
Chemical Source Localization Fusing Concentration Information in the Presence of Chemical Background Noise

 , ,
, ,  and
and 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Stochastic Models for Plume and Background
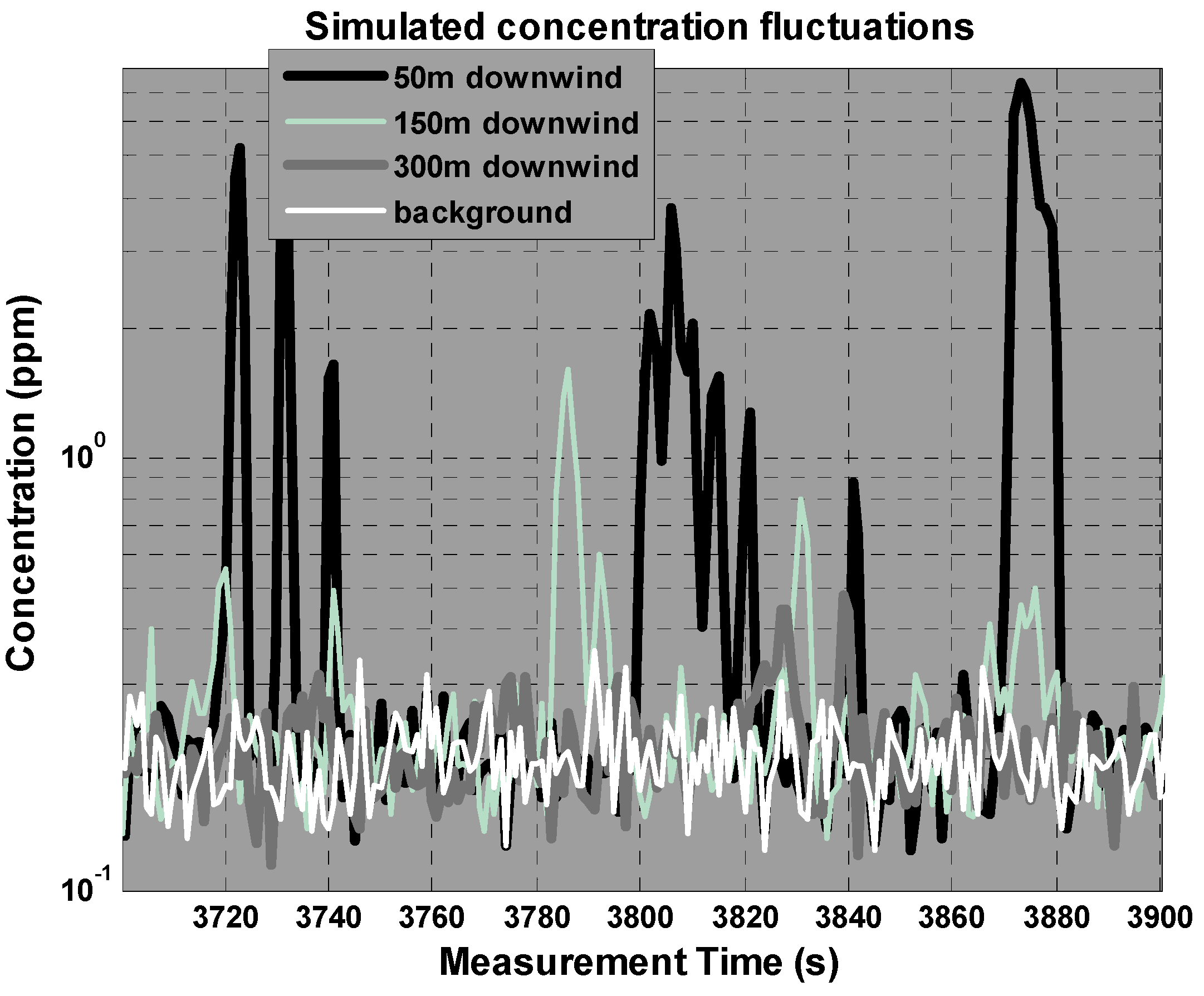
2.1.1. Stochastic Model for Chemical Concentration Measurements
2.1.2. Stochastic Background Model
2.2. Estimation of the Models From the Concentration Readings
2.2.1. Bayesian Estimation of the Likelihood Map for Chemical Source Presence
2.2.2. Background Estimation
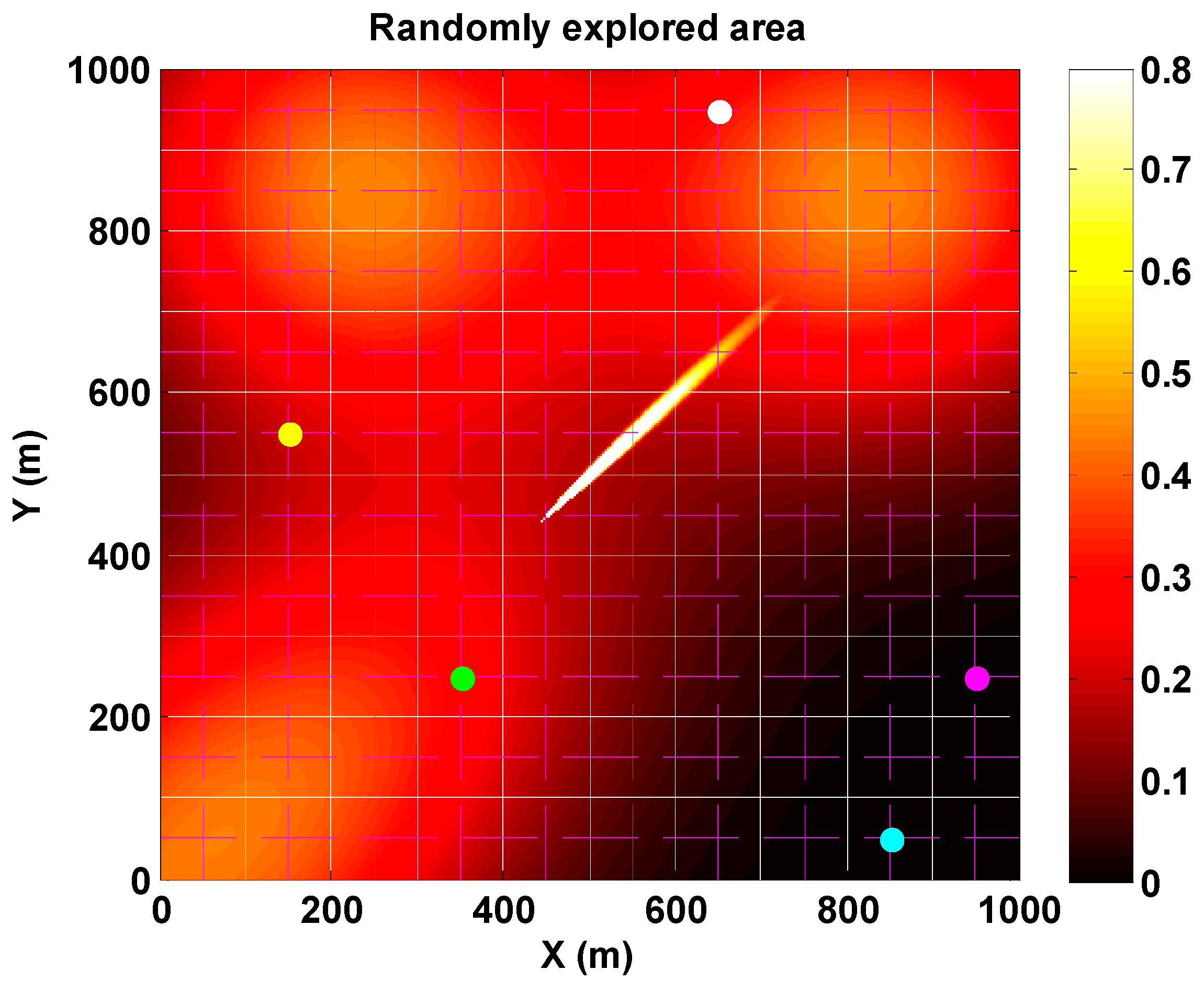
2.3. Description of the Synthetic Test Cases
2.3.1. Synthetic Scenario Description and Simulation
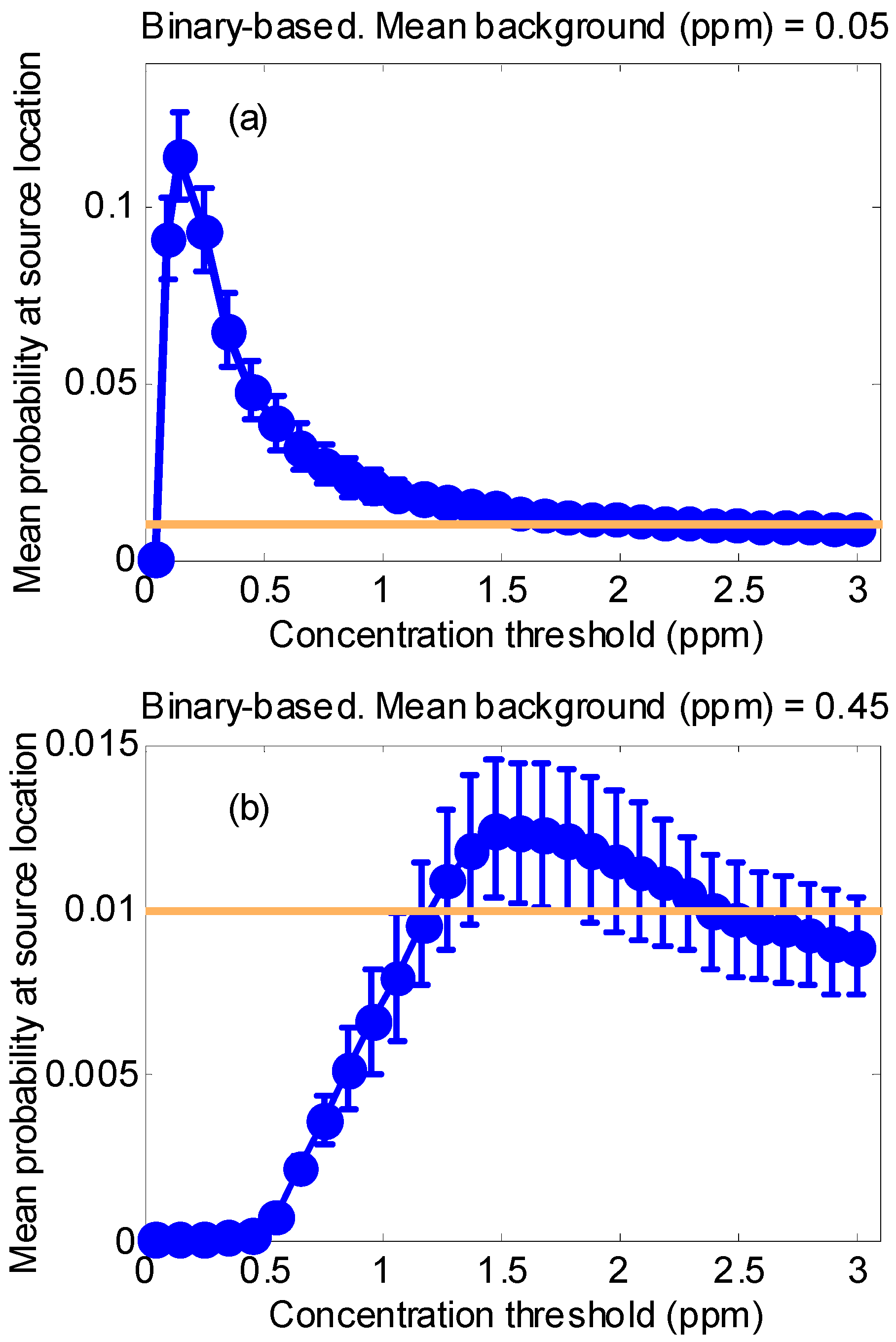
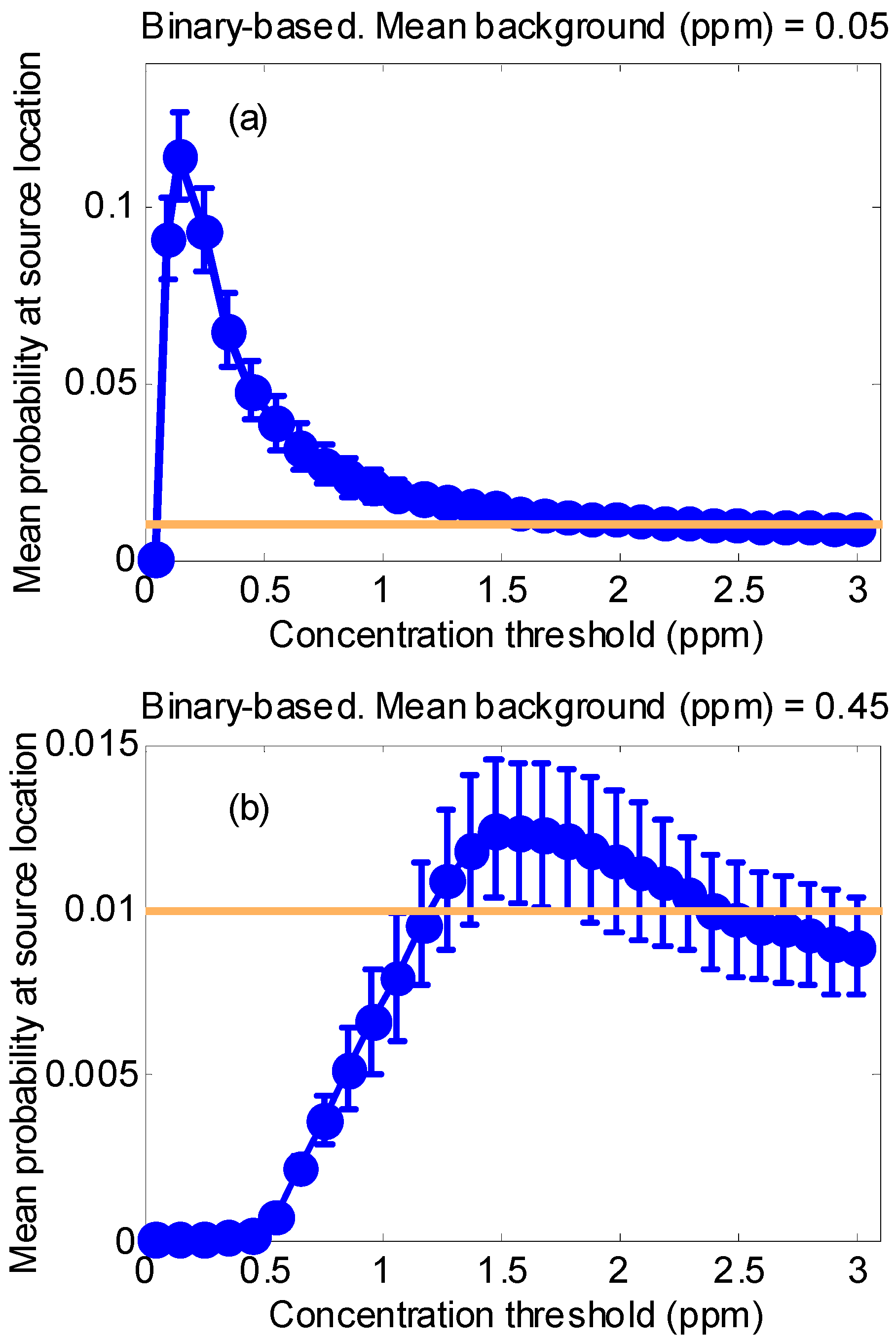
2.3.2. Synthetic Test Case 1: Behavior of the Binary Detector Algorithm Depending on the Background Level and Detector Threshold
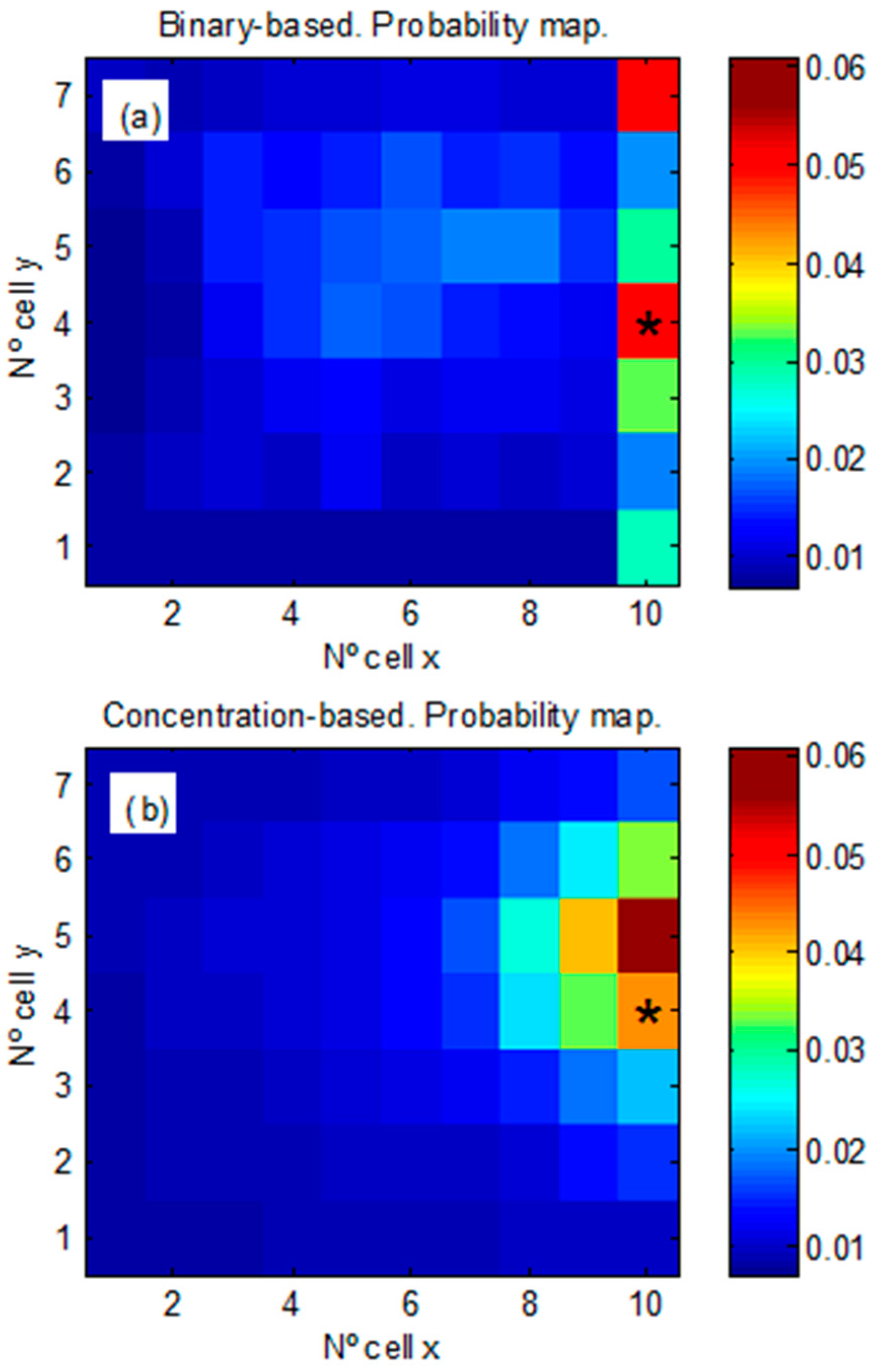
2.3.3. Synthetic Test Case 2: Accuracy in the Estimation of the Background Level and the Expected Position of the Chemical Source
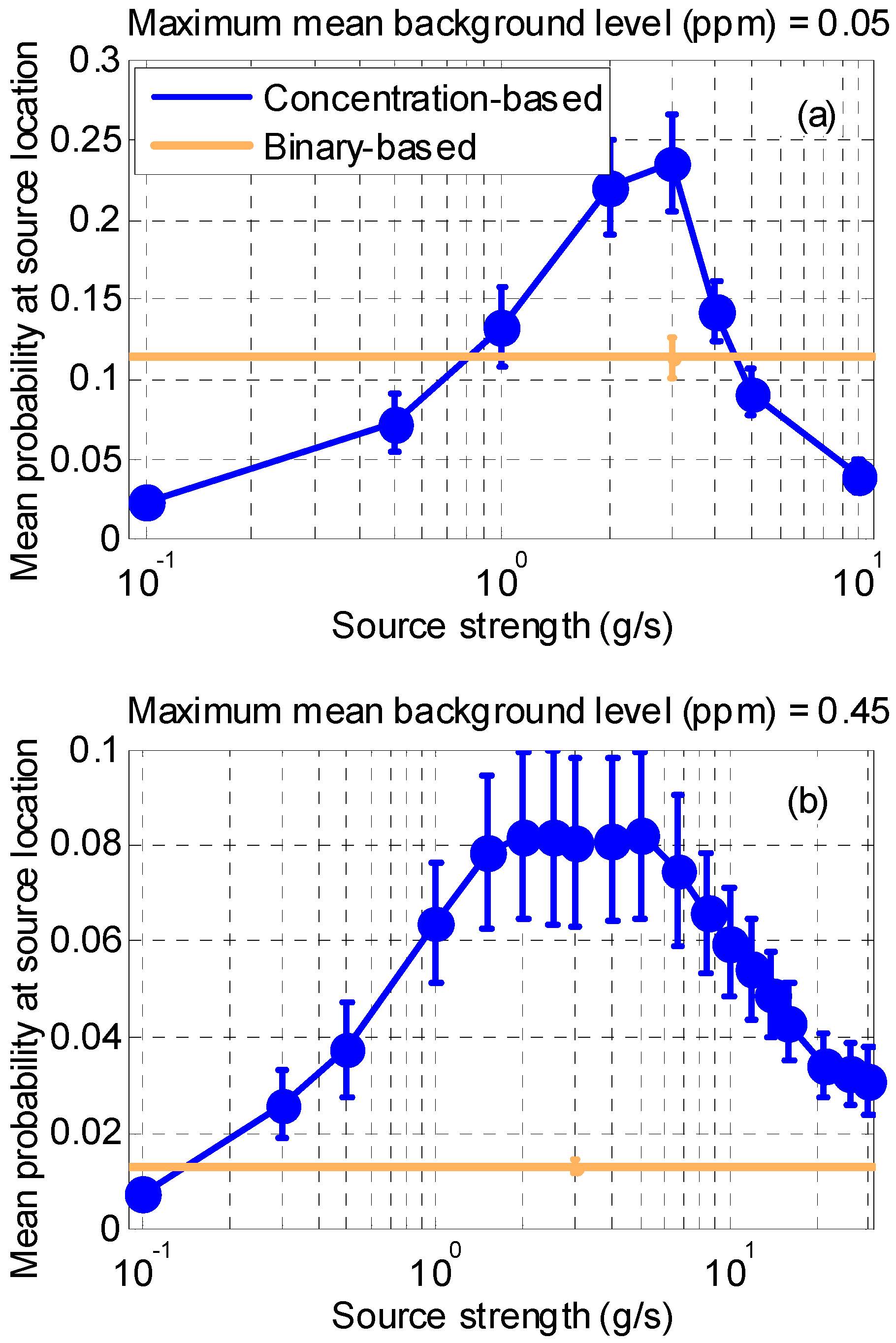
2.3.4. Synthetic Case 3: Influence of the Source Strength on the Concentration Based Algorithm
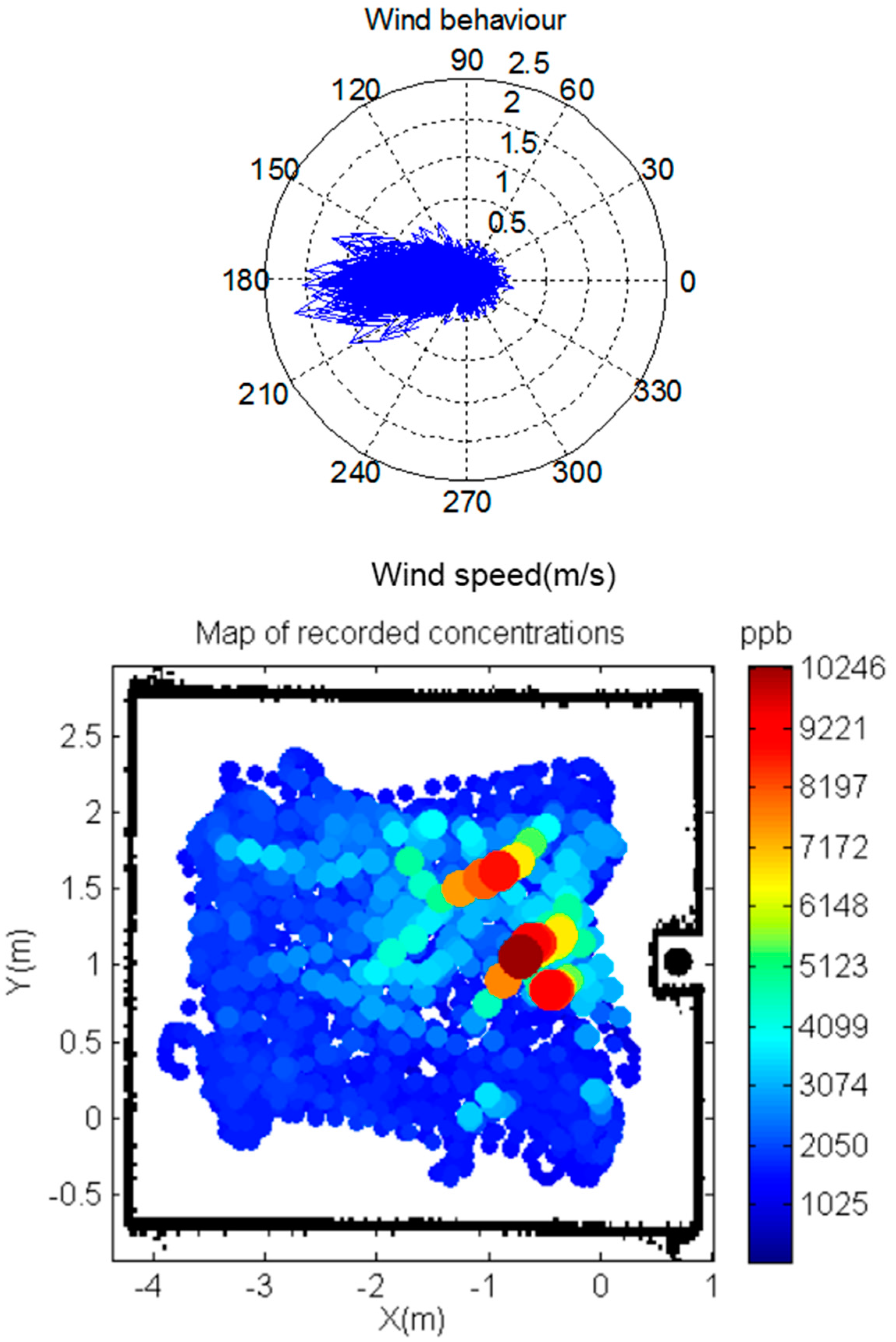
2.4. Scenario, Chemical Source Emission and Autonomous Vehicle Description for Real Experiments
3. Results and Discussion
3.1. Results of Algorithms Evaluation for Synthetic Experiments
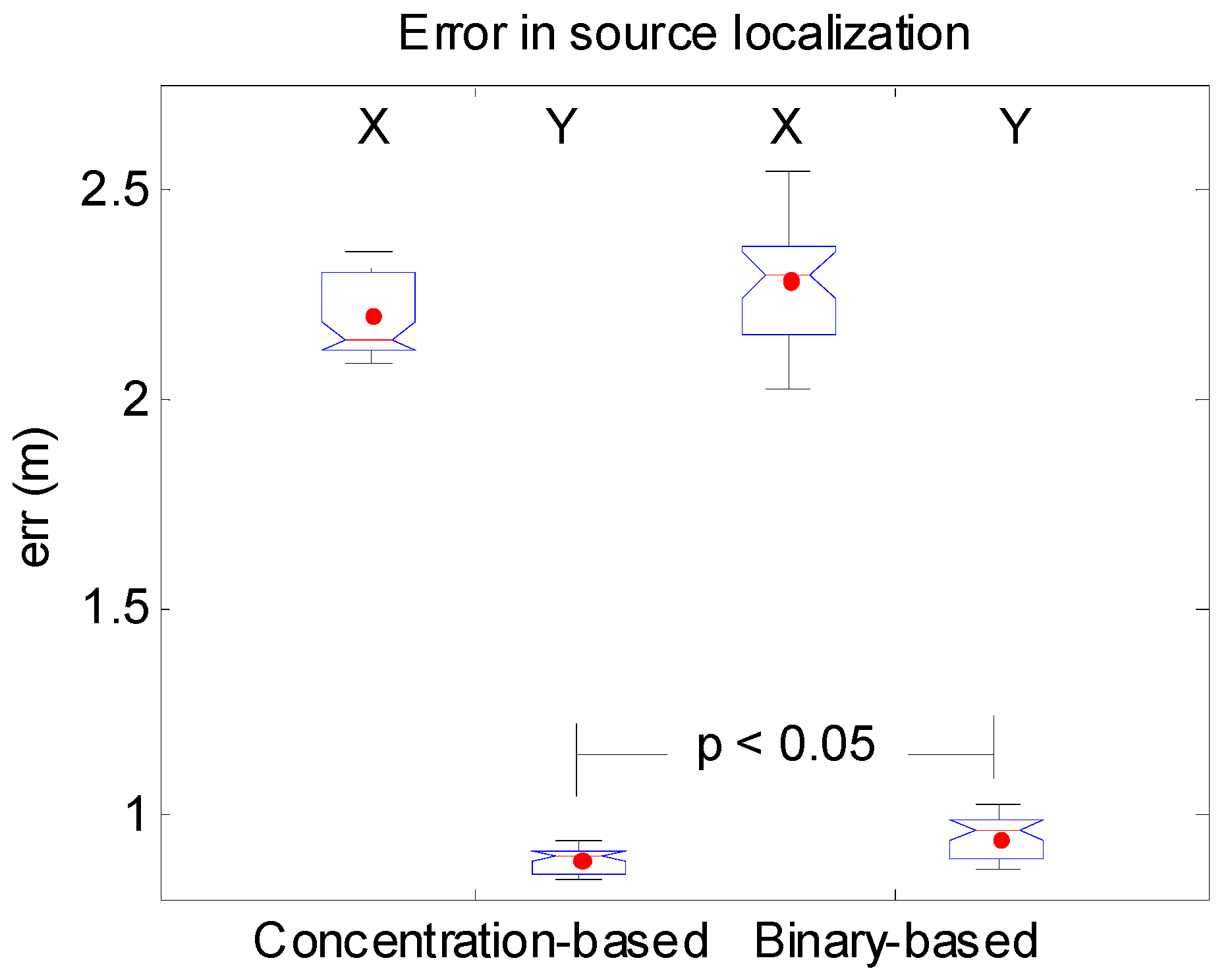
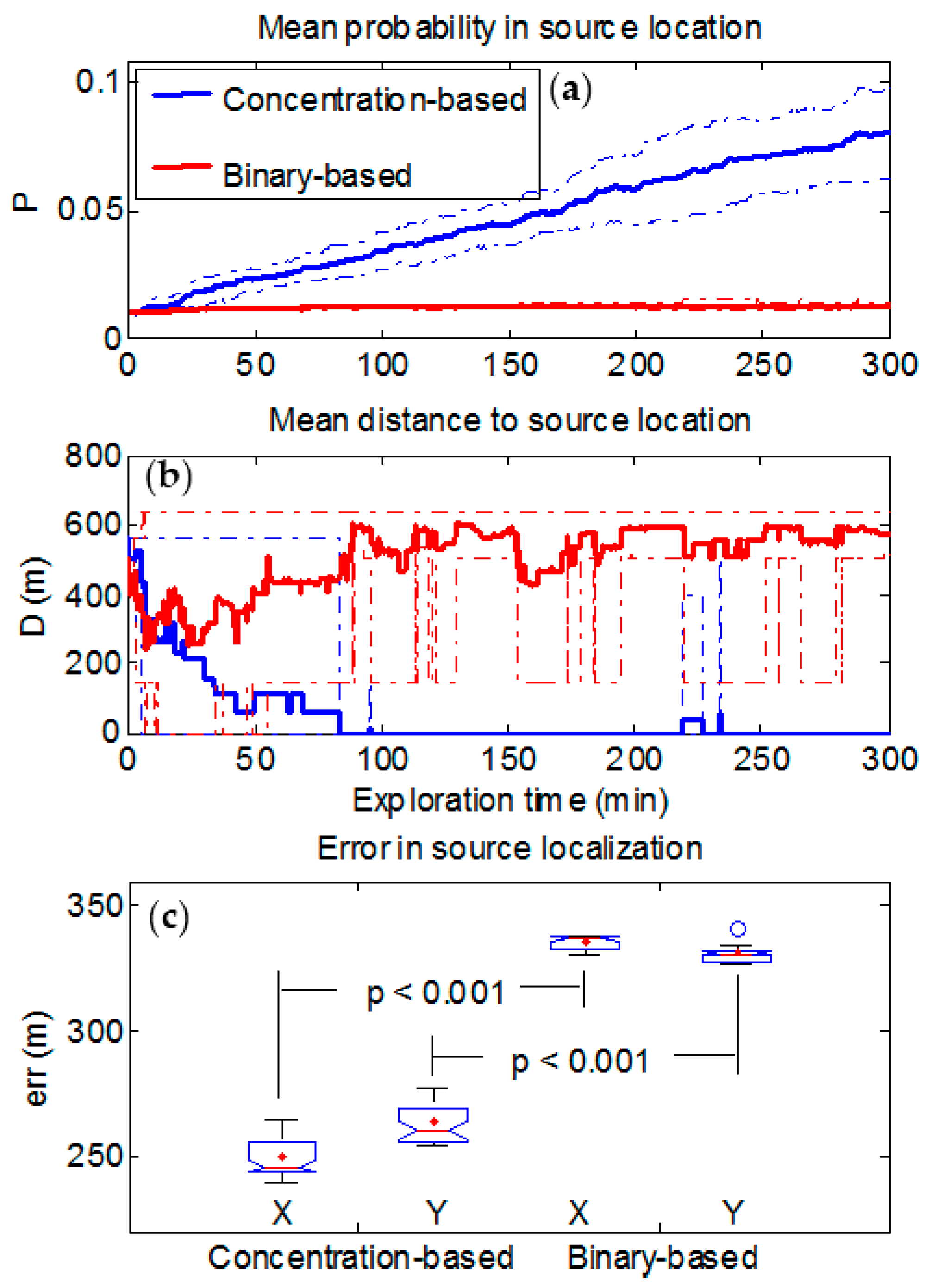
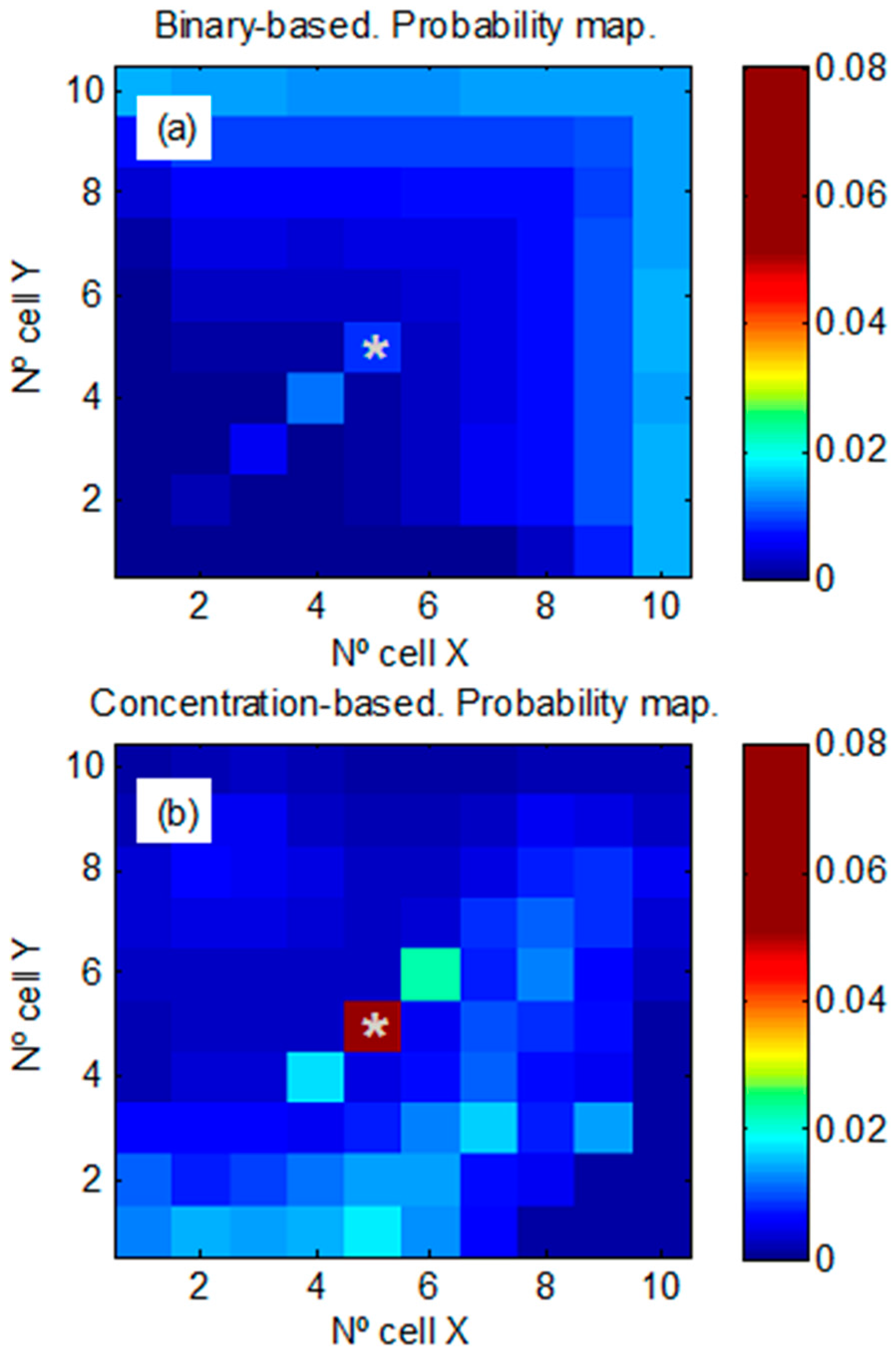
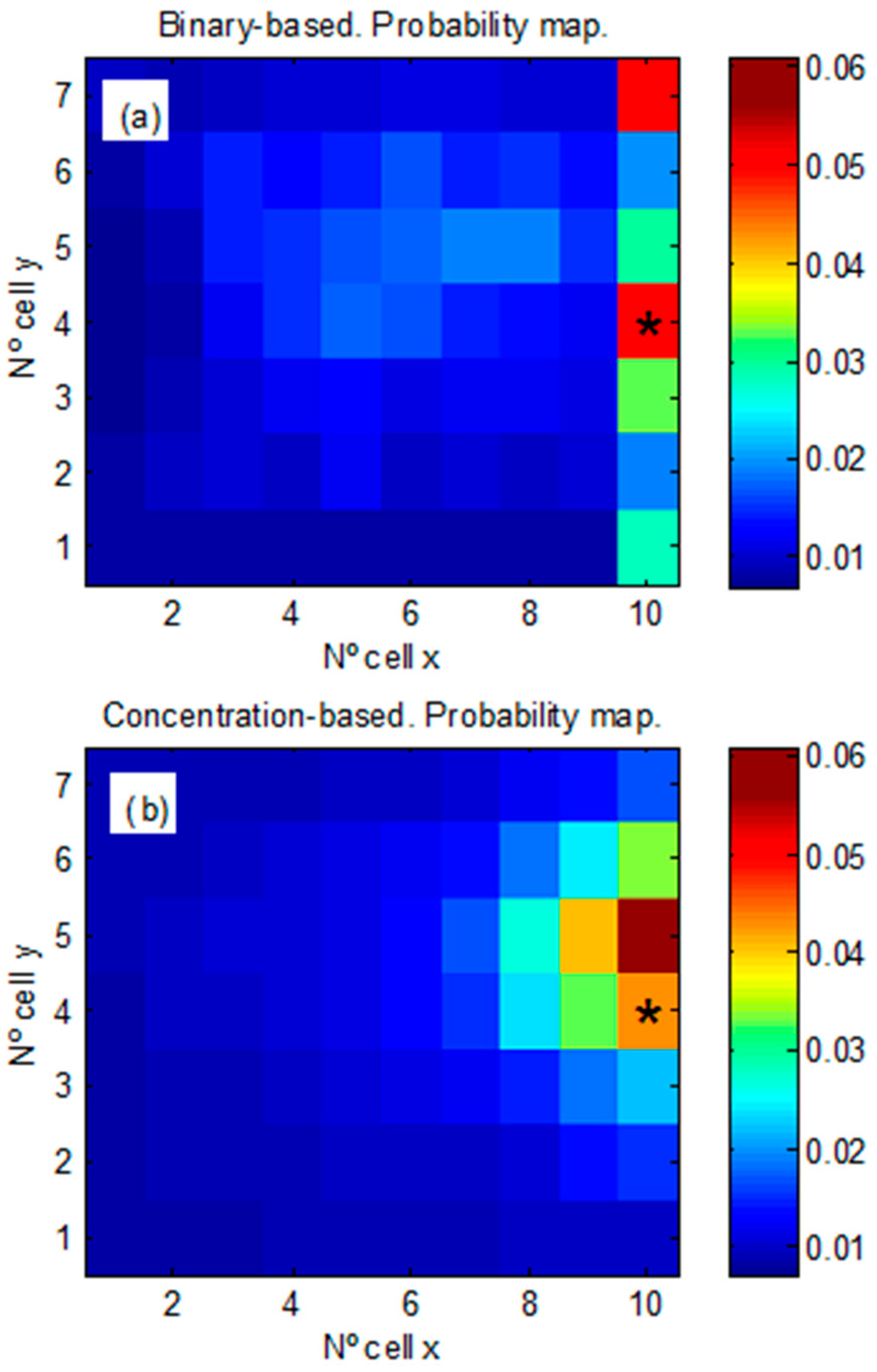
3.1.1. Synthetic Case 1
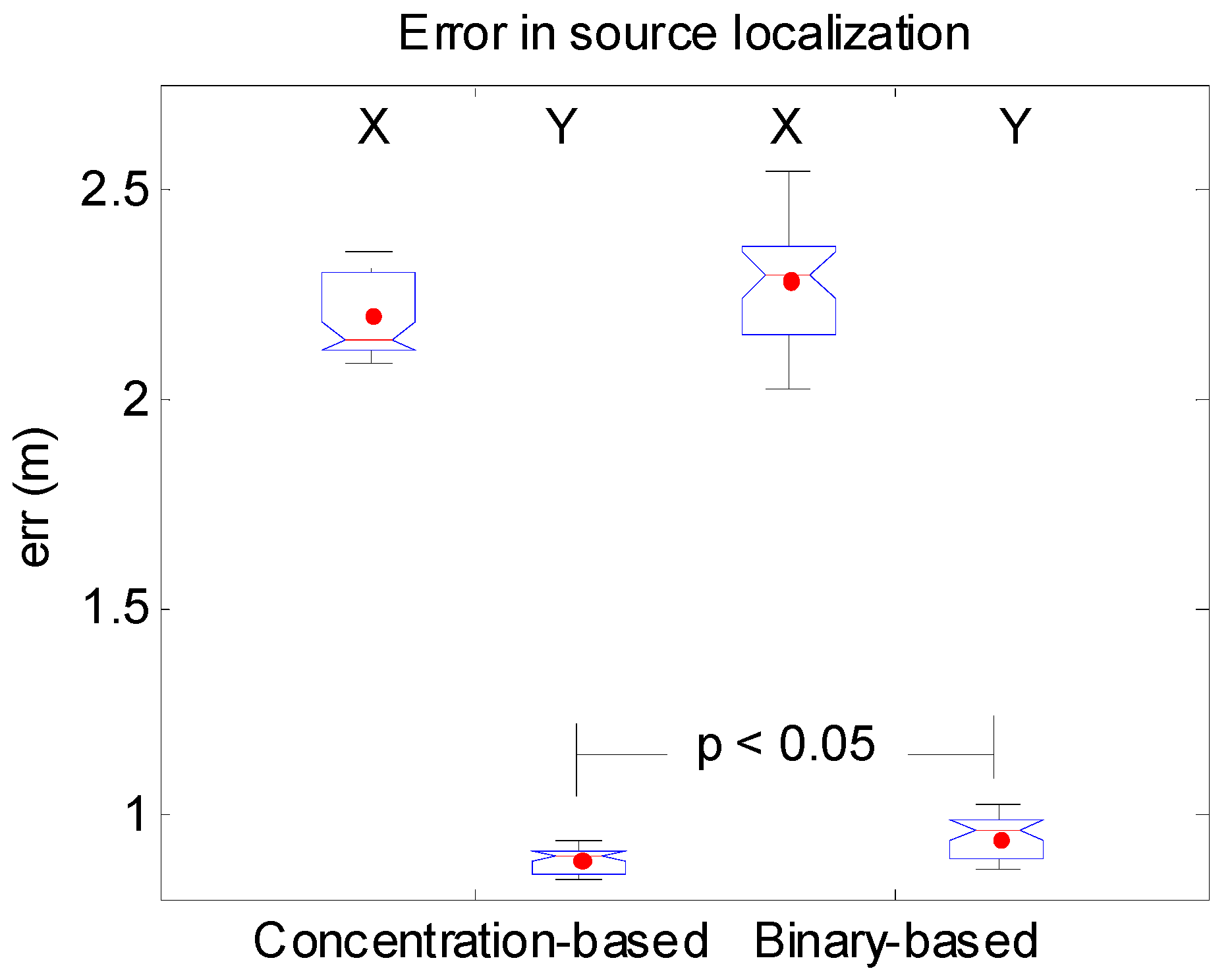
3.1.2. Synthetic Case 2
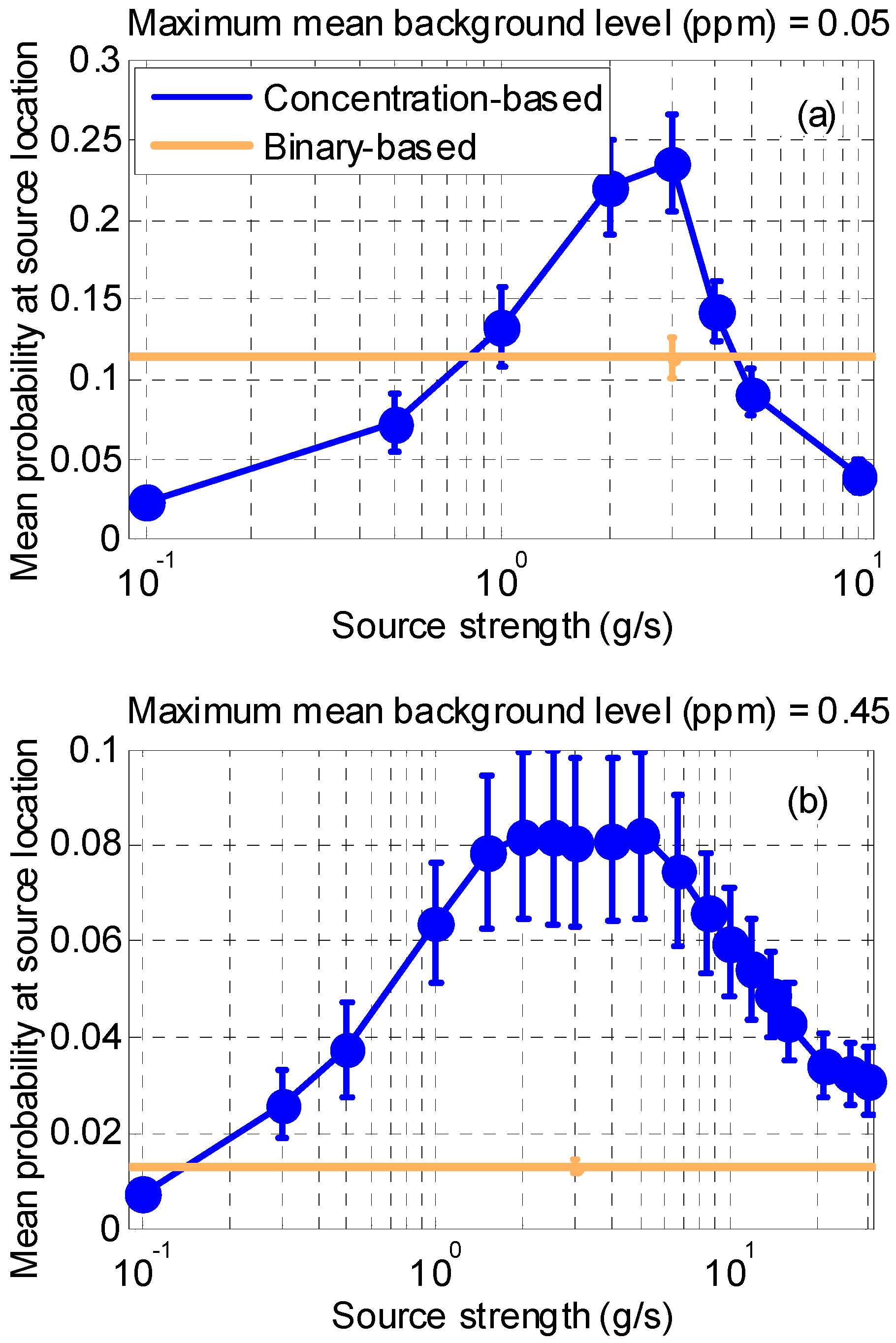
3.1.3. Synthetic Case 3
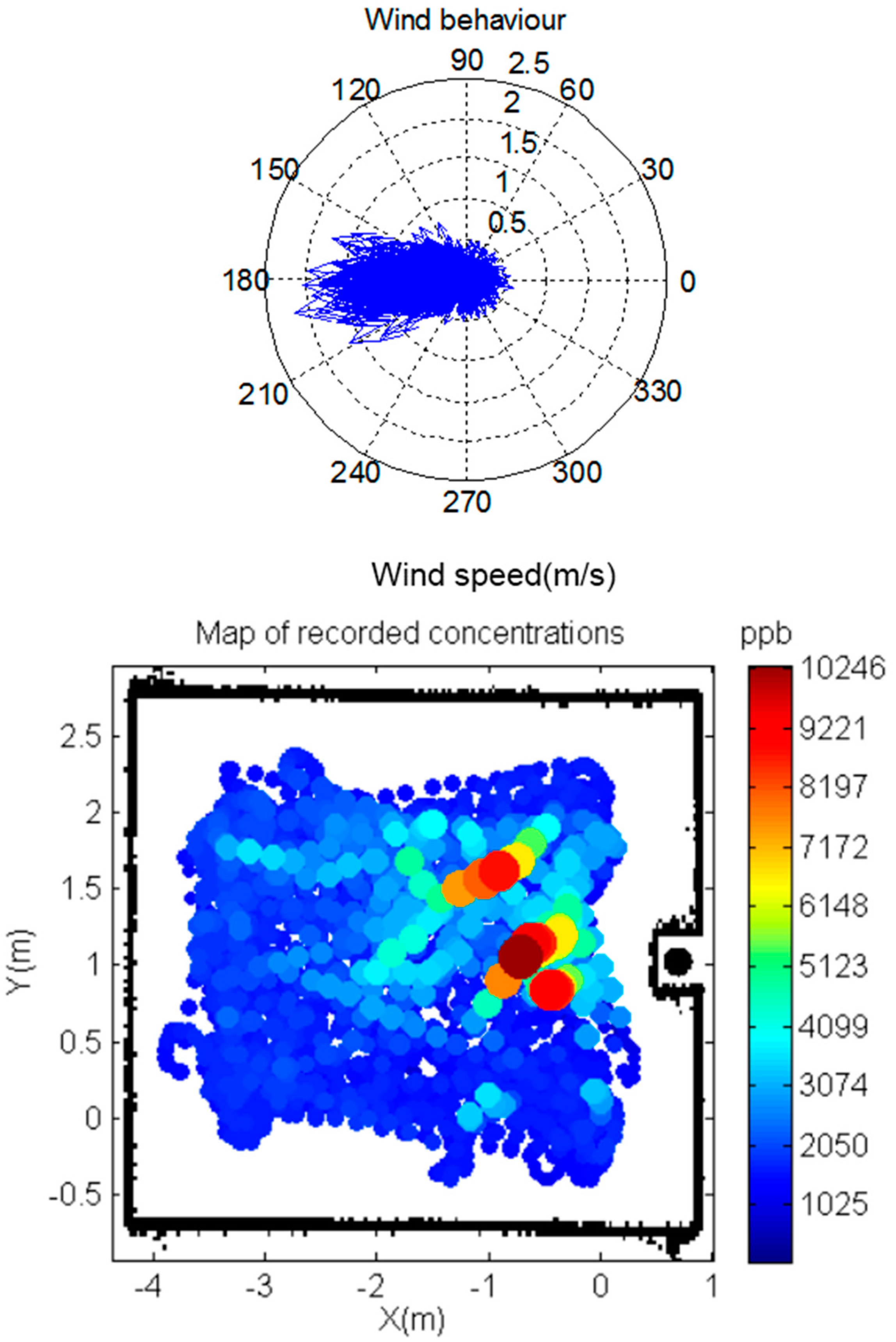
3.2. Results for the Real Experiments
3.3. Computatitonal Cost
4. Conclusions
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A. Supplementary Tables

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Nc | Number of Cells in the Grid Area |
| Lx | Length of each cell along the x-axis |
| Ly | Length of each cell along the y-axis |
| c | Instantaneously measured concentration |
| cb | Concentration contribution due to the background |
| cp | Concentration contribution due to the chemical plume |
| Mean concentration at a fixed location | |
| q | Source strength or release rate |
| Ua | Mean wind speed in the downwind direction |
| σy | Diffusion coefficient in the crosswind direction |
| σz | Diffusion coefficient in the vertical direction |
| Array of all possible instantaneous concentrations c | |
| γ | Intermittency factor related to the chemical plume |
| M | Mean concentration of a series of readings at a fixed location |
| Standard deviation of a series of readings at a fixed location | |
| Nb | Number of readings stored in the concentration buffer per each sensor |
| cj | Measured concentration within cell j |
| Ai | Event “there is a chemical source within cell i” |
| B(tk) | Sequence of measured concentrations along the trajectory of the robots until time tk |
| Prior probability of the presence of a chemical source within cell i | |
| Probability that the measurement within cell j is due to the addition of the background at cell j and a chemical plume due to a source within cell i | |
| Probability that the measurement of chemical at cell j is not due to a source emitting at cell i, thus cj is due to the current background at cell j | |
| Probability of having a source in cell i given that a certain amount of chemical was measured at cell j at time tk | |
| Normalized probability (over all cells) of having a chemical source within cell i based on a single measured concentration within cell j at time tk | |
| Normalized probability (over all cells) of having a chemical source within cell i based on the sequence of measured concentrations along the trajectory of the robots (index j) until time tk |
| For the Plume |
|---|
| Gaussian distribution for the time-averaged concentration |
| concentration fluctuations governed by turbulences |
| continuous release, source strength known q = 2.90 g/s |
| one uniquely source at the position (400 m, 400 m) |
| height, z = 2 m |
| For the Background |
| background is always present |
| background relatively constant for the exploration time |
| mean background level can change from one cell to another |
| no intermittency |
| Other Assumptions |
| uniform wind field over the exploration time, speed Ua = 2.5 m/s, and 45° direction |
| neutral atmospheric stability |
| no deposition of the substance on surfaces |
| cells are equally likely to contain the source at time t0 |
| height of sensors is 2 m |
| response-time of sensors faster than the typical 10min time-average of GPM |
References
- Kowadlo, G.; Russell, R.A. Robot Odor Localization: A Taxonomy and Survey. Int. J. Robot. Res. 2008, 27, 869–894. [Google Scholar] [CrossRef]
- Webster, D.R.; Volyanskyy, K.Y.; Weissburg, M.J. Bioinspired algorithm for autonomous sensor-driven guidance in turbulent chemical plumes. Bioinspir. Biomimetics 2012, 7, 3. [Google Scholar] [CrossRef] [PubMed]
- Meng, Q.-H.; Yang, W.-X.; Wang, Y.; Li, F.; Zeng, M. Adapting an ant colony metaphor for multi-robot chemical plume tracing. Sensors 2012, 12, 4737–4763. [Google Scholar] [CrossRef] [PubMed]
- Russell, R.A.; Bab-Hadiashar, A.; Shepherd, R.L.; Wallace, G.G. A comparison of reactive robot chemotaxis algorithms. Robot. Autom. Syst. 2003, 45, 83–97. [Google Scholar] [CrossRef]
- Webster, D.R. Structure of turbulent chemical plumes. In Trace Chemical Sensing of Explosives; Woodfin, R.L., Ed.; John Wiley & Sons: Hoboken, NJ, USA, 2007; pp. 109–129. [Google Scholar]
- Jatmiko, W.; Mursanto, P.; Kusumoputro, B.; Sekiyama, K.; Fukuda, T. Modified PSO algorithm based on flow of wind for odor source localization problems in dynamic environments. J. WSEAS Trans. Syst. 2008, 7, 106–113. [Google Scholar]
- Ishida, H.; Suetsugu, K.; Nakamoto, T.; Moriizumi, T. Study of autonomous mobile sensing system for localization of odor source using gas sensors and anemometric sensors. Sens. Actuators A Phys. 1994, 45, 153–157. [Google Scholar] [CrossRef]
- Vergassola, M.; Villermaux, E.; Shraiman, B.I. Infotaxis as a strategy for searching without gradients. Nature 2007, 445, 406–409. [Google Scholar] [CrossRef] [PubMed]
- Lilienthal, A.; Duckett, T. Building gas concentration gridmaps with a mobile robot. Robot. Autom. Syst. 2004, 48, 3–16. [Google Scholar] [CrossRef]
- Stachniss, C.; Plagemann, C.; Lilienthal, A.J. Learning gas distribution models using sparse Gaussian process mixtures. Auton. Robot. 2009, 26, 187–202. [Google Scholar] [CrossRef]
- Lilienthal, A.J.; Reggente, M.; Trincavelli, M.J.; Blanco, L.; Gonzalez, J. A Statistical Approach to Gas Distribution Modelling with Mobile Robots—The Kernel DM + V Algorithm. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), St. Louis, MO, USA, 10–15 October 2009; pp. 570–576. [Google Scholar]
- Farrell, J.A. Plume Mapping via hidden markov methods. IEEE Trans. Syst. Man Cybern. Part B 2003, 33, 850–863. [Google Scholar] [CrossRef] [PubMed]
- Farrell, J.A.; Pang, S.; Li, W. Chemical Plume Tracing via an Autonomous Underwater Vehicle. IEEE J. Ocean. Eng. 2005, 30, 428–442. [Google Scholar] [CrossRef]
- Pang, S.; Farrell, J.A. Chemical Plume Source Localization. IEEE Trans. Syst. Man Cybern. Part B 2006, 36, 1068–1080. [Google Scholar] [CrossRef]
- Kang, X.; Li, W. Moth-inspired plume tracing via multiple autonomous vehicles under formation control. Adapt. Behav. 2012, 20, 131–142. [Google Scholar] [CrossRef]
- La, H.M.; Sheng, W.; Chen, J. Cooperative and Active Sensing in Mobile Sensor Networks for Scalar Field Mapping. IEEE Trans. Syst. Man Cybern. 2015, 45, 1–12. [Google Scholar] [CrossRef]
- La, H.M.; Shen, W. Distributed Sensor Fusion and Scalar Field Mapping Using Mobile Sensor Networks. IEEE Trans. Syst. Man Cybern. 2013, 45, 766–778. [Google Scholar]
- Choi, J.; Oh, S.; Horowitz, R. Distributed learning and cooperative control for multi-agent systems. Automatica 2009, 45, 2802–2814. [Google Scholar] [CrossRef]
- Pomareda, V.; Marco, S. Chemical Plume Source Localization with Multiple Mobile Sensors using Bayesian Inference under Background Signals. In Proceedings of the International Symposium on Olfaction and Electronic Nose, New York, NY, USA, 2–5 May 2011; pp. 149–150. [Google Scholar]
- Papoulis, A. Probability, Random Variables, and Stochastic Processes, 2nd ed.; McGraw-Hill: New York, NY, USA, 1984. [Google Scholar]
- Turner, B. Workbook of Atmospheric Dispersion Estimates: An Introduction to Dispersion Modeling; CRC Press: Boca Raton, FL, USA, 1994. [Google Scholar]
- Beychok, M.R. Fundamentals of Stack Gas Dispersion, 4th ed.; Beychok, M.R.: New York, NY, USA, 2005. [Google Scholar]
- Sutton, O.G. The problem of diffusion in the lower atmosphere. Q. J. R. Meteorol. Soc. 1947, 73, 257–281. [Google Scholar] [CrossRef]
- Crimaldi, J.P.; Wiley, M.B.; Koseff, J.R. The relationship between mean and instantaneous structure in turbulent passive scalar plumes. J. Turbul. 2002, 3, 1–24. [Google Scholar] [CrossRef]
- Webster, D.R.; Weissburg, M.J. Chemosensory guidance cues in a turbulent chemical odor plume. Limnol. Oceanogr. 2001, 46, 1034–1047. [Google Scholar] [CrossRef]
- Bakkum, E.A.; Duijm, N.J. Chapter 4: Vapour cloud dispersion. In Methods for the Calculation of Physical Effects ‘Yellow Book’, 3rd ed.; van den Bosch, C.J.H., Weterings, R.A.P.M., Eds.; Ministerie van verkeer en waterstaat: The Hague, The Netherlands, 2005; pp. 1–139. [Google Scholar]
- Farrell, J.A.; Murlis, J.; Long, X.; Li, W.; Cardé, R.T. Filament-based atmospheric dispersion model to achieve short time-scale structure of odor plumes. Environ. Fluid Mech. 2002, 2, 143–169. [Google Scholar] [CrossRef]
- Yee, E.; Wang, B.-C.; Lien, F.-S. Probabilistic model for concentration fluctuations in compact-source plumes in an urbant environment. Bound.-Layer Meteorol. 2009, 130, 169–208. [Google Scholar] [CrossRef]
- Yee, E.; Biltoft, C.A. Concentration fluctuation measurements in a plume dispersing through a regular array of obstacles. Bound.-Layer Meteorol. 2004, 111, 363–415. [Google Scholar] [CrossRef]
- Yee, E.; Chan, R. A simple model for the probability density function of concentration fluctuations in atmospheric plumes. Atmos. Environ. 1997, 31, 991–1002. [Google Scholar] [CrossRef]
- Jones, A.R.; Thomson, D.J. Simulation of time series of concentration fluctuations in atmospheric dispersion using a correlation-distortion technique. Bound.-Layer Meteorol. 2006, 118, 25–54. [Google Scholar] [CrossRef]
- Hahn, I.; Brixey, L.A.; Wiener, R.W.; Henkle, S.W.; Baldauf, R. Characterization of traffic-related PM concentration distribution and fluctuation patterns in near-highway urban residential street canyons. J. Envorin. Monit. 2009, 11, 2136–2145. [Google Scholar] [CrossRef] [PubMed]
- Soriano, C.; Baldasano, J.M.; Buttler, W.T.; Moore, K.R. Circulatory patterns of air pollutants within the Barcelona air basin in a summertime situation: lidar and numerical approaches. Bound.-Layer Meteorol. 2000, 98, 33–55. [Google Scholar] [CrossRef]
- Martín, M.; Cremades, L.V.; Santabàrbara, J.M. Analysis and modelling of time series of surface wind speed and direction. Int. J. Climatol. 1999, 19, 197–209. [Google Scholar] [CrossRef]
- Gijbels, I.; Hubert, M. Robust and nonparametric statistical methods. In Comprehensive Chemometrics: Chemical and Biochemical Data Analysis, 1st ed.; Brown, S.D., Tauler, R., Walczak, B., Eds.; Elsevier: Amsterdam, The Netherlands, 2009; pp. 189–211. [Google Scholar]
- Papoulis, A. Chapter 8: Sequences of random variables. In Probability, Random Variables, and Stochastic Processes; McGraw-Hill: New York, NY, USA, 1984. [Google Scholar]


© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pomareda, V.; Magrans, R.; Jiménez-Soto, J.M.; Martínez, D.; Tresánchez, M.; Burgués, J.; Palacín, J.; Marco, S. Chemical Source Localization Fusing Concentration Information in the Presence of Chemical Background Noise . Sensors 2017, 17, 904. https://doi.org/10.3390/s17040904
Pomareda V, Magrans R, Jiménez-Soto JM, Martínez D, Tresánchez M, Burgués J, Palacín J, Marco S. Chemical Source Localization Fusing Concentration Information in the Presence of Chemical Background Noise . Sensors. 2017; 17(4):904. https://doi.org/10.3390/s17040904
Chicago/Turabian StylePomareda, Víctor, Rudys Magrans, Juan M. Jiménez-Soto, Dani Martínez, Marcel Tresánchez, Javier Burgués, Jordi Palacín, and Santiago Marco. 2017. "Chemical Source Localization Fusing Concentration Information in the Presence of Chemical Background Noise " Sensors 17, no. 4: 904. https://doi.org/10.3390/s17040904
APA StylePomareda, V., Magrans, R., Jiménez-Soto, J. M., Martínez, D., Tresánchez, M., Burgués, J., Palacín, J., & Marco, S. (2017). Chemical Source Localization Fusing Concentration Information in the Presence of Chemical Background Noise . Sensors, 17(4), 904. https://doi.org/10.3390/s17040904