1. Introduction
Three-dimensional (3D) object recognition and pose estimation are two open problems in the scientific community. There are many algorithms to solve them separately and some to solve them concurrently. In fact, both problems are deeply related, since a 3D object can be observed from different points of view, showing different shapes in each case. Knowing the point of view is equivalent to knowing the relative pose estimation between the object and the observer; once the point of view is known, recognizing the object is much simpler as the observer can explore the set of known objects only under this same point of view. Conversely, knowing the object simplifies pose estimation as well, since the problem is reduced to the exploration of different points of view for this given object.
The complexity of solving both problems increases dramatically when moving from an independent to a concurrent resolution. Therefore, this kind of algorithm is of great value in many applications where object recognition and pose estimation are critical, as is the case of, for instance, object manipulation using a robotic arm.
There have been many proposals to solve each problem separately, since, as stated before, they are critical to many applications. Due to the importance of both topics, reviews are published from time to time regarding them, so there are many sources of information for learning about the state of the art in these two areas.
Recent reviews of available techniques dealing with object recognition can be found in [
1] or [
2]. A more comprehensive review can be found in [
3], or, for a more theoretical point of view, in [
4]. Finally, in [
5] there is an extensive review of approaches and algorithms.
With respect to pose estimation, the case is much the same, as reviews can be easily found. For instance, in [
6] the reader can find an up-to-date review of the most important pose estimation techniques, while in many other sources the reader can find surveys on deeply related techniques as is the case of SLAM [
7]. In terms of concurrent solutions of both problems, there have been some remarkable contributions. In [
8] the authors introduce an algorithm which uses tensors to generate systems of linear equations that are solved to estimate the affine transformation leading to an object view. In [
9], an algorithm using appearance representation is introduced; for a given 3D object, it is coded by extracting brightness information of different views corresponding to different poses. Afterwards, authors perform a dimensionality reduction by applying a PCA to the database. An algorithm for object recognition and pose estimation based on keypoints (SIFT) that builds object models based on pairing keypoints in different views, camera calibration and structure from motion is introduced in [
10]. A very similar approach is presented in [
11], but in this case no camera calibration is provided. In [
12], authors introduce the Viewpoint Feature Histogram, a descriptor based on point clouds that simultaneously encodes geometry and pose, which requires depth information collected with a stereo vision system in order to work. In [
13] authors present a probabilistic framework for object recognition, combined with a pose estimation by means of Hu moments applied to the segmented image of tip-shaped objects. In [
14] authors combine features describing depth, texture and shape for object recognition, and solve the pose estimation problem by successive steps, using 3D features to find a coarse solution and ICP for fine estimation. In [
15], the authors combine 3D CAD descriptions and two-dimensional (2D) texture information to generate a model suitable for the recognition and pose estimation stage, using an approach based on generating multiple virtual snapshots from many different points of view. The authors of [
16] introduce an approach based on point cloud alignment, using an RGB-D camera to get a point cloud that is matched against point clouds describing the known 3D objects stored in a database; pose estimation is computed from the alignment process. In [
17], authors present an algorithm to estimate the pose of a reduced set of known colored objects; for that purpose, once the colored object is detected in the image and segmented, it is identified by its color and then its 3D model is used to perform a point-of-view sampling process. Finally, in [
18], the authors present an algorithm based on template matching and candidate clustering for object recognition and point cloud processing techniques for pose estimation.
In this paper, a new approach to simultaneous object recognition and pose estimation based on the computation of a set of orthonormal moments is introduced. With respect to other methods that use feature spaces or subspaces to solve the task, like for instance [
9], this new approach has two main advantages. Firstly, this is an analytic method, with an ability to recognize 3D objects and to estimate their poses as demonstrated in
Section 3. For other methods, this ability is a result of experimental work, and therefore is not analytically proved. Second, orthonormal moments are not features in the traditional way, as they capture the object shape itself, not some properties measured on them. In other words, a 3D object can be straightforwardly reconstructed from a complete or truncated series of orthonormal moments, but not from a set of brightness or texture features. Therefore, this algorithm need not be trained each time the database is modified; new objects are simply added by including the orthonormal moment information, formatted in the way that will be explained in
Section 3. During an off-line stage a four-dimensional (4D) tensor comprising the information on the 3D object’s shape observed under multiple points of view is built. Additional advantages are that they may be extracted from very low definition images, with a textureless description of detected objects, and that recognition and pose estimation are achieved by means of a matrix product, whose results are straightforwardly interpretable. All these features make it a good candidate for real-time implementations.
The remainder of this paper is organized as follows: related work is reviewed in
Section 2. In
Section 3 the proposed algorithm is thoroughly explained, first for a simplified case that allows an easier introduction to the underlying concepts where pose estimation is limited to a rotation angle, and after that for the complete case.
Section 4 describes how the problem of angular description and balancing has been solved in the proposed approach. In
Section 5 experimental results are presented and discussed. Finally, conclusions extracted out of this work are presented in
Section 6.
2. Related Work
Moments have been used for object recognition and pose estimation, and sometimes for performing both tasks at the same time. Since object recognition is probably the most classical application of moments, the reader is advised to read a comprehensive review on the topic in [
4]. Their application for pose estimation is not that extensive, and therefore it is worth mentioning the most significant efforts in this direction. In [
19], authors introduce an algorithm to estimate the pose of a satellite by means of computing Zernike moments and comparison with different views of the spacecraft described in the same way. In [
20], authors present two alternative methods to estimate the full pose of planar objects, combining the definition of the interaction matrix, central moments, and invariant definition. In [
21] authors calculate the moments of a 3D object with known geometry as it moves freely in 3D space, and compile them in a table whose entries are the rotation angles; observed moments are matched against tabulated descriptions. In [
22], the author propose invariants to translation, rotation and scaling departing from shifted geometric moments. In [
23] the authors propose a method for IBVS based on a set of moments and the definition of an interaction matrix for that set of moments. Finally, there have been some other methods for object recognition based on the characterization of a 3D object by means of the definition of its projections from multiple points of view. Examples of these works are presented by, for example, Ansary et al. [
24], who present the selection of multiple views as an adaptive clustering problem; Daras and Axenopoulos [
25], who introduce a 3D shape retrieval framework based on the description of an object by means of multiple views; Rusu et al. [
12], who introduce an algorithm to recognize an object and estimate its pose using point clouds captured from different points of view; Rammath et al. [
26], who describe and recognize cars based on matching 2D and 3D curves that can be observed in different views; Sarkar et al. [
15], who present an object recognition algorithm based on feature extraction from a set of computer generated object views; and finally, Liu et al. [
27], who introduce a combination of 3D and 2D features obtained from different captures of an object using RGB-D cameras.
4. Section vs. Projection: Projected Pseudo-Volume
In
Section 3.1 it has been proven that, departing from the orthogonal moment representation of an unknown section of a 3D object in a given set, it is possible not only to recognize what the original object is, but also the angle determining that section. Nevertheless, in any application a common situation is not having the image of a section but of a projection of the whole object that will be assumed to be parallel to a given direction, as is the case of the Radon transform. Yet, in
Section 3.2 it is supposed that the projection through a given direction is already defined.
Therefore, in order to make the algorithm work with projections instead of with sections, a transformation of the 3D object must be carried out. This transformation will yield another 3D object gathering all the considered projections through directions at different angles for the case of cylindrical coordinates, and will yield a 4D tensor comprising projections from every pair in the case of considering any projection direction.
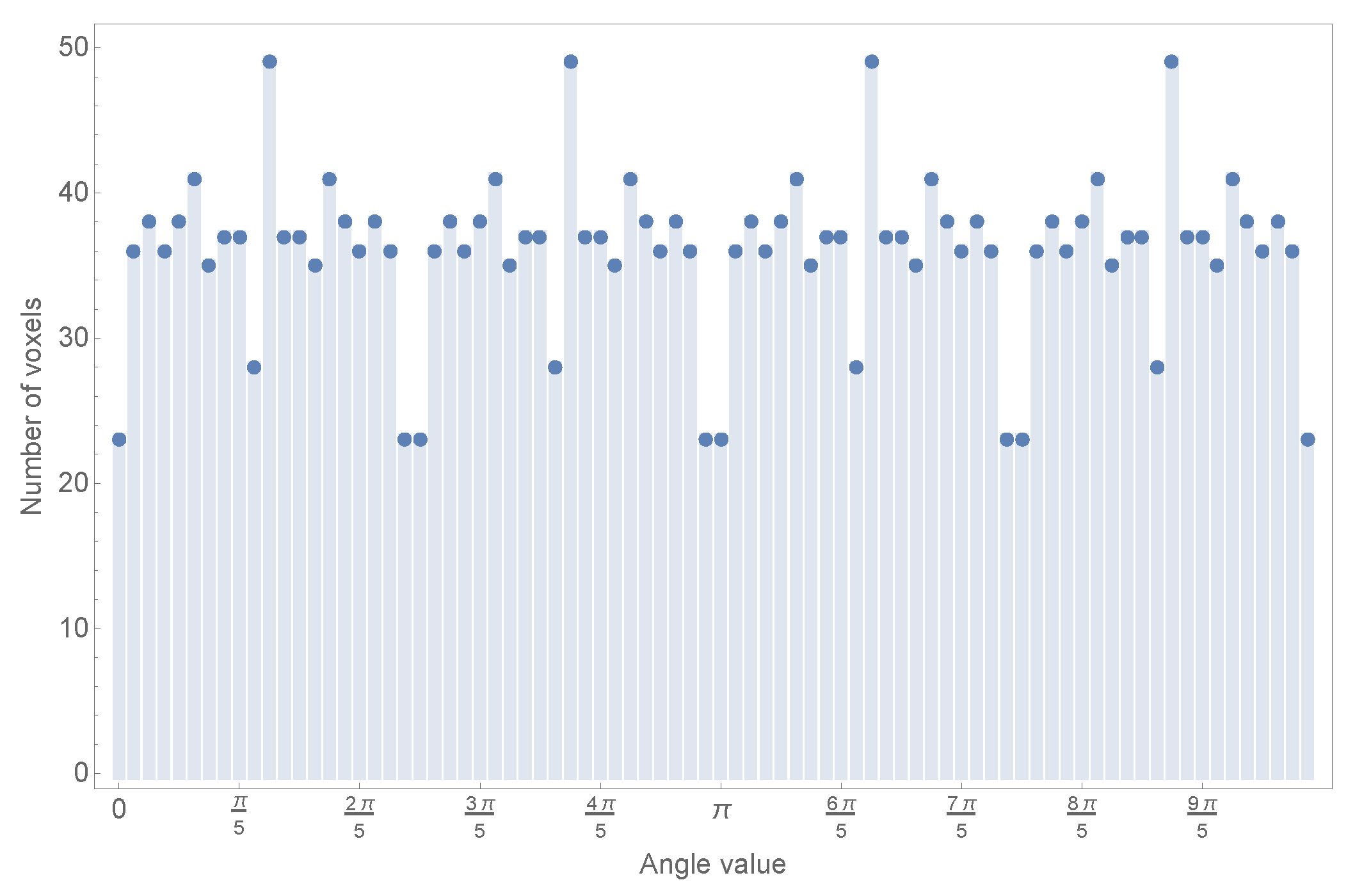
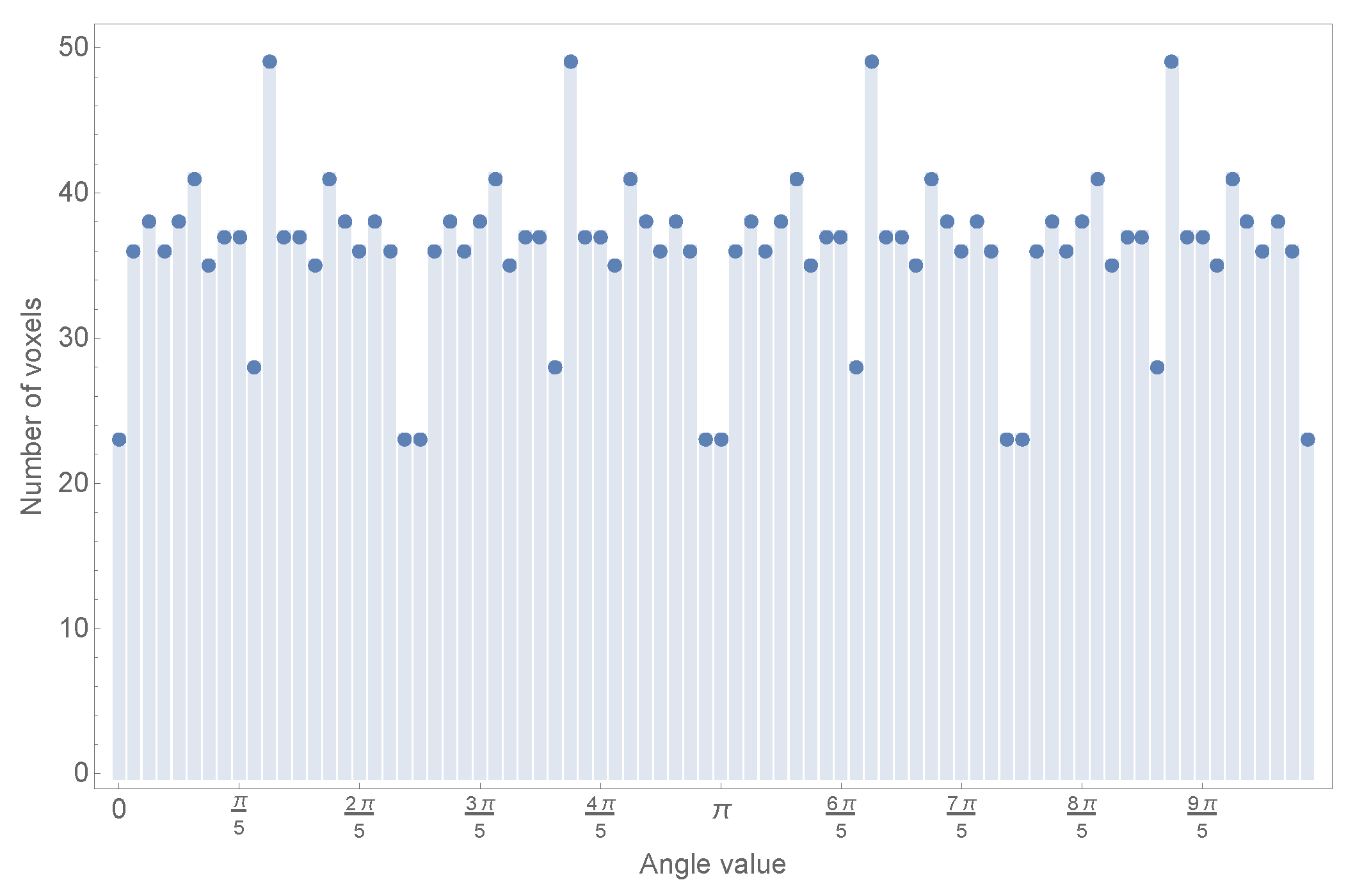
However, before starting with the definition of these transformed objects, it is necessary to study the problem of the polar translation of a Cartesian object in a discrete domain. The main problem is that when this object defined in a Cartesian discrete grid has to be defined through polar coordinates used in the derivation of the algorithm for both cases, the resulting representation is unbalanced in the angular coordinates. To illustrate this point a simple test has been conducted: a simple grid of 60 × 60 pixels has been defined, and the angles of every pixel with a radius under or equal to 60 have been collected in a histogram, where each bin has a width of
rad. The result of this simple test can be seen in
Figure 1.
As can be easily observed, the numbers of pixels assigned to each bin are clearly unbalanced. This causes different representation strengths for different angles, affecting the moment transformation as it is based on angular coordinates.
In the recognition stage, the unknown projection image will be represented within a normalized flat grid, with a fixed number of pixels, but, as can be seen from
Figure 1, each section for every known object is represented with a varying number of pixels depending on the angle. Obviously, this mismatch will cause the algorithm to perform poorly.
Therefore, as the problem stated herein is defined in angular coordinates, some strategy must be provided in order to balance the pixels contributing to each angle bin, as there is no strength mismatch between unknown projection and object representation.
The solution adopted for this case consists of building a transformed pseudo-volume that packs all these projections into a Cartesian grid, though some axes describe the angles at which the object has been rotated in order to generate a given projection. The construction of this pseudo-volume for cylindrical coordinates is as follows. Let the rotation of the object
by an angle
around the
z axis be defined as:
so the rotated object is defined in the same domain as the original object,
, defined in Equation (
1), and
,
. The upper limit for
will be explained later on.
In order to make the next steps clearer, the rotated object is now converted to Cartesian coordinates:
where
, as
as a result of the change in the coordinate system.
Now, after the object has been rotated, its projection through the
y axis is generated:
This projected image,
, is then binarized to bring it back to its original range, i.e.,
:
Extending this process to every
, and gathering all the resulting binarized projections, a new 3D object, called the projected pseudo-volume,
, is generated:
being:
Once the new 3D object, , is defined, the upper limit for rotation angles, , can be explained; it is set in order to avoid that any projection, or its reflected image, be represented more than once, as this fact would lead to multiple solutions in a pose estimation problem. Therefore, this upper limit will have a maximum value of , as both sides of any object have the same (reflected) projections. In case of symmetric objects this upper limit will have to be reduced in order to avoid a multiplicity of projections within . The limit case corresponds to objects having central symmetry around its z axis, for which pose estimation cannot be computed as the projections from every rotation angle are the same.
The process of generating this transformed object is resumed in
Figure 2. It starts with the 3D object with no rotation (a), i.e., with an initial alignment with
x and
y axes, and then it is rotated
around the
z axis (b). The resulting image has shifted its alignment with the original axes, so once it is projected through the
y axis, the result will be different for each rotation (c). This projection is included in the new object, as a slice with coordinate value
on the
axis (d).
In this way, the projected pseudo-volume, that has the same number of pixels assigned to each angle view, collects information about parallel projections in the sense of a Radon transform, instead of simple object sections.
The same idea has been applied to the generation of a 4D object that will be used in the general case as depicted in
Section 3.2.
Starting from the initial definition of the 3D object,
in
, it is initially converted to Cartesian coordinates to make the next steps clearer, using an expression similar to Equation (
45). As a result, the object is now defined in
, described in Equation (
46). Then, the 3D object is rotated an angle
around the
x axis, so it is now represented as:
After that, the object is rotated an angle
around the
z axis, so the object is redefined as:
From this point on, the algorithm progresses as in the previous case, starting from the projection through the
y axis, as in Equation (
47):
then there is binarization to bring the image back to its original range, as in Equation (
48):
and, finally, extending the rotation process to every
and
and gathering all the resulting projections in a new 4D object, the so-called projected pseudo-hypervolume
is generated:
where,
5. Experimental Results
5.1. Recognition and Pose Estimation in Cylindrical Coordinates
For testing this simple case, prior to testing the complete algorithm with the 4D objects described in the previous section, a set of 70 three-dimensional objects out of the the Pascal3D+ Benchmark set [
29] has been compiled, belonging to every included class but `Bottle’, since it has central symmetry and therefore is ill-posed for pose estimation. These 70 objects have been transformed from their original CAD format to a voxel-based representation, and are included in a grid of
(width, depth, height) voxels, in such a way that the object’s centroid is placed in the center of the grid, and it is touching some of the grid walls.
Once all these objects have been normalized in this way, a projected pseudo-volume has been defined for all of them, covering 20 equally spaced rotations between 0 and radians. The angle limit has not been extended to because of the observed four-fold symmetry: symmetric objects produce the same projection for different rotation angles (views), leading the algorithm to the impossibility of choosing the right orientation. In mathematical terms, symmetry leads the presented algorithm to ill-posedness, so the pseudoinverse suffers from numeric instability due to a very bad condition number. In this way, the pseudo-volume generated for each original 3D object is defined in a grid of ().
For every projected pseudo-volume in the collection, the orthogonal moment representation for each coordinate is by:
Legendre moments up to the 19th order for the Cartesian coordinates
x and
z. The Legendre polynomial of order
n in
x is defined as:
Fourier base. Note that although this coordinate is defined in a Cartesian grid, it represents an angle in the real world so it can be easily transformed using the Fourier basis that on the other hand allows this algorithm to determine the rotation angle of the observed pose. The Fourier base is up to 19th order for
as well, i.e.,:
In this way, each pseudo-volume has been represented with 8000 descriptors with a total of 18,000 voxels in the pseudo-volume that represent a 3D object initially defined through 54,000 voxels. All these data have been gathered in
Table 1.
Once the moments for each object have been generated and stored in the database, a set of unknown side views is generated. For this purpose, each of the 70 objects has been rotated 10 times at random angles in the interval and their projections along the y axis have been computed. Each projection has been represented through its Legendre moments up to the 19th order in x and z.
Using this unknown set, two different tests have been carried out. First, a test was run to determine the precision of the algorithm recognizing the object that generated each projection after rotation. Then, a second test has been conducted to evaluate the accuracy, estimating the rotation angle that has been used to generate each projection.
5.1.1. Recognition Tests
Two different rounds of precision tests have been conducted. In the first one, the orders of
x and
z moments have been varied from 0 to 19, keeping the order of moments on
fixed to 19. Mathematically, this means that calling back the general expression in Equation (
16), matrix
has been reduced in terms of its number of rows, keeping constant its number of columns, i.e., the least squares problem to be solved has been defined using fewer equations. This fact can be easily seen going back to the definition of matrix
in Equation (
13). In this way, for this round the problem has been reformulated in reduced versions through:
where
stands for a matrix
constructed using moments for
x and
z up to order
m and
n respectively. Also, according to the general expression in Equation (
13),
stands for a matrix of 2D moments constructed up to orders
m and
n as well. Finally,
stands for a matrix of Fourier basis elements up to order 19, and is particularized for
, where
is the unknown angle used for generating the projection image under analysis.
In a second round of tests the orders of the moments in
x and
z were fixed to 19, and the order in
was varied from 0 up to 19. Mathematically, this means that the least squares problem in Equation (
16) has been defined by always using the same number of equations given by the constant number of rows in matrix
, but with an increasing number of unknowns to be estimated, given by the varying number of columns and the corresponding number of elements in vector
:
Before starting both rounds of tests, 2D moments for each unknown projection image have been computed, obtaining . After that, tests have run in the following way:
First, the order of moments in x, y and is set.
Matrix is reconfigured according to those moment orders to .
Next,
is computed, according to Equations (
59) or (
60).
Vector
is computed for each object in the database:
The |RMS| is computed between the observed and estimated sets of moments:
The object
is obtained, for which the minimum RMS is chosen from the database:
The u-th projection image is recognized as having been generated by object
According to this test procedure the total number of pairs that has been tested is easily computed: 700 unknown images, in two rounds of 20 combinations. Ten comparisons for each combination results in 280,000 combinations.
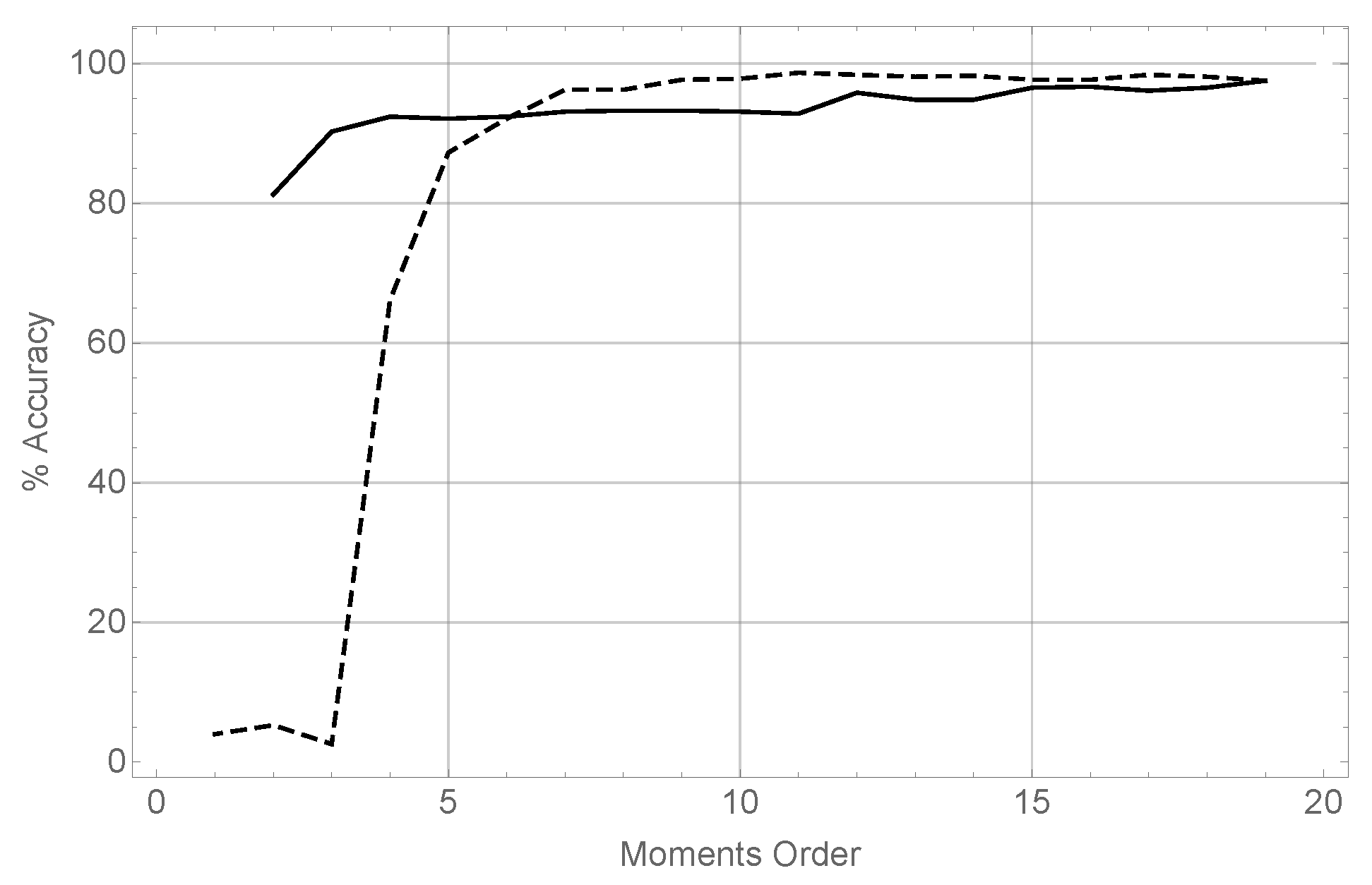
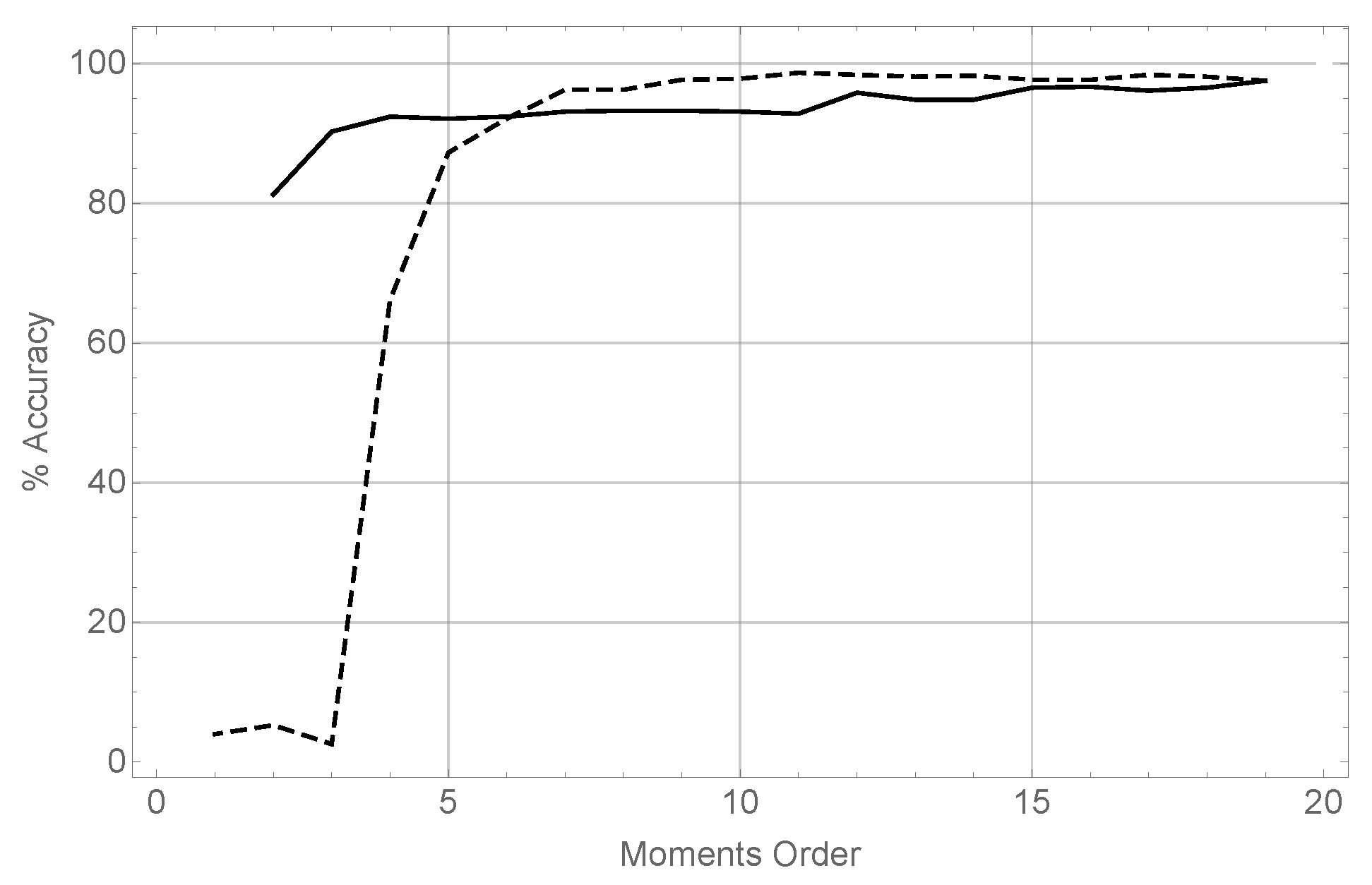
The results of running these two tests are summarized in
Figure 3.
The evolution of the precision using different orders for the coordinate, while keeping constant the orders of moments for the x and z coordinates both fixed to 19 has been represented using a dashed line. It can be seen how for very low moment orders the performance is very poor, as there is not enough data to estimate 2D moments. However when the order in the reaches 7, precision in recognizing the unknown object is above 95%, reaching at the end of the series a maximum value of 98%. This reveals that, in terms of precision, it is sufficient to keep a very low order in the angular moments, given a rich representation in x and z.
The evolution of the precision varying the orders for x and z (taking both the same value in each case), and keeping the order in always equal to 19, is represented using a solid line. It can be seen that the precision degrades smoothly but continuously as the moment order decreases. It is then clear that for good results in terms of precision, a rich representation in x and z is mandatory.
5.1.2. Pose (Angle) Estimation Tests
Following on from the results obtained for the unknown projection images in the tests explained in the previous section, the evaluation is now focused on the accuracy in the estimation of the relative pose of the 3D object (angle ) that has been used to generate each of the 100 unknown projections. For this, the starting point has been the recognition accomplished in the previous experiment, even if it is wrong. Once the projected 3D object is known, this experiment proceeds by estimating the relative angle between object and observer. Recall that in this simplified case only rotations around the z axis are allowed.
Given the structure of vector
given in Equation (
14), the estimated angle
is computed following Equation (
22), and then it is compared to the actual angle
that was used to generate each unknown projection. This angle estimation has been carried out, as in the experiment explained above, in two different rounds: first, keeping orders of moments for
x and
z fixed to 19 while varying order for
from 0 to 19, and the second one keeping order for
in 19 and varying orders for
x and
z at the same time from 0 to 19 as well.
The error between the actual angle,
, and the estimation,
has been computed for each combination of orders in both rounds, and for each one of the one hundred unknown projections, yielding a grand total of 28,000 analysis. Then, for each combination of orders, the RMS errors corresponding to the measured error for each one of the 100 unknowns has been computed:
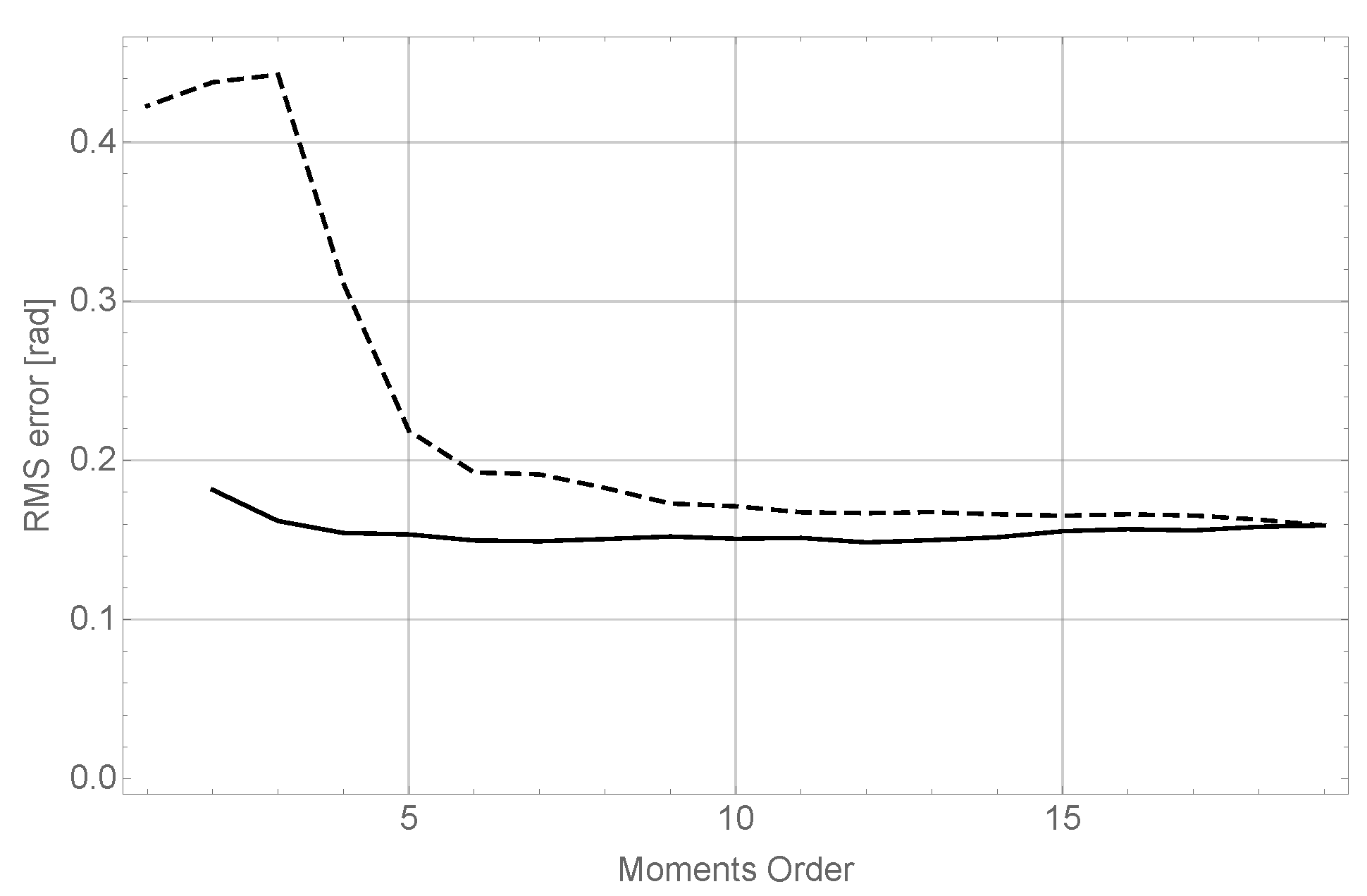
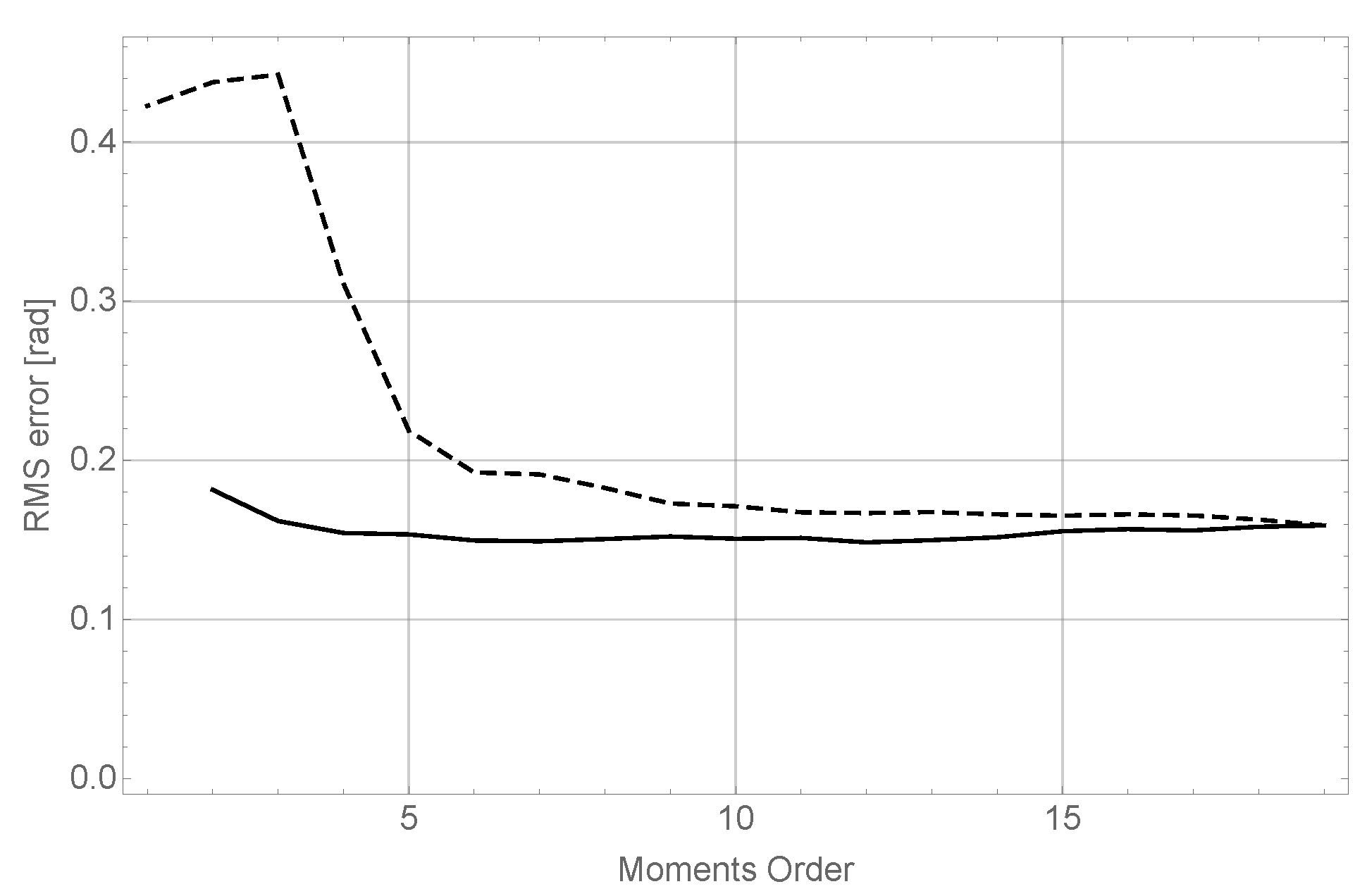
The results of this experiment can be observed in
Figure 4.
The conclusions of this experiment confirm the behavior observed in the experiments explained in the previous section. It can be seen (dashed line), that although for very low orders in results are very poor, they improve quickly to reach very good values for order 8 without significant enhancements as order 19 is reached. On the other hand, it can be seen as well (dashed line) that the behavior of varying orders in x and z keeps almost constant; nevertheless, as seen before, maintaining good precision in object recognition requires a high moment order for both coordinates.
In order to make a comparison with algorithms in the literature presenting results working with the same 3D object database, the overall results have been computed separately for each category. Two recently presented algorithms, by Su et al. [
30] and Tulsani et al. [
31], have been chosen as the basis for comparison; moreover, in those papers the reader can find further references to previous results. Although both of them use median error to evaluate the results and in this paper RMS is used instead,
Table 2 provides a good comparison of all these methods.
Quantitatively, the most remarkable result that can be observed is that the RMS value for the complete set has a value of , being in the same range, or even slightly better, than similar algorithms found in the literature. Nevertheless, it can be observed that the presented algorithm performs worse for some classes.
As an overall conclusion, from these two experiments it can be stated that it is important to keep high orders in x and z, both in terms of precision and pose estimation, whilst order in can be reduced to fairly low values without degrading the outcome of the recognition and pose estimation significantly.
5.2. Recognition and Pose Estimation in 4D
In order to test the ability of the algorithm to recognize and estimate the pose of a 3D object, the methodology has been the same as in the former case. The set of test objects has been the same, with the sole difference that, since in this case rotations can be performed over two axes, the 3D grid to define voxelized objects has been increased to a resolution of (height, width, depth), so it can completely hold the 3D object in any relative position. In these tests, the center of gravity of each 3D object has been placed in the center of the voxel grid, i.e., .
In this case, the projected pseudo-object, defined in 4D, has been built using 10 equally spaced rotations in the range ; once again, this restriction in the total span of the rotations is due to the symmetric nature of the 3D objects in the database. As a result, the dimensions of the 4D object are .
The definition of moments along each dimension is found in:
Cartesian coordinates, i.e.,
x and
z, and Legendre moments, based on the Legendre polynomials defined in Equation (
57), up to the 19th order
Angular coordinates, i.e., latitude and longitude, and a Fourier basis, as in Equation (
58), up to the 9th order. Therefore, the element
of the basis is defined as:
Computing the volume of data in each stage (3D object, pseudo-object in 4D and moment set), we find that the initial object is defined through 216,000 voxels, that leads to a pseudo-object in 4D of 360,000 elements, represented through 40,000 moments. All this information is gathered in
Table 3.
The decision to set the order of moments in each dimension in this manner has been guided by the results shown in the previous section, where it was demonstrated that keeping angular moments in low orders is enough to achieve good results in the pose estimation (in fact, results do not seem to improve when increasing this order). On the other hand, moments in the Cartesian coordinates have been kept at the same order as in the previous section, even though there are more pixels representing each section (recall that now each projection has 60 × 60 pixels, whereas in the previous experiments the size was 60 × 15). This means that having four times the amount of data per projection, the number of moments to represent it is kept the same. The reason is twofold: first, the data volume must kept as low as possible in order to favor computing time and therefore keep the algorithm as close as possible to real time; and second, the resilience of the algorithm should be checked in a situation of data starvation, as the problem now is much more complex than before.
Therefore, in this experimental moment orders have been kept fixed in every case. Once again, it has been split in two stages: object recognition and pose estimation. For the recognition stage, the procedure was the same as in the previous section:
One hundred different projections of the 3D objects in the database have been generated through randomly selected and angles.
For each projection, 2D moments up to the 19th order for both x and z have been computed. These moments have been arranged in the vector .
For each projection
u and each object
k in the database, the estimation of vector
has been computed, following Equation (
39).
With each computed estimation
, vector
has been reconstructed, using the expression in Equation (
34).
The RMS error between each estimated and observed vectors has been computed, as in Equation (
62).
The recognition is carried out by selecting the object that has generated a reconstruction with minimum RMS error, as in Equation (
63).
Finally, for the pose estimation stage, as in previous section, the angles defining the relative pose estimation have been computed following on from the assumption that the previous recognition is right, therefore, the calculations include the false positives. Angles
and
are computed following Equation (
43), and after that, RMS error has been computed for each angle separately, taking into account all the test projections that were generated.
Results for both experiments are summarized in
Table 4.
First, it is worth noting the recognition accuracy rate results, which are notably lower than the rate in the cylindrical coordinates problem presented before. The main reason is that many of 3D objects selected, for instance cars or buses, share almost the same look from above, being in every case roughly rectangle-shaped. Therefore, it is hard to precisely recognize which object is seen, leading to some misclassifications.
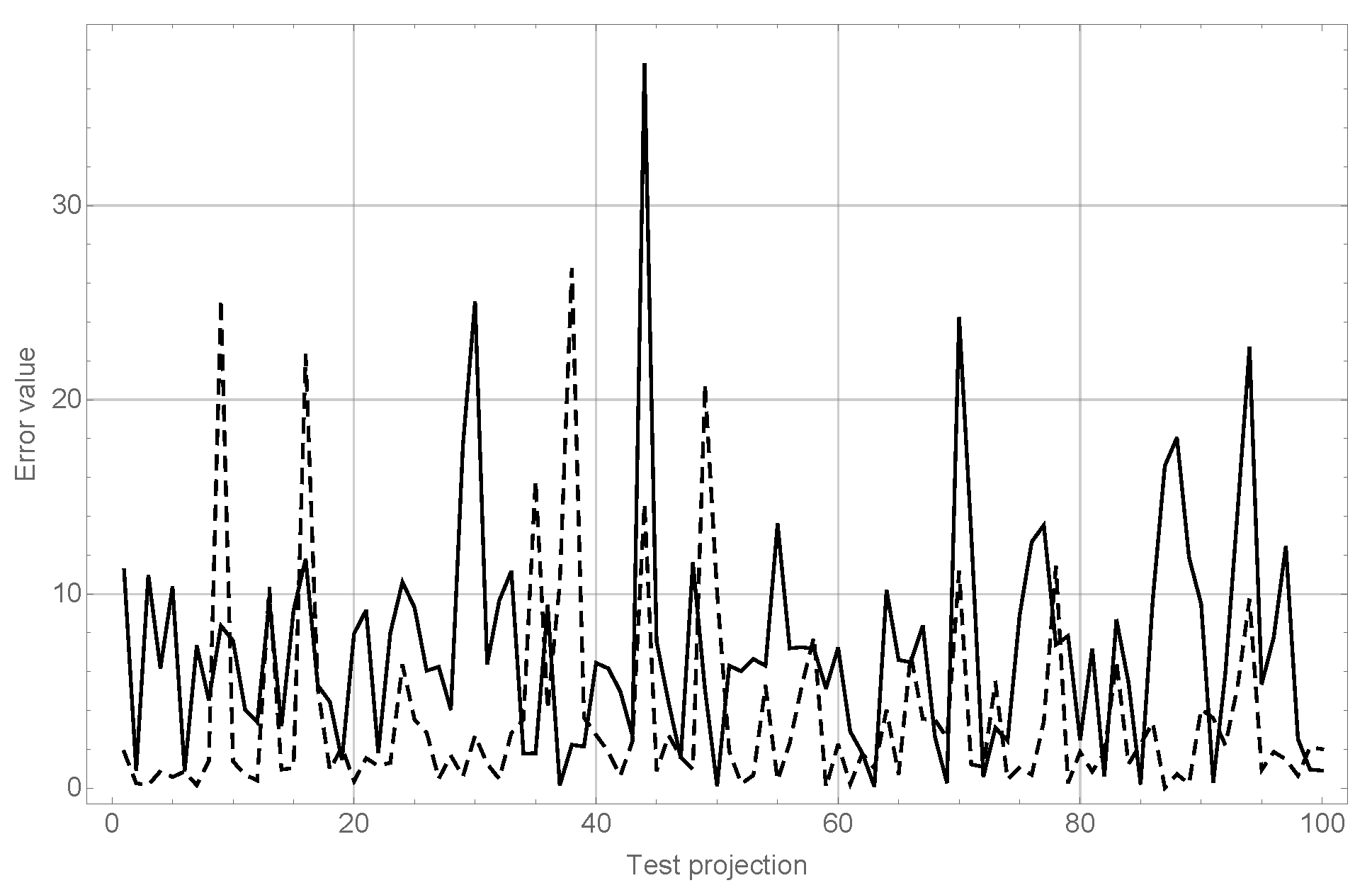
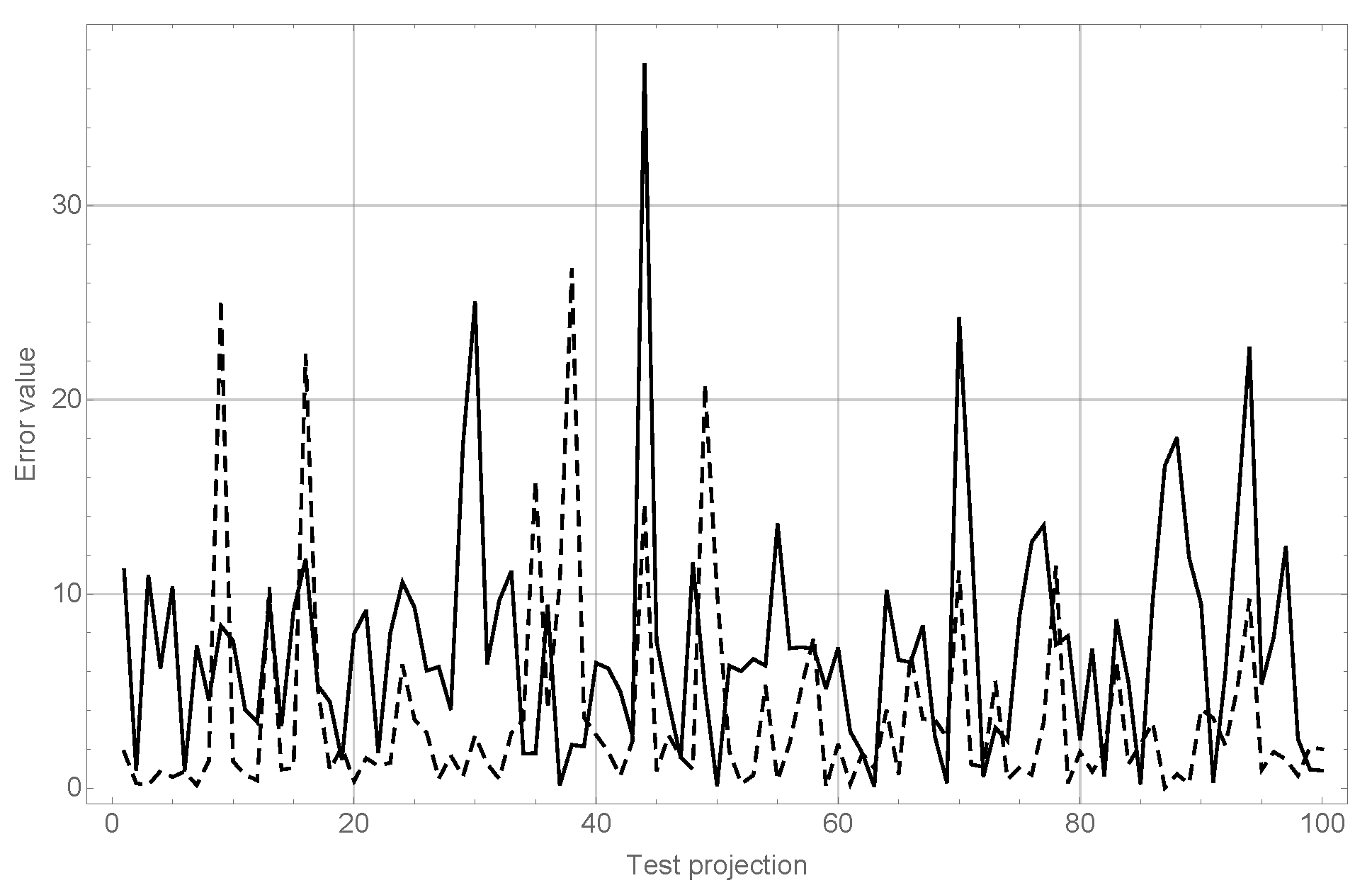
In
Table 4 the RMS values are significantly greater than mean values, showing that there could be outliers in the error series that can largely distort results. In
Figure 5 the module of the error value for both angle estimations and each test projection in the ‘Cars’ category can be observed in order to illustrate this fact.
As can be seen in
Figure 5, wrong recognitions have largely affected the error values, as they tend to generate estimation errors over 20 degrees whilst the trend for objects correctly recognized is to keep errors to under 10 degrees.
Table 5 shows the updated results from
Table 4 after removing these false positives from the series.
It can be seen that the values obtained for pose estimation are similar to those observed in the reduced cylindrical problem in the previous section.
These results show that the proposed algorithm achieves the same quality as other approaches in the literature in which angle estimation accuracy have been reported, such as in [
32] or [
17], or a better tradeoff between computing time and quality of estimation, as compared to the work in [
14].
5.3. Results on Real Images
In order to qualitatively test the algorithm in a real world scenario, in the same way as introduced in [
30], images depicting the same car models as those stored in the database were downloaded from the Internet. The only concerns in selecting them were, on one hand, the absence of a strong perspective effect, since the algorithm works under the assumption that projections are orthogonal (parallel), while on the other hand, lens distortions were avoided as well for the same reason. In a real application, these requirements should not be an issue, as the chosen camera can be calibrated previously.
Images were manually segmented and binarized. After that, they were converted to the same size as the projections defining each pseudo-volume stored in the database, i.e., pixels, and normalized in the same way as they were, i.e., with the full height and x coordinate of the CDG of the object in the middle of the image. After that, 2D moments up to the 19th order in each dimension, x and z, were computed and passed to the algorithm. The results obtained in this experiment are consistent with the observer evaluation, though, obviously, no ground truth data were available in order to quantitatively evaluate the outcome.
Real images, segmentation results, and projections from the 3D objects in the database using the pose estimation obtained with the algorithm, are collected in
Figure 6. Numerical results are gathered in
Table 6.
As can be seen, the 3D simulations and the projections generated after them (using the rotation angle obtained with the algorithm) are very close to the segmented images, showing that the estimations, though lacking ground truth data about their true generation, are very consistent with the observed reality.
6. Discussion
In this paper, a new method for simultaneous 3D object recognition and pose estimation based on the definition of a set of 4D moments is introduced. The proposed moment set combines Cartesian and angular representations to extract the maximum information of the polynomial approximation achieved by using orthonormal moment bases.
Four-dimensional tensors comprise all the information regarding projection generation, including the 2D Cartesian definition of the projection itself and two angular components to define both latitude and longitude defining the relative pose of the observer.
Cartesian moments allow an efficient representation of object projection, while Fourier moments ease the computation of pose angles through exponential terms. In this way, 3D objects are defined by compact matrices that can be computed off line, leaving recognition and pose estimation stages to rely on simple matrix calculations. Moreover, recognition and pose estimation are accomplished using very low-definition projection images and low-order moments, that allow this algorithm to run in real time.
In addition, this algorithm works for textureless objects, as it is only based on contours, this being a great advantage as opposed to algorithms that need textured objects in order to define keypoints to be matched against known sets.
Results show that both the recognition and pose estimation precision rates are at the level of the state-of-the-art algorithms, proving that this approach is a valuable option for performing both tasks with the advantage of doing it simultaneously.
References yes





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}