Comparison of Different Feature Sets for TLS Point Cloud Classification

Abstract
1. Introduction
2. Methodology
2.1. Supervoxels Generation
2.2. Feature Sets Extraction
2.3. Classifier
2.4. Performance Evaluation
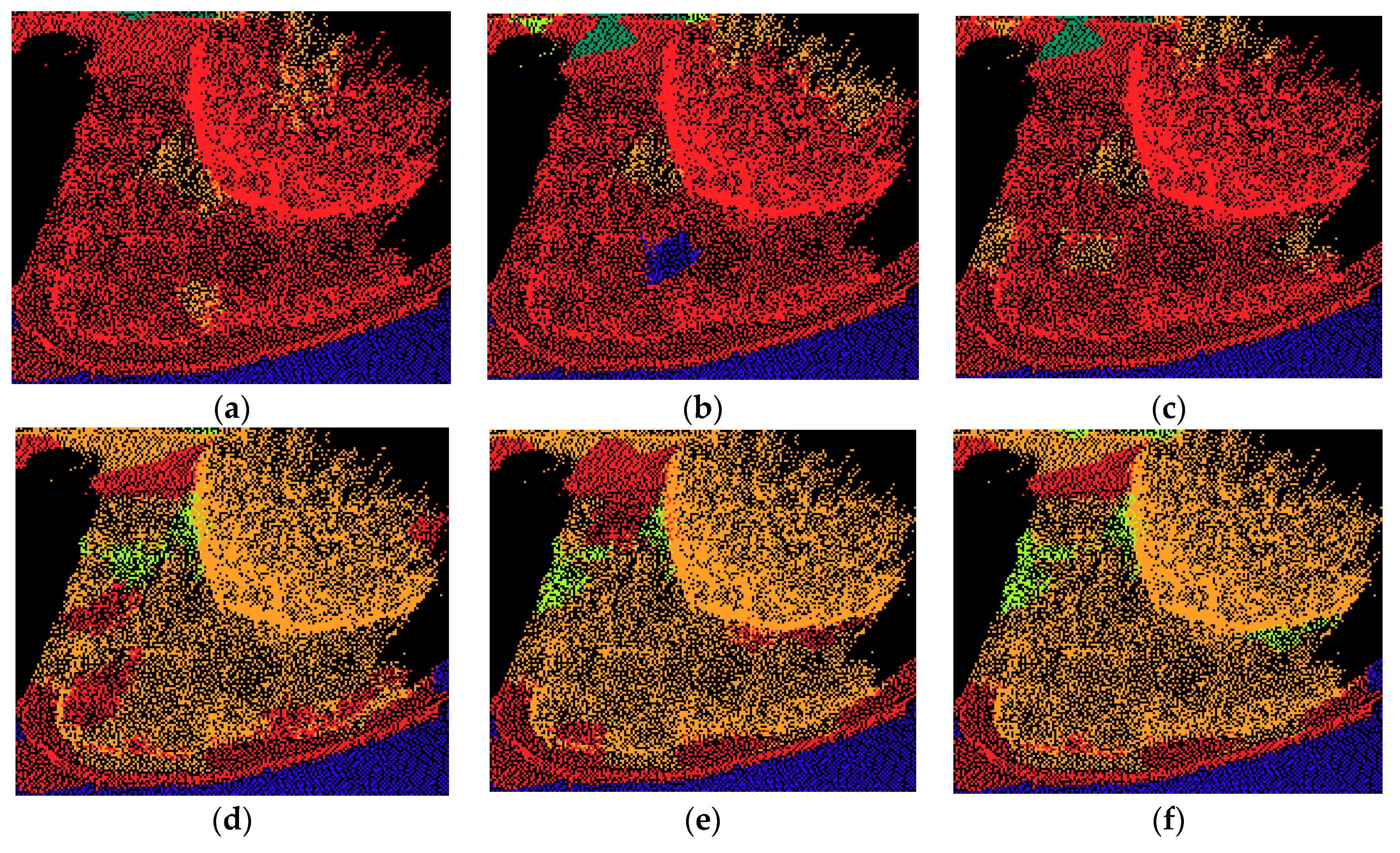
3. Experiment Results and Discussion
3.1. Data Sets
3.2. Classification and Evaluation
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Weinmann, M.; Jutzi, B.; Hinz, S.; Mallet, C. Semantic point cloud interpretation based on optimal neighborhoods, relevant features and efficient classifiers. ISPRS J. Photogramm. Remote Sens. 2015, 105, 286–304. [Google Scholar] [CrossRef]
- Lim, E.H.; Suter, D. 3D terrestrial LIDAR classifications with super-voxels and multi-scale Conditional Random Fields. Comput. Aided Des. 2009, 41, 701–710. [Google Scholar] [CrossRef]
- Ramiya, A.M.; Nidamanuri, R.R.; Ramakrishnan, K. A supervoxel-based spectro-spatial approach for 3d urban point cloud labelling. Int. J. Remote Sens. 2016, 37, 4172–4200. [Google Scholar] [CrossRef]
- Wang, H.; Wang, C.; Luo, H.; Li, P.; Chen, Y.; Li, J. 3-D point cloud object detection based on supervoxel neighborhood with Hough forest framework. IEEE J. Sel. Topics Appl. Earth Obs. Remote Sens. 2015, 8, 1570–1581. [Google Scholar] [CrossRef]
- Plaza-Leiva, V.; Gomez-Ruiz, J.A.; Mandow, A.; García-Cerezo, A. Voxel-Based Neighborhood for Spatial Shape Pattern Classification of Lidar Point Clouds with Supervised Learning. Sensors 2017, 17, 594. [Google Scholar] [CrossRef] [PubMed]
- Weinmann, M.; Hinz, S.; Weinmann, M. A hybrid semantic point cloud classification–segmentation framework based on geometric features and semantic rules. PFG Photogramm. Remote Sens. Geoinf. 2017, 85, 183–194. [Google Scholar] [CrossRef]
- Song, J.H.; Han, S.H.; Yu, K.Y.; Kim, Y.I. Assessing the possibility of land-cover classification using LIDAR intensity data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2002, 34, 259–262. [Google Scholar]
- Zhou, W. An object-based approach for urban land cover classification: Integrating LiDAR height and intensity data. IEEE Geosci. Remote Sens. 2013, 10, 928–931. [Google Scholar] [CrossRef]
- Zhang, J.X.; Lin, X.G.; Ning, X.G. Svm-based classification of segmented airborne lidar point clouds in urban areas. Remote Sens. 2013, 5, 3749–3775. [Google Scholar] [CrossRef]
- Guan, H.; Li, J.; Yu, Y.; Wang, C.; Chapman, M.; Yang, B. Using mobile laser scanning data for automated extraction of road markings. ISPRS J. Photogramm. Remote Sens. 2014, 87, 93–107. [Google Scholar] [CrossRef]
- Kumar, P.; McElhinney, C.P.; Lewis, P.; McCarthy, T. Automated road markings extraction from mobile laser scanning data. Int. J. Appl. Earth Obs. Geoinf. 2014, 32, 125–137. [Google Scholar] [CrossRef]
- Li, L.; Zhang, D.; Ying, S.; Li, Y. Recognition and reconstruction of zebra crossings on roads from mobile laser scanning data. ISPRS Int. J. Geo-Inf. 2016, 5, 125. [Google Scholar] [CrossRef]
- Hackel, T.; Wegner, J.D.; Schindler, K. Fast semantic segmentation of 3D point clouds with strongly varying density. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, III-3, 177–184. [Google Scholar] [CrossRef]
- Tan, K.; Cheng, X. Intensity data correction based on incidence angle and distance for terrestrial laser scanner. J. Appl. Remote Sens. 2015, 9, 94094. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, L.; Tong, X.; Du, B.; Wang, Y.; Zhang, L.; Zhang, Z.; Liu, H.; Mei, J.; Xing, X.; et al. A three-step approach for TLS point cloud classification. IEEE Trans. Geosci. Remote Sens. 2016, 54, 5412–5424. [Google Scholar] [CrossRef]
- Aijazi, A.K.; Checchin, P.; Trassoudaine, L. Segmentation based classification of 3D urban point clouds: A super-voxel based approach with evaluation. Remote Sens. 2013, 5, 1624–1650. [Google Scholar] [CrossRef]
- Lin, Y.; Wang, C.; Zhai, D.; Li, W.; Li, J. Toward better boundary preserved supervoxel segmentation for 3D point clouds. ISPRS J. Photogramm. Remote Sens. 2018, 143, 39–47. [Google Scholar] [CrossRef]
- Papon, J.; Abramov, A.; Schoeler, M.; Worgotter, F. Voxel cloud connectivity segmentation-supervoxels for point clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2027–2034. [Google Scholar]
- Kang, Z.; Yang, J. A probabilistic graphical model for the classification of mobile LiDAR point clouds. ISPRS J. Photogramm. Remote Sens. 2018, 143, 108–123. [Google Scholar] [CrossRef]
- Hofle, B.; Pfeifer, N. Correction of laser scanning intensity data: Data and model-driven approaches. ISPRS J. Photogramm. Remote Sens. 2007, 62, 415–433. [Google Scholar] [CrossRef]
- Kashani, A.; Olsen, M.; Parrish, C.; Wilson, N. A review of lidar radiometric processing: From AD HOC intensity correction to rigorous radiometric calibration. Sensors 2015, 15, 28099. [Google Scholar] [CrossRef] [PubMed]
- Kaasalainen, S.; Jaakkola, A.; Kaasalainen, M.; Krooks, A.; Kukko, A. Analysis of incidence angle and distance effects on terrestrial laser scanner intensity: Search for correction methods. Remote Sens. 2011, 3, 2207–2221. [Google Scholar] [CrossRef]
- Fang, W.; Huang, X.; Zhang, F.; Li, D. Intensity correction of terrestrial laser scanning data by estimating laser transmission function. IEEE Trans. Geosci. Remote Sens. 2015, 53, 942–951. [Google Scholar] [CrossRef]
- Tan, K.; Cheng, X. Correction of incidence angle and distance effects on tls intensity data based on reference targets. Remote Sens. 2016, 8, 251. [Google Scholar] [CrossRef]
- Jelalian, A.V. Laser Radar Systems; Artech House: Norwood, MA, USA, 1992. [Google Scholar]
- Demantké, J.; Vallet, B.; Paparoditis, N. Streamed vertical rectangle detection in terrestrial laser scans for facade database production. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2012, 1, 99–104. [Google Scholar] [CrossRef]
- Weinmann, M.; Jutzi, B.; Mallet, C. Semantic 3d scene interpretation: A framework combining optimal neighborhood size selection with relevant features. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2014, 2, 181–188. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Chehata, N.; Guo, L.; Mallet, C. Airborne LiDAR feature selection for urban classification using random forests. Int. Arch. Photogramm. Remote Sens. 2009, 38, 207–212. [Google Scholar]
- Hackel, T.; Wegner, J.D.; Schindler, K. Joint classification and contour extraction of large 3D point clouds. ISPRS J. Photogramm. Remote Sens. 2017, 130, 231–245. [Google Scholar] [CrossRef]
- Weinmann, M.; Weinmann, M.; Mallet, C.; Brédif, M. A Classification-Segmentation Framework for the Detection of Individual Trees in Dense MMS Point Cloud Data Acquired in Urban Areas. Remote Sens. 2017, 9, 277. [Google Scholar] [CrossRef]
- Li, Q.; Cheng, X. Damage Detection for Historical Architectures Based on TLS Intensity Data. ISPRS Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 42. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Geometric Features | Color and Intensity Features | ||
|---|---|---|---|
| Linearity | Mean R | ||
| Planarity | Mean G | ||
| Sphericity | Mean B | ||
| Omnivariance | R ratio | ||
| Anisotropy | G ratio: | ||
| Eigenentropy | B ratio: | ||
| Sum of eigenvalues | R variance | ||
| Change of curvature | G variance | ||
| Mean Z | B variance | ||
| Z variance | Maximum R difference | ||
| Maximum Z difference | Maximum G difference | ||
| Maximum B difference | |||
| Mean intensity | |||
| Intensity variance | |||
| Maximum intensity difference | |||
| Training Set | Testing Set 1 | Testing Set 2 | Testing Set 3 | Testing Set 4 | |
|---|---|---|---|---|---|
| Ground | 387,419 | 285,096 | 450,805 | 234,590 | 579,463 |
| Façade | 1,061,658 | 732,092 | 478,830 | 1,006,474 | 322,725 |
| Pole | 5678 | 7230 | 6320 | 4183 | 4696 |
| Tree | 390,699 | 637,980 | 156,989 | 473,145 | 402,273 |
| Vegetation | 242,325 | 255,365 | 262,837 | 330,093 | 195,834 |
| Curb | 42,001 | 104,175 | 22,327 | 29,139 | 19,239 |
| Total | 2,129,780 | 2,021,938 | 1,378,108 | 2,077,624 | 1,524,230 |
| Feature Set | Testing Set 1 | Testing Set 2 | Testing Set 3 | Testing Set 4 |
|---|---|---|---|---|
| Geo | 74.6 | 75.1 | 75.2 | 79.0 |
| Geo & OI | 76.0 | 75.1 | 76.2 | 80.2 |
| Geo & CI | 78.6 | 76.7 | 76.5 | 80.2 |
| Geo && C | 82.9 | 84.0 | 90.2 | 91.9 |
| Geo && C && OI | 83.8 | 84.0 | 89.8 | 91.8 |
| Geo && C && CI | 83.8 | 84.1 | 90.3 | 92.2 |
| Test Case 1 | Ground | Façade | Pole | Tree | Vegetation | Curb |
| Geo | 76.2/98.4 | 90.2/83.6 | 16.6/25.6 | 88.1/86.8 | 63.9/11.3 | 11.0/30.8 |
| 85.9 | 86.8 | 20.2 | 87.4 | 19.2 | 16.2 | |
| Geo & I | 76.7/97.9 | 93.7/83.1 | 15.9/20.1 | 86.8/91.1 | 70.2/12.0 | 12.3/33.9 |
| 86.0 | 88.1 | 17.8 | 88.9 | 20.5 | 18.1 | |
| Geo & CI | 76.2/97.6 | 97.2/86.1 | 22.4/34.4 | 89.0/94.6 | 73.2/16.6 | 12.6/31.6 |
| 85.6 | 91.3 | 27.1 | 91.7 | 27.1 | 18.0 | |
| Geo & C | 80.8/95.2 | 99.0/77.0 | 61.0/24.7 | 81.1/97.4 | 76.0/74.5 | 27.9/26.1 |
| 87.4 | 86.6 | 35.1 | 88.5 | 75.2 | 27.0 | |
| Geo & C & I | 82.3/95.5 | 98.8/76.1 | 66.6/26.3 | 82.0/97.7 | 79.5/81.3 | 30.6/30.1 |
| 88.4 | 86.0 | 37.7 | 89.1 | 80.4 | 30.3 | |
| Geo & C & CI | 81.5/95.8 | 98.9/76.0 | 72.9/26.3 | 79.4/97.9 | 81.1/81.1 | 38.0/29.1 |
| 88.1 | 86.0 | 38.6 | 87.7 | 81.1 | 32.9 | |
| Test Case 2 | Ground | Façade | Pole | Tree | Vegetation | Curb |
| Geo | 83.9/91.0 | 94.8/91.1 | 21.1/15.8 | 62.8/85.8 | 87.8/13.6 | 10.3/77.7 |
| 87.4 | 92.9 | 18.1 | 72.5 | 23.5 | 18.1 | |
| Geo & I | 80.9/93.3 | 97.0/88.8 | 42.0/14.6 | 58.2/92.0 | 89.6/10.1 | 12.5/78.5 |
| 86.7 | 92.7 | 21.7 | 71.3 | 18.2 | 21.6 | |
| Geo & CI | 82.3/96.3 | 98.0/88.4 | 33.8/21.2 | 60.4/93.4 | 84.6/13.1 | 13.1/76.9 |
| 88.7 | 92.9 | 26.0 | 73.4 | 22.7 | 22.3 | |
| Geo & C | 98.4/87.1 | 99.3/85.1 | 100.0/6.0 | 56.0/97.1 | 82.8/72.2 | 23.2/70.1 |
| 92.4 | 91.6 | 11.3 | 71.1 | 77.1 | 34.9 | |
| Geo & C & I | 99.1/86.5 | 99.2/84.3 | 100.0/6.0 | 56.4/97.2 | 87.7/74.4 | 19.1/71.8 |
| 92.4 | 91.1 | 11.3 | 71.4 | 80.5 | 30.1 | |
| Geo & C & CI | 98.9/88.5 | 99.3/81.8 | 100.0/6.0 | 56.1/96.4 | 81.8/76.3 | 24.2/71.5 |
| 93.4 | 89.7 | 11.3 | 71.0 | 79.0 | 36.2 | |
| Test Case 3 | Ground | Façade | Pole | Tree | Vegetation | Curb |
| Geo | 50.6/99.8 | 99.1/84.8 | 4.5/15.9 | 78.0/94.1 | 38.5/3.8 | 12.5/58.6 |
| 67.2 | 91.4 | 7.0 | 85.3 | 6.9 | 20.6 | |
| Geo & I | 49.6/99.8 | 99.5/86.3 | 5.1/15.2 | 79.2/95.0 | 46.4/4.0 | 13.9/59.1 |
| 66.3 | 92.4 | 7.6 | 86.4 | 7.4 | 22.5 | |
| Geo & CI | 50.3/99.8 | 99.4/87.1 | 7.7/25.3 | 80.7/94.7 | 41.3/4.0 | 13.4/59.4 |
| 66.9 | 92.9 | 11.9 | 87.1 | 7.2 | 21.9 | |
| Geo & C | 87.4/99.8 | 99.7/89.4 | 11.8/29.3 | 83.6/96.8 | 95.1/79.6 | 24.5/60.9 |
| 93.2 | 94.3 | 16.8 | 89.7 | 86.6 | 35.0 | |
| Geo & C & I | 88.7/99.8 | 99.8/88.6 | 20.9/34.3 | 81.5/97.4 | 96.3/78.5 | 24.3/65.9 |
| 93.9 | 93.9 | 26.0 | 88.7 | 86.5 | 35.5 | |
| Geo & C & CI | 86.8/99.8 | 99.8/89.3 | 15.6.28.4 | 82.5/97.0 | 95.1/80.3 | 28.3/62.8 |
| 92.9 | 94.2 | 20.2 | 89.1 | 87.1 | 39.0 | |
| Test Case 4 | Ground | Façade | Pole | Tree | Vegetation | Curb |
| Geo | 86.8/99.2 | 94.9/93.8 | 14.6/17.4 | 98.0/75.7 | 14.4/3.7 | 7.9/71.8 |
| 92.6 | 94.4 | 15.9 | 85.4 | 5.9 | 14.2 | |
| Geo & I | 86.8/99.0 | 96.0/94.2 | 15.2/17.7 | 97.7/80.4 | 20.1/3.6 | 8.1/73.2 |
| 92.5 | 95.1 | 16.3 | 88.2 | 6.2 | 14.5 | |
| Geo & CI | 86.9/99.5 | 97.5/95.5 | 17.5/23.8 | 97.6/77.6 | 17.4/4.9 | 8.8/74.2 |
| 92.8 | 96.5 | 20.2 | 86.5 | 7.7 | 15.7 | |
| Geo & C | 99.1/97.8 | 98.8/93.2 | 95.9/24.5 | 96.9/84.8 | 71.2/91.9 | 26.3/57.5 |
| 98.4 | 95.9 | 39.1 | 90.4 | 80.2 | 36.1 | |
| Geo & C & I | 99.0/97.0 | 98.7/92.7 | 97.2/28.2 | 96.5/85.3 | 72.9/92.7 | 24.4/60.6 |
| 98.0 | 95.6 | 43.7 | 90.5 | 81.6 | 34.8 | |
| Geo & C & CI | 97.9/98.2 | 98.6/94.7 | 97.7/33.9 | 96.2/84.9 | 71.5/90.2 | 39.1/60.1 |
| 98.0 | 96.6 | 50.3 | 90.2 | 79.8 | 47.4 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Q.; Cheng, X. Comparison of Different Feature Sets for TLS Point Cloud Classification. Sensors 2018, 18, 4206. https://doi.org/10.3390/s18124206
Li Q, Cheng X. Comparison of Different Feature Sets for TLS Point Cloud Classification. Sensors. 2018; 18(12):4206. https://doi.org/10.3390/s18124206
Chicago/Turabian StyleLi, Quan, and Xiaojun Cheng. 2018. "Comparison of Different Feature Sets for TLS Point Cloud Classification" Sensors 18, no. 12: 4206. https://doi.org/10.3390/s18124206
APA StyleLi, Q., & Cheng, X. (2018). Comparison of Different Feature Sets for TLS Point Cloud Classification. Sensors, 18(12), 4206. https://doi.org/10.3390/s18124206