Face Recognition Using the SR-CNN Model

Abstract
1. Introduction
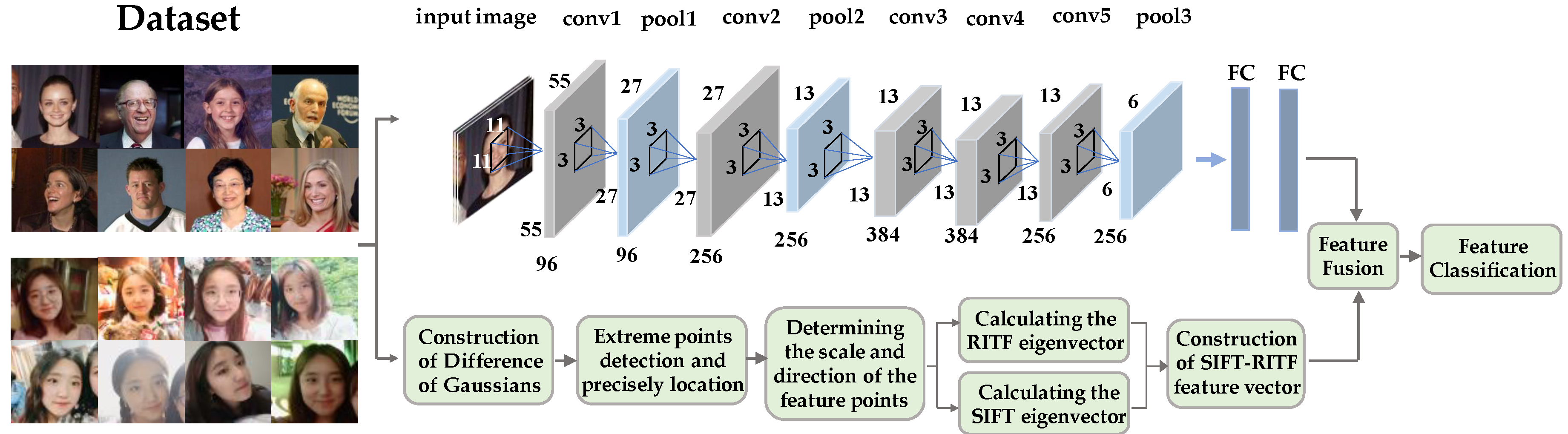
2. SR-CNN Model
2.1. Framework of the Proposed Method
2.2. Feature Extraction with SIFT/RITF Model
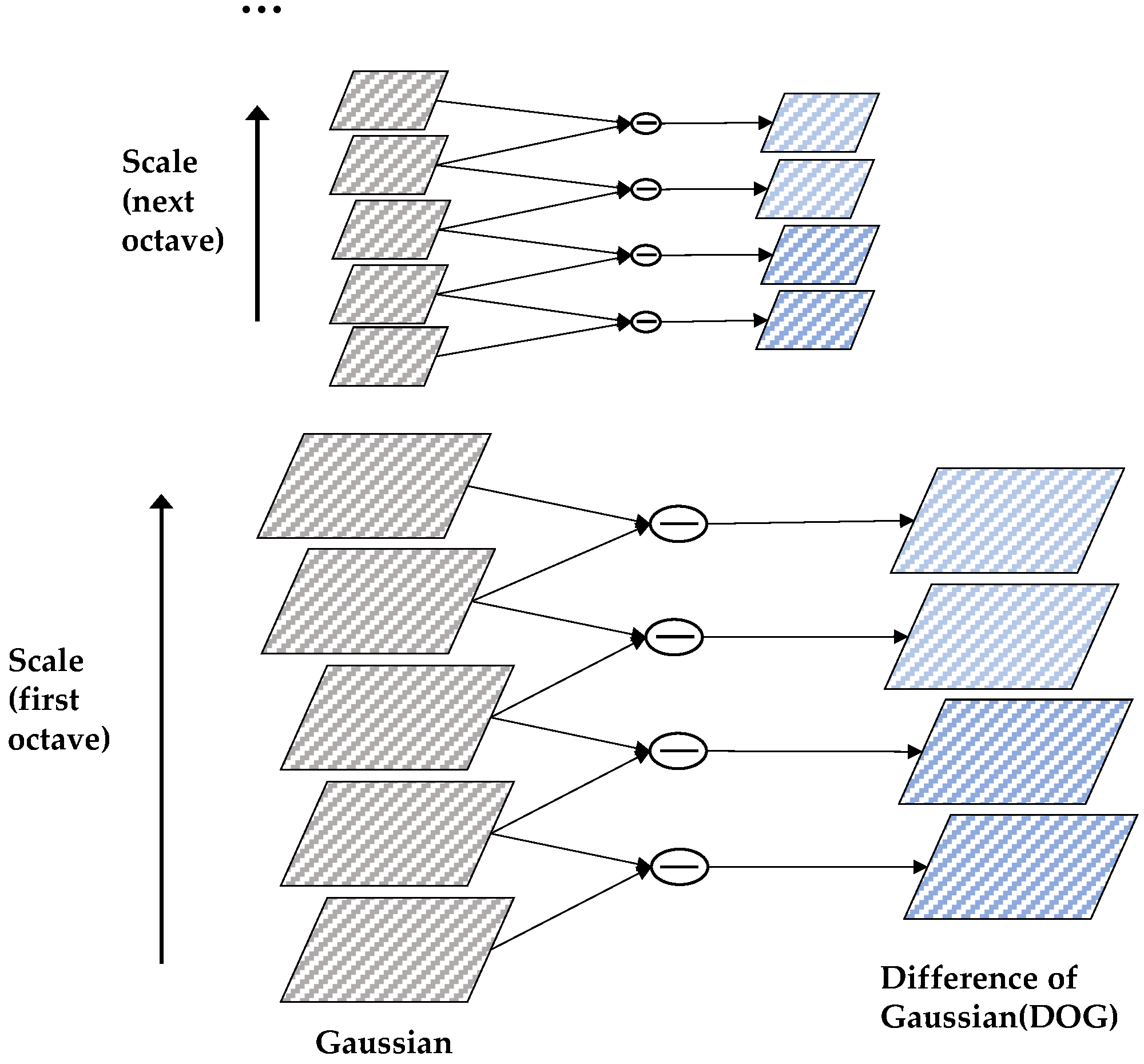
2.2.1. Detection of Scale-Space Extrema
2.2.2. Extrema Localization of Key Points
2.2.3. Orientation Assignment of the Feature Point
2.2.4. Construction of SIFT/RITF Descriptor
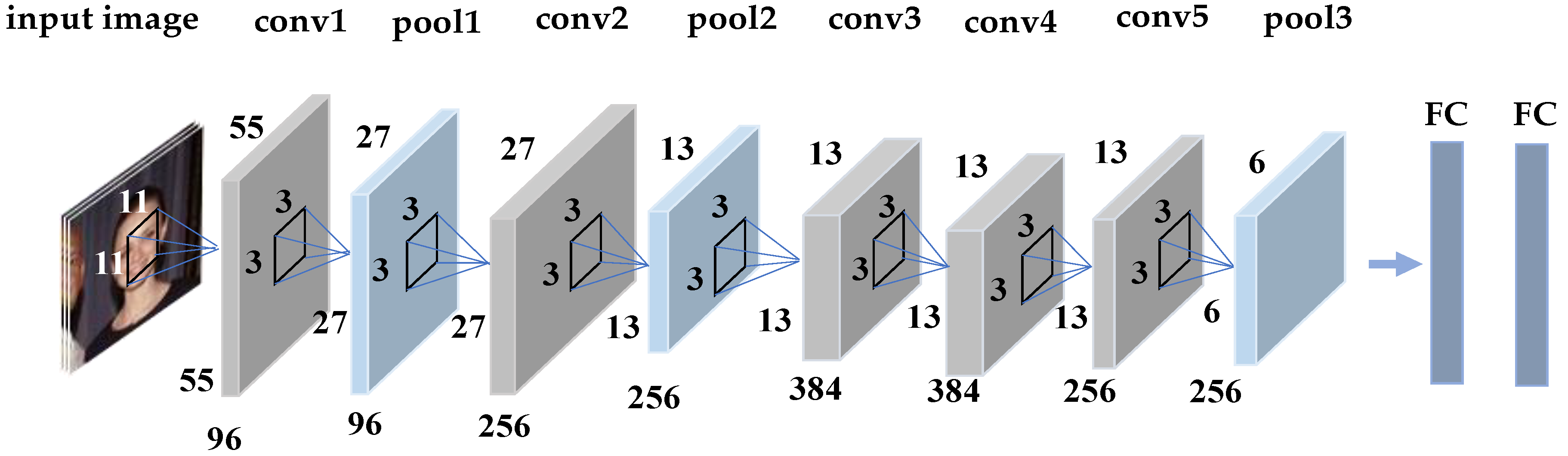
2.3. Feature Extraction with CNN Model
2.3.1. Batch Normalization Layer
| Algorithm 1. Batch normalization (BN) |
| Input: Values of over a mini-batch: ; Parameters to be learned: , . Output: ; . 1. Mini-batch mean: ; 2. Mini-batch variance: ; 3. Normalized value: ; 4. Scale and shift . |
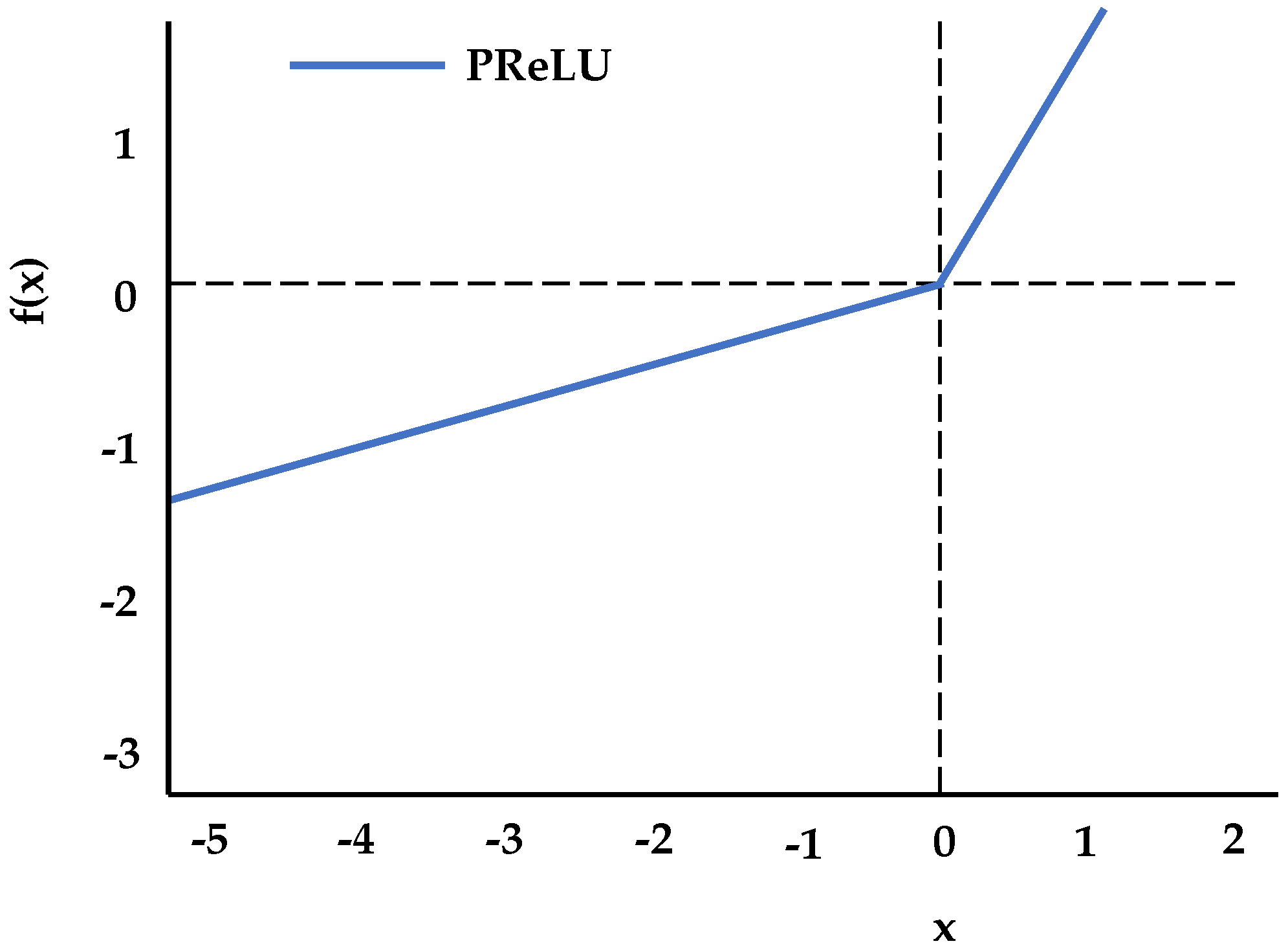
2.3.2. Activation Function Layer
2.3.3. Backpropagation (BP) of CNN Networks
2.3.4. Feature Vector Extraction
2.4. Feature Fusion and Classification
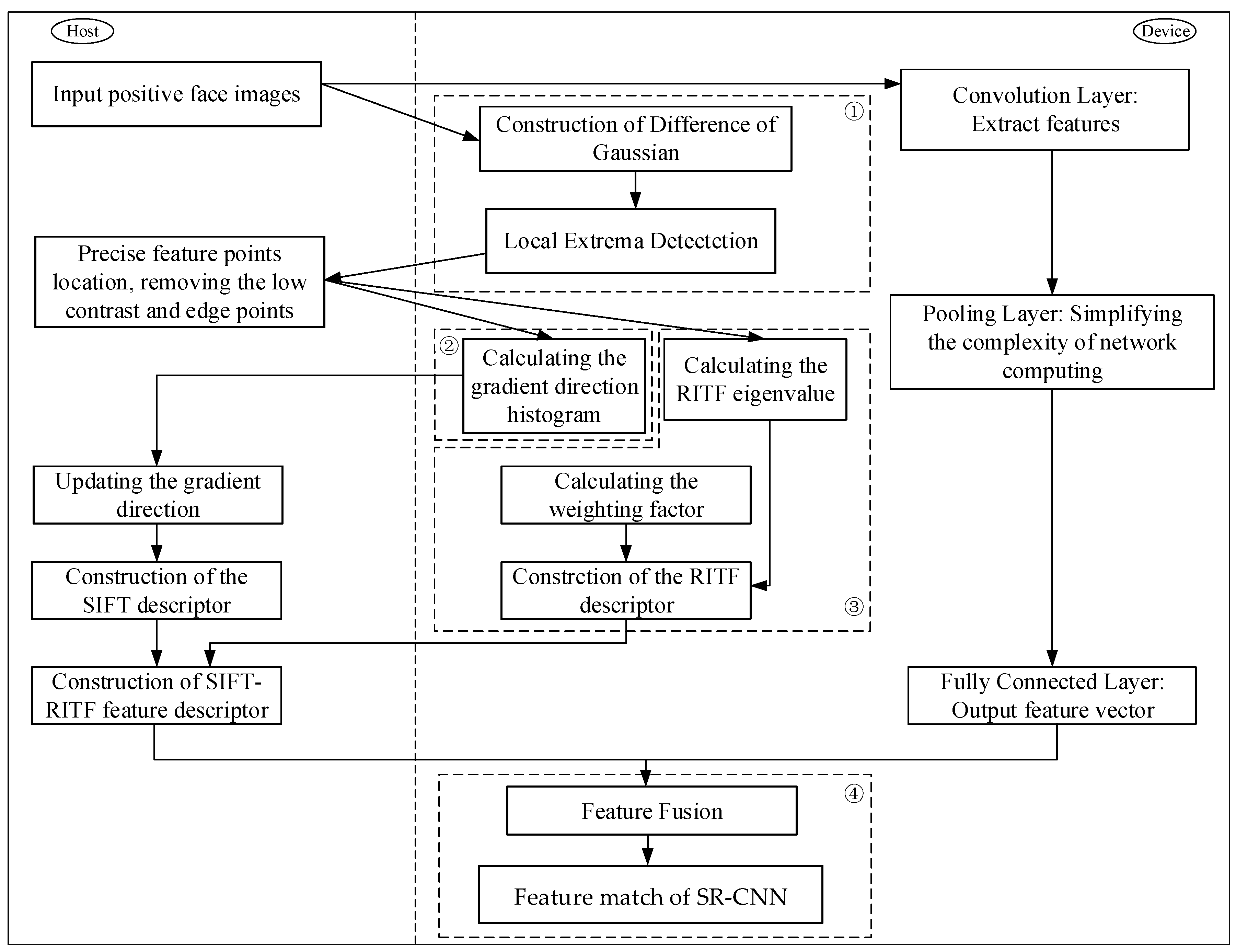
3. Parallel Optimization of SR-CNN Model
3.1. Architecture of Parallel Computing
3.2. Design of GPU Implementation
3.2.1. Establishment of DOG and Detection of Extrema
3.2.2. Histogram Statistics
3.2.3. Construction of RITF Descriptor
3.2.4. Feature Matching of SR-CNN
4. Experimental Results and Analysis
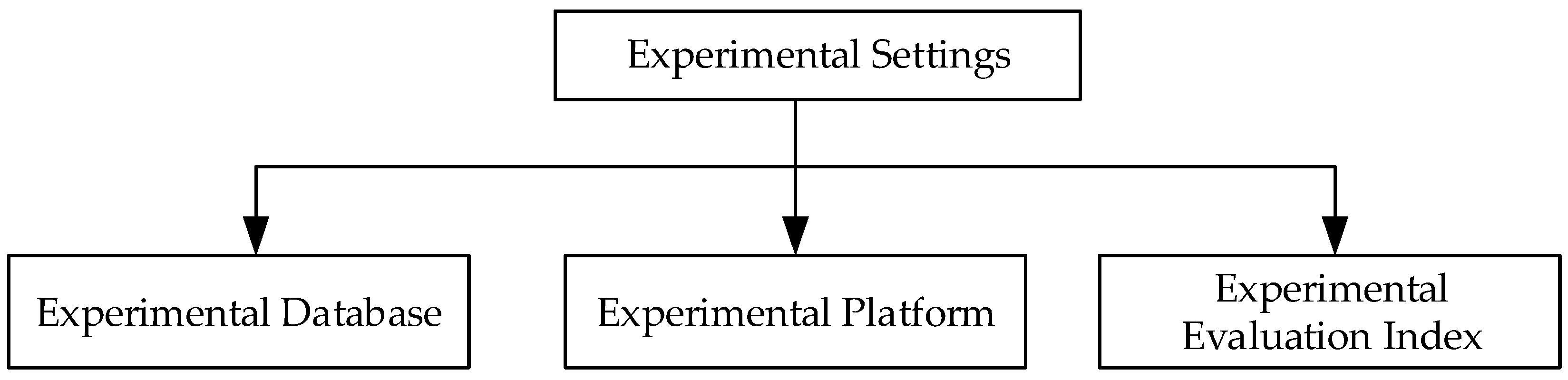
4.1. Experimental Settings
4.1.1. Experimental Database
4.1.2. Experimental Platform
4.1.3. Experimental Evaluation Index
4.2. Experimental Analysis
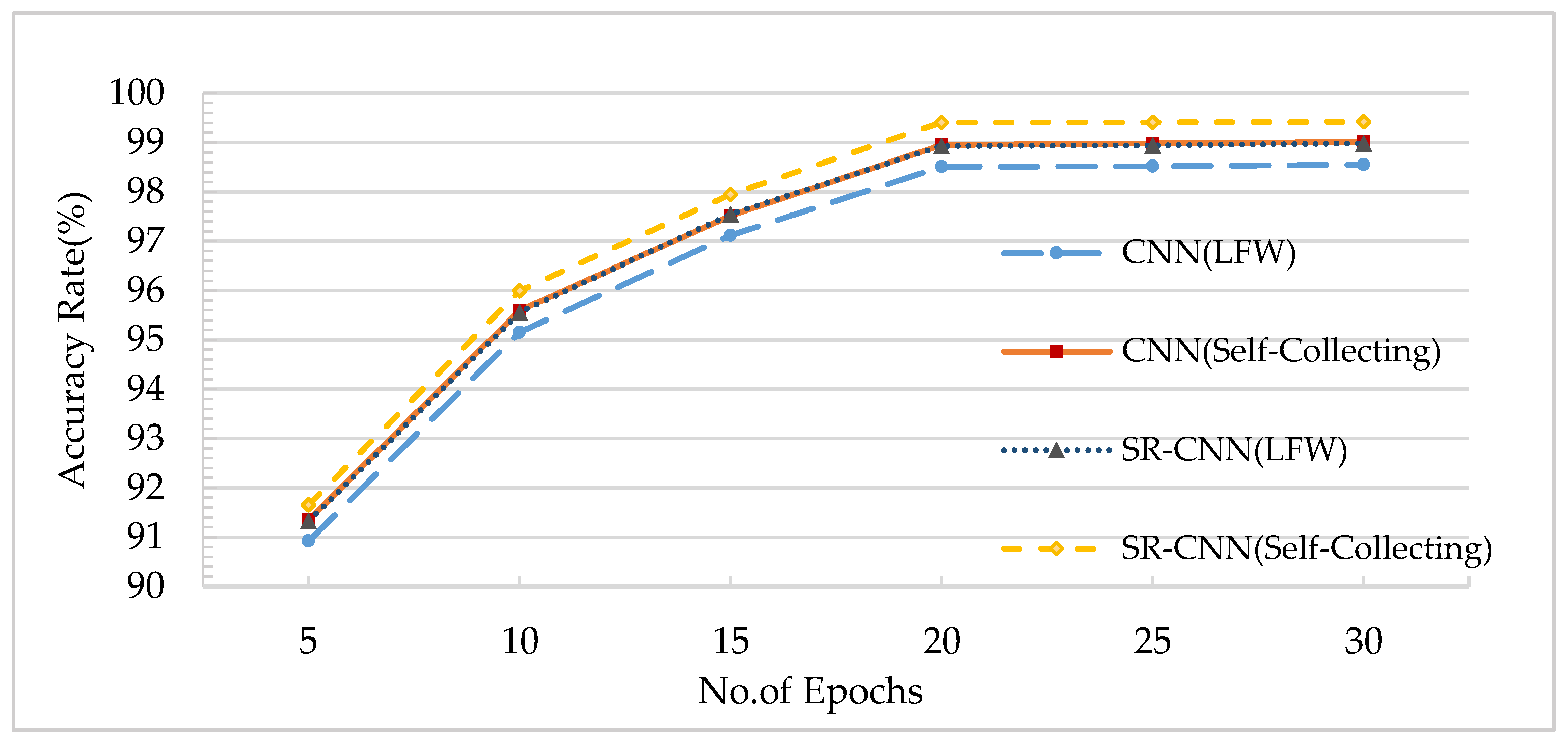
4.2.1. Analysis of the Accuracy in Different Training Epochs
4.2.2. Analysis of the Accuracy of Different Activation Functions
4.2.3. Analysis of Pre-Trained and Fine-Tuned CNN Networks
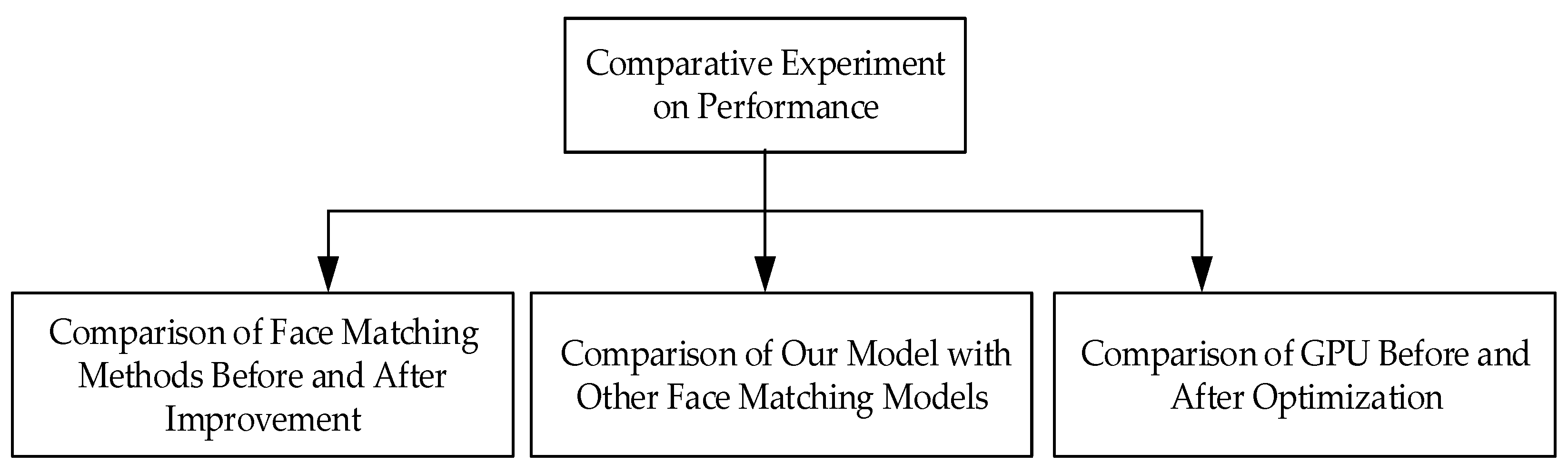
4.3. Comparative Experiment on Performance
4.3.1. Comparison of Face Matching Methods Before and After Improvement
4.3.2. Comparison of Our Model with Other Face Matching Models
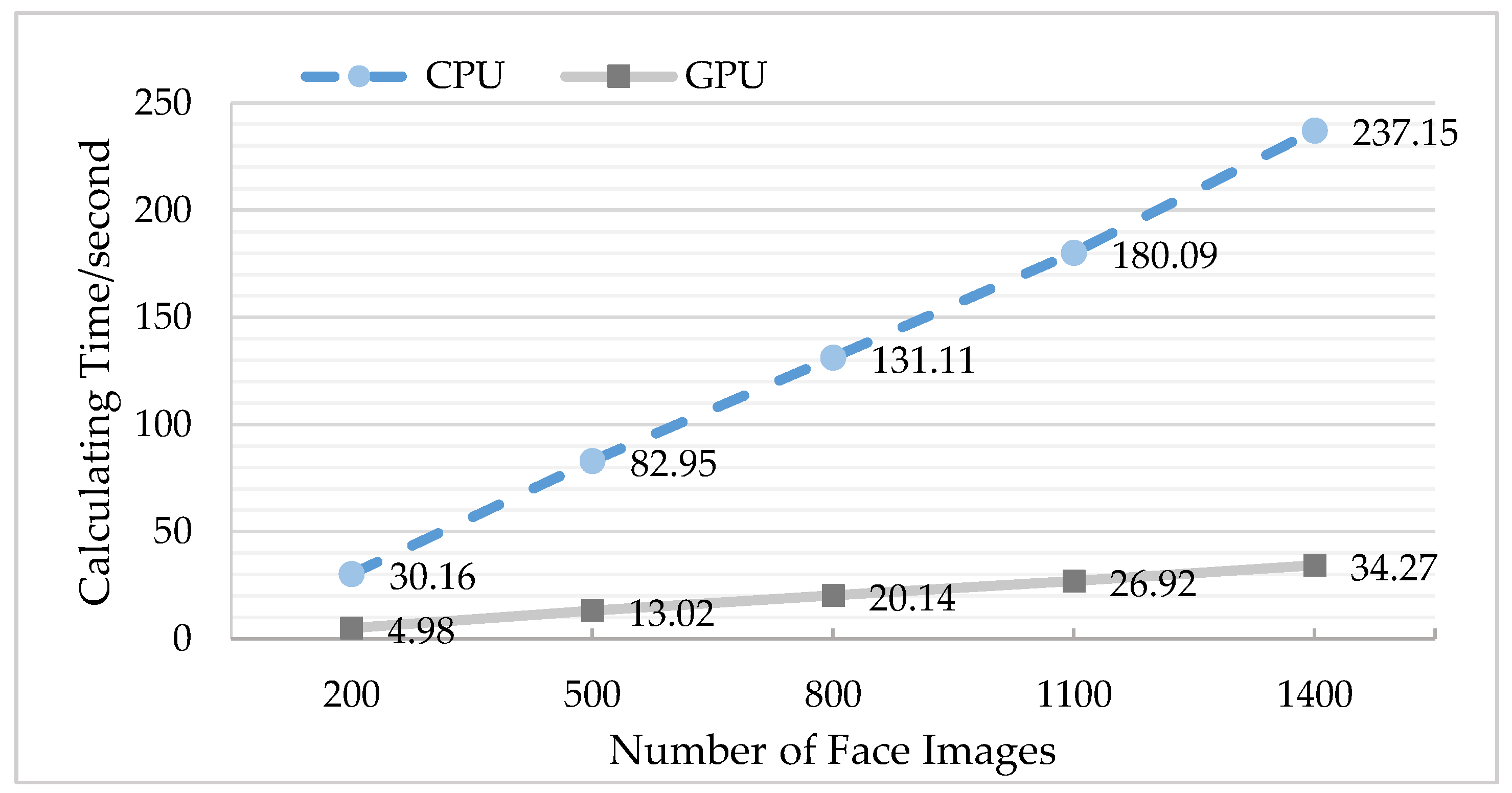
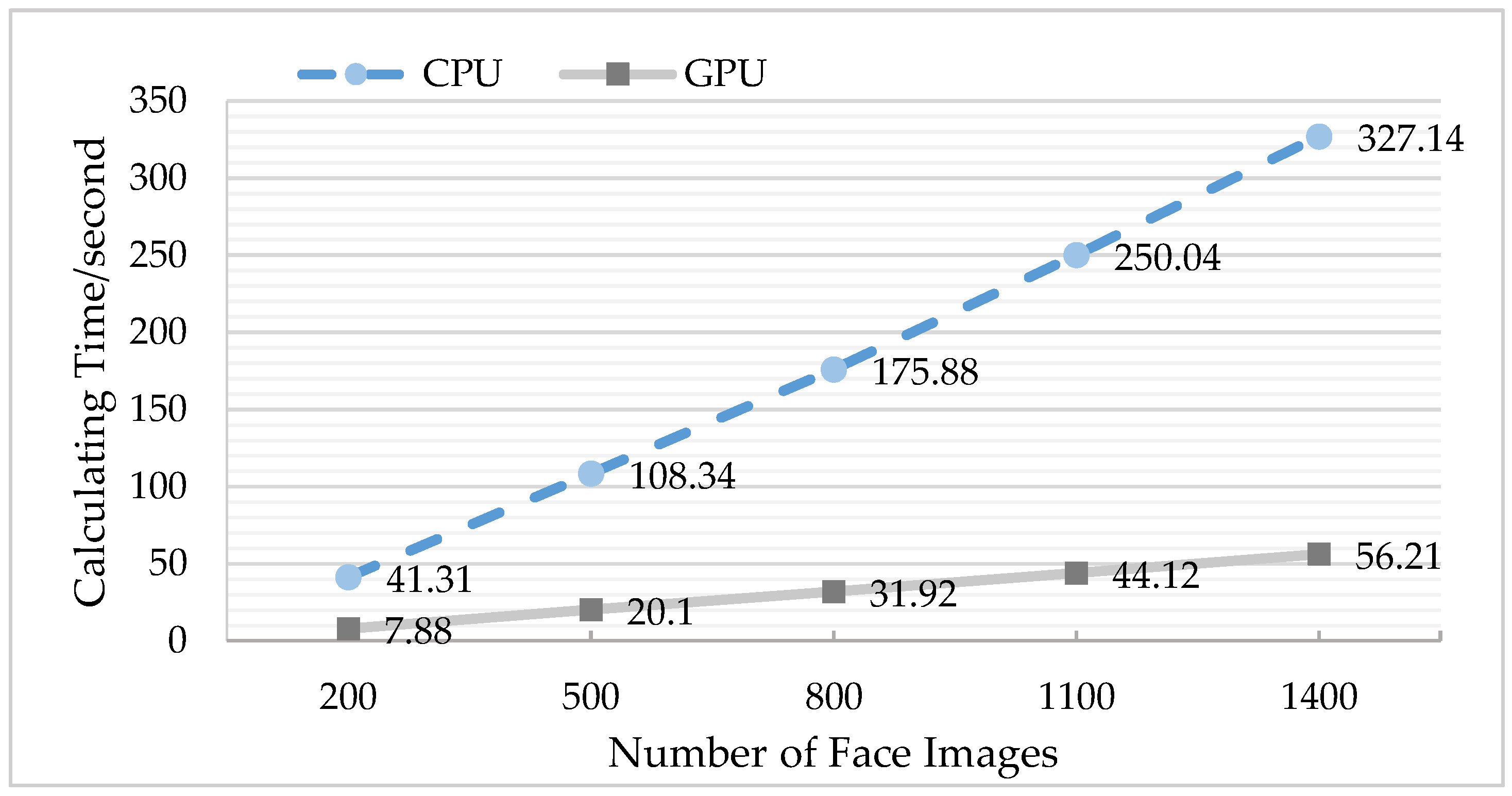
4.3.3. Comparison of GPU before and after Optimization
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Martino, L.D.; Preciozzi, J.; Lecumberry, F. Face matching with an a-contrario false detection control. Neurocomputing 2016, 173, 64–71. [Google Scholar] [CrossRef]
- Napoléon, T.; Alfalou, A. Pose invariant face recognition: 3D model from single photo. Opt. Lasers Eng. 2016, 89, 150–161. [Google Scholar] [CrossRef]
- Vezzetti, E.; Marcolin, F. Geometrical descriptors for human face morphological analysis and recognition. Robot. Auton. Syst. 2012, 60, 928–939. [Google Scholar] [CrossRef]
- Moos, S.; Marcolin, F.; Tornincasa, S. Cleft lip pathology diagnosis and foetal landmark extraction via 3D geometrical analysis. Int. J. Interact. Des. Manuf. 2017, 11, 1–18. [Google Scholar] [CrossRef]
- Poria, S.; Chaturvedi, I.; Cambria, E.; Hussain, A. Convolutional MKL Based Multimodal Emotion Recognition and Sentiment Analysis. In Proceedings of the IEEE International Conference on Data Mining, New Orleans, LA, USA, 18–21 November 2017. [Google Scholar]
- Mikolajczyk, K.; Schmid, C. A performance evaluation of local descriptors. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1615–1630. [Google Scholar] [CrossRef] [PubMed]
- Lu, J.; Liong, V.E.; Zhou, J. Cost-Sensitive Local Binary Feature Learning for Facial Age Estimation. IEEE Trans. Image Process 2015, 24, 5356–5368. [Google Scholar] [CrossRef]
- Perez, C.A.; Cament, L.A.; Castillo, L.E. Methodological improvement on local Gabor face recognition based on feature selection and enhanced Borda count. Pattern Recognit. 2011, 44, 951–963. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Ren, S.; He, K.; Girshick, R. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 1137–1149. [Google Scholar] [CrossRef]
- Sun, C.; Yang, Y.; Wen, C. Voiceprint Identification for Limited Dataset Using the Deep Migration Hybrid Model Based on Transfer Learning. Sensors 2018, 18, 2399. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Razavian, A.S.; Azizpour, H.; Sullivan, J. CNN Features Off-the-Shelf: An Astounding Baseline for Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 806–813. [Google Scholar]
- Li, J.; Qiu, T.; Wen, C. Robust Face Recognition Using the Deep C2D-CNN Model Based on Decision-Level Fusion. Sensors 2018, 18, 2080. [Google Scholar] [CrossRef]
- Gong, Y.; Wang, L.; Guo, R.; Lazebnik, S. Multi-scale Orderless Pooling of Deep Convolutional Activation Features. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Volume 8695, pp. 392–407. [Google Scholar]
- Xie, L.; Hong, R.; Zhang, B. Image Classification and Retrieval are ONE. In Proceedings of the 5th ACM on International Conference on Multimedia Retrieval, Shanghai, China, 23–26 June 2015; pp. 3–10. [Google Scholar]
- Farfade, S.S.; Saberian, M.J.; Li, L.J. Multi-view face detection using deep convolutional neural networks. In Proceedings of the 5th ACM on International Conference on Multimedia Retrieval, Shanghai, China, 23–26 June 2015; pp. 643–650. [Google Scholar]
- Jiang, H.; Learnedmiller, E. Face Detection with the Faster R-CNN. In Proceedings of the IEEE International Conference on Automatic Face and Gesture Recognition, Washington, DC, USA, 30 May–3 June 2017. [Google Scholar]
- Yang, S.; Luo, P.; Loy, C.C.; Tang, X. From facial parts responses to face detection: A deep learning approach. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3676–3684. [Google Scholar]
- Huang, L.; Yang, Y.; Deng, Y.; Yu, Y. Densebox: Unifying landmark localization with end to end object detection. arXiv, 2015; arXiv:1509.04874. [Google Scholar]
- Guo, J.; Xu, J.; Liu, S.; Huang, D.; Wang, Y. Occlusion-Robust Face Detection Using Shallow and Deep Proposal Based Faster R-CNN. In Proceedings of the Chinese Conference on Biometric Recognition, Chengdu, China, 14–16 October 2016; pp. 3–12. [Google Scholar]
- Qin, H.; Yan, J.; Li, X.; Hu, X. Joint training of cascaded CNN for face detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 456–3465. [Google Scholar]
- Sun, X.; Wu, P.; Hoi, S.C.H. Face detection using deep learning: An improved faster RCNN approach. Neurocomputing 2018, 299, 42–50. [Google Scholar] [CrossRef]
- Lowe, D.G. Object recognition from local scale invariant features. In Proceedings of the International Conference on Computer Vision (ICCV), Kerkyra, Greece, 21–22 September 1999; pp. 1150–1157. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant key-points. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Susan, S.; Jain, A.; Sharma, A. Fuzzy match index for scale-invariant feature transform (SIFT) features with application to face recognition with weak supervision. IET Image Process. 2015, 9, 951–958. [Google Scholar] [CrossRef]
- Park, S.; Yoo, J.H. Real-Time Face Recognition with SIFT-Based Local Feature Points for Mobile Devices. In Proceedings of the International Conference on Artificial Intelligence, Modelling and Simulation IEEE, Kota, Kinabalu, Malaysia, 3–5 December 2013; pp. 304–308. [Google Scholar]
- Narang, G.; Singh, S.; Narang, A. Robust face recognition method based on SIFT features using Levenberg-Marquardt Backpropagation neural networks. In Proceedings of the International Conference on Image and Signal Processing, Hangzhou, China, 16–18 December 2013; pp. 1000–1005. [Google Scholar]
- Zhang, T.; Zheng, W.; Cui, Z. A Deep Neural Network-Driven Feature Learning Method for Multi-view Facial Expression Recognition. IEEE Trans. Multimed. 2016, 18, 2528–2536. [Google Scholar] [CrossRef]
- Zheng, L.; Yang, Y.; Tian, Q. SIFT Meets CNN: A Decade Survey of Instance Retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 40, 1224–1244. [Google Scholar] [CrossRef] [PubMed]
- Chandrasekhar, V.; Lin, J.; Goh, H. A practical guide to CNNs and Fisher Vectors for image instance retrieval. Signal Process. 2016, 128, 426–439. [Google Scholar] [CrossRef]
- Tajbakhsh, N.; Shin, J.Y.; Gurudu, S.R. Convolutional Neural Networks for Medical Image Analysis: Fine Tuning or Full Training? IEEE Trans. Med. Imaging 2017, 35, 1299–1312. [Google Scholar] [CrossRef]
- Judd, T.; Ehinger, K.; Durand, F. Learning to predict where humans look. In Proceedings of the IEEE International Conference on Computer Vision, Kyoto, Japan, 27 September–4 October 2009; pp. 2106–2113. [Google Scholar]
- Zhao, Q.; Koch, C. Learning a saliency map using fixated locations in natural scenes. J. Vis. 2011, 11, 74–76. [Google Scholar] [CrossRef]
- Jeon, B.H.; Sang, U.L.; Lee, K.M. Rotation invariant face detection using a model-based clustering algorithm. In Proceedings of the International Conference on Multimedia and Expo, New York, NY, USA, 30 July–2 August 2000; pp. 1149–1152. [Google Scholar]
- Amiri, M.; Rabiee, H.R. A novel rotation/scale invariant template matching algorithm using weighted adaptive lifting scheme transform. Pattern Recognit. 2010, 43, 2485–2496. [Google Scholar] [CrossRef]
- Philbin, J.; Chum, O.; Isard, M. Object retrieval with large vocabularies and fast spatial matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 18–23 June 2007; pp. 1–8. [Google Scholar]
- Shen, X.; Lin, Z.; Brandt, J. Spatially-Constrained Similarity Measurefor Large-Scale Object Retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1229–1241. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Fischer, P.; Springenberg, J. Discriminative Unsupervised Feature Learning with Exemplar Convolutional Neural Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1734–1747. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Lam, E.Y. Facial expression recognition using deep neural networks. In Proceedings of the 2015 IEEE International Conference on Imaging Systems and Techniques (IST), Macau, China, 16–18 September 2015; pp. 1–6. [Google Scholar]
- Hossein, N.; Nasri, M. Image registration based on SIFT features and adaptive RANSAC transform. In Proceedings of the Conference on Communication and Signal Processing, Beijing, China, 6–8 April 2016; pp. 1087–1091. [Google Scholar]
- Elleuch, Z.; Marzouki, K. Multi-index structure based on SIFT and color features for large scale image retrieval. Multimed. Tools Appl. 2017, 76, 13929–13951. [Google Scholar] [CrossRef]
- Vinay, A.; Kathiresan, G.; Mundroy, D.A. Face Recognition using Filtered Eoh-sift. Procedia Comput. Sci. 2016, 79, 543–552. [Google Scholar] [CrossRef]
- Yu, D.; Yang, F.; Yang, C. Fast Rotation-Free Feature-Based Image Registration Using Improved N-SIFT and GMM-Based Parallel Optimization. IEEE Trans. Biomed. Eng. 2016, 63, 1653–1664. [Google Scholar] [CrossRef] [PubMed]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference Machine Learning (ICML), Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- He, K.; Zhang, X.; Ren, S. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 11–18 December 2015; pp. 1026–1034. [Google Scholar]
- Vens, C. Random Forest. Encycl. Syst. Biol. 2013, 45, 157–175. [Google Scholar]
- Devani, U.; Nikam, V.B.; Meshram, B. Super-fast parallel eigenface implementation on GPU for face recognition. In Proceedings of the Conference on Parallel, Distributed and Grid Computing, Solan, India, 11–13 December 2014; pp. 130–136. [Google Scholar]
- Huang, G.B.; Ramesh, M.; Berg, T.; Learned-Miller, E. Labeled Faces in the Wild: A Database for Studying Face Recognitionin Unconstrained Environments; No. 2. Technical Report 07-49; University of Massachusetts: Amherst, MA, USA, 2007; Volume 1. [Google Scholar]
- Ke, Y.; Sukthankar, R. PCA-SIFT: A more distinctive representation for local image descriptors. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Washington, DC, USA, 27 June–2 July 2004; pp. 506–513. [Google Scholar]
- Parua, S.; Das, A.; Mazumdar, D. Determination of Feature Hierarchy from Gabor and SIFT Features for Face Recognition. In Proceedings of the Conference on Emerging Applications of Information Technology, Kolkata, India, 19–20 February 2011; pp. 257–260. [Google Scholar]
- Vinay, A.; Hebbar, D.; Shekhar, V.S. Two Novel Detector-Descriptor Based Approaches for Face Recognition Using SIFT and SURF. Procedia Comput. Sci. 2015, 70, 185–197. [Google Scholar]
- Geng, C.; Jiang, X. Face recognition using SIFT features. In Proceedings of the Conference on Image Processing, Cairo, Egypt, 7–10 November 2009; pp. 3313–3316. [Google Scholar]
- Luo, J.; Ma, Y.; Takikawa, E. Person-Specific SIFT Features for Face Recognition. In Proceedings of the Conference on Acoustics, Speech and Signal Processing, Honolulu, HI, USA, 15–20 April 2007; pp. 593–596. [Google Scholar]
- Lenc, L. Automatic face recognition system based on the SIFT features. Comput. Electr. Eng. 2015, 46, 256–272. [Google Scholar] [CrossRef]
- Omidyeganeh, M.; Shirmohammadi, S.; Laganiere, R. Face identification using wavelet transform of SIFT features. In Proceedings of the Conference on Multimedia and Expo, Seattle, WA, USA, 15–19 July 2013; pp. 1–6. [Google Scholar]
- Azeem, A.; Sharif, M.; Shah, J.H. Hexagonal scale invariant feature transform (H-SIFT) for facial feature extraction. J. Appl. Res. Technol. 2015, 13, 402–408. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Target Datasets | Layer | LFW | Self-Collection |
|---|---|---|---|
| Pre-trained | Conv5 | 85.3 | 83.4 |
| FC6 | 86.8 | 85.8 | |
| FC7 | 86.0 | 85.4 | |
| Fine-tuned | Conv5 | 86.8 | 85.8 |
| FC6 | 87.7 | 87.5 | |
| FC7 | 88.7 | 88.6 |
| Method | ACC | TPR@FPR = 1% | TPR@FPR = 0.1% |
|---|---|---|---|
| PCA/SIFT | 92.34 | 89.53 | 80.46 |
| Gabor/SIFT | 94.37 | 91.76 | 82.72 |
| SURF/SIFT | 95.12 | 92.35 | 82.75 |
| PDSIF | 95.68 | 92.65 | 83.07 |
| Person-specific SIFT | 95.72 | 92.94 | 83.39 |
| SIFT/Kepenekci | 96.35 | 93.37 | 83.79 |
| Wavelet transform of the SIFT feature | 96.37 | 93.36 | 83.51 |
| H-SIFT | 96.42 | 93.44 | 83.86 |
| SIFT/RITF | 98.56 | 95.51 | 85.94 |
| CNN | 97.98 | 95.18 | 85.59 |
| Faster R-CNN | 98.45 | 95.67 | 85.97 |
| SR-CNN | 98.98 | 95.96 | 86.47 |
| Method | ACC | TPR@FPR = 1% | TPR@FPR = 0.1% |
|---|---|---|---|
| PCA/’SIFT | 92.51 | 89.45 | 80.52 |
| Gabor/SIFT | 93.86 | 90.81 | 82.84 |
| SURF/SIFT | 94.96 | 91.45 | 82.83 |
| PDSIF | 95.37 | 92.74 | 83.17 |
| Person-specific SIFT | 94.84 | 93.45 | 83.48 |
| SIFT/Kepenekci | 96.12 | 93.34 | 83.95 |
| Wavelet transform of the SIFT feature | 96.35 | 93.38 | 83.76 |
| H-SIFT | 96.58 | 93.56 | 83.97 |
| SIFT/RITF | 98.23 | 95.67 | 86.08 |
| CNN | 98.87 | 95.25 | 85.89 |
| Faster R-CNN | 99.10 | 95.86 | 86.53 |
| SR-CNN | 99.28 | 96.04 | 87.01 |
| Number of Face Images | Acceleration Ratio |
|---|---|
| 200 | 6.06 |
| 500 | 6.37 |
| 800 | 6.51 |
| 1100 | 6.69 |
| 1400 | 6.92 |
| Number of Face Images | Acceleration Ratio |
|---|---|
| 200 | 5.24 |
| 500 | 5.39 |
| 800 | 5.51 |
| 1100 | 5.66 |
| 1400 | 5.82 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Y.-X.; Wen, C.; Xie, K.; Wen, F.-Q.; Sheng, G.-Q.; Tang, X.-G. Face Recognition Using the SR-CNN Model. Sensors 2018, 18, 4237. https://doi.org/10.3390/s18124237
Yang Y-X, Wen C, Xie K, Wen F-Q, Sheng G-Q, Tang X-G. Face Recognition Using the SR-CNN Model. Sensors. 2018; 18(12):4237. https://doi.org/10.3390/s18124237
Chicago/Turabian StyleYang, Yu-Xin, Chang Wen, Kai Xie, Fang-Qing Wen, Guan-Qun Sheng, and Xin-Gong Tang. 2018. "Face Recognition Using the SR-CNN Model" Sensors 18, no. 12: 4237. https://doi.org/10.3390/s18124237
APA StyleYang, Y.-X., Wen, C., Xie, K., Wen, F.-Q., Sheng, G.-Q., & Tang, X.-G. (2018). Face Recognition Using the SR-CNN Model. Sensors, 18(12), 4237. https://doi.org/10.3390/s18124237