Active AU Based Patch Weighting for Facial Expression Recognition



Abstract
:1. Introduction
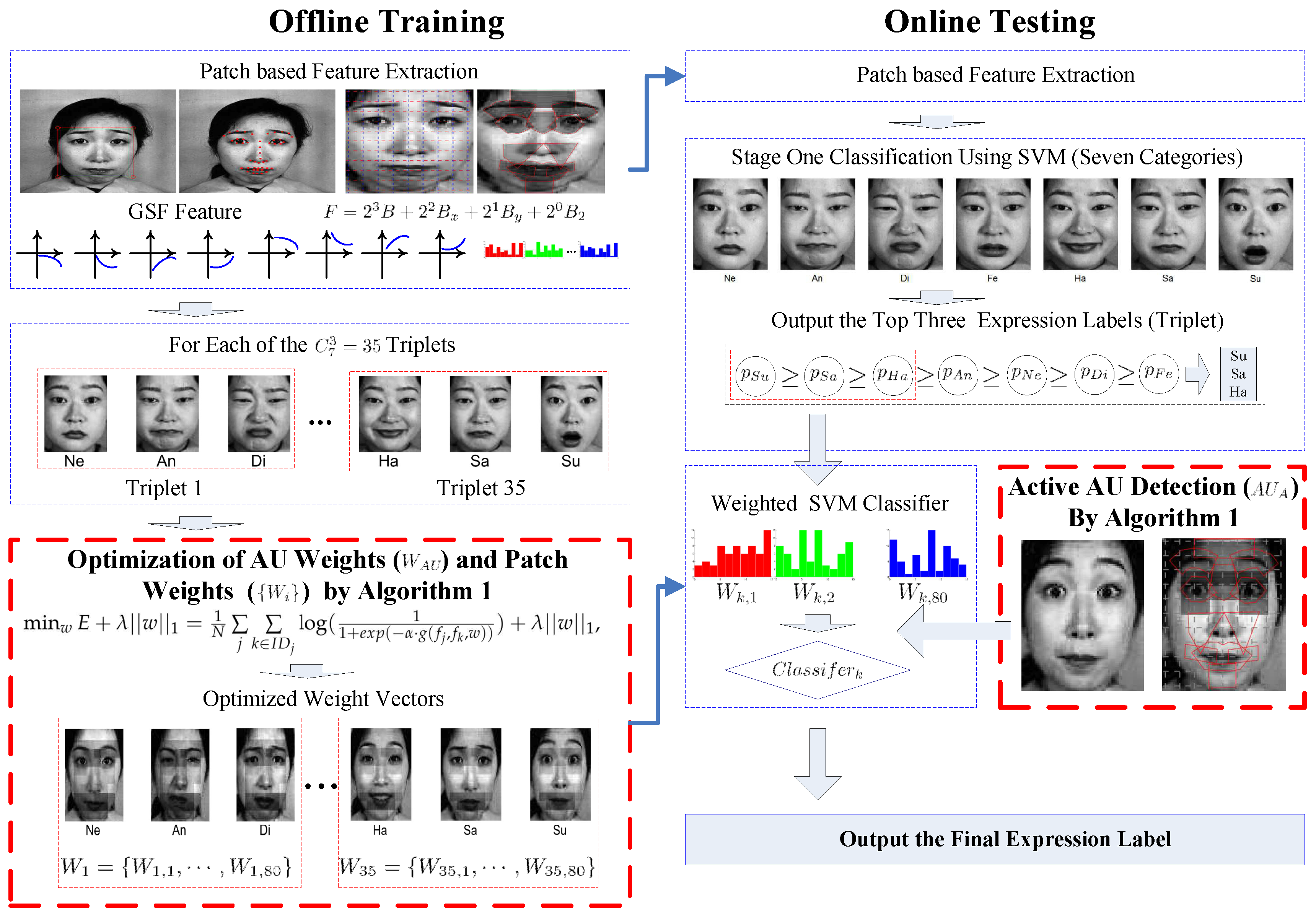
2. The Proposed Algorithm
2.1. Framework of the Algorithm
2.2. Region Definition and Feature Extraction
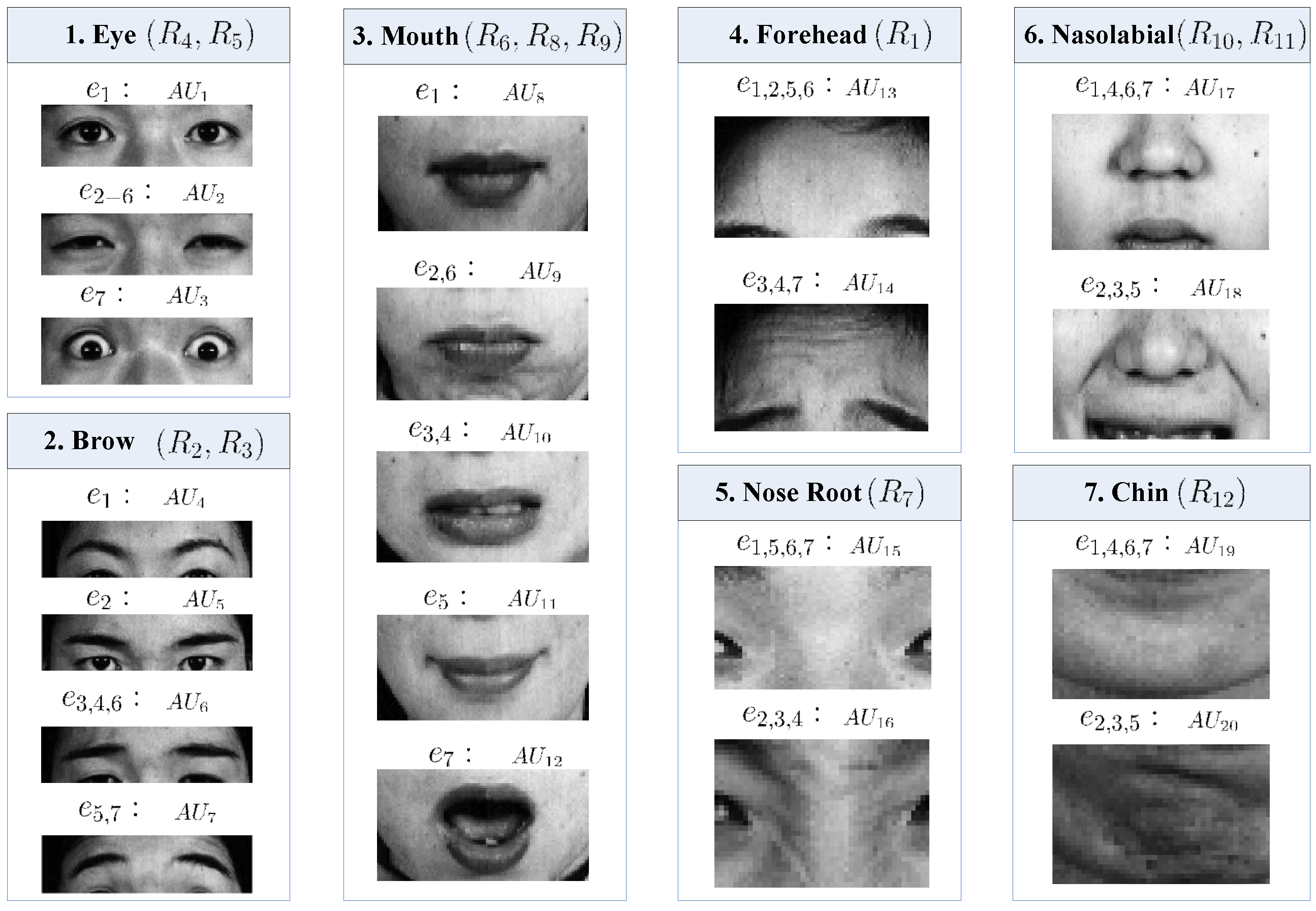
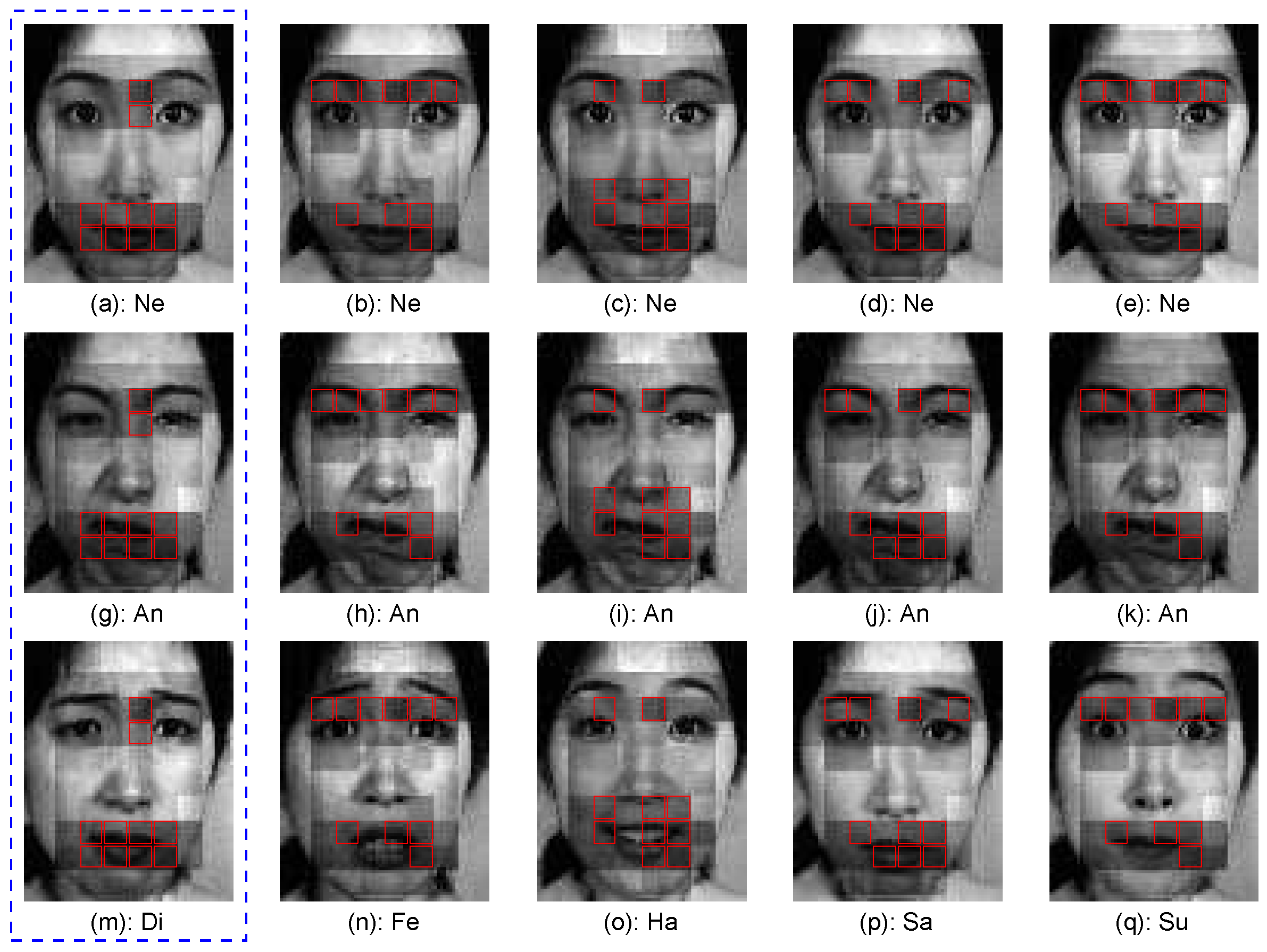
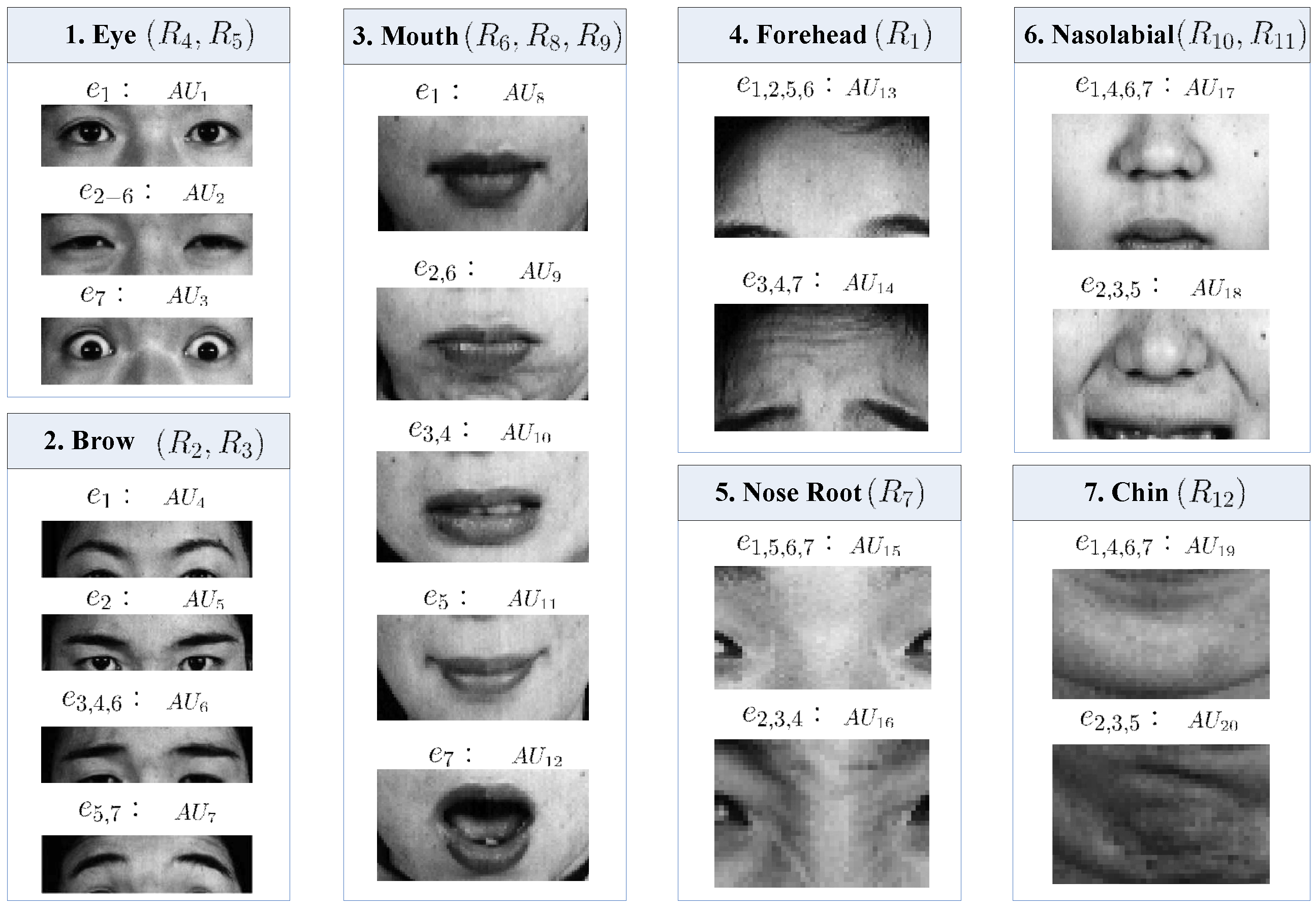
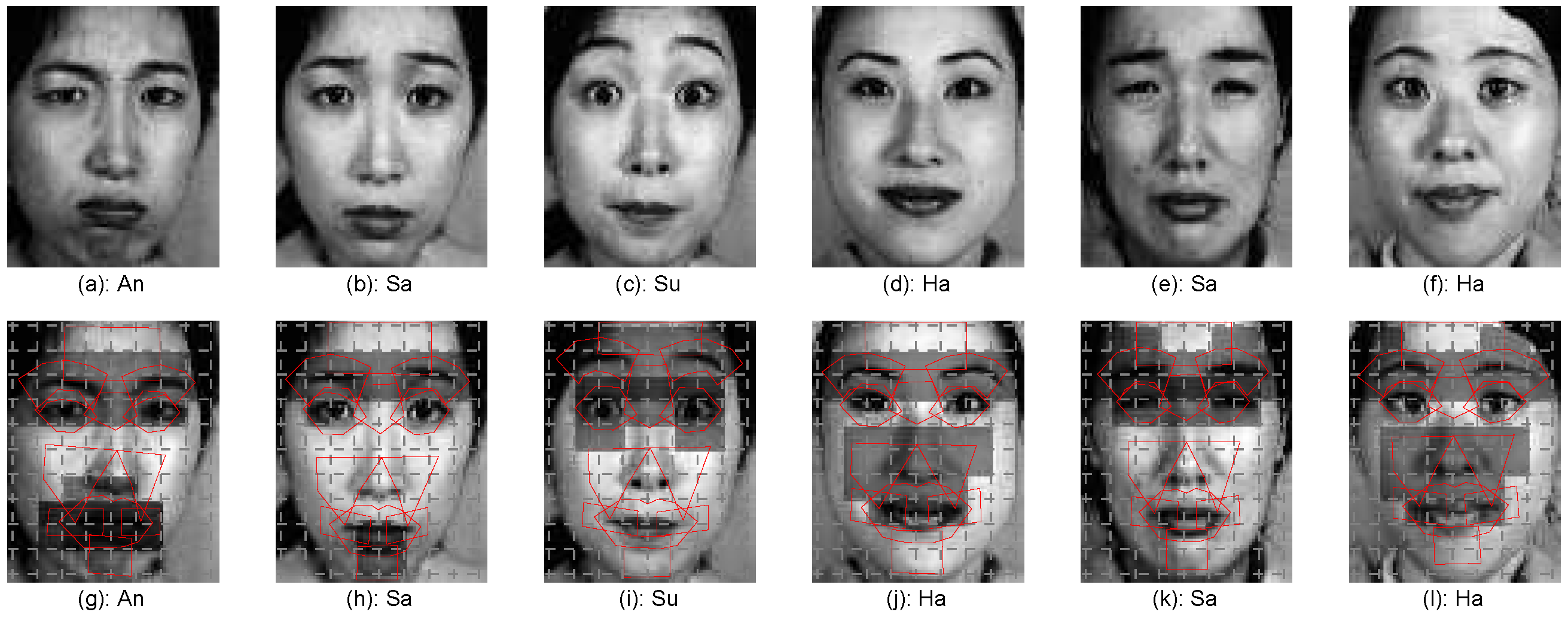
2.2.1. Definition of Patch, Region, Part and AU
2.2.2. Feature Extraction
2.3. Feature Optimization
| Algorithm 1 AU weighting, patch weight optimization and active AU detection. |
|
2.3.1. AU Weighting
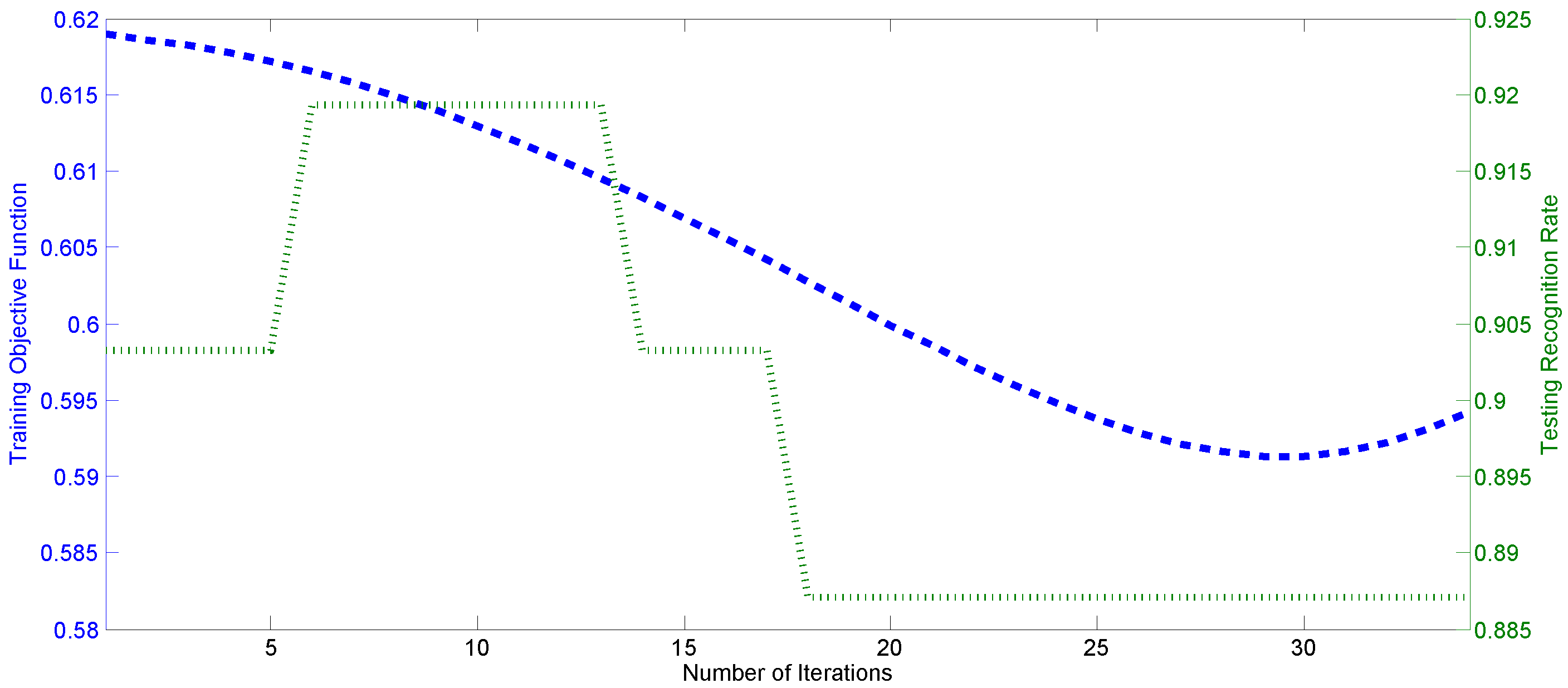
2.3.2. Patch Weight Optimization
- The weight of each patch is initialized as a ratio of the corresponding AU representative ability as follows:where i is the index of the part including the j-th patch, denotes the number of patches in the part and records the weights of the j-th patch . The initialization procedure is presented in Step 3 of Algorithm 2;
- The weight vector and auxiliary vector in the -th iteration of Algorithm 2 are normalized to satisfy the constraint defined in Equation (12) as follows:where i is the index of the part including the j-th patch and denotes the weights of the part . The normalization is employed in Steps 11 and 19;
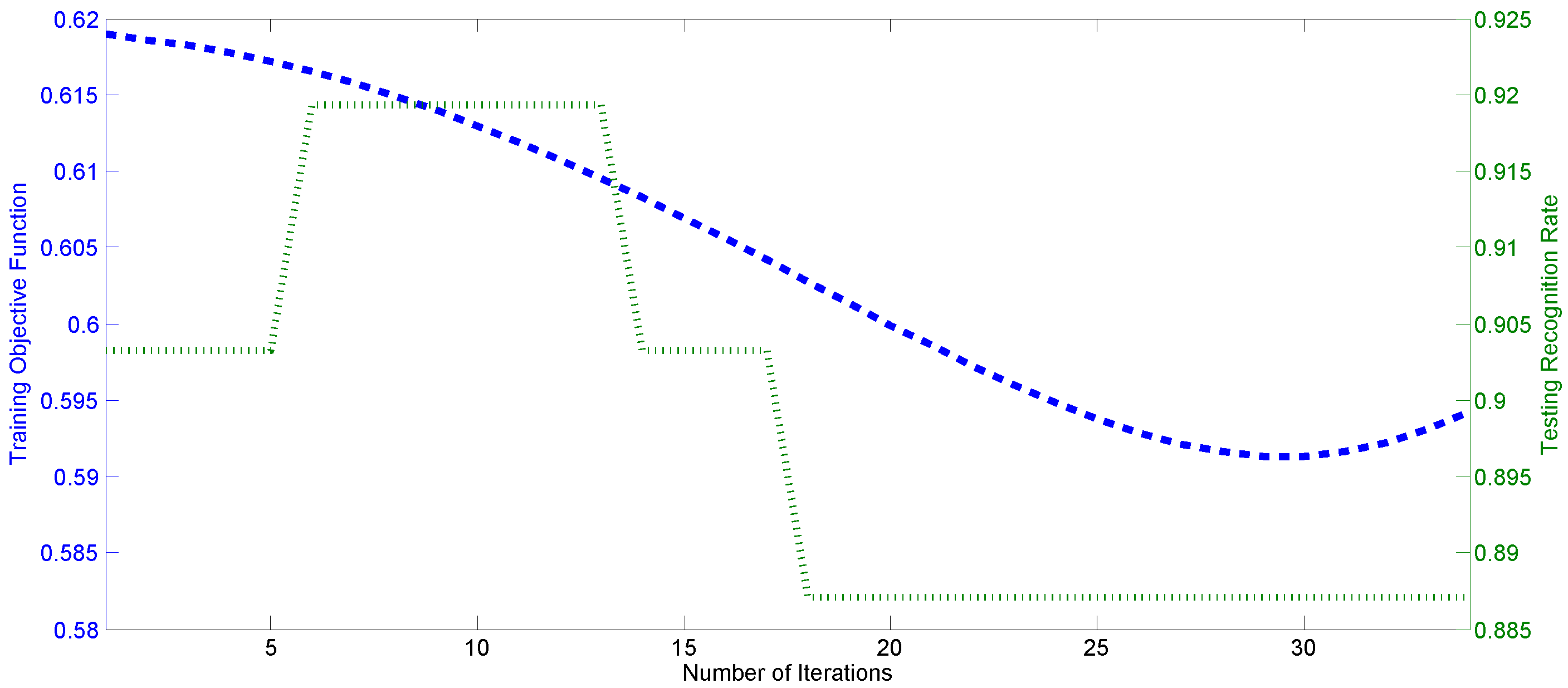
- Compared with [45], optimization Model (12) is proposed by minimizing the feature similarity bias of different expression classes in Equation (14), which uses the information of mutual feature difference and contains more information than that of expression label matching in [45]. The corresponding objective function and the gradient vector are changed according to Equations (12) and (15), as revealed in Step 5.
| Algorithm 2 The modified multi-task sparse optimization. |
|
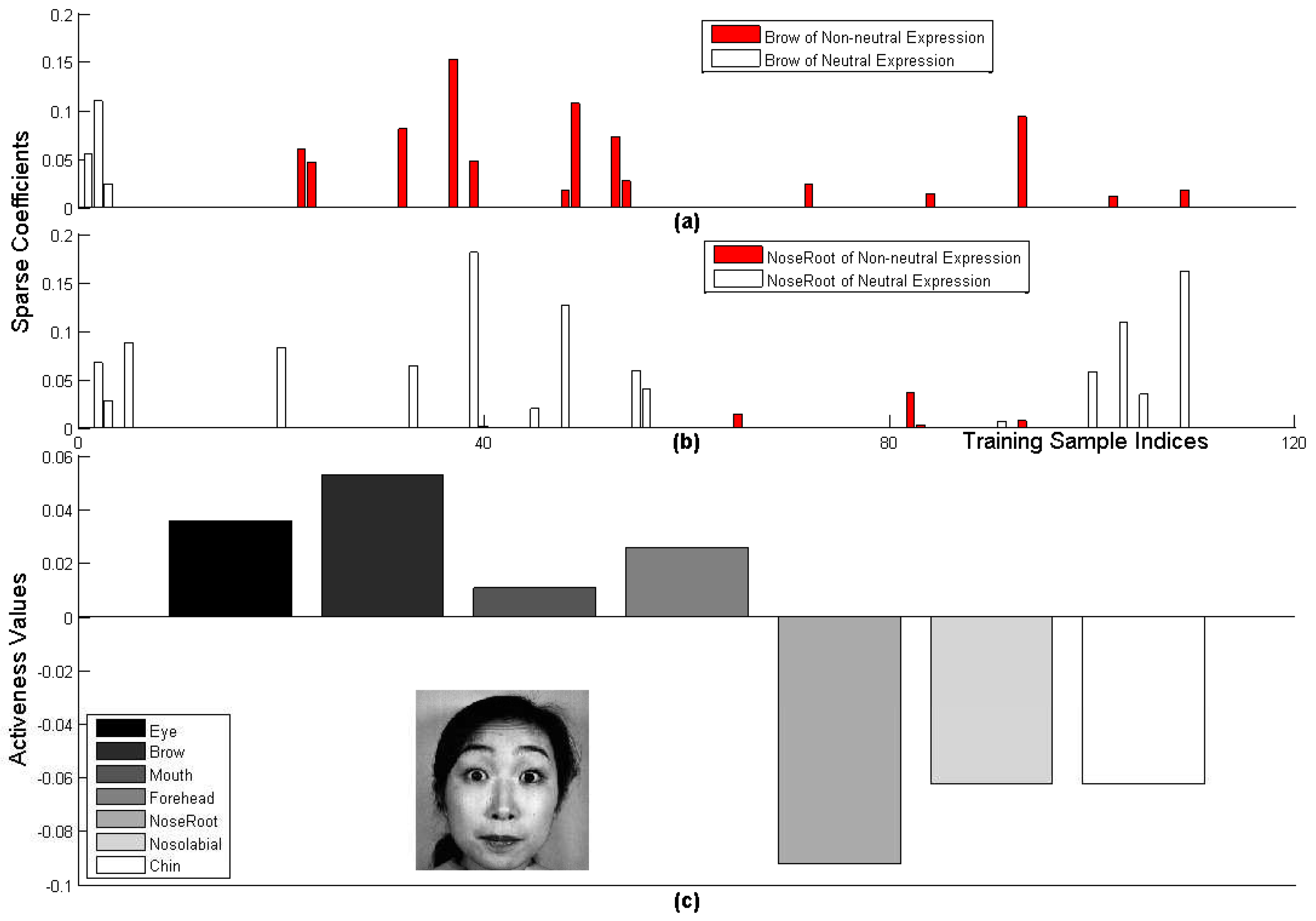
2.3.3. Active AU Detection
2.4. Weighted SVM for Classification
3. Experimental Results
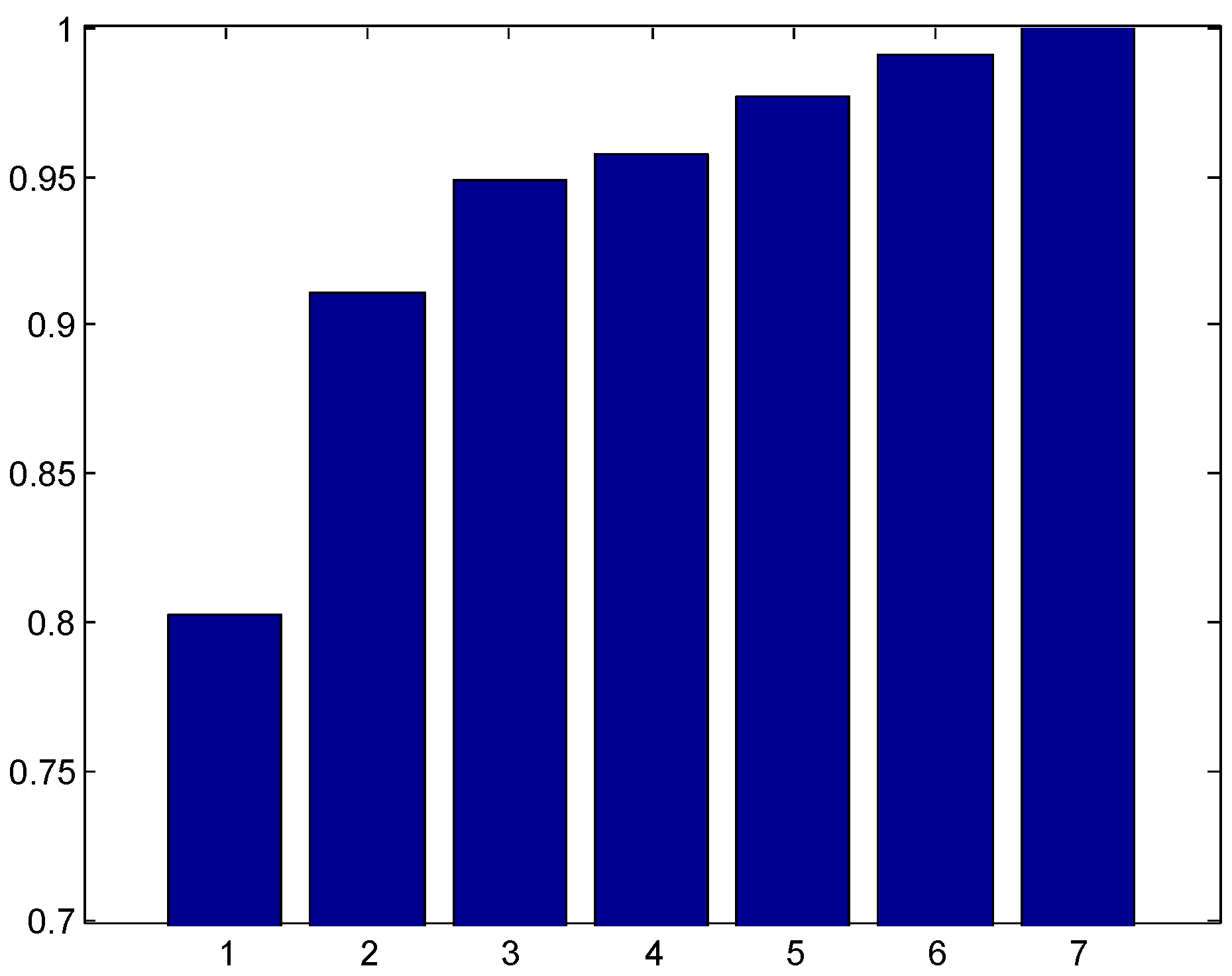
3.1. Number of Candidate Expressions Suggested by the First Stage Classifier
3.2. Recognition Performance Analysis
3.3. Feature Optimization Comparison
3.4. Comparison with the State-Of-The-Art
3.5. Cross-Database Performance Study
4. Discussion and Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Sandbach, G.; Zafeiriou, S.; Pantic, M.; Yin, L. Static and dynamic 3D facial expression recognition: A comprehensive survey. Image Vis. Comput. 2012, 30, 683–697. [Google Scholar] [CrossRef]
- Vezzetti, E.; Marcolin, F.; Fracastoro, G. 3D face recognition: An automatic strategy based on geometrical descriptors and landmarks. Rob. Auton. Syst. 2014, 62, 1768–1776. [Google Scholar] [CrossRef]
- Vezzetti, E.; Marcolin, F. 3D landmarking in multiexpression face analysis: A preliminary study on eyebrows and mouth. Aesthet. Plast. Surg. 2014, 38, 796–811. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Zhang, Q.; Tang, C. Base mesh extraction for different 3D faces based on ellipse fitting. In Proceedings of the IEEE Advanced Information Technology, Electronic and Automation Control Conference, Chongqing, China, 19–20 December 2015; pp. 285–294.
- Tian, Y.; Kanade, T.; Fcohn, J. Recognizing action units for facial expression analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 97–115. [Google Scholar] [CrossRef] [PubMed]
- Ekman, P.; Rosenberg, E.L. What the Face Reveals: Basic and Applied Studies of Spontaneous Expression Using the Facial Action Coding System, 2nd ed.; Oxford University Press: New York, NY, USA, 2005. [Google Scholar]
- Valstar, M.; Pantic, M. Fully automatic facial action unit detection and temporal analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshop, Washington, DC, USA, 17–22 June 2006; p. 149.
- Elaiwat, S.; Bennamoun, M.; Boussaid, F. A spatio-temporal RBM-based model for facial expression recognition. Pattern Recognit. 2016, 49, 152–161. [Google Scholar] [CrossRef]
- Liu, M.; Shan, S.; Wang, R.; Chen, X. Learning expressionlets on spatio-temporal manifold for dynamic facial expression recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1749–1756.
- Rudovic, O.; Pavlovic, V.; Pantic, M. Multi-output Laplacian dynamic ordinal regression for facial expression recognition and intensity estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2634–2641.
- Fasel, B. Multiscale facial expression recognition using convolutional neural networks. In Proceedings of the Third Indian Conference on Computer Vision, Graphics & Image Processing, Ahmadabad, India, 16–18 December 2002; p. 8123.
- Kim, B.K.; Roh, J.; Dong, S.Y.; Lee, S.Y. Hierarchical committee of deep convolutional neural networks for robust facial expression recognition. J. Multimodal User Interfaces 2016, 10, 173–189. [Google Scholar] [CrossRef]
- Burkert, P.; Trier, F.; Afzal, M.Z.; Dengel, A.; Liwicki, M. DeXpression: Deep convolutional neural network for expression recognition. arXiv 2016. [Google Scholar]
- Pramerdorfer, C.; Kampel, M. Facial expression recognition using convolutional neural networks: State of the art. arXiv 2016. [Google Scholar]
- Khorrami, P.; Paine, T.L.; Huang, T.S. Do deep neural networks learn facial action units when doing expression recognition? In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 11–12 December 2015; pp. 19–27.
- Liu, B.; Wang, M.; Foroosh, H.; Tappen, M.; Penksy, M. Sparse convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 806–814.
- Graham, B. Spatially-sparse convolutional neural networks. Comput. Sci. 2014, 34, 864–867. [Google Scholar]
- Yan, K.; Chen, Y.; Zhang, D. Gabor surface feature for face recognition. In Proceedings of the First Asian Conference on Pattern Recognition, Beijing, China, 28–30 November 2011; pp. 288–292.
- Whitehill, J.; Womlin, C. Haar features for FACS AU recognition. In Proceedings of the International Conference on Automatic Face and Gesture Recognition, Southampton, UK, 10–12 April 2006; pp. 97–101.
- Shan, C.; Gong, S.; Wmcowan, P. Facial expression recognition based on Local Binary Patterns: A comprehensive study. Image Vis. Comput. 2009, 27, 803–816. [Google Scholar] [CrossRef]
- Ouyang, Y.; Sang, N.; Huang, R. Accurate and robust facial expressions recognition by fusing multiple sparse representation based classifiers. Neurocomputing 2015, 149, 71–78. [Google Scholar] [CrossRef]
- Gu, W.; Xiang, C.; Vvenkatesh, Y.; Huang, D.; Lin, H. Facial expression recognition using radial encoding of local Gabor features and classifier synthesis. Pattern Recognit. 2012, 45, 80–91. [Google Scholar] [CrossRef]
- Ghimire, D.; Lee, J. Geometric feature-based facial expression recognition in image sequences using multi-class AdaBoost and support vector machines. Sensors 2013, 13, 7714–7734. [Google Scholar] [CrossRef] [PubMed]
- Kotsia, I.; Zafeiriou, S.; Pitas, I. Texture and shape information fusion for facial expression and facial action unit recognition. Pattern Recognit. 2008, 41, 833–851. [Google Scholar] [CrossRef]
- Xie, W.; Shen, L.; Jiang, J. A novel transient wrinkle detection algorithm and its application for expression synthesis. IEEE Trans. Multimedia 2017, 19, 279–292. [Google Scholar] [CrossRef]
- Bartlett, M.; Littlewort, G.; Bartonfrank, M.; Lainscsek, C.; Fasel, I.; Rmovellan, J. Recognizing facial expression: Machine learning and application to spontaneous behavior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; pp. 568–573.
- Hesse, N.; Gehrig, T.; Gao, H.; Kemalekenel, H. Multi-view facial expression recognition using local appearance features. In Proceedings of the International Conference on Pattern Recognition, Tsukuba, Japan, 11–15 November 2012; pp. 3533–3536.
- Sha, T.; Song, M.; Bu, J.; Chen, C.; Tao, D. Feature level analysis for 3D facial expression recognition. Neurocomputing 2011, 74, 2135–2141. [Google Scholar] [CrossRef]
- Liu, C.; Wechsler, H. Independent component analysis of Gabor features for face recognition. IEEE Trans. Neural Netw. 2003, 14, 919–928. [Google Scholar] [PubMed]
- Jlyons, M.; Budynek, J.; Akamatsu, S. Automatic classification of single facial images. IEEE Trans. Pattern Anal. Mach. Intell. 1999, 21, 1357–1362. [Google Scholar]
- Lai, Z.; Yong, X.; Jian, Y.; Shen, L.; Zhang, D. Rotational invariant dimensionality reduction algorithms. IEEE Trans. Cybern. 2016. [Google Scholar] [CrossRef] [PubMed]
- Nikitidis, S.; Tefas, A.; Pitas, I. Maximum margin projection subspace learning for visual data analysis. IEEE Trans. Image Process. 2014, 23, 4413–4425. [Google Scholar] [CrossRef] [PubMed]
- Liang, D.; Yang, J.; Zheng, Z.; Chang, Y. A facial expression recognition system based on supervised locally linear embedding. Pattern Recognit. Lett. 2005, 26, 2374–2389. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, L.; Ahossain, M. Adaptive 3D facial action intensity estimation and emotion recognition. Expert Syst. Appl. 2015, 42, 1446–1464. [Google Scholar] [CrossRef]
- Silapachote, P.; Rkaruppiah, D.; Rhanson, A. Feature selection using AdaBoost for face expression recognition. In Proceedings of the the Fourth IASTED International Conference on Visualization, Imaging, and Image Processing, Marbella, Spain, 6–8 September 2004; pp. 84–89.
- Jia, Q.; Gao, X.; Guo, H.; Luo, Z.; Wang, Y. Multi-layer sparse representation for weighted LBP-patches based facial expression recognition. Sensors 2015, 15, 6719–6739. [Google Scholar] [CrossRef] [PubMed]
- Zafeiriou, S.; Pitas, I. Discriminant graph structures for facial expression recognition. IEEE Trans. Multimedia 2008, 10, 1528–1540. [Google Scholar] [CrossRef]
- Giladbachrach, R.; Navot, A.; Tishby, N. Margin based feature selection-theory and algorithms. In Proceedings of the International Conference on Machine Learning, Banff, AB, Canada, 4–8 July 2004; pp. 43–50.
- Jia, S.; Hu, J.; Xie, Y.; Shen, L. Gabor cube selection based multitask joint sparse representation for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2016, 54, 1–14. [Google Scholar] [CrossRef]
- Wang, L.; Wang, K.; Li, R. Unsupervised feature selection based on spectral regression from manifold learning for facial expression recognition. IET Comput. Vis. 2015, 9, 655–662. [Google Scholar] [CrossRef]
- Liu, P.; Han, S.; Meng, Z.; Tong, Y. Facial expression recognition via a boosted deep belief network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1805–1812.
- Kyperountas, M.; Tefas, A.; Pitas, I. Salient feature and reliable classifier selection for facial expression classification. Pattern Recognit. 2010, 43, 972–986. [Google Scholar] [CrossRef]
- Happy, S.L.; Routray, A. Automatic facial expression recognition using features of salient facial patches. IEEE Trans. Affect. Comput. 2015, 6, 1–12. [Google Scholar] [CrossRef]
- Liu, P.; Tianyizhou, J.; Wtsang, I.; Meng, Z.; Han, S.; Tong, Y. Feature disentangling machine-A novel approach of feature selection and disentangling in facial expression analysis. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 151–166.
- Zhong, L.; Liu, Q.; Yang, P.; Huang, J.; Metaxas, D. Learning multiscale active facial patches for expression analysis. IEEE Trans. Cybern. 2015, 45, 2562–2569. [Google Scholar]
- Tong, Y.; Liao, W.; Ji, Q. Facial action unit recognition by exploiting their dynamic and semantic relationships. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1683–1699. [Google Scholar] [CrossRef] [PubMed]
- Liu, M.Y.; Li, S.X.; Shan, S.G.; Chen, X.L. AU-aware deep network for facial expression recognition. In Proceedings of the Tenth IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Shanghai, China, 22–26 April 2013; pp. 1–6.
- Zhao, G.; Huang, X.; Taini, M.; Li, S.Z.; Pietikainen, M. Facial expression recognition from near-infrared videos. Image Vis. Comput. 2011, 29, 607–619. [Google Scholar] [CrossRef]
- Li, Y.; Wang, S.; Zhao, Y.; Ji, Q. Simultaneous facial feature tracking and facial expression recognition. IEEE Trans. Image Process. 2013, 22, 2559–2573. [Google Scholar] [PubMed]
- Sun, Y.; Wang, X.; Tang, X. Deep convolutional network cascade for facial point detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3476–3483.
- Tzimiropoulos, G. Project-out cascaded regression with an application to face alignment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3659–3667.
- Tan, X.; Triggs, B. Enhanced local texture feature sets for face recognition under difficult lighting conditions. IEEE Trans. Image Process. 2010, 19, 1635–1650. [Google Scholar] [PubMed]
- Ekman, P.; Friesen, W.V. Facial Action Coding System: A Technique for the Measurement of Facial Movement; Consulting Psychologists Press: San Francisco, CA, USA, 1978. [Google Scholar]
- Shen, L.; Bai, L. A review on Gabor wavelets for face recognition. Pattern Anal. Appl. 2006, 9, 273–292. [Google Scholar] [CrossRef]
- Chen, X.; Pan, W.; Kwok, J.T.; Carbonell, J.G. Accelerated gradient method for multi-task sparse learning problem. In Proceedings of the IEEE International Conference on Data Mining, Miami, FL, USA, 6–9 December 2009; pp. 746–751.
- Lee, H.; Battle, A.; Raina, R.; Ng, A.Y. Efficient sparse coding algorithms. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 4–7 December 2006; pp. 801–808.
- Yang, M.; Zhang, L.; Yang, J.; Zhang, D. Robust sparse coding for face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 625–632.
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 389–396. [Google Scholar] [CrossRef]
- Xing, H.J.; Ha, M.H.; Tian, D.Z.; Hu, B.G. A novel support vector machine with its features weighted by mutual information. In Proceedings of the International Joint Conference on Neural Networks, Hong Kong, China, 1–8 June 2008; pp. 315–320.
- Jlyons, M.; Akamatsu, S.; Kamachi, M.; Gyoba, J. Coding facial expressions with Gabor wavelets. In Proceedings of the International Conference on Automatic Face and Gesture Recognition, Nara, Japan, 14–16 April 1998; pp. 200–205.
- Kanade, T.; Fcohn, J.; Tian, Y. Comprehensive database for facial expression analysis. In Proceedings of the International Conference on Automatic Face and Gesture Recognition, Grenoble, France, 26–30 March 2000; p. 46.
- Dhall, A.; Ramana Murthy, O.V.; Goecke, R.; Joshi, J.; Gedeon, T. Video and image based emotion recognition challenges in the wild: EmotiW 2015. In Proceedings of the ACM International Conference on Multimodal Interaction, Seattle, WA, USA, 9–13 November 2015; pp. 423–426.
- Chen, L.F.; Yen, Y.S. Brain Mapping Laboratory, Institute of Brain Science. Ph.D. Thesis, National Yang-Ming University, Taipei, Taiwan, 2007. [Google Scholar]
- Nbelhumeur, P.; Phespanha, J.; Jkriegman, D. Eigenfaces vs. Fisherfaces: Recognition using class specific linear projection. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 711–720. [Google Scholar] [CrossRef]
- Min, R.; Kose, N.; Dugelay, J. KinectFaceDB: A Kinect database for face recognition. IEEE Trans. Syst. Man Cybern. Syst. 2014, 44, 1534–1548. [Google Scholar] [CrossRef]
- Zhang, J.; Shan, S.; Kan, M.; Chen, X. Coarse-to-fine auto-encoder networks (CFAN) for real-time face alignment. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 1–16.
- Elguebaly, T.; Bouguila, N. Simultaneous high-dimensional clustering and feature selection using asymmetric Gaussian mixture models. Image Vis. Comput. 2015, 34, 27–41. [Google Scholar] [CrossRef]
- Mollahosseini, A.; Chan, D.; Mahoor, M.H. Going deeper in facial expression recognition using deep neural networks. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Lake Placid, NY, USA, 7–9 March 2016; pp. 1–10.
- Yu, Z.; Zhang, C. Image based static facial expression recognition with multiple deep network learning. In Proceedings of the ACM International Conference on Multimodal Interaction, Seattle, WA, USA, 9–13 November 2015; pp. 435–442.
- Ng, H.W.; Nguyen, V.D.; Vonikakis, V.; Winkler, S. Deep learning for emotion recognition on small datasets using transfer learning. In Proceedings of the ACM International Conference on Multimodal Interaction, Seattle, WA, USA, 9–13 November 2015; pp. 443–449.
- Hassner, T.; Harel, S.; Paz, E.; Enbar, R. Effective face frontalization in unconstrained images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4295–4304.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
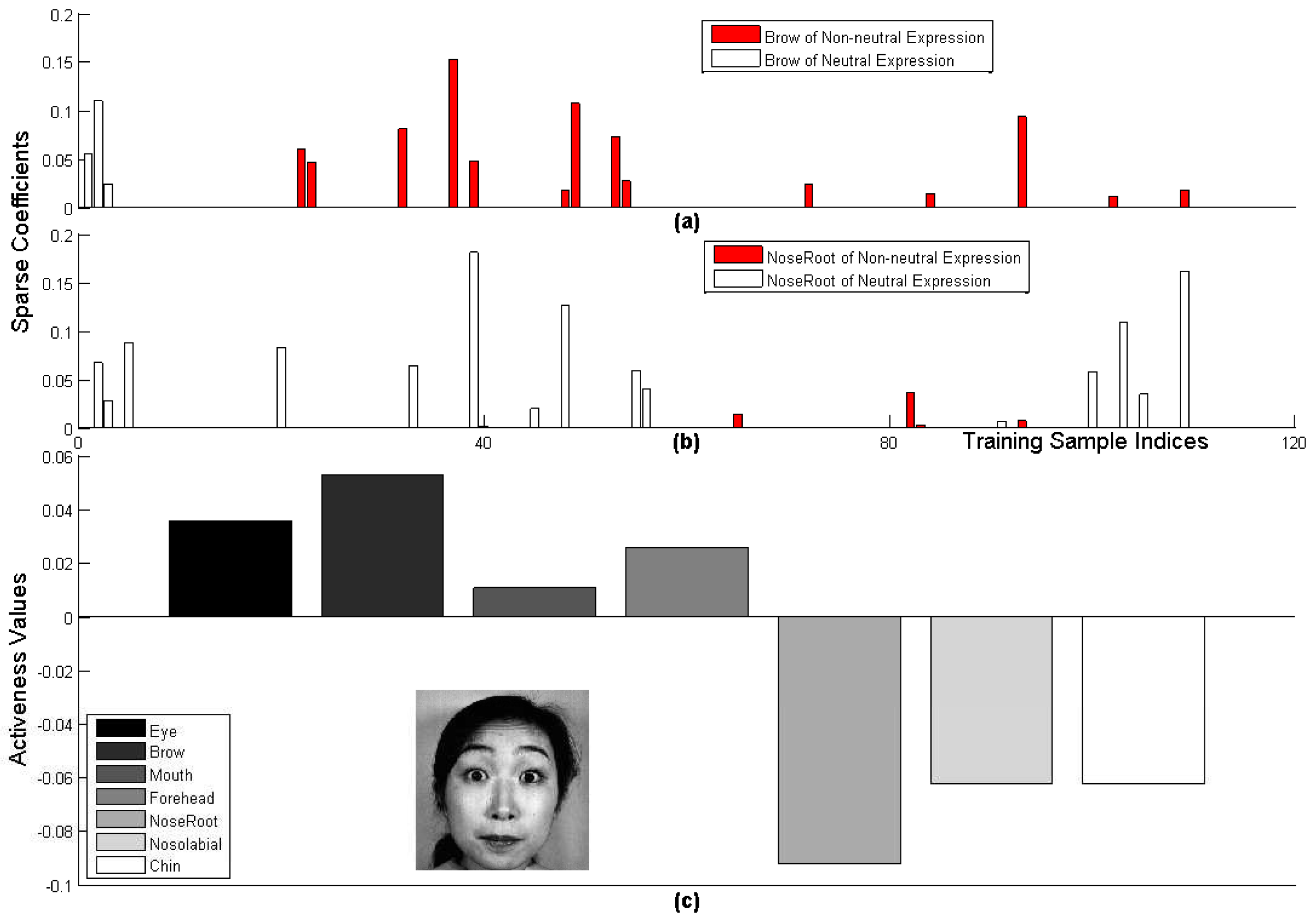
| , | , | , The same as | , |
| , The same as . | , | , , | |
| , The same as | , , | , The same as | , |
| Database | Seven Expression | Triplet-Wise-Based Two-Stage Classification | |||
|---|---|---|---|---|---|
| Patch Feature | Patch Feature | Patch Feature+ AU Weight | Patch Feature+ AU Weight+ Patch Weight | Patch Feature+ AU Weight+ Patch Weight+ Active AU Detection | |
| Jaffe | 82.63 | 83.10 | 84.04 | 86.85 | 89.67 |
| CK+ | 89.06 | 89.55 | 91.09 | 93.32 | 94.09 |
| SFEW2 | 42.2 | 42.2 | 42.66 | 43.81 | 46.1 |
| Expression | Ne | An | Di | Fe | Ha | Sa | Su |
|---|---|---|---|---|---|---|---|
| Ne | 90 | 3.33 | 0 | 0 | 0 | 0 | 6.67 |
| An | 0 | 83.33 | 6.67 | 0 | 0 | 10 | 0 |
| Di | 0 | 3.45 | 93.1 | 0 | 3.45 | 0 | 0 |
| Fe | 3.13 | 0 | 0 | 87.5 | 6.25 | 3.12 | 0 |
| Ha | 0 | 0 | 0 | 0 | 100 | 0 | 0 |
| Sa | 0 | 6.45 | 3.23 | 6.45 | 6.45 | 77.42 | 0 |
| Su | 0 | 0 | 0 | 0 | 3.33 | 0 | 96.67 |
| Expression | Ne | An | Di | Fe | Ha | Sa | Su |
|---|---|---|---|---|---|---|---|
| Ne | 94.34 | 2.84 | 0 | 0 | 0.94 | 0.94 | 0.94 |
| An | 9.63 | 85.93 | 4.44 | 0 | 0 | 0 | 0 |
| Di | 0 | 0 | 100 | 0 | 0 | 0 | 0 |
| Fe | 2.67 | 0 | 0 | 86.67 | 5.33 | 1.33 | 4 |
| Ha | 0 | 0 | 0 | 0 | 100 | 0 | 0 |
| Sa | 14.28 | 1.2 | 0 | 0 | 0 | 84.52 | 0 |
| Su | 2.81 | 0 | 0 | 0 | 0 | 0 | 97.19 |
| Database | UWs (Uniform Weights) | AdaBoost [35] | LDA [43] | CSS [48] | MTSPS [45] | Ours |
|---|---|---|---|---|---|---|
| Jaffe | 83.10 | 81.22 | 82.63 | 83.57 | 85.45 | 89.67 |
| CK+ | 89.55 | 88.58 | 90.71 | 90.22 | 92.45 | 94.09 |
| Algorithm | Category | Subjects | Protocol | Recognition Rate (%) |
|---|---|---|---|---|
| Feature and Classifier Selection [42] | Traditional | 10 | 10-fold | 85.92 |
| Radial Feature [22] | Traditional | 10 | 10-fold | 89.67 |
| Supervised LLE [33] | Traditional | 10 | 10-fold | 86.75 |
| Ours | Traditional | 10 | 10-fold | 89.67 |
| Deep CNN [11] | Deep learning-based | 10 | 10-fold | 88.6 |
| Deep Belief Network [41] | Deep learning-based | 10 | 10-fold | 91.8 |
| Algorithm | Category | Subjects | Protocol | Recognition Rate (%) |
|---|---|---|---|---|
| Maximum Margin Projection [32] | Traditional | 100 | 5-fold | 89.2 |
| Feature Selection with GMM [67] | Traditional | 97 | 10-fold | 89.1 |
| SVM (RBF) and Boosted-LBP [20] | Traditional | 96 | 10-fold | 91.4 |
| Radial Feature [22] | Traditional | 94 | 10-fold | 91.51 |
| Ours | Traditional | 106 | 10-fold | 94.09 |
| AU Deep Network [47] | Deep learning-based | 118 | 10-fold | 92.05 |
| Deep Neural Network [68] | Deep learning-based | 106 | 5-fold | 93.2 |
| Pyramid of Histogram of Gradients+Local Phase Quantization + Non-linear SVM [62] | Hierarchical Committee CNN [12] | Multiple CNN [69] | Transfer Learning Based CNN [70] | Ours |
|---|---|---|---|---|
| 35.93 | 56.4 | 56.19 | 48.5 | 46.1 |
| Algorithm | CK+ Training | Jaffe Training | CK+ and Jaffe Training | ||
|---|---|---|---|---|---|
| Jaffe Testing | CK+ Testing | TFEID | YALE | EURECOM | |
| SVM and LBP [20] | 41.3 | - | - | - | - |
| Radial Feature [22] | 55.87 | 54.05 | 61.94 | 60.66 | - |
| LPP [40] | 30.52 | 27.97 | - | - | - |
| SR [36] | 40.5 | - | - | - | - |
| Ours | 46.01 | 47.05 | 78.73 | 63.33 | 43.27 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, W.; Shen, L.; Yang, M.; Lai, Z. Active AU Based Patch Weighting for Facial Expression Recognition. Sensors 2017, 17, 275. https://doi.org/10.3390/s17020275
Xie W, Shen L, Yang M, Lai Z. Active AU Based Patch Weighting for Facial Expression Recognition. Sensors. 2017; 17(2):275. https://doi.org/10.3390/s17020275
Chicago/Turabian StyleXie, Weicheng, Linlin Shen, Meng Yang, and Zhihui Lai. 2017. "Active AU Based Patch Weighting for Facial Expression Recognition" Sensors 17, no. 2: 275. https://doi.org/10.3390/s17020275
APA StyleXie, W., Shen, L., Yang, M., & Lai, Z. (2017). Active AU Based Patch Weighting for Facial Expression Recognition. Sensors, 17(2), 275. https://doi.org/10.3390/s17020275