@choo: Tracking Pollen and Hayfever in the UK Using Social Media


Abstract
1. Introduction
2. Data Collection and Methods
2.1. Social Media Data
- Removing tweets from automated ‘bot’ accounts. Tweets that are produced automatically do not contain any useful information for detecting hayfever complaints. We first identified accounts that produced the largest volume of tweets, since bots typically create orders of magnitude more tweets than regular users. Initially, we chose a filter where an account was deemed a ‘bot’ if it contributed more than 1% of the total volume of tweets in the collection. An additional manual review of the top 100 most frequently tweeting accounts identified additional automated accounts, which we also removed. Most of the bots removed were marketing accounts focused on health and lifestyle products.
- Removing retweets. We wish to focus on original information, posted by the person who is themself suffering from hayfever. As retweets involve sharing someone else’s tweet, potentially at a different location, we are less confident that the information in a retweet is relevant. To remove this uncertainty, we filter out retweets.
- Applying machine learning to remove irrelevant tweets. This step removes tweets which are articles, business advertising or do not represent a hayfever symptoms, for example (fictional) ‘Hurray, no hayfever today!’. We manually curated a set of 1015 tweets, classifying each tweet as relevant or not, and used them as training data for a Multinomial Naive Bayes [18] classifier. These tweets were randomly chosen and manually classified as relevant or irrelevant. We used 1-g and 2-g extracted from the tweet text as the features on which to classify whole tweets; testing showed that adding higher n-grams provided no additional benefit. This relevance filtering step also helps to remove any automated tweets which were not captured in Stage 1. Using 25% of the data as a validation set the classifier correctly identified the relevance of 90% of the tweets. A 6-fold cross validation gave an score of 0.94 and the confusion matrix below:This confusion matrix implies a slight tendency to over-classify tweets as relevant. This filter is accurate and sufficient for our purposes, removing most of the irrelevant tweets. In future work, it could be improved with more training data, particularly more examples of irrelevant tweets.
2.2. Pollen Count Data
2.3. Other Data
3. Empirical Results and Discussion
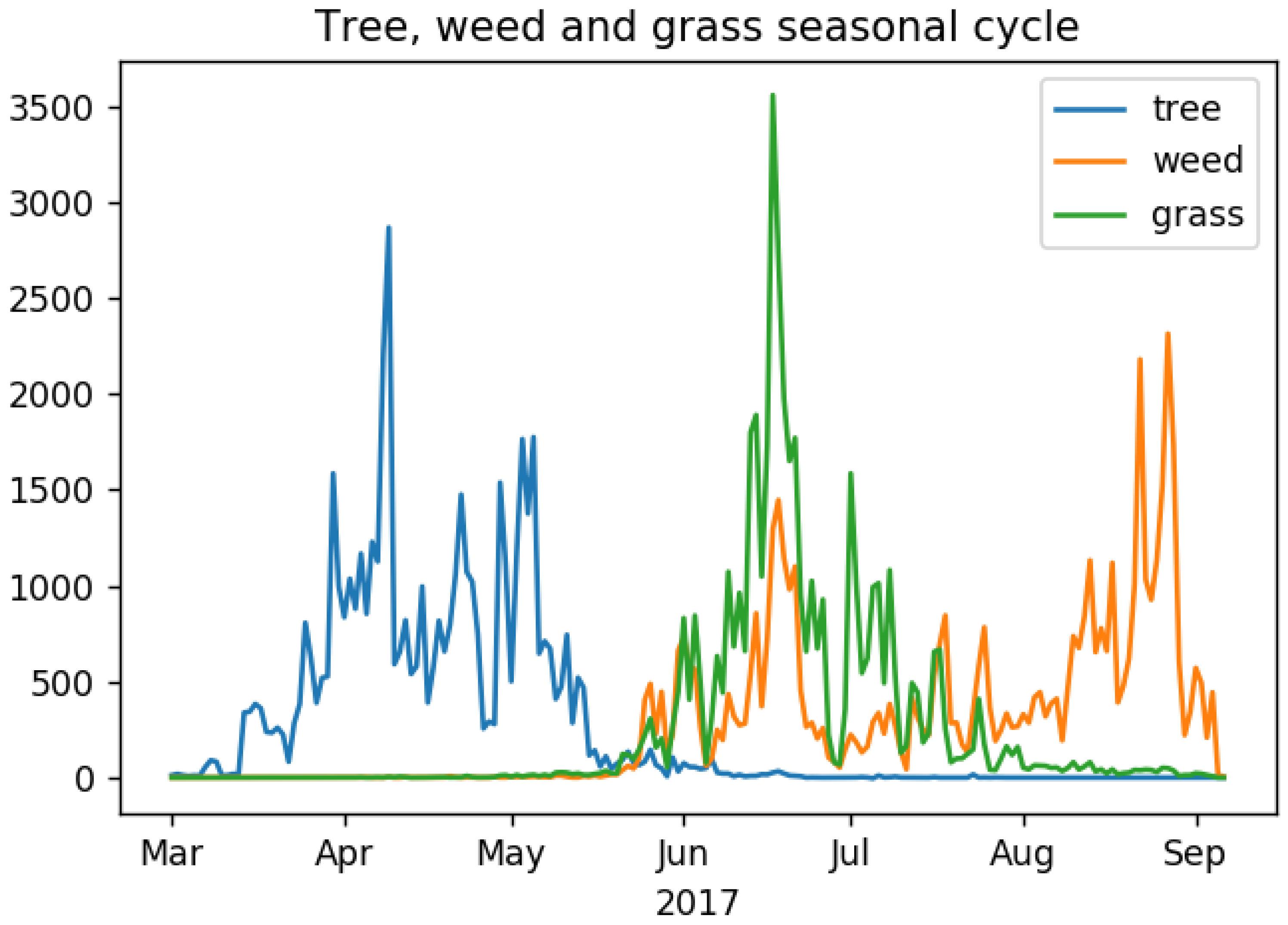
3.1. Pollen Count Seasonality
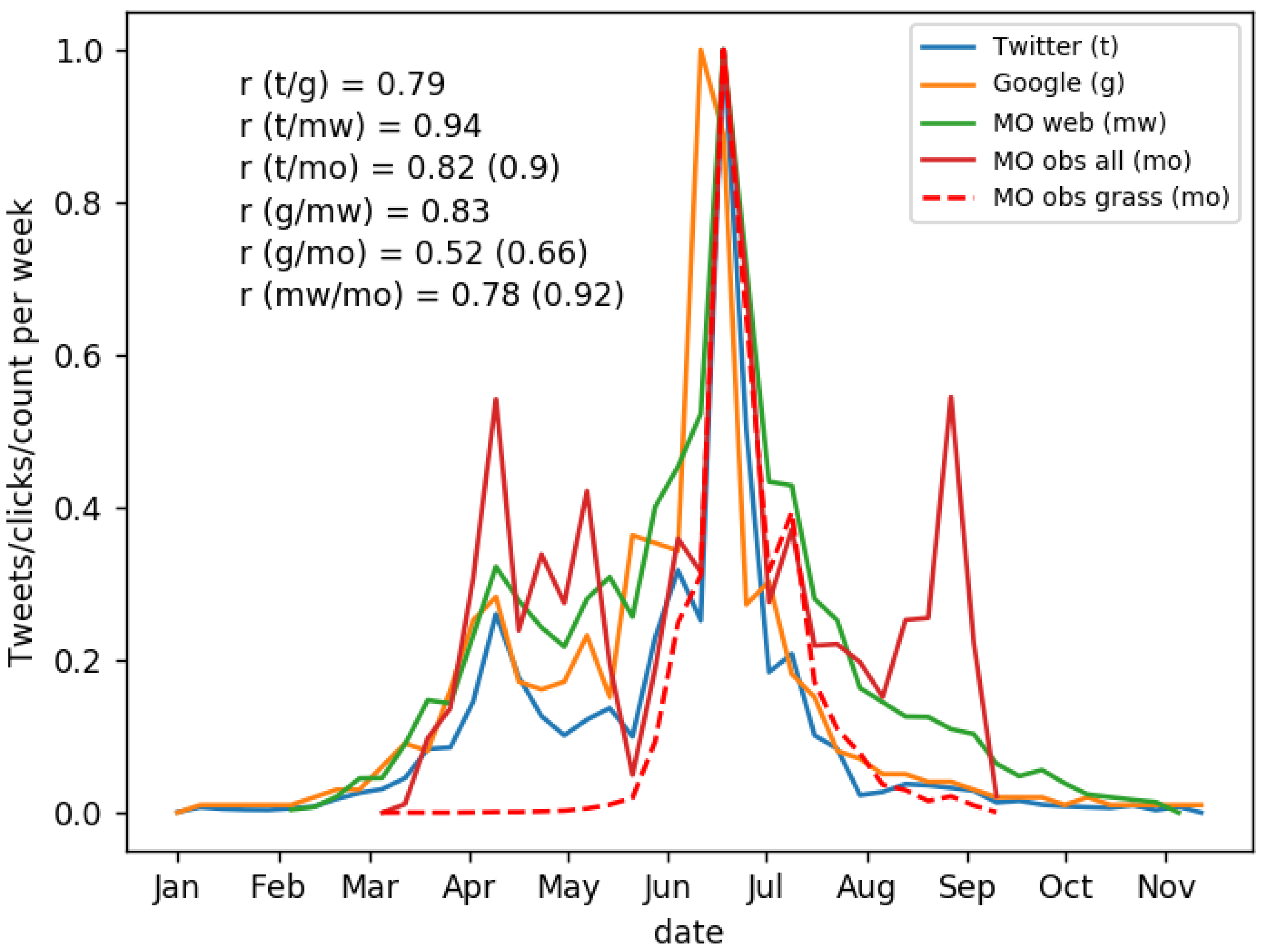
3.2. Comparison of Pollen Counts with Social Data Sources
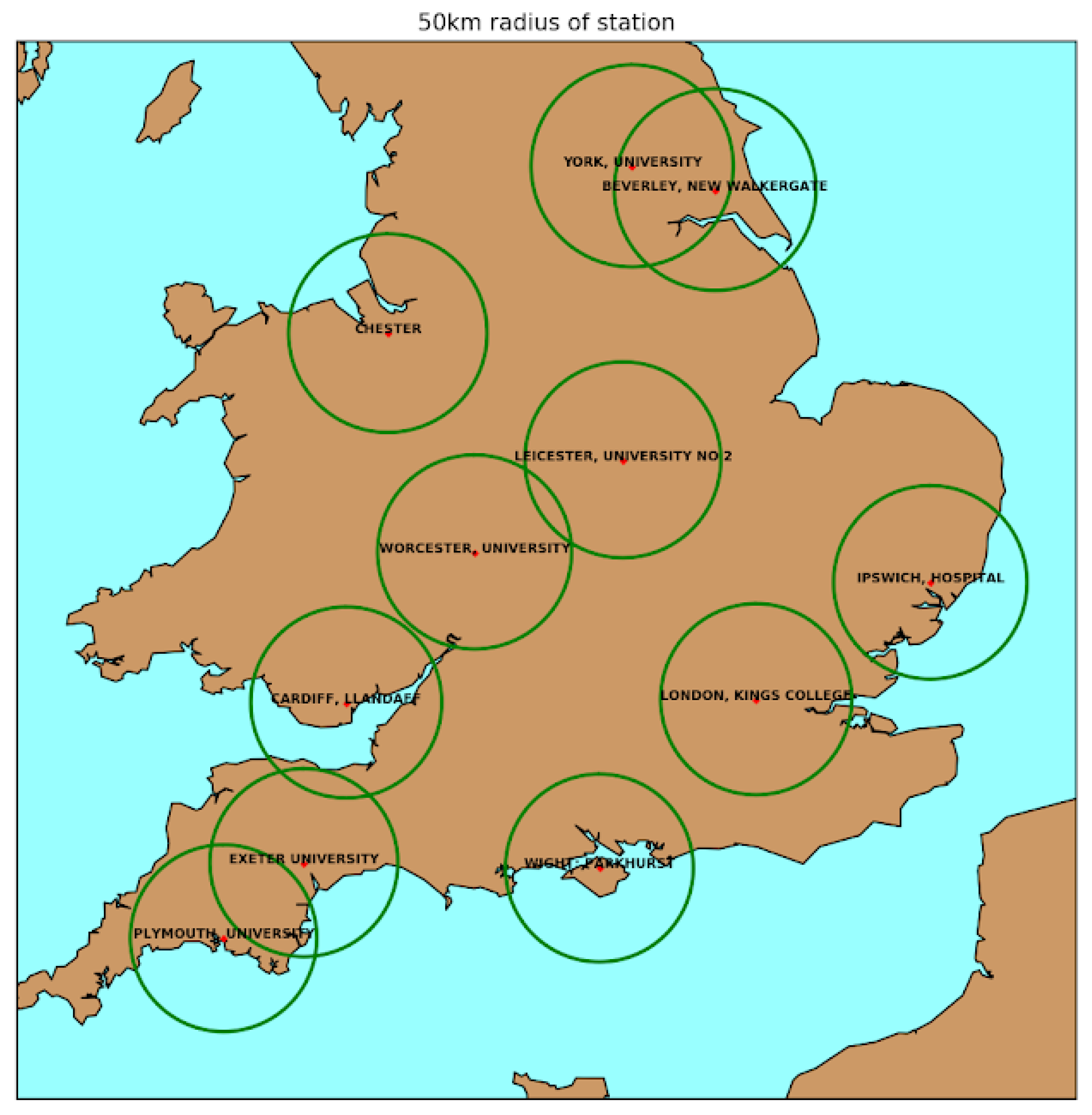
3.3. Local Comparison of Twitter Data and Pollen Counts
4. Prediction of Pollen Counts Using Models Including Social Sensing Data
4.1. Model Construction
4.1.1. Model 1—Nearest Pollen Station
4.1.2. Model 2—Weighted Average of Pollen Stations
4.1.3. Model 3—Local Tweets
4.1.4. Models 1T & 2T—Pollen and Tweets
4.2. Model Performance
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Austin, J.B.; Kaur, B.; Anderson, H.R.; Burr, M.; Harkins, L.S.; Strachan, D.P.; Warner, J.O. Hay fever, eczema, and wheeze: A nationwide UK study (ISAAC, International Study of Asthma and Allergies in Childhood). Arch. Dis. Child. 1999, 81, 225–230. [Google Scholar] [CrossRef] [PubMed]
- Gupta, R.; Sheikh, A.; Strachan, D.P.; Anderson, H. Burden of allergic disease in the UK: Secondary analyses of national databases. Clin. Exp. Allergy 2004, 34, 520–526. [Google Scholar] [CrossRef] [PubMed]
- Bousquet, J.; Neukirch, F.; Bousquet, P.J.; Gehano, P.; Klossek, J.M.; Le Gal, M.; Allaf, B. Severity and impairment of allergic rhinitis in patients consulting in primary care. J. Allergy Clin. Immunol. 2006, 117, 158–162. [Google Scholar] [CrossRef] [PubMed]
- Pawankar, R.; Canonica, R.W.; Holgate, S.T.; Lockey, R.L.; Blaiss, M. World Allergy Organisation (WAO) White Book on Allergy: Update 2013; World Allergy Organization: Milwaukee, WI, USA, 2013. [Google Scholar]
- Met Office Pollen Forecast. Available online: https://www.metoffice.gov.uk/public/weather/pollen-forecast/ (accessed on 5 September 2018).
- McInnes, R.N.; Hemming, D.; Burgess, P.; Lyndsay, D.; Osborne, N.J.; Skjøth, C.A.; Thomas, S.; Vardoulakis, S. Mapping allergenic pollen vegetation in UK to study environmental exposure and human health. Sci. Total Environ. 2017, 599, 483–499. [Google Scholar] [CrossRef] [PubMed]
- Kececi, M.C. Monitoring Pollen Counts and Pollen Allergy Index Using Satellite Observations in East Coast of the United States. Master’s Thesis, South Dakota State University, Brookings, SD, USA, 2017. Available online: https://openprairie.sdstate.edu/etd/1694 (accessed on 10 November 2018).
- Johnston, F.H.; Wheeler, A.J.; Williamson, G.J.; Campbell, S.L.; Jones, P.J.; Koolhof, I.S.; Lucani, C.; Cooling, N.B.; Bowman, D.M.J.S. Using smartphone technology to reduce health impacts from atmospheric environmental hazards. Environ. Res. Lett. 2018, 13, 044019. [Google Scholar] [CrossRef]
- Sakaki, T.; Okazaki, M.; Matsuo, Y. Earthquake shakes Twitter users: Real-time event detection by social sensors. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 851–860. [Google Scholar]
- Boulton, C.; Shotton, H.; Williams, H.T.P. Using Social Media to Detect and Locate Wildfires. In Proceedings of the Tenth International AAAI Conference on Web and Social Media, Cologne, Germany, 17–20 May 2016. [Google Scholar]
- Jiang, W.; Wang, Y.; Tsou, M.H.; Fu, X. Using Social Media to Detect Outdoor Air Pollution and Monitor Air Quality Index (AQI): A Geo-Targeted Spatiotemporal Analysis Framework with Sina Weibo (Chinese Twitter). PLoS ONE 2015, 10, e0141185. [Google Scholar] [CrossRef] [PubMed]
- Arthur, R.; Boulton, C.A.; Shotton, H.; Williams, H.T.P. Social sensing of floods in the UK. PLoS ONE 2018, 13, e0189327. [Google Scholar] [CrossRef] [PubMed]
- WOW. Met Office Weather Observations Website. Available online: https://wow.metoffice.gov.uk/ (accessed on 8 March 2018).
- UK Snow Map. Available online: http://uksnowmap.com/ (accessed on 8 March 2018).
- Andreu-Perez, J.; Poon, C.C.; Merrifield, R.D.; Wong, S.T.; Yang, G.Z. Big data for health. IEEE J. Biomed. Health Inform. 2015, 9, 1193–1208. [Google Scholar] [CrossRef] [PubMed]
- Culotta, A. Towards detecting influenza epidemics by analyzing Twitter messages. In Proceedings of the First Workshop on Social Media Analytics, Washington, DC, USA, 25–28 July 2010; pp. 115–122. [Google Scholar]
- Paul, M.J.; Dredze, M. You are what you Tweet: Analyzing Twitter for public health. In Proceedings of the Fifth International AAAI Conference on Weblogs and Social Media, Barcelona, Spain, 17–21 July 2011; pp. 265–272. [Google Scholar]
- Scikit-Learn. Naive Bayes. Available online: http://scikit-learn.org/stable/modules/naive_bayes.html (accessed on 9 March 2018).
- Geonames. Available online: http://www.geonames.org (accessed on 9 March 2018).
- National Pollen and Aerobiology Unit. Available online: https://www.worc.ac.uk/discover/national-pollen-and-aerobiology-research-unit.html (accessed on 5 September 2018).
- Hirst, J. An automatic volumetric spore trap. Ann. Appl. Biol. 1952, 39, 257–265. [Google Scholar] [CrossRef]
- Varney, V. Hayfever in the United Kingdom. Clin. Exp. Allergy 1991, 21, 757–762. [Google Scholar] [CrossRef] [PubMed]
- Google Trends. Available online: https://trends.google.com/trends/ (accessed on 5 September 2018).
- National Pollen and Aerobiology Unit. Pollen Calendar. 2012. Available online: https://www.worcester.ac.uk/discover/pollen-calendar.html (accessed on 12 February 2018).




{kind=link}
{kind=link}
{kind=link}
| Correlation Between GRASS Pollen Counts and Tweets | Correlation Between ALL Pollen Counts and Tweets | No. of Tweets in 50 km Radius of Station | |
|---|---|---|---|
| York | 0.9 | 0.76 | 637 |
| Beverley | 0.88 | 0.88 | 271 |
| Chester | 0.87 | 0.69 | 617 |
| Leicester | 0.44 | 0.07 | 790 |
| Worcester | 0.83 | 0.83 | 814 |
| Ipswich | 0.66 | 0.47 | 164 |
| London | 0.59 | 0.59 | 2325 |
| Cardiff | 0.88 | 0.55 | 544 |
| Plymouth | 0.8 | 0.53 | 217 |
| Exeter | 0.68 | 0.52 | 235 |
| Wight | 0.84 | 0.82 | 405 |
| MEAN | 0.76 | 0.61 | 638.1 |
| RMSE | ||
|---|---|---|
| Model 1 | 0.810 | 0.115 |
| Model 2 | 0.847 | 0.099 |
| Model 3 | 0.745 | 0.188 |
| Model 1T | 0.858 | 0.100 |
| Model 2T | 0.858 | 0.096 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cowie, S.; Arthur, R.; Williams, H.T.P. @choo: Tracking Pollen and Hayfever in the UK Using Social Media. Sensors 2018, 18, 4434. https://doi.org/10.3390/s18124434
Cowie S, Arthur R, Williams HTP. @choo: Tracking Pollen and Hayfever in the UK Using Social Media. Sensors. 2018; 18(12):4434. https://doi.org/10.3390/s18124434
Chicago/Turabian StyleCowie, Sophie, Rudy Arthur, and Hywel T. P. Williams. 2018. "@choo: Tracking Pollen and Hayfever in the UK Using Social Media" Sensors 18, no. 12: 4434. https://doi.org/10.3390/s18124434
APA StyleCowie, S., Arthur, R., & Williams, H. T. P. (2018). @choo: Tracking Pollen and Hayfever in the UK Using Social Media. Sensors, 18(12), 4434. https://doi.org/10.3390/s18124434