A Parallel Architecture for the Partitioning around Medoids (PAM) Algorithm for Scalable Multi-Core Processor Implementation with Applications in Healthcare

 ,
, {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Background
3. Theory and Design of the Parallel PAM Algorithm
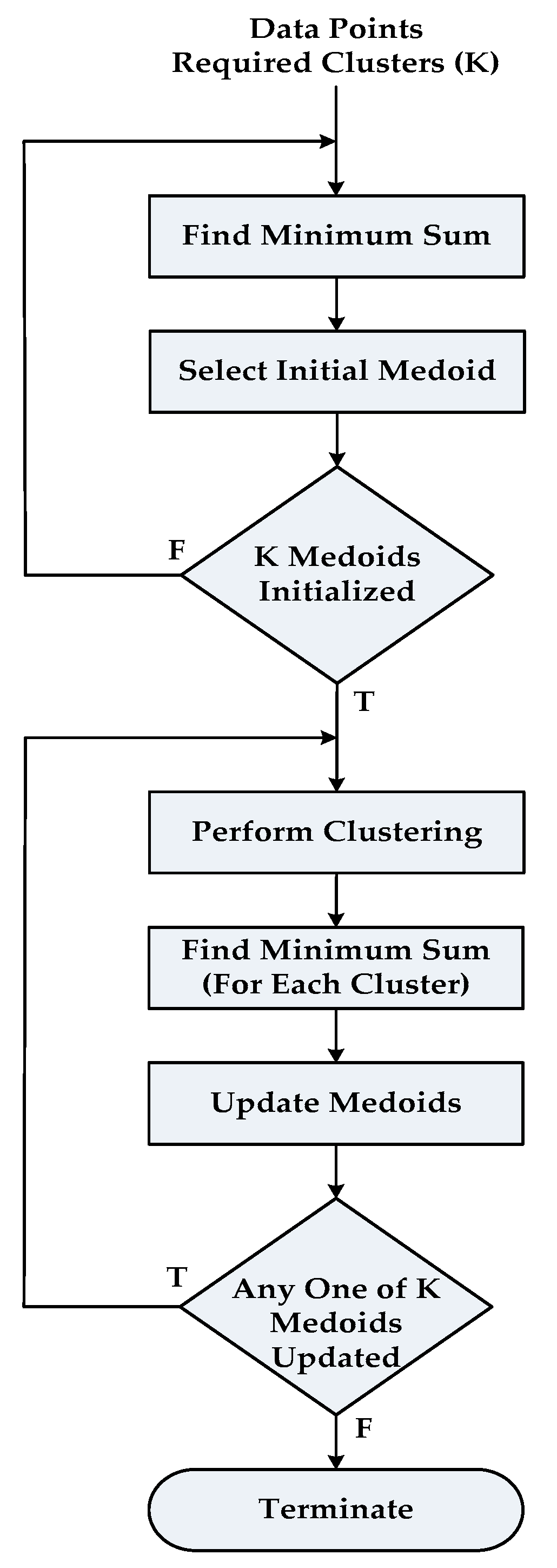
3.1. Overview of the PAM Algorithm
- In the first phase (called Build Phase) an initial clustering is obtained by the successive selection of K medoids. The first medoid is the one for which the sum of distances to all non-medoid objects is minimum. This is actually the most centrally located data point in set X. Subsequently, at each step another object is selected as a medoid, for which the objective function is minimum. The process is continued until K medoids have been found.
- In the second phase of the algorithm (called Swap Phase), it is attempted to improve the set M of medoids and therefore the clustering obtained by this set. The algorithm goes through each pair of objects (mj, xh), where mj is a medoid and xh is non-medoid object and xh belongs to cluster j. The effect on the objective function is determined when a swap is carried out i.e., when object xh is considered as a medoid in place of object mj. For each cluster j, the object xh is selected as its new medoid for which the objective function is minimized and thus the set M is updated. This process is iterated until no further decrease in objective function value is possible or in other words there is no update in set M between two consecutive iterations.
3.2. Proposed Design Flow
- Dividing the algorithm into a well-defined sequence of subtasks.
- Identifying the portions of the algorithm which can be executed in parallel.
- Running these subtasks for equal subsets of data simultaneously on multiple homogeneous cores.
- Combining the intermediate results from different PEs to produce a final clustering.
3.2.1. Sub-Tasking of PAM Algorithm
| Algorithm 1. Pseudo-code of PAM |
| Procedure: Partitioning Around Medoids (PAM) |
| Input:K (No. of clusters), X (Data Set) |
| Output:C (Vector containing cluster tags against each data object), M (Medoids) |
| 1. Initialize M /* Build Phase */ |
| 2. repeat /* Swap Phase */ |
| 3. Find clusters |
| 4. Perform swapping and update Medoids |
| 5. until no update in any of K Medoids |
| Algorithm 2. Pseudo-code of the Build Phase |
| 1. repeat |
| 2. for a := 1 → N do /* Find Minimum Sum */ |
| 3. Select Xa as temporary Medoid |
| 4. for i := 1 → N do |
| 5. for each Medoid selected yet (including Xa) do |
| 6. Find the minimum Euclidean distance b/w Xi and Medoid |
| 7. endfor |
| 8. Find sum of minimum distances |
| 9. endfor |
| 10. Find minimum sum |
| 11. endfor |
| 12. Select Xa as actual Medoid for which the sum is minimum /* Select Initial Medoid */ |
| 13. until ‘K’ initial Medoids are selected |
| Algorithm 3. Pseudo-code of the Swap Phase |
| 1. repeat |
| 2. for i := 1 → N do /* Perform Clustering */ |
| 3. for j := 1 → K do |
| 4. Find Euclidean distance b/w Xi and Mj |
| 5. Tag Xi with j for which this distance is minimum |
| 6. endfor |
| 7. endfor |
| 8. for j := 1 → K do /* Find Minimum Sum (For Each Cluster)*/ |
| 9. for each data point Xa ϵ cluster j do |
| 10. for each data point Xi ϵ cluster j do |
| 11. Find sum of Euclidean distances b/w Xa and Xi |
| 12. endfor |
| 13. Find minimum sum |
| 14. endfor |
| 15. Update Xa as jth Medoid for which the sum is minimum /* Update Medoid*/ |
| 16. endfor |
| 17. until no update in any of ‘K’ Medoids |
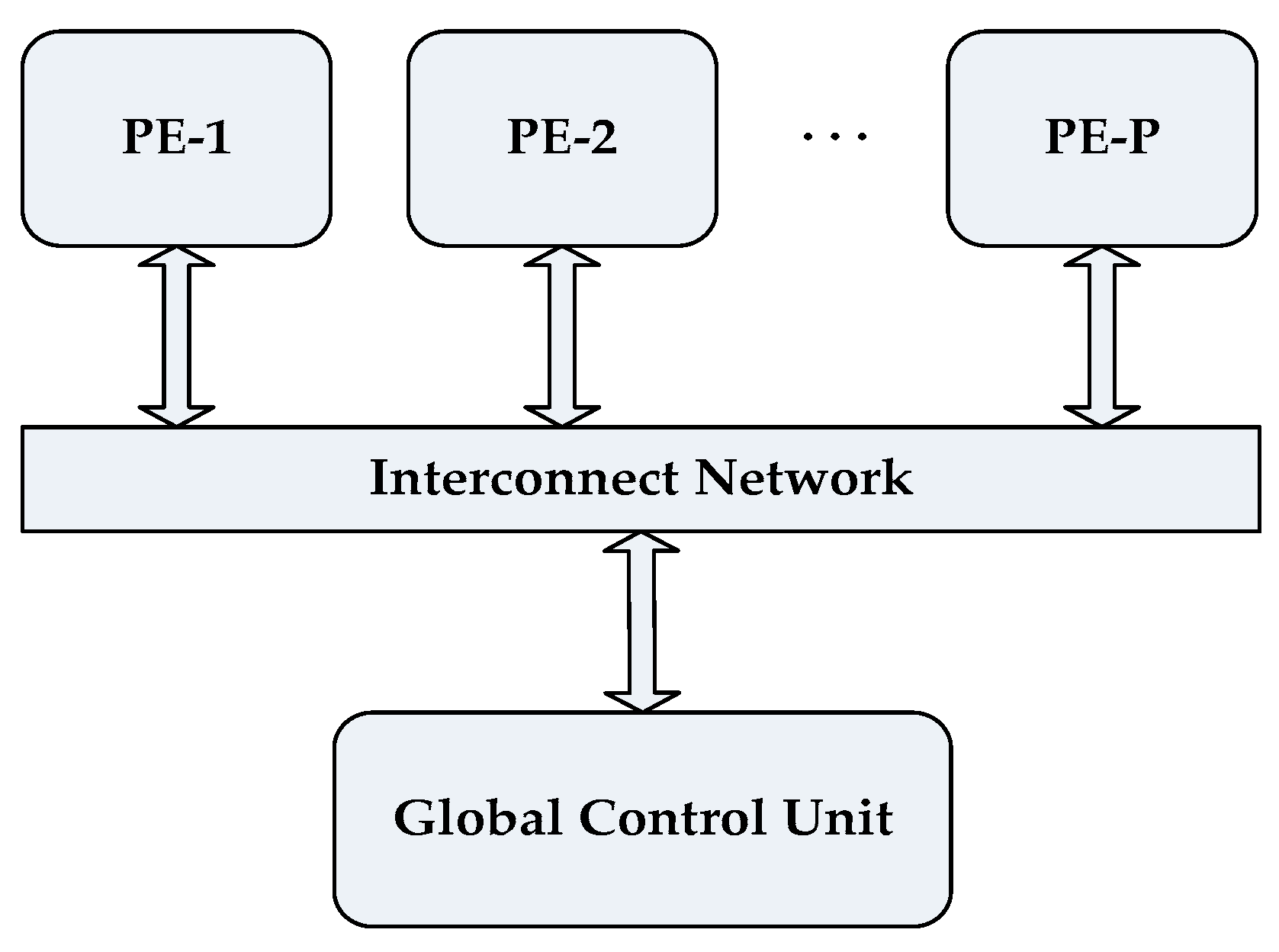
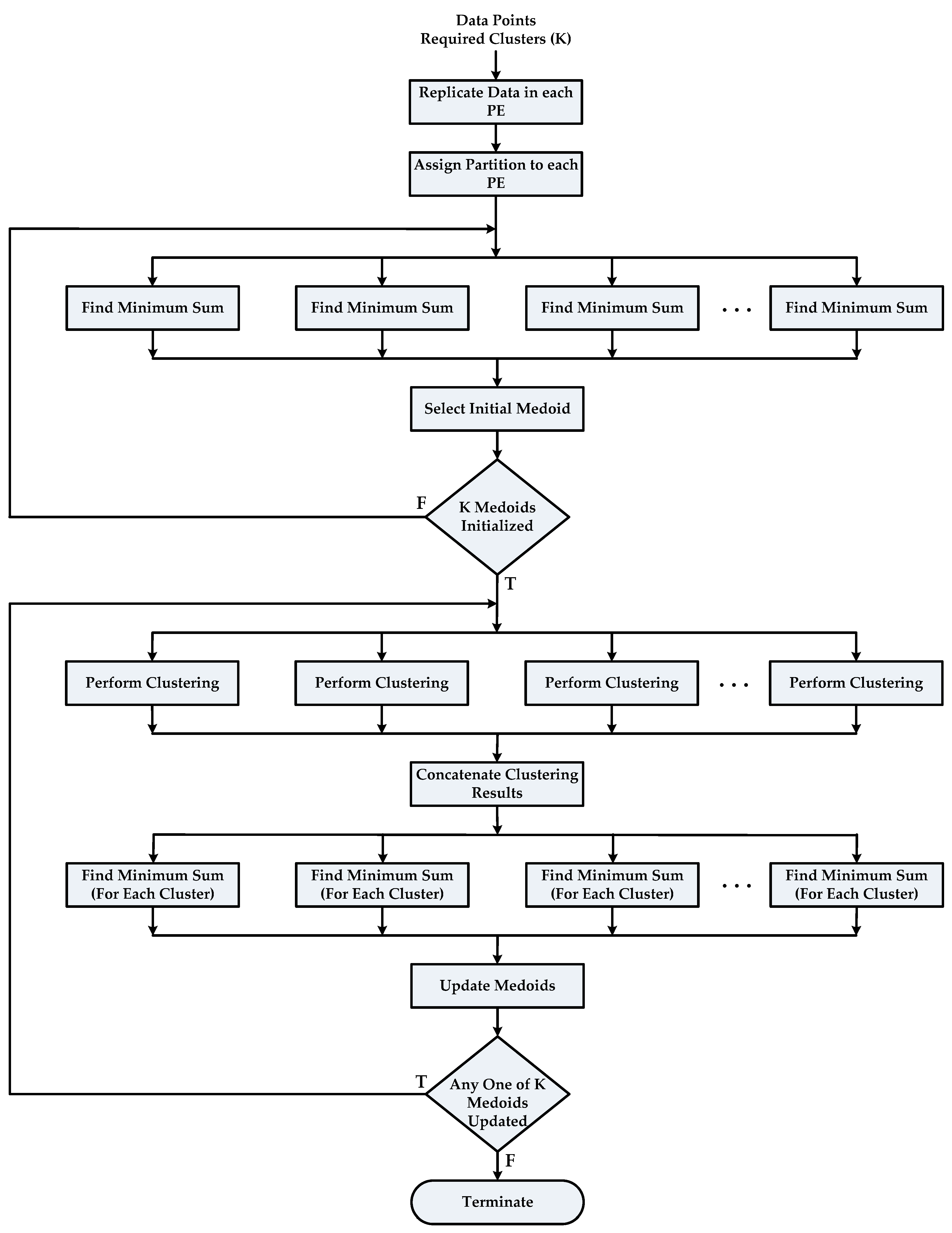
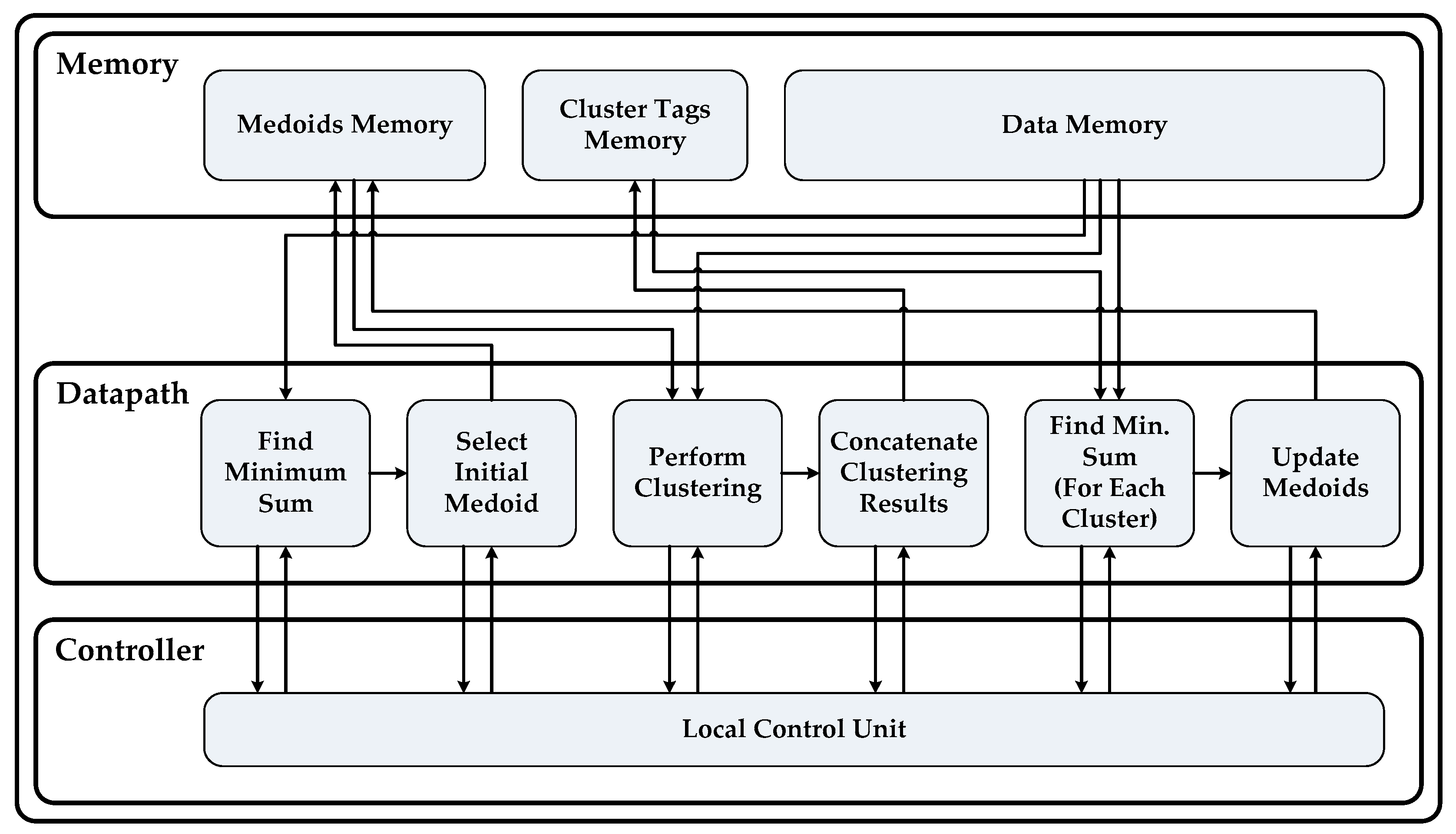
3.2.2. Paralleling the PAM Algorithm and Proposed Architecture
- A data set of size N is made completely divisible into the number of available cores P by appending zeros at the end of the data set so that equal subsets can be assigned to each core.
- The complete data set X is replicated in all available PEs and equal partitions of X are assigned to each PE.
- Each PE then executes the subtask “Find Minimum Sum” of the Build Phase for its respective data subset of size in parallel. Master PE (any processing element can be assigned to perform as master PE because all PEs are homogenous) will collect the results of the first subtask from each PE and perform the subtask “Select Initial Medoid”. This step is repeated until K medoids are initialized, as described in Algorithm 4 below.
- Final results of Build Phase are sent to all PEs so that they can proceed to the next phase of algorithm.
- Each PE will tag all its assigned data objects with their closest cluster numbers. These tags are stored in local memory associated with each data object. All PEs one by one broadcast their tags over the interconnect network so that each PE can have complete result of clustering.
- The subtask “Find Minimum Sum (For Each Cluster)” of the Swap Phase is executed by each core in parallel. A master PE will perform the subtask “Update Medoid” after receiving results from other PEs. Steps 5 and 6 are repeated until no update in any of K medoids is reported. Algorithm 5 depicts the working of the Swap Phase in case of parallel PAM.
| Algorithm 4. Pseudo-code of the Build Phase for Parallel PAM |
| 1. repeat |
| 2. for p := 1 → P do in parallel |
| 3. for each data point Xa ϵ p do /* All PEs do in parallel*/ |
| 4. Select Xa as temporary Medoid |
| 5. for i := 1 → N do |
| 6. for each Medoid selected yet (including Xa)do |
| 7. Find the minimum Euclidean distance b/w Xi and Medoid |
| 8. endfor |
| 9. Find sum of minimum distances |
| 10. endfor |
| 11. Find minimum sum |
| 12. endfor |
| 13. endfor |
| 14. for p := 1 → P do /* Only master PE will do this */ |
| 15. Select Xa as actual Medoid for which the sum is minimum from all PEs |
| 16. endfor |
| 17. until ‘K’ initial Medoids are selected |
| Algorithm 5. Pseudo-code of the Swap Phase for Parallel PAM |
| 1. repeat |
| 2. for p := 1 → P do in parallel |
| 3. for each data point Xi ϵ p do /* All PEs do in parallel*/ |
| 4. for j := 1 → K do |
| 5. Find Euclidean distance b/w Xi and Mj |
| 6. Tag Xi with j for which this distance is minimum |
| 7. endfor |
| 8. endfor |
| 9. endfor |
| 10. Concatenate clustering results from all PEs /* All PEs do this*/ |
| 11. for p := 1 → P do in parallel |
| 12. for j := 1 → K do /* All PEs do in parallel*/ |
| 13. for each data point Xa ϵ p & cluster j do |
| 14. for each data point Xi ϵ cluster j do |
| 15. Find sum of Euclidean distances b/w Xa and Xi |
| 16. endfor |
| 17. Find minimum sum for each cluster |
| 18. endfor |
| 19. endfor |
| 20. endfor |
| 21. for j := 1 → K do /* Only master PE will do this */ |
| 22. for p := 1 → P do |
| 23. Update Xa as jth Medoid for which the sum is minimum from all PEs |
| 24. endfor |
| 25. endfor |
| 26. until no update in any of ‘K’ Medoids |
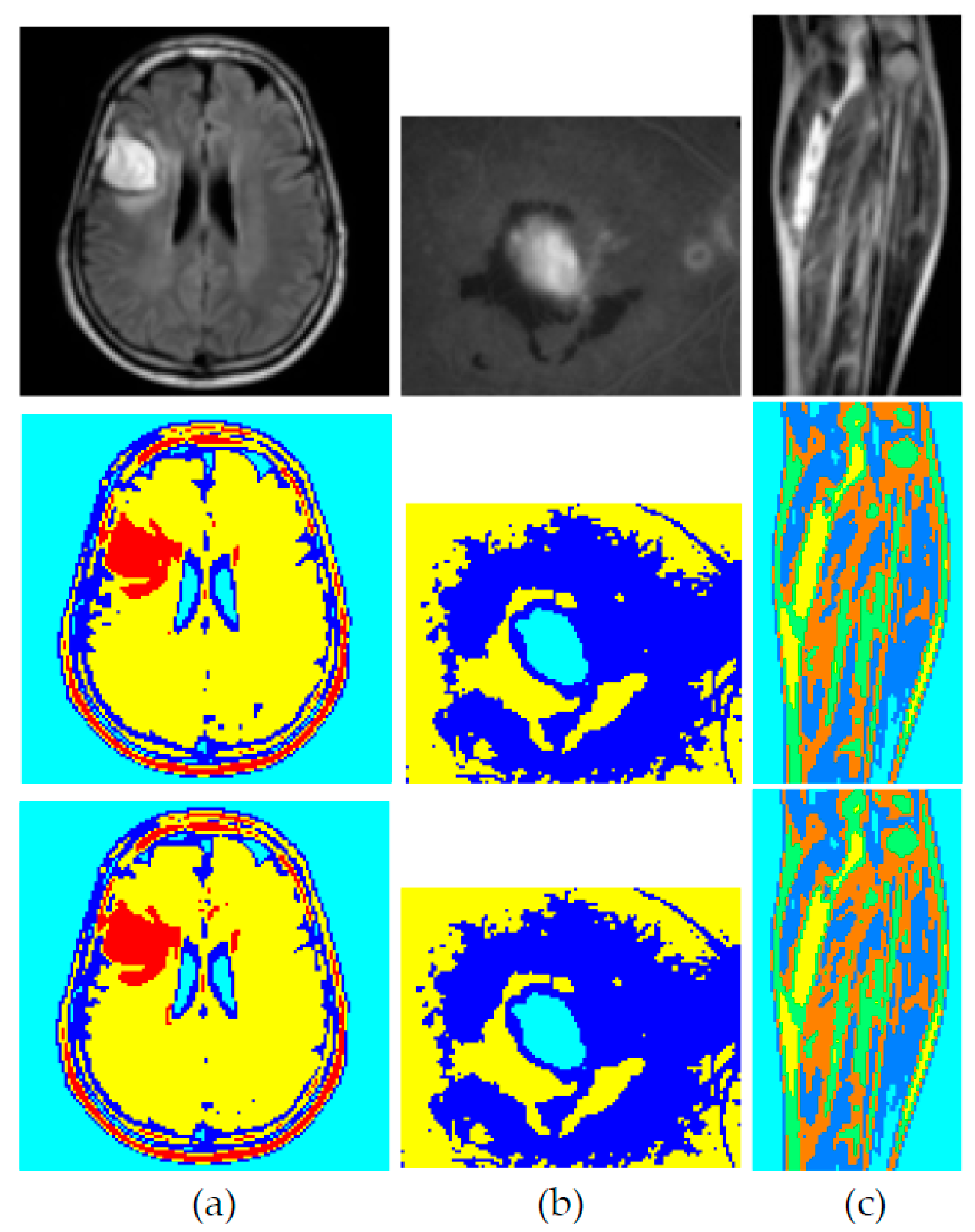
4. Experimentation and Results
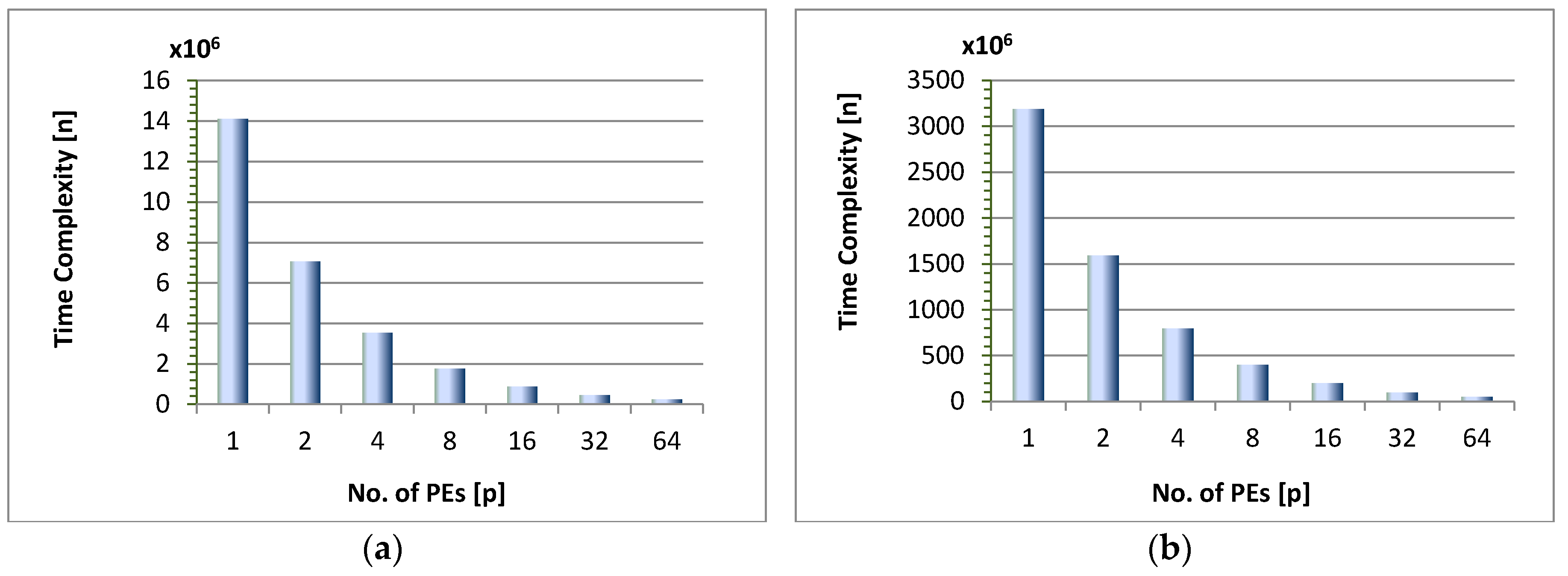
- The time complexity n of the algorithm reduces exponentially as we increase the number of cores for the same data set or image. Here by time complexity we mean the running time which is taken by all computations required by the build and swap phases. This computation complexity reduces as we increase the number of processing entities and divide the computations among them. For example, the running time of PAM algorithm for N = 800, d = 2, K = 4 and P = 1, is n ≈ 1.41 × 107. For P = 2, this value is half of the previous value i.e., n ≈ 7.1 × 106 plus a small communication overhead = 4948. Similarly, for P = 4, n ≈ 3.5 × 106 plus overhead is 3416 and so on. Figure 5 shows this trend for both the artificial data set of size 800 and an image of 9720 pixels in size. Furthermore, it is observed that when the size of the data is increased this trend becomes more uniform and gets close to , where n1 is the computational complexity of the sequential algorithm. This is evident from Figure 5a,b where the trend remains the same even if we increase the data points which need to be clustered.
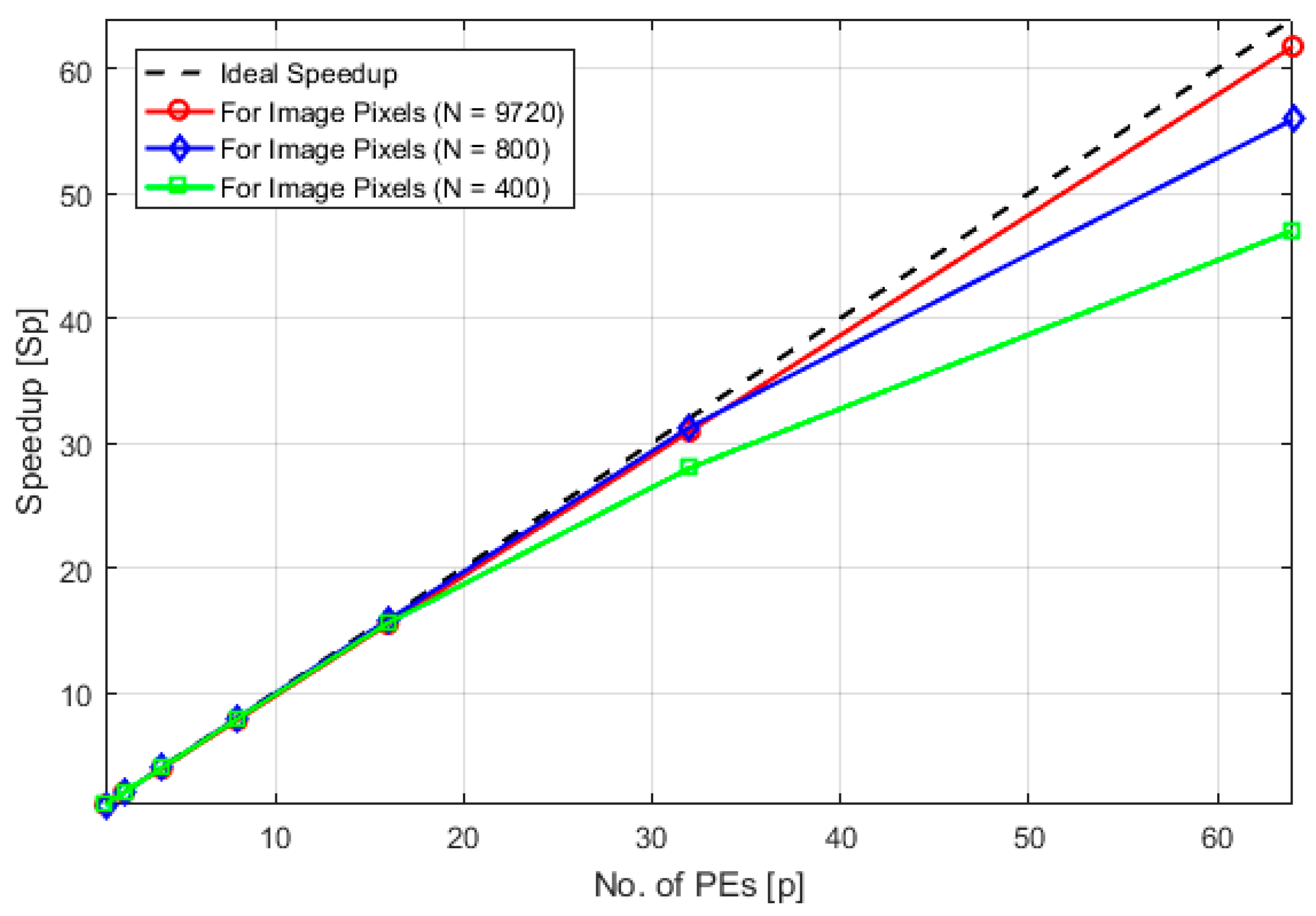
- The speedup of the algorithm is defined as Sp = , where n1 is running time of the algorithm for a single PE and np is the running time for P processing elements. It was observed that the speedup of the parallel PAM algorithm increases with the increase in the number of processing elements, but this increasing trend varies slightly for different scenarios discussed below.
- (1)
- The speedup graph gets more linear as the data size increases for the same number of PEs. This trend is shown in Figure 6.
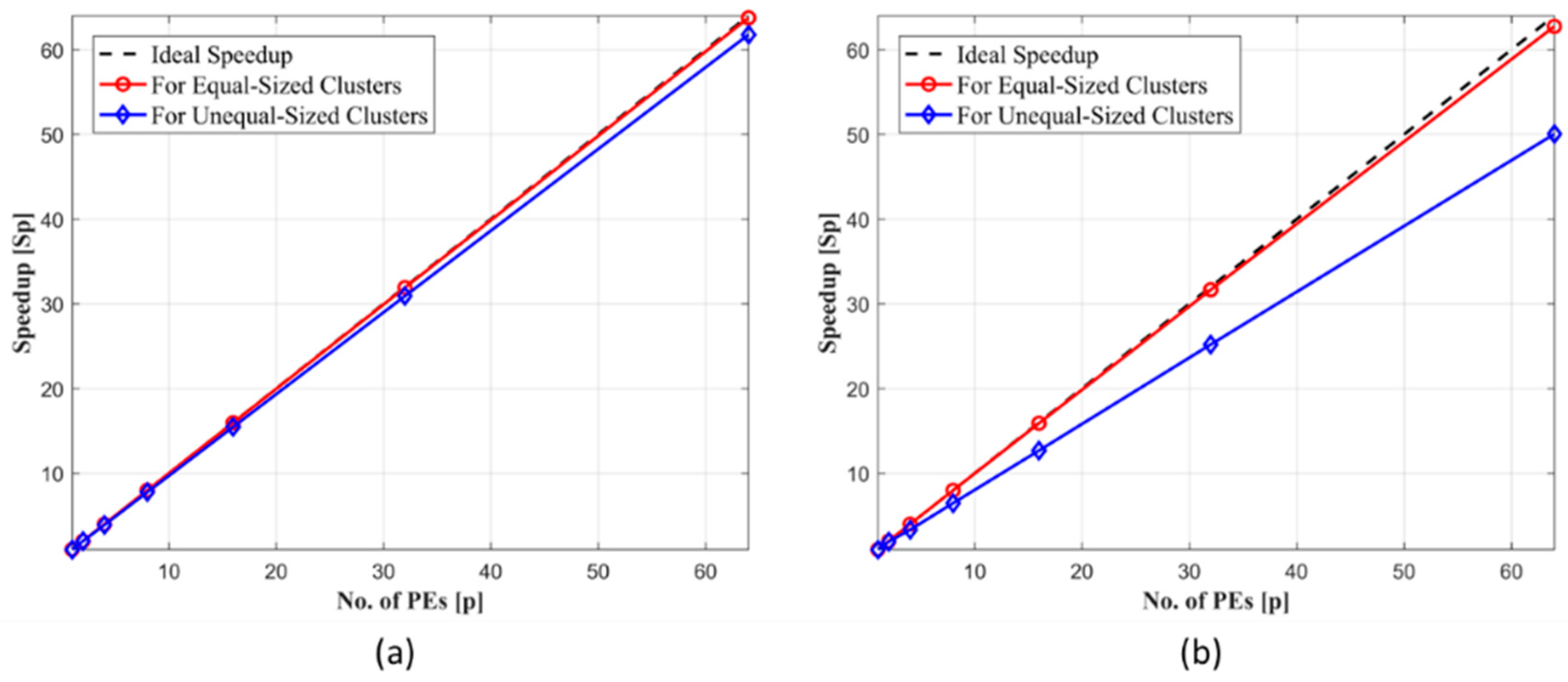
- (2)
- If the clusters to be formed are uniform i.e., the number of data objects is equal in each cluster then the speedup attained is slightly better than the case when clusters are non-uniform for same data set size.
- (1)
- It was observed that due to the high computation cost of the Build Phase, the total computation cost of the algorithm (order of N2) is much higher than the communication cost (order of N), for large values of N. Therefore, communication overhead doesn’t affect the speedup and it is almost equal to the number of PEs.
- (2)
- If we don’t include the effect of build phase or medoids are randomly initialized then communication overhead will affect the speedup achieved by our parallel PAM algorithm, otherwise this trend will be near linear, as shown in Figure 7.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Li, F.; Hong, J. Efficient certificateless access control for wireless body area networks. IEEE Sens. J. 2016, 16, 5389–5396. [Google Scholar] [CrossRef]
- Pirbhulal, S.; Zhang, H.; Wu, W.; Mukhopadhyay, S.C.; Zhang, Y.T. Heart-beats based biometric random binary sequences generation to secure wireless body sensor networks. IEEE Trans. Biomed. Eng. 2018. [Google Scholar] [CrossRef]
- Agrawal, D.P. Personal/body area networks and healthcare applications. In Embedded Sensor Systems; Springer: Singapore, 2017; pp. 353–390. [Google Scholar]
- Pirbhulal, S.; Zhang, H.; Alahi, M.E.; Ghayvat, H.; Mukhopadhyay, S.C.; Zhang, Y.T.; Wu, W. A novel secure IoT-based smart home automation system using a wireless sensor network. Sensors 2016, 17, 69. [Google Scholar] [CrossRef] [PubMed]
- Sodhro, A.H.; Pirbhulal, S.; Sangaiah, A.K. Convergence of IoT and product lifecycle management in medical health care. Future Gener. Comput. Syst. 2018, 86, 380–391. [Google Scholar] [CrossRef]
- Wu, W.; Pirbhulal, S.; Sangaiah, A.K.; Mukhopadhyay, S.C.; Li, G. Optimization of signal quality over comfortability of textile electrodes for ECG monitoring in fog computing based medical applications. Future Gener. Comput. Syst. 2018, 86, 515–526. [Google Scholar] [CrossRef]
- Pirbhulal, S.; Zhang, H.; Mukhopadhyay, S.C.; Li, C.; Wang, Y.; Li, G.; Wu, W.; Zhang, Y.T. An efficient biometric-based algorithm using heart rate variability for securing body sensor networks. Sensors 2015, 15, 15067–15089. [Google Scholar] [CrossRef] [PubMed]
- Rechkalov, T.V.; Zymbler, M. Accelerating Medoids-based Clustering with the Intel Many Integrated Core Architecture. In Proceedings of the 2015 9th International Conference on Application of Information and Communication Technologies (AICT), Rostov on Don, Russia, 14–16 October 2015; pp. 413–417. [Google Scholar] [CrossRef]
- Tehreem, A.; Khawaja, S.G.; Akram, M.U.; Khan, S.A. A Novel Mean-shift Architecture for Scalable Multiprocessor Implementation. In Proceedings of the 2016 Future Technologies Conference (FTC), San Francisco, CA, USA, 6–7 December 2016; pp. 1107–1111. [Google Scholar] [CrossRef]
- Girolami, M.; He, C. Probability density estimation from optimally condensed data samples. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 1253–1264. [Google Scholar] [CrossRef]
- Oyelade, O.J.; Oladipupo, O.O.; Obagbuwa, I.C. Application of K-Means Clustering algorithm for prediction of Students Academic Performance. arXiv, 2010; arXiv:1002.2425. [Google Scholar]
- Akkaya, K.; Senel, F.; McLaughlan, B. Clustering of wireless sensor and actor networks based on sensor distribution and connectivity. J. Parallel Distrib. Comput. 2009, 69, 573–587. [Google Scholar] [CrossRef]
- Schaible, T. Method and System to Derive Glycemic Patterns from Clustering of Glucose Data. U.S. Patent No. 9,504,412, 29 November 2016. [Google Scholar]
- Khawaja, S.G.; Akram, M.U.; Khan, S.A.; Shaukat, A.; Rehman, S. Network-on-Chip based MPSoC Architecture for K-Mean Clustering Algorithm. Microprocess. Microsyst. 2016, 46, 1–10. [Google Scholar] [CrossRef]
- Wu, W.; Zhang, Z.; Pirbhulal, S.; Mukhopadhyay, S.C.; Zhang, Y.T. Assessment of biofeedback training for emotion management through wearable textile physiological monitoring system. IEEE Sens. J. 2018, 15, 7087–7095. [Google Scholar] [CrossRef]
- Pirbhulal, S.; Shang, P.; Wu, W.; Sangaiah, A.K.; Samuel, O.W.; Li, G. Fuzzy vault-based biometric security method for tele-health monitoring systems. Comput. Electr. Eng. 2018, 71, 546–557. [Google Scholar] [CrossRef]
- Sodhro, A.H.; Pirbhulal, S.; Sangaiah, A.K.; Lohano, S.; Sodhro, G.H.; Luo, Z. 5G-Based Transmission Power Control Mechanism in Fog Computing for Internet of Things Devices. Sustainability 2018, 10, 1258. [Google Scholar] [CrossRef]
- Sodhro, A.H.; Sangaiah, A.K.; Pirphulal, S.; Sekhari, A.; Ouzrout, Y. Green media-aware medical IoT system. Multimed. Tools Appl. 2018, 77, 1–20. [Google Scholar] [CrossRef]
- Kaufman, L.; Rousseeuw, P.J. Clustering by Means of Medoids. In Statistical Data Analysis Based on the L1 Norm and Related Methods; Dodge, Y., Ed.; Birkhäuser: Amsterdam, The Netherlands, 1987; pp. 405–416. [Google Scholar]
- Lloyd, S.P. Least Squares Quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–136. [Google Scholar] [CrossRef]
- Huang, Z. Extensions to the k-Means Algorithm for Clustering Large Data Sets with Categorical Values. Data Min. Knowl. Discov. 1998, 2, 283–304. [Google Scholar] [CrossRef]
- Ibrahim, A.; Gastaldo, P.; Chible, H.; Valle, M. Real-time digital signal processing based on FPGAs for electronic skin implementation. Sensors 2017, 17, 558. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.A.; Chen, S.L.; Huang, H.Y.; Luo, C.H. An efficient micro control unit with a reconfigurable filter design for wireless body sensor networks (WBSNs). Sensors 2012, 12, 16211–16227. [Google Scholar] [CrossRef] [PubMed]
- Rodríguez, A.; Valverde, J.; Portilla, J.; Otero, A.; Riesgo, T.; de la Torre, E. FPGA-Based High-Performance Embedded Systems for Adaptive Edge Computing in Cyber-Physical Systems: The ARTICo3 Framework. Sensors 2018, 18, 1877. [Google Scholar] [CrossRef] [PubMed]
- Vishnoi, U.; Noll, T.G. Area-and energy-efficient CORDIC accelerators in deep sub-micron CMOS technologies. Adv. Radio Sci. 2012, 10, 207–213. [Google Scholar] [CrossRef]
- Gadea-Gironés, R.; Colom-Palero, R.; Herrero-Bosch, V. Optimization of Deep Neural Networks Using SoCs with OpenCL. Sensors 2018, 18, 1384. [Google Scholar] [CrossRef] [PubMed]
- Luo, J.H.; Lin, C.H. Pure FPGA implementation of an HOG based real-time pedestrian detection system. Sensors 2018, 18, 1174. [Google Scholar] [CrossRef] [PubMed]
- Mehmood, S.; Cagnoni, S.; Mordonini, M.; Farooq, M. Particle swarm optimisation as a hardware-oriented meta-heuristic for image Analysis. In Proceedings of the Workshops on Applications of Evolutionary Computation, Tübingen, Germany, 15–17 April 2009; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Vishnoi, U.; Noll, T.G. Cross-layer optimization of QRD accelerators. In Proceedings of the ESSCIRC (ESSCIRC), Bucharest, Romania, 16–20 September 2013. [Google Scholar]
- Aljoby, W.; Alenezi, K. Parallelization of K-Medoid Clustering Algorithm. In Proceedings of the 5th International Conference on Information and Communication Technology for the Muslim World (ICT4M), Rabat, Morocco, 26–27 March 2013. [Google Scholar] [CrossRef]
- Rechkalov, T.V. Partition Around Medoids Clustering on the Intel Xeon Phi Many-Core Coprocessor. In Proceedings of the 1st Ural Workshop on Parallel, Distributed, and Cloud Computing for Young Scientists (Ural-PDC 2015), Yekaterinburg, Russia, 17 November 2015; pp. 29–41. [Google Scholar]
- Velmurugan, T.; Santhanam, T. A Practical Approach of K-Medoids Clustering Algorithm for Artificial data points. In Proceedings of the International Conference on Semantics, E-business and E-Commerce, Tiruchirappalli, India, 4–6 November 2009. [Google Scholar]
- Park, H.S.; Jun, C.H. A simple and fast algorithm for K-medoids clustering. Expert Syst. Appl. 2009, 36, 3336–3341. [Google Scholar] [CrossRef]
- Tehreem, A.; Khawaja, S.G.; Khan, A.M.; Akram, M.U.; Khan, S.A. Multiprocessor architecture for real-time applications using mean shift clustering. J. Real-Time Image Process 2017, 1–14. [Google Scholar] [CrossRef]
- Saponara, S.; Fanucci, L.; Petri, E. A multi-processor NoC-based architecture for real-time image/video enhancement. J. Real-Time Image Process. 2013, 8, 111–125. [Google Scholar] [CrossRef]
- Mehmood, S.; Cagnoni, S.; Mordonini, M.; Khan, S.A. An embedded architecture for real-time object detection in digital images based on niching particle swarm optimization. J. Real-Time Image Process. 2015, 10, 75–89. [Google Scholar] [CrossRef]
- Li, H.-Y.; Hwang, W.-J.; Chang, C.-Y. Efficient Fuzzy C-Means Architecture for Image Segmentation. Sensors 2011, 11, 6697–6718. [Google Scholar] [CrossRef] [PubMed]
- Monemi, A.; Tang, J.W.; Palesi, M.; Marsono, M.N. ProNoC: A low latency network-on-chip based many-core system-on-chip prototyping platform. Microprocess. Microsyst. 2017, 54, 60–74. [Google Scholar] [CrossRef]
- Kaufman, L.; Rousseeuw, P.J. Partitioning of Medoids (Program PAM). In Finding Groups in Data an Introduction to Cluster Analysis; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2005; pp. 68–125. [Google Scholar]
- Ruaro, M.; Lazzarotto, F.B.; Marcon, C.A.; Moraes, F.G. DMNI: A specialized network interface for NoC-based MPSoCs. In Proceedings of the 2016 IEEE International Symposium on Circuits and Systems (ISCAS), Montreal, QC, Canada, 22–25 May 2016. [Google Scholar]
- Sievers, G.; Hübener, B.; Ax, J.; Flasskamp, M.; Kelly, W.; Jungeblut, T.; Porrmann, M. The CoreVA-MPSoC: A multiprocessor platform for software-defined radio. In Computing Platforms for Software-Defined Radio; Springer: Cham, Switzerland, 2017; pp. 29–59. [Google Scholar]
- Sepulveda, J.; Flórez, D.; Immler, V.; Gogniat, G.; Sigl, G. Efficient security zones implementation through hierarchical group key management at NoC-based MPSoCs. Microprocess. Microsyst. 2017, 50, 164–174. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, W.; Xu, J.; Li, B.; Iyer, R.; Illikkal, R.; Wu, X.; Mow, W.H.; Ye, W. A case study on the communication and computation behaviors of real applications in NoC-based MPSoCs. In Proceedings of the 2014 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), Tampa, FL, USA, 9–11 July 2014. [Google Scholar]
- Kiani, V.; Reshadi, M. Mapping multiple applications onto 3D NoC-based MPSoCs supporting wireless links. J. Supercomput. 2017, 73, 2187–2213. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]











© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mushtaq, H.; Khawaja, S.G.; Akram, M.U.; Yasin, A.; Muzammal, M.; Khalid, S.; Khan, S.A. A Parallel Architecture for the Partitioning around Medoids (PAM) Algorithm for Scalable Multi-Core Processor Implementation with Applications in Healthcare. Sensors 2018, 18, 4129. https://doi.org/10.3390/s18124129
Mushtaq H, Khawaja SG, Akram MU, Yasin A, Muzammal M, Khalid S, Khan SA. A Parallel Architecture for the Partitioning around Medoids (PAM) Algorithm for Scalable Multi-Core Processor Implementation with Applications in Healthcare. Sensors. 2018; 18(12):4129. https://doi.org/10.3390/s18124129
Chicago/Turabian StyleMushtaq, Hassan, Sajid Gul Khawaja, Muhammad Usman Akram, Amanullah Yasin, Muhammad Muzammal, Shehzad Khalid, and Shoab Ahmad Khan. 2018. "A Parallel Architecture for the Partitioning around Medoids (PAM) Algorithm for Scalable Multi-Core Processor Implementation with Applications in Healthcare" Sensors 18, no. 12: 4129. https://doi.org/10.3390/s18124129
APA StyleMushtaq, H., Khawaja, S. G., Akram, M. U., Yasin, A., Muzammal, M., Khalid, S., & Khan, S. A. (2018). A Parallel Architecture for the Partitioning around Medoids (PAM) Algorithm for Scalable Multi-Core Processor Implementation with Applications in Healthcare. Sensors, 18(12), 4129. https://doi.org/10.3390/s18124129