
Identifying Plant Part Composition of Forest Logging Residue Using Infrared Spectral Data and Linear Discriminant Analysis

 ,
,
Abstract
:1. Introduction
2. Experimental Section
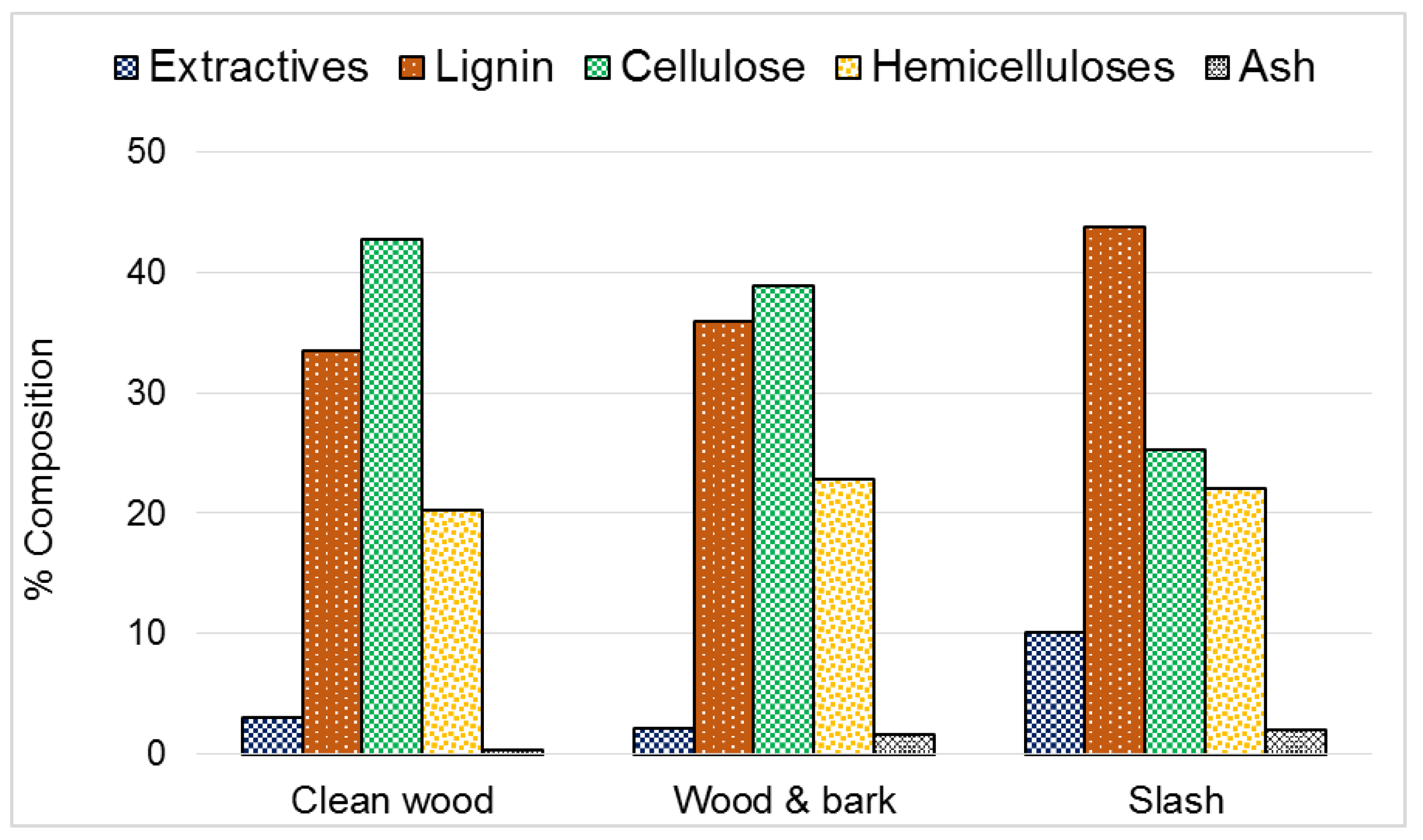
2.1. Materials
2.2. Methods
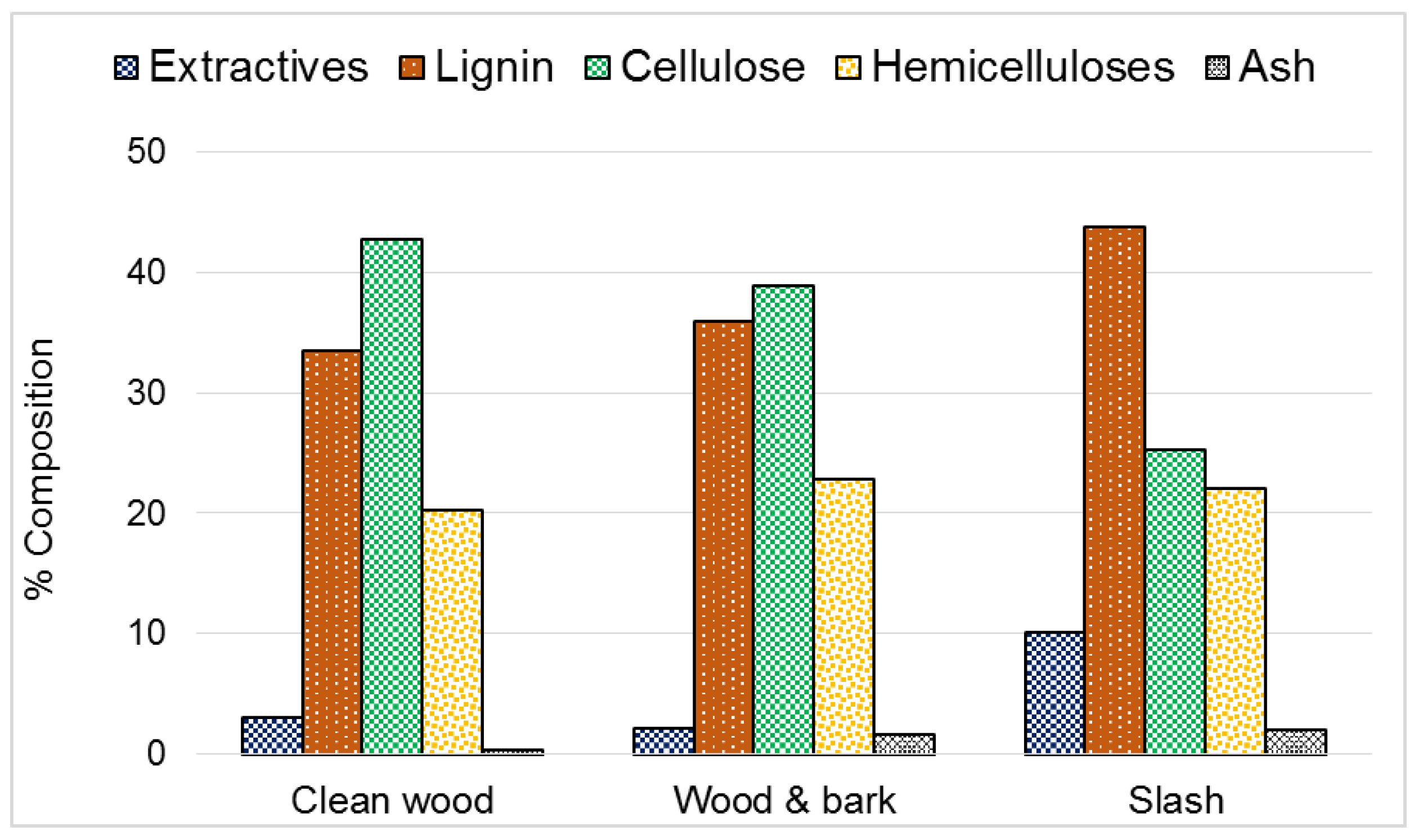
2.2.1. Determination of Chemical Composition and Ash Content
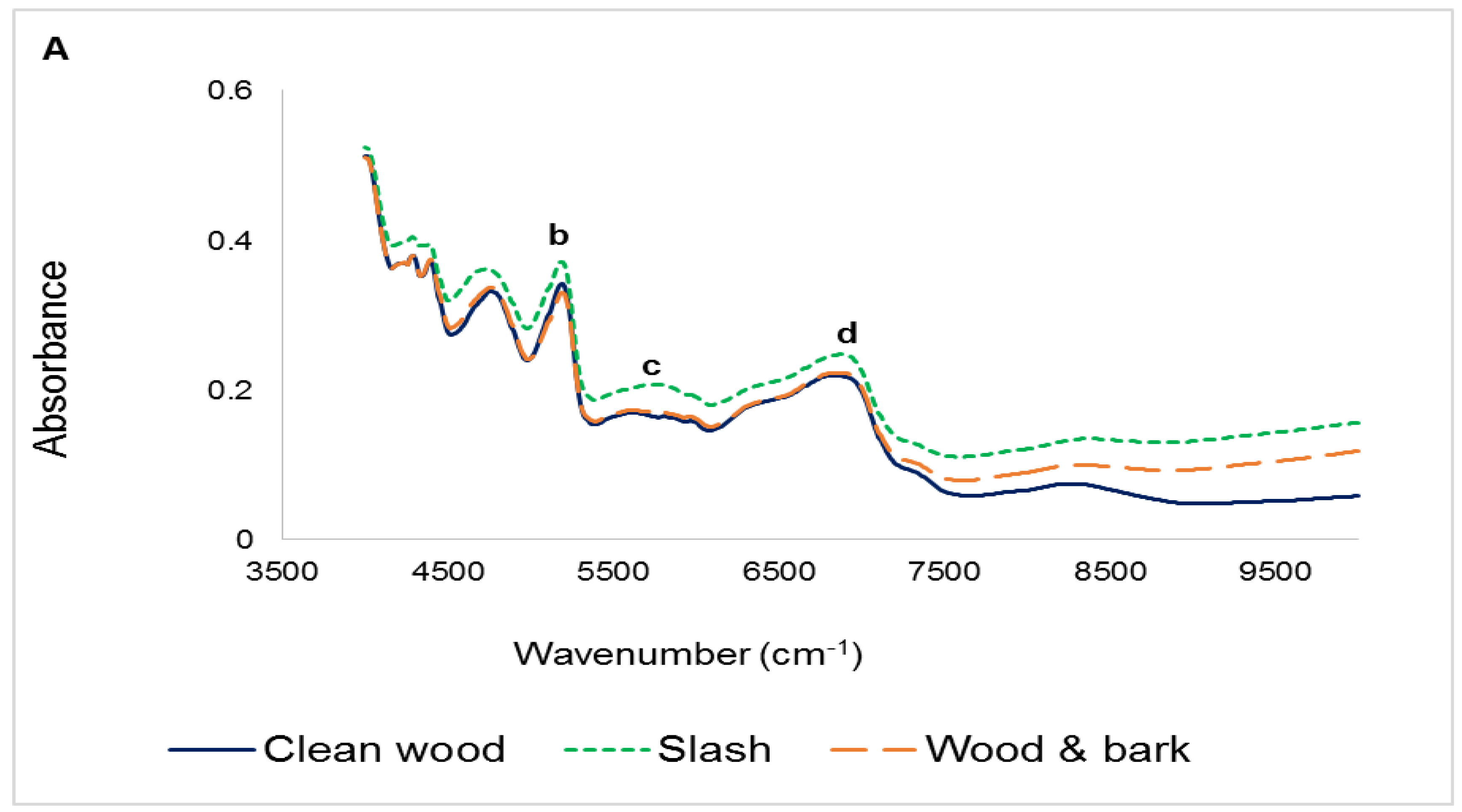
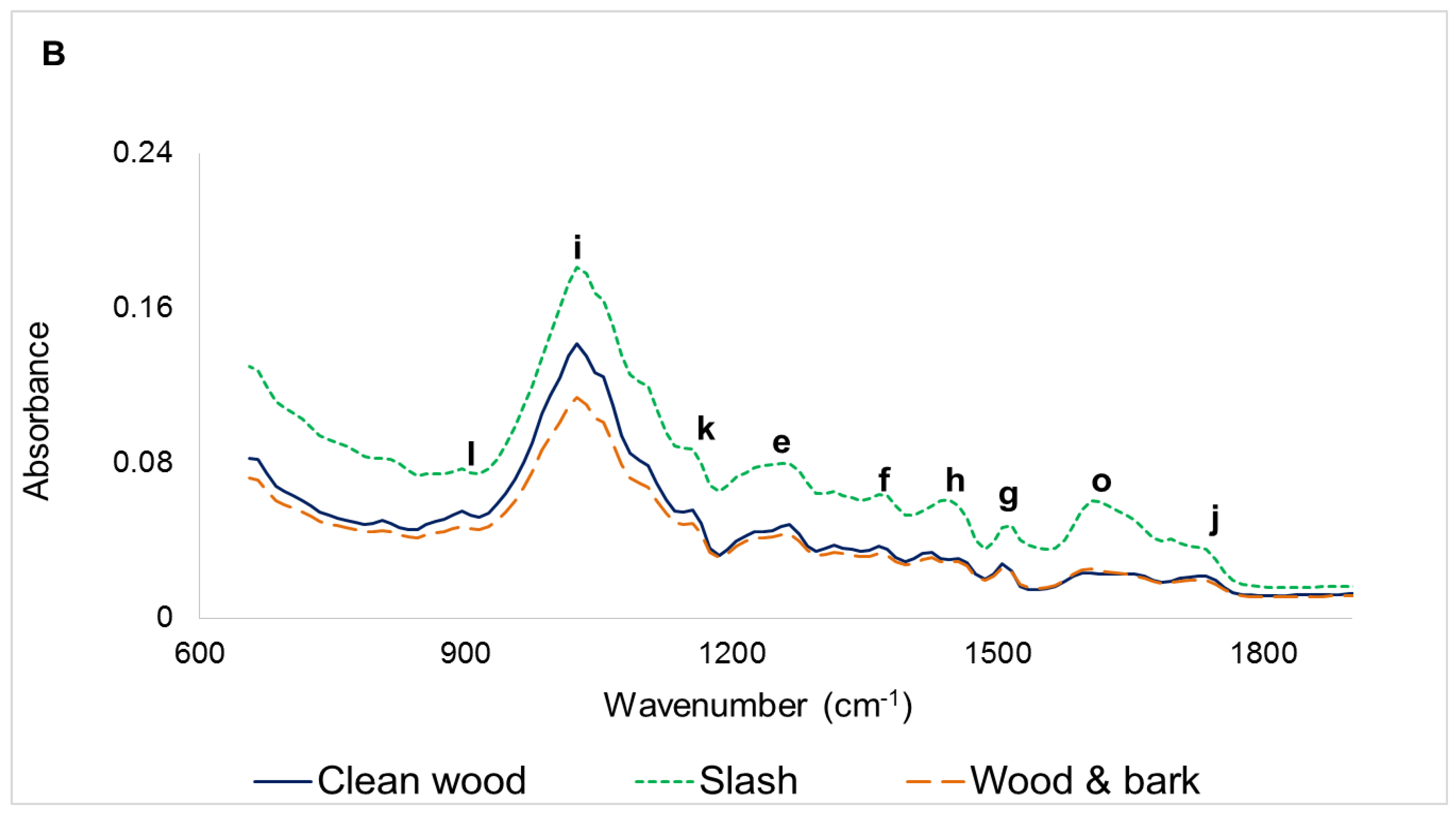
2.2.2. Infrared Spectra Collection
2.2.3. Multivariate Data Analysis
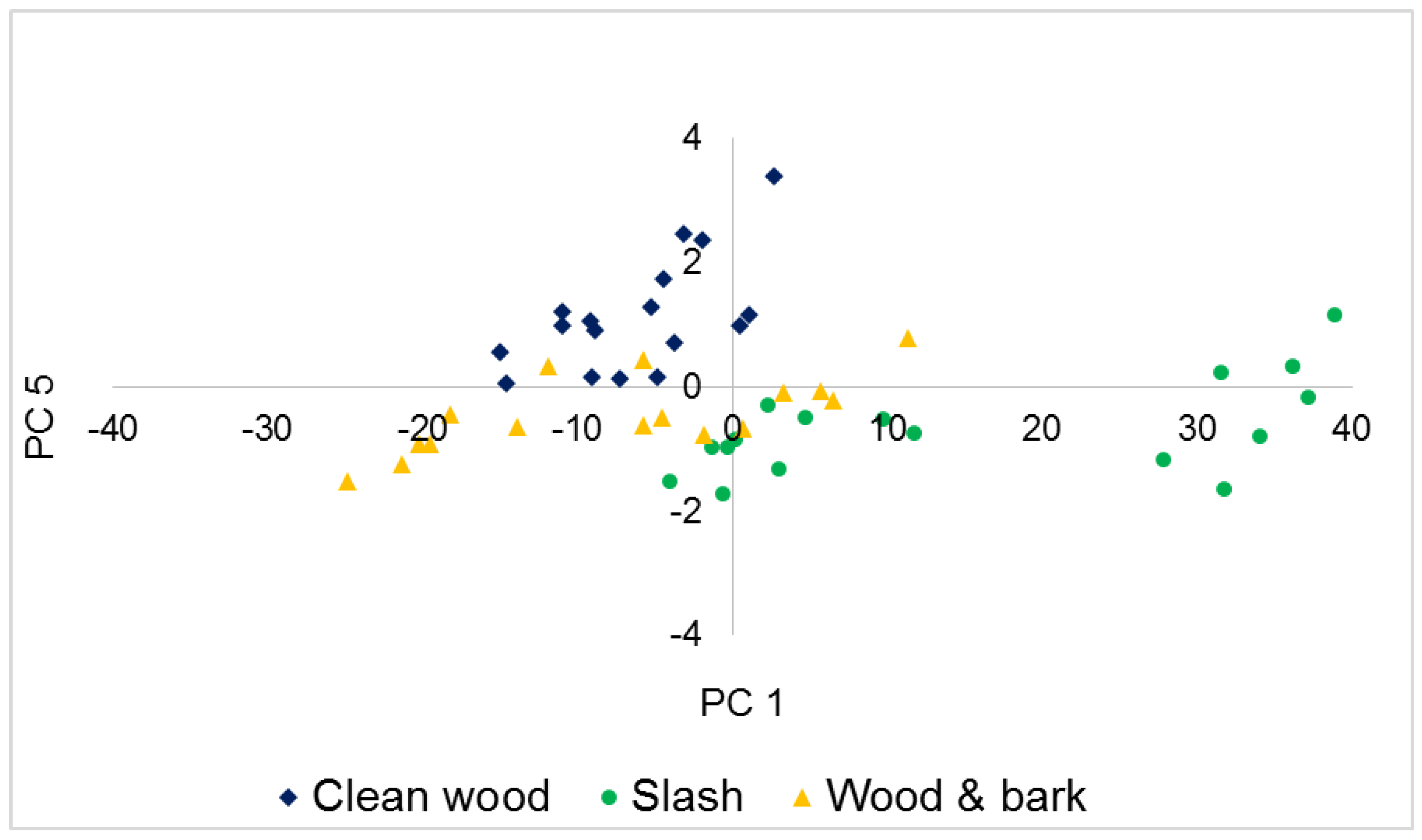
Principal Component Analysis (PCA)
Linear Discriminant Analysis (LDA)
3. Results and Discussion
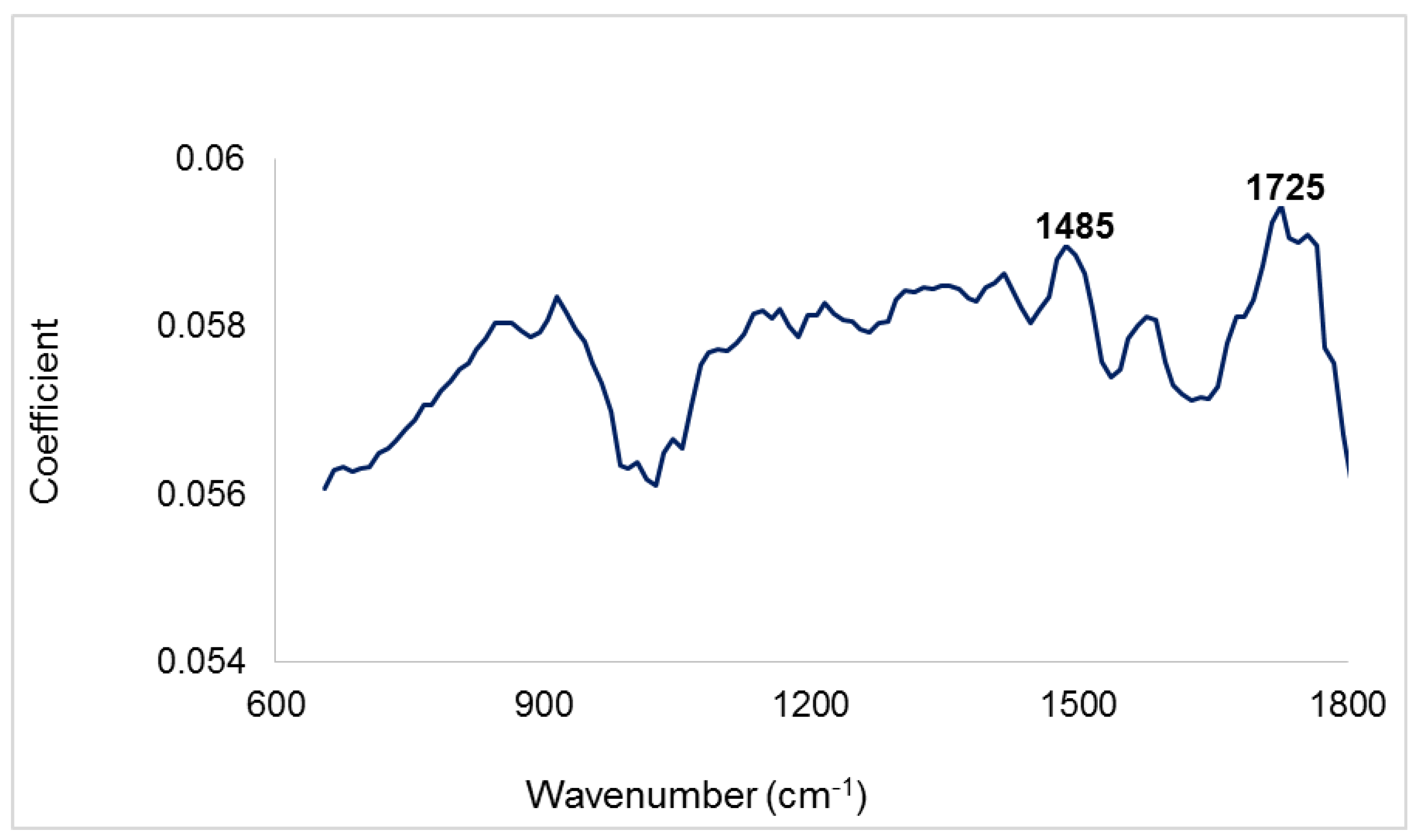
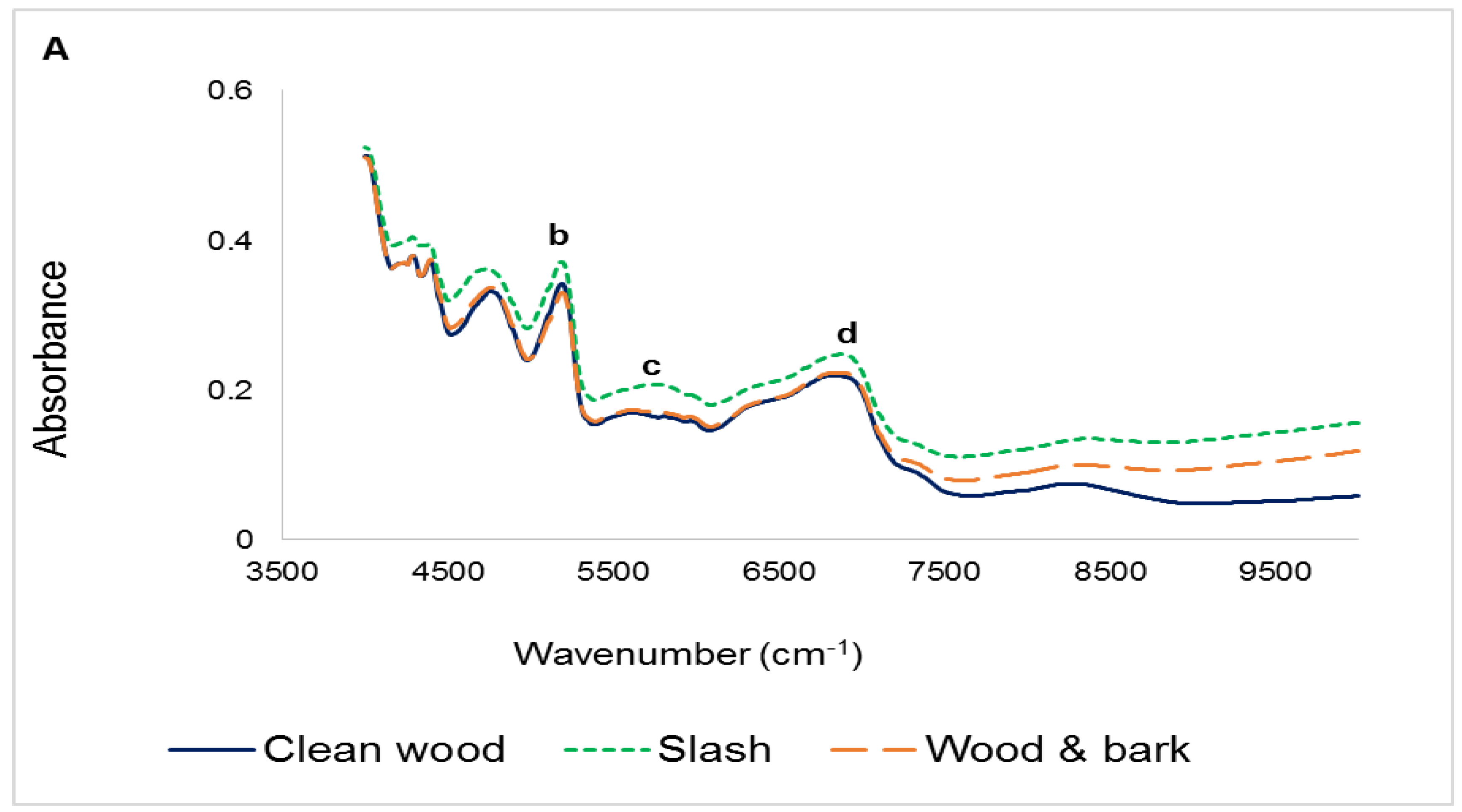
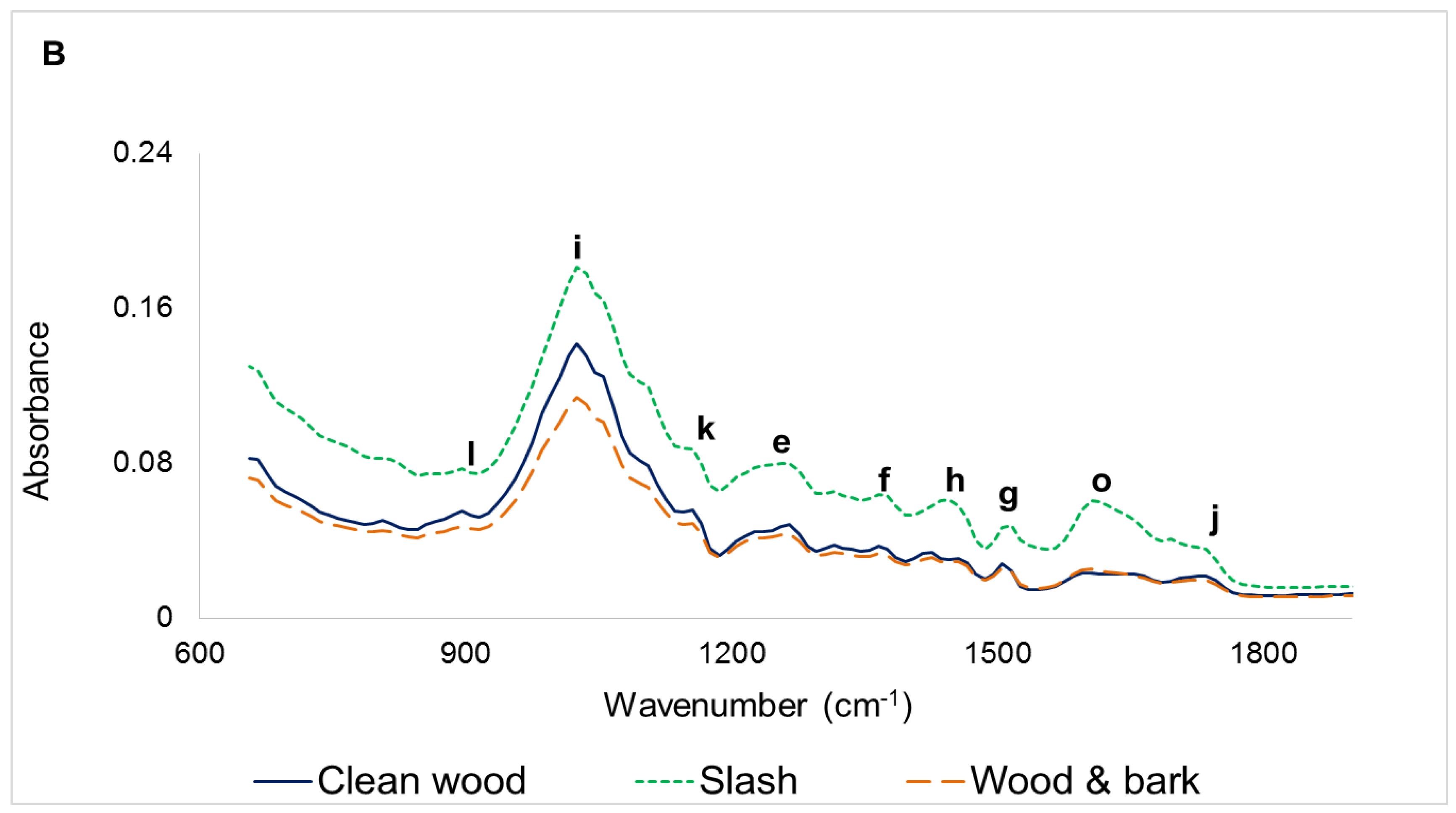
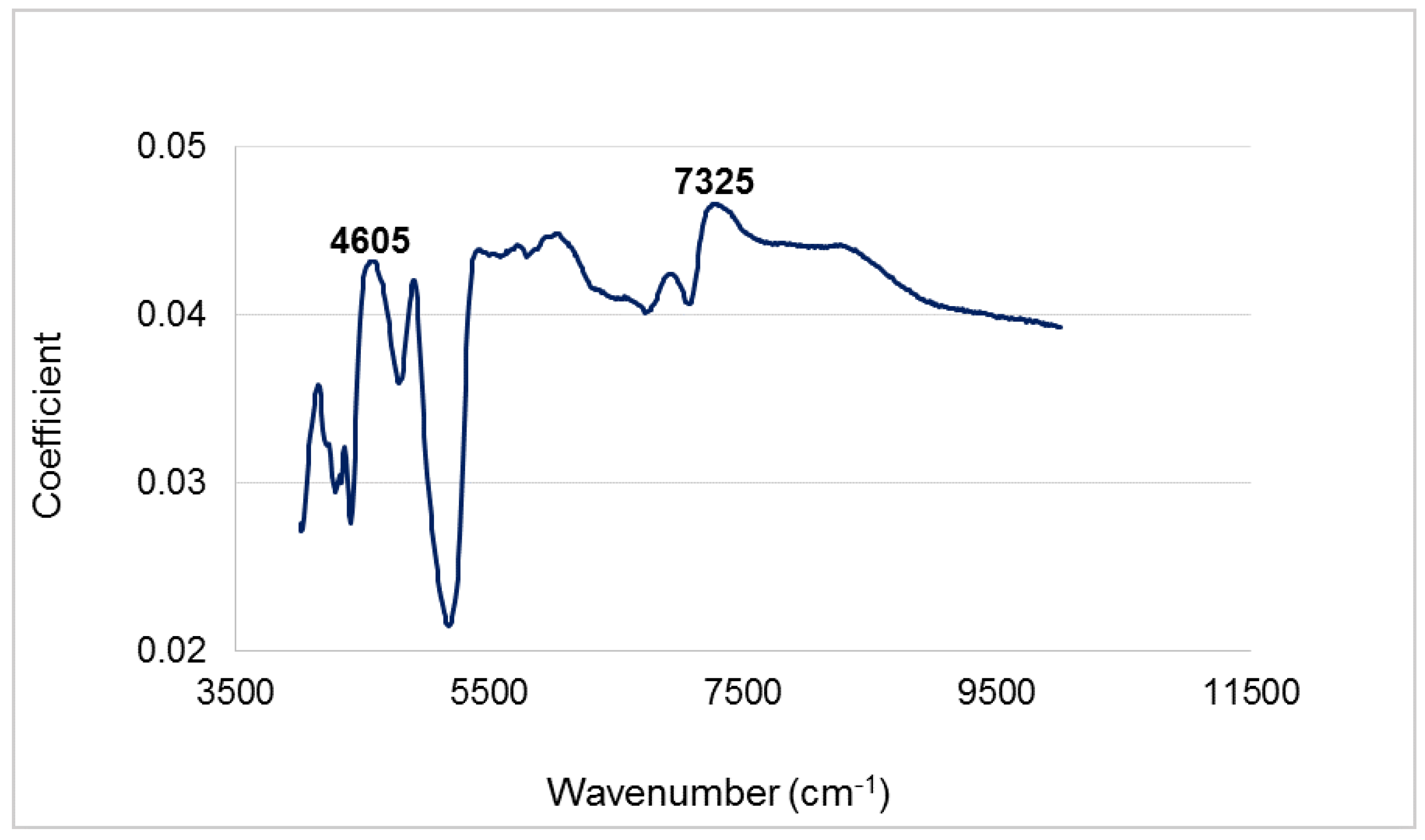
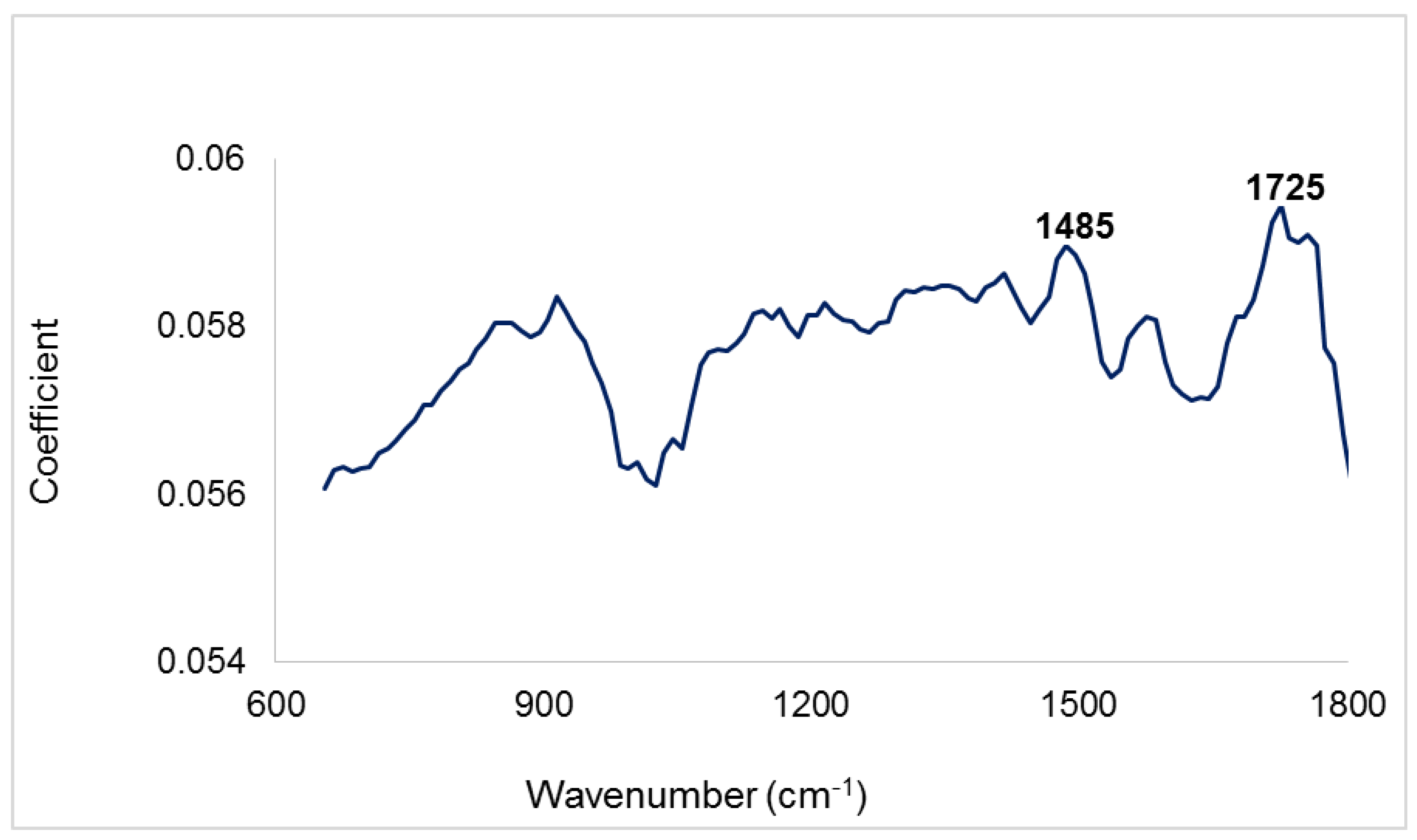
3.1. Infrared Spectra
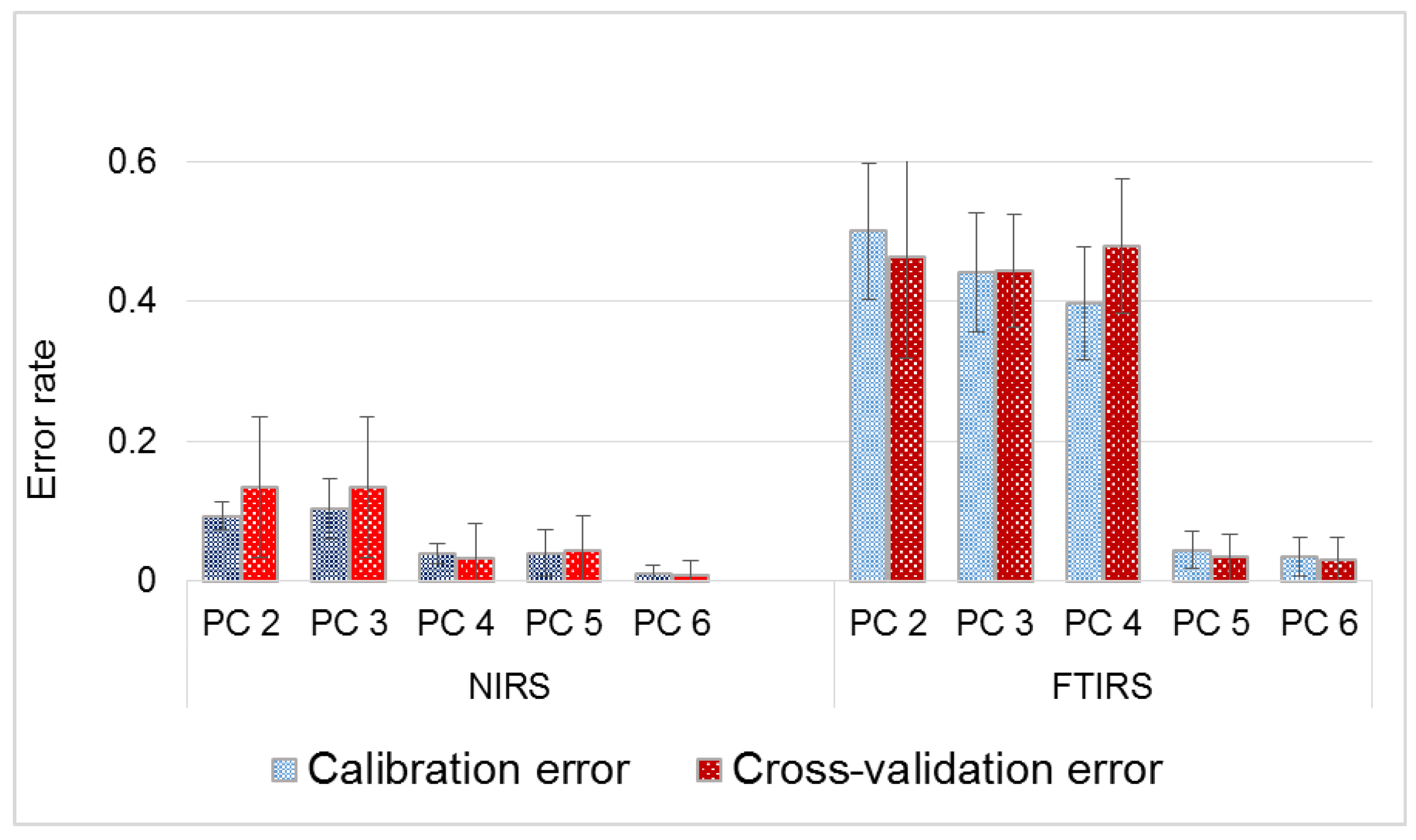
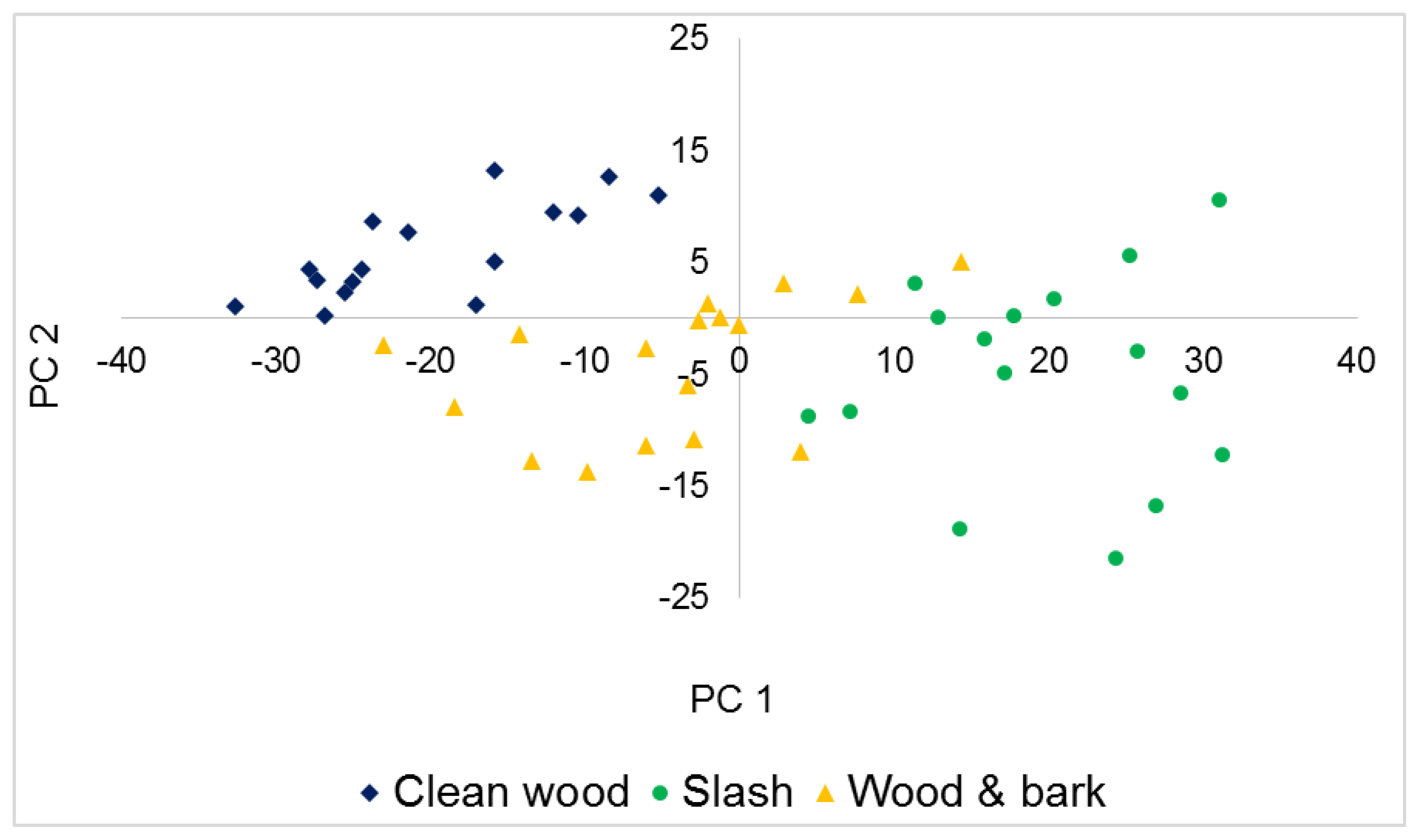
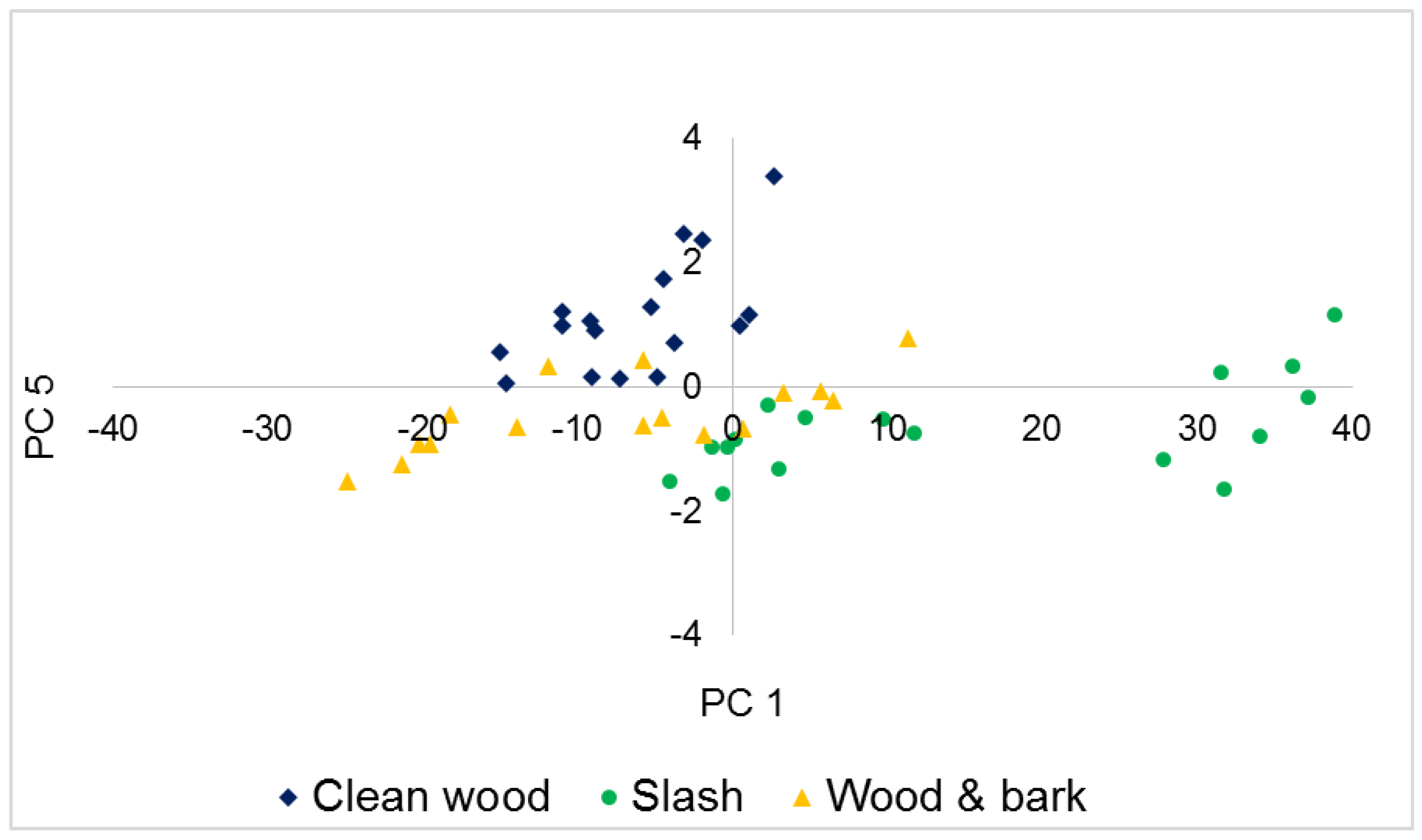
3.2. Principal Component Analysis
3.3. Linear Discriminant Analysis (LDA)
3.4. Remarks
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- US Department of Energy. Billion-Ton Update: Biomass Supply for a Bioenergy and Bioproducts Industry; Oak Ridge National Laboratory: Oak Ridge, TN, USA, 2011; p. 227.
- White, E.M. Woody Biomass for Bioenergy and Biofuels in the United States—A Briefing Paper; Pacific Northwest Research Station, USDA Forest Service: Portland, OR, USA, 2010.
- Adapa, P.; Karunakaran, C.; Tabil, L.; Schoenau, G. Potential applications of Infrared and Raman Spectromicroscopy for Agricultural Biomass. Agric. Eng. Int. CIGR J. 2009, XI, 1081. [Google Scholar]
- Benito, M.T.J.; Ojeda, B.C.; Rojas, F.S. Process analytical chemistry: Applications of near infrared spectroscopy in environmental and food analysis: An overview. Appl. Spectrosc. Rev. 2008, 43, 452–482. [Google Scholar] [CrossRef]
- Hsu, C.P.S. Infrared spectroscopy. In Handbook of Instrumental Techniques for Analytical Chemistry; Settle, F.A., Ed.; Prentice Hall PTR (ECS Professional): Upper Saddle River, NJ, USA, 1997; p. 1024. [Google Scholar]
- Stuart, B.H. Infrared Spectroscopy: Fundamentals and Applications; John Wiley & Sons, Ltd.: West Sussex, UK, 2004; p. 224. [Google Scholar]
- Reich, G. Near infrared spectroscopy and imaging: Basic principles and pharmaceutical applications. Adv. Drug Deliv. Rev. 2005, 57, 1109–1143. [Google Scholar] [CrossRef] [PubMed]
- Jorgensen, B.; Goegebeur, Y. Module 1: Chemometric and NIR Spectroscopy 2007. Available online: http://statmaster.sdu.dk/courses/ST02/module01/module.pdf (accessed on 16 November 2012).
- Acquah, G.E.; Via, B.K.; Fasina, O.O.; Eckhardt, L.G. Non-destructive prediction of the properties of forest biomass for chemical and bioenergy applications using near infrared spectroscopy. J. Near Infrared Spectrosc. 2015, 23, 93–102. [Google Scholar] [CrossRef]
- Poke, F.S.; Raymond, C.A. Predicting extractives, lignin, and cellulose contents using near infrared spectroscopy on solid wood in Eucalyptus globules. J. Wood Chem. Technol. 2006, 26, 187–199. [Google Scholar] [CrossRef]
- Jiang, Z.H.; Yang, Z.; So, C.-L.; Hse, C.-Y. Rapid prediction of wood crystallinity in Pinus elliotii plantation wood by near-infrared spectroscopy. J. Wood Sci. 2007, 53, 449–453. [Google Scholar] [CrossRef]
- Gierlinger, N.; Schwanninger, M.; Hinterstoisser, B.; Wimmer, R. Rapid determination of the heartwood extractives in Larix sp. by means of Fourier transform near infrared spectroscopy. J. Near Infrared Spectrosc. 2002, 10, 203–214. [Google Scholar] [CrossRef]
- Sykes, R.; Li, B.; Hodge, G.; Goldfarb, B.; Kadla, J.; Chang, H.M. Prediction of loblolly pine wood properties using transmittance near-infrared spectroscopy. Can. J. For. Res. 2005, 35, 2423–2431. [Google Scholar] [CrossRef]
- Derkyi, N.S.A.; Adu-Amankwa, B.; Sekyere, D.; Darkwa, N.A. Rapid prediction of extractives and polyphenolic contents in Pinus caribaea bark using near infrared reflectance spectroscopy. Int. J. Appl. Sci. 2011, 2, 1–11. [Google Scholar]
- Via, B.K.; Shupe, T.; Groom, L.; Stine, M.; So, C.-L. Multivariate modelling of density, strength and stiffness from near infrared spectra for mature, juvenile and pith wood of longleaf pine (Pinus palustris). J. Near Infrared Spectrosc. 2003, 11, 365–378. [Google Scholar] [CrossRef]
- McLean, J.P.; Jin, G.; Brennan, M.; Nieuwoudt, M.K.; Harris, P.J. Using NIR and ATR-FTIR spectroscopy to rapidly detect compression wood in Pinus radiata. Can. J. For. Res. 2014, 4, 820–830. [Google Scholar] [CrossRef]
- Jones, P.D.; Schimleck, L.R.; Peter, G.F.; Daniels, R.F.; Clark, A. Non-destructive estimation of Pinus taeda L tracheid morphological characteristics for samples from a wide range of sites in Georgia. Wood Sci. Technol. 2005, 39, 529–545. [Google Scholar] [CrossRef]
- Acquah, G.E.; Via, B.K.; Eckhardt, L.G.; Fasina, O.O. Screening Pinus taeda (loblolly pine) families for physical and mechanical properties using vibrational spectroscopy. In Proceedings of the 18th Biennial Southern Silvicultural Research Conference, Knoxville, TN, USA, 2–5 March 2015; Schweitzer, C.J., Clatterbuck, W.K., Oswalt, C.M., Eds.; U.S. Department of Agriculture Forest Service, Southern Research Station: Asheville, NC, USA, 2016. [Google Scholar]
- Downes, G.M.; Catela, F.; Meder, R. Developing and evaluating a multisite and multispecies NIR calibration for the prediction of Kraft pulp yield in eucalypts. South. For. 2009, 71, 155–164. [Google Scholar] [CrossRef]
- So, C.; Eberhardt, T.L. Chemical and calorific characterization of longleaf pine using near infrared spectroscopy. J. Near Infrared Spectrosc. 2010, 18, 417–423. [Google Scholar] [CrossRef]
- Fagan, C.C.; Everard, C.D.; McDonnell, K. Prediction of moisture, calorific value, ash and carbon content of two dedicated bioenergy crops using near-infrared spectroscopy. Bioresour. Technol. 2011, 102, 5200–5206. [Google Scholar] [CrossRef] [PubMed]
- Allison, G.G.; Morris, C.; Hodgson, E.; Jones, J.; Kubacki, M.; Barraclough, T.; Yates, N.; Shield, I.; Bridgwater, A.V.; Donnison, I.S. Measurement of key compositional parameters in two species of energy grass by Fourier transform infrared spectroscopy. Bioresour. Technol. 2009, 100, 6428–6433. [Google Scholar] [CrossRef] [PubMed]
- Via, B.K.; Oladiran, F.; Pan, H. Assessment of pine biomass density through mid-infrared spectroscopy and multivariate modeling. BioResources 2011, 6, 807–822. [Google Scholar]
- Via, B.K.; Adhikari, S.; Taylor, S. Modeling for proximate analysis and heating value of torrefied biomass with vibration spectroscopy. Bioresour. Technol. 2013, 133, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Nuopponen, M.H.; Birch, G.M.; Sykes, R.J.; Lee, S.J.; Stewart, D. Estimation of Wood Density and Chemical Composition by Means of Diffuse Reflectance Mid-Infrared Fourier Transform (DRIFT-MIR) Spectroscopy. J. Agric. Food Chem. 2006, 54, 34–40. [Google Scholar] [CrossRef] [PubMed]
- Tucker, M.P.; Mitri, R.K.; Eddy, F.P.; Nguyen, Q.A.; Gedvilas, L.M.; Webb, J.D. Fourier transform infrared quantification of sugars in pretreated biomass liquors. Appl. Biochem. Biotechnol. 2000, 84, 39–50. [Google Scholar] [CrossRef]
- Yang, Z.; Liu, Y.; Pang, X.; Li, K. Preliminary investigation into the identification of wood species from different locations by near infrared spectroscopy. BioResources 2015, 10, 8505–8517. [Google Scholar] [CrossRef]
- Bächle, H.; Zimmer, B.; Wegener, G. Classification of thermally modified wood by FTNIR spectroscopy and SIMCA. Wood Sci. Technol. 2012, 46, 1181–1192. [Google Scholar] [CrossRef]
- Labbé, N.; Seung-Hwan, L.; Hyun-Woo, C.; Jeong, M.K.; André, N. Enhanced discrimination and calibration of biomass NIR spectral data using non-linear kernel methods. Bioresour. Technol. 2008, 99, 8445–8452. [Google Scholar] [CrossRef] [PubMed]
- Ye, X.P.; Liu, L.; Hayes, D.G.; Womac, A.R.; Hong, K.; Sokhansanj, S. Fast classification and compositional analysis of cornstover fractions using Fourier transform near-infrared techniques. Bioresour. Technol. 2008, 99, 7323–7332. [Google Scholar]
- Tsuchikawa, S.; Yamato, K.; Inoue, K. Discriminant analysis of wood-based materials using near-infrared spectroscopy. J Wood Sci. 2003, 4, 275–280. [Google Scholar] [CrossRef]
- Carballo-Meilan, A.; Goodman, A.M.; Baron, M.G.; Rodriguez, J.G. A specific case in the classification of woods by FTIR and chemometric: Discrimination of Fagales from Malpighiales. Cellulose 2014, 21, 261–273. [Google Scholar] [CrossRef]
- Chen, H.; Ferrari, C.; Angiuli, M.; Yao, J.; Raspi, C.; Bramanti, E. Qualitative and quantitative analysis of wood samples by Fourier transform infrared spectroscopy and multivariate analysis. Carbohydr. Polym. 2010, 82, 772–778. [Google Scholar] [CrossRef]
- Rana, R.; Langenfeld-Heyser, R.; Finkeldey, R.; Polle, A. FTIR spectroscopy, chemical and histochemical characterisation of wood and lignin of five tropical timber wood species of the family of Dipterocarpaceae. Wood Sci. Technol. 2010, 44, 225–242. [Google Scholar] [CrossRef]
- Hobro, A.J.; Kuligowski, J.; Doll, M.; Lendl, B. Differentiation of walnut wood species and steam treatment using ATR-FTIR and partial least squares discriminant analysis (PLSDA). Anal. Bioanal. Chem. 2010, 398, 2712–2722. [Google Scholar] [CrossRef] [PubMed]
- Varmuza, K.; Filzmoser, P. Introduction to Multivariate Statistical Analysis in Chemometrics; CRC Press Taylor & Francis Group: Boca Raton, FL, USA, 2009. [Google Scholar]
- Johnson, R.A.; Wichern, D.W. Applied Multivariate Statistical Analysis, 6th ed.; Pearson Education Inc.: Upper Saddle River, NJ, USA, 2007. [Google Scholar]
- Sanderson, M.A.; Agblevor, F.; Collins, M.; Johnson, D.K. Compositional analysis of biomass feedstocks by near infrared reflectance spectroscopy. Biomass Bioeng. 1996, 11, 365–370. [Google Scholar] [CrossRef]
- Ono, K.; Hiraide, M.; Amari, M. Determination of lignin, holocellulose and organic solvent extractives in fresh leaf, litterfall and organic material on forest floor using near-infrared reflectance spectroscopy. J. For. Res. 2003, 8, 191–198. [Google Scholar]
- Schwanninger, M.; Rogrigues, J.C.; Fackler, K. A review of band assignments in near infrared spectra of wood and wood components. J. Near Infrared Spectrosc. 2011, 19, 287–308. [Google Scholar] [CrossRef]
- Brereton, R.G. Applied Chemometrics for Scientists; John Wiley & Sons Ltd.: West Sussex, UK, 2007. [Google Scholar]
- Lupoi, J.S.; Singh, S.; Davis, M.; Lee, D.J.; Shepherd, M.; Simmons, B.A.; Henry, R.J. High-throughput prediction of eucalypt lignin syringyl/guaiacyl content using multivariate analysis: A comparison between mid-infrared, near-infrared, and Raman spectroscopies for model development. Biotechnol. Biofuels 2014, 7, 93. [Google Scholar] [CrossRef] [PubMed]
- Olale, K.; Yenesew, A.; Jamnadass, R.; Sila, A.; Aynekulu, E.; Kuyah, S.; Shepherd, K. Limitations to use of infrared spectroscopy for rapid determination of carbon-nitrogen and wood density for tropical species. Adv. Anal. Chem. 2013, 3, 21–28. [Google Scholar]
- Sankaran, S.; Ehsani, R. Comparison of visible-near infrared and mid-infrared spectroscopy for classification of Huanglongbing and Citrus Canker infected leaves. Agric. Eng. Int. CIGR J. 2013, 15, 75–79. [Google Scholar]
- So, C.; Eberhardt, T.L.; Groom, L.H.; Shupe, T.F. A spectroscopic study on the fuel value of softwoods in relation to chemical composition. In Proceedings of the 55th International Convention of Society of Wood Science and Technology, Beijing, China, 27–31 August 2012.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| NIRS | FTIRS | |||||
|---|---|---|---|---|---|---|
| PC | Eigenvalue | Proportion of Variance Explained (%) | Cumulative Variance (%) | Eigenvalue | Proportion of Variance Explained (%) | Cumulative Variance (%) |
| 1 | 456.4 (4.8) | 76.1 | 76.1 | 271.0 (5.2) | 80.9 | 80.9 |
| 2 | 95.4 (3.7) | 15.9 | 92.0 | 49.9 (4.0) | 14.9 | 95.8 |
| 3 | 41.8 (6.5) | 7.0 | 98.9 | 9.6 (3.6) | 2.9 | 98.7 |
| 4 | 3.6 (1.3) | 0.6 | 99.5 | 1.8 (0.3) | 0.6 | 99.2 |
| 5 | 1.3 (0.1) | 0.6 | 99.7 | 1.3 (0.2) | 0.4 | 99.6 |
| 6 | 0.85 (0.08) | 0.14 | 99.88 | 0.29 (0.04) | 0.09 | 99.68 |
| 7 | 0.36 (0.03) | 0.06 | 99.94 | 0.16 (0.03) | 0.05 | 99.73 |
| 8 | 0.13 (0.01) | 0.02 | 99.96 | 0.09 (0.01) | 0.03 | 99.76 |
| 9 | 0.06 (0.01) | 0.01 | 99.97 | 0.07 (0.01) | 0.02 | 99.78 |
| 10 | 0.04 (0.01) | 0.01 | 99.98 | 0.06 (0.01) | 0.02 | 99.80 |
| NIRS | FTIRS | |||||
|---|---|---|---|---|---|---|
| Variable | Clean Wood | Slash | Wood and Bark | Clean Wood | Slash | Wood and Bark |
| Constant | −6.13 (0.71) | −9.29 (3.51) | −2.14 (0.36) | −6.89 (1.73) | −10.34 (3.96) | −2.02 (0.51) |
| PC1 | −0.39 (0.08) | 0.51 (0.17) | −0.11 (0.04) | −0.4 (0.08) | 0.56 (0.16) | −0.14 (0.03) |
| PC2 | 0.42 (0.03) | −0.43 (0.04) | 0.02 (0.06) | −0.16 (0.06) | 0.2 (0.07) | −0.05 (0.04) |
| PC3 | −0.04 (0.06) | 0.07 (0.05) | −0.03 (0.01) | 0.21 (0.23) | −0.41 (0.35) | 0.22 (0.13) |
| PC4 | 1.23 (0.35) | −2.35 (0.66) | 1.07 (0.19) | −3.06 (1.74) | 3.94 (1.52) | −1.12 (0.39) |
| PC5 | - | - | - | 6.56 (1.66) | −7.59 (2.84) | 0.78 (0.41) |
| NIRS | FTIRS | |||||
|---|---|---|---|---|---|---|
| From/Into | Clean Wood | Slash | Wood and Bark | Clean Wood | Slash | Wood and Bark |
| Clean wood | 2.2 (0.3) | 52.5 (12.9) | 10.6 (1.6) | 2.2 (0.3) | 59.9 (17.8) | 11.1 (1.7) |
| Slash | 52.5 (12.9) | 2.2 (0.3) | 28.2 (8.2) | 59.9 (17.8) | 2.2 (0.3) | 30.2 (7.3) |
| Wood & bark | 10.6 (1.6) | 28.2 (8.2) | 2.2 (0.3) | 11.1 (1.7) | 30.3 (7.3) | 2.2 (0.3) |
| NIRS | FTIRS | |||||||
|---|---|---|---|---|---|---|---|---|
| Clean Wood | Slash | Wood and Bark | Total | Clean Wood | Slash | Wood and Bark | Total | |
| Rate | 0% | 3.3% | 6.7% | 3.2% | 0% | 3.3% | 8.3% | 3.4% |
| NIRS | FTIRS | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Plant Part Component | ||||||||||
| Test Sample | Clean Wood | Slash | Wood & Bark | Total | % Correct Classification | Clean Wood | Slash | Wood & Bark | Total | % Correct Classification |
| Clean Wood | 17 | 0 | 0 | 17 | 100 | 17 | 0 | 0 | 17 | 100 |
| Slash | 0 | 16 | 1 | 17 | 96.7 | 0 | 16 | 1 | 17 | 96.7 |
| Wood and bark | 1 | 0 | 16 | 17 | 93.3 | 2 | 0 | 15 | 17 | 91.7 |
| % Total Accuracy | 96.7 (3.3) | 96.1 (4.2) | ||||||||
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Acquah, G.E.; Via, B.K.; Billor, N.; Fasina, O.O.; Eckhardt, L.G. Identifying Plant Part Composition of Forest Logging Residue Using Infrared Spectral Data and Linear Discriminant Analysis. Sensors 2016, 16, 1375. https://doi.org/10.3390/s16091375
Acquah GE, Via BK, Billor N, Fasina OO, Eckhardt LG. Identifying Plant Part Composition of Forest Logging Residue Using Infrared Spectral Data and Linear Discriminant Analysis. Sensors. 2016; 16(9):1375. https://doi.org/10.3390/s16091375
Chicago/Turabian StyleAcquah, Gifty E., Brian K. Via, Nedret Billor, Oladiran O. Fasina, and Lori G. Eckhardt. 2016. "Identifying Plant Part Composition of Forest Logging Residue Using Infrared Spectral Data and Linear Discriminant Analysis" Sensors 16, no. 9: 1375. https://doi.org/10.3390/s16091375
APA StyleAcquah, G. E., Via, B. K., Billor, N., Fasina, O. O., & Eckhardt, L. G. (2016). Identifying Plant Part Composition of Forest Logging Residue Using Infrared Spectral Data and Linear Discriminant Analysis. Sensors, 16(9), 1375. https://doi.org/10.3390/s16091375