
SDTCP: Towards Datacenter TCP Congestion Control with SDN for IoT Applications


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
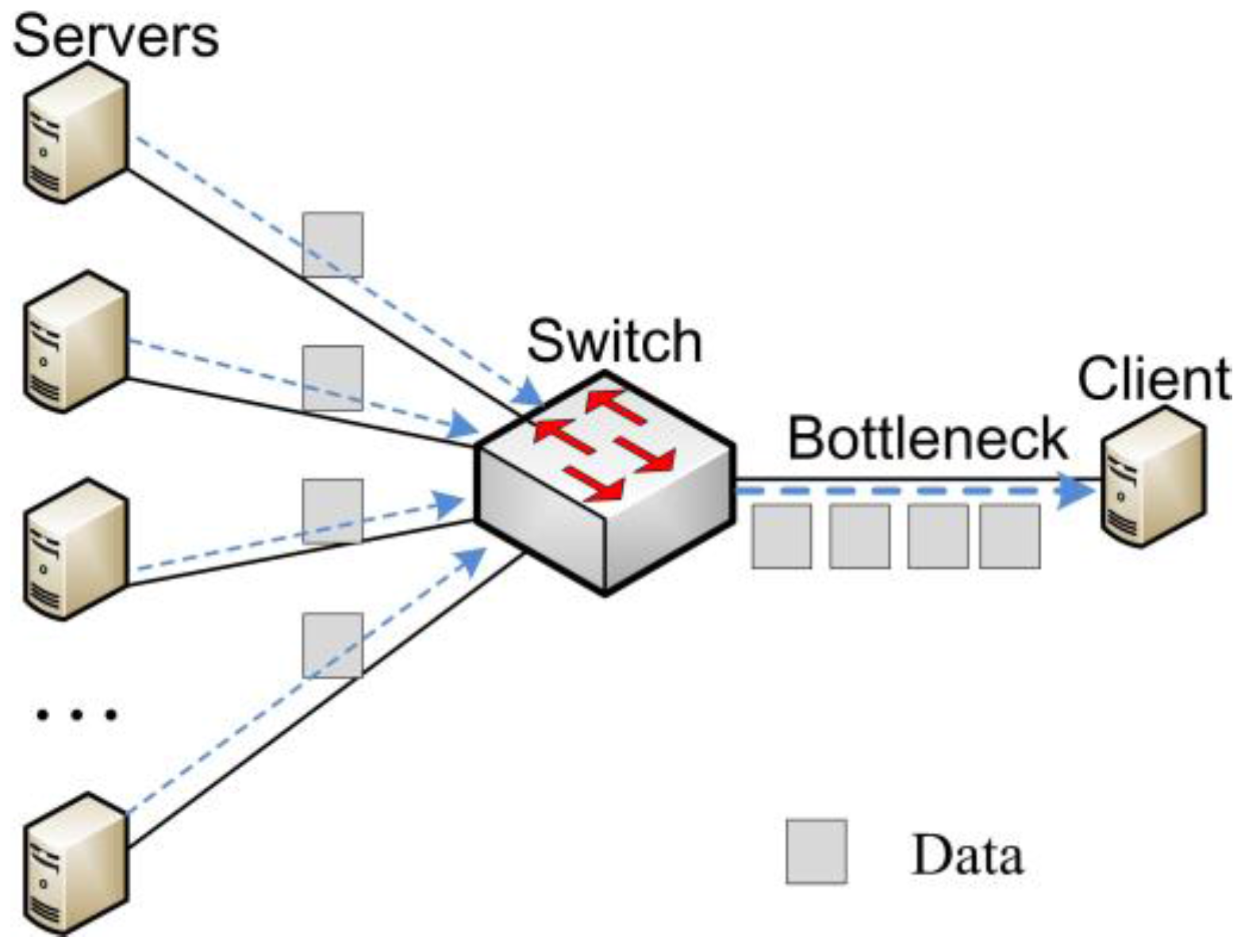
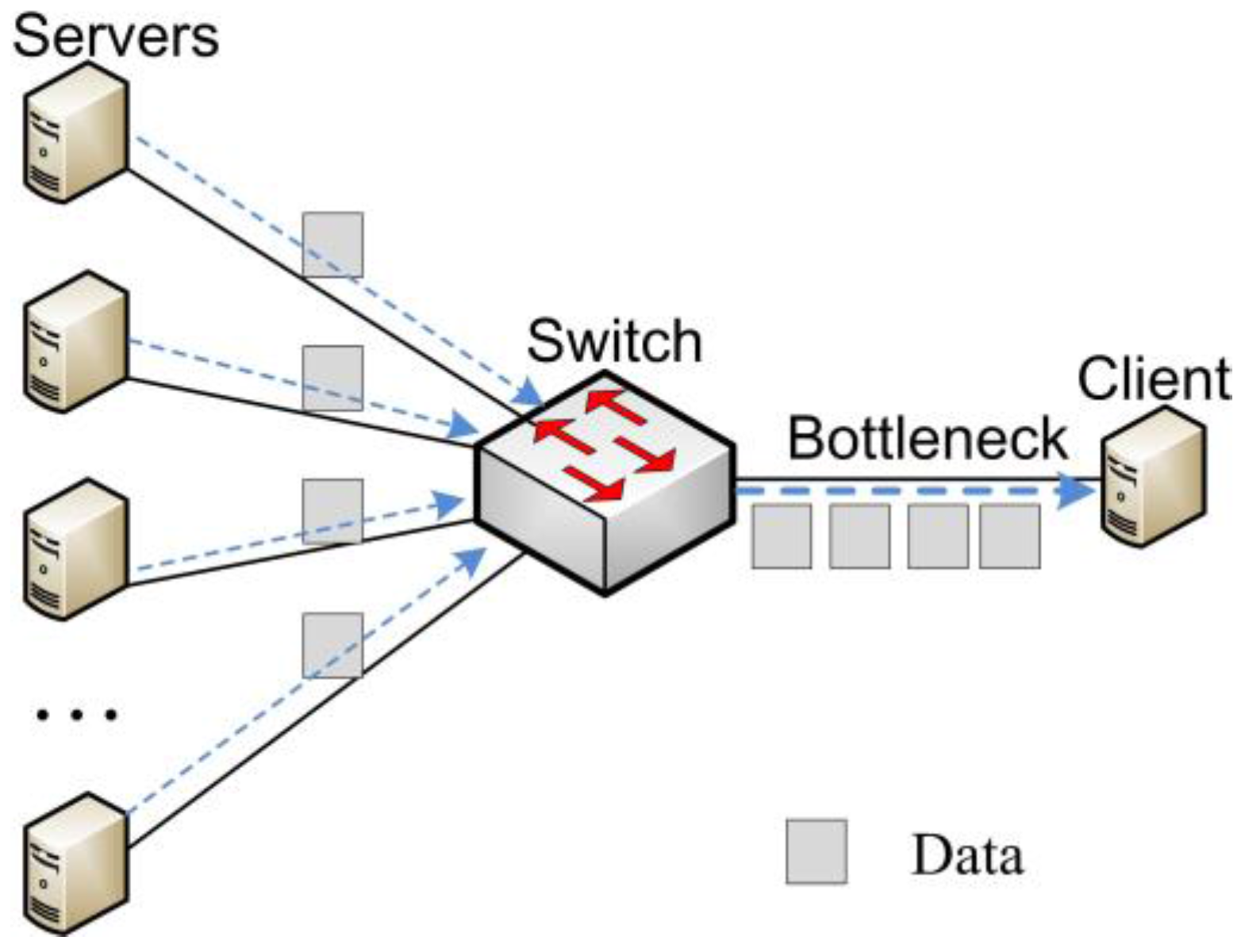
:1. Introduction
- (1)
- A SDN-based TCP congestion control mechanism is proposed in this paper and a fine-grained congestion trigger and congestion avoidance method are designed by using global view of network. SDTCP is a centralized approach that does not revise the legacy TCP stack. Thus, it is transparent to the end systems and easy to deploy. Our experimental results show that SDTCP is effective in improving the performance of burst flows, e.g., reducing transmission time, increasing the number of concurrent flows, and mitigating TCP incast collapse in DCN.
- (2)
- By carefully deploying the location of our controller, our extensive analysis results show that the control delay between OF-switch and controller can be virtually ignored. Additionally, theoretical analysis demonstrates that flow completion time of our SDTCP is less than that of other methods and SDTCP can satisfy weighted proportional fairness.
- (3)
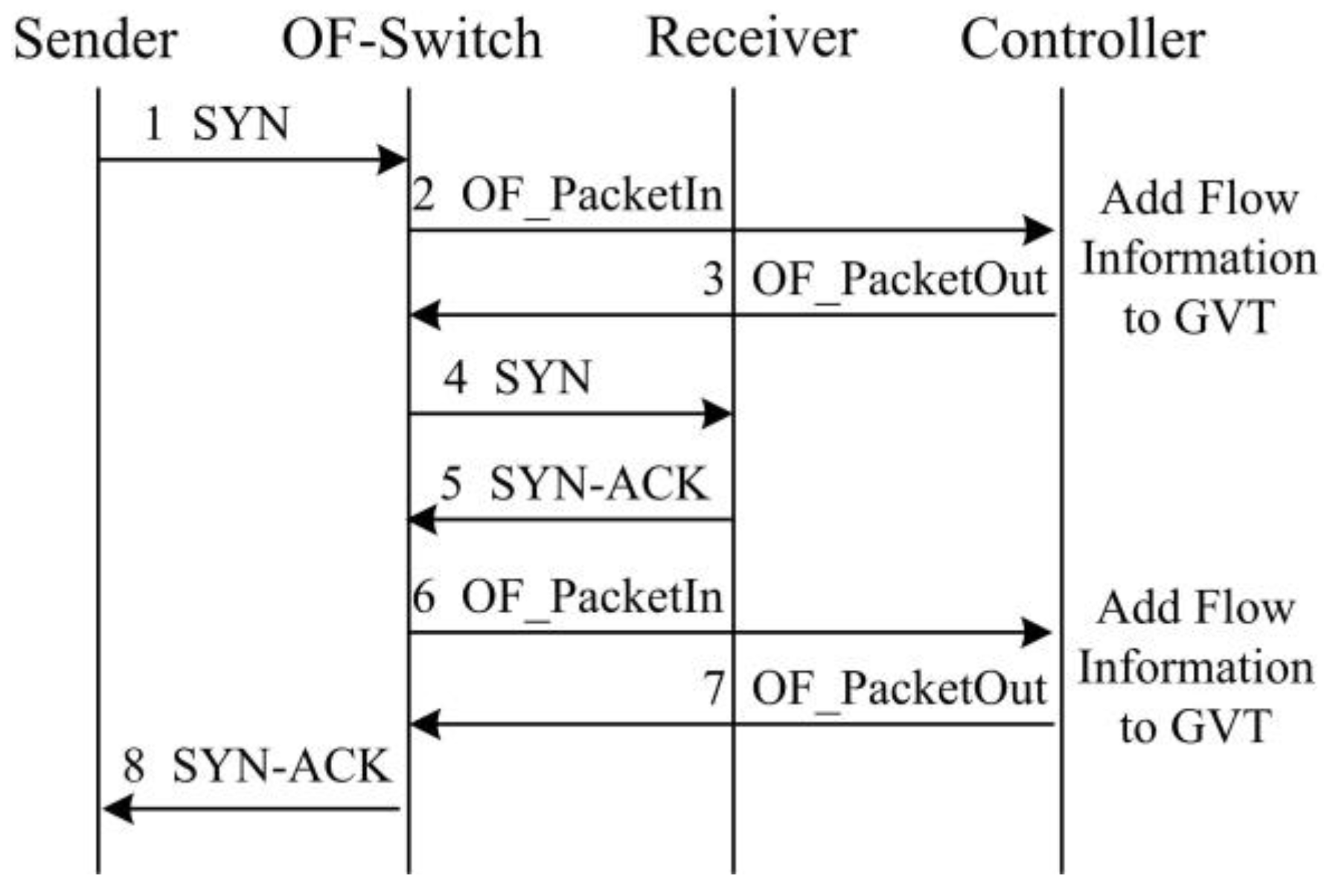
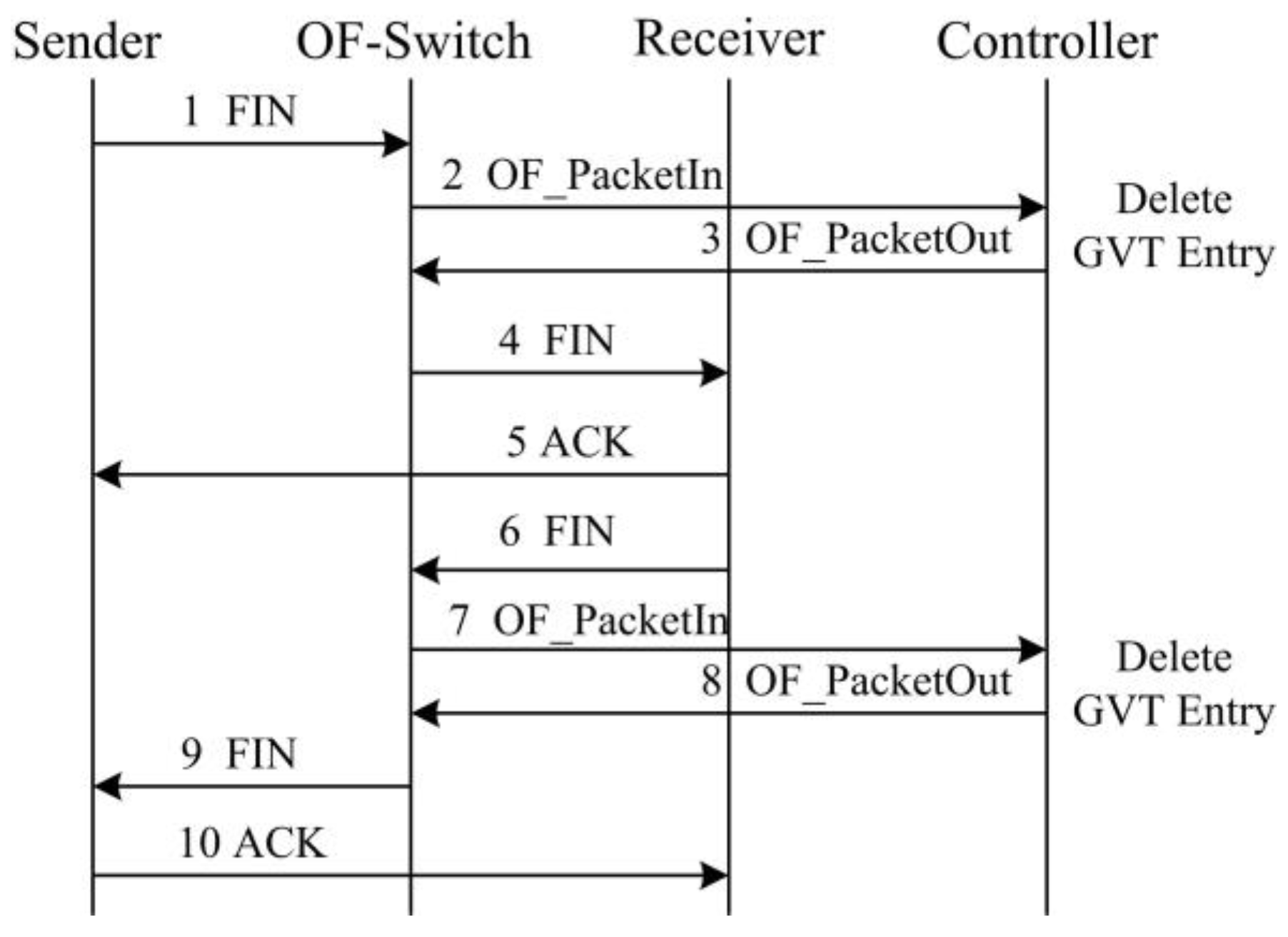
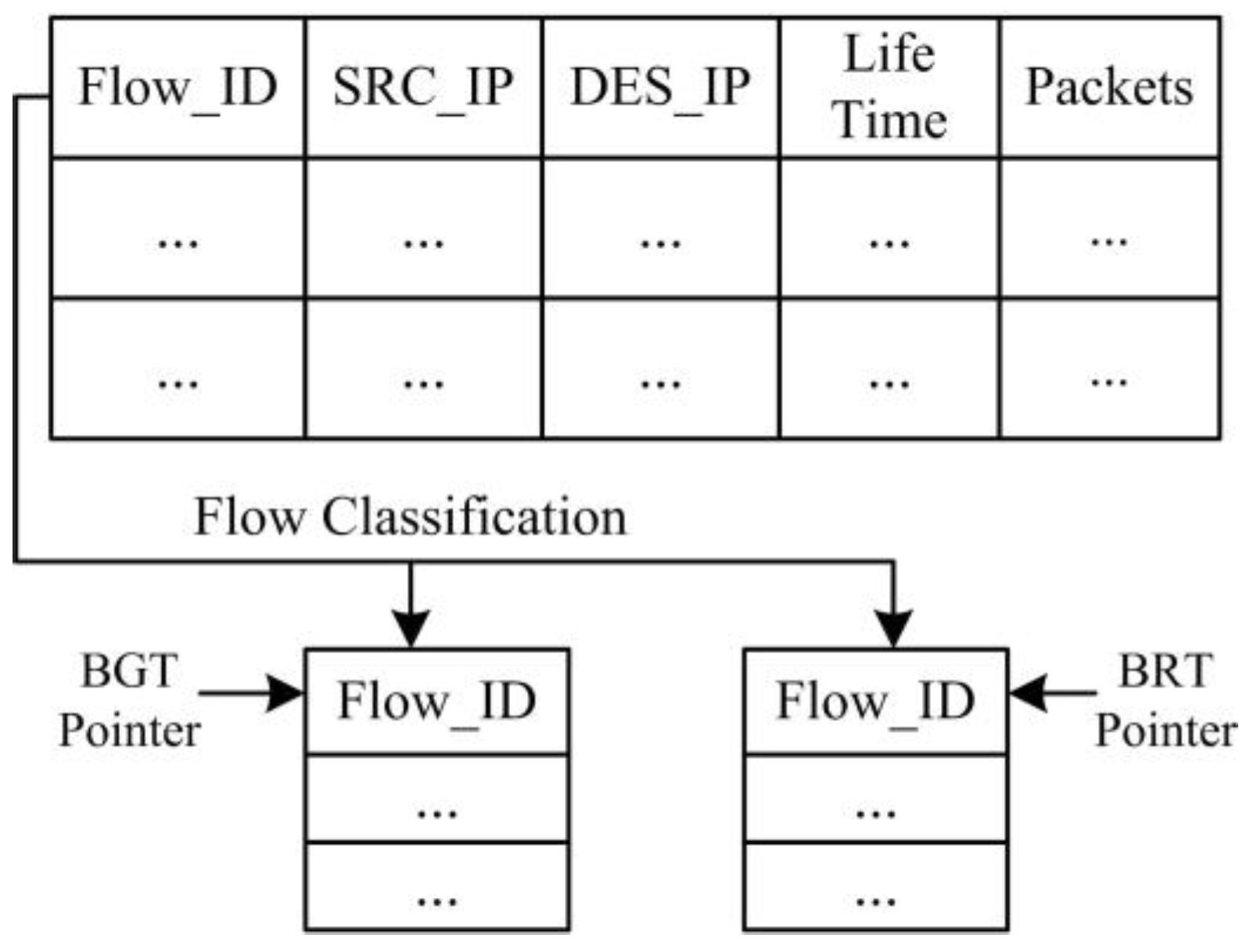
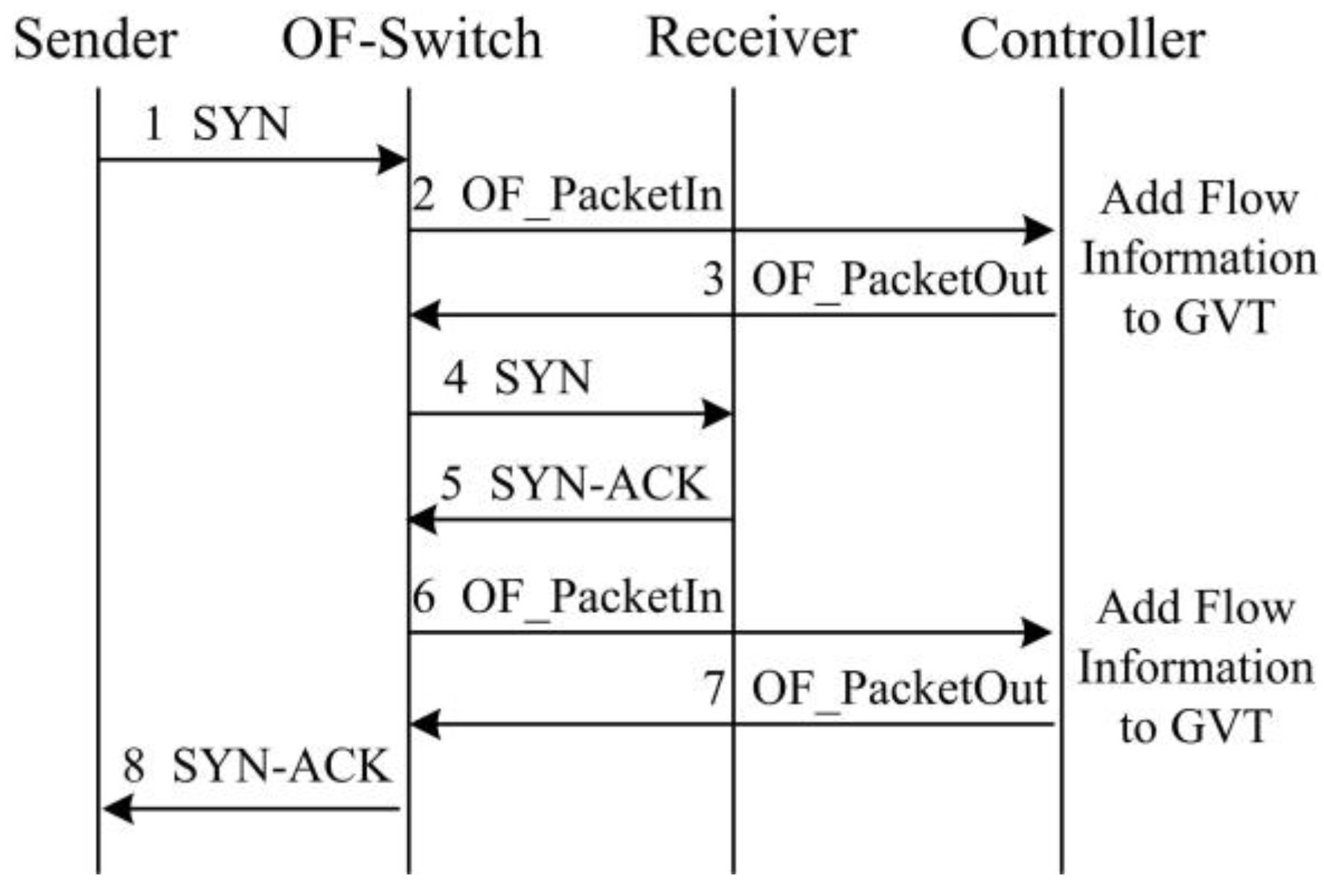
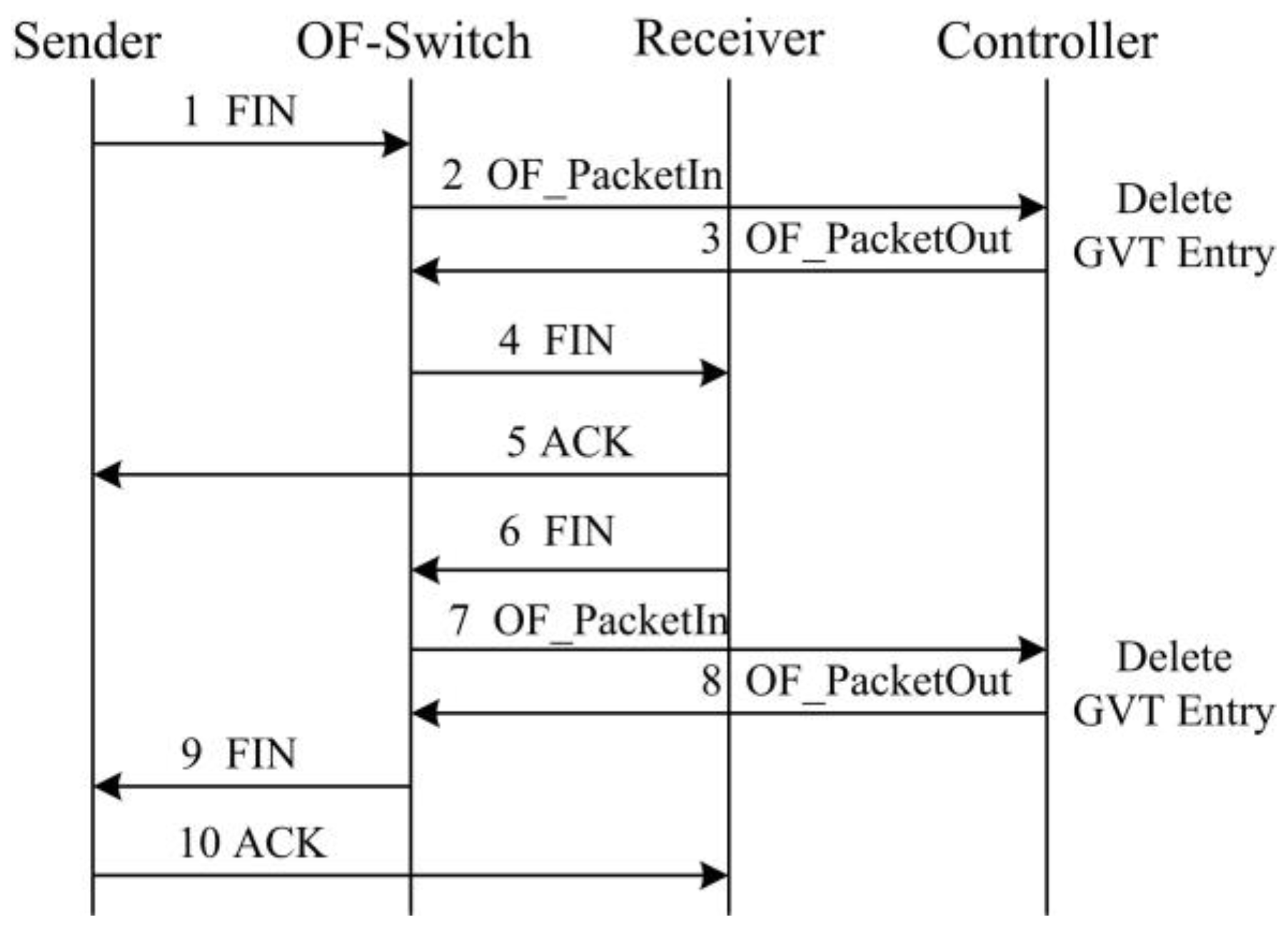
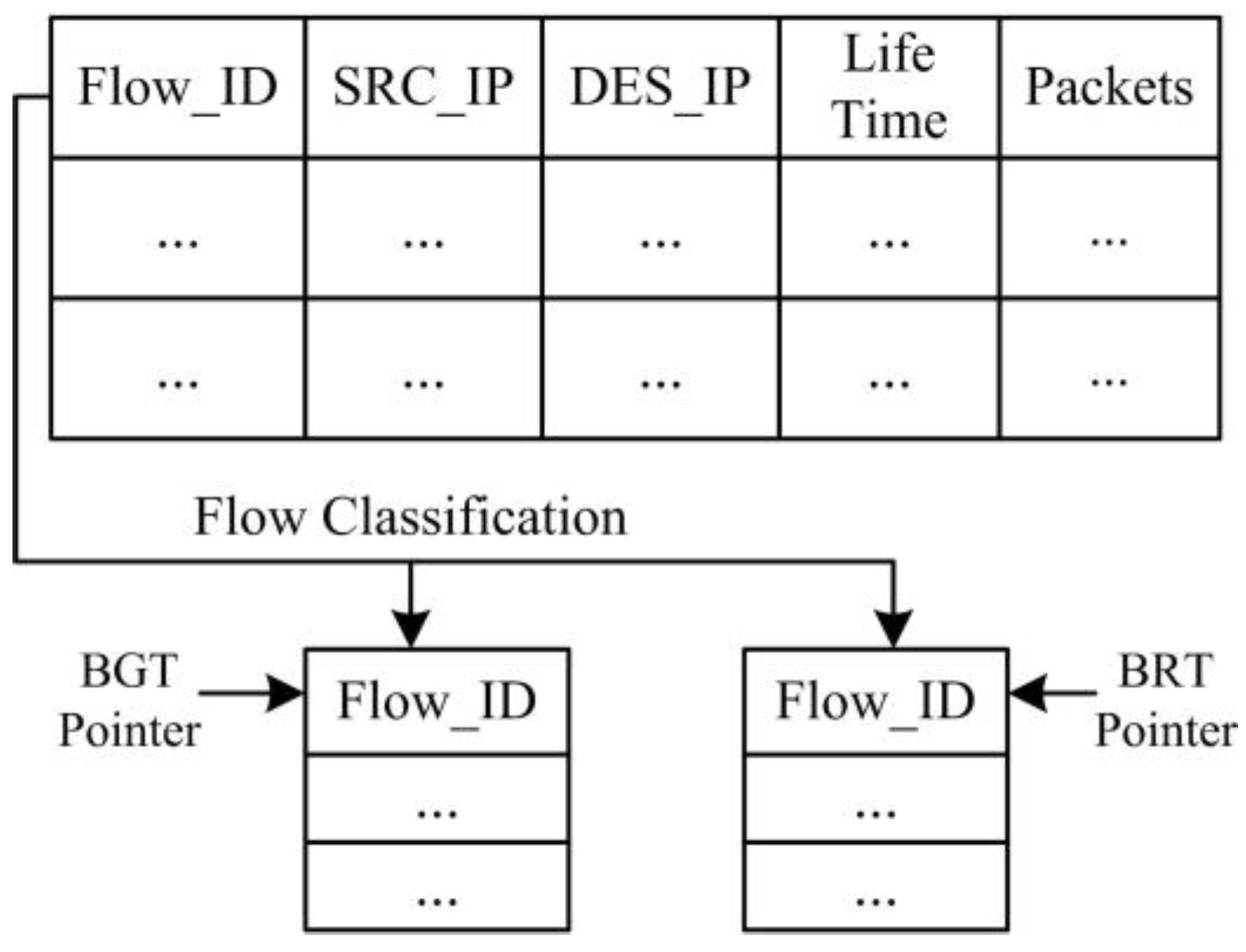
- We implement SDTCP by revising the OpenFlow protocol. During TCP connection establishment, we can generate a global-view flow table (GVT) that includes all of the TCP flows’ information in the network. GVT consists of a background flows table (BGT) and a burst flows table (BRT). Then we classify the background flows and burst flows into BGT and BRT, respectively, according to different flow traffic characteristics. Furthermore, we extend the standard OpenFlow protocol to support the congestion notification message, TCP ACK flag match function, and ACK advertised window regulation action.
2. Related Works
2.1. Window-Based Solutions
2.2. Recovery-Based Solutions
2.3. Application-Based Solutions
2.4. SDN-Based Solutions
3. SDTCP Mechanism
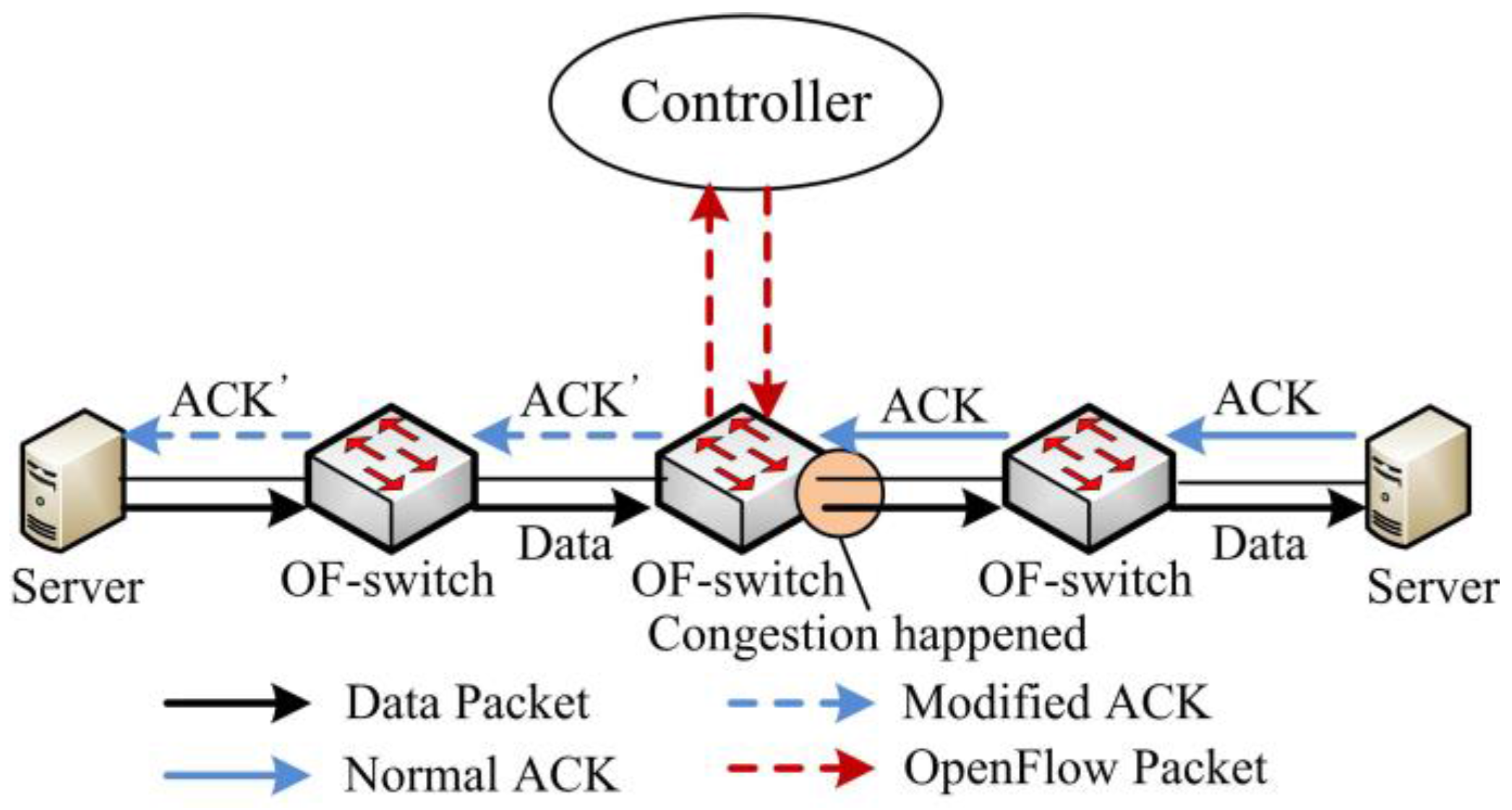
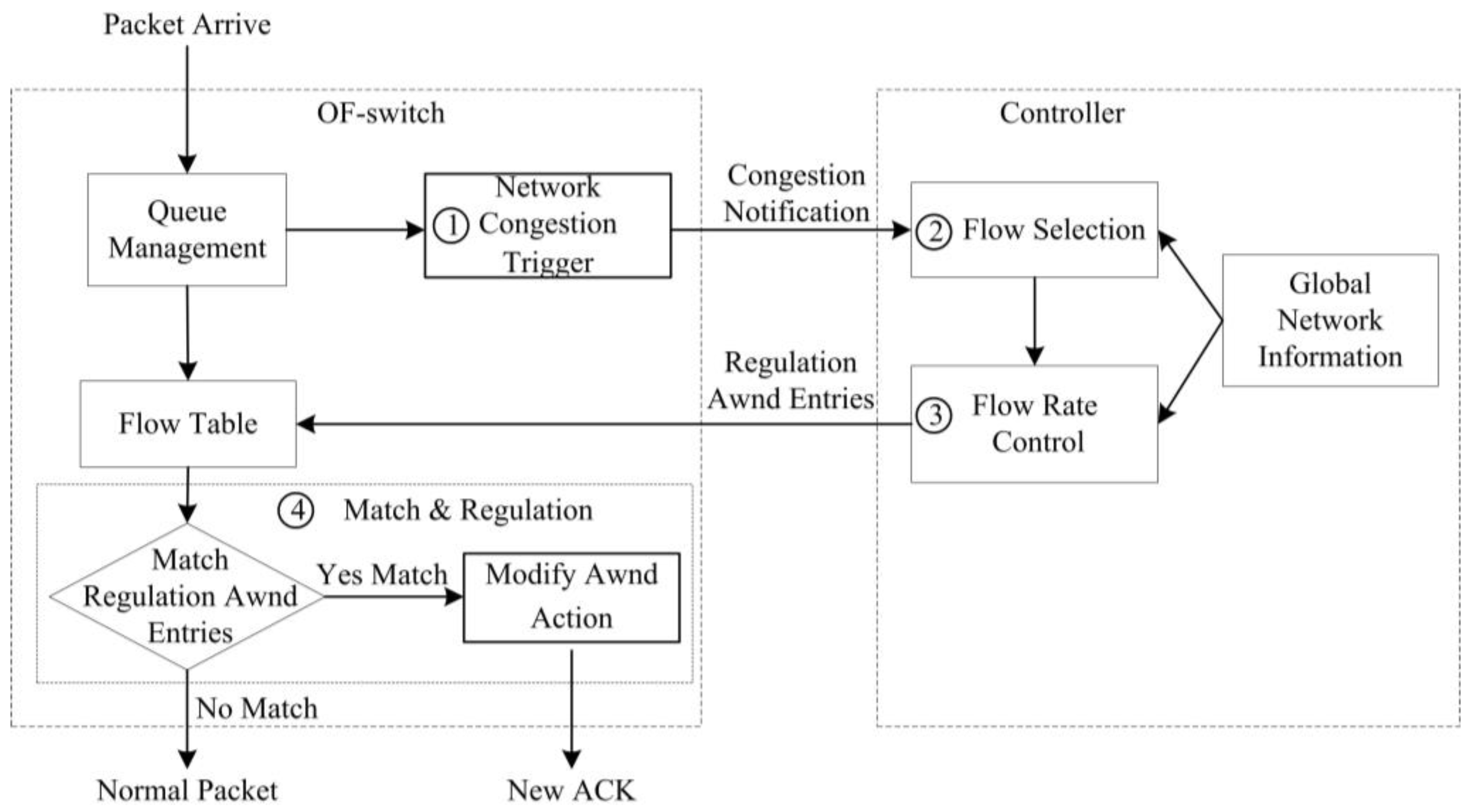
3.1. Basic Idea of SDTCP
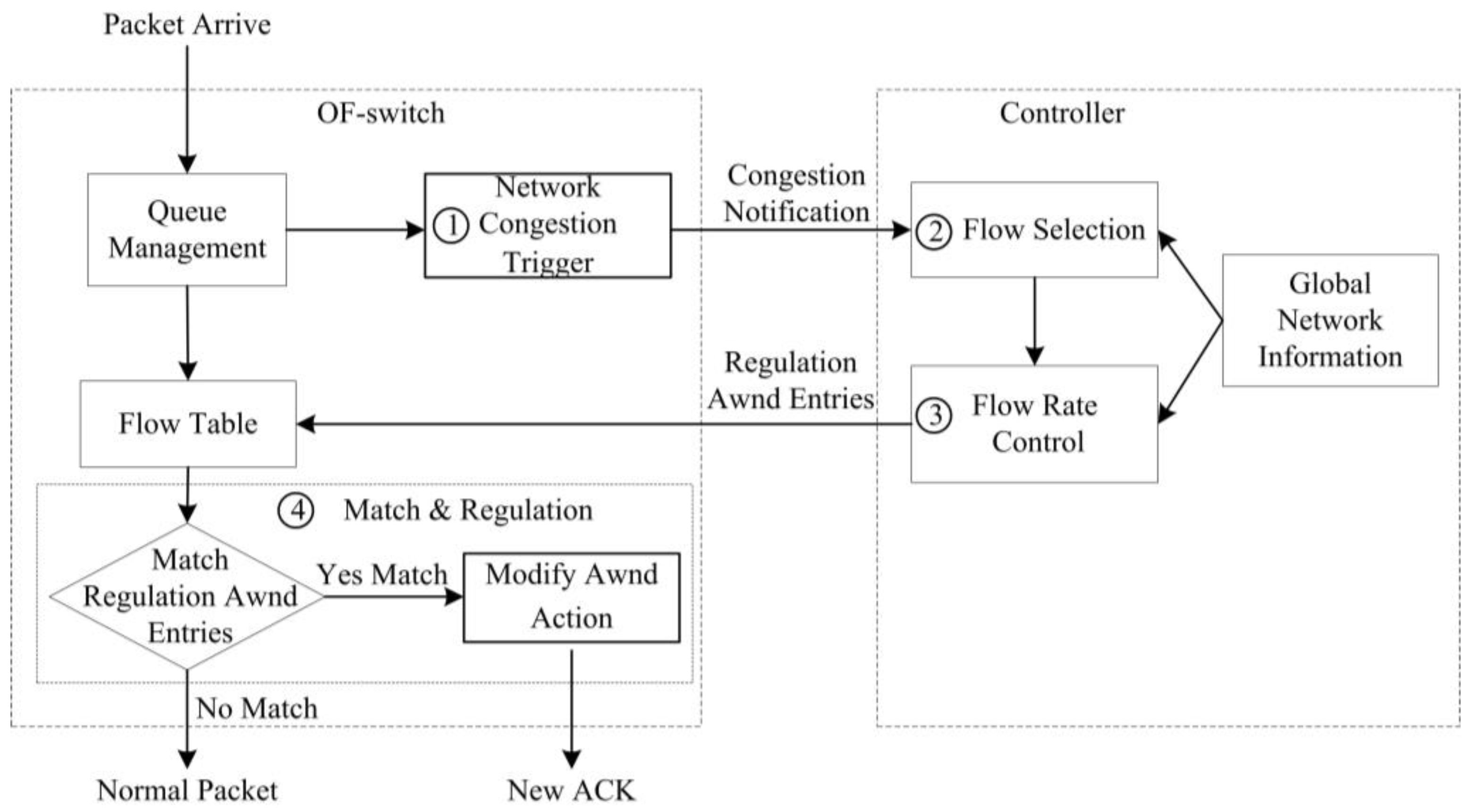
- Step 1
- Network Congestion Trigger. We design a network congestion trigger module at the OF-switch to leverage the queue length to determine if the network is congested. Once network congestion is discovered, it will send a congestion notification message to our controller.
- Step 2
- Flow Selection. Our flow selection module differentiates the background flows and burst flows by leveraging all of the TCP flow information, e.g., TTL (time-to-live), flow size, and IP addresses of TCP flows, gained from OF-switches through the OpenFlow protocol. Upon receiving a congestion notification message from a congested OF-switch, our controller will select all of the background flows passing through the OF-switch.
- Step 3
- Flow Rate Control. A flow rate control module at the controller side estimates the current bandwidth of these chosen background flows and then degrades their bandwidth to the desired one. We assess our desired bandwidth in terms of the network congestion level. Then, our controller generates new flow table entries (called a regulation awnd entry) that is used to regulate the background flow bandwidth to our desired one and sends them to the OF-switch.
- Step 4
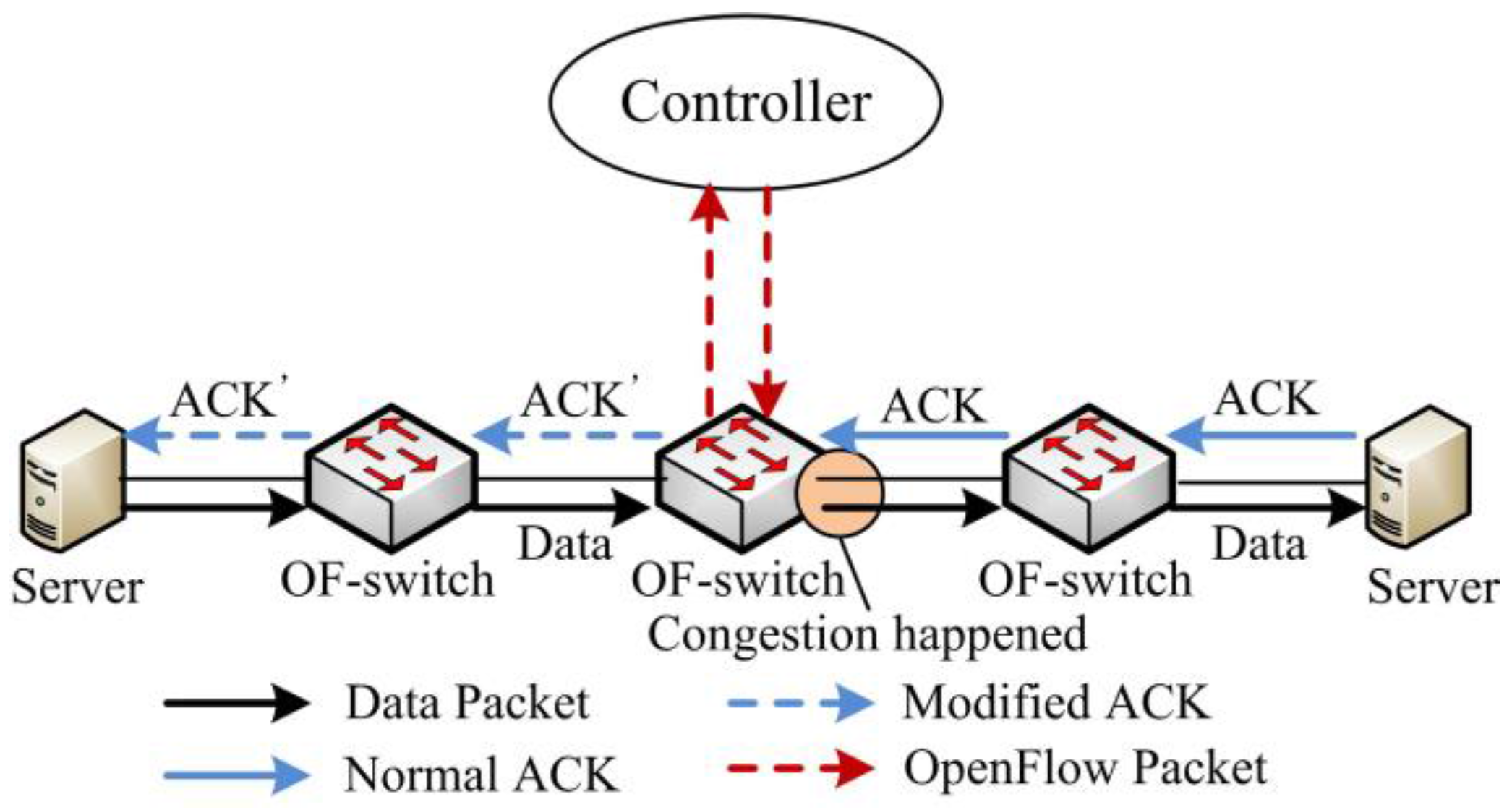
- Flow Match and Regulation. Once TCP ACK packets from the receiver match the regulation awnd entry at OF-switch, the awnd field of these packets will be modified to the desired one and then the packets are forwarded to the sender. After receiving these modified ACK packets, the sender will adjust swnd in terms of Equation (1). In this way, the sending rate can be decreased to our desired one.
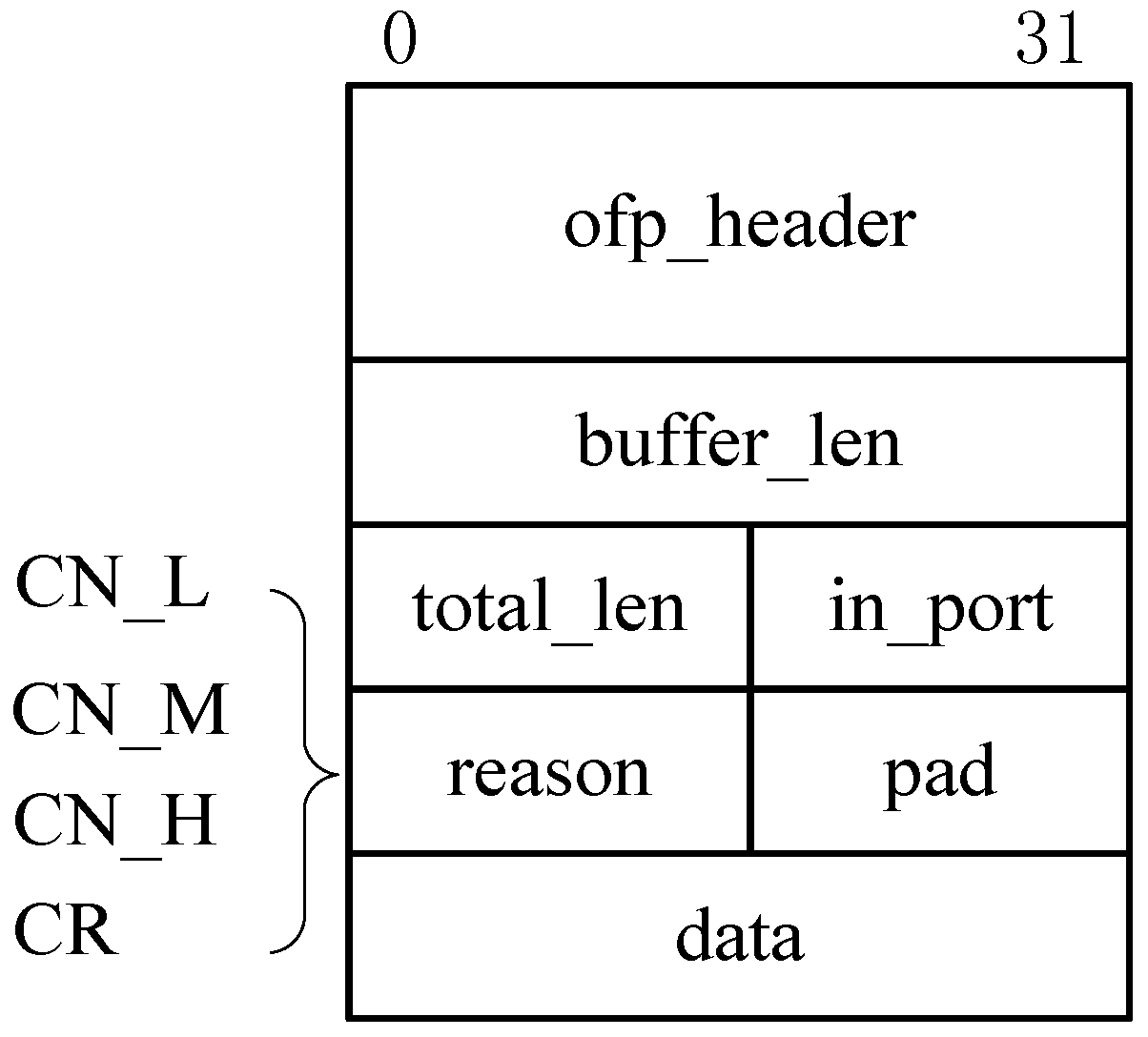
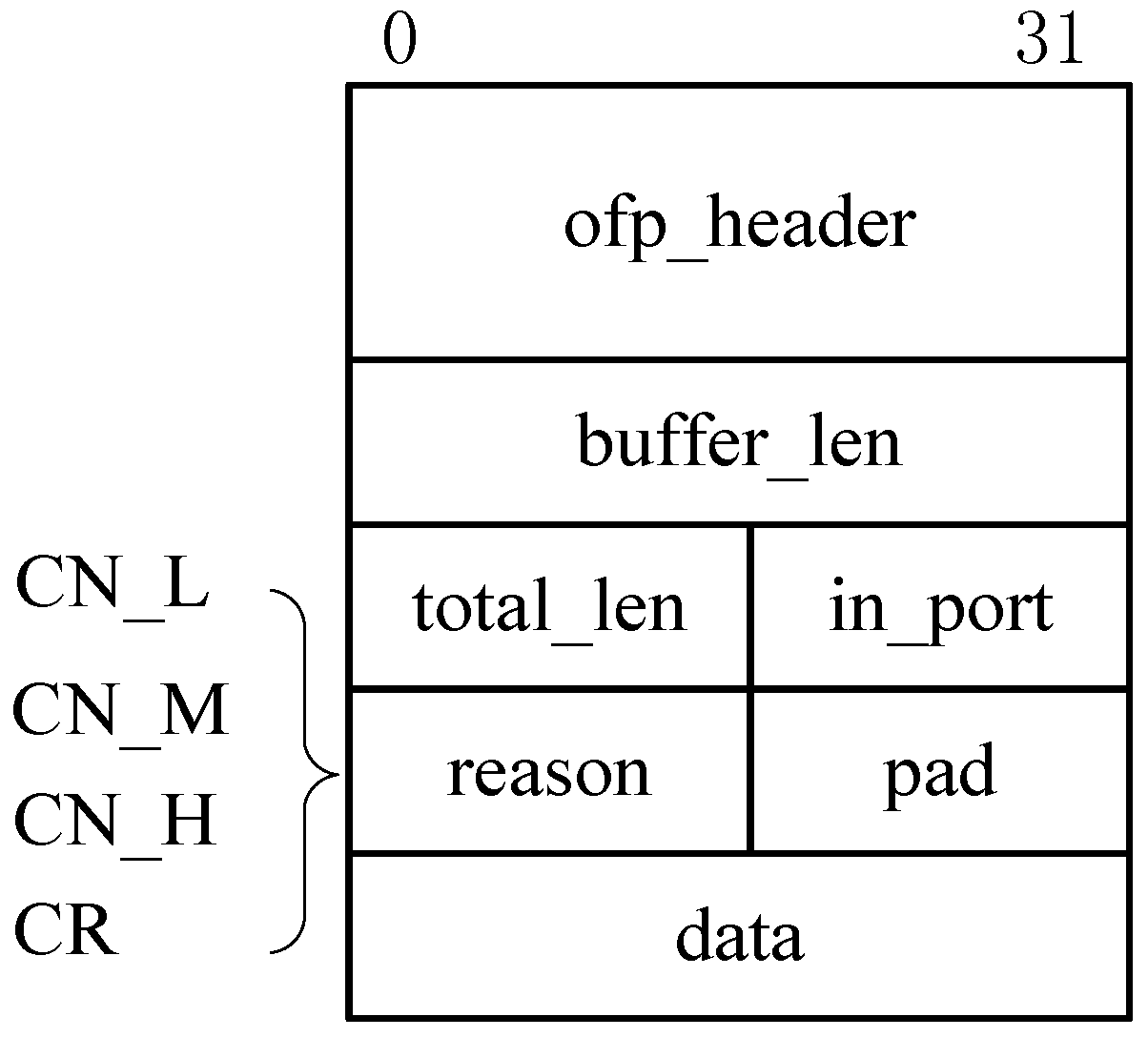
3.2. Step 1. Network Congestion Trigger
- (1)
- . In this case, OF-switch triggers a congestion notification message referred to as CN-L.
- (2)
- . In this case, congestion notification message is referred to as CN-M.
- (3)
- . In this case, congestion notification message is referred to as CN-H.
| Algorithm 1. Network Congestion Trigger |
| Input: packet P arrives Initial: state = 0, type = 0, TIMER is stopped
|
3.3. Step 2. Flow Selection
3.4. Step 3. Flow Rate Control
3.5. Step 4. Flow Match and Regulation
4. Analysis
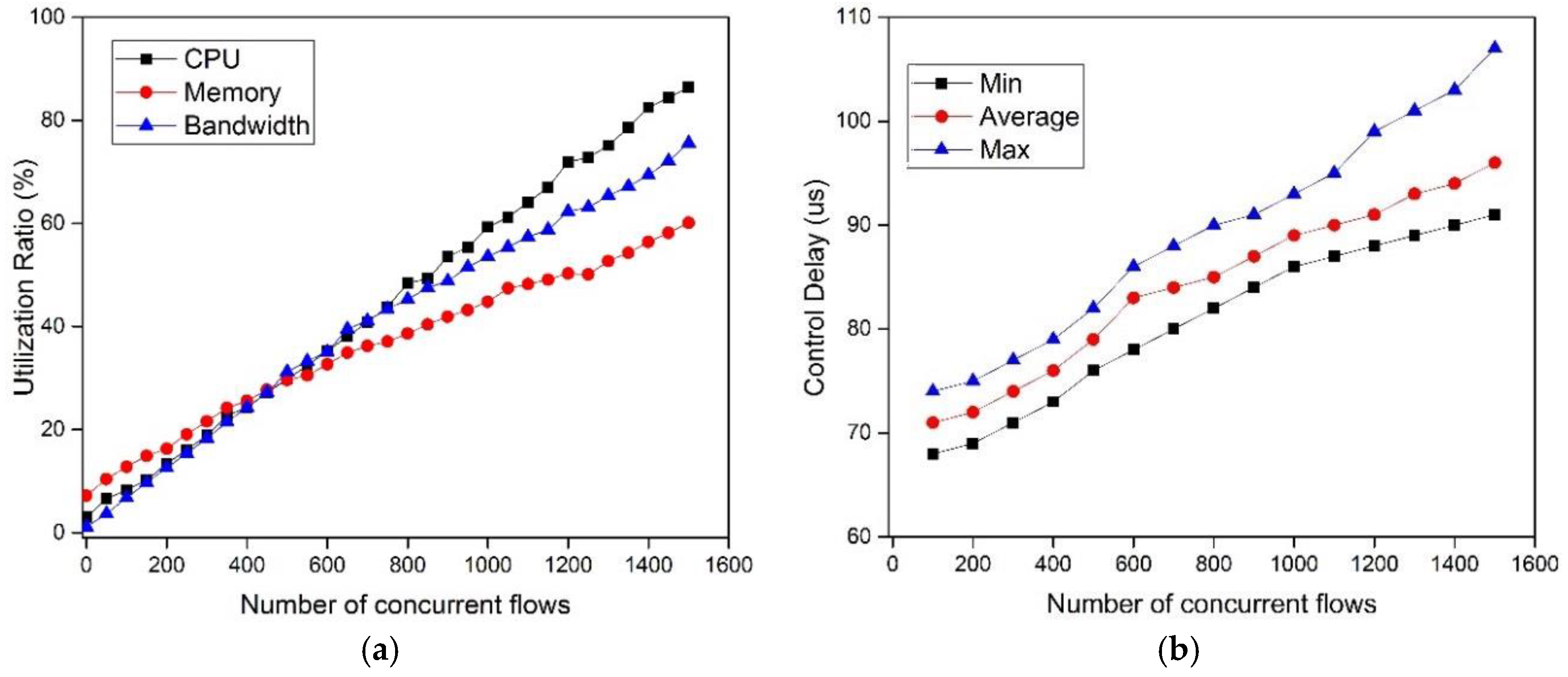
4.1. Control Delay
4.2. Flow Completion Time
4.3. Fairness
4.4. Scalability
5. Experimental Results
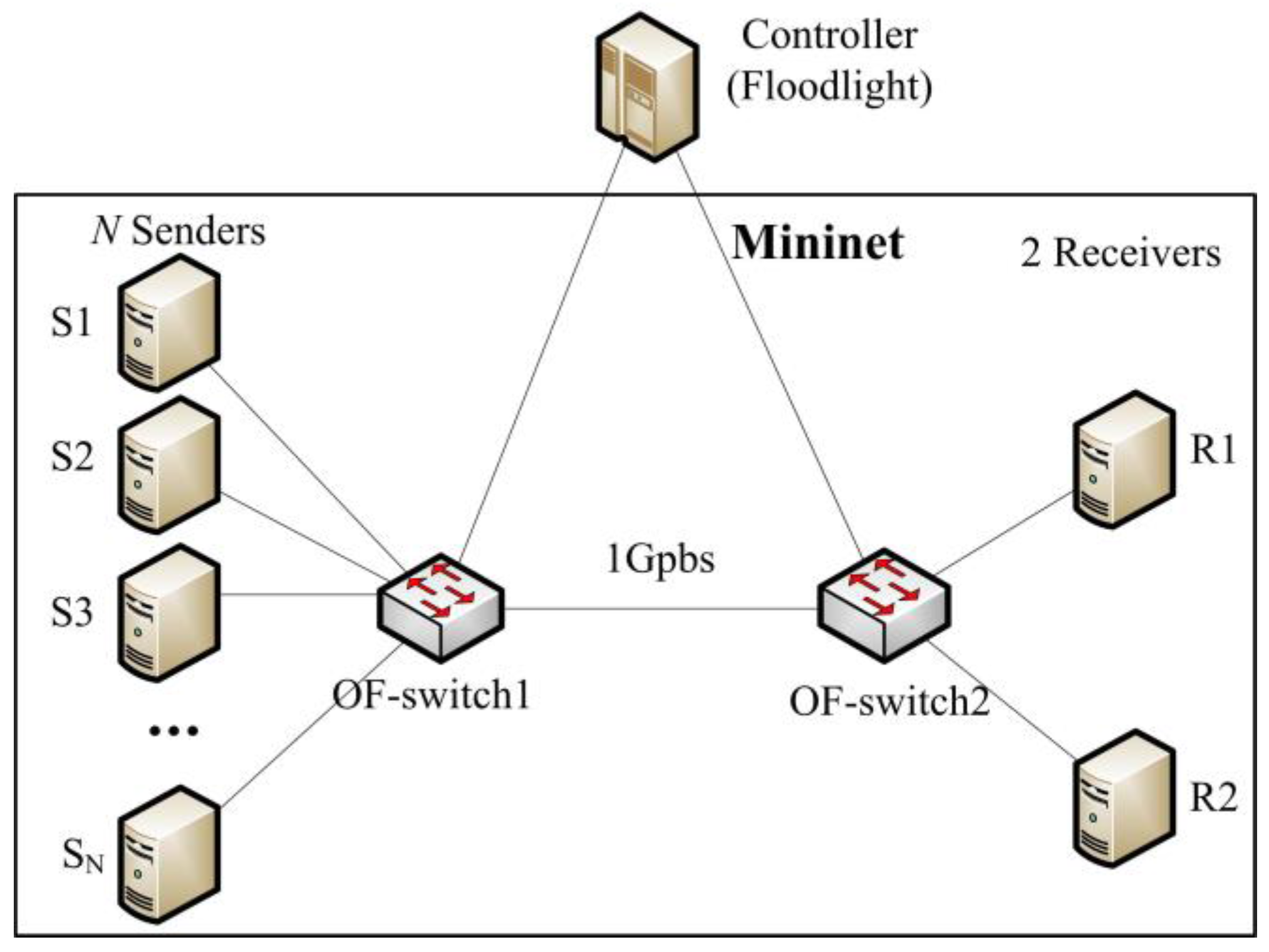
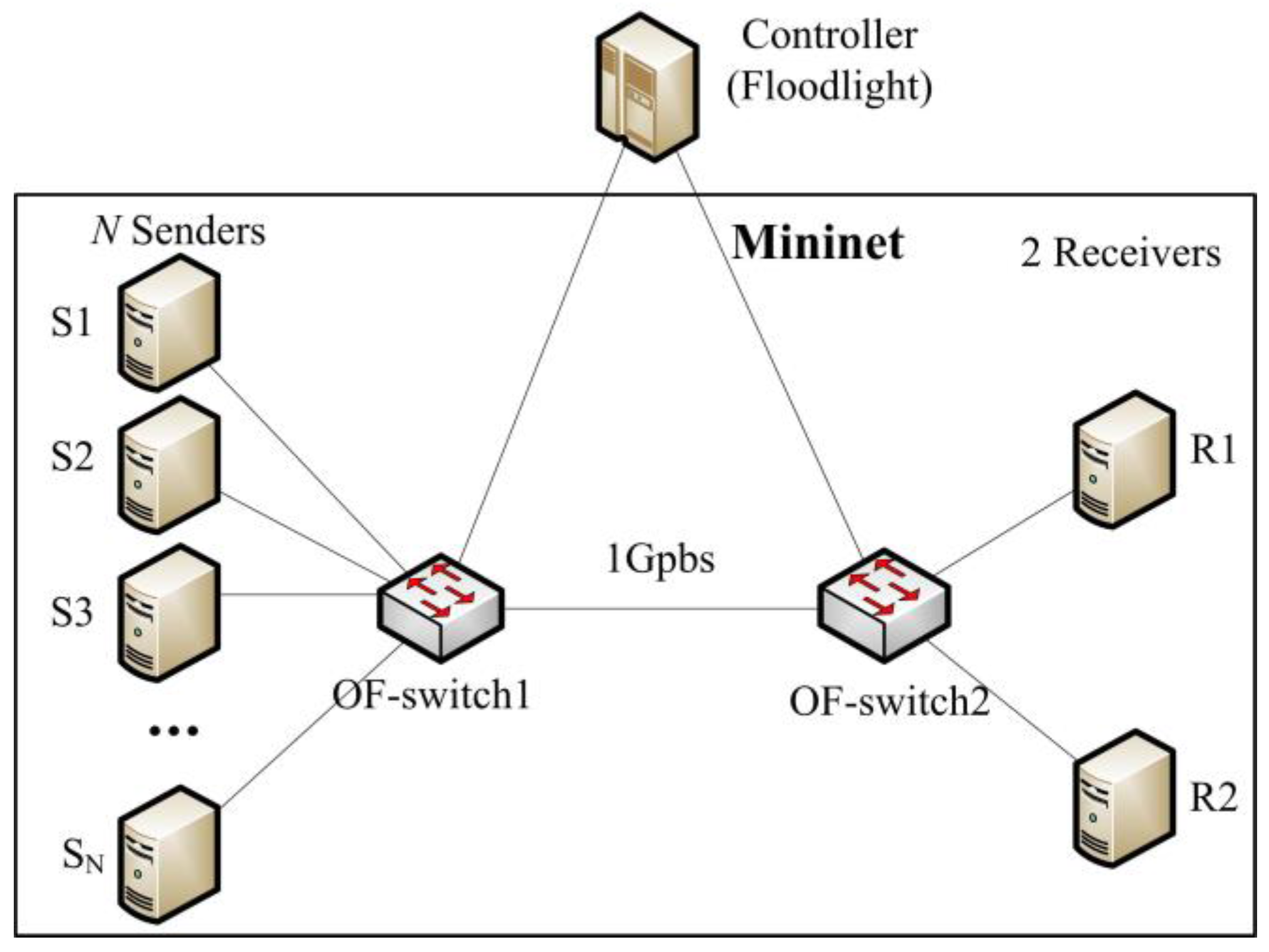
5.1. Experimental Setup
5.2. Experimental Results
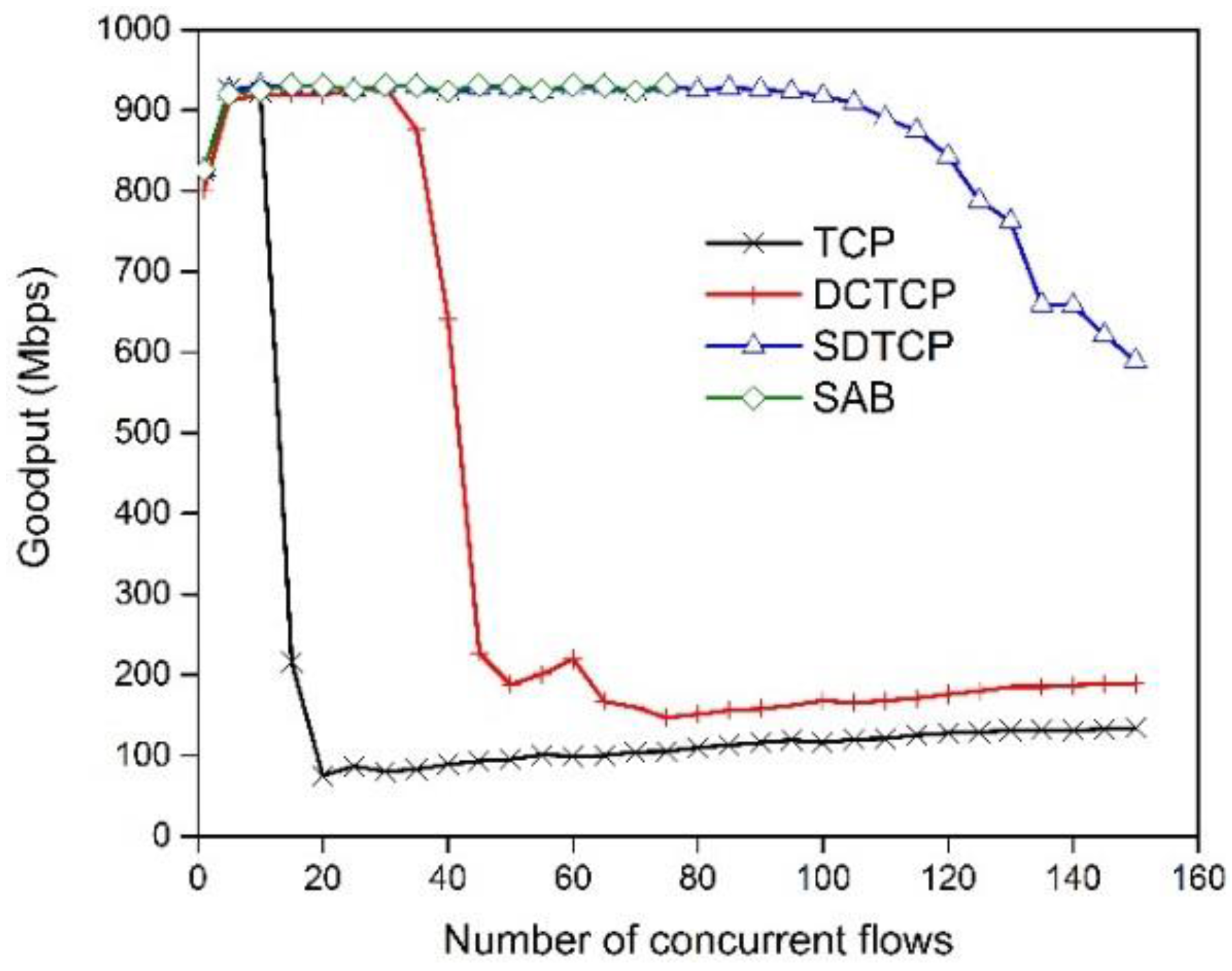
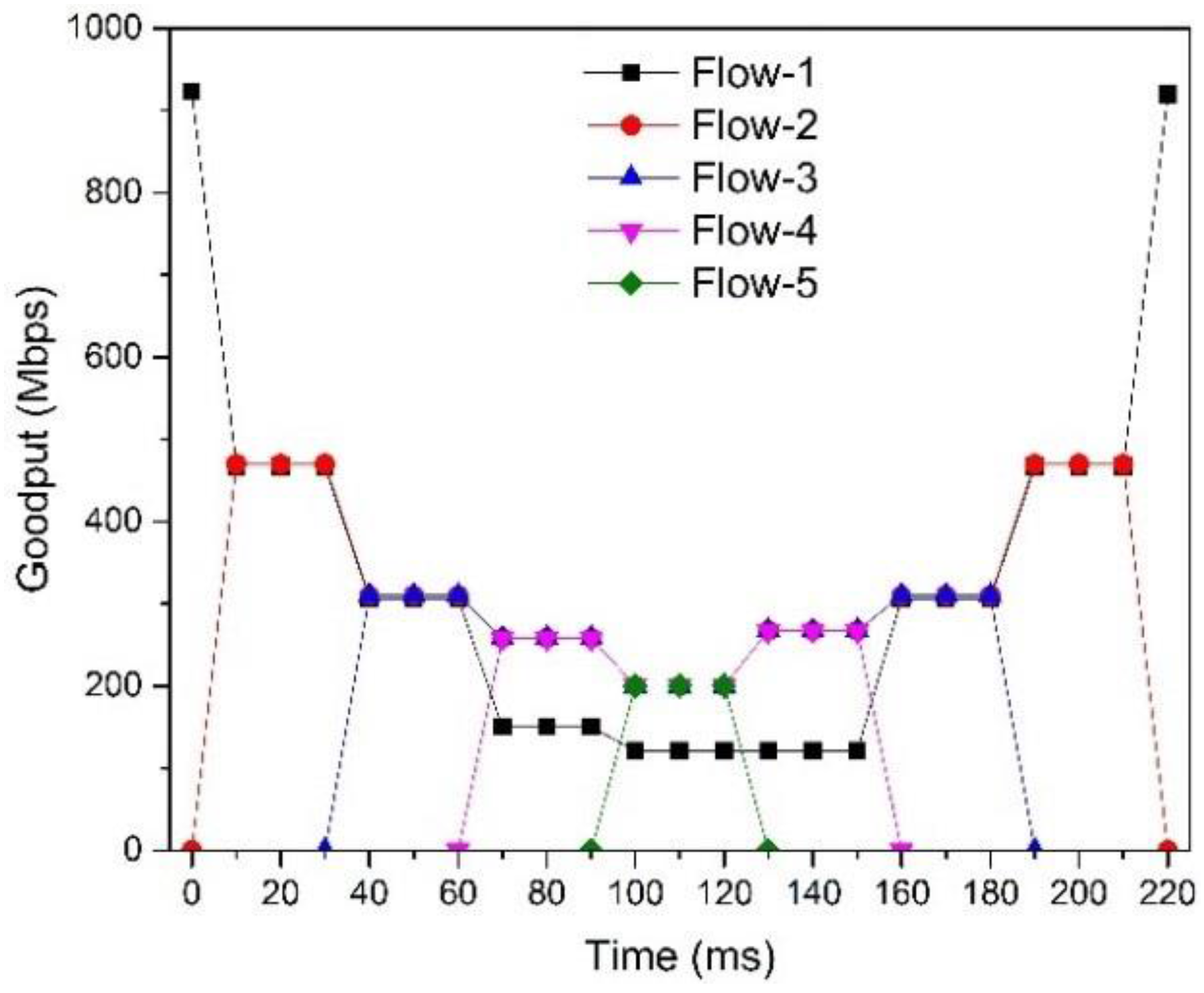
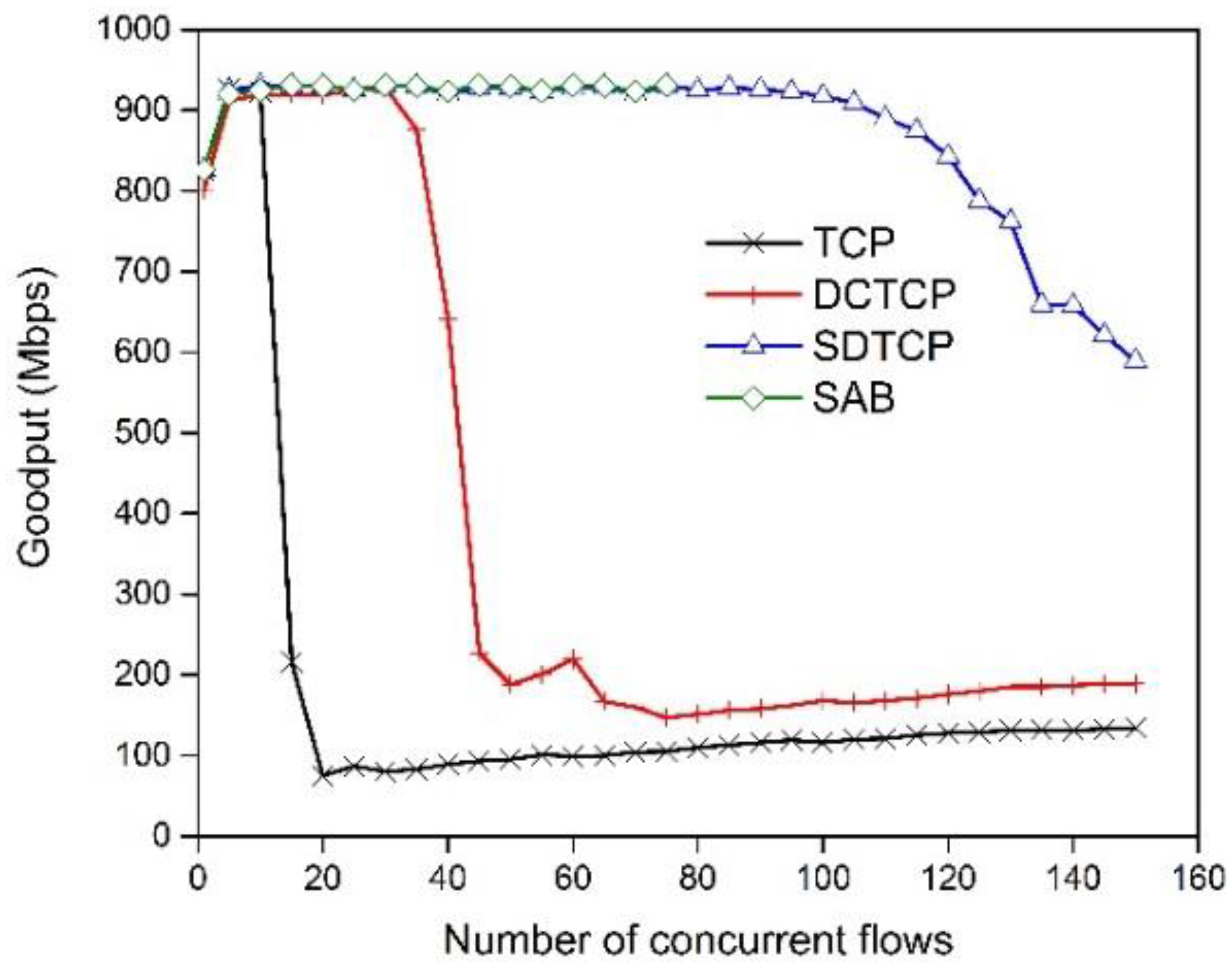
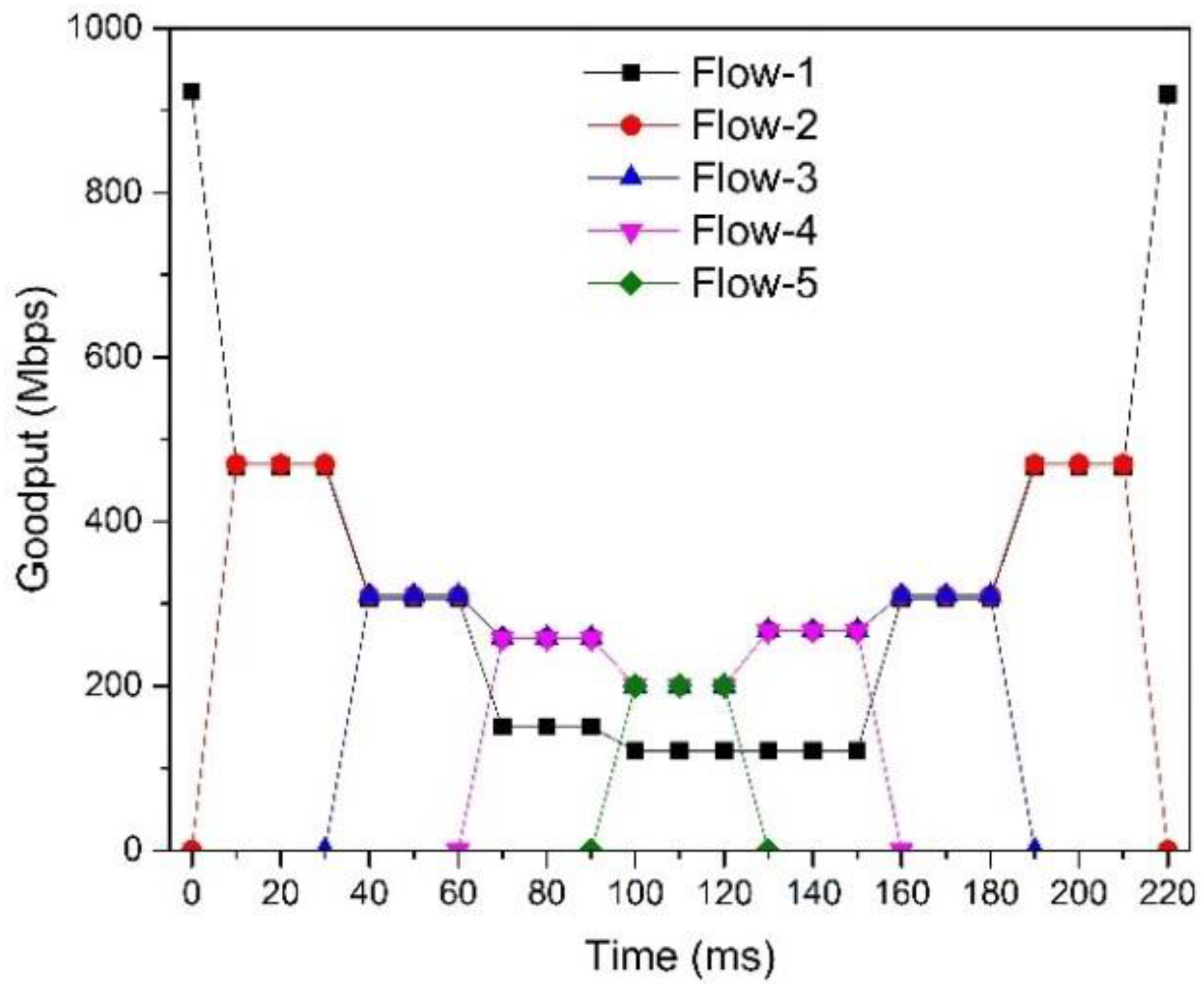
5.2.1. SDTCP Goodput
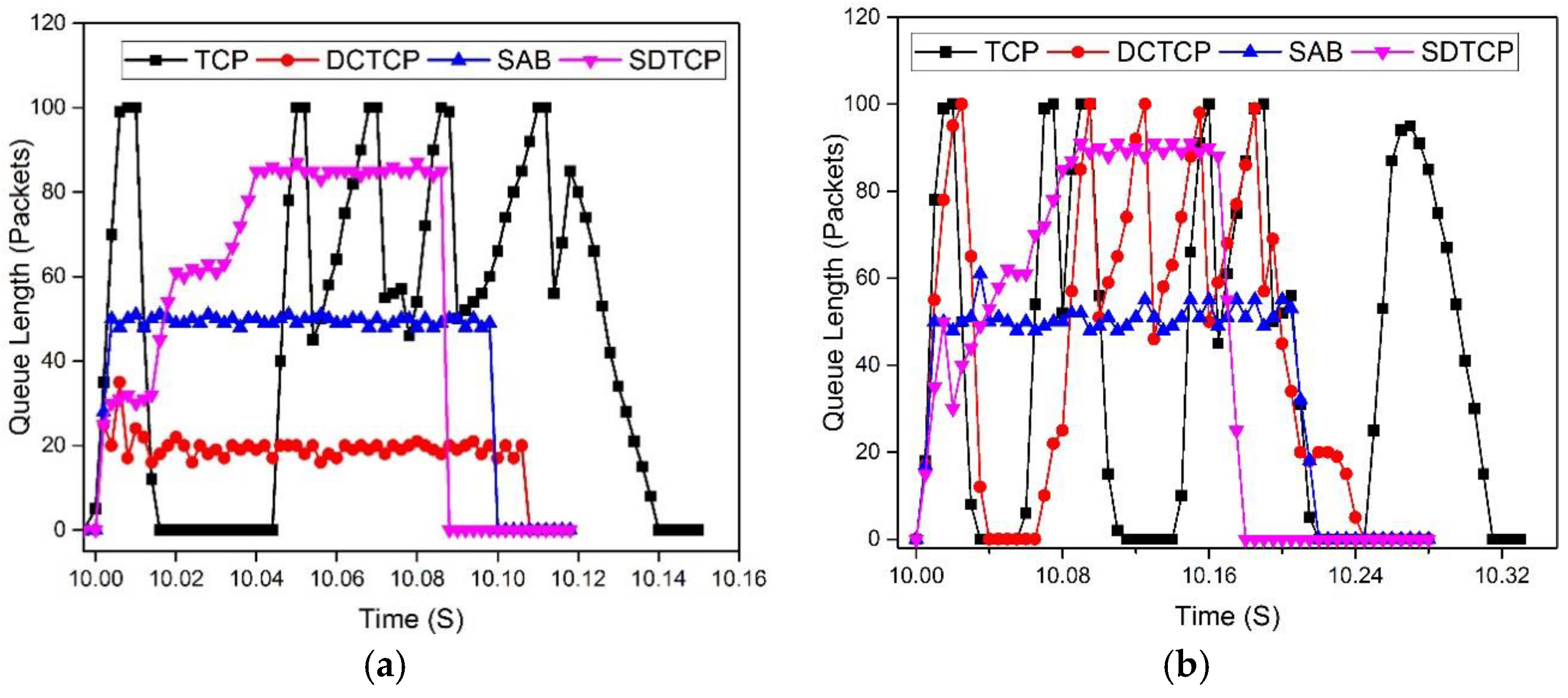
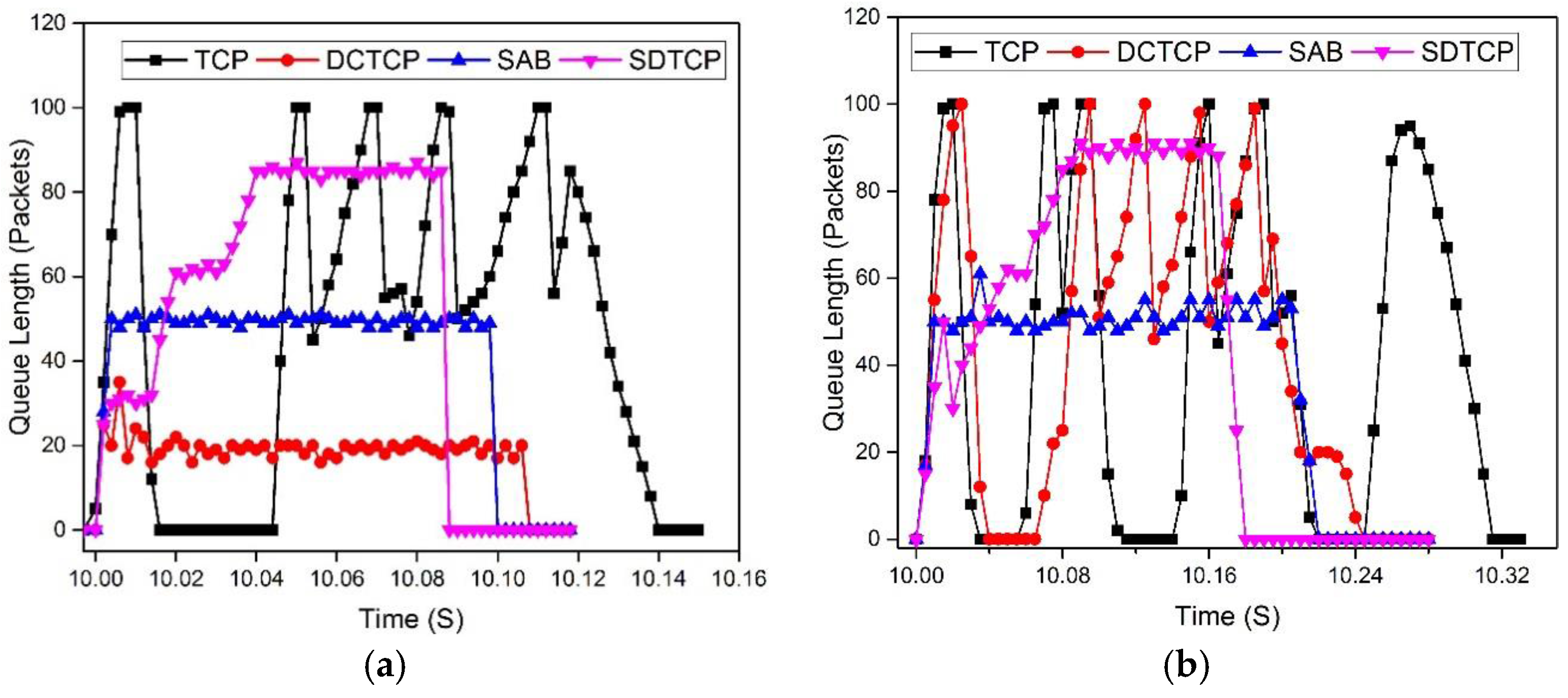
5.2.2. OF-Switch Queue Length
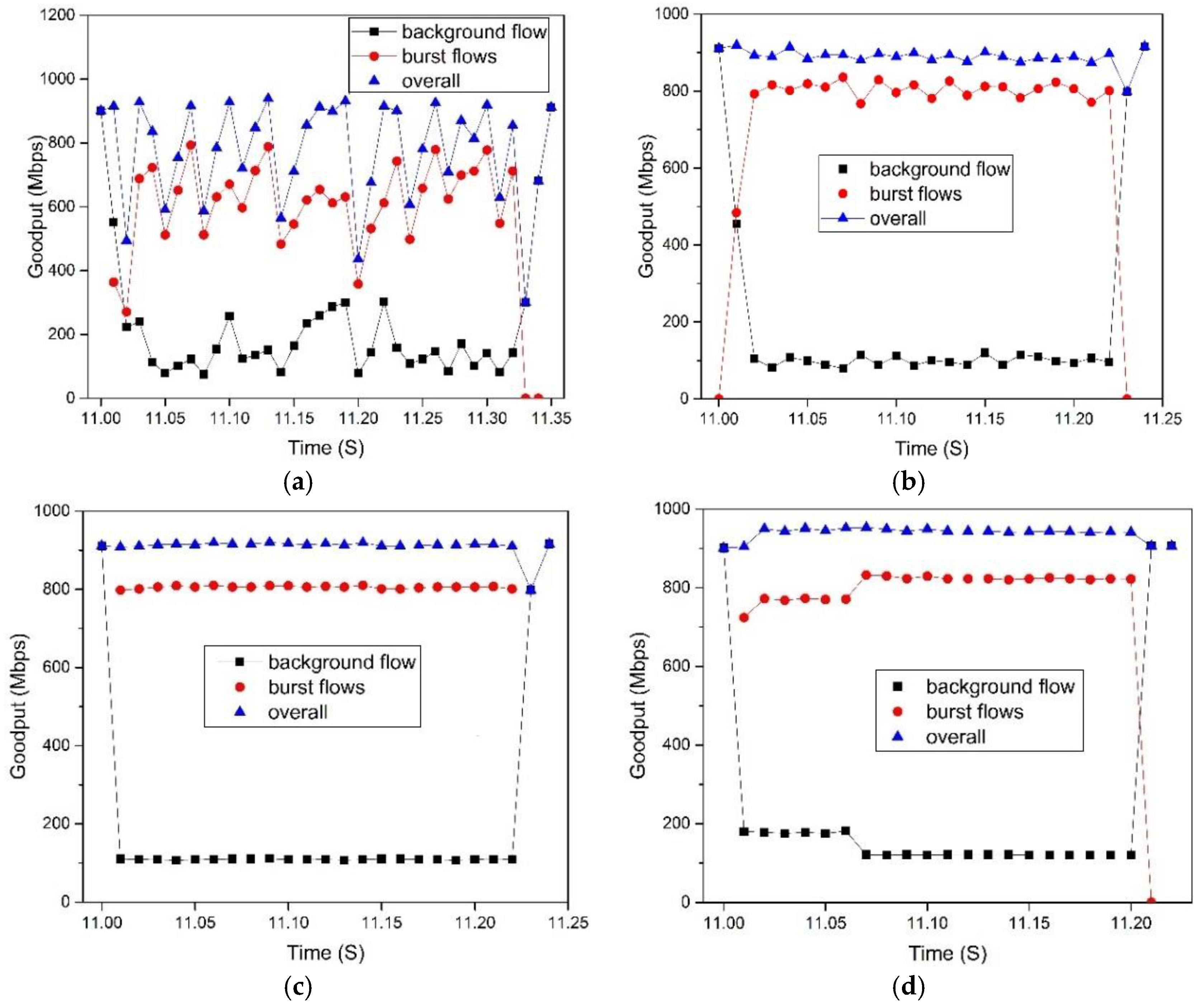
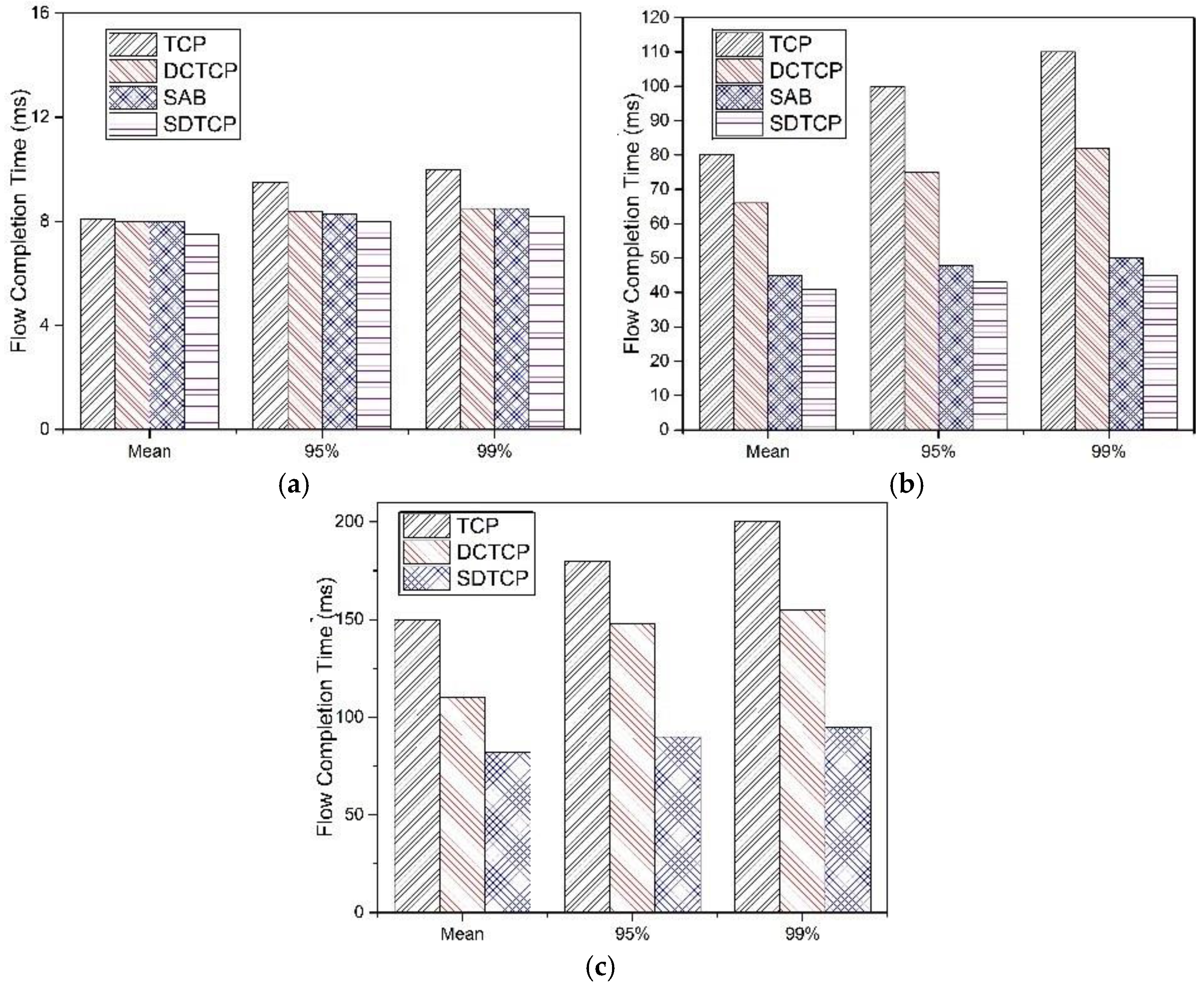
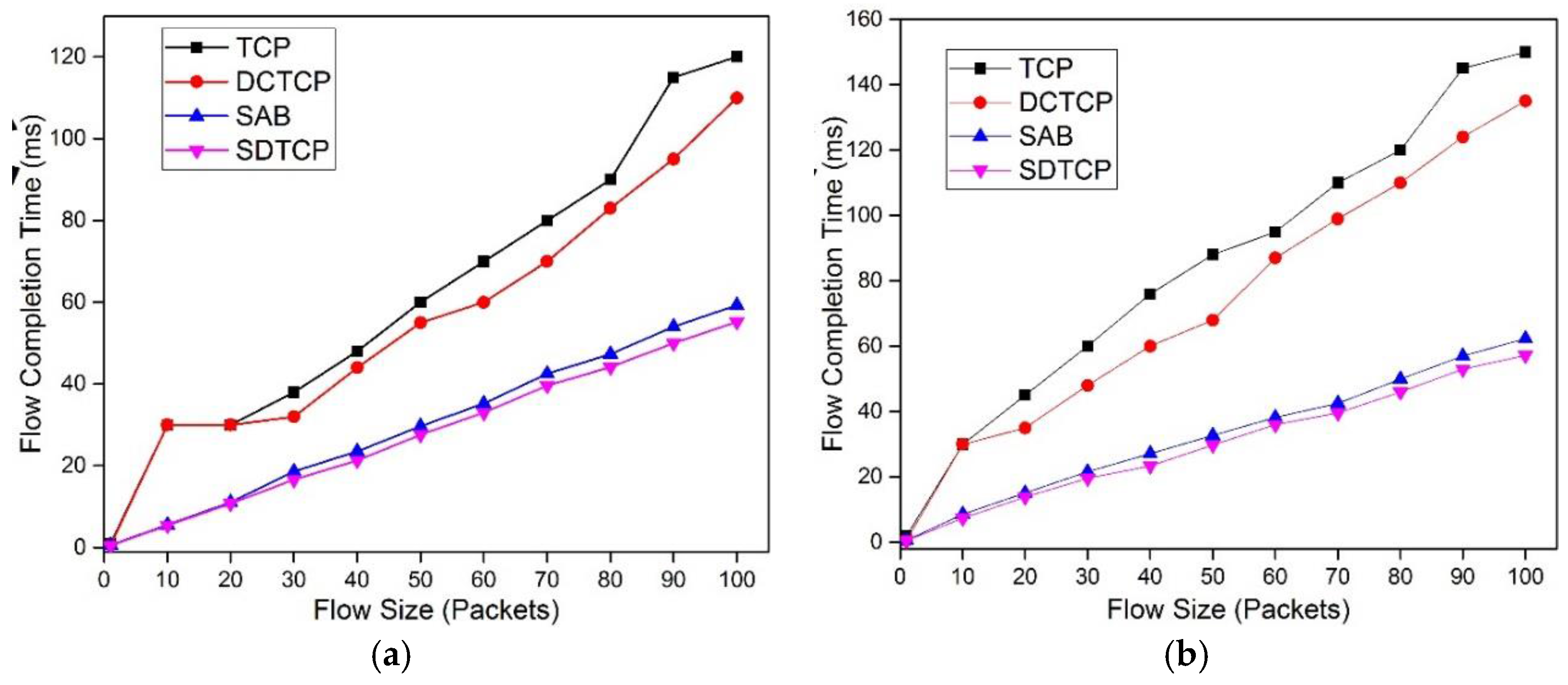
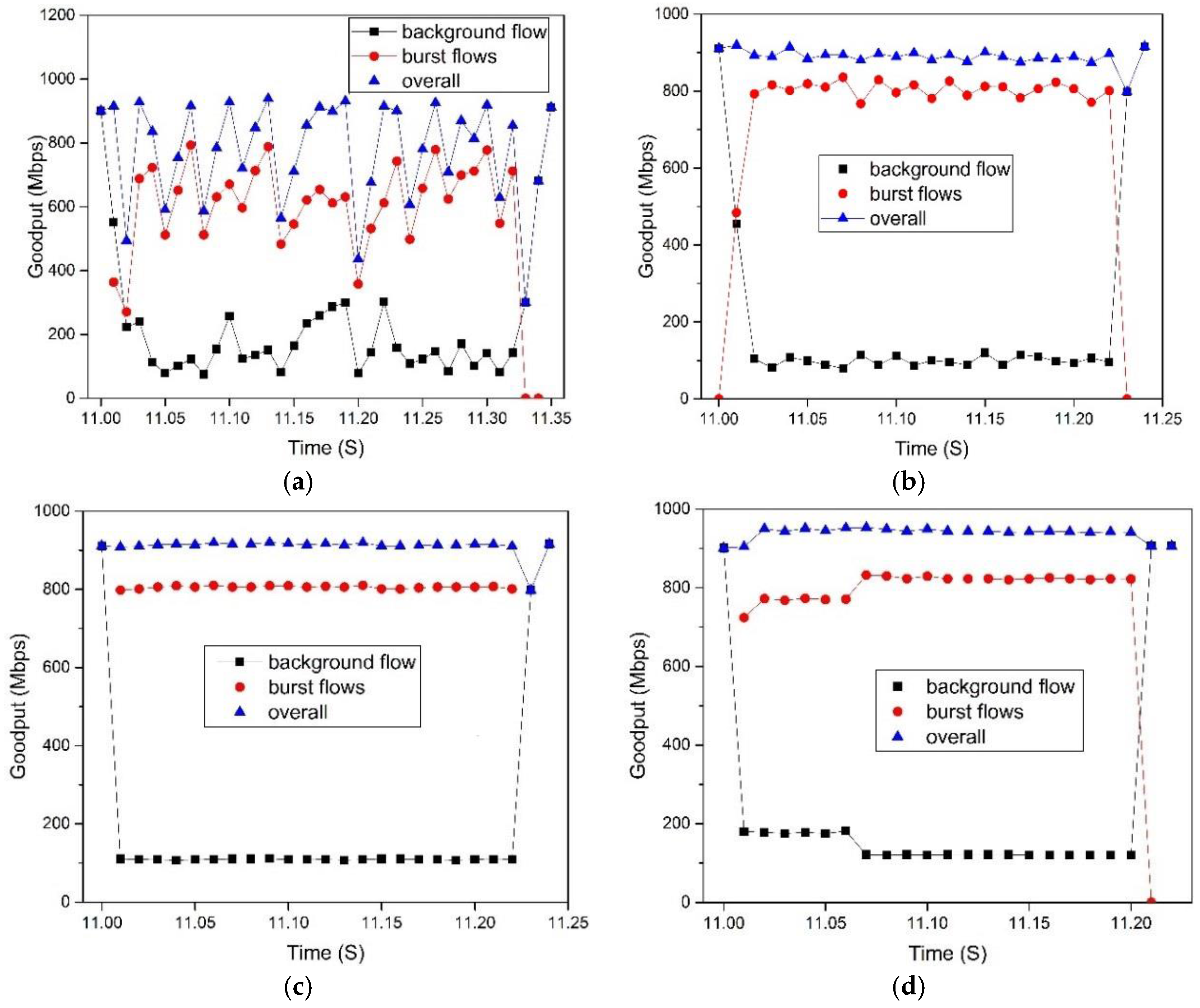
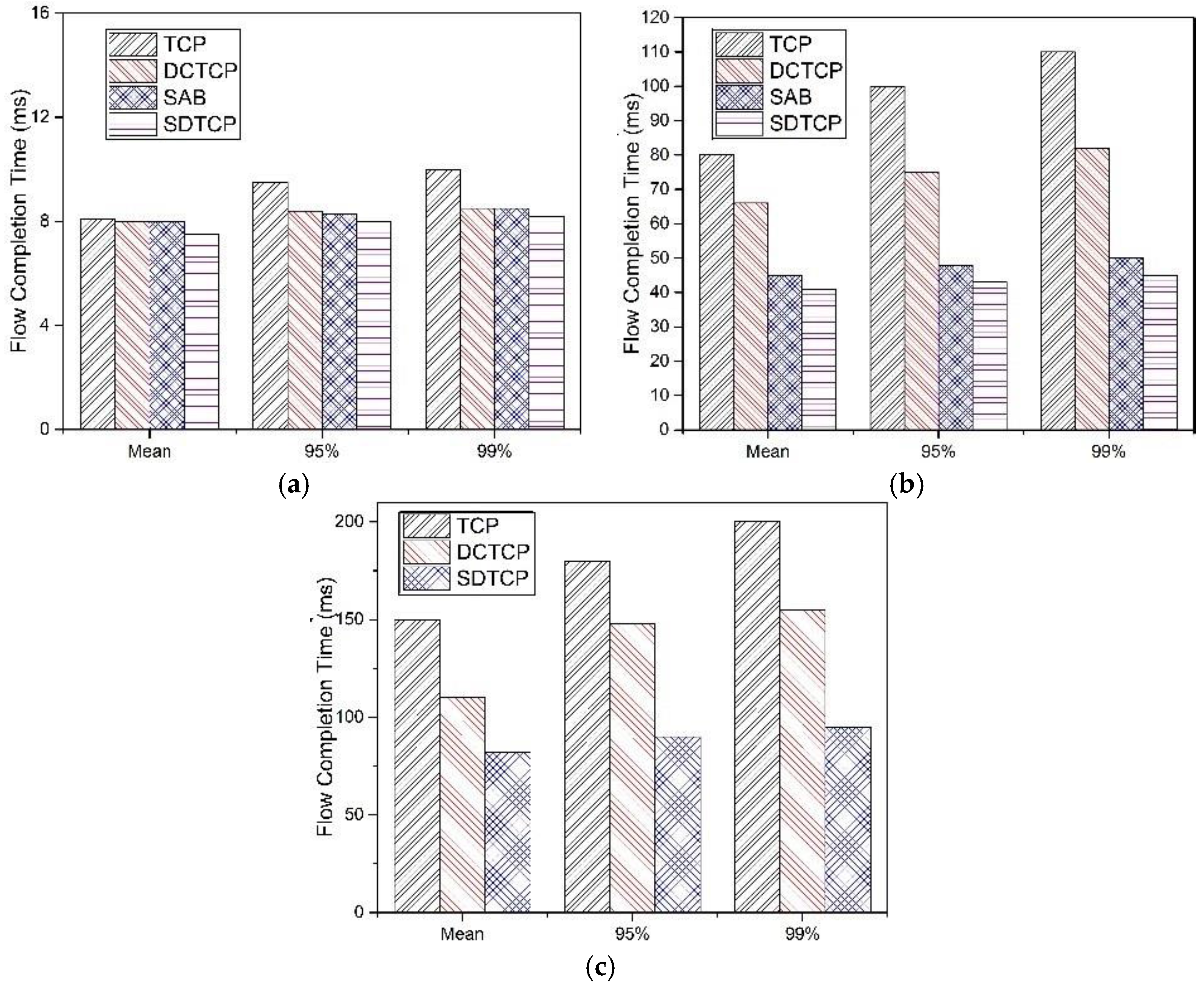
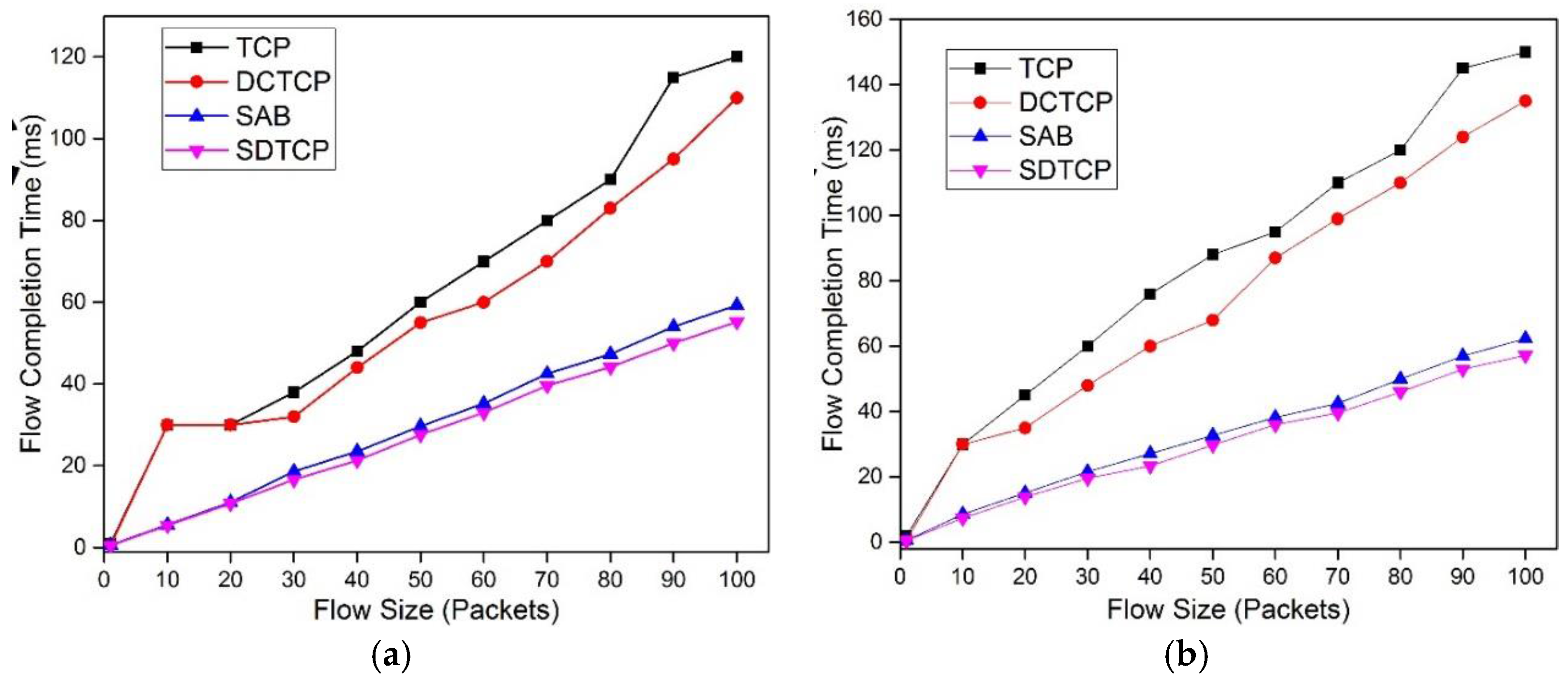
5.2.3. Flow Completion Time
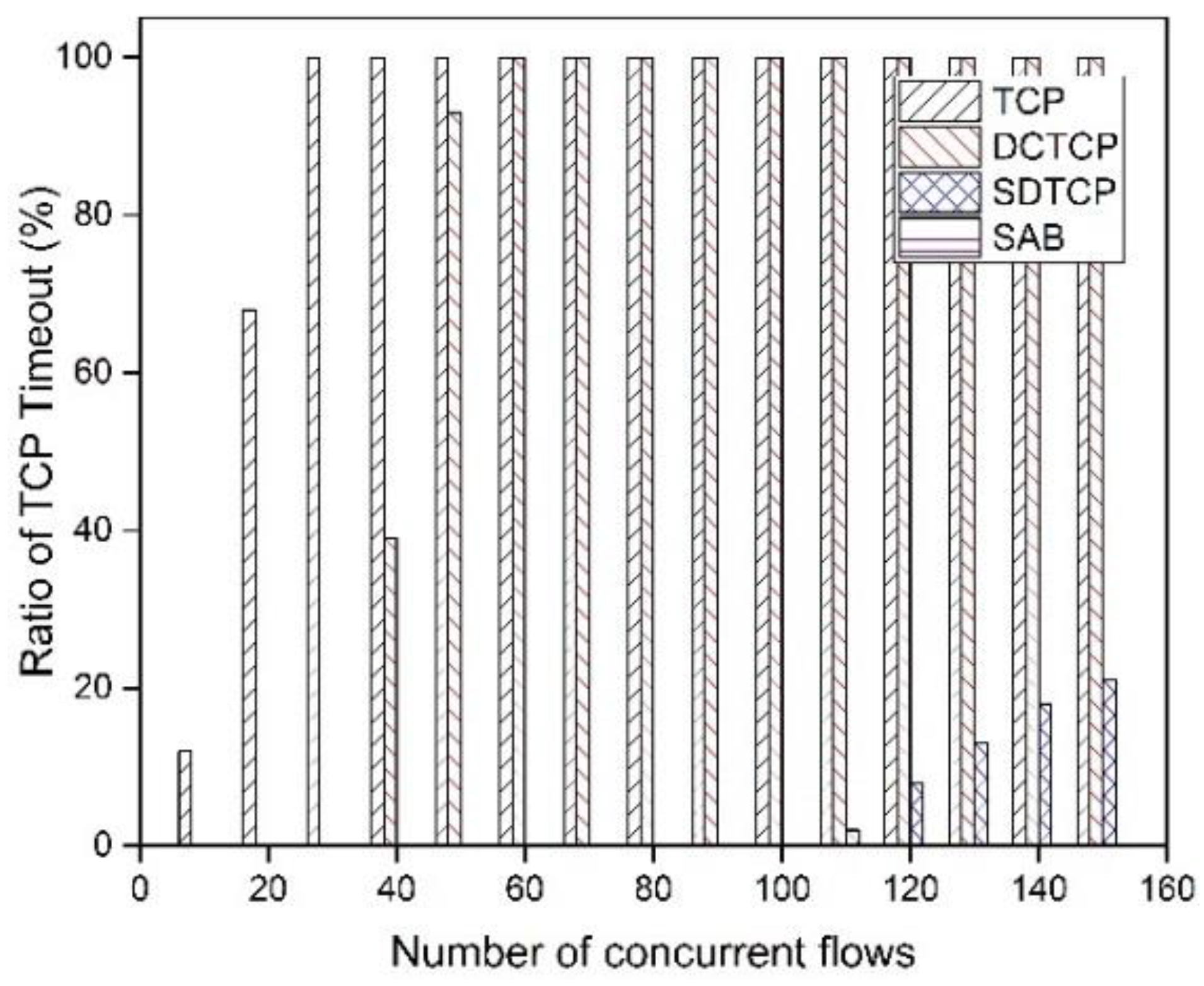
5.2.4. Fairness
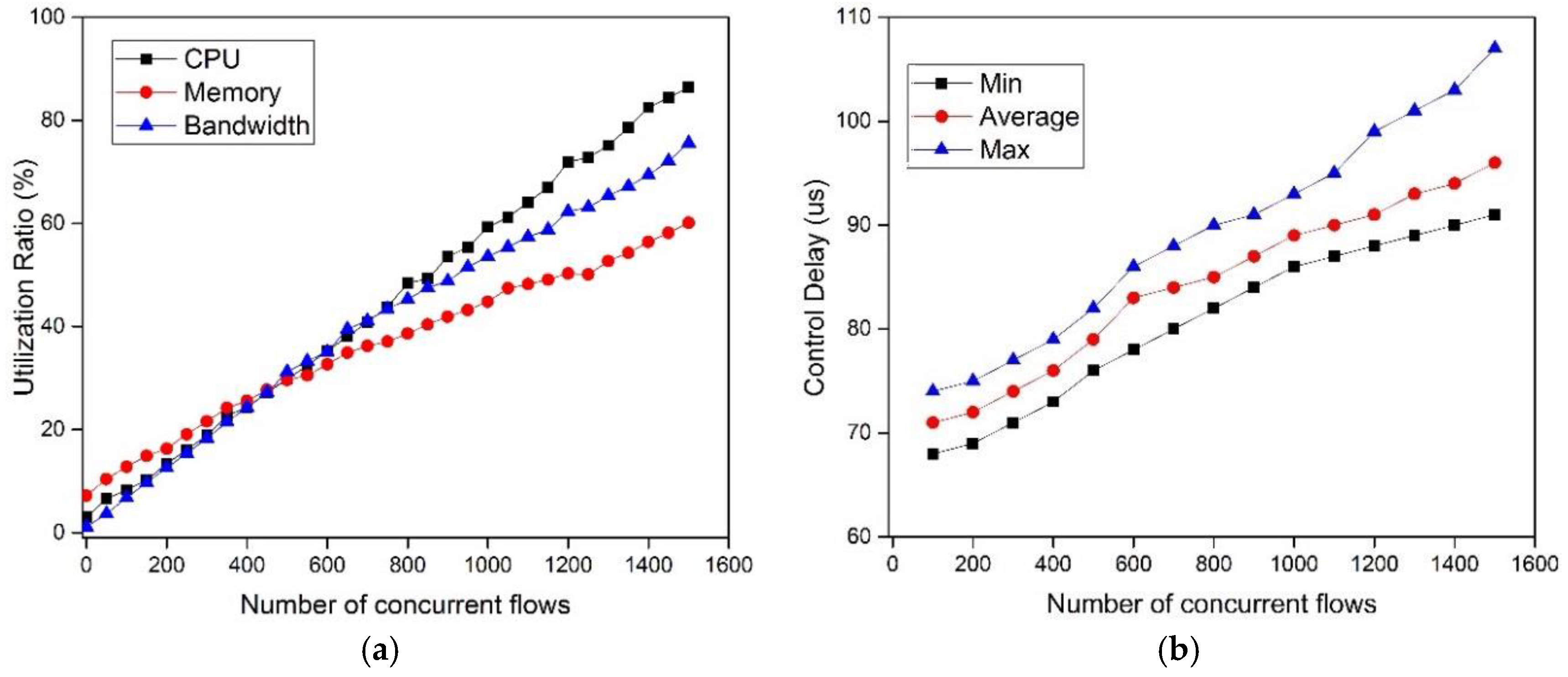
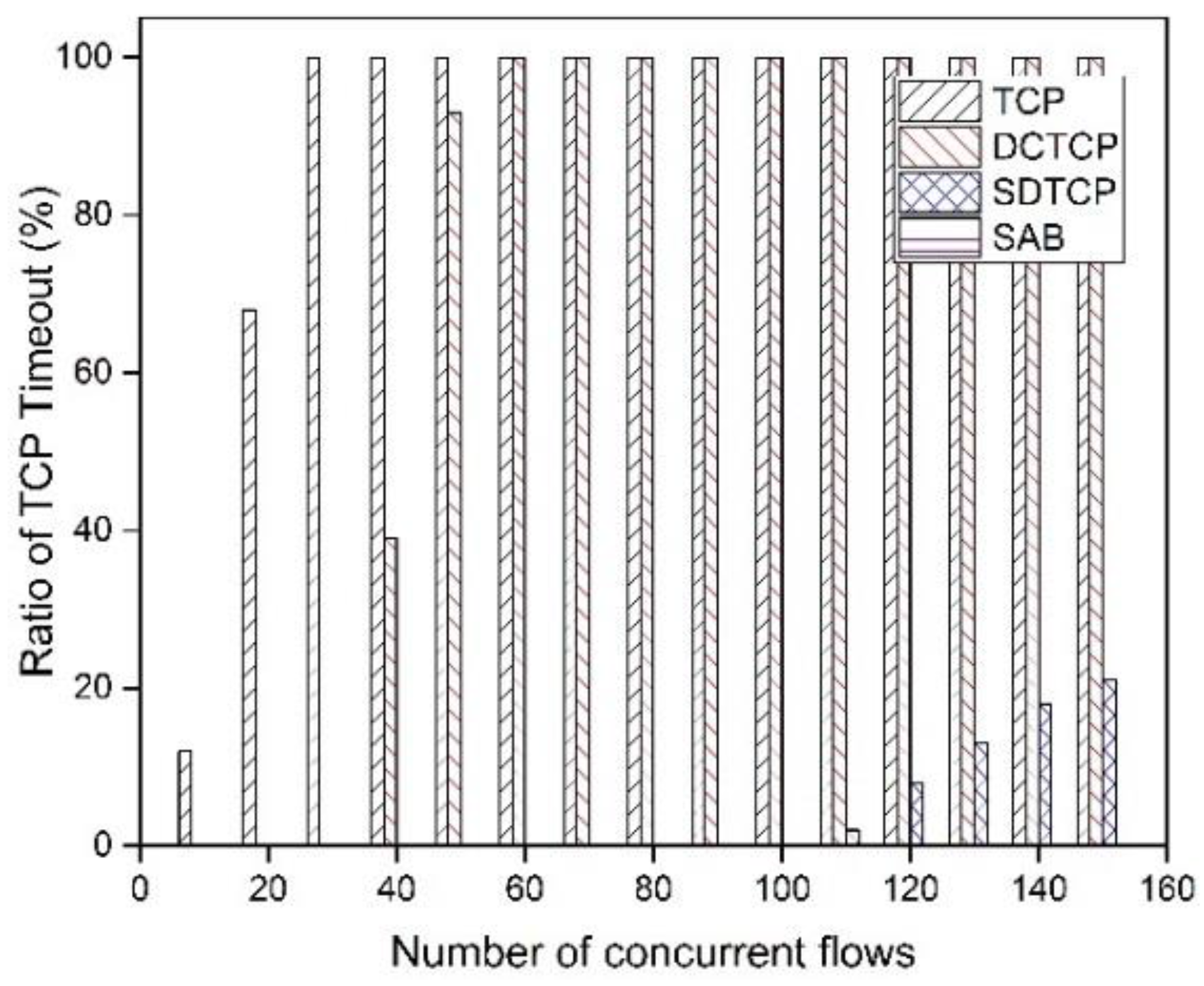
5.2.5. Controller Stress Test
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Jeschke, S.; Brecher, C.; Song, H.; Rawat, D. Industrial Internet of Things: Cybermanufacturing Systems; Springer: Cham, Switzerland, 2016; pp. 1–715. [Google Scholar]
- Nagle, D.; Serenyi, D.; Matthews, A. The Panasas ActiveScale Storage Cluster: Delivering scalable high bandwidth storage. In Proceedings of the 2004 ACM/IEEE Conference on Supercomputing, Pittsburgh, PA, USA, 6–12 November 2004; p. 53.
- Alizadeh, M.; Greenberg, A.; Maltz, D.A.; Padhye, J.; Patel, P.; Prabhakar, B.; Sengupta, S.; Sridharan, M. Data center TCP (DCTCP). In Proceedings of the SIGCOMM 2010, New Delhi, India, 30 August–3 September 2010; pp. 63–74.
- Phanishayee, A.; Krevat, E.; Vasudevan, V.; Andersen, D.G.; Ganger, G.R.; Gibson, G.A.; Seshan, S. Measurement and Analysis of TCP Throughput Collapse in Cluster-based Storage Systems. In Proceedings of the USENIX FAST 2008, San Jose, CA, USA, 26–29 February 2008; pp. 175–188.
- Podlesny, M.; Williamson, C. Solving the TCP-Incast Problem with Application-Level Scheduling. In Proceedings of the MASCOTS 2012, San Francisco, CA, USA, 7–9 August 2012; pp. 99–106.
- Podlesny, M.; Williamson, C. An Application-Level Solution for the TCP-Incast Problem in Data Center Networks. In Proceedings of the IWQoS 2011, San Jose, CA, USA, 6–7 June 2011; pp. 1–3.
- Benson, T.; Akella, A.; Maltz, D.A. Network traffic characteristics of data centers in the wild. In Proceedings of the IMC 2010, Melbourne, Australia, 1–3 November 2010; pp. 267–280.
- Kandula, S.; Sengupta, S.; Greenberg, A.; Patel, P.; Chaiken, R. The nature of data center traffic: Measurements & analysis. In Proceedings of the IMC 2009, Chicago, IL, USA, 4–6 November 2009; pp. 202–208.
- Greenberg, A.; Hamilton, J.R.; Jain, N.; Kandula, S.; Kim, C.; Lahiri, P.; Maltz, D.A.; Patel, P.; Sengupta, S. VL2: A Scalable and Flexible Data Center Network. In Proceedings of the SIGCOMM 2009, Barcelona, Spain, 16–21 August 2009; pp. 51–62.
- Dean, J.; Ghemawat, S. MapReduce: Simplified data processing on large clusters. Commun. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- Isard, M.; Budiu, M.; Yu, Y.; Birrell, A.; Fetterly, D. Dryad: Distributed data-parallel programs from sequential building blocks. In Proceedings of the EuroSys 2007, Lisbon, Portugal, 21–23 March 2007; pp. 59–72.
- Wilson, C.; Ballani, H.; Karagiannis, T.; Rowtron, A. Better never than late: Meeting deadlines in datacenter networks. In Proceedings of the SIGCOMM 2011, Toronto, ON, Canada, 15–19 August 2011; pp. 50–61.
- Vasudevan, V.; Phanishayee, A.; Shah, H.; Krevat, E.; Andersen, D.; Ganger, G.; Gibson, G.; Mueller, B. Safe and Effective Fine-grained TCP Retransmissions for Datacenter Communication. In Proceedings of the SIGCOMM 2009, Barcelona, Spain, 16–21 August 2009; pp. 303–314.
- Xu, K.; Wang, X.; Wei, W.; Song, H.; Mao, B. Toward software defined smart home. IEEE Commun. Mag. 2016, 54, 116–122. [Google Scholar] [CrossRef]
- Lu, Y.; Zhu, S. SDN-based TCP Congestion Control in Data Center Networks. In Proceedings of the 34th IEEE International Performance Computing and Communications Conference (IPCCC 2015), Nanjing, China, 14–16 December 2015; pp. 1–7.
- Wu, H.; Feng, Z.; Guo, C.; Zhang, Y. ICTCP: Incast Congestion Control for TCP in Data Center Networks. In Proceedings of the CoNEXT 2010, Philadelphia, PA, USA, 30 November–3 December 2010; p. 13.
- Zhang, J.; Ren, F.; Yue, X.; Shu, R. Sharing Bandwidth by Allocating Switch Buffer in Data Center Networks. IEEE J. Sel. Areas Commun. 2014, 32, 39–51. [Google Scholar] [CrossRef]
- Hwang, J.; Yoob, J.; Choi, N. Deadline and Incast Aware TCP for cloud data center networks. Comput. Netw. 2014, 68, 20–34. [Google Scholar] [CrossRef]
- Cheng, P.; Ren, F.; Shu, R.; Lin, C. Catch the Whole Lot in an Action: Rapid Precise Packet Loss Notification in Data Centers. In Proceedings of the USENIX NSDI 2014, Seattle, WA, USA, 2–4 April 2014; pp. 17–28.
- Zhang, J.; Ren, F.; Tang, L.; Lin, C. Taming TCP Incast throughput collapse in data center networks. In Proceedings of the ICNP 2013, Goettingen, Germany, 7–10 October 2013; pp. 1–10.
- Krevat, E.; Vasudevan, V.; Vasudevan, A. On Application-level Approaches to Avoiding TCP Throuthput Collapse in Cluster-based Storage Systems. In Proceedings of the PDSW’07, Reno, NV, USA, 11 November 2007; pp. 1–4.
- Ghobadi, M.; Yeganeh, S.; Ganjali, Y. Rethinking end-to-end congestion control in software-defined networks. In Proceedings of the 11th ACM Workshop on Hot Topics in Networks, Redmond, WA, USA, 29–30 October 2012; pp. 61–66.
- Jouet, S.; Pezaros, D.P. Measurement-Based TCP Parameter Tuning in Cloud Data Centers. In Proceedings of the ICNP 2013, Goettingen, Germany, 7–10 October 2013; pp. 1–3.
- Wenfei, W.; Yizheng, C.; Ramakrishnan, D.; Kim, D.; Anand, A.; Akella, A. Adaptive Data Transmission in the Cloud. In Proceedings of the IWQoS 2013, Montreal, QC, Canada, 3–4 June 2013.
- Altukhov, V.; Chemeritskiy, E. On real-time delay monitoring in software-defined networks. In Proceedings of the International Science and Technology Conference (MoNeTeC), Moscow, Russia, 28–29 October 2014; pp. 1–6.
- Vamanan, B.; Hasan, J.; Vijaykumar, T.N. Deadline-aware datacenter TCP. ACM SIGCOMM Comput. Commun. Rev. 2012, 42, 115–126. [Google Scholar] [CrossRef]
- Kelly, F. Fairness and stability of end-to-end congestion control. Eur. J. Control 2003, 9, 159–176. [Google Scholar] [CrossRef]
- Tavakoli, A.; Casado, M.; Koponen, T.; Shenker, S. Applying nox to the datacenter. In Proceedings of the Workshop on Hot Topics in Networks, New York, NY, USA, 22–23 October 2009.
- Mininet. Available online: http://mininet.org/ (accessed on 20 March 2016).
- Big Switch Networks. Floodlight. Available online: http://www.projectfloodlight.org/floodlight/ (accessed on 20 November 2016).
- DCTCP Patch. Available online: http://simula.stanford.edu/~alizade/Site/DCTCP.html (accessed on 20 November 2016).
- Kuzmanovic, A.; Mondal, A.; Floyd, S.; Ramakrishnan, K. Adding Explicit Congestion Notification (ECN) Capability to TCP’s SYN/ACK Packets. Available online: https://tools.ietf.org/html/rfc5562 (accessed on 20 November 2016).
- Floyd, S.; Henderson, T. The NewReno Modification to TCP’s Fast Recovery Algorithm. Available online: https://tools.ietf.org/html/rfc2582 (accessed on 20 November 2016).
© 2017 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, Y.; Ling, Z.; Zhu, S.; Tang, L. SDTCP: Towards Datacenter TCP Congestion Control with SDN for IoT Applications. Sensors 2017, 17, 109. https://doi.org/10.3390/s17010109
Lu Y, Ling Z, Zhu S, Tang L. SDTCP: Towards Datacenter TCP Congestion Control with SDN for IoT Applications. Sensors. 2017; 17(1):109. https://doi.org/10.3390/s17010109
Chicago/Turabian StyleLu, Yifei, Zhen Ling, Shuhong Zhu, and Ling Tang. 2017. "SDTCP: Towards Datacenter TCP Congestion Control with SDN for IoT Applications" Sensors 17, no. 1: 109. https://doi.org/10.3390/s17010109
APA StyleLu, Y., Ling, Z., Zhu, S., & Tang, L. (2017). SDTCP: Towards Datacenter TCP Congestion Control with SDN for IoT Applications. Sensors, 17(1), 109. https://doi.org/10.3390/s17010109