1. Introduction
While infrastructure is ageing, available economic and environmental resources are decreasing. Therefore, an optimal infrastructure management strategy is needed. Due to the justifiably conservative nature of design and construction of large civil structures, most structures have a significant amount of reserve capacity. Unfortunately, this reserve is largely unquantified, resulting in sub-optimal asset-management decisions. For example, knowledge of load capacity of bridges can be exploited to extend lifetimes of existing structures, optimize retrofit designs and prioritize inspection and maintenance activities.
Field-measurements, collected during load testing and through ambient vibration monitoring, have been extensively used in the last decades to identify bridge characteristics [
1]. Interpretation of the data provided by sensors is critical to identify accurate structural models and subsequently, to estimate bridge reserve capacity. Such interpretation is a type of inverse engineering where causes (behavior models and their inputs) are determined from effects (measurements). This type of inference is fundamentally ambiguous; many causes may explain the same effect, especially when modelling uncertainties are important at sensor locations. The difficulties associated with the inverse problem of structural identification have been recognized by [
2,
3] amongst many others.
The aim of model-based structural identification is to use field measurements to improve knowledge of the real behavior of structures. Several data-interpretation techniques exist to perform this task, such as residual minimization [
4] and Bayesian updating [
5,
6]. Such traditional model calibration methodologies cannot be justified for large civil structures [
7]. They often result in biased identification due to important systematic uncertainties that modify correlation values between measurement points. To overcome challenges associated with inverse problems, a multi-model approach was proposed by [
8,
9]. In this method, model-updating results consist of a set of candidate models that explain the measurements taken from a structure.
A probabilistic extension, called error-domain model falsification (EDMF) was presented by [
10]. In this methodology, a population of model instances are generated according to prior knowledge and engineering judgement. Threshold bounds are determined probabilistically using the Monte Carlo method and a target confidence level. Then, they are used to falsify model instances that significantly differ from measured values. Systematic uncertainties are transparently included and the use of uniform probability distributions increases robustness to unknown uncertainty correlations [
10]. This methodology has been successfully applied to other fields such as wind simulation around buildings [
11], leak detection in water-supply networks [
12] and performance following earthquake damage [
13].
Model updating outcomes depend on the choice of sensor types and locations. However, most of the practical applications of structural identification involve placement of sensors based on engineering judgement and experience. More rational studies on optimal sensor locations for structural identification have been carried out using information theory to improve model-parameter estimation. Various approaches have been used: maximizing the determinant of Fisher information matrix [
14,
15] and either minimizing the information entropy in posterior model-parameter distribution [
16,
17] or maximizing information entropy in multiple-model predictions [
18,
19]. Although entropy-based approaches have shown to be powerful to find the optimal sensor configuration, few studies have included systematic modelling uncertainties and information that is shared amongst sensors.
The effect of spatially-correlated prediction errors were included by [
20] to correct the information entropy of model-parameter posterior distribution, which was used as the objective function in the sensor placement methodology. The authors have shown that the minimum distance between sensors is controlled by the spatial correlation length of the prediction errors. By accounting for it, the redundancy of information of neighboring sensors can be avoided. In addition, they observed that an assumption of uncorrelated prediction errors in models may lead to sub-optimal sensor configurations. Limitations associated with potential redundancy of information using individual-sensor entropy metric was underlined by [
21]. The importance of the mutual information between sensors in optimal configuration of multi-type of sensors was shown by [
22].
Another approach, presented by [
23] and extended by [
24], used simulated measurements to provide probabilistic estimations of the expected number of candidate models obtained with a sensor configuration. The aim was to find the sensor configuration that minimizes the expected number of candidate models. Simulated measurements are generated based on the model instances adding a random value taken from the combined uncertainties. Sensor locations were evaluated using respectively 95% and 50% quantiles of the expected candidate-model-set size. However, the procedure is computationally costly [
25], because it requires the execution of the falsification procedure for a large number of simulated measurements and sensor locations.
The problem of finding the optimal sensor configuration is usually formulated as a discrete problem. As the number of possible sensor configurations is very large, an exhaustive search for the best configuration is exponentially complex with respect to the number of sensors. Some studies proposed global-search optimization algorithms to determine optimal solutions [
19]. However, most authors preferred to reduce the computational effort using greedy optimization algorithms [
26].
Entropy calculations based on sequential optimization strategies have involved inefficient search methods, assumed constant uncertainty levels at all sensor locations and most researchers have disregarded the mutual information between sensor locations. A methodology involving a hierarchical algorithm to examine placement alternatives efficiently and incorporating spatial distributions of modelling uncertainties was introduced by [
21]. The authors also proposed to maximize the joint entropy between sensor locations to account for mutual information. This methodology was able to improve model predictions at unmeasured locations compared with a methodology based on individual entropy maximization. This sensor placement algorithm was successfully applied to sensors for wind-around-building predictions [
27]. Sensor configurations using a multi-criteria decision-making approach and various information-gain metrics was evaluated by [
28], including the prediction range and type I and type II errors.
As highlighted by [
20], the optimal sensor placement for model-parameter estimation depends on the loading. Previous work has focused only on the information gained by adding a sensor to the sensor configuration and not by performing additional load tests using the same sensor configuration. In work on model falsification, the next sensor to add in the sensor configuration was associated with a pre-defined load test [
23,
24]. In these studies of sensor placement for structural identification, mutual information between multiple load tests is not considered within the sensor placement methodology.
This study presents a measurement-system design methodology to identify the best sensor locations and sensor types using information from several static load tests. First, the EDMF methodology for structural identification is presented. Then, the hierarchical strategy for sensor placement is adapted and extensions to the sensor placement algorithm are proposed. Optimal sensor configurations for independent static-load tests are computed. Then, two modifications of the sensor placement algorithm which take into account information for multiple static load tests are proposed. Finally, sensor placement strategies are illustrated and evaluated on a full-scale bridge.
2. Materials and Methods
2.1. Background—Error-Domain Model Falsfication
Presented by [
10], error-domain model falsification (EDMF) is a structural identification methodology. Within model parameter sets, multiple model instances are generated and falsified if their predictions differ significantly from field measurements. First, an initial-model instance population is generated from engineering judgment and prior knowledge. Model instances are instantiations of a model class, in which several combinations of primary parameter values
are assigned in order to generate an initial set of model instances Ω. Then, model instance predictions are compared with field measurements of the structural response in order to identify candidate models among the initial set of the model instance population. Modelling and measurement uncertainties are combined to determine threshold boundaries [
9]. Threshold boundaries are defined using the combined distribution of uncertainties and a target reliability of identification. Model instances are falsified if the residual value between predictions and measurements exceeds the boundaries at one or more sensor locations.
For each measurement location,
, model predictions and measurements are linked to the true behavior using Equation (1).
corresponds to the real responses of a structure (unknown) and
to the measured value at location i. Using finite element analysis (FEA), predictions
of the model class G
k is evaluated at location i.
is the set of instances of the parameter vector
,
and
correspond to model-prediction uncertainties and measurement uncertainties, respectively:
Equation (1) may be rearranged to Equation (2), where
is the difference between the modelling and measurement uncertainties. The left-hand side of Equation (2) represents the difference between a model prediction and a measurement:
The selection of candidate models representing realistic sets of model-parameter values, involves falsifying all model instances for which predictions cannot explain measurement data, given combined uncertainties and a target reliability of identification
. The set of candidate models obtained after falsification is defined using Equation (3), where
is the candidate model set (CMS) made up of initial model instances, which have not been falsified at one or more measurement locations. [
,
] are the upper and lower threshold bounds. They represent the shortest intervals, including a probability of identification
, through the probability density function (PDF) of combined uncertainties
at each measurement location:
The Šidák correction [
29] is used to maintain a constant level of confidence when multiple sensor measurements are compared with model instance predictions (Equation (4)):
All model instances that belong to the CMS,
, are labeled as candidate models. Since so little information is usually available to describe the form of modelling-uncertainty distributions, every candidate model is equally likely to be the correct model [
30]. Thus, they are assigned an equal probability as expressed in Equation (5):
Falsified model instances, which correspond to model instances that do not belong to the CMS, are assigned a null probability (Equation (6)):
Consequently,
is the set of random variables describing the parameter values of the candidate model instances given measurement data. Its PDF is defined using Equation (7):
If all initial model instances generated are falsified, the entire model class is falsified, then
. Thus, no models are compatible with observations given model and measurement uncertainties. Possible reasons are an incorrect model-class definition, incorrect uncertainty estimates, or wrong initial parameter values [
31]. This particular case highlights one of the main advantages of EDMF compared with traditional structural-identification approaches. In this situation, the results of EDMF leads to a re-evaluation of starting assumptions and, often, a new model class is generated.
Concerning the identifiability of the methodology, a key feature of EMDF is the following: if only a subset of sensors is considered and a small influence of the Šidák correction on thresholds is assumed, the candidate-model-set (CMS) value range will be wider than using all sensors due to the smaller decrease of parameter bounds compared with using all sensors. The resultant CMS using all sensors will still be part of the larger CMS obtained with a subset of sensors, which will lead to conservative conclusions in terms of type-I error (falsely rejecting a candidate model).
2.2. Sensor Placement Strategy
Assessing a full-scale infrastructure, such as estimating the reserve capacity of a bridge, requires the estimation of various unknown physical properties and boundary conditions. The aim of field measurements is to enhance knowledge of model parameters and improve structural assessments. The choice of sensor locations is fundamental for structural identification. A sensor placement strategy is usually developed to identify optimal sensor configurations prior to measuring when limited knowledge of the model parameter values is available.
A model-based sensor placement strategy requires several steps. First, a numerical model, such as a finite element model of a bridge, is built to obtain quantitative predictions of measurable variables, such as deflection, strain, or inclination at each possible sensor location. As the numerical model always requires geometrical and mathematical simplifications, a significant degree of non-parametric uncertainty is involved, which needs to be evaluated. Then, sensitivity analysis is employed to evaluate the effects of variation in model-parameter values on model predictions. A small number of parameters, which have the highest impact on predictions, are then selected. Several possible load tests are designed and multiple model instances are generated using a sampling technique to obtain a discrete population of possible model-parameter values within plausible ranges. For each load test, model instance predictions are computed and each instance is part of the initial model set. The initial model set is the dataset used in the sensor placement strategy.
In this section, several sensor placement strategies are presented. First, two objective functions for sensor placement—single-sensor information entropy and joint entropy—are presented. Then, originally developed for the prediction of wind around buildings, the initial version of the hierarchical algorithm is introduced. As this sensor placement algorithm was designed for wind assessment, two modifications are proposed for taking into account information from several static load tests.
2.2.1. Sensor Placement Objective Function
Joint Entropy
The joint entropy is a more recent sensor placement objective function that has been proposed for system identification by [
21]. The joint entropy is an information entropy measure associated with a set of locations, while assessing the mutual information of the locations. For a set of two sensors, it is defined in Equation (9), where
and N
I,i+1 is the maximum number of intervals at the i + 1 location and
with
the number of potential sensor locations:
The joint entropy is less than or equal to the sum of the individual entropies of the locations in the set (Equation (10)), where I is the mutual information between sensor i and i + 1:
2.2.2. Hierarchical Algorithm
A hierarchical algorithm for sensor placement using the concept of joint entropy was introduced in [
21]. The hierarchical algorithm is a sequential algorithm (greedy search) in which model instances are organized in a tree structure. At the root is the initial model set, and branches contain subsets of model instance predictions. Branches from a node represent separations of the parent model set into smaller subsets that can potentially be divided using measurements from the new sensor added to the configuration. This allows calculations of joint entropy of sensor configurations while avoiding exponential complexity, reducing the computational effort.
The pseudo-code of the original hierarchical algorithm is presented in
Figure 2. This algorithm can accommodate a single load test only. The first sensor (i = 1) is selected with the information entropy objective function. However, for i > 1, the location with the maximum joint entropy of the configuration is selected. This sensor placement algorithm takes into account mutual information between sensors because of the joint entropy objective function. It was shown to perform better than traditional sequential algorithms with forward or backward strategies [
21].
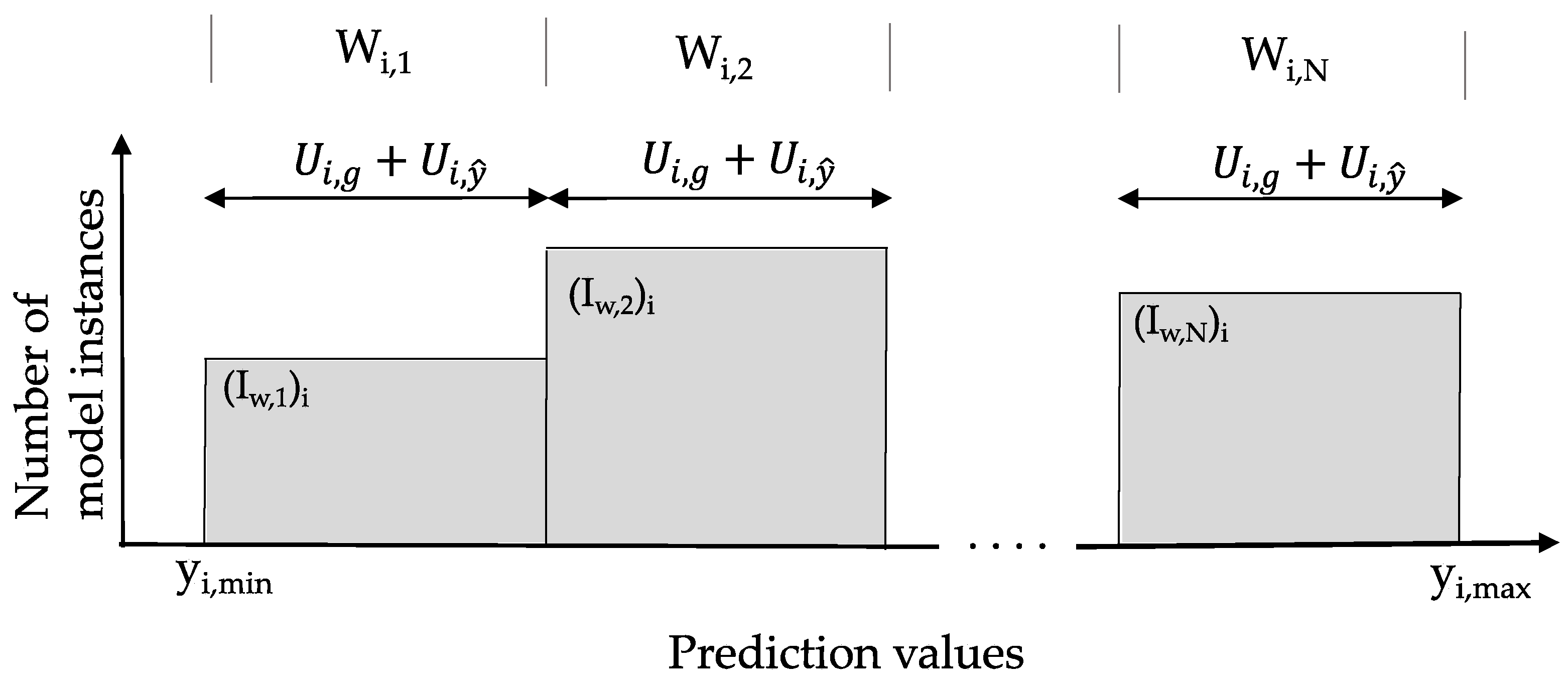
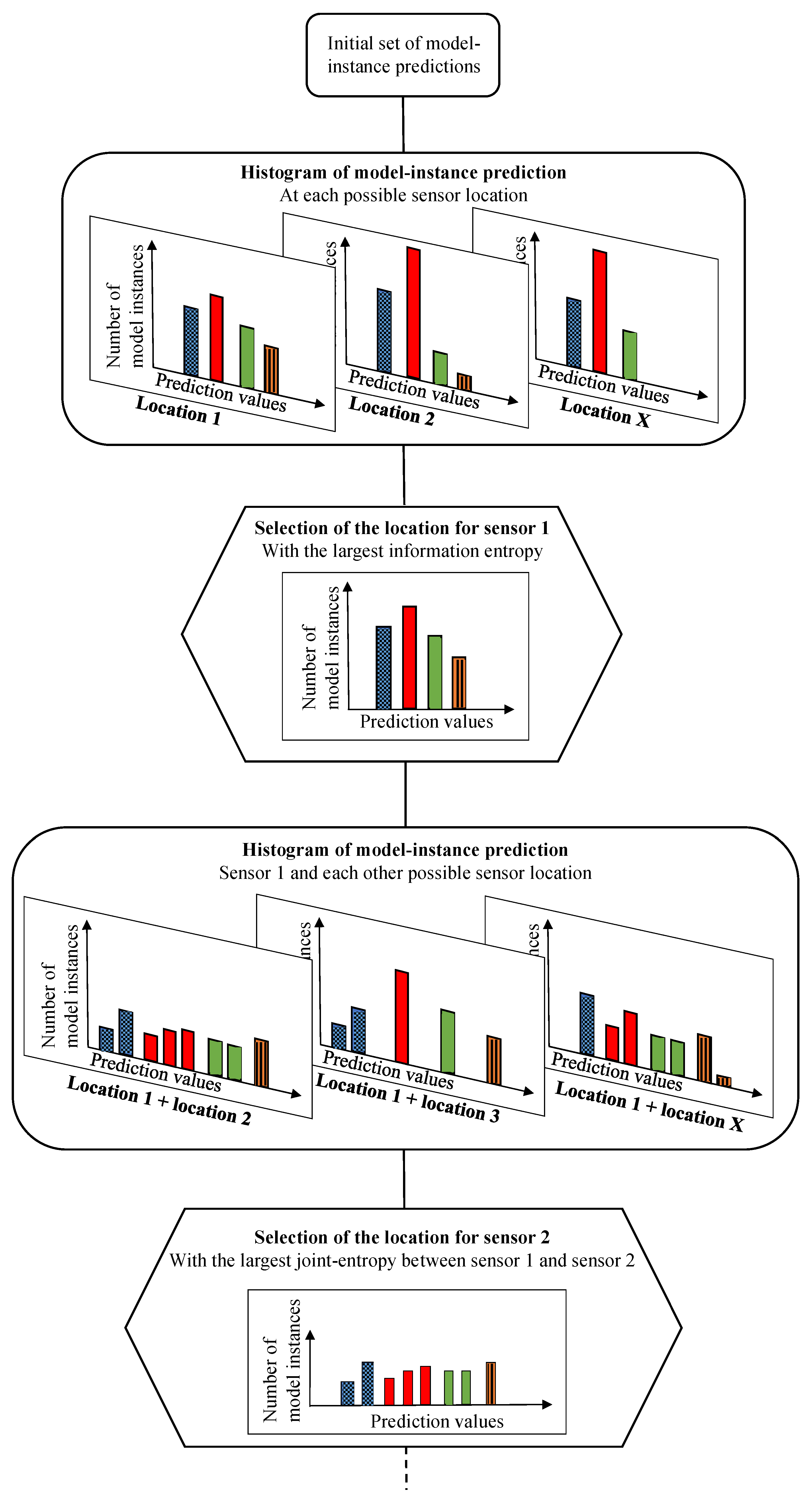
A schematic of the tree structure of the hierarchical algorithm is presented in
Figure 3. At the top of the figure is the initial set of model instance predictions at possible sensor locations. At each possible sensor location, a histogram of predictions of model instances in the initial set is generated, following
Figure 1. Histograms are composed of subset of model instances depicted in distinctive bars. In
Figure 3, clear spaces between the distinctive bars are added for clarity only. In most practical cases, model prediction values are continuous and, thus, the subset bars of the histograms would be touching.
Once histograms of model predictions are generated at each possible location, the location with the largest information entropy value is selected and Sensor 1 is added to the sensor configuration. To select the second sensor, information from the remaining sensors is used to further divide each subset of model instances of Sensor 1. The configuration of Sensor 1 and Sensor 2 with the largest joint entropy is selected and Sensor 2 is added to the sensor configuration. The process is repeated until all possible sensor locations are selected.
This process is repeated at every iteration by adding a sensor to the sensor configuration, forming a hierarchy of model subsets. At each stage of the sensor placement, a location is added to the configuration sensor optimum that has the highest potential in dividing the existing subsets of model instances into smaller subsets. The maximum number of iterations required is independent of the number of combinations of sensor locations and is equal to the number of possible subdivisions; the upper bound of this quantity is equal to the maximum number of model instances among all subsets of Sensor 1.
2.2.3. Modification of Hierarchical Algorithm for Multiple Load Tests
The original version of the hierarchical algorithm (
Figure 2 and
Figure 3) accommodates only a single load test. To consider information from various load tests, two modifications of the algorithm are presented in this section. The first modification includes only minor changes in the code to enable the hierarchical algorithm to select best sensor locations considering only the load test that maximizes their information content. The second modification includes significant changes in the code to enable the hierarchical algorithm to select the best sensor location considering all load tests.
First Modification—Minor Changes to the Original Hierarchical Algorithm
The first modification enables the algorithm to select best sensor locations considering only the load test that maximizes their information content. The pseudo-code for the hierarchical algorithm for multiple load tests is presented in
Figure 4. Differences with the pseudo-code of the hierarchical algorithm for a single load test (
Figure 2) are underlined. The tree structure remains unchanged. The sensor selection is based on the joint entropy of a location and a load test. Therefore, it allows the algorithm to select the best load test among a set of various load tests for each sensor location. However, the algorithm does not consider information provided by the other load tests at one sensor location. This approach to consider multiple load tests was used by [
23,
24] using a backward sequential algorithm instead of the hierarchical algorithm. As this modification is minor, this version of the hierarchical algorithm is called original hierarchical algorithm for multiple load tests.
Second Modification—Major Changes to the Hierarchical Algorithm
The first modification of the algorithm selects the sensor location associated with the load test that maximizes its information content. However, this location may not perform well for other load tests and another location may perform better when considering information from all load tests. Therefore, a modification to the hierarchical algorithm considering information provided by all load tests is justified.
In the original hierarchical algorithm, the joint entropy is an information entropy measure associated with a set of locations, while assessing the mutual information between locations. With the version proposed in this study, it is possible to calculate the joint entropy at a single location when multiple load tests are considered, through assessing the mutual information between load tests. In the proposed modification of the hierarchical algorithm, the assessment of mutual information between sensors remains applicable if multiple sensor locations are considered.
For a sensor location and a set of two load tests, it is defined in Equation (11), where
, and
is the maximum number of intervals at the location i associate with a load test l,
and
is the maximum number of intervals at the location i associated with another load test and
with
the number of potential load tests:
The joint entropy is less than or equal to the sum of the individual entropies of the sensor location with individual load test in the set, hence, Equation (10) is modified as follows:
where I is the mutual information between a sensor associate with the load test l and the same sensor associated with the load test l + 1.
The pseudo-code of the new hierarchical algorithm is presented in
Figure 5. Differences with the pseudo-code of the hierarchical algorithm for a single load test (
Figure 2) are underlined. A new loop is added to distribute model instance predictions into sub-intervals defined using the additional load tests. In the fifth point, the algorithm distributes previous subsets of model instances, obtained with the first load test, using model instance predictions obtained with a new load test. Consequently, the algorithm evaluates the mutual information between load tests at the same sensor location. As this modification includes major changes to the original hierarchical algorithm, this sensor placement algorithm is called the new hierarchical algorithm for multiple load tests.
4. Discussion
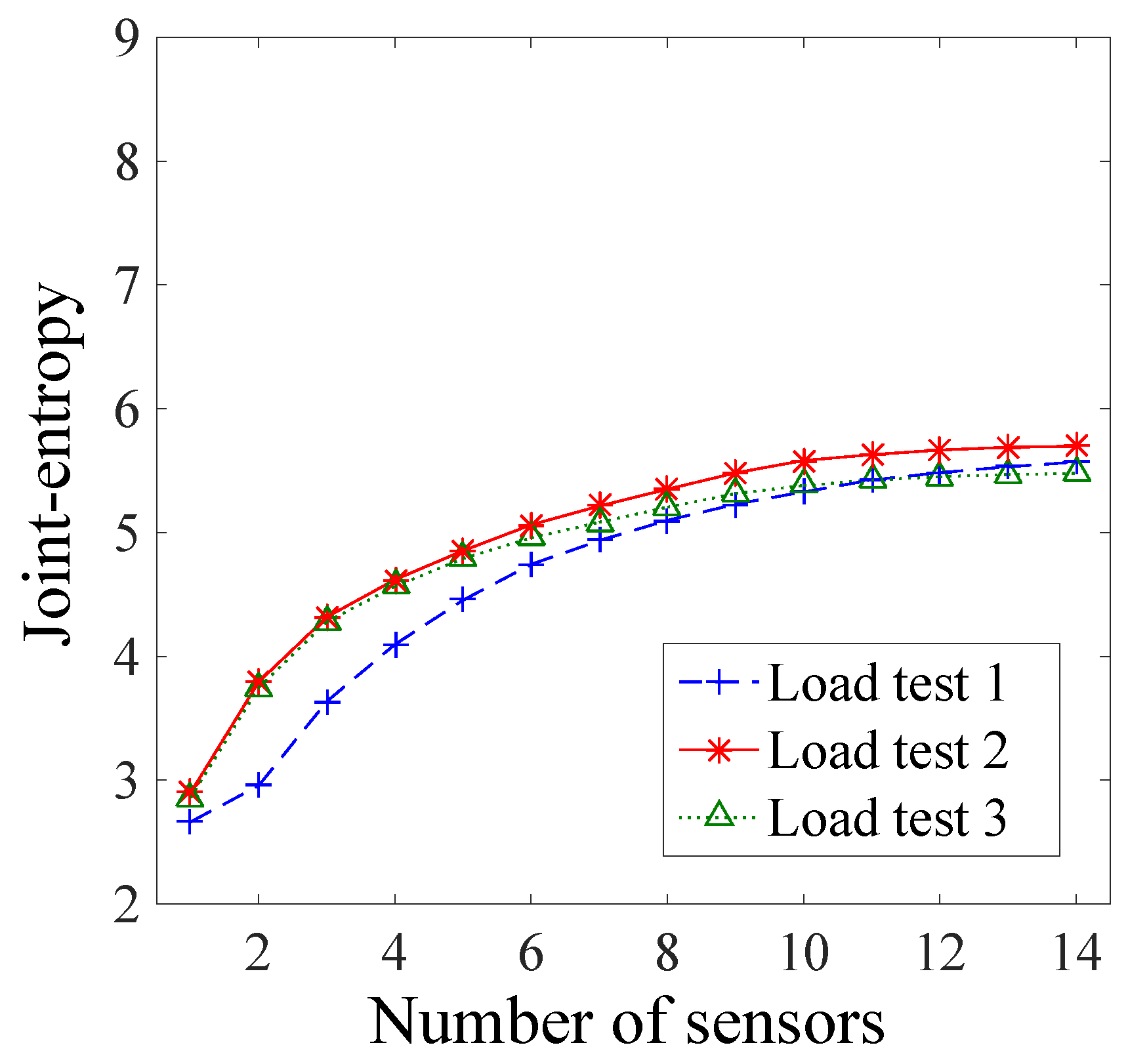
In this section, a comparison of the sensor ranking using the various sensor placement strategies in this study is presented and the limitations are discussed. A sensor placement strategy based on the joint entropy is able to identify the sensor configuration which will be the most beneficial to identify the parameters of a system, which is, in this case, a bridge. Outcomes of structural identification, such as reserve capacity estimation, are highly dependent on the quality of field measurements. The use of a sensor placement methodology may, thus, ensure that the maximum of information will be gained during load testing. Additionally, an advantage of both the original and the new hierarchical algorithms is the monotonic and bounded properties of the joint entropy objective function. Thus, a stop criterion, for instance, an increase of joint entropy between two sensor configurations smaller than a threshold, could be introduced to identify an optimal number of sensors. By decreasing the number of sensors, the cost of monitoring could often be reduced, guaranteeing that the information gain is not compromised.
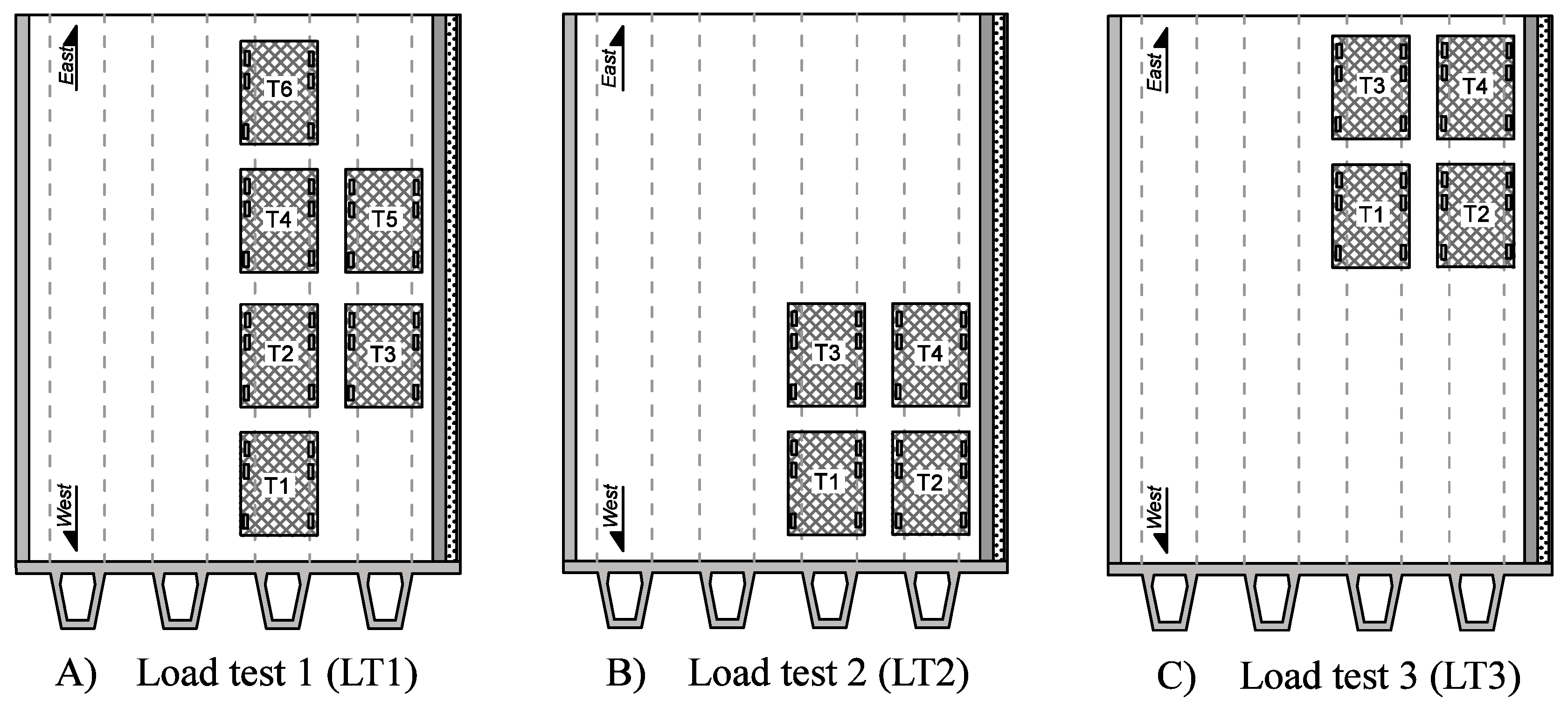
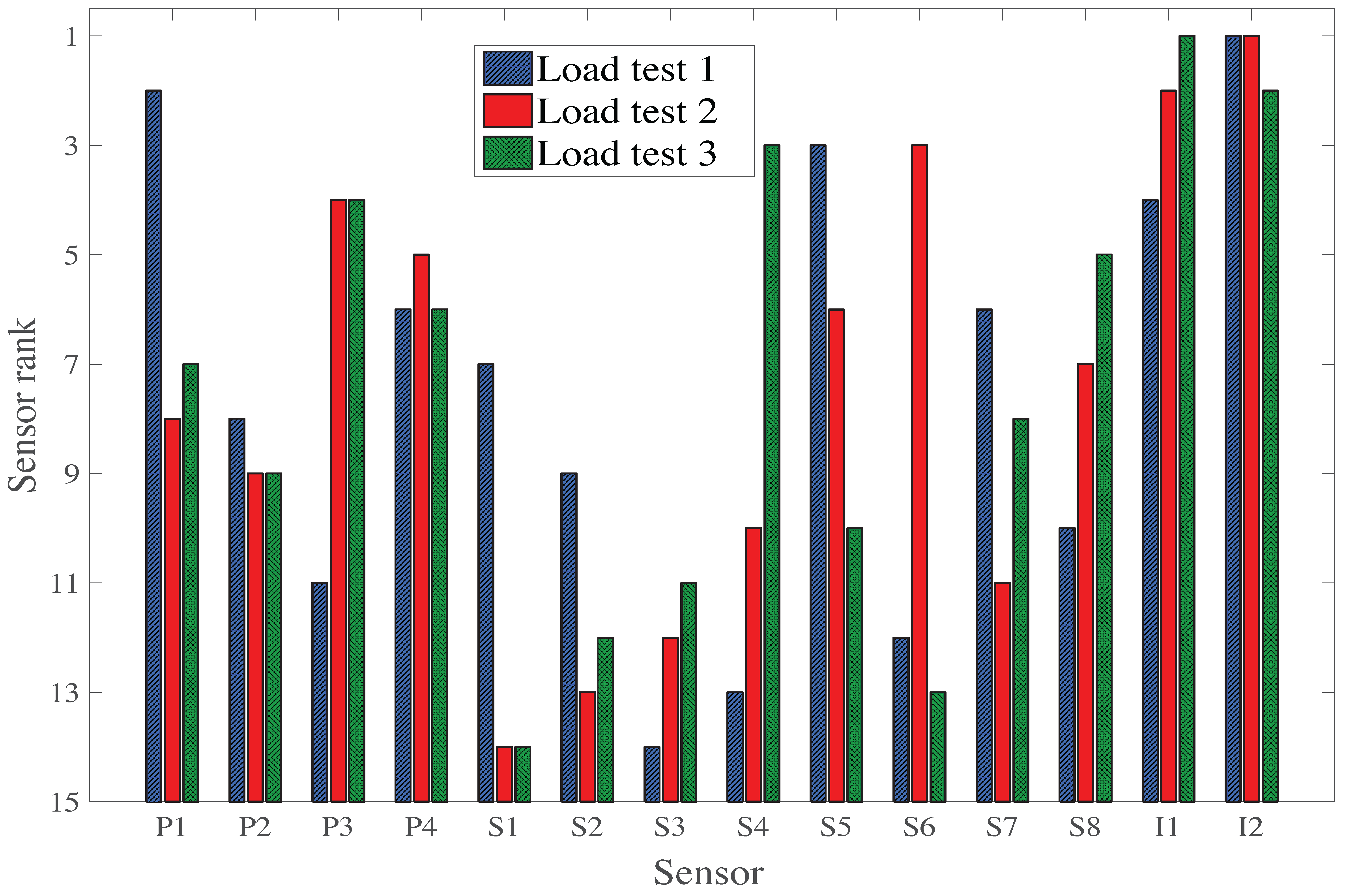
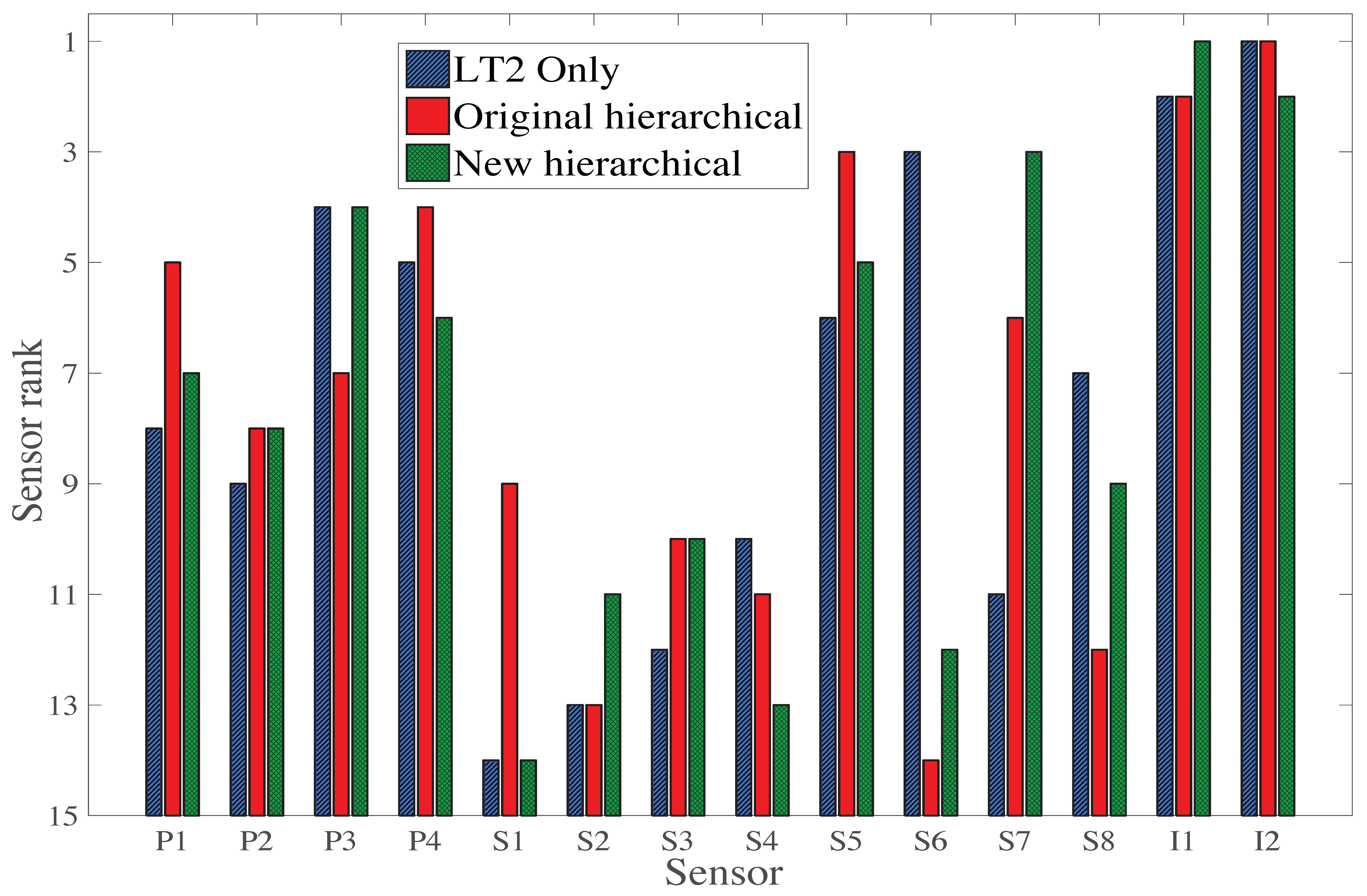
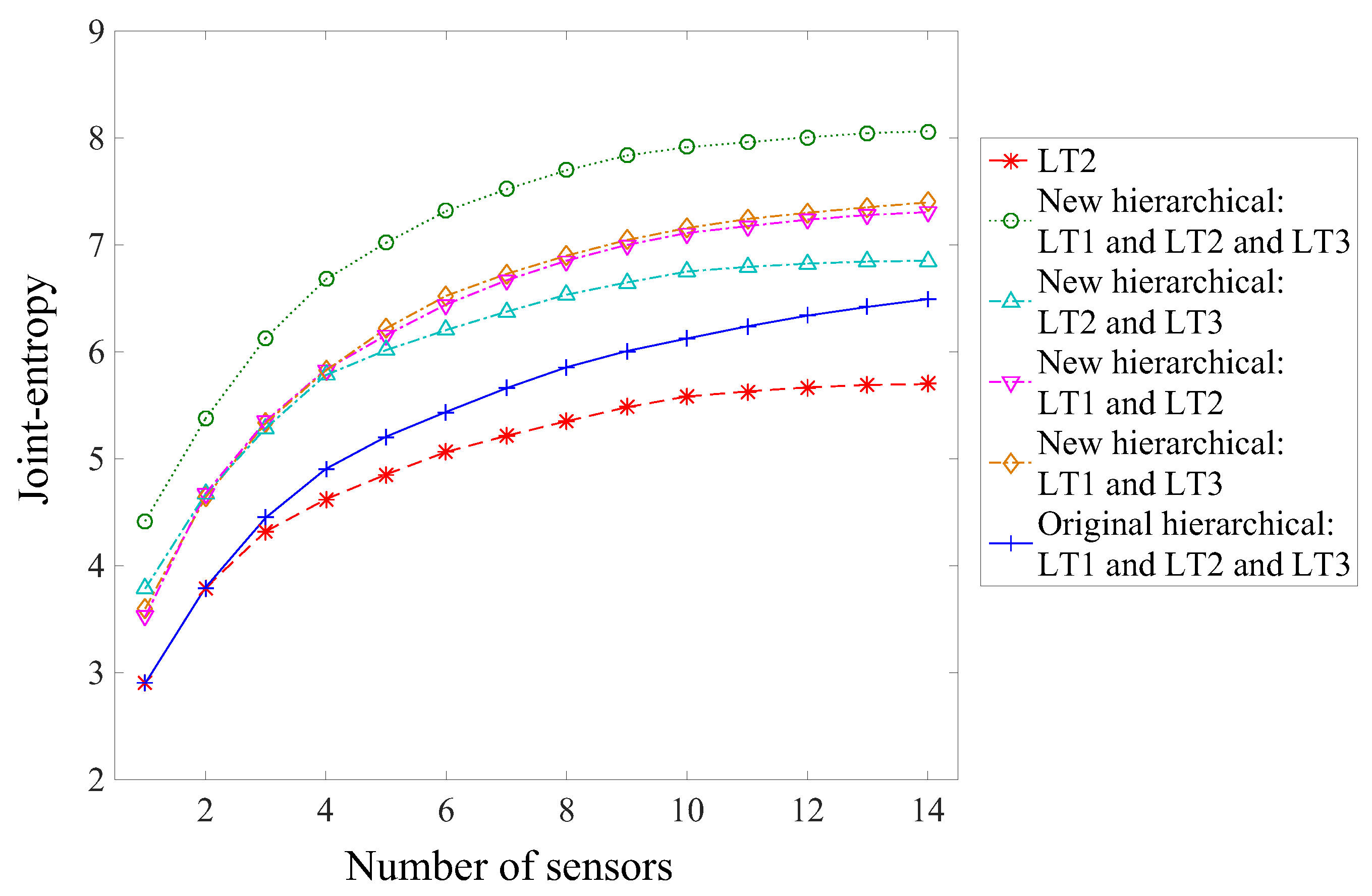
Table 3 displays a summary of the sensor ranking from the various sensor placement strategies proposed in this study. Except for the case of the first load test (LT1), all sensor placement strategies select sensor types in the same order: two inclinometers, then a strain gauge and a deflection target. However, the selection of sensor locations differs, indicating that this aspect is very sensitive to the choice of sensor placement strategy. If multiple static load tests are planned, a sensor placement strategy, which does not take into account information from multiple load tests, may lead to a sub-optimal sensor configuration. Additionally, the original hierarchical algorithm suggests that LT3 does not provide additional information compared with LT1 and LT2 (
Figure 12), while the new hierarchical algorithm suggests that LT3 provides unique information (
Figure 14). This contradiction shows that the uniqueness of information is difficult to estimate when the mutual information among multiple load tests is not evaluated, and this may lead to the wrong decision on, for example, whether or not to add a new test to load testing plans.
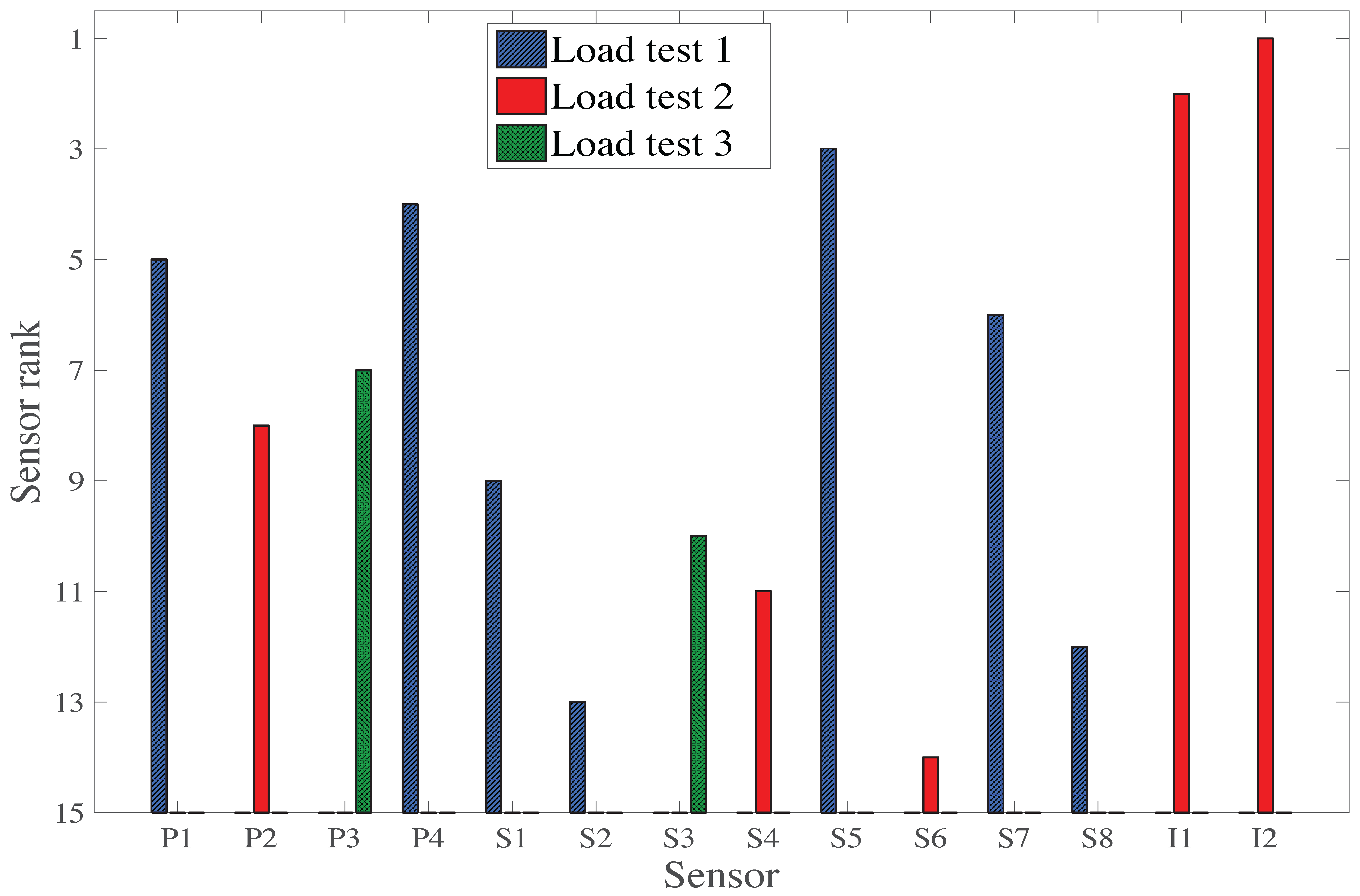
Both the original and the new hierarchical algorithms ranks highly all sensor types, even if individual information entropy values are small (
Figure 8). This means that each sensor type provides unique information. For a given number of measurements, placing multiple sensor types, associated with several load tests, is, thus, the best strategy to maximize information gain during a field measurement campaign.
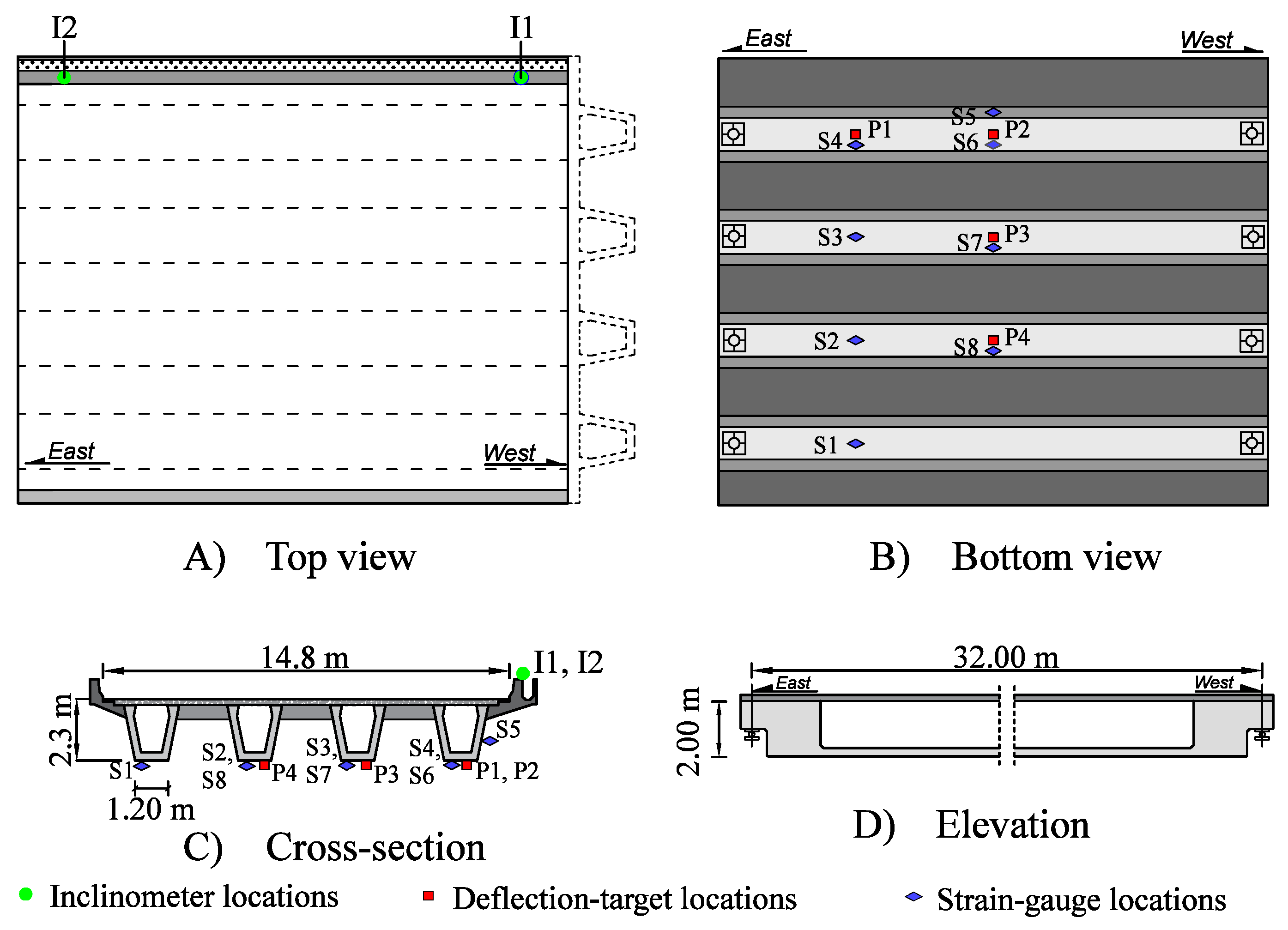
The following limitations of the work are recognized: The greedy algorithm used in the three sensor placement strategies does not necessarily lead to a global optimum. Moreover, the sampling technique and the estimation of modelling uncertainties at sensor locations influence the results. Finally, only fourteen locations were investigated, due to practical considerations which restricted the sensor installation to some parts of the bridge. Research is underway to assess the impact of these aspects on the results.
Another important restriction of any model-based sensor placement methodology is that the success of the study depends on the quality of the numerical model used to obtain predictions. Therefore, it is primordial to build a reliable model to get trustful predictions at possible sensor locations. Model assumptions should be verified during visual inspection, before load testing the bridge. Additionally, test configurations, such as possible load tests and available sensor types and numbers, should be defined sufficiently in advance of computing the model instance predictions and running the sensor placement algorithm to obtain the optimal sensor configuration.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}