
A Comparison Study of Classifier Algorithms for Cross-Person Physical Activity Recognition



Abstract
:1. Introduction
Motivations
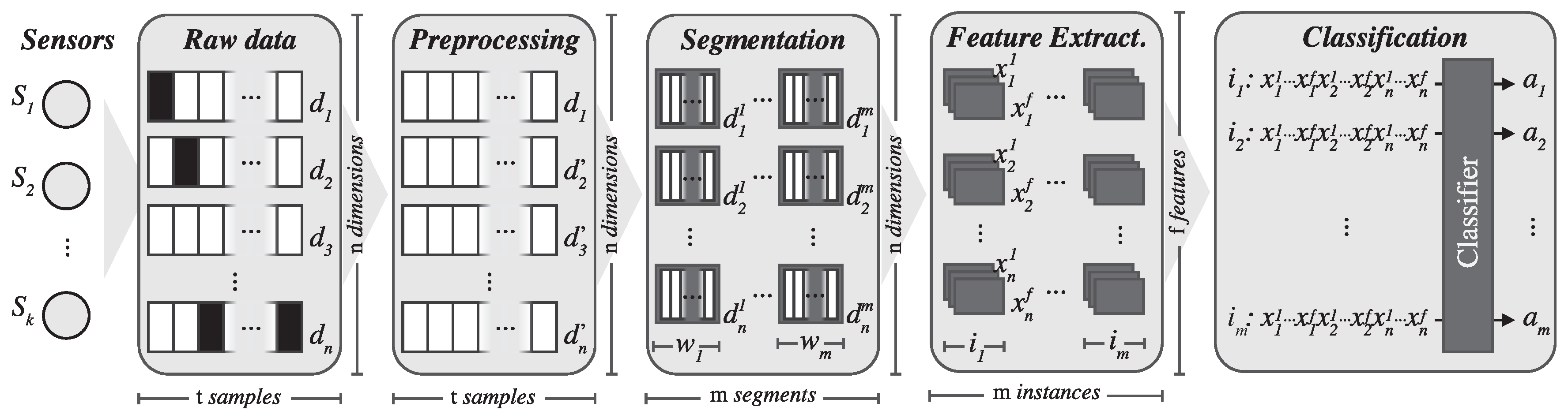
2. Methodology
2.1. Data Acquisition
2.1.1. Subjects
2.1.2. Devices
- An accelerometer with a scale of ±16 g and a 13-bit resolution
- An accelerometer with a scale of ±6 g and a 13-bit resolution
- A gyroscope with a scale of /s and a 16-bit resolution
- A magnetometer with a scale of ±1.3 Ga and a 12-bit resolution
2.1.3. Protocol
- lying quietly while doing nothing (small movements are allowed).
- sitting in a chair (changing postures is allowed).
- standing still (talking or gesticulating is allowed).
- ironing one or two shirts.
- vacuuming one or two rooms, moving objects if required.
- ascending stairs for a distance of five floors.
- descending stairs for a distance of five floors.
- walking outside with a speed of 4 to 6 km/h.
- Nordic walking on asphaltic terrain using asphalt pads on the walking poles.
- cycling with slow to moderate pace.
- running or jogging outside.
- jumping rope either with both feet at the same time or alternating feet.
- 1 timestamp (in s).
- 2 activity.
- 3 heart rate.
- 4 to 20 IMU on wrist.
- 21 to 37 IMU in chest.
- 38 to 54 IMU on ankle.
- 1 temperature (in C).
- 2 to 4 3D acceleration data (ms), scale ±16 g.
- 5 to 7 3D acceleration data (ms), scale ±6 g.
- 8 to 10 3D gyroscope data (rad/s), scale ±2000/s.
- 11 to 13 3D magnetometer data (T), scale ±1.3 Ga.
- 14 to 17 orientation.
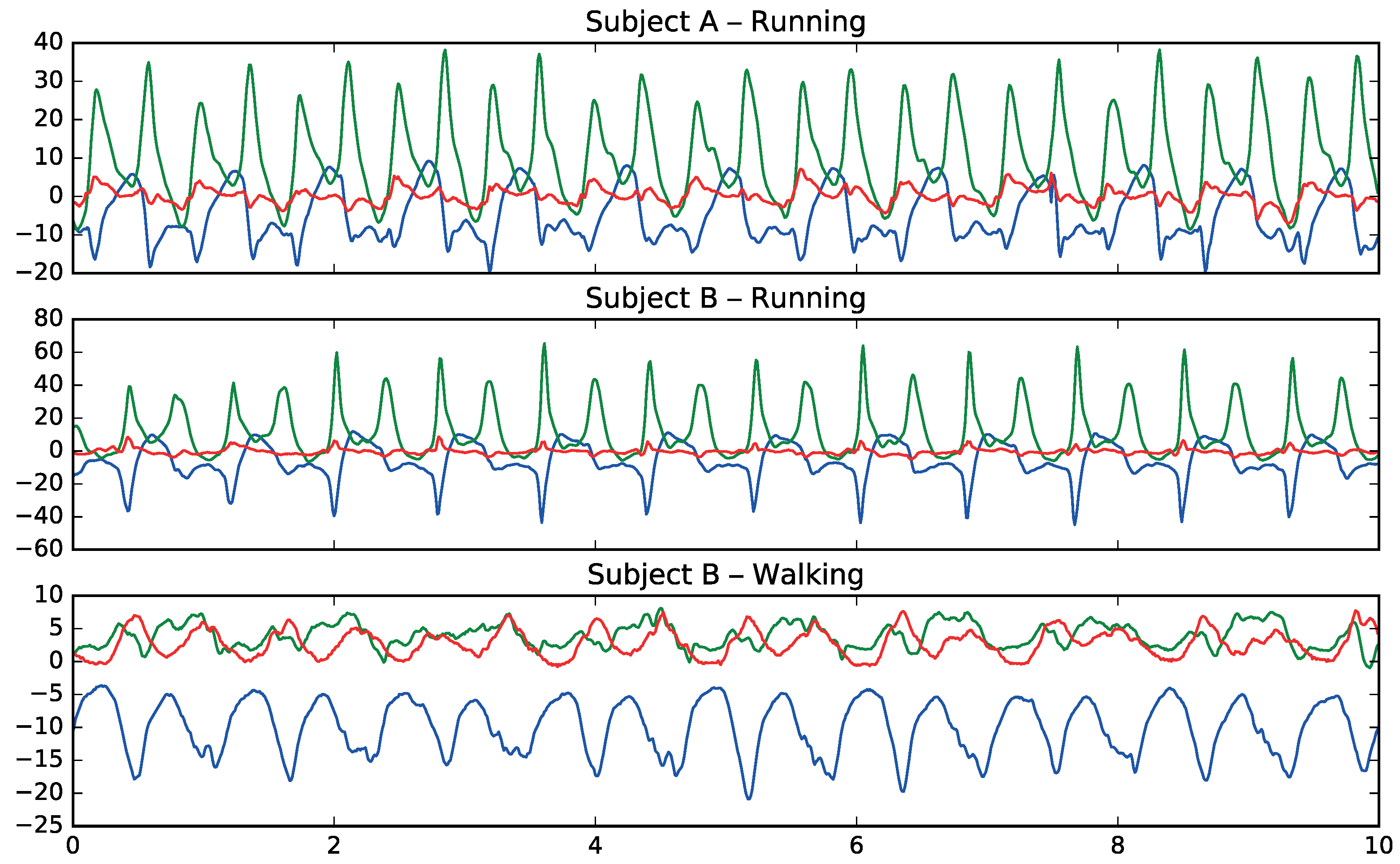
2.2. Signal Preprocessing
2.2.1. Remove the Timestamp
2.2.2. Remove the Orientation
2.2.3. Remove Transitions
2.2.4. Estimate Missing Values
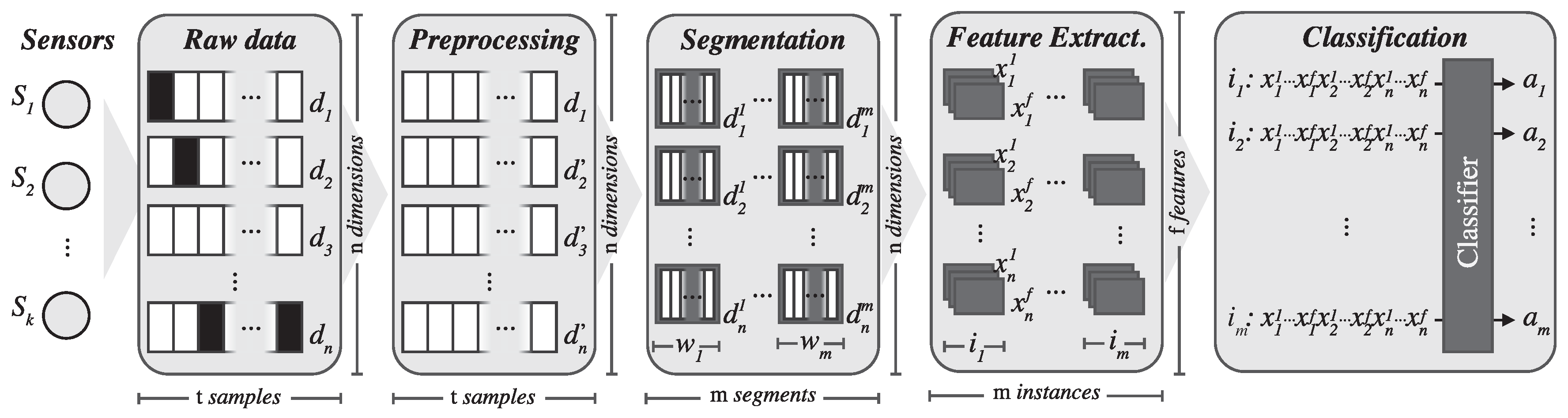
2.3. Signal Segmentation
2.4. Feature Extraction
2.5. Classifier Model Training
2.5.1. Distance-Based Methods
- The k-nearest neighbors algorithm (k-NN) is one of the simplest and most effective nonparametric machine learning algorithms for classification and regression [51]. The k-NN classifier obtained better results for online recognition when compared to C4.5 decision tree. [52]. After testing several parameters, we eventually used the k-NN algorithm with its default scikit-learn parameters (i.e., nearest neighbors, uniform weights and Minkowski distance with , which is equivalent to the standard Euclidean metric). The Euclidean distance is the most commonly-used distance metric for continuous variables; however, when working with high-dimensional data (e.g., more than 10 dimensions), it is highly recommended that dimension reduction by means of preprocessing techniques, such as principal component analysis (PCA) or linear discriminant analysis (LDA), be performed. However, for this work, as discussed earlier, we are not testing different feature selection methods or dimension reduction by means of decomposition algorithms for any of the proposed techniques.
2.5.2. Statistical Methods
- When using the Gaussian naive Bayes (Gaussian NB) to work with continuous data, the usual assumption is that the continuous values related to each class are distributed according to a Gaussian distribution [53]. We decided to include Gaussian NB both because it is a well-known technique in machine learning and because it was the best performer without signal segmentation, obtaining an average accuracy of 0.715. However, with the signal segmentation explained in Section 2.3, some of the variables are highly correlated within a class. This negatively affects Gaussian NB, which relies on a model that assumes zero off-diagonal covariance (i.e., no correlations between variables within a class). This technique implements the default version in scikit-learn, where the likelihood of the features is assumed to be Gaussian. In addition to Gaussian NB, we also tested the Bernoulli naive Bayes and multinomial methods. In both cases, these methods achieved worse results compared to Gaussian NB. For exact details on the algorithm used to update feature means and variance online, see the work by [54].
- The LDA technique is a generalization of Fisher’s linear discriminant [55] that is commonly used in statistics, pattern recognition and machine learning to find a linear combination of features that discriminate between two or more classes [56]. LDA can be used as a feature selection algorithm for dimensionality reduction or as a classifier. It is easily computed, has few parameters to tune, is inherently multiclass and has proven to perform very effectively in practice. LDA is closely related to naive Bayes in the sense that both classifiers assume within-class Gaussian distributions. However, LDA relies on a more flexible model that works better with correlations within a class. Therefore, one would expect the LDA results to be better than Gaussian NB under these settings. We also tested the quadratic discriminant analysis, but obtained poor results compared to LDA. We used the default scikit-learn parameters for the comparisons.
2.5.3. Kernel Methods
- Stochastic gradient descent (SGD) is a simple, but efficient approach to discriminative learning of linear classifiers under convex loss functions, such as logistic regression or support vector machines (linear). Although this technique has long been available in the machine learning community, it has recently received more attention due to its performance with large-scale problems [57]. SGD’s main drawback is that it requires a number of parameters that must be tuned for the method to perform well. For this work, after testing some parameter combinations, we finally used the scikit-learn implementation, which is based on a robust implementation of the averaged stochastic gradient descent algorithm [58]. For this mode, we used the default parameters, setting “hinge” as the loss function, which means that the SGD fits a linear support vector machine and “l2” as the penalty, which is the standard regularization for linear support vector machine models (squared Euclidean norm).
- Support vector machines (SVC linear, SVC RBF) provide state-of-the-art performance for classification, regression and outlier detection, scaling well even with a large-dimensional feature vector [59,60]. The choice of the parameter C is critical to achieve a properly trained support vector machine. Our experiments on this problem concluded the best settings are and for SVC linear and SVC RBF, respectively. The SVC was implemented using libsvm and tested with various kernel functions (i.e., linear, polynomial, radial basis function (RBF) and sigmoid). Finally, based on the test results, the linear and RBF kernel functions were selected for comparison purposes.
2.5.4. Decision Tree-Based Methods
- Among the different decision tree implementations, we selected one that is widely used: an optimized version of the classification and regression trees (CARTs) algorithm using Gini impurity as a node splitting measure. CART is very similar to C4.5, but differs in its support for numerical target variables. Moreover, it does not compute rule sets.We conducted several experiments with decision trees, but the results were not competitive when compared to other techniques, such as random forest or extreme trees. The results obtained with ensembles clearly point out that when executing decision trees, selecting only the relevant features would improve the results significantly. However, because the goal of this work is to compare the performance of algorithms out of the box, we decided not to execute decision trees with a prior feature selection step.
2.5.5. Ensemble Learners
- The random forest method consists of an ensemble of decision trees [62]. It combines the predictions made by multiple decision trees, each one generated using a different randomly selected subset of the features [63]. Because random forests are made of several weighted decision trees, they are not easy to interpret (sometimes decisions can be made through voting on contradicting rules). However, they do not require any domain knowledge or complicated parameter settings and perform very well with high-dimensional data. The main parameters to adjust when using these methods are n_estimators (i.e., the number of trees in the forest) and max_features (the size of the random subsets of features to consider when splitting a node). After testing some values, we set the number of trees to 30 with a maximum depth of 10. Empirically, a good default value is to use for classification tasks (where n_features is the number of features in the data, leading to a max_features value for this work of ).
- The extra randomized trees (extra trees) method is similar to the random forest method, but the randomness goes one step further in the way splits are computed [64]. The two main differences are that the extra trees method splits nodes by choosing fully random cut points and grows the trees using the entire learning sample. Similar to the random forest method, the main parameters to adjust are n_estimators and max_features. In this work, we set the number of trees to 30 and expanded the nodes of the tree until either all pf the leaves were pure or until all of the leaves contained less than 2 samples. As with random forest, max_features is set to 17.
- Adaptive boosting (AdaBoost) is a machine-learning meta-algorithm that can be used in conjunction with many other types of learning algorithms to improve their performance [65]. The methods for voting classification algorithms such as bagging and AdaBoost have been very successful for improving results with many different classifiers on both artificial and real-world datasets [66]. Particularly, AdaBoost has been called the best out-of-the-box classifier in the world [67]. The AdaBoost algorithm used is AdaBoost-SAMME.R, a variant of SAMME (Stagewise Additive Modeling using a Multi-class Exponential loss function) which is recommended for continuous multi-class domains [68]. We used AdaBoost to test the performance of random forest (AdaBoost random forest) and extra randomized trees (AdaBoost extra trees) algorithms. The parameters for the tree-based ensembles were the same as described earlier.
2.5.6. Deep Learning
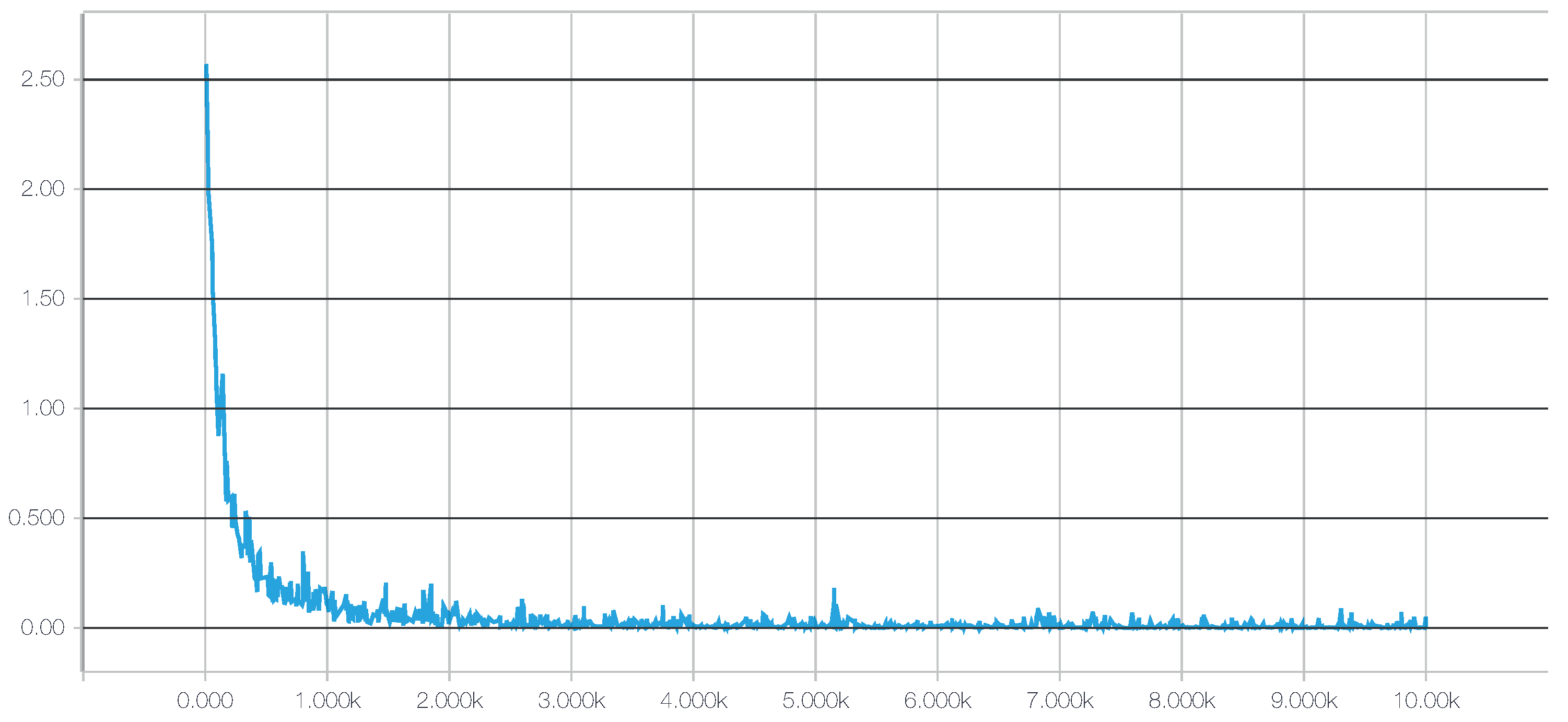
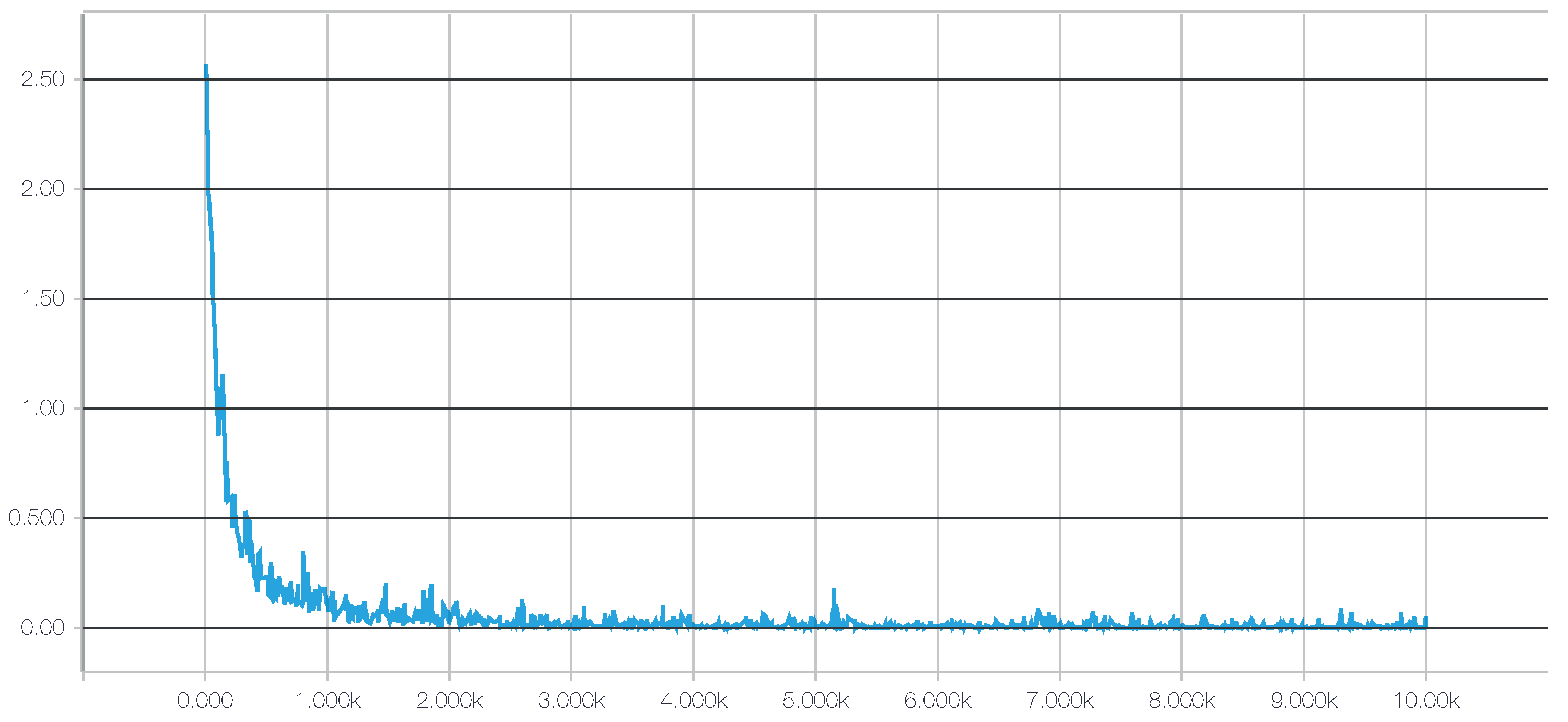
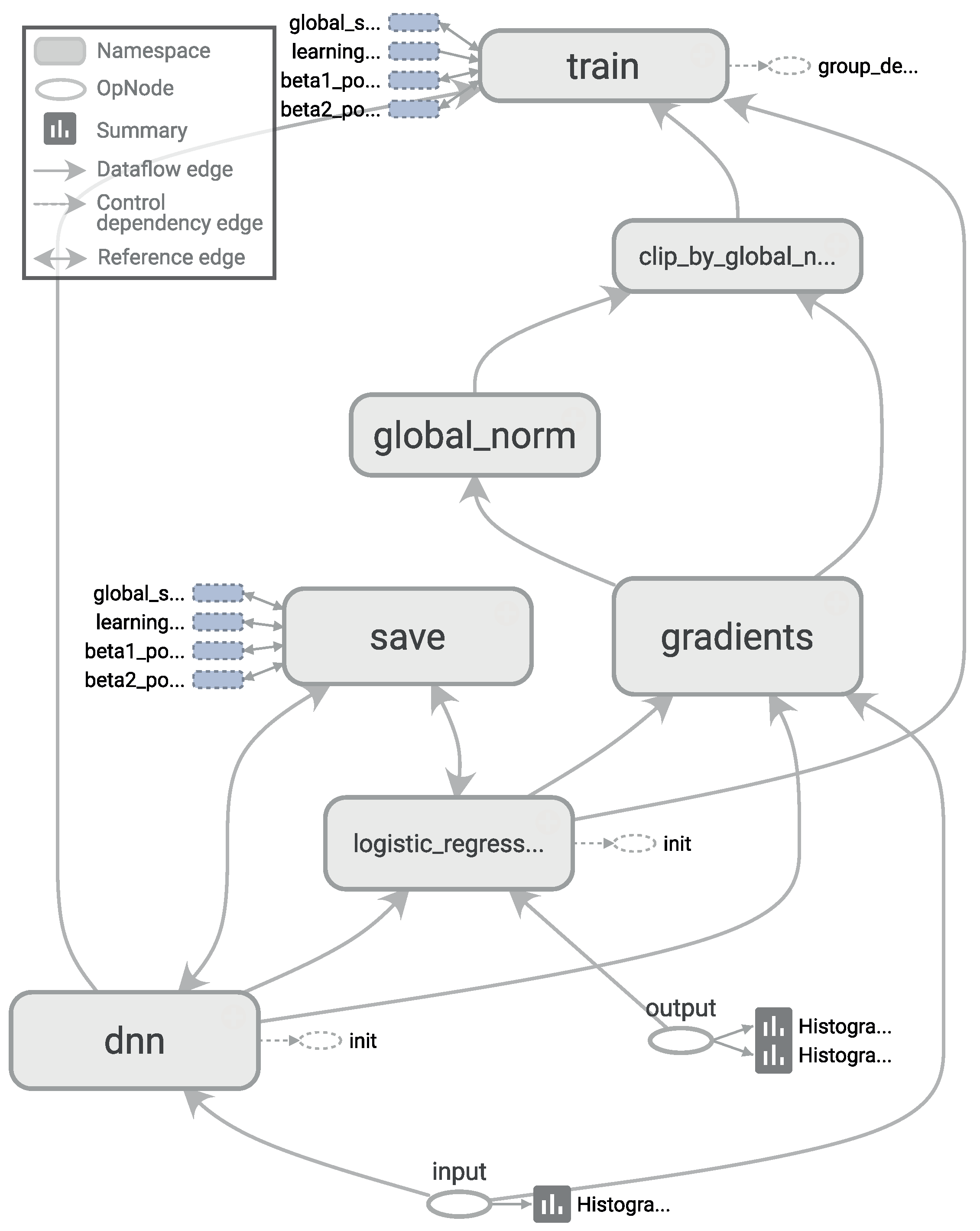
- For a deep neural network (DNN), we chose the TensorFlow framework, recently introduced by Google (Mountain View, CA, USA) [73]. Additionally, to achieve a better integration with scikit-learn, we used the skflow package, which provides a simplified interface for accessing and mimicking TensorFlow scikit. As mentioned before, deep learning techniques have the advantage of being able to build high-level representations of the raw input data without the need for data processing and segmentation. While this is an interesting approach, we have identified a very high impact of the network architecture on the results, a behavior consistent with what we have found in the literature [32], including the fact that some architectures do not work at all. Therefore, in this work, to create an objective comparison, we used the same preprocessed data to test all of the classifiers, including the DNNs. The main motivation for testing these techniques with preprocessed data is to investigate whether their ability to extract and/or transform features among the 280 attributes translates into competitive classification performances. Given the importance of the architecture design, for this work, we have tested numerous topologies (combinations of tensors and dense and convolutional layers). However, after running a large set of experiments, we observed through the evolution of the logistic regression loss function that simple architectures were sufficient to converge within a few iterations obtaining competitive results, as shown in Figure 4. Adding more complexity to the topology required considerably more computation time, all to achieve only very small improvements in accuracy (or even no improvement at all due to overfitting). The results of our tests with different architectures pointed out two things: (1) incorrect topology designs dramatically affect the results; and (2) the results obtained with simple architectures were probably so close to the global optimum that adding more complexity in the layers did not lead to any significant improvement.Consequently, for comparison purposes, we finally selected two configurations: DNN 1L, which has 1 hidden dense layer with 280 nodes, and DNN 2L, which has 2 hidden dense layers with 560 and 280 nodes, respectively. For both configurations, we used a logistic regression as the cost function, 10,000 iterations with the Adam optimizer, a dropout probability of and a learning rate of . The computational graph for training such a deep neural network, as generated by TensorBoard, is shown in Figure 5.
2.6. Parameter Setup
2.7. Quality Metrics
- y is the set of predicted (sample, label) pairs.
- is the set of true (sample, label) pairs.
- L is the set of labels.
- and are, respectively, the subsets of y and with label l.
3. Results
3.1. Preliminary Evaluation
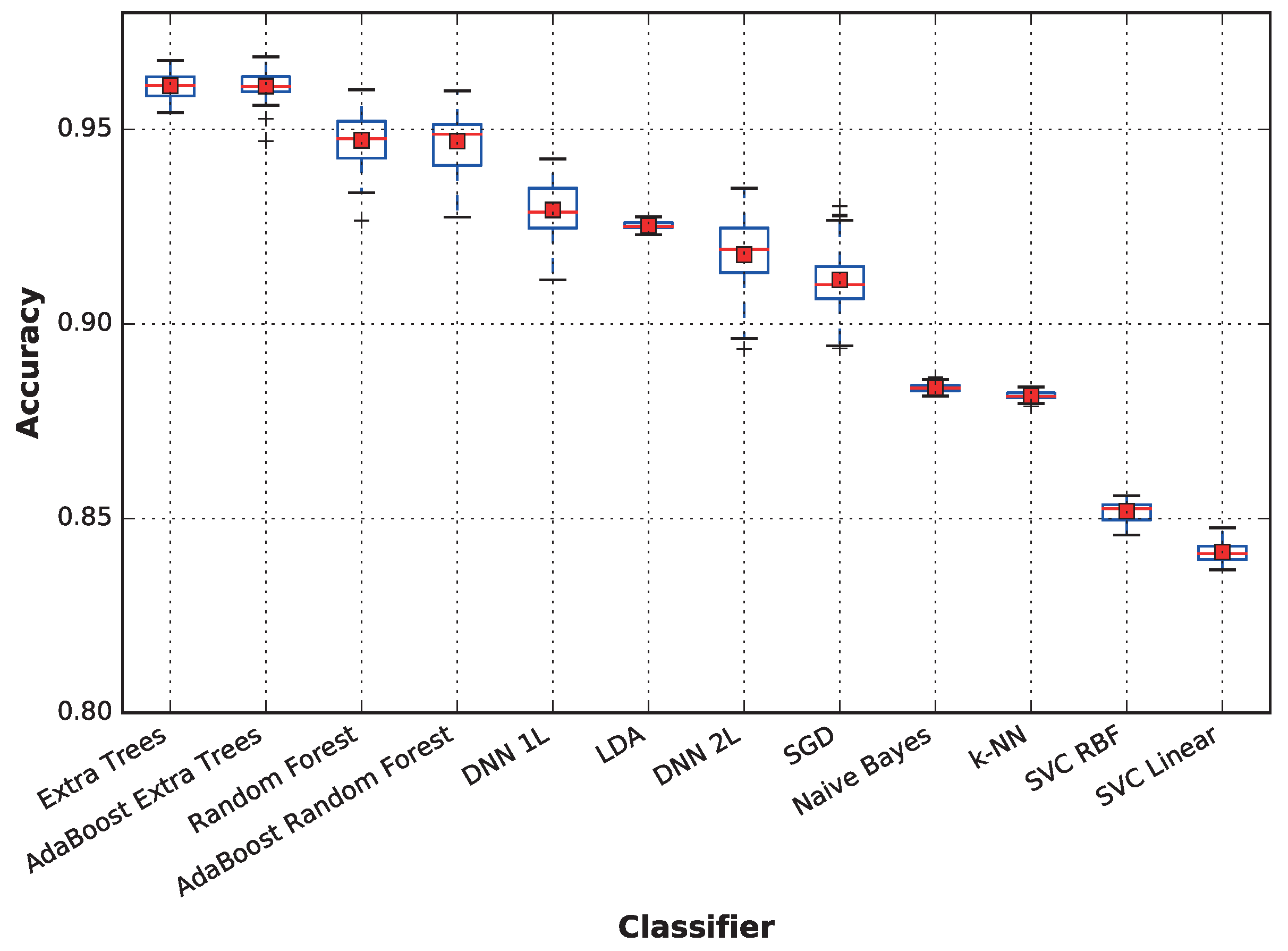
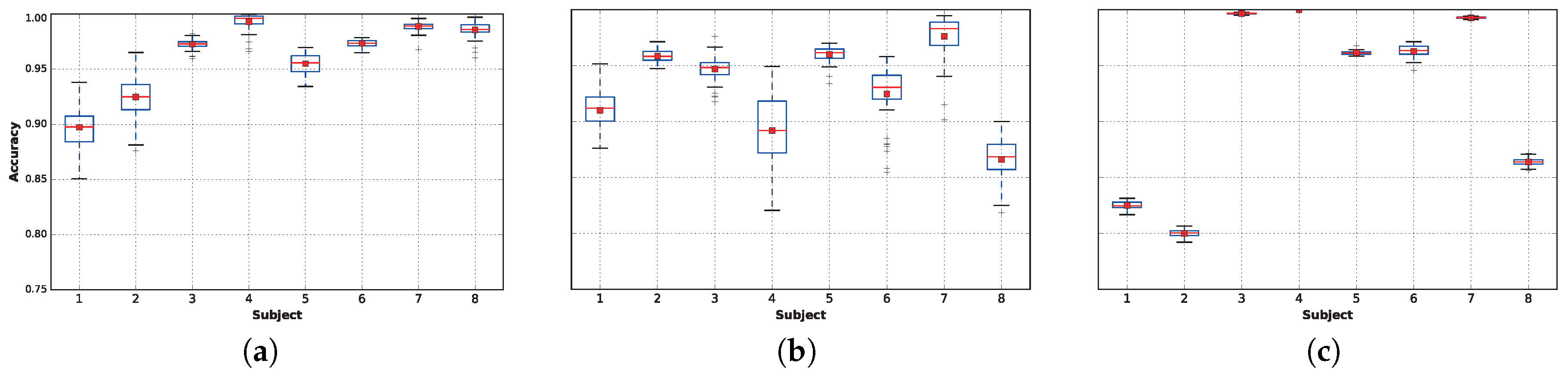
3.2. Classifiers’ Performances
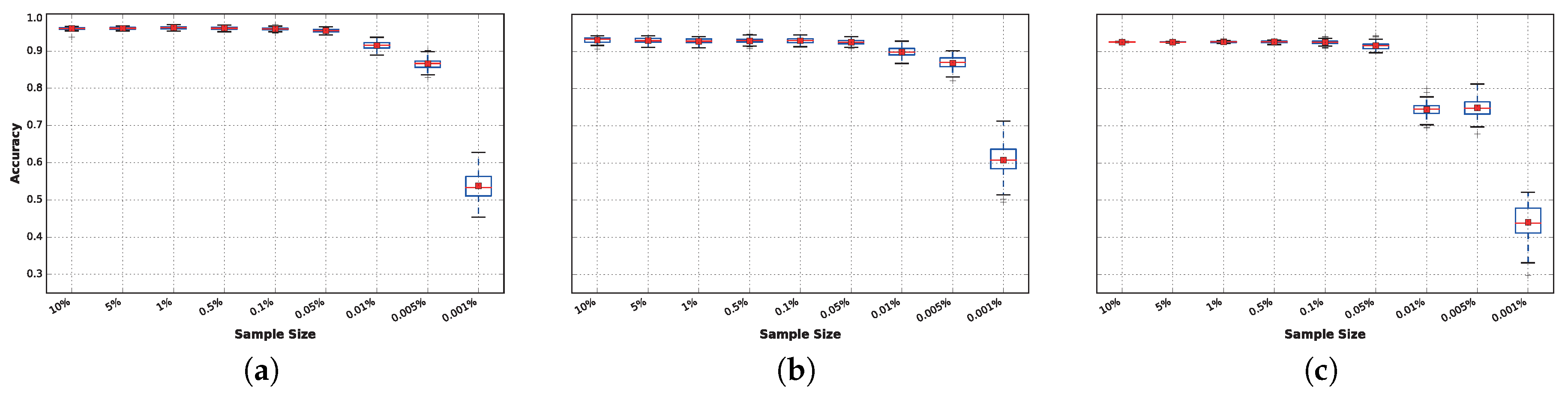
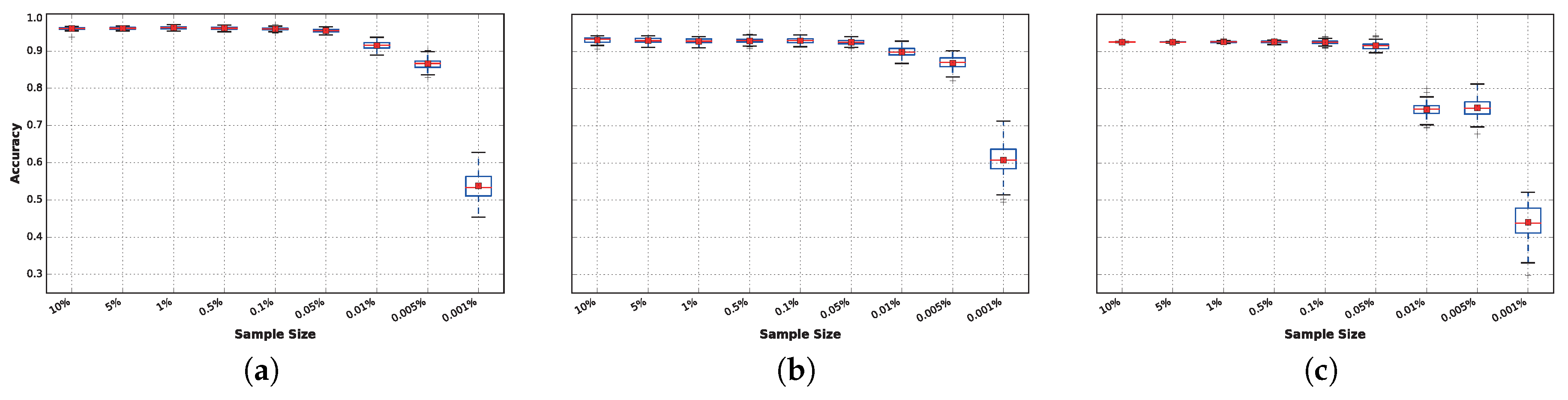
3.3. Sensitivity to Training Sample Size
3.4. Analysis of the Results
4. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Janssen, I.; Leblanc, A.G. Systematic review of the health benefits of physical activity and fitness in school-aged children and youth. Int. J. Behav. Nutr. Phys. Act. 2010, 7, 40. [Google Scholar] [CrossRef] [PubMed]
- Merglen, A.; Flatz, A.; Bélanger, R.E.; Michaud, P.A.; Suris, J.C. Weekly sport practice and adolescent well-being. Arch. Dis. Child. 2014, 99, 208–210. [Google Scholar] [CrossRef] [PubMed]
- Biddle, S.J.H.; Asare, M. Physical activity and mental health in children and adolescents: A review of reviews. Br. J. Sports Med. 2011, 45, 886–895. [Google Scholar] [CrossRef] [PubMed]
- Chodzko-Zajko, W. Exercise and physical activity for older adults. Univ. Access Inf. Soc. 2014, 3, 101–106. [Google Scholar] [CrossRef]
- Andreu-Perez, J.; Leff, D.R.; Ip, H.M.D.; Yang, G.Z. From Wearable Sensors to Smart Implants—Toward Pervasive and Personalized Healthcare. IEEE Trans. Biomed. Eng. 2015, 62, 2750–2762. [Google Scholar] [CrossRef] [PubMed]
- Vock, C.A.; Flentov, P.; Darcy, D.M. Activity Monitoring Systems and Methods. U.S. Patent No. 8,352,211 B2, 8 January 2013. [Google Scholar]
- Yuen, S.G.J.; Park, J.; Friedman, E.N. Activity Monitoring Systems and Methods of Operating Same. U.S. Patent No. 8,386,008 B2, 24 September 2013. [Google Scholar]
- Kahn, P.R.; Kinsolving, A.; Christensen, M.A.; Lee, B.Y.; Vogel, D. Human Activity Monitoring Device with Activity Identification. U.S. Patent No. 8,949,070 B1, 3 February 2015. [Google Scholar]
- Morris, D.; Kelner, I.; Shariff, F.; Tom, D.; Saponas, T.S.; Guillory, A. Personal Training with Physical Activity Monitoring Device. U.S. Patent No. 8,951,165 B2, 10 February 2015. [Google Scholar]
- White, K.L.; Orenstein, M.L.; Campbell, J.; Self, C.S.; Walker, E.; Micheletti, M.; McKeag, G.; Zipperer, J.; Lapinsky, M. Activity Recognition with Activity Reminders. U.S. Patent No. 20,150,042,468 A1, 12 February 2015. [Google Scholar]
- Ravi, N.; Nikhil, D.; Mysore, P.; Littman, M.L. Activity recognition from accelerometer data. In Proceedings of the 17th Conference Innovative Applications Artificial Intell (IAAI’05), Pittsburgh, PA, USA, 9–13 July 2005; pp. 1541–1546.
- Pirttikangas, S.; Fujinami, K.; Nakajima, T. Feature Selection and Activity Recognition from Wearable Sensors. In Ubiquitous Computing Systems; Lecture Notes in Computer Science; Springer: Berlin, Germany, 2006; Volume 4239, pp. 516–527. [Google Scholar]
- Antonsson, E.; Mann, R. The frequency content of gait. J. Biomech. 1985, 18, 39–47. [Google Scholar] [CrossRef]
- Lara, O.D.; Labrador, M.A. A Survey on Human Activity Recognition using Wearable Sensors. IEEE Commun. Surv. Tutor. 2013, 15, 1192–1209. [Google Scholar] [CrossRef]
- Mukhopadhyay, S. Wearable Sensors for Human Activity Monitoring: A Review. IEEE Sens. J. 2015, 15, 1321–1330. [Google Scholar] [CrossRef]
- Shoaib, M.; Bosch, S.; Incel, O.; Scholten, H.; Havinga, P. A Survey of Online Activity Recognition Using Mobile Phones. Sensors 2015, 15, 2059–2085. [Google Scholar] [CrossRef] [PubMed]
- Tapia, E. USing Machine Learning for Real-Time Activity Recognition and Estimation of Energy Expenditure. PhD Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2009. [Google Scholar]
- Reiss, A. Personalized Mobile Physical Activity Monitoring for Everyday Life. PhD Thesis, Technical University of Kaiserslautern, Kaiserslautern, Germany, 2013. [Google Scholar]
- Ponce, H.; Miralles-Pechuán, L.; Martínez-Villaseñor, M. A Flexible Approach for Human Activity Recognition Using Artificial Hydrocarbon Networks. Sensors 2016, 16, 1715. [Google Scholar] [CrossRef] [PubMed]
- Maguire, D.; Frisby, R. Comparison of feature classification algorithm for activity recognition based on accelerometer and heart rate data. In Proceedings of the 9th Information Technology and Telecommunications Conference (IT&T’09), Dublin, Ireland, 22–23 October 2009; p. 11.
- Ayu, M.; Ismail, S.; Matin, A.; Montoro, T. A Comparison Study of Classifier Algorithms for Mobile-Phone’s Accelerometer Based Activity Recognition. Procedia Eng. 2012, 41, 224–229. [Google Scholar] [CrossRef]
- Wu, W.; Dasgupta, S.; Ramirez, E.E.; Peterson, C.; Norman, G.J. Classification accuracies of physical activities using smartphone motion sensors. J. Med. Internet Res. 2012, 14, e130. [Google Scholar] [CrossRef] [PubMed]
- Mannini, A.; Intille, S.S.; Rosenberger, M.; Sabatini, A.M.; Haskell, W. Activity recognition using a single accelerometer placed at the wrist or ankle. Med. Sci. Sports Exerc. 2013, 45, 2193–2203. [Google Scholar] [CrossRef] [PubMed]
- Reiss, A.; Hendeby, G.; Stricker, D. A novel confidence-based multiclass boosting algorithm for mobile physical activity monitoring. Pers. Ubiquitous Comput. 2014, 19, 105–121. [Google Scholar] [CrossRef]
- Reiss, A.; Weber, M.; Stricker, D. Exploring and extending the boundaries of physical activity recognition. In Proceedings of the 2011 IEEE International Conference on Systems, Man, and Cybernetics (ICSMC’11), Anchorage, AK, USA, 9–12 October 2011; pp. 46–50.
- Kim, H.J.; Lee, J.S.; Yang, H.S. Human Action Recognition Using a Modified Convolutional Neural Network. In Proceedings of the 4th International Symposium on Neural Networks: Part II—Advances in Neural Networks (ISSN’07), Nanjing, China, 3–7 June 2007; pp. 715–723.
- Baccouche, M.; Mamalet, F.; Wolf, C.; Garcia, C.; Baskurt, A. Sequential Deep Learning for Human Action Recognition. In Proceedings of the 2nd International Conference on Human Behavior Understanding (HBU’11), Amsterdam, The Netherlands, 16 November 2011; pp. 29–39.
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D Convolutional Neural Networks for Human Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef] [PubMed]
- Charalampous, K.; Gasteratos, A. On-line deep learning method for action recognition. Pattern Anal. Appl. 2014, 19, 337–354. [Google Scholar] [CrossRef]
- Jiang, W.; Yin, Z. Human Activity Recognition Using Wearable Sensors by Deep Convolutional Neural Networks. In Proceedings of the 23rd ACM International Conference on Multimedia (MM’15), Brisbane, Australia, 26–30 October 2015; pp. 1307–1310.
- Ordoñez, F.J.; Roggen, D. Deep convolutional and LSTM recurrent neural networks for multimodal wearable activity recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef] [PubMed]
- Hammerla, N.Y.; Halloran, S.; Ploetz, T. Deep, Convolutional, and Recurrent Models for Human Activity Recognition using Wearables. In Proceedings of the 25th International Joint Conference on Artificial Intelligence (IJCAI’16), New York, NY, USA, 9–15 July 2016; pp. 1533–1540.
- Wang, Y.; Lin, J.; Annavaram, M.; Jacobson, Q.; Hong, J.; Krishnamachari, B.; Sadeh, N. A Framework of Energy Efficient Mobile Sensing for Automatic User State Recognition. In Proceedings of the 7th International Conference on Mobile Systems, Applications, and Services (MobiSys’09), Kraków, Poland, 22–25 June 2009; pp. 179–192.
- Yan, Z.; Subbaraju, V.; Chakraborty, D.; Misra, A.; Aberer, K. Energy-Efficient Continuous Activity Recognition on Mobile Phones: An Activity-Adaptive Approach. In Proceedings of the 2012 16th Annual International Symposium on Wearable Computers (ISWC’12), Newcastle, UK, 18–22 June 2012; pp. 17–24.
- Khan, A.; Siddiqi, M.; Lee, S.W. Exploratory Data Analysis of Acceleration Signals to Select Light-Weight and Accurate Features for Real-Time Activity Recognition on Smartphones. Sensors 2013, 13, 13099–13122. [Google Scholar] [CrossRef] [PubMed]
- Morillo, L.; Gonzalez-Abril, L.; Ramirez, J.; de la Concepcion, M. Low Energy Physical Activity Recognition System on Smartphones. Sensors 2015, 15, 5163–5196. [Google Scholar] [CrossRef] [PubMed]
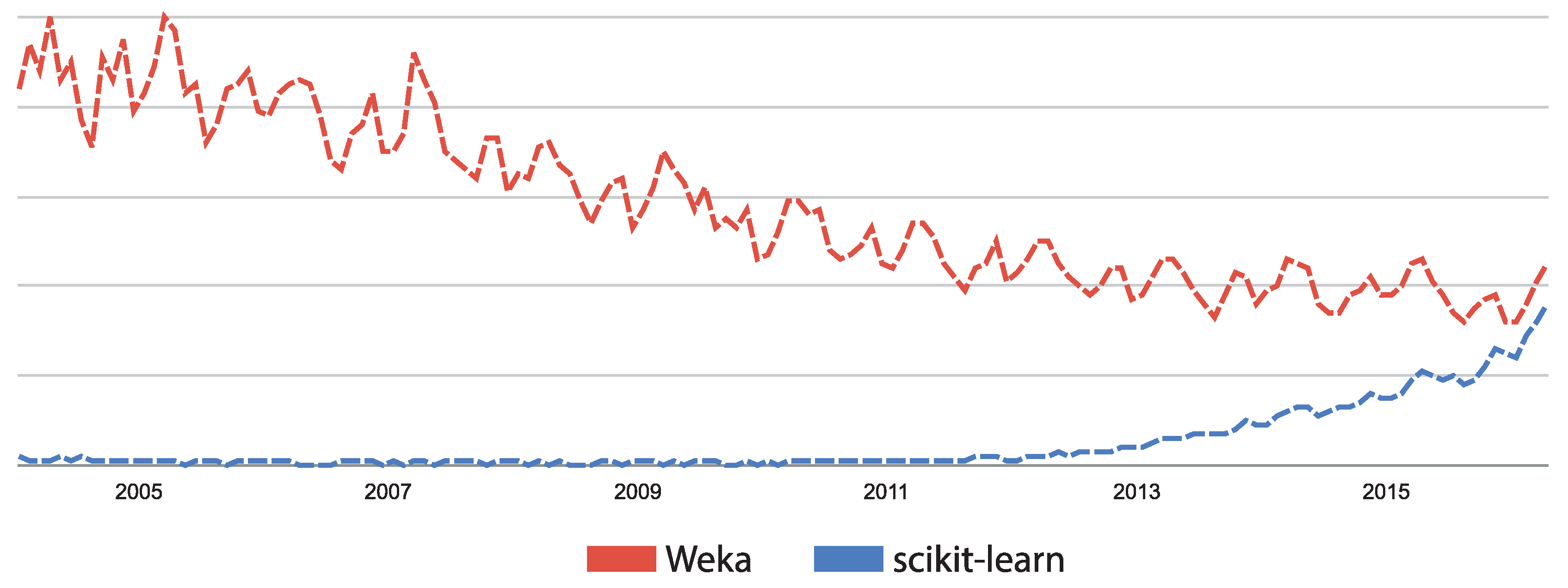
- Google Trends. Web Search Interest: Weka vs. Scikit-Learn. 2016. Available online: https://www.google.com/trends/explore#q=725%2Fm%2F0h97pvq%2C%20%2Fm%2F0b2358 (accessed on 14 April 2016).
- Bulling, A.; Blanke, U.; Schiele, B. A tutorial on human activity recognition using body-worn inertial sensors. ACM Comput. Surv. (CSUR) 2014, 46, 33. [Google Scholar] [CrossRef]
- Reiss, A.; Stricker, D. Towards global aerobic activity monitoring. In Proceedings of the 4th International Conference on PErvasive Technologies Related to Assistive Environments (PETRA’11), Heraklion, Greece, 25–27 May 2011.
- Reiss, A.; Stricker, D. Introducing a new benchmarked dataset for activity monitoring. In Proceedings of the 2012 16th Annual International Symposium on Wearable Computers (ISWC’12), Newcastle, UK, 18–22 June 2012; pp. 108–109.
- Reiss, A.; Stricker, D. Creating and benchmarking a new dataset for physical activity monitoring. In Proceedings of the 5th International Conference on Pervasive Technologies Related to Assistive Environments (PETRA’12), Heraklion, Greece, 6–8 June 2012; pp. 40:1–40:8.
- Reiss, A.; Stricker, D.; Lamprinos, I. An integrated mobile system for long-term aerobic activity monitoring and support in daily life. In Proceedings of the 2012 IEEE 11th International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom’12), Liverpool, UK, 25–27 June 2012; pp. 2021–2028.
- Reiss, A.; Stricker, D. Aerobic activity monitoring: Towards a long-term approach. Univ. Access Inf. Soc. 2013, 13, 101–114. [Google Scholar] [CrossRef]
- Ainsworth, B.; Haskell, W.; Whitt, M.; Irwin, M.; Swartz, A.; Strath, S.; O’Brien, W.; Bassett, D.; Schmitz, K.; Emplaincourt, P.; et al. Compendium of physical activities: An update of activity codes and MET intensities. Med. Sci. Sports Exerc. 2000, 32, 498–516. [Google Scholar] [CrossRef]
- Baldominos, A.; Sáez, Y.; Isasi, P. Feature Set Optimization for Physical Activity Recognition Using Genetic Algorithms. In Proceedings of the 2015 Annual Conference on Genetic and Evolutionary Computation (GECCO’15), Madrid, Spain, 11–15 July 2015; pp. 1311–1318.
- Guyon, I.; Elisseeff, A. An Introduction to Variable and Feature Selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Margarito, J.; Helaoui, R.; Bianchi, A.; Sartor, F.; Bonomi, A. User-Independent Recognition of Sports Activities From a Single Wrist-Worn Accelerometer: A Template-Matching-Based Approach. IEEE Trans. Biomed. Eng. 2016, 63, 788–796. [Google Scholar] [CrossRef] [PubMed]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Wu, X.; Kumar, V.; Ross Quinlan, J.; Ghosh, J.; Yang, Q.; Motoda, H.; McLachlan, G.J.; Ng, A.; Liu, B.; Yu, P.S.; et al. Top 10 Algorithms in Data Mining. Knowl. Inf. Syst. 2007, 14, 1–37. [Google Scholar] [CrossRef]
- Nef, T.; Urwyler, P.; Büchler, M.; Tarnanas, I.; Stucki, R.; Cazzoli, D.; Müri, R.; Mosimann, U. Evaluation of Three State-of-the-Art Classifiers for Recognition of Activities of Daily Living from Smart Home Ambient Data. Sensors 2015, 15, 11725–11740. [Google Scholar] [CrossRef] [PubMed]
- Cover, T.; Hart, P. Nearest Neighbor Pattern Classification. IEEE Trans. Inf. Theory 2006, 13, 21–27. [Google Scholar] [CrossRef]
- Lombriser, C.; Bharatula, N.B.; Roggen, D.; Tröster, G. On-body Activity Recognition in a Dynamic Sensor Network. In Proceedings of the ICST 2nd International Conference Body Area Networks (BodyNets’07), Brussels, Belgium, 11–13 June 2007; pp. 17:1–17:6.
- Mitchell, T.M. Machine Learning; McGraw-Hill: New York, NY, USA, 1997. [Google Scholar]
- Chan, T.F.; Golub, G.H.; LeVeque, R.J. Updating Formulae and a Pairwise Algorithm for Computing Sample Variances; Technical Report; Stanford University: Stanford, CA, USA, 1979. [Google Scholar]
- Fisher, R.A. The Use of Multiple Measurements in Taxonomic Problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Johnson, R.A.; Wichern, D.W. Applied Multivariate Statistical Analysis; Prentice-Hall: Upper Saddle River, NJ, USA, 1988. [Google Scholar]
- Bottou, L.; Bousquet, O. The Tradeoffs of Large Scale Learning. In Advances in Neural Information Processing Systems; NIPS Foundation: La Jolla, CA, USA, 2008; Volume 20, pp. 161–168. [Google Scholar]
- Ruppert, D. Efficient Estimators from a Slowly Convergent Robbins-Monro Procedure; Technical Report; School of Operations Research and Industrial Engineering, Cornell University: Ithaca, NY, USA, 1988. [Google Scholar]
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer-Verlag New York: New York, NY, USA, 1995. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Quinlan, J.R. Induction of Decision Trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Mingers, J. An Empirical Comparison of Selection Measures for Decision-Tree Induction. Mach. Learn. 1989, 3, 319–342. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely Randomized Trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Bauer, E.; Kohavi, R. An Empirical Comparison of Voting Classification Algorithms: Bagging, Boosting, and Variants. Mach. Learn. 1999, 36, 105–139. [Google Scholar] [CrossRef]
- Breiman, L. Bagging Predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Hastie, T.; Rosset, S.; Zhu, J.; Zou, H. Multi-class AdaBoost. Stat. Its Interface 2009, 2, 349–360. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning Internal Representations by Error Propagation. In Parallel Distributed Processing: Explorations in the Microstructure of Cognition; MIT Press: Cambridge, MA, USA, 1986; Volume 1, pp. 318–362. [Google Scholar]
- Le, Q.V.; Zou, W.Y.; Yeung, S.Y.; Ng, A.Y. Learning Hierarchical Invariant Spatio-temporal Features for Action Recognition with Independent Subspace Analysis. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR’11), Colorado Springs, CO, USA, 20–25 June 2011; pp. 3361–3368.
- Dean, J.; Corrado, G.; Monga, R.; Chen, K.; Devin, M.; Mao, M.; Ranzato, M.; Senior, A.; Tucker, P.; Yang, K.; et al. Large Scale Distributed Deep Networks. In Advances in Neural Information Processing Systems; NIPS Foundation: La Jolla, CA, USA, 2012; Volume 25, pp. 1232–1240. [Google Scholar]
- Deng, L.; Yu, D. Deep Learning: Methods and Applications. Found. Trends Signal Process. 2014, 7, 197–387. [Google Scholar] [CrossRef]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneus Distributed Systems; Technical Report; Google Research: Mountain View, CA, USA, 2015. [Google Scholar]
- Allwein, E.L.; Schapire, R.E.; Singer, Y. Reducing Multiclass to Binary: A Unifying Approach for Margin Classifiers. J. Mach. Learn. Res. 2001, 1, 113–141. [Google Scholar]
- Landgrebe, T.; Duin, R.P.W. Approximating the multiclass ROC by pairwise analysis. Pattern Recognit. Lett. 2007, 28, 1747–1758. [Google Scholar] [CrossRef]
- Arif, M.; Kattan, A. Physical Activities Monitoring Using Wearable Acceleration Sensors Attached to the Body. PLoS ONE 2015, 10, e0130851. [Google Scholar] [CrossRef] [PubMed]
- Gupta, P.; Dallas, T. Feature Selection and Activity Recognition System Using a Single Triaxial Accelerometer. IEEE Trans. Biomed. Eng. 2014, 61, 1780–1786. [Google Scholar] [CrossRef] [PubMed]
- Shoaib, M.; Scholten, H.; Havinga, P. Towards physical activity recognition using smartphone sensors. In Proceedings of the 10th IEEE International Conference on Ubiquitous Intelligence and Computing and 10th International Conference on Autonomic and Trusted Computing (UIC/ATC), Vietri sul Mare, Italy, 18–21 December 2013; pp. 80–87.
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J.L. A Public Domain Dataset for Human Activity Recognition Using Smartphones. In Proceedings of the 21st European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, ESANN 2013, Bruges, Belgium, 24–26 April 2013.
- Gyllensten, I.; Bonomi, A. Identifying Types of Physical Activity With a Single Accelerometer: Evaluating Laboratory-trained Algorithms in Daily Life. IEEE Trans. Biomed. Eng. 2011, 58, 2656–2663. [Google Scholar] [CrossRef] [PubMed]
- Khan, A.M.; Lee, Y.K.; Lee, S.Y.; Kim, T.S. A Triaxial Accelerometer-based Physical-activity Recognition via Augmented-signal Features and a Hierarchical Recognizer. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 1166–1172. [Google Scholar] [CrossRef] [PubMed]
- Bao, L.; Intille, S.S. Activity recognition from user-annotated acceleration data. In Pervasive Computing; Lecture Notes in Computer Science; Springer: Berlin, Germany, 2004; Volume 3001, pp. 1–17. [Google Scholar]
- Kwapisz, J.R.; Weiss, G.M.; Moore, S.A. Activity Recognition Using Cell Phone Accelerometers. ACM SIGKDD Explor. Newsl. 2011, 12, 74–82. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | Sex | Age (years) | Height (cm) | Weight (kg) | Resting HR (bpm) | Max HR (bpm) | Dominant Hand |
|---|---|---|---|---|---|---|---|
| 1 | Male | 27 | 182 | 83 | 75 | 193 | right |
| 2 | Female | 25 | 169 | 78 | 74 | 195 | right |
| 3 | Male | 31 | 187 | 92 | 68 | 189 | right |
| 4 | Male | 24 | 194 | 95 | 58 | 196 | right |
| 5 | Male | 26 | 180 | 73 | 70 | 194 | right |
| 6 | Male | 26 | 183 | 69 | 60 | 194 | right |
| 7 | Male | 23 | 173 | 86 | 60 | 197 | right |
| 8 | Male | 32 | 179 | 87 | 66 | 188 | left |
| 9 | Male | 31 | 168 | 65 | 54 | 189 | right |
| # | Activity | Code | Effort (MET) | Time (min) |
|---|---|---|---|---|
| 1 | lying | 07011 | 1.0 | 3 |
| 2 | sitting | 09040 | 1.8 | 3 |
| 3 | standing | 09050 | 1.8 | 3 |
| 4 | ironing | 05070 | 2.3 | 3 |
| 5 | break | 1 | ||
| 6 | vacuuming | 05043 | 3.5 | 3 |
| 7 | break | 1 | ||
| 8 | ascending stairs | 17130 | 8.0 | 3 |
| 9 | break | 2 | ||
| 10 | descending stairs | 17070 | 3.0 | 3 |
| 11 | break | 1 | ||
| 12 | ascending stairs | 17130 | 8.0 | 3 |
| 13 | descending stairs | 17070 | 3.0 | 3 |
| 14 | break | 2 | ||
| 15 | walking | 17190, 17200 | 3.3–3.8 | 3 |
| 16 | break | 1 | ||
| 17 | Nordic walking | ? | 5.0–6.0 | 3 |
| 18 | break | 1 | ||
| 19 | cycling | 01010 | 4.0 | 3 |
| 20 | break | 1 | ||
| 21 | running | 12020, 12030 | 7.0–8.0 | 3 |
| 22 | break | 2 | ||
| 23 | jumping rope | 15551, 15552 | 8.0–10.0 | 3 |
| Sub. 1 | Sub. 2 | Sub. 3 | Sub. 4 | Sub. 5 | Sub. 6 | Sub. 7 | Sub. 8 | Sub. 9 | |
|---|---|---|---|---|---|---|---|---|---|
| Lying | 271.86 | 234.29 | 220.43 | 230.46 | 236.98 | 233.39 | 256.10 | 241.64 | 0.00 |
| Sitting | 234.79 | 223.44 | 287.60 | 254.91 | 268.63 | 230.40 | 122.81 | 229.22 | 0.00 |
| Standing | 217.16 | 255.75 | 205.32 | 247.05 | 221.31 | 243.55 | 257.50 | 251.59 | 0.00 |
| Walking | 222.52 | 325.32 | 290.35 | 319.31 | 320.32 | 257.20 | 337.19 | 315.32 | 0.00 |
| Running | 212.64 | 92.37 | 0.00 | 0.00 | 246.45 | 228.24 | 36.91 | 165.31 | 0.00 |
| cycling | 235.74 | 251.07 | 0.00 | 226.98 | 245.76 | 204.85 | 226.79 | 254.74 | 0.00 |
| Nordic walk | 202.64 | 297.38 | 0.00 | 275.32 | 262.70 | 266.85 | 287.24 | 288.87 | 0.00 |
| Ascending stairs | 158.88 | 173.40 | 103.87 | 166.92 | 142.79 | 132.89 | 176.44 | 116.81 | 0.00 |
| Descending stairs | 148.97 | 152.11 | 152.72 | 142.83 | 127.25 | 112.70 | 116.16 | 96.53 | 0.00 |
| Vacuuming | 229.40 | 206.82 | 203.24 | 200.36 | 244.44 | 210.77 | 215.51 | 242.91 | 0.00 |
| Ironing | 235.72 | 288.79 | 279.74 | 249.94 | 330.33 | 377.43 | 294.98 | 329.89 | 0.00 |
| Jumping rope | 129.11 | 132.61 | 0.00 | 0.00 | 77.32 | 2.55 | 0.00 | 88.05 | 64.90 |
| Classifier | Normalized |
|---|---|
| sklearn.neighbors.KNeighborsClassifier (k = 5) | Yes |
| sklearn.naive_bayes.GaussianNB | No |
| sklearn.discriminant_analysis.LinearDiscriminantAnalysis | No |
| sklearn.linear_model.SGDClassifier (loss = hinge, penalty = 12) | Yes |
| sklearn.svm.SVC (kernel = linear, max_iter = − 1, C = 0.025) | Yes |
| sklearn.svm.SVC (kernel = rbf, max_iter = −1, C = 1) | Yes |
| sklearn.ensemble.ExtraTreesClassifier (n_estimators = 30) | No |
| sklearn.ensemble.RandomForestClassifier (n_estimators = 30, max_depth = 10) | No |
| sklearn.ensemble.AdaBoostClassifier (ExtraTreesClassifier, n_estimators = 30) | No |
| sklearn.ensemble.AdaBoostClassifier (RandomForestClassifier, n_estimators = 30, max_depth = 10) | No |
| skflow.ops.dnn ([280], logistic_regression, keep_prob = 0.5, steps = 10000, optimizer = Adam, learning_rate = 0.001) | Yes |
| skflow.ops.dnn ([560, 280], logistic_regression, keep_prob = 0.5, steps = 10000, optimizer = Adam, learning_rate = 0.001) | Yes |
| Classifier | Accuracy | Average | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Sub. 1 | Sub. 2 | Sub. 3 | Sub. 4 | Sub. 5 | Sub. 6 | Sub. 7 | Sub. 8 | ||
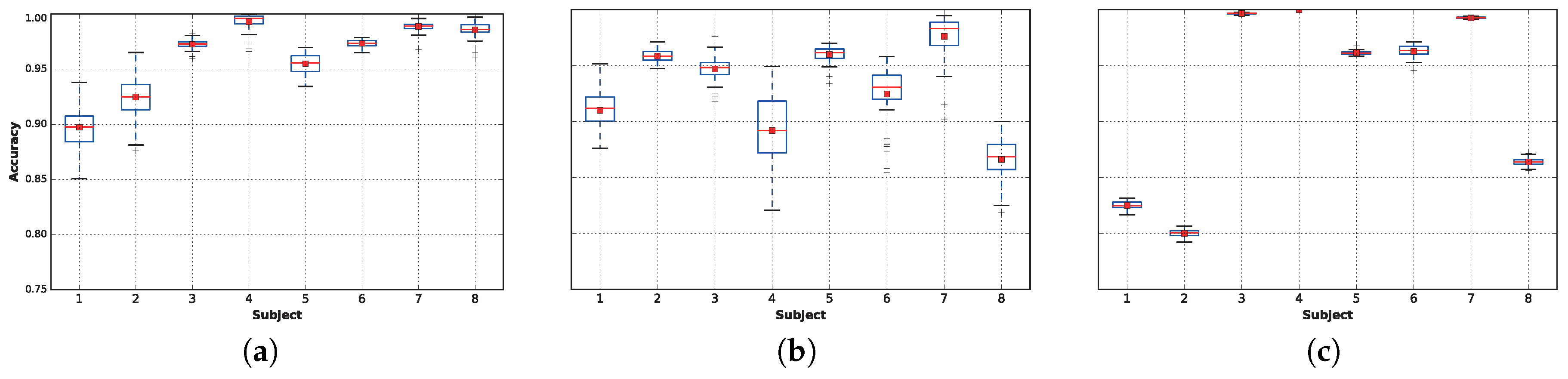
| Extra Trees | 0.897 (0.019) | 0.925 (0.018) | 0.973 (0.004) | 0.993 (0.008) | 0.955 (0.009) | 0.973 (0.003) | 0.989 (0.004) | 0.986 (0.007) | 0.961 (0.009) |
| AdaBoost (ET) | 0.900 (0.018) | 0.922 (0.022) | 0.972 (0.004) | 0.993 (0.009) | 0.954 (0.008) | 0.973 (0.003) | 0.989 (0.004) | 0.985 (0.008) | 0.961 (0.009) |
| Random Forest | 0.874 (0.012) | 0.895 (0.045) | 0.955 (0.010) | 0.982 (0.020) | 0.953 (0.014) | 0.966 (0.008) | 0.975 (0.012) | 0.978 (0.005) | 0.947 (0.016) |
| AdaBoost (RF) | 0.873 (0.011) | 0.897 (0.042) | 0.955 (0.010) | 0.983 (0.021) | 0.951 (0.017) | 0.966 (0.007) | 0.975 (0.012) | 0.977 (0.005) | 0.947 (0.015) |
| DNN 1L | 0.910 (0.016) | 0.959 (0.006) | 0.947 (0.012) | 0.892 (0.033) | 0.960 (0.007) | 0.925 (0.024) | 0.976 (0.002) | 0.866 (0.019) | 0.929 (0.017) |
| LDA | 0.825 (0.003) | 0.800 (0.003) | 0.997 (0.001) | 1.000 (0.000) | 0.961 (0.002) | 0.963 (0.005) | 0.993 (0.001) | 0.864 (0.003) | 0.925 (0.002) |
| DNN 2L | 0.908 (0.021) | 0.956 (0.008) | 0.913 (0.027) | 0.870 (0.053) | 0.948 (0.012) | 0.934 (0.025) | 0.955 (0.031) | 0.858 (0.029) | 0.918 (0.026) |
| SGD | 0.862 (0.011) | 0.826 (0.043) | 0.973 (0.006) | 0.923 (0.025) | 0.971 (0.005) | 0.922 (0.014) | 0.983 (0.001) | 0.831 (0.034) | 0.911 (0.017) |
| Naive Bayes | 0.821 (0.006) | 0.604 (0.004) | 0.961 (0.001) | 0.991 (0.001) | 0.922 (0.002) | 0.955 (0.001) | 0.941 (0.002) | 0.874 (0.003) | 0.884 (0.003) |
| k-NN | 0.860 (0.003) | 0.950 (0.001) | 0.855 (0.004) | 0.719 (0.005) | 0.942 (0.002) | 0.886 (0.003) | 0.955 (0.003) | 0.886 (0.002) | 0.882 (0.003) |
| SVC RBF | 0.865 (0.003) | 0.864 (0.017) | 0.815 (0.006) | 0.619 (0.006) | 0.975 (0.001) | 0.933 (0.002) | 0.869 (0.005) | 0.876 (0.005) | 0.852 (0.006) |
| SVC Linear | 0.858 (0.004) | 0.820 (0.011) | 0.816 (0.010) | 0.601 (0.009) | 0.974 (0.002) | 0.917 (0.004) | 0.883 (0.007) | 0.861 (0.007) | 0.841 (0.007) |
| Extra Trees | DNN | LDA | ||
|---|---|---|---|---|
| 5% | Precision | 0.967 (0.003) | 0.949 (0.005) | 0.926 (0.001) |
| Recall | 0.961 (0.003) | 0.929 (0.007) | 0.925 (0.001) | |
| Score | 0.959 (0.004) | 0.927 (0.007) | 0.912 (0.001) | |
| Score | 0.960 (0.004) | 0.927 (0.007) | 0.917 (0.001) | |
| 0.001% | Precision | 0.476 (0.005) | 0.547 (0.006) | 0.384 (0.005) |
| Recall | 0.538 (0.004) | 0.607 (0.005) | 0.440 (0.005) | |
| Score | 0.455 (0.005) | 0.536 (0.006) | 0.361 (0.005) | |
| Score | 0.491 (0.004) | 0.567 (0.005) | 0.393 (0.005) |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saez, Y.; Baldominos, A.; Isasi, P. A Comparison Study of Classifier Algorithms for Cross-Person Physical Activity Recognition. Sensors 2017, 17, 66. https://doi.org/10.3390/s17010066
Saez Y, Baldominos A, Isasi P. A Comparison Study of Classifier Algorithms for Cross-Person Physical Activity Recognition. Sensors. 2017; 17(1):66. https://doi.org/10.3390/s17010066
Chicago/Turabian StyleSaez, Yago, Alejandro Baldominos, and Pedro Isasi. 2017. "A Comparison Study of Classifier Algorithms for Cross-Person Physical Activity Recognition" Sensors 17, no. 1: 66. https://doi.org/10.3390/s17010066
APA StyleSaez, Y., Baldominos, A., & Isasi, P. (2017). A Comparison Study of Classifier Algorithms for Cross-Person Physical Activity Recognition. Sensors, 17(1), 66. https://doi.org/10.3390/s17010066