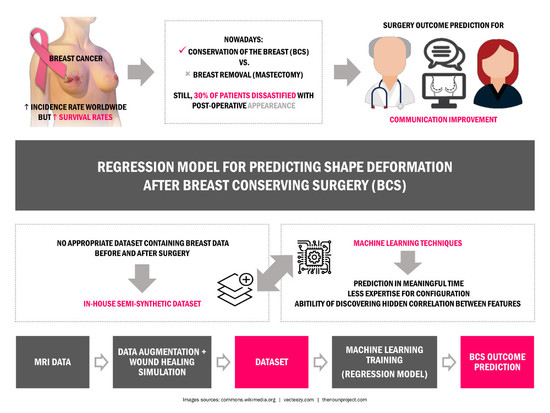
1. Introduction
Breast cancer is a widely known disease that mostly affects women around the world. With one of the highest incidence rates of female cancer, the success of treatment really depends on diagnosing the cancer in its earlier stages [
1]. Treatments have progressed to have lower secondary effects, but breast cancer surgery is still a reality for most patients. For decades, Mastectomy was prescribed for almost every breast cancer case with a high rate of success for removing the tumor; however, this surgical option comprises the removal of the entire breast and it has a profound impact on the aesthetic appearance and self-confidence of women [
2]. With the widespread of screening mammography, the average size of the detected tumors has decreased and breast conservative treatment may be appropriate for most of patients (50–75%) with breast cancer at early stages [
3]. Breast conserving surgery (BCS) is an important part of conservative treatment, comprising the excision of the tumor plus a margin of healthy tissues to eliminate cancerous cells. With better cosmesis results, BCS is nowadays the preferred alternative to mastectomy. Yet, a treatment plan is always tailored based on both medical and personal choices. Treatment options are conditioned by the biology of the tumor, the stage of breast cancer, the patient’s health conditions and preferences [
1].
Several studies have shown that the survival rate is almost the same for both mastectomy and BCS, with the benefit that the second imposes less deformation on breast and a more satisfactory aesthetic outcome can be achieved [
4]. Still, despite the smaller deformation after BCS, it has been reported that up to 30% of patients are dissatisfied with their post-operative appearance [
5]. Actually, the final aesthetic outcome can be affected by so many different variables, from different surgical practices and expertise, to some breast specific characteristics, such as volume and density, tumor size and location, hardening the prediction and patient/surgeon communication about surgical procedure results. Patients are usually involved in the decision process regarding their surgery, but most of the time surgeons lack the means to provide visual clues about the post-surgery results of different alternatives. Even though, this is an important step, regarding the acceptance of the final outcome, as also the contribution of breasts to the sense of femininity and beauty of most women. In fact, follow-up studies after breast cancer treatment show the harmful impact of poor aesthetic results on the psychosocial health of women, who describe loss of self-esteem [
2], sexual impairment [
6] and dislike towards their bodies after treatment [
7]. On the other hand, physicians have been recognizing the value of support decision systems for planning BCS, to compare the outcome of different surgical options and facilitate surgeon/patient communication. The value of such systems is further supported by studies confirming that women are more willing to deal with the aesthetic results when they are included in the decision process [
8]. These visual sensor tools could inform better the patient about the aesthetic consequences of the treatment and improve the feeling about all the process.
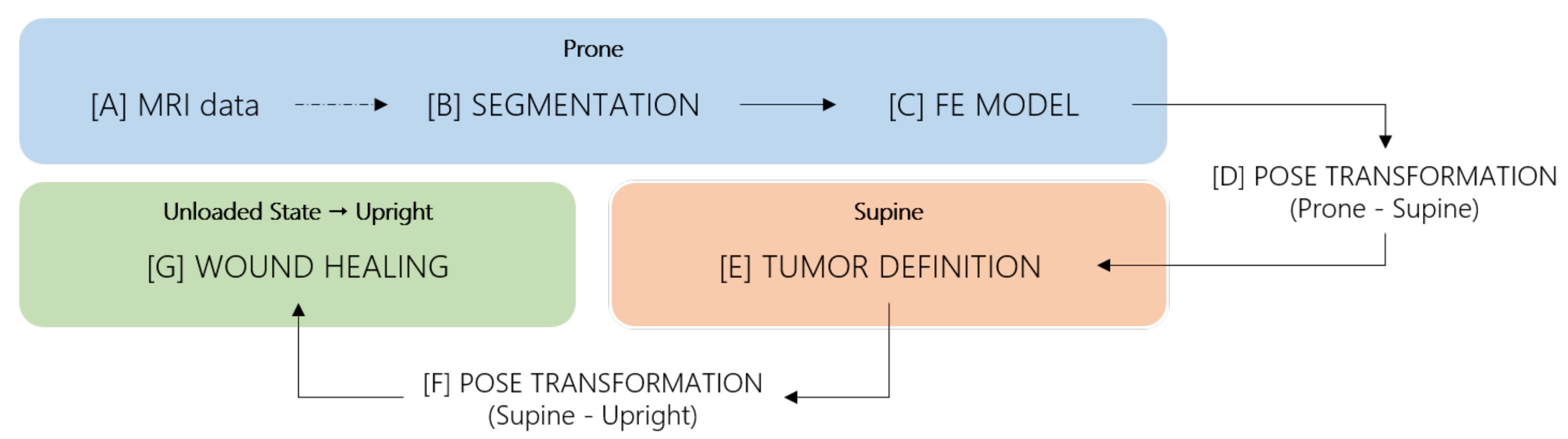
The development of a planning/simulation tool for surgery demands the creation of three dimensional (3D) models of the breast that can be deformed in a realistic fashion, to reproduce known deformations imposed by surgery; however, the creation of such models is a challenging task due to the deformable characteristics of the breast, the lack of landmarks to define its shape and the complex nature of the deformations imposed by the surgery. To the best of our knowledge, there are currently no tools, other than surgical experience and clinical judgment [
9], to predict the impact of BCS on the shape and deformation of the treated breast [
10]. In fact, the available solutions usually rely on generic models, are mainly targeted to plastic surgery (namely breast augmentation) and do not comprise complex deformations, such as the ones resulting from BCS. Moreover, they usually demand expensive and large equipment to scan patient’s torso and require expertise to handle those scans [
11].
Still, in literature, strategies to model breast deformations are abundant and designed to different applications: estimate pose transformation [
12,
13,
14], assist registration tasks among different radiological imaging modalities [
15,
16,
17], model breast deformation [
18,
19,
20], guide surgery [
21,
22], predict the healing process of the breast after tumor removal [
23,
24], among others. In particular, we highlight the work of Vavourakis et al. [
24], that proposed a 3D surgical simulator to predict a patient-specific outcome after BCS. This framework predicts the breast shape after surgery taking the wound healing process into account. The simulator relies on a coupled multiscale Finite Element (FE) numerical procedure to solve two mathematical models: a biochemical model for wound healing and angiogenesis, and a biomechanical model for soft tissues and pose estimation. The first considers both wound healing biochemical process and the formation of new blood vessels, while the second predicts the breast shape as function of the breast tissues mass density and the body force vector. The final shape of the breast is then predicted as an integration of both models.
The aforementioned applications have in common the use of biomechanical models to predict deformations that, due to some inherent limitations, is not the most suitable approach to include in a tool designed to be used in the daily clinical practice. First, the computational process for most algorithms might take hours, days or even almost a week, depending on the complexity of the models. As a principle aim, to ease the patient/physician communications during their consultations, the planning tool must provide the solution in an expected short time. However, the biomechanical models demand high-end requirements which are not accessible in all clinics. Considering the common computation power of the available machines in clinics, the biomechanical models might take days to provide the required planning, which is too late to satisfy the aforesaid aim. Therefore, faster methodologies should be considered instead of faster machines. Second, most models are simple representations of the breast biomechanics, using unverified parameters, posing fidelity concerns on the predictions. Third, the characterization of individual-specific parameters to create personalized models of the breast, alongside with precise representation of loading and boundary constraints during different clinical procedures, is still an unsolved challenge [
25]. The aforesaid applications are intended to provide patient-specific treatment solutions. Thus, the model parameters should be easily personalized with respect to patient and tumor characterizations during the consultations. Alternative strategies to model breast deformations encompass the fitting of parametric models [
26,
27,
28,
29,
30], physical equations to describe known breast deformations [
31], user-intuitive parameters to change breast shape [
32,
33] or dataset of known cases to simulate breast surgery outcomes [
34]. These strategies model the breast with limited number of parameters and produce results in a timely manner more adequate to clinical practice, but the modelling of breast deformations has still to be improved for clinical surgery planning applications.
In this study, the use of Machine Learning (ML) regression methodologies, such as Random Forests (RF) and Gradient Boosting Regression (GBR), will be explored to learn breast deformations from exemplar data.
Although ML methodologies have not been visited as a solution for real data, not only are they capable of performing the prediction in a meaningful time, but also they need less expertise for configuration. Besides the mentioned advantages, the ability of discovering the hidden correlation between different features distinguish ML from the other possible methodologies to solve this problem. In [
35], Bessa et al. were able to use regression models to predict the deformation parameters of some of the physical equations proposed by Chen et al. [
31] and model the breast shape according to the degree of deformation defined by the user. Despite the promising results, it was limited by the usage of a completely synthetic dataset and by the dependence on previous knowledge of the physical equations of deformations. Here, the aim is to expand the described work by using real data, avoiding the usage of specific physical equations to model the breast deformations. Besides, to accomplish the requirement of providing a dataset with the demanded properties, an in-house dataset is generated using data from Magnetic Resonance Imaging (MRI) of real patients and an available breast cancer surgery simulator [
24].
The rest of this paper is organized in five sections.
Section 2 is focused on the design and construction of a dataset, with a brief description of the breast anatomy and a detailed explanation of the surgery simulator used to generate the dataset instances. In
Section 3, the methodology followed in this work is described, from the feature engineering step to the machine learning approaches used. Implementation of the aforementioned regressions, together with numerical evaluations are explained in
Section 4, indicating a promising prediction of the breast shape. Then, the complementary discussions will be expressed in
Section 5. Finally, the explanations of the proposed methodology and generated dataset are wrapped up in
Section 6, as conclusion.
3. Methodology
The prediction of the post-surgery shape of the breast after surgical intervention is a complex task that requires modelling the influence of several factors on the aesthetic outcome of surgery. Approaches to model these deformations are typically based on biomechanical models. However, FEM takes longer than expectations, from hours on high-end machines, up to some days on normal computers used in clinics. In this work, an alternative strategy-based on machine learning techniques is proposed which overcomes the timing demands of biomechanical simulation, keeping most of the properties and characteristics of the breast.
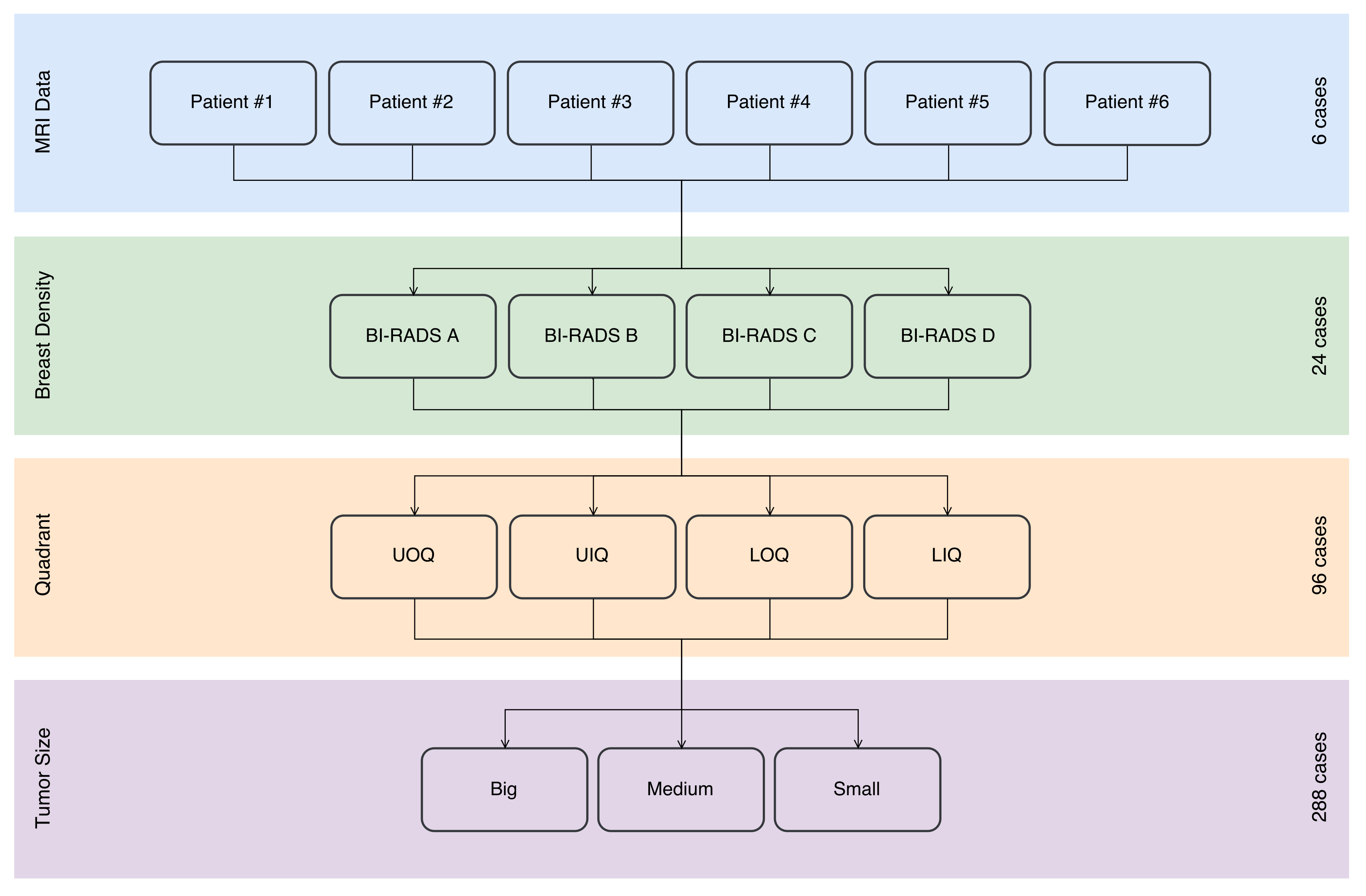
3.1. Features
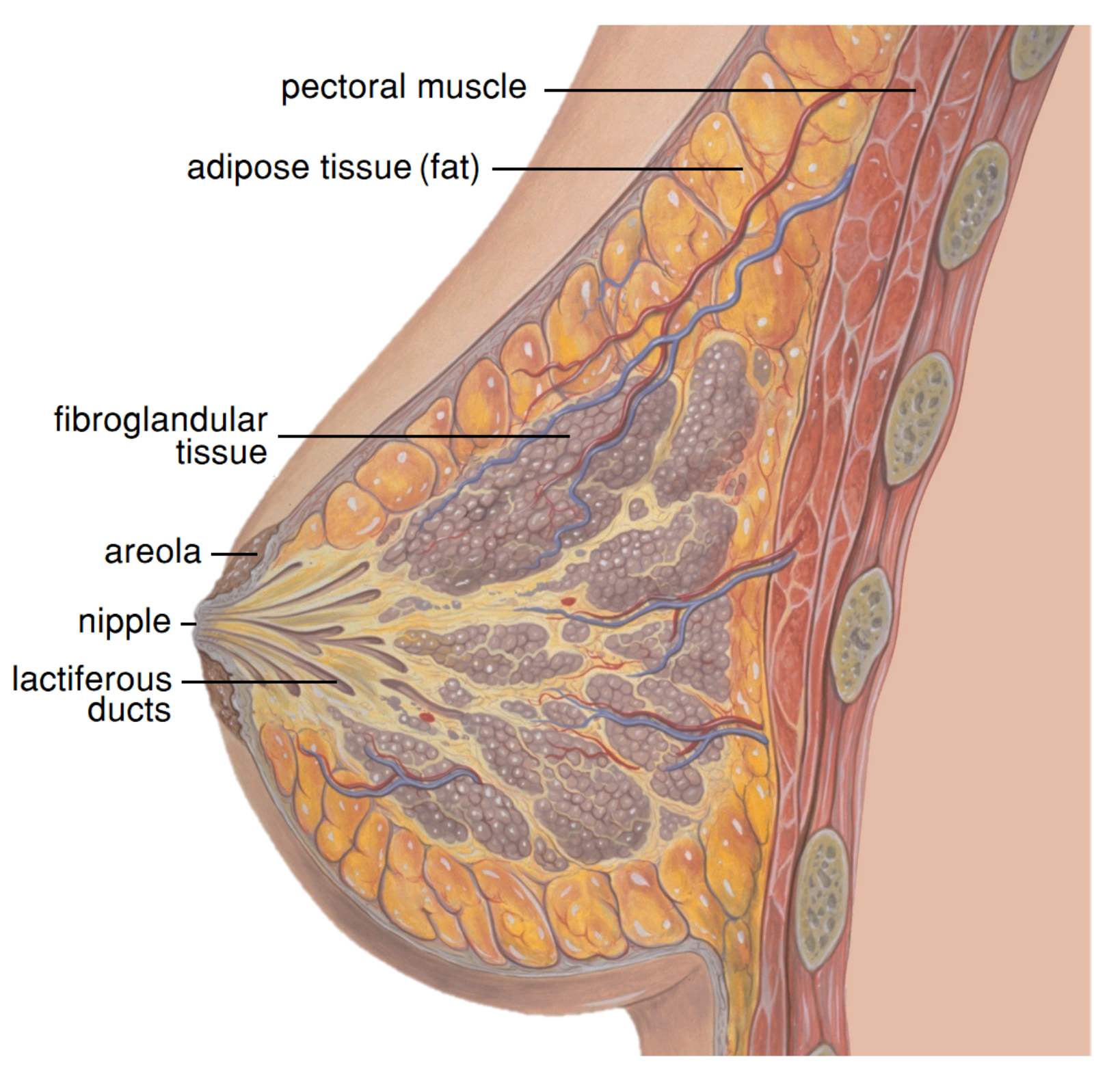
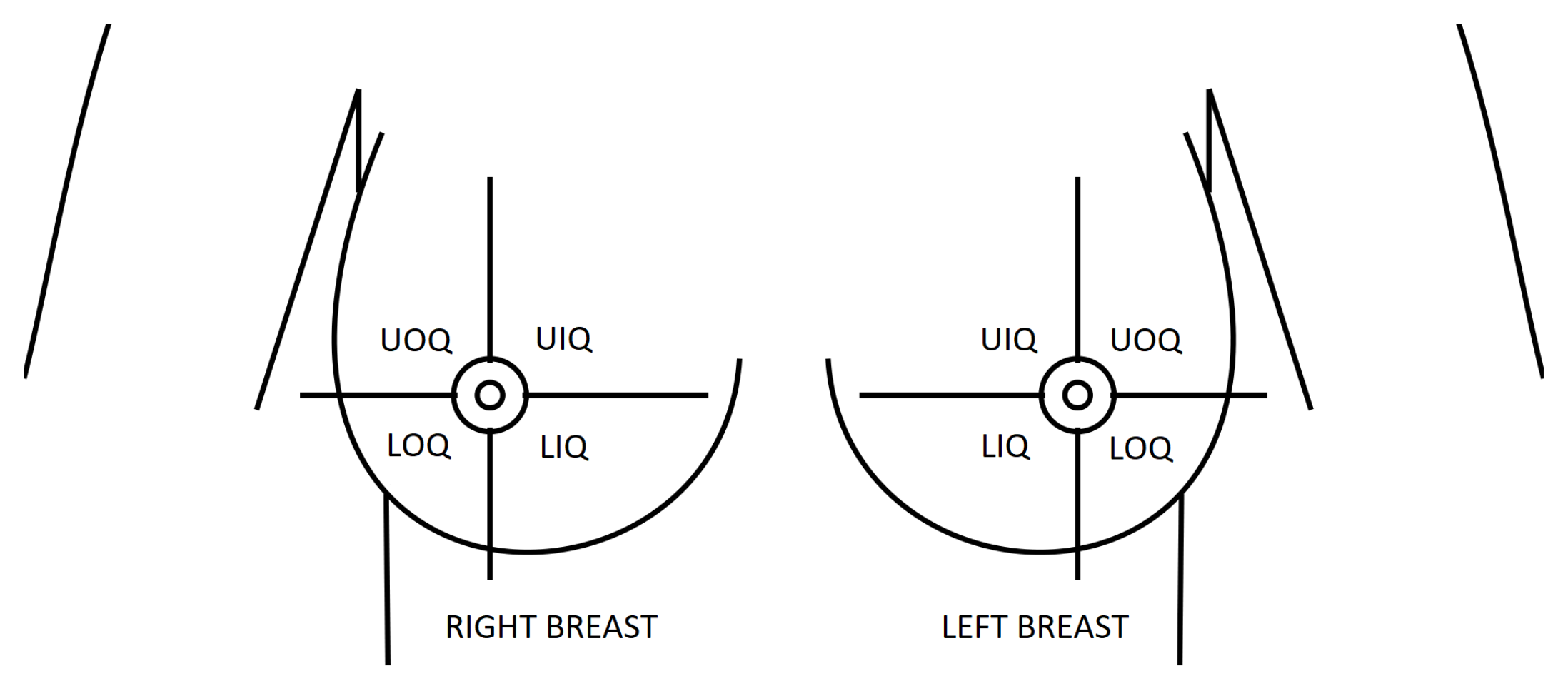
Feature extraction and representation is an important step in any machine learning task. Although clinical evidence suggests that a prediction model for breast deformation after BCS should take breast shape (laterality), volume and density into account, considering tumor characteristics such as quadrant (position) or size as inputs, such factors should be inspected in a more systematic way to confirm their influence and effects. Moreover, such analysis is important to suggest the best suited machine learning algorithms to model the problem at hand. For visual purposes, the feature investigation was constrained only to the breast surface.
3.1.1. Breast Characteristics
Regarding breast characteristics, both density and shape are known to affect the extent of breast points displacements.
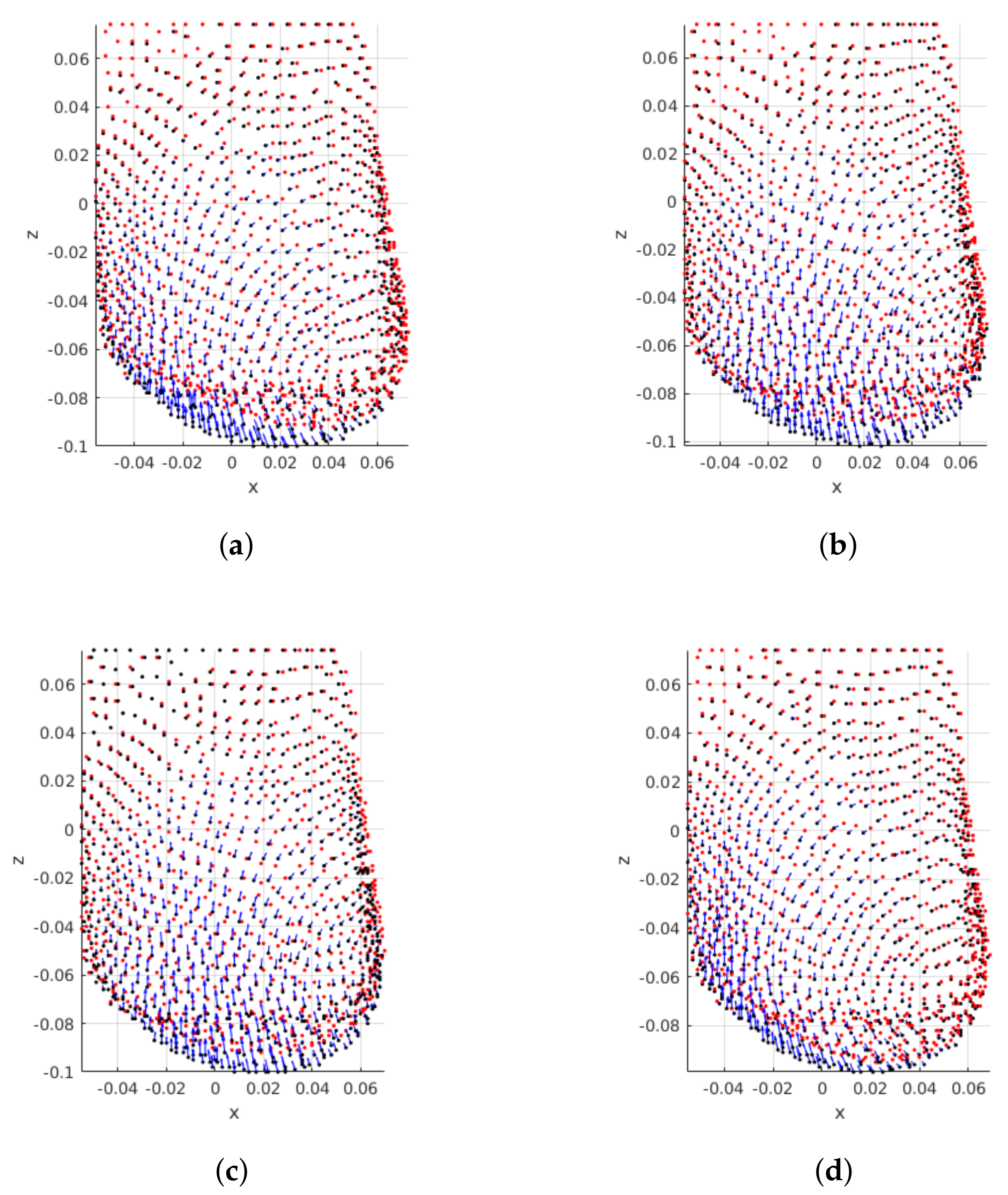
Figure 9 shows the superposition of pre- and post-surgical breasts of the same patient, when different densities are modelled. The resulting plots show that breast density impacts the magnitude of points displacements: the magnitude of displacements decreases as the breast density increases. In fact, this was the expected behaviour, because denser breasts have a higher fraction of glandular tissue, which is less deformable than fat.
As for breast laterality the mirroring of displacements can be seen when right and left breasts are compared (
Figure 10). Although the magnitude of displacements is similar, the direction changes according to the breast laterality.
3.1.2. Tumor Characteristics
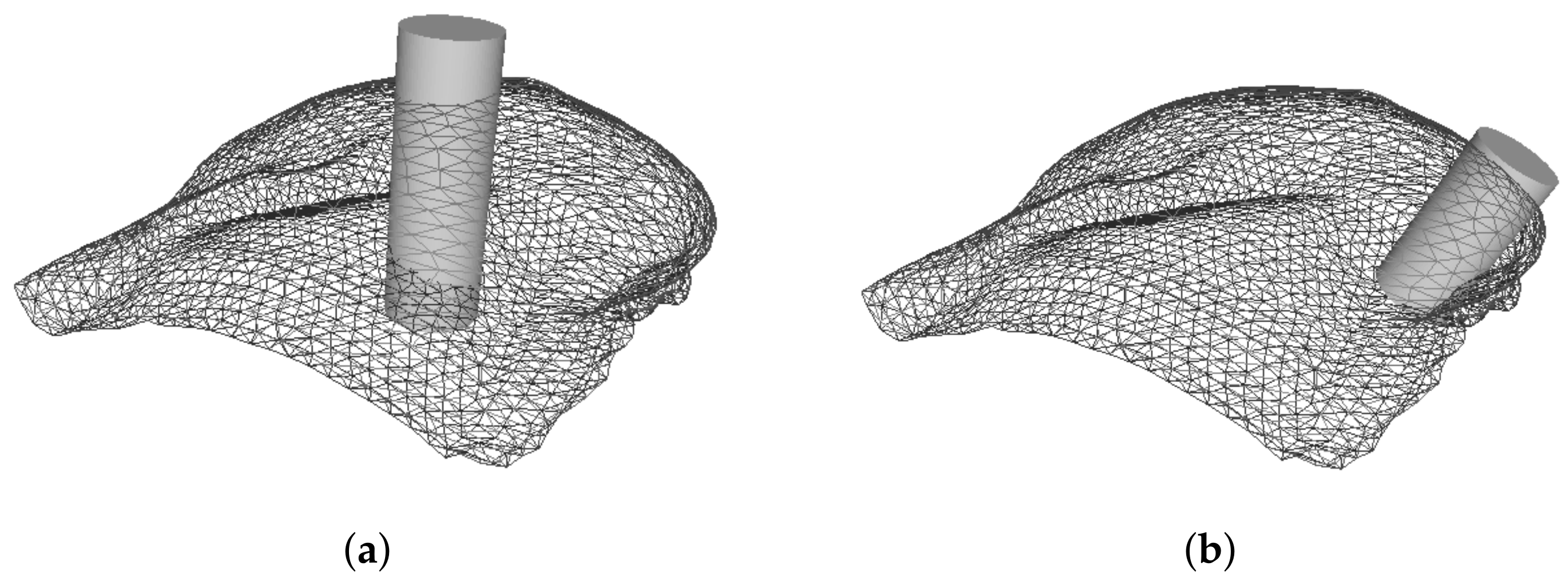
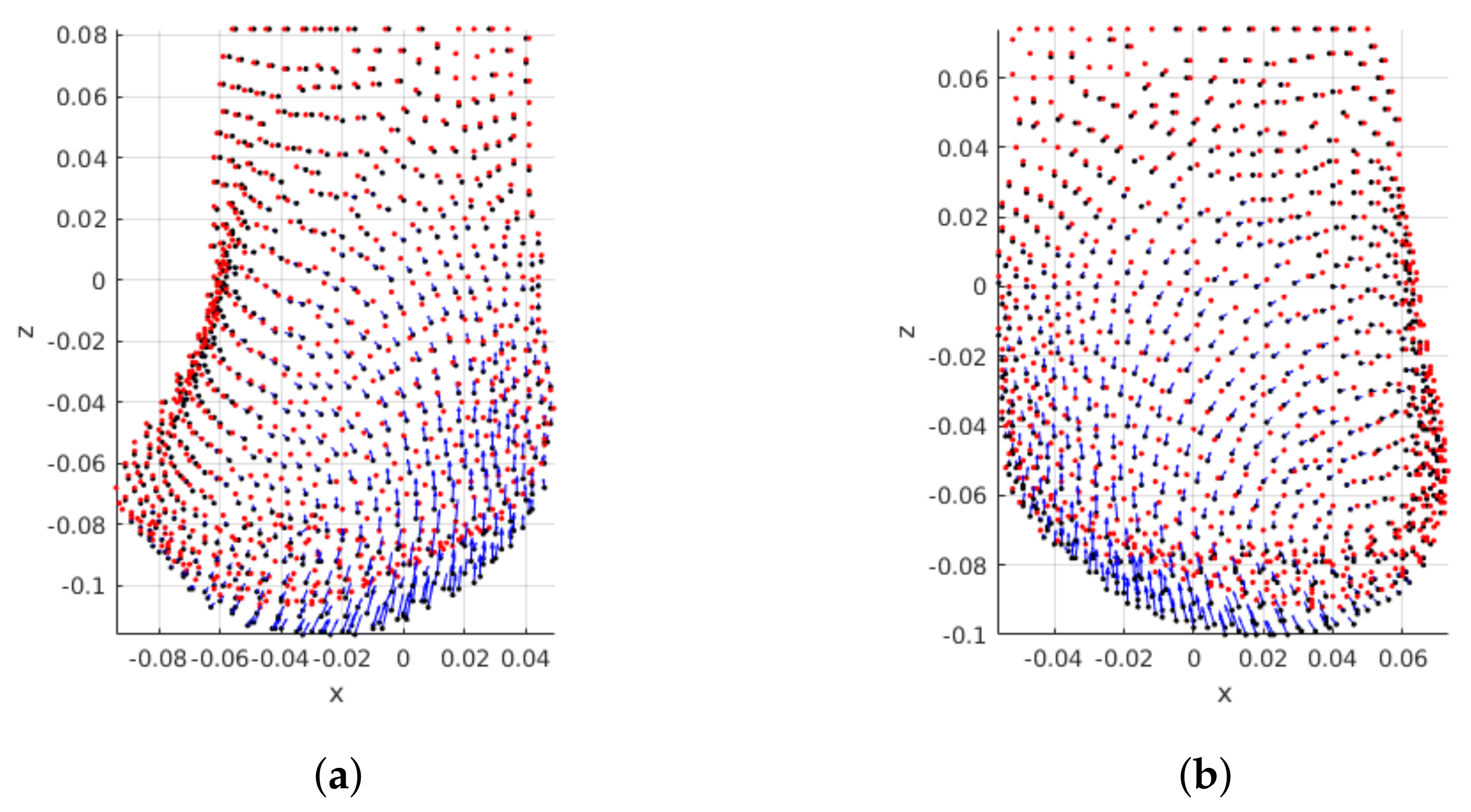
Figure 11 shows the effect of the tumor position on the displacements between pre- and post-surgical data. An interesting effect can be noticed: the distribution of displacements on the breast is dependent on the breast quadrant where the tumor is positioned. Larger displacements are centered around the tumor, vanishing as the distance to the tumor center increases. Hence, a feature space transformation might be helpful to describe the displacements distribution as function of the tumor position. In alternative, Euclidean and polar distance to tumor could benefit the modelling of the points displacements.
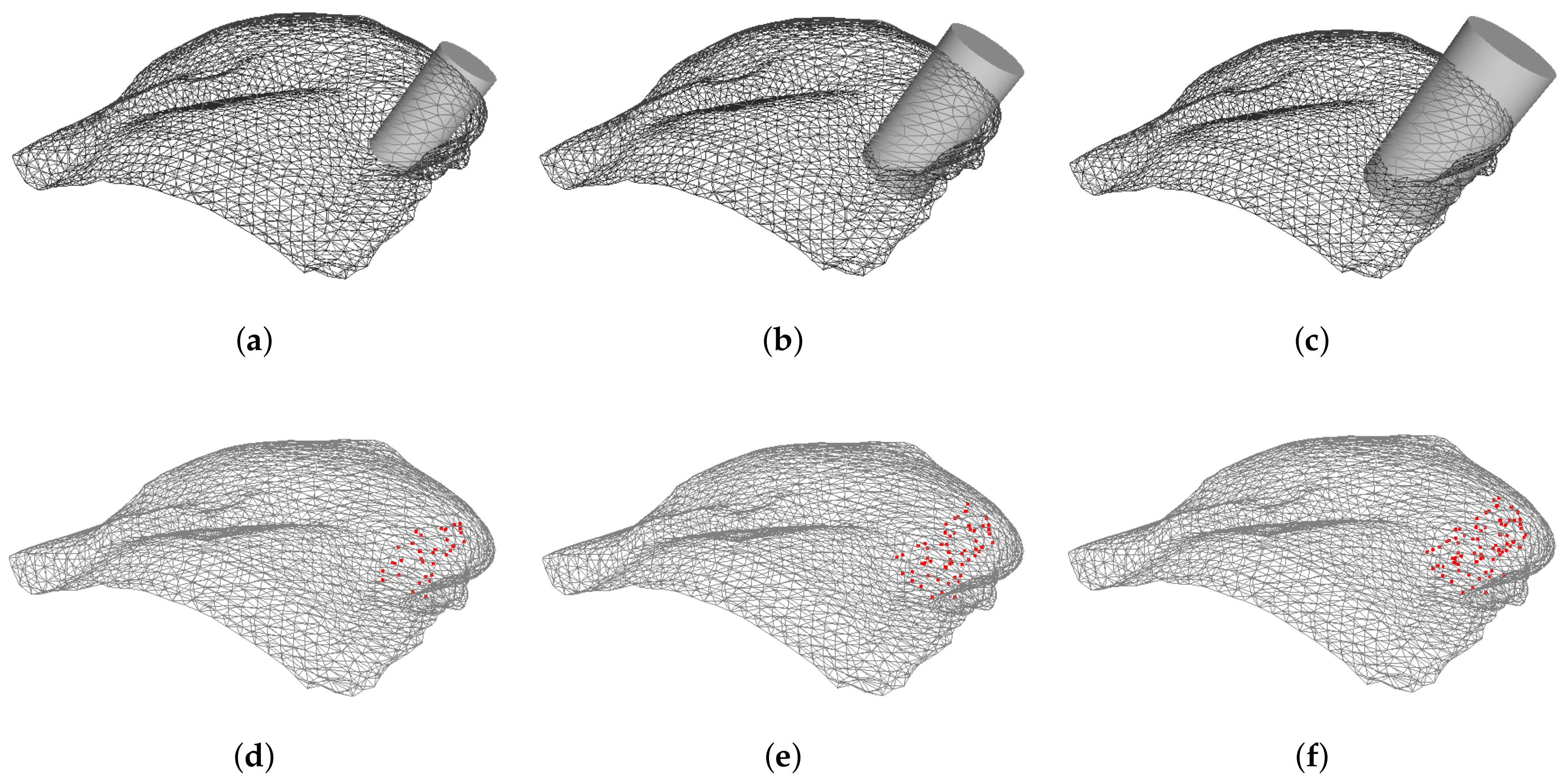
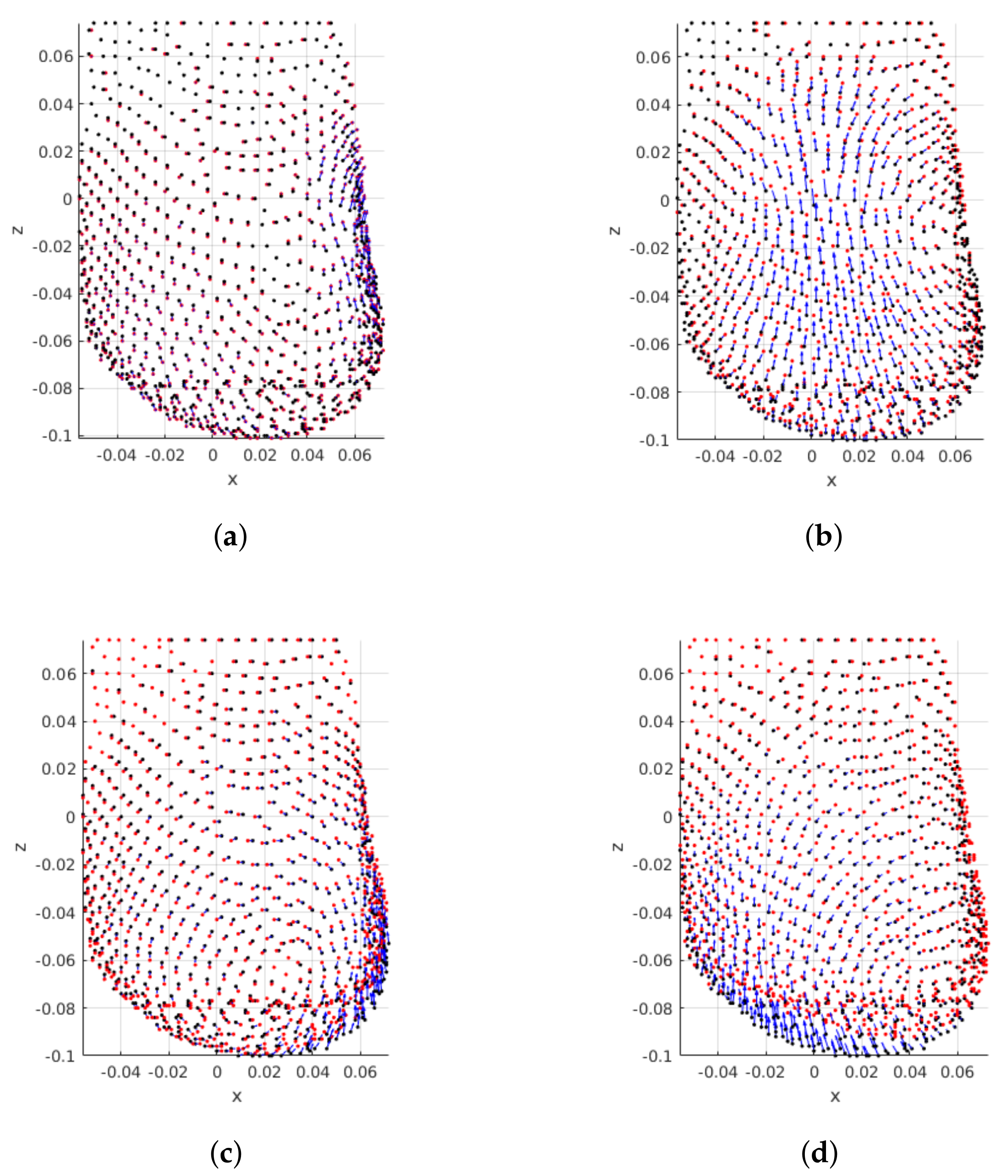
Finally, the influence of the tumor size on the magnitude of breast displacement is shown in
Figure 12. Results evidence that larger tumors cause larger breast displacements after surgery wound healing. In fact, this was the expected behaviour: after tumor removal the remaining breast tissues adapt to fill the left void. This results in breast contraction, which is a function of the excised volume.
3.1.3. Feature Engineering
A brief look to
Figure 9,
Figure 10,
Figure 11,
Figure 12 denotes how different breast and tumor characteristics influence breast deformations after BCS and respective wound healing process. Breast density and tumor size have particular impact on the magnitude of the displacements, while the quadrant where the tumor is positioned and the breast laterality influences the distribution of those displacement. Therefore, one can expect that breast deformations can be modelled using the spatial coordinates of points, the distance of each point to the tumor position (the distance from a point perpendicular to the tumor cylinder), while accounting for categorical features such as breast density, tumor region, breast laterality and tumor size, as described in
Table 4. Despite being appointed as an important clinical factor influencing the aesthetics of breasts after BCS, the volume of the breast is not explicitly listed. However, that information is implicitly covered due to the categorization of tumor sizes (expected excision volumes) which are defined as a percentage of the breast volume.
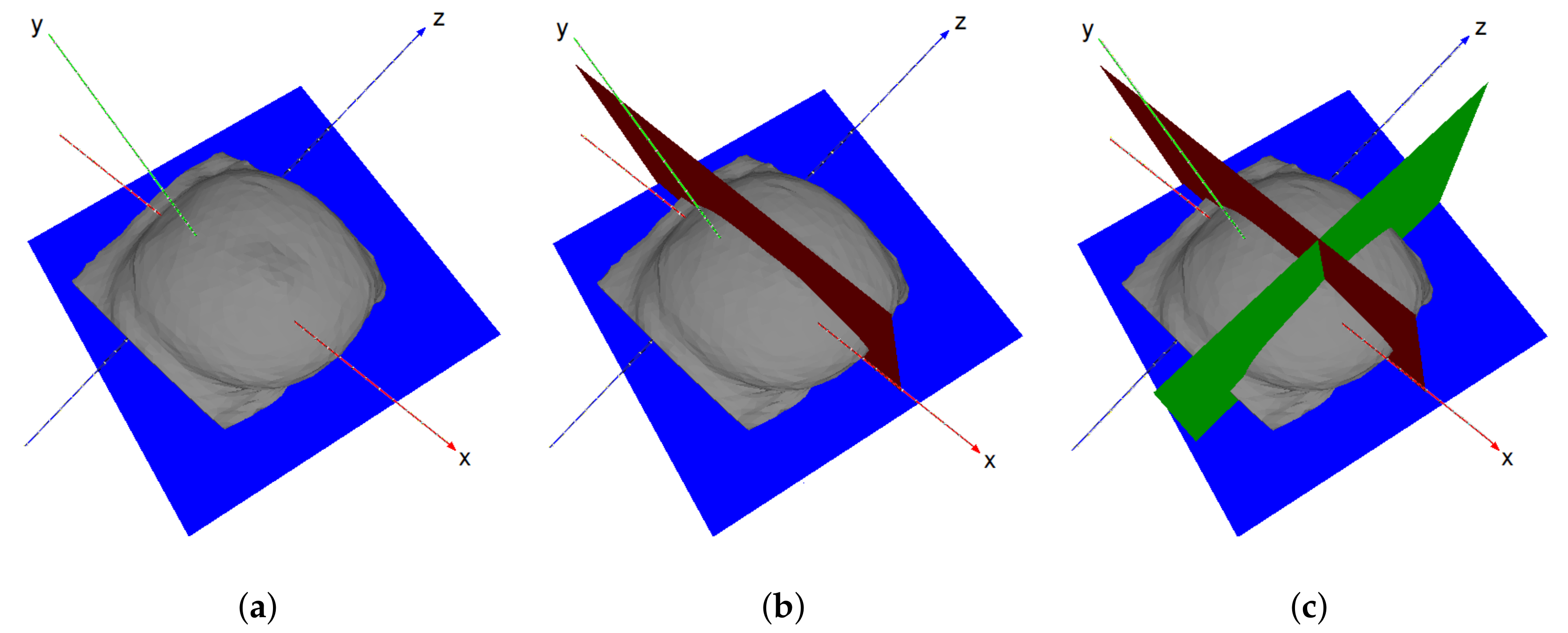
Definition of the features has been conducted aligned with the aforesaid expectations. The constructed feature list comprises three data attributes: points’ coordinates, points’ difference to the excised cylinder (both Euclidean and polar) and points’ distance to the excised cylinder as quantitative continuous, tumor size and breast density with categorical ordinal, and breast laterality and tumor region with categorical nominal attribute. The point coordinates simply expresses the location of each point in the 3D coordinate system, while the point coordinates difference feature reflects the difference between healthy points and the excised cylinder in each axis of the coordinate system. While the distance to the excised cylinder highlights the Euclidean distance from each healthy point, the polar distance to the excised cylinder expresses the same distance, but in polar notation. It is important to note that the coordinate difference and distance features for damaged points (inside the excised cylinder) are considered to be zero.
3.2. Regression Models
In this section, it will be explored solution taken into consideration the feature analysis above. The intention of exploiting machine learning in breast shape prediction is to estimate the point coordinates after surgery healing, taking as input the points positions before surgery, as well as breast and tumor characteristics. Since the points coordinates are continuous variables in 3D space, learning techniques providing regression methodologies are taken into consideration; however, prediction of the points coordinates poses a challenge to transfer breasts with different laterality or size, into the same coordinate system. Such circumstance can be prevented by re-formulating the demanded output from the regression. Instead of predicting the exact point coordinate, required displacement to translate a pre-surgery point to its post-surgery location can be predicted, alternatively. The post-surgery PCL is then attainable by applying predicted displacement on the pre-surgery PCL. Described in mathematical notation, the regression model can be expressed as in Equation (
1):
where
is pre-surgery PCL,
F is the feature list per instances (pre-surgery points),
f is the demanded regression model, and finally
expresses the required displacements to convert pre-surgery PCL to post-surgery. Having predicted the displacement, predicted breast shape (
) is attainable via Equation (
2):
Looking back to the objective of predicting breast shape after BCS, the expected prediction should be performed considering the points of both pre- and post-surgery models, together with clinical features. Therefore, the possible learning approach to be proposed must be able to deal with large number of inputs (points), and correlate them with the features (clinical features). In ensemble learning the key idea is that different algorithms explore different search spaces and hypotheses, so composite systems could outperform single ones [
46]. The strategy of exploiting ensemble learning methodology assures to gain improvement of not only the robustness, but also the performance of the learners via combining the votes of stronger single regressors combined to build the prediction model. As an ensemble learning approach, tree-based learners provide an appropriate framework (both in time and performance evaluations) to take part in training with large number of inputs. Therefore, within this research, tree-based learning methodologies are taken into consideration to perform the required regression in finding the predicted coordinate of breast shape.
Regression methods also can be categorized based on the number of their outputs. While single output regression are the most used ones, the internal correlation between their voters can be set such that they can generate multiple outputs. Therefore, taking the problem of predicting breast shape into account, regressors can be categorized in the two types of Multiple Input Single Output (MISO), or Multiple Input Multiple Output (MIMO). Both types of the aforesaid regressors are studied and evaluated in this work.
3.2.1. Random Forests
Depending on the goal whether to decrease bias error and overfitting, or to decrease both bias and variance, bagging and boosting are generally used, respectively. Concentrating in the bagging, unstable models, i.e., models whose performance is sensible to small perturbations of the training set, are trained with different replicas of the training set, obtained with replacement to keep the same number of examples (bootstrap aggregation). Then, new examples are predicted by uniform voting between the regressors trained with different dataset replicas. A special variant of bagging applied to decision tress results in the RF method, which operates by constructing multiple decision trees with bagging and random selection of features at each split of each tree. This mechanism assures that the constructed trees become correlated with one or more features which are strong predictors [
47].
In this study, the use of bagging is exploit by learning RF models. This method requires the optimization of the number of trees to use as forest, as well as the number of features considered during the construction of trees.
3.2.2. Gradient Boosting Regression
The algorithm for Gradient Boosting Regression is a recasted adaptation of AdaBoost that employs boosting methods in regression trees [
48]. The general idea is to compute a sequence of simple trees, where each successive tree is constructed for the prediction residuals of the preceding tree [
48]. Minimization of the loss (residuals) of the model (or regressor) is pursued by adding weak learners using a gradient descent procedure. Therefore, three elements are considered directly in developing a regressor with gradient boosting: a loss function, a weak learner, and finally an additive model to add weak learners to minimize the loss function. Considering decision trees as the weak learner, they are added one at the time, while the existing trees are kept unchanged. To ensure the simplicity of the learned trees, it is common to assign specific constraints to control the growth of trees, for instance, defining a maximum limit for depth, or the number of leaf nodes.
The capability of optimization is granted to the trees since they are constructed with parameters to be modified in direction of reducing the total loss function of the regressor. A tree which reduces the total loss is added to the existing sequence of trees [
49,
50].
As a greedy algorithm, gradient boosting has overfitting potential in training data, quickly. Therefore, common techniques such as regularization, assists the performance of prediction by penalizing various parts of the algorithm. The discussed constraints on tree construction is a example of the regularization methods to control the greediness of gradient boosting [
51].
3.2.3. Multi-Output Regression
Regression models are normally characterized by only one output; however, taken into consideration the problem here presented, it make sense to think in a strategy based in MIMO regressors. In order to predict more than one output, it can be simple considered a regressor for each output, by concatenating several MISO regressors [
52]; however, ignoring possible relationship among the constructed models could result in a drawback for the solution. A smarter solution is also suggested to construct several regressors not only by the input training data, but also by the possible internal relationships between them. In particular, this solution takes the advantage of constructing a MIMO regressor which is smaller than the size of those MISO regressors. It should be noted that the discussed solution leads to better predictions when there is a strong correlation between the features and the targets.
3.3. Summary
Through a comprehensive study between the pre- and post-surgery PCLs, the influence of each breast and tumor characteristics features were determined. Aligned with the objective of the current research to predict the shape of the breast after surgery, regression was taken into consideration as the main solution. Further discussions unveiled that the tree-based methodologies are capable enough to satisfy the input/output demands of the solution.
4. Results
The definition of training and testing sets is carried out with a careful approach, in which a patient leave-one-patient-out (LOPO) strategy is advised to obtain test and train subsets. In each split, all example data generated from the same input patient would be used for testing, and the remaining patient’s data would compose the training subset. In the particular case of having 6 patients, the LOPO strategy is followed to prevent overfitting, due to the similarities between the PCLs of a single patient. To assess the model performance through LOPO strategy and tuning parameters at the same time, a cross-validation approach was used in order to find the parameters’ which presents the best configuration of the model.
As there is a deterministic correspondence between the points of the predicted (as the source) and the post-surgery PCL (as the target) for each patient, the evaluation metric can be defined by the Euclidean
point-wise distance (p2p). Denoted in Equation (
3), the point-wise distance evaluates the performance of the regression model, since it measures the amount of displacement of each pair of points regardless of the total PCL displacements. Less distance means the regression model predicted the coordinate of each point closer to its expected location.
where
N and
d denote the number of points and Euclidean distance, respectively, and
is the corresponding point of
. Not only point-wise, but also
global distance can be calculated, as well. Unlike the point-wise, the global distance appraises the displacement between the two comparing sets in whole. That means the discussed metric gives an overview of the similarities between the source set with the target. The global measurement of the distance results in reporting two distances: from the source to target PCL and from the target PCL to the source. Closer reported distances signify the more similarity between the two PCLs.
where the
is the nearest point to
.
Since the deformation of breast is correlated with both internal and surface tissue (described in
Section 2.2.3), both so-called points are considered during the training stage; however, numerical evaluation only comprises the analysis of the surface points.
Note that for the both presented metrics, the mean distance (), the standard deviation from the mean () and the maximum distance () between the comparing sets are reported as well. The maximum distance expresses the furthest distance between two corresponding points of the predicted and pre-surgery PCLs. Also, and symbols stand for pre- and post-surgery PCLs, and denotes the predicted breast PCL (wherever it is needed the predictions are also compared visually with the post-surgery models).
Finally, the machine learning implementations for RF and GBT were accomplished in python 3, by using
scikit-learn package [
53] on a machine powered by intel
Core i7
at 3.2 GHz with 128 GB of memory (for cross validation). As long as the
scikit-learn package includes multi-output regressor which is based on concatenation of individual regressors, the implementation of MOR was carried out with a package in
R, called
Multivariate Random Forest [
54].
4.1. Random Forests
Following the approach of individual regressor for each axis, three RF regressors were trained. The cross-validation inner loop was set to optimize the number of estimators (trees), the maximum number of features in each tree, and the leaf size are of those parameters through , , and , respectively.
The criterion to select the tuned parameters was chosen considering two objective functions (OF): the average, and the Hausdorff (maximum). Focusing on the average, the best set of tuned parameters are selected such that it minimizes the average distance between the predicted and the post-surgery models. The other OF which is based on the Hausdorff distance, intends to decrease the maximum distance between the points in each set of comparison of predicted and post-surgery PCLs, although the average distance may increase.
4.1.1. PCL Sampling
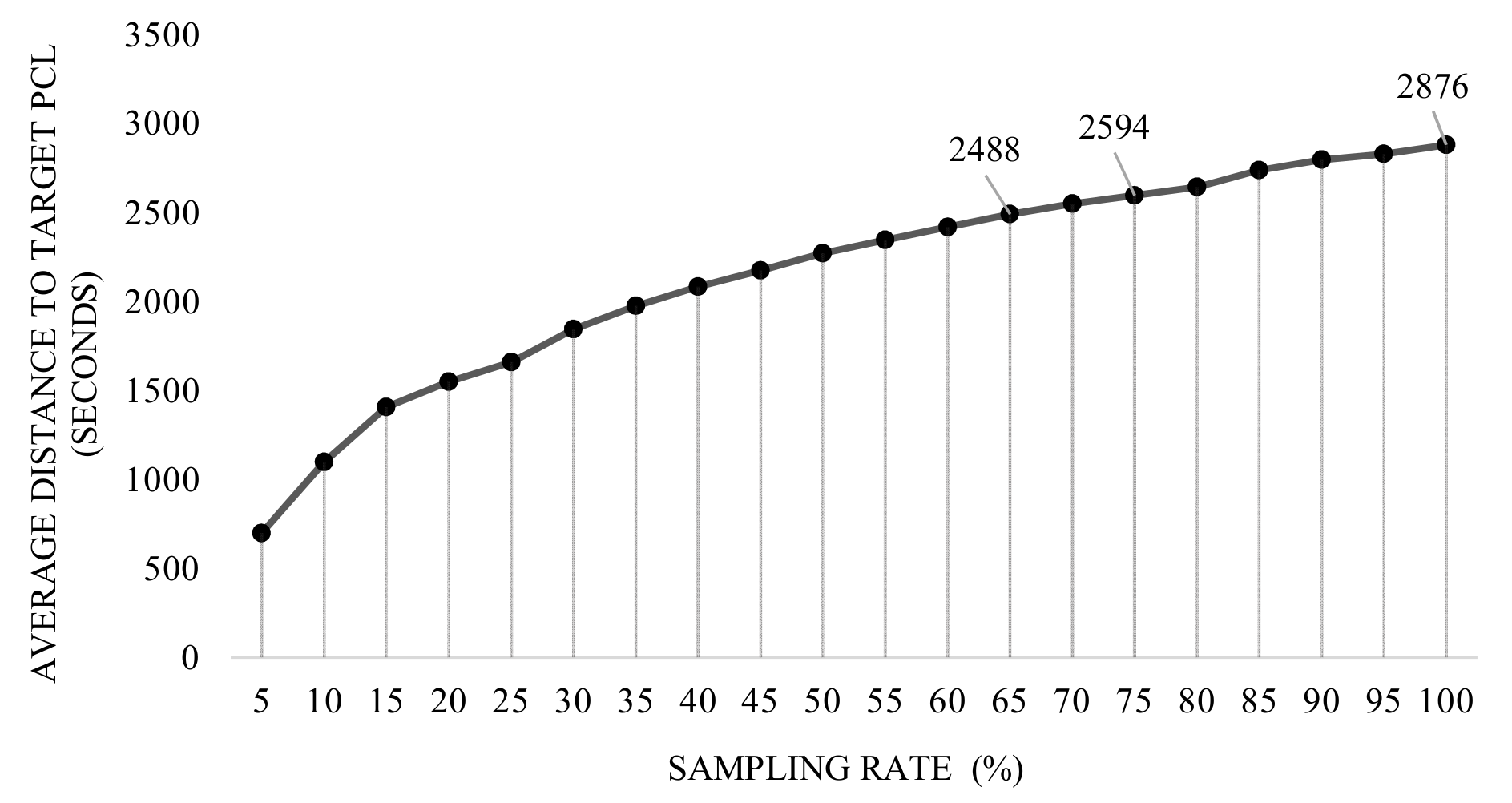
Theoretically in RF, inclusion of more points (more sampling rate) is thought to increment the gain of the regressor by declining the average distance between the predictions and the target, though, not only the training time continues its incremental trend, but also the aforesaid slope of the distance decelerates [
55]. In this regard, a comprehensive study was designed to find an optimized sampling rate in the range of
, according to both distance error and training time. The timing complexity reported in
Figure 13 depicts the aforesaid evolution as the training size set increases, as expected. Besides, shown in
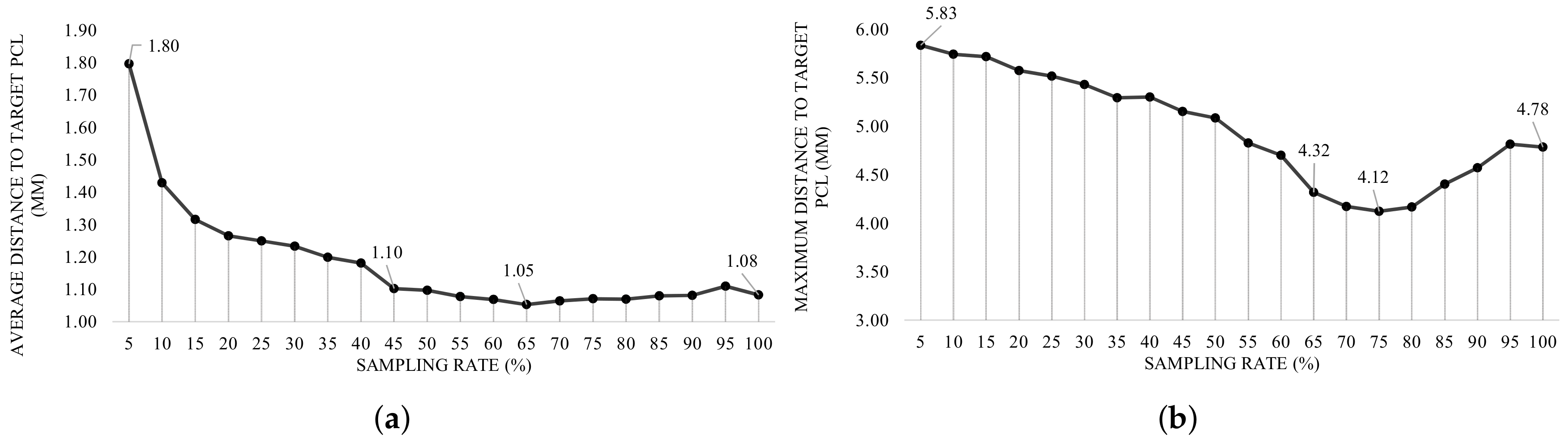
Figure 14a, considering the average OF, the declining slope of the distance error decreases in defiance of sampling rate, until it reaches to
. Although the difference of the reported distances between the rates of
and
is less than
mm, to satisfy the condition of the OF, it was decided to use the sampling rate correlated with the global minimum distance (
).
With the same argument, and in accordance with the Hausdorff OF, the sampling rate of
was selected due to the least evaluated maximum distance, though the difference between the rates
and
is measured around
mm.
Figure 14b depicts the evolution of maximum distance according to the Hausdorff OF. Considering the aforesaid sampling rates, numerical evaluations with respect to average and Hausdorff OFs are calculated and reported in
Table 5 and
Table 6, respectively. To evaluate the magnitude of the reported distances, an extra comparison is performed with the distance between the two comparing PCLs in case no method is applied (meaning that prediction data is exactly equal to the pre-surgery data). This comparison, so-called
baseline evaluation, is reported in the last column of
Table 5 and the last two columns of
Table 6, for both the average and the Hausdorff OFs.
4.1.2. Assigning Weights
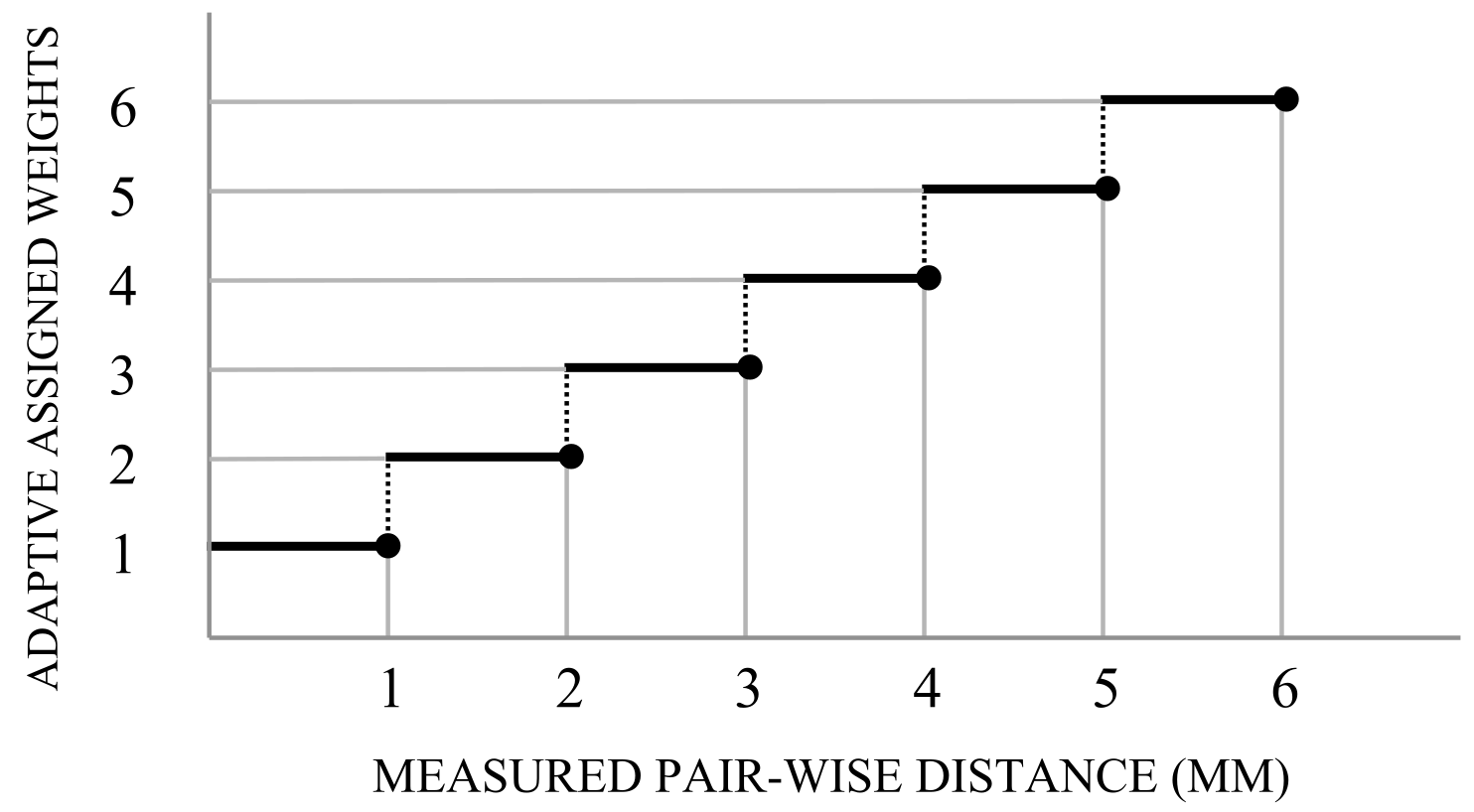
Deep investigation of the trained RF reveals that the nature of problem demands to define different weights for the points belonging to healthy or damaged tissue. In this work a weight assigning strategy is followed in which the weights are initially assigned to the training instances and then they are updated iteratively in accordance to the distance from their correspondences in the target model. Thus, in each iteration, each point is assigned a weight that is proportional to the distance from its corresponding point of the target. This proposed iterative approach, called adaptive weighting, continues until either a fixed number of number of iteration is reached (in this case 100), or the OF is not satisfied within three consecutive iterations.
A glance to the results obtained in the previous section reveals that the distance for a point is near to 1 mm while the maximum distance is higher than 5 mm. Taken this in consideration we considered a weighting strategy by defining the values for the weights as the
ceiling of the
point-wise distance (p2p) in a range of 1 to 6, as shown in
Figure 15.
Obtained results from evaluation show an interesting trend in decreasing both average and Hausdorff distances.
Table 7 and
Table 8 express the numerical evaluation based on average and Hausdorff OFs, respectively. Comparing with the best set of results (obtained by using RF with
sampling), a slight improvement is observed (
mm for weighted RF vs.
mm for weightless). Note that both regressors are built using sampled dataset with the rate of
. Same decreasing trend is observed while the Hausdorff OF in considered (comparing
mm for weighted RF vs.
mm for weightless RF). This improvement certifies the assumption that the provision of a suitable weighting approach can lead the regression to predict post-surgery models with less distance evaluations. It should be noted that the weight assignment strategy has a significant impression to decrease the distance between predicted and post-surgery PCLs. Therefore, a new line of research is opened to investigate appropriate strategies to improve the prediction of breast shape using RF.
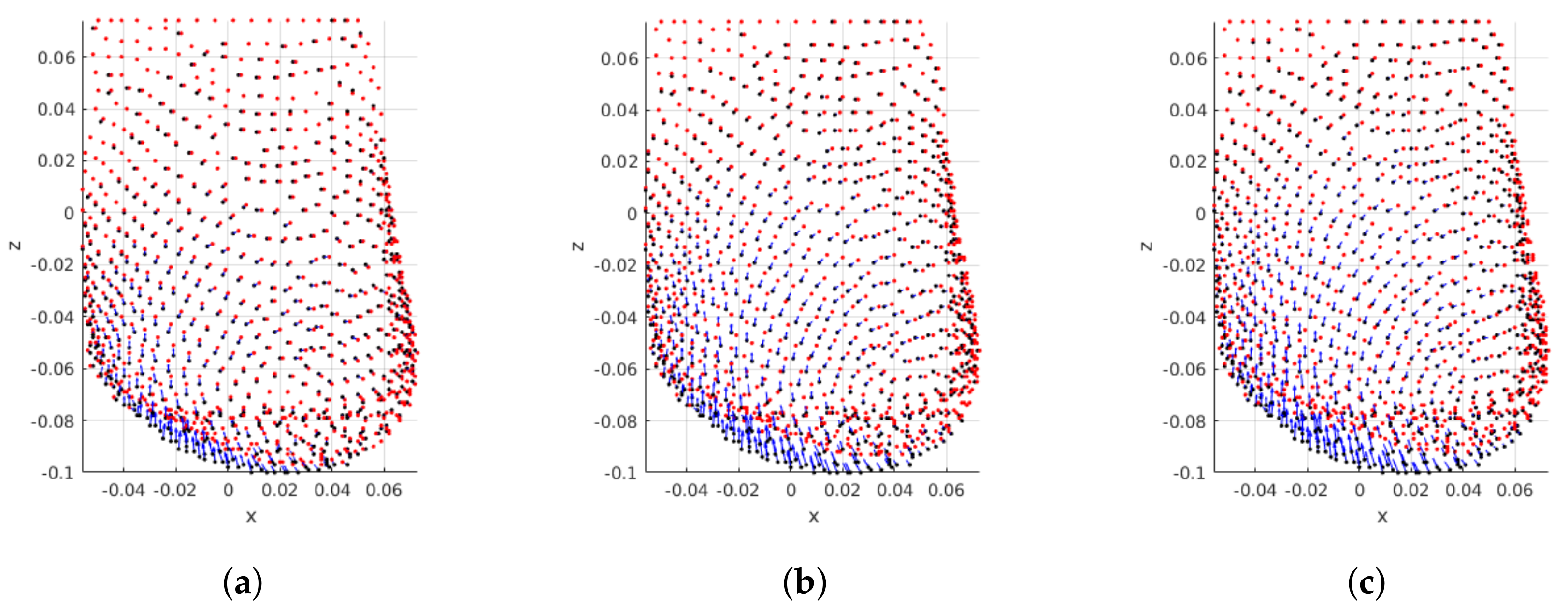
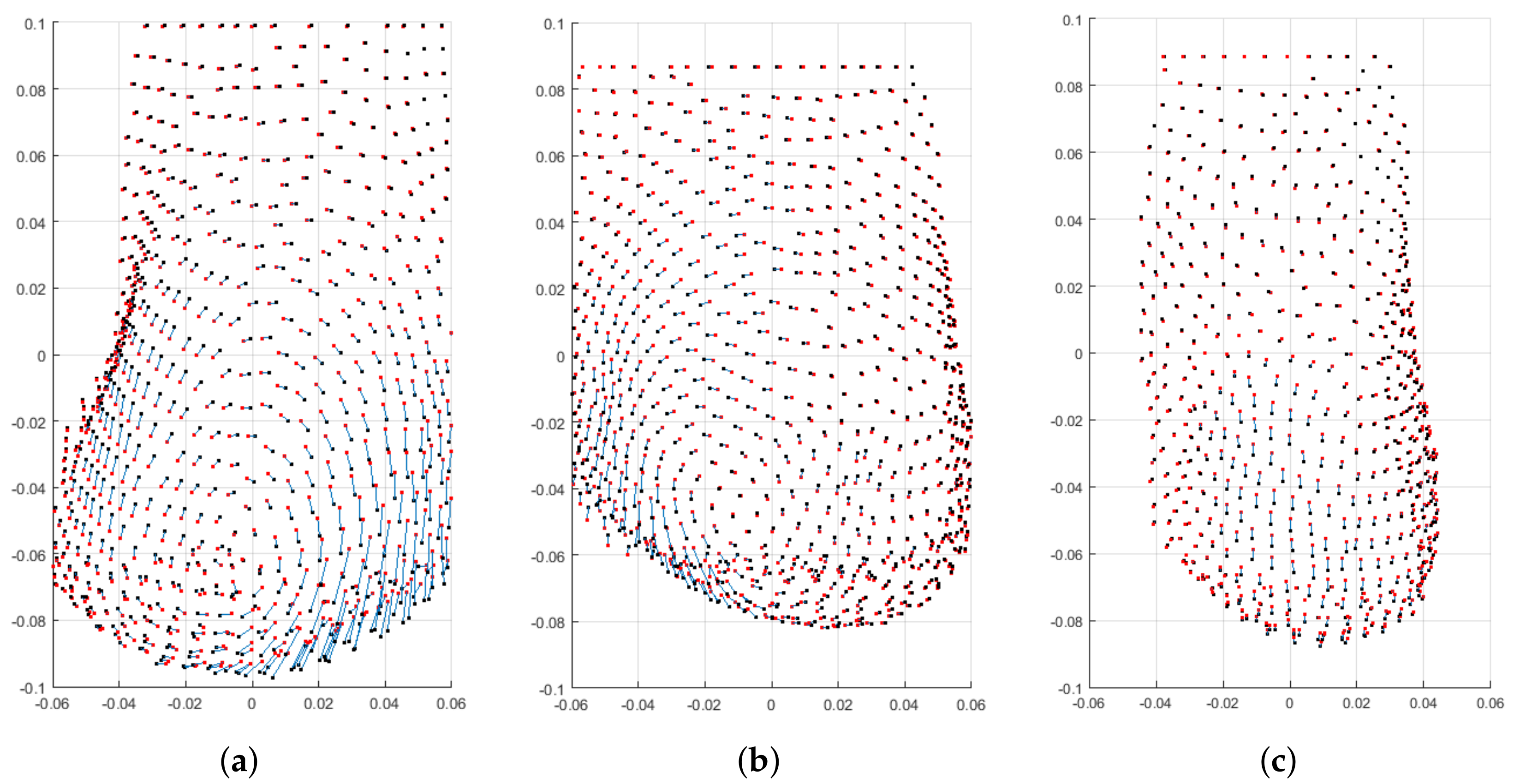
Besides the reported numerical evaluation, visual comparisons of three predicted breasts are depicted in
Figure 16. The depicted predictions have been evaluated with average pair-wise distance of
mm (
Figure 16a) as a poor prediction,
mm (
Figure 16b) as a fair prediction, and
mm (
Figure 16c) as a good prediction.
4.1.3. Feature Importance
Although the displacement of the points plays an important role in finding the regression, the used clinical features contribute in adjusting the amount of prediction required for each point of healthy or damaged region. The construction of trees in RF allows to report the importance of each feature. In this regard, clinical studies can be accompanied with the resulted features’ importance to highlight the ones which contribute more in the prediction. Based on the conducted analysis, the clinical features applied in the training procedure are studied to determine their level of importance to construct the regressor.
Table 9 denotes the importance of features in percentage, for the regressors trained in each of the three axes. Additionally, for the features belonging to the same group, not only the individual importance, but also the grouped importance (average of individuals) is reported, as well.
From the obtained results it is observed that the point coordinates has the most significant effect in prediction and as expected, each coordinate point, individually, contribute more in their own axis. The second remarkable feature is the distance to tumor which reflects the Euclidean distance of each point to the tumor (represented as a cylinder). Such trait was also relevant to the features’ behavior observed in clinical analysis, since points in larger distances from the tumor region are deformed less (see
Section 3.1.2). Another interesting observed trend is the impression of the
Z axis on the importance of the features. While the breast is more affected in the
Z axis with respect to the tumor location (see
Section 3.1), it is expected that features related with it, are more represented on that axis. Reported analysis of the two features,
coordinate difference to the excised cylinder and
polar distance to the excised cylinder satisfy the expected hypothesis. Far from expectations, it can be deduced that the tumor size feature not only influences the breast final deformation less than other clinical features, but also shows an irrelevant behaviour compared with the tumor region or the breast density features.
Additionally, to complete the investigation of features on the evaluation results, each clinical feature is assessed individually with respect to its impression of the best obtained prediction.
Table 10 reports the results of individual evaluations on the three studied clinical features including breast density, tumor size, and tumor region. By looking to the breast density, it is observed that the average distance error decreases with a direct relation to the amount of the adipose tissue (
Table 10), as was previously observed in
Section 3.1.1. It can be deduced, breasts with more fibro-glandular tissue, are less affected. The results reported in
Table 9 signifies the weakest role of the tumor size among clinical features; however, the outcome presented in
Table 10 provide more evidence to evaluate the contribution of this feature. It is observed that large tumors imposes more deformation, which is also an expected result, based on the results obtained in
Section 3.1.2. Regarding tumour region, it is difficult to conclude anything relevant, since, by looking to the obtained results, the magnitude of the deformation seem independent on the quadrant.
4.2. Gradient Boosting Regression
As in RF, in GBR a cross validation is performed with LOPO strategy, the following range for each parameter of the model:number of estimators (trees), in the rage of
; the maximum number of features in each tree in
; the leaf size in
; and the learning rate in the range of
. Besides, the criterion which measures the quality of a split is set
friedman mse. The numerical evaluation are reported in
Table 11 and
Table 12, for both the average and Hausdorff OFs.
Numerical comparisons indicate that the average pair-wise distance obtained by GBR was mm and for the average global distance. The performance of GBR should be investigated through the definition of the learners. To keep the learners weak, constraints were imposed on the number of leaves and the depth of the trees. The assigned constraints to maintain the trees small, have led to propagate error in the whole sequence of model, which is noticeable through the increase of the errors in comparison with RF; however, more research could be performed in future in order to improve the understanding of this behaviour.
By comparing with results obtained with RF, GBR presented worse results.
4.3. Multi-Output Regression
Contrarily to expectations, MOR presents poor results in both OF optimization, comparing to the RF. Numerical results of
Table 13 and
Table 14 express the performance of MOR with
pair-wise and
global distances.
Discussed in
Section 4.1.3, some of the most important features, presents a high correlation of each individual axis with each specific direction. This fact might influence the MOR to present poor predictions. More experiments should be performed in the future, but by the obtained results we can say that the point coordinates could play an independent role in predicting the displacement of each axis.
4.4. Summary
In this section two machine learning methodologies were studied; RF and GBR. The influence of sampling the data was studied taken into account the performance of the algorithm in terms of computational time and error of the prediction. Additionally, the use of adaptive weights were shown to have positive influence in the prediction. In any case, it might be difficult to understand the magnitude of the error, due to the lack of comparative approach, which could lead to the weak understanding of the obtained results. For this reason, a Heuristic Model (HM) was designed, taken into account the feature analysis performed in
Section 3.1. With this simple and heuristic method, we could understand how difficult is to achieve a good result without using complex models, taken into account only the knowledge of the problem.
The method comprises the computation of mean displacement (expressed in Equation
5) of each point in the PCL data. This is performed separately in each axis and in each quadrant independently.
where
and
are corresponding points of pre- and post-surgery PCL, respectively, and
N is the number of points in each PCL. The proposed HM follows the following strategy: the displacement of each point belonging to the healthy quadrants is computed based on the average displacement of each specific quadrant; for the points belonging to the unhealthy quadrant, the displacement is computed taken into account the average displacement of that quadrant, but multiplied both by
for the breast density (
, respectively), and by
for tumor size (
, respectively), following the knowledge obtained in
Section 3.1 (see Equation (
6)):
where
b,
s, and
are breast density, tumor size, and displacement of the equivalent breast quadrant, respectively, and finally,
denotes the calculated post-surgery PCL. The presented results of
Table 15 are obtained by this this approach.
By comparing this simple approach with the learning models presented previously, we can state that the magnitude of the error obtained with RF is acceptable. The framework designed in this work, composed by data, features and models, presented some simplification regarding the reference framework from Vavourakis et al. [
24], which could lead to some errors on the prediction, but with not so high influence in the visual aspect. Some new directions for this line of research are already planned trying to improve the obtained results, which will be presented in Conclusions Section.
5. Discussion
Considering the characteristics of the problem, such as the type of features, and the demanded output, RF-based methodologies were primarily chosen as learning models for this problem. We started by studying the influence of data sampling for the performance of the model, and it was observed that less sampling generally leads to less errors on the prediction, but took to high computational time. Focusing on the pair-wise distance, the declining trend of errors stops when the sampling rate reaches to . More sampling rates result in the errors oscillating in a the range of mm. Although the difference errors between the distances in the range of to remains about mm, the sampling rate with the minimum distance ( mm) was chosen as the final sampling rate (). Same argument has been carried out to select the sampling rate of when the OF is set to be Hausdorff distance. The minimum distance with respect to the Hausdorff OF is reported near to mm.
The influence of weighting was also taken into account. Following the strategy of adaptive weight assignment, the points on training data PCLs were weighted based on the errors to the corresponding point in the target PCL. It should be noted that the trained model in each iteration is evaluated to determine the new weights for the next iteration. The obtained results highlight the effectiveness of using an adaptive weighting function, obtaining better results, even they are not so significant. Additional investigation should be performed in this part, in order to find the most suitable weighting function for this problem.
RF were compared with GBR methodology. As previously discussed, learners of the GBR was kept weak intentionally to refrain the greedy growth of the methodology. The imposed constraints kept the learner leaves less (or equal) than 3, and the learners depth less (or equal) than 5. Therefore, in both lines of OF, an increase of the distances were observed. However, it should be mentioned that the current strategy to consider the aforementioned constraints, limited the range of reported distances, in which the average and maximum distance in the two OFs approached to each other.
A MOR approach was also taken into consideration. Although the results showed that it fell behind the single output RF, this weak result might lay in the facts that not only the MOR trainer was unable to find a correlation between the points’ displacements of multiple coordinates, but also the features of different coordinates intruded the learner such that they cancel the impression of each others. The aforementioned hypothesis needs to be investigated more to determine the weak performance of MIMO methodology.
Finally, to close the discussion, it should be noted that all the regressors were design with a the same sampling rate. The RF with adaptive weights outperforms the other regressors with mm and mm for the average and the Hausdorff optimization, respectively. In the second rank, RF without consideration of adaptive weights stands with an average distance of mm and maximum distance of mm. Third and forth ranks were obtained by MOR (with average of mm, and Hausdorff of mm), and GBT(with average of mm, and Hausdorff of mm).
6. Conclusions and Future Work
In this study, the use of machine learning techniques to predict the breast deformation after BCS is developed to use real MRI data of patients without depending on the knowledge of physical equations to describe the deformations.
To overcome the nonexistence of dataset suited for learning breast healing deformations, an in-house dataset was generated using MRI data from real patients combined with a multiscale biomechanical and biochemical models to simulate post-surgical breast shape. Several clinical features that might impact breast healing deformations, including breast density, tumor region, and tumor size, were considered in the creation of the dataset that is representative of the population distributions.
The learning process was divided into two main tasks: feature inspection and model selection. In the first task, the complex interplay of clinical features for conditioning the breast shape after surgery healing was untangled by comparing the influence of different sets of features in the deformed breast after resulted from BCS. Here, it was concluded that breast density had the highest impact on the breast displacements while the quadrant where comprises the tumor was determining to predict the directions of shape adjustments. Further analyses of the importance of features resulted from learning process reinforced the experimental findings. In the model selection task, several regression methodologies, including Random Forest, Gradient Boosting Regression, and Multi-Output Regression were studied. Beside the learning model, a heuristic model was also proposed to validate the veracity of learning methodologies and understand the magnitude of the distances. Additional investigations were conducted with respect to sample PCL data, as well as a complementary study to assign different weights to the training instances, which resulted in predictions with slightly better evaluations. The numerical evaluations with the pair-wise and global distances indicated that the RF regressor constructed with the adaptive weighted training set outperformed MOR and GBR in both lines of average and Hausdorff OFs.
Improvement of results by assigning adaptive weights opens a new line of investigation for the future work, in order to define better mechanisms to improve the performance of regressor. Additionally, regression based on GBR can be improved by re-defining new learners and putting better constraints to keep the learners weak enough to avoid overfitting. Besides, more investigations are needed to study the correlations between the features in order to provide more evidence to the hypothesis of poor performance of MOR. As an alternative solution, it is worth studying a combined methodology of predicting breast deformation with machine learning techniques followed by some final steps of the biomechanical models; hence the required computational time for the biomechanical models is decreased since the predecessor machine learning methodology has provided a partial solution. Last but not least, new learning methodologies such as convolution neural network regression, and deep geometric learning can be investigated, as well as performing the prediction of breast shape directly on the 3D surface data.

 ,
, 

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}