Pre-Scheduled and Self Organized Sleep-Scheduling Algorithms for Efficient K-Coverage in Wireless Sensor Networks




Abstract
:1. Introduction
- Novel PSKGS and SKS algorithms are designed to improve the performance of the pre-scheduled and self-organized approaches of WSNs, respectively.
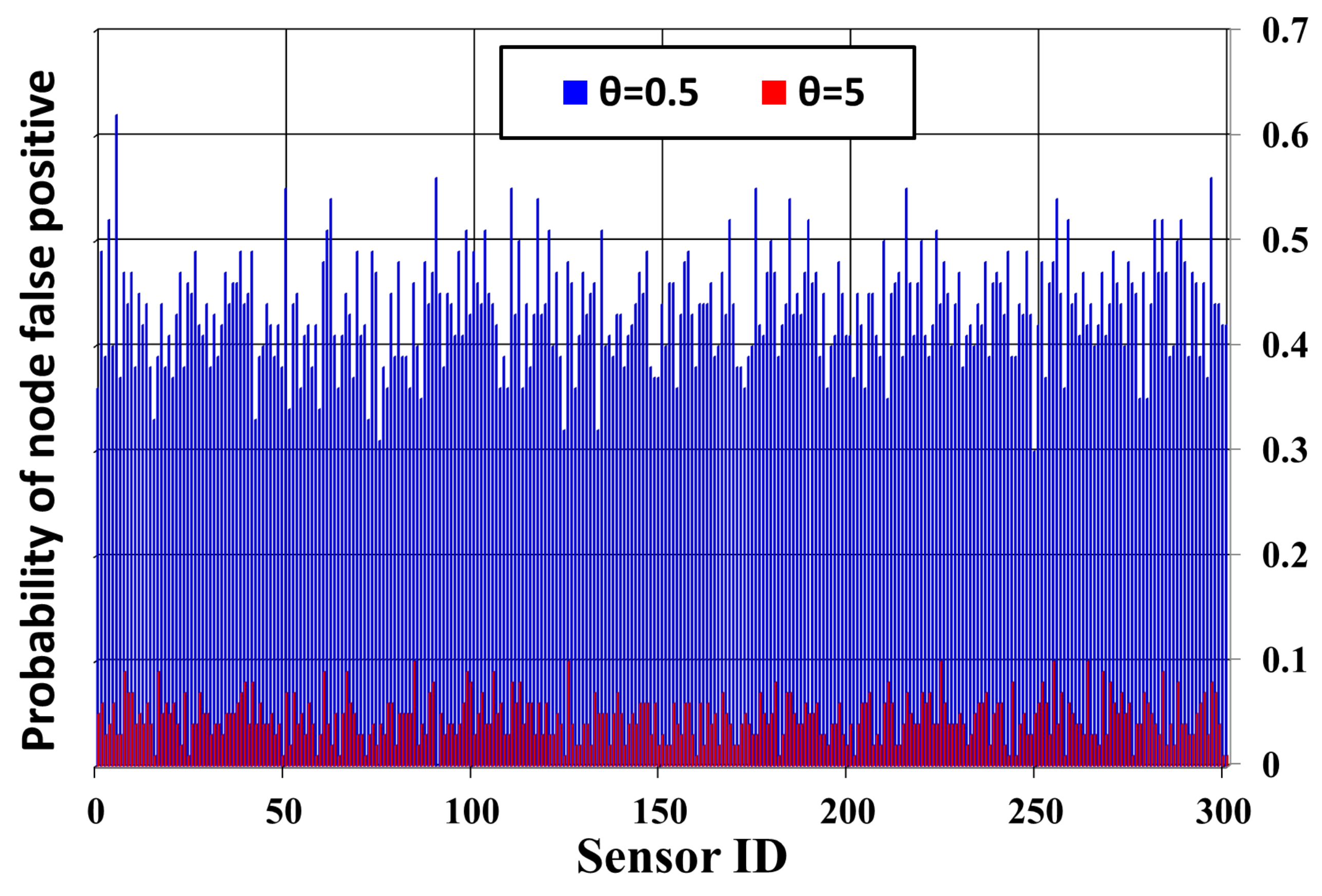
- Detection performance of the K-coverage sleep scheduling is measured in terms of explicit metrics introduced in [8], i.e., by using the probability of system false positives and system false negatives.
- The network lifetime of PSKGS and SKS is evaluated, and the impact of the sleep-scheduling algorithms on the overall detection quality is analyzed.
- Though both pre-scheduled and self-organized approaches are widely used, the proposed work analyzes the suitability of self-organized and pre-scheduling approaches to guarantee the K-coverage configuration while maximizing the network lifetime.
2. Related Works
2.1. Background and Problem Analysis
2.1.1. Pre-Scheduled Approach
2.1.2. Self-Organized Approach
3. Pre-Scheduling Based K-Coverage Group Scheduling
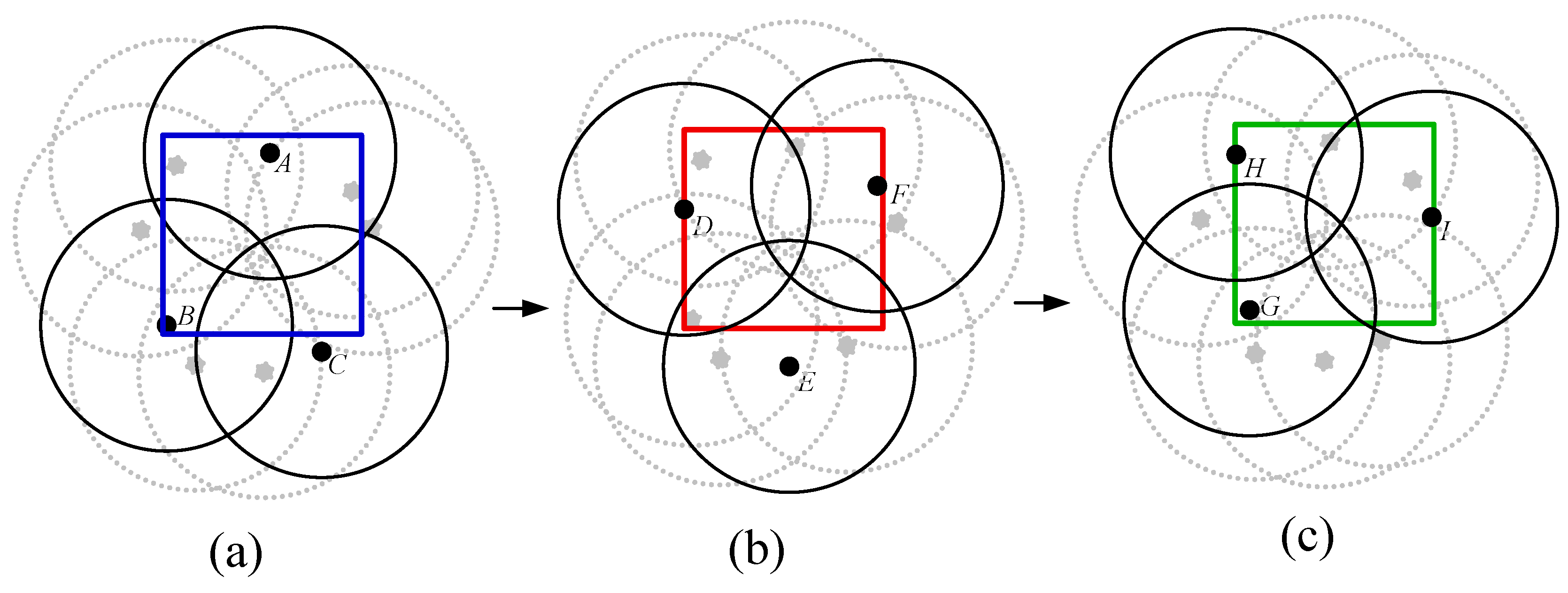
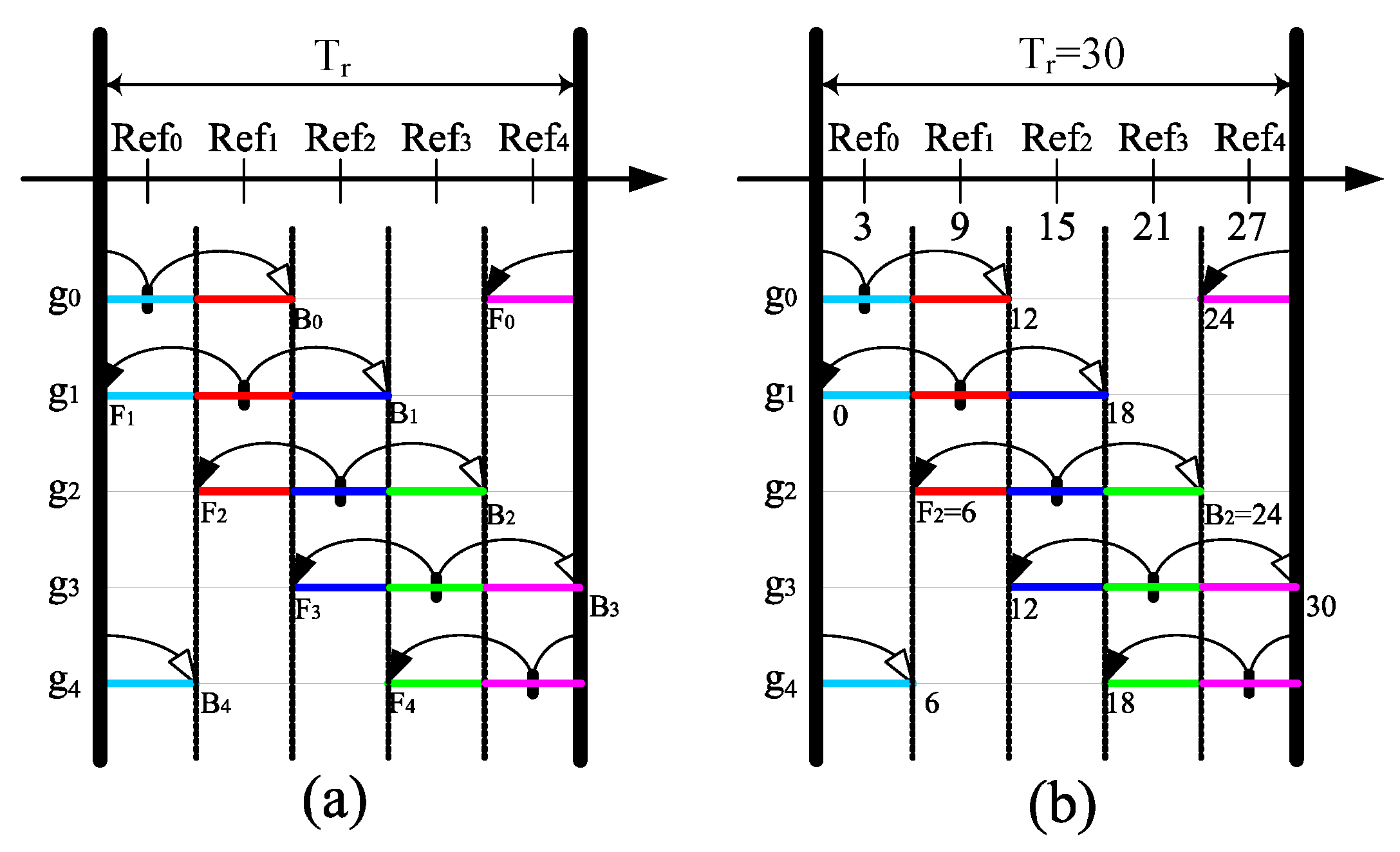
3.1. Formation of Groups
3.2. Scheduling of Nodes
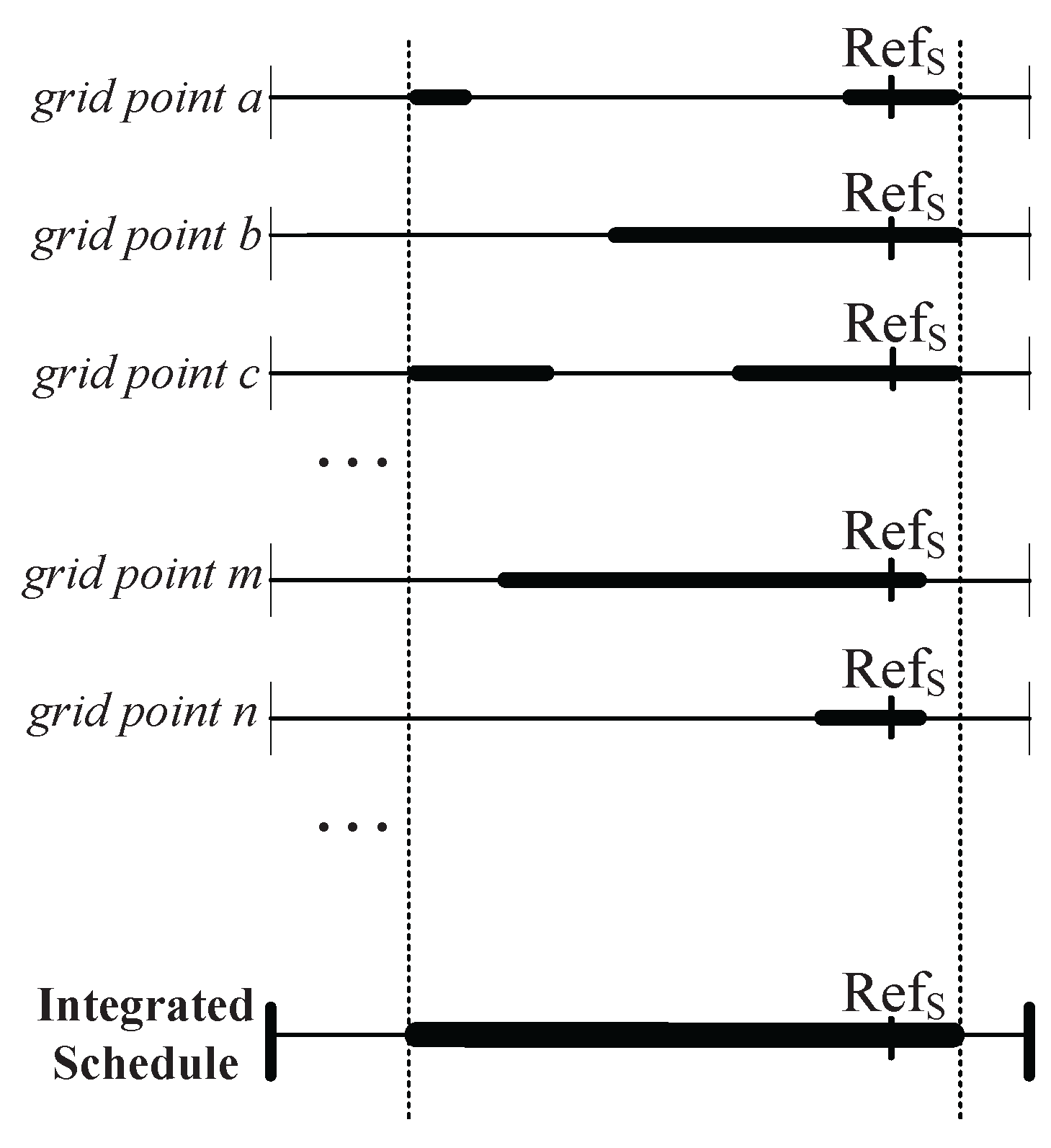
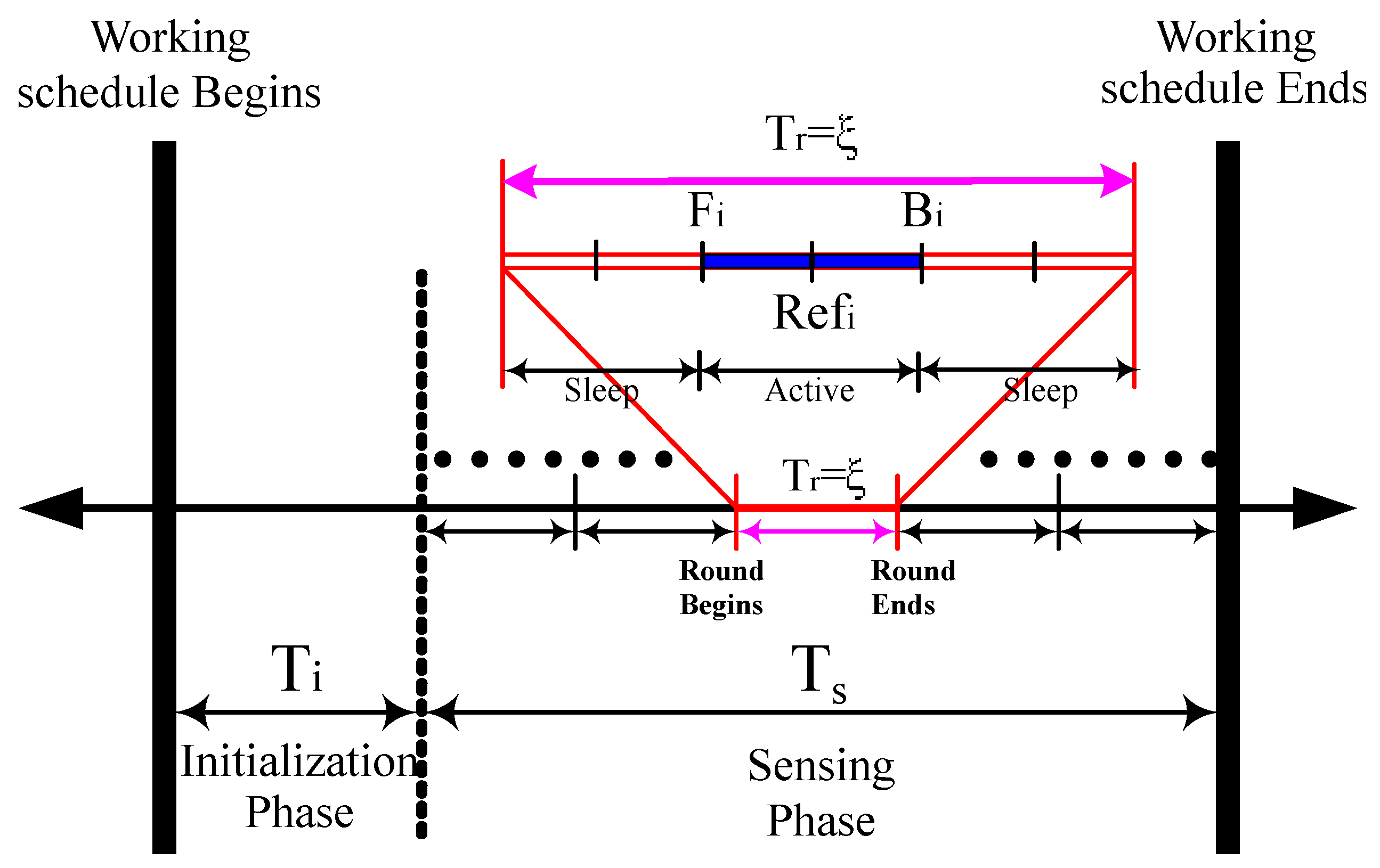
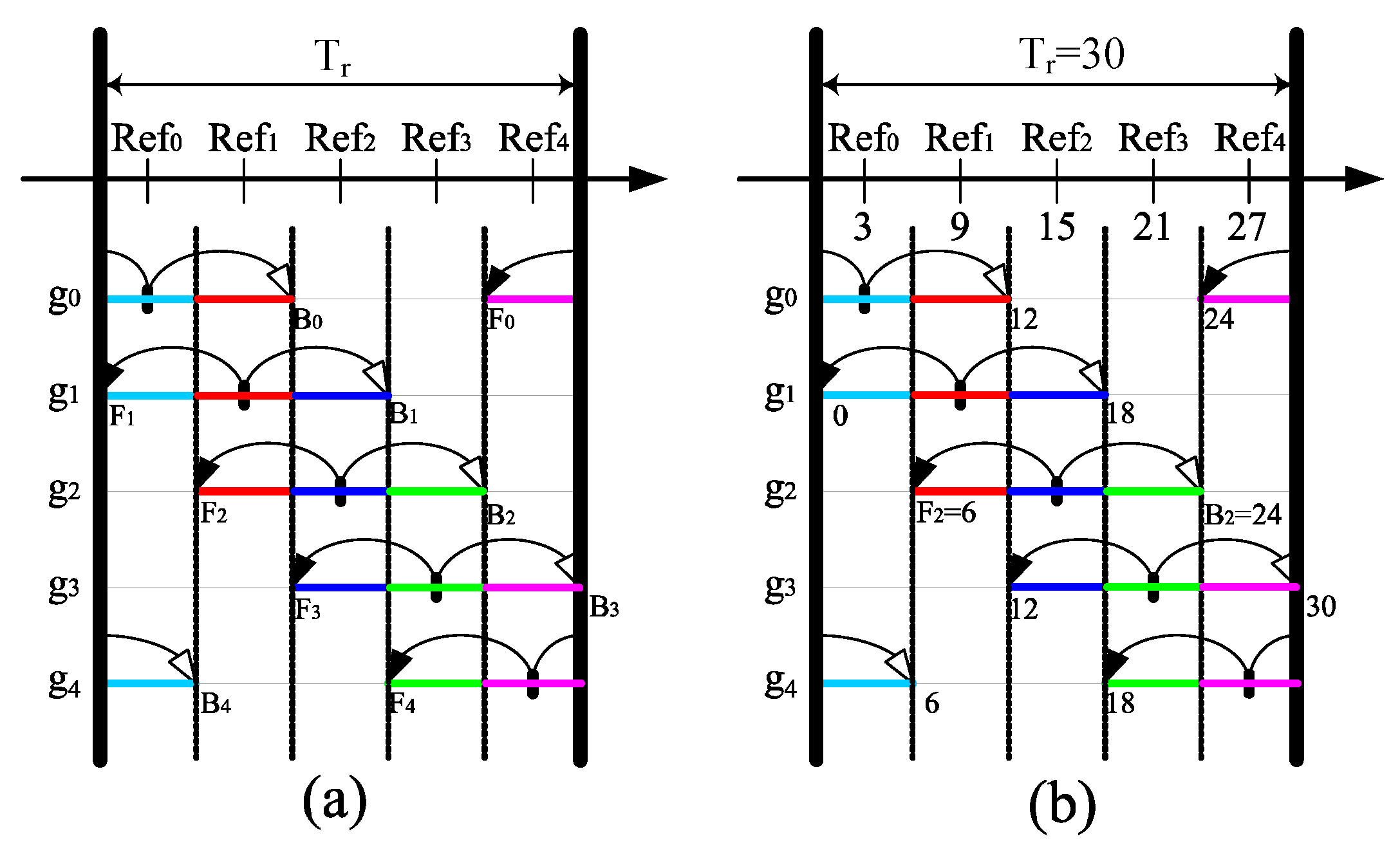
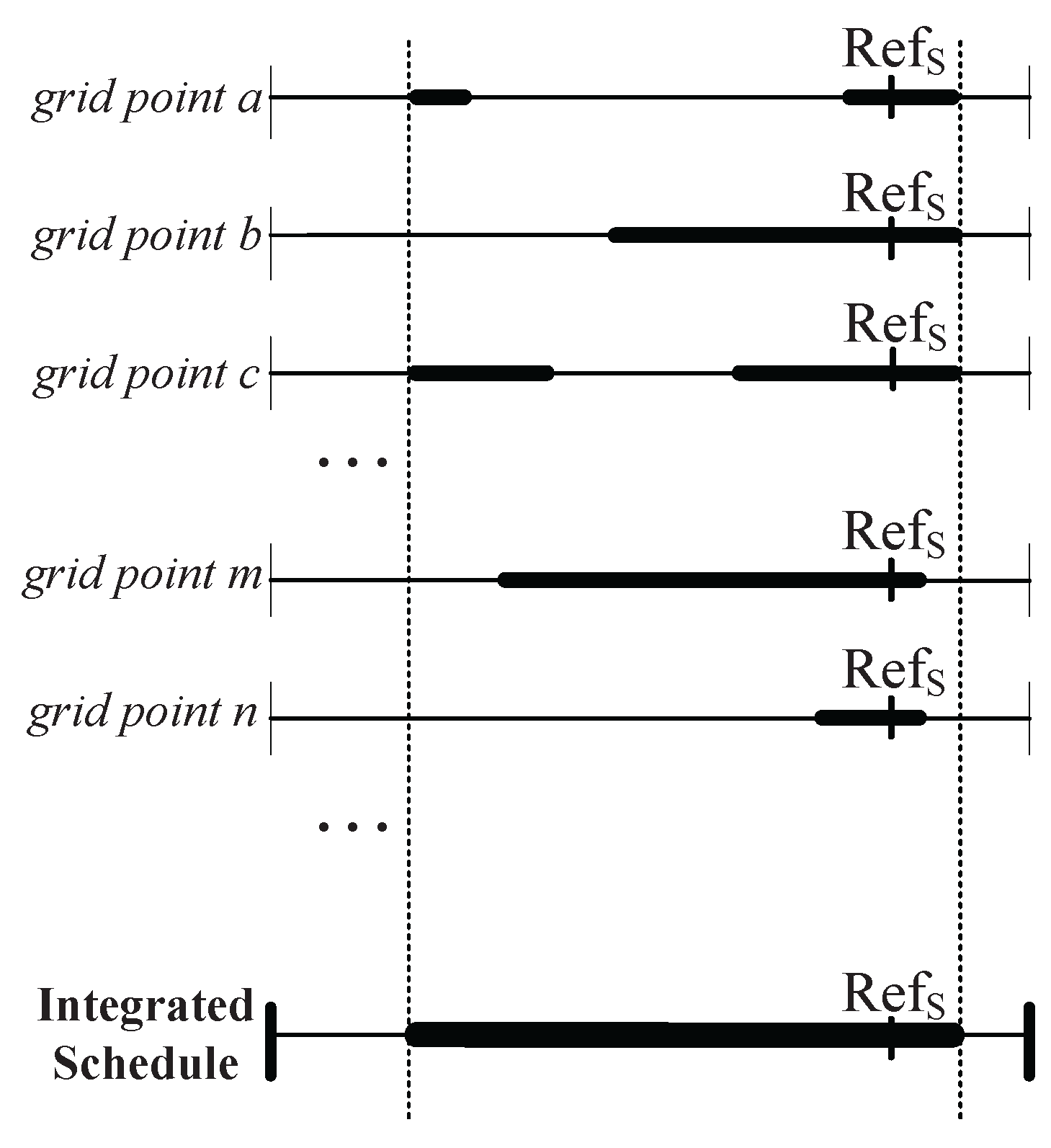
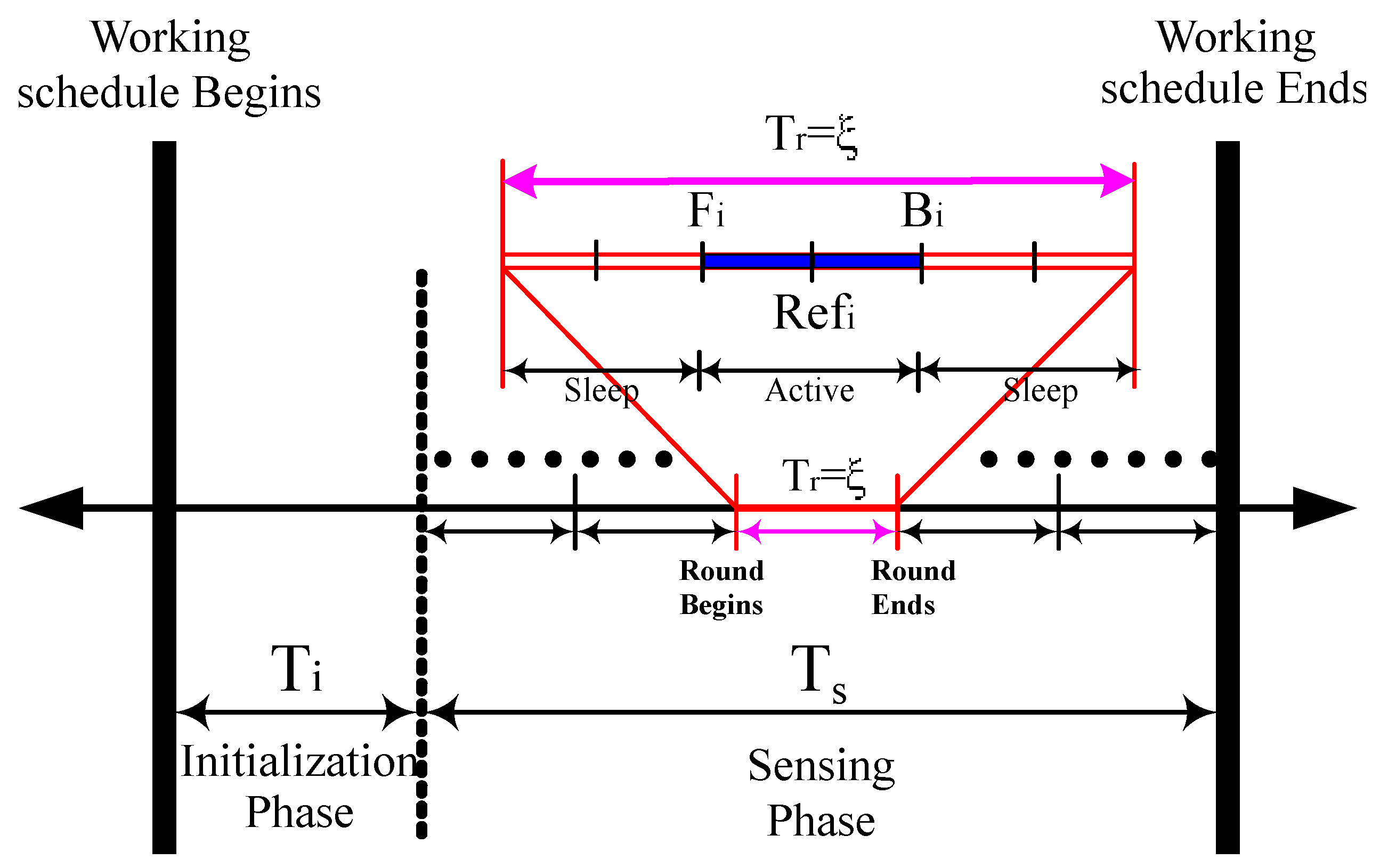
3.2.1. Working Schedule Structure
3.2.2. PSKGS Mechanism
| Algorithm 1: Calculation of and for the r-th round of time duration . |
| Input: , , , , , , , , |
| Output: , |
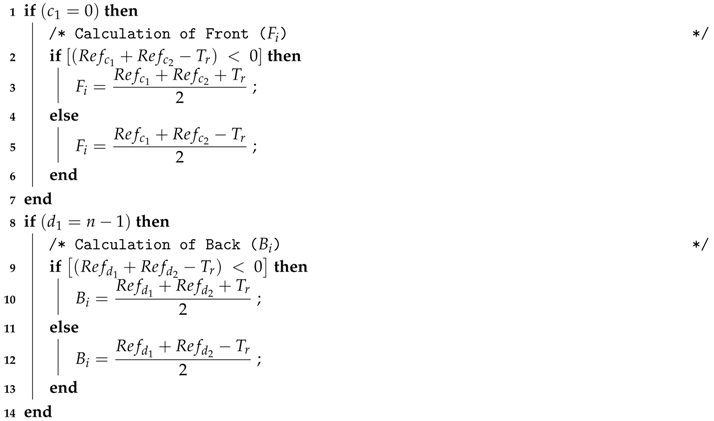 |
3.3. Computational Complexity of PSKGS
3.3.1. Computational Complexity of Forming Groups
3.3.2. Computational Complexity of Node Scheduling
4. Self-Organized-Based K-Coverage Scheduling Algorithm
4.1. Assumptions and Definitions
- : For any sensor i, is defined as .
- : For any sensor i, is defined as R-.
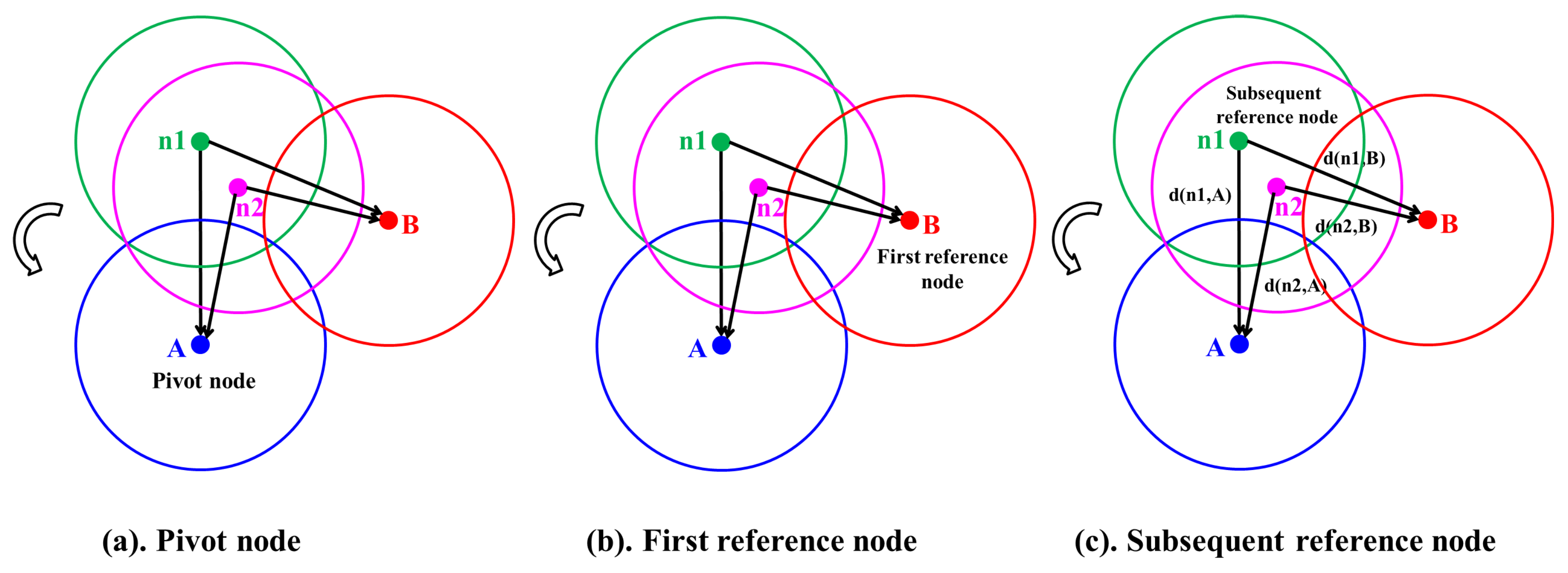
4.2. SKS Mechanism
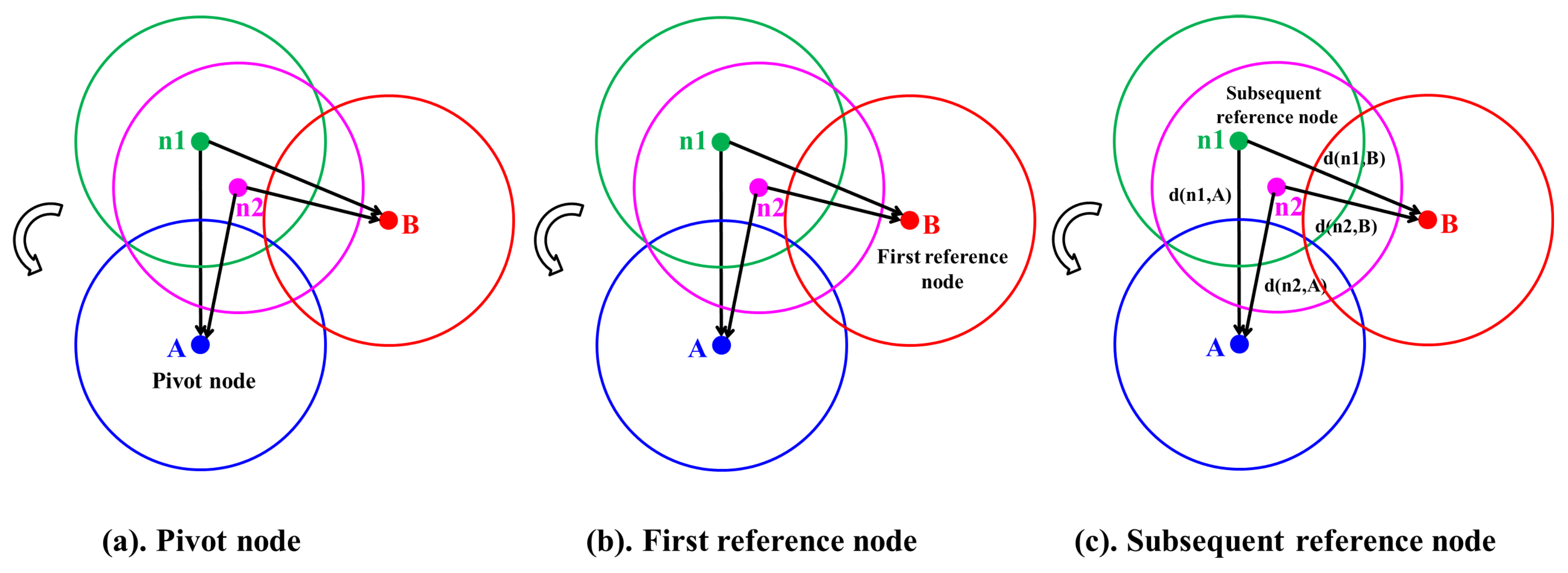
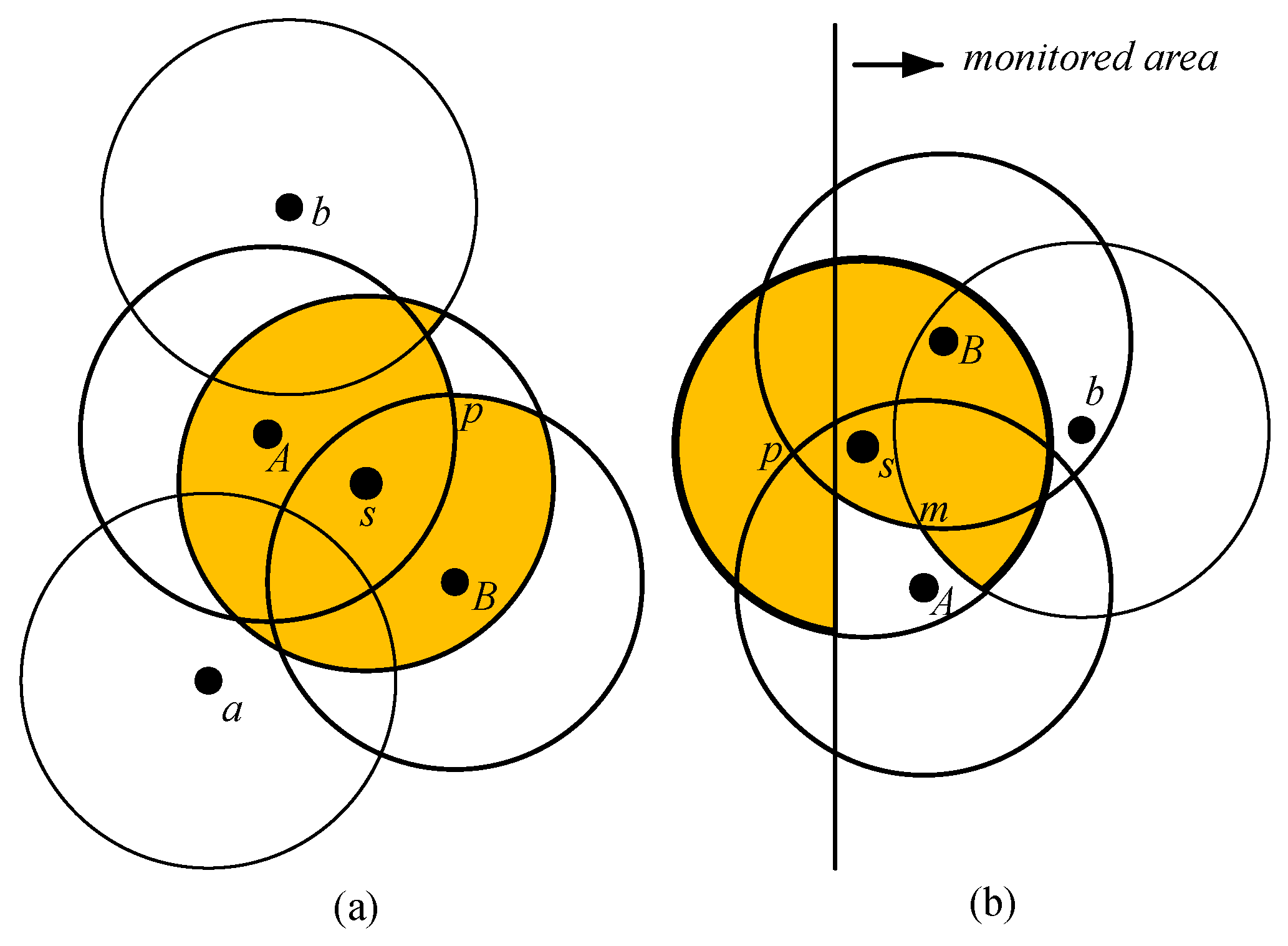
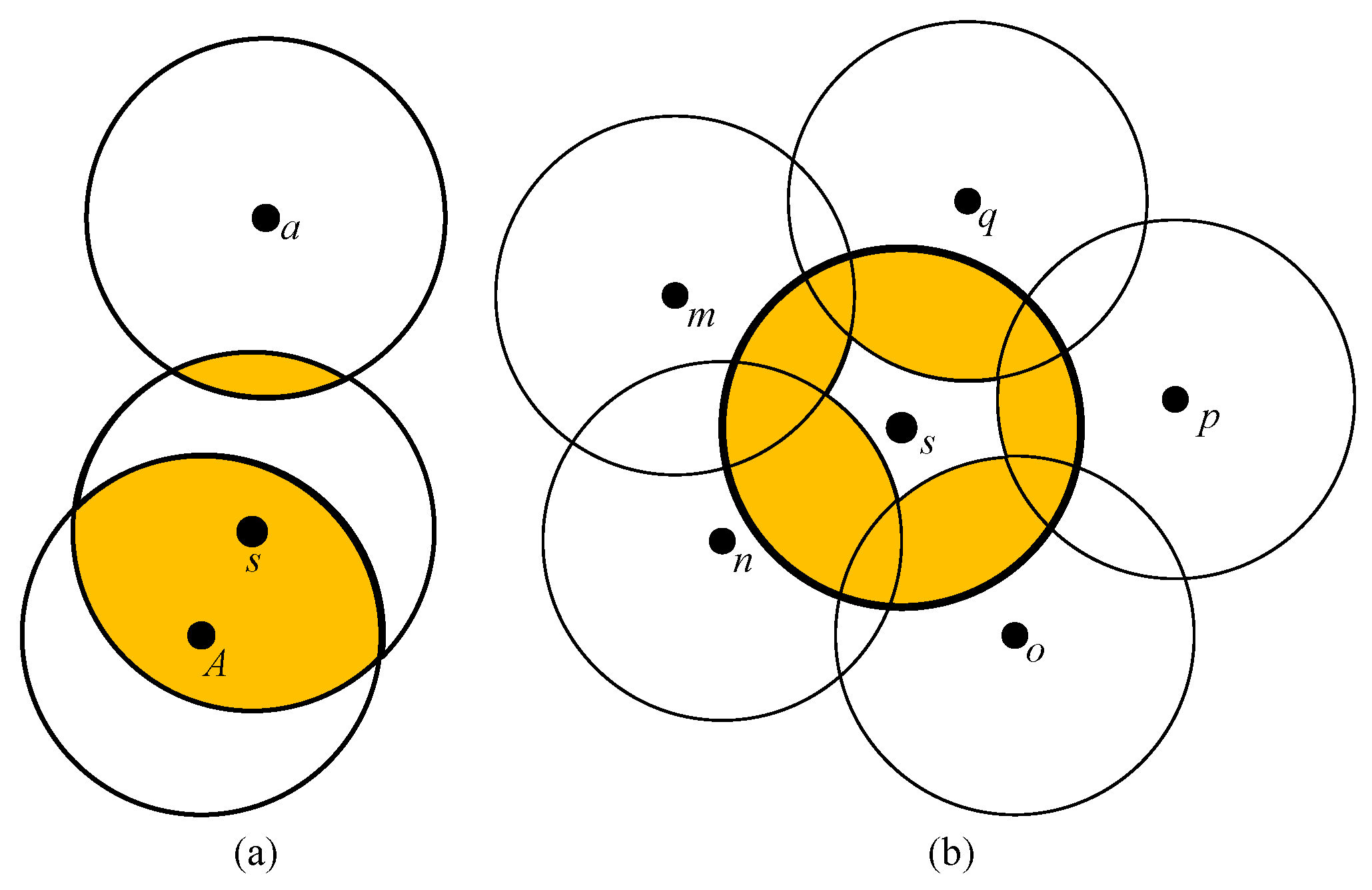
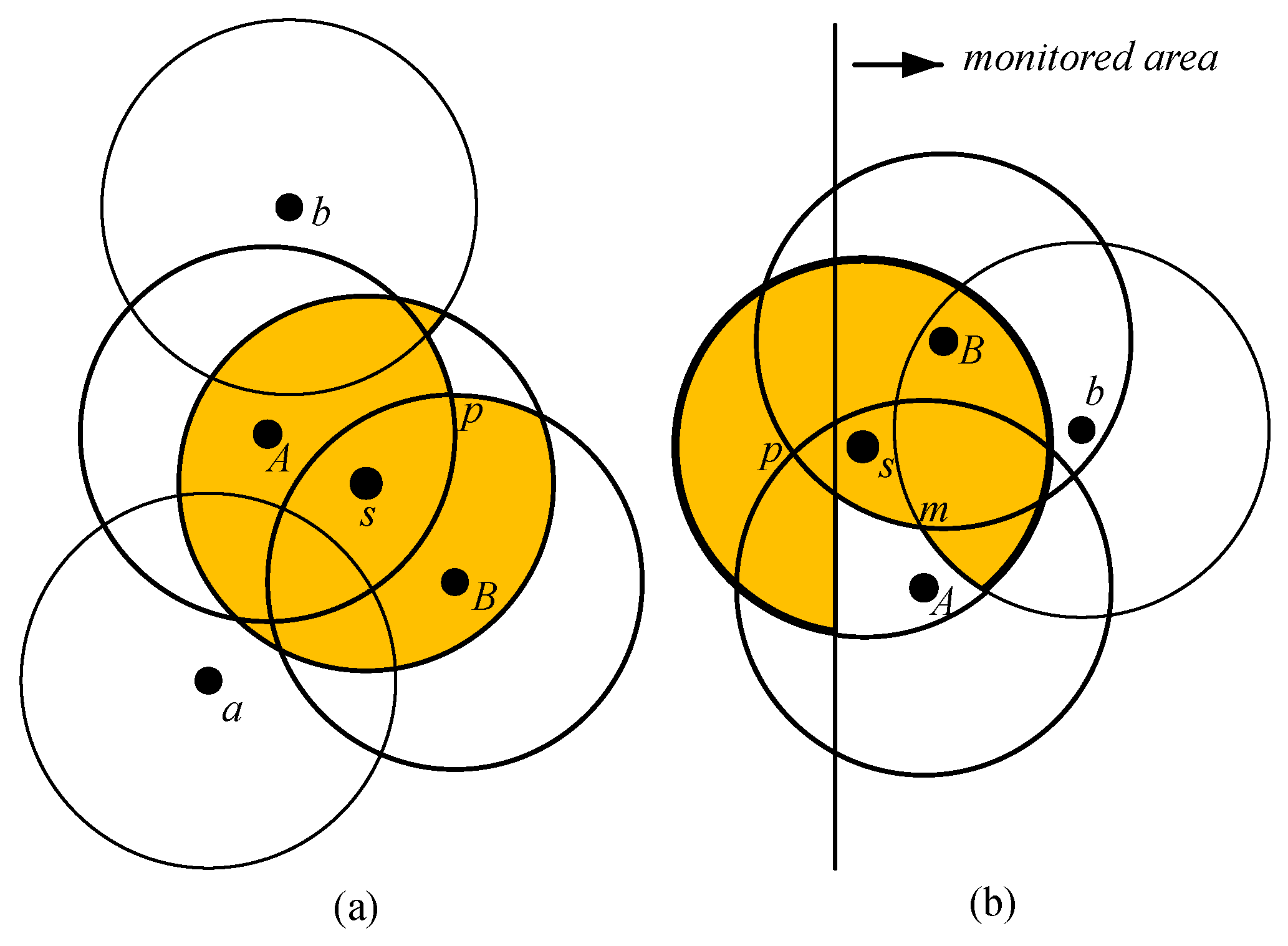
4.2.1. Candidate Regions with Lower Coverage Degree
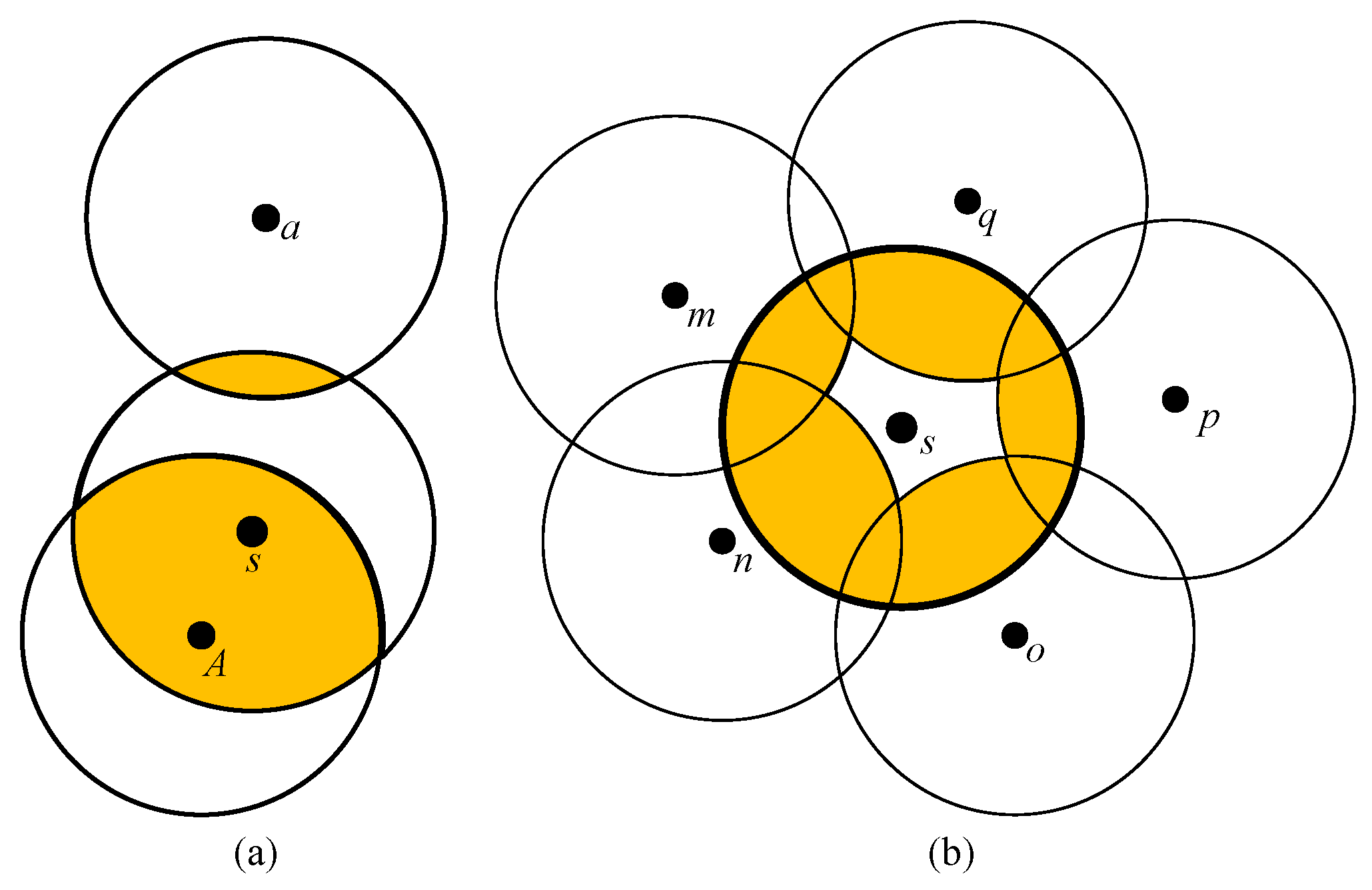
- Candidate Intersection Points (CIPs): The points intersected by any two and covered by the fewest .
- Candidate : The , which form the CIPs.
- Candidate : The , which cover the CIPs.
- Decision points: The points intersected by the candidate or candidate .
| Algorithm 2: Pseudocode of SKS. |
| Input: The set of sensors in the monitoring region |
| Output: Eligible or Ineligible |
 |
4.3. Computational Complexity of SKS
5. Performance Evaluation
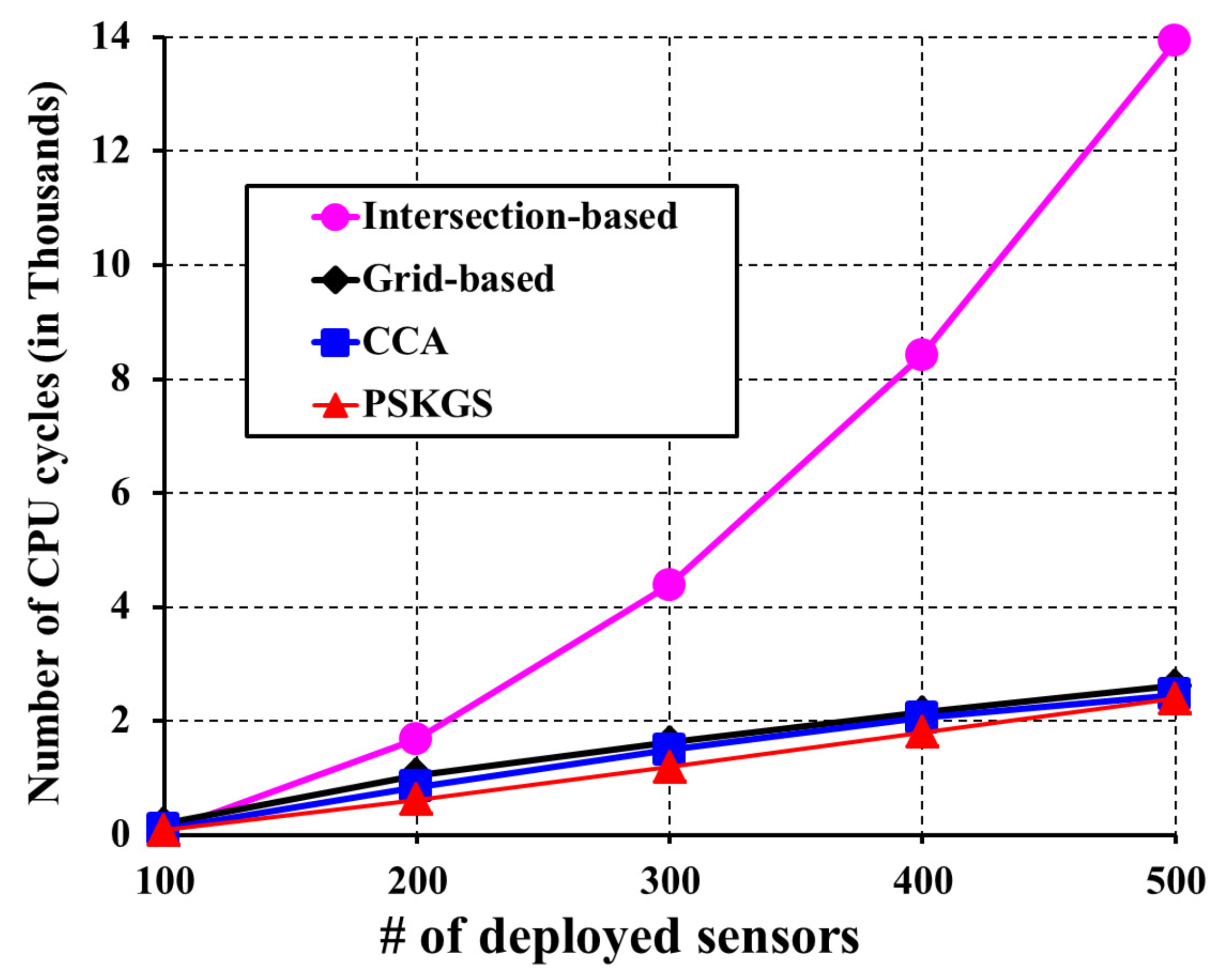
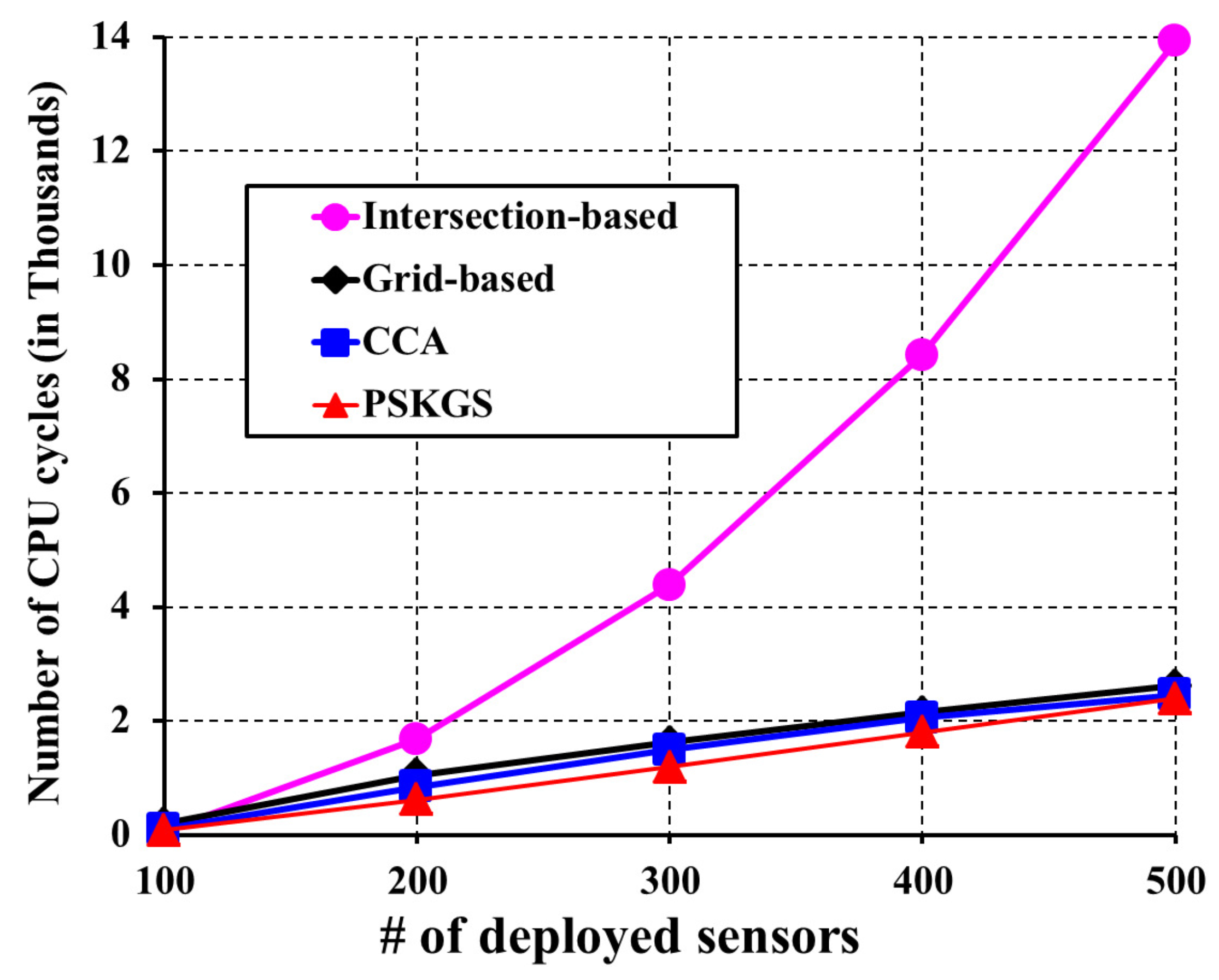
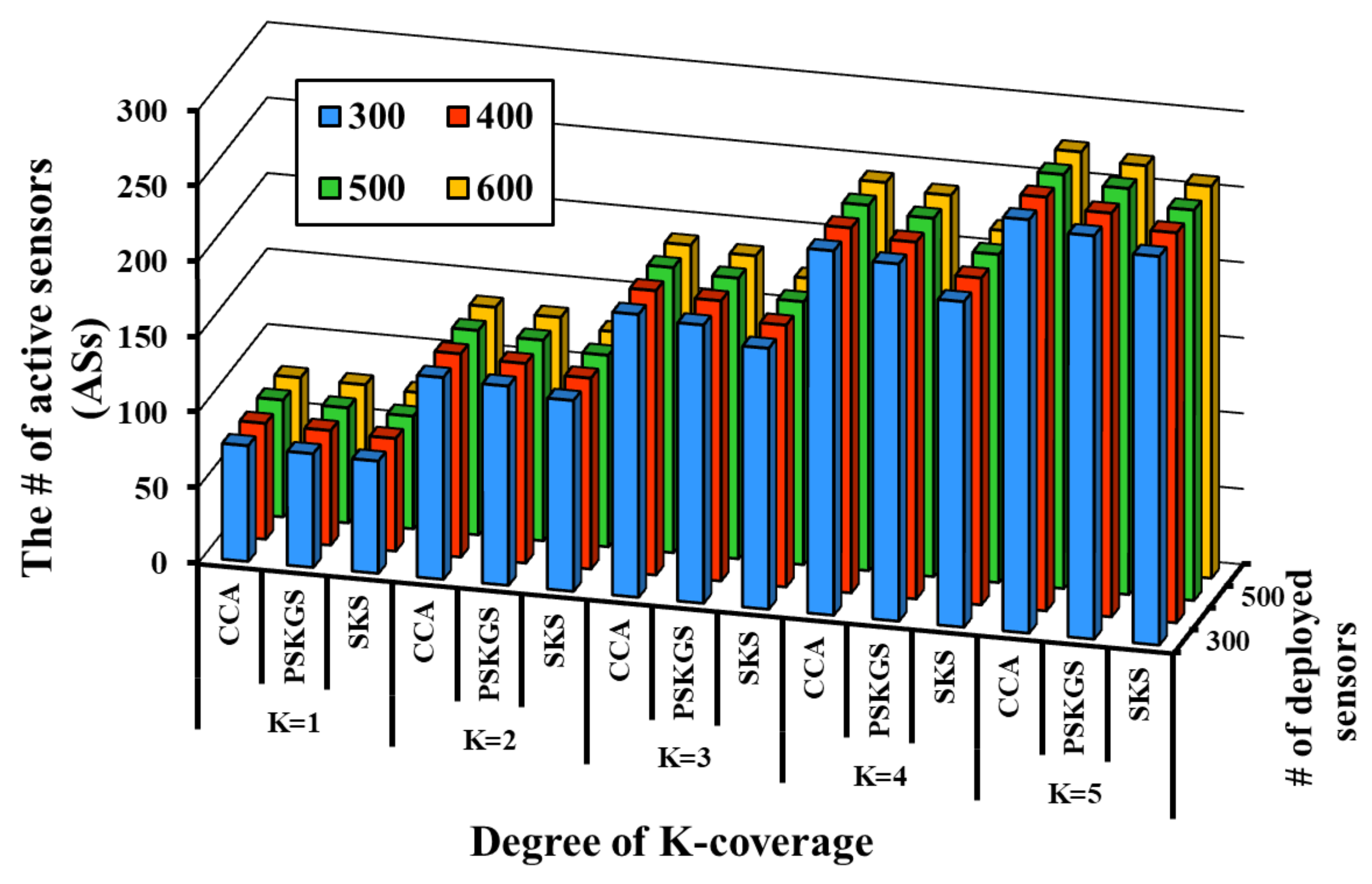
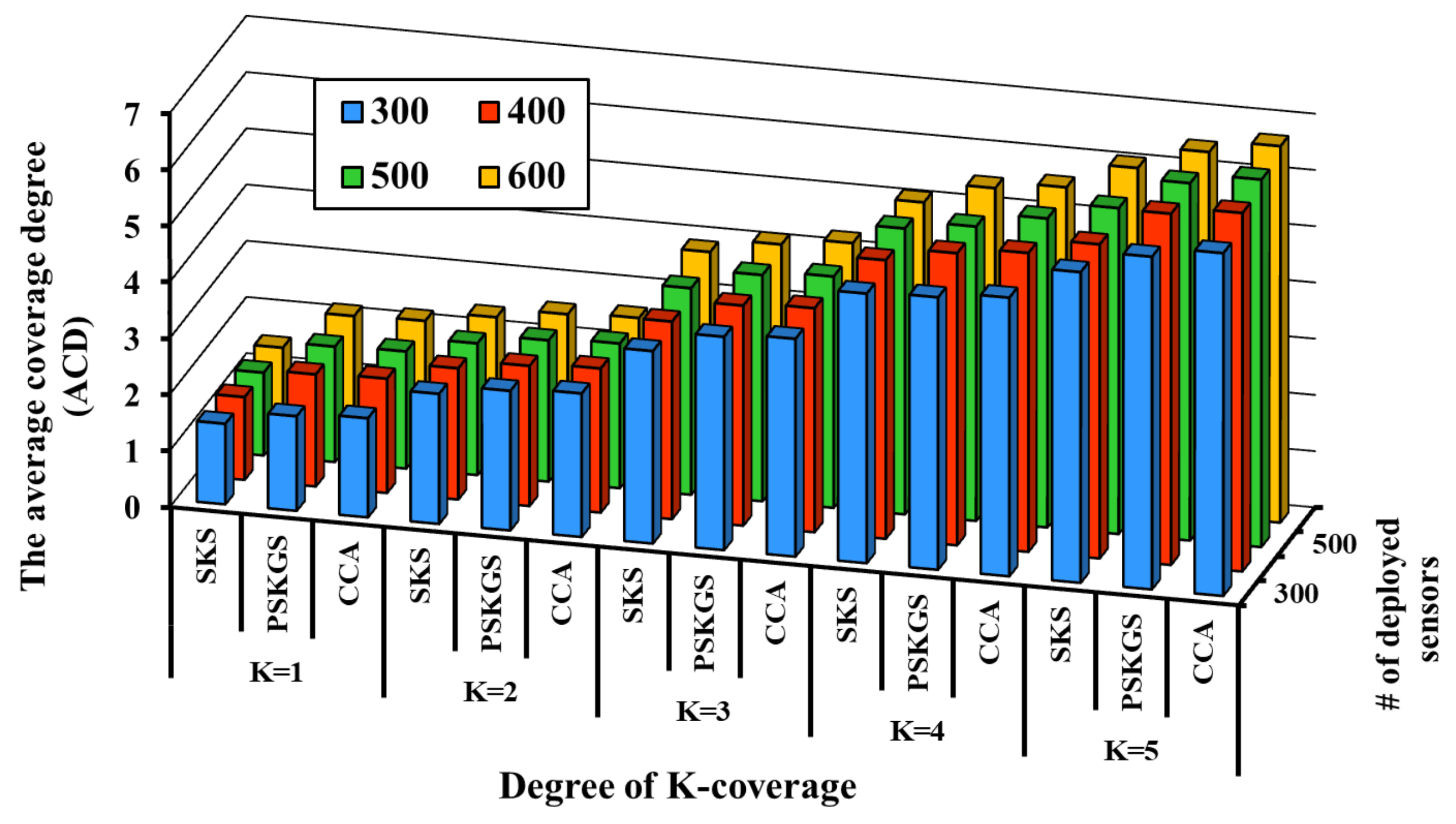
5.1. Pre-Scheduled Approach
5.2. Self-Organized Approach
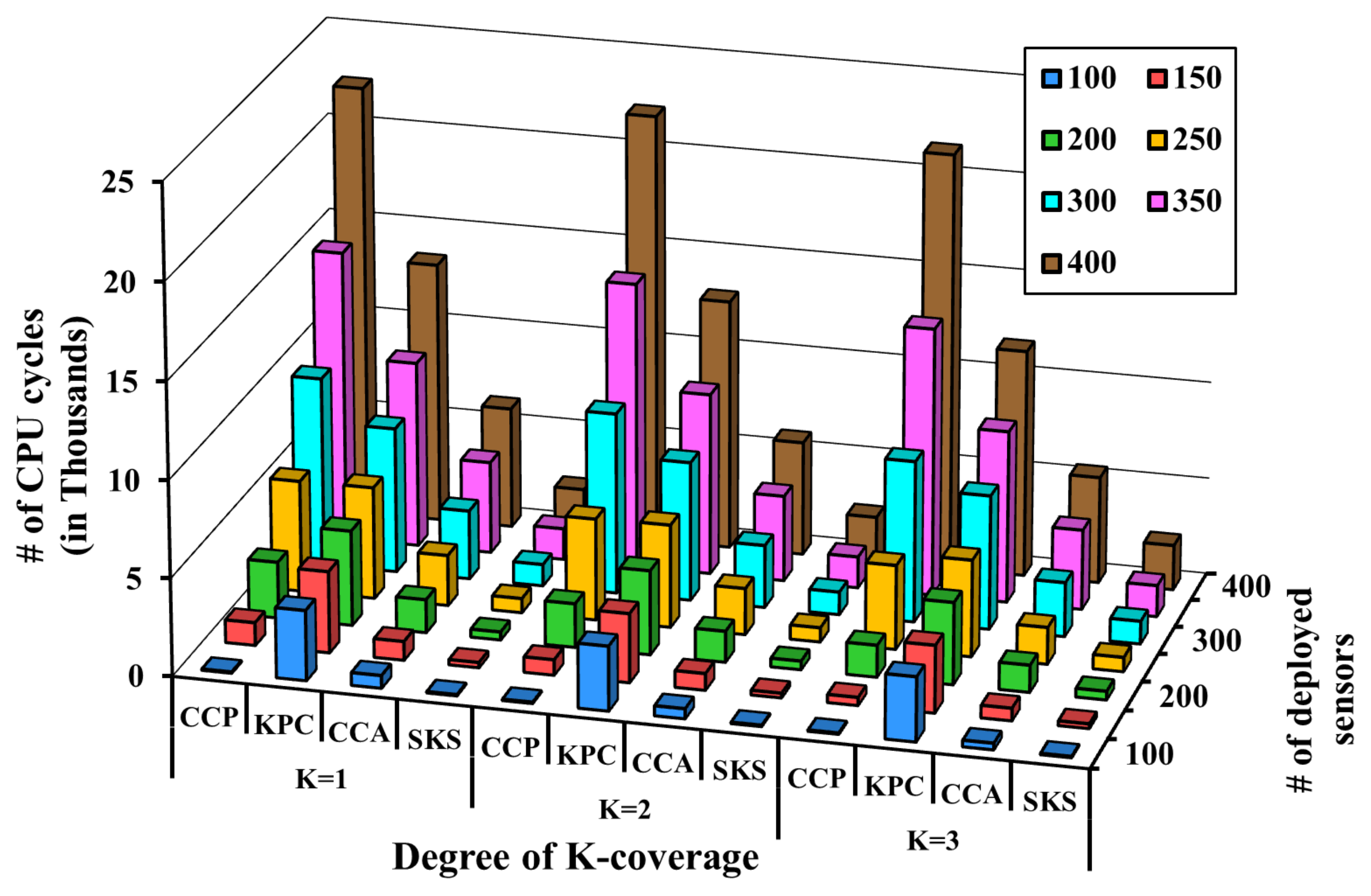
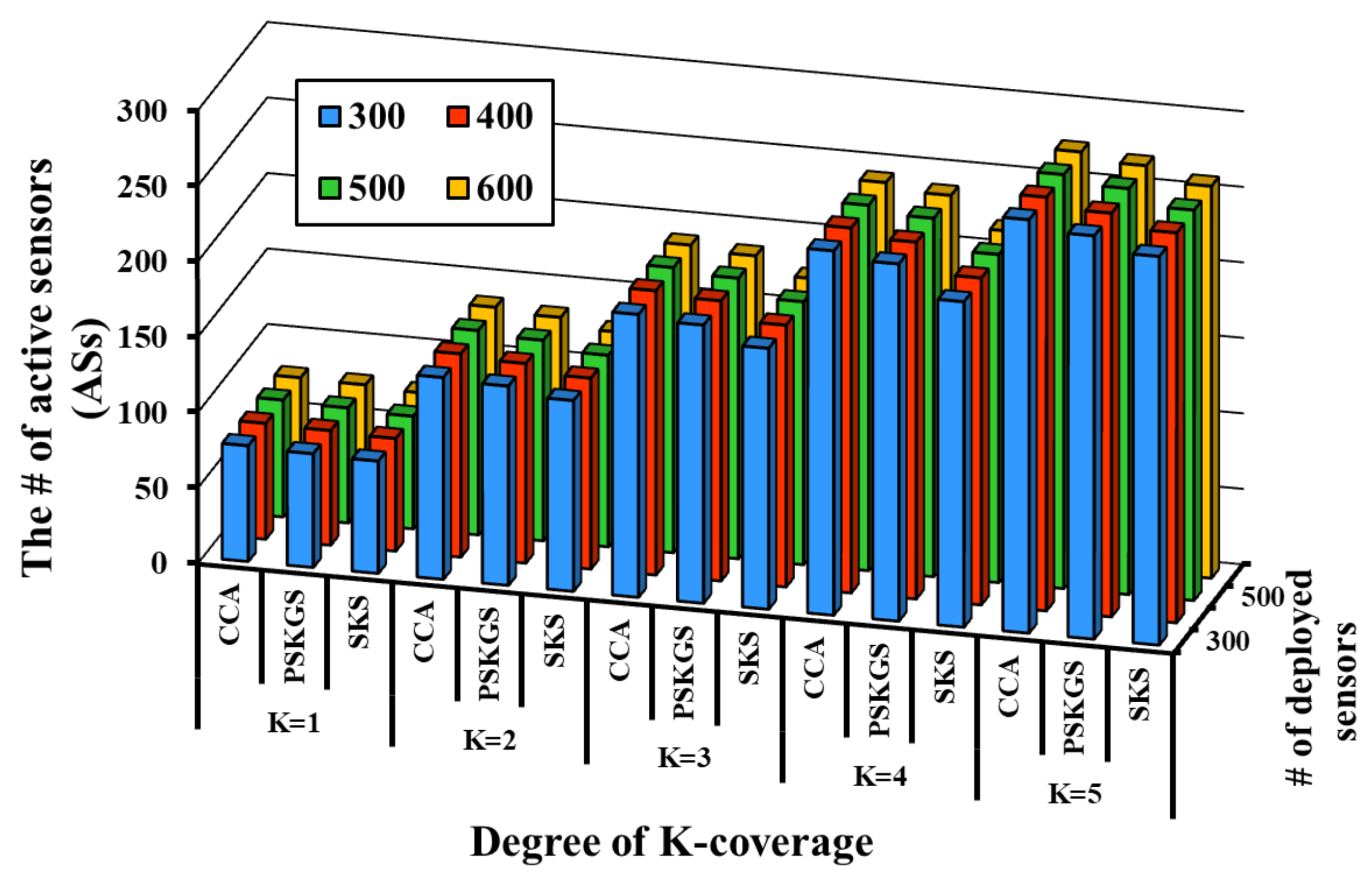
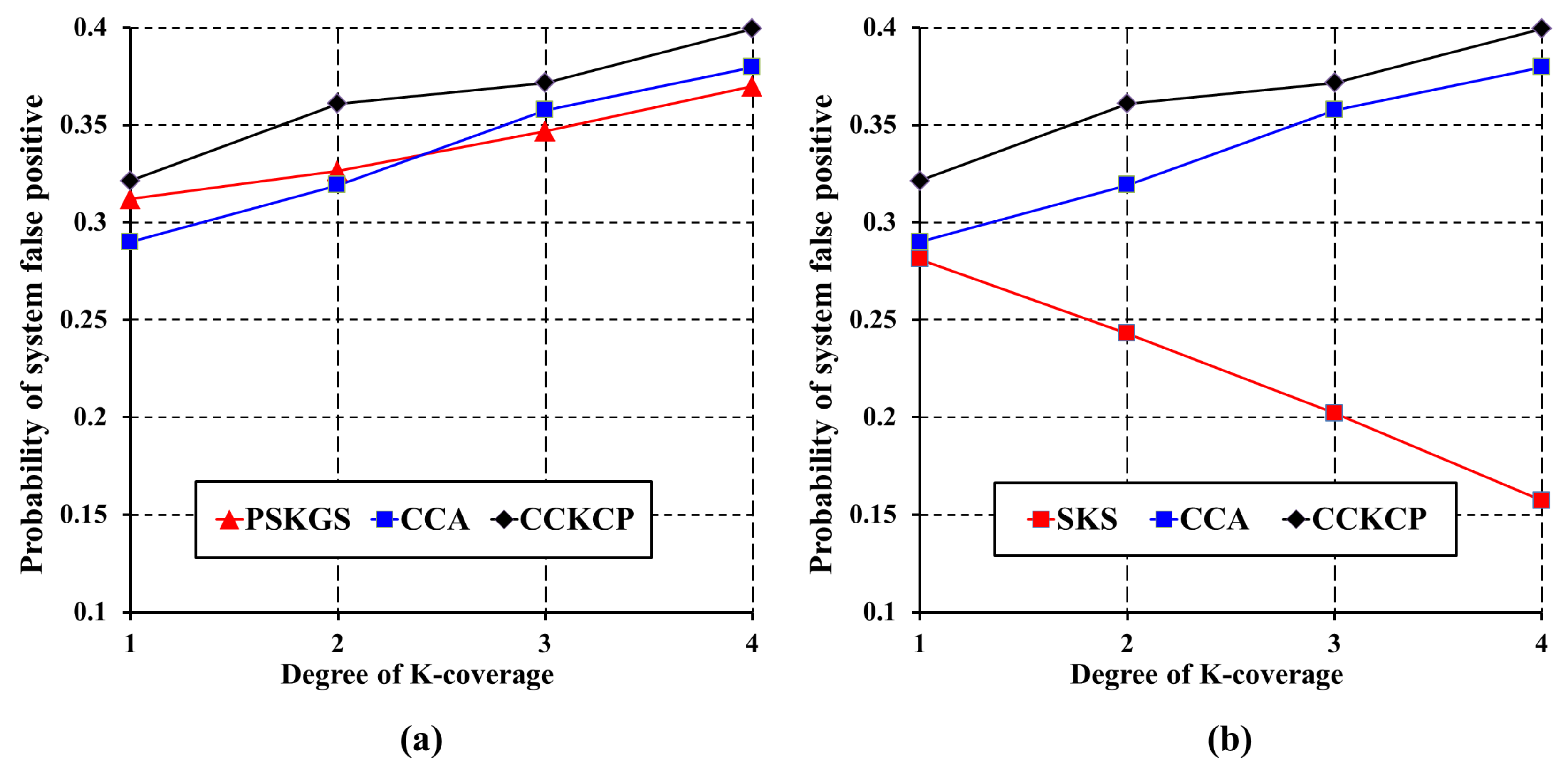
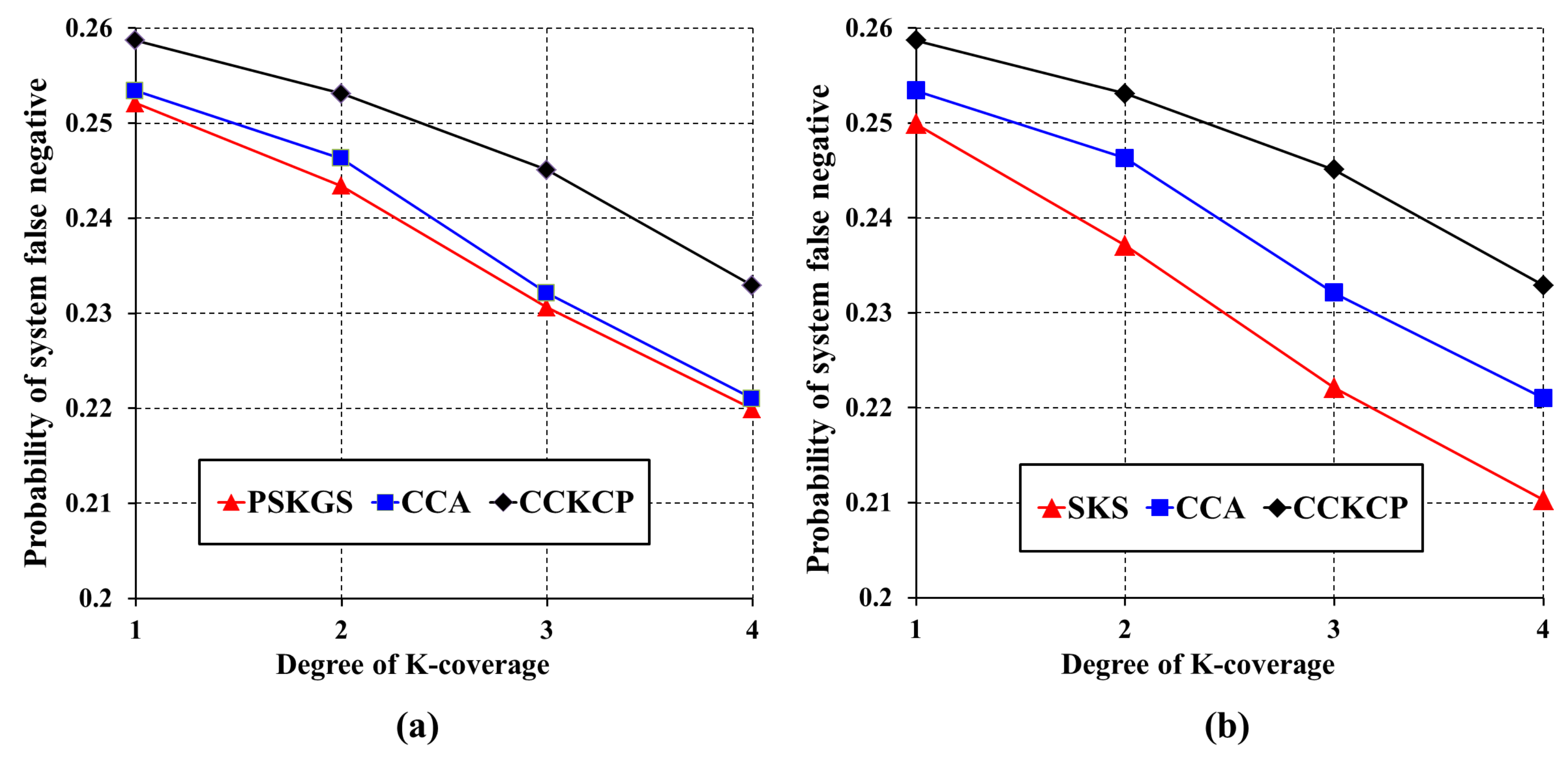
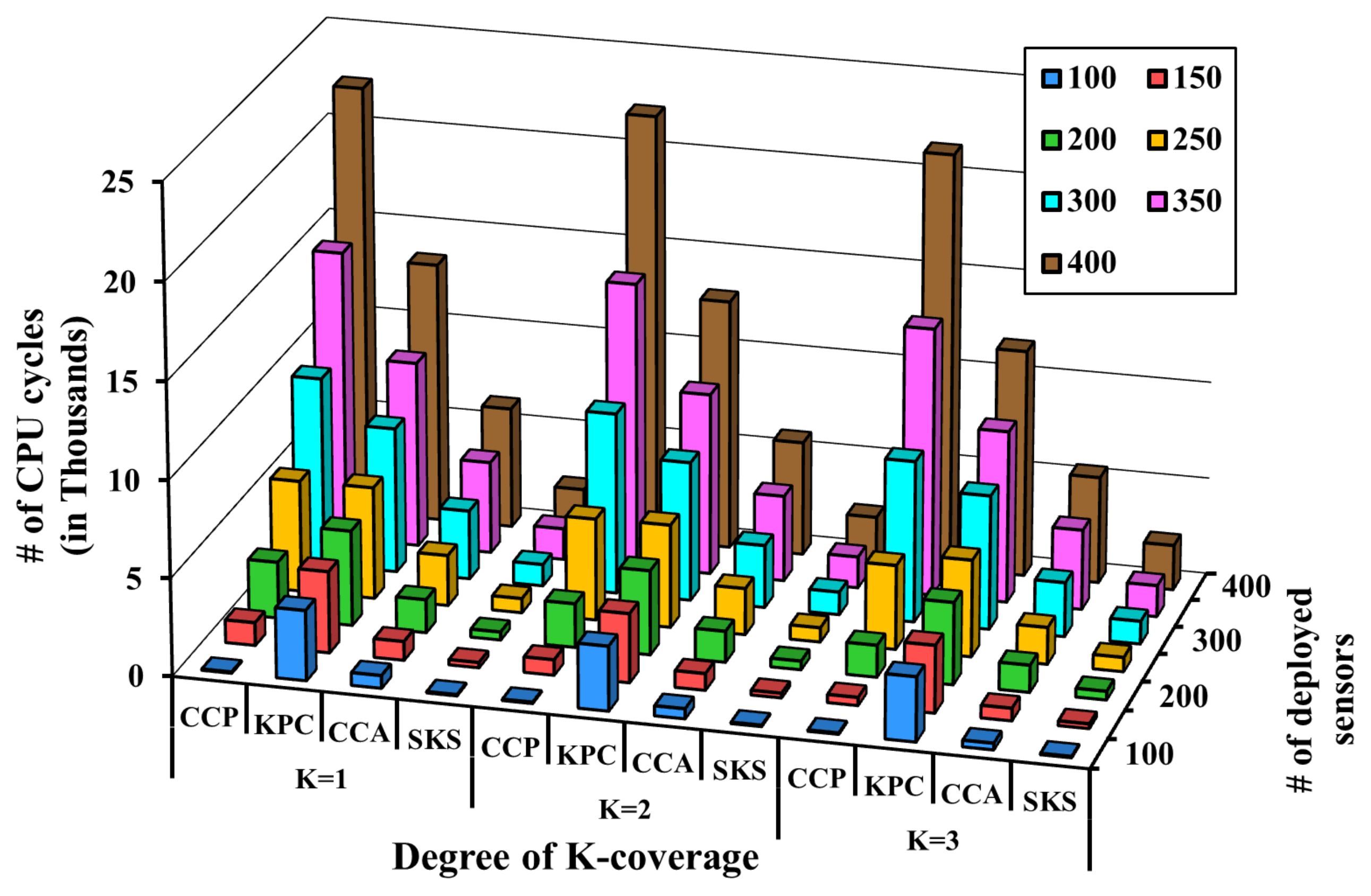
5.3. Detection Quality and Network Lifetime Evaluation
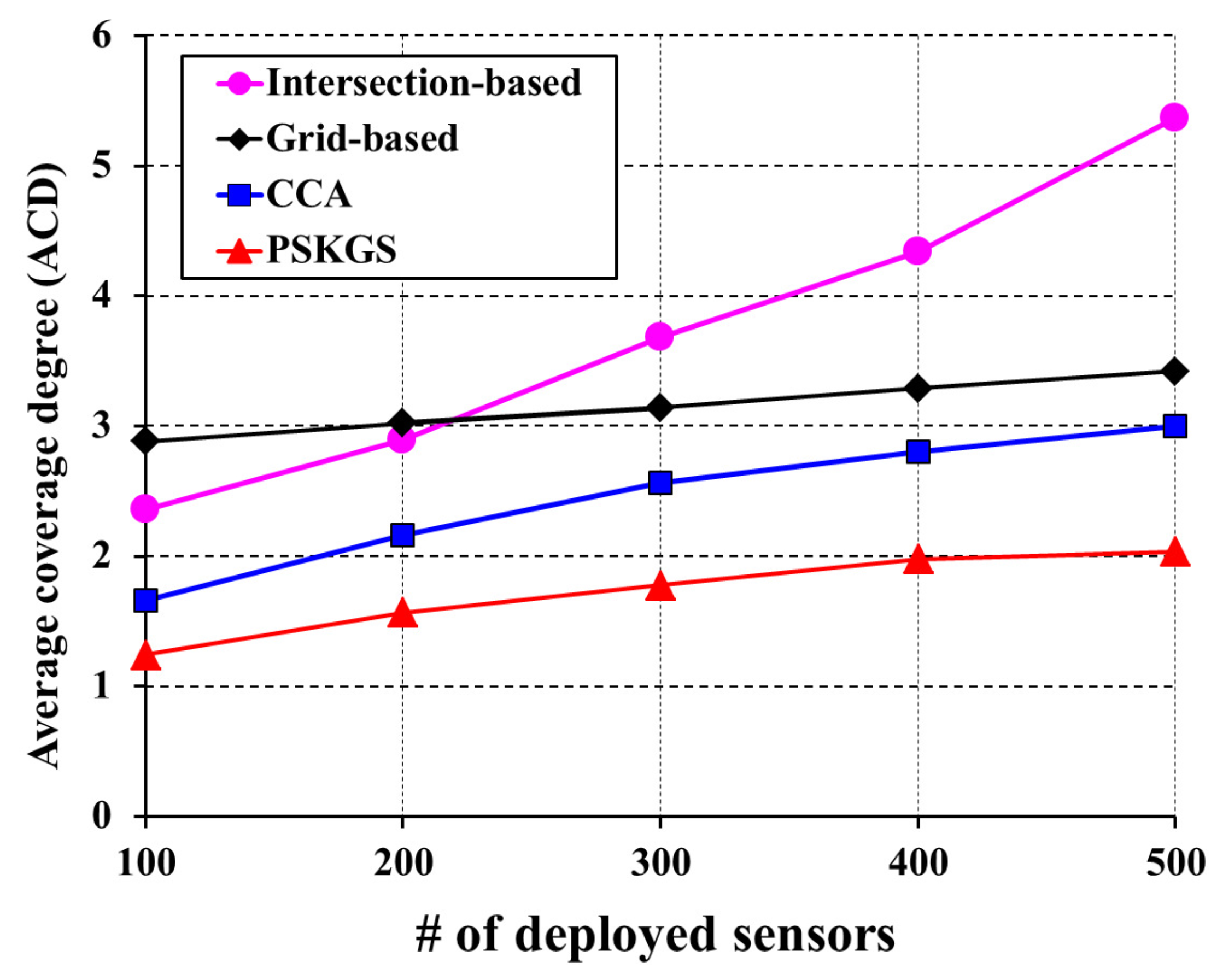
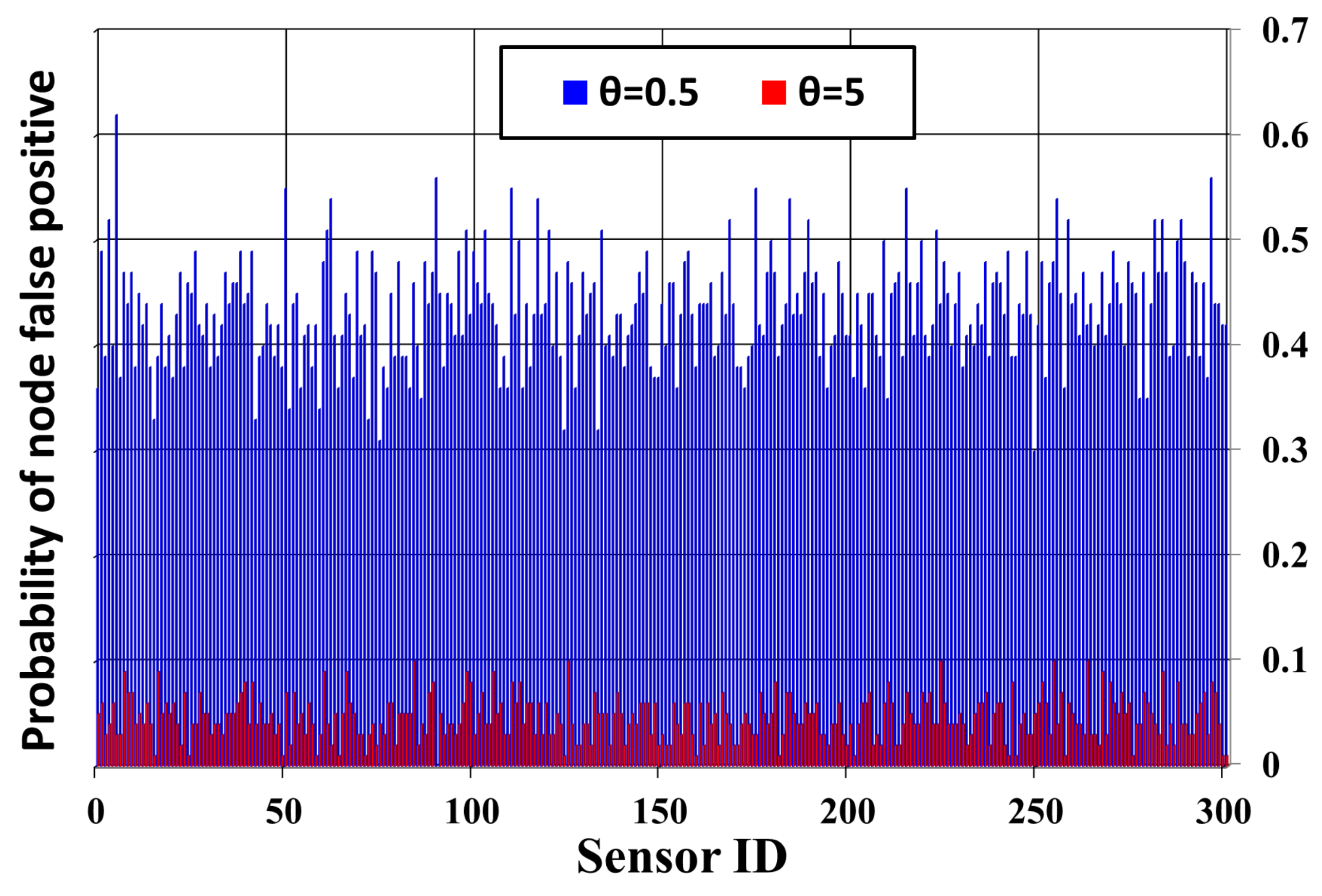
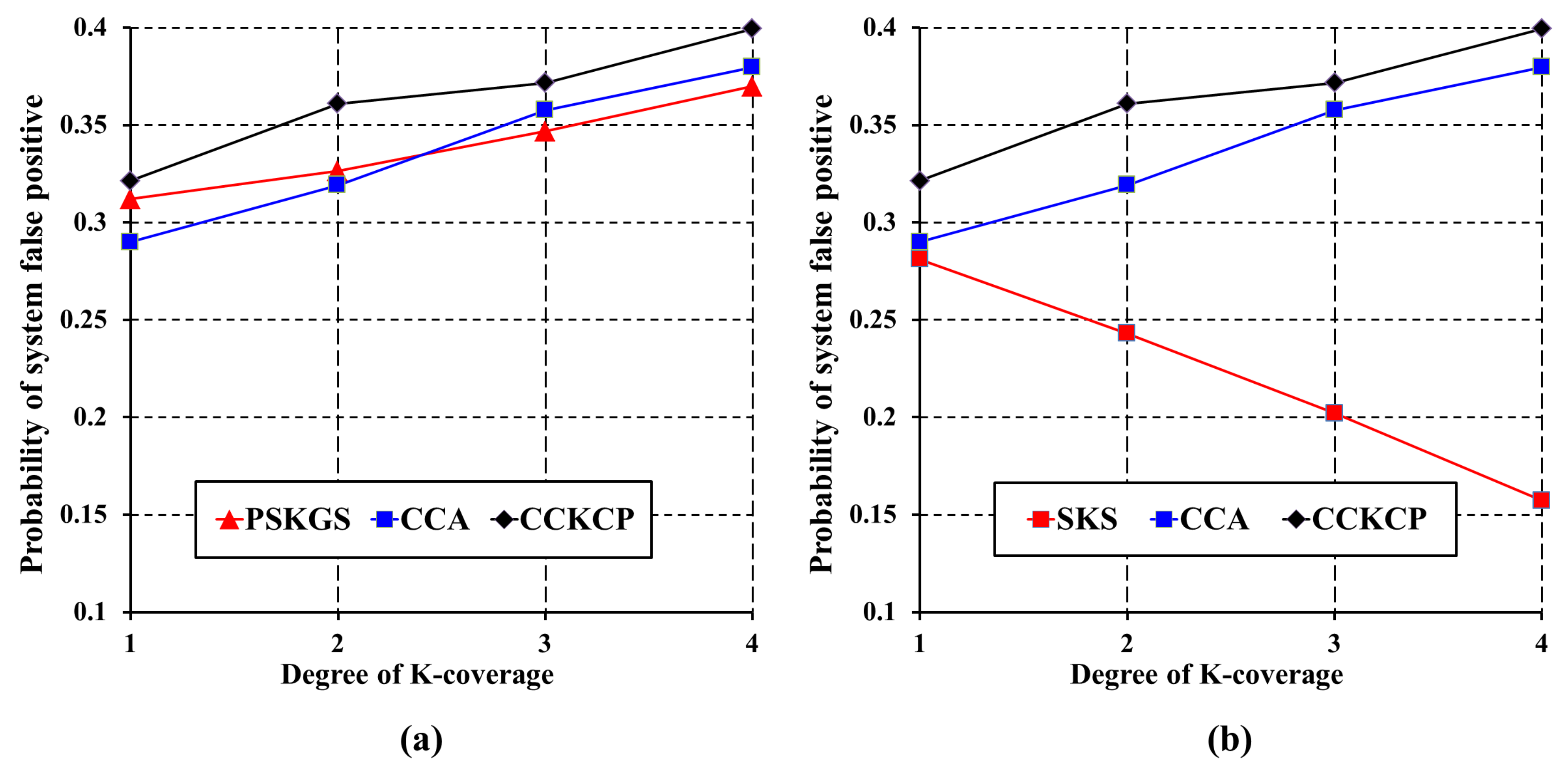
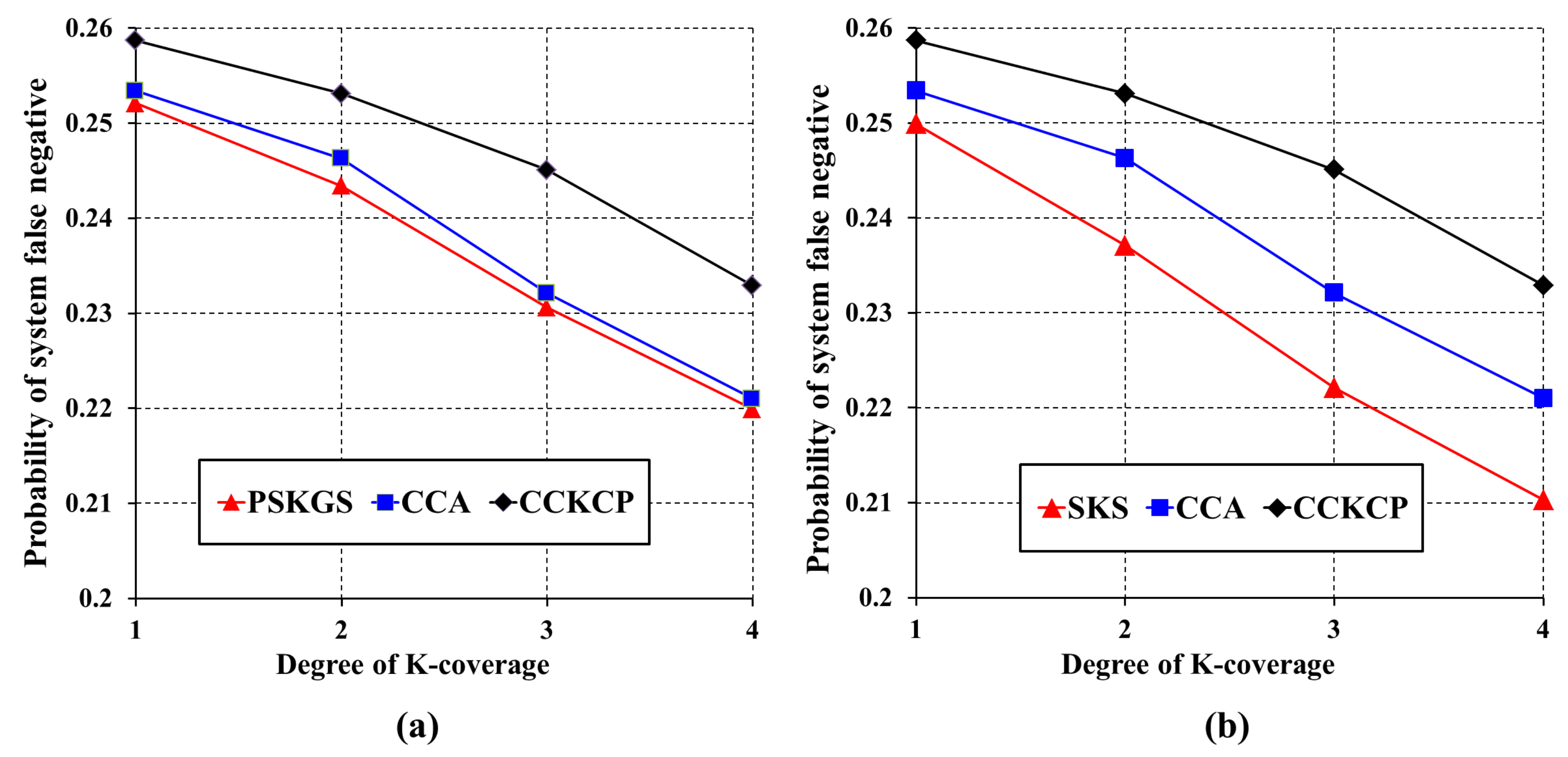
5.3.1. Detection Quality
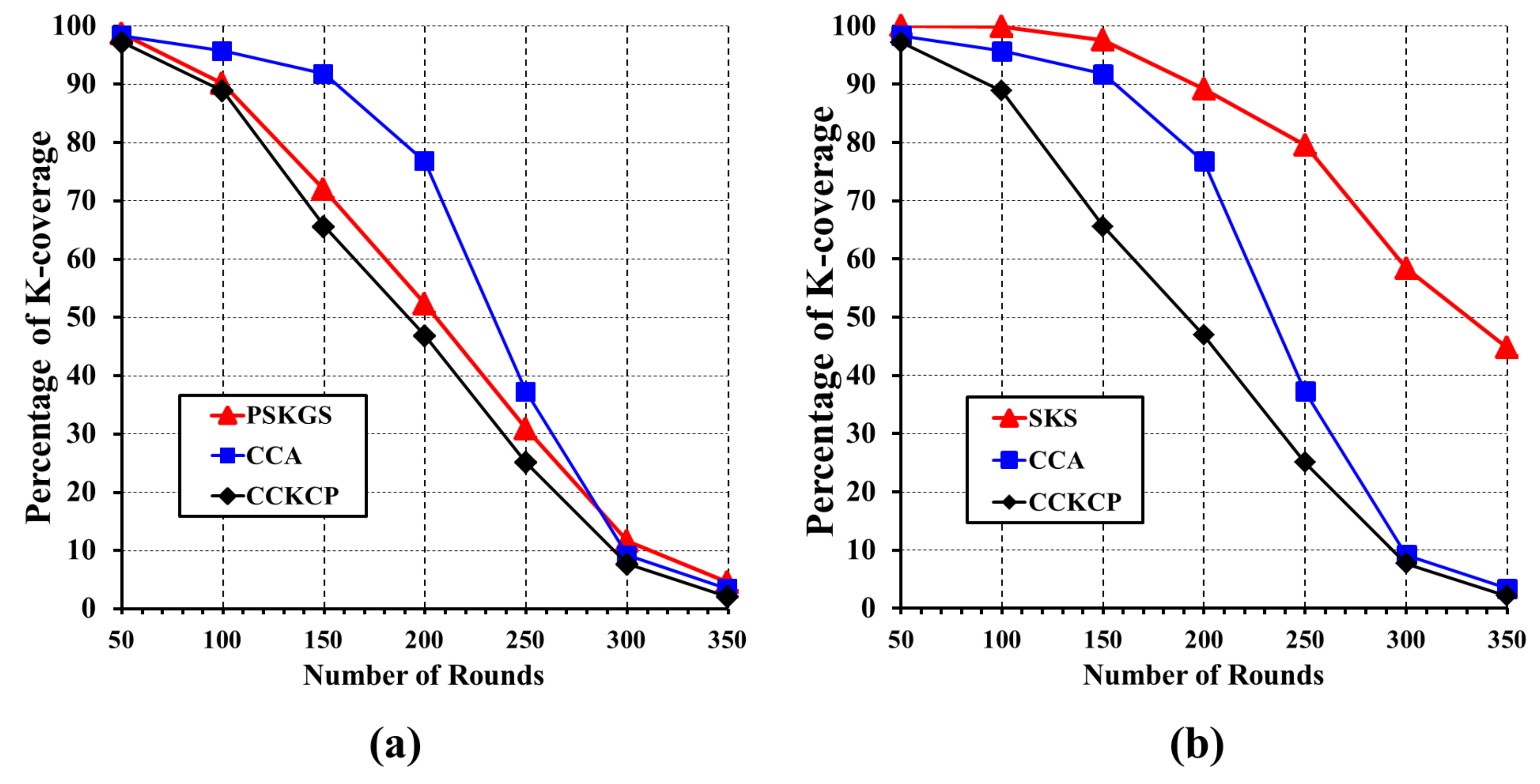
5.3.2. Network Lifetime
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Mohapatra, S.K.; Sahoo, P.K.; Wu, S.L. Big data analytic architecture for intruder detection in heterogeneous wireless sensor networks. J. Netw. Comput. Appl. 2016, 66, 236–249. [Google Scholar] [CrossRef]
- Sahoo, P.K.; Thakkar, H.K.; Lee, M.Y. A Cardiac Early Warning System with Multi Channel SCG and ECG Monitoring for Mobile Health. Sensors 2017, 17, 711. [Google Scholar] [CrossRef] [PubMed]
- Lee, S.; Younis, M.; Lee, M. Connectivity restoration in a partitioned wireless sensor network with assured fault tolerance. Ad Hoc Netw. 2015, 24, 1–19. [Google Scholar] [CrossRef]
- Huang, C.F.; Lo, L.C.; Tseng, Y.C.; Chen, W.T. Decentralized energy-conserving and coverage-preserving protocols for wireless sensor networks. ACM Trans. Sensor Netw. (TOSN) 2006, 2, 182–187. [Google Scholar] [CrossRef]
- Yan, T.; Gu, Y.; He, T.; Stankovic, J.A. Design and optimization of distributed sensing coverage in wireless sensor networks. ACM Trans. Embed. Comput. Syst. (TECS) 2008, 7, 33. [Google Scholar] [CrossRef]
- Xing, G.; Wang, X.; Zhang, Y.; Lu, C.; Pless, R.; Gill, C. Integrated coverage and connectivity configuration for energy conservation in sensor networks. ACM Trans. Sens. Netw. (TOSN) 2005, 1, 36–72. [Google Scholar] [CrossRef]
- Huang, C.F.; Tseng, Y.C. The coverage problem in a wireless sensor network. Mob. Netw. Appl. 2005, 10, 519–528. [Google Scholar] [CrossRef]
- Luo, X.; Dong, M.; Huang, Y. On distributed fault-tolerant detection in wireless sensor networks. IEEE Trans. Comput. 2006, 55, 58–70. [Google Scholar] [CrossRef]
- Alam, K.M.; Kamruzzaman, J.; Karmakar, G.; Murshed, M. Dynamic adjustment of sensing range for event coverage in wireless sensor networks. J. Netw. Comput. Appl. 2014, 46, 139–153. [Google Scholar] [CrossRef]
- Elhoseny, M.; Tharwat, A.; Farouk, A.; Hassanien, A.E. K-coverage model based on genetic algorithm to extend wsn lifetime. IEEE Sens. Lett. 2017, 1, 1–4. [Google Scholar] [CrossRef]
- Shan, A.; Xu, X.; Cheng, Z. Target Coverage in Wireless Sensor Networks with Probabilistic Sensors. Sensors 2016, 16, 1372. [Google Scholar] [CrossRef] [PubMed]
- Gupta, H.P.; Rao, S.V.; Venkatesh, T. Sleep Scheduling Protocol for k-Coverage of Three-Dimensional Heterogeneous WSNs. IEEE Trans. Veh. Technol. 2016, 65, 8423–8431. [Google Scholar] [CrossRef]
- Yang, C.; Chin, K.W. On nodes placement in energy harvesting wireless sensor networks for coverage and connectivity. IEEE Trans. Ind. Inf. 2017, 13, 27–36. [Google Scholar] [CrossRef]
- Han, G.; Liu, L.; Jiang, J.; Shu, L.; Hancke, G. Analysis of energy-efficient connected target coverage algorithms for industrial wireless sensor networks. IEEE Trans. Ind. Inf. 2017, 13, 135–143. [Google Scholar] [CrossRef]
- Sen, A.; Shen, B.H.; Zhou, L.; Hao, B. Fault-tolerance in sensor networks: A new evaluation metric. In Proceedings of the INFOCOM 2006: 25th IEEE International Conference on Computer Communications, Barcelona, Spain, 23–29 April 2006. [Google Scholar]
- Ammari, H.M.; Das, S.K. Fault tolerance measures for large-scale wireless sensor networks. ACM Trans. Auton. Adapt. Syst. (TAAS) 2009, 4, 2. [Google Scholar] [CrossRef]
- Keskin, M.E.; Altınel, İ.K.; Aras, N.; Ersoy, C. Wireless sensor network lifetime maximization by optimal sensor deployment, activity scheduling, data routing and sink mobility. Ad Hoc Netw. 2014, 17, 18–36. [Google Scholar] [CrossRef]
- Younis, M.; Senturk, I.F.; Akkaya, K.; Lee, S.; Senel, F. Topology management techniques for tolerating node failures in wireless sensor networks: A survey. Comput. Netw. 2014, 58, 254–283. [Google Scholar] [CrossRef]
- Lu, Z.; Li, W.W.; Pan, M. Maximum lifetime scheduling for target coverage and data collection in wireless sensor networks. IEEE Trans. Veh. Technol. 2015, 64, 714–727. [Google Scholar] [CrossRef]
- Wang, H.; Roman, H.E.; Yuan, L.; Huang, Y.; Wang, R. Connectivity, coverage and power consumption in large-scale wireless sensor networks. Comput. Netw. 2014, 75, 212–225. [Google Scholar] [CrossRef]
- Mini, S.; Udgata, S.K.; Sabat, S.L. Sensor deployment and scheduling for target coverage problem in wireless sensor networks. IEEE Sens. J. 2014, 14, 636–644. [Google Scholar] [CrossRef]
- Sahoo, P.K.; Hwang, I. Collaborative localization algorithms for wireless sensor networks with reduced localization error. Sensors 2011, 11, 9989–10009. [Google Scholar] [CrossRef] [PubMed]
- Yu, J.; Chen, Y.; Ma, L.; Huang, B.; Cheng, X. On connected target k-coverage in heterogeneous wireless sensor networks. Sensors 2016, 16, 104. [Google Scholar] [CrossRef] [PubMed]
- Zorlu, O.; Sahingoz, O.K. Increasing the coverage of homogeneous wireless sensor network by genetic algorithm based deployment. In Proceedings of the 2016 Sixth International Conference on Digital Information and Communication Technology and its Applications (DICTAP), Konya, Turkey, 21–23 July 2016; pp. 109–114. [Google Scholar]
- Gupta, H.P.; Rao, S.V.; Venkatesh, T. Sleep scheduling for partial coverage in heterogeneous wireless sensor networks. In Proceedings of the 2013 Fifth International Conference on Communication Systems and Networks (COMSNETS), Bangalore, India, 7–10 January 2013; pp. 1–10. [Google Scholar]
- Wang, X.; Han, S.; Wu, Y.; Wang, X. Coverage and energy consumption control in mobile heterogeneous wireless sensor networks. IEEE Trans. Autom. Control 2013, 58, 975–988. [Google Scholar] [CrossRef]
- Bara’a, A.A.; Khalil, E.A. A new evolutionary based routing protocol for clustered heterogeneous wireless sensor networks. Appl. Soft Comput. 2012, 12, 1950–1957. [Google Scholar]
- Sahoo, P.K.; Sheu, J.P. Limited mobility coverage and connectivity maintenance protocols for wireless sensor networks. Comput. Netw. 2011, 55, 2856–2872. [Google Scholar] [CrossRef]
- Liao, Z.; Wang, J.; Zhang, S.; Cao, J.; Min, G. Minimizing movement for target coverage and network connectivity in mobile sensor networks. IEEE Trans. Parallel Distrib. Syst. 2015, 26, 1971–1983. [Google Scholar] [CrossRef]
- Yang, Q.; He, S.; Li, J.; Chen, J.; Sun, Y. Energy-efficient probabilistic area coverage in wireless sensor networks. IEEE Trans. Veh. Technol. 2015, 64, 367–377. [Google Scholar] [CrossRef]
- Yu, J.; Wan, S.; Cheng, X.; Yu, D. Coverage Contribution Area based k-Coverage for Wireless Sensor Networks. IEEE Trans. Veh. Technol. 2017, 66, 8510–8523. [Google Scholar] [CrossRef]
- Ammari, H.M.; Das, S.K. Centralized and clustered k-coverage protocols for wireless sensor networks. IEEE Trans. Comput. 2012, 61, 118–133. [Google Scholar] [CrossRef]
- Sahoo, P.K.; Liao, W.C. HORA: A distributed coverage hole repair algorithm for wireless sensor networks. IEEE Trans. Mob. Comput. 2015, 14, 1397–1410. [Google Scholar] [CrossRef]
- Liu, N.; Cao, W.; Zhu, Y.; Zhang, J.; Pang, F.; Ni, J. Node Deployment with k-Connectivity in Sensor Networks for Crop Information Full Coverage Monitoring. Sensors 2016, 16, 2096. [Google Scholar] [CrossRef] [PubMed]
- Shi, B.; Wei, W.; Wang, Y.; Shu, W. A Novel Energy Efficient Topology Control Scheme Based on a Coverage-Preserving and Sleep Scheduling Model for Sensor Networks. Sensors 2016, 16, 1702. [Google Scholar] [CrossRef] [PubMed]
- Wueng, M.C.; Sahoo, P.K.; Hwang, I.S. Time-synchronized versus self-organized k-coverage configuration in wsns. In Proceedings of the 2011 40th International Conference on Parallel Processing Workshops (ICPPW), Taipei City, Taiwan, 13–16 September 2011; pp. 27–32. [Google Scholar]
- Wueng, M.C.; Hwang, I.S. Quality of Surveillance Measures in K-covered Heterogeneous Wireless Sensor Networks. In Proceedings of the 2010 39th International Conference on Parallel Processing Workshops (ICPPW), San Diego, CA, USA, 13–16 September 2010; pp. 586–593. [Google Scholar]
- Titzer, B.L.; Lee, D.K.; Palsberg, J. Avrora: Scalable sensor network simulation with precise timing. In Proceedings of the IPSN 2005: Fourth International Symposium on Information Processing in Sensor Networks, Boise, ID, USA, 15 April 2005; pp. 477–482. [Google Scholar]
- Yu, L.; Yuan, L.; Qu, G.; Ephremides, A. Energy-driven detection scheme with guaranteed accuracy. In Proceedings of the IPSN 2006: The Fifth International Conference on Information Processing in Sensor Networks, Nashville, TN, USA, 19–21 April 2006; pp. 284–291. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
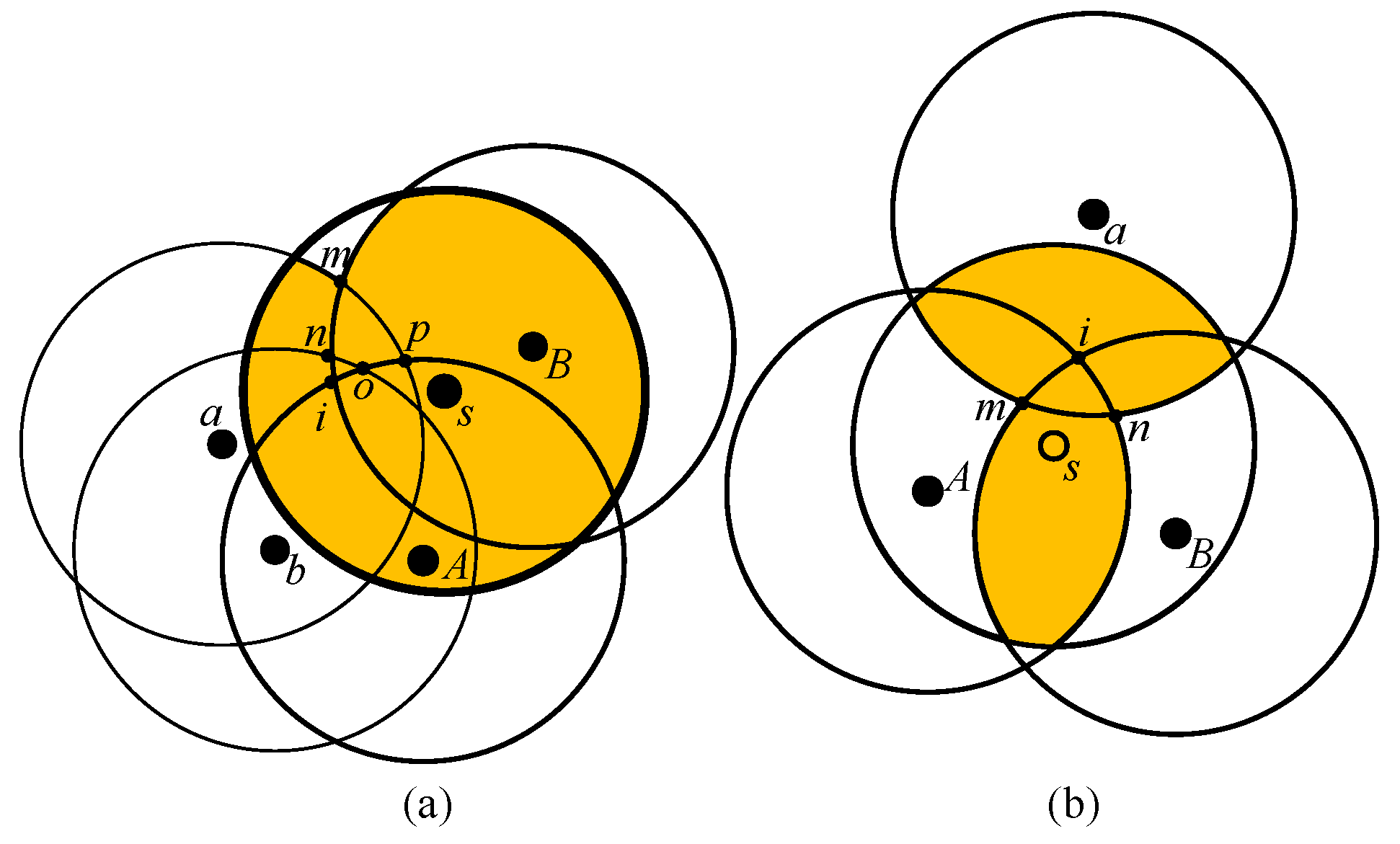{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sahoo, P.K.; Thakkar, H.K.; Hwang, I.-S. Pre-Scheduled and Self Organized Sleep-Scheduling Algorithms for Efficient K-Coverage in Wireless Sensor Networks. Sensors 2017, 17, 2945. https://doi.org/10.3390/s17122945
Sahoo PK, Thakkar HK, Hwang I-S. Pre-Scheduled and Self Organized Sleep-Scheduling Algorithms for Efficient K-Coverage in Wireless Sensor Networks. Sensors. 2017; 17(12):2945. https://doi.org/10.3390/s17122945
Chicago/Turabian StyleSahoo, Prasan Kumar, Hiren Kumar Thakkar, and I-Shyan Hwang. 2017. "Pre-Scheduled and Self Organized Sleep-Scheduling Algorithms for Efficient K-Coverage in Wireless Sensor Networks" Sensors 17, no. 12: 2945. https://doi.org/10.3390/s17122945
APA StyleSahoo, P. K., Thakkar, H. K., & Hwang, I.-S. (2017). Pre-Scheduled and Self Organized Sleep-Scheduling Algorithms for Efficient K-Coverage in Wireless Sensor Networks. Sensors, 17(12), 2945. https://doi.org/10.3390/s17122945