An Efficient Audio Coding Scheme for Quantitative and Qualitative Large Scale Acoustic Monitoring Using the Sensor Grid Approach


Abstract
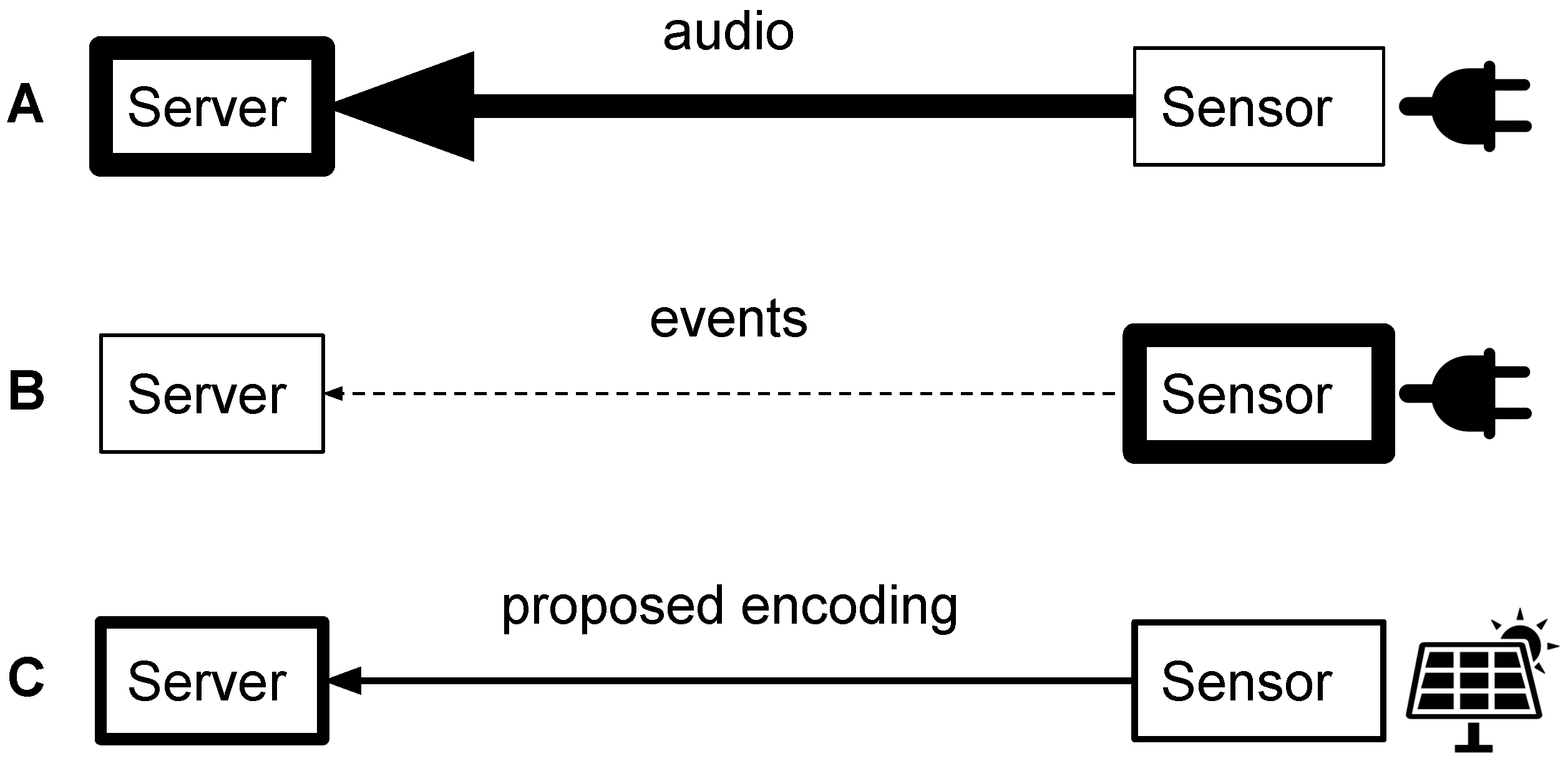
:1. Introduction
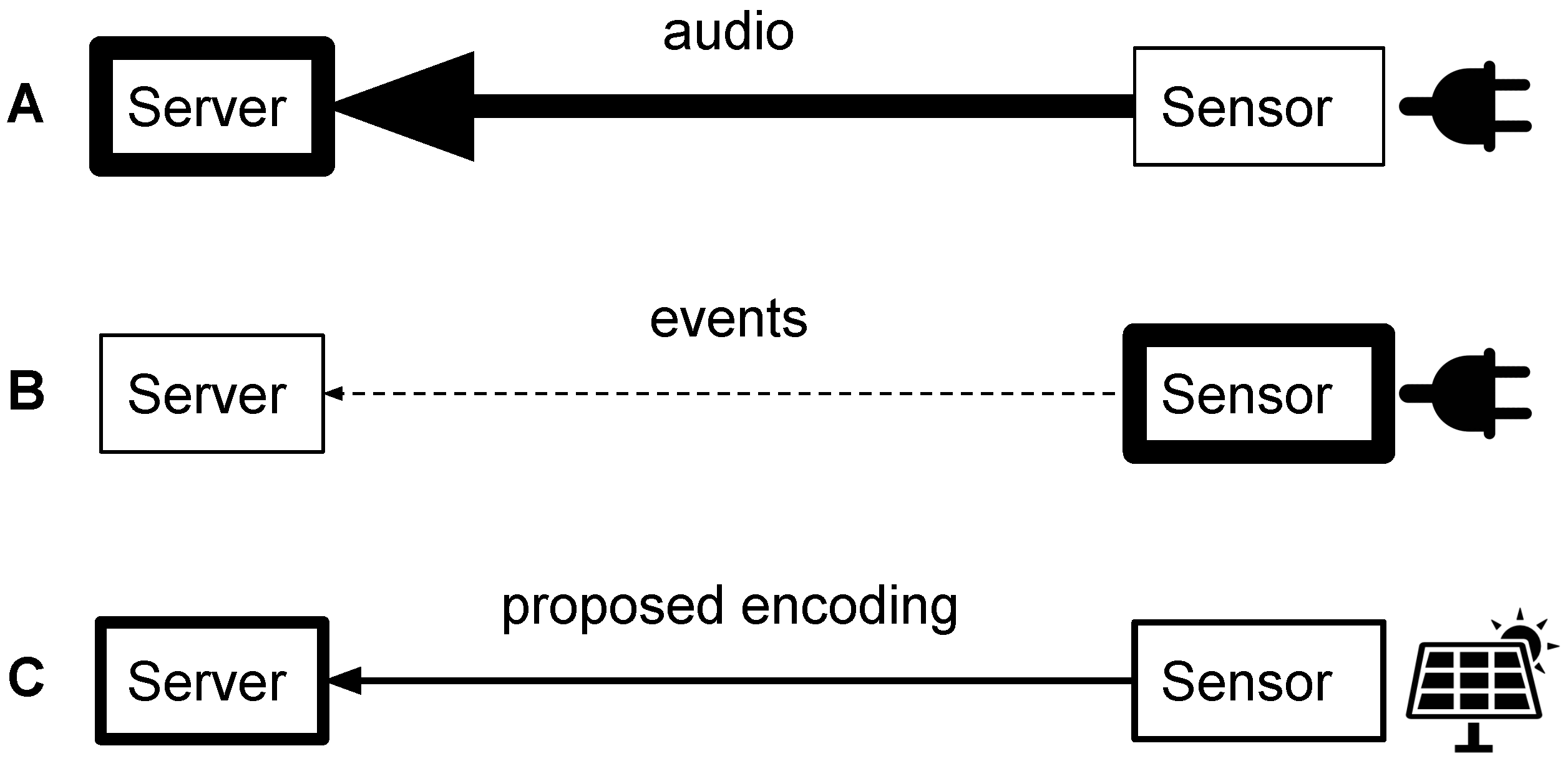
2. Proposed Encoding Scheme
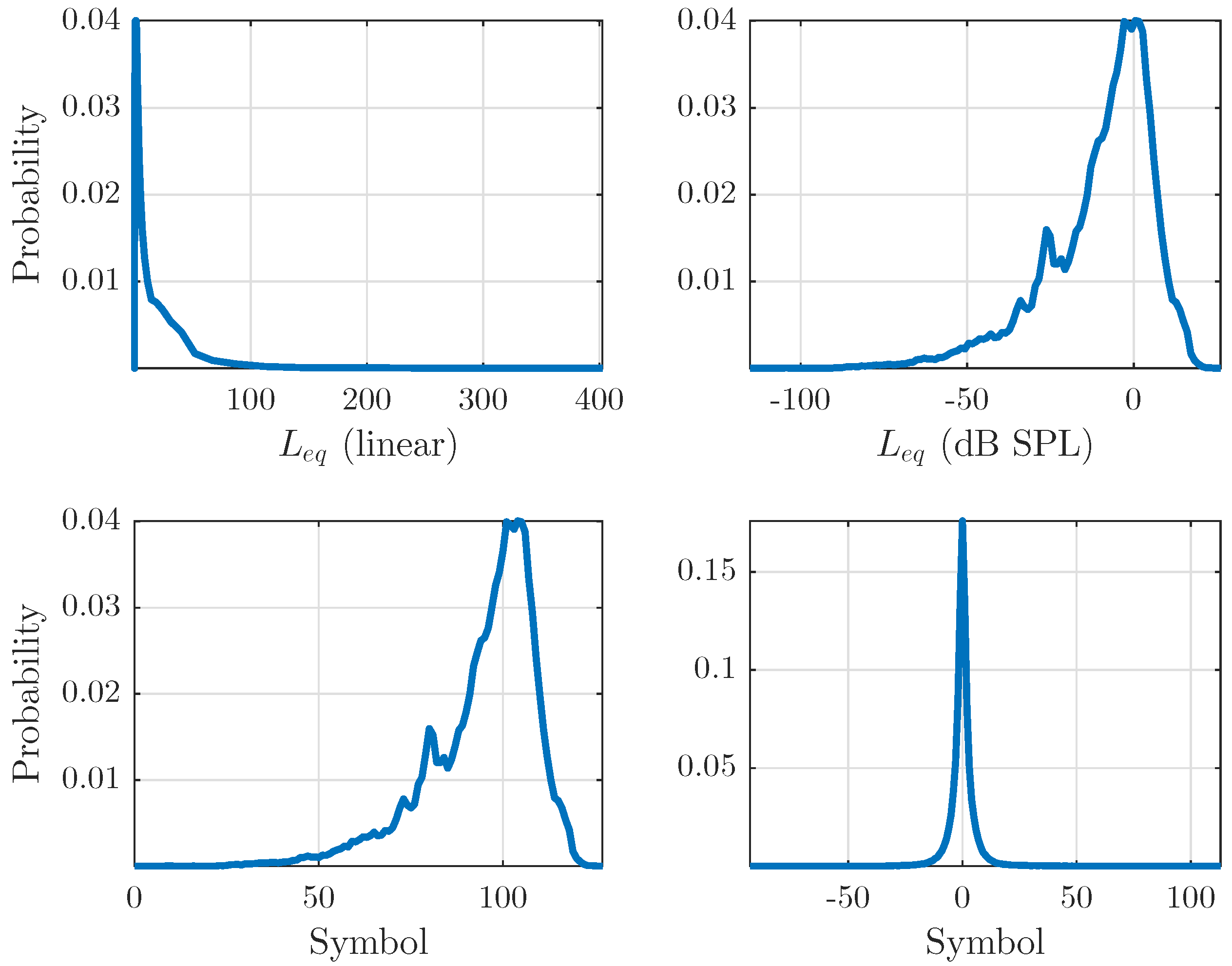
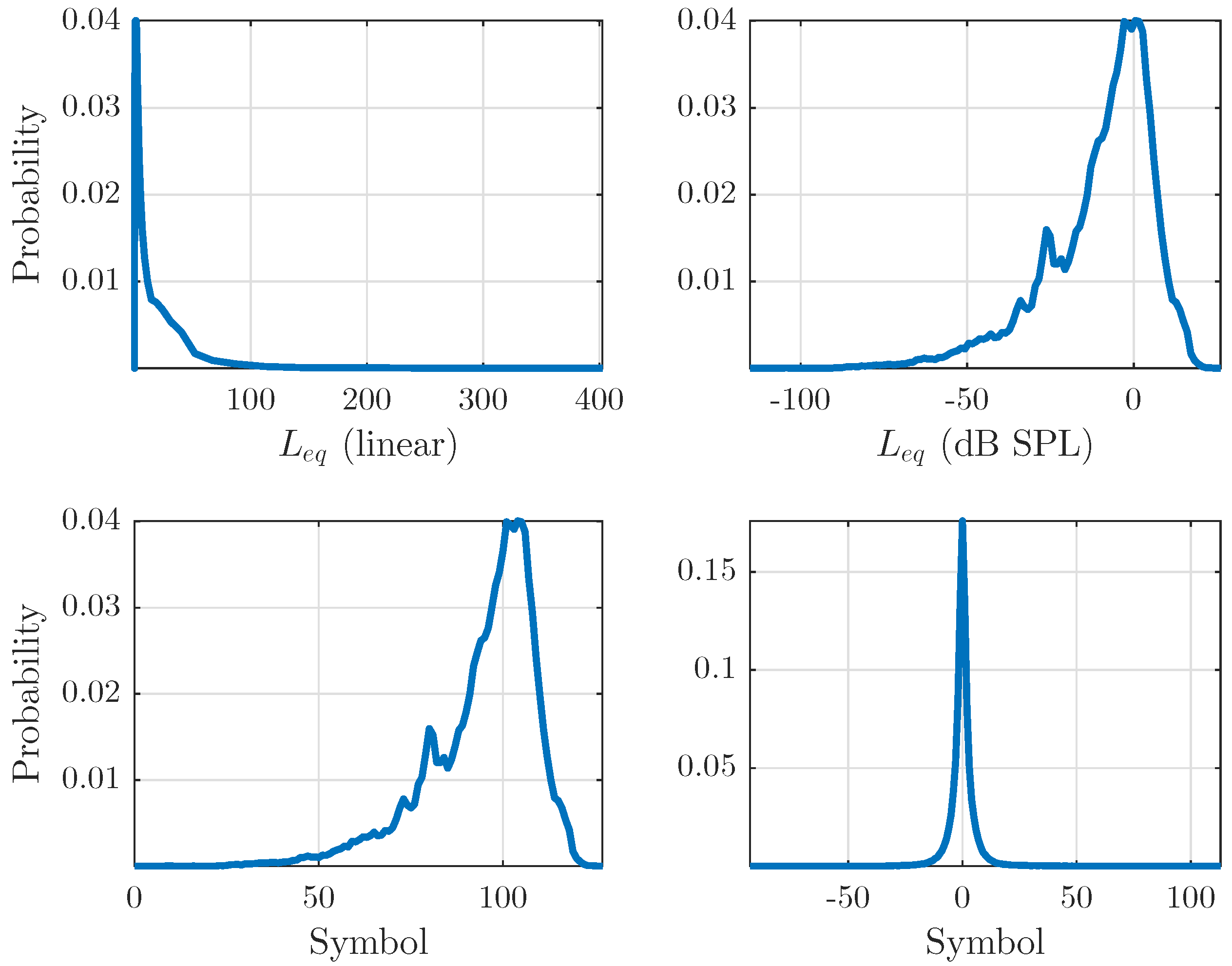
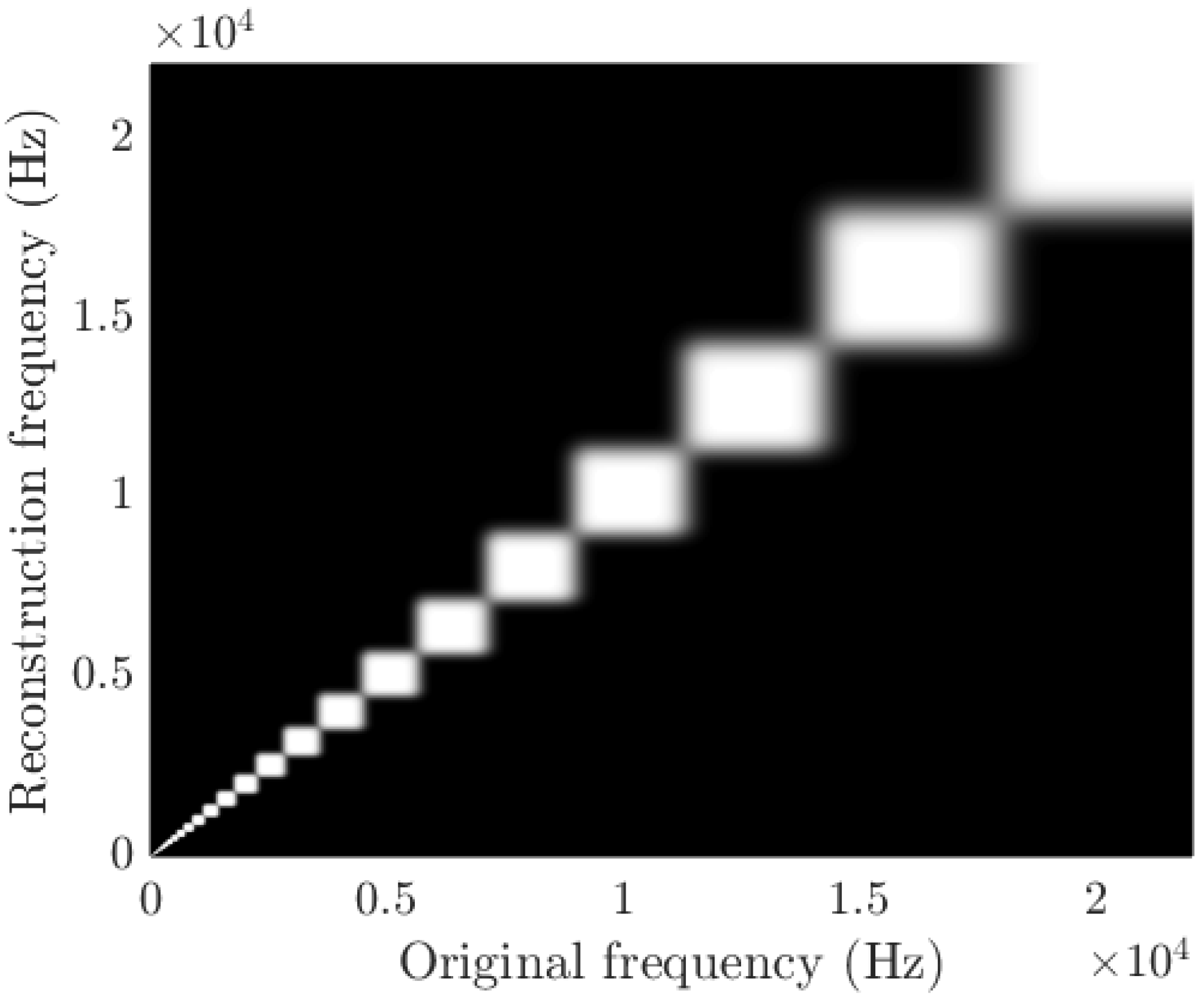
2.1. Data Representation
2.2. Signal Analysis
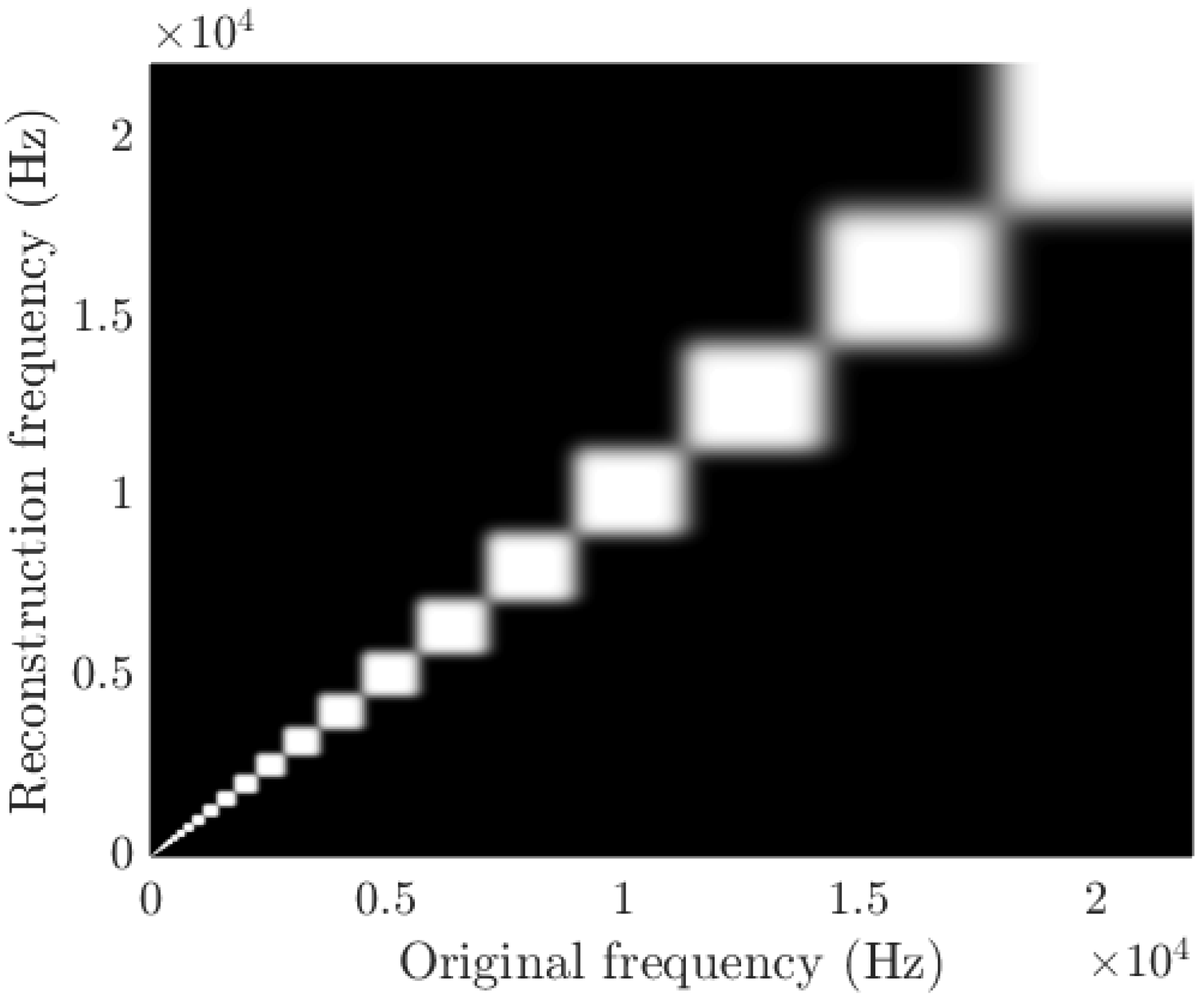
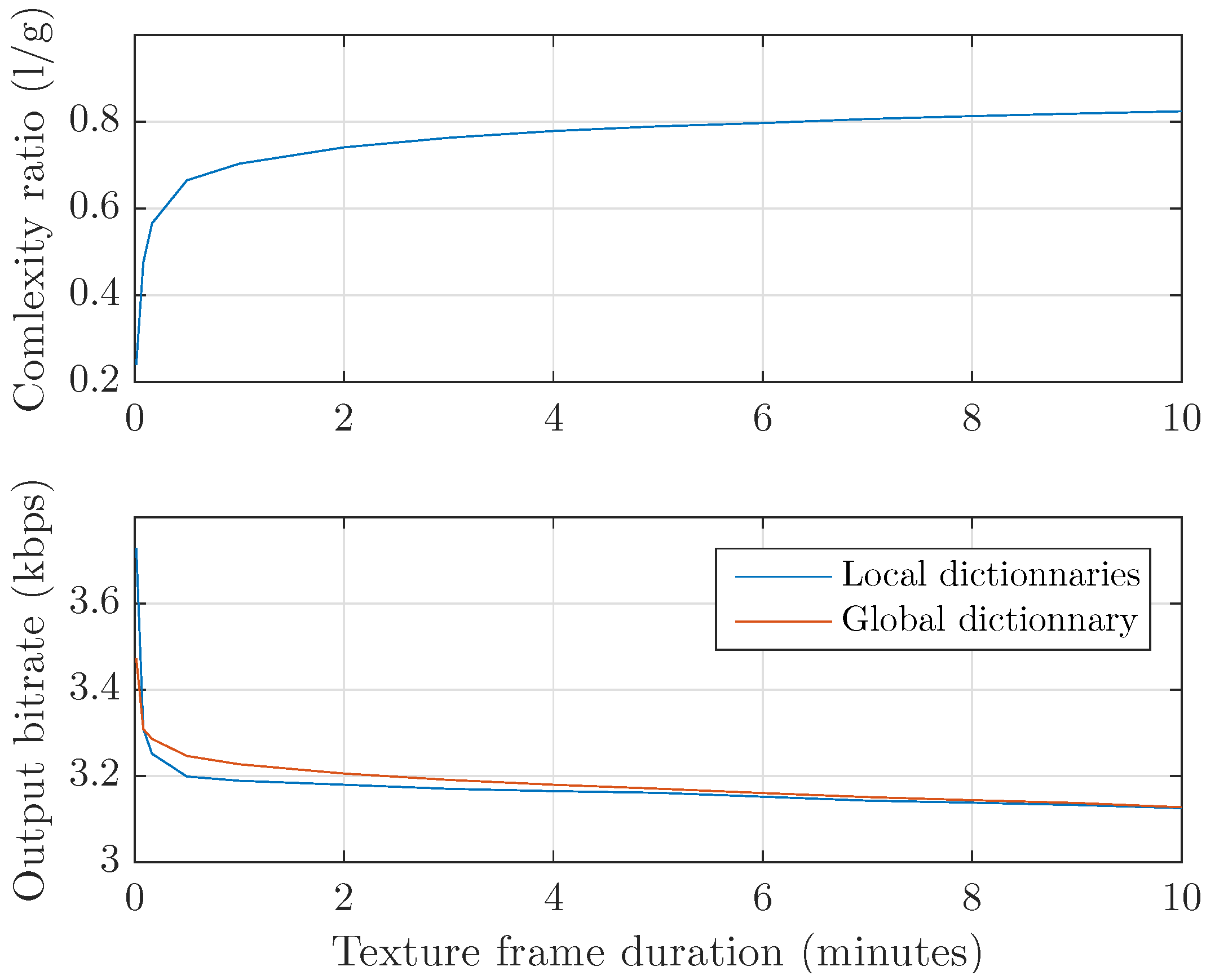
2.3. Data Encoding
3. Validation Protocol
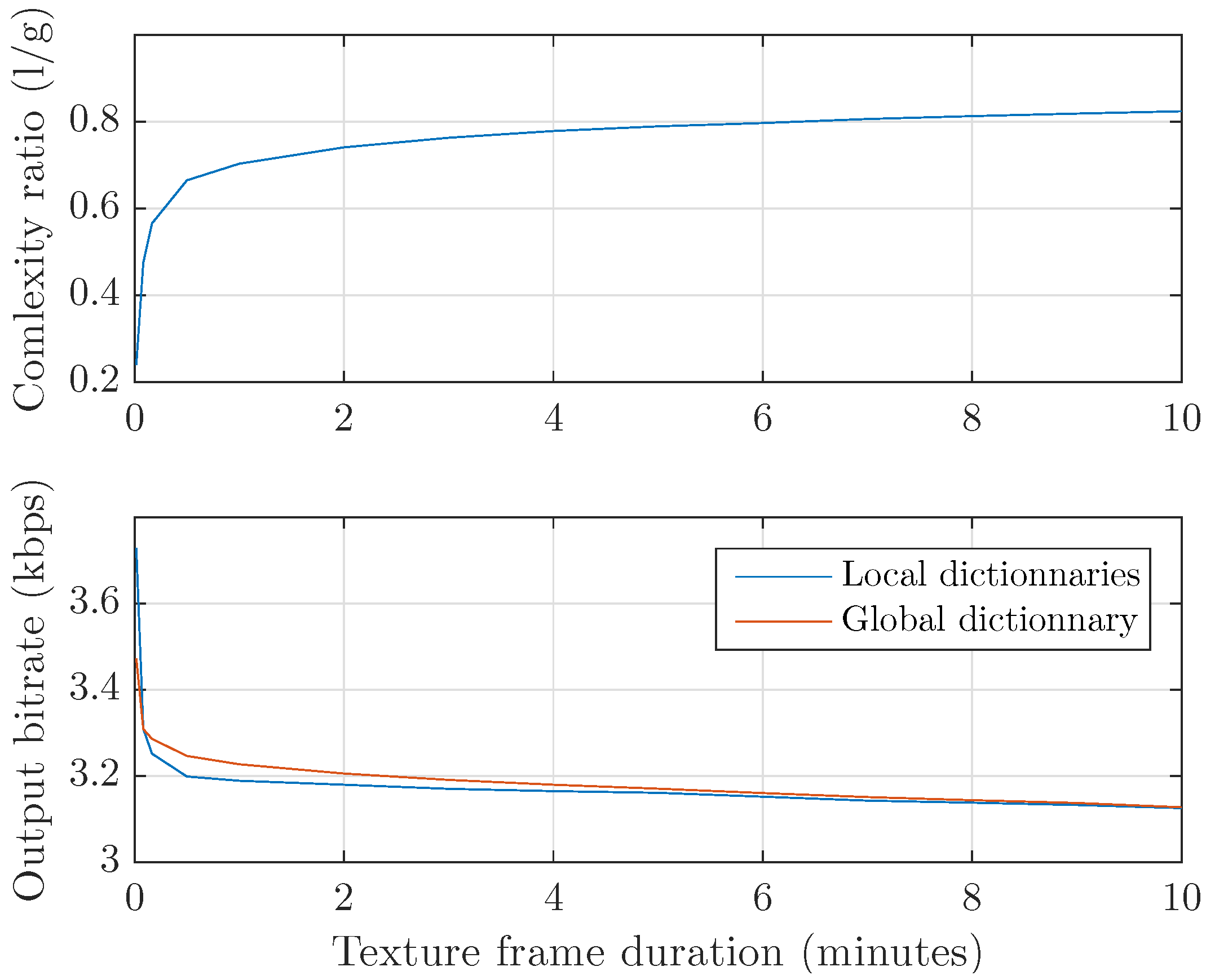
3.1. Efficiency
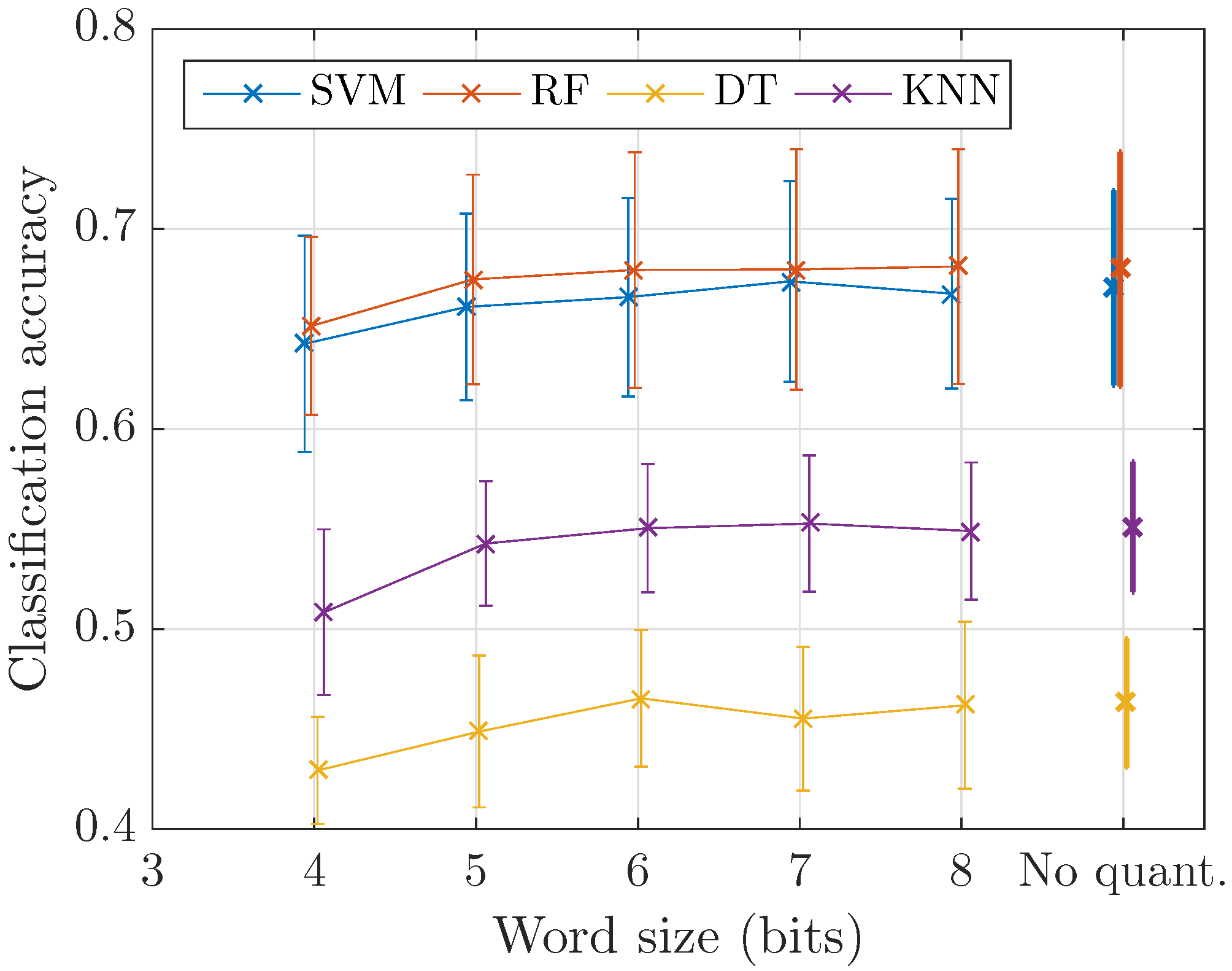
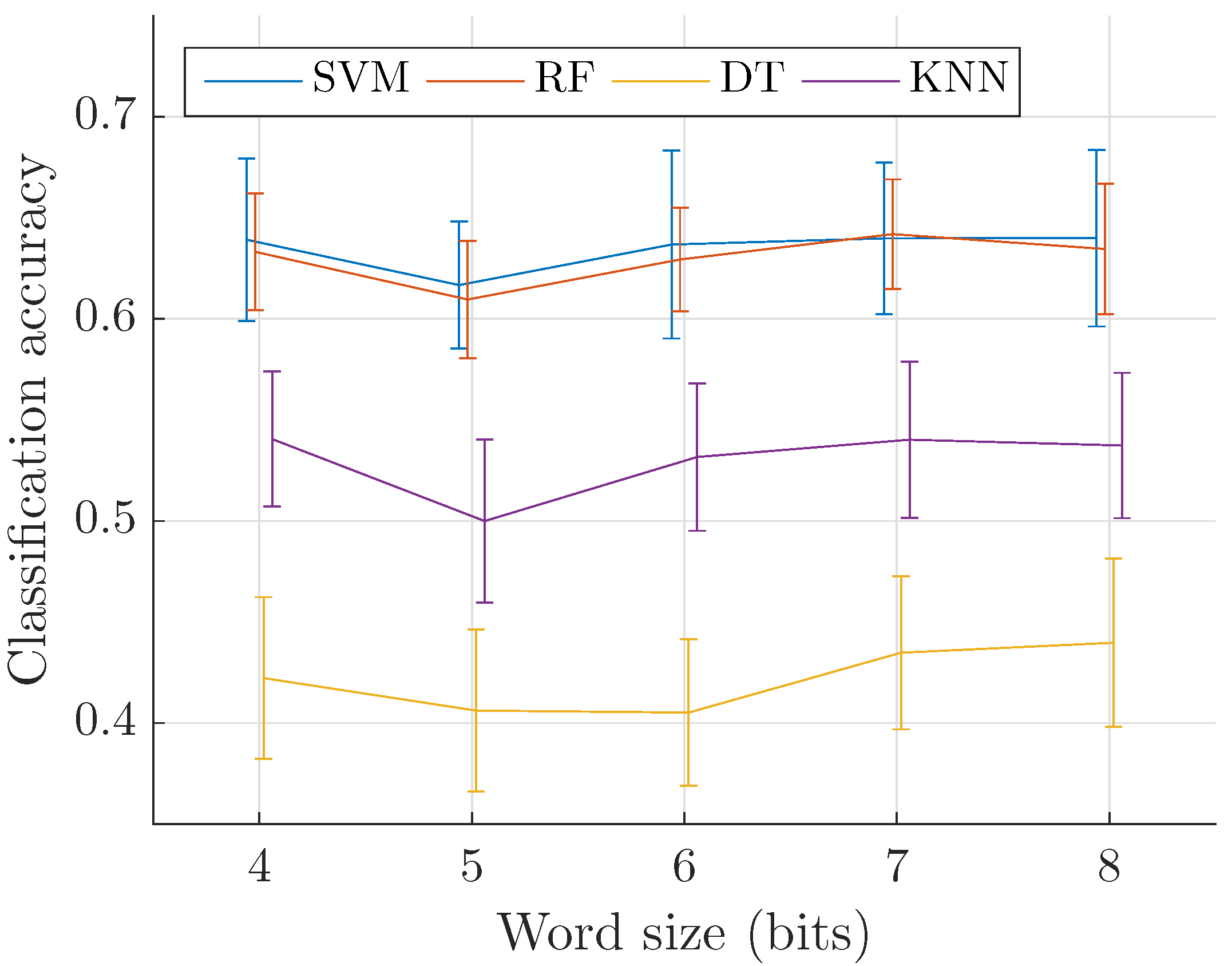
3.2. Preserving Event Recognition Performance at Low Bitrate
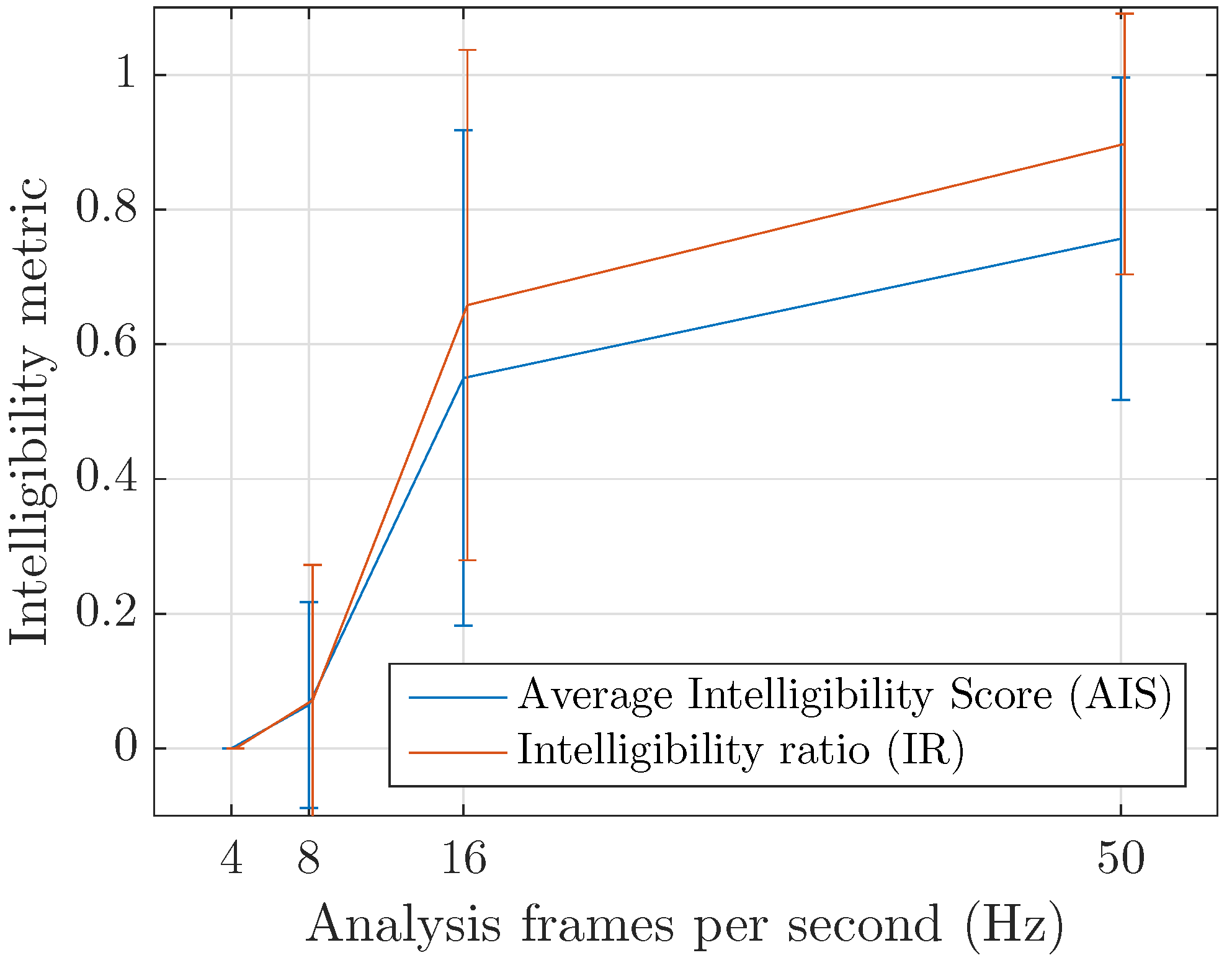
3.3. Inintelligibility
4. Results
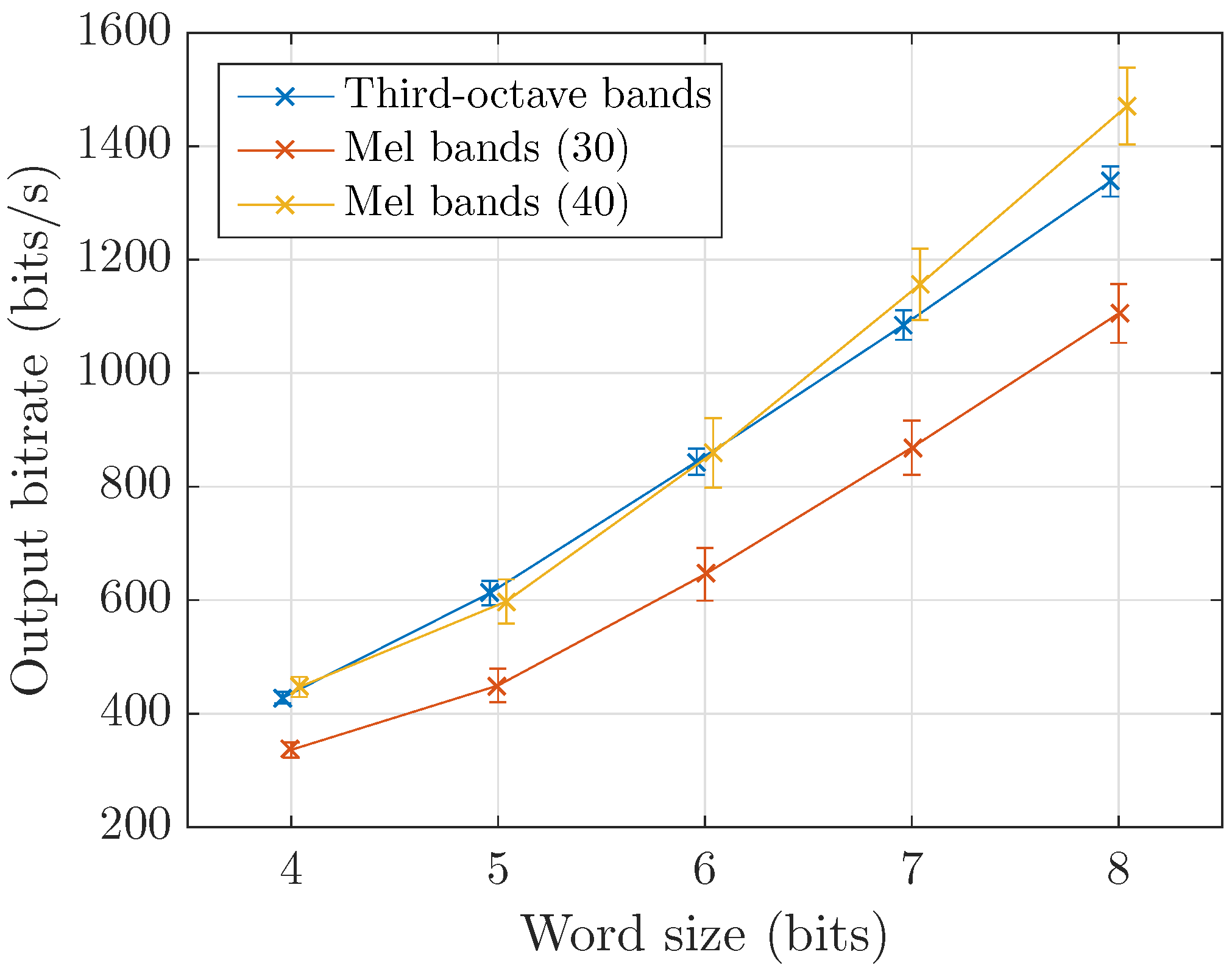
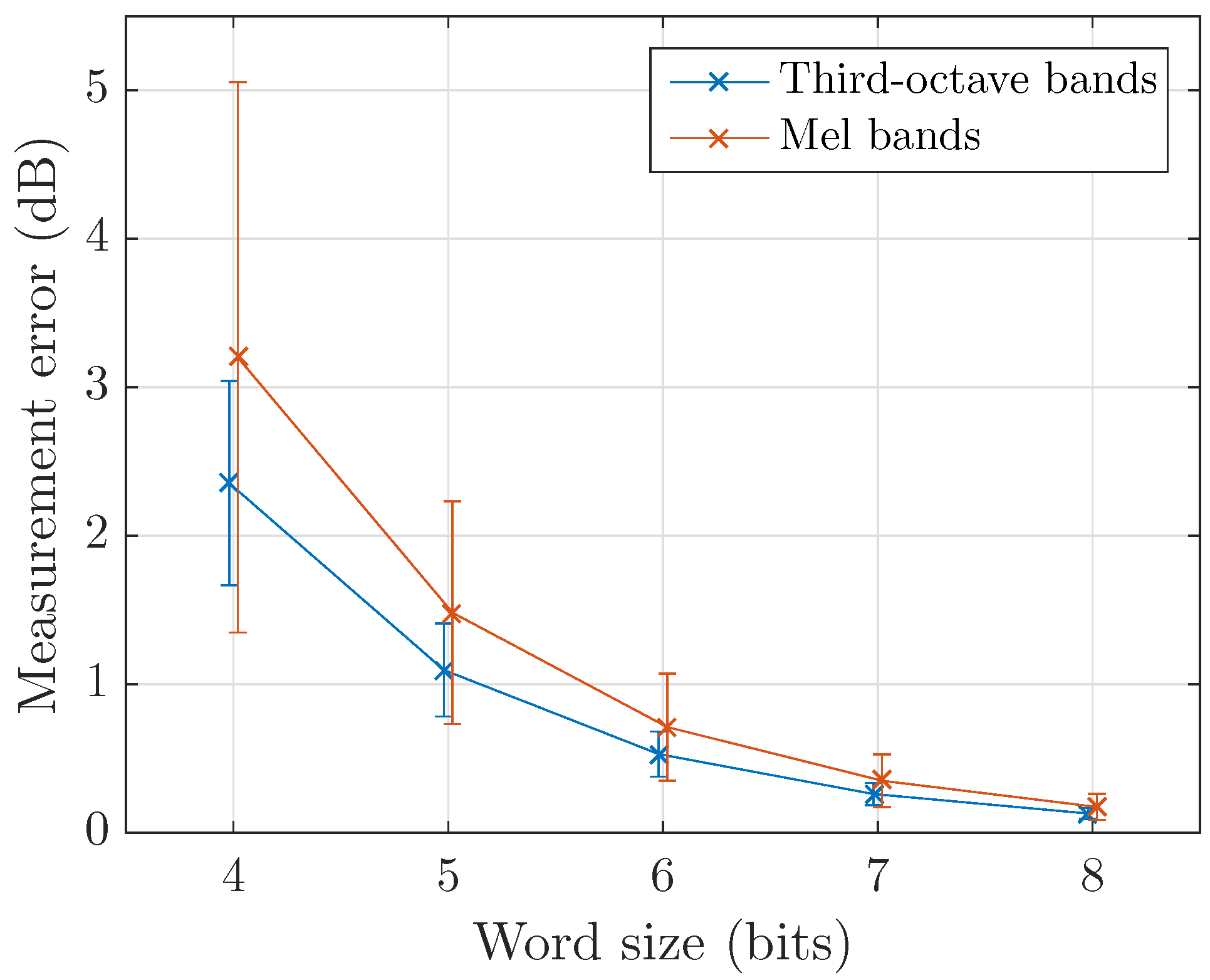
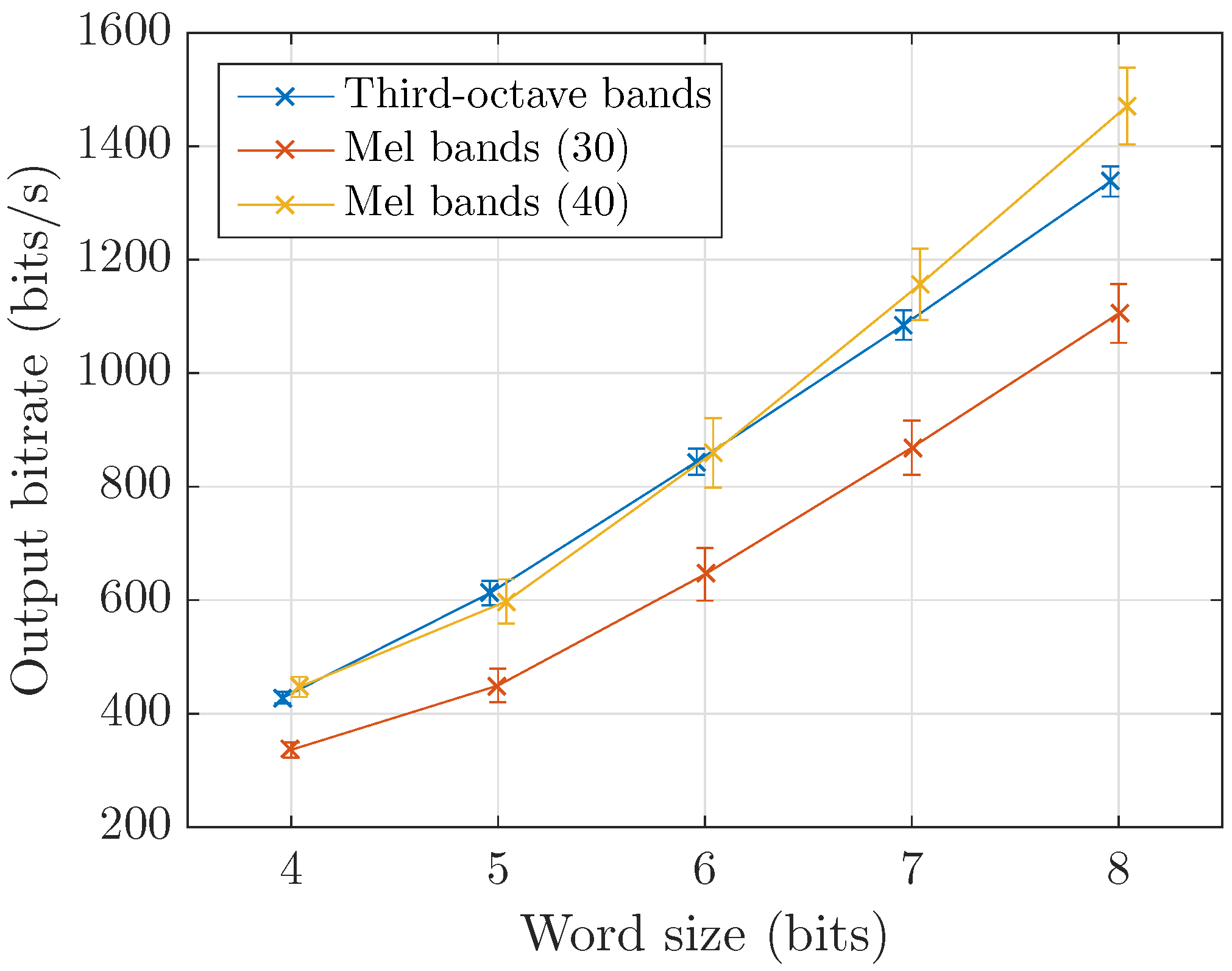
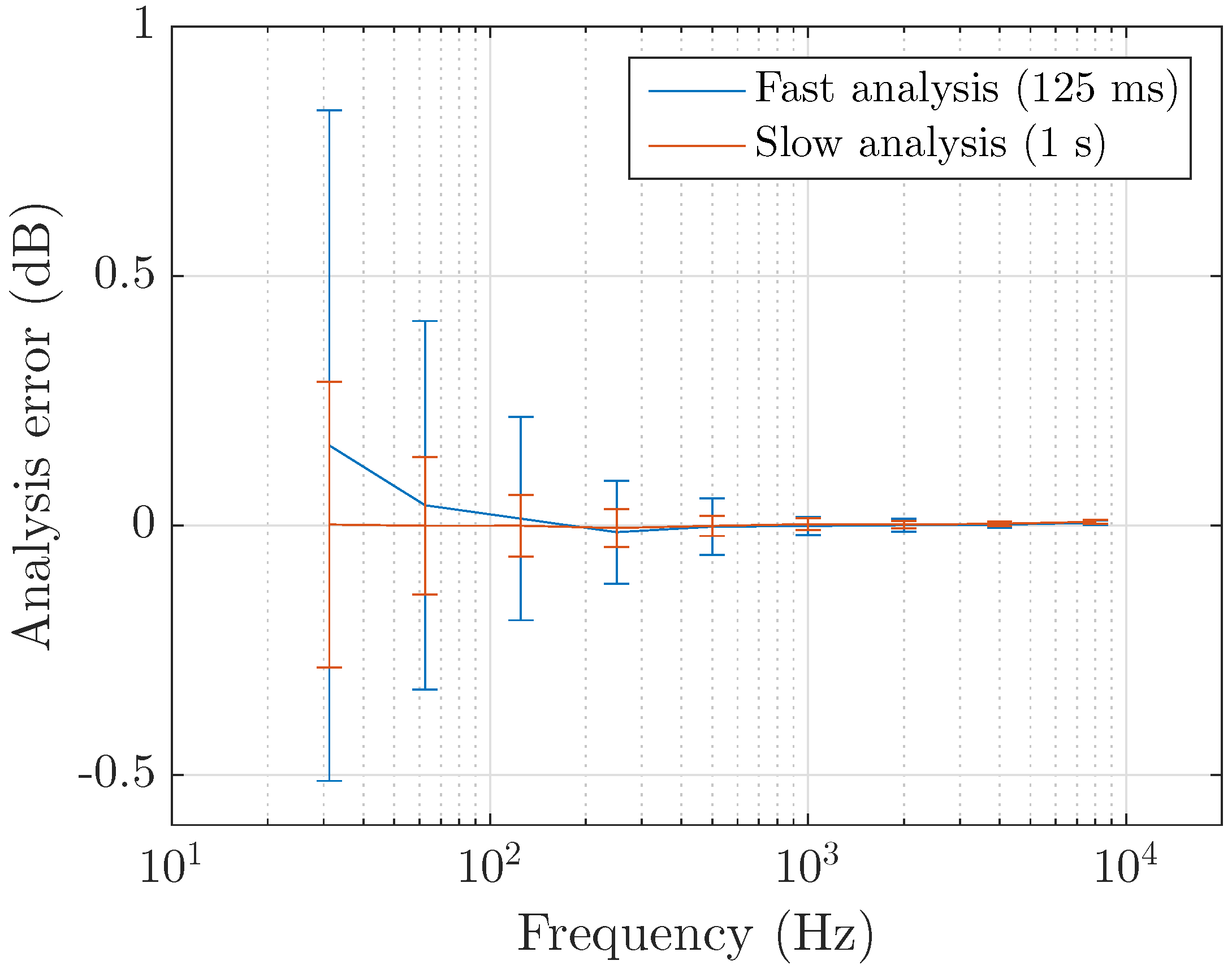
4.1. Coder Efficiency
4.2. Event Recognition
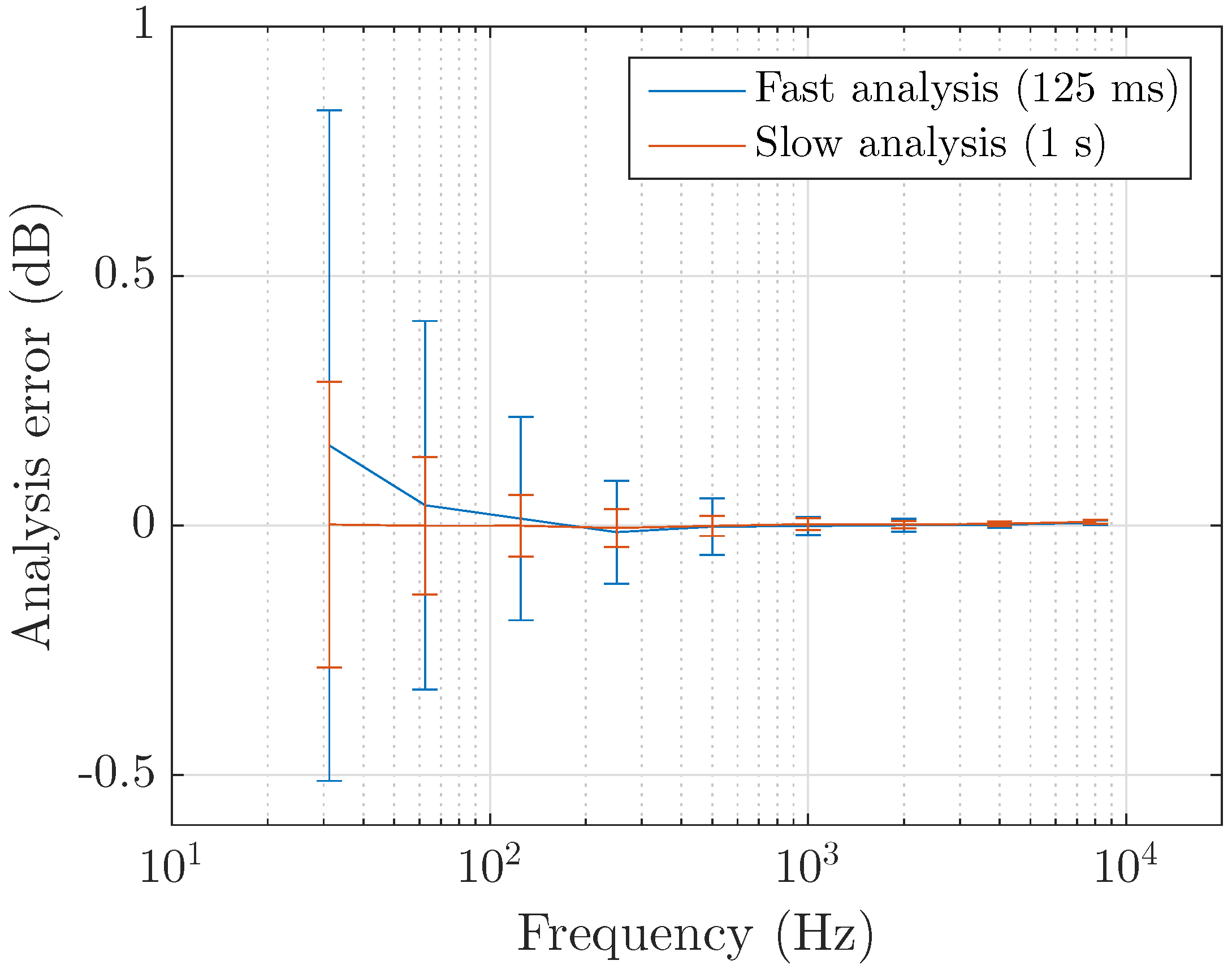
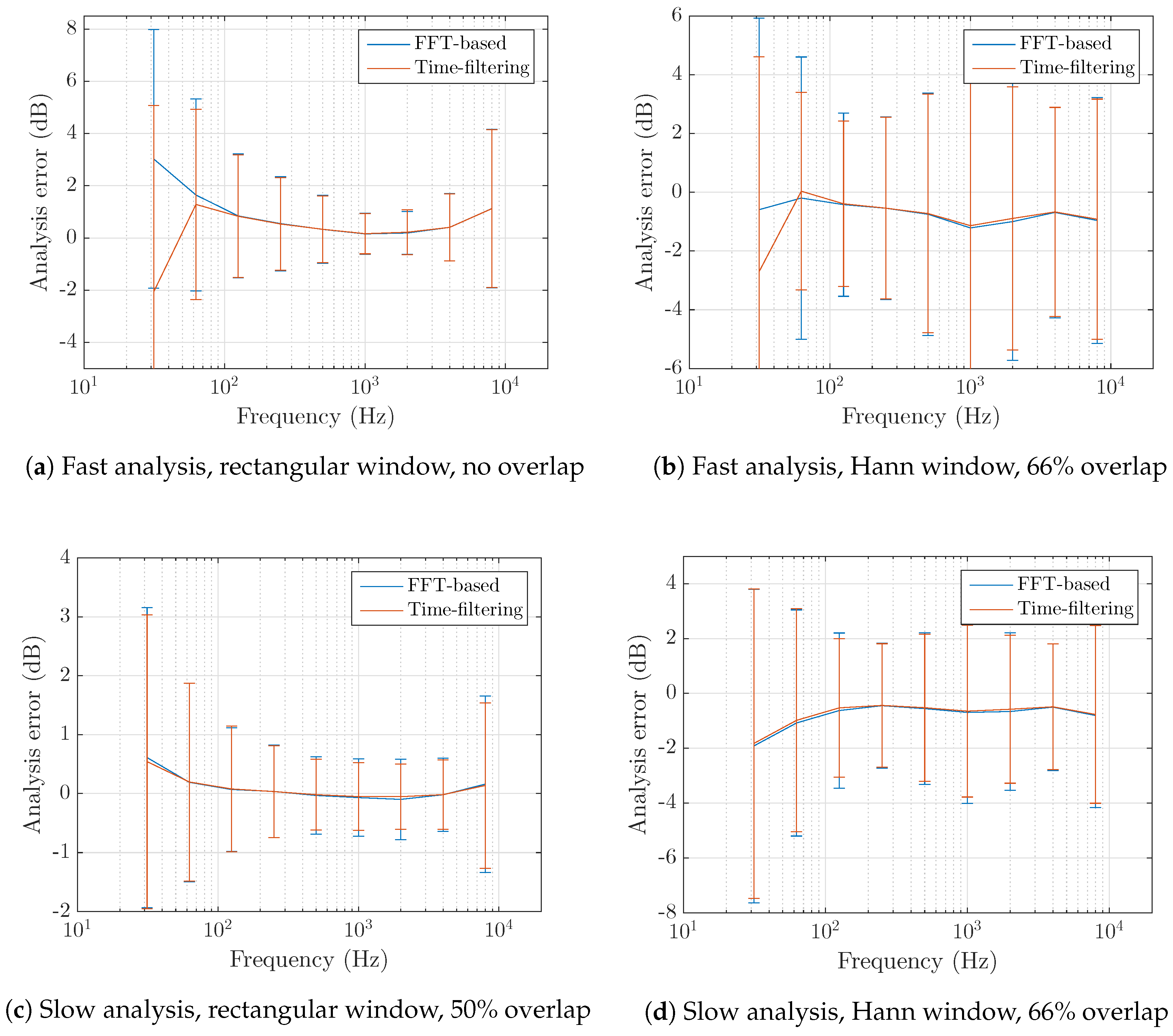
4.3. Third-Octave Bands as Base Descriptors
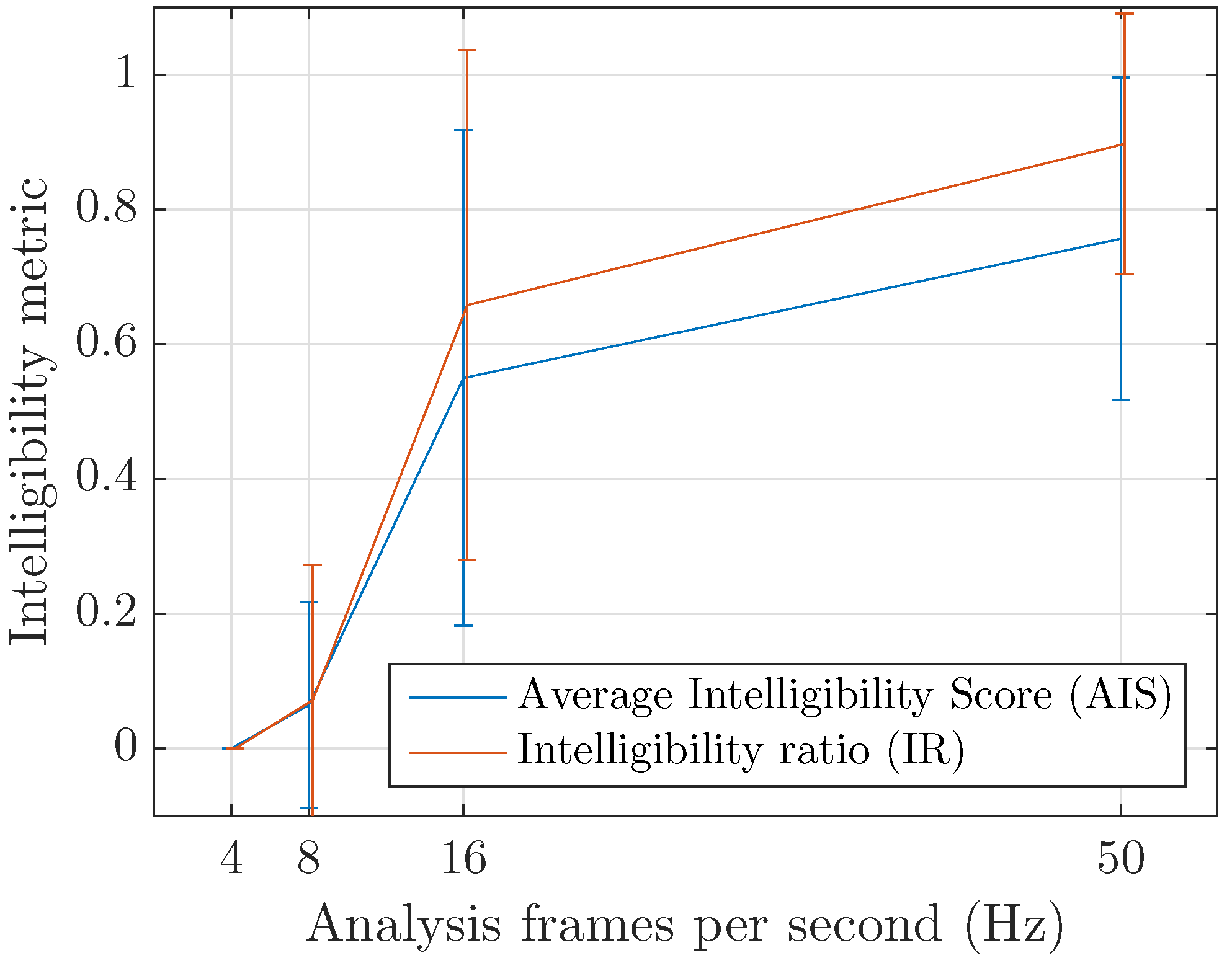
4.4. Inintelligibility
5. Conclusions
- Precision: The impact of the quantization step for 8 bits codewords is found to be very small (<0.2 dB), and thus:
- -
- does not impact the quality of the acoustics indicators (Section 3.1 and Section 4.1); and
- -
- enables sound event recognition with the same quality than directly from the spectrogram (Section 3.2, Section 4.2 and Section 4.3).
- Efficiency: Using the high precision parameters, the bitrate is about 1.4 kbps and 0.4 kbps for fast and slow modes respectively (Section 4.1).
- Privacy: At all operating modes, the reverted audio signal is found to be inintelligible according to a perceputal test done using clean speech recorded at very low background level. Additionaly, the sensors being typically hanged at 4 m high in a usually very noisy environment, we believe that the intelligibility risk of the proposed approach is negligible (Section 3.3 and Section 4.4).
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Mydlarz, C.; Salamon, J.; Bello, J. The implementation of low-cost urban acoustic monitoring devices. Appl. Acoust. 2017, 117, 207–218. [Google Scholar] [CrossRef]
- Picaut, J.; Can, A.; Ardouin, J.; Crépeaux, P.; Dhorne, T.; Écotière, D.; Lagrange, M. Characterization of urban sound environments using a comprehensive approach combining open data, measurements, and modeling. J. Acoust. Soc. Am. 2017, 141, 3808. [Google Scholar] [CrossRef]
- Lim, H.; Teo, Y.; Mukherjee, P.; Lam, V.; Wong, W.; See, S. Sensor grid: Integration of wireless sensor networks and the grid. In Proceedings of the 2005 30th Anniversary IEEE Conference on Local Computer Networks, Sydney, Australia, 17 November 2005; pp. 91–99. [Google Scholar]
- Tham, C.K.; Buyya, R. SensorGrid: Integrating sensor networks and grid computing. CSI Commun. 2005, 29, 24–29. [Google Scholar]
- Rey Gozalo, G.; Trujillo Carmona, J.; Barrigon Morillas, J.; Gomez Escobar, V. Relationship between objective acoustic indices and subjective assessments for the quality of soundscapes. Appl. Acoust. 2015, 97, 1–10. [Google Scholar] [CrossRef]
- Rychtarikova, M.; Vermeir, G. Soundscape categorization on the basis of objective acoustical parameters. Appl. Acoust. 2013, 74, 240–247. [Google Scholar] [CrossRef]
- Can, A.; Aumond, P.; Michel, S.; De Coensel, B.; Ribeiro, C.; Botteldooren, D.; Lavandier, C. Comparison of noise indicators in an urban context. In Proceedings of the 45th International Congress and Exposition on Noise Control Engineering, Hamburg, Germany, 21–24 August 2016; pp. 5678–5686. [Google Scholar]
- Can, A.; Gauvreau, B. Describing and classifying urban sound environments with a relevant set of physical indicators. J. Acoust. Soc. Am. 2015, 137, 208–218. [Google Scholar] [CrossRef] [PubMed]
- Brocolini, L.; Lavandier, C.; Quoy, M.; Ribeiro, C. Measurements of acoustic environments for urban soundscapes: Choice of homogeneous periods, optimization of durations, and selection of indicators. J. Acoust. Soc. Am. 2013, 134, 813–821. [Google Scholar] [CrossRef] [PubMed]
- Nilsson, M.; Botteldooren, D.; De Coensel, B. Acoustic indicators of soundscape quality and noise annoyance in outdoor urban areas. In Proceedings of the 19th International Congress on Acoustics, Madrid, Spain, 2–7 September 2007. [Google Scholar]
- Lavandier, C.; Defréville, B. The contribution of sound source characteristics in the assessment of urban soundscapes. Acta Acust. United Acust. 2006, 92, 912–921. [Google Scholar]
- Aumond, P.; Can, A.; De Coensel, B.; Botteldooren, D.; Ribeiro, C.; Lavandier, C. Modeling soundscape pleasantness using perceptual assessments and acoustic measurements along paths in urban context. Acta Acust. United Acust. 2017, 103, 430–443. [Google Scholar] [CrossRef]
- Alsina-Pagès, R.; Hernandez-Jayo, U.; Alías, F.; Angulo, I. Design of a mobile low-cost sensor network using urban buses for real-time ubiquitous noise monitoring. Sensors 2016, 17, 57. [Google Scholar] [CrossRef] [PubMed]
- Alías, F.; Socoró, J. Description of anomalous noise events for reliable dynamic traffic noise mapping in real-life urban and suburban soundscapes. Appl. Sci. 2017, 7, 146. [Google Scholar] [CrossRef]
- Gloaguen, J.R.; Can, A.; Lagrange, M.; Petiot, J.F. Estimating traffic noise levels using acoustic monitoring: A preliminary study. In Proceedings of the Detection and Classification of Acoustic Scenes and Events (DCASE 2016), Budapest, Hungary, 3 September 2016. [Google Scholar]
- Defréville, B.; Pachet, F.; Rosin, C.; Roy, P. Automatic recognition of urban sound sources. In Proceedings of the Audio Engineering Society Convention 120, Paris, France, 20–23 May 2006; Audio Engineering Society: New York, NY, USA, 2006. [Google Scholar]
- Mydlarz, C.; Shamoon, C.; Baglione, M.; Pimpinella, M. The design and calibration of low cost urban acoustic sensing devices. In Proceedings of the EuroNoise 2015, Maastricht, The Netherlands, 31 May–3 June 2015. [Google Scholar]
- Pan, D. A tutorial on MPEG/audio compression. IEEE Multimedia 1995, 2, 60–74. [Google Scholar] [CrossRef]
- Ishiyama, T.; Hashimoto, T. The impact of sound quality on annoyance caused by road traffc noise: An influence of frequency spectra on annoyance. JSAE Rev. 2000, 21, 225–230. [Google Scholar] [CrossRef]
- Anusuya, M.; Katty, S. Speech recognition by machine, a review. Int. J. Comput. Sci. Inf. Secur. 2009, 6, 181–205. [Google Scholar]
- Tzanztakis, G.; Essl, G.; Cook, P. Automatic musical genre classification of audio signals. IEEE Trans. Speech Audio Process. 2002, 10, 293–302. [Google Scholar] [CrossRef]
- Ntalampiras, S. Universal background modeling for acoustic surveillance of urban traffic. Digit. Signal Process. 2014, 31, 69–78. [Google Scholar] [CrossRef]
- Aucouturier, J.; Defreville, B.; Pachet, F. The bag-of-frames approach to audio pattern recognition: A sufficient model for urban soundscapes but not for polyphonic music. J. Acoust. Soc. Am. 2007, 122, 881–891. [Google Scholar] [CrossRef] [PubMed]
- Foggia, P.; Petkov, N.; Saggese, A.; Strisciuglio, N.; Vento, M. Reliable detection of audio events in highly noisy environments. Pattern Recognit. Lett. 2015, 65, 22–28. [Google Scholar] [CrossRef]
- Kumar, A.; Raj, B. Features and Kernels for Audio Event Recognition. Available online: https://arxiv.org/abs/1607.05765 (accessed on 28 November 2017).
- Radhakrishnan, R.; Divakaran, A.; Smaragdis, P. Audio analysis for surveillance applications. In Proceedings of the IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, New Paltz, NY, USA, 16 October 2005. [Google Scholar]
- Salamon, J.; Bello, J. Deep convolutional neural networks and data augmentation for environmental sound classification. IEEE Signal Process. Lett. 2017, 24, 279–283. [Google Scholar] [CrossRef]
- Piczak, K. Environmental sound classification with convolutional neural networks. In Proceedings of the IEEE 25th International Workshop on Machine Learning for Signal Processing, Boston, MA, USA, 17–20 September 2015. [Google Scholar]
- Khunarsal, P.; Lursinsap, C.; Raicharoen, T. Very short time environmental sound classification based on spectrogram pattern matching. Inf. Sci. 2013, 243, 57–74. [Google Scholar] [CrossRef]
- Couvreur, L.; Laniray, M. Automatic noise recognition in urban environments based on artificial neural networks and hidden markov models. In Proceedings of the 33rd International Congress and Exposition on Noise Control Engineering, Prague, Czech Republic, 22–25 August 2004. [Google Scholar]
- Cai, R.; Lu, L.; Hanjalic, A.; Zhang, H.; Cai, L. A flexible framewok for key audio effects detection and auditory context inference. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 1026–1039. [Google Scholar] [CrossRef]
- Chu, S.; Narayanan, S.; Kuo, C. Environmental sound recognition with time-frequency audio features. IEEE Trans. Audio Speech Lang. Process. 2009, 17, 1142–1158. [Google Scholar] [CrossRef]
- Baugé, C.; Lagrange, M.; Andén, J.; Mallat, S. Representing environmental sounds using the separable scattering transform. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013. [Google Scholar]
- Salamon, J.; Bello, J. Feature learning with deep scattering for urban sound analysis. In Proceedings of the 23rd European Signal Processing Conference, Nice, France, 31 August–4 September 2015. [Google Scholar]
- Salamon, J.; Bello, J. Unsupervised feature learning for urban sound classification. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing, Brisbane, Australia, 19–24 April 2015. [Google Scholar]
- Ntalampiras, S.; Potamitis, I.; Fakotakis, N. Acoustic detection of human activities in natural environments. J. Audio Eng. Soc. 2012, 60, 686–695. [Google Scholar]
- Chachada, S.; Kuo, C. Environmental sound recognition: A survey. In Proceedings of the 2013 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference, Kaohsiung, Taiwan, 29 October–1 November 2013. [Google Scholar]
- Torija, A.; Ruiz, D.; Ramos-Ridao, A. Application of a methodology for categorizing and differentiating urban soundscapes using acoustical descriptors and semantic-differential attributes. J. Acoust. Soc. Am. 2013, 134, 791–802. [Google Scholar] [CrossRef] [PubMed]
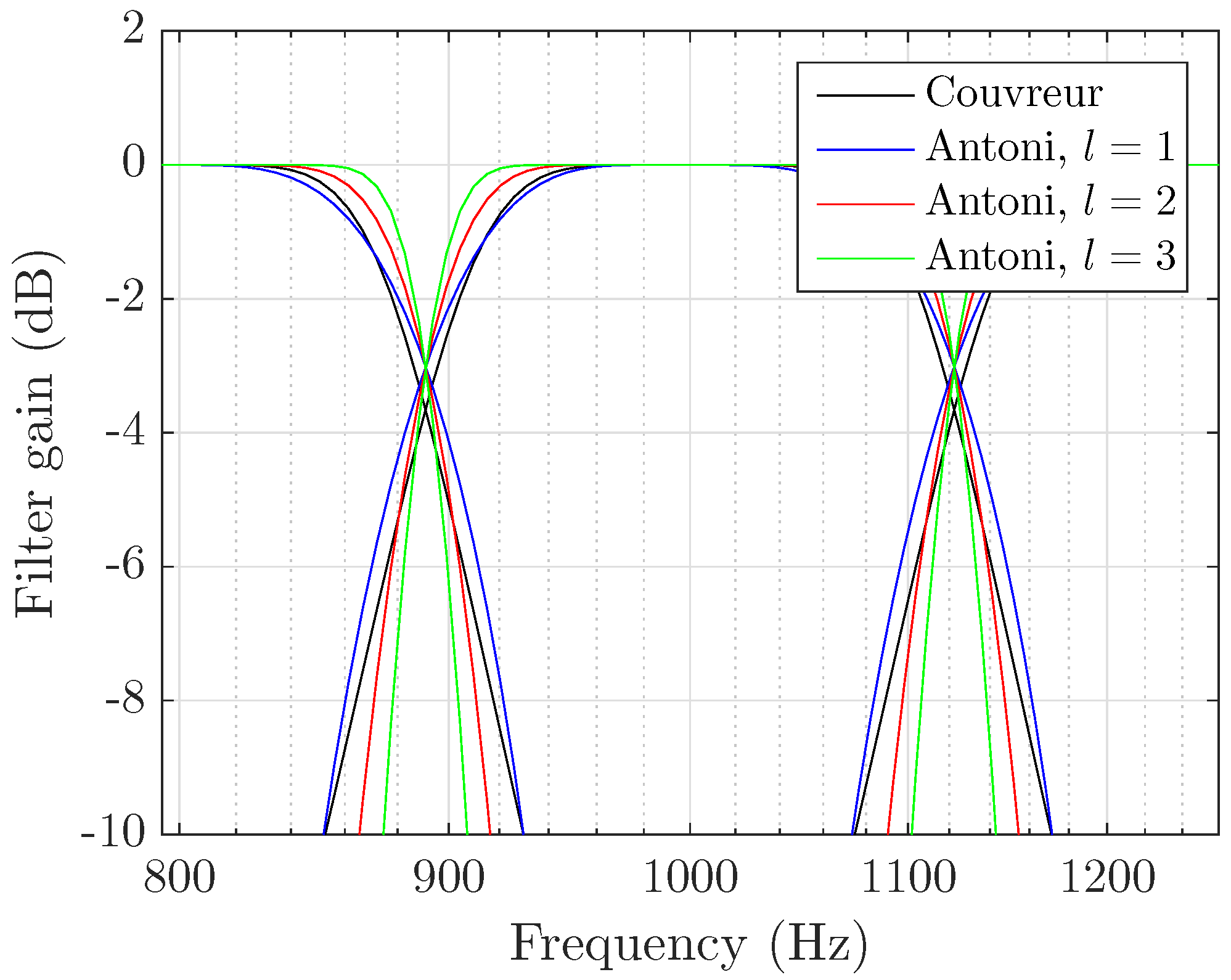
- Davis, S. Octave and fractional-octave band digital filtering based on the proposed ANSI standard. In Proceedings of the 1986 IEEE International Conference on Acoustics, Speech and Signal Processing, Tokyo, Japan, 7–11 April 1986. [Google Scholar]
- Antoni, J. Orthogonal-like fractional-octave-band filters. J. Acoust. Soc. Am. 2010, 127, 884–895. [Google Scholar] [CrossRef] [PubMed]
- ANSI S1.1-1986, (ASA 65-1986)—Specifications for Octave-Band and Fractional-Octave-Band Analog and Digital Filters; ANSI: Washington, DC, USA, 1993.
- IEC 61260-1:2014 —Electroacoustics—Octave-Band and Fractional-Octave-Band Filters–Part 1: Specifications; IEC: Geneva, Switzerland, 2014.
- Couvreur, C. Implementation of a One-Third-Octave Filter Bank in Matlab. Available online: http://citeseer.ist.psu.edu/24150.html (accessed on 15 May 2017).
- Huffman, D. A method for the construction of minimum-redundancy codes. Proc. IRE 1952, 40, 1098–1101. [Google Scholar] [CrossRef]
- Berzborn, M.; Bomhardt, R.; Klein, J.; Richter, J.G.; Vorländer, M. The ITA-Toolbox: An open source MATLAB toolbox for acoustic measurements and signal processing. In Proceedings of the 43th Annual German Congress on Acoustics, Kiel, Germany, 6–9 March 2017. [Google Scholar]
- Salamon, J.; Jacoby, C.; Bello, J. A dataset and taxonomy for urban sound research. In Proceedings of the 22nd ACM international conference on Multimedia, Orlando, FL, USA, 3–7 November 2014. [Google Scholar]
- Ntalampiras, S. A novel holistic modeling acoustic approach for generalized sound recognition. IEEE Signal Process. Lett. 2013, 20, 185–188. [Google Scholar] [CrossRef]
- Ellis, D. PLP and RASTA (and MFCC, and Inversion) in Matlab. Available online: http://www.ee.columbia.edu/ ~dpwe/resources/matlab/rastamat/ (accessed on 6 March 2017).
- Baldwin, J.; French, P. Forensic Phonetics; Pinter Publishers: London, UK, 1990. [Google Scholar]
- Boë, L.J. Forensic voice identification in France. Speech Commun. 2000, 31, 205–224. [Google Scholar] [CrossRef]
- Kuwabara, H. Acoustic properties of phonemes in continuous speech for different speaking rate. In Proceedings of the Fourth International Conference on Spoken Language (ICSLP 96), Philadelphia, PA, USA, 3–6 October 1996; Volume 4, pp. 2435–2438. [Google Scholar]
- Rosen, S. Temporal information in speech: Acoustic, auditory and linguistic aspects. Philos. Trans. R. Soc. Lond. B Biol. Sci. 1992, 336, 367–373. [Google Scholar] [CrossRef] [PubMed]
- ITU-T P.835: Subjective Test Methodology for Evaluating Speech Communication Systems That Include Noise Suppression Algorithm; ITU: Geneva, Switzerland, 2003.
- Ntalampiras, S.; Ganchev, T.; Potamitis, I. Objective comparison of speech enhancement algorithms under real world conditions. In Proceedings of the 1st International Conference on PErvasive Technologies Related to Assistive Environments, Athens, Greece, 15–19 July 2008. [Google Scholar]
- Griffin, D.; Lim, J. Signal estimation from modified short-time fourier transform. IEEE Trans. Acoust. Speech Signal Process. 1984, 32, 236–243. [Google Scholar] [CrossRef]
- IEC 61672-1:2013—Electroacoustics—Sound Level Meters—Part 1: Specifications; IEC: Geneva, Switzerland, 2013.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (a) | ||||||||
| SVM | Frames per second | |||||||
| 2 | 4 (4.1) | 6 (6.1) | 8 (7.7) | 10 (9.5) | 20 (21) | 85 | ||
| Mel bands | 10 | 55 ± 3 | 60 ± 3 | 61 ± 4 | 62 ± 3 | 62 ± 4 | 63 ± 6 | 65 ± 6 |
| 20 | 58 ± 4 | 62 ± 4 | 63 ± 4 | 64 ± 4 | 63 ± 4 | 65 ± 5 | 67 ± 6 | |
| 30 | 60 ± 3 | 64 ± 4 | 64 ± 4 | 65 ± 4 | 65 ± 3 | 67 ± 4 | 68 ± 4 | |
| 40 | 60 ± 3 | 63 ± 4 | 64 ± 4 | 64 ± 4 | 64 ± 4 | 66 ± 4 | 68 ± 5 | |
| (b) | ||||||||
| RF-500 | Frames per second | |||||||
| 2 | 4 (4.1) | 6 (6.1) | 8 (7.7) | 10 (9.5) | 20 (21) | 85 | ||
| Mel bands | 10 | 60 ± 3 | 62 ± 3 | 62 ± 3 | 63 ± 3 | 63 ± 3 | 65 ± 4 | 67 ± 5 |
| 20 | 61 ± 4 | 63 ± 3 | 64 ± 3 | 64 ± 3 | 64 ± 4 | 66 ± 6 | 69 ± 6 | |
| 30 | 62 ± 3 | 63 ± 3 | 64 ± 3 | 64 ± 3 | 64 ± 4 | 67 ± 5 | 69 ± 6 | |
| 40 | 62 ± 4 | 63 ± 4 | 63 ± 4 | 64 ± 4 | 63 ± 4 | 67 ± 6 | 68 ± 6 | |
| (c) | ||||||||
| DT | Frames per second | |||||||
| 2 | 4 (4.1) | 6 (6.1) | 8 (7.7) | 10 (9.5) | 20 (21) | 85 | ||
| Mel bands | 10 | 42 ± 3 | 46 ± 4 | 46 ± 2 | 44 ± 3 | 45 ± 3 | 46 ± 5 | 49 ± 3 |
| 20 | 43 ± 5 | 43 ± 3 | 43 ± 2 | 44 ± 3 | 45 ± 3 | 45 ± 5 | 47 ± 5 | |
| 30 | 42 ± 4 | 43 ± 2 | 44 ± 3 | 45 ± 5 | 43 ± 3 | 43 ± 4 | 45 ± 5 | |
| 40 | 42 ± 6 | 43 ± 3 | 43 ± 3 | 42 ± 3 | 44 ± 3 | 46 ± 3 | 46 ± 4 | |
| (d) | ||||||||
| KNN-5 | Frames per second | |||||||
| 2 | 4 (4.1) | 6 (6.1) | 8 (7.7) | 10 (9.5) | 20 (21) | 85 | ||
| Mel bands | 10 | 43 ± 2 | 51 ± 4 | 53 ± 4 | 53 ± 5 | 53 ± 4 | 54 ± 4 | 56 ± 3 |
| 20 | 44 ± 3 | 52 ± 4 | 53 ± 3 | 54 ± 4 | 54 ± 4 | 55 ± 4 | 58 ± 4 | |
| 30 | 45 ± 4 | 54 ± 5 | 55 ± 5 | 55 ± 4 | 55 ± 4 | 56 ± 4 | 56 ± 4 | |
| 40 | 46 ± 3 | 53 ± 5 | 55 ± 5 | 55 ± 4 | 55 ± 5 | 57 ± 4 | 57 ± 3 | |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gontier, F.; Lagrange, M.; Aumond, P.; Can, A.; Lavandier, C. An Efficient Audio Coding Scheme for Quantitative and Qualitative Large Scale Acoustic Monitoring Using the Sensor Grid Approach. Sensors 2017, 17, 2758. https://doi.org/10.3390/s17122758
Gontier F, Lagrange M, Aumond P, Can A, Lavandier C. An Efficient Audio Coding Scheme for Quantitative and Qualitative Large Scale Acoustic Monitoring Using the Sensor Grid Approach. Sensors. 2017; 17(12):2758. https://doi.org/10.3390/s17122758
Chicago/Turabian StyleGontier, Félix, Mathieu Lagrange, Pierre Aumond, Arnaud Can, and Catherine Lavandier. 2017. "An Efficient Audio Coding Scheme for Quantitative and Qualitative Large Scale Acoustic Monitoring Using the Sensor Grid Approach" Sensors 17, no. 12: 2758. https://doi.org/10.3390/s17122758
APA StyleGontier, F., Lagrange, M., Aumond, P., Can, A., & Lavandier, C. (2017). An Efficient Audio Coding Scheme for Quantitative and Qualitative Large Scale Acoustic Monitoring Using the Sensor Grid Approach. Sensors, 17(12), 2758. https://doi.org/10.3390/s17122758