust in Social Networks. In Proceedings of the 4th International Conference on Trust International Conference on Trust Management, Pisa, Italy, 16–19 May 2006; Springer: Berlin/Heidelberg, Germany; pp. 93–104. [Google Scholar]
- Deng, S.; Huang, L.; Xu, G. Social network-based service recommendation with trust enhancement. Expert Syst. Appl. 2014, 41, 8075–8084. [Google Scholar] [CrossRef]
- Li, G.; Zheng, Z.; Wang, H.; Yang, Z.; Xu, Z.; Liu, L. A Novel Service Recommendation Approach Considering the User’s Trust Network. In Proceedings of the International Conference on Collaborative Computing: Networking, Applications and Worksharing, Beijing, China, 10–11 November 2016; pp. 429–438. [Google Scholar]
- Xiao, Y.; Bu, Z.; Hsu, C.-H. Trust-Aware Recommendation in Social Network. In Proceedings of the International Conference on Knowledge Science, Engineering and Management, Melbourne, Australia, 19–20 August 2017. [Google Scholar]
- Wu, J.; Chen, L.; Yu, Q.; Han, P.; Wu, Z. Trust-Aware Media Recommendation in Heterogeneous Social Networks. World Wide Web 2015, 18, 139–157. [Google Scholar] [CrossRef]
- Wang, N.; Chen, Z.; Li, X. Heterogeneous Trust-Aware Recommender Systems in Social Network. In Proceedings of the 2017 IEEE 2nd International Conference on Big Data Analysis (ICBDA), Beijing, China, 10–12 March 2017. [Google Scholar]
- Schnabel, T.; Bennett, P.N.; Dumais, S.T.; Joachims, T. Using shortlists to support decision making and improve recommender system performance. In Proceedings of the 25th International Conference on World Wide Web, Montréal, QC, Canada, 11–15 April 2016. [Google Scholar]
- Liu, B.; Kong, D.; Cen, L.; Gong, N.Z.; Jin, H.; Xiong, H. Personalized mobile app recommendation: Reconciling app functionality and user privacy preference. In Proceedings of the Eighth ACM International Conference on Web Search and Data Mining, Shanghai, China, 2–6 February 2015. [Google Scholar]
- Zhu, H.; Xiong, H.; Ge, Y.; Chen, E. Mobile app recommendations with security and privacy awareness. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014. [Google Scholar]
- Meyffret, S.; Médini, L.; Laforest, F. Trust-based local and social recommendation. In Proceedings of the 4th ACM RecSys Workshop on Recommender Systems and the Social Web, Dublin, Ireland, 9 September 2012; pp. 53–60. [Google Scholar]
- Dienlin, T.; Metzger, M.J. An extended privacy calculus model for SNSs: Analyzing self-disclosure and self-withdrawal in a representative US sample. J. Comput. Mediat. Commun. 2016, 21, 368–383. [Google Scholar] [CrossRef]
- Wang, N.; Wisniewski, P.; Xu, H.; Grossklags, J. Designing the default privacy settings for facebook applications. In Proceedings of the 17th ACM Conference on Computer Supported Cooperative Work & Social Computing, Baltimore, MD, USA, 15–19 February 2014. [Google Scholar]
- Sivaraman, V.; Gharakheili, H.H.; Vishwanath, A.; Boreli, R.; Mehani, O. Network-level security and privacy control for smart-home IoT devices. In Proceedings of the IEEE 11th International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob), Abu Dhabi, UAE, 19–21 October 2015. [Google Scholar]
- Guo, G.; Zhang, J.; Zhu, F.; Wang, X. Factored similarity models with social trust for top-N item recommendation. Knowl. Based Syst. 2017, 122, 17–25. [Google Scholar] [CrossRef]
- Lee, J.; Marcus, K.; Abdelzaher, T.; Amin, M.T.A.; Bar-Noy, A.; Dron, W.; Govindan, R.; Hobbs, R.; Hu, S.; Kim, J.-E.; et al. Athena: Towards Decision-Centric Anticipatory Sensor Information Delivery. J. Sens. Actuator Netw. 2018, 7, 5. [Google Scholar] [CrossRef]
- Wu, H.; Wang, X.; Peng, Z.; Li, Q. Div-clustering: Exploring active users for social collaborative recommendation. J. Netw. Comput. Appl. 2013, 36, 1642–1650. [Google Scholar] [CrossRef]
- Wu, H.; Zhang, H. DLPDS: Learning Users’ Information Sharing Behaviors for Privacy Default Setting in Recommender System. In Proceedings of the International Conference on Cloud Computing and Security, Nanjing, China, 16–18 June 2017. [Google Scholar]
- Kabbur, S.; Ning, X.; Karypis, G. FISM: Factored Item Similarity Models for Top-N Recommender Systems. In Proceedings of the Acm Sigkdd International Conference on Knowledge Discovery & Data Mining, Chicago, IL, USA, 11–14 August 2013. [Google Scholar]
- Zhao, T.; McAuley, J.; King, I. Leveraging social connections to improve personalized ranking for collaborative filtering. In Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management, Shanghai, China, 3–7 November 2014; pp. 261–270. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set | |Users| | |Items| | |Ratings| | |Trusts| | Density |
|---|---|---|---|---|---|
| Epinions | 31,922 | 139,738 | 51,093 | 42,109 | 0.03% |
| Ciao | 5970 | 99,746 | 25,108 | 89,219 | 0.13% |
| DLPDS | 553 | 872 | 10,739 | 760 | 4.13% |
| Measurement | Precision | F1-Measure | ||||||
|---|---|---|---|---|---|---|---|---|
| Data Set | MostPop | FISM | FST | UISTD | MostPop | FISM | FST | UISTD |
| Epinions | 0.1169 | 0.1147 | 0.1290 | 0.1290 | 0.1298 | 0.1307 | 0.1396 | 0.1417 |
| Ciao | 0.2677 | 0.2704 | 0.2916 | 0.3017 | 0.2436 | 0.2495 | 0.2614 | 0.2756 |
| DLPDS | 0.2915 | 0.3018 | 0.3318 | 0.3812 | 0.3032 | 0.4216 | 0.3717 | 0.4218 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, H.; Li, M.; Zhang, H. UISTD: A Trust-Aware Model for Diverse Item Personalization in Social Sensing with Lower Privacy Intrusion. Sensors 2018, 18, 4383. https://doi.org/10.3390/s18124383
Wu H, Li M, Zhang H. UISTD: A Trust-Aware Model for Diverse Item Personalization in Social Sensing with Lower Privacy Intrusion. Sensors. 2018; 18(12):4383. https://doi.org/10.3390/s18124383
Chicago/Turabian StyleWu, Hongchen, Mingyang Li, and Huaxiang Zhang. 2018. "UISTD: A Trust-Aware Model for Diverse Item Personalization in Social Sensing with Lower Privacy Intrusion" Sensors 18, no. 12: 4383. https://doi.org/10.3390/s18124383
APA StyleWu, H., Li, M., & Zhang, H. (2018). UISTD: A Trust-Aware Model for Diverse Item Personalization in Social Sensing with Lower Privacy Intrusion. Sensors, 18(12), 4383. https://doi.org/10.3390/s18124383