Figure 1.
Example of abandoned luggage for the AVSS_AB_2007 sequence (
http://www.eecs.qmul.ac.uk/~andrea/avss2007_d.html). Subfigure (
a) shows an abandoned object when it is attended. An object (black box) is considered attended if a person (blue box) lies within a distance of twice the object’s width radius. In subfigure (
b) the object is unattended since the person moves away farther than the defined distance.
Figure 1.
Example of abandoned luggage for the AVSS_AB_2007 sequence (
http://www.eecs.qmul.ac.uk/~andrea/avss2007_d.html). Subfigure (
a) shows an abandoned object when it is attended. An object (black box) is considered attended if a person (blue box) lies within a distance of twice the object’s width radius. In subfigure (
b) the object is unattended since the person moves away farther than the defined distance.
Figure 2.
Canonical framework for abandoned object detection.
Figure 2.
Canonical framework for abandoned object detection.
Figure 3.
Examples of different adaptation rates for background subtraction based on the Mixture of Gaussians approach [
45] for Frame 1180 of the sequence AVSS_AB_2007 (
http://www.eecs.qmul.ac.uk/~andrea/avss2007_d.html). Subfigures (
a,
c) show Foreground (FG) masks with different parameter
, which controls the update rate of the Background (BG) models, that are depicted in subfigures (
b,
d).
Figure 3.
Examples of different adaptation rates for background subtraction based on the Mixture of Gaussians approach [
45] for Frame 1180 of the sequence AVSS_AB_2007 (
http://www.eecs.qmul.ac.uk/~andrea/avss2007_d.html). Subfigures (
a,
c) show Foreground (FG) masks with different parameter
, which controls the update rate of the Background (BG) models, that are depicted in subfigures (
b,
d).
Figure 5.
People detection results using HOG [
95] (
a) and Deformable Part Model (DPM) [
96] (
b) algorithms in AVSS AB 2007
http://www.eecs.qmul.ac.uk/~andrea/avss2007_d.html. As we can observe, the holistic HOG model is not able to detect the woman sitting, while the part-based DPM detects her, although it fails at detecting the other sitting people.
Figure 5.
People detection results using HOG [
95] (
a) and Deformable Part Model (DPM) [
96] (
b) algorithms in AVSS AB 2007
http://www.eecs.qmul.ac.uk/~andrea/avss2007_d.html. As we can observe, the holistic HOG model is not able to detect the woman sitting, while the part-based DPM detects her, although it fails at detecting the other sitting people.
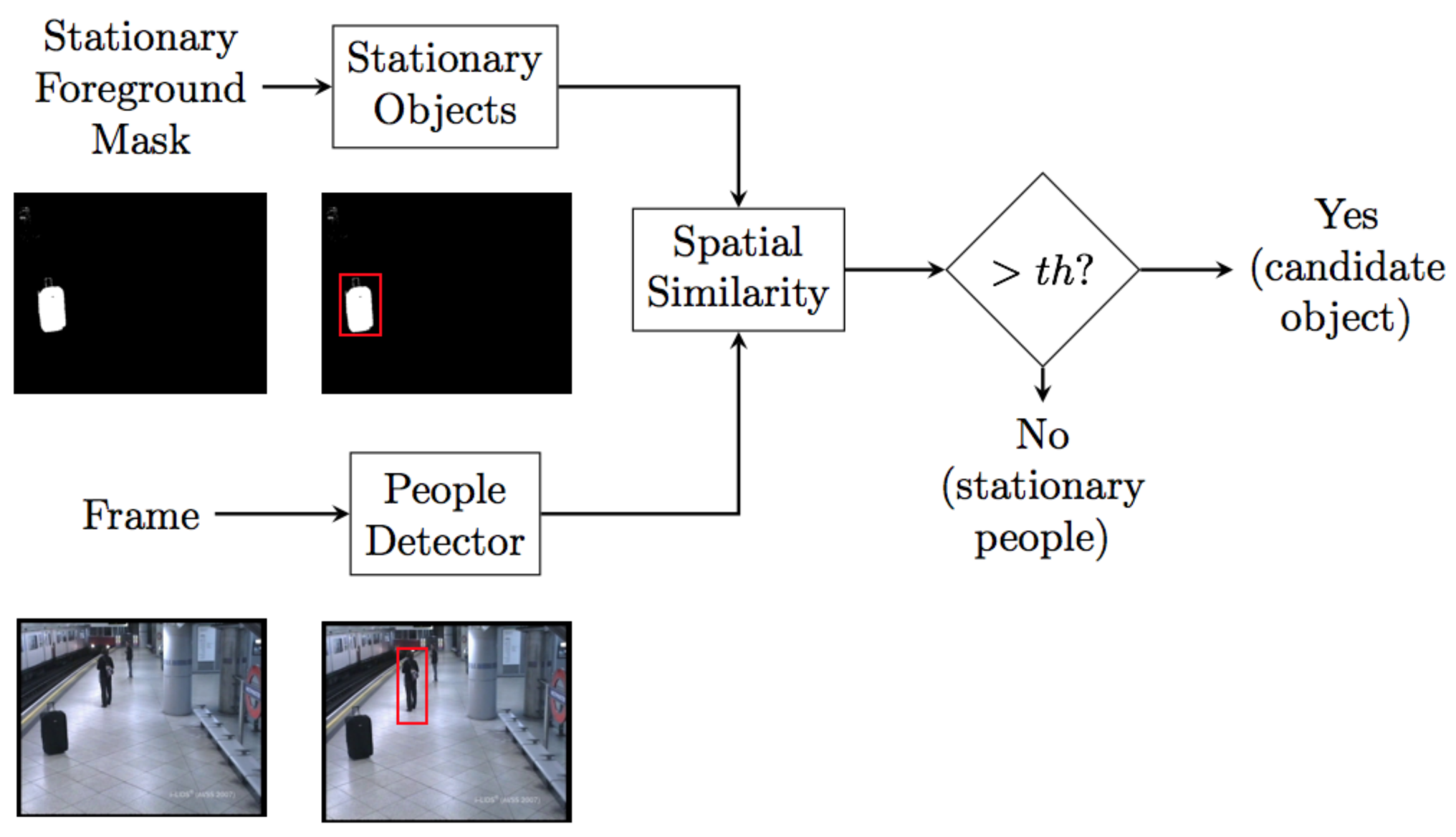
Figure 6.
Block diagram of the candidate generation module. Stationary objects and people detection blobs are independently extracted and then spatially compared. If a stationary object overlaps with people detection, it is considered as a static person, otherwise the object is a potential abandoned object candidate.
Figure 6.
Block diagram of the candidate generation module. Stationary objects and people detection blobs are independently extracted and then spatially compared. If a stationary object overlaps with people detection, it is considered as a static person, otherwise the object is a potential abandoned object candidate.
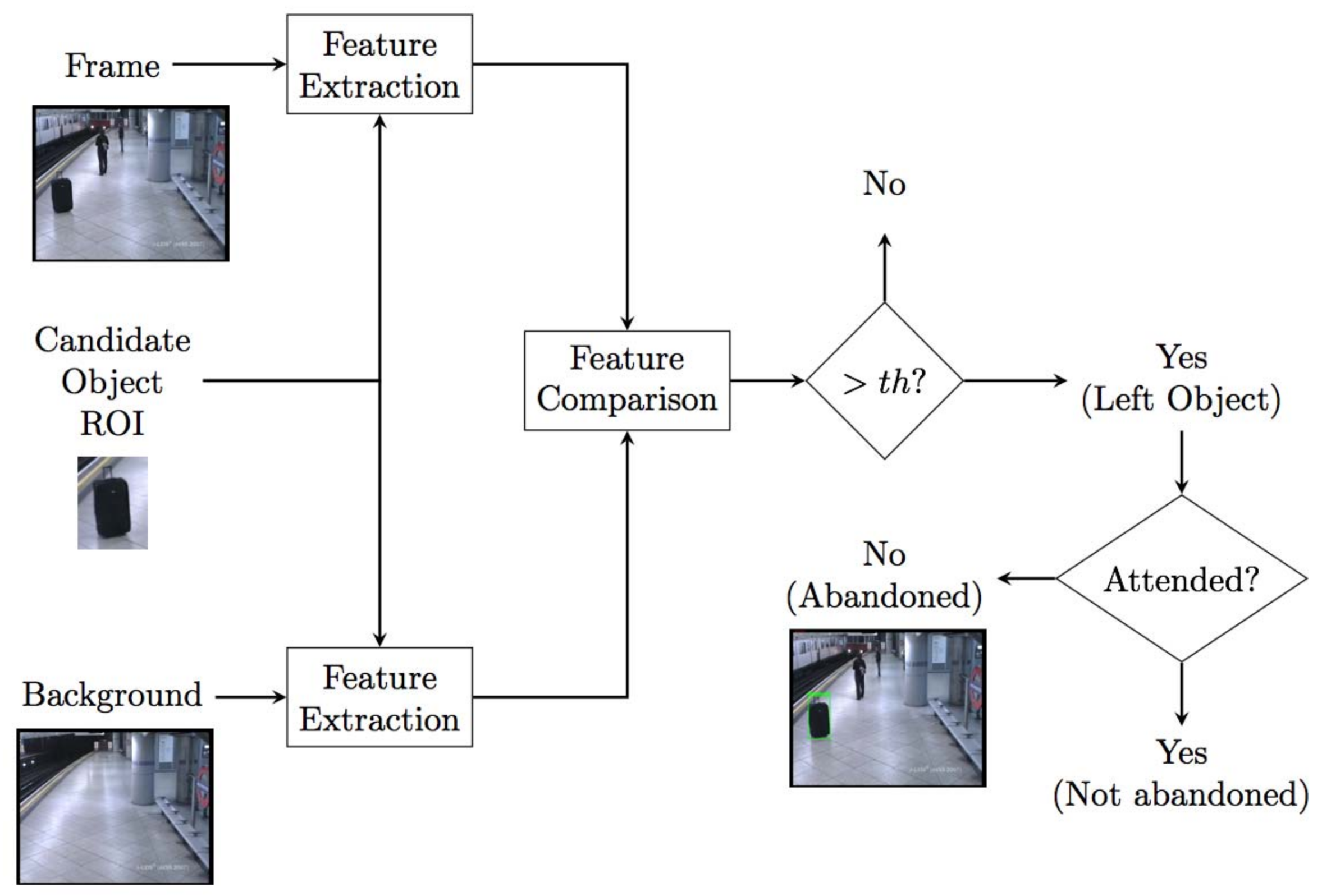
Figure 7.
Block diagram of candidate validation module. In simple terms, for each candidate, its region of interest is extracted, and certain features are extracted comparing them with the background and current frame. Through this comparison, false objects are discarded. Finally it is checked if the object is attended.
Figure 7.
Block diagram of candidate validation module. In simple terms, for each candidate, its region of interest is extracted, and certain features are extracted comparing them with the background and current frame. Through this comparison, false objects are discarded. Finally it is checked if the object is attended.
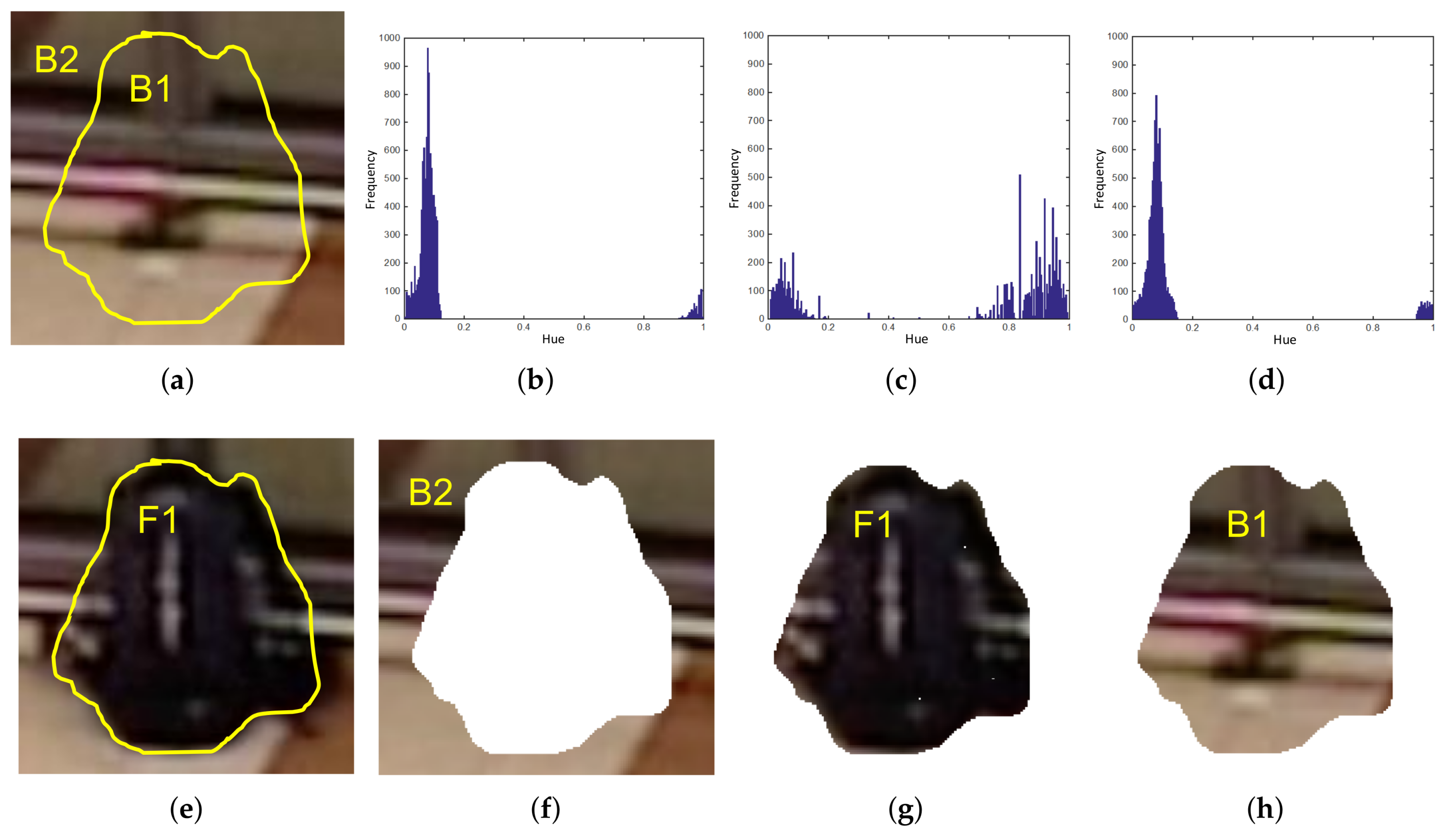
Figure 8.
Example of Pixel Color Contrast algorithm operation. Subfigure (a) shows initial frame and (e) depicts an abandoned bag in a posterior frame. PCC computes Hue histograms, (b–d), from B2 (f) , F1 (g) and B1 (h), respectively. Histogram comparisons (b,c) and (c,d) are made and final abandoned decision is taken from the results. Since (b) is more similar to (d) than to (c), this means (e) represents an abandoned object.
Figure 8.
Example of Pixel Color Contrast algorithm operation. Subfigure (a) shows initial frame and (e) depicts an abandoned bag in a posterior frame. PCC computes Hue histograms, (b–d), from B2 (f) , F1 (g) and B1 (h), respectively. Histogram comparisons (b,c) and (c,d) are made and final abandoned decision is taken from the results. Since (b) is more similar to (d) than to (c), this means (e) represents an abandoned object.
Figure 9.
Sample frames from: (a) PETS 2006 camera 1, (b) PETS 2006 camera 3, (c) PETS 2006 camera 4, (d) AVSS AB 2007, (e) VISOR View 1, and (f) VISOR View 2.
Figure 9.
Sample frames from: (a) PETS 2006 camera 1, (b) PETS 2006 camera 3, (c) PETS 2006 camera 4, (d) AVSS AB 2007, (e) VISOR View 1, and (f) VISOR View 2.
Figure 10.
Columns from left to right show the frame image with event ROI marked in yellow, foreground mask, static foreground mask, and final decision. The first and second row show visual results at different stages of Frame 2010, when the object has just been left. Both default and tuned PAWCS detect the object as part of the foreground; however, for a further frame (third and fourth rows), only tuned PAWCS maintains the object detection, while default PAWCS misses the abandoned object.
Figure 10.
Columns from left to right show the frame image with event ROI marked in yellow, foreground mask, static foreground mask, and final decision. The first and second row show visual results at different stages of Frame 2010, when the object has just been left. Both default and tuned PAWCS detect the object as part of the foreground; however, for a further frame (third and fourth rows), only tuned PAWCS maintains the object detection, while default PAWCS misses the abandoned object.
Figure 11.
The first row shows the obtained foreground mask of the same frame of sequence PETS07 S7 C3 with the MOG, KNN, and PAWCS algorithm, respectively. The second row shows the correspondent abandoned discrimination. The ground-truth is marked in red; green shows the abandoned detections; and the non-interest region is colored in white. Significant differences between algorithms may be observed regarding the quality of the foreground masks. In this example. MOG and KNN are providing a ghost detection resulting in a false positive detection, which brings precision down.
Figure 11.
The first row shows the obtained foreground mask of the same frame of sequence PETS07 S7 C3 with the MOG, KNN, and PAWCS algorithm, respectively. The second row shows the correspondent abandoned discrimination. The ground-truth is marked in red; green shows the abandoned detections; and the non-interest region is colored in white. Significant differences between algorithms may be observed regarding the quality of the foreground masks. In this example. MOG and KNN are providing a ghost detection resulting in a false positive detection, which brings precision down.
Figure 12.
All images correspond to the same frame of the AVSS medium sequence. The image on the left shows in blue the detections provided by the ACF people detector. The top row illustrates the static foreground mask obtained with the ACC and MHI algorithms, respectively, and the bottom row shows their corresponding abandoned discrimination.
Figure 12.
All images correspond to the same frame of the AVSS medium sequence. The image on the left shows in blue the detections provided by the ACF people detector. The top row illustrates the static foreground mask obtained with the ACC and MHI algorithms, respectively, and the bottom row shows their corresponding abandoned discrimination.
Figure 13.
The first column shows the frame under consideration and its computed stationary foreground mask (DBM); the second column reports the visual results of the implemented people detector; and the third column presents the abandoned object discrimination of the system. It can be observed that the Haar-like feature classifier for full (HaarF) and upper body parts (HaarU) were not able to detect the standing stationary person; therefore, the system was mistakenly detecting him as an abandoned object.
Figure 13.
The first column shows the frame under consideration and its computed stationary foreground mask (DBM); the second column reports the visual results of the implemented people detector; and the third column presents the abandoned object discrimination of the system. It can be observed that the Haar-like feature classifier for full (HaarF) and upper body parts (HaarU) were not able to detect the standing stationary person; therefore, the system was mistakenly detecting him as an abandoned object.
Figure 14.
From left to right are shown the abandoned discrimination obtained with the HG, CH, and PCC algorithms for the same frame of the VISOR 00 sequence. HG and PCC correctly detected both cars as abandoned, while CH missed one of the detections (marked in grey) due to the wrong classification.
Figure 14.
From left to right are shown the abandoned discrimination obtained with the HG, CH, and PCC algorithms for the same frame of the VISOR 00 sequence. HG and PCC correctly detected both cars as abandoned, while CH missed one of the detections (marked in grey) due to the wrong classification.
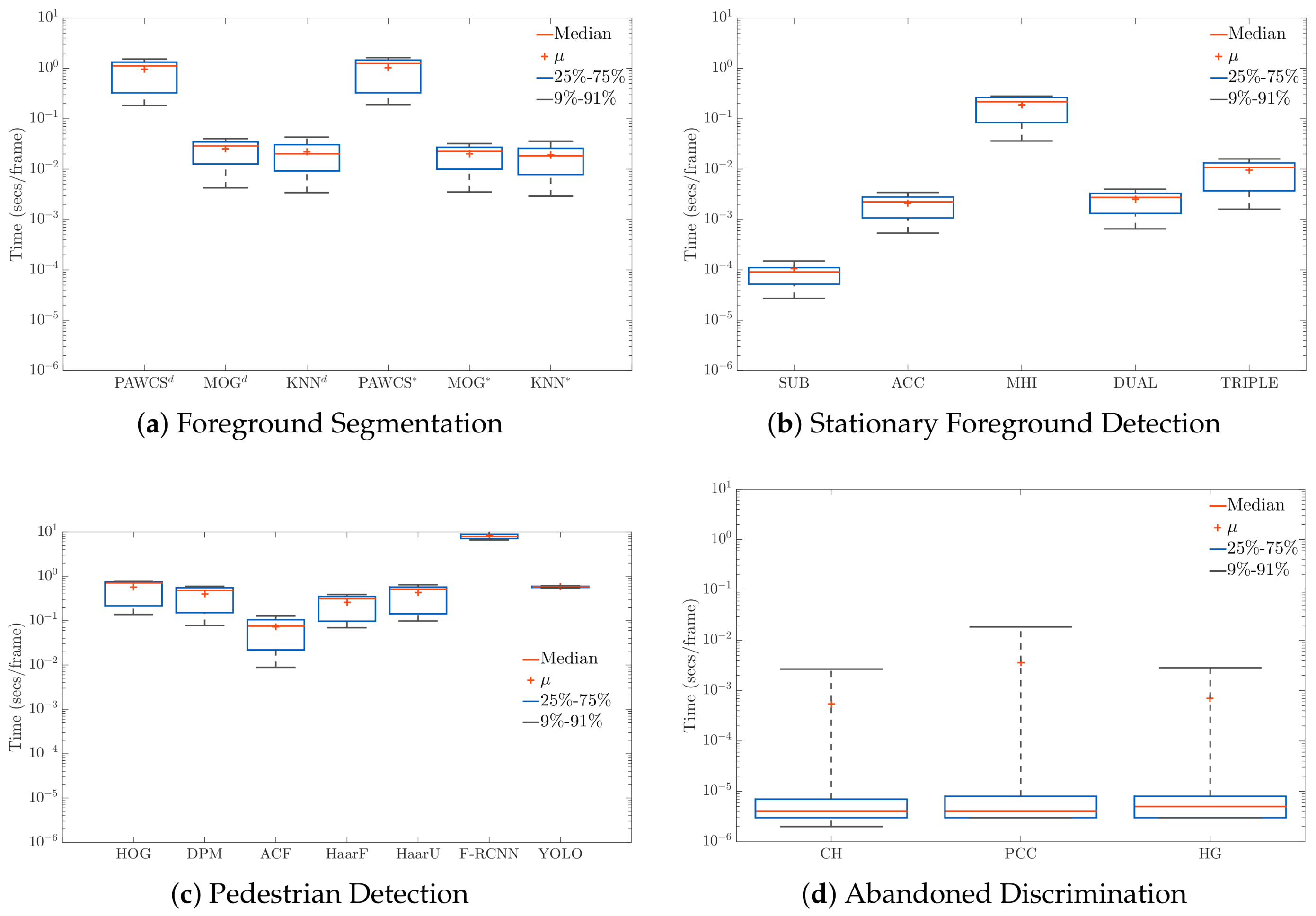
Figure 15.
Computational cost analysis, in terms of seconds per frame, of every algorithm implemented at each stage: Foreground Segmentation (a), Stationary Foreground Detection (b), Pedestrian Detection (c) and Abandoned Discrimination (d).
Figure 15.
Computational cost analysis, in terms of seconds per frame, of every algorithm implemented at each stage: Foreground Segmentation (a), Stationary Foreground Detection (b), Pedestrian Detection (c) and Abandoned Discrimination (d).
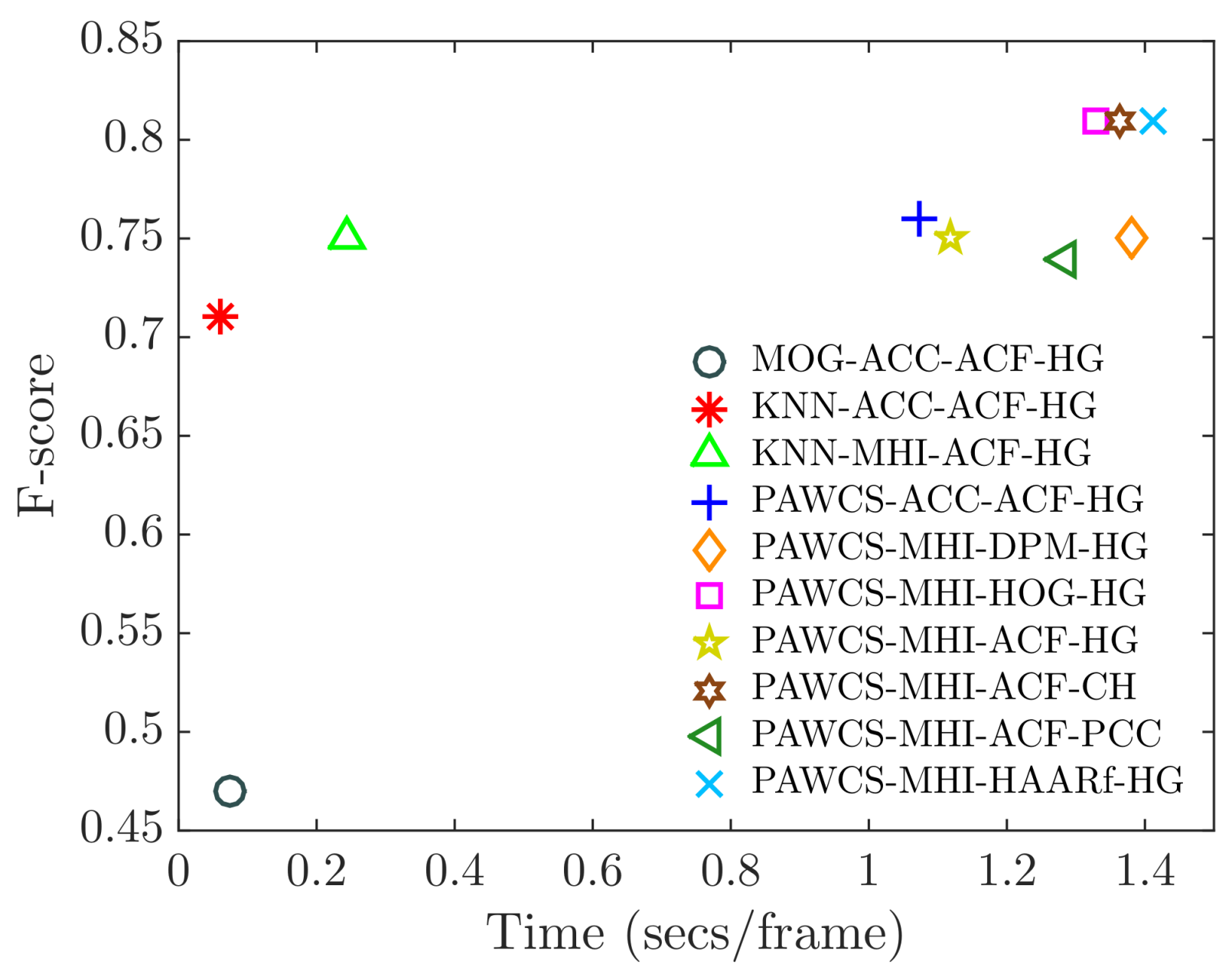
Figure 16.
Relation between performance (F-score) and computational time (seconds per frame) of a selection of relevant configurations.
Figure 16.
Relation between performance (F-score) and computational time (seconds per frame) of a selection of relevant configurations.
Figure 17.
Sample frames from the (a) AVSS 2007 PV, (b) CANTATA C2, (c) HERMES Indoor, and (d) HERMES Outdoor datasets.
Figure 17.
Sample frames from the (a) AVSS 2007 PV, (b) CANTATA C2, (c) HERMES Indoor, and (d) HERMES Outdoor datasets.
Table 1.
Comparison with related surveys for the video-surveillance domain.
Table 1.
Comparison with related surveys for the video-surveillance domain.
| Reference | Topic Coverage for Abandoned Object Detection |
|---|
| Moving Foreground Segmentation | Stationary Object Detection | People Detection | Behavior Recognition | Abandoned Classification | Dataset Analysis | Experimental Validation | Software Provided |
|---|
| [3] | ✓ | | | ✓ | | | | |
| [6] | | ✓ | | | | | ✓ | |
| [8] | | | ✓ | | | | ✓ | |
| [12] | | | | ✓ | | ✓ | | |
| [14] | ✓ | | | ✓ | | | | |
| [16] | ✓ | | | | | | | |
| [10] | ✓ | | | ✓ | | ✓ | | |
| [11] | | | | ✓ | | ✓ | | |
| [4] | ✓ | | | | | ✓ | | |
| [17] | | | | ✓ | | | ✓ | |
| [9] | | | ✓ | | | | ✓ | |
| [7] | ✓ | ✓ | | | | | | |
| [15] | ✓ | | | ✓ | | ✓ | | |
| [18] | ✓ | | | ✓ | | | | |
| [13] | | | | ✓ | | ✓ | | |
| [5] | ✓ | | | | | ✓ | | |
| Proposed | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
Table 2.
Most relevant stationary foreground detection algorithms.
Table 2.
Most relevant stationary foreground detection algorithms.
| Algorithm | Type | Static Foreground Refinements |
|---|
| Filtering | Object Model | Alarm Type | Object Owner |
|---|
| [56] | Single FG mask | ✓ | | ✓ | |
| [57] | ✓ | | | |
| [58] | | ✓ | ✓ | ✓ |
| [59] | Multiple FG mask | | | | |
| [46] | ✓ | | ✓ | |
| [60] | | | | ✓ |
| [61] | Model stability | ✓ | ✓ | | |
| [47] | ✓ | ✓ | | |
| [62] | ✓ | ✓ | ✓ | ✓ |
Table 3.
People detection categories’ robustness summary.
Table 3.
People detection categories’ robustness summary.
| Category | Partial Occlusions | Pose Variations |
|---|
| Motion-based | No | Depending on the model |
| Holistic Appearance | No | No |
| Part-based Appearance | Yes | No |
| Hybrid | Yes | Depending on the model |
Table 4.
Abandoned Object Detection (AOD) datasets available. Key: I = Illumination changes/shadows; R = Remoteness/small objects; P = stationary People; O = Occlusions; LR = Low Resolution; RO = Removed Objects.
Table 4.
Abandoned Object Detection (AOD) datasets available. Key: I = Illumination changes/shadows; R = Remoteness/small objects; P = stationary People; O = Occlusions; LR = Low Resolution; RO = Removed Objects.
| Dataset | # of Sequences | Avg Length (min) | Scenario | Challenges |
|---|
| ABODA (http://imp.iis.sinica.edu.tw/ABODA/) | 11 | 1 | Indoor/Outdoor | I, R, P, O |
| AVSSAB2007 (http://www.eecs.qmul.ac.uk/~andrea/avss2007_d.html) | 3 | 3.5 | Railway Station | I, R, P, O |
| AVSS PV2007 (http://www.eecs.qmul.ac.uk/~andrea/avss2007_d.html) | 4 | 3 | Road Way | I, P, O, RO |
| CANDELA (http://www.multitel.be/image/research-development/research-projects/candela/abandon-scenario.php) | 16 | 0.5 | Indoor | R, O, LR |
| CANTATA (http://www.multitel.be/~va/cantata/LeftObject/) | 20 | 2 | Outdoor | I, RO |
| CAVIAR (http://groups.inf.ed.ac.uk/vision/CAVIAR/CAVIARDATA1/) | 5 | 1 | Terrace | I, R, LR, RO |
| ETISEOBC (https://www-sop.inria.fr/orion/ETISEO/download.htm#video_data) | 6 | 2 | Indoor | I, R, LR |
| ETISEO MO (https://www-sop.inria.fr/orion/ETISEO/download.htm#video_data) | 9 | 3 | Subway | I, R, O, LR |
| HERMESIndoor (http://iselab.cvc.uab.es/silverage.php?q=indoor-cams) | 4 | 2 | Indoor | P, O |
| HERMES Outdoor (http://iselab.cvc.uab.es/silverage.php?q=outdoor-cams) | 4 | 2 | Road Way | P, O |
| PETS2006 (http://www.cvg.reading.ac.uk/PETS2006/data.html) | 28 | 1.5 | Railway Station | I, R, P, O |
| PETS 2007 (http://www.cvg.reading.ac.uk/PETS2007/data.html) | 32 | 2.5 | Railway Station | I, P, O, RO |
| VISORAB (http://imagelab.ing.unimore.it/visor/video_videosInCategory.asp?idcategory=14) | 9 | 0.16 | Indoor | - |
| VISOR SV (http://imagelab.ing.unimore.it/visor/video_videosInCategory.asp?idcategory=12) | 4 | 0.16 | Outdoor | I,R |
Table 5.
Summary of annotated abandoned objects.
Table 5.
Summary of annotated abandoned objects.
| ID | # of AO | Sequence | Lifespan | Unattended |
|---|
| 1 | 2 | VISOR 00 | 64/33 | ✓ |
| 2 | 1 | VISOR 01 | 70 | ✓ |
| 3 | 2 | VISOR 02 | 74/46 | ✓ |
| 4 | 1 | VISOR 03 | 56 | ✓ |
| 5 | 1 | AVSS07 E | 64 | ✓ |
| 6 | 1 | AVSS07 M | 69 | ✓ |
| 7 | 1 | AVSS07 H | 90 | ✓ |
| 8 | 1 | PETS06 S1 C1 | 34 | ✓ |
| 9 | 1 | PETS06 S1 C3 | 34 | ✓ |
| 10 | 1 | PETS06 S1 C4 | 34 | ✓ |
| 11 | 1 | PETS06 S4 C1 | 73 | - |
| 12 | 1 | PETS06 S4 C3 | 73 | - |
| 13 | 1 | PETS06 S4 C4 | 73 | - |
| 14 | 1 | PETS06 S5 C1 | 50 | ✓ |
| 15 | 1 | PETS06 S5 C3 | 50 | ✓ |
| 16 | 1 | PETS06 S5 C4 | 50 | ✓ |
| 17 | 1 | PETS07 S7 C3 | 35 | ✓ |
| 18 | 1 | PETS07 S8 C3 | 40 | ✓ |
| 19 | 1 | ABODA 01 | 23 | ✓ |
| 20 | 1 | ABODA 03 | 29 | ✓ |
| 21 | 1 | ABODA 09 | 45 | ✓ |
Table 6.
Results comparing foreground segmentation approaches for AOD performance. Bold indicates the best results. Key: FS = Foreground Segmentation. SFD = Stationary Foreground Detection. PD = Pedestrian Detection. AD = Abandoned Discrimination. P = Precision. R = Recall. F = F-score. ACF = Aggregated Channel Feature. HG = High Gradients.
Table 6.
Results comparing foreground segmentation approaches for AOD performance. Bold indicates the best results. Key: FS = Foreground Segmentation. SFD = Stationary Foreground Detection. PD = Pedestrian Detection. AD = Abandoned Discrimination. P = Precision. R = Recall. F = F-score. ACF = Aggregated Channel Feature. HG = High Gradients.
| Stage Configuration | AOD Performance |
|---|
| # | FS | SFD | PD | AD | P | R | F |
|---|
| 1 | MOG2_d | ACC | ACF | HG | - | 0.00 | - |
| 2 | KNN_d | - | 0.00 | - |
| 3 | PAWCS_d | 0.58 | 0.61 | 0.59 |
| 4 | MOG2 * | 0.38 | 0.61 | 0.47 |
| 5 | KNN * | 0.75 | 0.67 | 0.71 |
| 6 | PAWCS * | 0.81 | 0.72 | 0.76 |
Table 7.
Results comparing stationary foreground segmentation approaches for AOD performance. Bold indicates the best results. Key: FS = Foreground Segmentation. SFD = Stationary Foreground Detection. PD = Pedestrian Detection. AD = Abandoned Discrimination. P = Precision. R = Recall. F = F-score.
Table 7.
Results comparing stationary foreground segmentation approaches for AOD performance. Bold indicates the best results. Key: FS = Foreground Segmentation. SFD = Stationary Foreground Detection. PD = Pedestrian Detection. AD = Abandoned Discrimination. P = Precision. R = Recall. F = F-score.
| Stage Configuration | AOD Performance |
|---|
| # | FS | SFD | PD | AD | P | R | F |
|---|
| 1 | KNN * | ACC | ACF | HG | 0.75 | 0.67 | 0.71 |
| 2 | SUB | 0.58 | 0.61 | 0.59 |
| 3 | MHI | 0.86 | 0.67 | 0.75 |
| 4 | DBM | 0.73 | 0.61 | 0.67 |
| 5 | TBM | 0.61 | 0.61 | 0.61 |
| 6 | PAWCS * | ACC | ACF | HG | 0.81 | 0.72 | 0.76 |
| 7 | SUB | 0.86 | 0.67 | 0.75 |
| 8 | MHI | 0.93 | 0.72 | 0.81 |
| 9 | DBM | 0.80 | 0.67 | 0.73 |
| 10 | TBM | 0.85 | 0.61 | 0.71 |
Table 8.
Results comparing people detectors for AOD performance. Bold indicates the best results. Key: FS = Foreground Segmentation. SFD = Stationary Foreground Detection. PD = Pedestrian Detection. AD = Abandoned Discrimination. P = Precision. R = Recall. F = F-score. YOLO = You Only Look Once.
Table 8.
Results comparing people detectors for AOD performance. Bold indicates the best results. Key: FS = Foreground Segmentation. SFD = Stationary Foreground Detection. PD = Pedestrian Detection. AD = Abandoned Discrimination. P = Precision. R = Recall. F = F-score. YOLO = You Only Look Once.
| Stage Configuration | AOD Performance |
|---|
| # | FS | SFD | PD | AD | P | R | F |
|---|
| 1 | PAWCS * | MHI | HOG | HG | 0.86 | 0.67 | 0.75 |
| 2 | DPM | 0.93 | 0.72 | 0.81 |
| 3 | ACF | 0.93 | 0.72 | 0.81 |
| 4 | HaarF | 0.76 | 0.72 | 0.74 |
| 5 | HaarU | 0.72 | 0.72 | 0.72 |
| 6 | F-RCNN | 0.92 | 0.67 | 0.77 |
| 7 | YOLOv2 | 1 | 0.72 | 0.84 |
Table 9.
Results comparing the approaches of abandoned discrimination for AOD performance. Bold indicates the best results. Key: FS = Foreground Segmentation. SFD = Stationary Foreground Detection. PD = Pedestrian Detection. AD = Abandoned Discrimination. P = Precision. R = Recall. F = F-score. CH = Color Histograms.
Table 9.
Results comparing the approaches of abandoned discrimination for AOD performance. Bold indicates the best results. Key: FS = Foreground Segmentation. SFD = Stationary Foreground Detection. PD = Pedestrian Detection. AD = Abandoned Discrimination. P = Precision. R = Recall. F = F-score. CH = Color Histograms.
| Stage Configuration | AOD Performance |
|---|
| # | FS | SFD | PD | AD | P | R | F |
|---|
| 1 | PAWCS * | MHI | YOLOv2 | HG | 1 | 0.72 | 0.84 |
| 2 | CH | 1 | 0.67 | 0.81 |
| 3 | PCC | 1 | 0.72 | 0.84 |
Table 10.
Results comparing the approaches of abandoned discrimination for AOD performance. Bold indicates average results. Key: FS = Foreground Segmentation. SFD = Stationary Foreground Detection. PD = Pedestrian Detection. AD = Abandoned Discrimination. P = Precision. R = Recall. F = F-score.
Table 10.
Results comparing the approaches of abandoned discrimination for AOD performance. Bold indicates average results. Key: FS = Foreground Segmentation. SFD = Stationary Foreground Detection. PD = Pedestrian Detection. AD = Abandoned Discrimination. P = Precision. R = Recall. F = F-score.
| AOD Performance |
|---|
| Stage Configuration | Average | AVSS PV | CANTATA | HERMES I | HERMES O |
|---|
| # | BS | SFD | PD | AD | P | R | F | P | R | F | P | R | F | P | R | F | P | R | F |
|---|
| 1 | PAWCS * | MHI | YOLOv2 | HG | 0.73 | 0.92 | 0.81 | 0.67 | 1 | 0.8 | 1 | 0.83 | 0.91 | 0.5 | 1 | 0.67 | 0.67 | 1 | 0.8 |
| 2 | KNN * | ACC | ACF | HG | 0.26 | 0.92 | 0.41 | 0.12 | 1 | 0.21 | 0.36 | 0.83 | 0.5 | 0.22 | 1 | 0.36 | 1 | 1 | 1 |




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}