Cross-Spectral Local Descriptors via Quadruplet Network

Abstract
:1. Introduction
- We propose and evaluate three ways of using triplets for learning cross-spectral descriptors. Triplet networks were originally designed to work on visible imagery, so the performance on cross-spectral images is unknown.
- We propose a new training CNN-based architecture that outperforms the state-of-the-art in a public Visible and Near-Infrared (VIS-NIR) cross-spectral image pair dataset. Additionally, our experiments show that our network is also useful for learning local feature descriptors in the visible domain.
- Fully trained networks and source code are publicly available at [5].
2. Background and Related Work
2.1. Near-Infrared Band
2.2. Dataset
2.3. Cross-Spectral Descriptors
2.4. CNN-Based Feature Descriptor Approaches
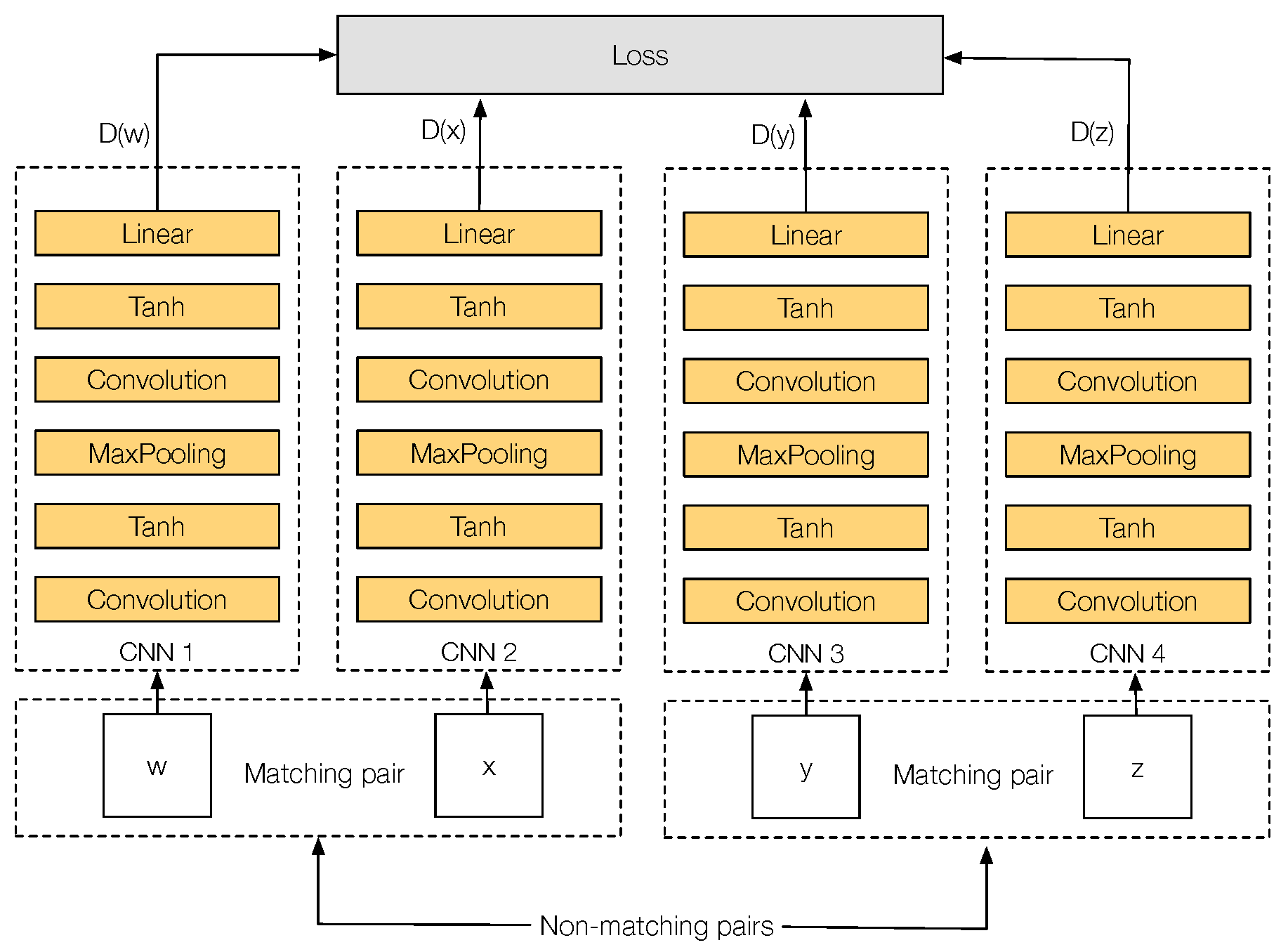
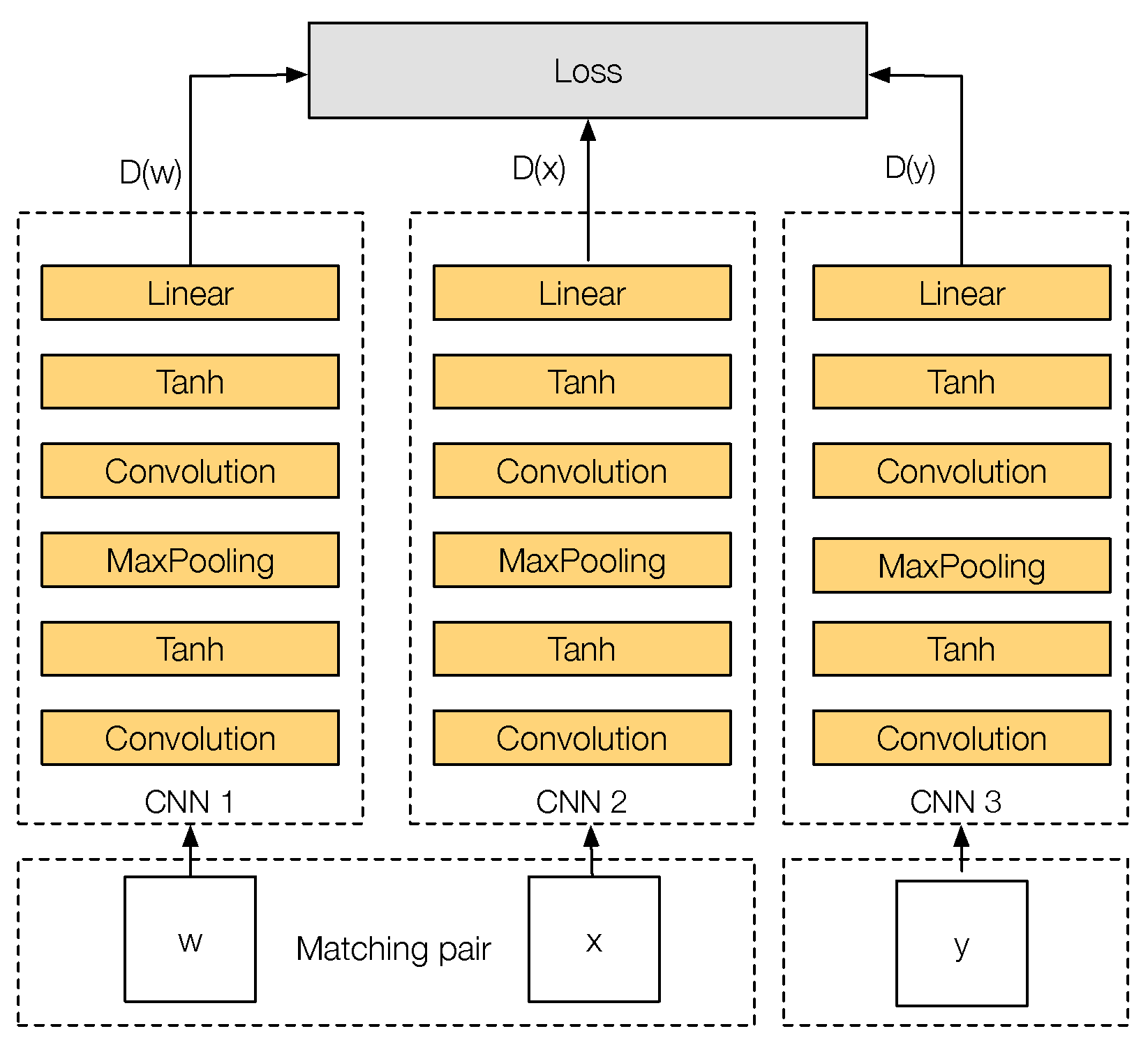
3. PN-Net (Triplet Network)
- As previously stated, our network is similar to the triplet network but specifically designed to learn cross-spectral local feature descriptors. A brief description of this network will help to set the basis of our proposal in Section 4.
- We explain the motivation behind our proposal through several experiments. After training PN-Net to learn cross-spectral feature descriptors, we discovered that the network performance improved when we randomly alternated between non-matching patches from both spectra.
3.1. PN-Net Architecture
3.2. PN-Net Loss
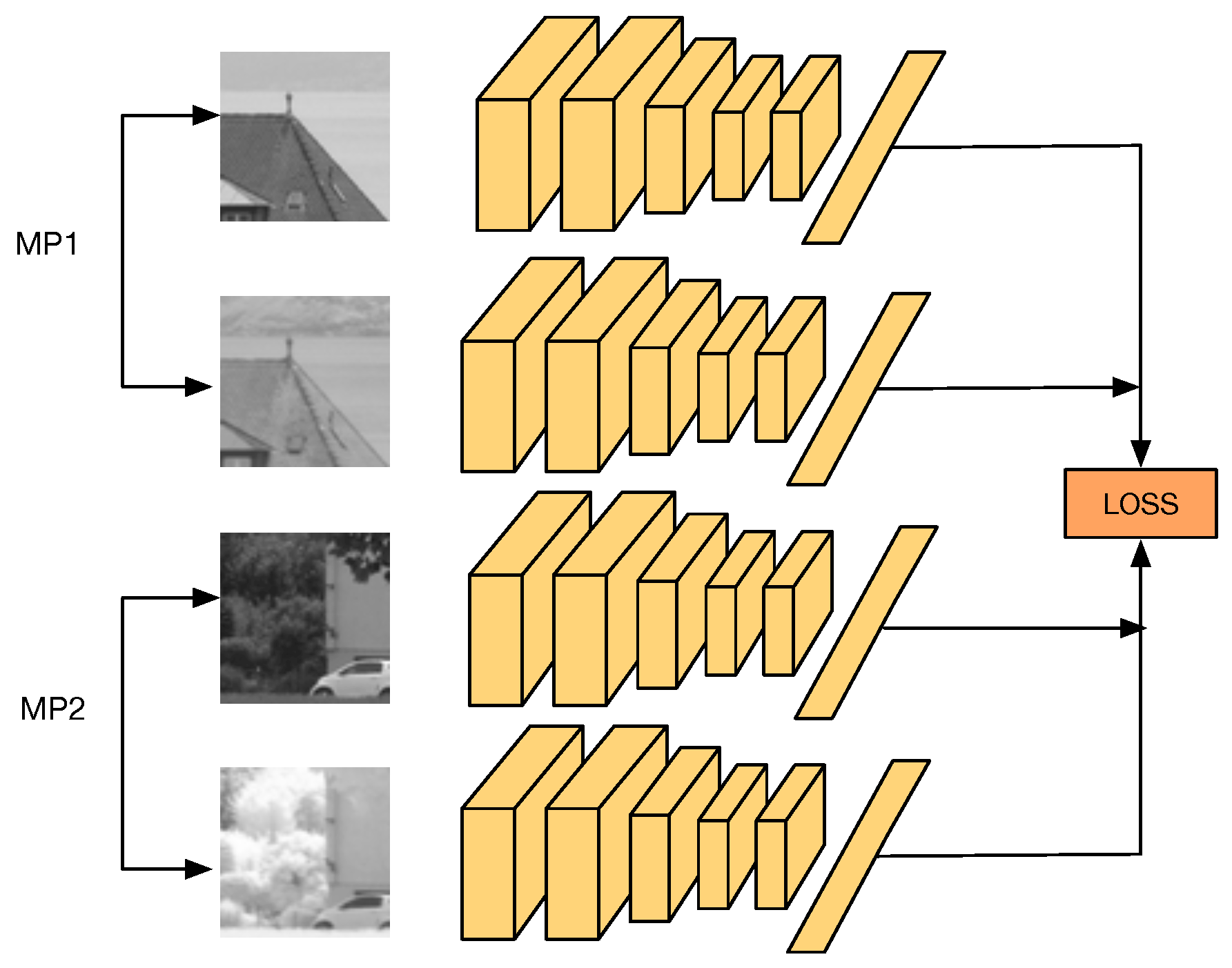
3.3. Cross-Spectral PN-Net
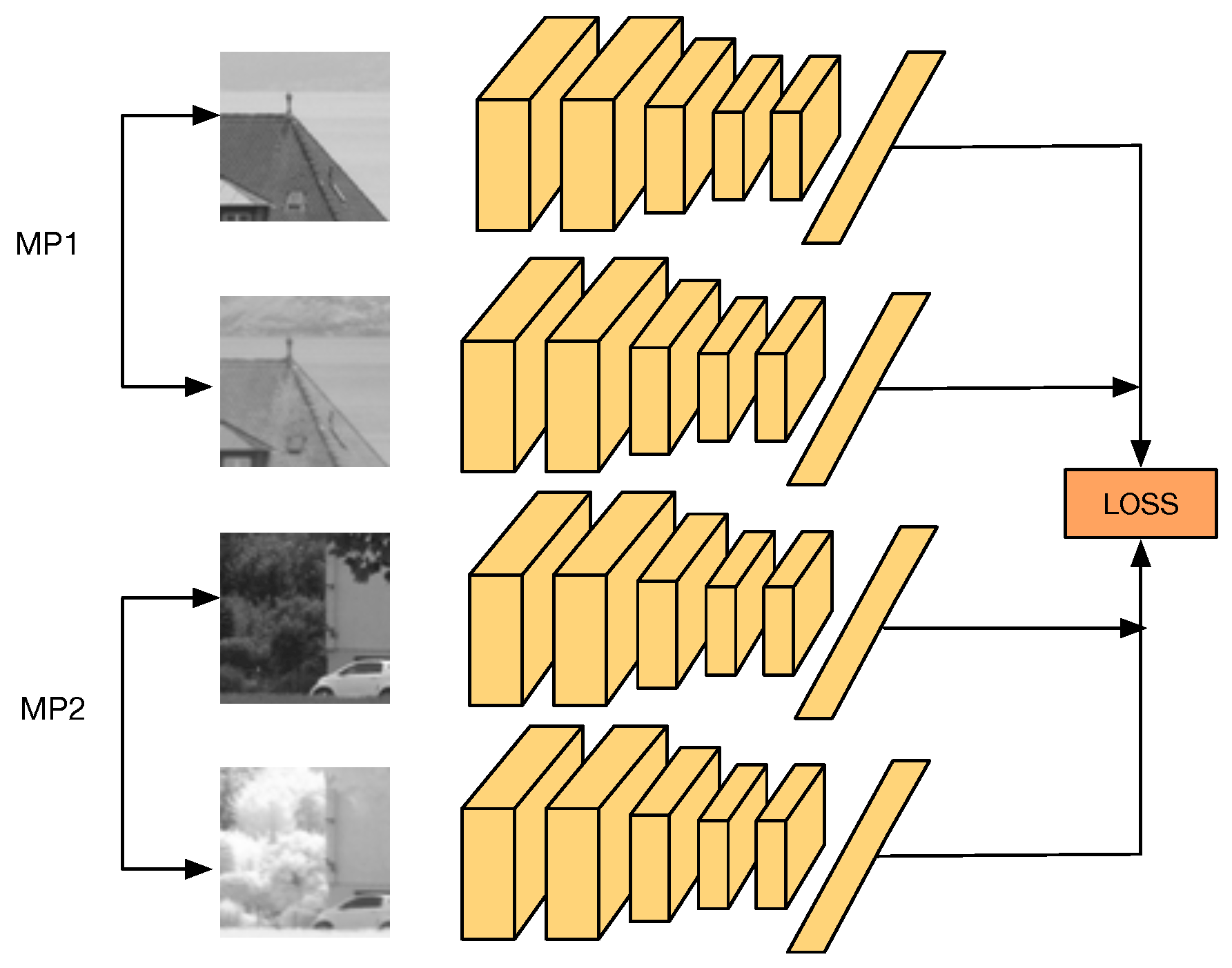
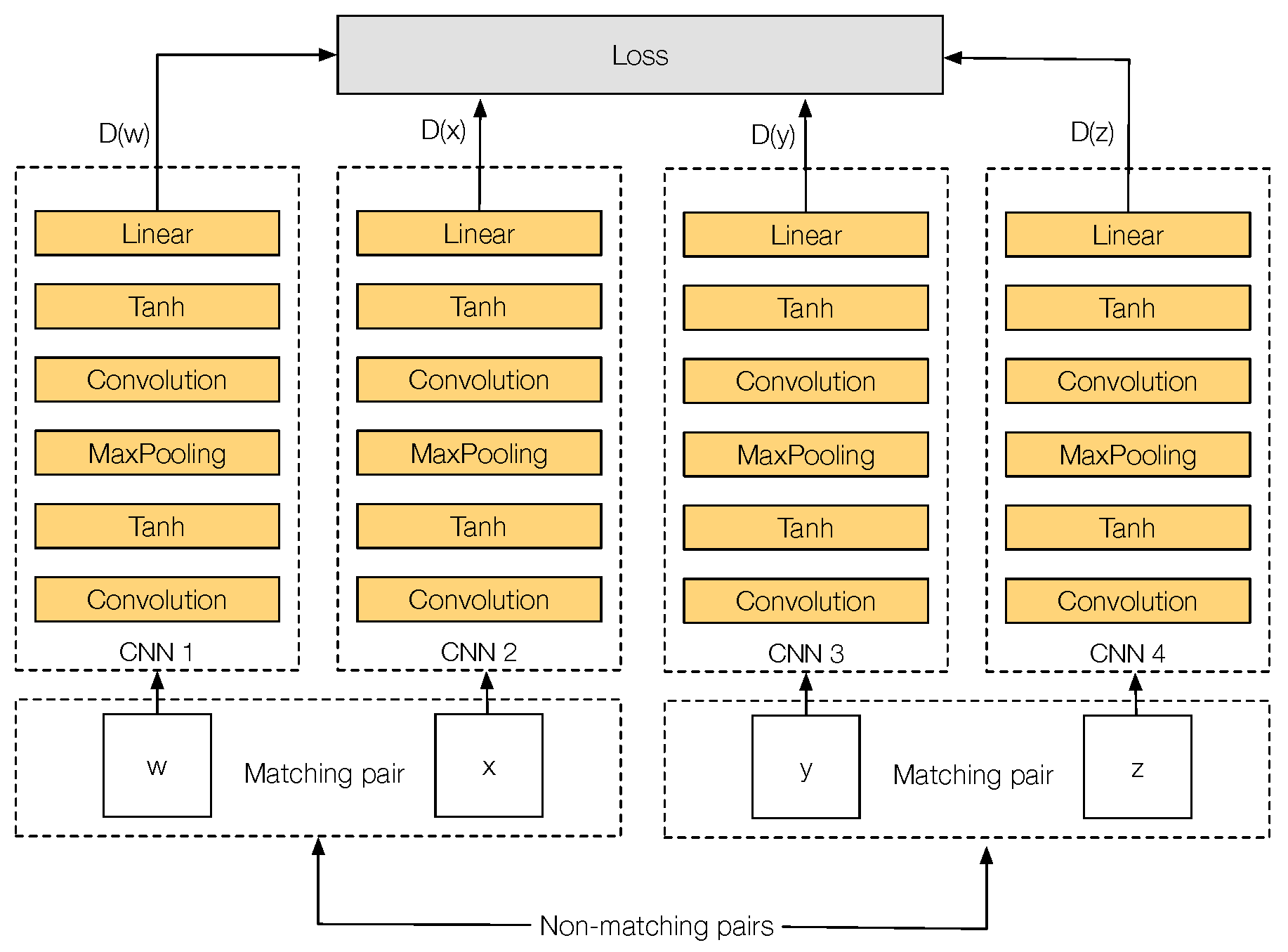
3.4. Q-Net Architecture
4. Q-Net
4.1. Q-Net Loss
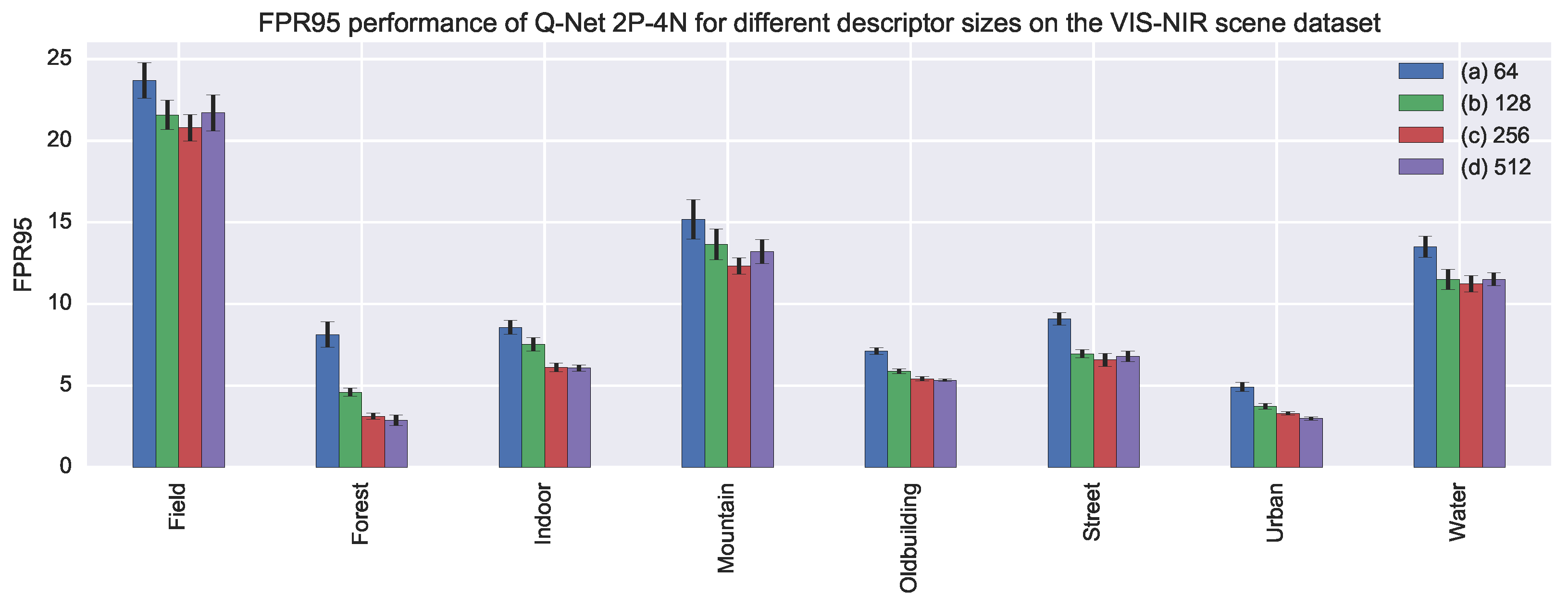
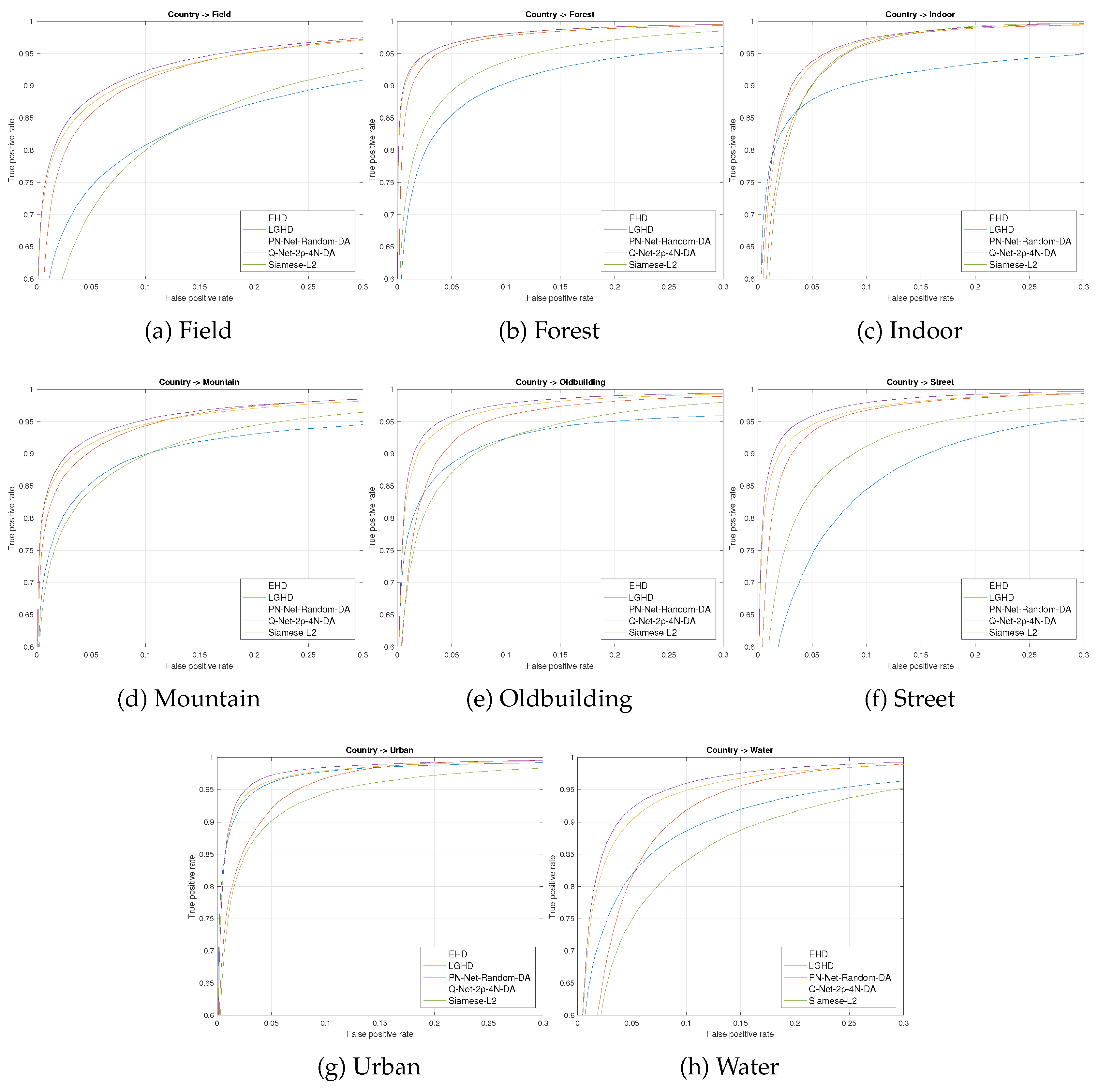
5. Experimental Evaluation
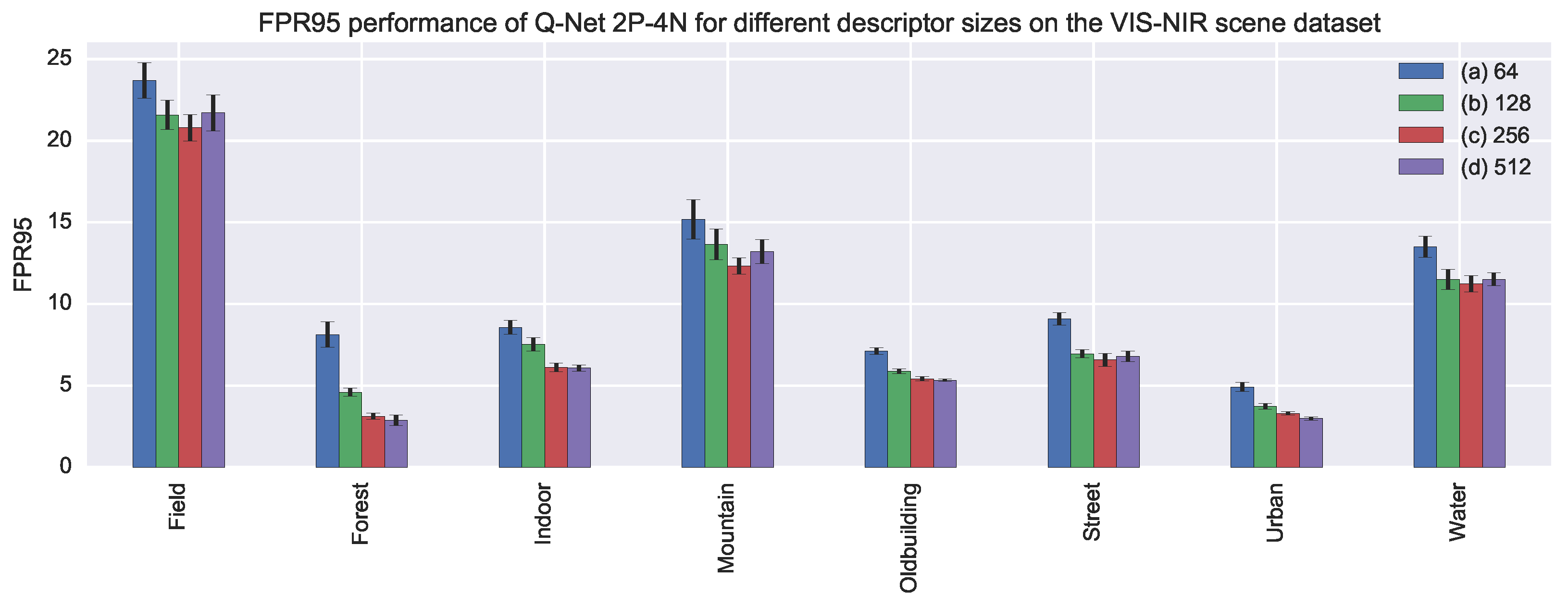
5.1. VIS-NIR Scene Dataset
5.2. Multi-View Stereo Correspondence Dataset
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Zhang, Z. Microsoft Kinect Sensor and Its Effect. IEEE MultiMedia 2012, 19, 4–10. [Google Scholar] [CrossRef]
- You, C.W.; Lane, N.D.; Chen, F.; Wang, R.; Chen, Z.; Bao, T.J.; Montes-de Oca, M.; Cheng, Y.; Lin, M.; Torresani, L.; et al. CarSafe app: Alerting drowsy and distracted drivers using dual cameras on smartphones. Proceeding of the 11th Annual International Conference on Mobile Systems, Applications, and Services (ACM 2013), Taipei, Taiwan, 25–28 June 2013; pp. 13–26. [Google Scholar]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Balntas, V.; Johns, E.; Tang, L.; Mikolajczyk, K. PN-Net: Conjoined Triple Deep Network for Learning Local Image Descriptors. arXiv, 2016; arXiv:1601.05030. [Google Scholar]
- Github. Qnet. Available online: http://github.com/ngunsu/qnet (accessed on 15 April 2017).
- Yi, D.; Lei, Z.; Li, S.Z. Shared representation learning for heterogenous face recognition. Proceeding of the 2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Ljubljana, Slovenia, 4–8 May 2015; Volume 1, pp. 1–7. [Google Scholar]
- Ring, E.; Ammer, K. The technique of infrared imaging in medicine. In Infrared Imaging; IOP Publishing: Bristol, UK, 2015. [Google Scholar]
- Klare, B.F.; Jain, A.K. Heterogeneous face recognition using kernel prototype similarities. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1410–1422. [Google Scholar] [CrossRef] [PubMed]
- Aguilera, C.A.; Aguilera, F.J.; Sappa, A.D.; Aguilera, C.; Toledo, R. Learning cross-spectral similarity measures with deep convolutional neural networks. Proceeding of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Brown, M.; Susstrunk, S. Multi-spectral SIFT for scene category recognition. Proceeding of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 177–184. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Van Gool, L. Surf: Speeded up robust features. In European Conference on Computer Vision; Springer: New York, NY, USA, 2006; pp. 404–417. [Google Scholar]
- Firmenichy, D.; Brown, M.; Süsstrunk, S. Multispectral interest points for RGB-NIR image registration. Proceeding of the 2011 18th IEEE International Conference on Image Processing (ICIP), Brussels, Belgium, 11–14 September 2011; pp. 181–184. [Google Scholar]
- Pinggera, P.; Breckon, T.; Bischof, H. On Cross-Spectral Stereo Matching using Dense Gradient Features. Proceeding of the British Machine Vision Conference, Surrey, UK, 3–7 September 2012; pp. 526.1–526.12. [Google Scholar]
- Morris, N.J.W.; Avidan, S.; Matusik, W.; Pfister, H. Statistics of Infrared Images. Proceeding of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 18–23 June 2007; pp. 1–7. [Google Scholar]
- Aguilera, C.; Barrera, F.; Lumbreras, F.; Sappa, A.; Toledo, R. Multispectral image feature points. Sensors 2012, 12, 12661–12672. [Google Scholar] [CrossRef]
- Mouats, T.; Aouf, N.; Sappa, A.D.; Aguilera, C.; Toledo, R. Multispectral Stereo Odometry. IEEE Trans. Intell. Transp. Syst. 2015, 16, 1210–1224. [Google Scholar] [CrossRef]
- Aguilera, C.A.; Sappa, A.D.; Toledo, R. LGHD: A feature descriptor for matching across non-linear intensity variations. Proceeding of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec, Canada, 27–30 September 2015; pp. 178–181. [Google Scholar]
- Ma, J.; Zhao, J.; Ma, Y.; Tian, J. Non-rigid visible and infrared face registration via regularized Gaussian fields criterion. Pattern Recognit. 2015, 48, 772–784. [Google Scholar] [CrossRef]
- Shen, X.; Xu, L.; Zhang, Q.; Jia, J. Multi-modal and Multi-spectral Registration for Natural Images. In European Conference on Computer Vision; Springer: New York, NY, USA, 2014; pp. 309–324. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Learning to compare image patches via convolutional neural networks. Proceeding of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4353–4361. [Google Scholar]
- Simo-Serra, E.; Trulls, E.; Ferraz, L.; Kokkinos, I.; Fua, P.; Moreno-Noguer, F. Discriminative Learning of Deep Convolutional Feature Point Descriptors. In Proceedings of the International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015. [Google Scholar]
- Han, X.; Leung, T.; Jia, Y.; Sukthankar, R.; Berg, A.C. MatchNet: Unifying Feature and Metric Learning for Patch-Based Matching. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Zbontar, J.; LeCun, Y. Stereo matching by training a convolutional neural network to compare image patches. J. Mach. Learn. Res. 2016, 17, 1–32. [Google Scholar]
- Winder, S.; Hua, G.; Brown, M. Picking the best DAISY. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2009), Miami, FL, USA, 20–25 June 2009; pp. 178–185. [Google Scholar]
- Collobert, R.; Kavukcuoglu, K.; Farabet, C. Torch7: A matlab-like environment for machine learning. In Proceedings of the BigLearn, NIPS Workshop, Granada, Spain, 12–17 December 2011. Number EPFL-CONF-192376. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | # Cross-Spectral Pairs |
|---|---|
| country | 277,504 |
| field | 240,896 |
| forest | 376,832 |
| indoor | 60,672 |
| mountain | 151,296 |
| old building | 101,376 |
| street | 164,608 |
| urban | 147,712 |
| water | 143,104 |
| Train seq. | PN-Net Gray | PN-Net NIR | PN-Net Random |
|---|---|---|---|
| country | 11.79 | 11.63 | 10.65 |
| field | 17.84 | 16.56 | 16.10 |
| forest | 36.00 | 32.47 | 32.19 |
| indoor | 48.21 | 47.26 | 46.48 |
| mountain | 29.35 | 26.29 | 25.67 |
| old building | 29.22 | 27.25 | 27.69 |
| street | 18.23 | 16.71 | 16.73 |
| urban | 32.78 | 36.61 | 33.35 |
| water | 18.16 | 17.76 | 15.84 |
| average | 26.84 | 25.84 | 25.08 |
| Layer | Description | Kernel | Output Dim |
|---|---|---|---|
| 1 | Convolution | 7 × 7 | 32 × 26 × 26 |
| 2 | Tanh | - | 32 × 26 × 26 |
| 3 | MaxPooling | 2 × 2 | 32 × 13 × 13 |
| 4 | Convolution | 6 × 6 | 64 × 8 × 8 |
| 5 | Tanh | - | 64 × 8 × 8 |
| 6 | Linear | - | 256 |
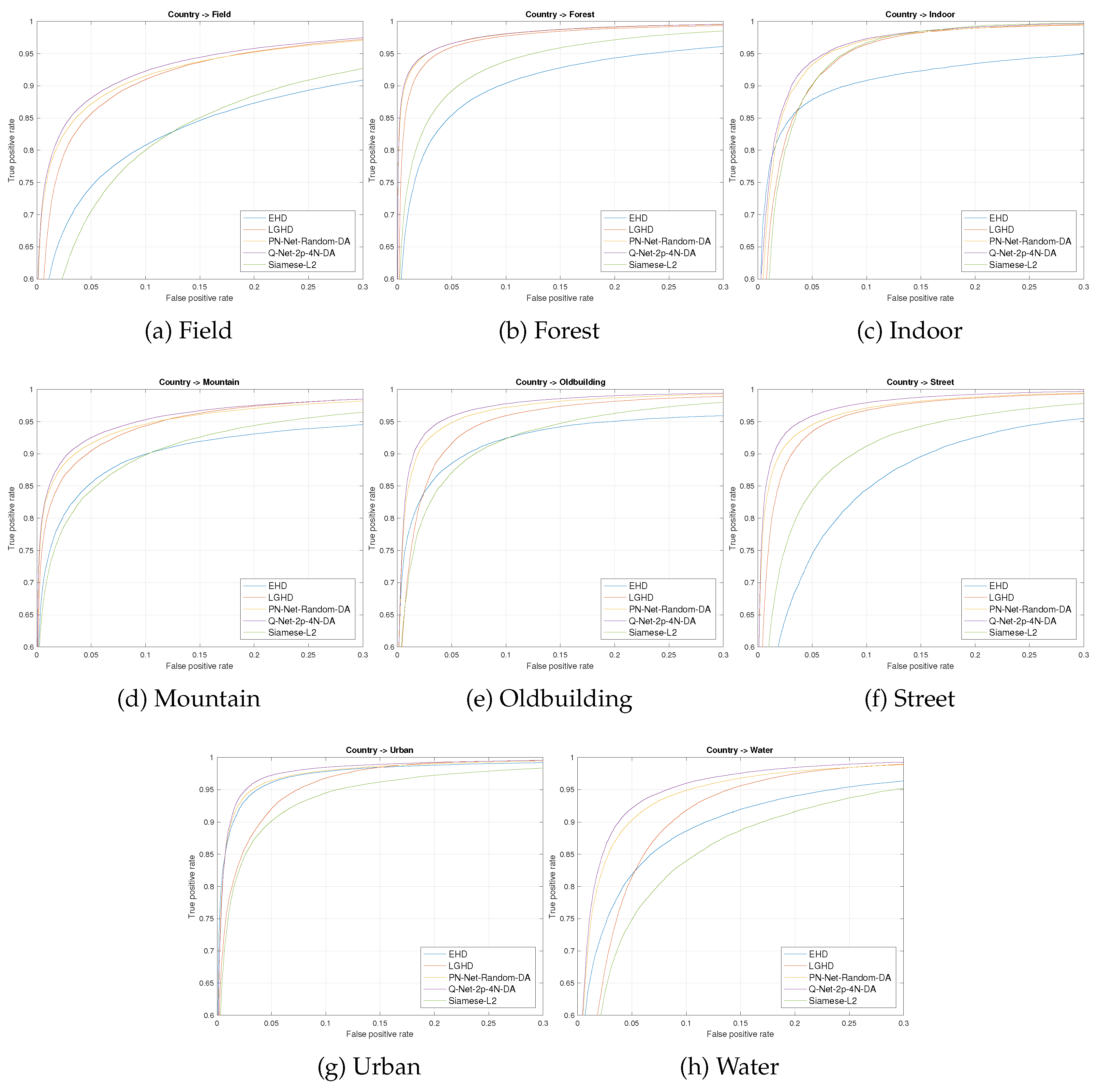
| Descriptor/Network | Field | Forest | Indoor | Mountain | Old Building | Street | Urban | Water | Mean |
|---|---|---|---|---|---|---|---|---|---|
| EHD | |||||||||
| LGHD | |||||||||
| siamese-L2 | |||||||||
| PN-Net RGB | |||||||||
| PN-Net NIR | |||||||||
| PN-Net Random | |||||||||
| Q-Net 2P-4N (ours) | |||||||||
| PN-Net Random DA | |||||||||
| Q-Net 2P-4N DA (ours) |
| Training | Notredame | Liberty | Notredame | Yosemite | Yosemite | Liberty | |
|---|---|---|---|---|---|---|---|
| Testing | Yosemite | Liberty | Notredame | ||||
| Descriptor | mean | ||||||
| siamese-L2 | |||||||
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aguilera, C.A.; Sappa, A.D.; Aguilera, C.; Toledo, R. Cross-Spectral Local Descriptors via Quadruplet Network. Sensors 2017, 17, 873. https://doi.org/10.3390/s17040873
Aguilera CA, Sappa AD, Aguilera C, Toledo R. Cross-Spectral Local Descriptors via Quadruplet Network. Sensors. 2017; 17(4):873. https://doi.org/10.3390/s17040873
Chicago/Turabian StyleAguilera, Cristhian A., Angel D. Sappa, Cristhian Aguilera, and Ricardo Toledo. 2017. "Cross-Spectral Local Descriptors via Quadruplet Network" Sensors 17, no. 4: 873. https://doi.org/10.3390/s17040873
APA StyleAguilera, C. A., Sappa, A. D., Aguilera, C., & Toledo, R. (2017). Cross-Spectral Local Descriptors via Quadruplet Network. Sensors, 17(4), 873. https://doi.org/10.3390/s17040873