1. Introduction
Failure mode and effects analysis (FMEA) is a widely used technology in many fields to identify potential failures or errors and further improve the reliability of systems by avoiding the occurrence of these failures or errors [
1,
2,
3]. Risk evaluation is a crucial step in FMEA, which aims to identify failure modes with high risk so as to perfect system design to eliminating the risk [
4,
5]. In FMEA, risk priority number (RPN) approach is a classical method for the risk evaluation [
6,
7]. Since having clear physical meaning and easy to implement, the RPN approach has been received extensively concern and application. However, there still are some shortcomings in the RPN approach [
8,
9], for example the possible missing of risk factors, without considering the relative importance of risk factors, and so on. Among these drawbacks, failing to address the uncertainty in risk evaluation is one of the most concerned, and has attracted increasing attention [
10,
11,
12,
13].
In the risk evaluation of FMEA, domain experts’ knowledge and evaluations play a very importance role. Because there are human being’s judgments, it inevitably involves various types of uncertainties such as ignorance and fuzziness. Fuzzy set theory [
14] provides a useful framework to describe the uncertain information. Therefore, risk evaluation under fuzzy environment, also known as fuzzy risk evaluation, has become an important research direction in FMEA. Many technologies have been developed to solve the problem of fuzzy risk evaluation in FMEA. Chin et al. [
15] presented a data envelopment analysis (DEA) based FMEA to determine the risk priorities of failure modes. Jee et al. [
16] proposed a fuzzy inference system (FIS)-based RPN model for the prioritization of failures. In [
17], the authors have given applied a model of evolving tree to allow the failure modes in FMEA to be clustered and visualized. Reference [
18] gives a detained literature review to the risk evaluation approaches in FMEA. By summarizing the existing approaches [
10,
18], one of the main branches is to regard the fuzzy risk evaluation in FMEA as a multiple criteria decision making (MCDM) problem under fuzzy environment. Many MCDM or multi-sensor information fusion technologies [
19,
20,
21,
22,
23,
24,
25,
26] have been used in FMEA, such as TOPSIS [
27], VIKOR [
28], evidential reasoning [
29], and so on.
In this paper, we address the fuzzy risk evaluation in FMEA from a perspective of multi-sensor information fusion. Each risk factor in FMEA is regarded as a sensor or information source that yields an evaluation regarding the risk of each failure mode. Then, the risk evaluation of every failure mode therefore becomes the process of fusing these evaluations generated from the information sources that correspond to risk factors. Different from existing multi-sensor information fusion method used in FMEA, in this paper the non-exclusiveness between the evaluations of fuzzy linguistic variables to failure modes is taken into consideration. A novel model called D numbers [
30,
31,
32,
33] which is an extension of Dempster-Shafer evidence theory [
34,
35] is used to model the non-exclusive fuzzy evaluations. At first, a new D numbers based multi-sensor information fusion method is proposed. Then, the proposed multi-sensor information fusion method is applied to FMEA, which results in a novel model for fuzzy risk evaluation. At last, an illustrative example is given to demonstrate the effectiveness of the proposed model.
The rest of the paper is organized as follows.
Section 2 gives a brief introduction about fuzzy set theory, RPN approach, as well as Dempster-Shafer evidence theory and D numbers. In
Section 3, a novel multi-sensor information fusion method is proposed based on D numbers. Then, the new model for fuzzy risk evaluation in FMEA is presented in
Section 4.
Section 5 gives an illustrative example of the proposed model to show its effectiveness. Lastly,
Section 6 concludes this paper. In addition, the notations of this paper are briefly introduced here:
represents a fuzzy set or fuzzy number, and
is its corresponding membership function, and
represents the area of
in the graph;
and
stand for the frame of discernment in Dempster-Shafer theory and D numbers respectively,
m represents a mass function and
D is a D number;
is the non-exclusive degree between
and
;
represents a distribution of pignistic probabilities;
is the defuzzified value of fuzzy number
.
3. Proposed Multi-Sensor Information Fusion Method Based on D Numbers
Let us consider a multiple criteria decision making (MCDM) problem, where each criterion can be regarded as an independent sensor or information source. Therefore, the process of resolving the MCDM problem can be treated as a process of multi-sensor information fusion. Assume there are
p alternatives, indicated by
,
, and
q criteria, denoted as
,
, and the weight of each criterion is
,
. Due to the uncertainty of decision-making environment, the evaluation to alternative
on criterion
is expressed as a D number indicated by
, thus the decision matrix is represented as
In this paper, we assume that each evaluation in the decision matrix M is information-complete, i.e., for any and . Now the overall objective is to find the best alternative according to the decision matrix M and criteria’s weights mentioned above. In this study, we develop a new multi-sensor information fusion method based on D numbers to solve that problem. The key points of the proposed approach are presented as follows.
3.1. Non-Exclusiveness in D Numbers
Since the evaluations are in the form of D numbers and the theory of D numbers is found on the basis of non-exclusiveness assumption, the first step is to calculate the non-exclusive degrees in D numbers. The non-exclusiveness is the opposite of exclusiveness, representing a potential connection between elements in D numbers framework. By contrast, the exclusiveness refers to the characteristic that one object excludes the others, which is an either-or related thing but not the similarity.
Definition 4. Let and be two non-empty elements belonging to , the non-exclusive degree between and is characterized by a fuzzy membership function :withand If letting the exclusive degree between and be denoted as , then .
In our previous study [
59], a simple approach was proposed to determine the non-exclusive degrees in D numbers. In that approach it assumes that all non-exclusive degrees among elements in FOD
have already been determined, then each exclusive degree in the power set space
can be calculated by the following formula:
An illustrative example regarding the calculation of non-exclusive degrees is given as follows.
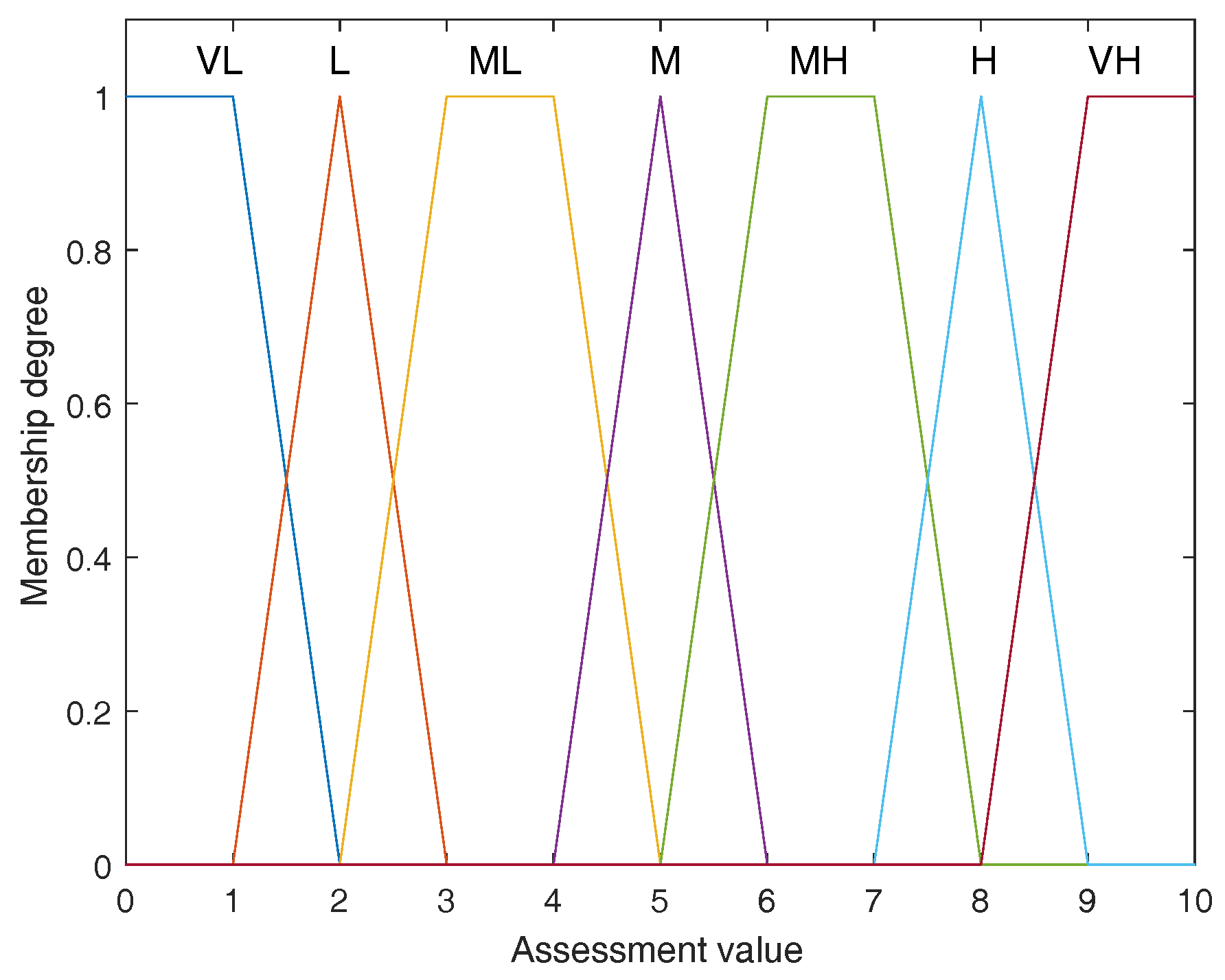
Example 1. Supposing each evaluation in decision matrix M shown in Equation (11) is defined on a set of linguistic variables in which every linguistic variable is represented by a trapezoidal fuzzy number given in Table 4 and graphically presented as Figure 2. The set Θ
is seen as the FOD. At first, let us calculate the non-exclusive degrees between elements in FOD Θ.
In this paper, an approach based on fuzzy numbers’ areas is utilized. Assume the areas of fuzzy numbers and are respectively denoted as and , and the area of the overlap of and is , then the non-exclusive degree between and is defined as According to Equation (16), each non-exclusive degree between elements in FOD Θ
therefore can be obtained as shown in the following matrix Having the above non-exclusive degree matrix of between elements in Θ,
according to Equation (15), we can easily calculate the non-exclusive degree of any pair of elements in . For example, as for and , we have 3.2. Fusing the Evaluations to the Same Alternative on Different Criteria
In order to implement the overall assessment to each alternative, all evaluations belonging to the same alternative on different criteria should be combined according to the perspective of multi-sensor information fusion. In this paper since the evaluations are given in the form of D numbers, it becomes the fusion of D numbers. In our recent study [
59], a D numbers combination rule (DNCR) has been proposed from a perspective of conflict redistribution. The proposed DNCR is shown as follows.
Definition 5. Let and be two D numbers defined on Θ
with and , the combination of and , indicated by , is defined bywith The above rule for D numbers is a generalization of Dempster’s rule for the model of D numbers, because it can totally reduce to the classical Dempster’s rule when for any . Different from the D-S theory, in this rule the impact of of non-exclusiveness in D numbers is taken into consideration.
Although the rule defined in Definition 5 provides a solution for the combination of D numbers, it must point out that such rule does not preserve the associative property, i.e.,
, and it is only suitable for the combination of two D numbers. In order to implement the effective combination of multiple D numbers, a novel combination rule for multiple D numbers is developed in this paper by utilizing the idea of induced ordered weighted averaging (IOWA) operator [
60] which imports an order variable compared with other aggregation operators [
61,
62].
Definition 6. Let , , ⋯, be n D numbers, and be an order variable for each , , therefore each piece of information is indicated by tuple . The combination operation of these information represented by D numbers is defined as a mapping , such thatwhere is the corresponding in tuple having the i-th largest order variable . In this paper, for the MCDM problem the weight of each criterion is regarded as the order variable of corresponding D numbers so as to fuse the evaluations to each alternative on multiple criteria. For each alternative , , the obtained aggregated evaluation is denoted as which is defined over the FOD consisting of fuzzy linguistic variables.
3.3. Decision-Making Based on the Aggregated Evaluations under Fuzzy Environment
In this paper, each aggregated evaluation is also a D number, indicated by
,
, which is defined on FOD
composed by fuzzy linguistic variables. Assume
, and each element
is represented by a trapezoidal fuzzy number
. Each
is firstly transformed to a distribution of pignistic probabilities, denoted as
, by means of the PPT as follows
Once the
is obtained, it then be transformed to a fuzzy aggregated evaluation
to express the overall assessment to alternative
i, represented as
in which
At last, these fuzzy aggregated evaluation
,
, are converted to crisp values through a defuzzification process in order to rank all alternatives. Among existing defuzzification techniques, the centroid defuzzification approach is a common used one. Given a fuzzy number
with membership function
, in terms of the centroid defuzzification approach we can have
where
is the defuzzified value of
. In terms of the study in [
63], while
is a trapezoidal fuzzy number indicated by
the centroid-based defuzzified value turns out to be
Via the defuzzification process, for each fuzzy aggregated evaluation , a defuzzified value can be derived. The best alternative is finally determined by finding the one with the largest defuzzified value.
5. Illustrative Example
In the section, an illustrative example is given to show the effectiveness of the proposed model for fuzzy risk evaluation in FMEA. This example is original from literature [
28]. In [
28], the authors developed an extended VIKOR method for risk evaluation in FMEA under fuzzy environment. In this paper, we will solve the problem by using our proposed model and compare the obtained result with that of literature [
28].
Step 1: Identify all potential failure modes. By following literature [
28], a hospital wants to rank the most serious failure modes during general anesthesia process, and six potential failure modes are identified which are denoted as FM 1, FM 2, FM 3, FM 4, FM 5, FM 6.
Step 2: Identify all possible risk factors. In this application, the risk factors are consistent with the RPN approach, therefore there are three risk factors, namely O, S, D.
Step 3: Determine fuzzy linguistic variables for the evaluation. As for the evaluation of failure modes, a set of linguistic variables including Very Low (VL), Low (L), Medium Low (ML), Medium (M), Medium High (MH), Very High (VH) is used as shown in
Table 4. In addition, for the evaluation of risk factors’ weights, the fuzzy linguistic variables are given in
Table 5.
Step 4: Evaluate failure modes and the weights of risk factors using fuzzy linguistic variables. As given in literature [
28], a FMEA team of five decision makers, DM 1, DM 2, DM 3, DM 4, DM 5, is employed to evaluate failure modes and the weights of risk factors. With respect to risk factors’ weights, all five decision makers’ evaluations are given in
Table 6. For the six failure modes, the evaluations from the FMEA team are given in
Table 7.
Step 5: At this step, the weight of each risk factor is calculated at first. Since the calculation of risk factors’ weights is not the core concern of this paper, we simply continue to use the weights obtained in literature [
28]. The importance of O is 0.768, and S 0.878, and D 0.650, therefore the weights of these risk factors are
,
,
. Secondly, let us transform the fuzzy evaluations of failure modes on risk factors to D numbers. In this example since multiple decision makers are included so as to form a group decision making environment, we use the proportion of each evaluation to construct the D numbers. For example, for FM 1 on risk factor O, five decision makers respectively give evaluations M, M, M, MH, M, hence we can construct a D number
,
. In terms of this means, the evaluations to failure modes are transformed to the form of D numbers, as shown in
Table 8.
Step 6: Rank the failure modes using the proposed multi-sensor information fusion method. At first, the fuzzy linguistic variables in
Table 4 form a FOD
. Each exclusive degree between elements in
has been obtained in Example 1. According to Equation (
15), the non-exclusive degree of any pair of elements in
can be easily obtained. Secondly, for every failure mode the evaluations on O, S, and D can be fused based on the proposed combination operation in Definition 6. For FM 1, the aggregated evaluation is
Thirdly, by using the PPT, we have:
,
,
for FM 1;
,
,
for FM 2;
,
for FM 3;
,
,
,
for FM 4;
,
,
,
for FM 5; and
,
,
for FM 6. Fourthly, these pignistic probabilities are then transformed to fuzzy aggregated evaluations according to Equations (
21) and (
22) which are
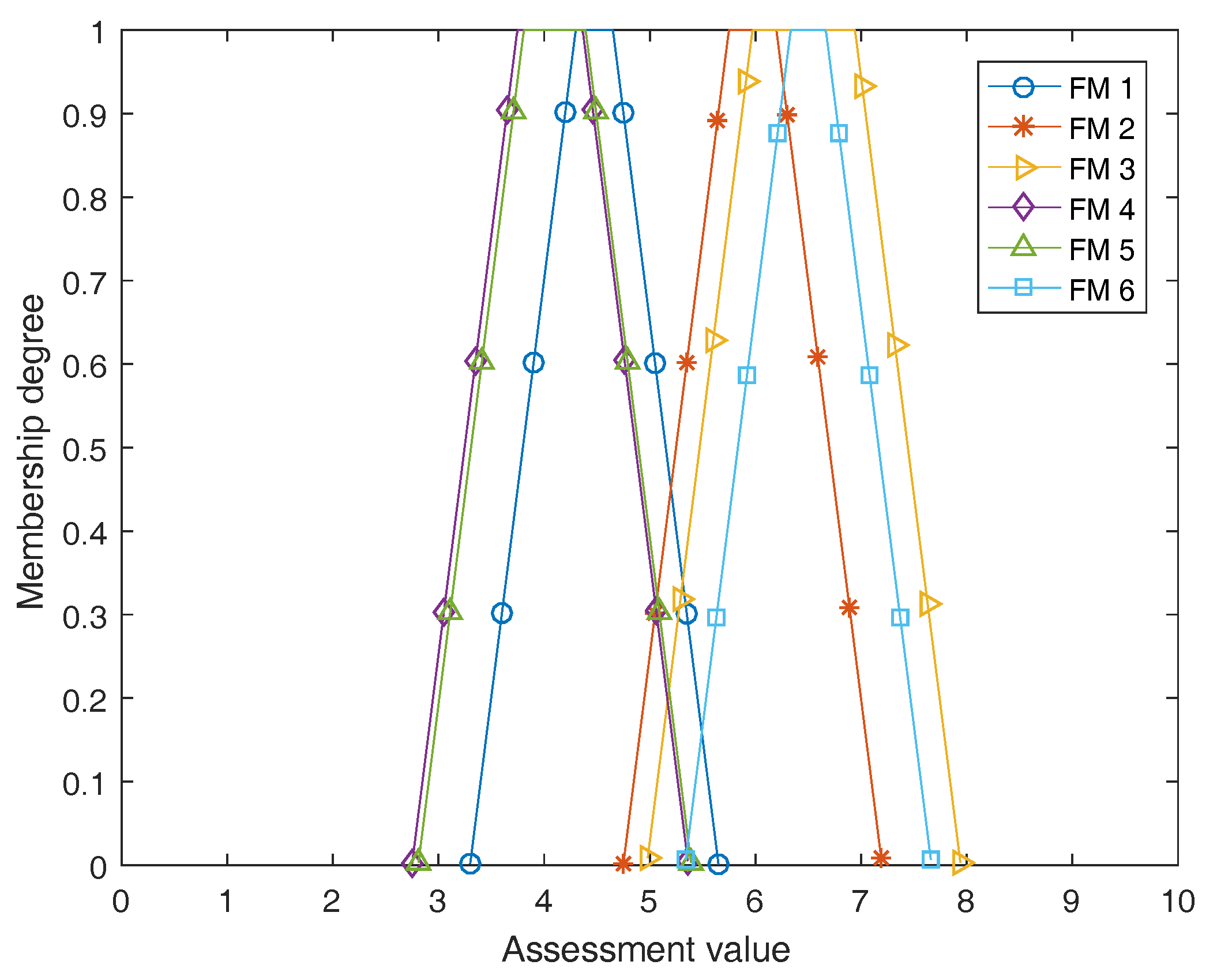
These fuzzy aggregated evaluations are graphically shown in
Figure 4. At last, in terms of the centroid defuzzification approach we can have
,
,
,
,
,
. Therefore, the risk ranking of all failure modes from high to low is
. From the result, it is found that the failure mode with the highest risk is FM 6 and that having the lowest risk is FM 4.
The above steps have clearly shown the process of using the proposed model to do the risk evaluation in FMEA under fuzzy environment. Now we compare the result obtained by the proposed model with that from other method. In literature [
28], Liu et al. dealt with the risk evaluation in FMEA with an extended VIKOR method. The results of the risk ranking are given in
Table 9. In [
28], the failure modes are ranked in terms of three indicators S, R, Q. By S, the failure modes with the highest and lowest risk are FM 3 and FM 4; By R, the failure modes having the highest and lowest risk are respectively FM 6 and FM 4; By Q, the failure modes with the highest and lowest risk are FM 3 and FM 4, respectively. Comparing the proposed model and the extended VIKOR method in [
28], the ranking obtained by the proposed model is basically same with that of R. In addition, both the two methods have identified FM 4 is the failure mode of lowest risk. In addition, as a whole the failure modes can be classified into two groups by S, R, Q, and the first group which has higher risk is composed by FM 3, FM 6, FM 2, the second group having lower risk includes FM 1, FM 5, FM 4. By using the proposed model, we also obtain the same classification that FM 6, FM 3, FM 2 are in the group with higher risk and FM 1, FM 5, FM 4 constitute the group with lower risk. Through the above analysis and comparison, therefore it shows that the proposed model is effective for risk evaluation in FMEA.







{kind=link}
{kind=link}
{kind=link}
{kind=link}