An Improved YOLOv2 for Vehicle Detection

 , ,
, ,
Abstract
:1. Introduction
2. Brief Introduction of YOLO and YOLOv2
3. Dataset
4. The Improved YOLO_v2 Vehicle Detection Model
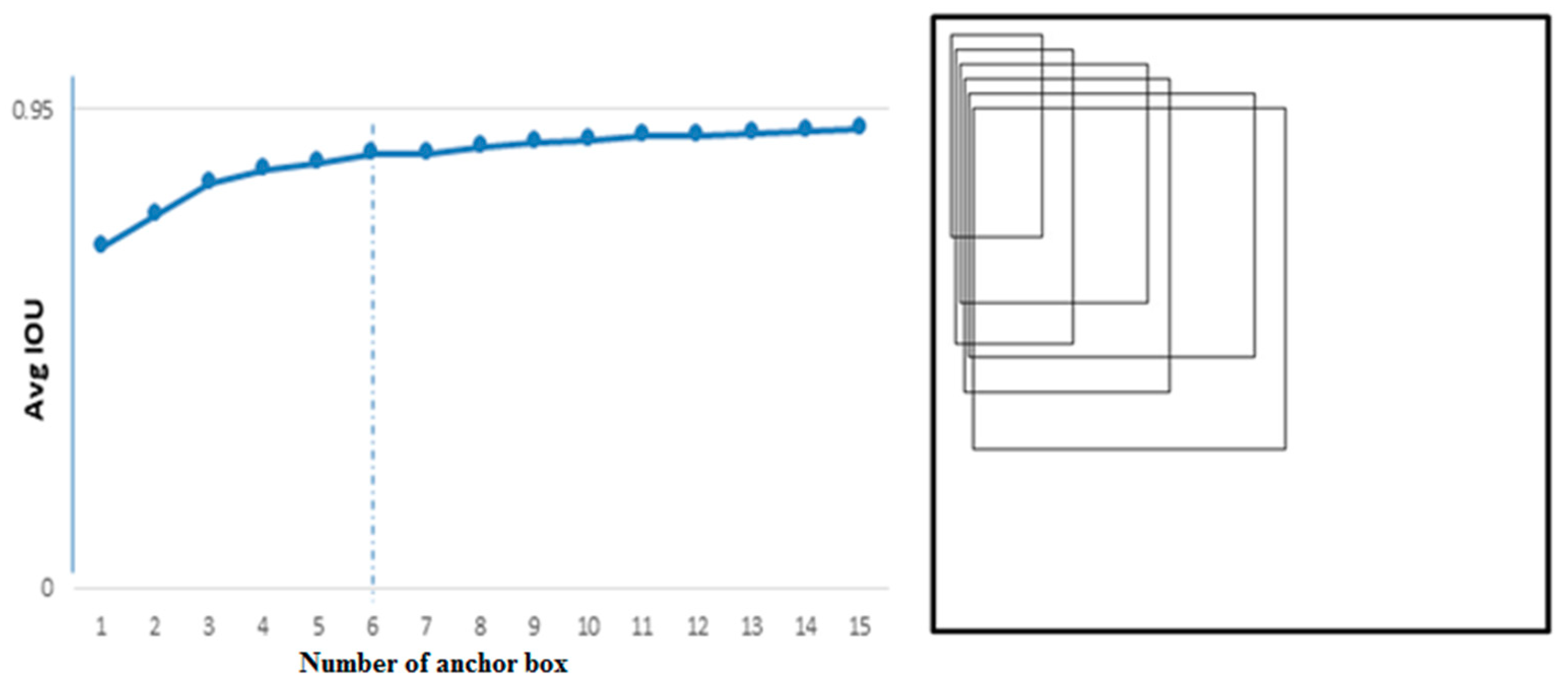
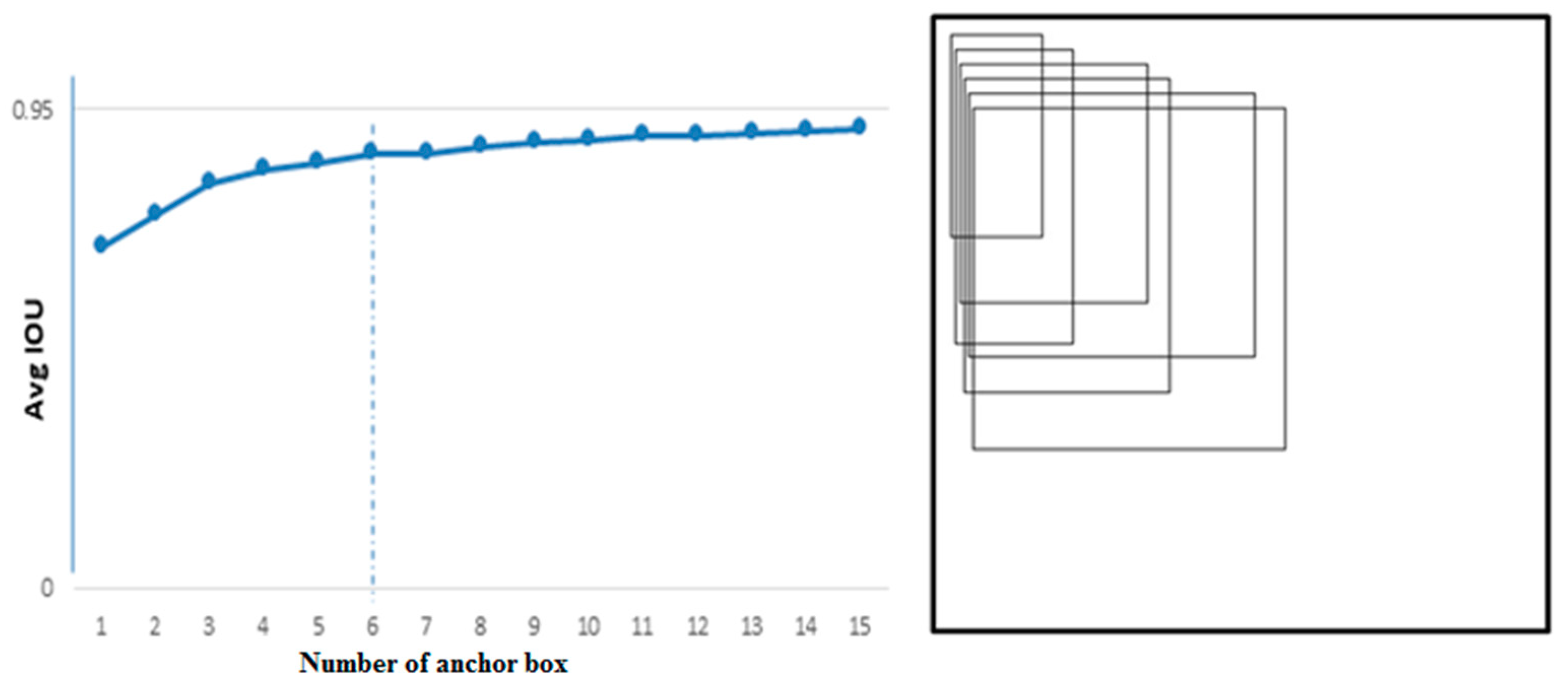
4.1. Selection of Anchor Boxes
4.2. Improvement of Loss Function
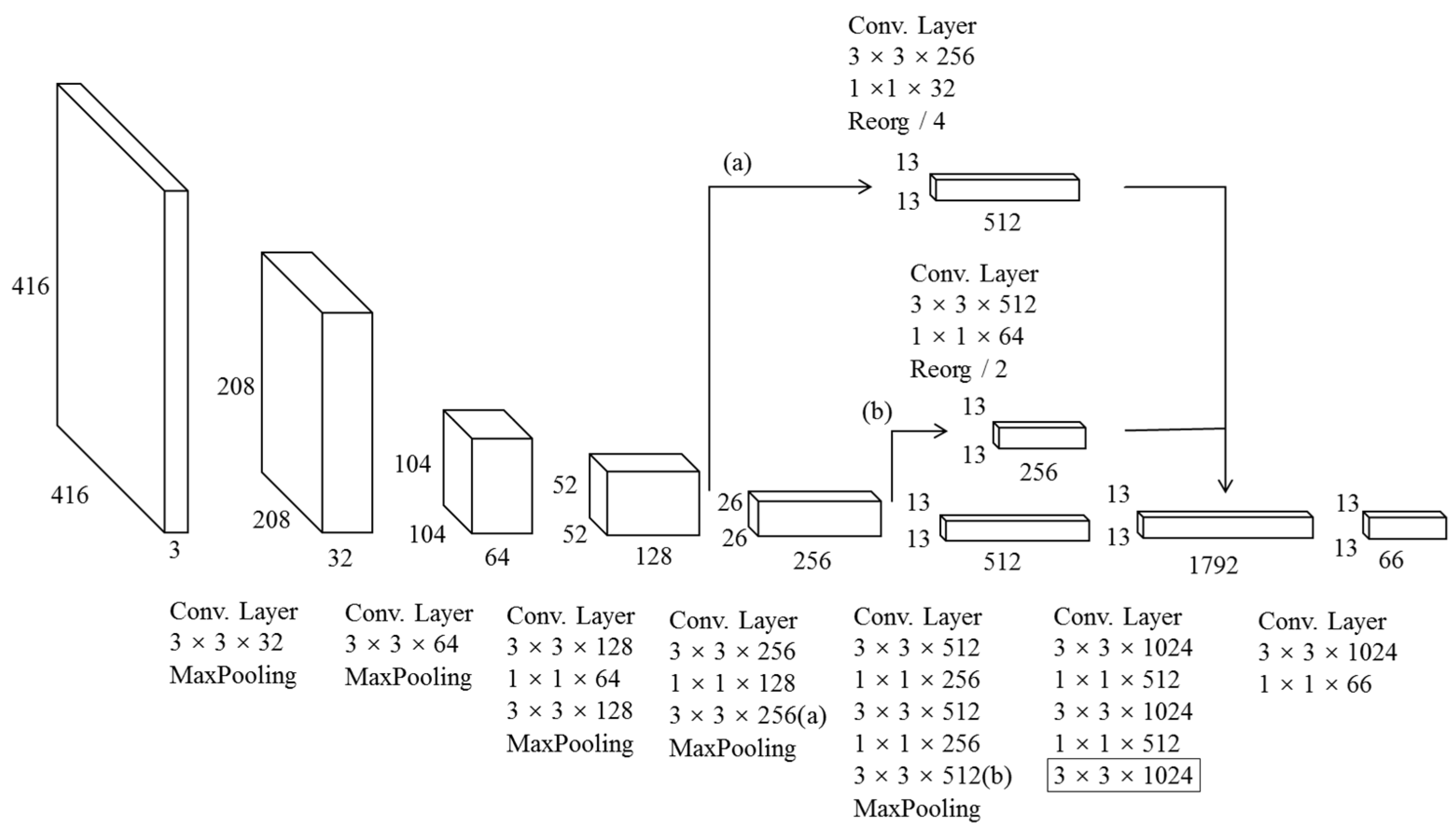
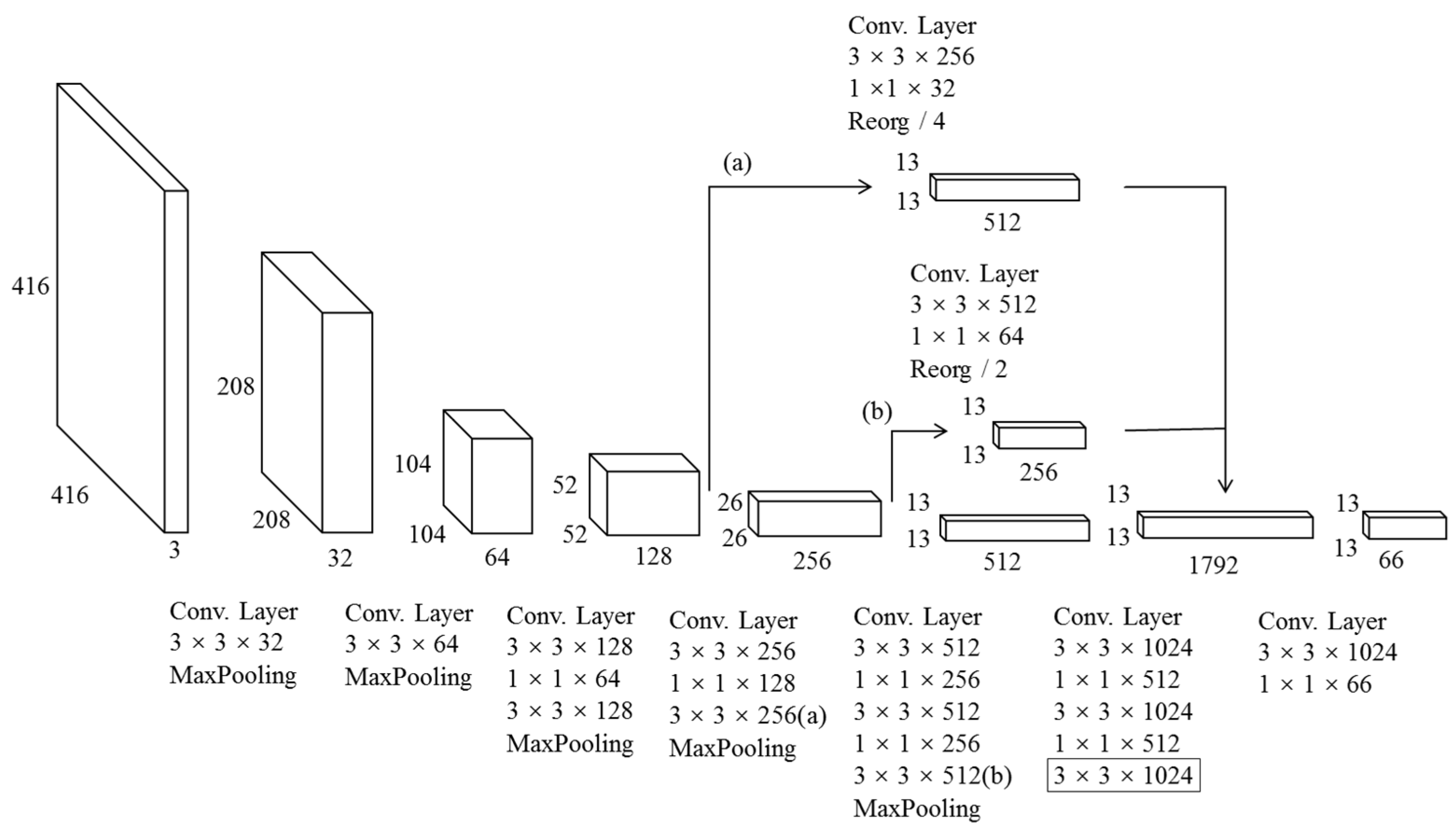
4.3. Design of Network
5. Experiments
5.1. Environment
5.2. Results and Analysis
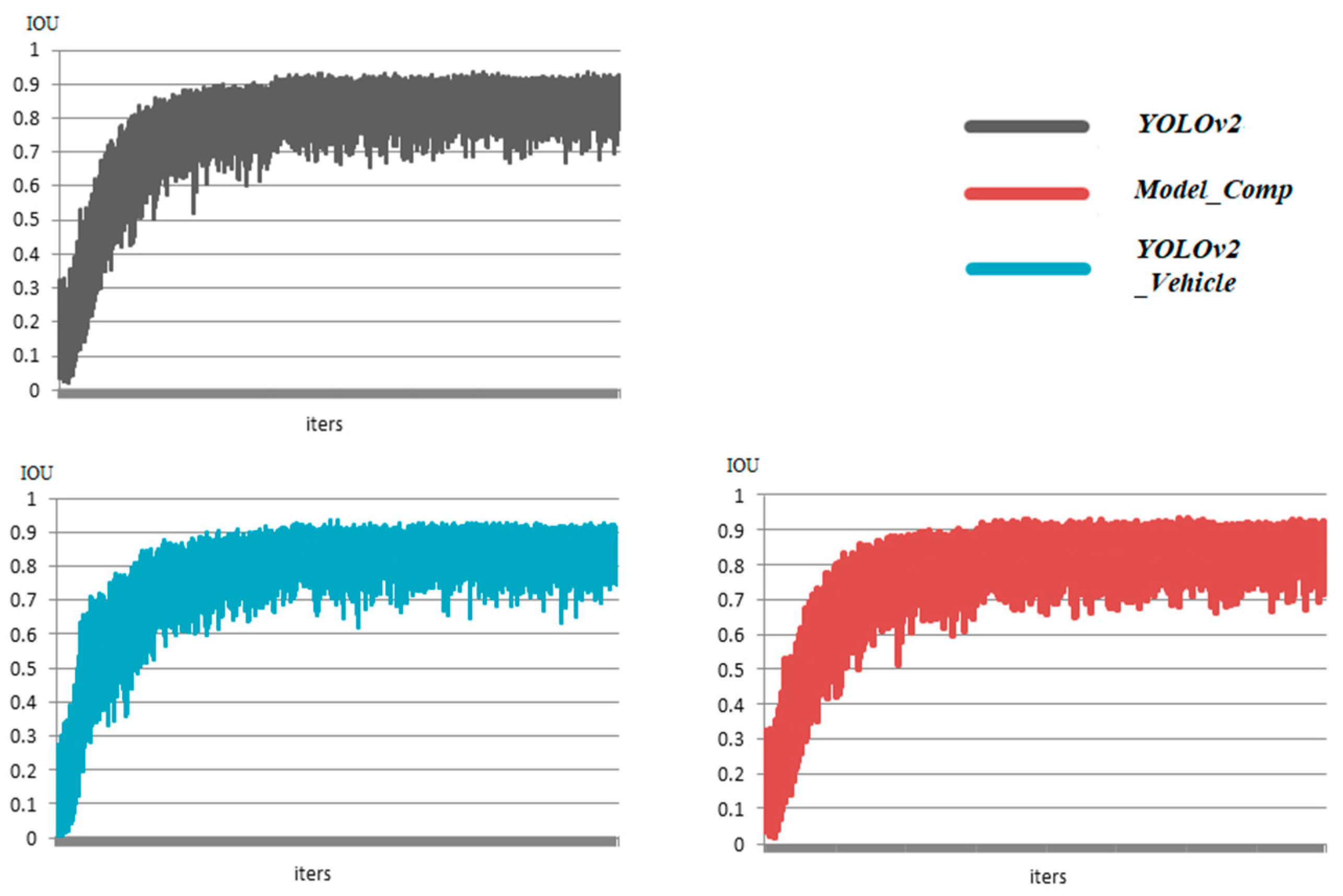
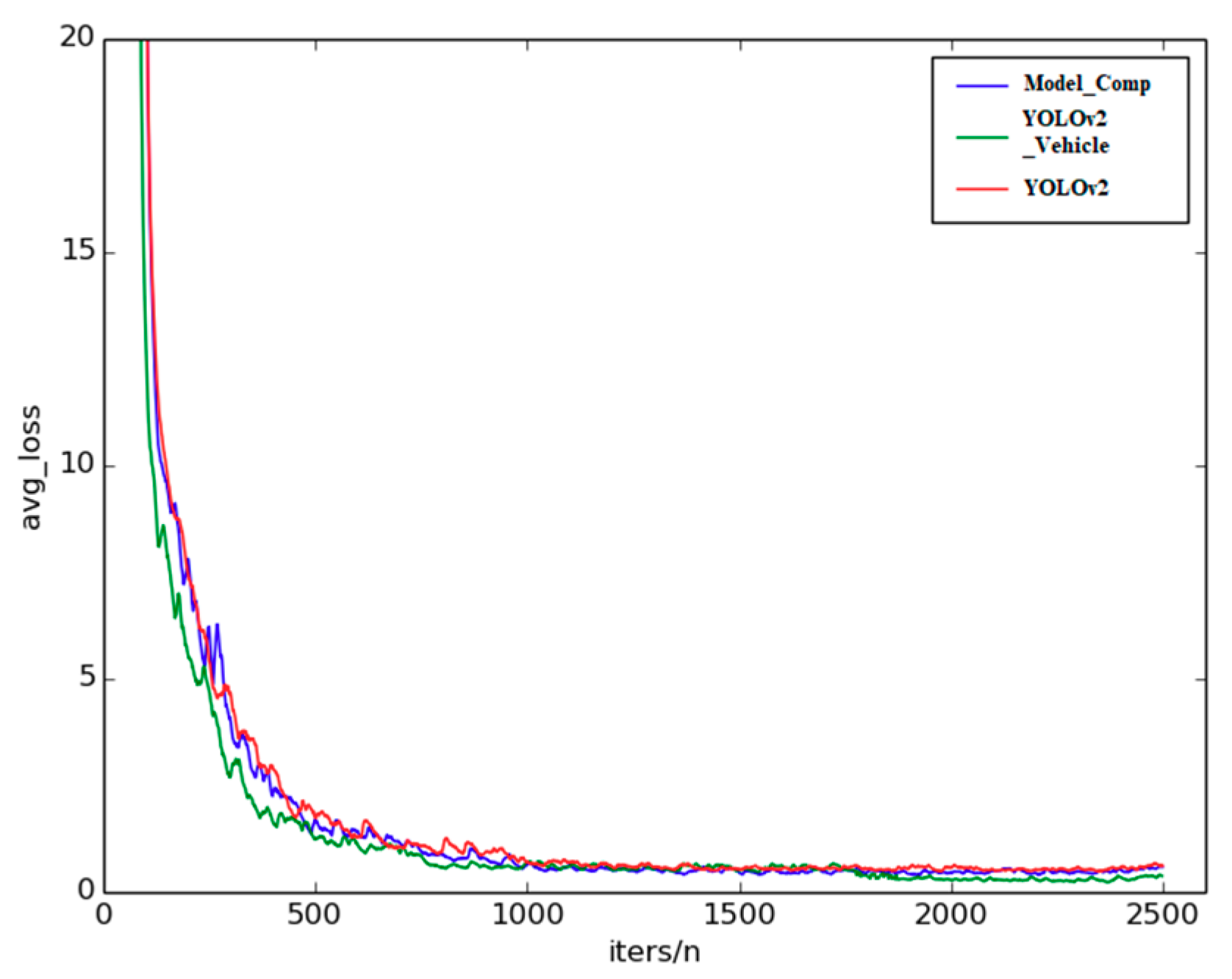
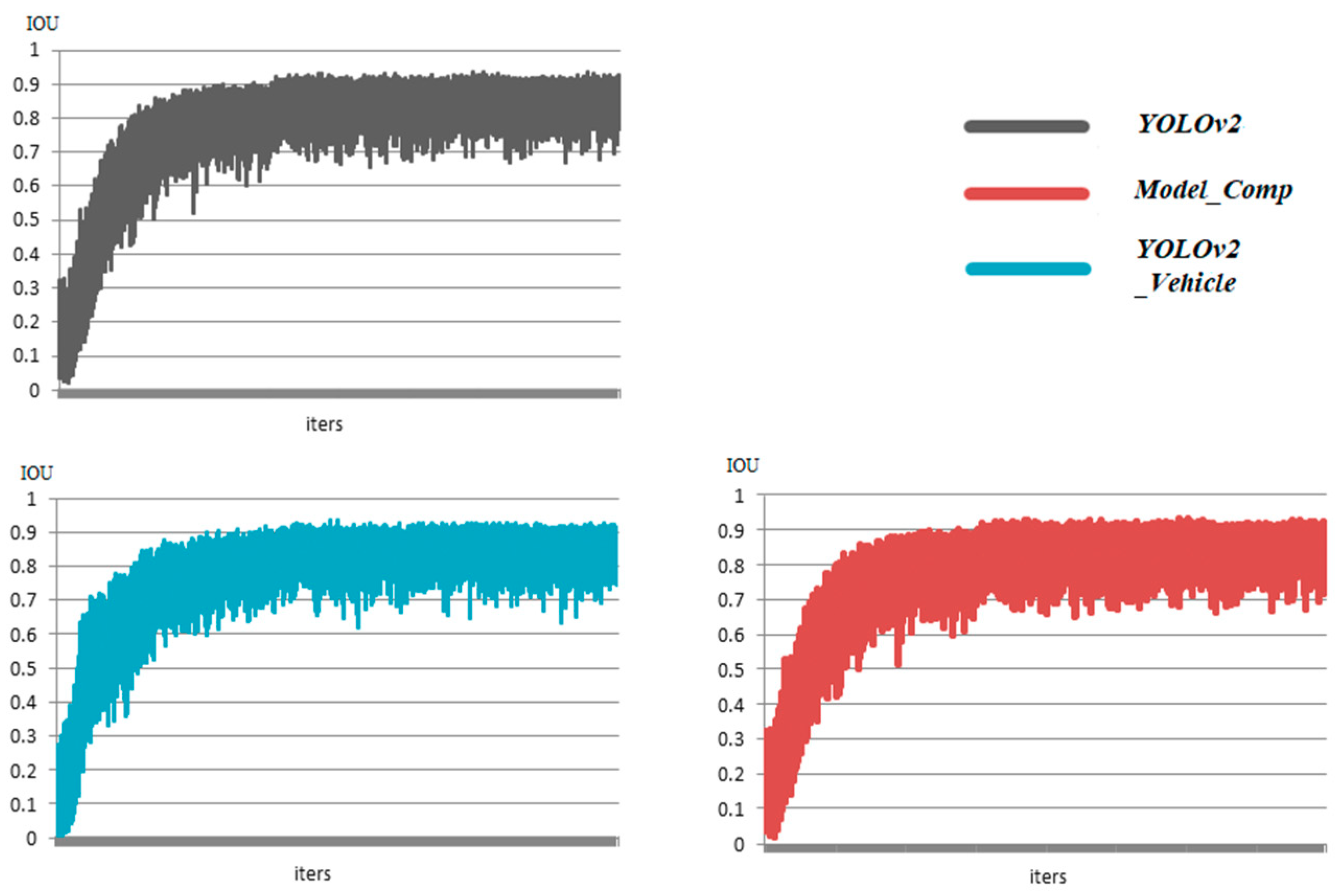
5.2.1. Analysis of Training Stage
5.2.2. Analysis of Test Stage
5.2.3. Visualizing the Network
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Cao, X.; Wu, C.; Yan, P.; Li, X. Linear SVM classification using boosting HOG features for vehicle detection in low-altitude airborne videos. In Proceedings of the 2011 IEEE International Conference Image Processing (ICIP), Brussels, Belgium, 11–14 September 2011; pp. 2421–2424. [Google Scholar]
- Guo, E.; Bai, L.; Zhang, Y.; Han, J. Vehicle Detection Based on Superpixel and Improved HOG in Aerial Images. In Proceedings of the International Conference on Image and Graphics, Shanghai, China, 13–15 September 2017; pp. 362–373. [Google Scholar]
- Laopracha, N.; Sunat, K. Comparative Study of Computational Time that HOG-Based Features Used for Vehicle Detection. In Proceedings of the International Conference on Computing and Information Technology, Helsinki, Finland, 21–23 August 2017; pp. 275–284. [Google Scholar]
- Pan, C.; Sun, M.; Yan, Z. The Study on Vehicle Detection Based on DPM in Traffic Scenes. In Proceedings of the International Conference on Frontier Computing, Tokyo, Japan, 13–15 July 2016; pp. 19–27. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 22–25 July 2017; pp. 2261–2269. [Google Scholar]
- Pyo, J.; Bang, J.; Jeong, Y. Front collision warning based on vehicle detection using CNN. In Proceedings of the International SoC Design Conference (ISOCC), Jeju, Korea, 23–26 October 2016; pp. 163–164. [Google Scholar]
- Tang, Y.; Zhang, C.; Gu, R. Vehicle detection and recognition for intelligent traffic surveillance system. Multimed. Tools Appl. 2017, 76, 5817–5832. [Google Scholar] [CrossRef]
- Gao, Y.; Guo, S.; Huang, K.; Chen, J.; Gong, Q.; Zou, Y.; Bai, T.; Overett, G. Scale optimization for full-image-CNN vehicle detection. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 785–791. [Google Scholar]
- Huttunen, H.; Yancheshmeh, F.S.; Chen, K. Car type recognition with deep neural networks. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Gothenburg, Sweden, 19–22 June 2016; pp. 1115–1120. [Google Scholar]
- Dong, Z.; Pei, M.; He, Y. Vehicle type classification using unsupervised convolution neural network. In Proceedings of the 2014 IEEE International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 172–177. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. In Proceedings of the 2014 IEEE International Conference of European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 346–361. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv, 2016; arXiv:1506.01497v3. [Google Scholar] [CrossRef] [PubMed]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object detection via region-based fully convolutional networks. In Proceedings of the 2016 IEEE International Conference of Advances in neural information processing systems, Barcelona, Spain, 5–8 December 2016; pp. 379–387. [Google Scholar]
- Konoplich, G.V.; Putin, E.O.; Filchenkov, A.A. Application of deep learning to the problem of vehicle detection in UAV images. In Proceedings of the 2016 XIX IEEE International Conference on Soft Computing and Measurements (SCM), St. Petersburg, Russia, 25–27 May 2016; pp. 4–6. [Google Scholar]
- Cai, Z.; Fan, Q.; Feris, R.S.; Vasconcelos, N. A unified multi-scale deep convolutional neural network for fast object detection. In Proceedings of the 2016 European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 354–370. [Google Scholar]
- Azam, S.; Rafique, A.; Jeon, M. Vehicle pose detection using region based convolutional neural network. In Proceedings of the International Conference on Control, Automation and Information Sciences (ICCAIS), Ansan, Korea, 27–29 October 2016; pp. 194–198. [Google Scholar]
- Tang, T.; Zhou, S.; Deng, Z.; Zou, H.; Lei, L. Vehicle detection in aerial images based on region convolutional neural networks and hard negative example mining. Sensors 2017, 17, 336. [Google Scholar] [CrossRef] [PubMed]
- Sang, J.; Guo, P.; Xiang, Z.; Luo, H.; Chen, X. Vehicle detection based on faster-RCNN. J. Chongqing Univ. (Nat. Sci. Ed.) 2017, 40, 32–36. (In Chinese) [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Arthur, D.; Vassilvitskii, S. k-means++: The advantages of careful seeding. In Proceedings of the eighteenth annual ACM-SIAM symposium on Discrete algorithms, New Orleans, LA, USA, 7–9 January 2007; pp. 1027–1035. [Google Scholar]
- Neubeck, A.; Van Gool, L. Efficient non-maximum suppression. In Proceedings of the International Conference on Pattern Recognition (ICPR), Hong Kong, China, 20–24 August 2006; pp. 850–855. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2005; pp. 448–456. [Google Scholar]
- Dong, Z.; Wu, Y.; Pei, M.; Jia, Y. Vehicle type classification using a semisupervised convolutional neural network. IEEE Trans. Intel. Transp. Syst. 2015, 16, 2247–2256. [Google Scholar] [CrossRef]
- Yang, L.; Luo, P.; Change Loy, C.; Tang, X. A large-scale car dataset for fine-grained categorization and verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3973–3981. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer\Model | YOLOv2 | Model_Comp | YOLOv2_Vehicle |
|---|---|---|---|
| 0 | Conv3-32 | Conv3-32 | Conv3-32 |
| 1 | Maxpool/2 | Maxpool/2 | Maxpool/2 |
| 2 | Conv3-64 | Conv3-64 | Conv3-64 |
| 3 | Maxpool/2 | Maxpool/2 | Maxpool/2 |
| 4 | Conv3-128 | Conv3-128 | Conv3-128 |
| 5 | Conv1-64 | Conv1-64 | Conv1-64 |
| 6 | Conv3-128 | Conv3-128 | Conv3-128 |
| 7 | Maxpool/2 | Maxpool/2 | Maxpool/2 |
| 8 | Conv3-256 | Conv3-256 | Conv3-256 |
| 9 | Conv1-128 | Conv1-128 | Conv1-128 |
| 10 | Conv3-256 | Conv3-256 | Conv3-256 |
| 11 | Maxpool/2 | Maxpool/2 | Maxpool/2 |
| 12 | Conv3-512 | Conv3-512 | Conv3-512 |
| 13 | Conv1-256 | Conv1-256 | Conv1-256 |
| 14 | Conv3-512 | Conv3-512 | Conv3-512 |
| 15 | Conv1-256 | Conv1-256 | Conv1-256 |
| 16 | Conv3-512 | Conv3-512 | Conv3-512 |
| 17 | Maxpool/2 | Maxpool/2 | Maxpool/2 |
| 18 | Conv3-1024 | Conv3-1024 | Conv3-1024 |
| 19 | Conv1-512 | Conv1-512 | Conv1-512 |
| 20 | Conv3-1024 | Conv3-1024 | Conv3-1024 |
| 21 | Conv1-512 | Conv1-512 | Conv1-512 |
| 22 | Conv3-1024 | Conv3-1024 | Conv3-1024 |
| 23 | Conv3-1024 | Conv3-1024 | Route 10 |
| 24 | Conv3-1024 | Route 16 | Conv3-256 |
| 25 | Route 16 | Conv3-512 | Conv3-32 |
| 26 | Conv1-64 | Conv1-64 | Reorg/4 |
| 27 | Reorg/2 | Reorg/2 | Route 16 |
| 28 | Route 27 24 | Route 27 23 | Conv3-512 |
| 29 | Conv3-1024 | Conv3-1024 | Conv1-64 |
| 30 | Conv1-66 | Conv1-66 | Reorg/2 |
| 31 | Detection | Detection | Route 30 26 22 |
| 32 | Conv3-1024 | ||
| 33 | Conv1-66 | ||
| 34 | Detection |
| Hardware | Environment |
|---|---|
| Computer | GPU server |
| CPU | Intel(R) Xeon(R) CPU E5-2683 v3 @ 2.00 GHz |
| GPU | Nvidia Tesla K80 × 4 |
| Memory Size | 64 GB |
| Model | Recall | Precision | Avg IOU |
|---|---|---|---|
| YOLOv2 | 99.32% | 99.20% | 84.43% |
| Model_Comp | 100% | 99.41% | 84.80% |
| YOLOv2_Vehicle | 100% | 99.51% | 89.97% |
| Model | Bus | Microbus | Minivan | Sedan | SUV | Truck | mAP | s/Img |
|---|---|---|---|---|---|---|---|---|
| Model_Comp | 97.43% | 94.47% | 90.86% | 97.46% | 93.05% | 91.69% | 94.16% | 0.038 |
| YOLOv2_Vehicle | 97.54% | 93.76% | 92.18% | 98.48% | 94.62% | 92.09% | 94.78% | 0.038 |
| YOLOv2 | 96.39% | 92.24% | 90.61% | 98.57% | 91.49% | 90.57% | 93.31% | 0.045 |
| Faster R-CNN + ResNet [22] | 90.62% | 94.42% | 90.67% | 90.63% | 91.25% | 90.07% | 91.28% | 0.68 |
| Model | mAP |
|---|---|
| Model_Comp | 54.37% |
| YOLOv2_Vehicle | 68.19% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sang, J.; Wu, Z.; Guo, P.; Hu, H.; Xiang, H.; Zhang, Q.; Cai, B. An Improved YOLOv2 for Vehicle Detection. Sensors 2018, 18, 4272. https://doi.org/10.3390/s18124272
Sang J, Wu Z, Guo P, Hu H, Xiang H, Zhang Q, Cai B. An Improved YOLOv2 for Vehicle Detection. Sensors. 2018; 18(12):4272. https://doi.org/10.3390/s18124272
Chicago/Turabian StyleSang, Jun, Zhongyuan Wu, Pei Guo, Haibo Hu, Hong Xiang, Qian Zhang, and Bin Cai. 2018. "An Improved YOLOv2 for Vehicle Detection" Sensors 18, no. 12: 4272. https://doi.org/10.3390/s18124272
APA StyleSang, J., Wu, Z., Guo, P., Hu, H., Xiang, H., Zhang, Q., & Cai, B. (2018). An Improved YOLOv2 for Vehicle Detection. Sensors, 18(12), 4272. https://doi.org/10.3390/s18124272