1. Introduction
The Internet of Things (IoT) is a term used for a set of technologies, systems and devices that enable connectivity to the Internet and that are based on the physical environment [
1]. With a wide range of potential applications, IoT devices are rapidly spreading, and forecasts are predicting a huge growth of these devices over the next few years [
2].
Recently, cellular systems are being considered as an option to provide connectivity to IoT devices due to their ubiquitous presence, widespread coverage, reliability and support for mobility [
3]. Within the cellular context, the IoT connectivity solution is referred to as Machine-to-Machine (M2M). However, cellular systems have been designed for Human to Human communications (H2H) or Mobile Broadband Access (MBB), and consequently, the widespread provision of M2M services with these systems entails significant technical challenges [
4]. Some of these challenges are: the scalability issues raised by the huge number of expected devices; the time-varying traffic characteristics of M2M applications, which are very different from MBB or H2H; and the very heterogeneous QoS demands in terms of bandwidth, latency and reliability.
The 3rd Generation Partnership Project (3GPP) has included enhancements in Long-Term Evolution (LTE) networks for the deployment of IoT. One of them is data transport in Control Plane Cellular IoT Evolved packet system Optimization (CPCEO) [
5]. This is a set of transmission procedures specifically designed for small and infrequent data transmissions from/to M2M devices. CPCEO procedures employ Non-Access Stratum (NAS) messages to transfer data packets from/to the device, instead of the establishment and utilization of data plane bearers.
The adoption of the CPCEO procedures can mitigate relevant issues caused by small and infrequent data packet transmissions by a huge number of M2M connected devices. CPCEO procedures reduce the signaling explosion generated by the establishment and release of data bearers. This reduction affects the core and especially the radio interface due to the limited radio resources. However, CPCEO procedures imply a major increase of the processing load on the control plane of the Evolved Packet Core (EPC) and, in particular, on the Mobility Management Entity (MME). In addition, the current exposition of the EPC entities to the signaling in LTE [
6], combined with the fixed capacity of current core LTE hardware-based infrastructure, can limit the scalability of the CPCEO solution.
Currently, major efforts are being made to research and develop new technologies for future 5G systems [
7]. Network Function Virtualization (NFV) is one of the promising new technologies for 5G. NFV provides a novel framework to deploy network services onto virtualized servers. The use of the NFV paradigm to virtualize the EPC entities and, in particular, the MME could facilitate the wide deployment of M2M communications in 5G. It improves the scalability and flexibility of the network compared to hardware-based entities. This benefit is crucial for the foreseen signaling explosion generated by M2M connected devices. Due to the promising benefits of NFV, there are works that have tackled the architectural and implementation issues of applying this virtualization paradigm to the LTE EPC; see, for example, [
8,
9,
10,
11]. However, these proposals do not specifically consider support for M2M traffic.
In this paper, we propose two designs for a virtualized MME that specifically aim at facilitating the IoT support in 5G systems. The first proposed design partially separates the processing resources dedicated to different traffic classes; while the second design includes traffic shaping to control the traffic of each class. In our system, we have considered MBB, low latency M2M and delay-tolerant M2M traffic classes. Our proposed schemes adjust the processing resources considering the traffic classes to serve and their QoS requirements.
We have analyzed the running costs of the resources needed and the delay performance. We have compared our proposed schemes to two other schemes: (i) a baseline virtualized MME design, which does not apply any specific traffic treatment per class; (ii) an overdimensioned virtualized MME. For the cost analysis, we have considered a theoretical model to dimension the required resources, and the data center setup and billing model of the Amazon Elastic Compute Cloud (EC2). For the delay performance evaluation, we have simulated each scheme.
The results show that our schemes provide much lower costs than the overdimensioned one. Furthermore, they provide similar delay performance for MBB and low latency M2M communications. The obtained delay satisfies the exigent requirements of MBB and low latency M2M communications. However, our proposed schemes apply a specific delay requirement per traffic class. This allows the saving of processing resources for delay-tolerant M2M traffic.
The remainder of this paper is organized as follows.
Section 2 gives an introduction to the main topics on which this work is based and poses the addressed problem.
Section 3 introduces a detailed description of the system model and assumptions made. The adopted traffic models are explained in
Section 4. In
Section 5, we explain the considered schemes to study, including our proposed schemes.
Section 6 presents the queue model used in the dimensioning of the virtualized MME.
Section 7 analyzes the results. Finally, the conclusion is in
Section 8.
2. Background
2.1. Internet of Things
The convergence of the digital and the physical world provided by the Internet of Things (IoT) allows the interaction between the environment and the devices connected to the network that collect information. Under this umbrella, many applications can be envisaged, which have led to several markets (verticals) for IoT. In IoT applications, machines (or devices) connected to the network can communicate among them, or with the application server, without human interaction. This is known as Machine-to-Machine (M2M) communications.
IoT applications are designed for specific verticals, such as industry (e.g., monitoring industrial plants, boarding operation), energy (e.g., inventory, waste collection), automotive (e.g., bike sharing, parking system), healthcare (e.g., diagnostics, mobile assistance) or media and entertainment (e.g., payment systems, comfortable living) [
12]. These verticals have different requirements that determine IoT applications’ design, as for example, the particular connectivity needs, device energy consumption, capabilities, security or traffic characteristics.
Despite there being many possible requirements for IoT applications, M2M communications used in IoT are being classified by organizations, such as the 3GPP or the Mobile and wireless communications Enablers for the Twenty-twenty Information Society (METIS), in two big trends [
13], based on their Quality of Service (QoS) requirements:
Massive M2M (mM2M): characterized by low cost/energy devices, small data volumes and a massive number of devices connected. Among others, relevant examples are smart metering, fleet tracking or building automation.
Low latency M2M (lM2M): characterized by strict requirements, such as ultra reliability, low latency and high availability. The distinct requirements depend on the specific application. For instance, the end-to-end latency can reach down to a few milliseconds or even lower [
14]. To achieve that, low latency services could be served by different core entities in the network. For simplicity, we assume that the lM2M devices considered in this work can be handled by the MME. Industrial monitorization, security or healthcare, and tactic Internet are examples of this trend.
For most of M2M communications used in IoT applications, small and infrequent data transmissions are a common traffic characteristic, as mentioned in [
15]. Nevertheless, this traffic characteristic is handled inefficiently by current mobile networks, such as LTE. This is mainly due to the prior resource reservation required before the transmission [
16]. To solve that, the 3GPP has included LTE enhancements for M2M in its specifications, recently integrated into the context of Cellular IoT (CIoT). For example, the 3GPP has introduced in [
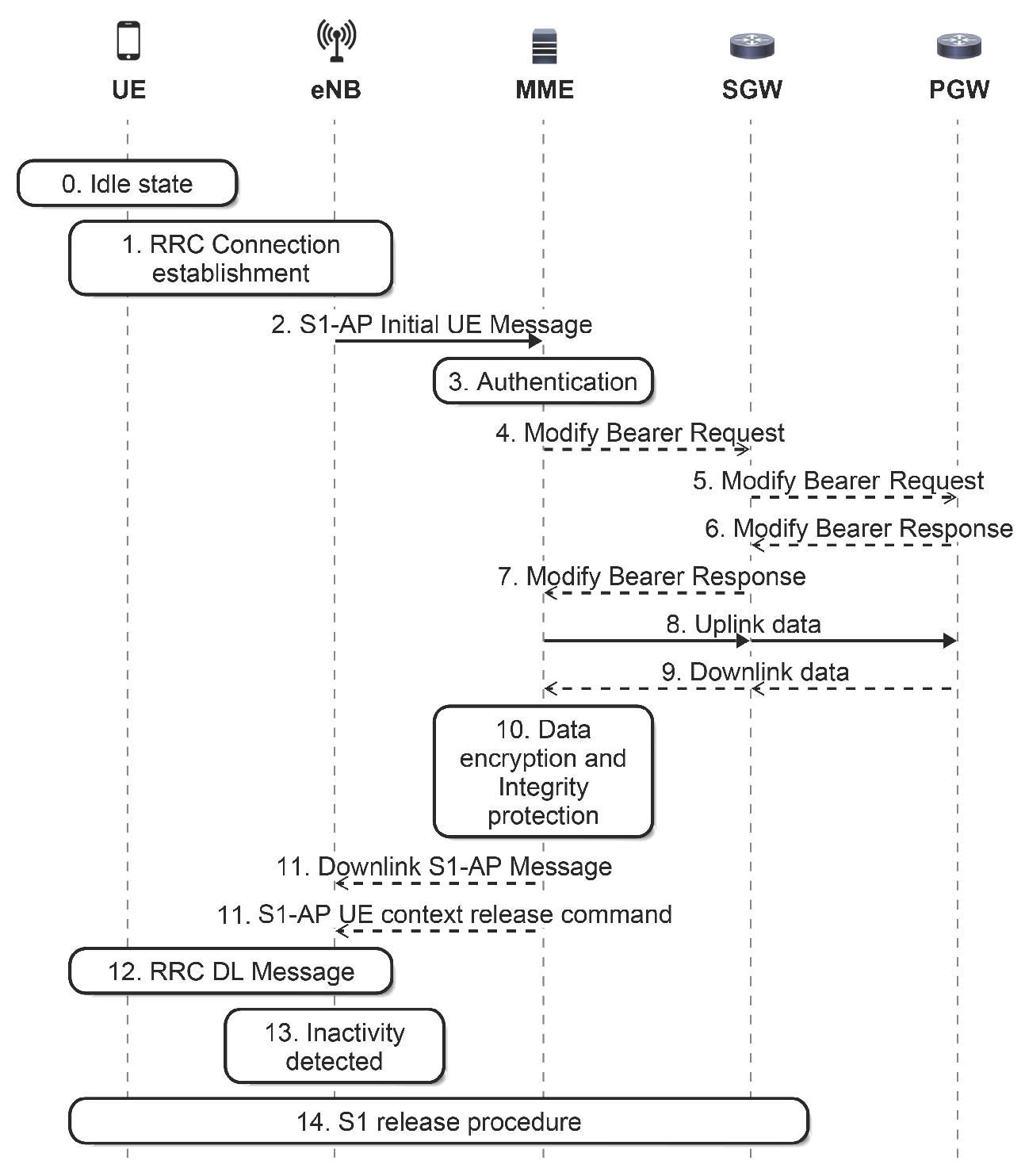
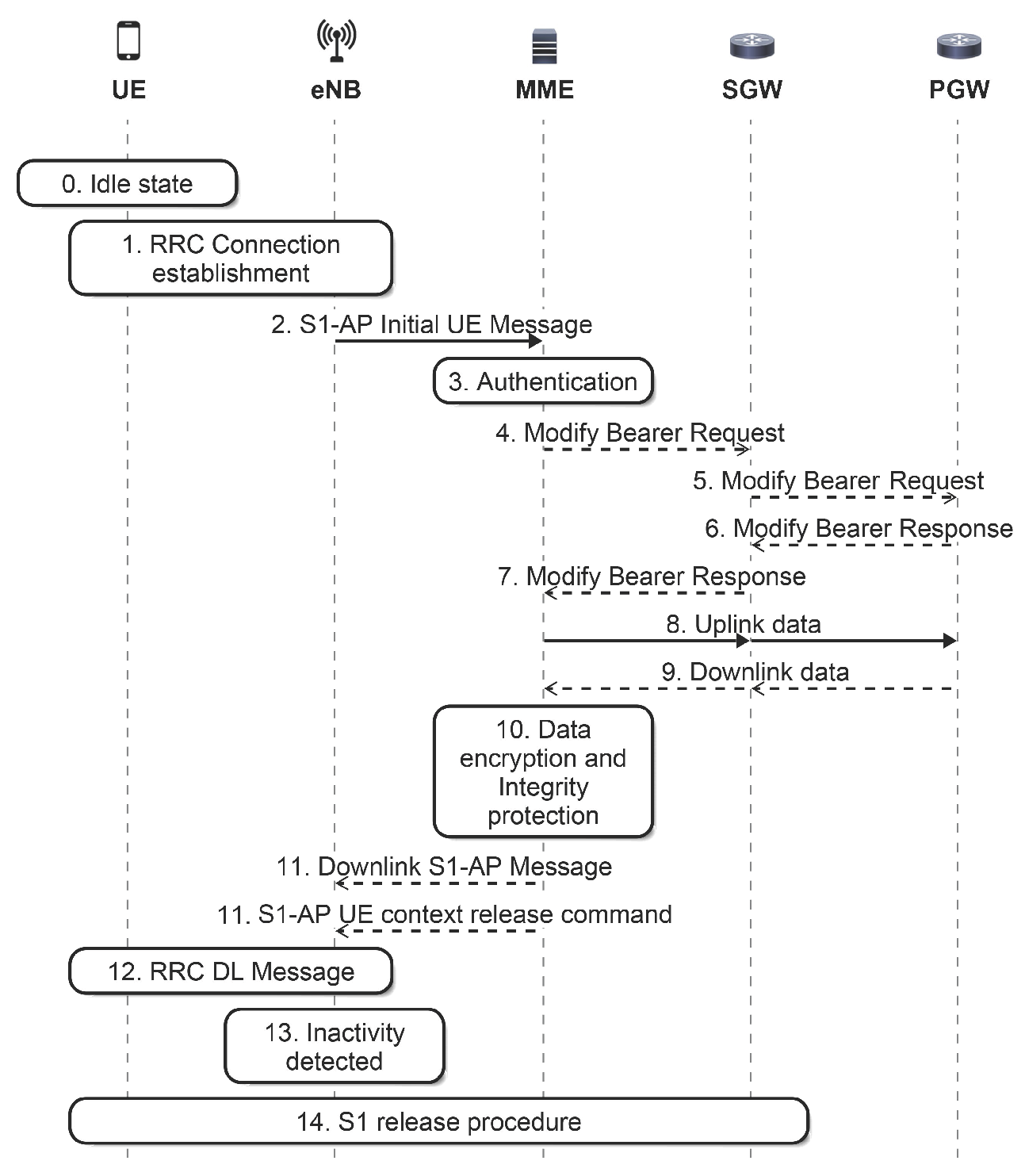
5] new procedures to reduce signaling to transfer data packets from or to the device, named data transport in Control Plane CIoT Evolved packet system Optimization (CPCEO). To this end, the procedures use Non-Access Stratum (NAS) transport capabilities. In LTE, NAS is used to transfer non-radio signaling between the User Equipment (UE) and the MME. In the transmission of uplink data, with this new procedure, the data packet is sent as NAS signaling by the UE to the MME after Radio Resource Control (RRC) establishment. Next, the MME carries out the security check, and then, it forwards the data packet to the Serving Gateway (SGW) (see
Figure 1). The CPCEO procedures avoid the establishment and release of data plane bearers for small and infrequent packets from M2M devices, but the MME has to process these packets from the data plane transmitted as NAS signaling.
In the LTE Evolved Packet Core (EPC) architecture, the MME deals with the control plane. That is, this entity is the main signaling node in the EPC. Its main functions are: NAS signaling, user authentication, mobility management (e.g., paging, user tracking) and bearer management. For more information about the MME entity, see [
5]. Therefore, the main drawback of these new procedures for cellular IoT is the increased processing capacity required by the MME [
17].
In addition to this transfer optimization, a new narrowband radio technology for IoT was developed in Release 13, called the Narrowband Internet of Things (NB-IoT). The objective of NB-IoT is to reduce complexity, increase coverage, achieve long battery lifetime and support a massive number of devices. To achieve these objectives, NB-IoT has low data rates, a 164-dB maximum coupling loss target for standalone mode operation and limited mobility support, and it allows only the half-duplex frequency-division duplexing operation. NB-IoT requires a reduced bandwidth of 180 kHz for both downlink and uplink and further protocol optimizations [
18]. For UEs that support the NB-IoT, the 3GPP agreed that the control plane CIoT Evolved Packet System optimization feature explained above will be mandatory [
5]. For more information about NB-IoT, see [
19].
2.2. Virtualization
NFV is one of the enabling technologies of 5G systems, because it will allow network operators to cope with challenges, such as the traffic increase and IoT support while reducing CAPEX and OPEX. With NFV, network functionalities are implemented with Commercial Off-The-Shelf (COTS) hardware, which is much less expensive than the very specialized hardware used in 4G networks. In this way, operators can create, scale and deploy network components whenever they are needed, according to the particular real-time traffic conditions. These benefits are relevant for the deployment of IoT in cellular networks. NFV could facilitate the adaptation of the network entities to the new demand. With NFV, the infrastructure services can be programmed, instead of re-architecting the infrastructure of the network [
20].
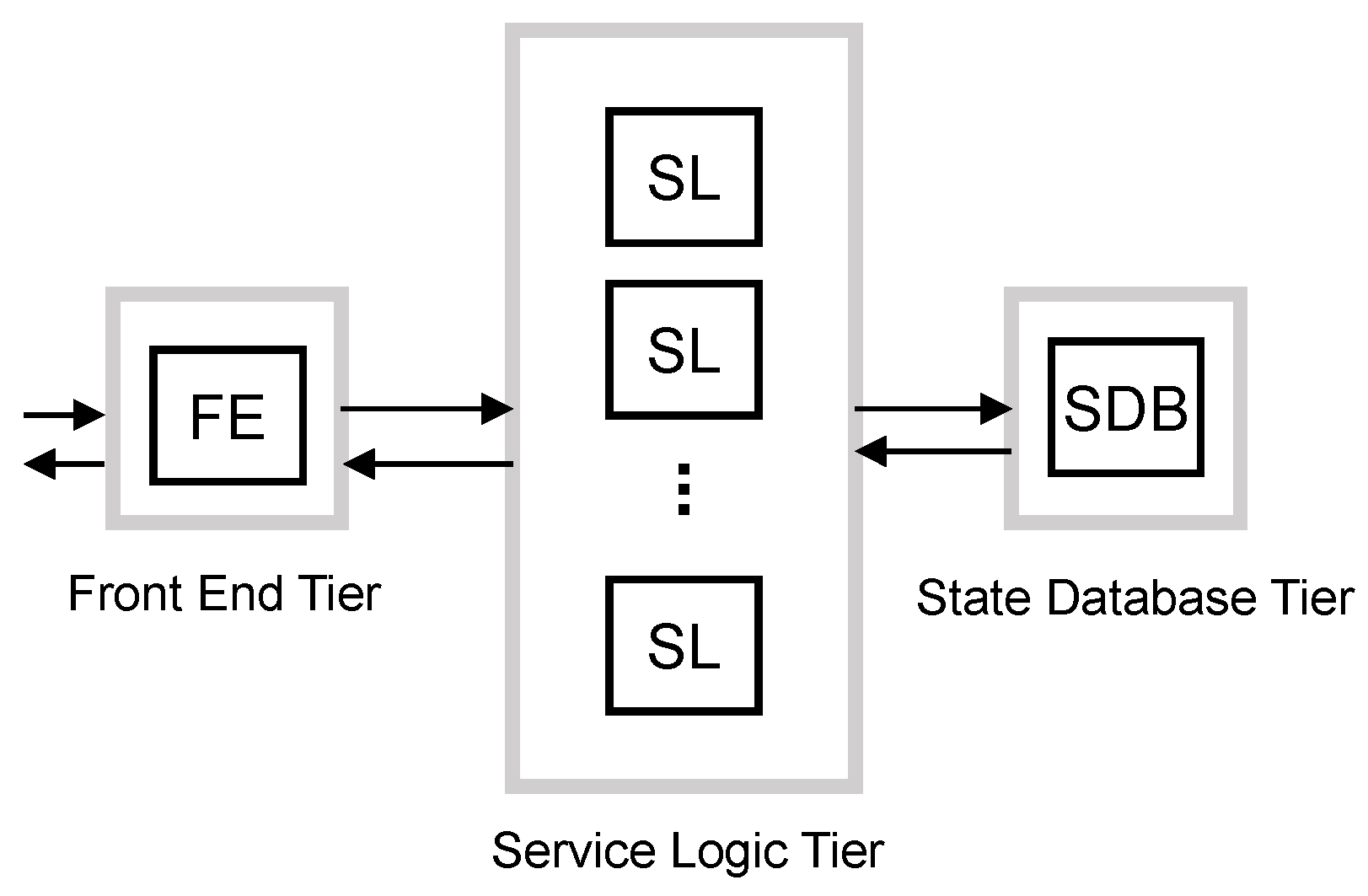
In [
9], the authors discuss the design of a virtualized EPC for implementation in a cloud computing environment and its offering “as a Service” (EPCaaS). They present and analyze a number of different implementation options for the virtualized EPC. Focusing on the 1:N mapping option, each entity of the EPC is decomposed into three logical components: a Front End (FE), Service Logic (SL) and State Database (SDB). The FE acts as a communication interface with other entities of the network, for example the FE terminates Stream Control Transmission Protocol (SCTP) sessions between eNodeB and MME [
21] and balances the load among several SLs. SLs implement the processing. The SDB stores the user session state, making the SLs stateless. This design follows the multi-tiered web services paradigm for cloud-based applications. Each of the three logical components is a tier of the multi-tier architecture. SLs are stateless, and therefore, they can scale out/in without impacting externally-connected peers and independently from other SLs. The scaling of SDB and FE, which are stateful components, is possible [
22], although it requires a careful design.
In multi-tiered web services, dedicated hosting refers to the case where a server is allocated to at most one application at any given time [
23]. On the contrary, in shared hosting, multiple small applications share each server. Dedicated hosting is used for running large clustered applications where server sharing is unfeasible due to the workload demand imposed on each individual application.
Dimensioning is the classic process to determine the amount of resources required to process a set of requests with a specific Quality of Service (QoS) target. However, dimensioning is a static process, whereas the traffic in mobile networks strongly fluctuates. However, dynamic provisioning of resources according to the fluctuations in the request rate is feasible thanks to the virtualization technologies and the wide adoption of cloud computing system infrastructures [
24]. As in the case of Internet workloads, mobile network traffic exhibits long-term variations, such as time-of-day or seasonal effects, as well as short-term fluctuations caused by unexpected events. Therefore, it is reasonable to consider applying dynamic provisioning techniques of multi-tiered web services for virtualized EPC entities.
In [
22], the authors study the provision resources in multi-tier applications and propose a strategy to avoid bottleneck shifting. They propose to break down the end-to-end response time
into per-tier response times
,
,...
, such that:
Then, they propose to determine how many servers to allocate to each tier separately, such that tier
j processes the requests with a service response time equal to
. For this capacity prediction, an estimate of the peak session rate is used. In
Section 5, we will use this strategy in the estimation of resources for the virtualized MME entity.
We will further assume that the virtualized EPC entities are deployed using a cloud provider service, such as Amazon’s Elastic Computing Cloud (EC2), in which the computing resources can be dynamically scaled in or out on demand and with a pay-as-you-go price scheme. For example, Amazon EC2 charges a per-hour price for the service use [
25]. Additionally, a relevant aspect in cloud services such as EC2 is that the time required to obtain and boot a new server instance can be in the range of tens of seconds to minutes [
26].
2.3. Characteristics of M2M Traffic in Cellular Networks
The penetration of connected machines in the near future is expected to outnumber human connections, reaching values up to one order of magnitude above [
27]. This number and the traffic characteristics of M2M devices make difficult their wide deployment in current cellular networks, such as LTE [
28].
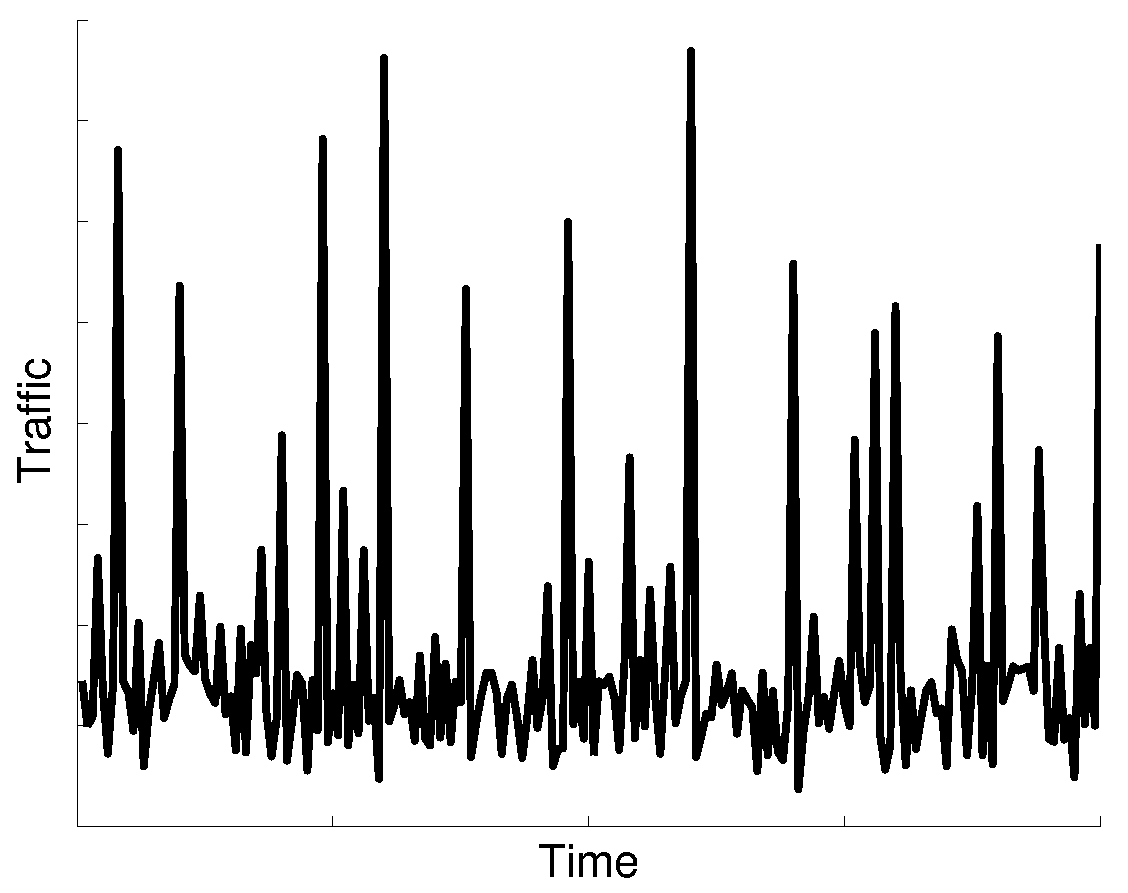
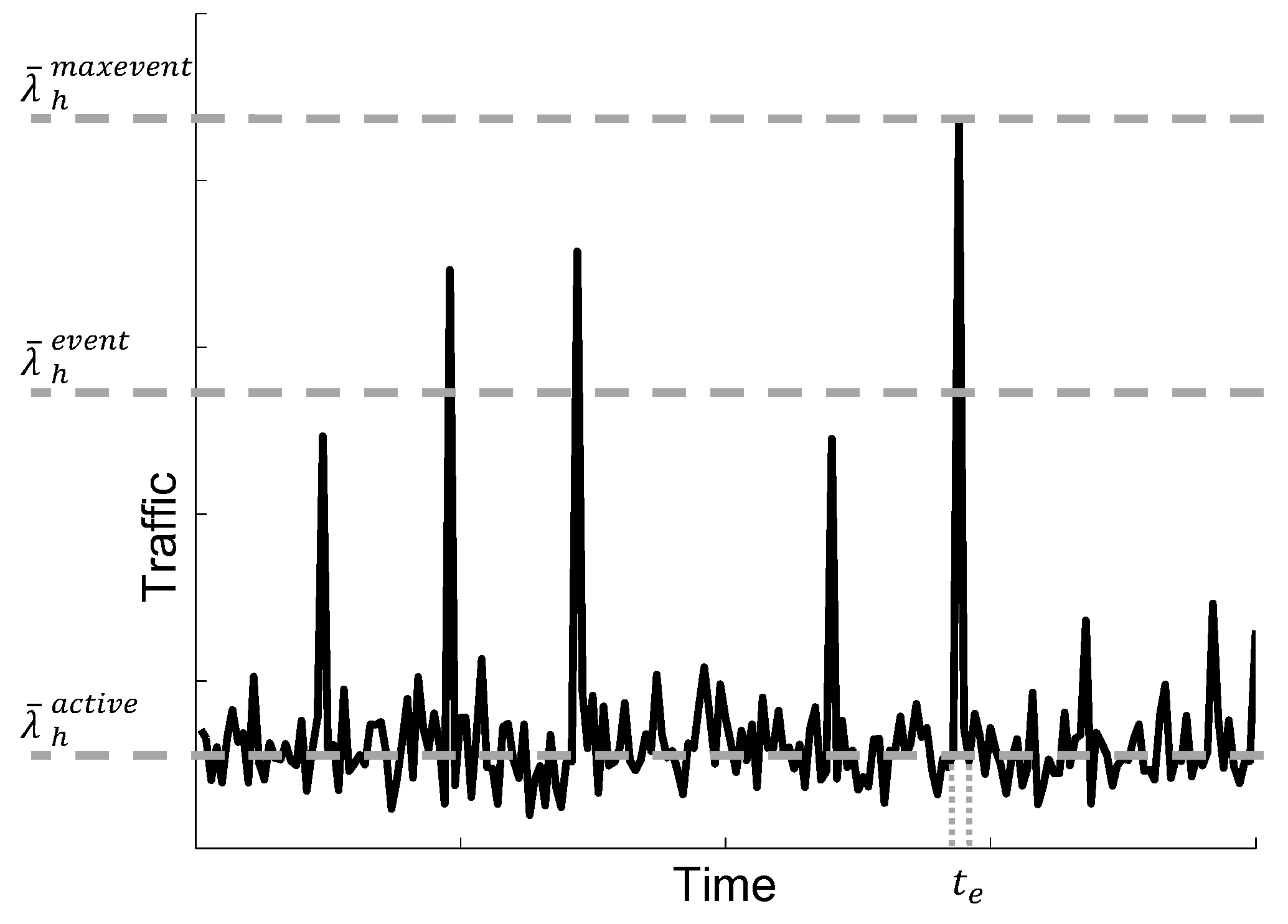
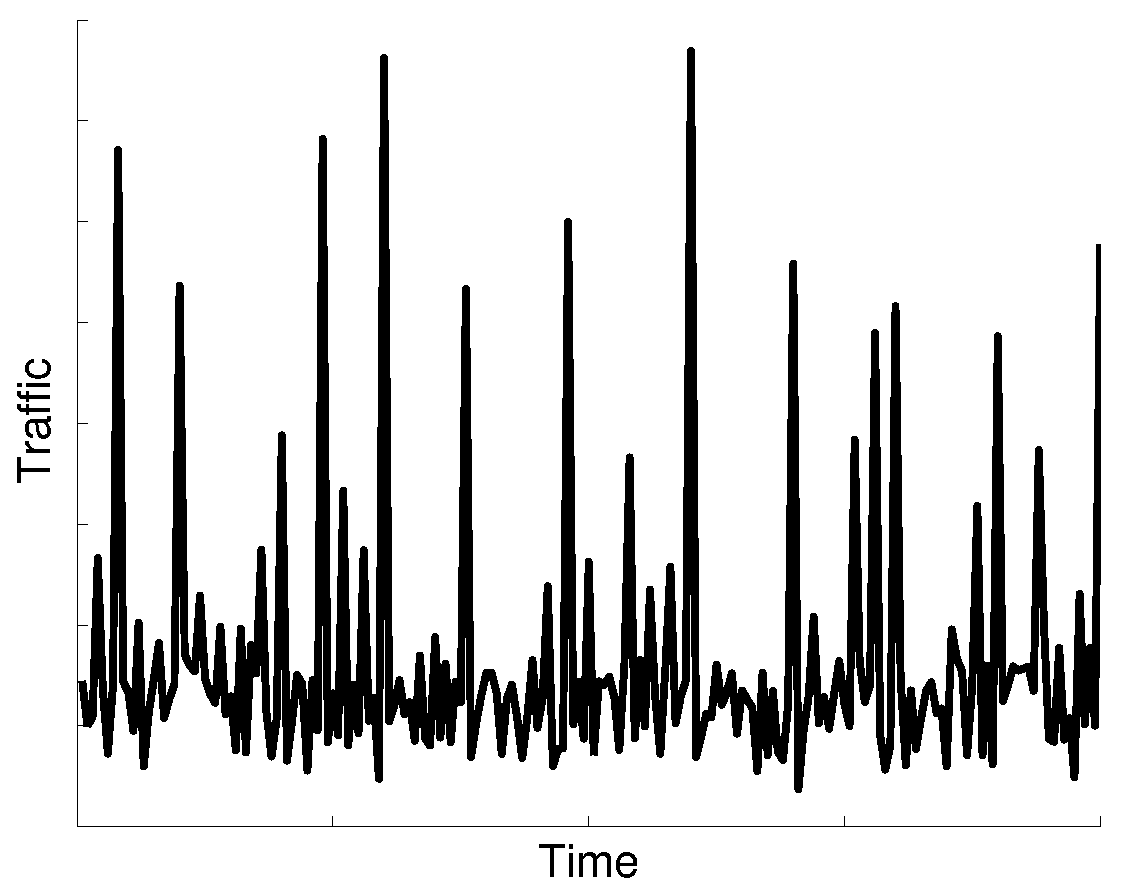
M2M communications have different characteristics compared to conventional human-based communications. M2M average traffic volume is small, about two orders of magnitude lower than MBB traffic volume. The M2M ratio of uplink traffic volume is higher than downlink traffic volume. Furthermore, synchronized communication from a large number of devices causes traffic peaks, e.g., in periods of 1 h, 30 min or 15 min, as shown in the time series analysis of M2M traffic [
29]. Besides report transmission synchronization events, there will be alarms caused by unpredictable events. Together, all of these events could imply peaks of signaling load two- or four-times higher than the average load [
30]; see
Figure 2.
From the network point of view, the scalability of the control procedures triggered by these transmissions is one of the most important challenges for M2M support. As with the CPCEO, the MME is to convey these data packets; it has to be designed to be able to deal with this traffic increase and to avoid any associated congestion. Dynamic provisioning of processing resources is of little use for the vMME to carry the traffic caused by these traffic peaks. First, the billing models of cloud providers (such as Amazon EC2) typically charge per hour, and traffic peaks usually occur at shorter time intervals. Second, there will be M2M traffic peaks caused by alarm events that cannot be predicted, and therefore, they would cause congestion during the tens of seconds or minutes needed to boot new server instances. For these reasons, we will assume that the amount of resources required to serve these traffic peaks has to be dimensioned in advance.
3. System Model
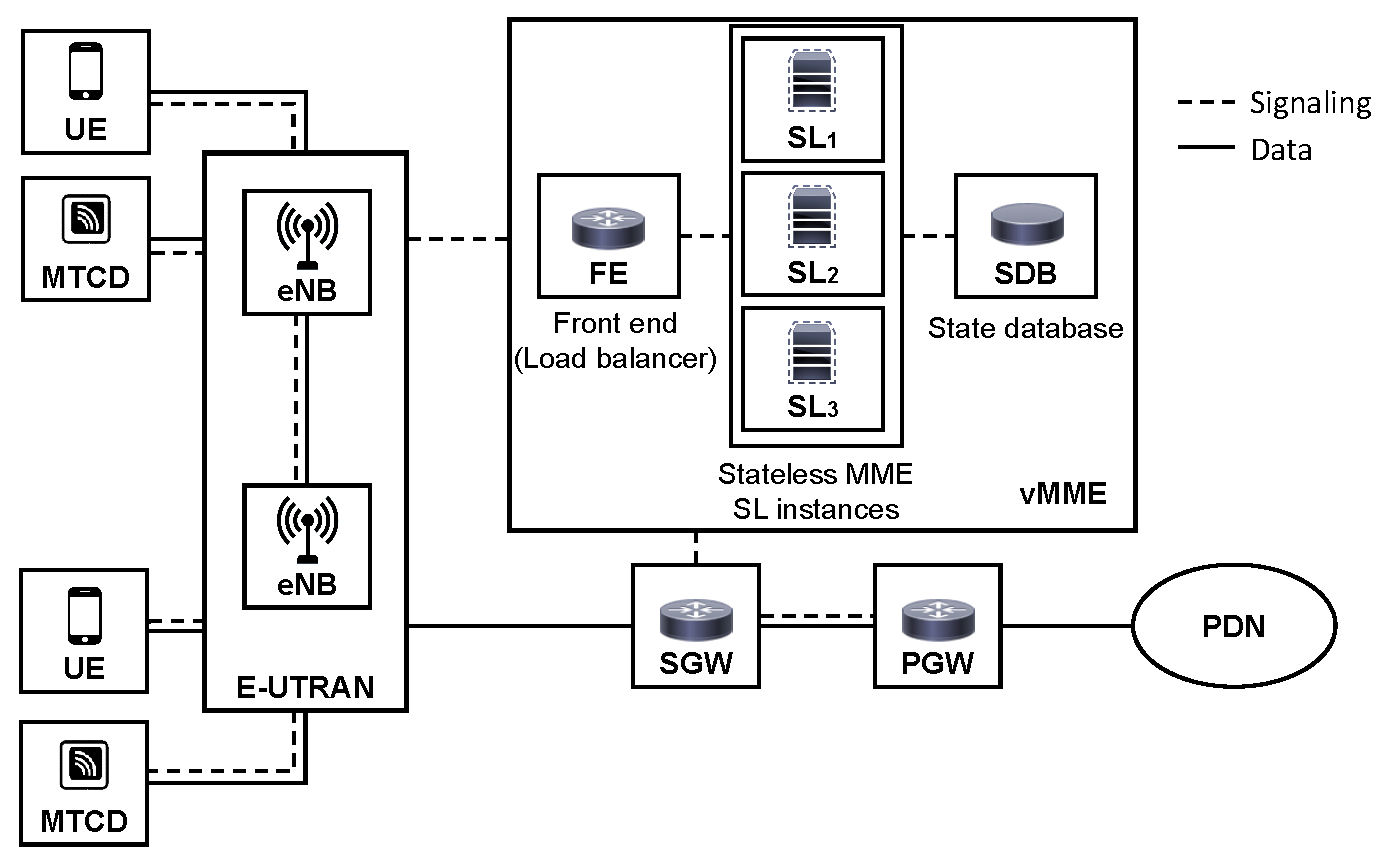
In this work, we assume an access cellular network architecture based on LTE, which provides service to Users Equipment (UE) and Machine-Type Communications Devices (MTCDs). Although this architecture assumes the entities defined in LTE/EPC, it could also be extended to other cellular architectures. The overall system model is depicted in
Figure 3.
The main entities are explained next. Additionally, the notation and main definitions used in this work are summarized in
Table 1.
3.1. The User Equipment
UEs are the terminals that allow each human user to connect to the network via the eNodeB base stations. The UEs run the users’ applications, which generate or consume network traffic (see the traffic model in
Section 4). If a UE is in the idle state and it has data to transmit, it carries out a Service Request (SR) procedure to establish a bearer, which will convey the data packets. We assume that UEs move following a fluid-flow mobility model. When a UE crosses the border between two cells, it triggers an X2-based Handover (HO) procedure.
3.2. MTC Devices
We assume that MTCDs are placed in fixed locations, and they send small data packets (reports) infrequently to centralized servers. Following the 3GPP and METIS guidelines (see
Section 2.1), we consider two types of MTCDs, mM2M and lM2M devices. We assume mM2M devices run delay-tolerant M2M applications, which can tolerate seconds of delay [
31], such as smart metering or agriculture applications. We also assume that lM2M devices run strict M2M applications, such as industrial applications or healthcare, which are characterized by low latency requirements among other demands. We also assume a large number of MTCDs connected to the network, which will cause traffic peaks due to M2M synchronization or alarm events. For simplicity, we assume there is no coordination among mM2M and lM2M events.
As the M2M ratio of uplink traffic volume is higher than downlink (see [
29]), we only consider uplink M2M traffic. To transmit a report, we assume that an M2M device triggers the Mobile-Originated data transport signaling procedure, defined in the Control Plane CIoT Evolved packet system Optimization (MO-CPCEO) [
5]. Regarding the MO-CPCEO procedure, we assume that the following control messages do not take place (see
Figure 1):
Messages 4 to 7 are not used, since there is a connection established between MME and SGW, and there is no important change to inform the Packet data network Gateway (PGW);
Messages 9 to 13 are not used as, no downlink data are expected by the MTCD.
Then, the MME has to process one control message for each MO-CPCEO procedure.
3.3. eNodeB Stations
eNodeB (eNB) stations receive signaling messages from the UEs and forward them to the virtualized MME. Each eNB keeps a user inactivity timer, which has an expiration time
, for each attached UE within its coverage area. Using this timer, the eNB detects the users’ inactivity (i.e., a user does not perform any data transmission over a period of length
). If the timer expires, the eNB triggers a Service Release (SRR) procedure to release the bearer [
5].
3.4. The Virtualized Mobility Management Entity
The virtualized MME (vMME) is the main control plane entity of the network. It maintains the mobility state of the UE and is responsible for the bearers’ management. For simplicity reasons, we assume that the vMME is collocated with the SGW and the PGW at a centralized data center of the network.
We consider that the MME is virtualized following the NFV paradigm, and in particular, we adopt the 1:N mapping architectural option. Thus, following the implementation in [
9,
21], the vMME is split into three tiers: FE, MME SL and SDB. We further assume that when an MME SL instance finishes processing a control plane message, it saves the transaction state into the SDB. When a subsequent request arrives at an MME SL instance, it first gathers the transaction state from the database from which to continue. This differs from the vMME implementation in [
21], and it allows fully stateless MME SLs. Different messages of the same procedure for the same user can be processed by different MME SL instances. Therefore, the number of MME SL instances, denoted as
, can grow without affecting in-session users.
As in [
22], we assume that all tiers can be replicated within limits. When the processing capacity assigned to the vMME cannot withstand the current load, a new MME SL instance must be instantiated, and a new processor is added to the processing resources pool.
For simplicity, we will assume that every processor in the data center facility provides the same computational power, and the SDB follows a shared-everything architecture, which eases the scale-out or scale-in. Then, the scaling of the SDB can be done on-demand, but with certain constraints [
22]. These constraints are due to the shared resources by multiple processors, which may result in choking off the bandwidth for simultaneous memory access or difficult synchronization mechanisms to maintain a shared consistent state. Furthermore, we will assume each tier has enough memory resources to store an unlimited amount of requests that arrive at the tier, while they are waiting to be processed.
4. Traffic Models
We assume three classes of traffic: Mobile Broadband traffic (MBB), massive M2M (mM2M) and low latency M2M (lM2M) traffic. In the next subsections, we explain each one.
4.1. Mobile Broadband Traffic Model
We adopt the compound data traffic and user behavior model proposed in [
32] for MBB UEs. This traffic model considers three types of applications, namely:
Web browsing.
HTTP progressive video (e.g., YouTube).
Video calling (e.g., Skype service).
which are redesigned to generate the data rates predicted for future mobile networks in the METIS project [
33]. Then, the mean data rates per user used are higher than the current demand. For web browsing, the mean data rate per user depends on the number of web pages visited, the main object size of each web and the number of embedded objects and their sizes. For HTTP progressive video, the mean data rate per user depends on the number of downloaded video clips, the size of each video and the video encoding rate. While for video calling, the mean data rate per user depends on the constant bit rate of the call. Consequently, from [
32], the mean data rates per user obtained are 233.28 kbps, 5.25 Mbps and 142.07 kbps for web browsing, HTTP progressive video and video calling, respectively.
Most of the signaling workload generated by UEs depends on their activity and their traffic characteristics [
32]. Here, we only consider those LTE control procedures that generate the most signaling load on the MME [
10]. In particular, we consider Service Request (SR), Service Release (SRR) and X2-based Handover (HO) procedures. According to [
32], for each of these procedures, the MME respectively will process 3, 3 and 2 control messages.
Let
be the number of MBB UEs and
,
and
be the mean generation rate per UE for the SR, SRR and HO control procedures, respectively. Let
be defined as the mean arrival rate of control messages processed by the MME that are generated by MBB UEs. Then, it can be computed as:
4.2. Machine to Machine Traffic Model
We consider two types of M2M devices: massive M2M (mM2M) devices and low latency M2M (lM2M) devices. Let
, where
, denote the percentage of each type of M2M devices, and let
r be the ratio of M2M devices per MBB UE. Then, the number of M2M devices of each type,
, is given by:
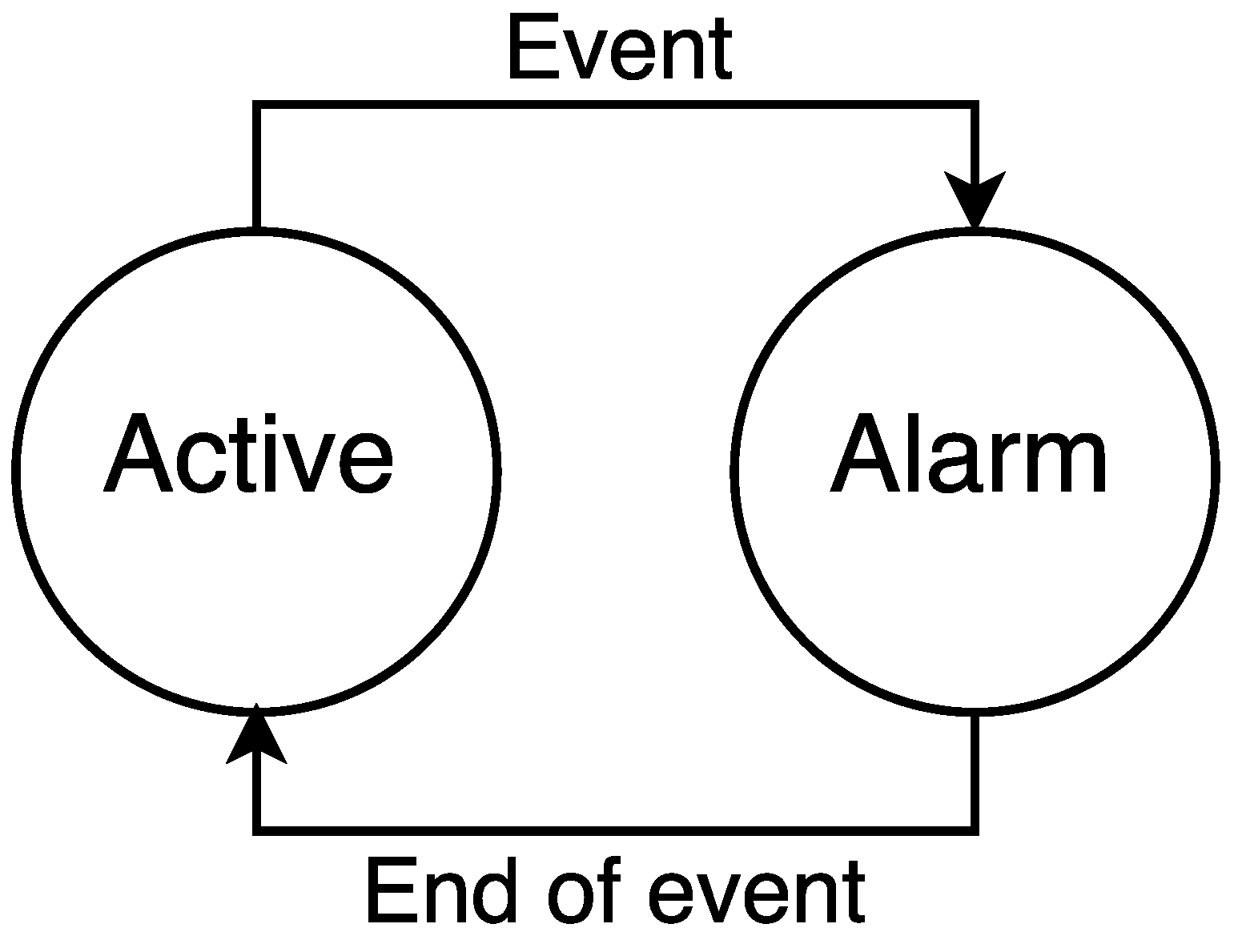
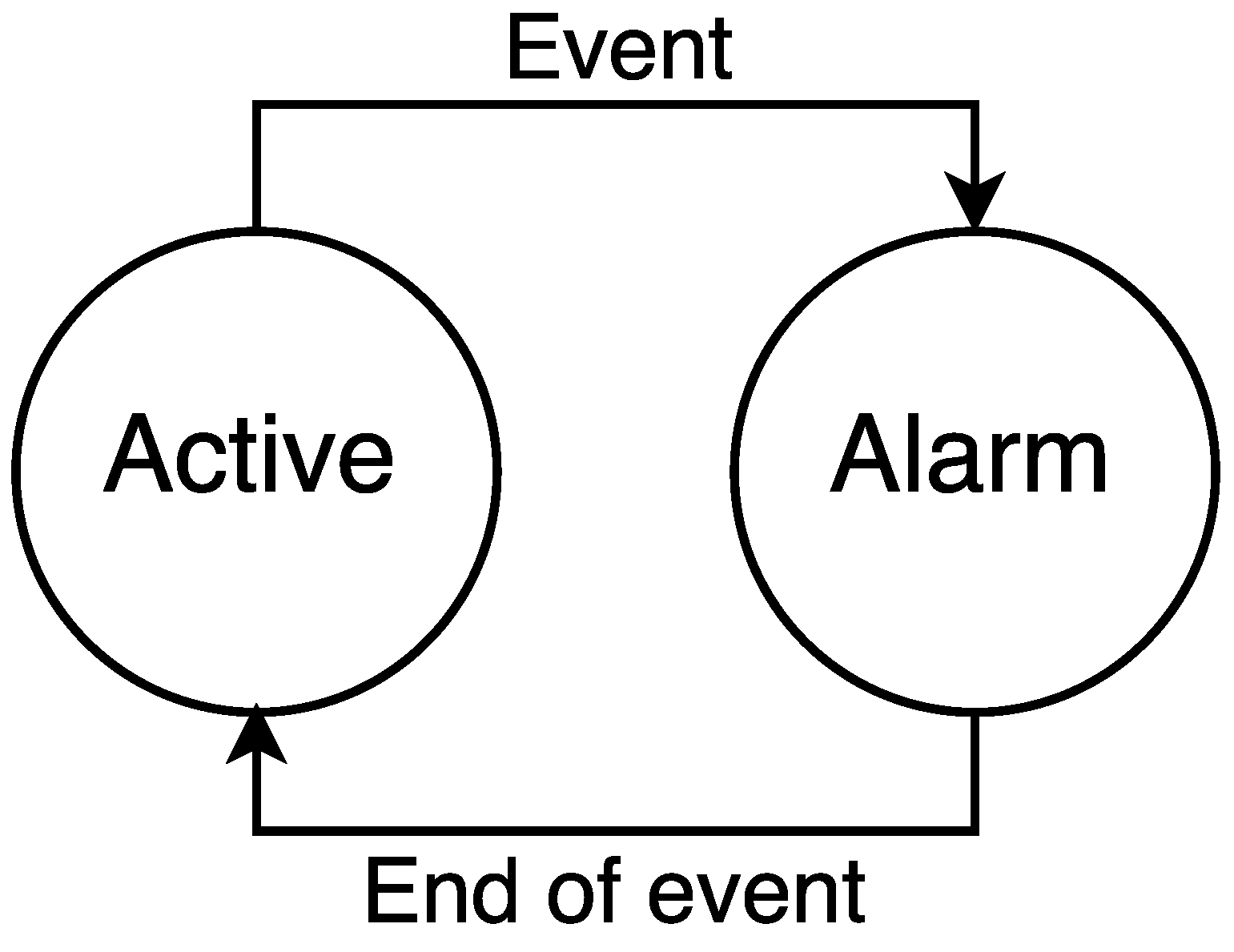
For both types of M2M devices, we assume a traffic model based on the transmission of reports. Particularly, the traffic model of any M2M device has two possible states:
active and
alarm (see
Figure 4). M2M devices generate small data packets following a Poisson process in both states. In the
active state, packets are generated infrequently, with a mean rate
. When an event happens, a percentage of massive or low latency M2M devices, denoted by
where
, change to the
alarm state. During the
alarm state, M2M devices generate packets more frequently, with a mean rate denoted as
. We assume that the event has a fixed time duration
, and the probability that in a certain instant of time an M2M device is in the
alarm state is denoted as
, where
. After the event, all devices in the
alarm state return to the
active state.
Massive M2M device events occur at certain instants in time caused by a large number of mM2M devices synchronizing their report transmissions (see
Section 2.3). Some of these events are periodic, whereas others are not. For simplicity, in our model, we assume that mM2M synchronization events take place at periodic instants of time. On the other hand, lM2M events are caused by alarm situations; that is, they are unpredictable. Consequently, in our model, lM2M events occur at random instants in time.
Furthermore, we assume that the percentage of M2M devices participating in a synchronization event,
, is a discrete random variable. By appropriately choosing
,
and
, we can model the traffic peaks (as explained in
Section 2.3).
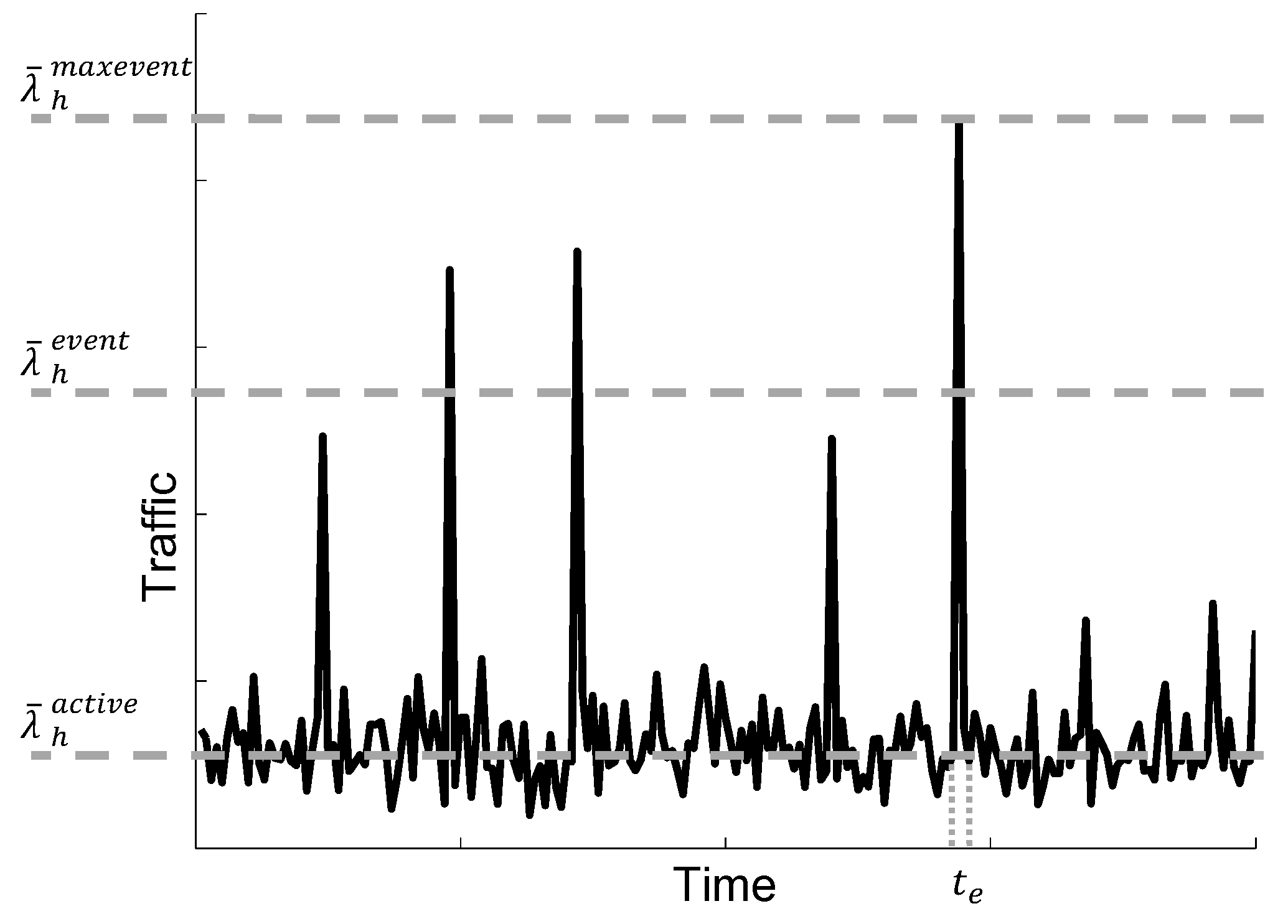
Let us analyze the mean generation rate of the MO-CPCEO procedure per M2M class. As there is one control message per MO-CPCEO procedure (see
Section 3.2), the mean generation rate of the MO-CPCEO procedure also defines the mean arrival rate of the MO-CPCEO control messages per M2M class to be processed by the MME. Let us denote this mean arrival rate as
. The parameter
v defines the time interval used for averaging the arrival rate. Particularly,
v can take three possible values
, which corresponds to the three following different traffic situations (see
Figure 5):
: intervals of time in which all M2M devices are in the active state; that is, in the absence of events.
: intervals of time in which an event takes place; that is, intervals of time where devices are in the alarm state. The averaging is carried out over all possible events, each with a given .
: time interval in which the largest event takes place; that is, the interval of time where devices are in the alarm state.
Then, for each averaging time interval,
can be calculated as:
Let
, with
, be the mean arrival rate of MO-CPCEO control messages to the vMME per M2M class. For
estimation, the entire period of time is considered. Then, it follows that:
5. Virtualized MME Design for M2M
This section describes the main points relevant to the virtualized MME (vMME) design adopted. Firstly, we introduce a design parameter named the target arrival rate per tier . This parameter defines the arrival rate used in the dimensioning of the vMME resources. Secondly, we explain two baseline schemes assumed in this work, named the Baseline Scheme (BS) and the Overdimensioned Scheme (OS). These baseline schemes highlight the impact of the overdimensioning of resources due to the inclusion of M2M events. Finally, the last subsection explains the two proposed schemes, called the Traffic separated Scheme (TS) and the traffic Shaper Scheme (SS). These proposed schemes include new mechanisms to optimize the dimensioning of the vMME, while at the same time they satisfy to the target arrival rate per tier defined.
5.1. Target Arrival Rate Design
The dimensioning of the schemes is done at each tier of the vMME separately, based on [
22]. To dimension the resources needed at each tier of the vMME model in advance, we define a design parameter name the
target arrival rate per tier. The target arrival rate is the maximum arrival rate of control messages for which the vMME has to satisfy a mean response time budget (
) for tier
j. That is, the vMME is required to have sufficient processing capacity at tier
j to satisfy
with an arrival rate up to the target.
On the one hand, for MBB communications, we set the target arrival rate,
, equal to the mean arrival rate of MBB control messages (see
Section 4.1), then
. On the other hand, for M2M communications, the target arrival rate
, with
, depends on whether we choose the vMME to satisfy
at each tier
j during the traffic peaks caused by M2M events. We consider the following three approaches to serve the traffic peaks:
Peak : denoted by
, we set the target arrival rate equal to the mean arrival rate during the largest event,
. With this setting, each tier
j of the vMME has to satisfy
for all traffic peaks, including the largest one. Therefore, it follows that:
Intense smoothing of peaks : denoted by
, we set the target arrival rate equal to a weighted sum of the mean arrival rates in absence of an event and during an event (see Equation (
4)). Therefore,
The parameter
, with
, defines the weighting factor of both M2M arrival rates. We select
such that
is slightly higher than
(see Equation (
5)). With this setting, each tier
j of the vMME is not able to satisfy
during the traffic peaks. Part of the signaling messages arriving during a traffic peak will be served after the end of the event.
Moderate smoothing of peaks: denoted by
, we set the target arrival rate equal to a weighted sum of the mean arrival rates in absence of an event and during the largest event (see Equation (
4)). Therefore, it follows that:
With this setting, each tier j of the vMME is also not able to satisfy during the traffic peaks. However, ; therefore, the signaling messages arriving during a traffic peak will be served faster than in the previous case.
5.2. Baseline Schemes
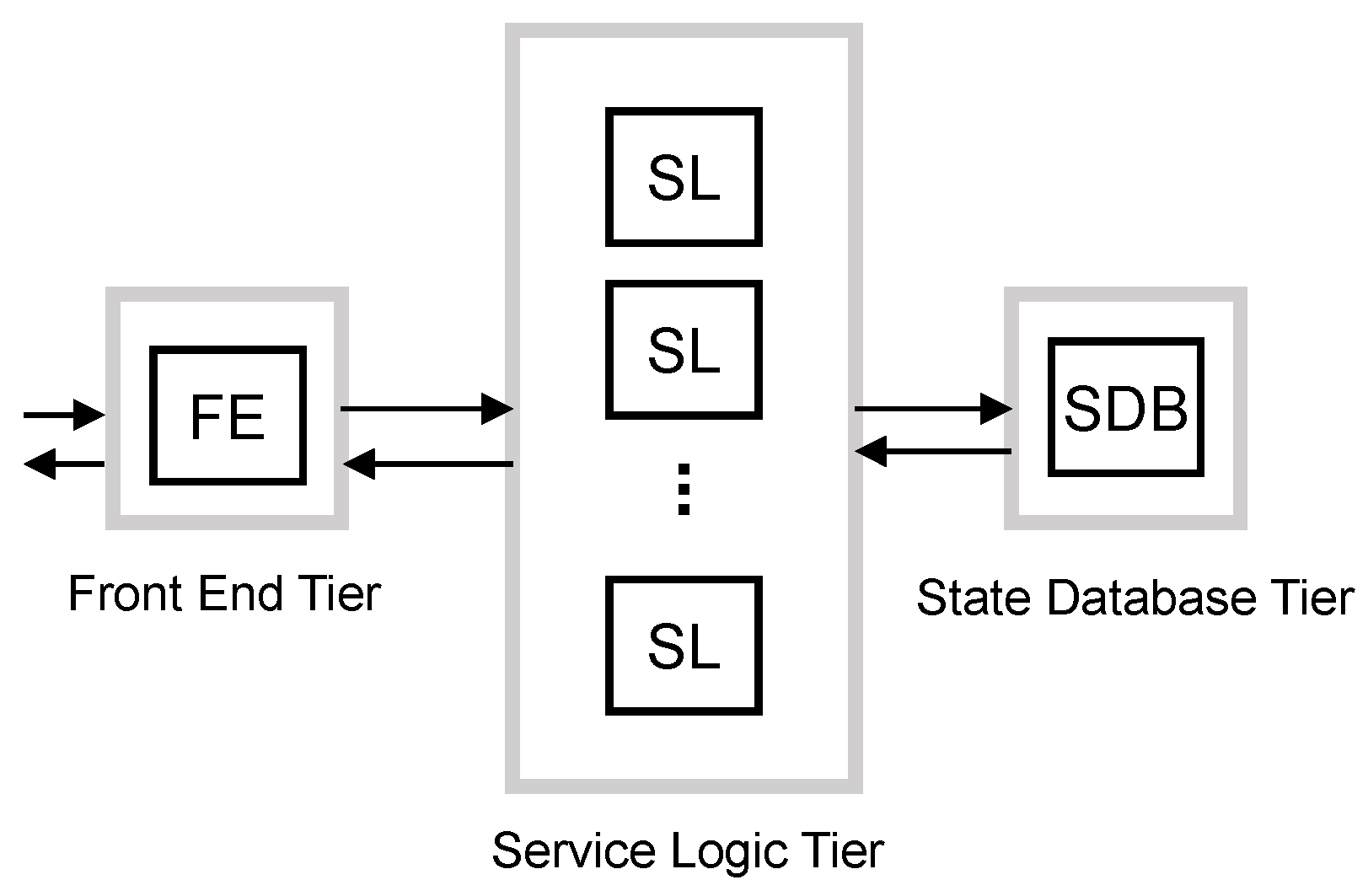
5.2.1. Baseline Scheme
This scheme is based on the system model presented in
Section 3 and also shown in
Figure 6. BS is composed of the aforementioned three tiers:
In this scheme, all resources are shared by all traffic classes, and all tiers have to convey the same target arrival rate.
For the baseline scheme, we set the target arrival rate such that each tier is able to serve the mean arrival rate from MBB UEs, mM2M devices and lM2M devices. Hence, with this scheme, each tier j is not able to satisfy during the M2M traffic peaks. For them, we apply the intense smoothing approach mentioned above. Hence, the vMME will be overloaded for a period of time during and after traffic peaks.
Let
,
and
respectively denote the target arrival rate of control messages in the FE tier, the SL tier and the SDB tier. In BS, we calculate them as:
Note that this design requires enough memory resources to store all packets while they are queued, as assumed in
Section 3.
5.2.2. Overdimensioned Scheme
The second baseline scheme considered is the same as the baseline scheme, but in this case, it is overdimensioned to satisfy at each tier of the vMME at all times, including during the traffic peaks caused by M2M devices.
Hence, this scheme is designed with a target arrival rate equal to the sum of the mean arrival rate for MBB and the mean arrival rate during the largest event of mM2M and lM2M devices. Since we assume there is no coordination of mM2M and lM2M events (see
Section 3.2), the resources do not need to be designed for simultaneous mM2M and lM2M events. Peaks from mM2M devices are expected to have a bigger impact on the vMME because of the massive number of mM2M devices. Then, we focus the arrival rate on mM2M peaks, using the mean arrival rate during the largest mM2M traffic peak,
. Therefore, the target arrival rate used in this scheme, which is the same for all tiers, can be computed as:
5.3. Proposed Schemes
5.3.1. Traffic Separated Scheme
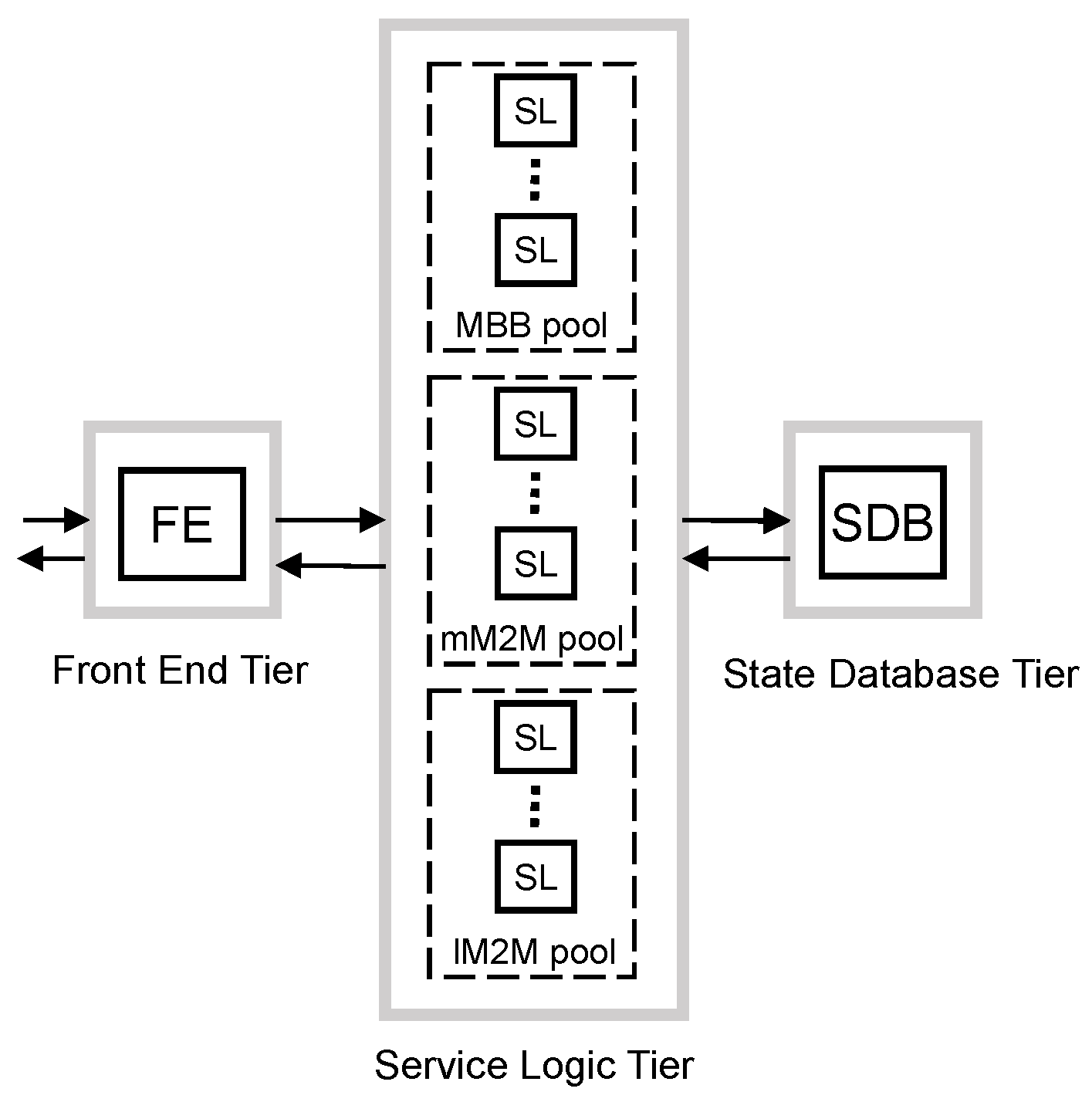
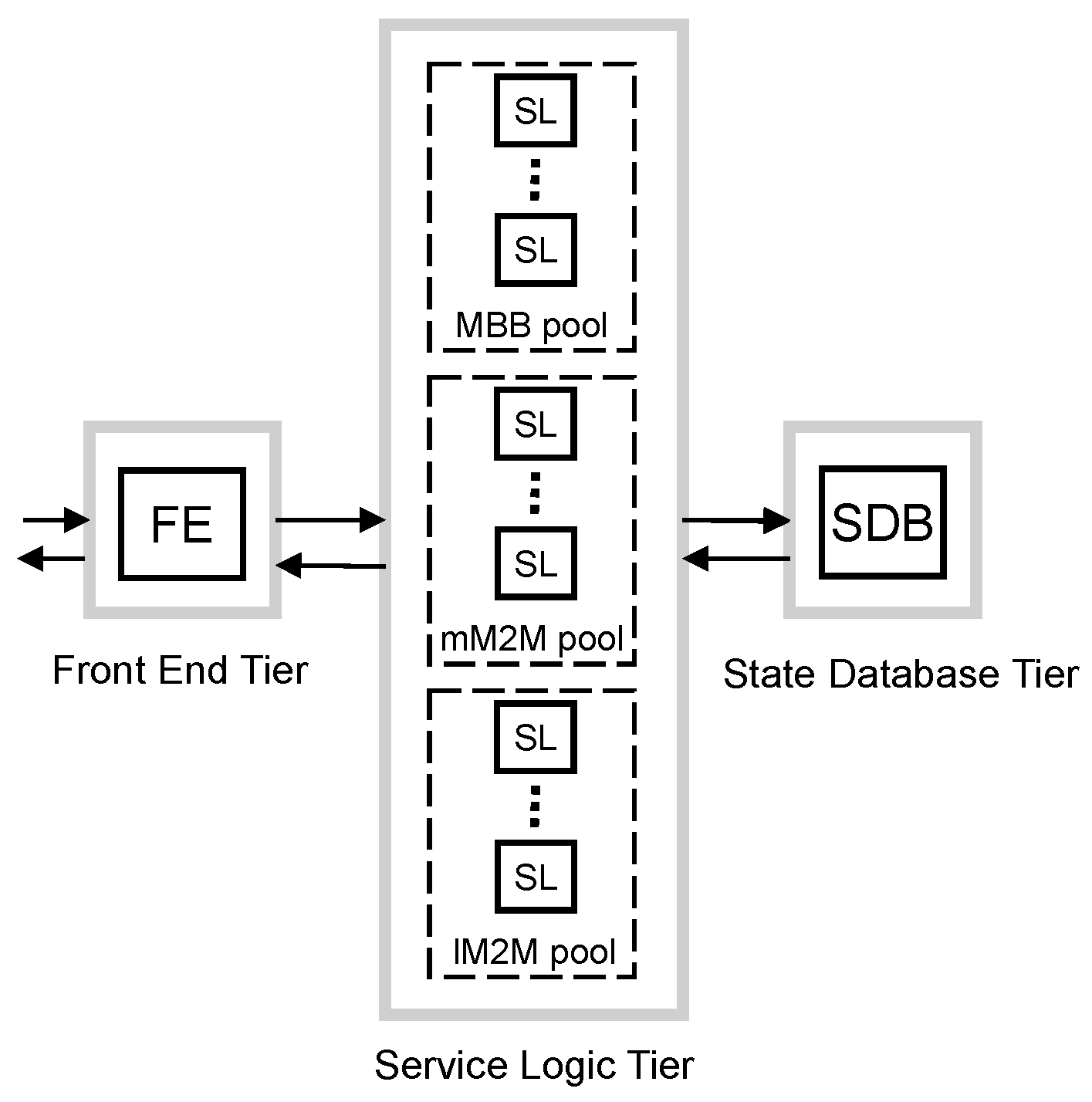
To mitigate the overdimensioning caused by the synchronization events of massive M2M devices, the first proposed scheme separates the processing of the traffic classes. To do that, we propose to use dedicated resources and dimension them separately for each traffic class. However, it is challenging to apply such separation at all tiers.
Regarding the FE tier, the vMME has to be seen as a single entity by the remaining elements of the 3GPP architecture. Additionally, the FE has to classify the traffic into the defined traffic classes. For these reasons, we do not consider the option of dividing the FE tier per traffic class. In addition, we also do not consider the option of dividing the SDB tier per traffic class. The rationale is that the SDB is considerably more expensive than the other elements of the design [
34], and therefore, such a division per traffic class would yield a costly and, therefore, unattractive design.
Consequently, we apply the separation of dedicated resources for each traffic class only at the SL tier (see
Figure 7). The benefit of this scheme is that the target arrival rate of each pool of SL can be optimized using the main traffic characteristics of the traffic served. Additionally, the mean response time budget
at the SL tier can be set differently for each traffic class.
This scheme, unlike previous ones, has a different target arrival rate defined per tier. This is due to the FE tier having to convey all traffic to avoid bottlenecks at this tier. However, SL and SDB tiers can be optimized to reduce overdimensioning. Then, we set the target arrival rate in the FE tier as in the overdimensioned scheme explained above:
Since SLs are dimensioned differently for each traffic class, we set their target arrival rate differently. For MBB traffic, the mean arrival rate, for mM2M traffic, we apply moderate smoothing of traffic peaks, ; and for lM2M, the traffic peak, .
Note that the mM2M pool of SL instances is not designed to support mM2M traffic peaks, but this is not expected to be a major issue as mM2M devices are assumed to be delay tolerant. Furthermore, as mentioned in
Section 3, the SL tier is assumed to have enough memory resources to store all packets while they are queued. Then, we set the target arrival rate for each traffic class as:
At the SDB tier, the target arrival rate is a sum of the target arrival rate of each class of SLs, then:
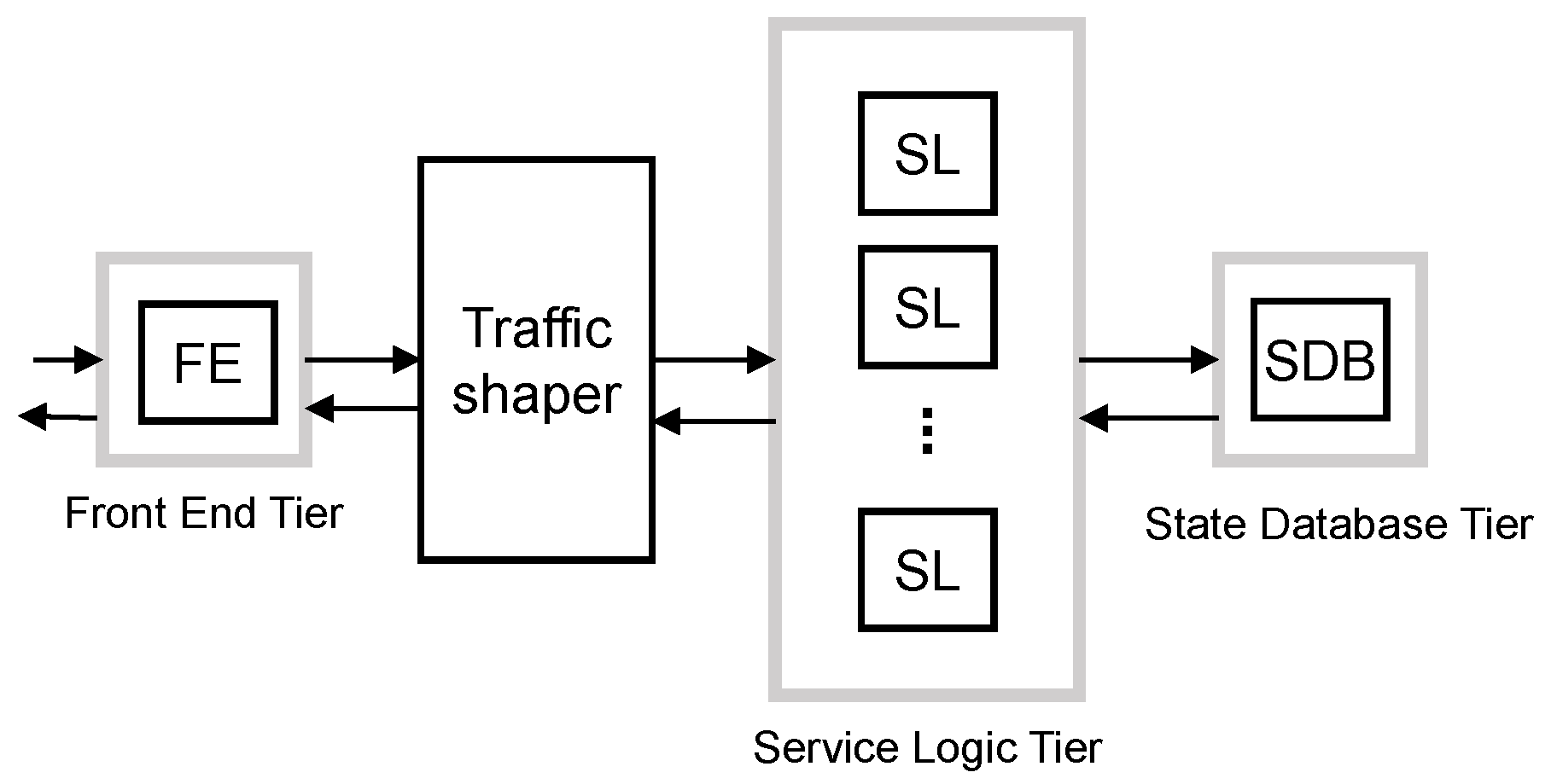
5.3.2. Traffic Shaper Scheme
The second proposed scheme adds a traffic shaper after the front end tier to control the traffic of each class to be processed by the SL and SDB tiers. This can be considered as a middle approach between the overdimensioned and the traffic separated schemes; see
Figure 8.
As in the overdimensioned scheme, in SS, all resources are shared among all traffic classes. However, the traffic shaper can smooth traffic peaks and benefit some traffic classes through their shaping criteria. In addition, this scheme avoids the multiplexing loss of processing resources suffered by the separated traffic scheme due to the spare capacity of the dedicated workers that cannot be used for other traffics classes.
As in the overdimensioned scheme, each tier has to satisfy
with a target arrival rate. However, for this scheme, the SL and the SDB tiers have the same target arrival rate as they process the same traffic after the shaping of the traffic shaper. The target arrival rate used to design the FE tier is the same as in the traffic separated scheme. Therefore, it can be calculated as:
We assume that the traffic shaper is implemented with a token bucket for each traffic class. The token rates of the buckets are set equal to the target arrival rate for each class, respectively. We set the target arrival rate for each class as in the traffic separated scheme. That is, for MBB traffic, the mean arrival rate; for mM2M traffic, we apply moderate smoothing of traffic peaks, ; and for lM2M, the traffic peak, .
After the traffic shaper, the SL and the SDB tiers have a target arrival rate equal to the sum of the target arrival rate of all classes. Then, the target arrival rate can be calculated as:
This design also requires enough memory resources at traffic shaper queues to store all packets while they are queued, as assumed in
Section 3.
Table 2 summarizes the target arrival rate criteria of each baseline and proposed scheme.
6. Dimensioning
The dimensioning of the schemes presented above requires a model that provides an estimation of the service response time as a function of the processing resources. To do that, we assume the vMME model proposed in [
32], which is based on the model of a typical cloud processing chain [
35].
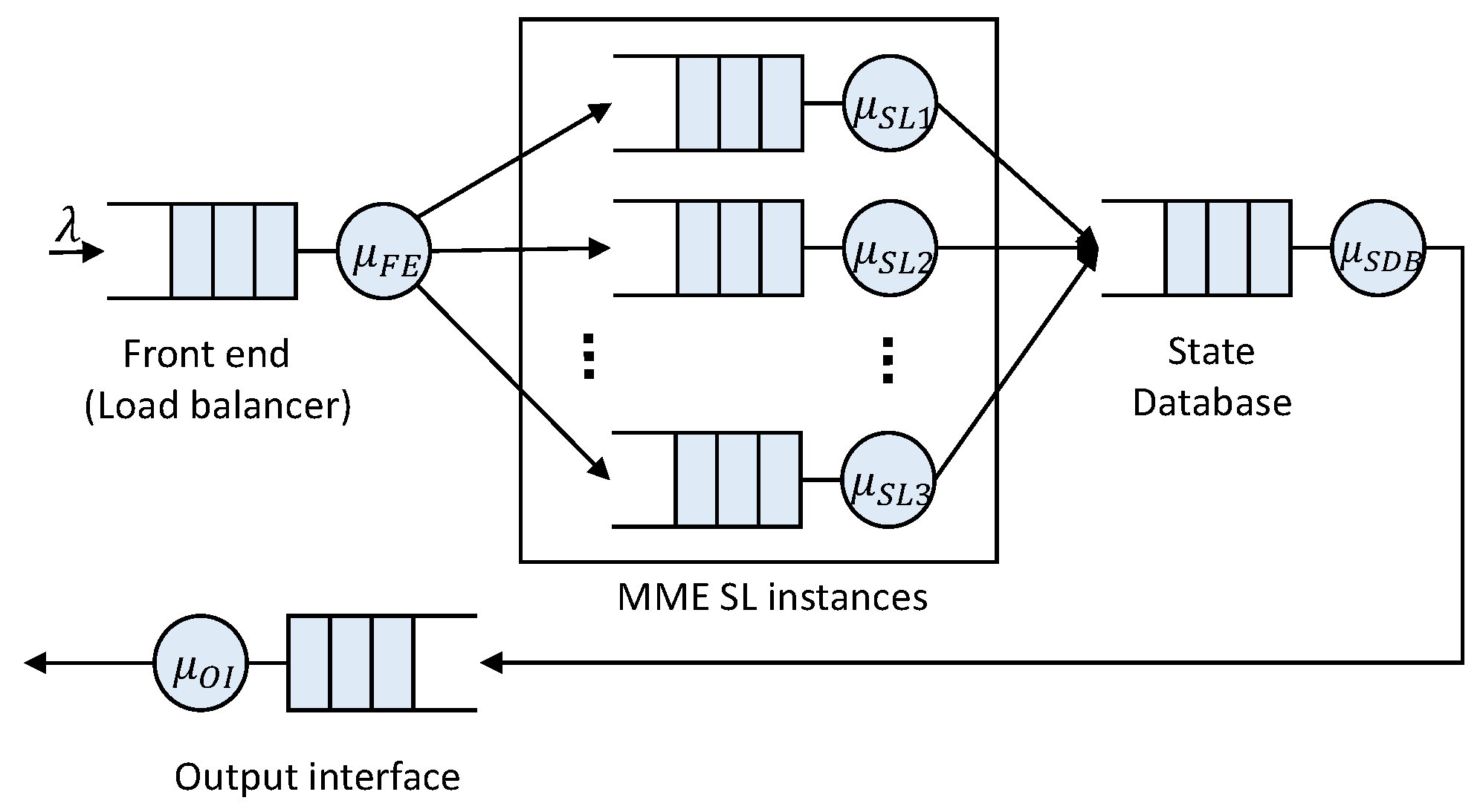
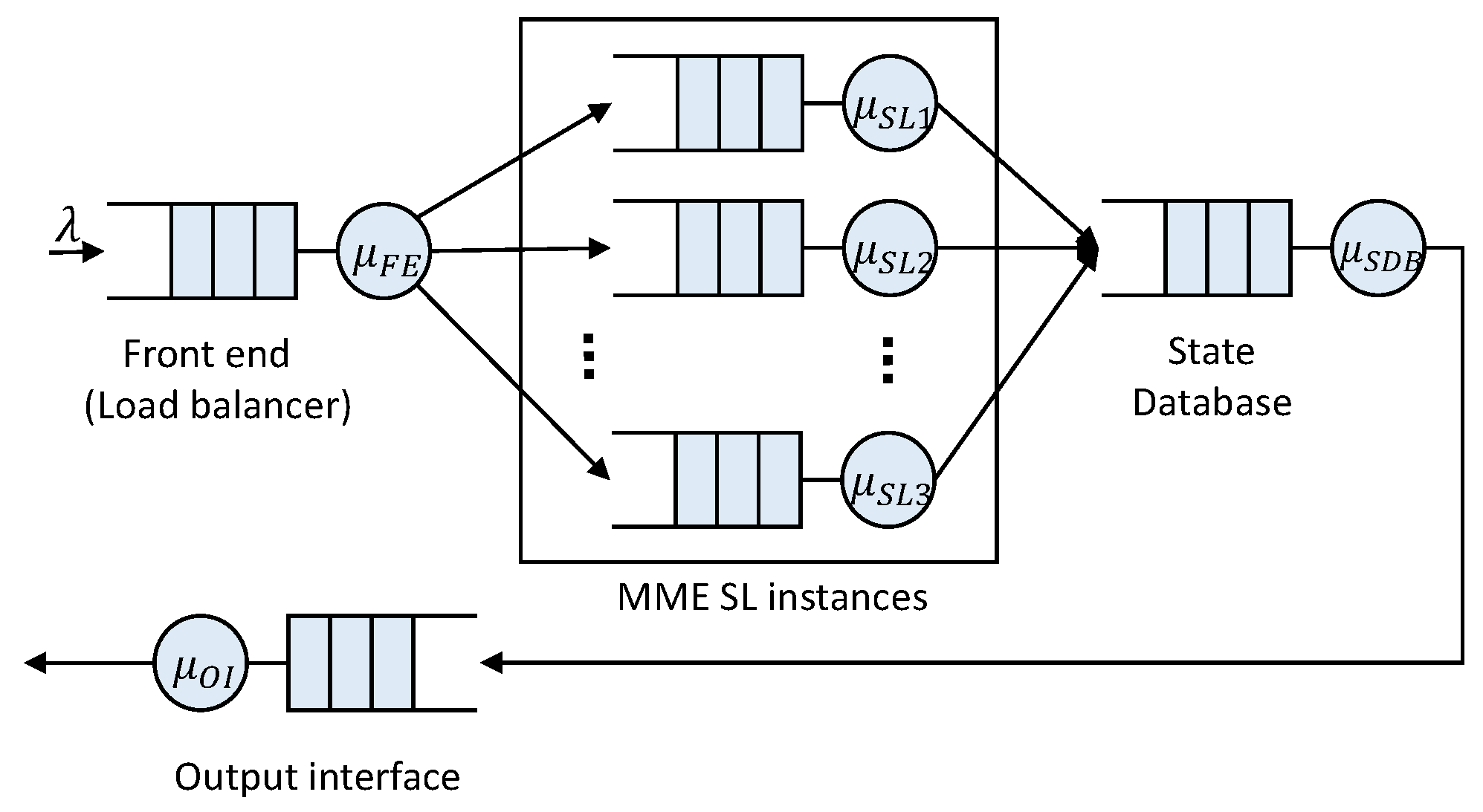
This proposal uses Jackson’s open queuing network (see
Figure 9) to model the vMME architecture (explained in
Section 3). In this approach, the SDB and the FE tiers are modeled by M/M/1 queues, and the SL tier is modeled by an M/M/m queue.
Jackson’s theorem states that the numbers of messages in the system’s queues are independent of the other queues, and consequently, the service response time of the complete system is equal to the sum of the service response time of the queue in each tier. In the present work, we also assume that the SDB and the FE can be replicated, and therefore, we also model SDB and FE tiers by an M/M/m queue.
Given a target arrival rate, the goal of our vMME dimensioning is to determine the minimum number of instances required at each tier
j to guarantee the mean response time budget
. Since we consider Jackson’s open queuing network, the mean response time of the system
can be computed as:
where
is the mean response time at each tier
j . Since we assume that each tier is modeled by an M/M/m queue, it holds that:
where
,
is the service rate of one tier instance,
is the target arrival rate considered for dimensioning at tier
j (see
Table 2),
is the number of instances of the tier and
is Erlang’s C formula.
represents the probability that an arriving packet has to wait in the queue of the tier because all of the instances are busy, and it has the following expression:
The processing times of the FE, SDB and output interface are constant. However, the processing time of an SL is different for each control message [
32]. Consequently, the mean service time of an SL,
, will depend on the frequency with which each type of control procedure occurs. For this reason,
will be different for each scheme considered in this work.
Let
,
,
and
denote the processing time of the
i-th message of the SR, SRR, HO and MO-CPCEO procedure, respectively. The mean service times of an SL for each scheme considered are summarized in
Table 3.
We perform dimensioning for each tier individually. The dimensioning problem for each tier can be formulated as:
where
is the target mean response time for each tier. Hence,
can be computed with a simple iterative algorithm that increases the number of tier instances until the condition
is met.
7. Evaluation
This section includes the simulation results obtained to evaluate the four vMME schemes (
Section 5). After the simulation setup subsection, we compare the required resources and their associated costs in the dimensioning subsection. Later, we compare the delay experienced by each traffic class in the vMME with the four virtualized schemes.
7.1. Simulation Setup
Our evaluation methodology includes three steps, namely:
The dimensioning of each tier of the vMME model and the estimation of the associated cost using the target arrival rate as input; this estimation is done for a range of UEs and a given ratio of M2M devices per UE;
The generation of signaling traces for each traffic class (MBB, mM2M and lM2M); similarly, this trace generation is done assuming a specific number of UEs and a given ratio of M2M devices per UE;
Finally, the simulation of the vMME queuing model using the signaling trace as input.
We use the MATLAB Simulink framework to simulate the queuing system presented in
Section 6, which provides the vMME response time experienced by a control plane message. The queuing model is fed with the traces of signaling packets generated by each traffic class. In the model, the service rates of the FE tier, SL tier, SDB tier and output interface are extracted from [
32].
For the MO-CPCEO procedure, we obtained that the processing time needed at an SL instance is 145.05
s. Other main parameters of the simulation are summarized in
Table 4. To avoid excessively long simulations, we assume a period of time between mM2M events equal to 60 s.
To estimate the system running cost, we consider the Amazon EC2 service, with the costs and configuration detailed in
Table 5. We assume a medium-sized CPU instance
m3.xlarge with an average of
float operations per second [
36]. We use the price of the load balancing service provided by Amazon to estimate the cost of the FE tier. Our setup also includes the Amazon Aurora database [
37], which is reported to provide
updates/s transactions. The overall cost includes the per instance cost, the time-based rental fee and the data traffic processed.
7.2. Results
7.2.1. Dimensioning
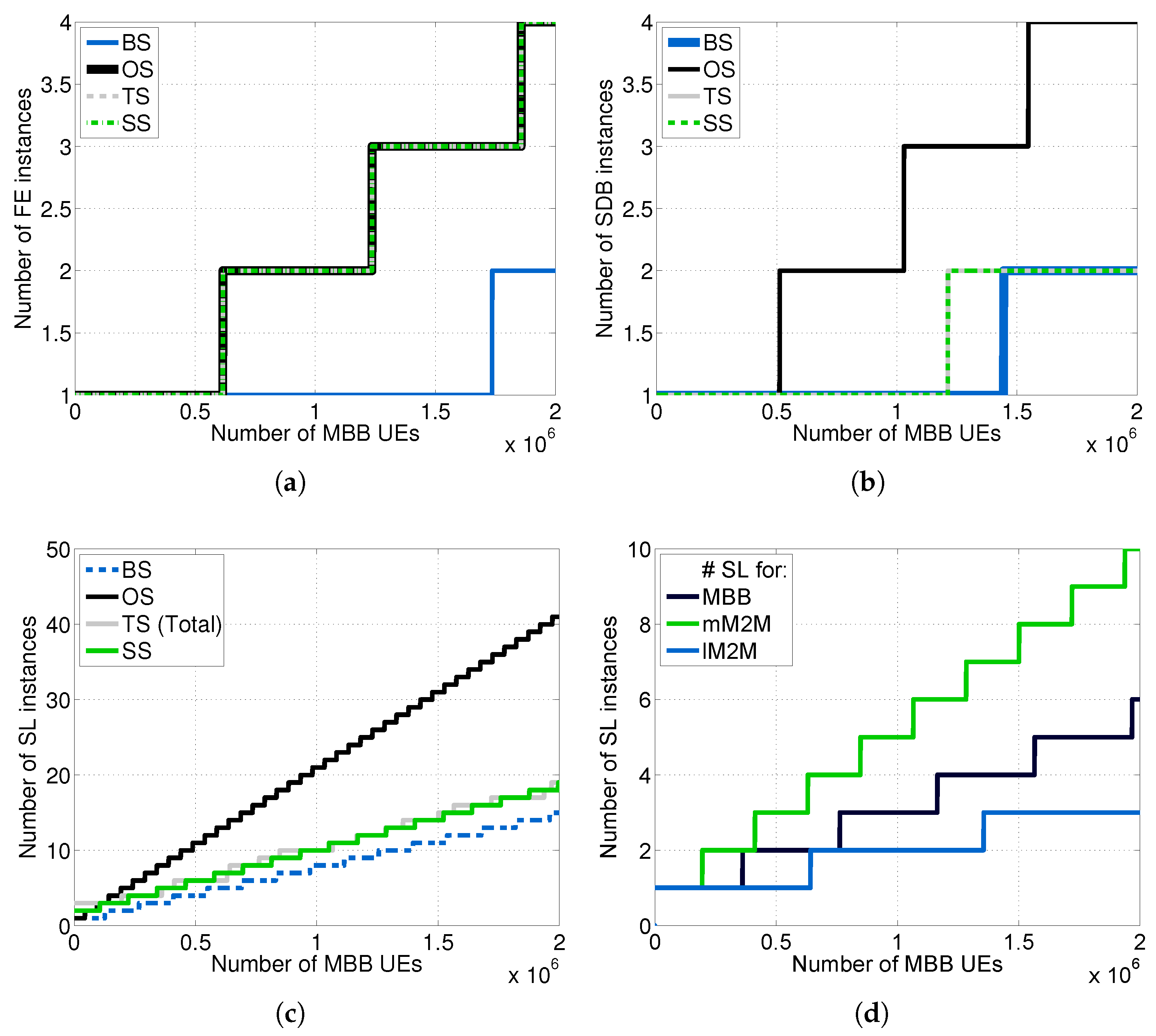
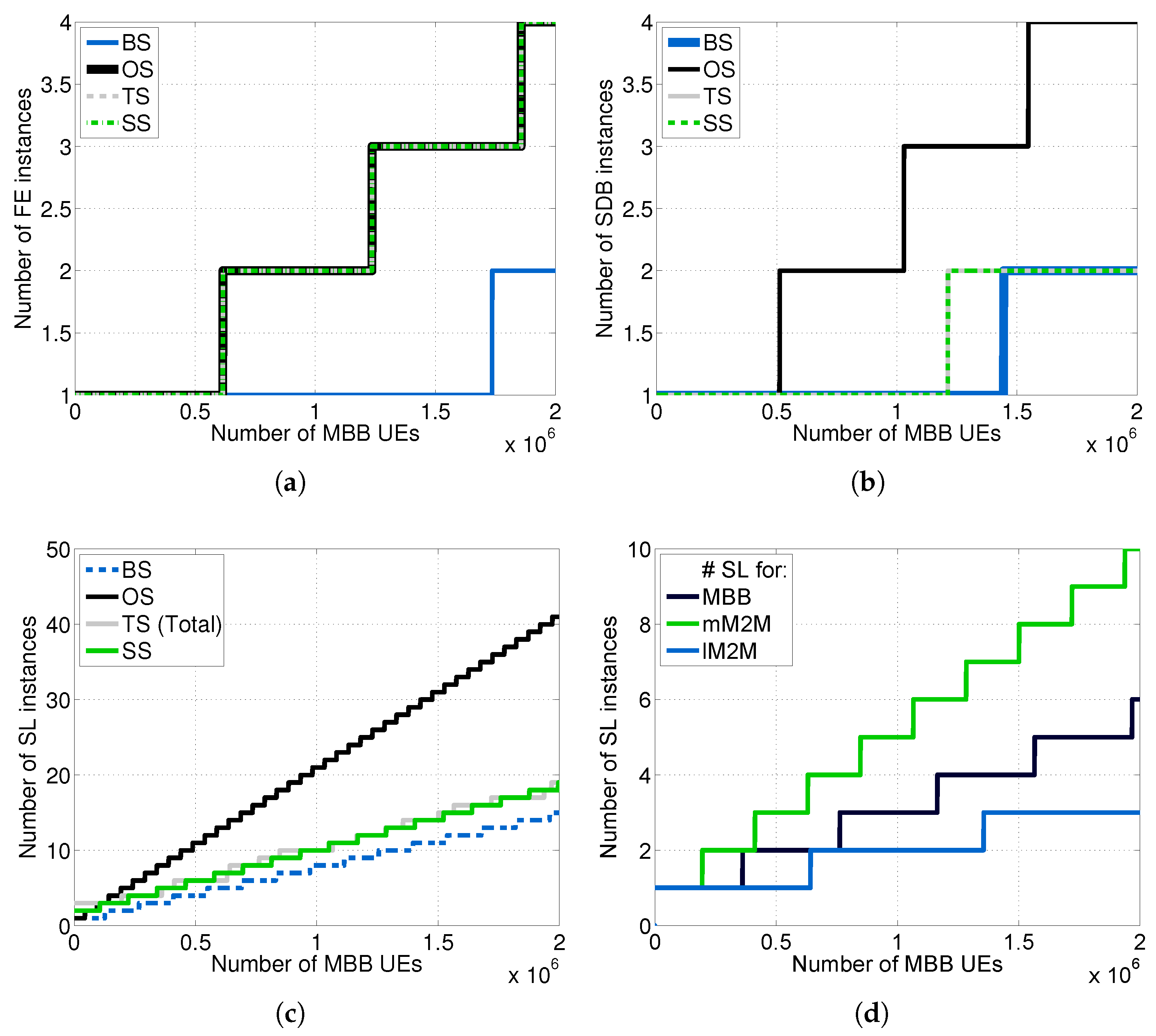
We carried out the dimensioning at each tier of the vMME versus
for all of the schemes considered (see
Figure 10) by using the theoretical framework described in
Section 6 and assuming
.
Notably, to simplify the comparisons in the Traffic separated Scheme (TS), we set the same response time budget for MBB and lM2M traffic classes; however, this scheme enables one to set different budgets for each class. Note additionally that, for the TS scheme, the required number of SL instances
is the sum of the required number of SL instances for each type of traffic, which are depicted in
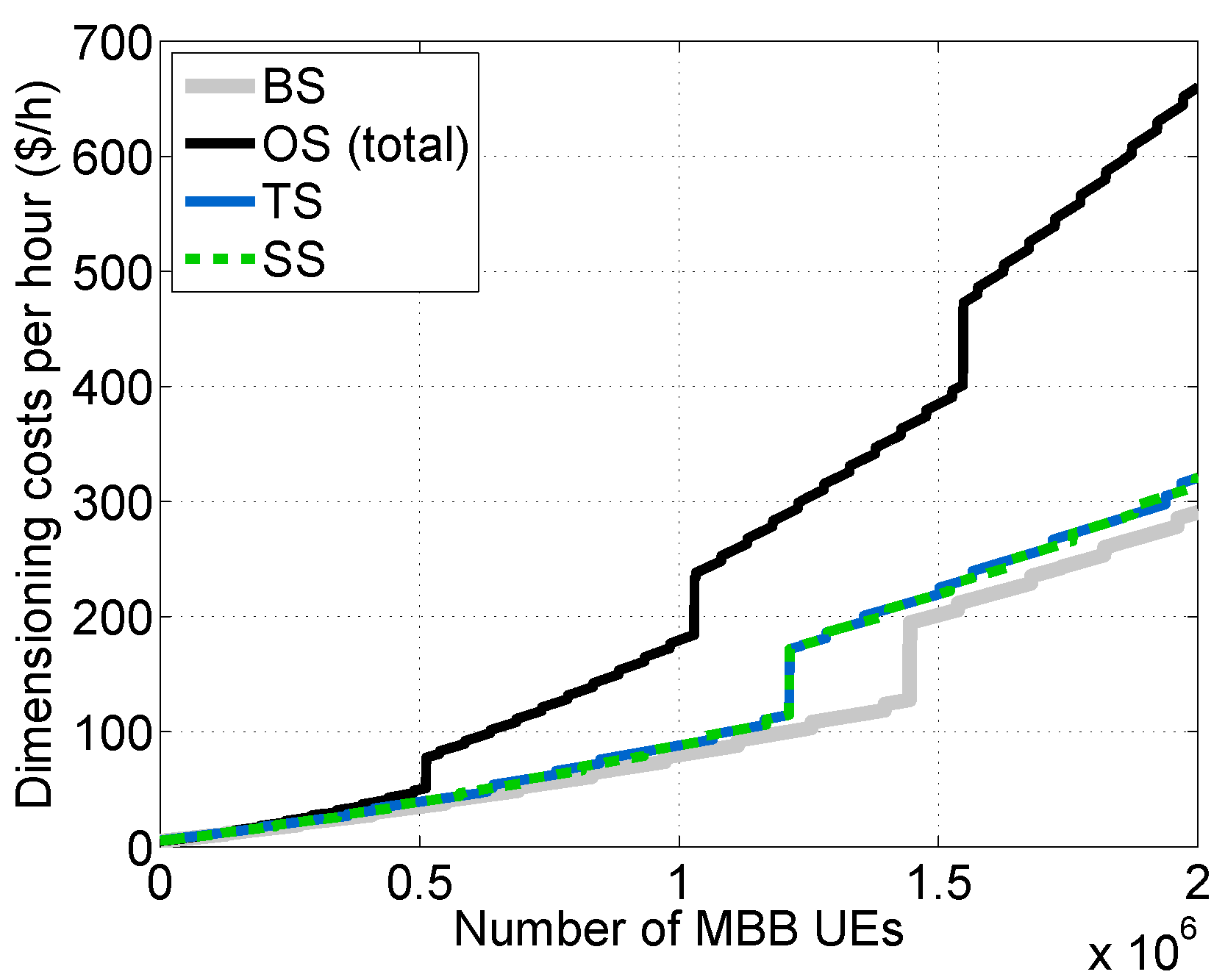
Figure 10d. Additionally, we computed the cost per hour for each scheme considered (see
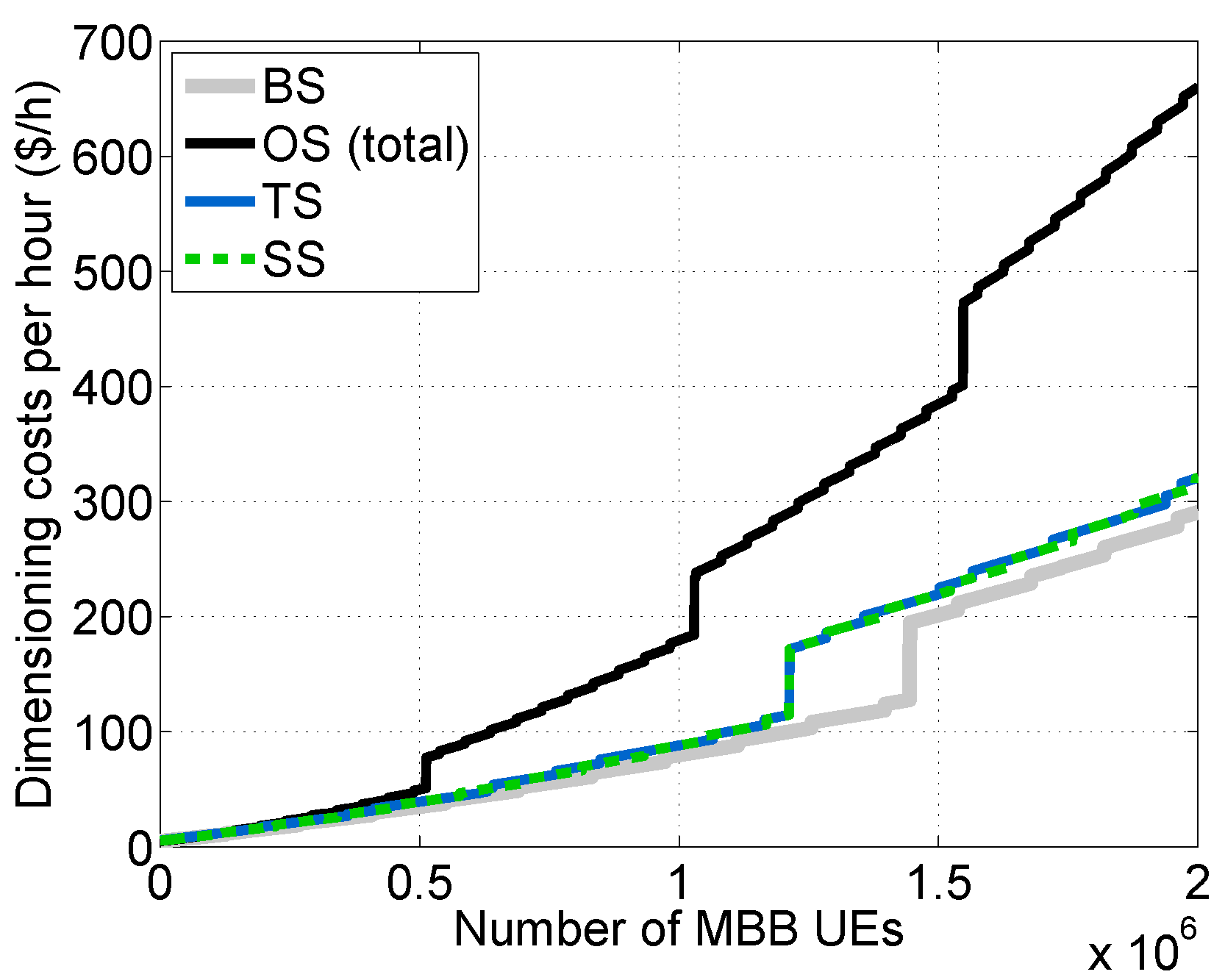
Figure 11).
As was expected, the Overdimensioned Scheme (OS) demands the greatest amount of resources, being the most expensive scheme. Conversely, the Baseline Scheme (BS) is the least expensive one. The Traffic separated Scheme (TS) and the traffic Shaper Scheme (SS), which have a similar cost, achieve a noticeable reduction in cost in comparison with OS. This is mainly thanks to the isolation between traffic types in the TS case and the limitation imposed by the traffic shaper on the mM2M traffic arrival rate in the SS case. In such cases, the dimensioning at the SL and SDB tiers can be performed without considering , which is around 12.47-times greater than in our experimental setup. However, both the TS and SS schemes are designed to satisfy the delay constraint for lM2M traffic.
Additionally,
Table 6 summarizes the estimation of the memory consumption for each tier of the vMME. It assumes the same number of MBB UEs and M2M devices than the simulation setup. We use the number of SL instances from
Figure 10c. We utilize 16,545 packets queued in the system. This number is the worst case of packets queued of the traffic separated scheme proposed, calculated from the results obtained in the next subsection.
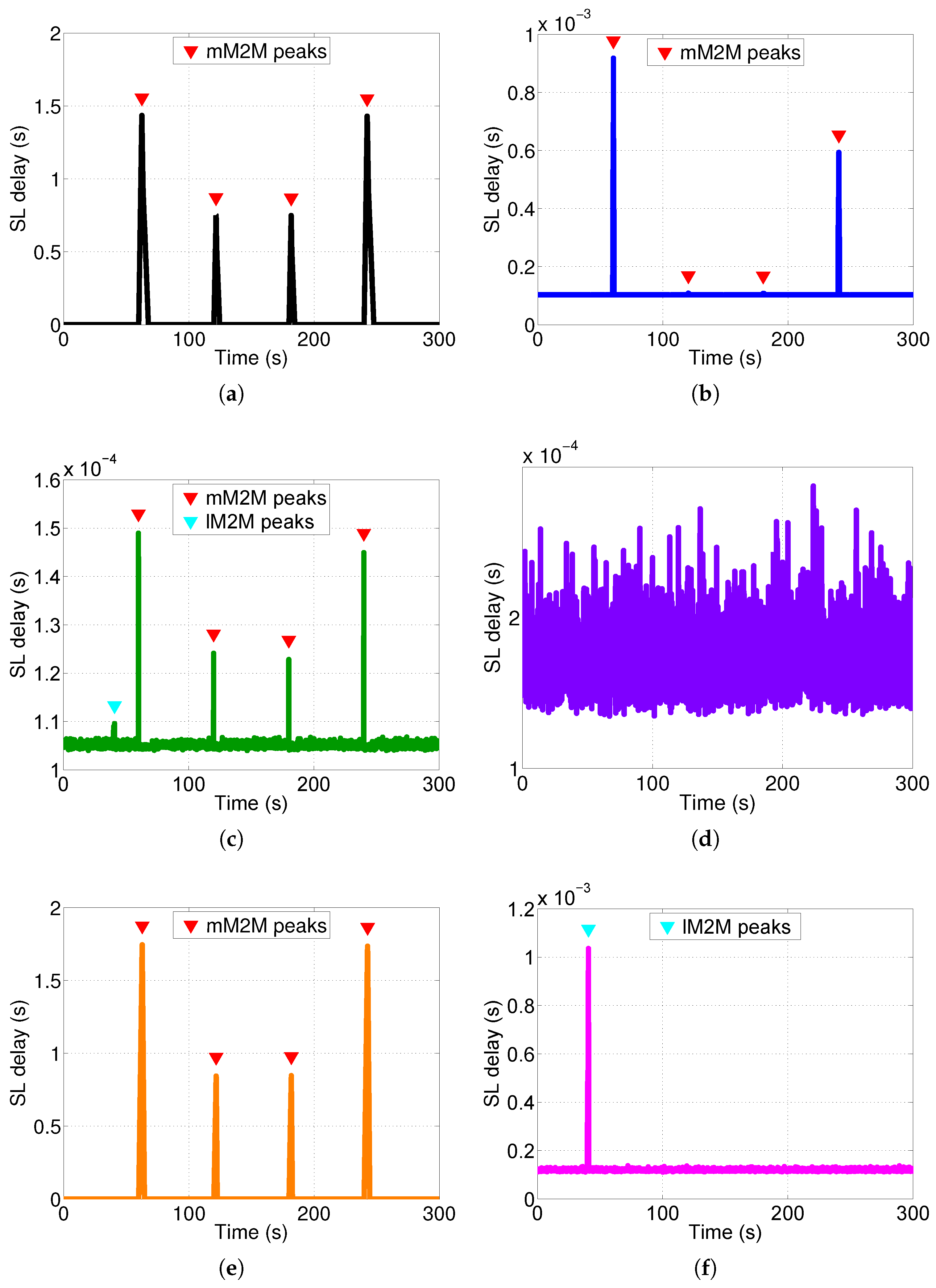
7.2.2. Delay
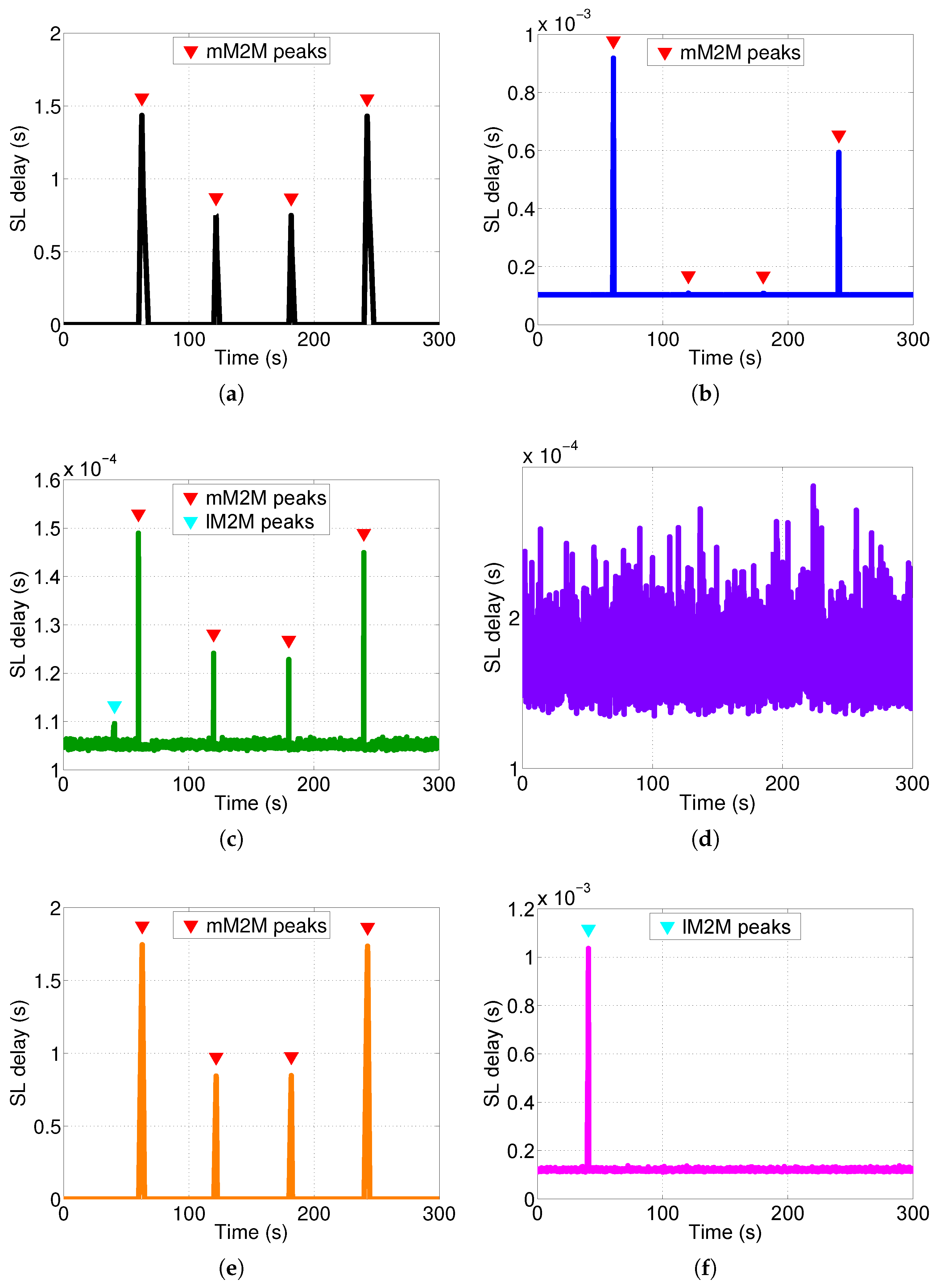
We studied the response time experienced by a control packet at the SL’s tier of the vMME for all of the schemes (see
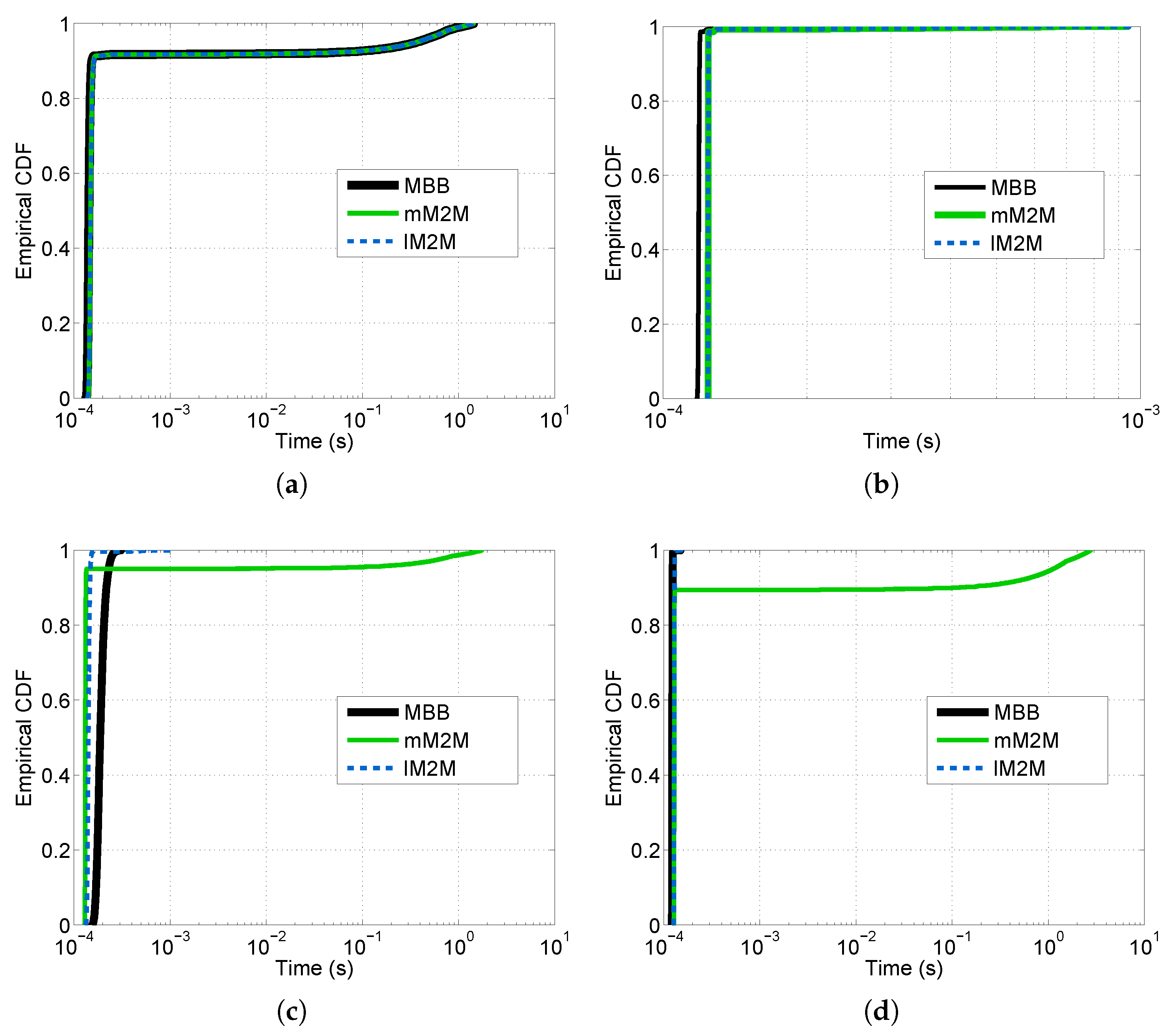
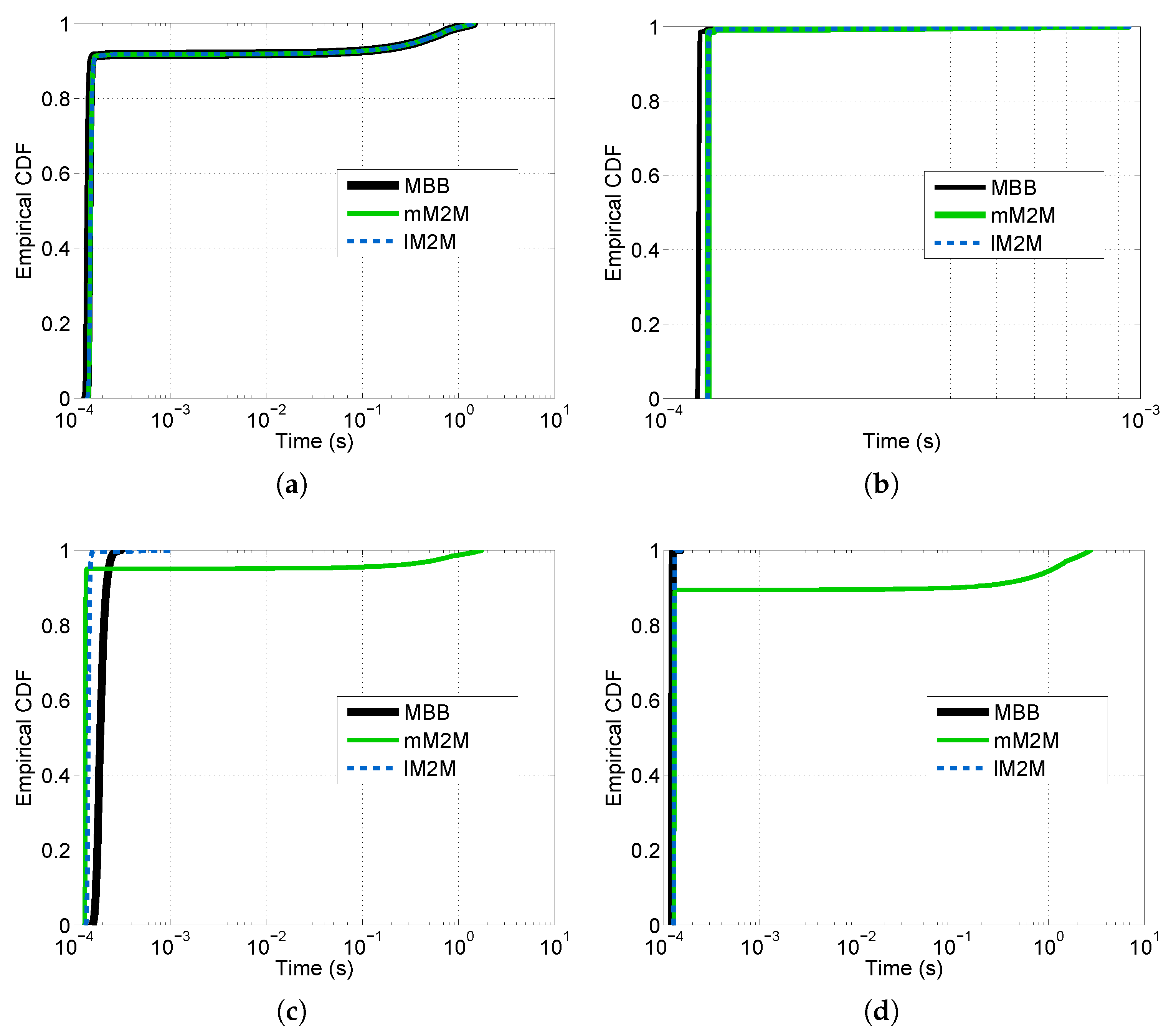
Figure 12). Additionally, we computed the CDF of the overall system response time, which is the sum of the delay experienced by a packet at each tier of the vMME (see
Figure 13). To that end, we generated a signaling trace for 636,000 MBB UEs and 300 s of duration. The trace includes the three considered classes.
Table 7 summarizes the results for this point. The number of UEs is selected such that the processing capacity of the OS scheme and the lM2M SL pool in the TS scheme are about to require an additional SL instance to satisfy
. However, with this number of users, the remaining schemes do not experience the same situation. The same signaling traces were used for the four schemes considered. The response time results are filtered with a simple 90-ms moving average. The results show that response time is higher than the target mean response time at the SL tier (
= 1 ms) during the mM2M alarm events for the BS case (
Figure 12a). That is because the SL tier is under-dimensioned to support the mM2M traffic peaks. Consequently, in such situations, the mM2M traffic might delay the other traffic types, which may be delay-sensitive, such as lM2M (see
Figure 13a). On the contrary, for the OS case, the response time at the SL tier is all of the time below
since the system is overdimensioned (
Figure 12b).
For the SS approach, the SL tier response time always meets the condition
(
Figure 12c). That is because the mM2M traffic peaks are limited by the traffic shaper. Moreover, during the lM2M traffic peaks, the system takes advantage of the multiplexing gain. In the TS case, the lM2M pool of the SL tier also meets the condition
during the lM2M traffic peak (see
Figure 12f). On the contrary, the mM2M pool of the SL tier exceeds by several orders of magnitude the response time budget during and after the mM2M traffic peaks (see
Figure 12e), as moderate smoothing of the peaks is applied. The MBB pool of the SL tier also meets the response time budget condition (see
Figure 12d). Recall that, with the selected number of UEs, only the OS (
Figure 12b) and the lM2M class in the TS scheme (
Figure 12f) have a processing load close to the dimensioned capacity.
8. Conclusions
In this paper, we propose two designs for a virtualized MME, which aim at facilitating IoT support in 5G systems. The first proposed design partially separates the processing resources devoted to each traffic class; while the second design includes traffic shaping to control the traffic of each class.
We have considered three traffic classes: MBB, massive M2M and low latency M2M. In M2M communications, we have included M2M events to analyze the performance of the virtualized MME. M2M events considered are caused by the report synchronization of massive M2M devices and alarm events of low latency M2M devices. Additionally, we assume the use of the CPCEO procedure to transfer these reports from M2M devices.
We have compared our proposed designs with two other schemes: (i) a baseline virtualized MME design, which does not apply such resource separation; (ii) an overdimensioned virtualized MME.
The reported comparisons include: (i) dimensioning of the required resources; (ii) estimation of the costs based on the model of Amazon EC2; (iii) the evaluation of the response time of the virtualized MME schemes for each traffic class.
After the conducted simulations, the results show that our proposed schemes provide much lower costs than the overdimensioned scheme while they satisfy the exigent delay requirements of MBB and low latency M2M communications. Furthermore, the comparison of the traffic separation scheme and the traffic shaper scheme shows that the multiplexing gain of the latter provides benefits in terms of latency reduction. However, the traffic separation scheme enables one to have different delay requirements for each traffic class, and additionally, it can isolate their performance.
In addition to the above results, we identify the following advantages of the considered solution: (i) CPCEO procedures mitigate the signaling explosion generated by a huge number of M2M connected devices. However, it increases the processing load on the control plane of the EPC. (ii) NFV increases the scalability of the network to deal with such load increase of signaling. (iii) The usage of our proposed schemes further optimize the costs while satisfying the delay demands.
However, our solution has also the following implications: (i) the dimensioning of the resources is more complex; (ii) CPCEO procedures use the transport network of the control plane to send data packets, which imposes an additional load. Furthermore, regarding the bottlenecks of the proposed schemes, the state database tier is critical. This is due to the state database scaling with certain constraints, and our solution makes heavy use of it. Moreover, the service logic tier design is determinant, as it considerably affects the performance of each traffic class.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}