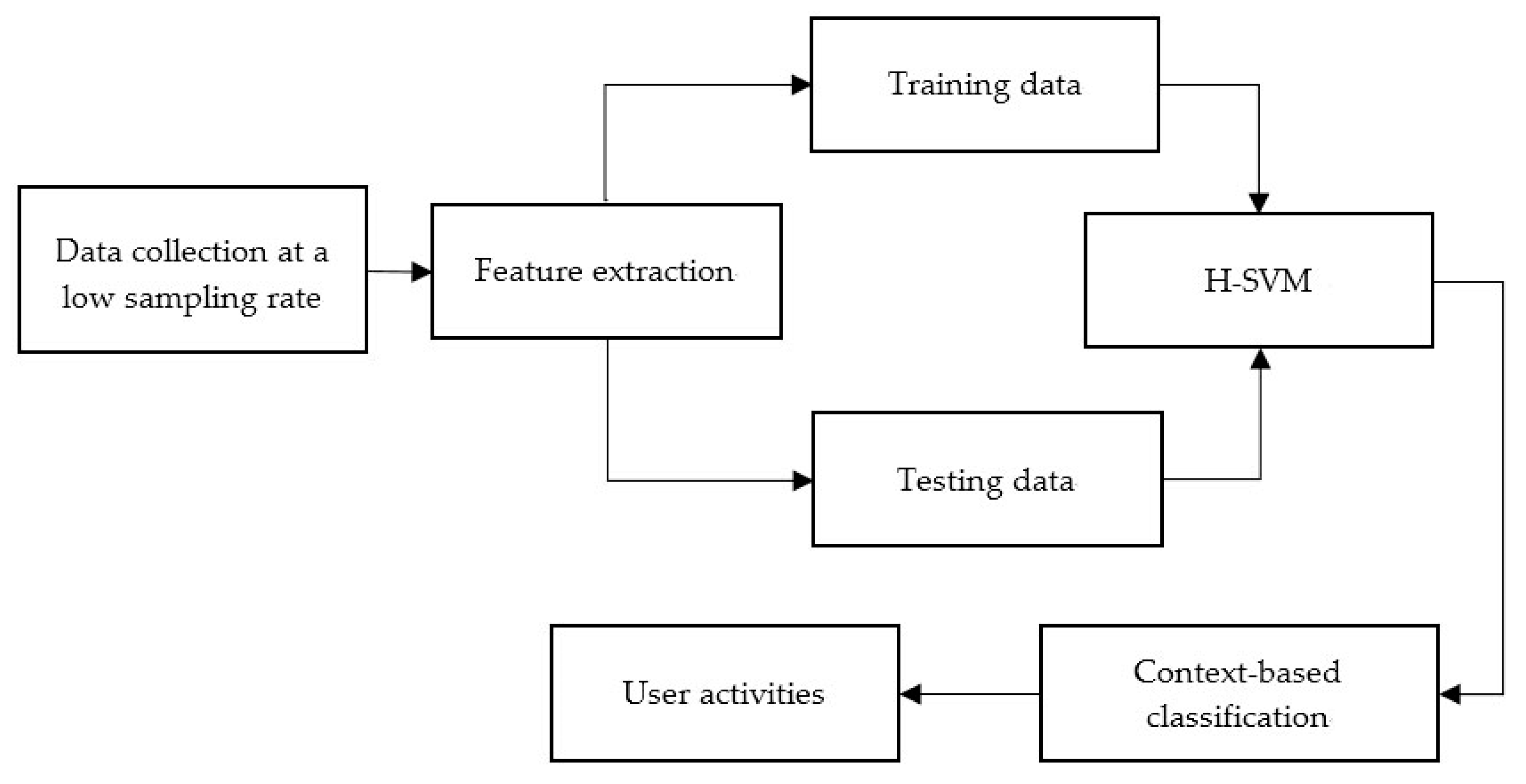
The experiments include four parts: (1) data collection; (2) parameter selections; (3) classification performance; and (4) the power consumption of the proposed energy-efficient online ARS.
4.1. Data Collection
For data collection, a smartphone (Nexus 5, Google Inc., Mountain View, CA, United States of America) was placed in the right-front pocket of the pants, showed in
Figure 3. The sensors used in the experiments were barometer and accelerometer inside the smartphone. As shown in
Table 1, four independent data collections were carried out separately in the study.
Data collection 1 (Training datasets): the sampling rate was set to 1 Hz, the time window was 5 s, without overlap. One volunteer (male, 23 years old, healthy student) was asked to perform six types of activities: sitting, standing, walking, running, climbing upstairs and going downstairs. The volunteer sat and stood indoors, walked in the corridor or in the room, ran on a treadmill at 9 km/h, climbed upstairs and went downstairs in our lab building, which is six-floors. Each activity was carried out 15 times (15 samples collected). In total, 90 samples were collected as the training data-sets.
Data collection 2: The sampling rate was set to 1 Hz, the time window was 5 s, without overlap. Twenty volunteers (14 males and six females, ages between 22 to 25) participated in the data collection. The volunteers were asked to undertake the six activities as described in the Data collection 1. Each activity (sitting, standing, walking and running) was consecutively carried out for 5 min. The volunteers were asked to climb upstairs from the second floor to the sixth floor and go downstairs from the sixth floor to the second floor, five times repeatedly. All these data collected in Data collection 2 are only used for testing, as shown in
Table 2. For each activity, we removed the data of the first time window (5 s) and the last time window (5 s) to ensure that the data obtained only contained one type of activity.
To compare the accuracy of activity recognition at different sampling rates, five volunteers (from the above 20 volunteers in the Data collection 2) participated again in the following two new data collections.
Data collection 3: The purpose of this data collection is to verify that using a low sampling rate (1 Hz) can also achieve high accuracy of recognition, compared with the sampling rate agreed with the Nyquist theorem. Thus, the sampling rate was set as 5 Hz, which agreed with the Nyquist theorem and was close to twice the frequency of human activity obtained by phone sensor. The time window was 1 s.
Data collection 4: The aim of this data collection is to verify that different sampling rates that agreed with the Nyquist theorem achieve almost the same accuracy. Activity data were collected at the sampling rates of 10 Hz and then 50 Hz. The time window of different sampling rates was 1 s.
4.2. The K-Means Clustering and H-SVM
In general, the feature extraction aims to identify the main characteristics that accurately represented the original data [
36]. The process is to find the most useful, valid and meaningful information to recognize activities with high accuracy. In previous studies [
1,
10,
13], the common features include time domains and frequency domains, such as means, standard deviation, magnitude of acceleration and FFT (Fast Fourier Transform). There are no fixed features that are suitable for all ARS.
In this paper, we firstly constructed a feature set. The feature set is the combination of all features, that is (pressure difference), (absolute value of pressure difference), (the means of X-/Y-/Z-axis accelerometer values), and (the sum of root mean squares of the difference of adjacent points in a time window).
After constructing the feature set, algorithm 1 was applied to feature selections and classification. Based on the power consumption of the sensor and the computational cost of feature extraction, m features () with the higher priority from the set of optimal features were selected.
(1) Pressure difference
: The difference of pressure value is measured by barometer built-in the mobile phone, as shown in Equation (6). The barometer value is considered as height changing. When the altitude increases, the pressure value decreases, and vice versa:
where
is the last pressure value and
is the first pressure value in the time window (sampling period). The
value is negative when the user climbs upstairs, and it is positive when going downstairs.
(2) The absolute value of pressure difference (
): The
is calculated as follows:
(3)
X-/
Y-/
Z-axis accelerometer value (
): This is the means of the
X-/
Y-/
Z-axis accelerometer values. The values of tri-axial accelerometer we got from the smartphone (Android API) contained the gravity values. The following is the calculation for
:
(4) The wave of three-axis accelerometer (
): this is the sum of the RMS (Root Mean Square) of the difference of adjacent points in a time window, and can be calculated using Equation (9):
where
are the three-axis values of accelerometer at time stamp
i, respectively.
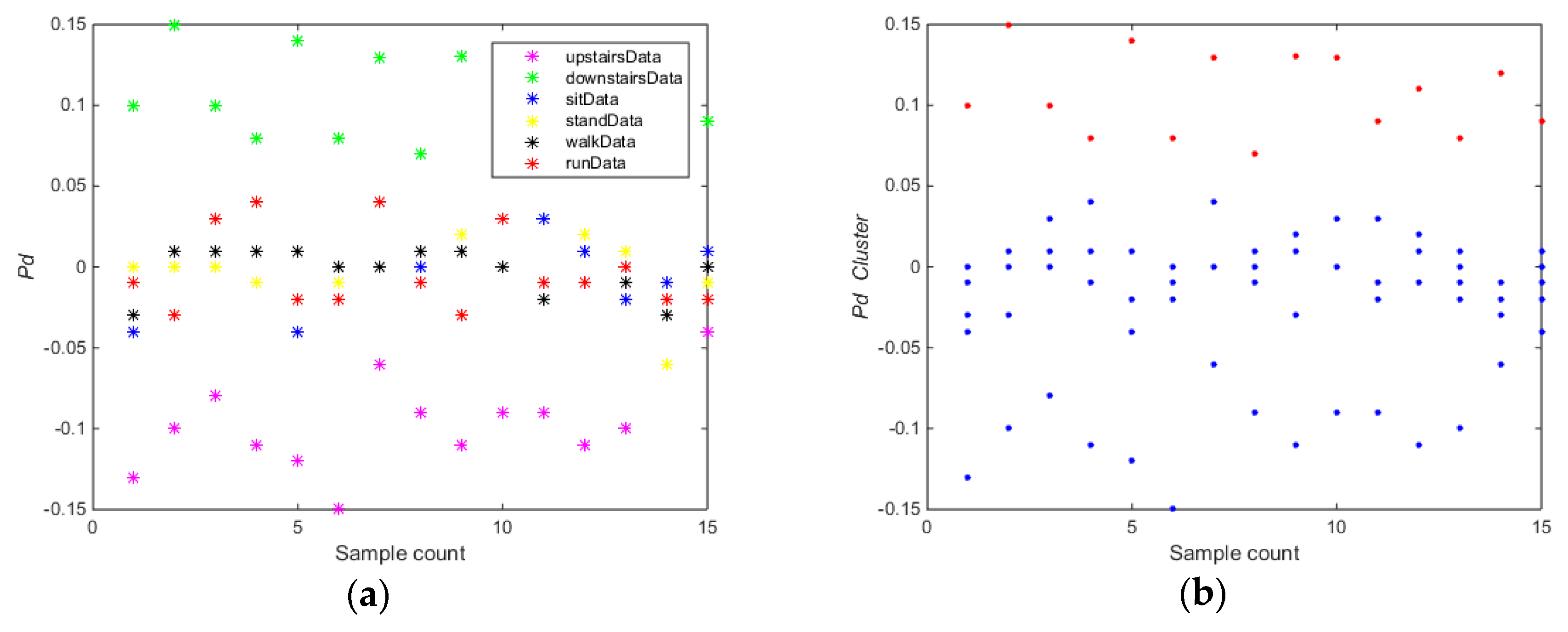
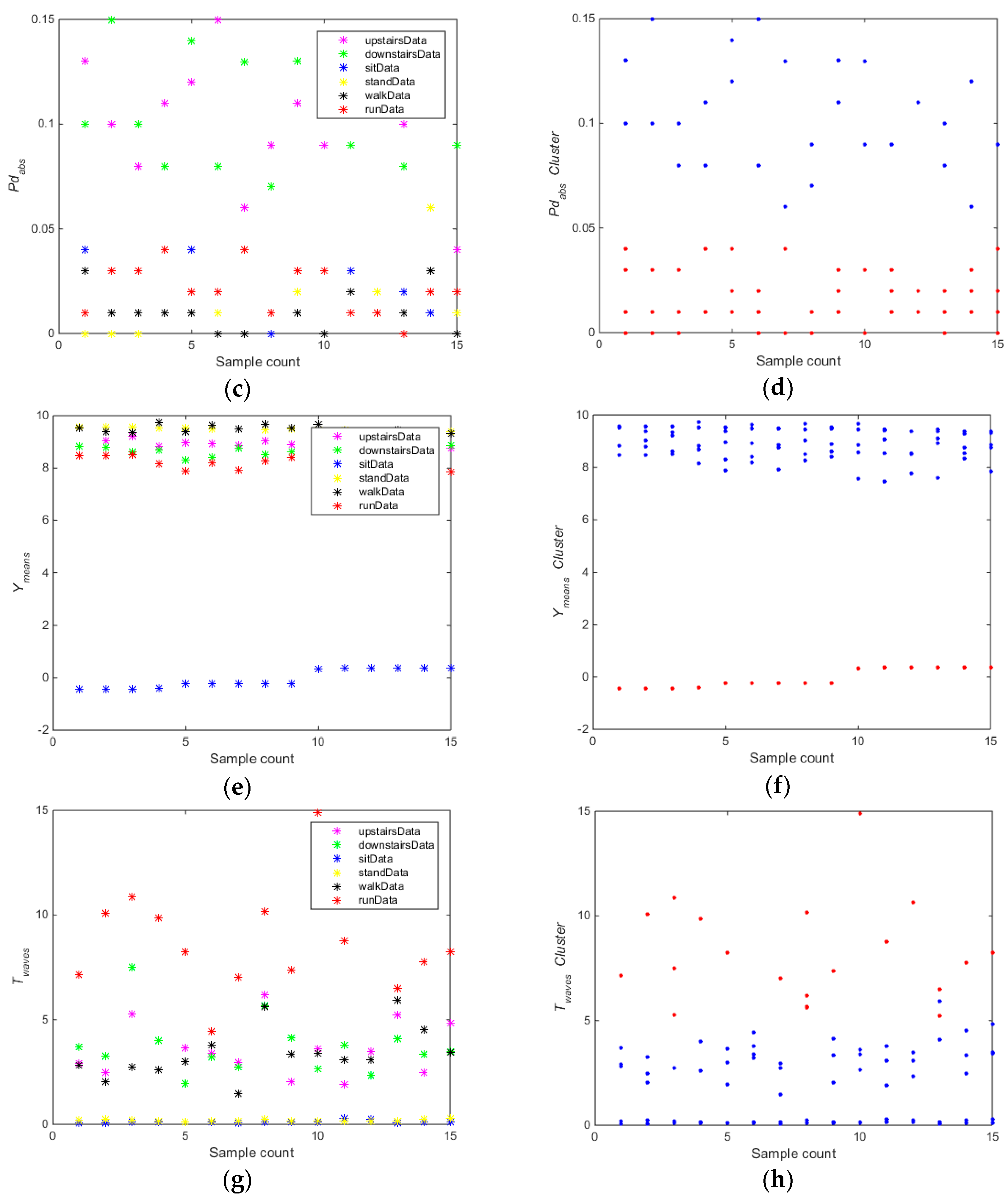
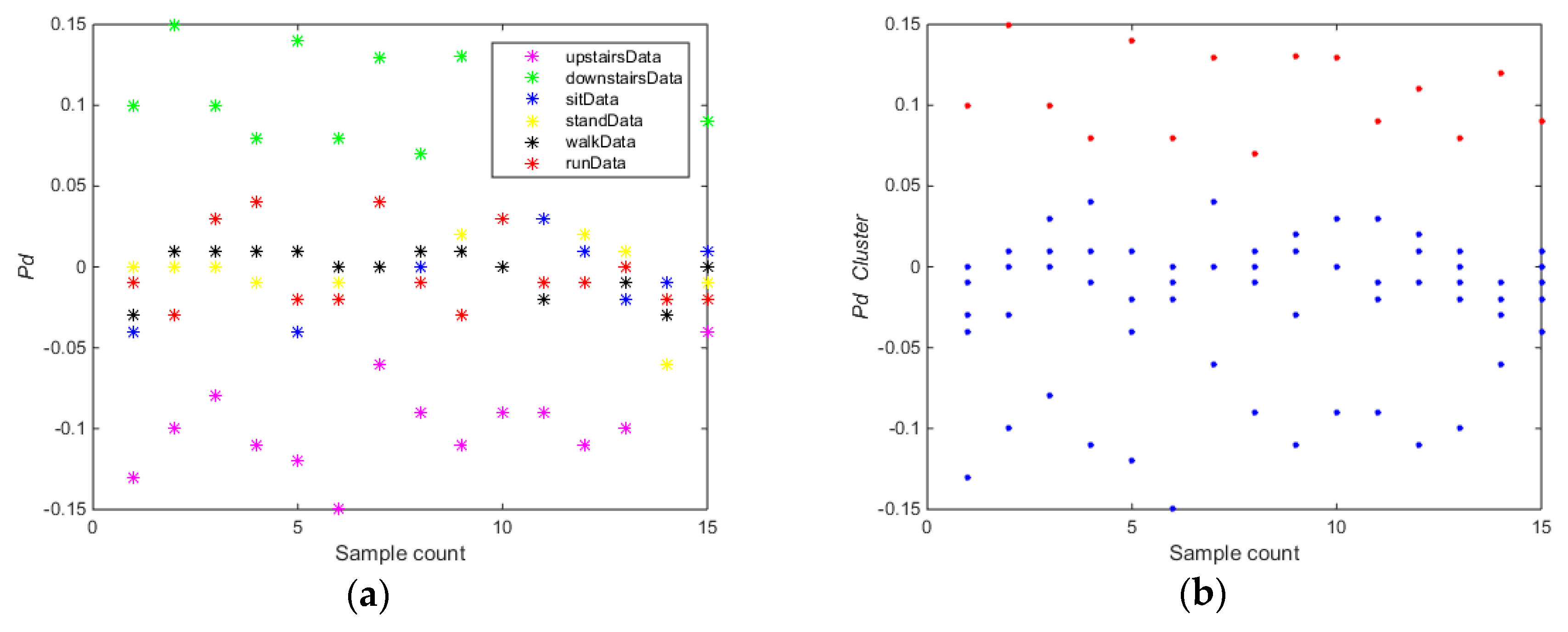
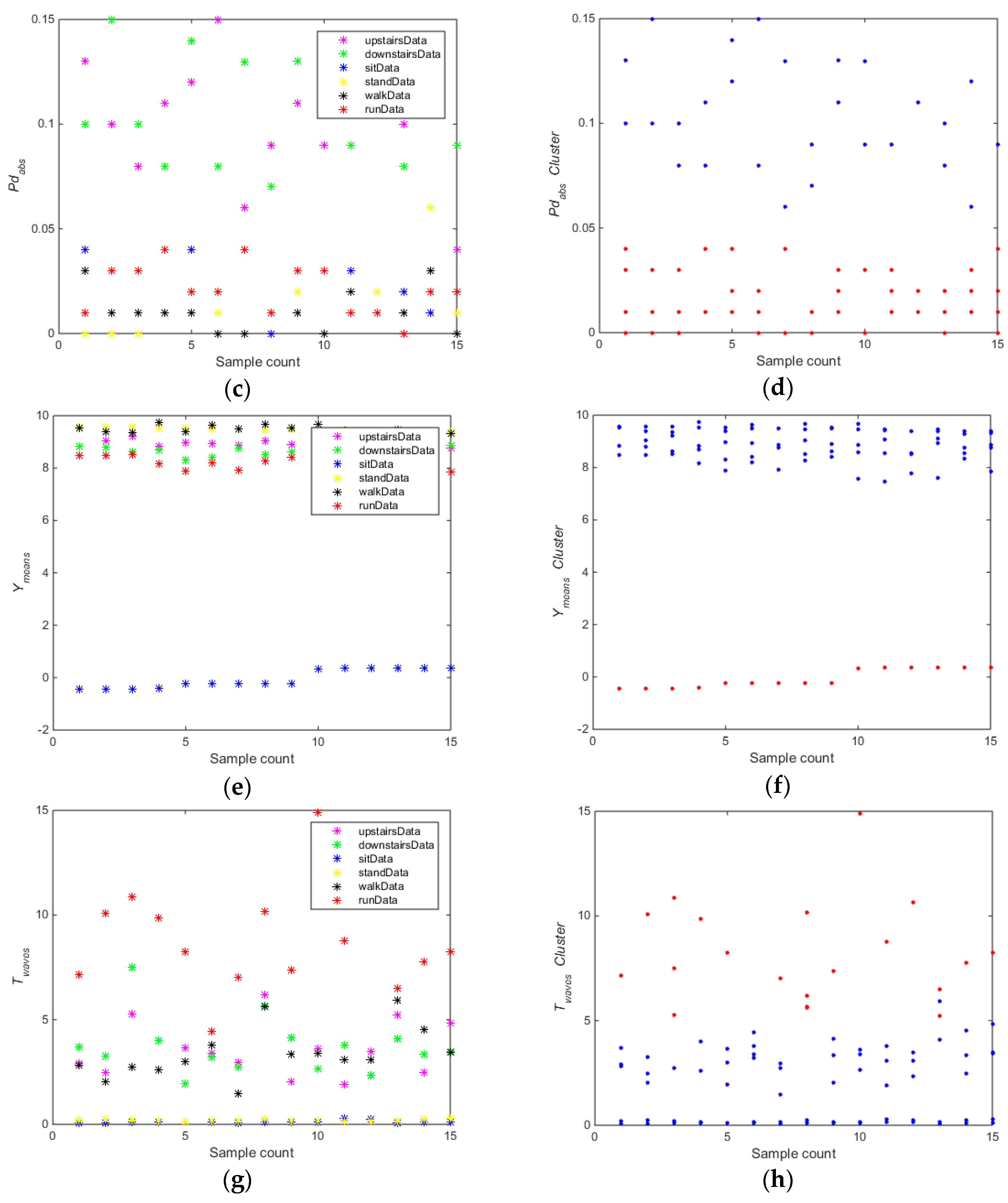
The training carried out on the whole dataset (Data collection 1) using algorithm 1. As shown in
Figure 4, for the feature
(
Figure 4a,b), the whole training dataset was divided into subset A (downstairs) and B (upstairs, sitting, standing, walking, running). For the feature
(
Figure 4c,d), the whole training dataset was divided into two subsets A (upstairs and downstairs) and subset B (sitting, standing, walking, running) using the
k-means clustering algorithm. For the feature
(
Figure 4e,f), the whole training dataset was divided into subset A (sitting) and B (downstairs, upstairs, standing, walking, running). For the feature
(
Figure 4g,h), the whole training dataset was divided into subset A (running) and B (downstairs, upstairs, sitting, standing, walking).
As shown in
Figure 4, the accuracy and partition degree of
k-means clustering of different features were assessed. The equilibrium of two subsets was also considered.
Figure 4b,d,f shows the results that
k-means clustering can get good performance using the selected features, but only the feature
can meet the equilibrium requirement. Thus, the selected feature
is the optimal feature for training the first SVM classifier (SVM1). In the Algorithm 1, the data were randomly divided into 80% for training and 20% for testing in order to select the optimal features and build the SVM classification models.
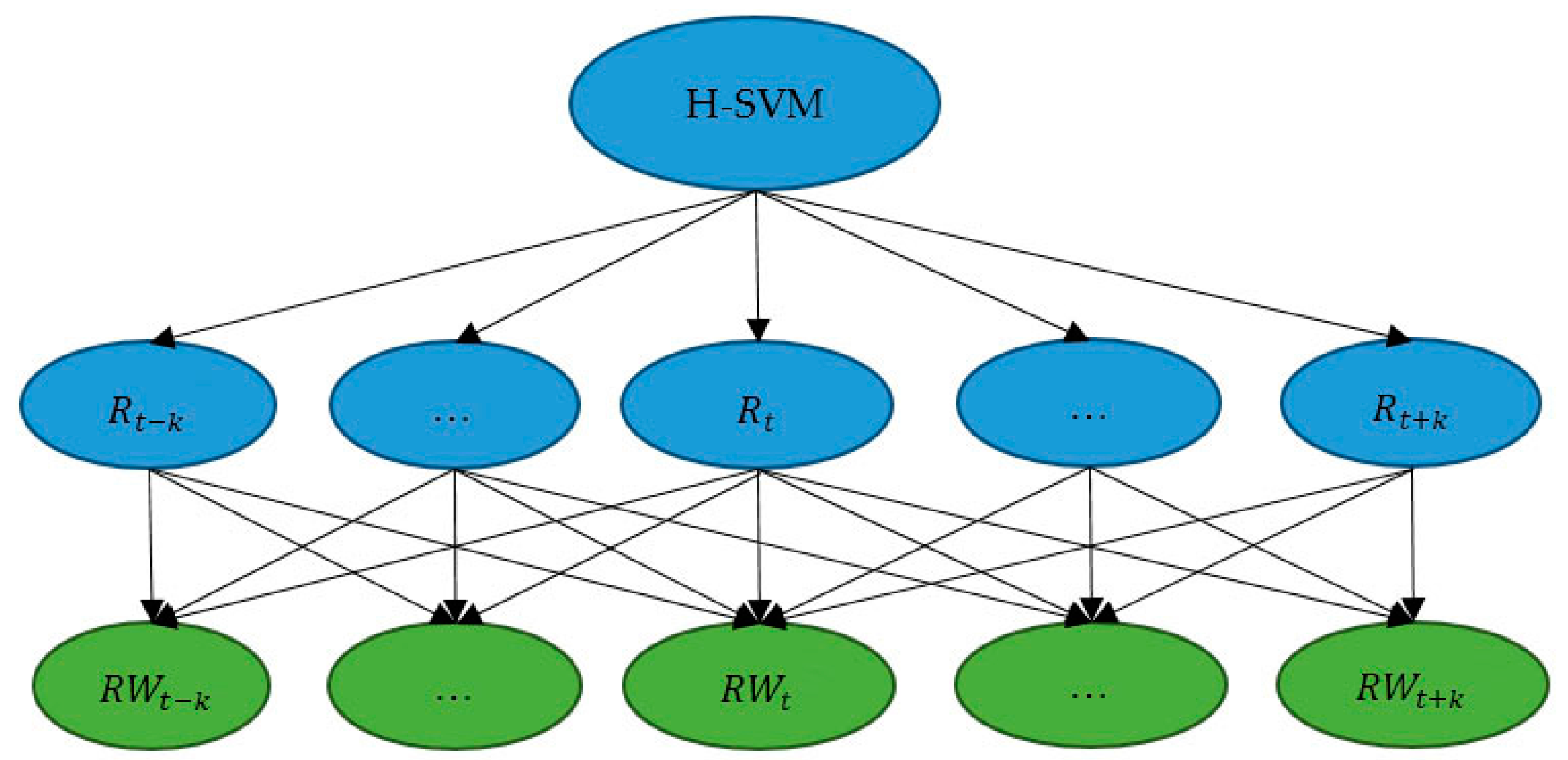
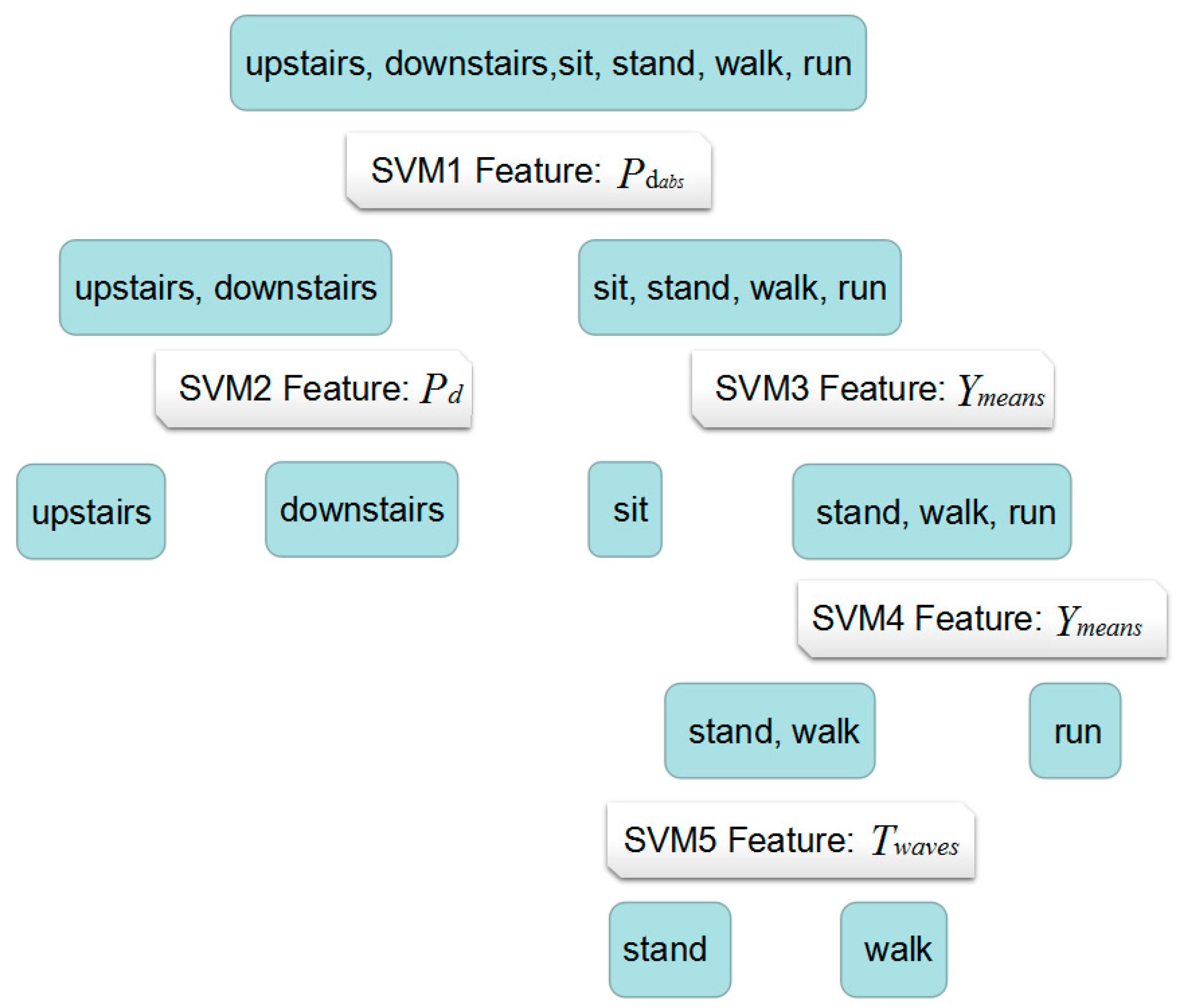
According to Algorithm 2, for subset (upstairs or downstairs), feature is the optimal feature for training SVM classifier (SVM2) to partition the upstairs or downstairs because it is the most accuracy ones. For subset (sitting, standing, walking, running), feature is suitable for classification (SVM3), dividing dataset (sitting, standing, walking, running) into subset (sitting) and subset (standing, walking, running) with the highest accuracy. In addition, is also the optimal feature for dividing dataset (standing, walking, running) into subset (standing, walking) and running (SVM4). Finally, the is used for partition standing and walking (SVM5). The whole H-SVM classification model is shown as follows.
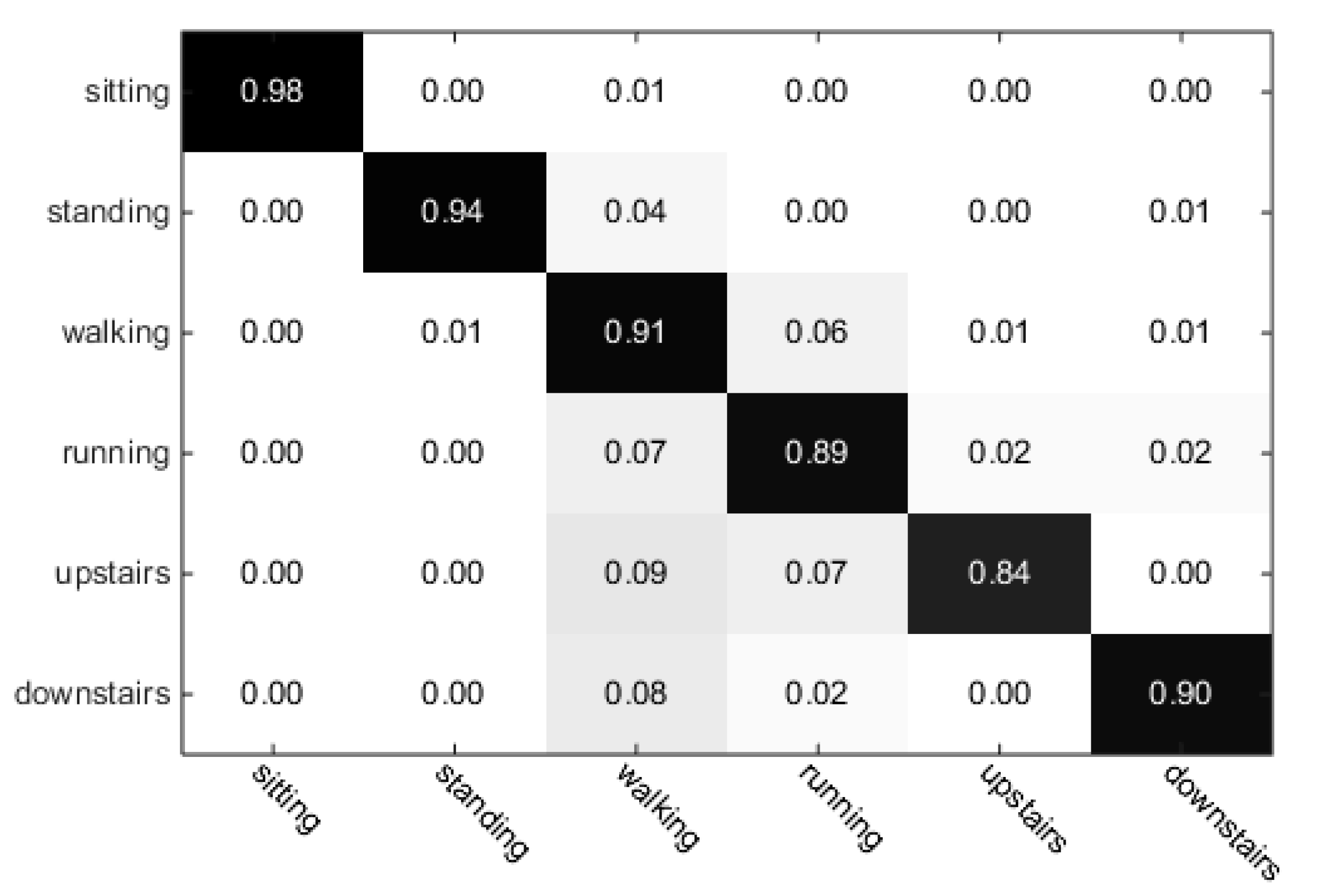
The whole training dataset (Data collection 1) contains 90 samples. After training, the five-node SVM classifier was built. As illustrated in
Figure 5, the dataset is divided into two sets whether the activity is climbing stairs or not. If the classification result of classifier SVM1 is climbing stairs, classifier SVM2 is used to judge if the activity is climbing upstairs or going downstairs. If the result of SVM1 is not stair climbing, classifier SVM3 is applied to classify sitting or standing, walking, running and then classifier SVM4 will contribute to recognize standing, walking or running. Finally, classifier SVM5 is used to differentiate standing or walking. Considering the
k-means clustering results discussed before,
can be used as the input feature for SVM1 to detect climbing stairs or not. Furthermore,
,
can be used as input feature for SVM2 and SVM5, respectively, and
can be input as feature for SVM3 and SVM4. These may reflect the body movement efforts and acceleration patterns when carrying out different types of activities, that is: (1) the pressure used in climbing stairs activities is different from activities on flat ground; (2) changing of acceleration on the
Y-axis can be used to differentiate the sitting status from standing/walking/running and further differentiate running from walking/standing; (3) information of changes in all three directions needs to be taken into account in order to classify standing from walking.
4.3. The Parameter Settings of Proposed ARS.
The sampling rate and time window of accelerometer during data collection and sliding window size of context-based classification are three crucial parameters that may affect the power consumption and accuracy of proposed ARS.
The frequency of human activity is about 2 Hz. For example, the frequency of going downstairs with fast speed is less than 2 Hz, and the step time of fast walking is 0.35 s/step [
37]. The time windows were usually 1 s in previous studies [
38]. In our research, the sampling rate of accelerometer was 1 Hz. According to Equation (4), the time window was about 5 s.
In
Section 3.3, we proposed context-based classification to improve the accuracy of recognition. For different values of the probability of recognition error
(0.3, 0.2, 0.1, and 0.05), the
of different sliding window size (2
k + 1) is shown in
Figure 6:
Figure 6 shows that the
has improved with the increase of
k-values. For example, the
has improved 8% with the change of value
k from 0 to 1 when
= 0.3. However, the time delay will also increase, which may be harmful to the online ARS. Especially when the recognition error
is becoming closer to 0, with the increase of value
k, the improvement of
is becoming smaller, but the time delay is becoming greater.
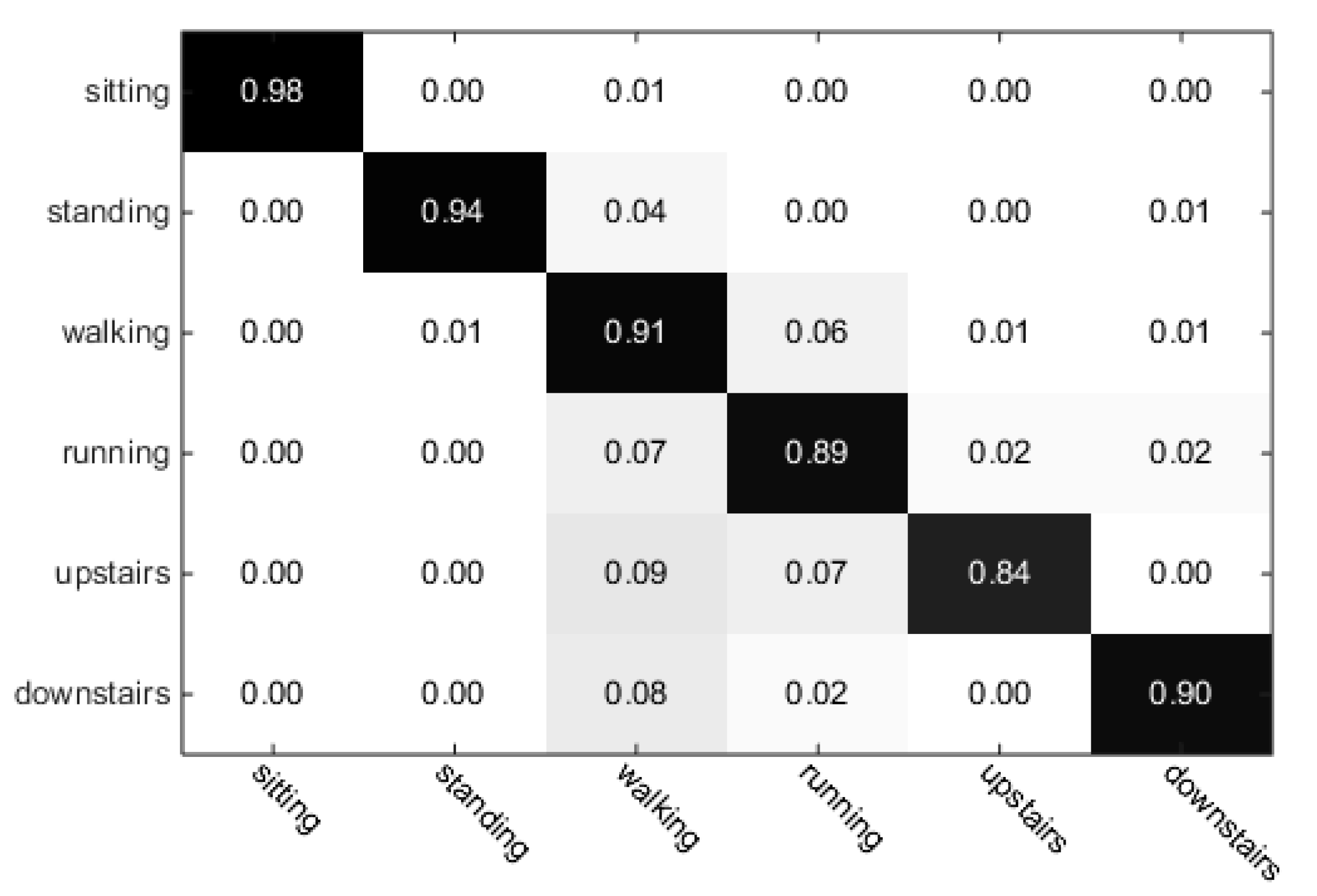
The classification performance of our proposed ARS shows that the largest recognition error
is less than 0.2 and the average recognition error is less than 0.1. As shown in
Figure 6, no matter
= 0.2 or
= 0.1 or
= 0.05, the accuracy is improved quickly when
k is increased from 0 to 1. However, the improvement of
slows down when
k ≥ 1, but the time delay became greater. Therefore, the slide window size is set as 3 (
k = 1).
4.5. The Power Consumption of the Energy-Efficient ARS
The research about the compositions of energy consumption in ARS can help us to assess whether the proposed energy-efficient strategies are effective or not. Furthermore, the analysis of the composition of energy consumption in ARS can provide guidance for the researchers in energy-efficient fields.
An online ARS consists of data collection, data processing and activity recognition. Thus, the main composition of energy consumption in ARS can be divided into three parts. The first part is the power consumption used by the sensors. In our research, this part does not contain the data collection. The second part is the power consumption used in data processing, including data collection, feature extraction and data storage. The last part is the power consumption used by the activity recognition algorithm.
In our previous work [
32], we proposed that the low sampling rate can decrease the power consumption. Power consumption for ARS is caused by the sensor running [
10] or the total power consumption [
13]. In this paper, we carried out the experiments to analyze the composition of power consumption in ARS.
We use the other mobile phone (Nexus 5, with an Android 4.4.2 system) for experiments. Firstly, we restored the phone to factory data to avoid power consumption caused by other applications, and we installed the requiring applications in the phone. Then, we put the phone in a shaker to do the experiments.
The experiments can be divided into two categories.
Category 1: we carried out the experiments in the shaker with the setting of 5 mm amplitude and 5–10 Hz variant-frequency vibration and a total of 17 experiments were undertaken.
Category 2: we carried out the experiments in the shaker with the static state and a total of 17 experiments were undertaken.
The purpose of contrasting two states (shaker and static state) is to simulate the real situations. We used the shaker to simulate the status of moving such as walking. Similarly, the static state was used to simulate standing and sitting status.
For each category, we conducted four experiments (sampling rate of 1 Hz, 5 Hz, 10 Hz, 50 Hz respectively) with the setting of running the whole ARS, four experiments with the setting of only running sensors, four experiments with the setting of running the ARS without activity recognition and result processing, four experiments with the setting of running the ARS without result processing and one experiment when the phone was on standby. The details are listed in
Table 5.
For each experiment, we fixed the mobile phone in the shaker (
Figure 11a) and connected an external signal generator (3.8 V) to the mobile phone (
Figure 11b), and then connected the signal generator with computer to collect data of current (the time is set as 20 min). We turned on the phone and started the application (five experiment settings shown in
Table 5) under the experiment condition (shaker or static state). In the end, we clicked the button (“start to save data”) to collect the data of current.
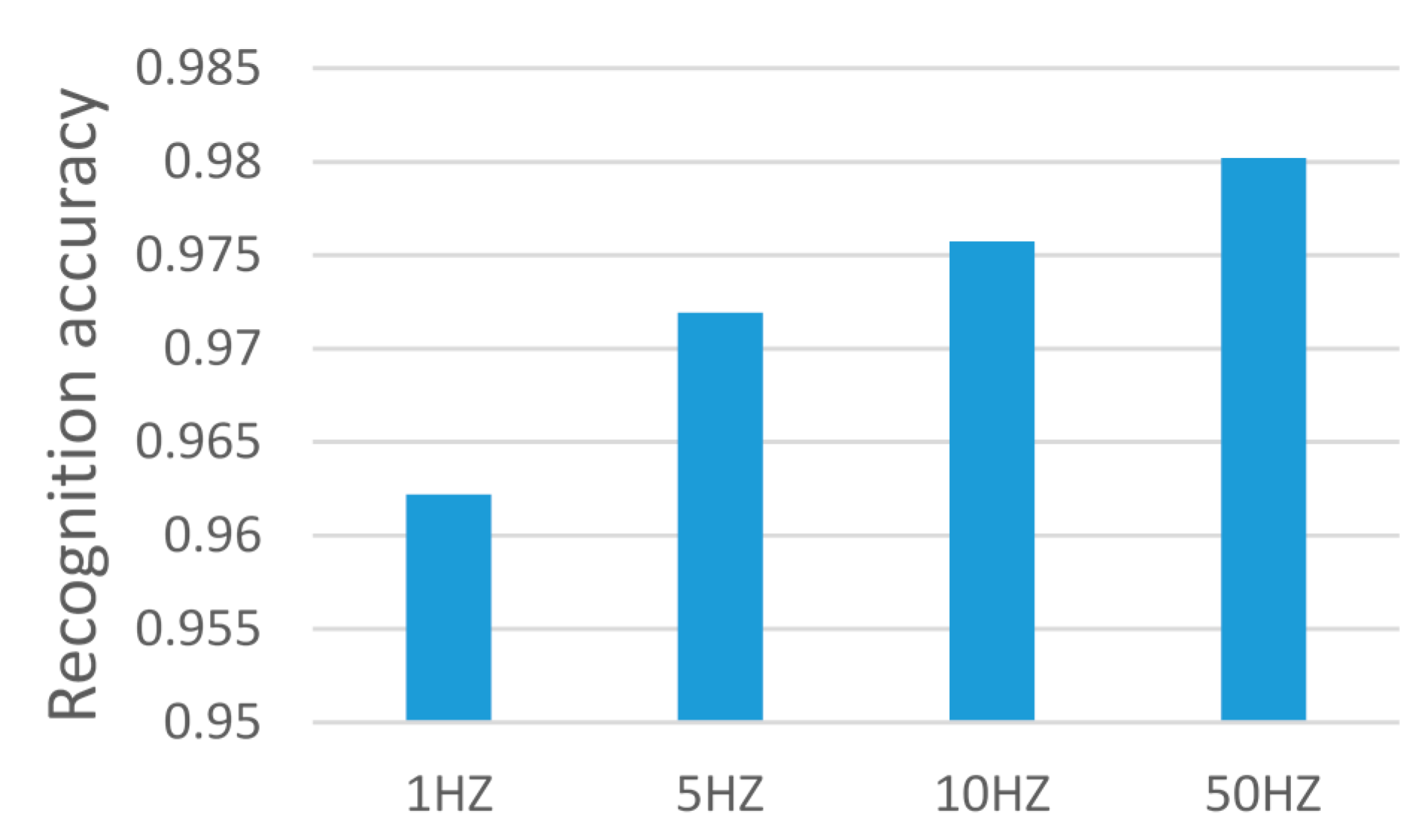
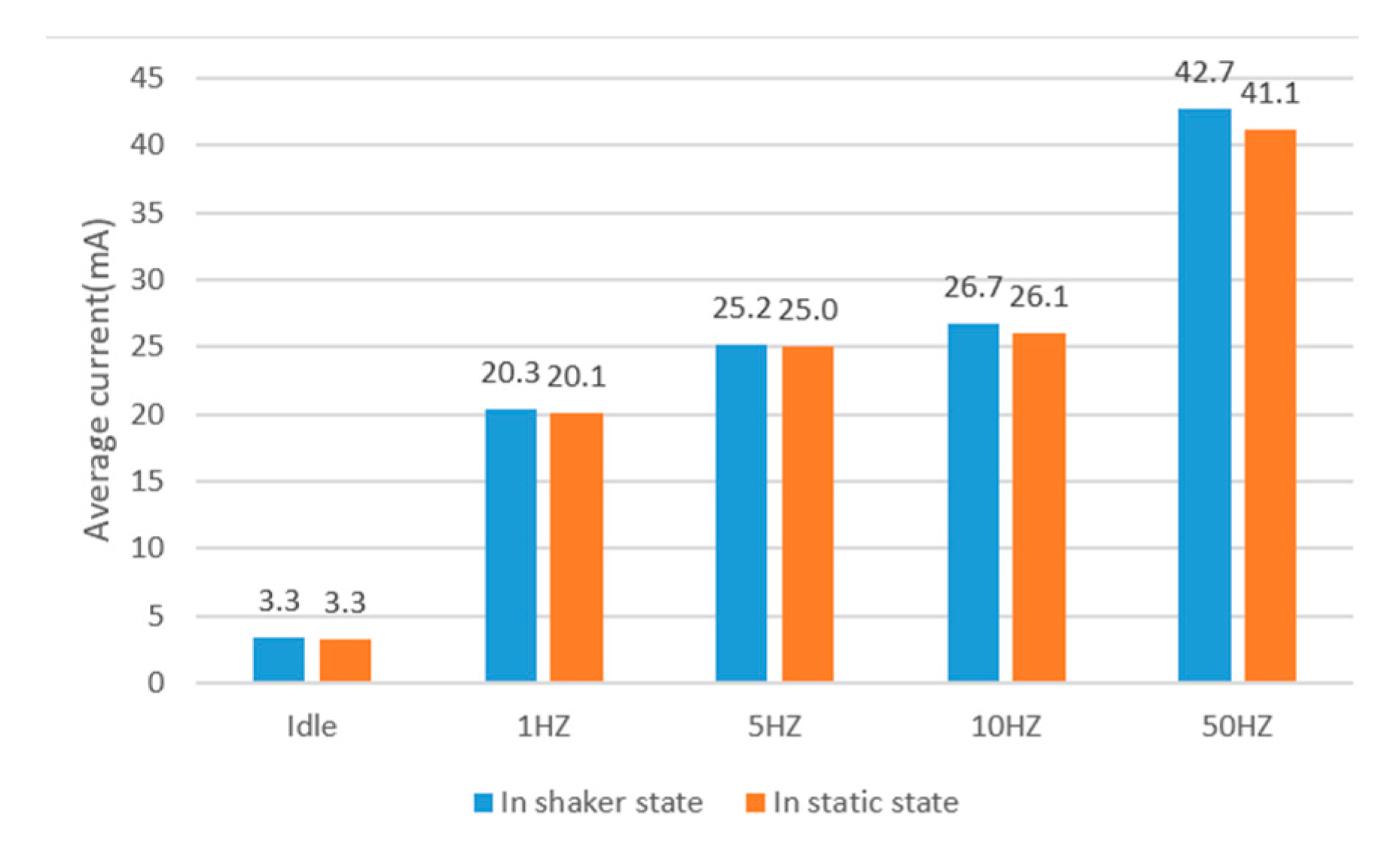
Figure 12 illustrates the average current of ARS at different sampling rates. It shows that the average current increases with the increase of the sampling rate. The average current is 20.3 mA at 1 Hz, and it is 42.7 mA at 50 Hz when the phone is in the shaker state. The average current is 20.1 mA at 1 Hz, and it is 41.1 mA at 50 Hz when the phone is in the static state. It also infers that the power consumption of ARS at rate of 10 Hz has slightly increased compared with 5 Hz. There is a large increase of power consumption when the sampling rate changes from 10 Hz to 50 Hz. There are two main reasons. One reason is that the sensor running has a great increase when the rate changes from 10 Hz to 50 Hz (as shown in
Figure 13). The other reason is the amount of data increase greatly when the sampling rate increases from 10 Hz to 50 Hz, which causes more power consumption in data processing.
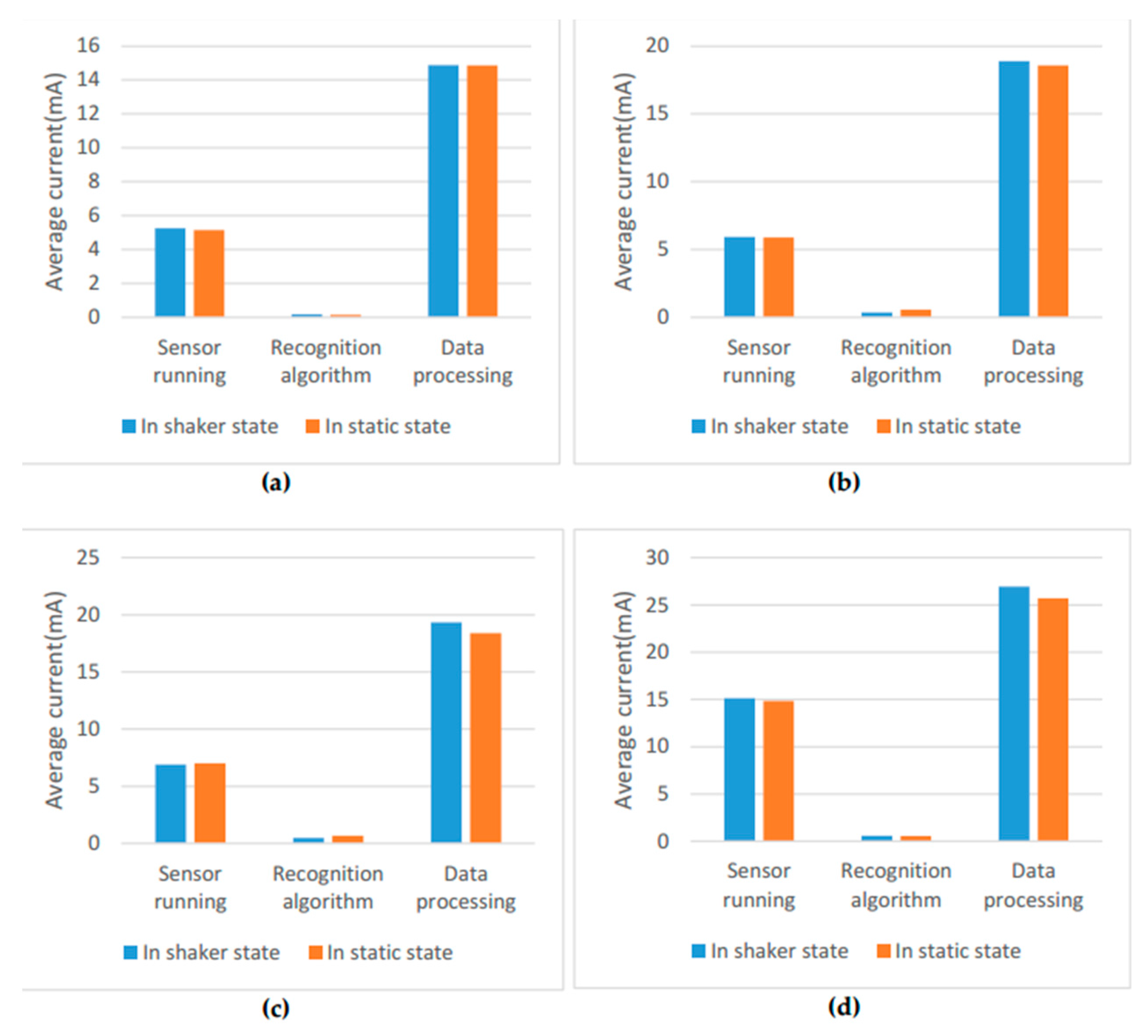
Figure 13 also shows the average current of different parts in ARS. The data processing consumes most of the power in the online ARS. The second large power consumption is the sensor running. The power consumption of the proposed recognition algorithm is very small and can even be negligible. With the decrease of the sampling rate, the energy is saved in the sensor running and data processing for the reason that the amount of data is smaller.
We carried out another experiment to evaluate the power performance with different sampling rates. We turned on the phone when the phone was fully charged, and started phone application at four different sampling rates (1 Hz, 5 Hz, 10 Hz, 50 Hz) or idle state, respectively. Then, put the phone statically on the table, unplugged the charging cable and turned off the screen. After 24 h, we turned on the screen, stopped the application and recorded the data. Experiments on each sampling rate and the idle state were repeated four times. We also installed an external application called Battery Monitor Weight [
41] on the phone to record the battery states (the recording interval was 2 min).
Another metric for evaluation Power Consumption Ratio (PCR) is introduced in this paper:
where
represents the power consumption at the sampling rate of
after 24 h. When the phone is in idle state,
is set as 0.
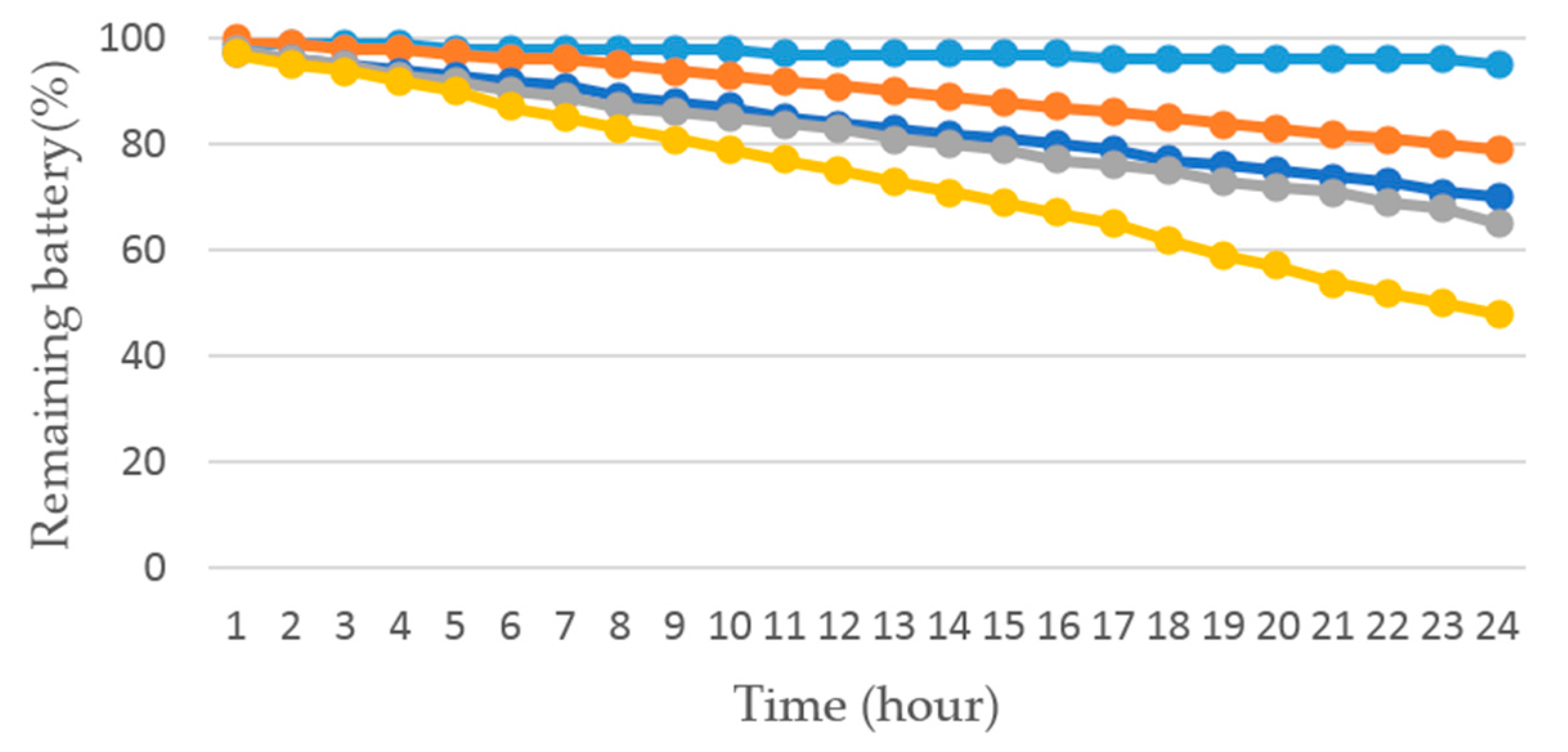
Figure 14 shows the tendency of power consumption at different sampling rates and the idle state. From the chart, we found that our ARS at the sampling rate of 1 Hz consumed 21% energy in 24 h. The ARS at the sampling rate of 5 Hz consumed 30% battery. The ARS at the sampling rate of 10 Hz and 50 Hz consumed 35% and 52% power, respectively. The battery was expended 5% when the phone was in an idle state. It can be concluded that the lower sampling rate is, the less power the phone consumed.
Table 6 summarizes the PCR in different experiment conditions. From the results presented in
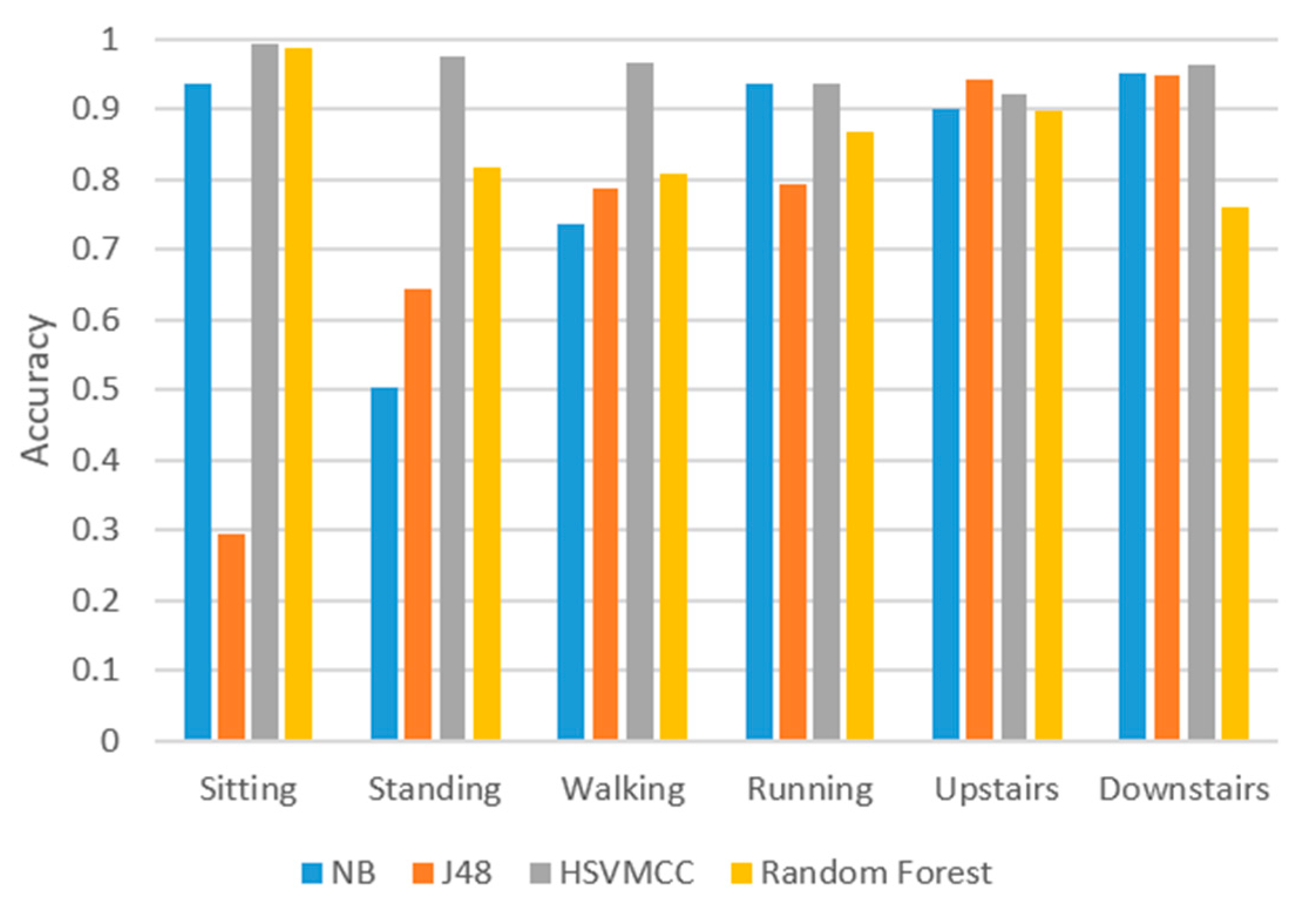
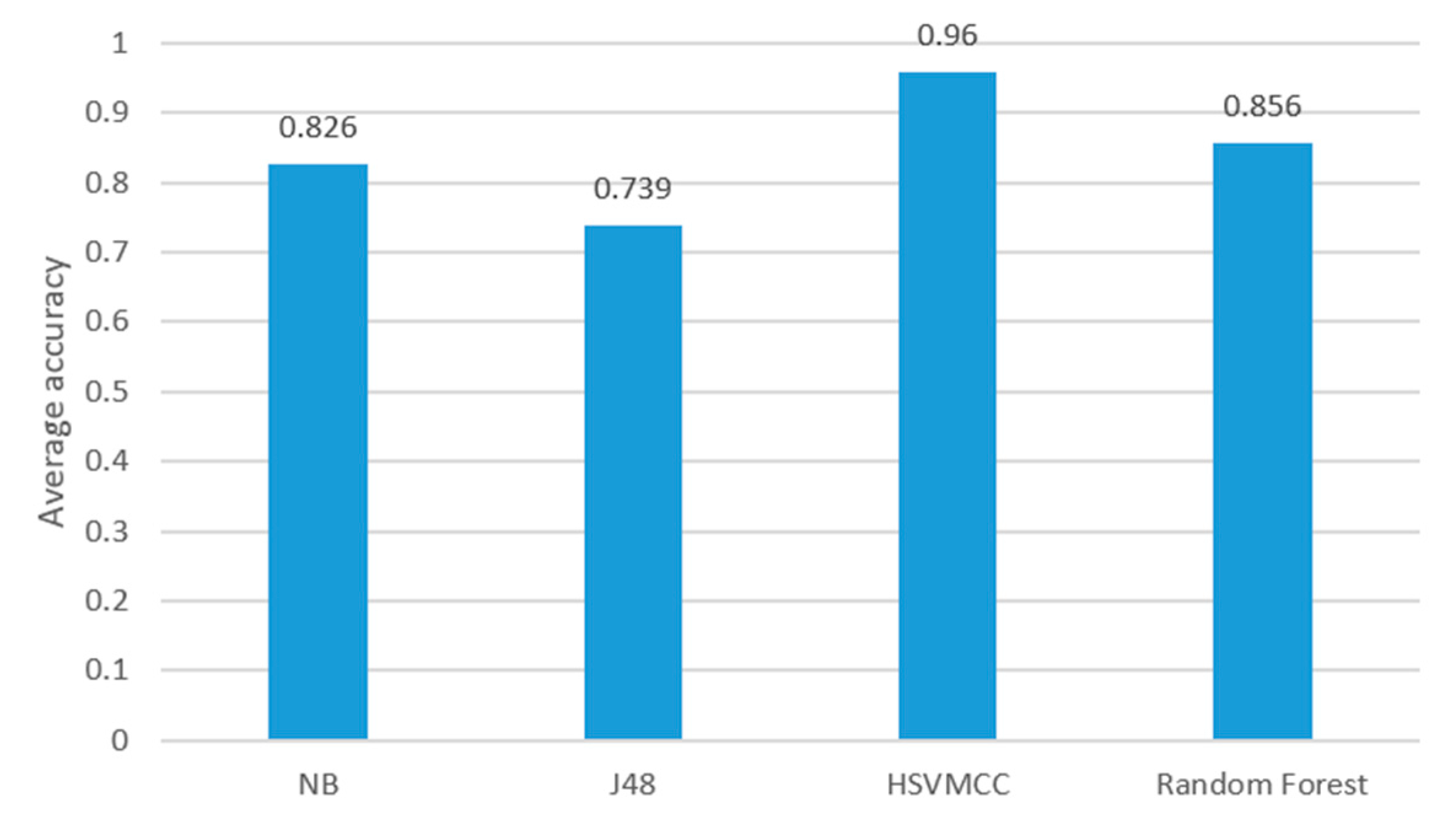
Figure 11 and
Table 6, we can conclude that the proposed ARS of using the sampling rate of 1 Hz can save 17.3% power than the rate of 5 Hz, and there is no significant difference of accuracy achieved in the activity recognition. Comparing the sampling rates of 5 Hz or 10 Hz or 50 Hz, it can be concluded that the power consumption becomes higher with the increase of the sampling rate, but there is little improvement of accuracy. In particular, when the sampling rate increases from 10 Hz to 50 Hz, the power consumption increases 32.7%, but the accuracy only increases 0.03%. Furthermore, the ARS by using the sampling rate of 1 Hz can save 59.6% power than ARS by using the sampling rate of 50 Hz. The working time of ARS by using the sampling rate of 1 Hz is almost twice more than that of using 50 Hz.

 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}