1. Introduction
Light detection and ranging (LiDAR) remote sensing technology has rapidly developed since it can collect 3D point clouds of object surfaces efficiently [
1]. Terrestrial LiDAR scanning (TLS) with a LiDAR sensor mounted on a fixed platform [
2] is widely used in various fields such as reverse engineering [
3], cultural heritage documentation [
4,
5] and environmental monitoring [
6,
7,
8]. Mobile LiDAR scanning (MLS) by integrating with several LiDAR sensors, a high-accuracy positioning and orientation system and a high-precision controlling system on a van or car provides a safer and more efficient way to capture large-scale geo-referenced point clouds [
9,
10]. It is being used at an increasing rate in the transportation industry [
11,
12], especially for road asset inventory [
13,
14] and in the production of high accuracy driving maps for intelligence driving [
15].
The registration of point clouds is a fundamental issue in LiDAR remote sensing because point clouds are scanned from multiple scan stations or by different platforms, and they should be merged to obtain full coverage of a scene [
16]. The aim of registration of different point clouds is to transform point clouds in different coordinate frames to a uniform coordinate reference frame. This paper deals with the registration problem of two TLS point clouds and the registration problem between TLS and MLS point clouds.
The traditional registration method is based on artificial markers that are placed in the scene during data acquisition. The positions of the markers must be manually extracted as tie points for registration. The marker-based registration is very reliable, but it requires very careful arrangements and is time-consuming [
17]. Many automatic registration algorithms are proposed to improve the efficiency of the registration. The published methods can be classified into two categories: auxiliary data-based methods and 3D point-based methods [
18]. Auxiliary data-based methods usually incorporate photographic images and point clouds for registration [
19,
20], or incorporate intensity images and point clouds for registration [
21,
22]. The image-assisted or intensity-assisted registration may bring up extra calibration of cameras and scanners, and the quality of the third-party data also has a direct effect on the registration process.
Many experts have directly used 3D point-based methods to solve the registration problem. The 3D point-based methods are usually divided into a coarse registration step and a fine registration step [
23]. The feature-based algorithm is a common way to achieve coarse registration, which establishes correspondences between two point clouds using extracted features. The used features, such as geometric curvature, main frame and point signature, are invariant with rotation and translation [
24,
25]. Johnson and Hebert proposed a local shape descriptor called ‘spin image’ to match or recognize an object [
26]. This histogram-feature registration is strongly affected by the given parameters—bin size, image width, and support angle. Rusu, et al. proposed a local non-linear optimizer called ‘sample consensus initial alignment’ (SAC-IA) to accomplish the registration, which employed their own fast point feature histogram (FPFH) as the feature descriptor [
27]. Tombari, et al. and Hänsch, et al. reviewed the existing feature descriptors and compared their performance, and the results indicate that the specific method to extract features has to be carefully chosen [
28,
29]. It is hard to establish robust correspondences by the extracted features because of the uneven point density, clutters and outliers, repeated objects, sheer size, and partial overlap of the point clouds [
17,
30]. The optimization of feature-based registration also needs exhausted computation [
31].
A well-known fine registration method is the iterative closest points (ICP) algorithm [
32], where each point in a one point cloud is paired with the closest point in the other point cloud to form correspondences, and then a point-to-point error metric (the mean of the squared distances of the correspondences) is minimized. The process is iterated until the error becomes smaller than a threshold or the maximum iteration is achieved. Chen and Medioni proposed a point-to-plane error metric ICP [
33], which is more accurate than the point-to-point ICP [
34]. Hereafter, some modified ICP methods are proposed and they are distinct from four aspects [
35]: (1) selection of candidate points; (2) search strategy of nearest points to establish correspondences; (3) weighting relationship of correspondences or rejection of invalid correspondences; and (4) error metric and optimization. Many ICP algorithms have been achieved in the Point Cloud Library (PCL) [
36]. However, ICP is easy to fall into local optimum, which is inherently determined by the employed local optimizer [
37]. Hence, their performance critically relies on the initialization quality (the quality of coarse registration), and only local optimality is guaranteed.
Unlike the above coarse-fine registration, registration based on genetic algorithm (GA) uses a global search strategy which automatically finds the optimal solution in the search space [
38]. GA is a heuristic optimizer that simulates the evolution of nature—selection (survival of the fittest), crossover, and mutation. Jacq and Roux presented a framework of 3D medical point cloud registration based on GA [
39]. Brunnstrom and Stoddart proposed a GA registration method for free-form surface matching for the first time, which achieved finding correspondences rather than searching optimal solutions in search space [
40]. This method is not applicable when there are too many matching points. Yamany, et al. presented a GA registration method whose fitness function was to maximize the reciprocal of the sum of squared errors (SSE) between correspondences [
41]. Silva, et al. gave more details of GA registration and proposed a better objective function to minimize the mean squared errors (MSE) between correspondences with outlier rejection [
42,
43]. Hereafter, the scholars also presented some different GA registration methods and their fitness functions were also based on the MSE [
37,
44,
45]. MSE is originated from local optimization and it may not be globally optimal. The fitness values are often needed to scale into maximum values by a negative exponential function. In addition, GA registration is complicated and time-consuming because of the global search strategy of GA and the complexity of scanned point clouds.
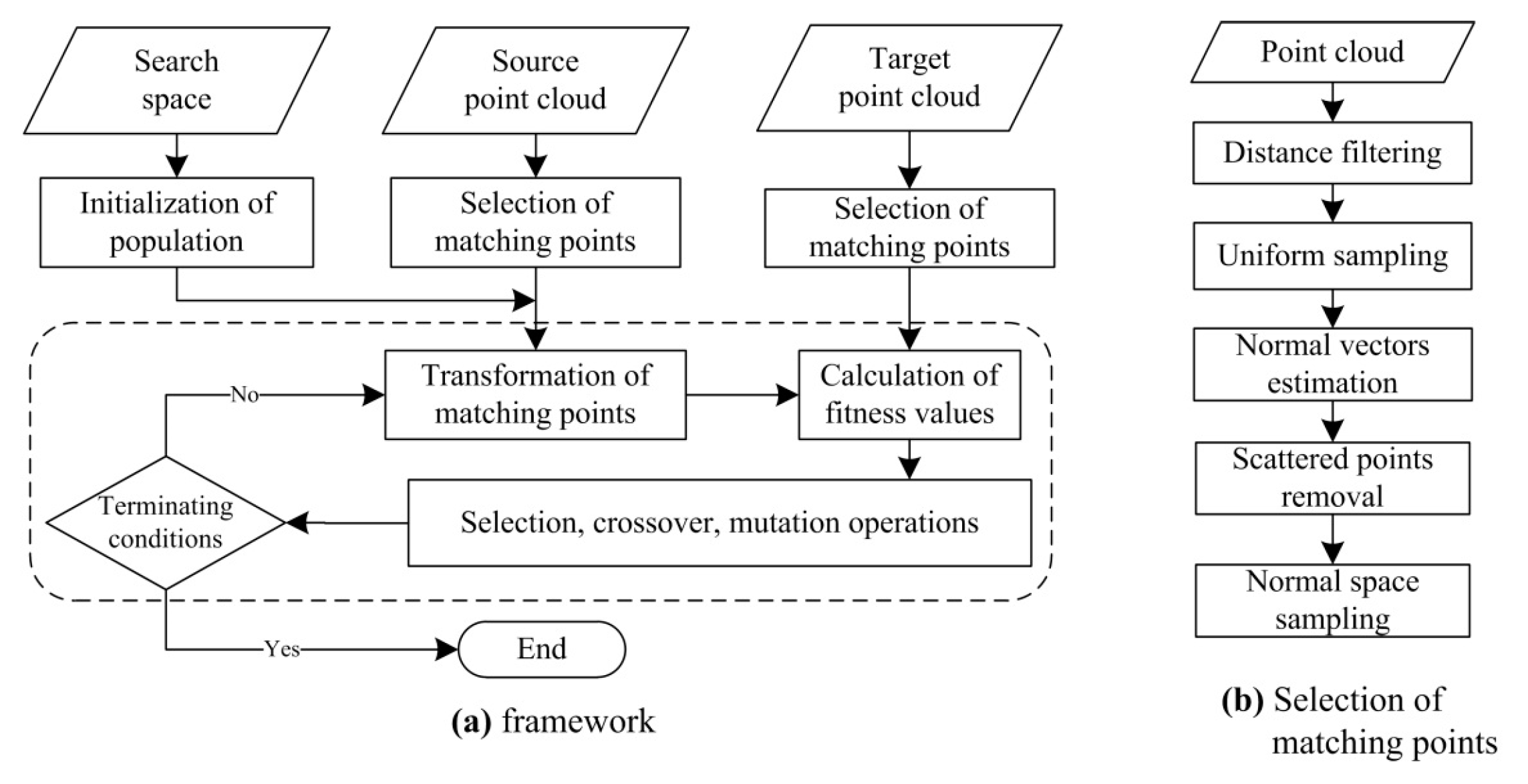
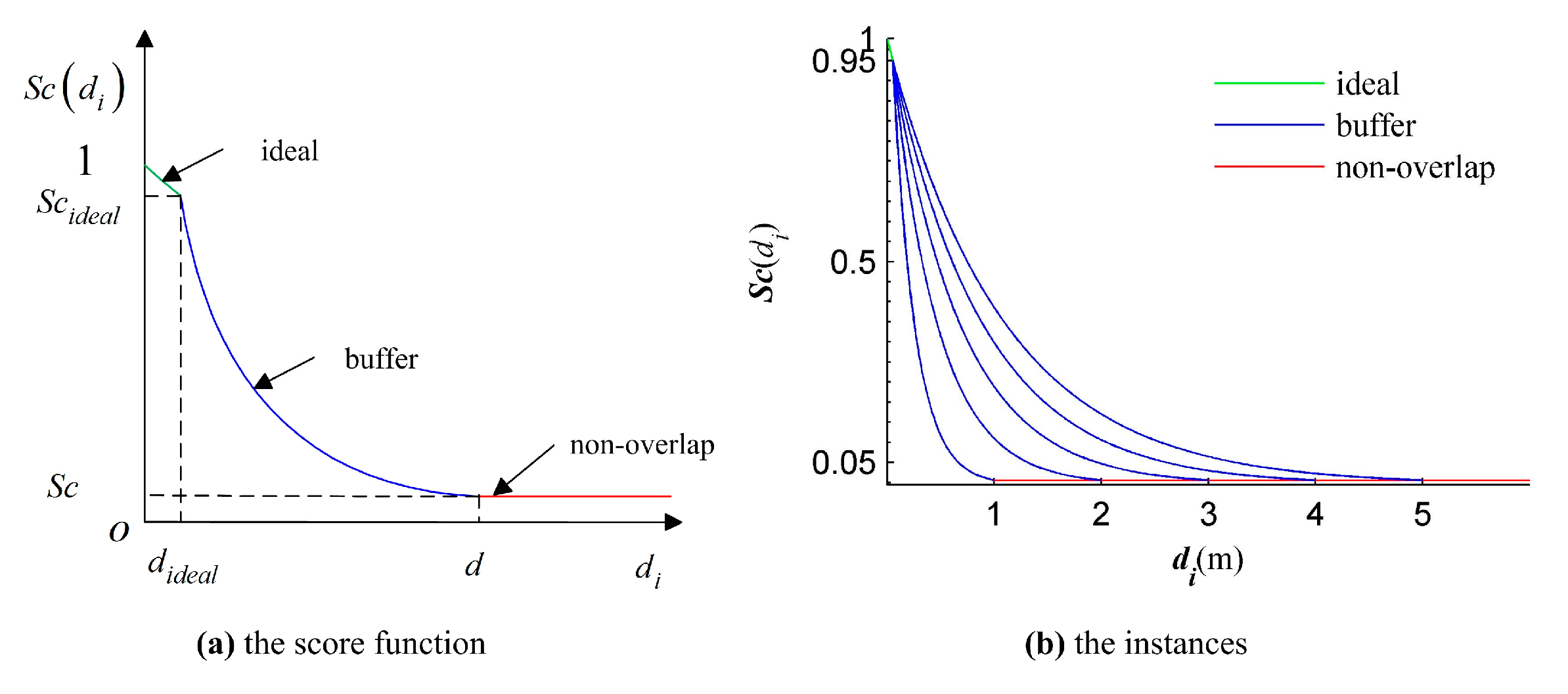
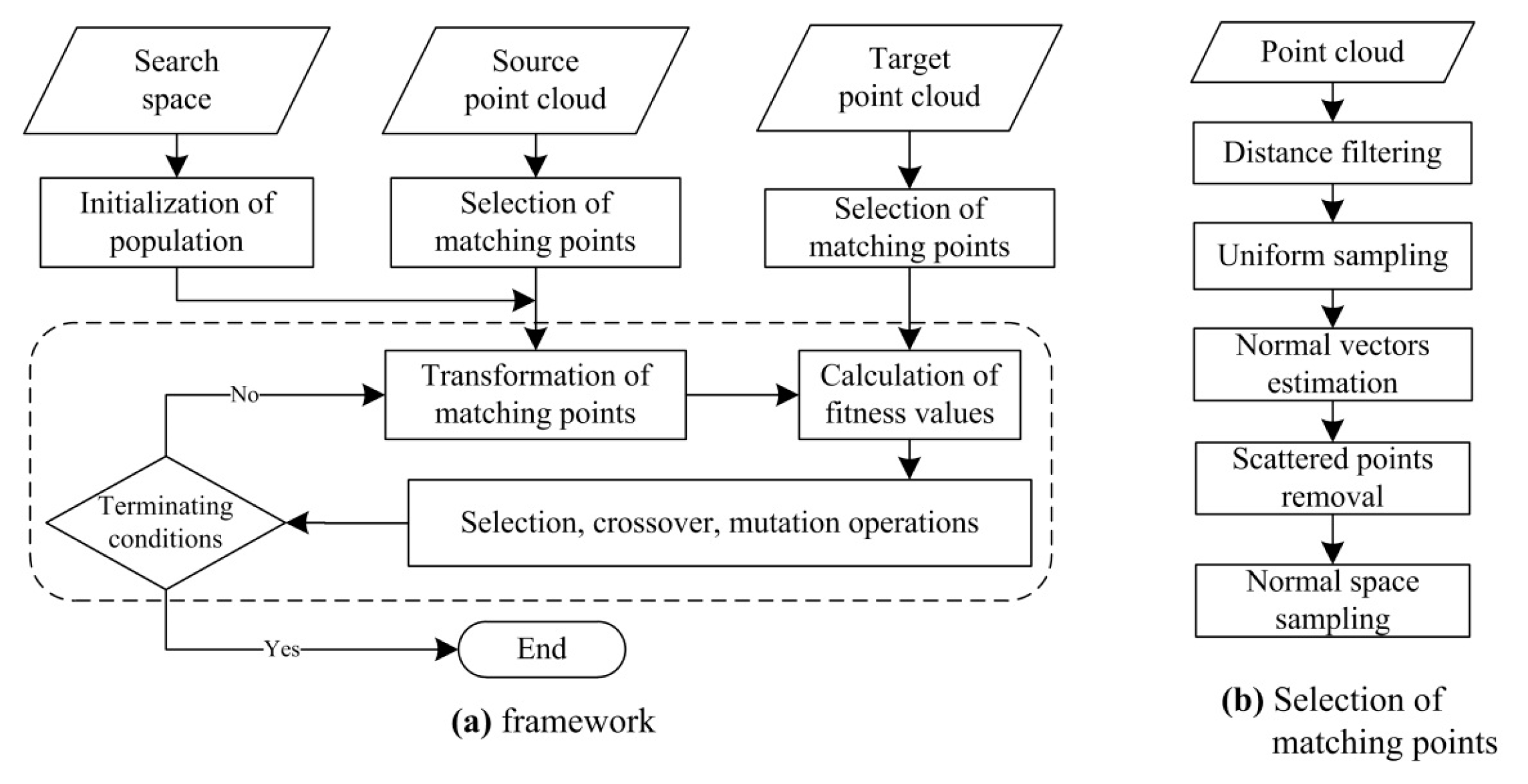
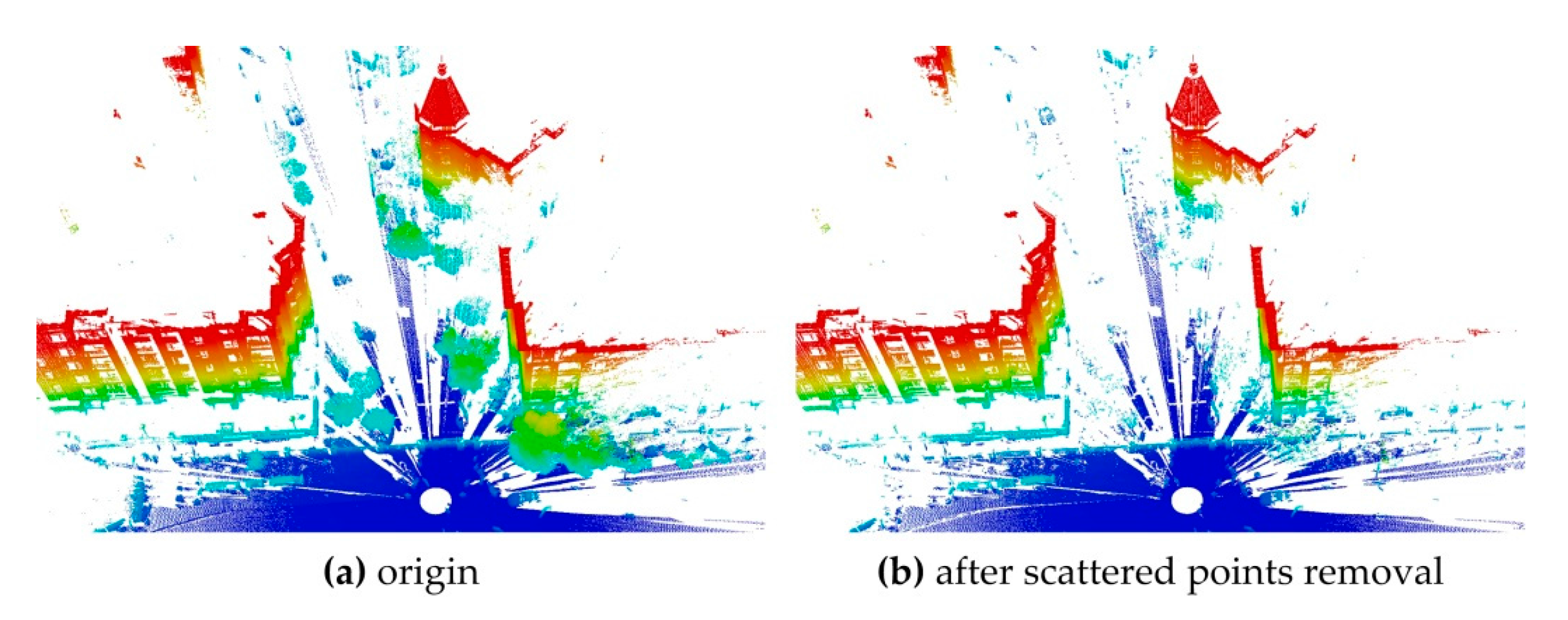
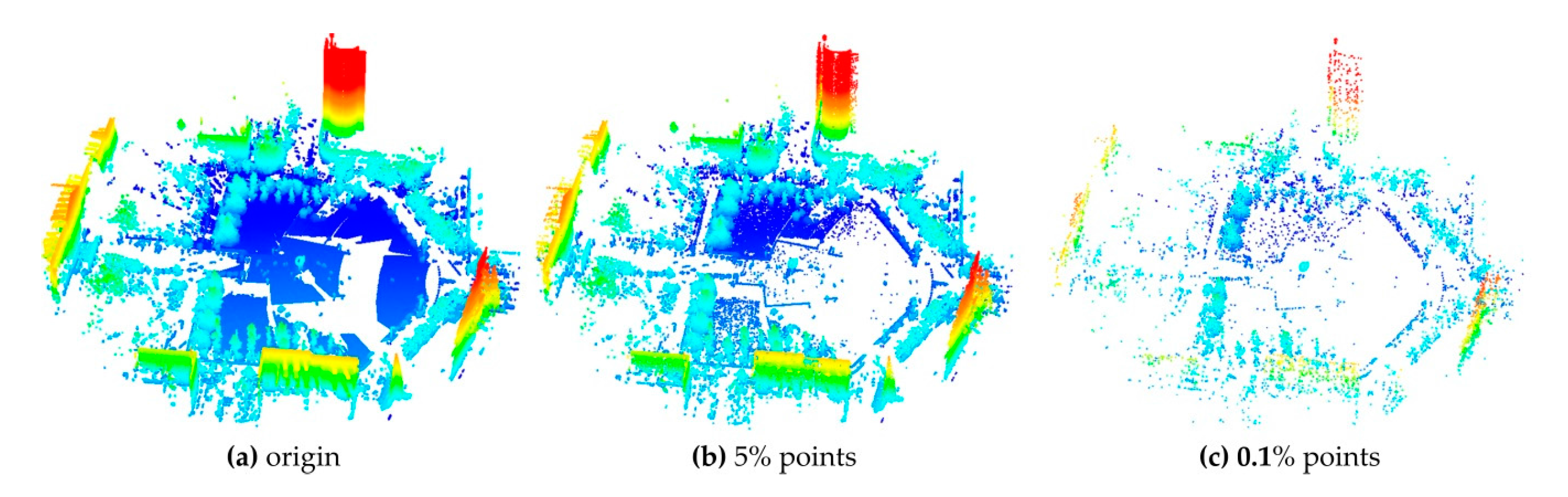
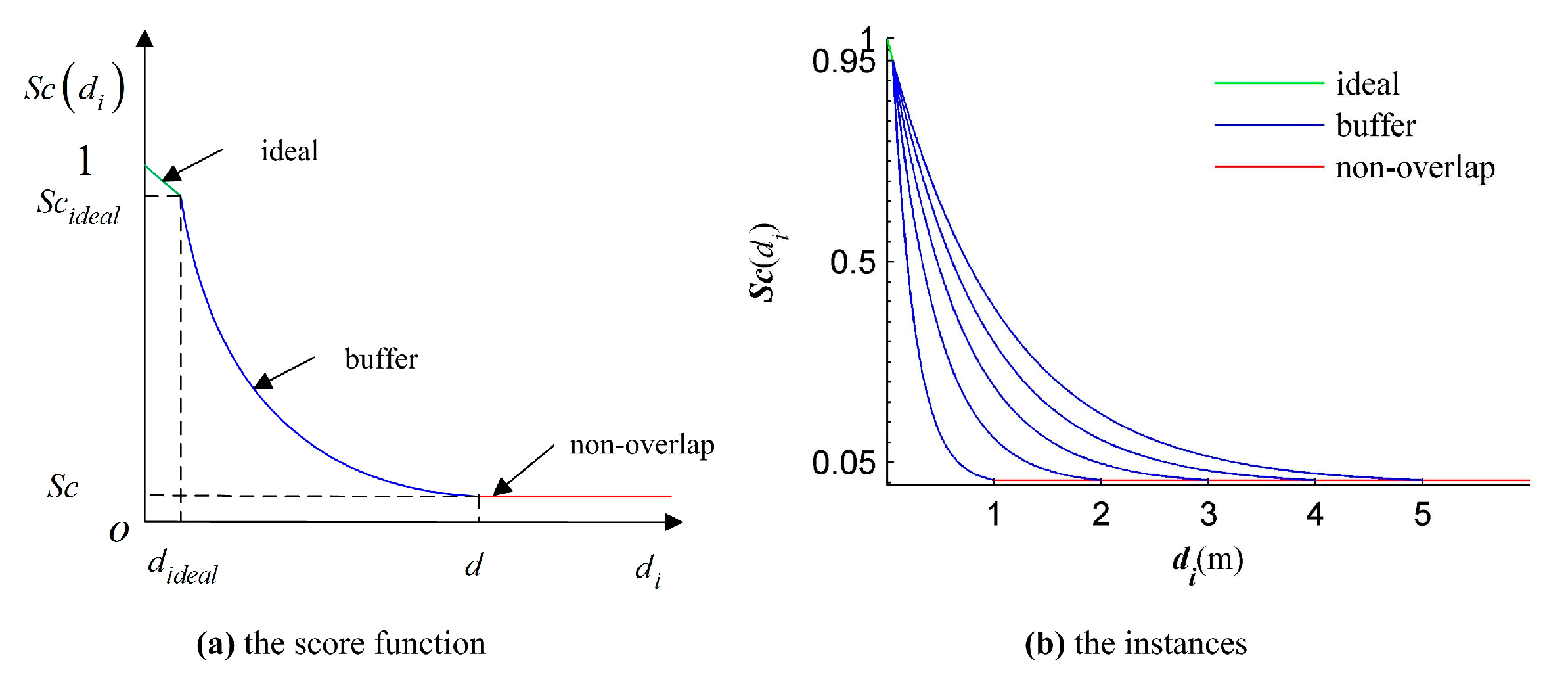
This paper proposes an efficient GA registration method for registering two TLS point clouds or two point clouds where one is scanned by TLS and the other is scanned by MLS. In order to make the GA registration workable and improve the registration efficiency, the selection of matching points is first applied to eliminate the far, redundant and noisy points and to select partial points representing the main features before GA evolution. Besides, the scanning station position acquired by the TLS built-in GPS and the quasi-horizontal orientation of LiDAR sensor in data acquisition are used as constraints to narrow the search space in GA. Furthermore, the calculation of fitness values—the most time-consuming step of GA registration—is parallel-computed. Instead of the MSE-based fitness function, a new and more accurate fitness function, named ‘Normalized Sum of Matching Scores’ (NSMS), is proposed to evaluate the solutions.
The remainder of the paper is structured as follows. The GA is firstly introduced in
Section 2. The proposed GA registration is described in
Section 3. Then the experimental results and the discussions are described in
Section 4, where the registration integrating ICP with GA is presented. The conclusions are described in the last section.
2. Genetic Algorithm
Genetic algorithm (GA) is a global and heuristic optimizer which simulates biological evolution. It maintains a population of candidate solutions and evolves by iteratively applying three genetic operators: selection (survival of the fittest), crossover, and mutation. In this section, the GA is briefly introduced. More details can be referred in [
38,
46,
47].
In order to apply GA, the encoding mode should be first determined. Encoding is to present a solution in the search space as a chromosome that is composed of genes and can be computed by the genetic operation. The inverse mode is called decoding. The common numerical encoding methods are binary encoding and float encoding. The binary encoding is to convert a real to a binary and the corresponding decoding is to inversely transform a binary to a real. The float encoding directly uses a parameter as an encoding gene, which the genes do not need in order to be decoded. Float encoding is therefore more efficient in the optimization of multivariable functions and there is no conversion accuracy loss.
A standard GA is divided into three steps—initialization of population, calculation of fitness values, and genetic operation. A population is a set of chromosomes {P|Ch1, Ch2, …}. In its initialization, a chromosome is often uniform-randomly generated in the search space. The pseudo code of initialization for float encoding is presented in Algorithm 1. The size of the population M is often empirically set to a few hundred. The search space is the solution domain of the optimization problem, which is defined between the negative and positive upper bound vector. Defining search space is a core issue in actual optimization.
| Algorithm 1. The pseudo code of population initialization. |
| 1 | Input the upper bound vector of the solution |
| 2 | domain U and population size M; |
| 3 | For I = 1:M |
| 4 | For k = 1:DIMENSION(U) |
| 5 | Randomly generate r in [−Uk, Uk]; |
| 6 | Chi,k = r; |
| 7 | End |
| 8 | End |
The calculation of fitness values is based on a fitness function. The fitness function that is defined to evaluate the solutions is another core issue in actual optimization. It is scaled from the objective function of the optimization problem and provides the guidance for the GA selection operation. Therefore it directly affects the GA performance and should be carefully designed.
The genetic operation is a simulation of biological gene manipulation, including selection, crossover, and mutation. The selection operator is to select
M chromosomes from the parent population for reproduction. The chance of selecting one chromosome as a father or mother should be proportional to the population size
M. Remainder stochastic selection is a better method than the direct stochastic selection by fitness proportion. It can ensure the chromosomes with higher fitness proportions are chosen and have higher proportions in the selected population. Firstly, each chromosome in the population is copied several times for reproduction. The copied number of the
ith chromosome is
where,
Fi is the fitness value of the
ith chromosome.
chromosomes are copied, and then the remained fitness value of the
ith chromosome is
All remaining fitness values of the population are used to produce the other chromosomes by direct stochastic selection.
The crossover operator mates parents to produce two new offspring and the mutation operator alters one or more gene values in a chromosome from its initial state. To ensure that the genes of the optimal chromosome at each generation are not eliminated and damaged, the chromosome with the highest fitness is directly copied into the next generation. The crossover operator and mutation operator are dependent on the encoding. If the float encoding is applied, arithmetic crossover and non-uniform mutation are suitable for generating new chromosomes. Their pseudo codes are given in Algorithm 2. Here, two parameters, the crossover probability Pc and mutation probability Pm, should be set. Empirically, Pc is 0.6~1 and Pm is not more than 0.1.
| Algorithm 2. The pseudo code of arithmetic crossover and non-uniform mutation. |
| arithmetic crossover | non-uniform mutation |
| 1 | Input a mother chromosome Ch1 and | 1 | Input the upper bound vector of the solution |
| 2 | a father chromosome Ch2; | 2 | domain U and a chromosome Ch; |
| 3 | Randomly generate pc in [0, 1]; | 3 | Randomly generate pm in [0, 1]; |
| 4 | If pc < Pc | 4 | If pm < Pm |
| 5 | For k = 1:DIMENSION(Ch1) | 5 | T = (1 − Currentg/MAXg)2; |
| 6 | Randomly generate r in [0, 1]; | 6 | For k = 1:DIMENSION(Ch) |
| 7 | Tk = r*(Ch2,k−Ch1,k); | 7 | Randomly generate r in [0, 1]; |
| 8 | Ch1,k = Ch1,k + Tk; | 8 | If r > 0.5 |
| 9 | Ch2,k = Ch1,k − Tk; | 9 | Chk = Chk+(Uk − Chk)*r*T; |
| 10 | End | 10 | Else |
| 11 | End | 11 | Chk = Chk − (Uk + Chk)*r*T; |
| | | 12 | End |
| | | 13 | End |
| | | 14 | End |
The calculation of fitness values and genetic operation are iteratively applied, which constitutes the evolution of GA. The GA evolution is terminated when either of the following two criteria is satisfied:
Maximum number of generations: exceeding the maximum generation MAXg makes the evolution stopped.
Maximum number of generations that the best fitness keeps stable: if the number of generations, which the current best fitness value is unchanged, is equal to a given value MAXb, the evolution is also stopped. To find out the globally optimal solution, MAXb should not be too small.
5. Conclusions
This paper proposes an accurate and efficient GA registration method for automatic alignment of two TLS point clouds or two point clouds scanned by TLS and MLS respectively. It is divided into five main steps: selection of matching points, initialization of the population, transformation of matching points, calculation of fitness values, and genetic operation. In order to make the GA registration workable, the aided localization and priori quasi-horizontal orientation of the scan station were used as constraints to narrow the search space. To get accurate results, a new fitness function named ‘normalized sum of matching scores’ (NSMS) is proposed to evaluate the solutions instead of the MSE-based fitness function. To improve the registration efficiency, the selection of matching points was first applied to eliminate the far, redundant and noisy points and to select partial points representing the main features before GA evolution. Besides, the calculation of fitness values, the most time-consuming step of GA evolution, was parallel-computed.
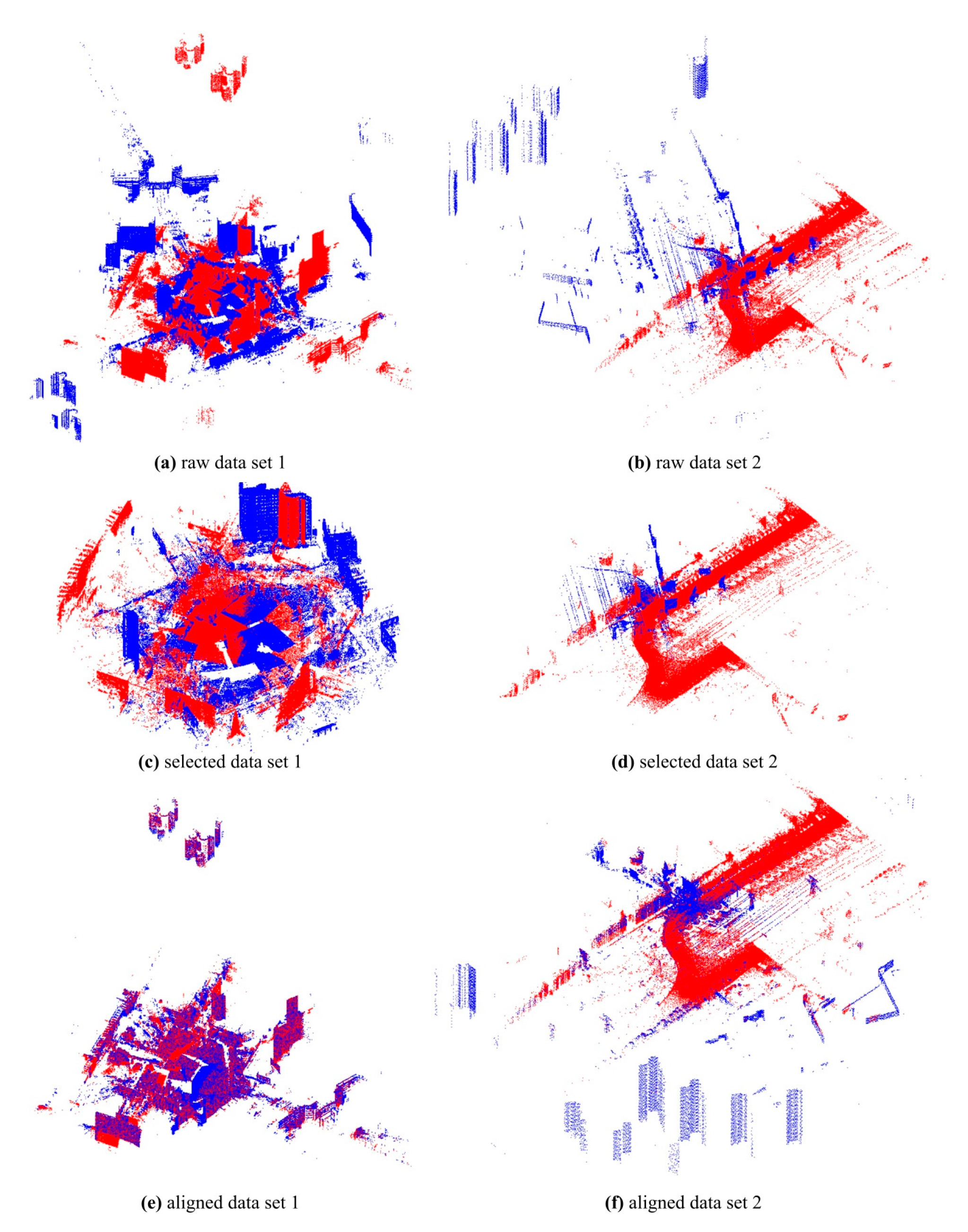
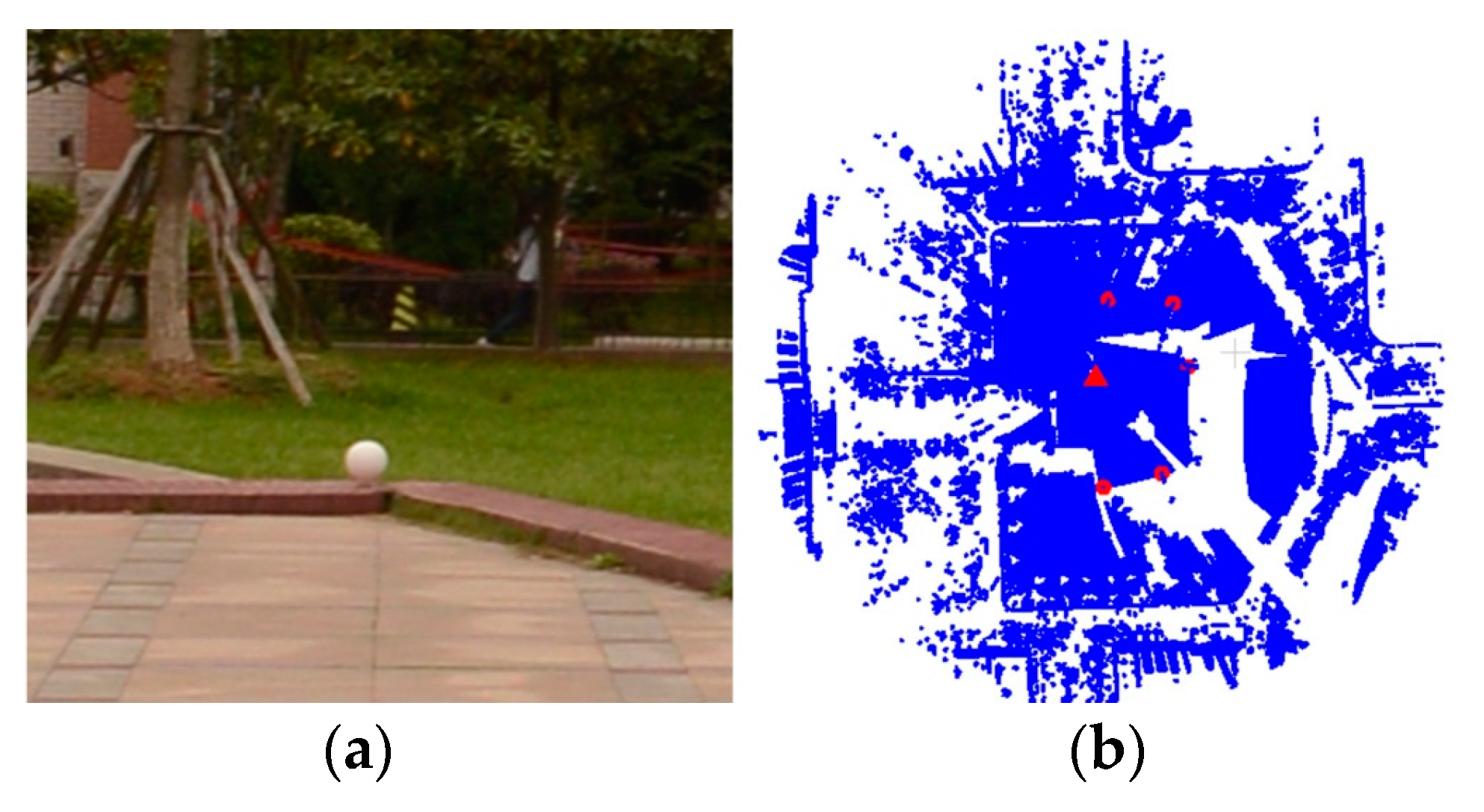
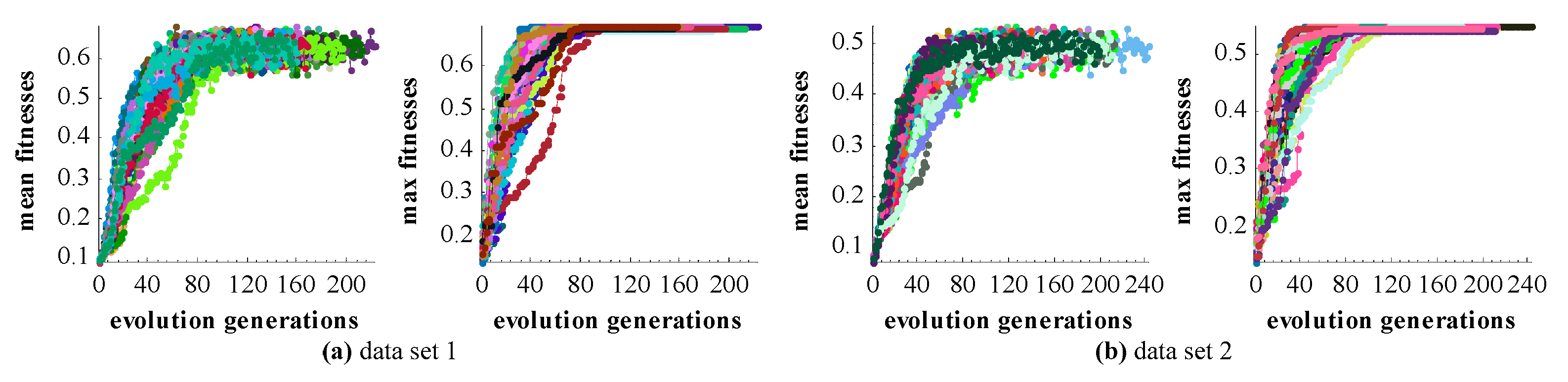
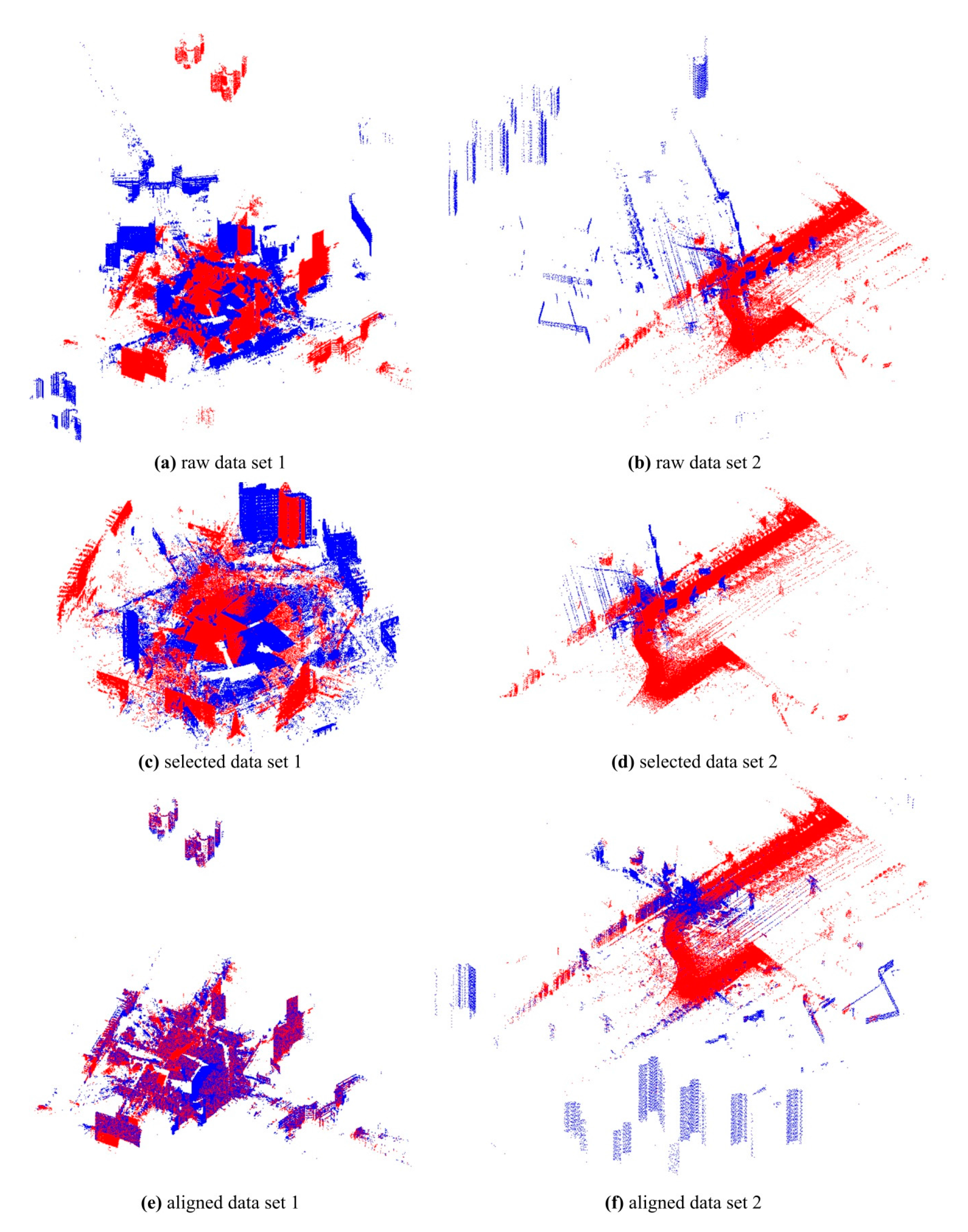
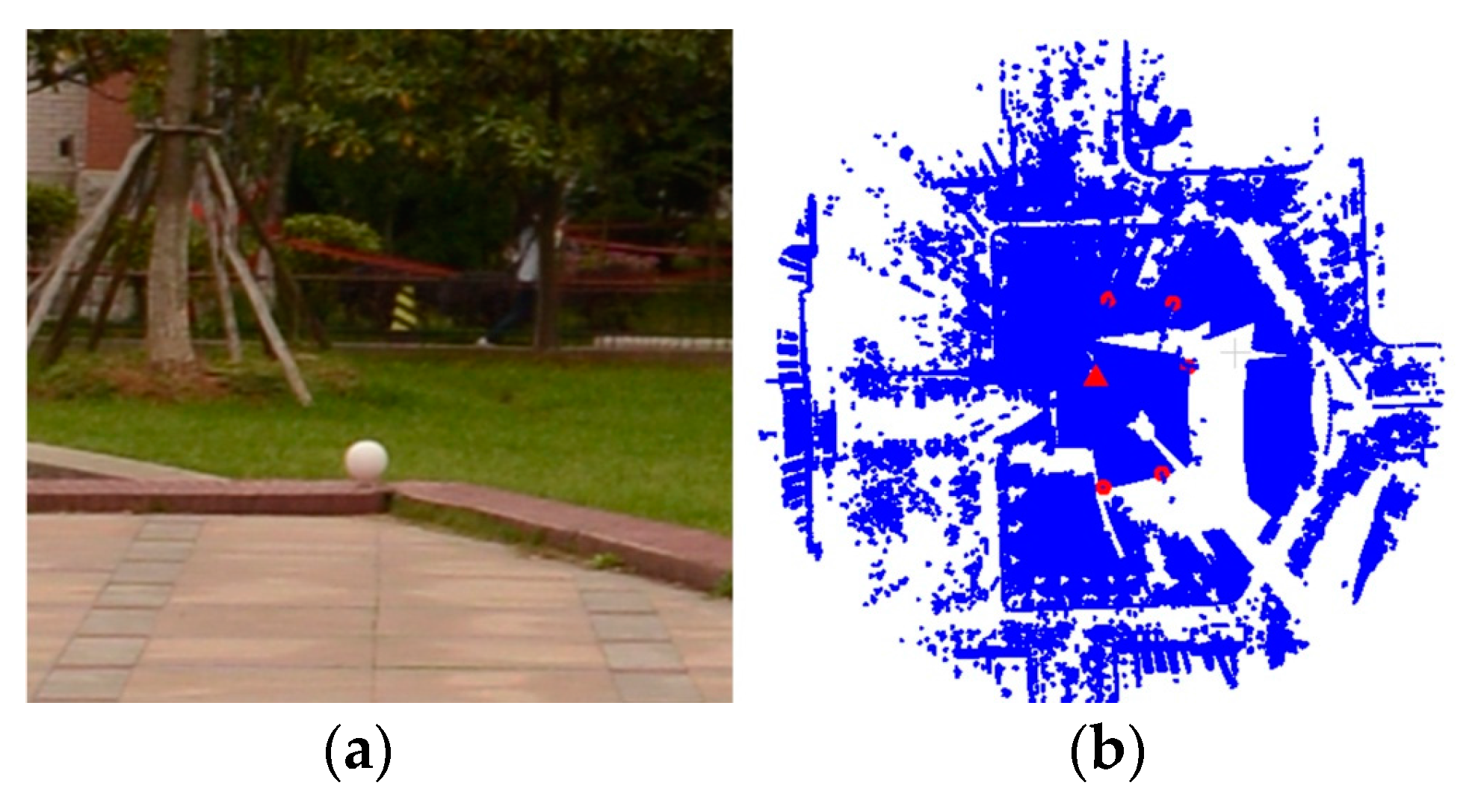
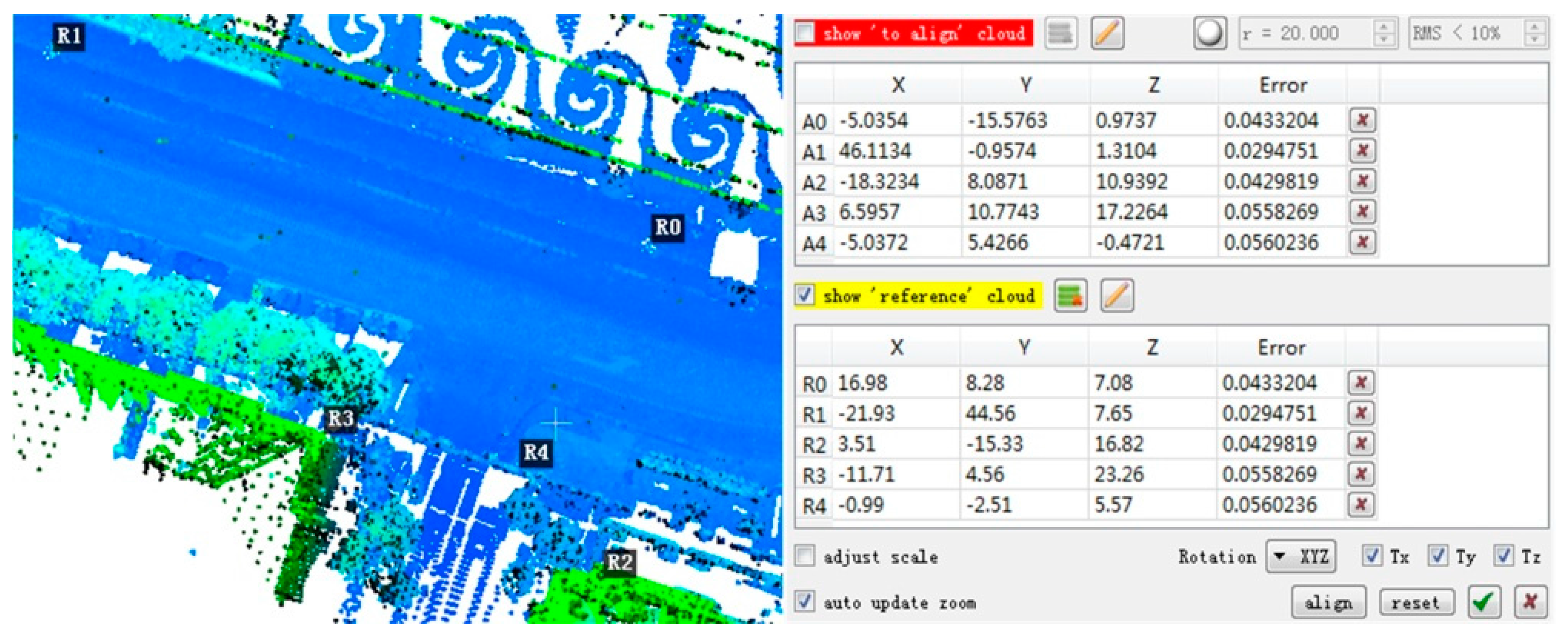
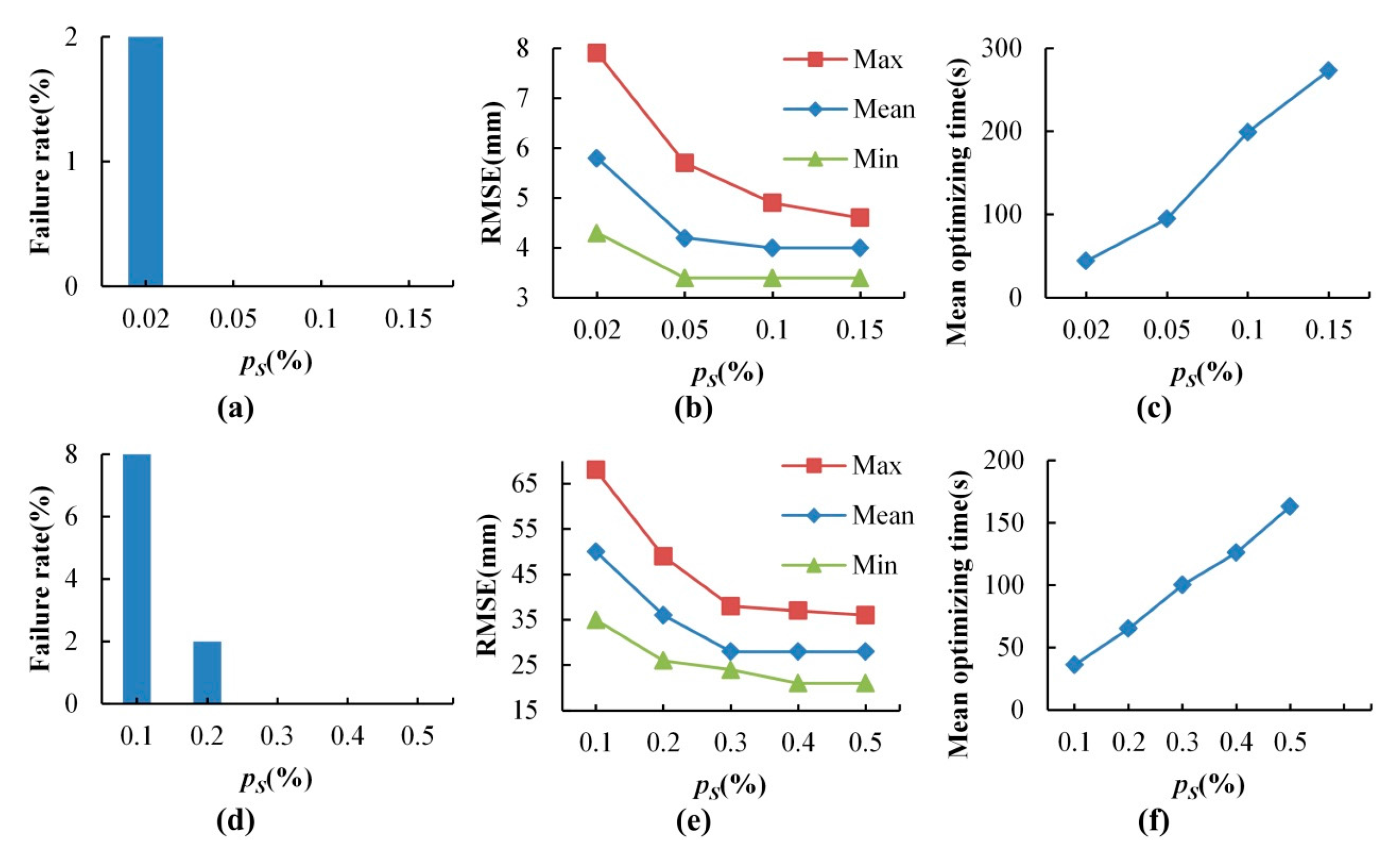
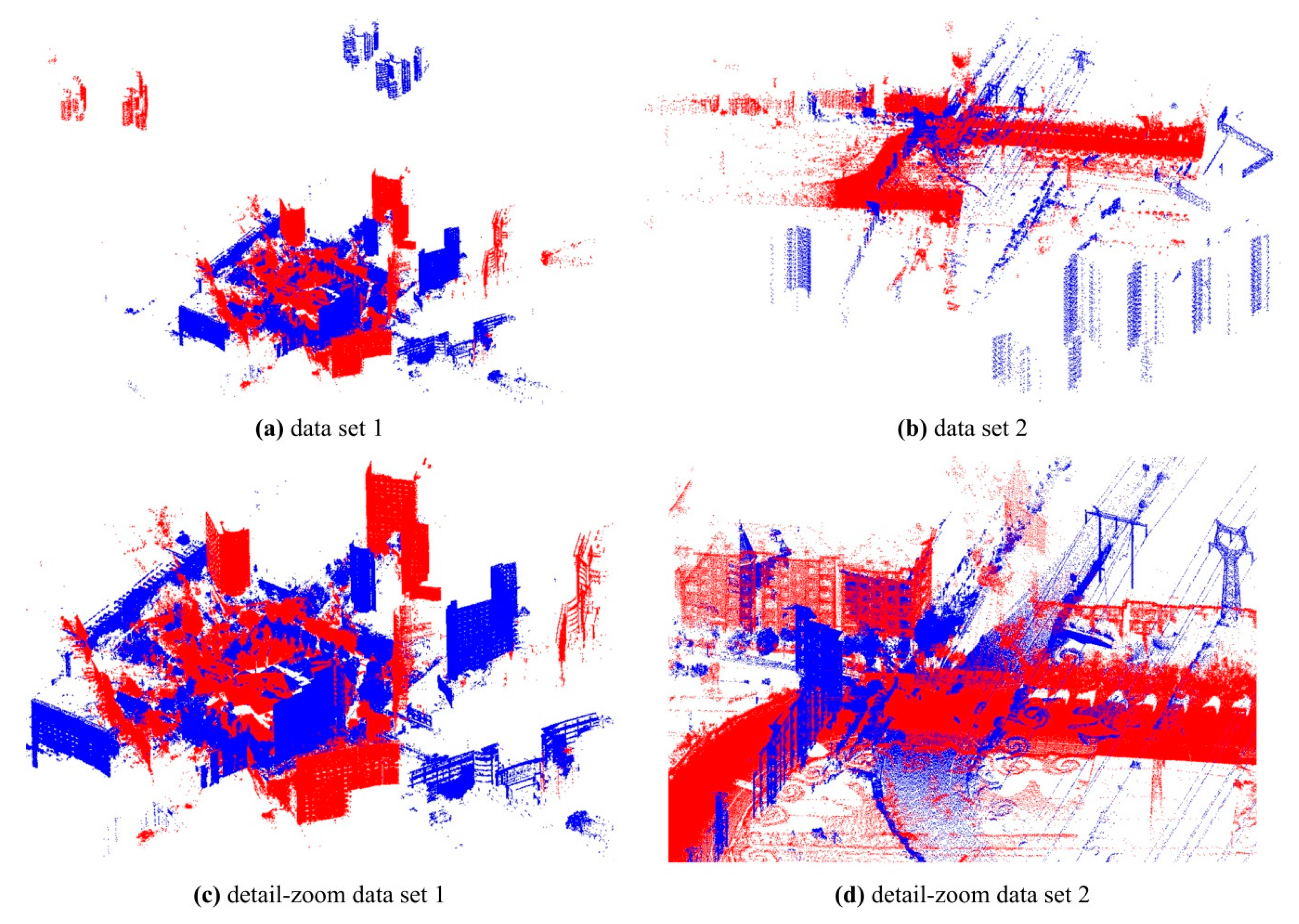
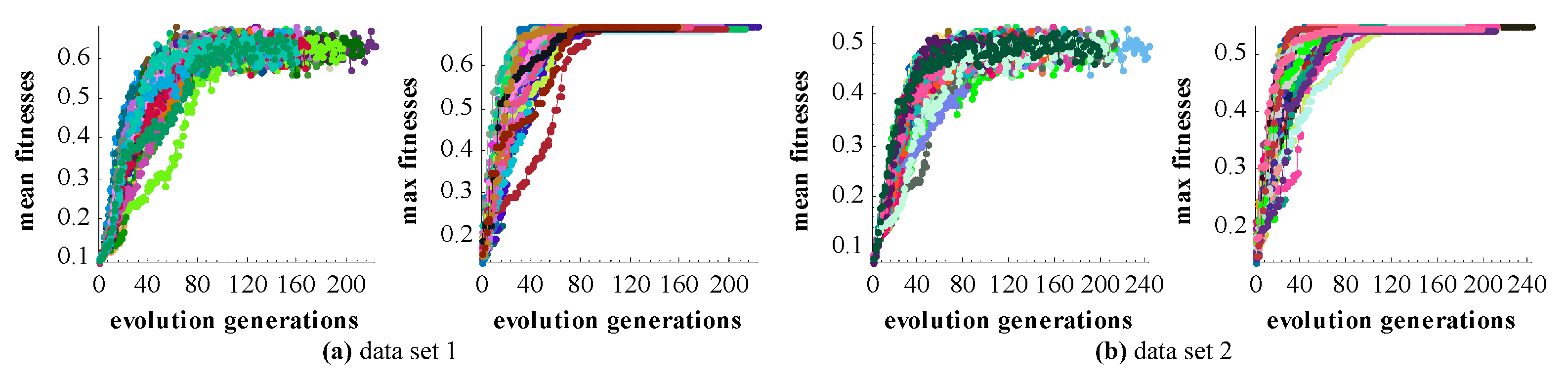
Two test datasets including a TLS-TLS data set and a TLS-MLS data set were scanned to validate the effectiveness of the proposed GA registration. The experimental results indicate that the RMSE of TLS point clouds registration is 3~5 mm and the RMSE of registration between TLS and MLS point clouds is 2~4 cm. In addition, the proposed NSMS fitness function is more accurate and efficient than the existing Silva fitness function.
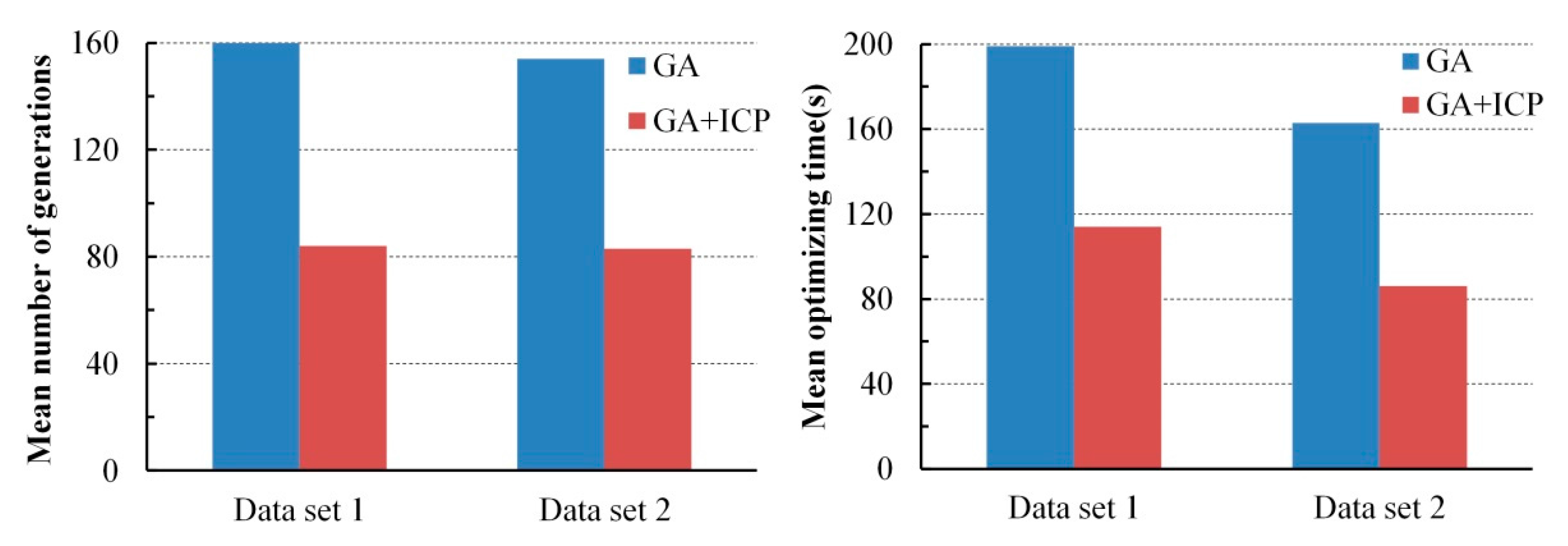
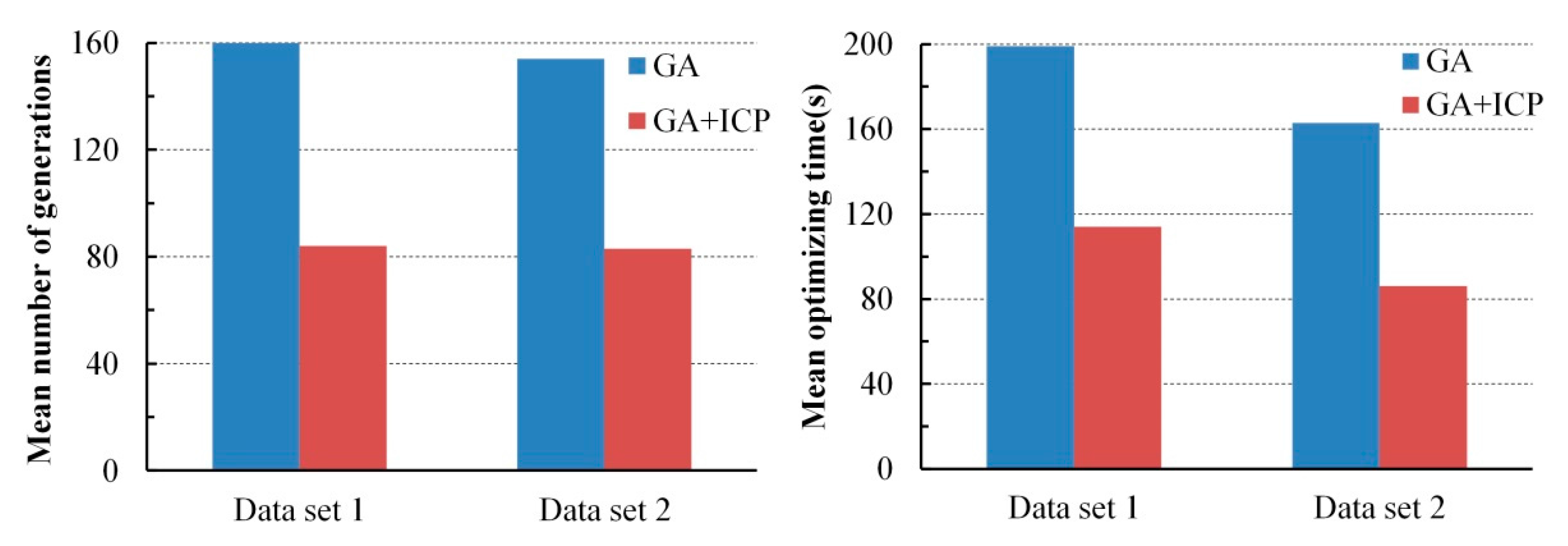
To accelerate the convergence of optimization, the ICP was integrated with GA for registration. The integrating strategy is that ICP is executed after GA evolves some generations and most of the individuals in the population are located in a narrowed search space. The combined method was also tested with the two test datasets. The optimizing efficiency of the integrated method was increased by about 50% compared with that of GA registration alone.
The proposed GA registration method can get globally optimal solutions in the search space without initial solutions and the feature extraction is also not required. However, in current algorithms of the first step, only the moving tree leave points can be removed out. The other moving points—e.g., the moving car point—can not be removed. A few moving points may not effect the registration. But it may not be true when there are too many moving objects in the scene. This special case would be considered and perfected in the follow-up work. Further research will mainly focus on extending the proposed method to automatically align multi-view TLS point clouds, multi-strip MLS point clouds or hybrid multi-view point clouds.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}