
Convolutional Neural Network-Based Human Detection in Nighttime Images Using Visible Light Camera Sensors

Abstract
:1. Introduction
2. Related Works
- This was the first research on human detection using a single visible light camera image in an outdoor long-distance nighttime low-illumination environment.
- We performed intensive training on the CNN using a huge number of images obtained through data augmentation from three kinds of nighttime databases of images captured in a variety of environments by fixed and moving cameras in order to improve the CNN-based human detection performance, making it robust for a variety of cameras and environment changes.
- We compared the performance of an original image-based CNN and an HE image-based CNN in order to compare the properties and human detection performances based on the relationship between the nighttime image capturing environment and the image pre-processing. In the analysis results, when HE images were used rather than the original images and the three databases were combined for training rather than training being done separately for each database, the system showed better human detection performance.
- The test database was self-constructed using images obtained from cameras installed in nighttime surveillance environments, and this database has been made public so that other researchers can compare and evaluate its performance.
3. Proposed Human Detection in Nighttime Image Based on CNN
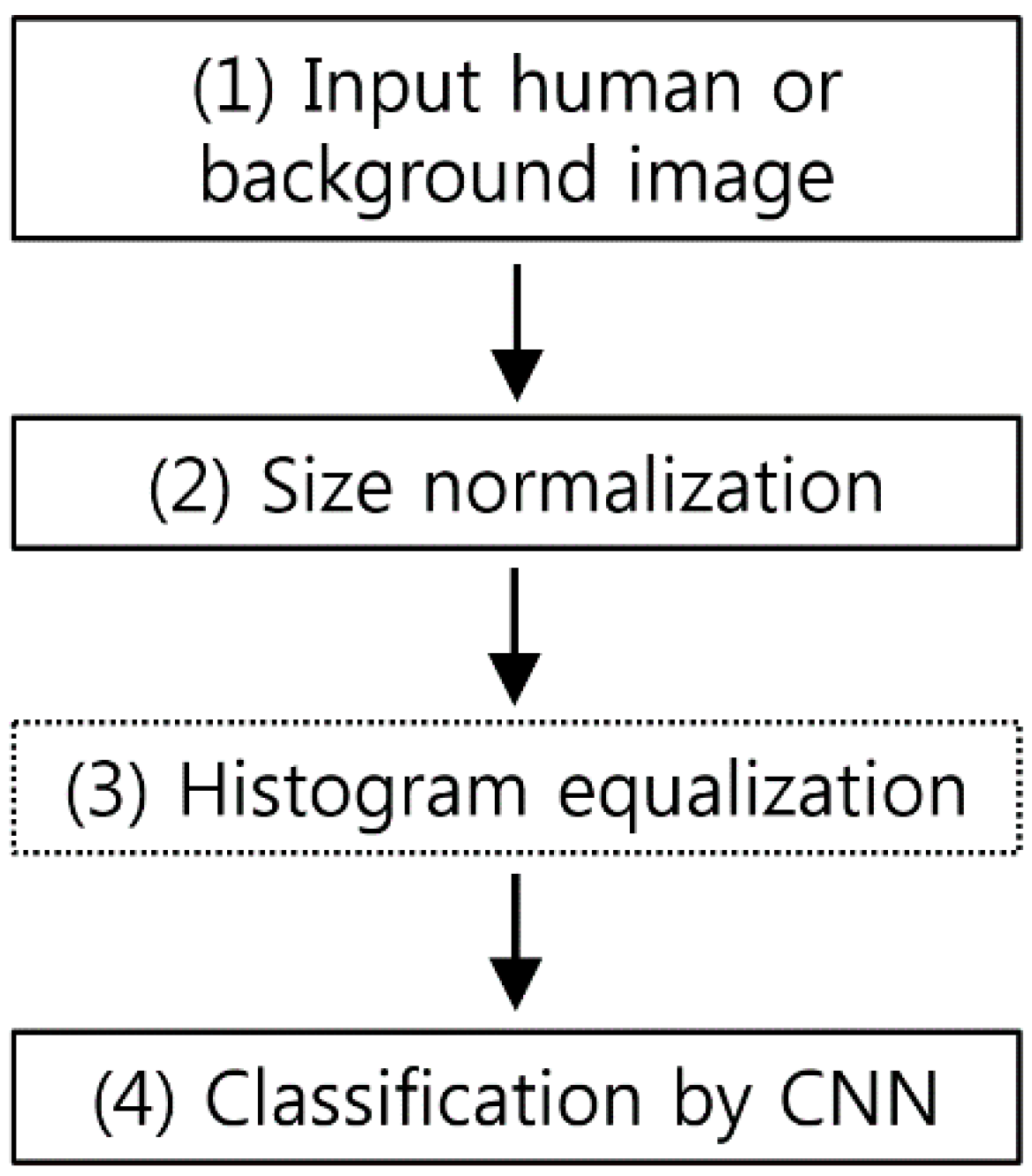
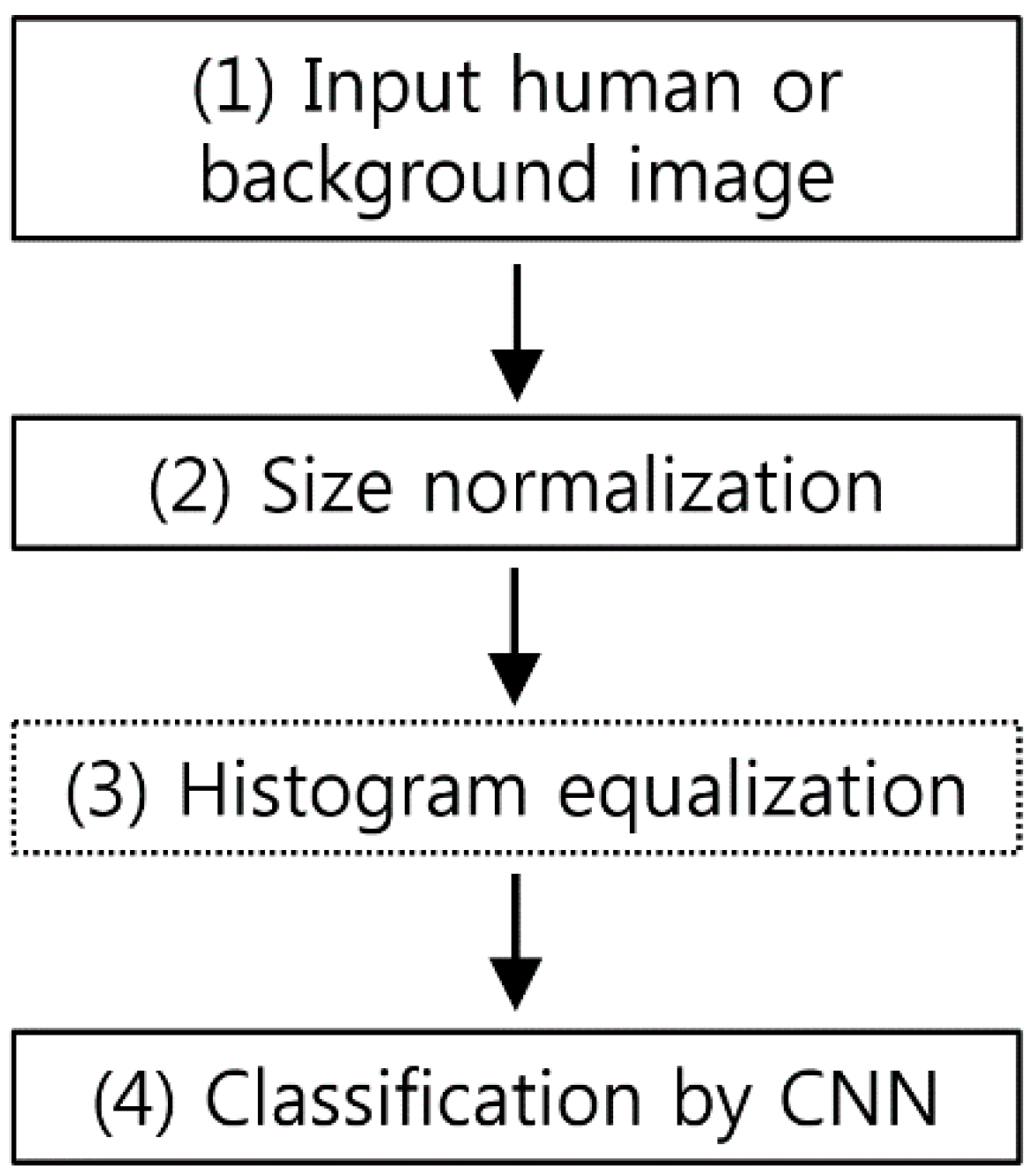
3.1. Overall Procedure of Proposed Method
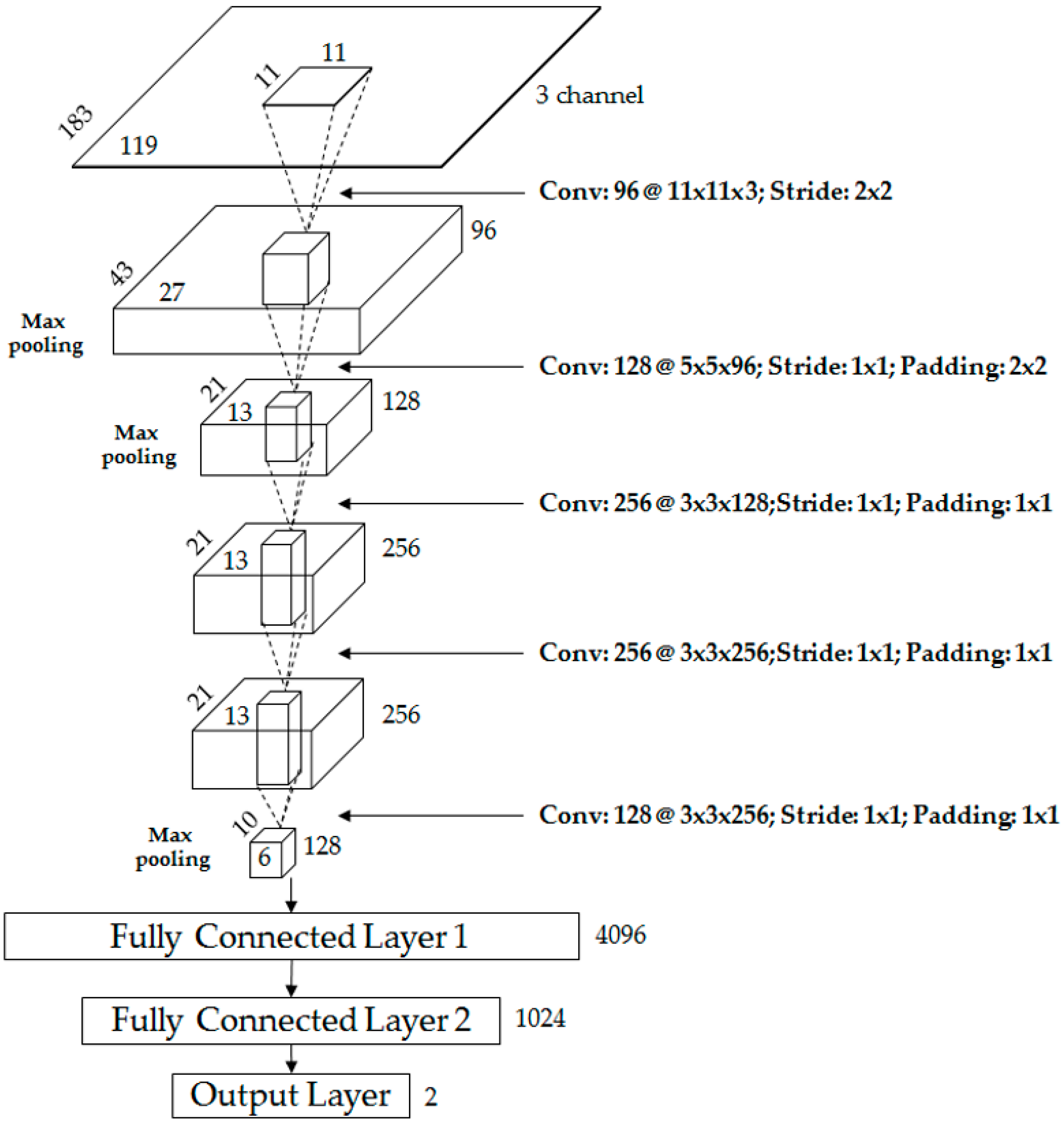
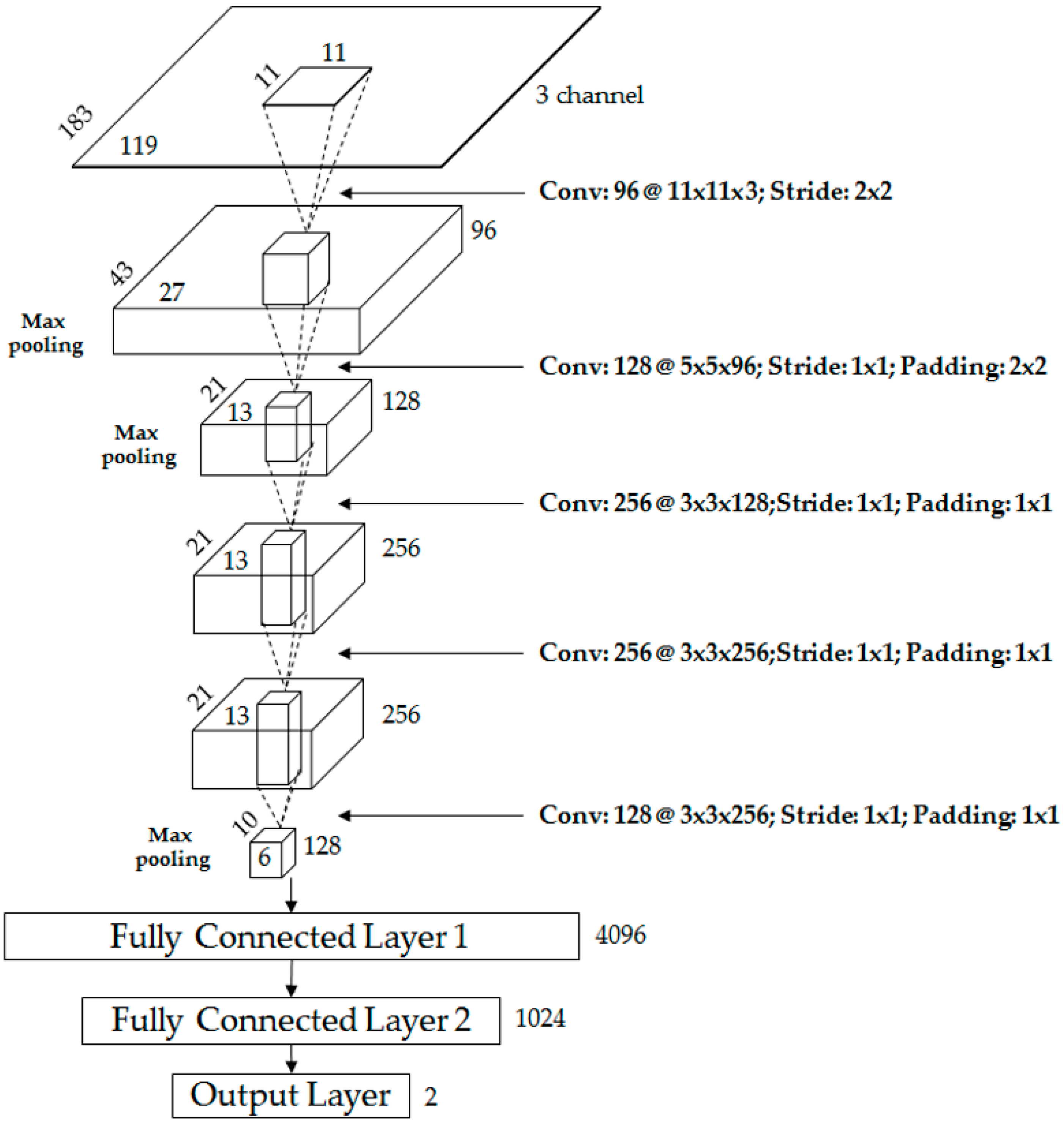
3.2. Convolutional Layers of CNN
3.3. Fully Connected Layers of CNN
4. Experimental Results
4.1. Experimental Data and Environment
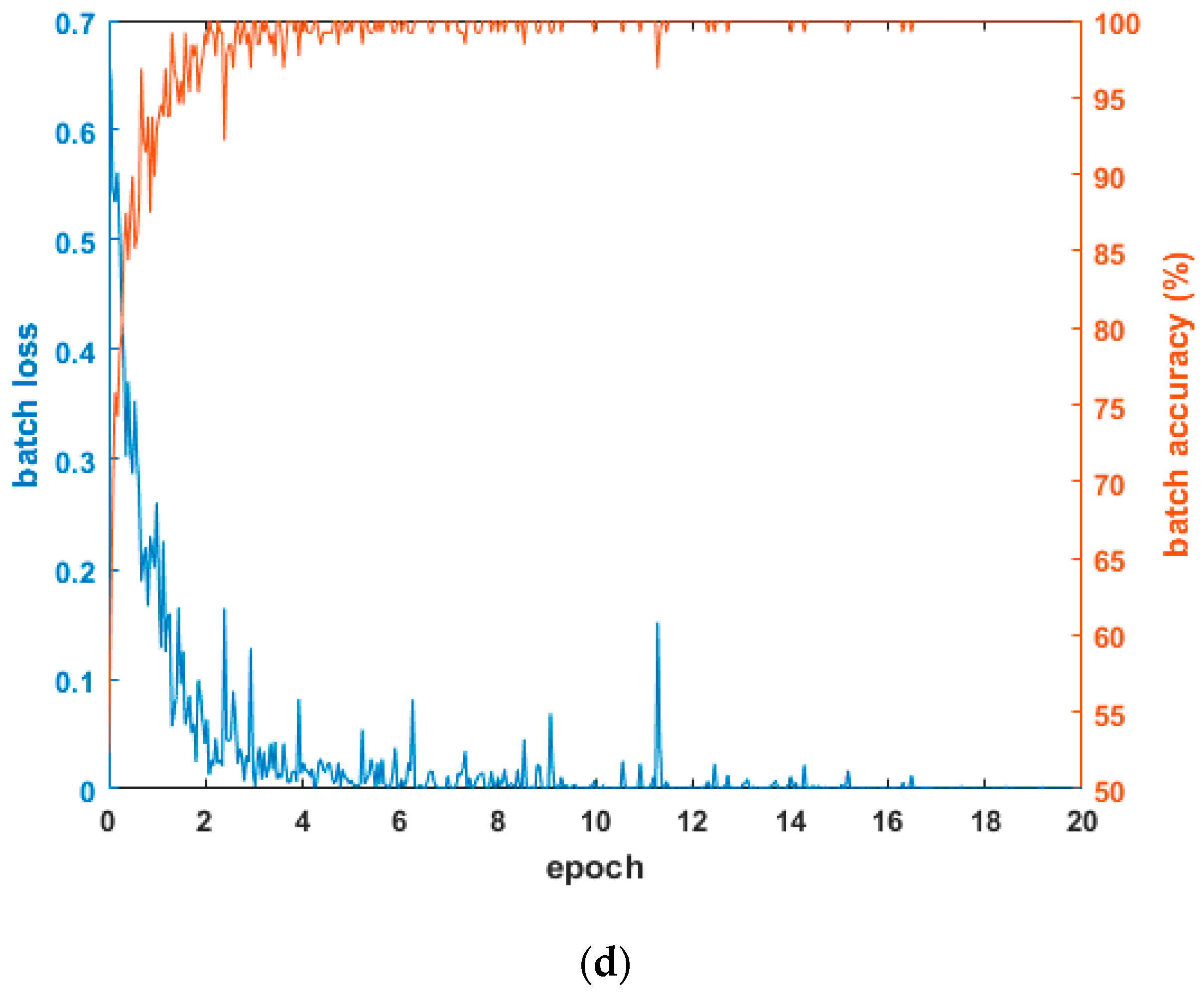
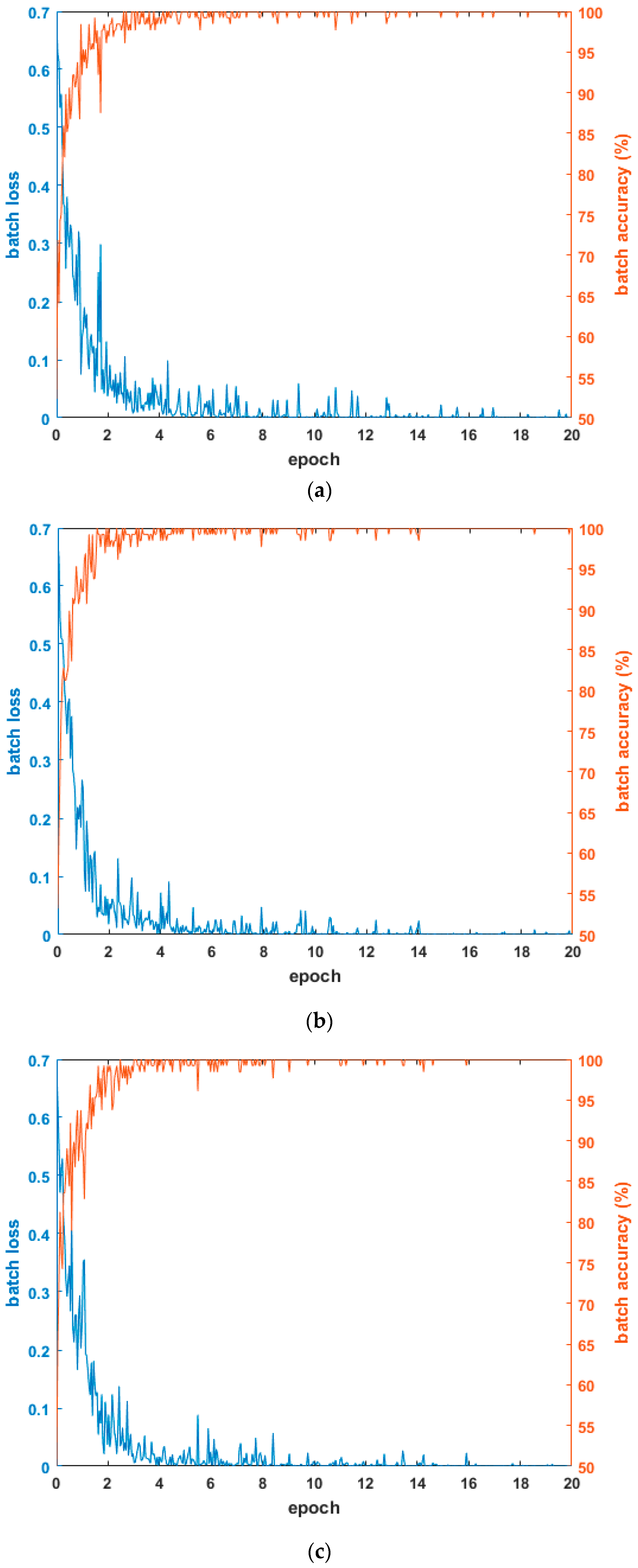
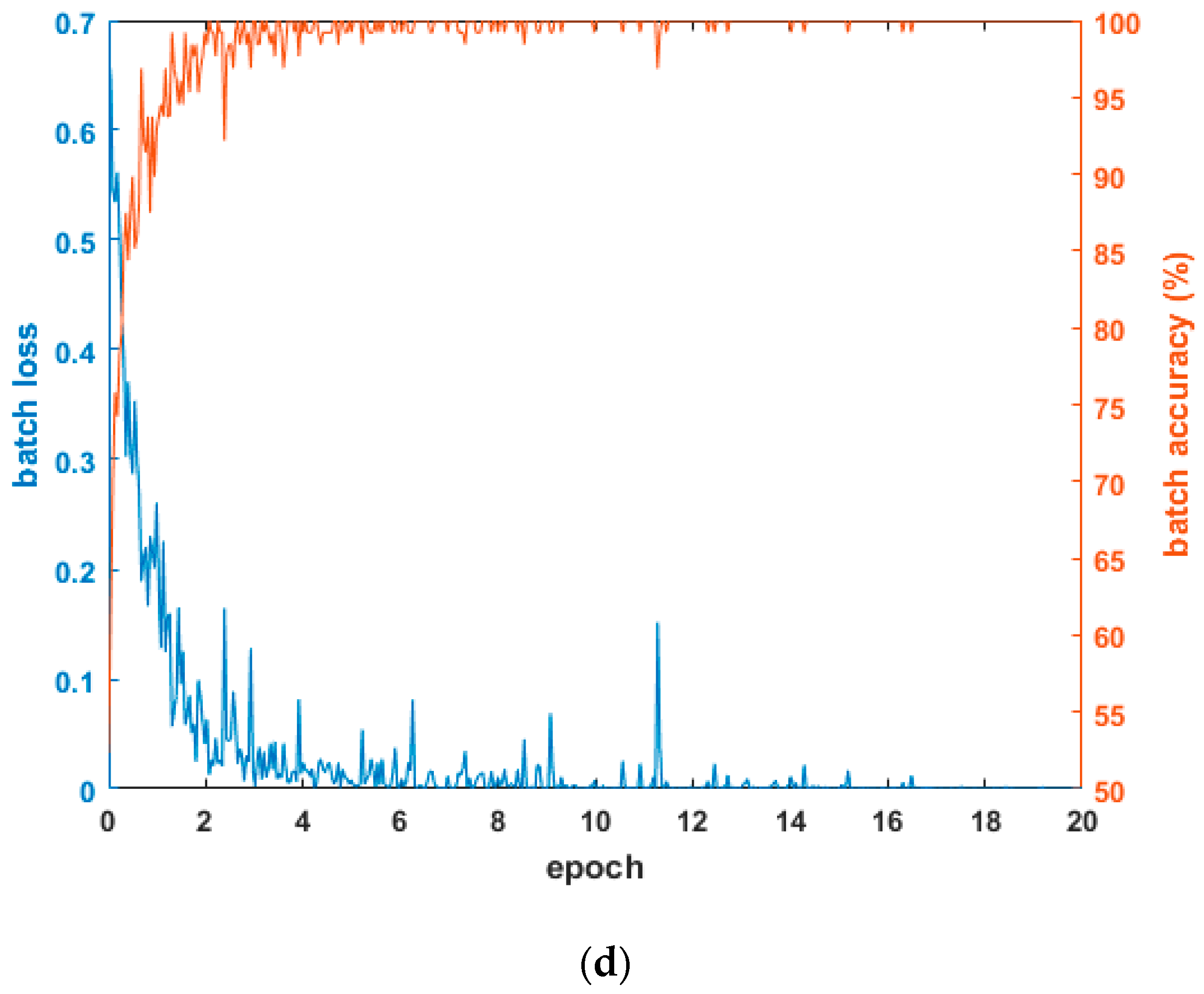
4.2. Training of CNN Model
4.3. Testing of Proposed CNN-Based Human Detection
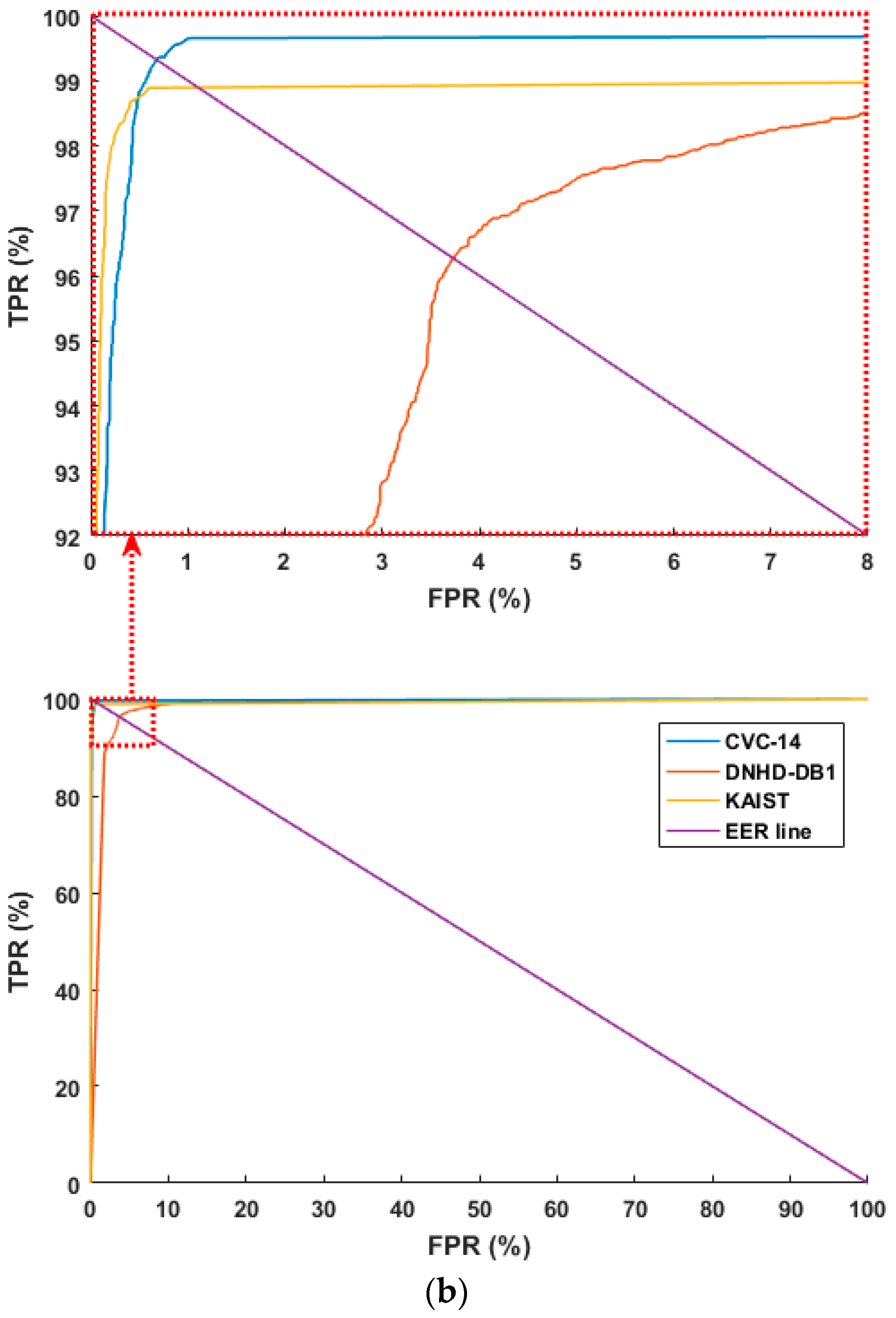
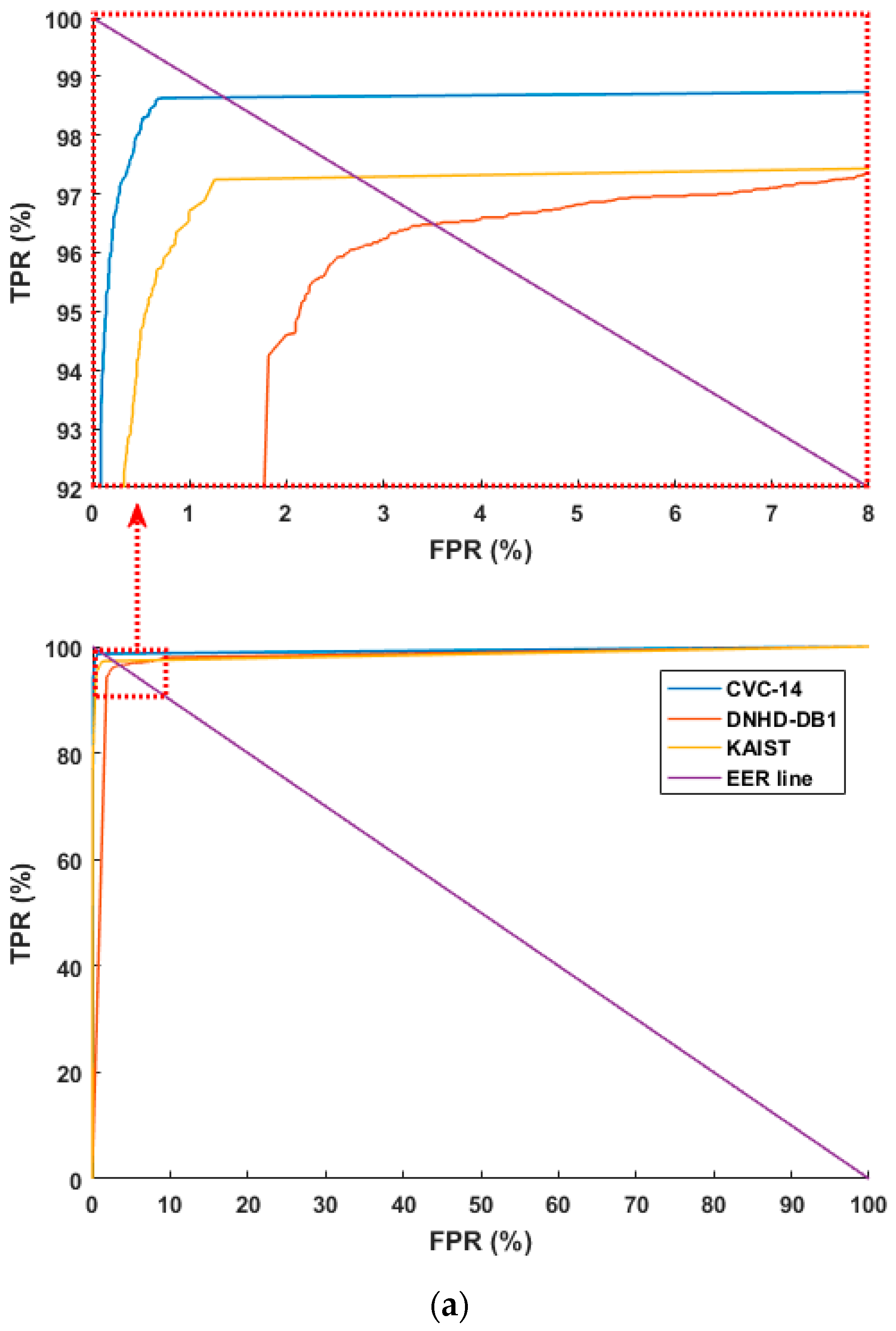
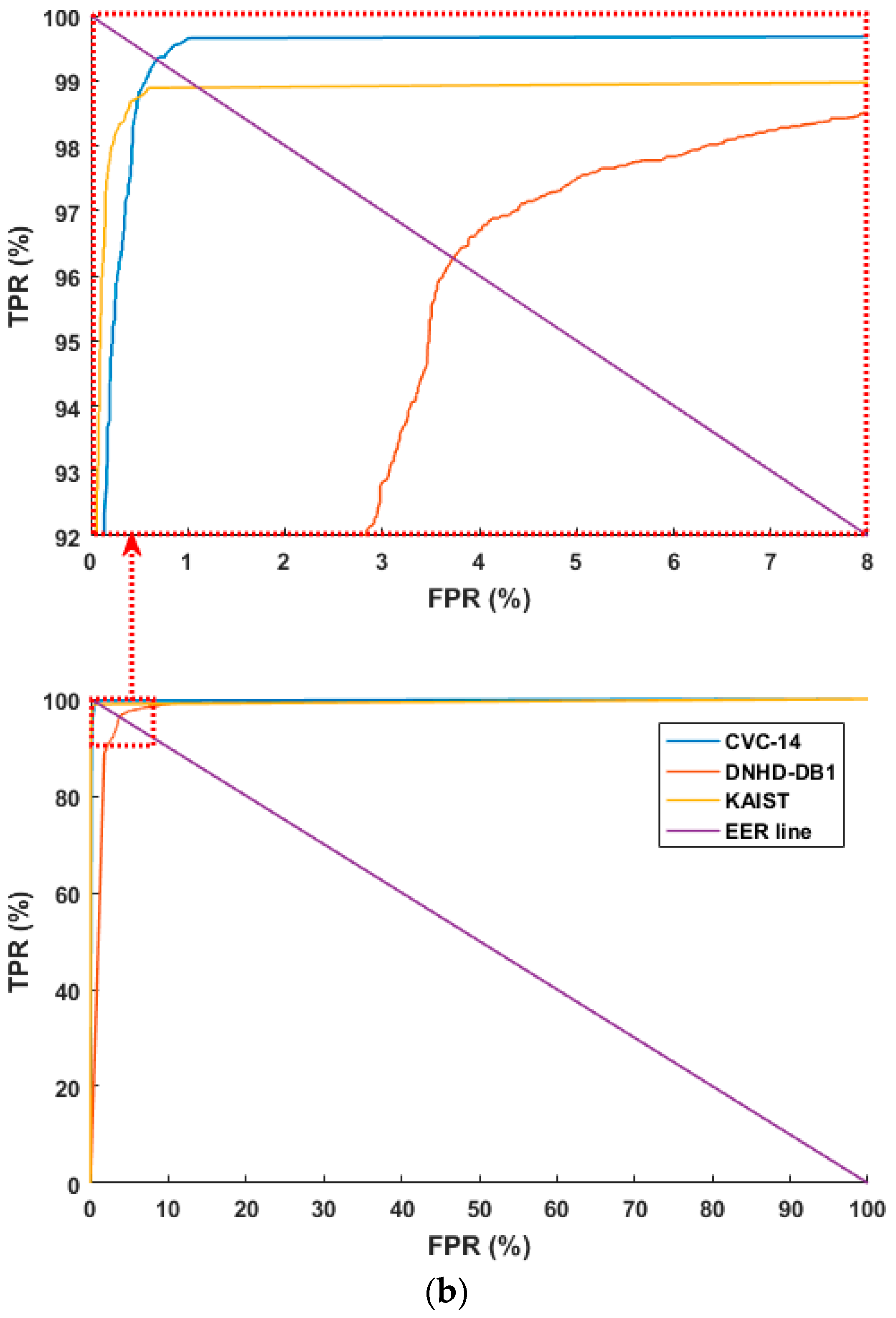
4.3.1. Testing with Separate Database
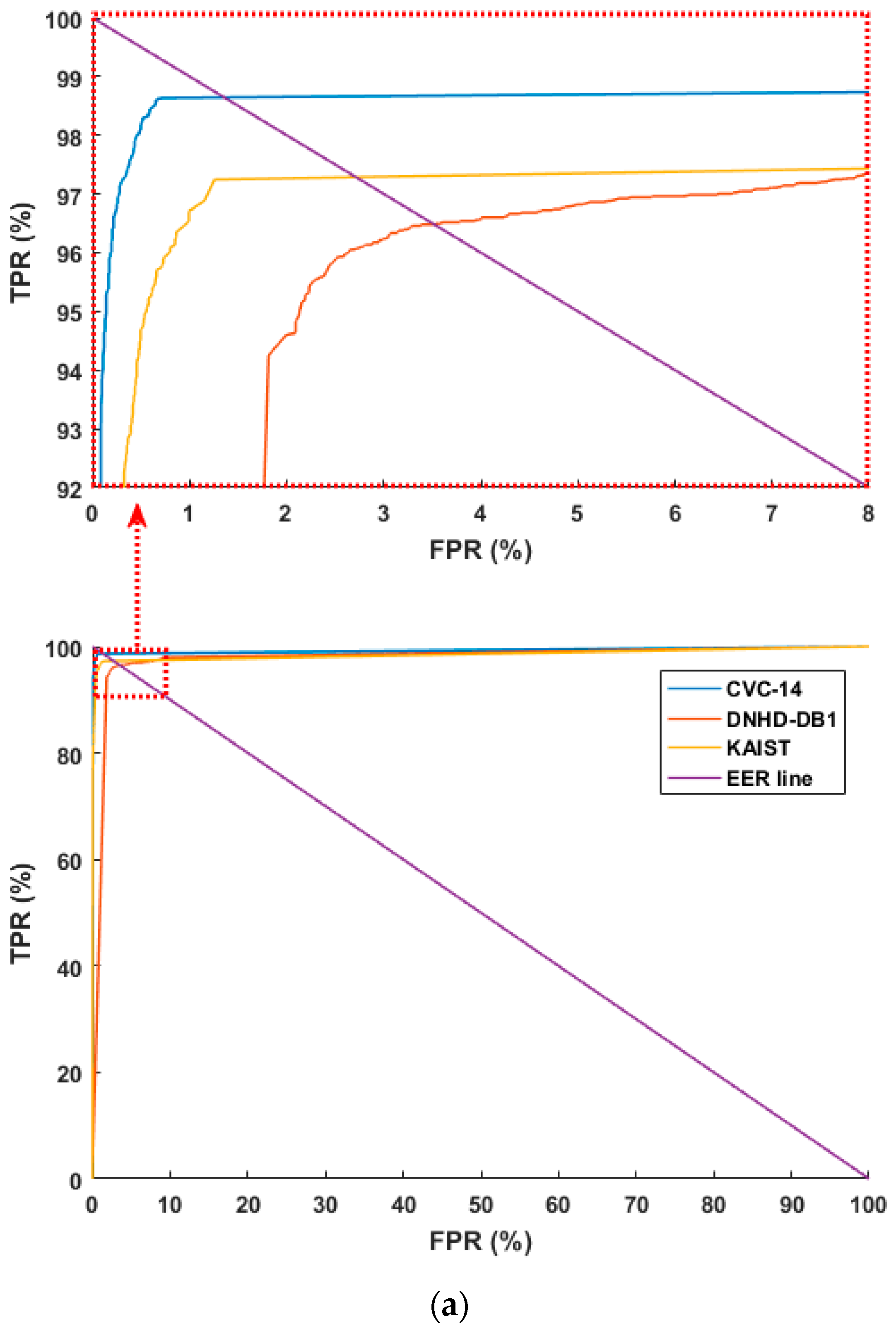
4.3.2. Testing with Combined Database
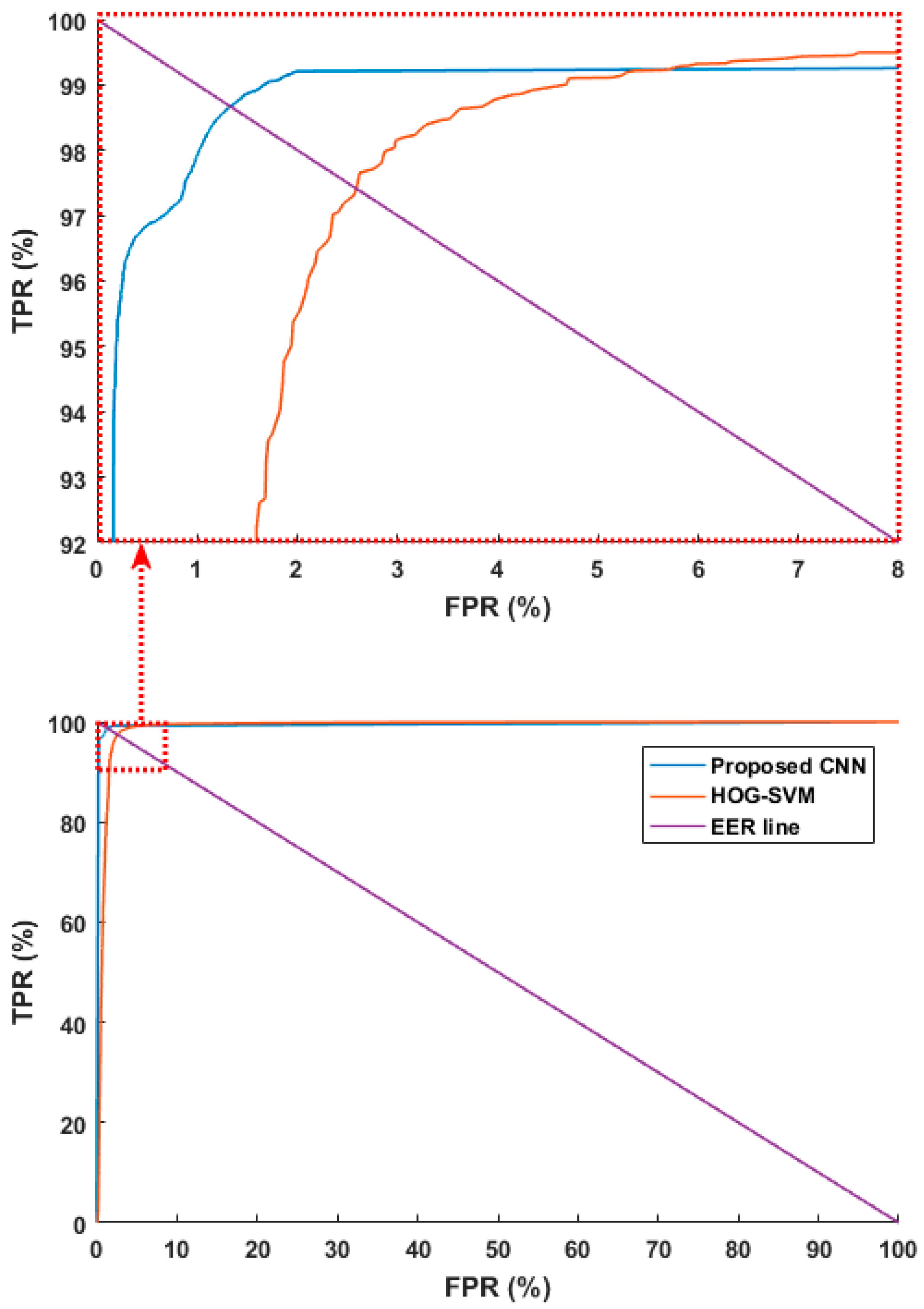
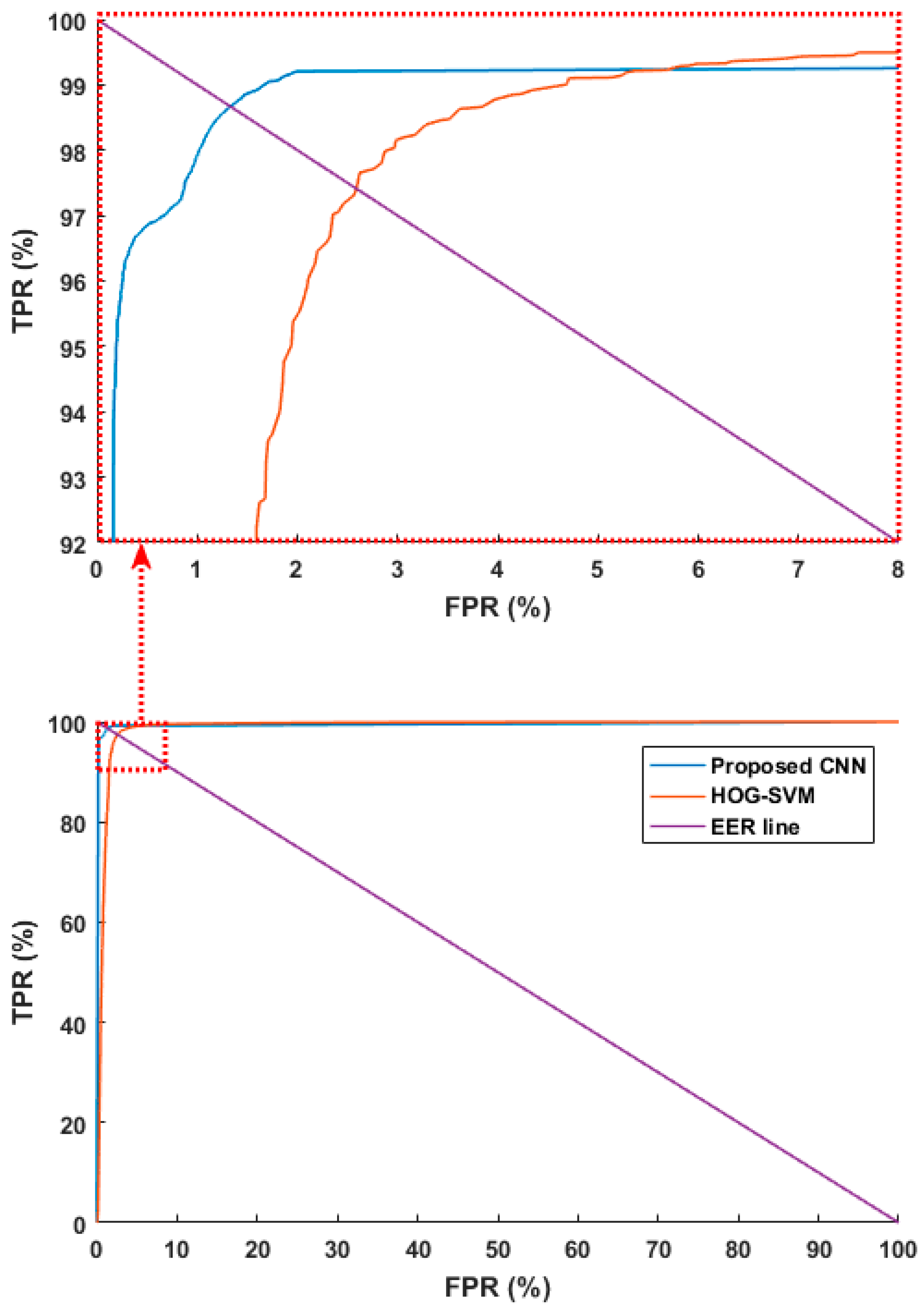
4.3.3. Comparison with Previous Methods
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Lipton, A.J.; Fujiyoshi, H.; Patil, R.S. Moving target classification and tracking from real-time video. In Proceedings of the IEEE Workshop on Applications of Computer Vision, Princeton, NJ, USA, 19–21 October 1998; pp. 8–14. [Google Scholar]
- Oren, M.; Papageorgiou, C.; Sinha, P.; Osuna, E.; Poggio, T. Pedestrian detection using wavelet templates. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Juan, Puerto Rico, 17–19 June 1997; pp. 193–199. [Google Scholar]
- Viola, P.; Jones, M.J.; Snow, D. Detecting pedestrians using patterns of motion and appearance. In Proceedings of the IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; pp. 734–741. [Google Scholar]
- Mikolajczyk, K.; Schmd, C.; Zisserman, A. Human detection based on a probabilistic assembly of robust part detectors. Lect. Notes Comput. Sci. 2004, 3021, 69–82. [Google Scholar]
- Arandjelović, O. Contextually learnt detection of unusual motion-based behaviour in crowded public spaces. In Proceedings of the 26th Annual International Symposium on Computer and Information Science, London, UK, 26–28 September 2011; pp. 403–410. [Google Scholar]
- Martin, R.; Arandjelović, O. Multiple-object tracking in cluttered and crowded public spaces. Lect. Notes Comput. Sci. 2010, 6455, 89–98. [Google Scholar]
- Khatoon, R.; Saqlain, S.M.; Bibi, S. A robust and enhanced approach for human detection in crowd. In Proceedings of the International Multitopic Conference, Islamabad, Pakistan, 13–15 December 2012; pp. 215–221. [Google Scholar]
- Rajaei, A.; Shayegh, H.; Charkari, N.M. Human detection in semi-dense scenes using HOG descriptor and mixture of SVMs. In Proceedings of the International Conference on Computer and Knowledge Engineering, Mashhad, Iran, 31 October–1 November 2013; pp. 229–234. [Google Scholar]
- Lee, J.H.; Choi, J.-S.; Jeon, E.S.; Kim, Y.G.; Le, T.T.; Shin, K.Y.; Lee, H.C.; Park, K.R. Robust pedestrian detection by combining visible and thermal infrared cameras. Sensors 2015, 15, 10580–10615. [Google Scholar] [CrossRef] [PubMed]
- Batchuluun, G.; Kim, Y.G.; Kim, J.H.; Hong, H.G.; Park, K.R. Robust behavior recognition in intelligent surveillance environments. Sensors 2016, 16, 1010. [Google Scholar] [CrossRef] [PubMed]
- Serrano-Cuerda, J.; Fernández-Caballero, A.; López, M.T. Selection of a visible-light vs. thermal infrared sensor in dynamic environments based on confidence measures. Sensors 2014, 4, 331–350. [Google Scholar] [CrossRef]
- Fukui, H.; Yamashita, T.; Yamauchi, Y.; Fujiyoshi, H.; Murase, H. Pedestrian detection based on deep convolutional neural network with ensemble inference network. In Proceedings of the IEEE Intelligent Vehicles Symposium, Seoul, Korea, 28 June–1 July 2015; pp. 223–228. [Google Scholar]
- Angelova, A.; Krizhevsky, A.; Vanhoucke, V.; Ogale, A.; Ferguson, D. Real-time pedestrian detection with deep network cascades. In Proceedings of the 26th British Machine Vision Conference, Swansea, UK, 7–10 September 2015; pp. 1–12. [Google Scholar]
- Komagal, E.; Seenivasan, V.; Anand, K.; Anand raj, C.P. Human detection in hours of darkness using Gaussian mixture model algorithm. Int. J. Inform. Sci. Tech. 2014, 4, 83–89. [Google Scholar] [CrossRef]
- Xu, F.; Liu, X.; Fujimura, K. Pedestrian detection and tracking with night vision. IEEE Trans. Intell. Transp. Syst. 2005, 6, 63–71. [Google Scholar] [CrossRef]
- Pawłowski, P.; Piniarski, K.; Dąbrowski, A. Pedestrian detection in low resolution night vision images. In Proceedings of the IEEE Signal Processing: Algorithms, Architectures, Arrangements, and Applications, Poznań, Poland, 23–25 September 2015; pp. 185–190. [Google Scholar]
- Wang, W.; Zhang, J.; Shen, C. Improved human detection and classification in thermal images. In Proceedings of the IEEE International Conference on Image Processing, Hong Kong, China, 26–29 September 2010; pp. 2313–2316. [Google Scholar]
- Wang, W.; Wang, Y.; Chen, F.; Sowmya, A. A weakly supervised approach for object detection based on soft-label boosting. In Proceedings of the IEEE Workshop on Applications of Computer Vision, Tampa, FL, USA, 15–17 January 2013; pp. 331–338. [Google Scholar]
- Li, W.; Zheng, D.; Zhao, T.; Yang, M. An effective approach to pedestrian detection in thermal imagery. In Proceedings of the International Conference on Natural Computation, Chongqing, China, 29–31 May 2012; pp. 325–329. [Google Scholar]
- Neagoe, V.-E.; Ciotec, A.-D.; Barar, A.-P. A concurrent neural network approach to pedestrian detection in thermal imagery. In Proceedings of the International Conference on Communications, Bucharest, Romania, 21–23 June 2012; pp. 133–136. [Google Scholar]
- Olmeda, D.; Armingol, J.M.; Escalera, A.D.L. Discrete features for rapid pedestrian detection in infrared images. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura, Portugal, 7–12 October 2012; pp. 3067–3072. [Google Scholar]
- Lin, C.-F.; Lin, S.-F.; Hwang, C.-H.; Chen, Y.-C. Real-time pedestrian detection system with novel thermal features at night. In Proceedings of the IEEE International Instrumentation and Measurement Technology Conference, Montevideo, Uruguay, 12–15 May 2014; pp. 1329–1333. [Google Scholar]
- Olmeda, D.; Premebida, C.; Nunes, U.; Armingol, J.M.; Escalera, A.D.L. Pedestrian detection in far infrared images. Integr. Comput. Aided Eng. 2013, 20, 347–360. [Google Scholar]
- Jeon, E.S.; Choi, J.-S.; Lee, J.H.; Shin, K.Y.; Kim, Y.G.; Le, T.T.; Park, K.R. Human detection based on the generation of a background image by using a far-infrared light camera. Sensors 2015, 15, 6763–6788. [Google Scholar] [CrossRef] [PubMed]
- Jeon, E.S.; Kim, J.H.; Hong, H.G.; Batchuluun, G.; Park, K.R. Human detection based on the generation of a background image and fuzzy system by using a thermal camera. Sensors 2016, 16, 453. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Gong, W. Real time pedestrian tracking using thermal infrared imagery. J. Comput. 2010, 5, 1606–1613. [Google Scholar] [CrossRef]
- Chen, Y.; Han, C. Night-time pedestrian detection by visual-infrared video fusion. In Proceedings of the 7th World Congress on Intelligent Control and Automation, Chongqing, China, 25–27 June 2008; pp. 5079–5084. [Google Scholar]
- Huang, K.; Wang, L.; Tan, T.; Maybank, S. A real-time object detecting and tracking system for outdoor night surveillance. Pattern Recognit. 2008, 41, 432–444. [Google Scholar] [CrossRef]
- Nazib, A.; Oh, C.-M.; Lee, C.W. Object detection and tracking in night time video surveillance. In Proceedings of the 10th International Conference on Ubiquitous Robots and Ambient Intelligence, Jeju island, Korea, 31 October–2 November 2013; pp. 629–632. [Google Scholar]
- Tau 2. Available online: http://www.flir.com/cores/display/?id=54717 (accessed on 26 August 2016).
- Ge, J.; Luo, Y.; Tei, G. Real-time pedestrian detection and tracking at nighttime for driver-assistance systems. IEEE Trans. Intell. Transp. Syst. 2009, 10, 283–298. [Google Scholar]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing, 3rd ed.; Prentice Hall: New Jersey, NJ, USA, 2010. [Google Scholar]
- Coltuc, D.; Bolon, P.; Chassery, J.-M. Exact histogram specification. IEEE Trans. Image Process. 2006, 15, 1143–1152. [Google Scholar] [CrossRef] [PubMed]
- Coltuc, D.; Bolon, P. Strict ordering on discrete images and applications. In Proceedings of the IEEE International Conference on Image Processing, Kobe, Japan, 24–28 October 1999; pp. 150–153. [Google Scholar]
- Jen, T.-C.; Hsieh, B.; Wang, S.-J. Image contrast enhancement based on intensity-pair distribution. In Proceedings of the IEEE International Conference on Image Processing, Genova, Italy, 11–14 September 2005; pp. 1–4. [Google Scholar]
- Rivera, A.R.; Ryu, B.; Chae, O. Content-aware dark image enhancement through channel division. IEEE Trans. Image Process. 2012, 21, 3967–3980. [Google Scholar] [CrossRef] [PubMed]
- Abdullah-Al-Wadud, M.; Hasanul Kabir, M.; Ali Akber Dewan, M.; Chae, O. A dynamic histogram equalization for image contrast enhancement. IEEE Trans. Consum. Electron. 2007, 53, 593–600. [Google Scholar] [CrossRef]
- Li, L.; Wang, R.; Wang, W.; Gao, W. A low-light image enhancement method for both denoising and contrast enlarging. In Proceedings of the IEEE International Conference on Image Processing, Québec City, QC, Canada, 27–30 September 2015; pp. 3730–3734. [Google Scholar]
- Malm, H.; Oskarsson, M.; Warrant, E.; Clarberg, P.; Hasselgren, J.; Lejdfors, C. Adaptive enhancement and noise reduction in very low light-level video. In Proceedings of the IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–20 October 2007; pp. 1–8. [Google Scholar]
- Vezzetti, E.; Marcolin, F.; Tornincasa, S.; Maroso, P. Application of geometry to RGB images for facial landmark localization—A preliminary approach. Int. J. Biometrics 2016, 8, 216–236. [Google Scholar] [CrossRef]
- Marcolin, F.; Vezzetti, E. Novel descriptors for geometrical 3D face analysis. Multimedia Tools Appl. 2016, 1–30. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 1–8. [Google Scholar]
- Hajizadeh, M.A.; Ebrahimnezhad, H. Classification of age groups from facial image using histograms of oriented gradients. In Proceedings of the 7th Iranian Conference on Machine Vision and Image Processing, Iran University of Science and Technology (IUST), Tehran, Iran, 16–17 November 2011; pp. 1–5. [Google Scholar]
- Karaaba, M.; Surinta, O.; Schomaker, L.; Wiering, M.A. Robust face recognition by computing distances from multiple histograms of oriented gradients. In Proceedings of the IEEE Symposium Series on Computational Intelligence, Cape Town International Convention Center, Cape Town, South Africa, 7–10 December 2015; pp. 203–209. [Google Scholar]
- Cao, L.; Dikmen, M.; Fu, Y.; Huang, T.S. Gender recognition from body. In Proceedings of the 16th ACM International Conference on Multimedia, Vancouver, BC, Canada, 26–31 October 2008; pp. 725–728. [Google Scholar]
- Nguyen, D.T.; Park, K.R. Body-based gender recognition using images from visible and thermal cameras. Sensors 2016, 16, 156. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems 25; Curran Associates, Inc.: New York, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Taigman, Y.; Yang, M.; Ranzato, M.A.; Wolf, L. Deepface: Closing the gap to human-level performance in face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar]
- Convolutional Neural Networks. Available online: http://www.mathworks.com/help/nnet/convolutional-neural-networks.html (accessed on 20 February 2017).
- CS231n Convolutional Neural Networks for Visual Recognition. Available online: http://cs231n.github.io/convolutional-networks/#overview (accessed on 23 February 2017).
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Convolutional Neural Network. Available online: https://en.wikipedia.org/wiki/Convolutional_neural_network (accessed on 28 February 2017).
- Heaton, J. Artificial Intelligence for Humans. In Deep Learning and Neural Networks; Heaton Research, Inc.: St. Louis, MO, USA, 2015; Volume 3. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the 14th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Dongguk Night-Time Human Detection Database (DNHD-DB1). Available online: http://dm.dgu.edu/link.html (accessed on 28 February 2017).
- Webcam C600. Available online: http://www.logitech.com/en-us/support/5869 (accessed on 28 February 2017).
- Hwang, S.; Park, J.; Kim, N.; Choi, Y.; Kweon, I.S. Multispectral pedestrian detection: Benchmark dataset and baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- González, A.; Fang, Z.; Socarras, Y.; Serrat, J.; Vázquez, D.; Xu, J.; López, A.M. Pedestrian detection at day/night time with visible and FIR cameras: A comparison. Sensors 2016, 16, 820. [Google Scholar] [CrossRef] [PubMed]
- Intel® Core™ i7-6700 Processor. Available online: http://ark.intel.com/products/88196/Intel-Core-i7-6700-Processor-8M-Cache-up-to-4_00-GHz (accessed on 20 February 2017).
- GeForce GTX TITAN X. Available online: http://www.geforce.com/hardware/desktop-gpus/geforce-gtx-titan-x/specifications (accessed on 20 February 2017).
- Stochastic Gradient Descent. Available online: https://en.wikipedia.org/wiki/Stochastic_gradient_descent (accessed on 28 February 2017).
- TrainingOptions. Available online: http://kr.mathworks.com/help/nnet/ref/trainingoptions.html (accessed on 28 February 2017).
- Precision and Recall. Available online: https://en.wikipedia.org/wiki/Precision_and_recall (accessed on 28 February 2017).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Method | Advantages | Disadvantages | |
|---|---|---|---|---|
| Multiple camera-based method | Using visible light and FIR cameras [27] | Spatial-temporal filtering, seeded region growing, and min-max score fusion | Uses data from two cameras to improve human detection accuracy |
|
| Single camera-based methods | Using IR camera (NIR or FIR camera) | GMM [14], SVM classifier with feature vector from human region [15] and by HOG [16] | Uses one camera, which eliminates the need for calibration, and has a faster processing time than multiple camera-based methods | |
| Using visible light camera | Uses local change in contrast over time [28,29] | Uses low-cost visible light cameras |
| |
| Histogram processing or intensity mapping-based image enhancement [32,33,34,35,36,37] | Uses low-cost visible light cameras |
| ||
| Denoising and image enhancement [38,39] | Effectively removes noise that occurs during image enhancement |
| ||
| CNN (proposed method) | Independently processes single images. Thus, even stationary objects can be detected. Can be used with moving or fixed cameras |
| ||
| Layer Type | Number of Filters | Size of Feature Map | Size of Kernel | Number of Stride | Number of Padding |
|---|---|---|---|---|---|
| Image input layer | 183 (height) × 119 (width) × 3 (channel) | ||||
| 1st convolutional layer | 96 | 87 × 55 × 96 | 11 × 11 × 3 | 2 × 2 | 0 × 0 |
| ReLU layer | 87 × 55 × 96 | ||||
| Cross channel normalization layer | 87 × 55 × 96 | ||||
| Max pooling layer | 1 | 43 × 27 × 96 | 3 × 3 | 2 × 2 | 0 × 0 |
| 2nd convolutional layer | 128 | 43 × 27 × 128 | 5 × 5 × 96 | 1 × 1 | 2 × 2 |
| ReLU layer | 43 × 27 × 128 | ||||
| Cross channel normalization layer | 43 × 27 × 128 | ||||
| Max pooling layer | 1 | 21 × 13 × 128 | 3 × 3 | 2 × 2 | 0 × 0 |
| 3rd convolutional layer | 256 | 21 × 13 × 256 | 3 × 3 × 128 | 1 × 1 | 1 × 1 |
| ReLU layer | 21 × 13 × 256 | ||||
| 4th convolutional layer | 256 | 21 × 13 × 256 | 3 × 3 × 256 | 1 × 1 | 1 × 1 |
| ReLU layer | 21 × 13 × 256 | ||||
| 5th convolutional layer | 128 | 21 × 13 × 128 | 3 × 3 × 256 | 1 × 1 | 1 × 1 |
| ReLU layer | 21 × 13 × 128 | ||||
| Max pooling layer | 1 | 10 × 6 × 128 | 3 × 3 | 2 × 2 | 0 × 0 |
| 1st fully connected layer | 4096 | ||||
| ReLU layer | 4096 | ||||
| 2nd fully connected layer | 1024 | ||||
| ReLU layer | 1024 | ||||
| Dropout layer | 1024 | ||||
| 3rd fully connected layer | 2 | ||||
| Softmax layer | 2 | ||||
| Classification layer (output layer) | 2 |
| DNHD-DB1 | CVC-14 Database | KAIST Database | ||
|---|---|---|---|---|
| Number of images | Human | 19,760 | 36,920 | 37,336 |
| Background | 19,760 | 36,920 | 37,336 | |
| Number of channel | Color (3 channels) | Gray (1 channel) | Color (3 channels) | |
| Width of human (background) image (min.~max.) (pixels) | 15–219 | 64 | 21–106 | |
| Height of human (background) image (min.~max.) (pixels) | 45–313 | 128 | 27–293 | |
| Environment of database collection |
|
| ||
| (a) | |||
| 1st fold | Recognized | ||
| Human | Background | ||
| Actual | Human | 96.59 | 3.41 |
| Background | 0.27 | 99.73 | |
| (b) | |||
| 2nd fold | Recognized | ||
| Human | Background | ||
| Actual | Human | 97.11 | 2.89 |
| Background | 0.22 | 99.78 | |
| (c) | |||
| 3rd fold | Recognized | ||
| Human | Background | ||
| Actual | Human | 96.27 | 3.73 |
| Background | 0.38 | 99.62 | |
| (d) | |||
| 4th fold | Recognized | ||
| Human | Background | ||
| Actual | Human | 97.27 | 2.73 |
| Background | 0.21 | 99.79 | |
| (e) | |||
| 1st fold | Recognized | ||
| Human | Background | ||
| Actual | Human | 96.36 | 3.64 |
| Background | 2.61 | 97.39 | |
| (f) | |||
| 2nd fold | Recognized | ||
| Human | Background | ||
| Actual | Human | 95.99 | 4.01 |
| Background | 7.01 | 92.99 | |
| (g) | |||
| 3rd fold | Recognized | ||
| Human | Background | ||
| Actual | Human | 96.82 | 3.18 |
| Background | 4.54 | 95.46 | |
| (h) | |||
| 4th fold | Recognized | ||
| Human | Background | ||
| Actual | Human | 96.68 | 3.32 |
| Background | 2.90 | 97.10 | |
| (i) | |||
| 1st fold | Recognized | ||
| Human | Background | ||
| Actual | Human | 92.63 | 7.37 |
| Background | 0.14 | 99.86 | |
| (j) | |||
| 2nd fold | Recognized | ||
| Human | Background | ||
| Actual | Human | 83.02 | 16.98 |
| Background | 0.32 | 99.68 | |
| (k) | |||
| 3rd fold | Recognized | ||
| Human | Background | ||
| Actual | Human | 86.16 | 13.84 |
| Background | 0.50 | 99.50 | |
| (l) | |||
| 4th fold | Recognized | ||
| Human | Background | ||
| Actual | Human | 95.02 | 4.98 |
| Background | 0.25 | 99.75 | |
| (a) | |||
| 1st fold | Recognized | ||
| Human | Background | ||
| Actual | Human | 96.08 | 3.92 |
| Background | 0.26 | 99.74 | |
| (b) | |||
| 2nd fold | Recognized | ||
| Human | Background | ||
| Actual | Human | 98.88 | 1.12 |
| Background | 0.31 | 99.69 | |
| (c) | |||
| 3rd fold | Recognized | ||
| Human | Background | ||
| Actual | Human | 95.99 | 4.01 |
| Background | 0.46 | 99.54 | |
| (d) | |||
| 4th fold | Recognized | ||
| Human | Background | ||
| Actual | Human | 96.42 | 3.58 |
| Background | 0.31 | 99.69 | |
| (e) | |||
| 1st fold | Recognized | ||
| Human | Background | ||
| Actual | Human | 92.55 | 7.45 |
| Background | 3.73 | 96.27 | |
| (f) | |||
| 2nd fold | Recognized | ||
| Human | Background | ||
| Actual | Human | 97.69 | 2.31 |
| Background | 4.80 | 95.20 | |
| (g) | |||
| 3rd fold | Recognized | ||
| Human | Background | ||
| Actual | Human | 97.17 | 2.83 |
| Background | 6.34 | 93.66 | |
| (h) | |||
| 4th fold | Recognized | ||
| Human | Background | ||
| Actual | Human | 97.15 | 2.85 |
| Background | 3.16 | 96.84 | |
| (i) | |||
| 1st fold | Recognized | ||
| Human | Background | ||
| Actual | Human | 93.03 | 6.97 |
| Background | 0.14 | 99.86 | |
| (j) | |||
| 2nd fold | Recognized | ||
| Human | Background | ||
| Actual | Human | 96.19 | 3.81 |
| Background | 0.11 | 99.89 | |
| (k) | |||
| 3rd fold | Recognized | ||
| Human | Background | ||
| Actual | Human | 97.98 | 2.02 |
| Background | 0.13 | 99.87 | |
| (l) | |||
| 4th fold | Recognized | ||
| Human | Background | ||
| Actual | Human | 96.50 | 3.50 |
| Background | 0.14 | 99.86 | |
| Database | PPV | TPR | ACC | F_Score |
|---|---|---|---|---|
| CVC-14 database | 99.72 | 96.81 | 98.27 | 98.24 |
| DNHD-DB1 | 95.73 | 96.46 | 96.09 | 96.09 |
| KAIST database | 99.64 | 89.21 | 94.60 | 94.07 |
| Average | 98.36 | 94.16 | 96.32 | 96.13 |
| Database | PPV | TPR | ACC | F_Score |
|---|---|---|---|---|
| CVC-14 database | 99.65 | 96.84 | 98.25 | 98.23 |
| DNHD-DB1 | 95.48 | 96.14 | 95.81 | 95.79 |
| KAIST database | 99.85 | 95.93 | 97.95 | 97.84 |
| Average | 98.33 | 96.30 | 97.34 | 97.29 |
| Kinds of Input Image to CNN | PPV | TPR | ACC | F_Score |
|---|---|---|---|---|
| Original | 99.31 | 93.44 | 96.44 | 96.26 |
| HE | 99.11 | 97.65 | 98.41 | 98.38 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.H.; Hong, H.G.; Park, K.R. Convolutional Neural Network-Based Human Detection in Nighttime Images Using Visible Light Camera Sensors. Sensors 2017, 17, 1065. https://doi.org/10.3390/s17051065
Kim JH, Hong HG, Park KR. Convolutional Neural Network-Based Human Detection in Nighttime Images Using Visible Light Camera Sensors. Sensors. 2017; 17(5):1065. https://doi.org/10.3390/s17051065
Chicago/Turabian StyleKim, Jong Hyun, Hyung Gil Hong, and Kang Ryoung Park. 2017. "Convolutional Neural Network-Based Human Detection in Nighttime Images Using Visible Light Camera Sensors" Sensors 17, no. 5: 1065. https://doi.org/10.3390/s17051065
APA StyleKim, J. H., Hong, H. G., & Park, K. R. (2017). Convolutional Neural Network-Based Human Detection in Nighttime Images Using Visible Light Camera Sensors. Sensors, 17(5), 1065. https://doi.org/10.3390/s17051065