1. Introduction
The development of synthetic aperture radar (SAR) technology has witnessed the explosive growth of available SAR images. Manual interpretation of numerous SAR images is time-consuming and almost impractical. This has significantly accelerated the development of automatic target recognition (ATR) algorithms. Choosing efficient features is important for traditional SAR ATR techniques and many feature extraction methods have been developed to describe the targets in SAR images [
1,
2,
3,
4,
5]. In practical applications, however, it is difficult to fully describe target characteristics to achieve a high recognition accuracy with a single feature.
Feature-level fusion of SAR images can not only increase the feature information of the images to perform comprehensive analysis and integration processing, but also can effectively integrate the advantages of various features to reduce the complexity of training and improve algorithm adaptability. Currently, the feature fusion algorithms are mainly divided into three categories [
6]: The first category is a method of feature combination, specifically, combining the features in series or in parallel according to certain weights for obtaining a new feature vector [
7]. Feature selection, the second category which utilizes a variety of preferred methods, selects an optimum feature combination to obtain a low-dimensional feature showing a better discrimination [
8,
9]. The third category is feature transformation, which is a way to convert raw features into new feature representations [
10,
11]. However, due to the difficulties in exploring deep information from raw features, the traditional methods have unsatisfactory performance on redundancy reduction and efficiency improvement.
Recently, feature fusion based on a deep neural networks has performed excellently in various fields [
12,
13,
14], which has prompted scholars to conduct research on SAR imagery target recognition with neural networks [
15,
16,
17]. However, the remarkable performance of a deep neural network requires a large number of tagged data as training samples, which is hard to accomplish in SAR target recognition. In addition, complex SAR images usually require a complicated network structure to fit them. With the increaing complexity, the training time of the network will significantly increase. Thus, under the condition of a relatively small amount of sample labels, simplifying the network structure and enhancing the training efficiency can improve the performance of SAR ATR technology.
Stacked autoencoder (SAE) [
18], as a type of unsupervised learning network, converts raw data into more abstract expressions through a simple non-linear model and fuses features by optimization algorithms. The feature integration based on SAE can substantially reduce the redundancy and complement information between the features. With its relatively simple structure, SAE can effectively adapt to the needs of fast SAR image interpretation and achieve stronger generalization capability with less training samples. Many scholars have conducted research on this area. Ni et al. [
19] flattened the SAR images into one-dimensional vectors and fed them into SAE after preprocessing and segmentation, and this method obtained a more competitive result. To fit the complex raw data, 64 × 64 neurons are required in the first layer of the SAE, which leads to a complex SAE structure and low network training efficiency. In [
20], texture features of SAR images extracted with a Gray Level Co-Occurrence Matrix (GLCM) and Gabor wavelet transform were optimized to a higher-level feature by SAE. However, due to the great redundancy between texture features, the added information is relatively small, and accordingly, the effect of the integration is not obvious. Chen et al. [
21] combined the spatial features and spectral information of hyperspectral images with SAE. This achieved a better performance in classification tasks, but the raw spectral information with high dimensions led to a relatively complicated network structure. Additionally, by employing a multi-layer autoencoder, reference [
22] extracted contour and shadow features of SAR images and integrated into the synergetic neural network (SNN) to identify the target, which enhances the classification accuracy to some extent. It has to be noted that the algorithm requires segmenting the shaded area of targets and this processing is relatively complex.
The main goals of this work were to obtain distinctive features by fusing features and to improve the efficiency of recognition by simplifying the network structure of SAE. With an unsupervised learning algorithm, SAE can not only prevent network from overfitting when the number of labeled samples is relatively small, but also effectively provide a deep integration of features with its nonlinear mapping ability. In addition, considering the information redundancy and complementation, 23 baseline features [
23] and a local texture feature called Three-Patch Local Binary Pattern (TPLBP) [
24] of SAR images are extracted. The selected features will describe SAR images from local and global perspectives, and provide complementary information for the SAE network under the condition of lower feature dimensions. Therefore, the fused features will be more robust and discriminative.
The remainder of this paper is organized as follows:
Section 2 displays the framework of the proposed algorithm.
Section 3 describes the details of baseline features and TPLBP features.
Section 4 introduces the SAE and the softmax classifier utilized in this paper. Experiments based on MSTAR database [
25] are carried out in
Section 5 to evaluate the proposed method and compare its performance with other algorithms.
Section 6 concludes this paper.
2. Proposed Approach
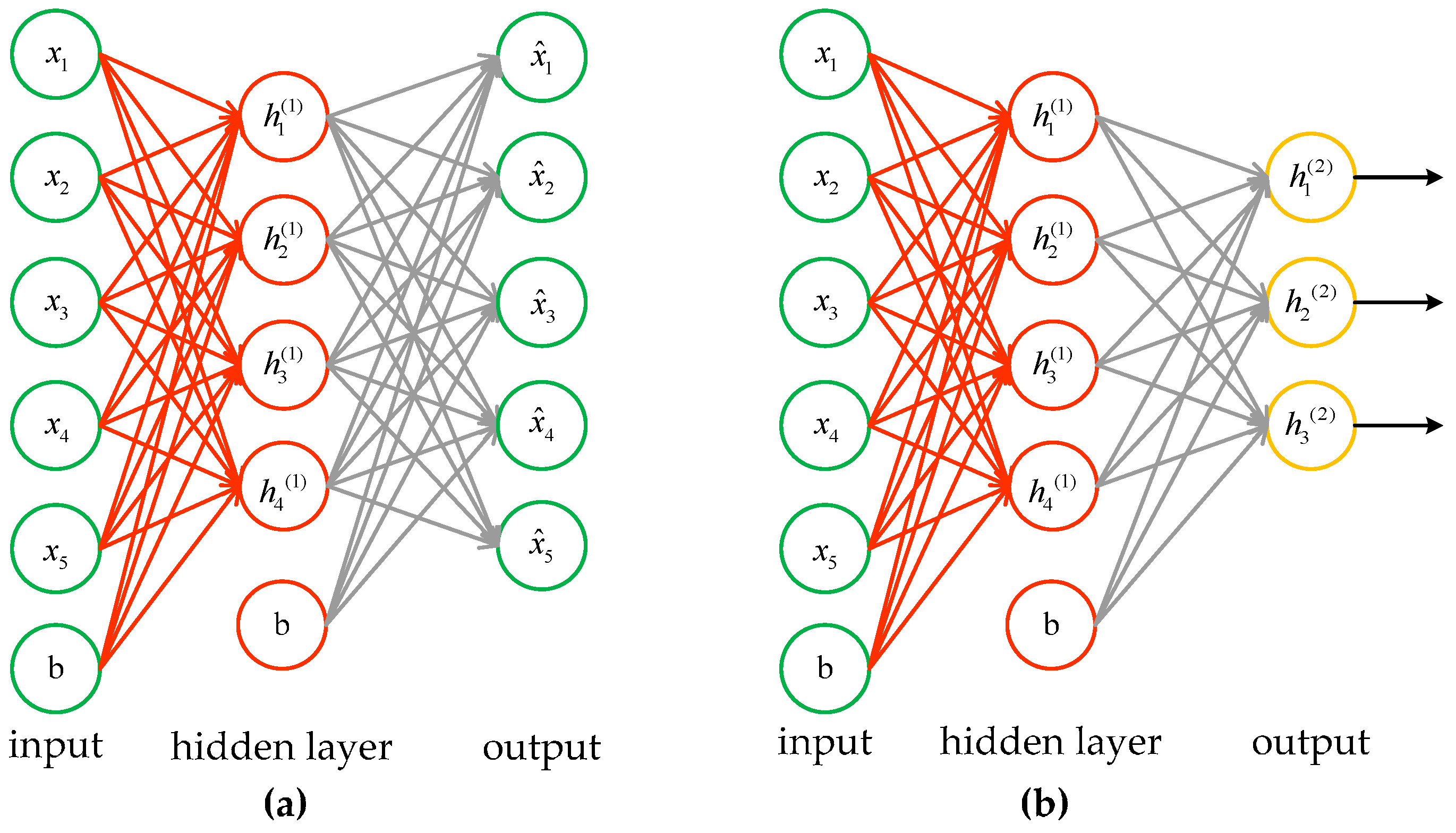
This section introduces the structure of the proposed approach. Similar to most successful and commonly used feature learning models, the procedure of the feature fusion algorithm proposed in this paper is divided into a training stage and a testing stage, presented with the flow chart shown in
Figure 1. The proposed algorithm consists of the following steps to learn robust fused features: (1) cut the SAR images into the same size and extract features from these images; (2) subtract the mean value and then apply Zero Component Analysis (ZCA) whitening to pre-process the features; (3) cascade the features and feed them into the SAE to pre-train the network; (4) train the softmax classifier with the fused features and fine-tune the model according to the training data labels.
(1) Feature Extraction
For a SAR ATR system, feature selection plays an important role in the target recognition. In this paper, features with less redundancy are extracted to simplify the SAE inputs. Firstly, the geometric parameters of the targets are extracted in order to get the baseline features with 88 dimensions. Meanwhile the 128-dimensional texture feature vector, which is obtained by connecting the histogram of TPLBP value in series, combines with the baseline features to form a cascaded feature vector with 216 dimensions. Compared with the deep learning methods which import the whole image into neural network, the proposed approach decreases the dimension of raw data from 16,384 to 216. This greatly reduces the number of neurons in the first layer. The details of the features will be introduced in
Section 3.
(2) Normalization and Whitening
In this step, 216-dimensional features are normalized by subtracting the mean value of the feature space and then apply ZCA whitening [
26],which is common in deep learning. The purpose of ZCA whitening is to reduce the redundancy between features, and to make all input elements have the same variance. The ZCA whitened data are calculated as
XZCAWhite =
TX, where
T =
UP−(1/2)UT and
U and
P are the eigenvectors and eigenvalues of the covariance matrix of
X:
.
(3) Deep Model
After being normalized and whitened, the cascaded vectors are imported into the SAE to train the first layer with a gradient descent algorithm which is able to optimize the cost function. The hidden layer provides what it learned as the inputs for the next layer of SAE. Meanwhile, it is necessary to fix the first layer’s weights of the network when the second layer is training, and all of the following layers are supposed to be trained in this way.
The features obtained from the SAE can be applied to classification by feeding the output of the last layer to a classifier. In this paper, a softmax classifier is adopted. According to the distance between labels and the result of classification, the network weights are fine-tuned with a back-propagation algorithm. When the training of the network is completed, the classification performance is evaluated with the extracted feature of test samples. The deep model consists of a SAE and a softmax classifier, which will be described in
Section 4.
3. Feature Extraction
In this section, 23 kinds of baseline features and local texture features are chosen as the fusion data. Two types of features will be integrated to supply richer information for the SAE to learn. Fisher score [
27] is utilized to select the baseline features of SAR images. Moreover, comparing the LBP value of different regions, TPLBP texture features obtain a robust representations of the targets.
3.1. Baseline Features
Baseline features [
23] are a collection of geometry parameters about SAR target area. For a pixel in a complex-valued SAR image, the position of the pixel is represented with (
a,b), and it can be expressed as
c(
m,n) =
i(
a,b) +
j*
q(
a,b), where
i(
a,b) and
q(
a,b) are the real and imaginary parts of the complex-valued SAR image, respectively. Then the following equation can be used to describe the power detection of the pixel’s magnitude:
With the method of an adaptive threshold based on entropy, which is proposed by Kapur et al. [
28], a binary image can be obtained. After morphological dilations [
29], unconnected region of the image is removed to extract geometry features of the binary image or the dilated image, which form the multi-dimensional baseline features.
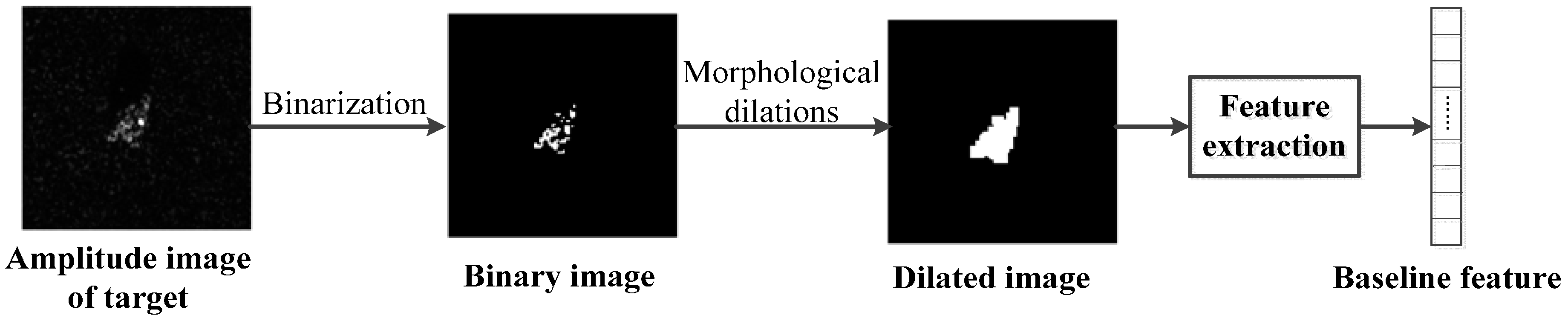
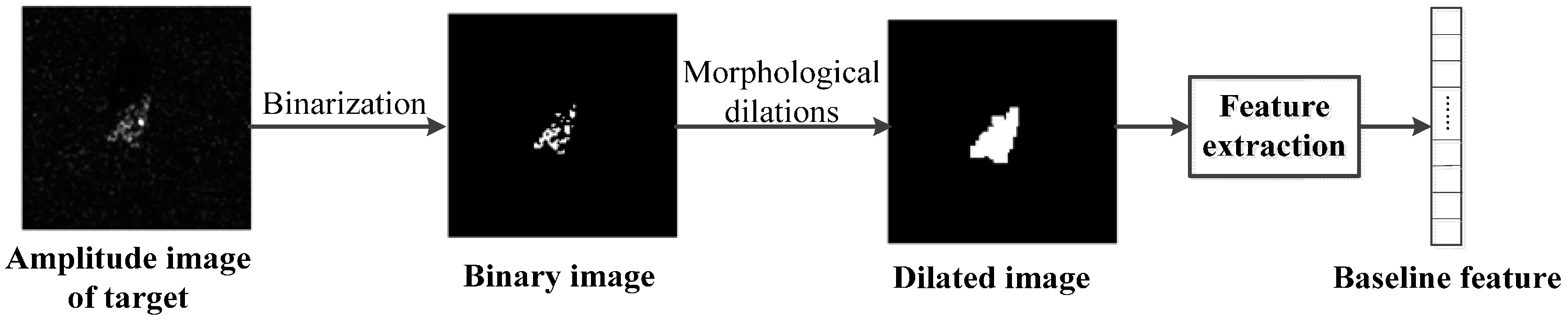
This paper selects 23 kinds of geometry features that achieve higher score in feature ranking and obtains an 88-demensional baseline feature vector. The framework of this procedure and the categories of features are shown in
Figure 2 and
Table 1, respectively.
The details of the features are as follows:
- (1)
NumConRegion: the number of connected regions in the binary or dilated binary image.
- (2)
Area: the total number of pixels with value one in the binary or dilated binary image.
- (3)
Centroid: the center of the mass of the binary or dilated binary image.
- (4)
BoundingBox: the smallest rectangle containing the mass of the binary or dilated binary image
- (5)
MajorLength: the length (in pixels) of the major axis of the ellipse that has the same normalized second central moments as the mass of the binary or dilated binary image.
- (6)
MinorLength: the length (in pixels) of the minor axis of the ellipse that has the same normalized second central moments as the mass of the binary or dilated binary image.
- (7)
Eccentricity: the eccentricity of the ellipse that has the same second-moments as the mass of the binary or dilated binary image. The eccentricity is the ratio of the distance between the foci of the ellipse and its major axis length. The value is between 0 and 1.
- (8)
Orientation: the angle (in degrees ranging from −90 to 90 degrees) between the x-axis and the major axis of the ellipse that has the same second-moments as the mass of the binary or dilated binary image.
- (9)
ConvexHull: the matrix that specifies the smallest convex polygon that can contain the mass of the binary or dilated binary image. Each row of the matrix contains the x- and y-coordinates of one vertex of the polygon. The first row is selected here to construct the feature vector.
- (10)
ConvexHullNum: the number of the vertices of the smallest convex polygon that can contain the mass of the binary or dilated binary image.
- (11)
ConvexArea: the number of the pixels in the convex hull that specifies the smallest convex polygon that can contain the mass of the binary or dilated binary image.
- (12)
FilledArea: the number of pixels with value one in the Filled image, which is a binary image (logical) of the same size as the bounding box of the mass of the binary or dilated binary image, with all holes filled in.
- (13)
EulerNumber: the number of objects in the mass of the binary or dilated binary image minus the number of holes in those objects.
- (14)
Extrema: the matrix that specifies the extrema points in the mass of the binary or dilated binary image. Each row of the matrix contains the x- and y-coordinates of one of the points. The format of the vector is [top-left top-right right-top right-bottom bottom-right bottom-left left-bottom left-top].
- (15)
EquivDiameter: the diameter of a circle with the same area as the mass of the binary or dilated binary image.
- (16)
Solidity: the proportion of the pixels in the convex hull that are also in the mass of the binary or dilated binary image.
- (17)
Extent: the ratio of pixels in the mass of the binary or dilated binary image to pixels in the total bounding box.
- (18)
Perimeter: the distance between each adjoining pair of pixels around the border of the mass of the binary or dilated binary image.
- (19)
WeightCentroid: the center of the mass of the binary or dilated binary image based on location and intensity value. This measure is also based on the power-detected SAR chip.
- (20)
MeanIntensity: the mean of all the intensity values in the mass of the power-detected image as defined by the binary image or the dilated binary image.
- (21)
MinIntensity: the value of the pixel with the lowest intensity in the mass of the power-detected image as defined by the binary image or the dilated binary image.
- (22)
MaxIntensity: the value of the pixel with the greatest intensity in the mass of the power-detected image as defined by the binary image or the dilated binary image.
- (23)
SubarrayIndex: the cell-array containing indices of pixels within the bounding box of the binary image or the dilated binary image. The first and last elements of each cell are selected here to construct the features.
Figure 3 shows a portion of the features extracted from BMP2 slices in the MSTAR database. They are SAR chip after power detection, binary image, dilated image and partial features, respectively. Meanwhile, the centroid, boundingbox, extreme and center of gravity of target area were marked in blue, red, green and magenta.
3.2. TPLBP Operators
The echo signals of radar waves vary because of the differences in structure, roughness and physical characteristics of a target, while the texture information of SAR targets changes little along with the azimuth of the target. Thus, texture features can be used for target identification. Local Binary Pattern (LBP) is a simple and effective local texture extraction operator. It can effectively use the spatial information and adequately reflect the local spatial correlation of images with gray-scale and rotation invariance.
The traditional LBP operator is described as follows: within a window sized 3 × 3, compare the gray value of the center pixel with that of the other adjacent eight pixels. If the gray value of adjacent pixels is greater than the central pixel’s, the value of adjacent pixels is marked as 1, otherwise it is marked as 0. In this way, the eight pixels in the neighborhood will produce an unsigned 8-bit number called LBP value, which reflects the texture information of the region. Limited by the size of the neighborhood, LBP operator cannot describe the large-scale texture information, and original LBP operator does not have a rotational invariance. In terms of these aspects, it is not suitable to describe the target in azimuth sensitive SAR images.
Wolf et al. [
24] improved the LBP operator and proposed the Three-Patch Local Binary Pattern (TPLBP). Firstly, for each pixel in the image, considering a
patch centered on the pixel, S additional patches distributed uniformly in a ring of radius r around it. Utilizing the LBP operator mentioned above, the center pixel of each patch can obtain the LBP value. Specifically, as is shown in
Figure 4, with the parameter set as
, the LBP value of
S patches of a certain pixel is produced in an area of the red box which is marked in the SAR image. The values of two patches, which are α-patches apart along the circle, are compared with those of the central patch and their similarity is calculated further.
Then applying the following equation to each pixel, the TP LBP value can be calculated:
where
and
are pairs of patches along the ring and
is the central patch. The function
is a certain distance function between two patches and
is defined in Equation (3), where
is set to 0.01 [
24,
30]:
After the TPLBP value of every pixel in the image is obtained, the whole image is divided into non-overlapping rectangular patches of equal size (B × B). After the frequency for TPLBP value of each rectangular patch is calculated, the histogram vector of each rectangular window will be connected in series in order to form TPLBP feature vector.
Compared with LBP, the TPLBP operator suppresses the speckle noise more effectively. It contrasts the LBP value of patches, which describes the relationship between adjacent patches, rather than the gray value between pixels. In addition, selecting the patches in a circle allows the features to have rotation invariance. Furthermore, the parameters r enables TPLBP to compare different texture features of various scale, which overcomes the shortcomings of LBP with limited range and effectively describes texture features in large-scale SAR images.
5. Experiments
To verify the validity of the proposed algorithm, the following experiments were designed. Firstly, in order to determine the structure of the SAE and achieve the best target recognition performance the influence of network structure on classification accuracy was investigated by changing the number of neurons in the hidden layers of the SAE. Subsequently, the distribution of features is visualized, which contributes to figuring out what the SAE did in the fusion procedure. The comparison of classification accuracy between raw features and fused features demonstrates the effectiveness of feature fusion. Compared with other algorithms, the SAR feature fusion algorithm based on SAE is demonstrated to have better performance on recognition performance and efficiency.
The experiments are conducted on the MSTAR dataset for 10-class targets recognition (armored personnel carrier: BMP-2, BRDM-2, BTR-60, and BTR-70; tank: T-62, T-72; rocket launcher: 2S1; air defense unit: ZSU-234; truck: ZIL-131; bulldozer: D7). In order to comprehensively assess the performance, this paper chooses SAR images of 17° and 15° aspect as training samples and test samples, respectively. Details are displayed in
Figure 6 and
Table 2.
Experimental parameters: according to reference [
23], the parameters of the TPLBP operator are set as
in order to extract the 128-dimensional TPLBP feature. Then it is combined with 88-dimensional baseline features in series. After importing the feature vectors into a SAE, the softmax classifier is employed for target recognition.
5.1. The Influence of the SAE Network Structure on Performance
In the training stage it is easy for a neural network to get trapped into “overfitting” and “underfitting” problems. With a certain scale of training data, the probability of overfitting will rise with the increase of the neurons. Thus, it would be advisable to keep the number of layers as less as possible on the premise of accuracy. Therefore, a SAE with two hidden layers for feature fusion is adopted to explore the effect of neurons number on generalization capacity.
In order to correctly configure the SAE network, 20% of the training samples (17°) were randomly selected as the validation set, and the remaining were used as the training set. The training set is used to adjust the parameters of SAE network, and the best model is selected according to the accuracy on the validation set. Finally, the performance of the model is tested on the testing set (15°).
Geng et al. [
20] pointed out that in order to prevent the network from overfitting or underfitting, the number of hidden layer neurons should not be too small nor too large. Thus, in this paper,
and
represent the neural number of the first hidden layer and the second hidden layer, respectively, where
and
. Weight decay parameter
controls the relative importance of the mean squared error term and weight decay of cost function as mentioned earlier. In this paper, a small
ranging from
to
is adopted, so that the mean squared error term accounts for more proportion of cost function than weight decay. Furthermore, sparsity parameter is usually a small value approximating to 0, leading to better generalization ability in the network. Parameter
controls the weight of sparsity penalty factor, and the parameters are set as follows
.
Next, under the condition of the same parameters and inputs, the classification accuracy on validation set with changed number of neurons is recorded. To ensure the precision of the results, the experiment was executed five times under each group of parameters, and the mean value on each case was calculated. The comparison results are shown in
Figure 7.
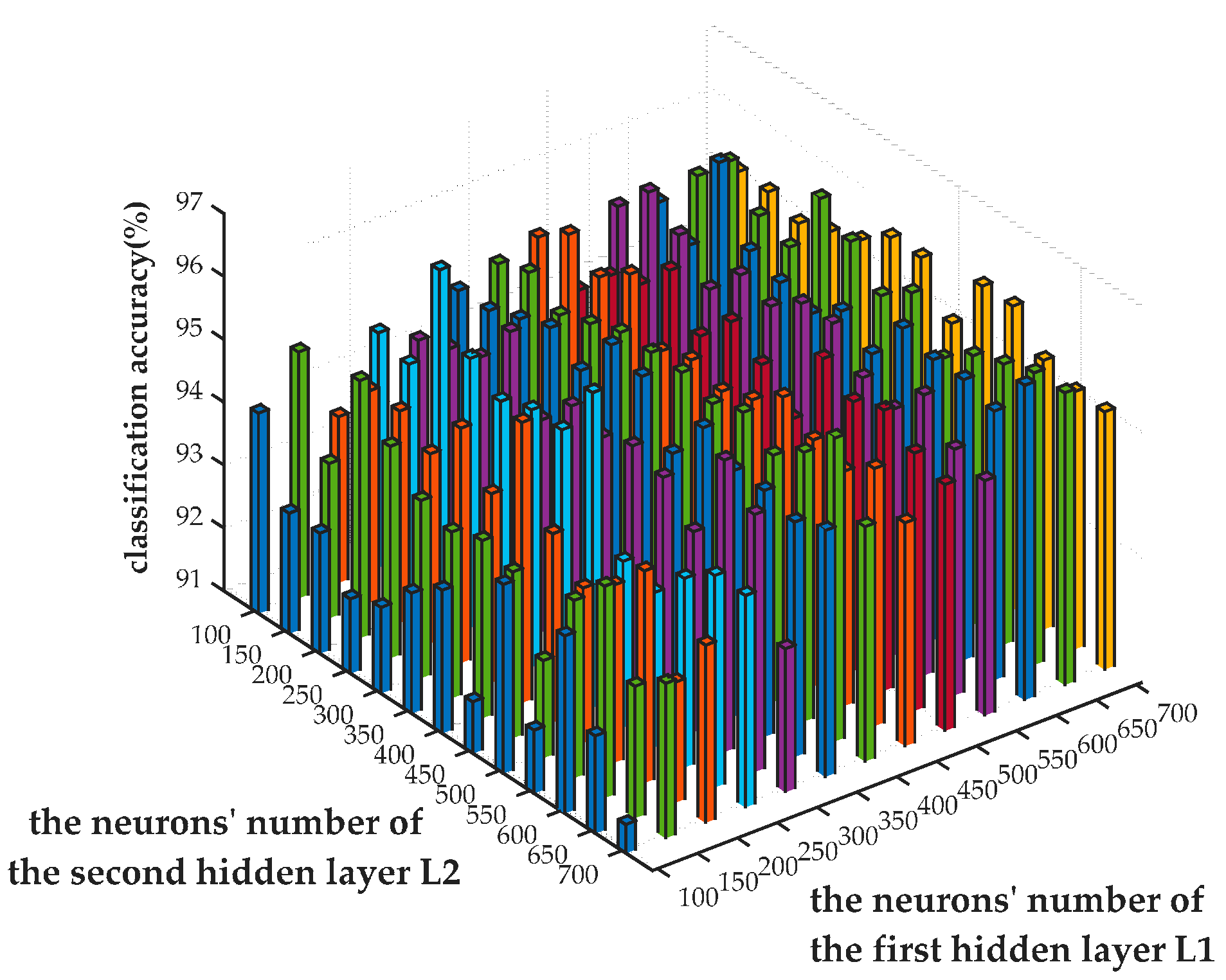
Figure 7 shows that the number of neurons in each layer has a significant impact on network performance. When
is fixed, the classification accuracy varied along with the change of
. Best performance was achieved while the value of
approximates to 600. Similarly, the value of
is supposed to be set to 200 for higher accuracy with a fixed value of
. Given
, the network obtained the highest recognition accuracy on validation set, amounting to 96.36%. Therefore
is considered the best SAE configuration and it is tested with the testing set independently, obtaining a classification accuracy of 95.43%.
As can be seen from the figure, the accuracy is relatively higher when is larger than . It is possible that the input data can be precisely fitted when the number of neurons in the first hidden layer is larger than the second one’s, which decreases the reconstruction error in the first hidden layer. Conversely, if the number of neurons in the first hidden layer is relatively small, the reconstruction error of the input data will accumulate in the network, degrading the network performance. However, with limited samples, the classification accuracy will not increase unlimitedly since the parameters of network model will grow rapidly with the increase of hidden neurons. This leads to more freedom of network parameters and probably causes over-fitting.
5.2. The Comparison of Different Features
In this experiment, 88-dimensional baseline features and 128-dimensional TPLBP features were extracted from SAR images at 17° in MSTAR collection, and then they were compared with the fusion features. Utilizing t-distributed stochastic neighbor embedding proposed in reference [
35], the cascaded features and fusion features were visualized so as to obtain the distribution in a two-dimensional space. The results are shown in
Figure 8.
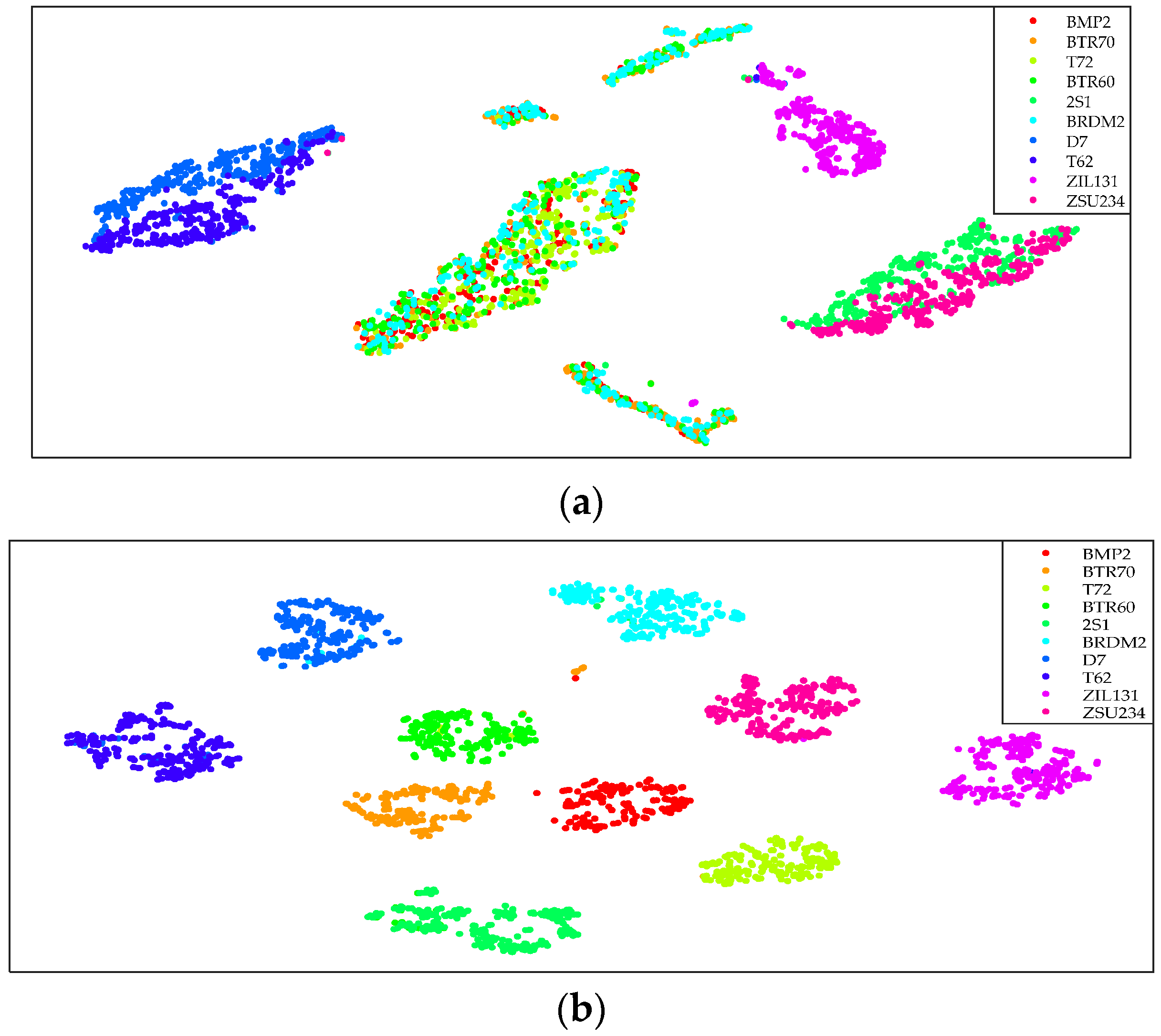
As shown in
Figure 8, in two-dimensional space, the distribution of cascaded features obviously presents interclass overlap and intraclass dispersion. However, the fusion features of 10-class targets are separated independently. Therefore, in the process of feature fusion, SAE learns more useful information from the input data and fuses the features effectively by changing the spatial distribution of input data.
Next, baseline features and TPLBP features are provided as training data for SAE, respectively, and their recognition performance is compared with fused features, in which SAE network has two hidden layers. The structure and parameters of network are adjusted to achieve the best outcomes. The results are recorded in
Table 3.
Table 3 shows that the classification accuracies of baseline features and TPLBP features are 90.81% and 89.19%, respectively. The classification accuracy of fusion features is up to 95.43%, increasing by almost 5%. Additionally, the baseline features have a relatively lower classification performance on the BRDM2, while the TPLBP features show better discrimination in this category. After the feature fusion, the classification accuracy of BRDM2 is up to 97.08%. The same situation occurs to ZSU234. It is shown that the proposed method integrates the complementary information in the raw features, thus making up the shortage of a single kind of features. It is found that the recognition rate of BMP2, BTR60 and BTR70 is relatively low. Correspondingly, the distribution of those targets is near in the feature space. The reason is that all of the three categories belong to armored personnel carriers. And they have some similarities on shapes and structural characteristics, which increases the difficulty in distinguishing. In addition,
Figure 9a shows that the fused features have a similarity trend with baseline features and TPLBP features in classification accuracy. This indicates that the selection of raw features has a direct impact on the fusion results. Moreover, the higher accuracy on the most of categories of fused features reveals that SAE is able to extract more distinguishable features from the raw features. After representation conversion with SAE, fused features is more robust and distinctive.
In order to verify the advantages of the fused features on recognition, this paper employs Support Vector Machines (SVM) for classification with the baseline features, TPLBP features, cascaded features and fused features, respectively. Similar to the proposed method, the training set (17°) mentioned in
Table 2 are applied to training the SVM, and the optimal parameters are obtained by 5-fold cross-validation. After the model was determined, its performance is evaluated on the testing set (15°). As is shown in
Table 4, the classification accuracy of fused features is higher than other features, which demonstrates that the proposed method effectively integrates the information of features to improve the discrimination of features.
5.3. Comparisons with Other Methods
Table 5 shows the classification accuracy of different algorithms. In reference [
36], two typical classification approaches, Sparse Representation-based Classification (SRC) and SVM, were applied for 10-class targets recognition on MSTAR dataset, obtaining the classification accuracy 86.73% and 89.76%, respectively. Reference [
37] proposed a convolutional neural network (CNN) to extract features from 128 × 128 SAR images to train a softmax classifier, in which the classification accuracy with the same experiment settings was up to 92.3%, which it is lower than the accuracy achieved by the proposed algorithm. A comparison of classification accuracy of 10-class targets was plotted in
Figure 9b, which shows that the proposed algorithm has better classification accuracy than the other algorithms’ in six target categories. Although the other four categories are slightly lower than with the other algorithms, the classification accuracy is still acceptable.
To display the advantages of the feature fusion algorithm on time complexity and classification accuracy, after pre-processing with ZCA whitening, the 128 × 128 SAR images were flattened into one-dimensional vectors and were directly fed into a SAE comprised of two hidden layers. The classification accuracy obtained from the SAE is 93.61%, which is lower than the proposed algorithm.
Table 6 shows the 10-class targets confusion matrices of the SAE trained on images and the proposed method. Compared with the SAE trained on images, the proposed method achieved the same accuracy on BPM2 and T72 and higher accuracy on the rest of categories except for BTR70. As is shown on
Table 3, the baseline features and TPLBP features both have a relative low accuracy classification on BTR70. Therefore, they provide less discriminative information for SAE to fuse, which leads to a poor performance of proposed method.
As shown in
Table 7, the training time and testing time of the two algorithms mentioned above were compared. Experiments are implemented with Matlab R2014a on a computer equipped with a 3.4 GHz CPU and 64 G RAM memory. The proposed method is almost 12 times faster than SAE in training time and 72.5 times faster in testing time. Consequently, feature fusion based on SAE can effectively reduce the number of neurons, simplify the network structure and improve the efficiency of algorithms with limited training samples.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}