
ROI-Based On-Board Compression for Hyperspectral Remote Sensing Images on GPU



Abstract
:1. Introduction
2. Related Works
3. ROI-Based on Board Compression
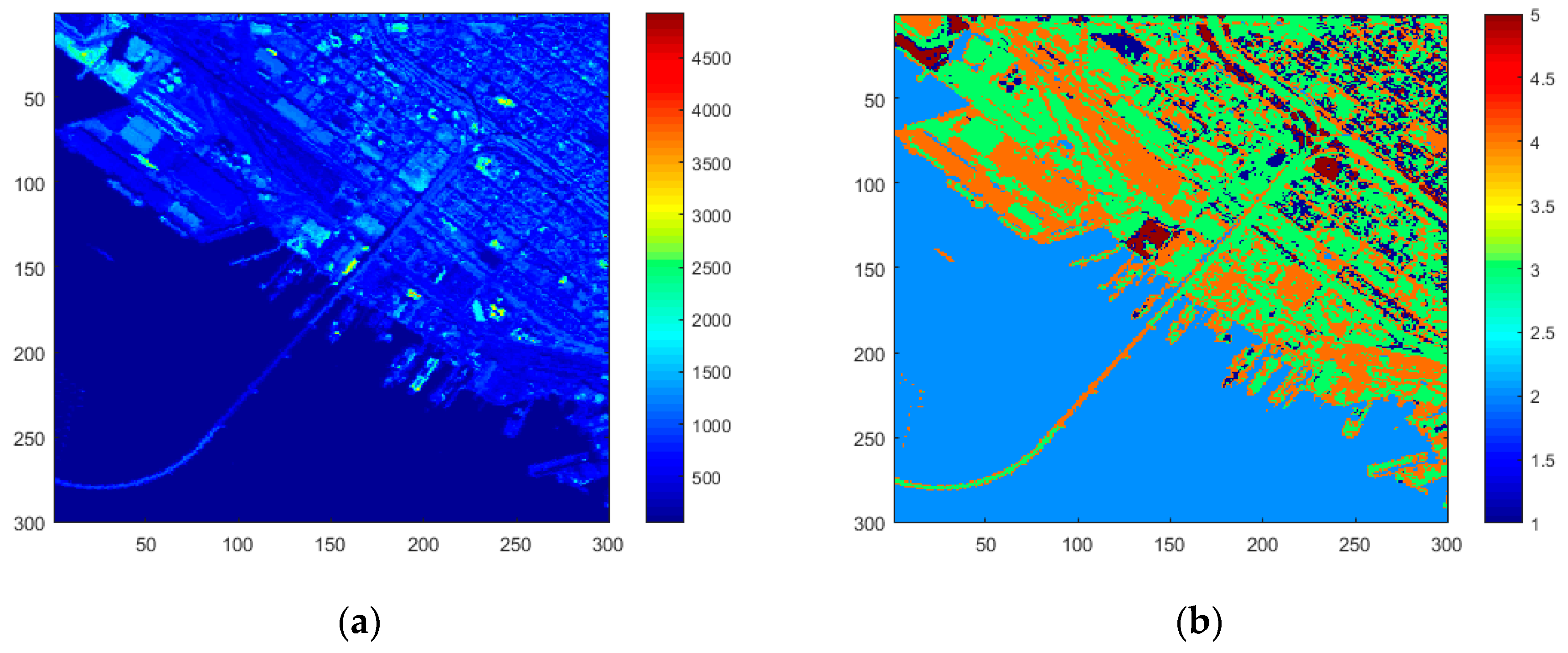
3.1. ROI Detection
3.1.1. The Clustering Algorithm
- It is not necessary to employ considerable resources to learn features of large sets of images to identify ROIs, making the application general purpose;
- By using the intrinsic characteristics of the image, the computational time is reduced, making possible a real-time automatic detection of ROIs;
- The characteristics of some patterns may change over time, but a clustering algorithm applied on single images circumvent this problem.
- Extraction of the main diagonal;
- Computation of the histogram of the values of the main diagonal;
- Detection of the local maximum of the histogram.
3.1.2. Automatic Extraction of Signatures and ROI Labeling Process
3.2. ROI and Not-ROI Compression and Encoding
3.3. Quantization and Encoding
- break the source message into symbols, where the symbol is some logical grouping of characters;
- associate each distinct symbol with a interval of the unit [0…..1);
- tighten the unit interval by an amount determined by the interval associated with each symbol in the message;
- represent the final interval by choosing some fraction within it.
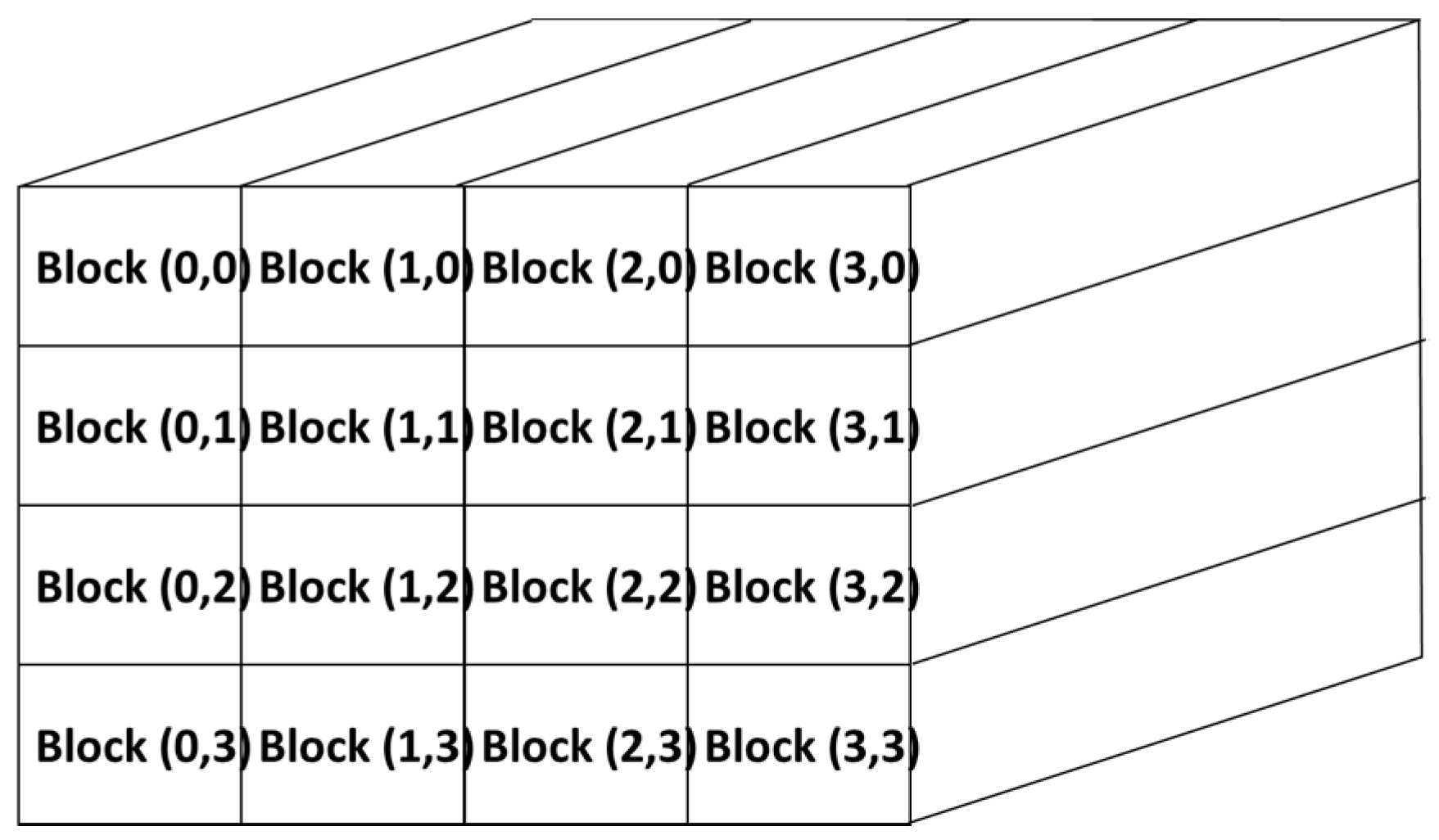
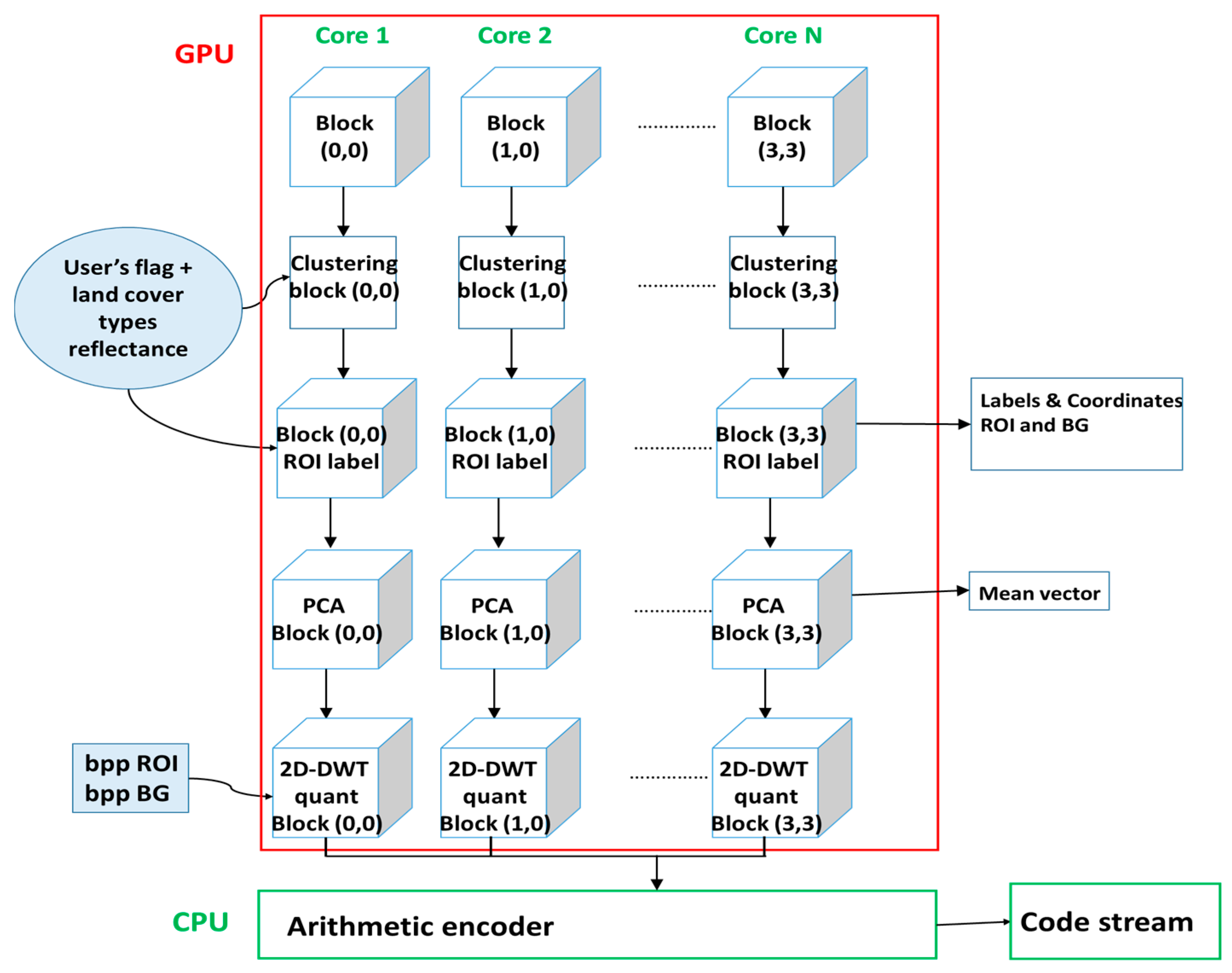
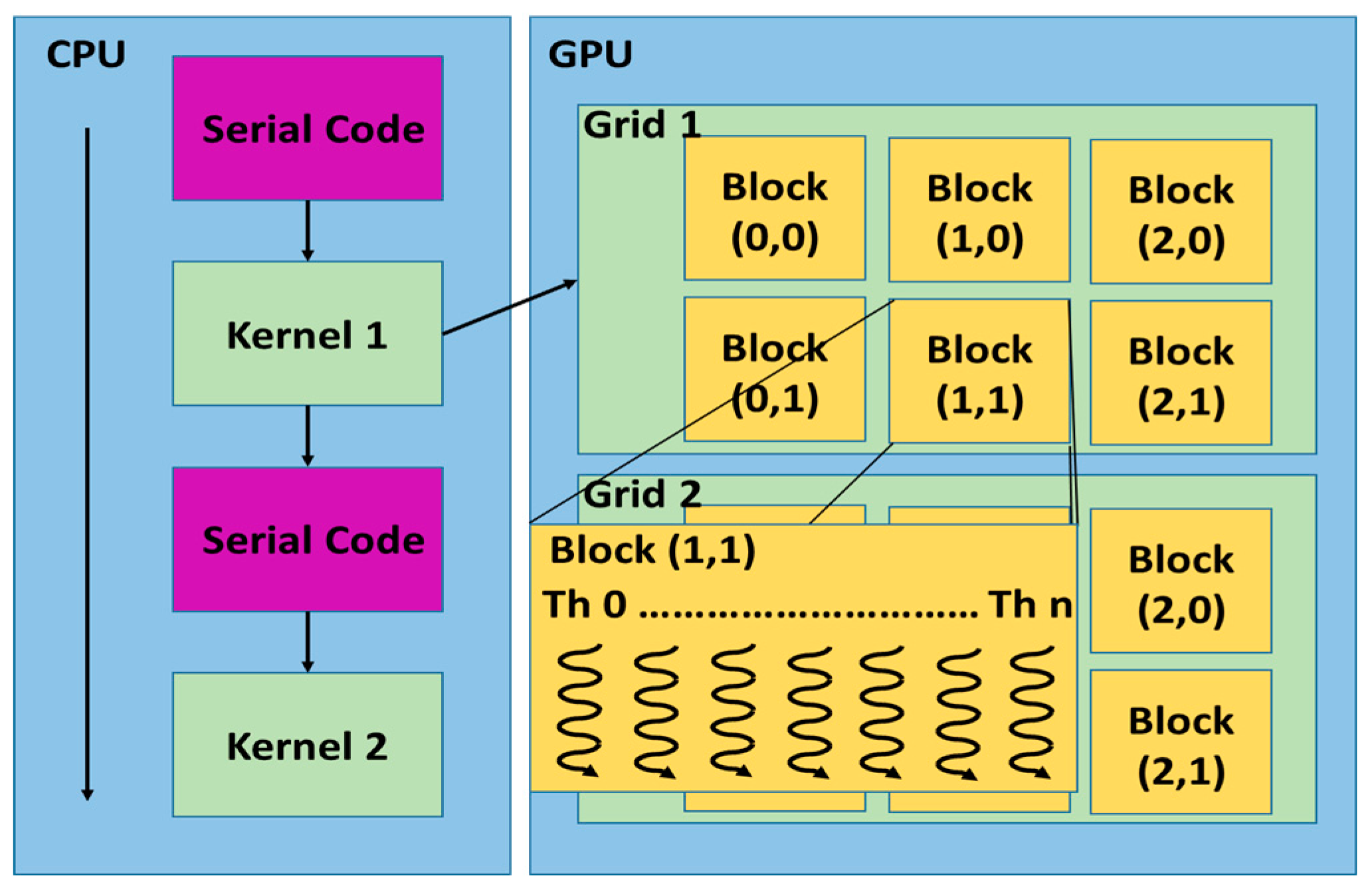
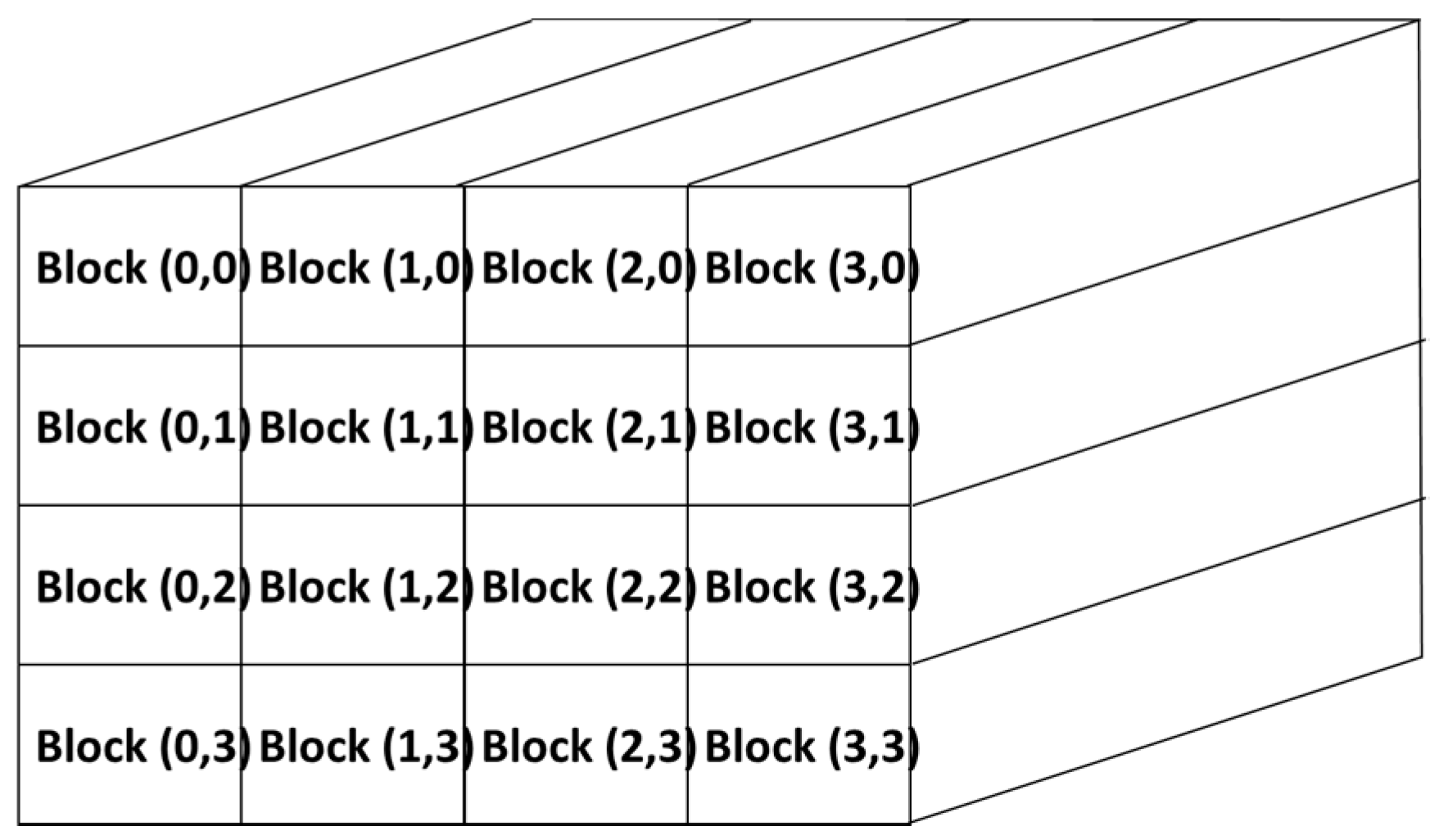
3.4. Implementation on GPU
4. Results
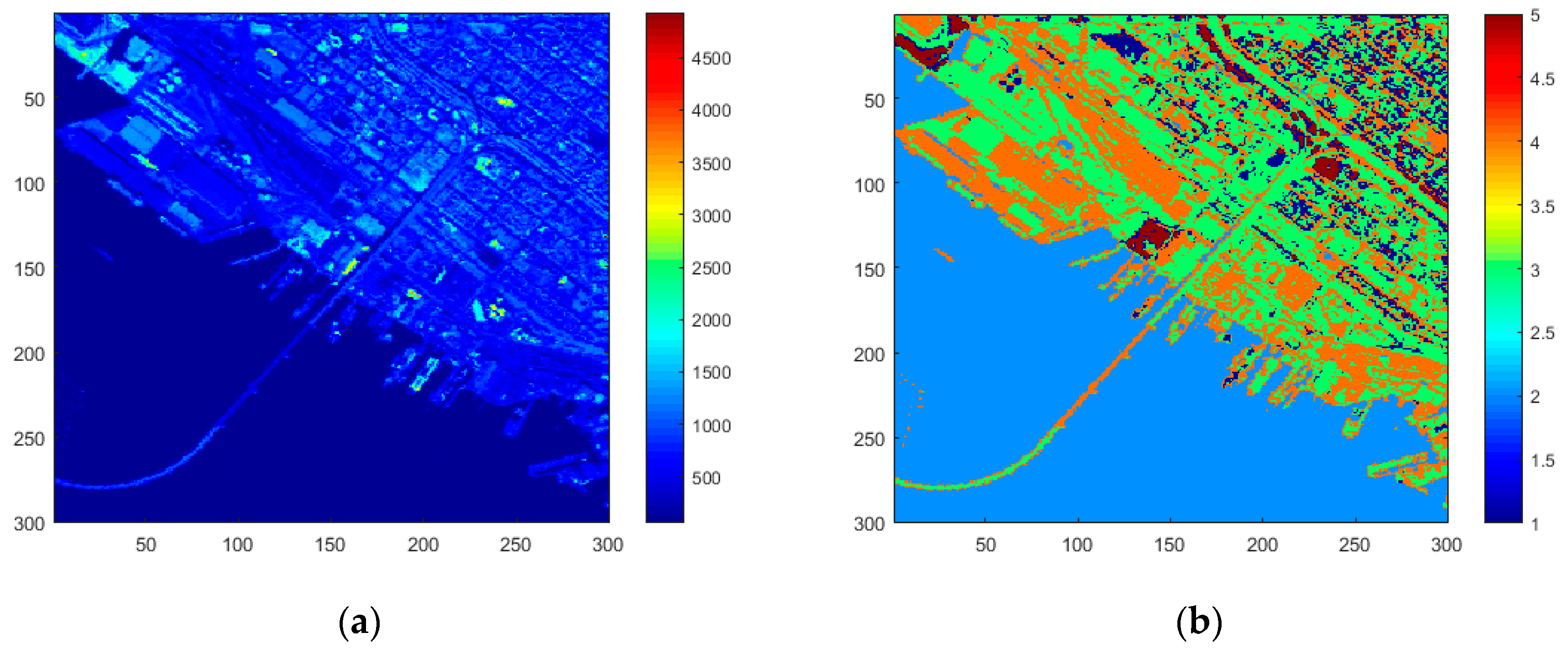
4.1. Dataset Description
4.2. Processing Steps
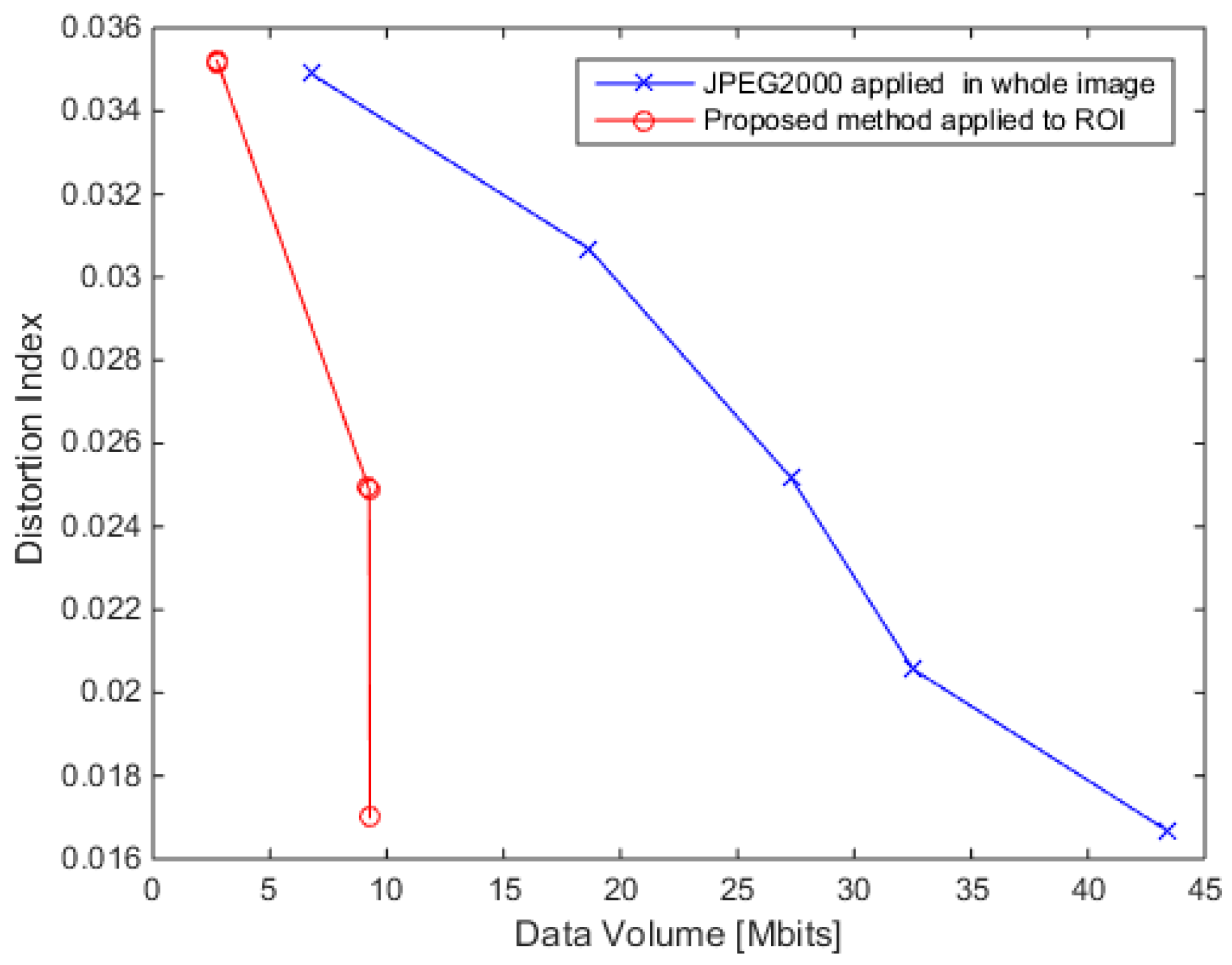
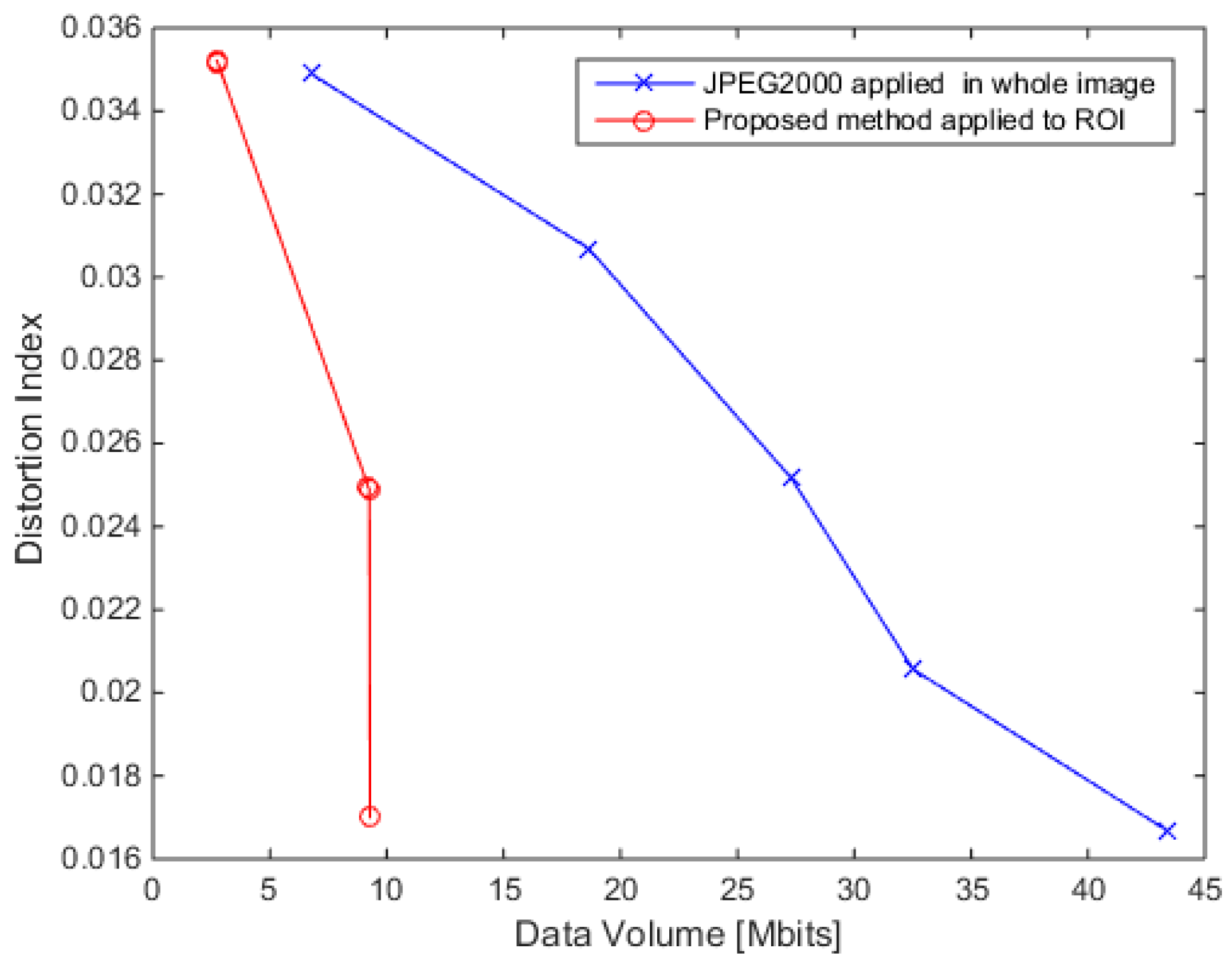
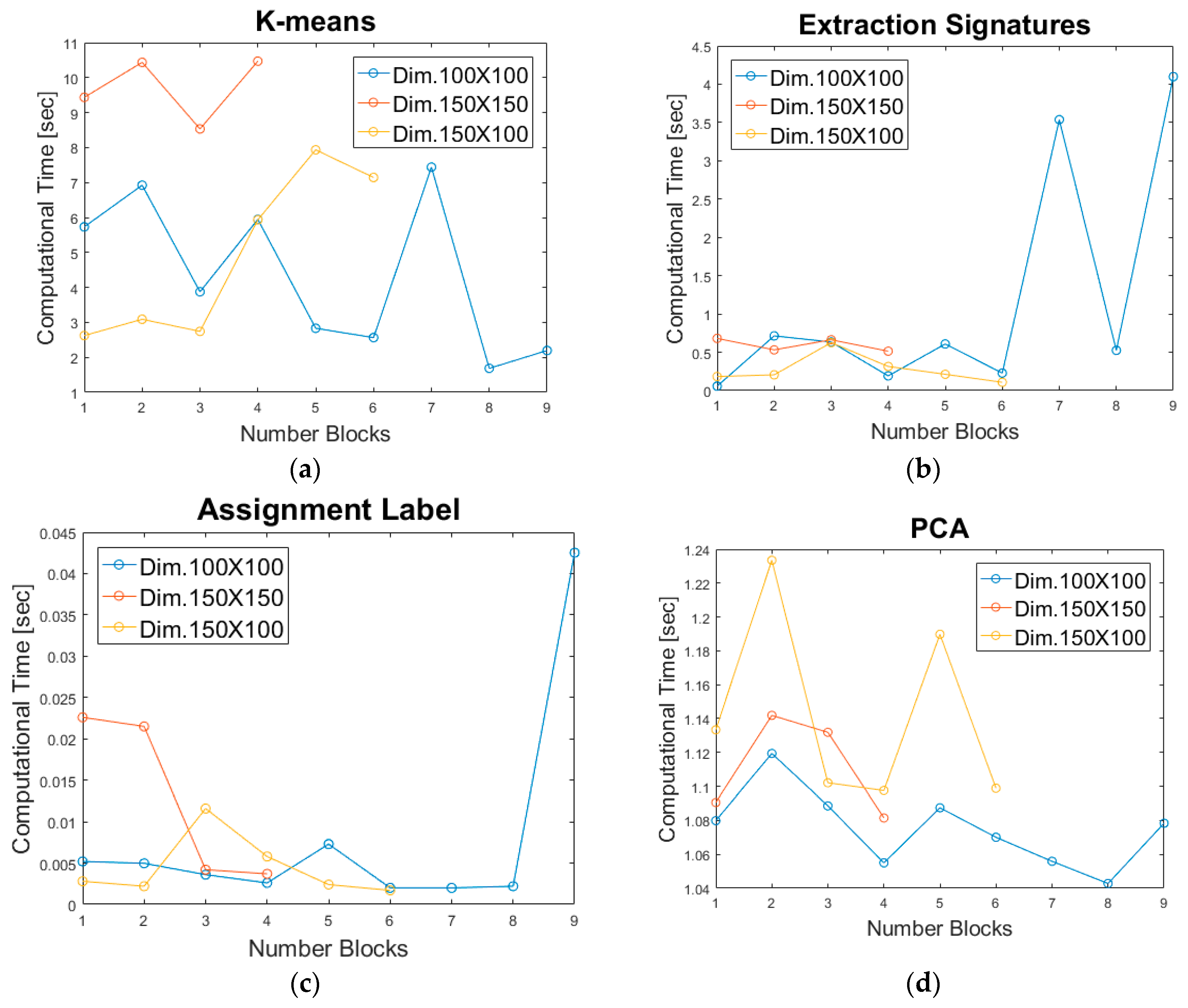
4.3. Performance Results
4.4. Implementation Results
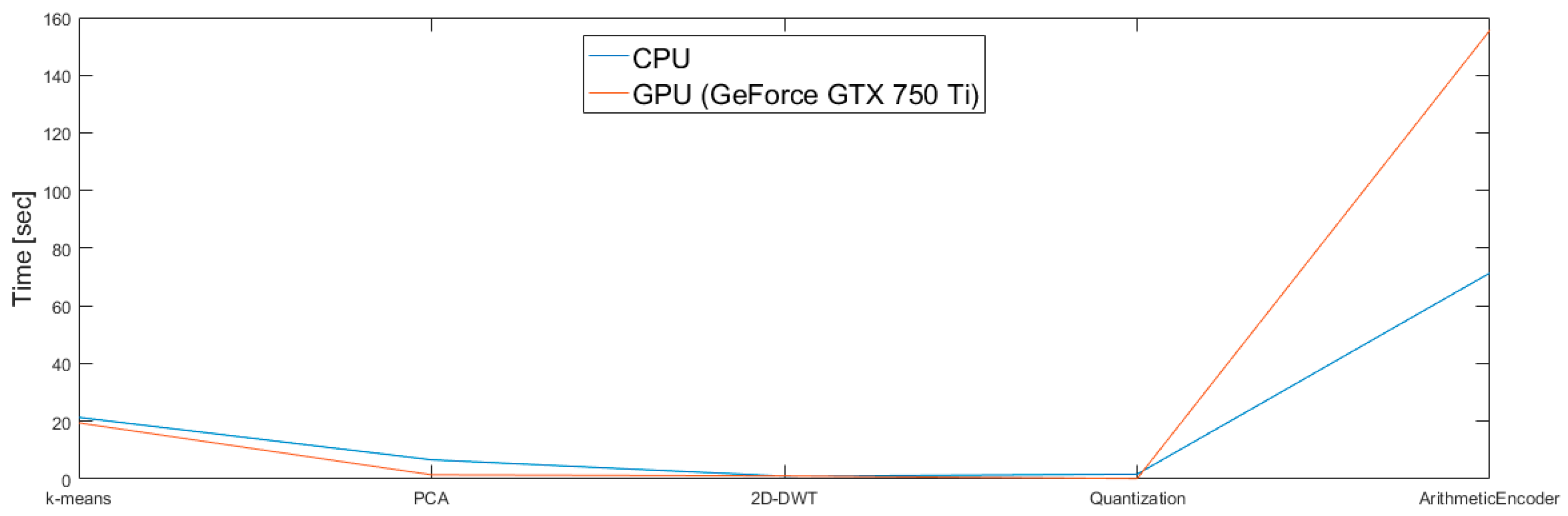
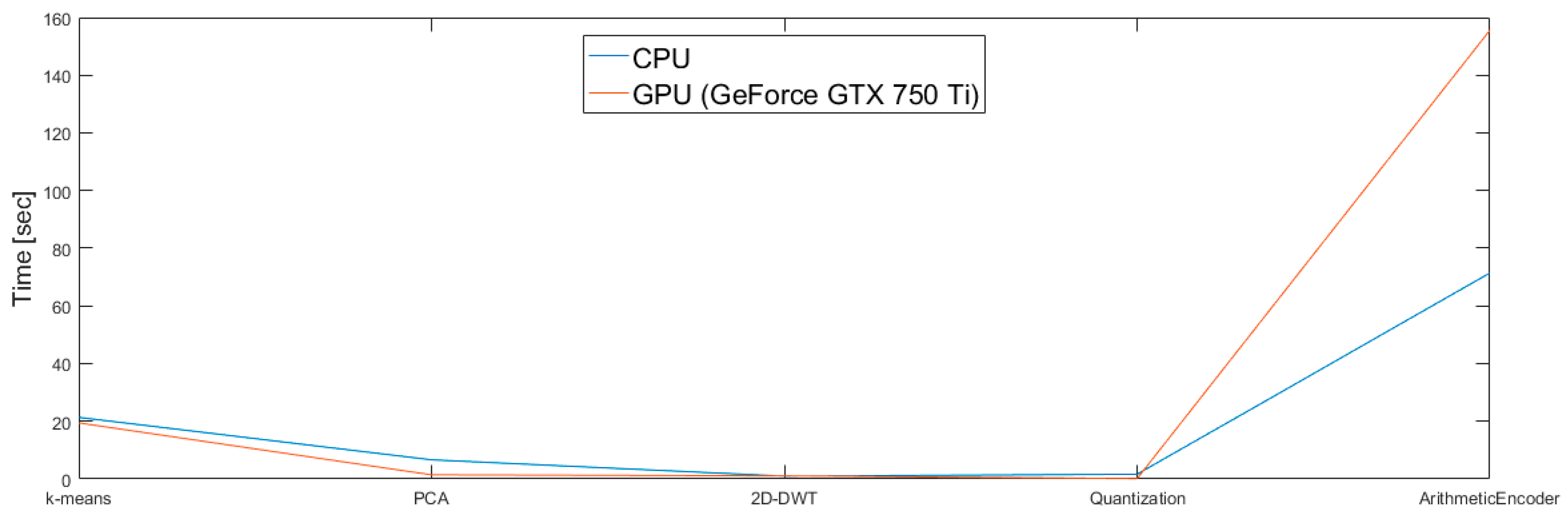
4.4.1. Comparison of CPU and GPU Implementation
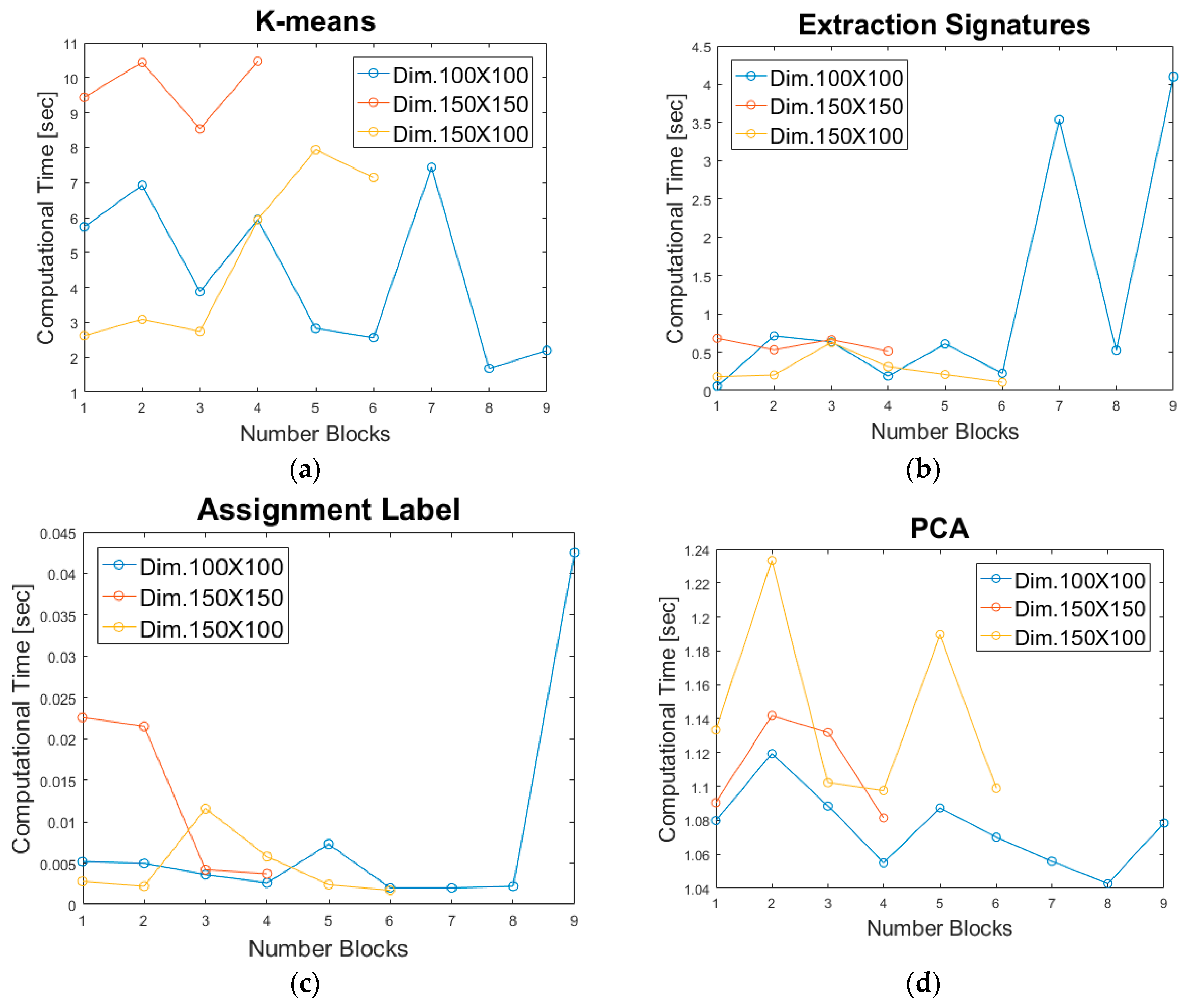
4.4.2. Results for GPU Parallel Implementation
4.4.3. Processing Time for Different Accuracy
5. Discussion
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Grahn, H.F.; Geladi, P. Techniques and Applications of Hyperspectral Image Analysis; Wiley: London, UK, 2007. [Google Scholar]
- Hunt, S.; Rodriguez, L.S. Fast piecewise linear predictors for loss-less compression of hyperspectral imagery. In Proceedings of the 2004 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Anchorage, AK, USA, 20–24 September 2004. [Google Scholar]
- Mallat, S. A Wavelet Tour of Signal Processing; Accademic: San Diego, CA, USA, 1998. [Google Scholar]
- Shlens, J. A Tutorial on Principal Component Analysis; University of California: San Diego, CA, USA, 2005. [Google Scholar]
- Jolliffe, I. Principal Component Analysis; Springer: New York, NY, USA, 2008. [Google Scholar]
- NVIDIA Home Page. Available online: http://www.nvidia.com/object/doc_gpu_compute.html (accessed on 18 May 2017).
- Plaza, A.; Plaza, J.; Paz, A.; Sanchez, S. Parallel Hyperspectral Image and Signal Processing. IEEE Signal Process. Mag. 2011, 28, 119–126. [Google Scholar] [CrossRef]
- Plaza, A.; Du, Q.; Chang, Y.L.; King, R.L. High performance computing for hyperspectral remote sensing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2011, 4, 528–544. [Google Scholar] [CrossRef]
- Zhao, C.; Li, J.; Meng, M.; Yao, X. A Weighted Spatial-Spectral Kernel RX Algorithm and Efficient Implementation on GPUs. Sensors 2017, 17, 441. [Google Scholar] [CrossRef] [PubMed]
- Ren, H.; Wang, Y.L.; Huang, M.Y.; Kao, Y.L.C.H.M. Ensemble Empirical Mode Decomposition Parameters Optimization for Spectral Distance Measurement in Hyperspectral Remote Sensing Data. Remote Sens. 2014, 6, 2069–2083. [Google Scholar] [CrossRef]
- Martel, E.; Guerra, R.; López, S.; Sarmiento, R. A GPU-Based Processing Chain for Linearly Unmixing Hyperspectral Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 818–834. [Google Scholar] [CrossRef]
- Sevilla, J.; Martín, G.; Nascimento, J.; Bioucas-Dias, J. Hyperspectral image reconstruction from random projections on GPU. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 280–283. [Google Scholar]
- Torti, E.; Danese, G.; Leporati, F.; Plaza, A. A Hybrid CPU–GPU Real-Time Hyperspectral Unmixing Chain. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 945–951. [Google Scholar] [CrossRef]
- Hihara, H.; Moritani, K.; Inoue, M.; Hoshi, Y.; Iwasaki, A.; Takada, J.; Inada, H.; Suzuki, M.; Seki, T.; Ichikawa, S.; et al. Onboard Image Processing System for Hyperspectral Sensor. Sensors 2015, 15, 24926–24944. [Google Scholar] [CrossRef] [PubMed]
- Conoscenti, M.; Coppola, R.; Magli, E. Constant SNR, Rate Control, and Entropy Coding for Predictive Lossy Hyperspectral Image Compression. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7431–7441. [Google Scholar] [CrossRef]
- Giordano, R.; Lombardi, A.; Guccione, P. Efficient clustering and on-board ROI-based compression for Hyperspectral Radar. In Proceedings of the IARIA Conference 2016, Lisbon, Portugal, 26–30 June 2016. [Google Scholar]
- Jain, A.K.; Murty, M.N.; Flynn, P.J. Data Clustering: A review. ACM Comput. Surv. 1999, 3, 264–323. [Google Scholar] [CrossRef]
- Koonsanit, K.; Jaruskulchai, C. A simple estimation the number of classes in satellite imagery. In Proceedings of the 2011 9th International Conference on IEEE on ICT and Knowledge Engineering, Bangkok, Thailand, 12–13 January 2012; pp. 124–128. [Google Scholar]
- Kurani, A.S.; Xu, D.H.; Furst, J.; Raicu, D.S. Co-occurrence matrices for volumetric data. In Proceedings of the 7th IASTED Conference on Computer Graphics and Imaging, Kauai, HI, USA, 16–18 August 2004; pp. 447–452. [Google Scholar]
- Kutser, T.; Vahtmäe, E.; Paavel, B. Removing air/water interface effects from hyperspectral radiometry data. In Proceedings of the 2012 Oceans-Yeosu, Yeosu, Korea, 21–24 May 2012; pp. 1–3. [Google Scholar]
- Bernstein, L.S.; Adler-Golden, S.M.; Perkins, T.C.; Berk, A.; Levine, R.Y. Method for Performing Automated in-Scene Based Atmospheric Compensation for Multi-and Hyperspectral Imaging Sensors in the Solar Reflective Spectral Region. Available online: https://www.google.ch/patents/US6909815 (accessed on 21 June 2005).
- Hogg, R.V.; Craig, A.T. Introduction to Mathematical Statistics; Pearson Education Limited: Harlow, UK, 2014. [Google Scholar]
- Cohen, A.; Daubechies, I.; Feauveau, J.C. Biorhogonal bases of compactly supported wavelets. Commun. Pure Appl. Math. 1992, 45, 485–560. [Google Scholar] [CrossRef]
- Antonini, M.; Barlaud, M.; Mathieu, P.; Daubechies, I. Image coding using wavelet transform. IEEE Trans. Image Process. 1992, 1, 205–220. [Google Scholar] [CrossRef] [PubMed]
- Yu, J. Advantages of Uniform Scalar Dead_zone Quantization in Image Coding. In Proceedings of the Communications, Circuits and Systems, ICCAS 2004, Chengdu, China, 27–29 June 2004; Volume 2, pp. 805–808. [Google Scholar]
- Storer, J.A. Image and Text Compression; Kluwer Academic Publisher: Norwell, MA, USA, 1992; pp. 85–112. [Google Scholar]
- Langdon, G. An introduction to Arithmetic Coding. IBM J. Res. Dev. 1984, 28, 135149. [Google Scholar] [CrossRef]
- Zhang, F.; Hu, C.; Li, W.; Li, H.-C. Accelerating Time-Domain SAR Raw Data Simulation for Large Areas Using Multi-GPUs. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 3956–3966. [Google Scholar] [CrossRef]
- Tang, H.; Li, G.; Zhang, F.; Hu, W.; Li, W. A spaceborne SAR on-board processing simulator using mobile GPU. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 1198–1201. [Google Scholar]
- NVIDIA GeForce. Available online: http://www.nvidia.it/object/geforce-gtx-750-ti-it.html (accessed on 18 May 2017).
- National Aeronautics and Space Administration (NASA). Airborne Visible/Infrared Imaging Spectometer (Aviris), 2014. Available online: https://aviris.jpl.nasa.gov/ (accessed on 18 May 2017).
- Jang, J.-W.; Choi, S.B.; Prasanna, V.K. Energy- and time-efficient matrix multiplication on FPGAs. IEEE Trans. Very Large Scale Integr. Syst. 2005, 13, 1305–1319. [Google Scholar] [CrossRef]
- Huang, S.; Xiao, S.; Feng, W. On the energy efficiency of graphics processing units for scientific computing. In Proceedings of the 2009 IEEE International Symposium on Parallel & Distributed Processing, Rome, Italy, 23–29 May 2009; pp. 1–8. [Google Scholar]
- Wang, Q.; PingKun, Y.; Yuan, Y.; Xuelong, L. Multi-spectral saliency detection. Pattern Recognit. Lett. 2013, 34, 34–41. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
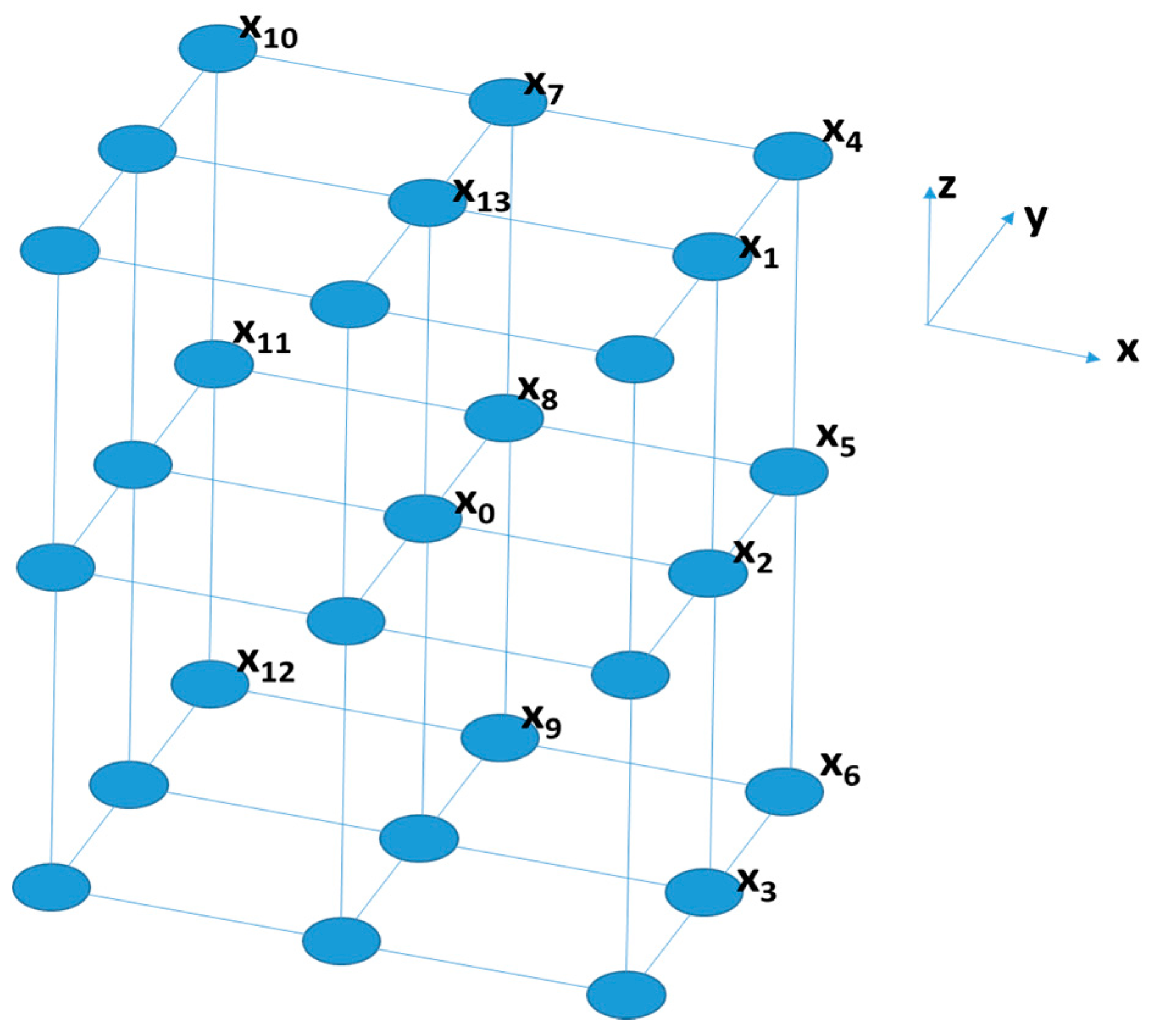
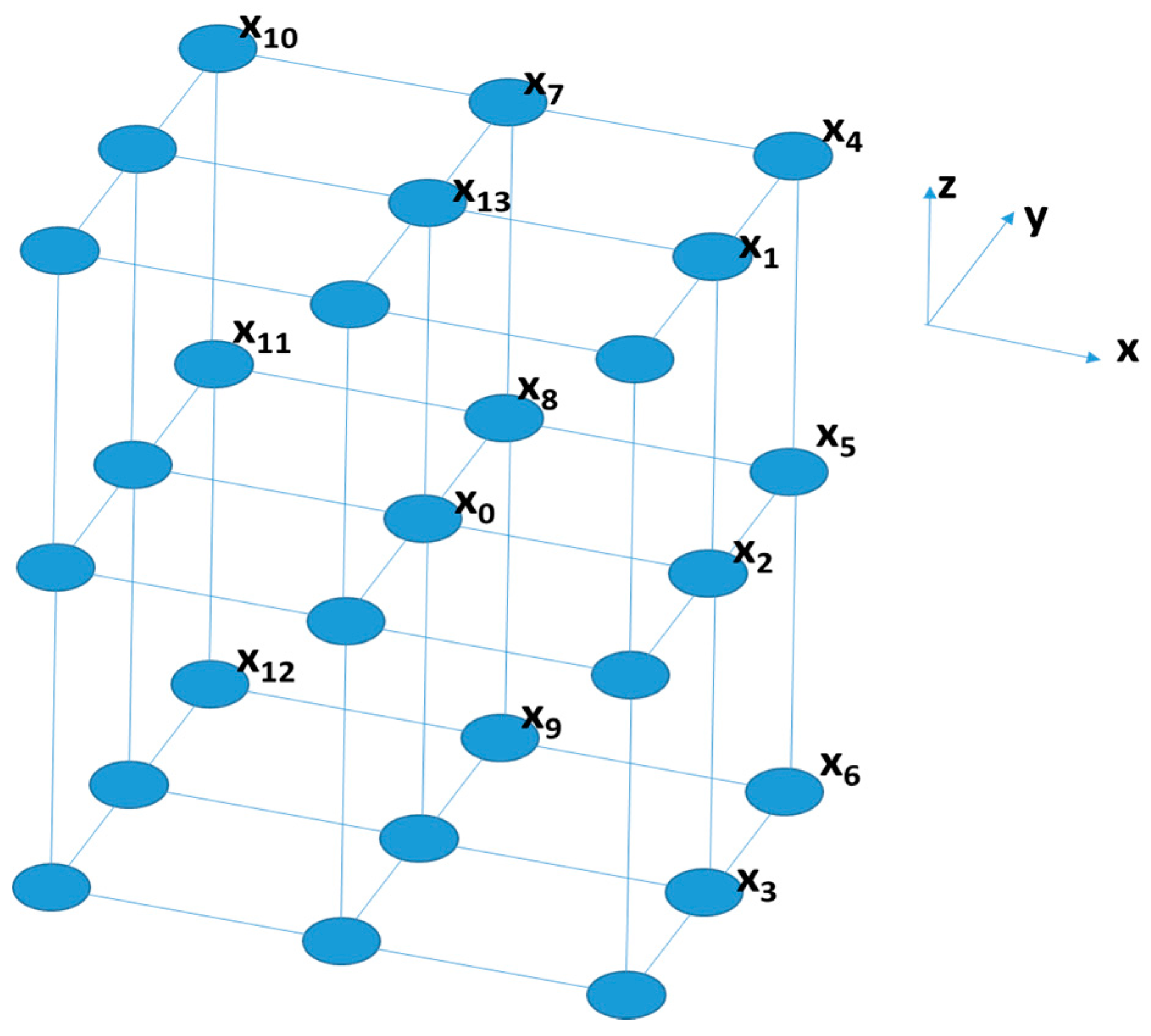
| Displacement Vectors | Directions |
|---|---|
| (D,0,D) | (0°,45°) |
| (D,0,0) | (0°,90°) |
| (D,0,−D) | (0°,135°) |
| (D,D,D) | (45°,45°) |
| (D,D,0) | (45°,90°) |
| (D,D,−D) | (45°,135°) |
| (0,D,D) | (90°,45°) |
| (0,D,0) | (90°,90°) |
| (0,D,−D) | (90°,135°) |
| (−D,D,D) | (135°,45°) |
| (−D,D,0) | (135°,90°) |
| (−D,D,−D) | (135°,135°) |
| (0,0,D) | (-,0°) |
| Size Block (pixel) | CPU Time (s) | GPU Time (s) | GPU + CPU Time (s) |
|---|---|---|---|
| 100 100 | 60.8227 | 77.3068 | 18.9352 |
| Size Block/Number Blocks (pixel) | Total Execution Time (s) |
|---|---|
| 100 × 100/9 blocks | 50.858 |
| 150 × 100/6 blocks | 46.4282 |
| 150 × 150/4 blocks | 40.4222 |
| AritEnco 8bpp Time (s) | AritEnco 4bpp Time (s) | AritEnco 2bpp Time (s) |
|---|---|---|
| 15.1296 | 6.7934 | 2.8123 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Giordano, R.; Guccione, P. ROI-Based On-Board Compression for Hyperspectral Remote Sensing Images on GPU. Sensors 2017, 17, 1160. https://doi.org/10.3390/s17051160
Giordano R, Guccione P. ROI-Based On-Board Compression for Hyperspectral Remote Sensing Images on GPU. Sensors. 2017; 17(5):1160. https://doi.org/10.3390/s17051160
Chicago/Turabian StyleGiordano, Rossella, and Pietro Guccione. 2017. "ROI-Based On-Board Compression for Hyperspectral Remote Sensing Images on GPU" Sensors 17, no. 5: 1160. https://doi.org/10.3390/s17051160
APA StyleGiordano, R., & Guccione, P. (2017). ROI-Based On-Board Compression for Hyperspectral Remote Sensing Images on GPU. Sensors, 17(5), 1160. https://doi.org/10.3390/s17051160