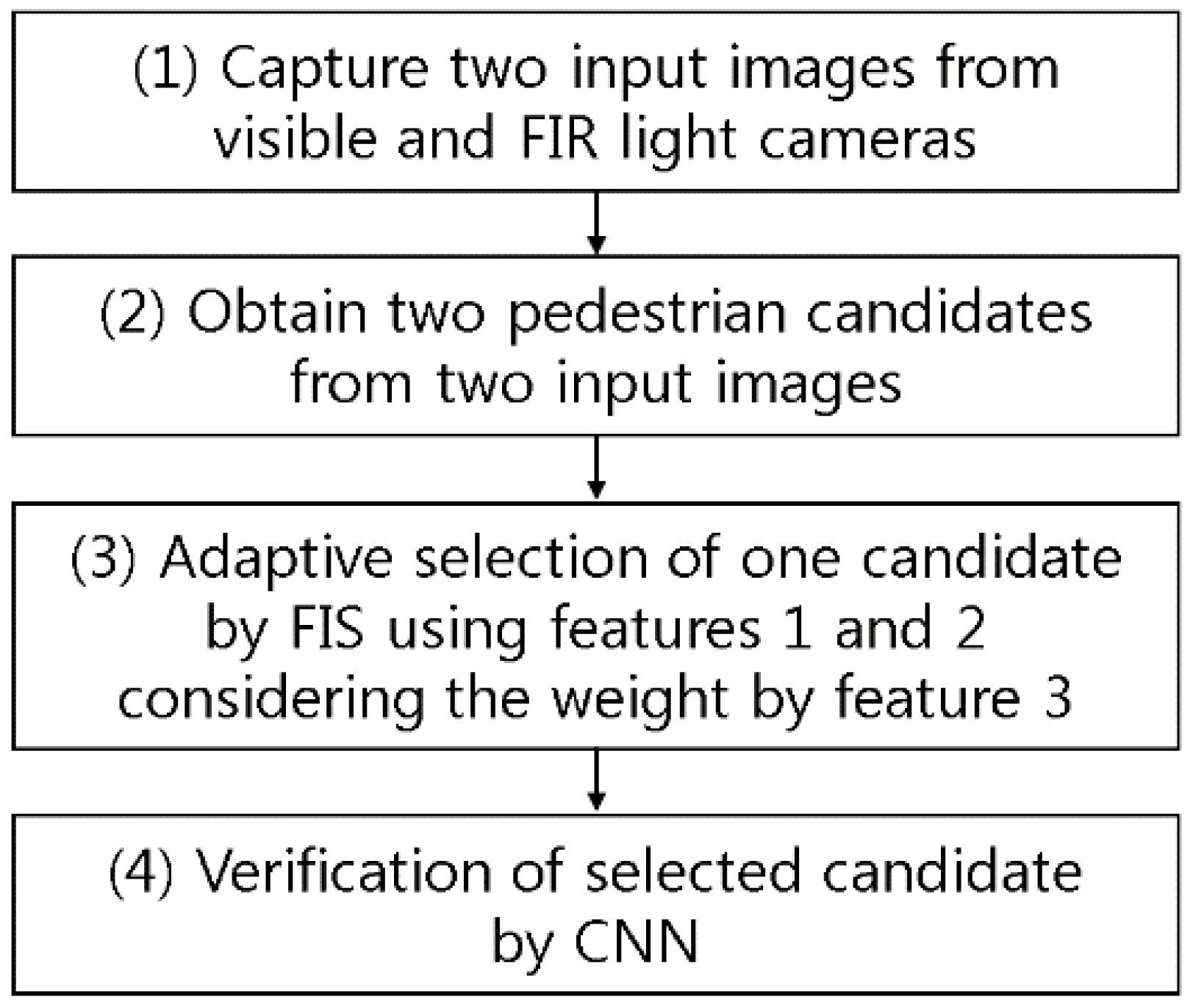
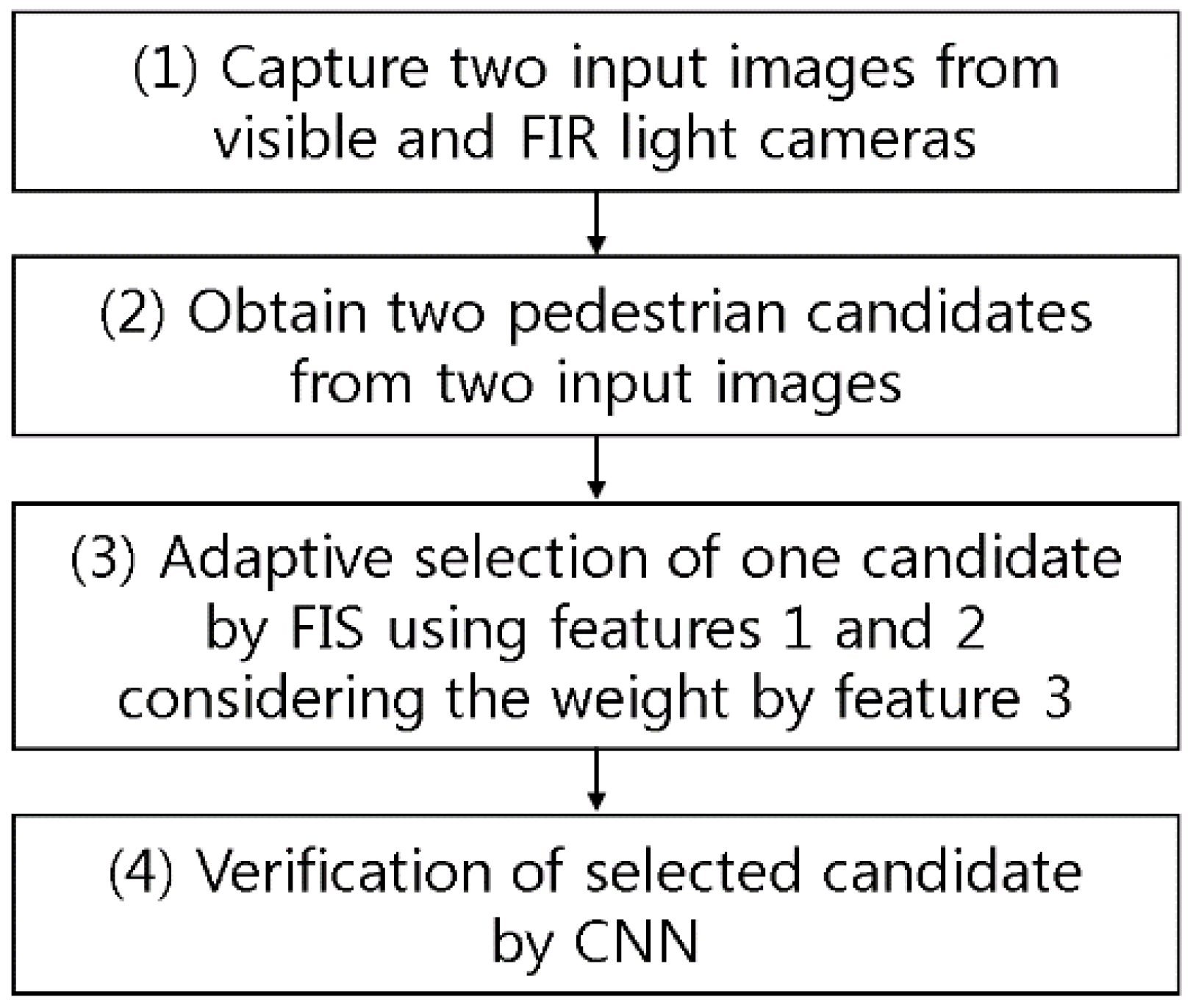
3.1. Overall Procedure of the Proposed System
Figure 1 describes the overall procedure of the proposed system. The system receives the data from both visible light and FIR light images through dual cameras (step (1) and
Figure 2a). It detects the candidate based on background subtraction and noise reduction by using difference images (
Figure 2b) between the background image and the input images [
12]. Here, the mean value of the candidate within the difference image obtained from the visible light image is “feature 1”, and that gained by the FIR light image is “feature 2”. In general, the mean value of the difference images increases along with the increase of difference between the pedestrian and the background, which causes the consequent increment of possibility of correct pedestrian. However, as shown in
Figure 2c, the output candidate exists not only in the red box (pedestrian candidate) but also in the yellow box (non-pedestrian candidate).
As mentioned earlier, the pedestrian candidate usually has a high mean value in the difference image while the non-pedestrian candidate has a low mean value in the difference image as shown in
Figure 2b. Nevertheless, because all the regions inside pedestrian candidate do not show high mean value in the difference image of
Figure 2b, a low threshold value for image binarization should be used to correctly detect the whole regions inside pedestrian candidate, which causes the incorrect detection of non-pedestrian candidate as pedestrian one as shown in
Figure 2c. It is difficult to correctly discriminate between the pedestrian and non-pedestrian candidates, and the FIS is designed using the mean value of the gradient magnitude of pedestrian or non-pedestrian candidate in difference images as “feature 3”. The system adaptively selects a more appropriate candidate to be verified by the CNN between the two boxes of
Figure 2c—after adding “feature 3” as weights, and using the FIS with “feature 1” and “feature 2” as an input (see step (3) of
Figure 1). Then, it uses the selected candidates of pedestrian and non-pedestrian (
Figure 2d) as the pre-trained input for the CNN to ultimately classify it into a pedestrian or non-pedestrian case (see step (4) of
Figure 1 and
Figure 2e).
3.2. Adaptive Selection by FIS
The FIS in this paper is designed to adaptively select one candidate between two pedestrian candidates derived from visible light and FIR camera images, which is deemed most appropriate for the pedestrian detection process.
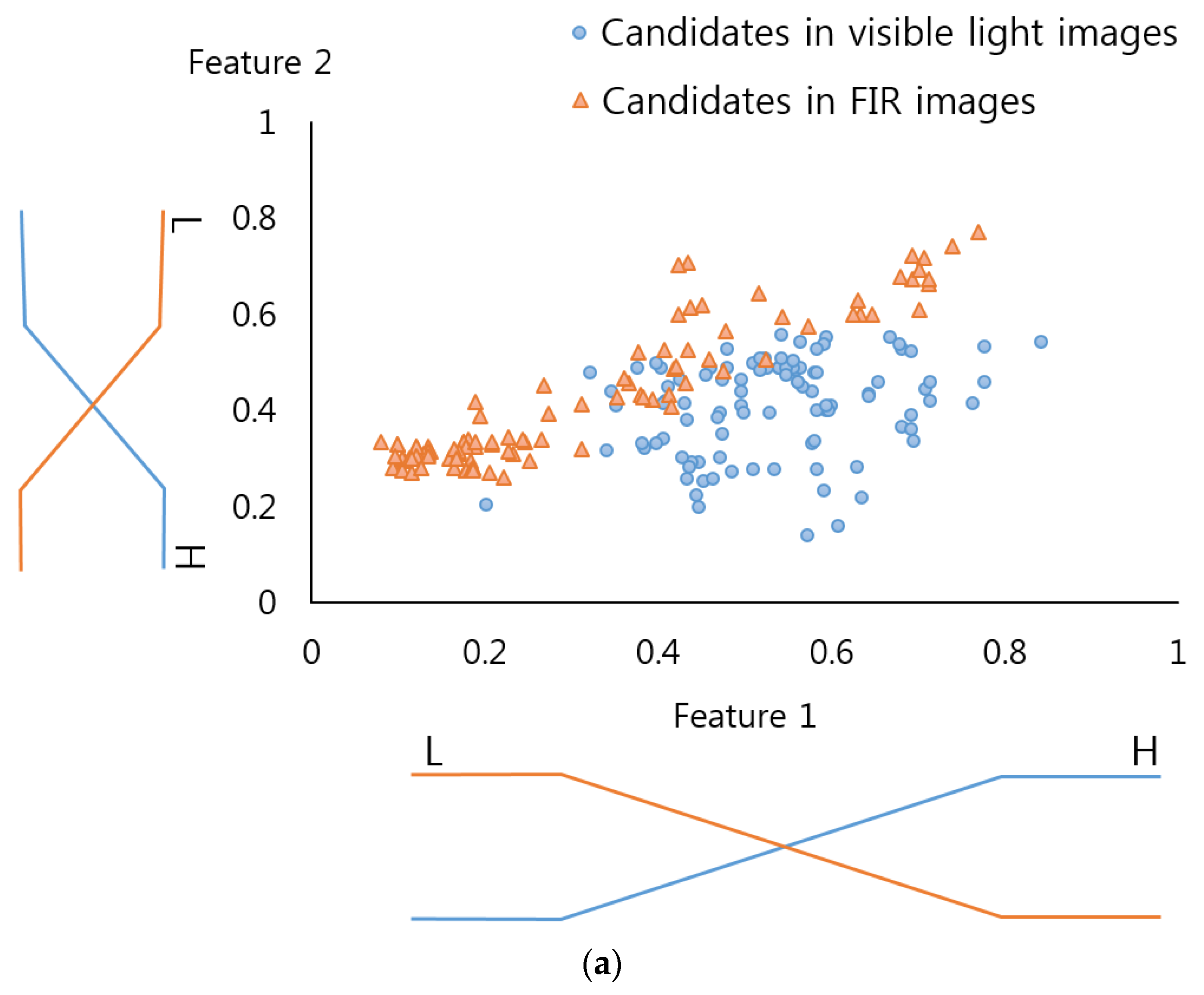
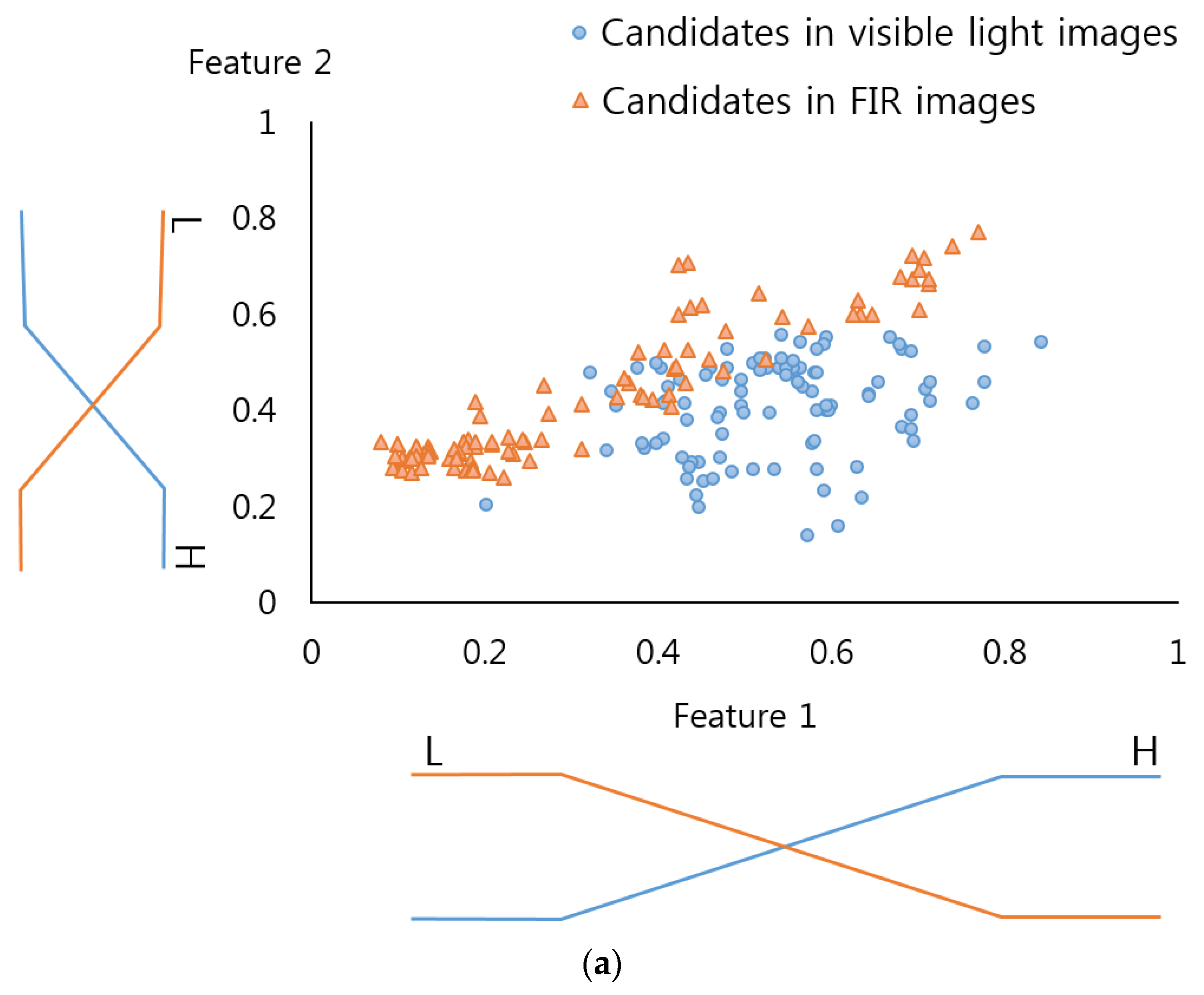
Table 2 presents a fuzzy rule table designed through this research to be used for the FIS. This research uses two features, and has “Low” and “High” as inputs, and “Low” “Medium” and “High” as outputs. The two features consist of “feature 1”, a mean value of the candidate gained from the visible light image, and “feature 2”, a mean value from the FIR light image. That is because, in general, the bigger the difference between the pedestrian and the background is, the bigger the mean value in difference image is, meaning that the outcome is more likely to be the correct pedestrian.
For instance, as listed in
Table 2a, when “feature 1” and “feature 2” are “Low” (a lower mean value) and “High” (a higher mean value), respectively, the difference between the pedestrian and the background of the FIR light images is larger than that of the visible light image. Therefore, the output value becomes “High” meaning that the candidate of the FIR light image is selected. However, the opposite case implies that the difference of the visible light image is larger than that of the FIR light image. The output value becomes “Low” which in other words implies that the candidate of the visible light image is selected. If the “feature 1” and “feature 2” are both “Low” or “High”, it is difficult to determine which candidate is more desirable (between the two candidates of visible light and FIR light images), giving the output a “Medium” Value.
However, as shown in
Figure 2c, the selected candidate is present not only in the pedestrian candidate (the red box) but also in the non-pedestrian candidate (the yellow box). Although the pedestrian candidate has high mean value in the difference image as mentioned before, the non-pedestrian candidate has a low mean value as shown in
Figure 2b. Considering that, this study designs the rule table for non-pedestrian features as shown in
Table 2b in order to have opposite features from
Table 2a.
In general, when the FIS uses two inputs, it employs the IF-THEN rule [
28], and the output will be produced by AND or OR calculation depending on the relationship between the FIS inputs. This research selected an AND calculation among the IF-THEN rules as the FIS makes adaptive selection while considering “feature 1” and “feature 2” together.
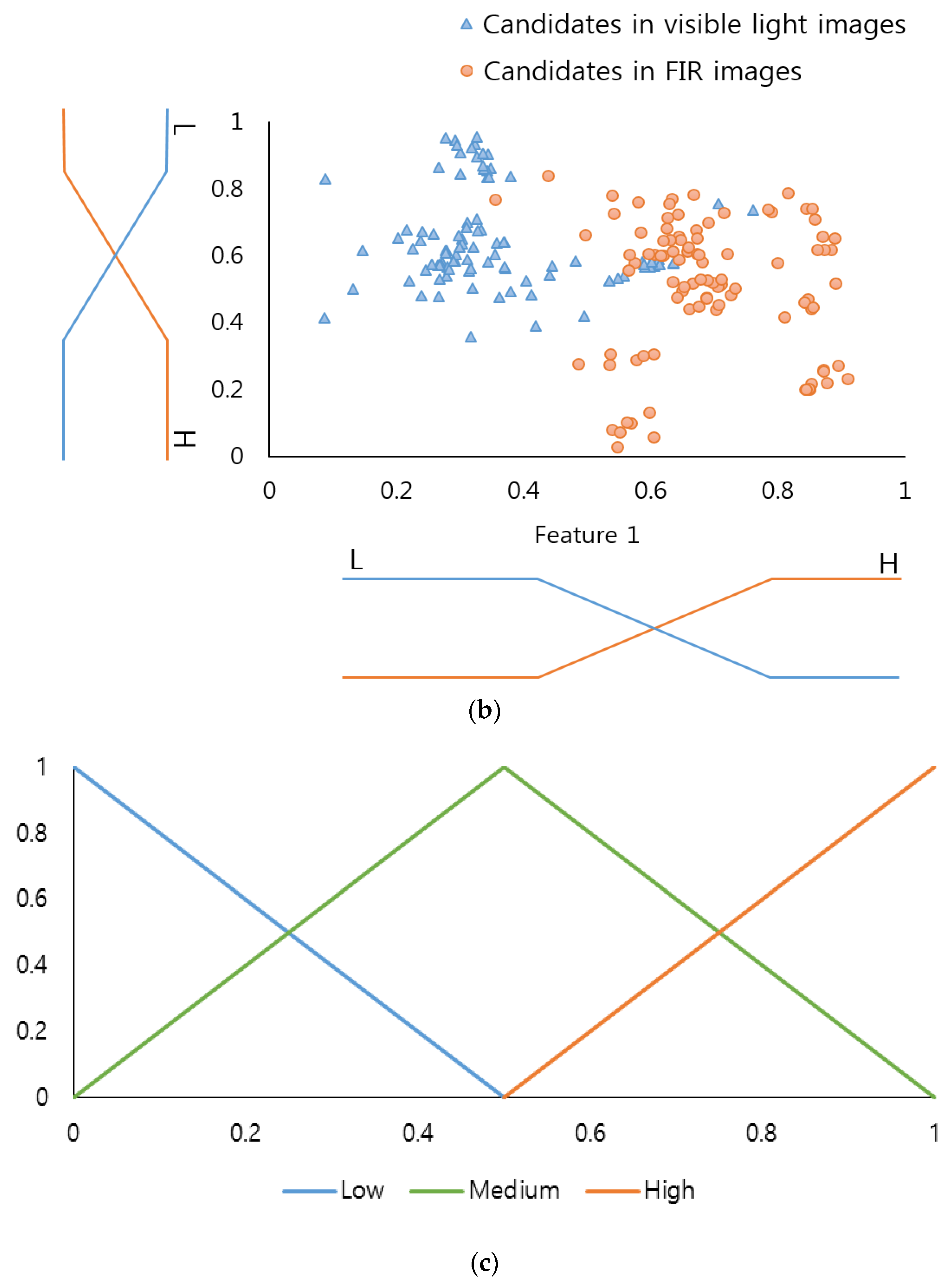
Figure 3 describes the linear membership function used in this research, which is widely used in the FIS as its calculation speed is very fast and its algorithm is less complex compared to the non-linear membership function [
29,
30,
31]. As mentioned, the input images have pedestrian and non-pedestrian categories, and two fuzzy rule tables (see
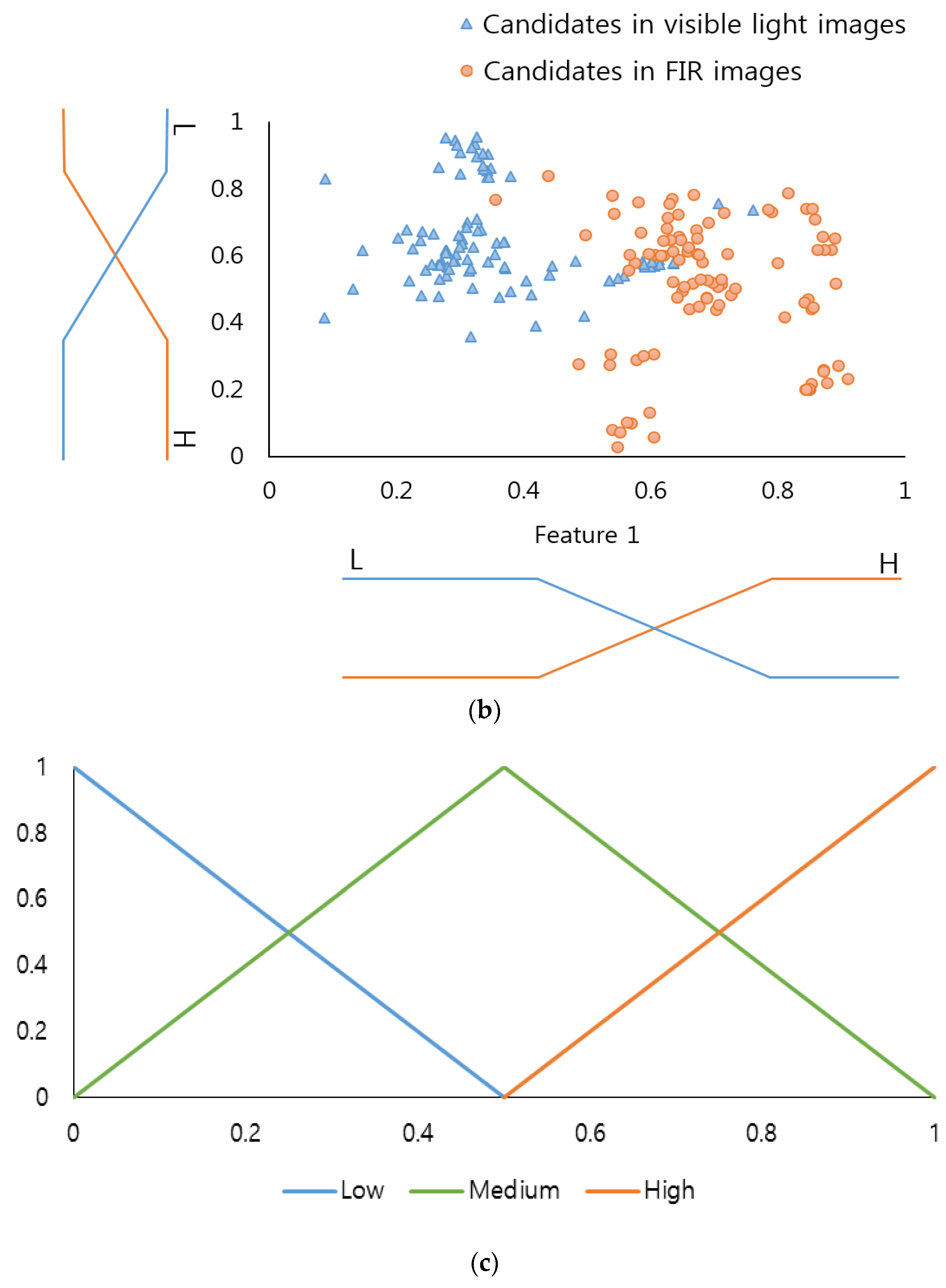
Table 2) were designed to reflect the differences in their features. In this regard, two input membership functions were used: one for the pedestrian and the other for the non-pedestrian. In order to more accurately determine the frame of the linear input membership function, this study gained a data distribution for “feature 1” and “feature 2” (see
Figure 3a,b) by using part of the training data of the CNN(to be illustrated in
Section 3.3). Based on this, each linear input membership function for pedestrian and non-pedestrian is separately (“Low”, “High”) designed. Also, as shown in
Figure 3c, the output membership functions were designed for three outputs, “Low” “Medium” and “High”.
Figure 3c is not related to the data of
Figure 3a,b. In conventional fuzzy inference system, the output membership function is usually designed heuristically. Therefore, we use the three linear membership functions, which have been widely used in the fuzzy inference system.
The “feature 1” (
f1) and “feature 2” (
f2) in this research can be “Low” and “High” each shown in
Table 2. Therefore, their outputs become (G
f1L(
f1), G
f1H(
f1)) and (G
f2L(
f2), G
f2H(
f2)) due to function (G
f1L(⋅),G
f1H(⋅),G
f2L(⋅), and G
f2H(⋅)) of the input membership of
Figure 3a,b. Four pairs of combinations were obtained from this and these became (G
f1L(
f1), G
f2L(
f2)), (G
f1L(
f1), G
f2H(
f2)), (G
f1H(
f1), G
f2L(
f2)), and (G
f1H(
f1), G
f2H(
f2)). The fuzzy rule table of the Max and Min rules [
29], and the
Table 2 help gain four inference values from four pairs of combinations.
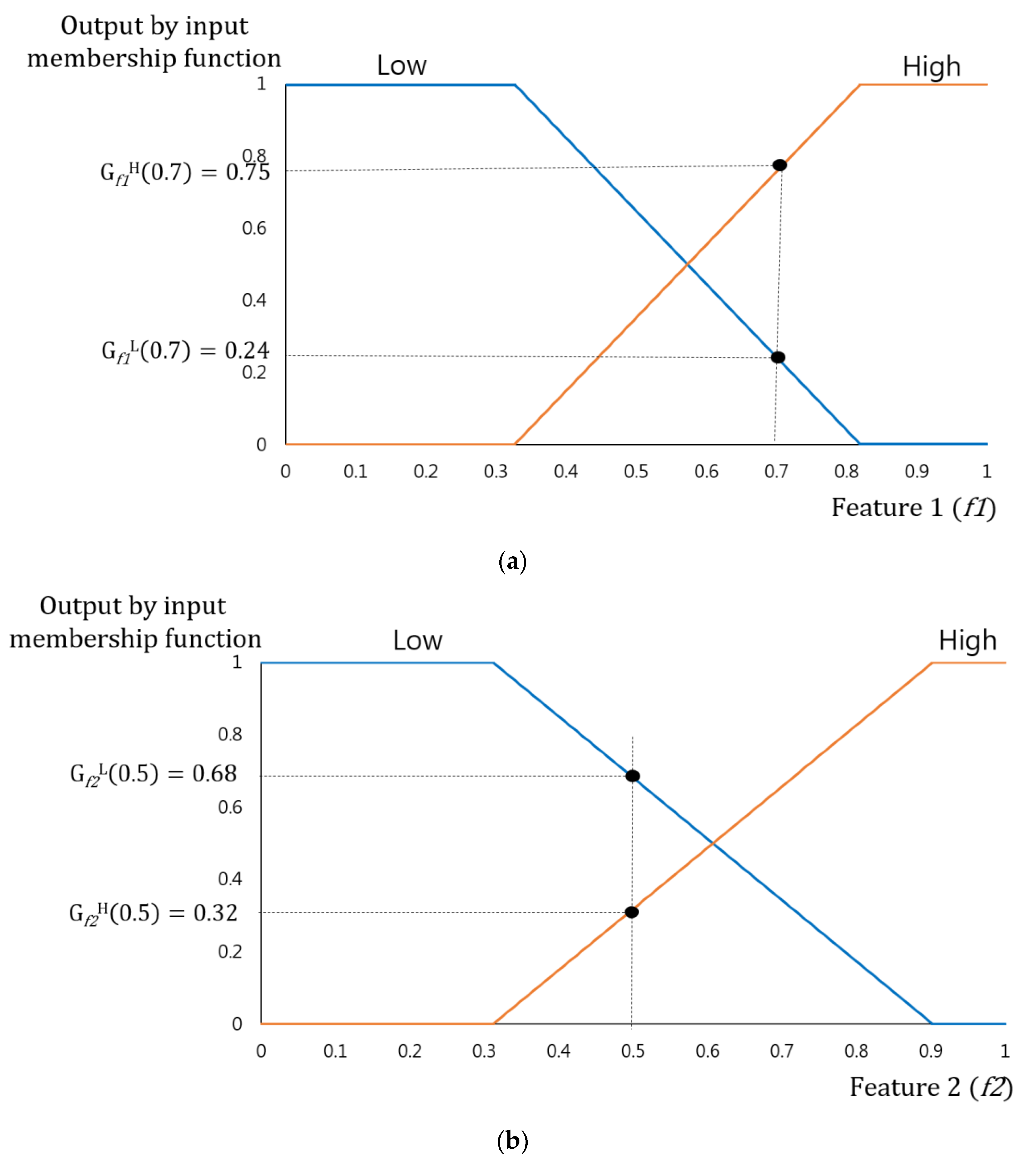
For instance, when
f1 = 0.7,
f2 = 0.5 as shown in
Figure 4, the output value gained by the input membership function becomes (G
f1L(0.7) = 0.24, G
f1H(0.7) = 0.75), (G
f2L(0.5) = 0.68, G
f2H(0.5) = 0.32). As mentioned earlier, these four output values lead to four combinations, including (0.24(L), 0.68(L)), (0.24(L), 0.32(H)), (0.75(H), 0.68(L)), (0.75(H), 0.32(H)). An inference value may be determined for each combination according to Min rule, Max rule, and fuzzy rule table of
Table 2. If (0.24(L), 0.68(L)), when applying the Min rule and the fuzzy rule of
Table 2b (IF “Low” and “Low”, THEN “Medium”), inference value will be determined as 0.2 (M). If (0.75(H), 0.68(L)) and applying the Max rule and the fuzzy rule of
Table 2a (IF “High” and “Low”, THEN “Low”), the inference value will be 0.75(L). Likewise, the inference value resulting from the four combinations are described in
Table 3 and
Table 4.
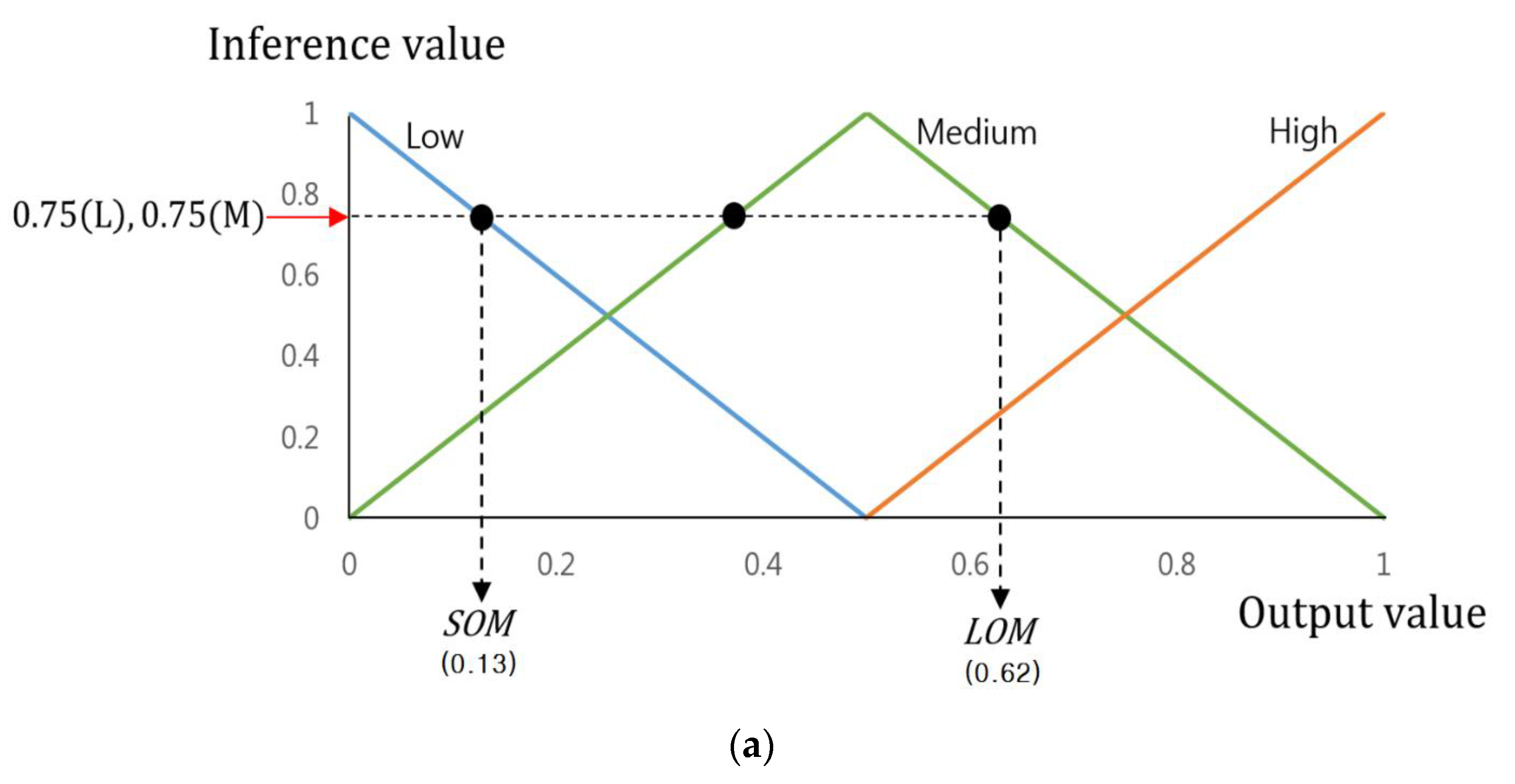
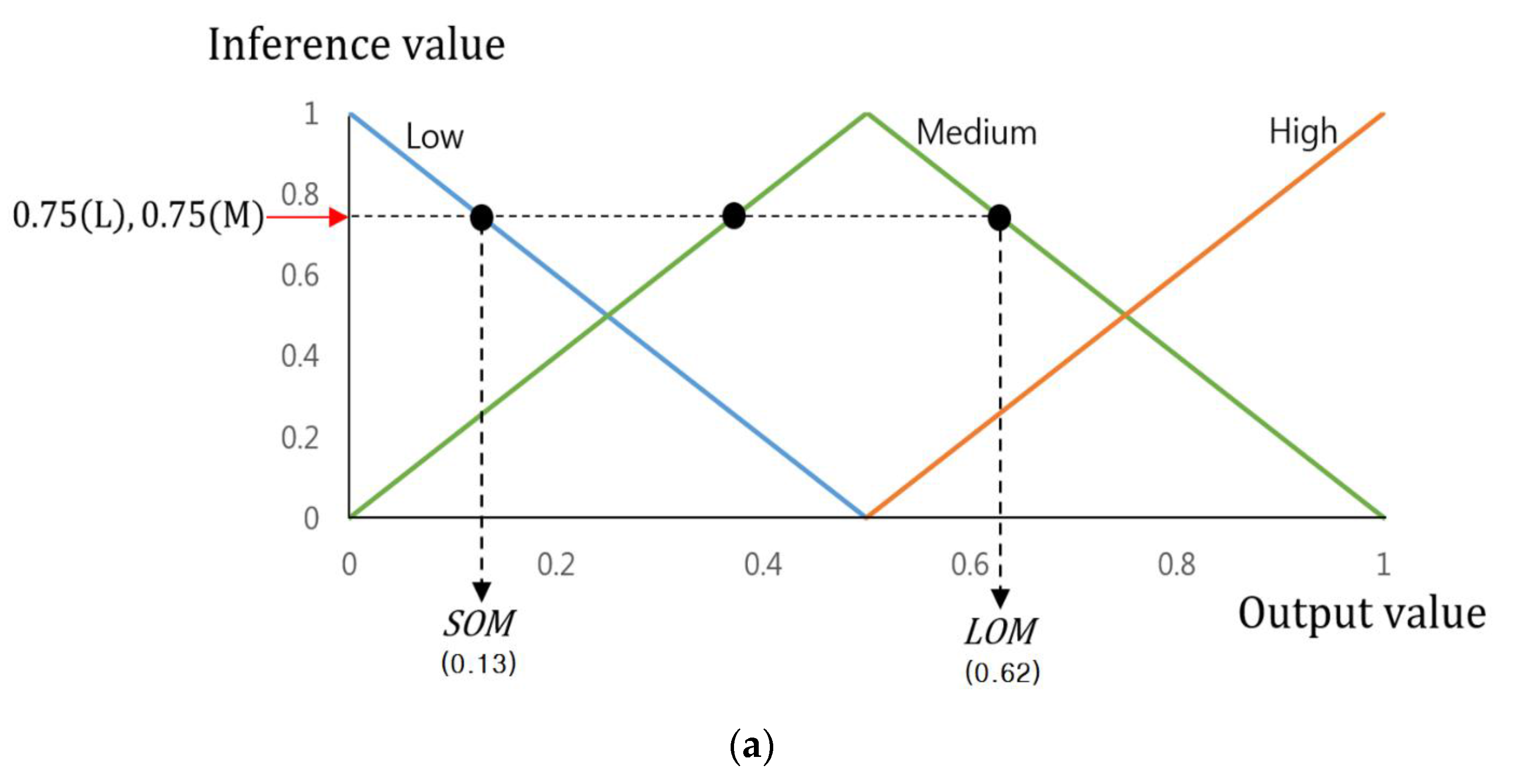
Therefore, the final output value of the FIS will be calculated through various defuzzification and the output membership function with its input of the inference values as shown in
Figure 5. This study employed the smallest of maximum (SOM), the middle of maximum (MOM), the largest of maximum (LOM), Bisector, and Centroid methods, most widely used among various defuzzification methods [
32,
33,
34]. Among those, the SOM, MOM, and LOM methods establish the FIS output values by maximum inference values among many inference values. The SOM and LOM methods establish the final output values using the smallest and largest values, which are gained by maximum inference. The MOM method uses the average value of the smallest and largest as the final output value.
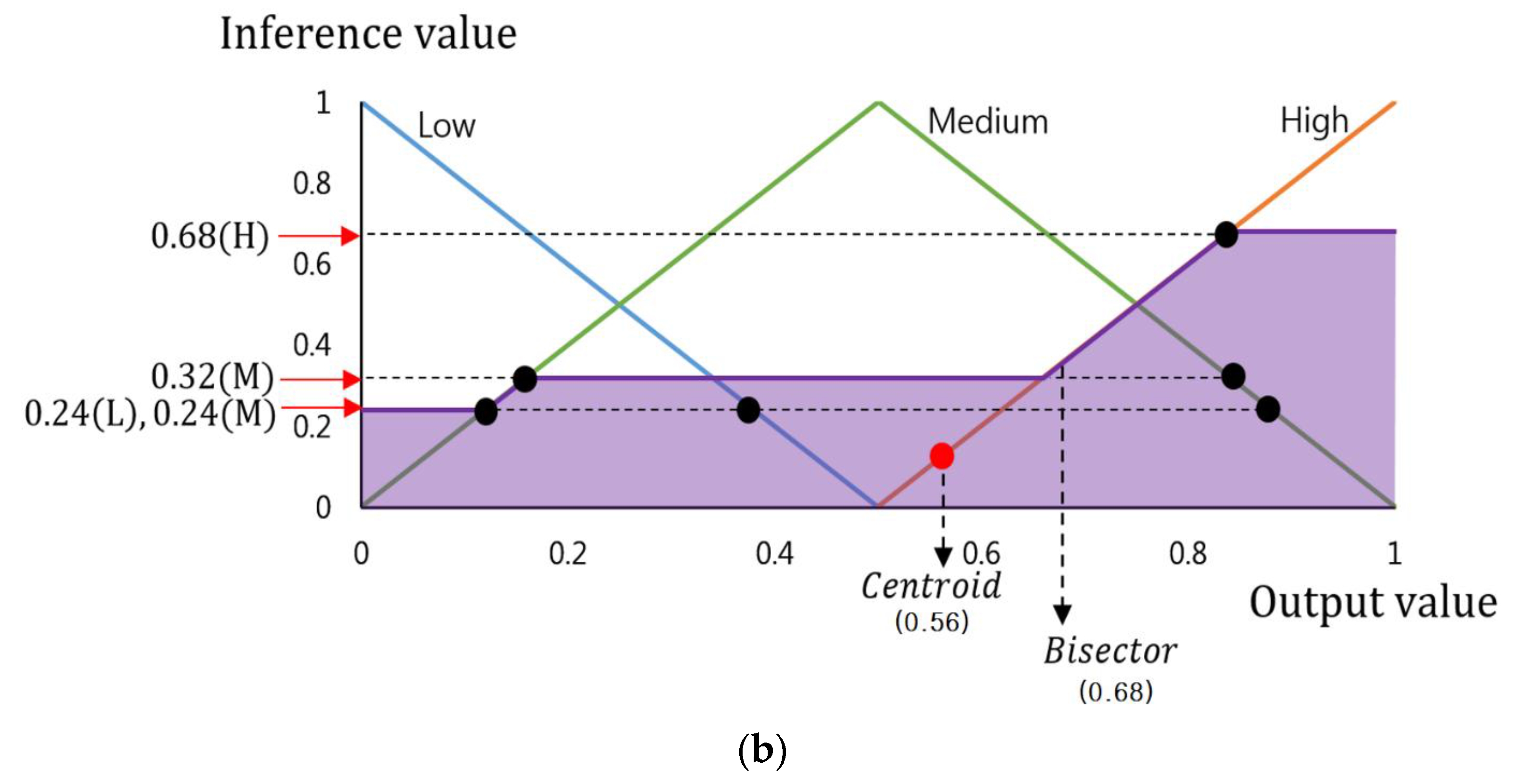
Figure 5a is an example of a defuzzification process based on the inference values by Max rule of
Table 3 (0.32(H), 0.68(M), 0.75(L), and 0.75(M)). This figure only uses these values as its maximum inference values are 0.75(L) and 0.75(M). Therefore, as shown in
Figure 5a, two output values (0.13 and 0.62) are produced by SOM and LOM methods, and their average value is gained as (0.375 = (0.13 + 0.62)/2) by MOM method.
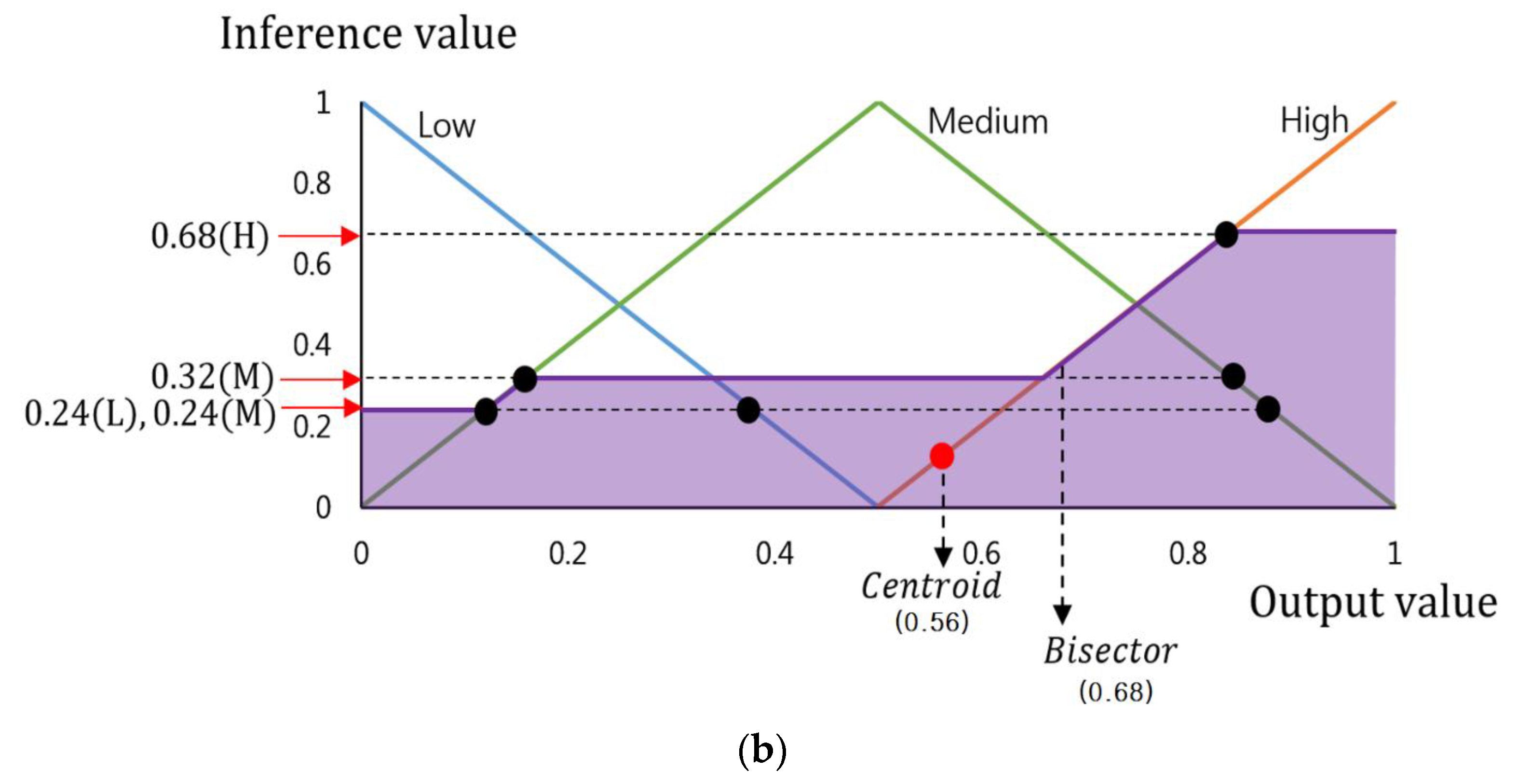
Bisector and centroid methods are the means to determine the FIS output value by using all the inference values. The centroid method determines the FIS output value based on the geometric center of the area from the area (the purple colored area of
Figure 5a) defined by all the inference values. The bisector method identifies the FIS output value based on the line dividing the defined area into two having the same size.
Figure 5b is an example of a defuzzification process based on the inference values by Min rule of
Table 4 (0.24(L), 0.24(M), 0.32(M), and 0.68(H)), which produces two output value (0.56 and 0.68) by the centroid and bisector methods.
As seen in
Figure 2c, the produced candidate area exists not only in the red box (pedestrian candidate) but also in the yellow box (non-pedestrian candidate). As mentioned earlier, the pedestrian candidate has a higher mean value in the difference image while the non-pedestrian candidate has a low mean value just as
Figure 2b. In the current level, it is possible to know whether the produced candidate area is under a pedestrian or a non-pedestrian category. Therefore, in order to design the FIS based on that, this study used the mean value of the gradient magnitude in the difference image within the produced candidate as “feature 3”. By reflecting such a “feature 3” as a weight into the FIS output value, as shown in
Figure 5, this work makes an adaptive selection among the two candidates, (the yellow and red boxes of
Figure 2c), which results in one appropriate candidate for verification by the CNN.
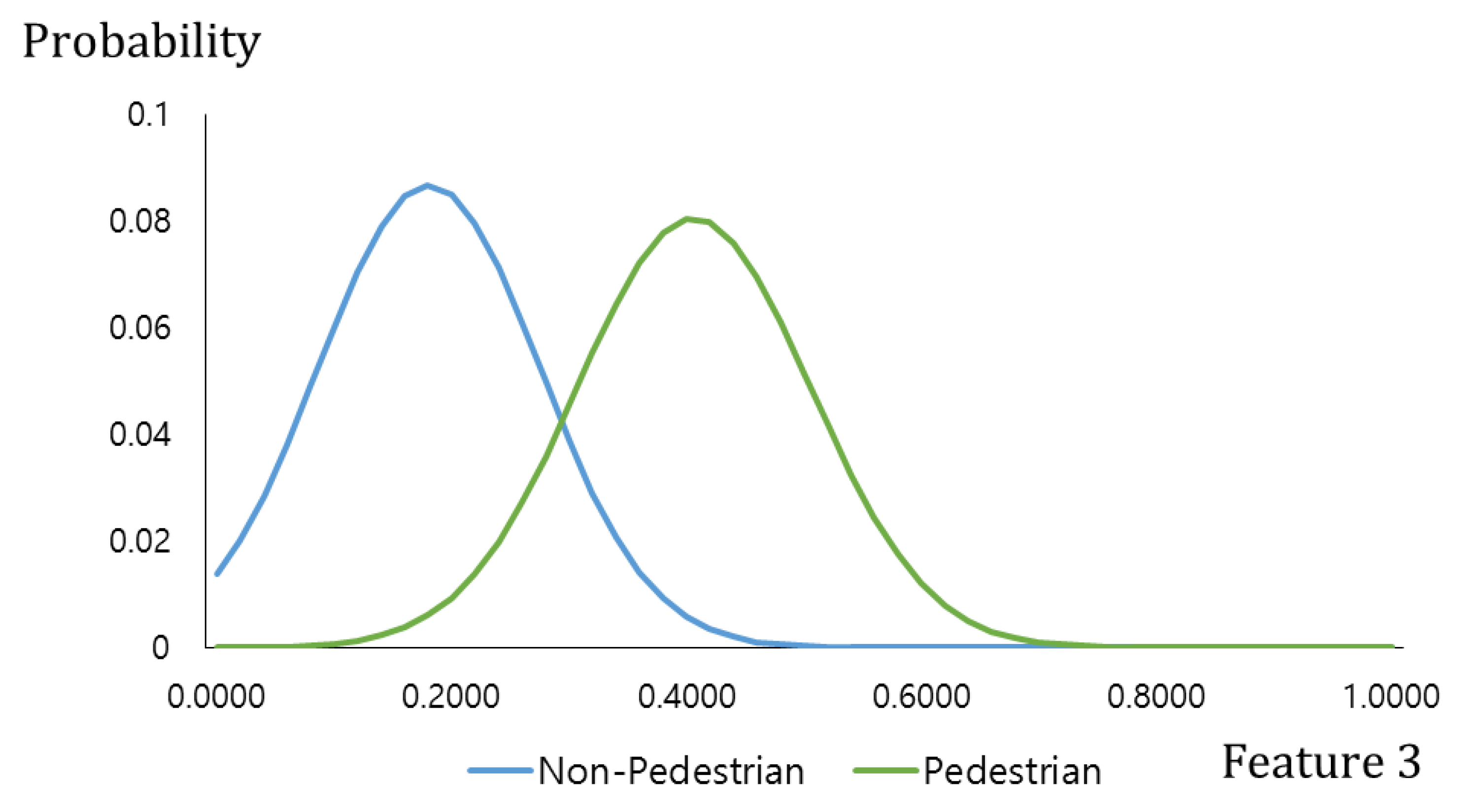
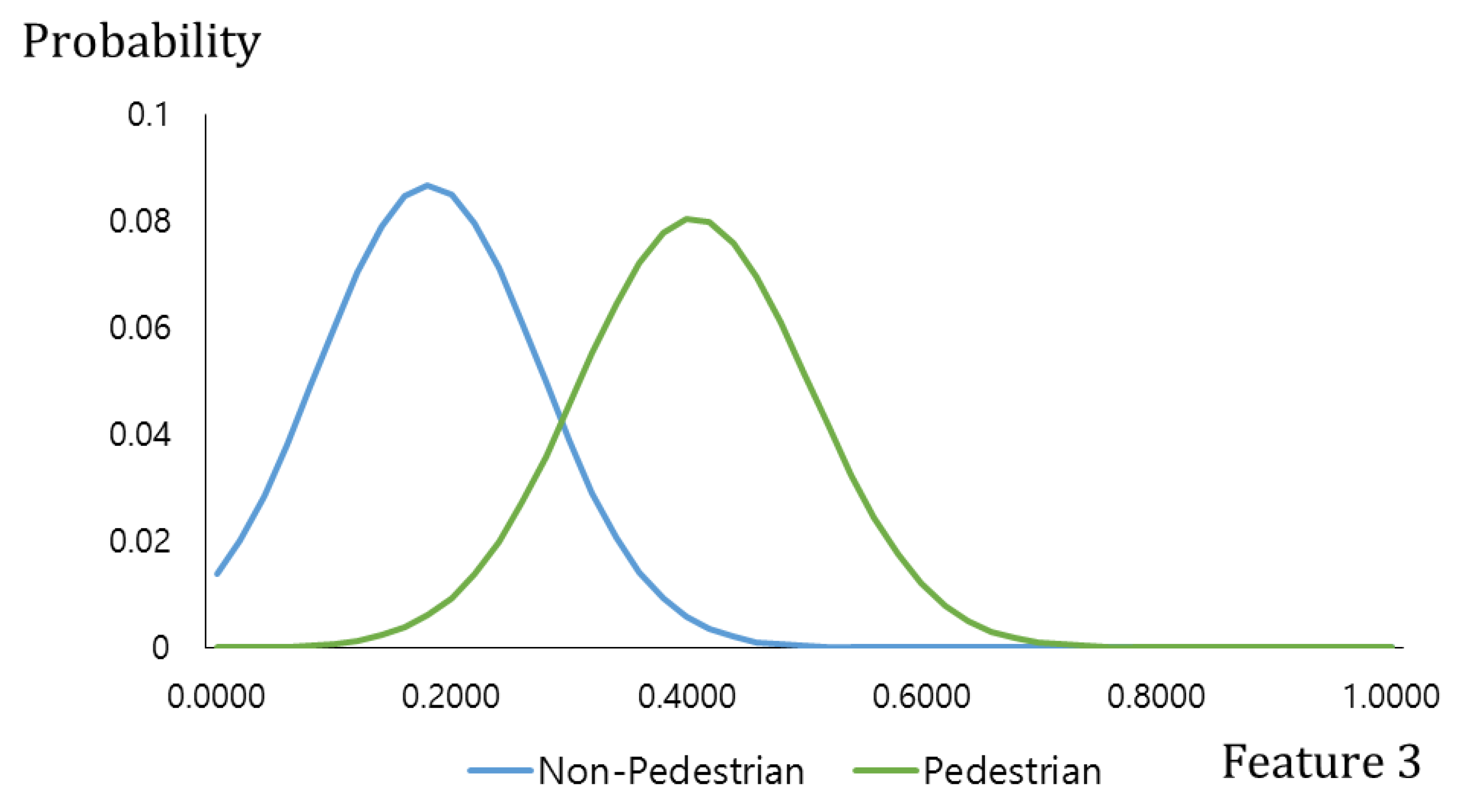
Figure 6 describes two distributions of “feature 3”, produced from the pedestrian and the non-pedestrian data used in
Figure 3a,b by using a Gaussian fitting. Similar to the difference image of
Figure 2b, the gradient magnitude of the pedestrian candidate is generally higher than that of the non-pedestrian candidate. Therefore, the pedestrian distribution is on the right side of the non-pedestrian distribution as shown in
Figure 6.
In this study, the FIS output value for the pedestrian, shown in
Figure 5, is defined as
and the FIS output value for the non-pedestrian is defined as
. It defines the probability for finding a pedestrian to be (via
Figure 6), and the probability for finding a non-pedestrian as
and
, respectively. This leads to the final output value (
) given through Equation (1):
Finally, as given in Equation (2), the system adaptively selects one candidate that is more appropriate for the CNN-based classification of pedestrian and non-pedestrian. This selection is done between two (pedestrian) candidates in visible light and FIR images. The optimal threshold of Equation (2) is experimentally determined based on the pedestrian and non-pedestrian data used in
Figure 3a,b:
3.3. Classification of Pedestrian and Non-Pedestrian by CNN
This research uses a CNN in order to classify the chosen candidate by Equation (2). The classification yields whether the candidate is of pedestrian or non-pedestrian (background) category. As shown in
Figure 2d, the candidate can be gained by visible light image or the FIR image. Therefore, the candidate from the visible light image is used as the CNN input learned through the visible light image training set. On the other hand, the candidate from the FIR image is used as the input learned through the FIR image training set. Both structures are equal and are illustrated in
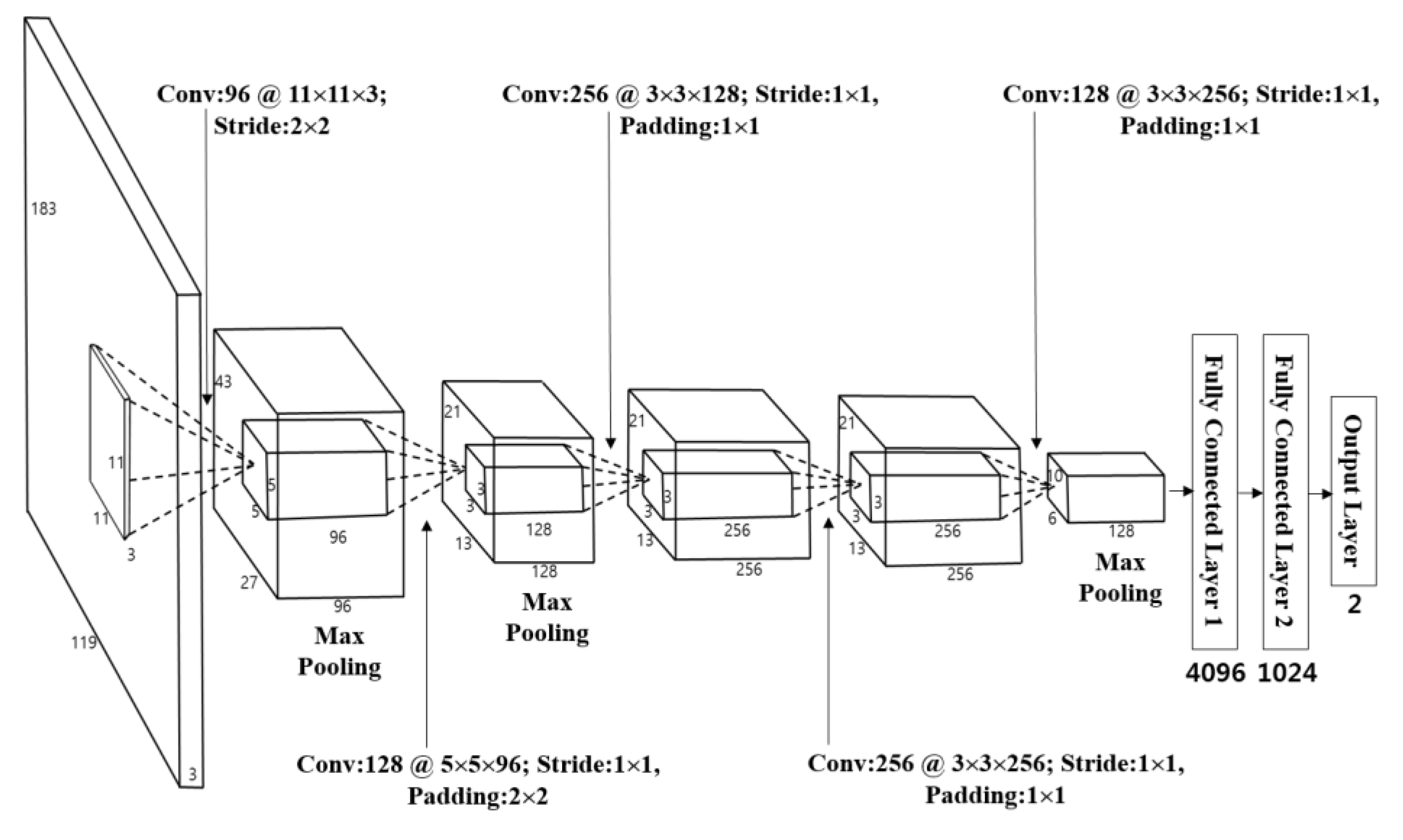
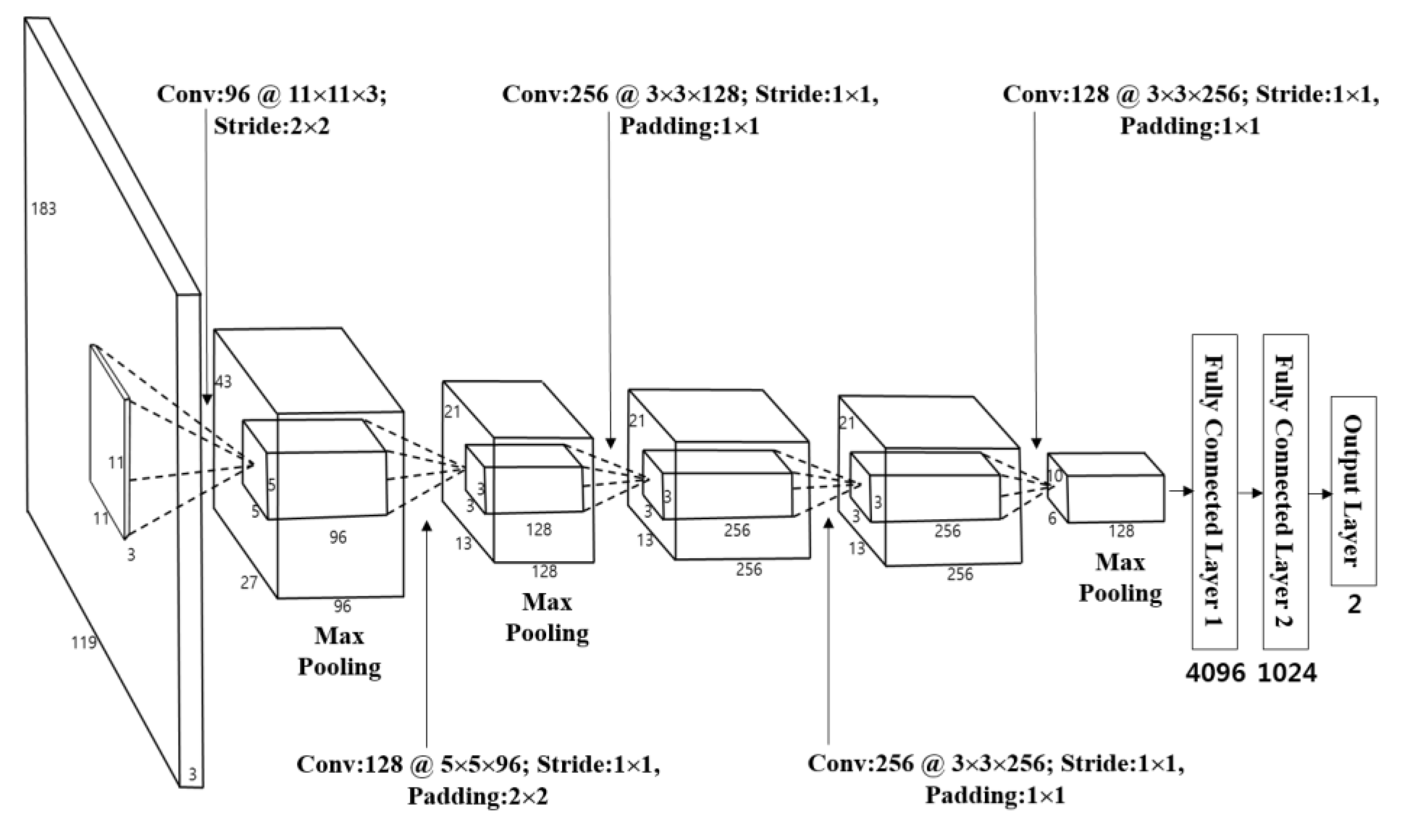
Table 5 and
Figure 7.
As seen in this table and figure, the CNN in this research includes five convolutional layers and three fully connected layers [
35]. Input images are the pedestrian and the non-pedestrian candidate images. As each input candidate image has a different size, this paper considers the ratio of the width and length of the general pedestrian, and resizes them into 119 pixels (width), 183 pixels (height), three (channels) through bilinear interpolation.
Several previous studies, including AlexNet [
36] and others [
37,
38], used a square shape with the same width and length as input images. However, the general pedestrian area, which this study aims to find, has longer length than its width. Therefore, when normalizing the size into a square shape, the image is unacceptably stretched toward its width compared to its length, and distorts its pedestrian area, making it difficult to extract the features accurately. Also, when selecting the CNN input image as a square shape without stretching toward the width direction, the background area (especially, on the left and right to the pedestrian), is heavily reflected on the output yielding inaccurate features. Considering this aspect, this study uses the pedestrian or the non-pedestrian images with a normalized size of 119-by-183 pixels (width-by-height) as the CNN input. Through such size normalization, when the object’s size changes depending on its location relative to the camera, such change can be compensated. In addition, this study normalized the brightness of the input image by the zero-center method discussed in [
39]. The 119-by-183 pixels (width-by-height) used in this method is much smaller than the 227-by-227 pixels (height-by-width) discussed in AlexNet [
36]. Therefore, we can significantly reduce the number of filters in each convolution layers and the number of nodes in fully-connected layers than those in stated in the AlexNet. Also, AlexNet was designed in order to classify 1000 classes. However, this research can reduce the training time as it can distinguish only two classes of the pedestrian and non-pedestrian areas [
35].
In the 1st convolutional layer, 96 filters with the size of 11 × 11 × 3 are used at a stride of 2 × 2 pixels in the horizontal and vertical directions. The size of the feature map is 55 × 87 × 96 in the 1st convolutional layer, such that 55 and 87 are the output width and height, respectively. The calculations are based on: (output width (or height) = (input width (or height) − filter width (or height) + 2× padding)/stride + 1 [
40]). For instance, in
Table 5, input height, filter height, padding, and stride are 183, 11, 0, and 2, respectively. Therefore, the output height becomes 87 ((183 − 11 + 2× 0)/2 + 1). Unlike the previous studies [
41,
42], this research relatively enlarges the filter size of the 1st convolutional layer as the input image is very dark with high level of noise by its nature. Therefore, the enlarged filter can control the feature, which can be extracted wrongly due to the noise. Therefore, a rectified linear unit (ReLU) layer is used for the calculation as given by Equation (3) [
43,
44,
45]:
where x and y are the input and output values, respectively. This formula can lessen the vanishing gradient problem [
46], which can cause a faster processing speed than a non-linear activation function [
35].
The local response normalization layer is used behind the ReLU layer, as described in
Table 5, which has a formula as follows:
In Equation (4),
is a value obtained by normalization [
36]. In this research, we used 1, 0.0001, and 0.75 for the values of
p,
, and
, respectively.
is the neuron activity computed by the application of the
ith kernel at the location (x, y), and it performs normalization for the adjacent
n kernel maps at the identical spatial position [
36]. In this study,
n was set as 5. N implies the total number of filters in the layer. In order to make the CNN structure resilient to the image translation and local noise, the feature map gained through the local response normalization layer goes through the max pooling layer as given in
Table 5. Max pooling layer uses the output after selecting the maximum value among the figures within the defined mask ranges. This is similar to conducting a subsampling. Once it goes through the Max pooling layer, it will produce 96 feature maps with sizes of 27 × 43 pixels as shown in
Table 5 and
Figure 7.
In order to fine-tune the 1st convolutional layer, as given in
Table 5 and
Figure 7, the 2nd convolutional layer that has 128 filters with a size of 5 × 5 × 96, a stride of 1 × 1 pixels (in the horizontal and vertical directions), and a padding of 2 × 2 pixels (in the horizontal and vertical directions) can be used behind the 1st convolutional layer. Similar to the 1st convolutional layer, after going through ReLU, cross channel normalization, and max pooling layers, we obtained 128 feature maps with the size of 13 × 21 pixels as shown in
Figure 7 and
Table 5. The first two layers are used to extract the low-level image features, such as blobs texture feature or edges.
Then, three additional convolutional layers are used for the high-level feature extraction as given in
Figure 7 and
Table 5. In details, the 3rd convolutional layer adopts 256 filters with the size of 3 × 3 × 128, the 4th convolutional layer has 256 filters with the size of 3 × 3 × 256, and the 5th convolutional layer uses 128 filters with the size of 3 × 3 × 256.
Through these five convolutional layers, 128 feature maps with the size of 6 × 10 pixels are finally obtained, which are fed to the additional three fully connected layers including 4096, 1024, and 2 neurons, respectively. This research will finally classify two classes of pedestrian areas and non-pedestrian areas through a CNN. Therefore, the last (3rd) fully connected layer (called as “output layer”) of
Figure 7 and
Table 5 has only two nodes. The 3rd fully connected layer uses Softmax function, as given through Equation (5) [
44]:
Given that the array of the output neurons is set as s, we can obtain the probability of neurons belonging to the
th class by dividing the value of the
th element by the summation of the values of all the elements. As illustrated in the previous studies [
36,
47], the CNN-based recognition system has an over-fitting problem, which can cause low recognition accuracy with testing data although the accuracy with the training data is still high. To address such problems, this research employs data augmentation and dropout methods [
36,
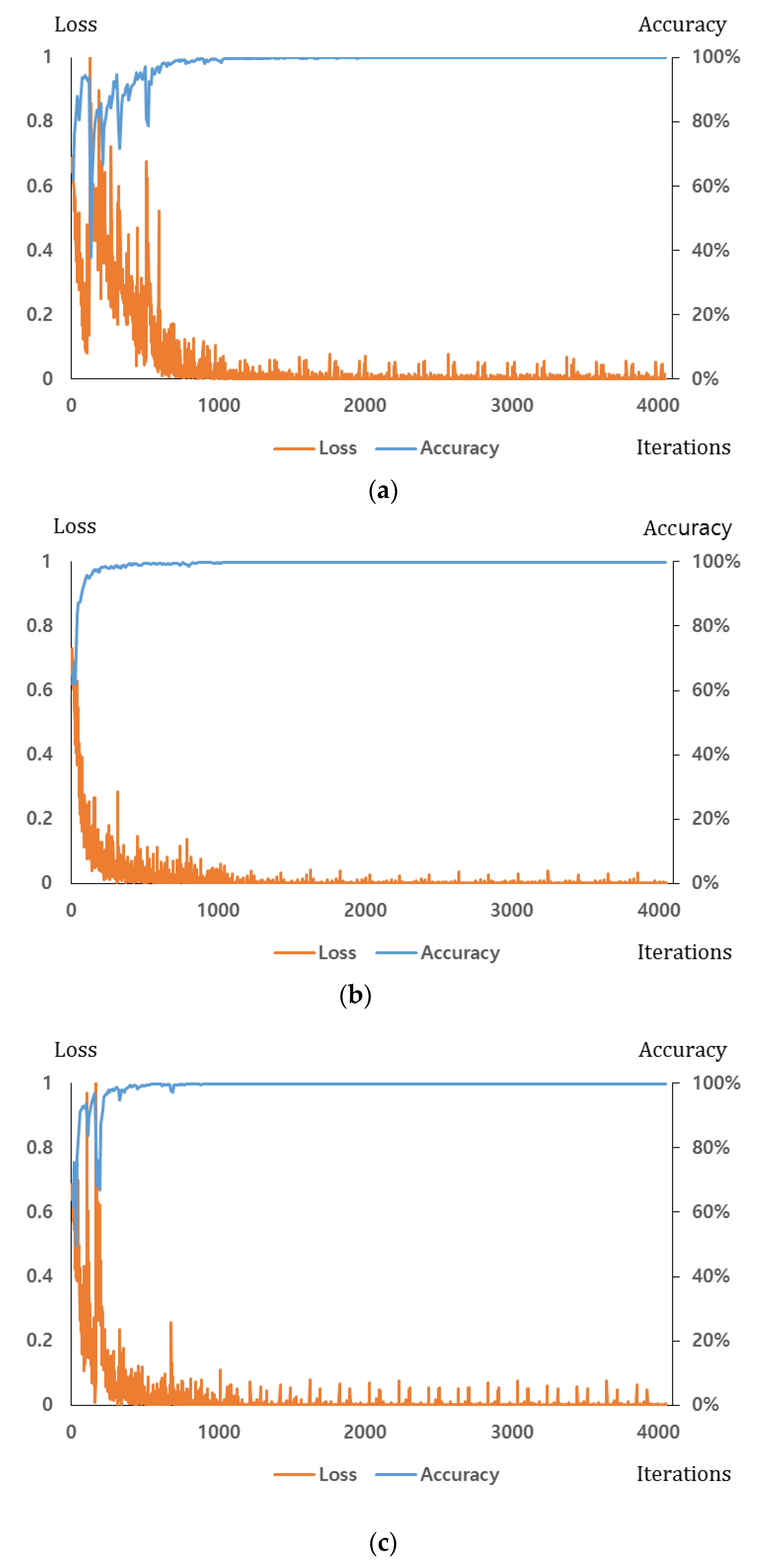
47], which can reduce the effects of over-fitting problem. More details about the outcome of the data augmentation are presented in
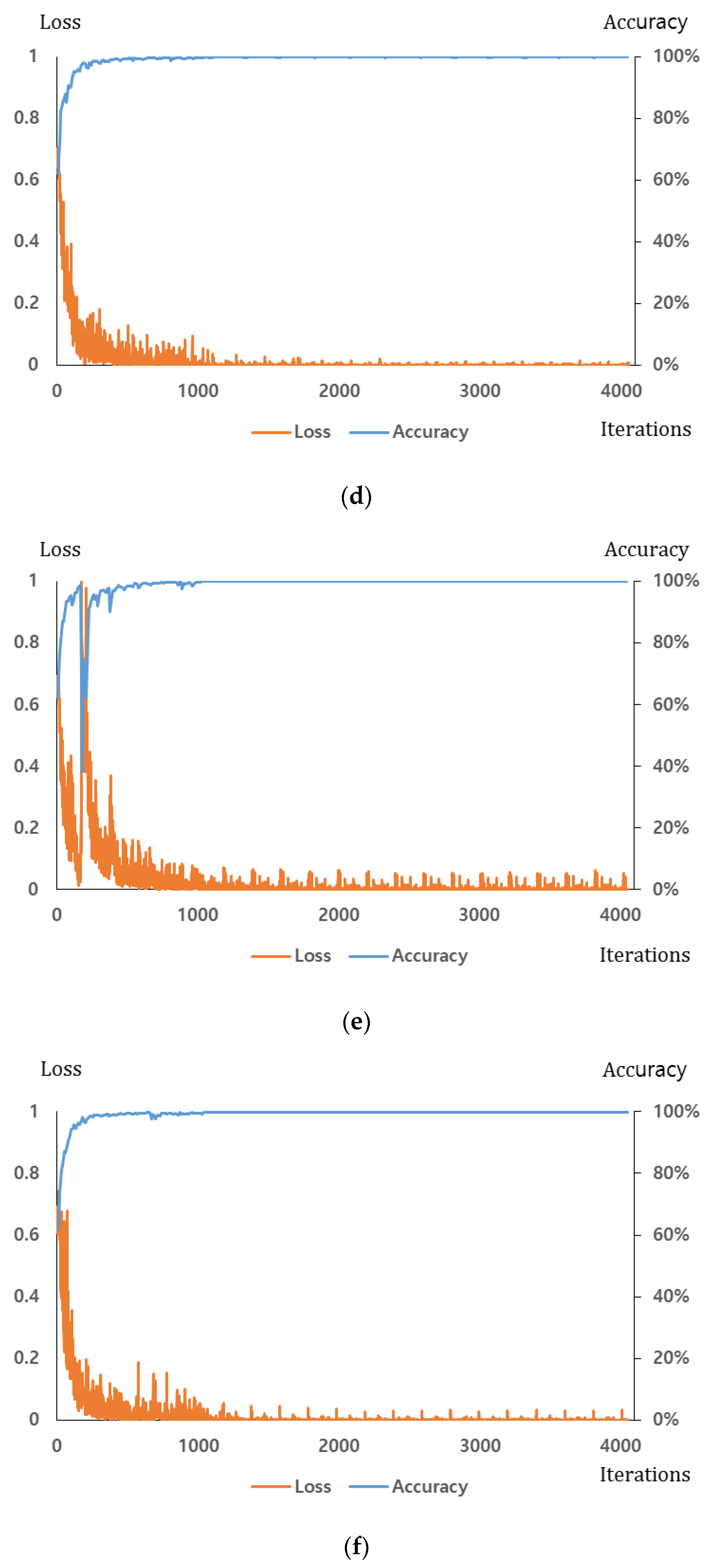
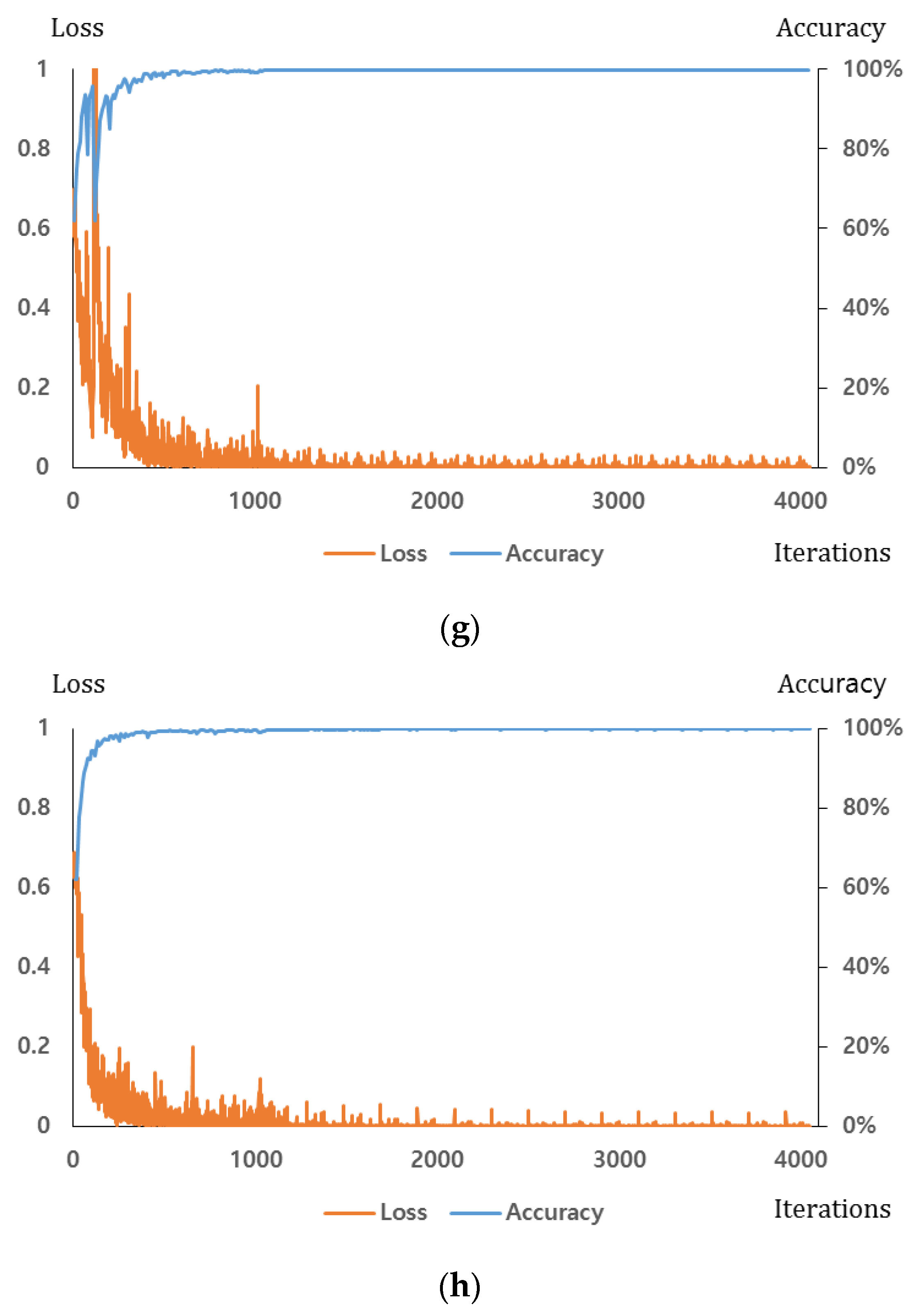
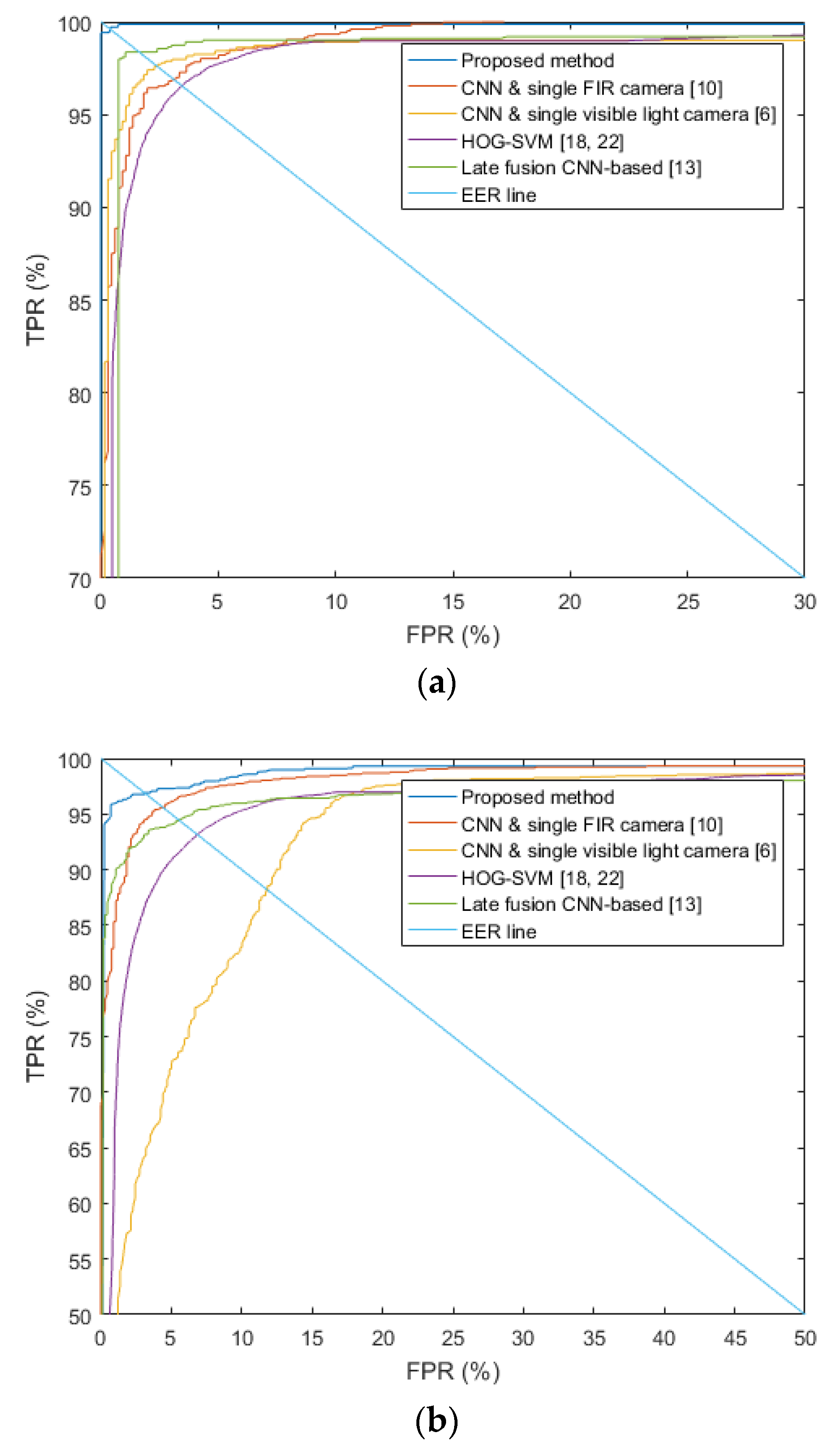
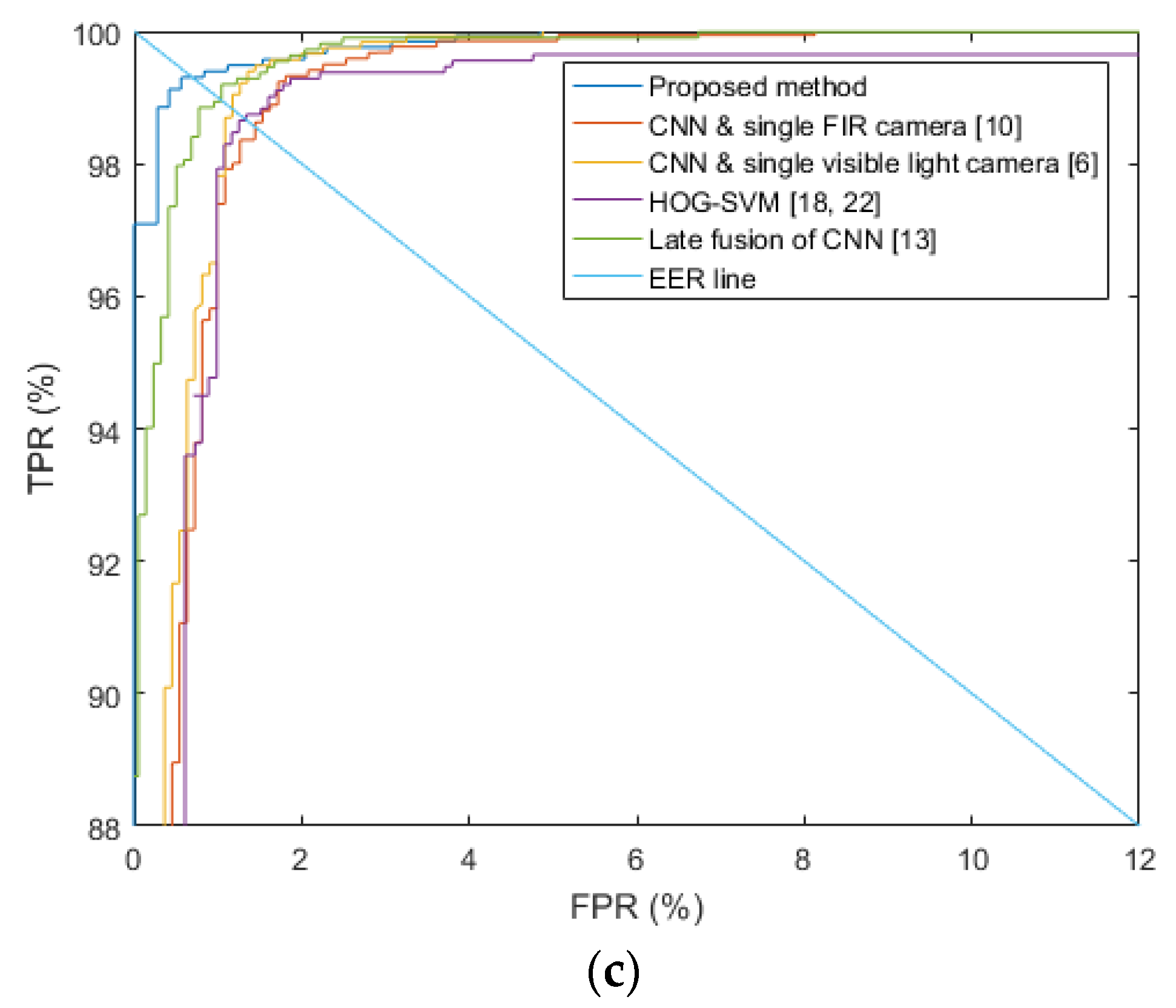
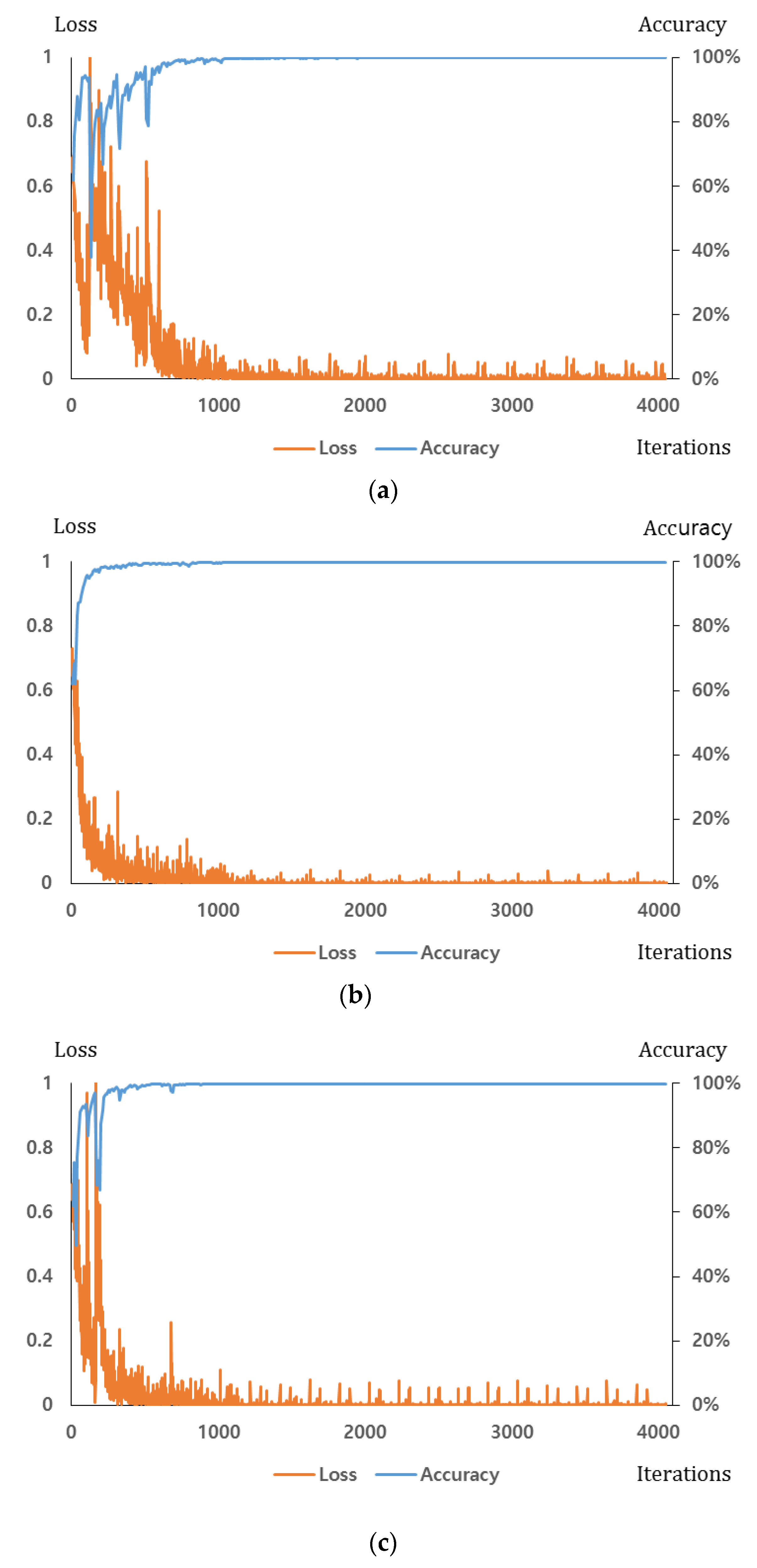
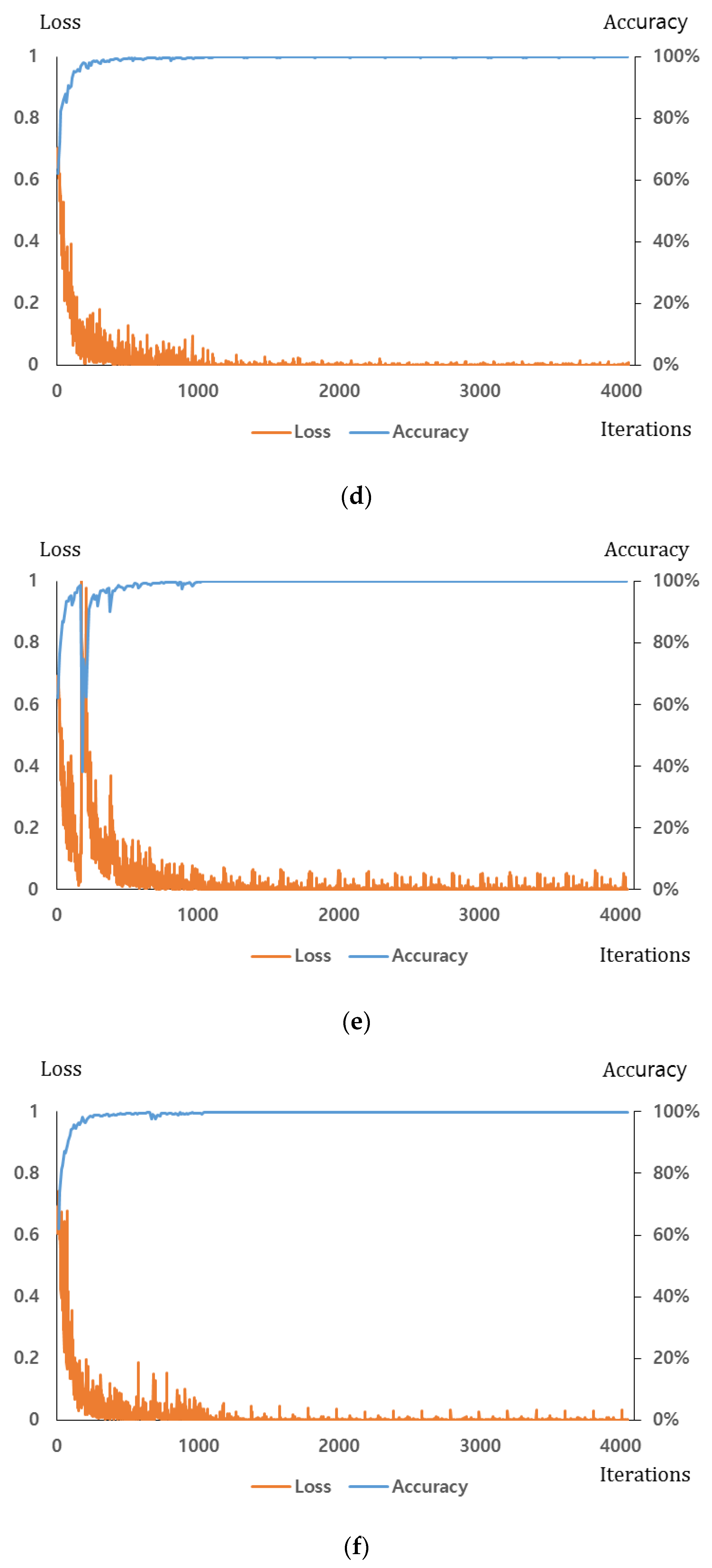
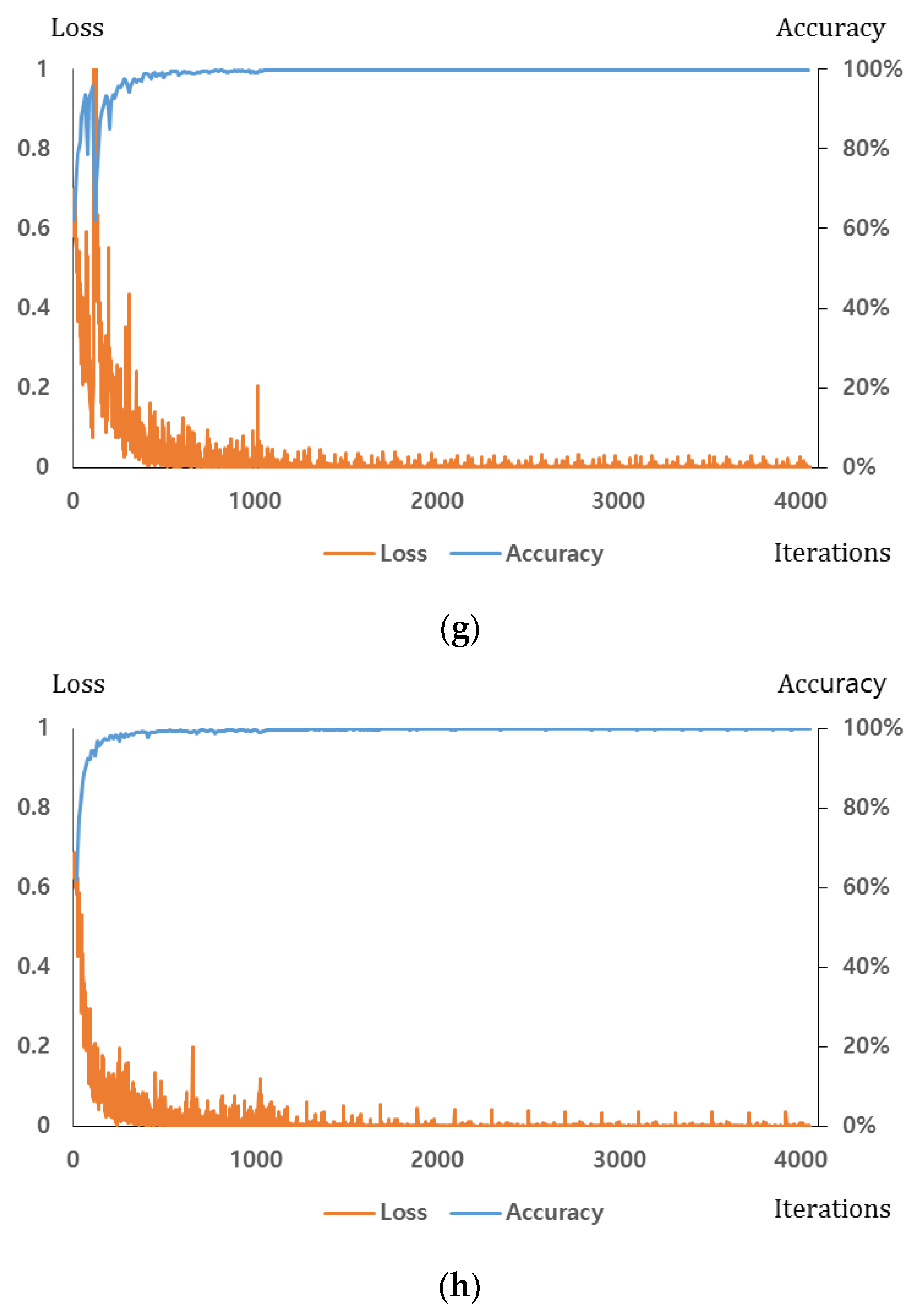
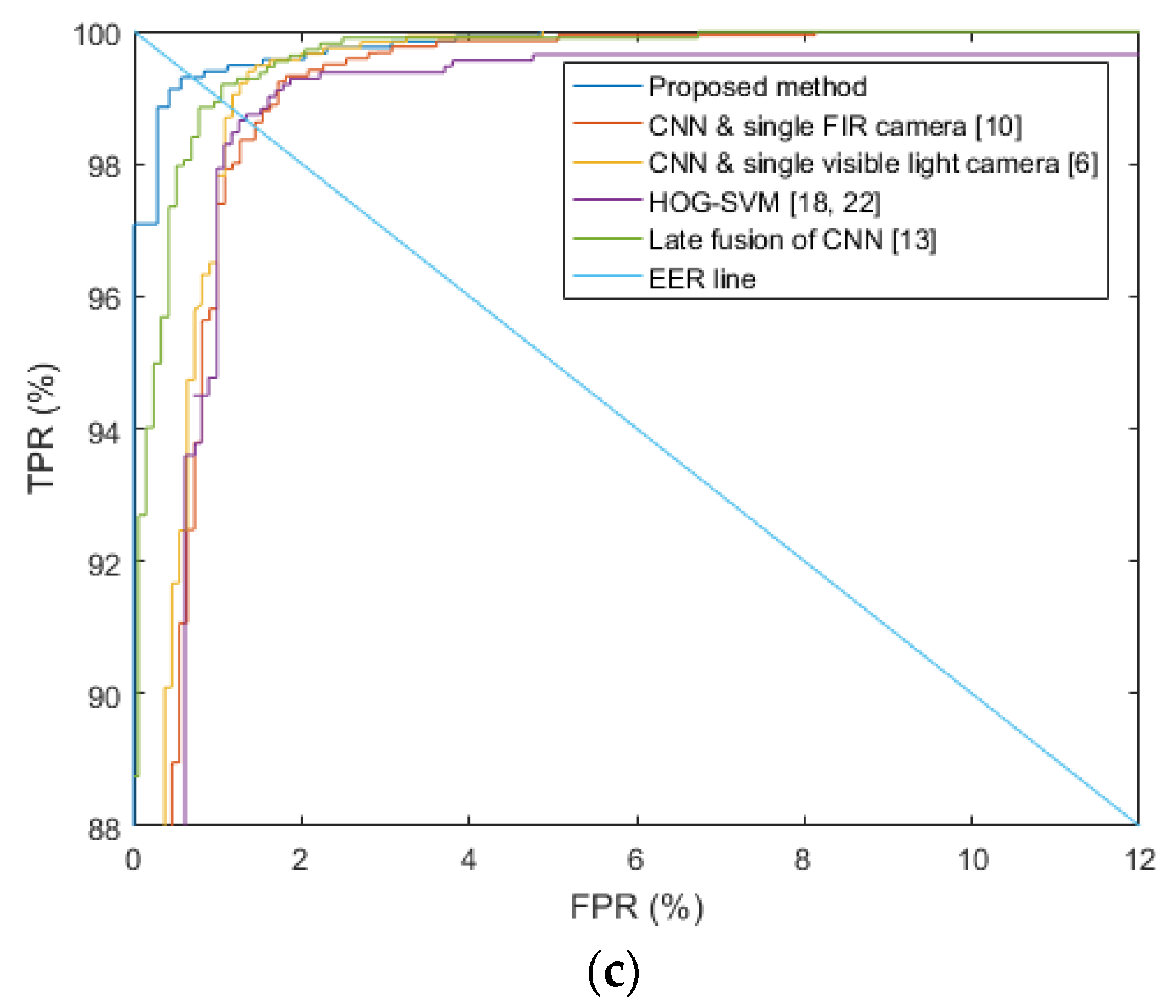
Section 4.1. For the dropout method, we adopt the dropout probability of 50% to disconnect the connections several neurons between previous layer and the next layers in the fully connected network [
35,
36,
47].













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}