An Automatic Multi-Target Independent Analysis Framework for Non-Planar Infrared-Visible Registration

Abstract
:1. Introduction
2. Related Work
2.1. Area-Based Methods
2.2. Feature-Based Methods
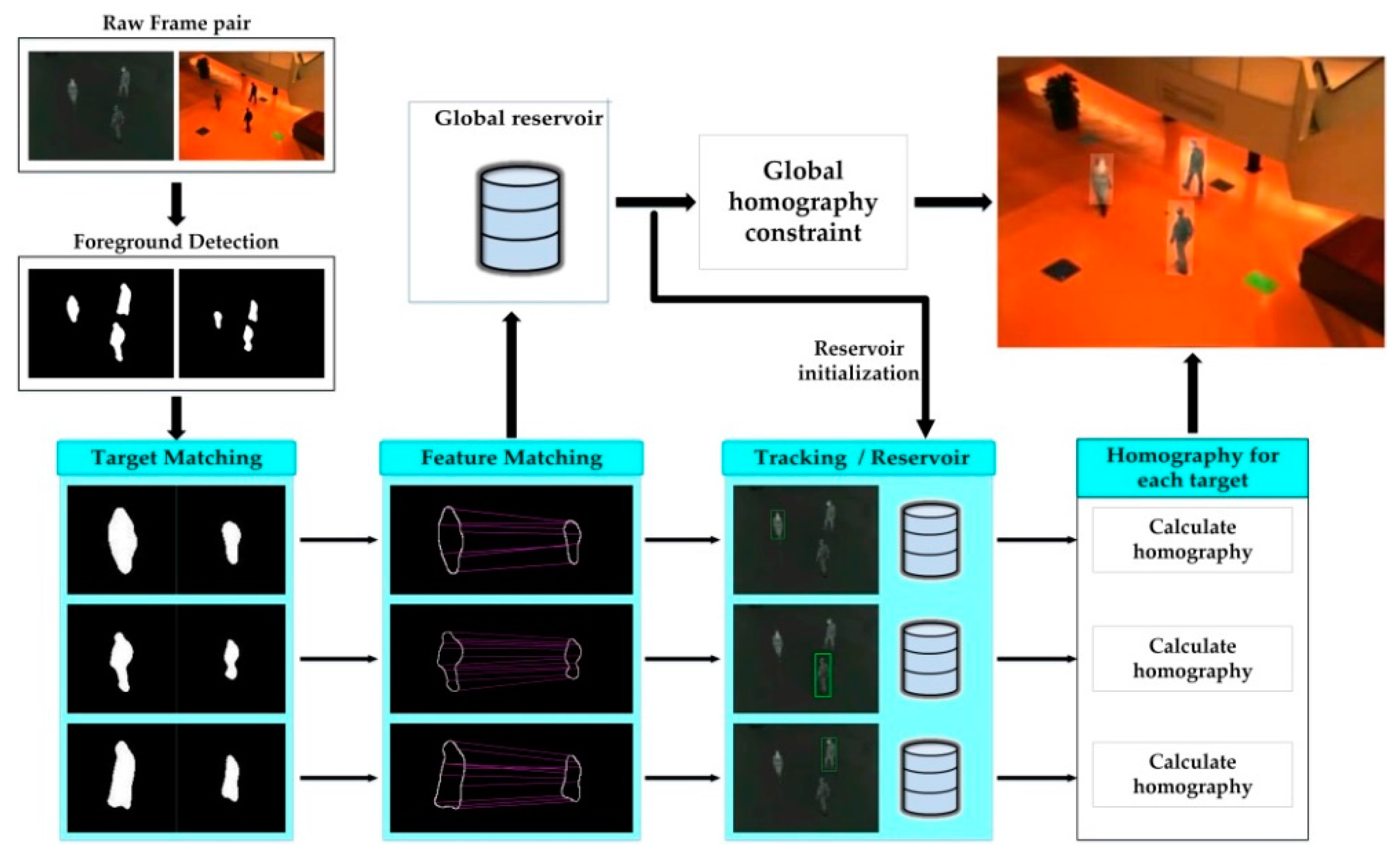
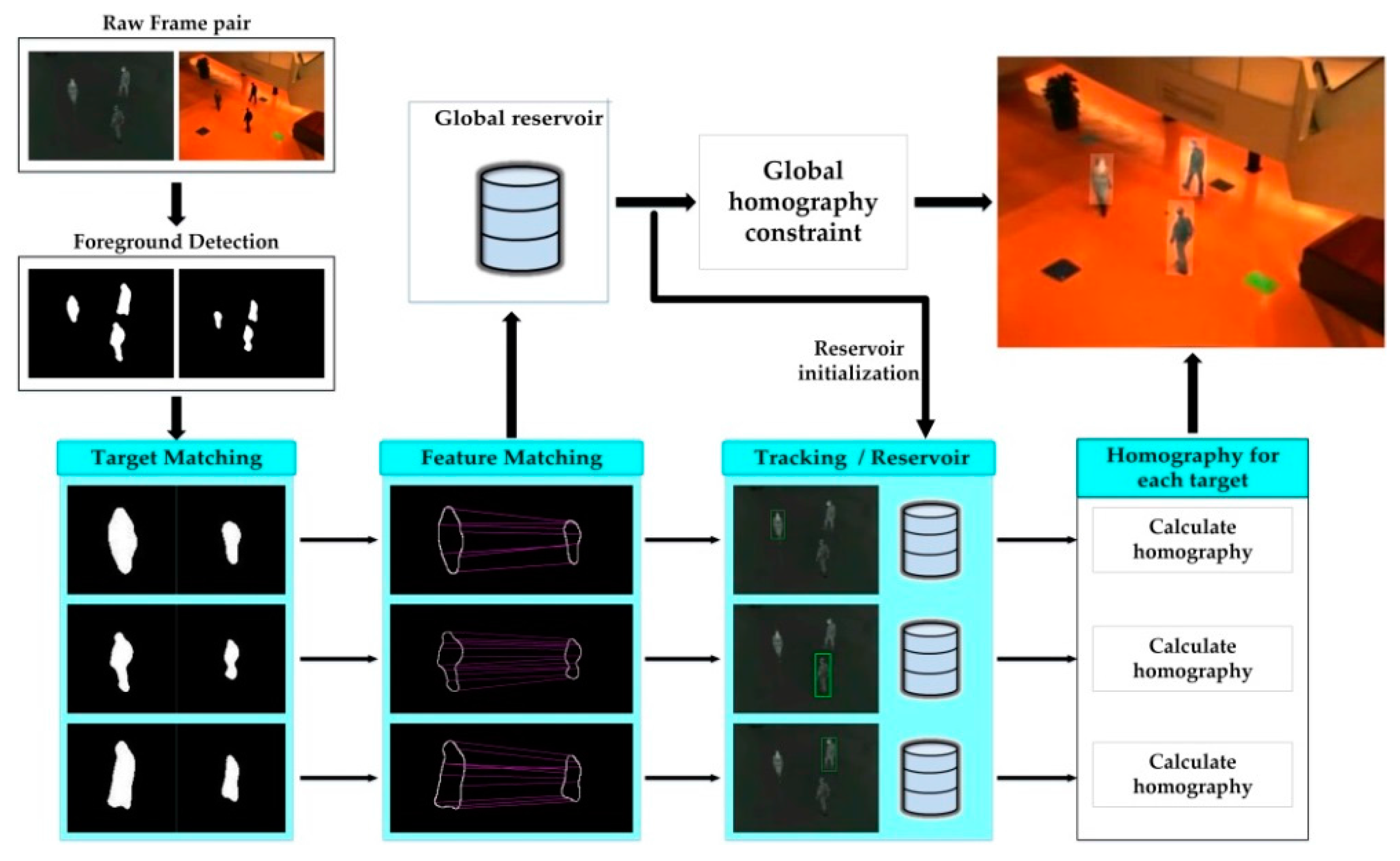
3. Proposed Framework
3.1. Foreground and Feature Extraction
3.2. Feature Matching
3.3. Reservoir Creating and Assignment
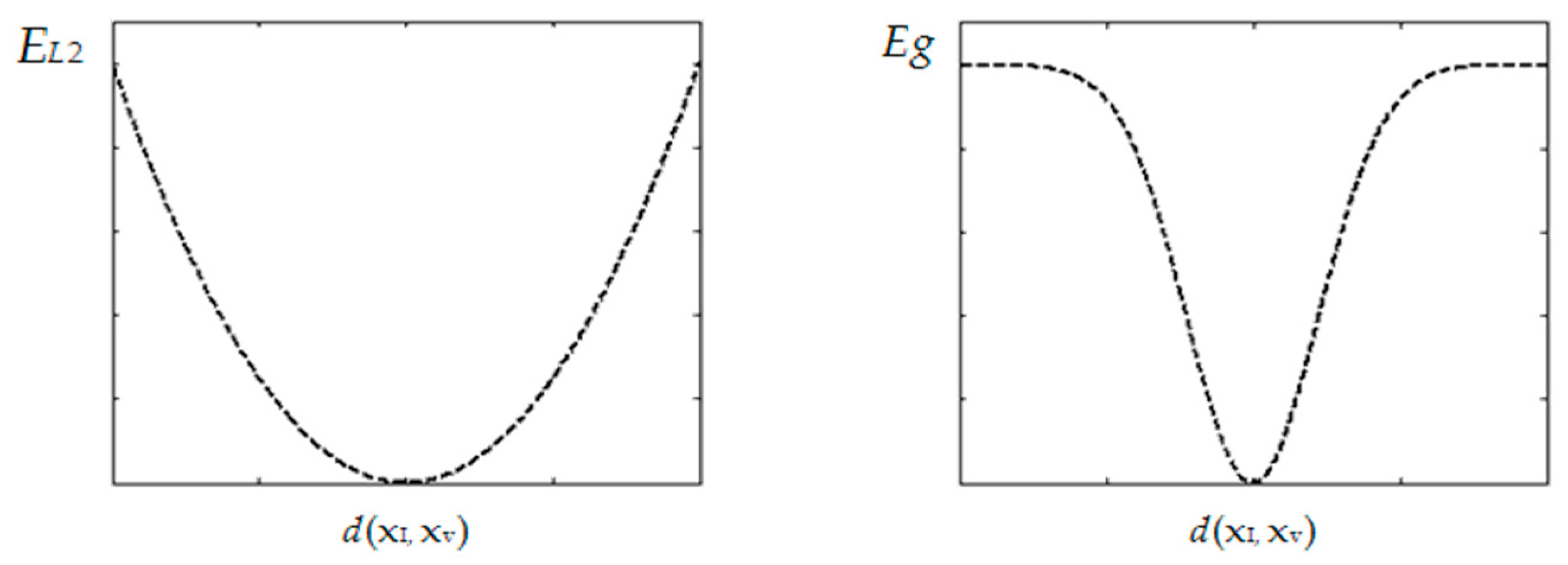
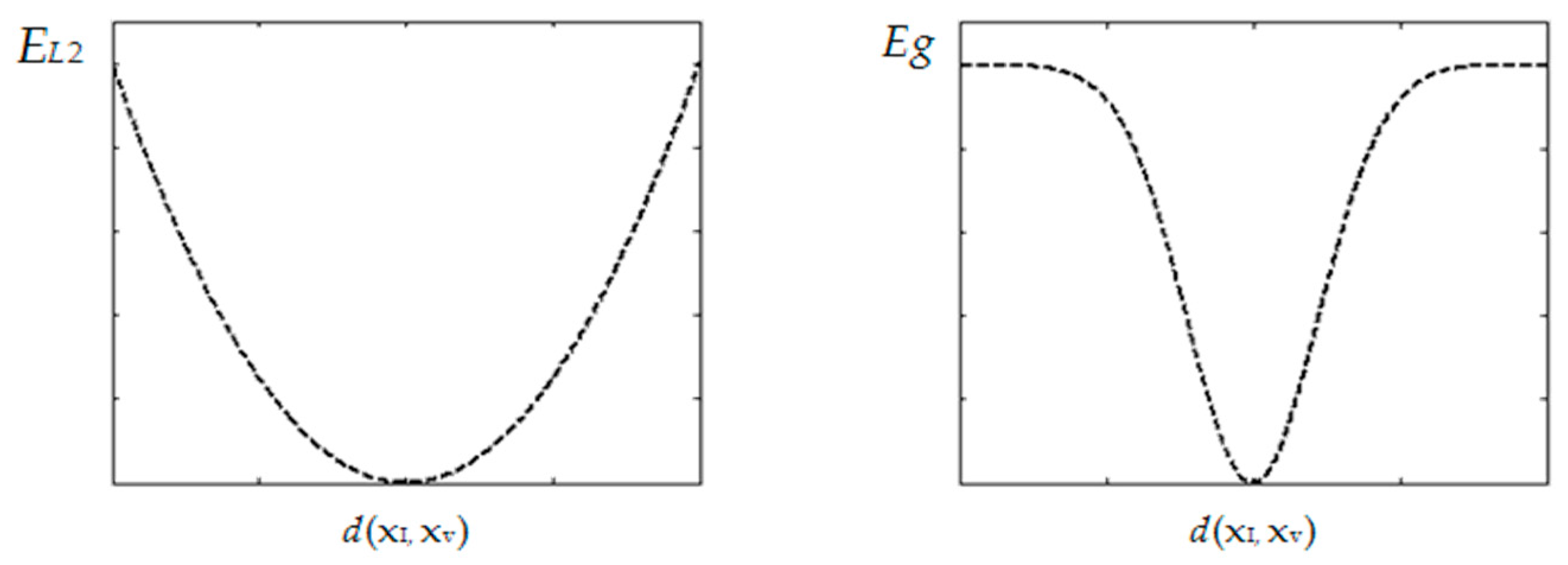
3.3.1. Reservoir Creating with Gaussian Criterion
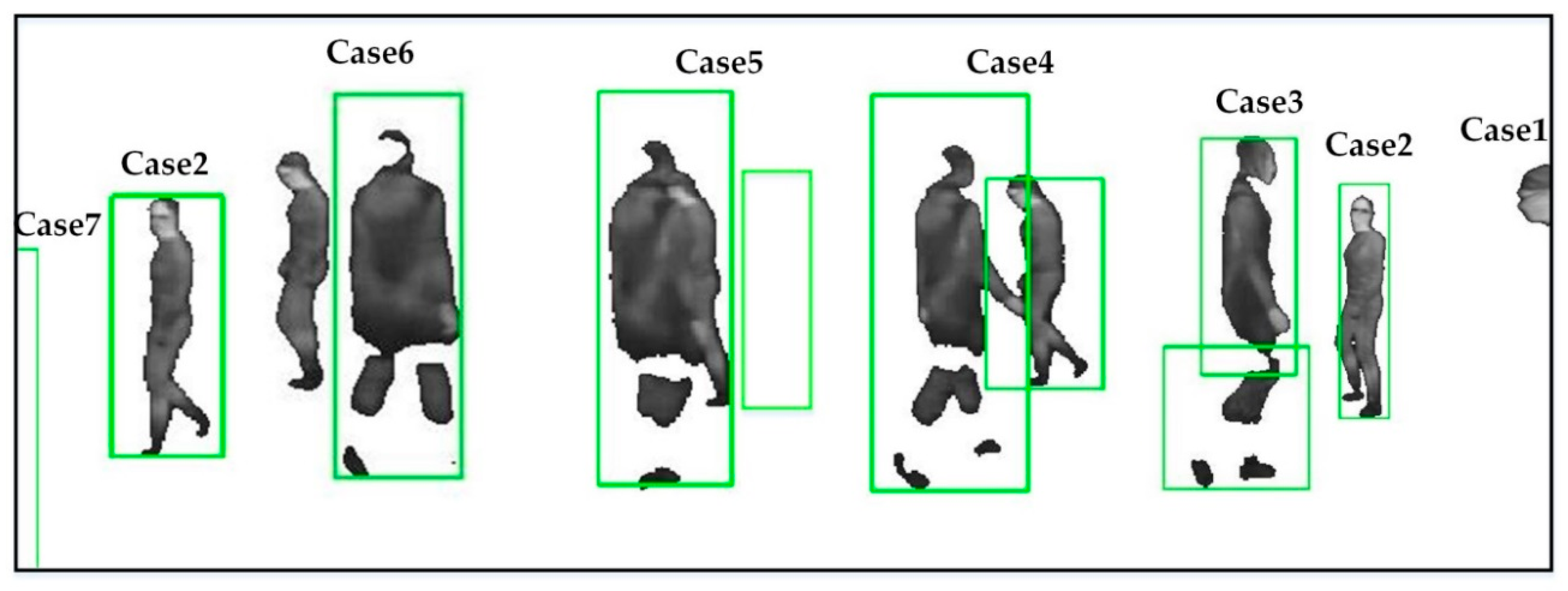
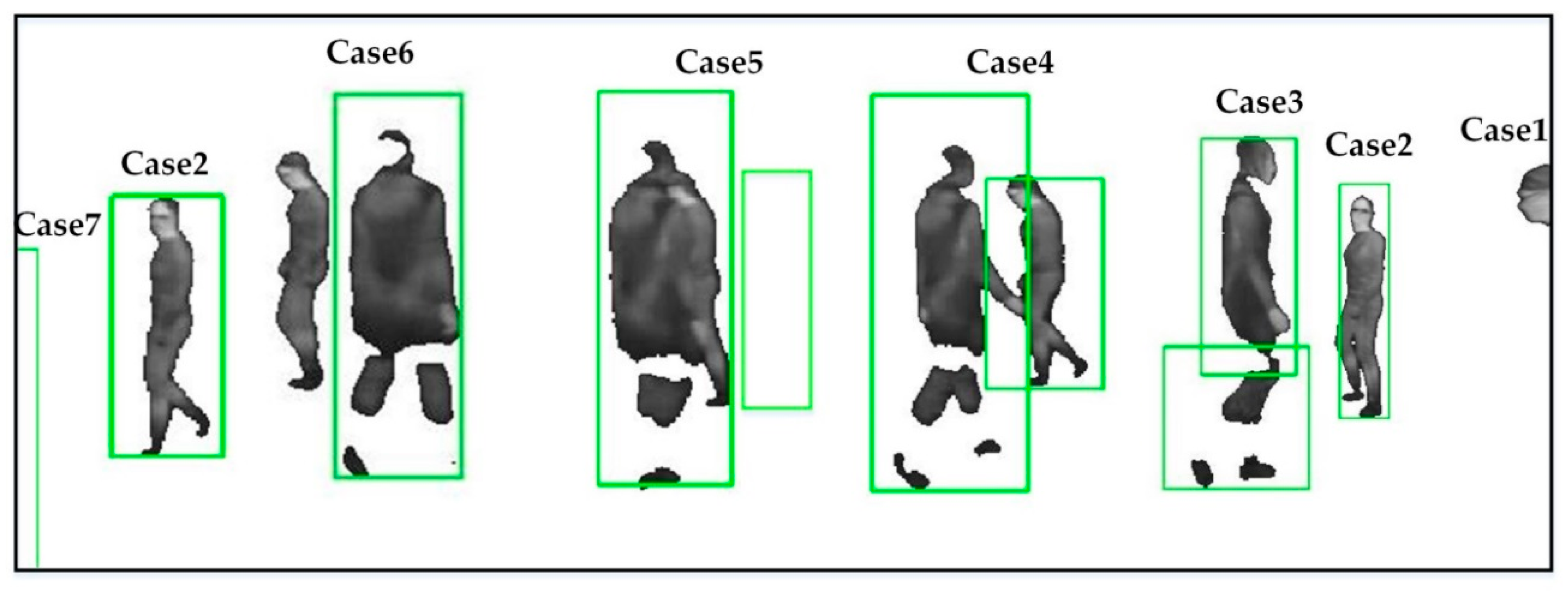
3.3.2. Reservoir Assignment Using Multi-Target Tracking
- If only one tracker is associated with a foreground , it means the target is being tracked normally (Case 2 in Figure 3). At this time, the reservoir of is directly assigned to the tracker , and the matches from the foreground are saved in the reservoir.
- More than one tracker may be associated with a foreground , which could be caused by an occlusion (Case 4) or fragmentation (Case 3). We differentiate the two cases according to the way presented in [13]: if the area of the blob is smaller than the sum of the two trackers in some consecutive frames, it is very likely caused by fragmentation. Otherwise, we assume that two targets are under occlusion. If caused by an occlusion, there are multiple trackers for the foreground. The reservoir of each is assigned to the corresponding tracker . Each match from the foreground is saved in the reservoir with the tracker closest to the match. If caused by fragmentation, we combine these trackers to produce a new tracker for the foreground, and merge their reservoirs to bring in a new reservoir for the current tracker. The matches from the foreground are reserved in the reservoir.
- If no tracker is associated with a foreground , it means a new target is entering the scene (Case 1) or tracking is lost (Case 6). At this moment, a new tracker is built for the foreground, and a new reservoir is created to keep the point pairs in the foreground. Since the matches in the reservoir may be insufficient to estimate a reliable homography, we introduce part of matches from the global buffer to the reservoir. Next, if caused by tracking failure, the lost reservoir would be merged into the new reservoir, when the lost tracker is recalled.
- If a tracker is not associated with any foreground , it means a target is invisible (Case 5) or leaving (Case 7). In this case, the tracker and its reservoir are saved in some consecutive frames. As presented in [13], if the tracker is associated with a foreground again in these frames, the lost tracker and the reservoir are recalled. Otherwise, the tracker and the reservoir are both removed.
3.4. Homography Estimation
| Algorithm 1 Estimating Homography for a Foreground in Current Frame |
| Input: Infrared foreground: . visible foreground: . Moving state: . |
| Reservoir group: . Previous homography group: . Global matrix: |
| Output: current frame-wide homography group: |
| Proceduce Homography estimation |
| If |
| , |
| If end if; |
| If end if; |
| If end if; |
| Else |
| For do |
| , |
| , |
| End for |
| End if |
| End proceduce |
4. Experiments and Results
4.1. Experiments
4.1.1. Datasets
4.1.2. Approach Comparison
4.1.3. Evaluation Metric
4.1.4. Parameter Settings
4.2. Results
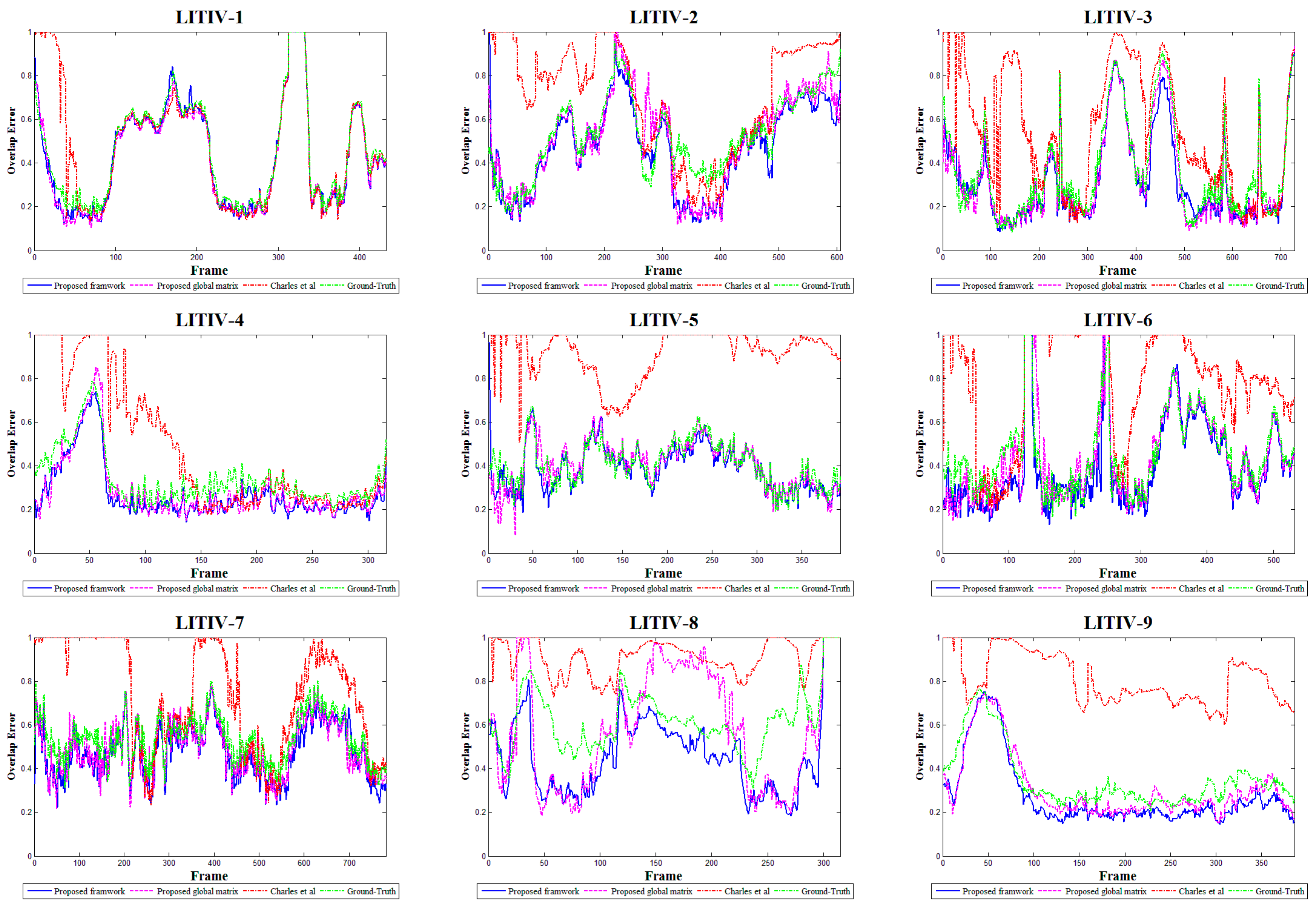
4.2.1. Results for Near-Planar Scenes
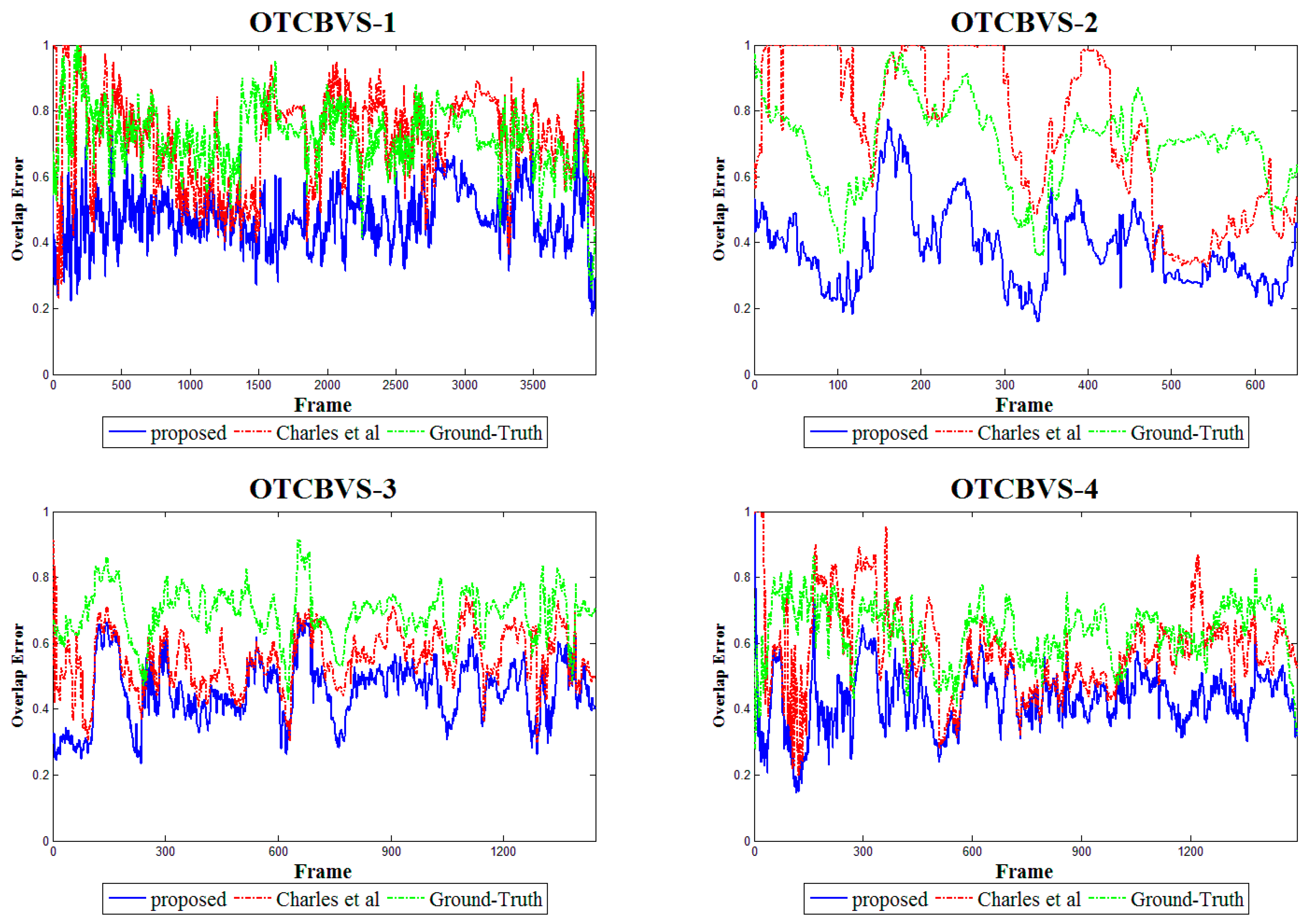
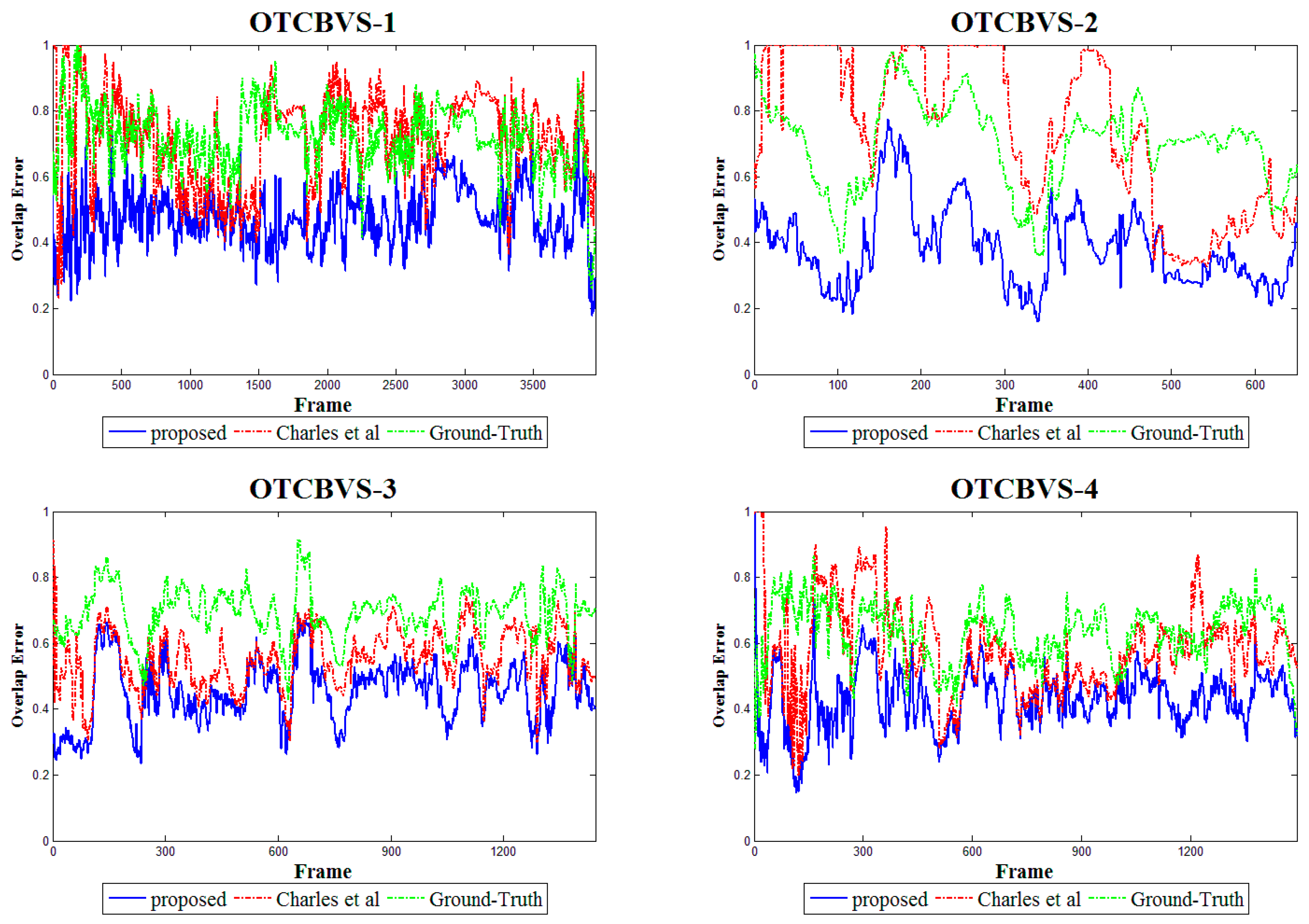
4.2.2. Results for Non-Planar Scenes
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Tsagaris, V.; Anastassopoulos, V. Fusion of visible and infrared imagery for night color vision. Displays 2005, 26, 191–196. [Google Scholar] [CrossRef]
- Li, S.; Kang, X.; Hu, J. Image fusion with guided filtering. IEEE Trans. Image Process. 2013, 22, 2864–2875. [Google Scholar] [PubMed]
- Hermosilla, G.; Gallardo, F.; Farias, G.; Martin, C.S. Fusion of Visible and Thermal Descriptors Using Genetic Algorithms for Face Recognition Systems. Sensors 2015, 15, 17944–17962. [Google Scholar] [CrossRef] [PubMed]
- Han, J.; Bhanu, B. Fusion of color and infrared video for moving human detection. Pattern Recognit. 2007, 40, 1771–1784. [Google Scholar] [CrossRef]
- Shen, R.; Cheng, I.; Basu, A. Cross-scale coefficient selection for volumetric medical image fusion. IEEE Trans. Biomed. Eng. 2013, 60, 1069–1079. [Google Scholar] [CrossRef] [PubMed]
- Roche, A.; Malandain, G.; Pennec, X.; Ayache, N. The correlation ratio as a new similarity measure for multimodal image registration. In Proceedings of the Springer International Conference on Medical Image Computing and Computer-Assisted Intervention, Cambridge, MA, USA, 11–13 October 1998. [Google Scholar]
- Krotosky, S.J.; Trivedi, M.M. Mutual information based registration of multimodal stereo videos for person tracking. Comput. Vis. Image Underst. 2007, 106, 270–287. [Google Scholar] [CrossRef]
- Bilodeau, G.-A.; Torabi, A.; St-Charles, P.-L.; Riahi, D. Thermal–visible registration of human silhouettes: A similarity measure performance evaluation. Infrared Phys. Technol. 2014, 64, 79–86. [Google Scholar] [CrossRef]
- Hrkać, T.; Kalafatić, Z.; Krapac, J. Infrared-visual image registration based on corners and hausdorff distance. In Proceedings of the Springer 15th Scandinavian Conference on Image Analysis, Aalborg, Denmark, 10–14 June 2007. [Google Scholar]
- Sonn, S.; Bilodeau, G.-A.; Galinier, P. Fast and accurate registration of visible and infrared videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Chakravorty, T.; Bilodeau, G.-A.; Granger, E. Automatic Image Registration In infrared-Visible Videos Using Polygon Vertices. Available online: https://arxiv.org/abs/1403.4232 (accessed on 21 March 2017).
- St-Charles, P.-L.; Bilodeau, G.-A.; Bergevin, R. Online multimodal video registration based on shape matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Yang, Y.; Bilodeau, G.-A. Multiple Object Tracking with Kernelized Correlation Filters in Urban Mixed Traffic. Available online: https://arxiv.org/abs/1611.02364 (accessed on 24 March 2017).
- Fuentes, L.M.; Velastin, S.A. People tracking in surveillance applications. Image Vis. Comput. 2006, 24, 1165–1171. [Google Scholar] [CrossRef]
- Viola, P.; Wells, W.M., III. Alignment by maximization of mutual information. Int. J. Comput. Vis. 1997, 24, 137–154. [Google Scholar] [CrossRef]
- Kim, K.S.; Lee, J.H.; Ra, J.B. Robust multi-sensor image registration by enhancing statistical correlation. In Proceedings of the IEEE 7th International Conference on Information Fusion, Philadelphia, PA, USA, 25–28 July 2005. [Google Scholar]
- Anuta, P.E. Spatial registration of multispectral and multitemporal digital imagery using fast fourier transform techniques. IEEE Trans. Geosci. Electron. 1970, 8, 353–368. [Google Scholar] [CrossRef]
- Cheolkon, J.; Na, Y.; Liao, M. Super-surf image geometrical registration algorithm. IET Image Process. 2016, 10. [Google Scholar]
- Coiras, E.; Santamarı, J.; Miravet, C. Segment-based registration technique for visual-infrared images. Opt. Eng. 2000, 39, 282–289. [Google Scholar] [CrossRef]
- Mokhtarian, F.; Suomela, R. Robust image corner detection through curvature scale space. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1376–1381. [Google Scholar] [CrossRef]
- Ma, J.; Zhao, J.; Ma, Y.; Tian, J. Non-rigid visible and infrared face registration via regularized gaussian fields criterion. Pattern Recognit. 2014, 48, 772–784. [Google Scholar] [CrossRef]
- Torabi, A.; Massé, G.; Bilodeau, G.-A. An iterative integrated framework for thermal–visible image registration, sensor fusion, and people tracking for video surveillance applications. Comput. Vis. Image Underst. 2012, 116, 210–221. [Google Scholar] [CrossRef]
- Caspi, Y.; Simakov, D.; Irani, M. Feature-based sequence-to-sequence matching. Int. J. Comput. Vis. 2006, 68, 53–64. [Google Scholar] [CrossRef]
- Torabi, A.; Massé, G.; Bilodeau, G.-A. Feedback scheme for thermal-visible video registration, sensor fusion, and people tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- St-Charles, P.-L.; Bilodeau, G.-A.; Bergevin, R. A self-adjusting approach to change detection based on background word consensus. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 6–9 January 2015. [Google Scholar]
- Belongie, S.; Malik, J.; Puzicha, J. Shape matching and object recognition using shape contexts. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 509–522. [Google Scholar] [CrossRef]
- Kuhn, H.W. The hungarian method for the assignment problem. Naval Res. Logist. 2005, 52, 7–21. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Hartigan, J.A.; Wong, M.A. A k-means clustering algorithm. Appl. Stat. 1979, 28, 100–108. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequence Pair | Ground-Truth | Charles et al. | Proposed Global Matrix | Proposed Framework |
|---|---|---|---|---|
| LITIV-1 | 0.4515 | 0.4850 | 0.4227 | |
| LITIV-2 | 0.5290 | 0.7196 | 0.5031 | |
| LITIV-3 | 0.3646 | 0.5545 | 0.3340 | |
| LITIV-4 | 0.3418 | 0.4838 | 0.2854 | |
| LITIV-5 | 0.4085 | 0.9130 | 0.4047 | |
| LITIV-6 | 0.4564 | 0.7852 | 0.4395 | |
| LITIV-7 | 0.5380 | 0.7524 | 0.4947 | |
| LITIV-8 | 0.6232 | 0.9118 | 0.5840 | |
| LITIV-9 | 0.3533 | 0.8091 | 0.3107 |
| Sequence Pair | Ground-Truth | Charles Et. Al. | Proposed Global Matrix | Proposed Framework |
|---|---|---|---|---|
| LITIV-1 | 0.1571 | 0.1308 | 0.1135 | |
| LITIV-2 | 0.1678 | 0.1971 | 0.1250 | |
| LITIV-3 | 0.1093 | 0.0897 | 0.0844 | |
| LITIV-4 | 0.1851 | 0.1746 | 0.1504 | |
| LITIV-5 | 0.1922 | 0.5075 | 0.1875 | |
| LITIV-6 | 0.1675 | 0.1923 | 0.1475 | |
| LITIV-7 | 0.3125 | 0.2343 | 0.2222 | |
| LITIV-8 | 0.3107 | 0.7281 | 0.1837 | |
| LITIV-9 | 0.2072 | 0.6036 | 0.1509 |
| Sequence Pair | Ground-Truth | Charles et al. | Proposed |
|---|---|---|---|
| OTCBVS-1 | 0.7220 | 0.7176 | |
| OTCBVS-2 | 0.6983 | 0.7423 | |
| OTCBVS-3 | 0.6920 | 0.5537 | |
| OTCBVS-4 | 0.6346 | 0.5839 |
| Sequence Pair | Ground-Truth | Charles et al. | Proposed |
|---|---|---|---|
| OTCBVS-1 | 0.2582 | 0.2300 | |
| OTCBVS-2 | 0.3806 | 0.3263 | |
| OTCBVS-3 | 0.4291 | 0.2981 | |
| OTCBVS-4 | 0.2797 | 0.1978 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, X.; Xu, T.; Zhang, J.; Zhao, Z.; Li, Y. An Automatic Multi-Target Independent Analysis Framework for Non-Planar Infrared-Visible Registration. Sensors 2017, 17, 1696. https://doi.org/10.3390/s17081696
Sun X, Xu T, Zhang J, Zhao Z, Li Y. An Automatic Multi-Target Independent Analysis Framework for Non-Planar Infrared-Visible Registration. Sensors. 2017; 17(8):1696. https://doi.org/10.3390/s17081696
Chicago/Turabian StyleSun, Xinglong, Tingfa Xu, Jizhou Zhang, Zishu Zhao, and Yuankun Li. 2017. "An Automatic Multi-Target Independent Analysis Framework for Non-Planar Infrared-Visible Registration" Sensors 17, no. 8: 1696. https://doi.org/10.3390/s17081696
APA StyleSun, X., Xu, T., Zhang, J., Zhao, Z., & Li, Y. (2017). An Automatic Multi-Target Independent Analysis Framework for Non-Planar Infrared-Visible Registration. Sensors, 17(8), 1696. https://doi.org/10.3390/s17081696