
A Smart Spoofing Face Detector by Display Features Analysis



Abstract
:1. Introduction
2. Design Concept and Principal Theory
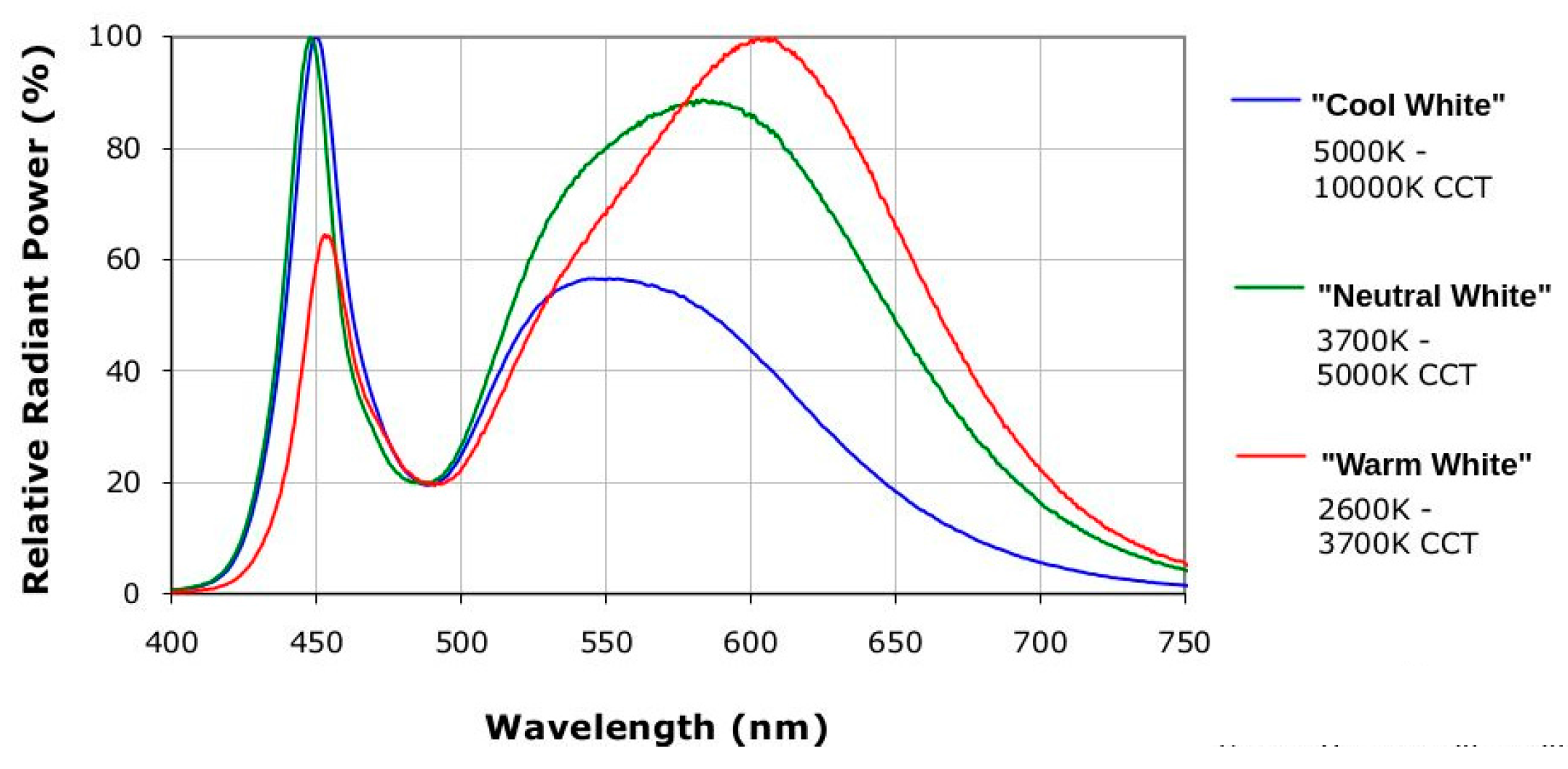
2.1. Features of Current LED-Backlight Display
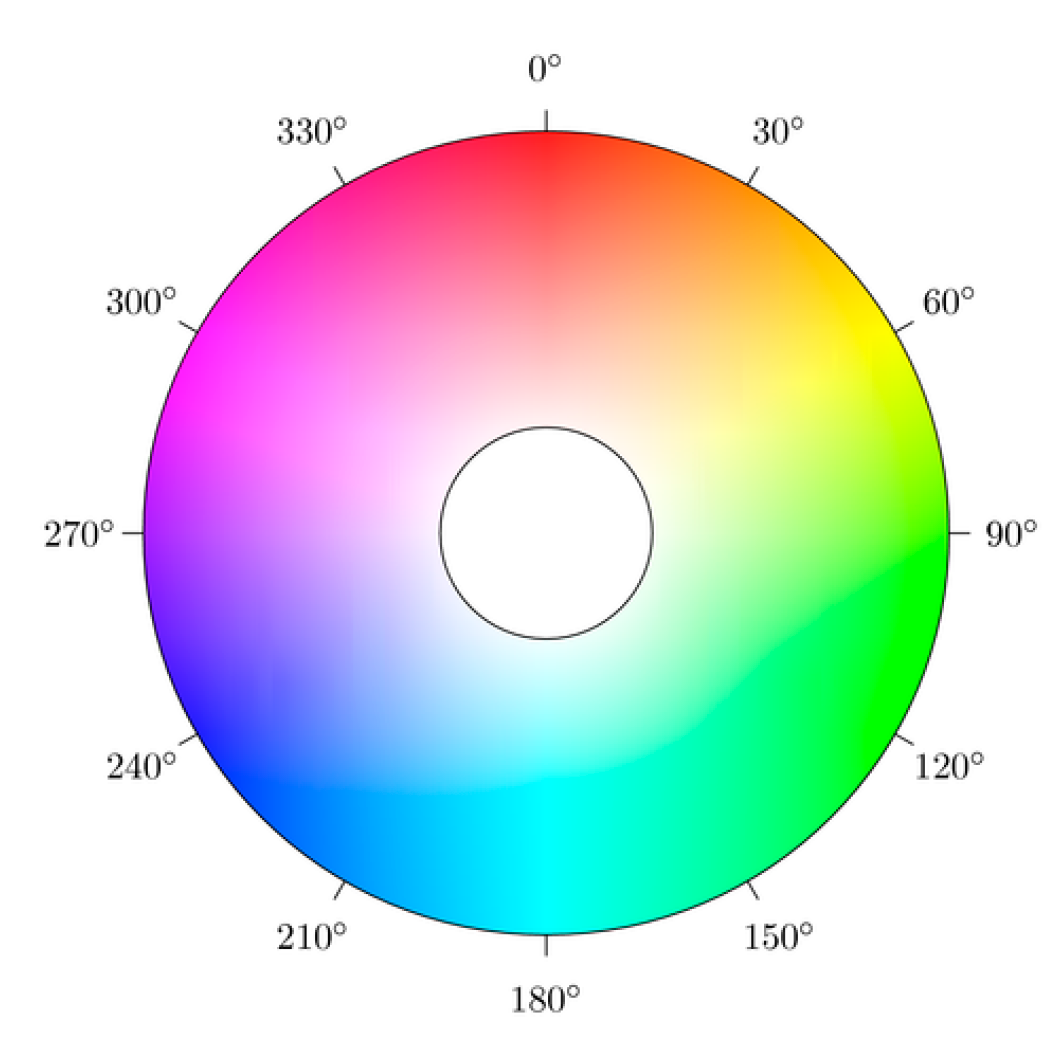
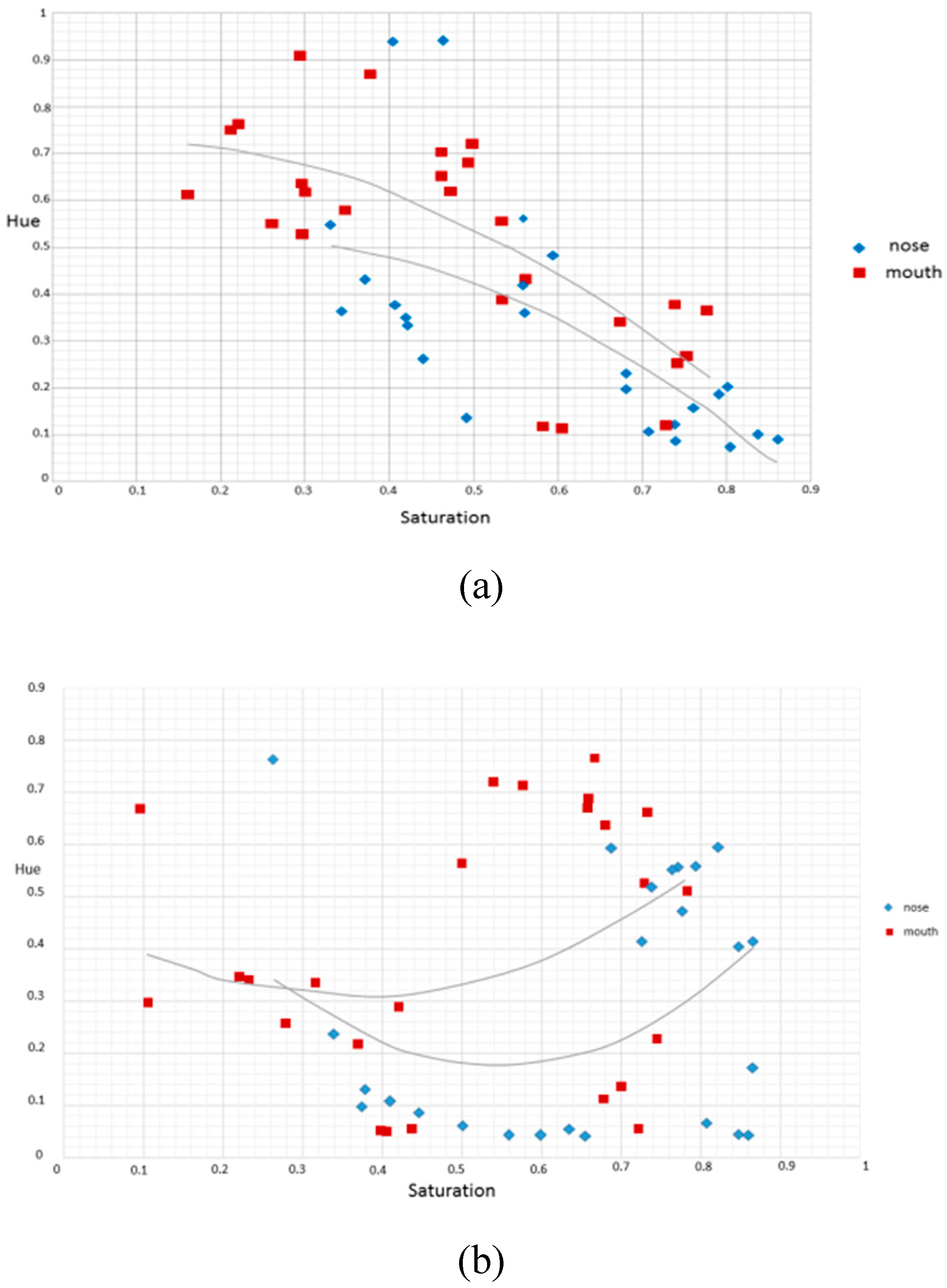
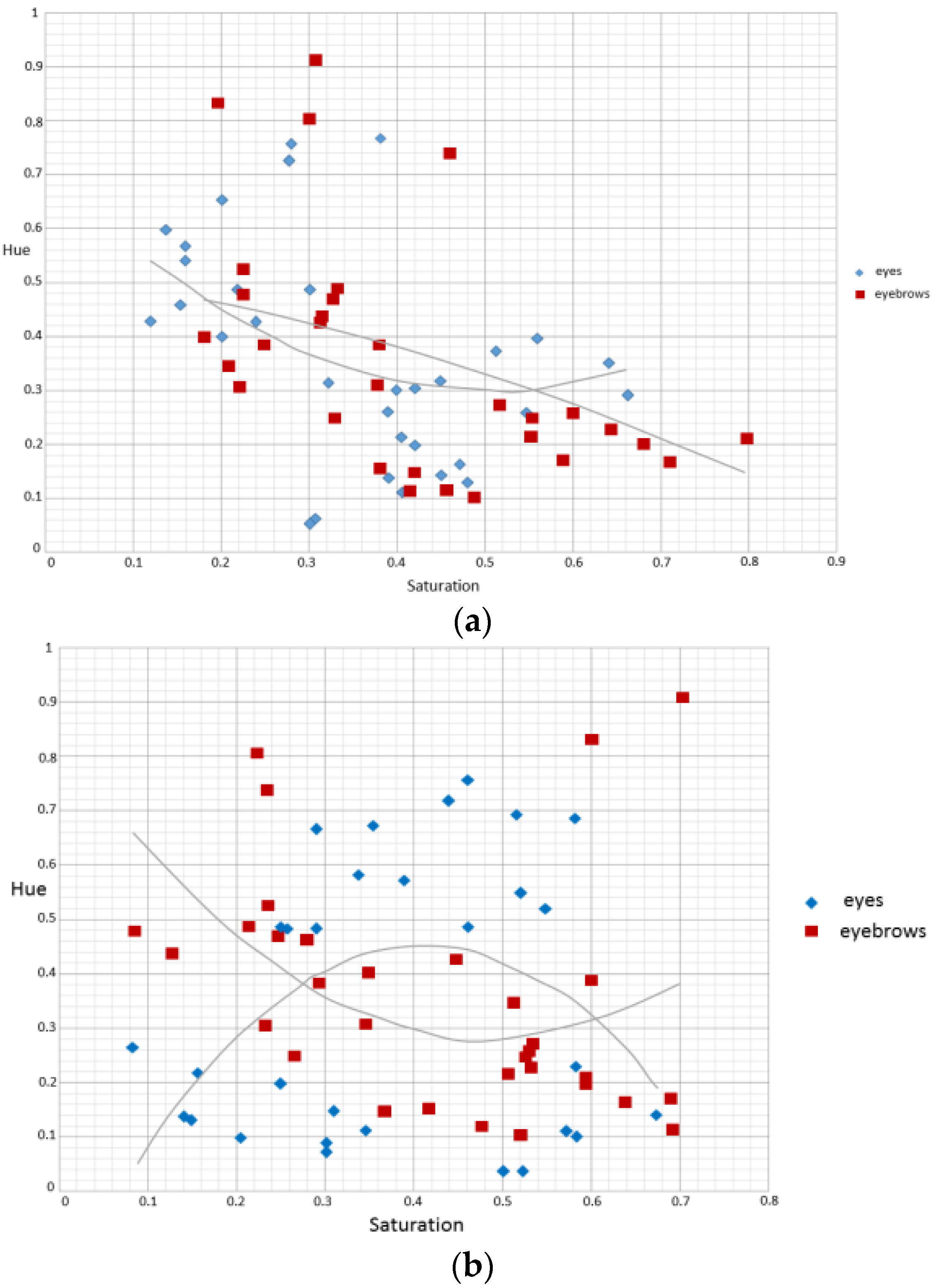
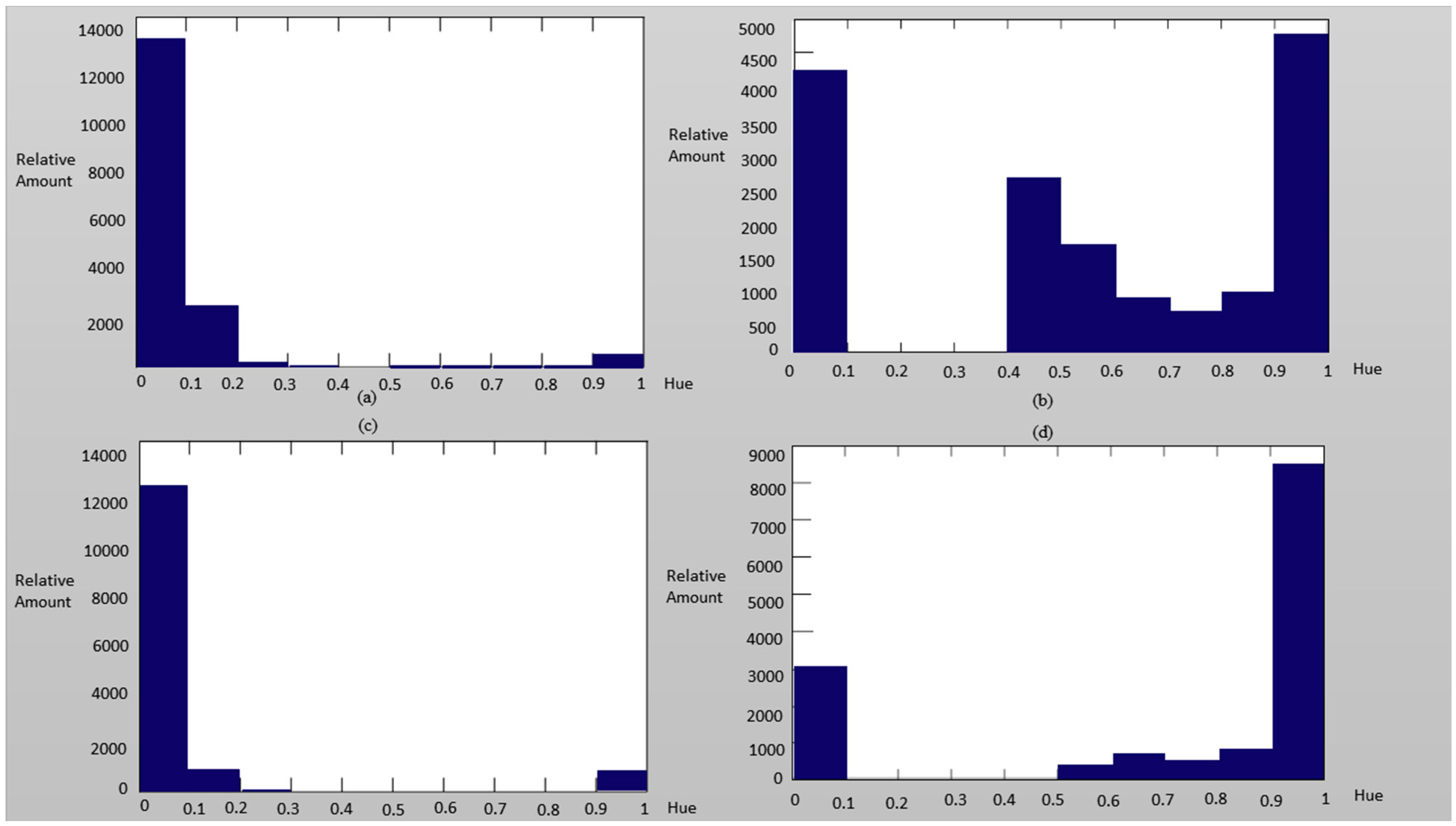
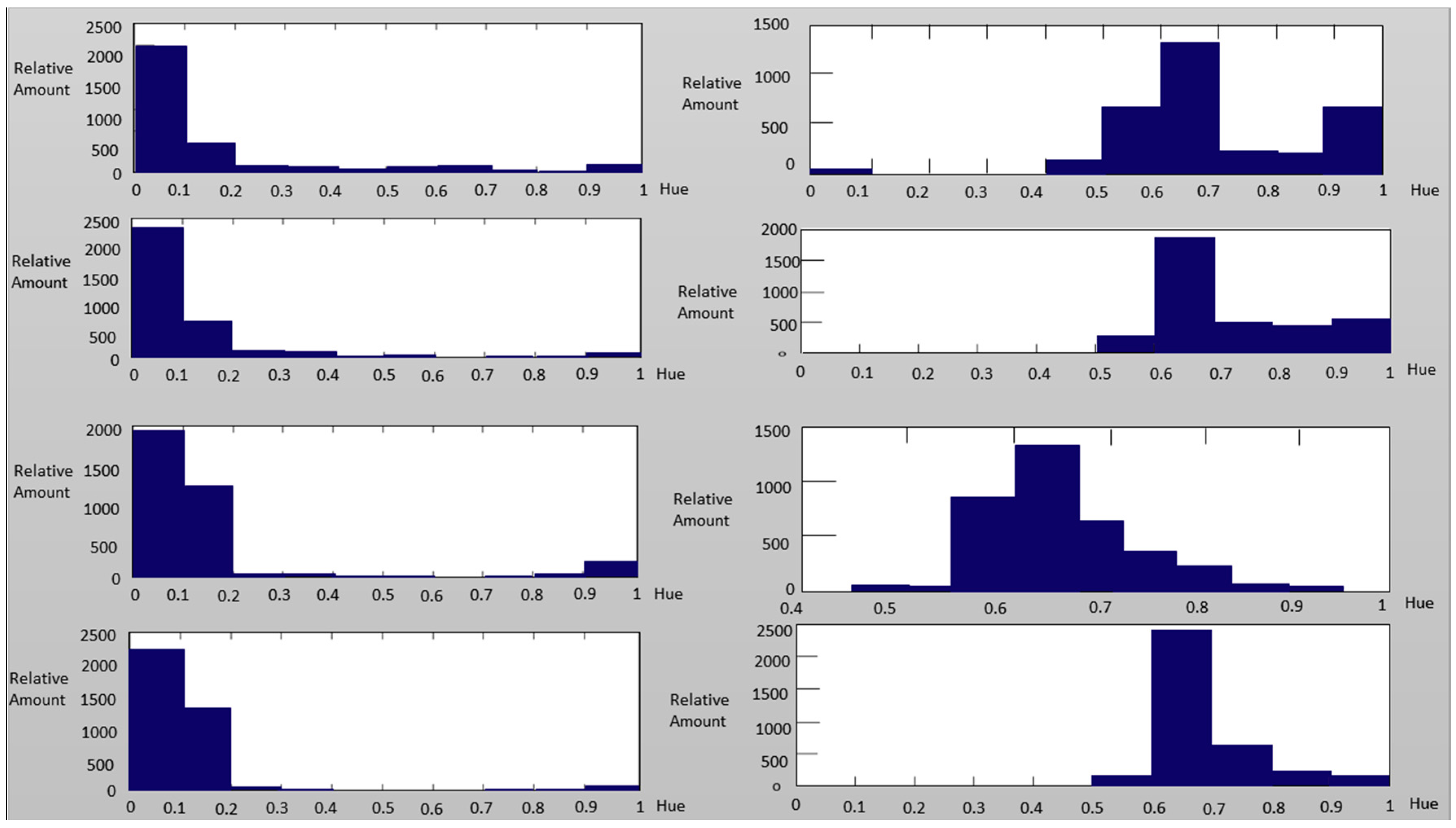
2.2. Color Space Analysis for LED Displays
3. The Designed Algorithms
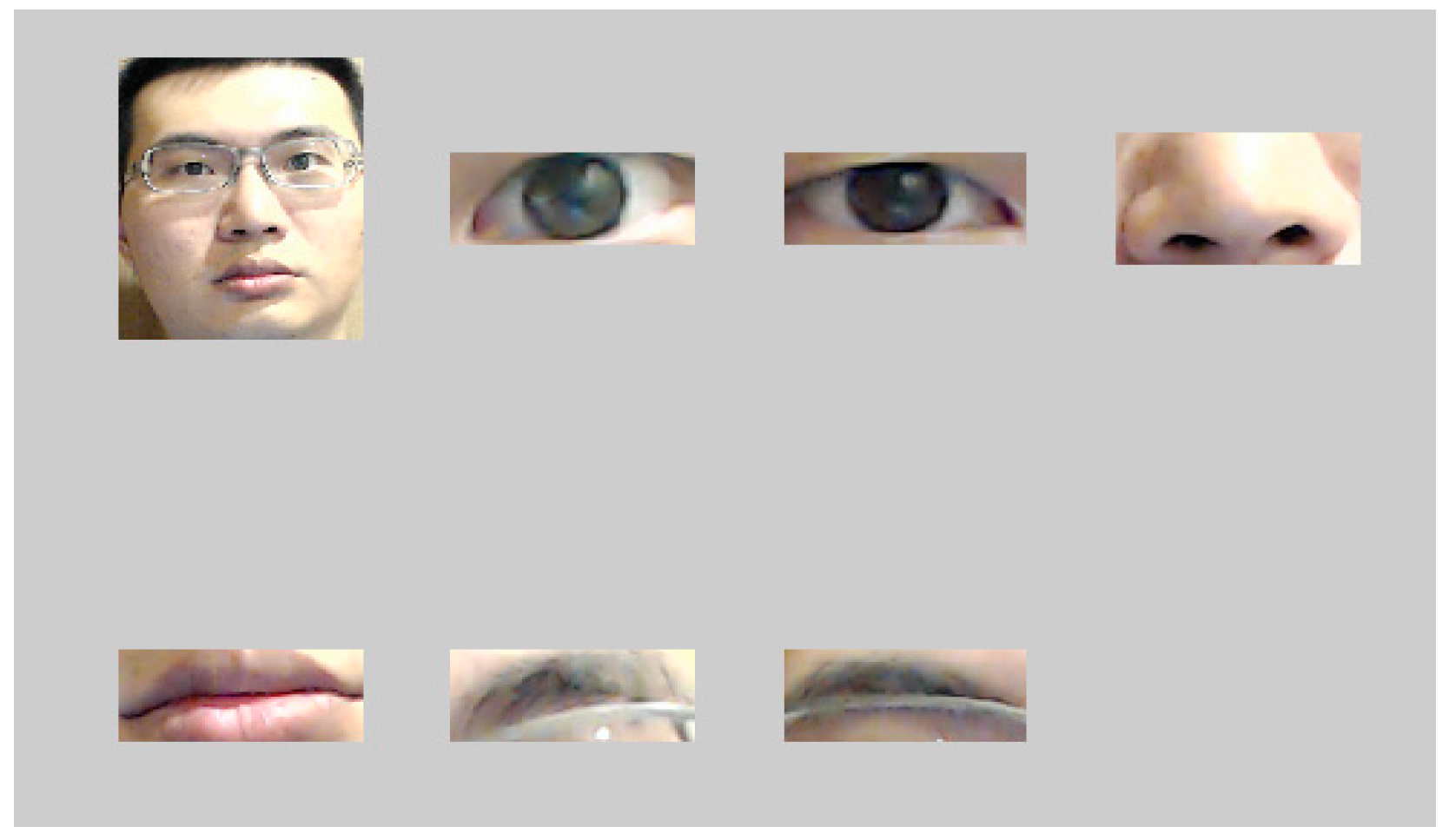
3.1. Face Features Positioning and Preprocessing
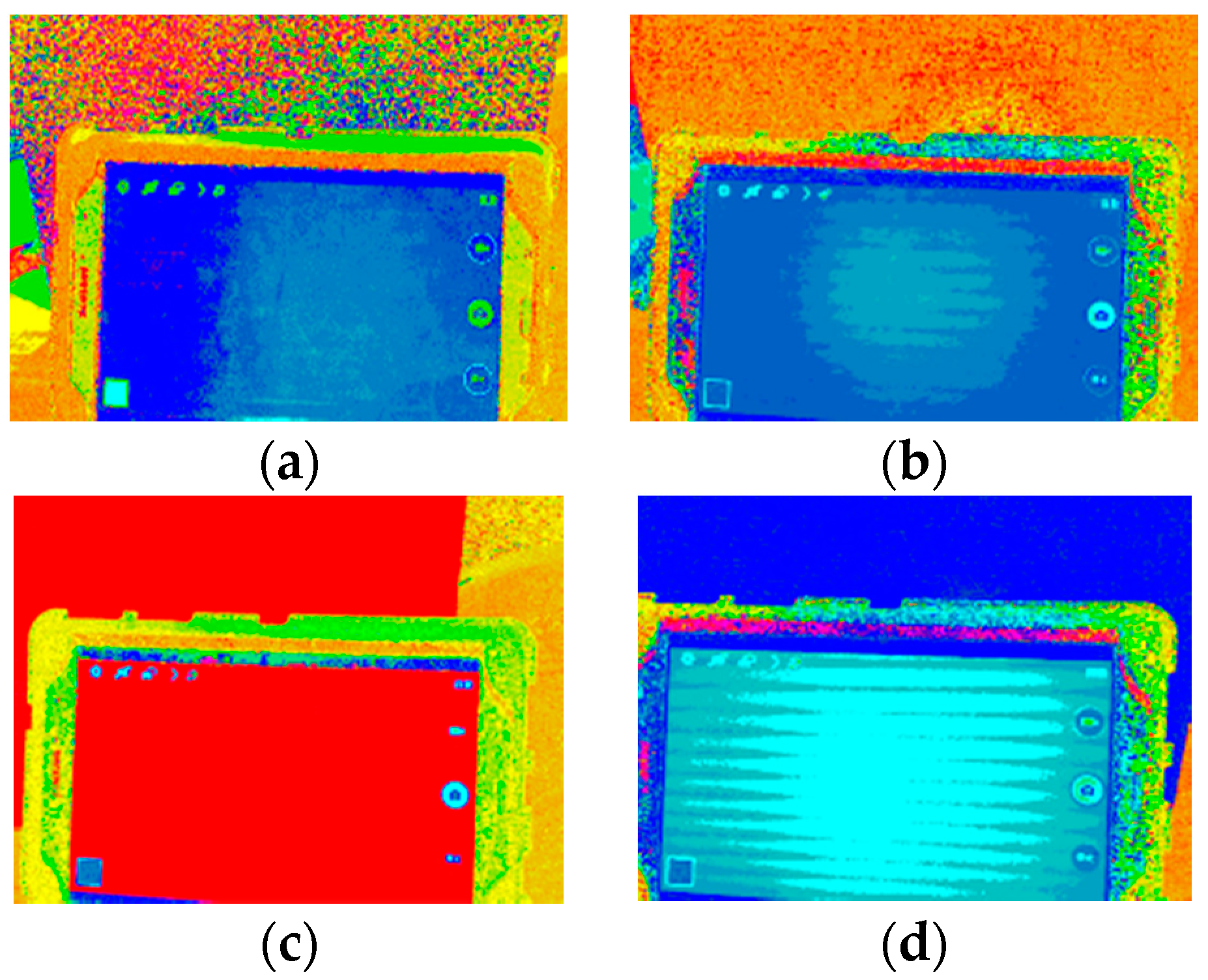
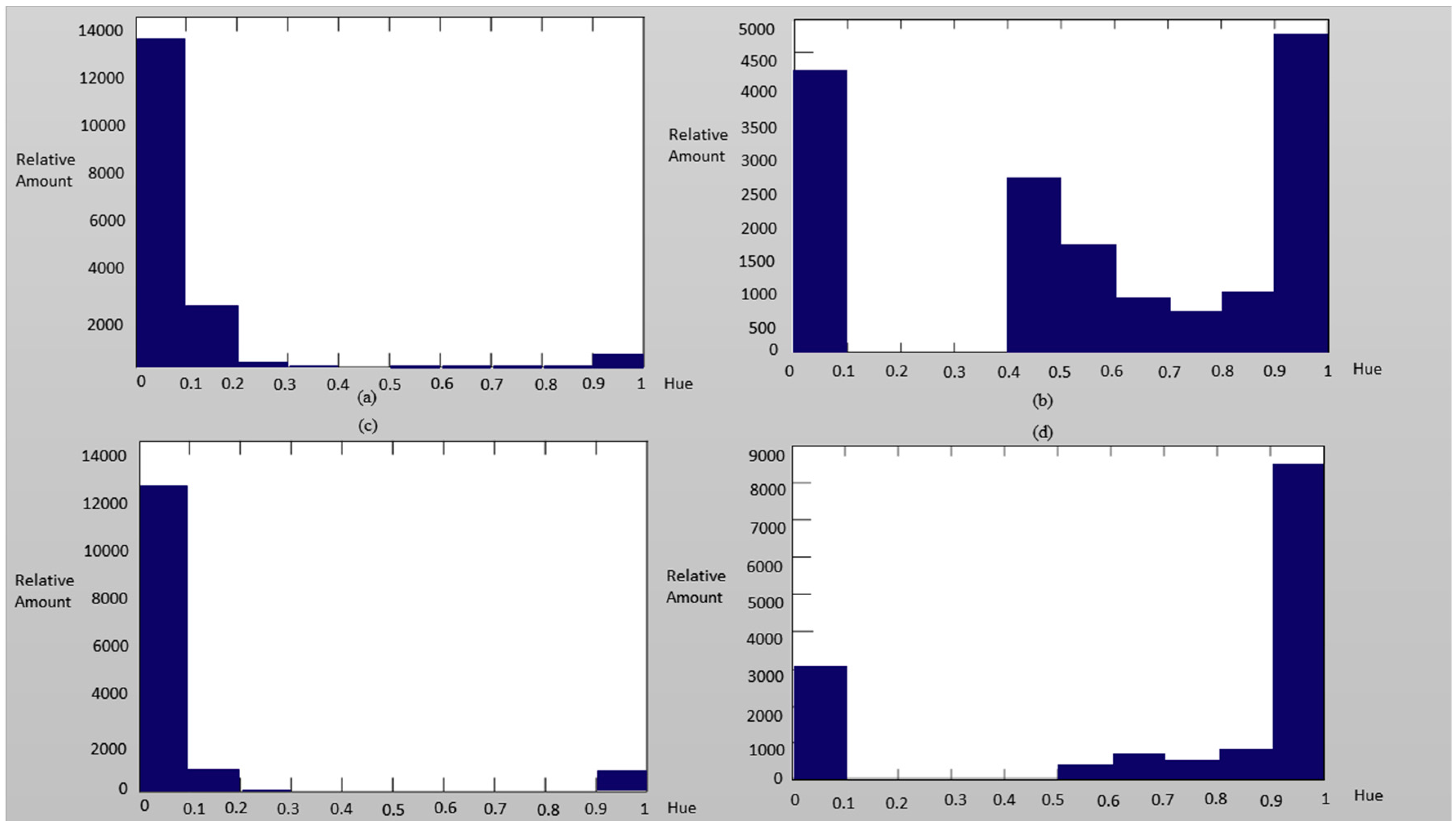
3.2. Color Space Transform and Analysis over ROI
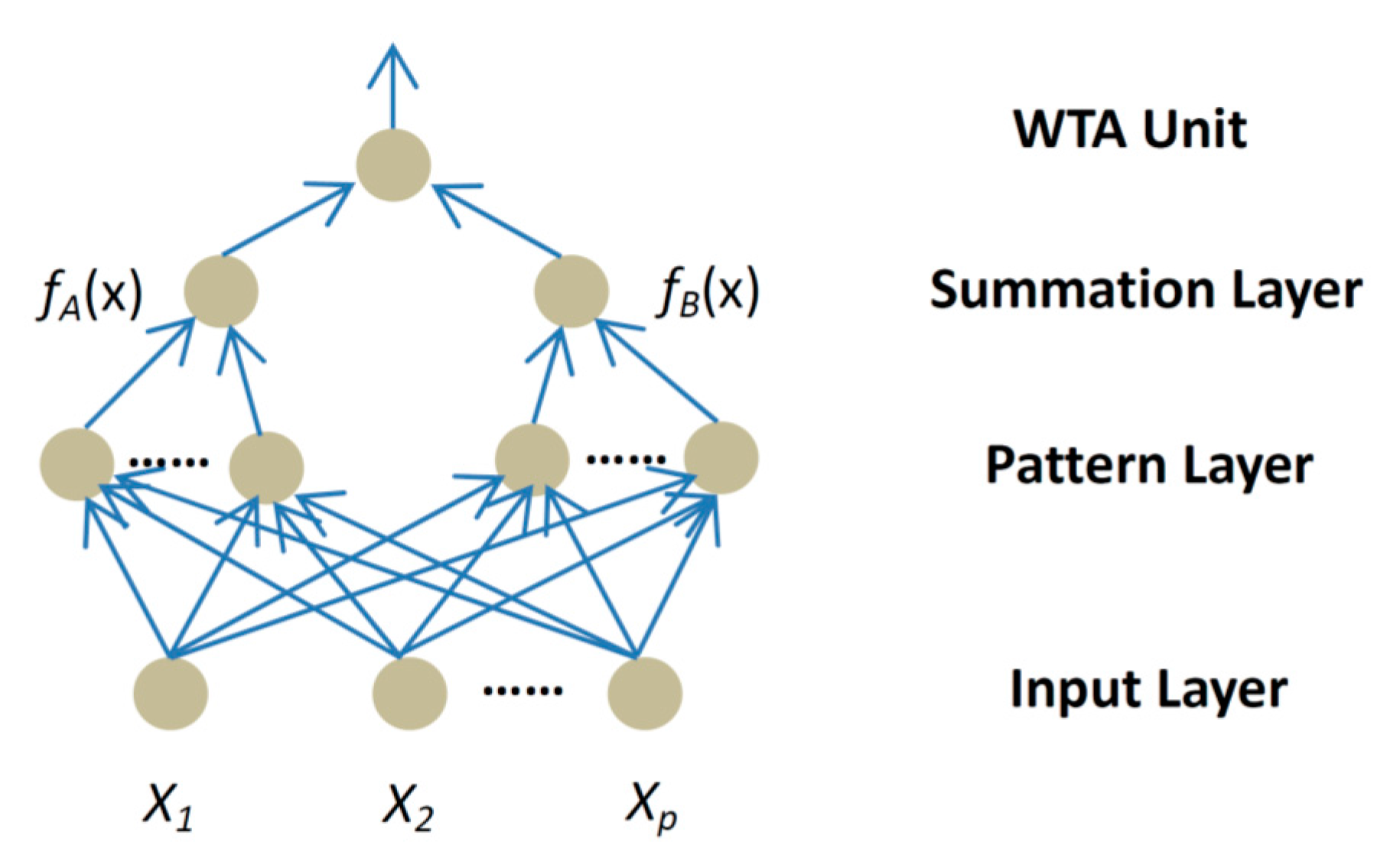
3.3. Expert Decision Making by PNN Model
4. Experiment Methods, Results and Discussions
5. Conclusions and the Future Works
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Ratha, N.K.; Connell, J.H.; Bolle, R.M. Enhancing security and privacy in biometrics-based authentication systems. IBM Syst. J. 1995, 40, 614–634. [Google Scholar] [CrossRef]
- Nixon, K.A.; Aimale, V.; Rowe, R.K. Spoof Detection Schemes. In Handbook of Biometrics; Springer: New York, NY, USA, 2008; pp. 403–423. [Google Scholar]
- Chakraborty, S.; Das, D. An overview of face liveness detection. Int. J. Inf. Theory 2014, 3, 11–25. [Google Scholar] [CrossRef]
- Kahm, O.; Damer, N. 2D Face Liveness Detection: An Overview. In Proceedings of the International Conference of the Biometrics Special Interest Group (BIOSIG), Darmstadt, Germany, 6–7 September 2012; pp. 171–182.
- Kollreider, K.; Fronthaler, H.; Bigun, J. Non-intrusive liveness detection by face images. Image Vis. Comput. 2009, 27, 233–244. [Google Scholar] [CrossRef]
- De Marsico, M. Moving face spoofing detection via 3D projective invariants. In Proceedings of the IEEE 5th IAPR International Conference on Biometrics (ICB), New Delhi, India, 29 March–1 April 2012.
- Komulainen, J.; Hadid, A.; Pietikäinen, M. Face Spoofing Detection Using Dynamic Texture. Lecture Notes Comput. Sci. 2013, 7728, 146–157. [Google Scholar]
- Pan, G.; Sun, L.; Wu, Z.; Lao, S. Eyeblink-based Anti-Spoofing in Face Recognition from a Generic Webcamera. In Proceedings of the International Conference on Computer Vision—ICCV, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8.
- Kose, N.; Dugelay, J.-L. Mask Spoofing in Face Recognition and Countermeasures. Image Vis. Comput. 2014, 32, 779–789. [Google Scholar] [CrossRef]
- Michelassi, P.C.; Rocha, A. Face Liveness Detection under Bad Illumination Conditions. In Proceedings of the IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011; pp. 3557–3560.
- Tan, X.; Li, Y.; Liu, J.; Jiang, L. Face Liveness Detection from a Single Image with Sparse Low Rank Bilinear Discriminative Model. In Proceedings of the European Conference on Computer Vision, Crete, Greece, 5–11 September 2010; pp. 504–517.
- Da Silva, P.A.; Pedrini, H.; Schwartz, W.R.; Rocha, A. Video-Based Face Spoofing Detection through Visual Rhythm Analysis. In Proceedings of the 2012 XXV SIBGRAPI Conference on Graphics, Patterns and Images, Ouro Preto, Brazil, 22–25 August 2012.
- Li, J.; Wang, Y.; Tan, T.; Jain, A.K. Live Face Detection Based on the Analysis of Fourier Spectra. Proc. SPIE 2004, 5404. [Google Scholar] [CrossRef]
- Jee, H.-K.; Jung, S.-U.; Yoo, J.-H. Liveness Detection for Embedded Face Recognition System. Int. J. Biol. Med. Sci. 2006, 1, 235–238. [Google Scholar]
- Bao, W.; Li, H.; Li, N.; Jiang, W. A Liveness Detection Method for Face Recognition Based on Optical Flow Field. In Proceedings of the IEEE International Conference on Image Analysis and Signal, Processing, Taizhou, China, 11–12 April 2009; pp. 233–236.
- Schwartz, W.R.; Rocha, A.; Pedrini, H. Face Spoofing Detection through Partial Least Squares and Low-Level Descriptors. In Proceedings of the International Joint Conference on Biometrics, Washington, DC, USA, 11–13 October 2011; pp. 1–8.
- Li, J.-W. Eye Blink Detection Based on Multiple Gabor Response Waves. In Proceedings of the IEEE International Conference on Machine Learning and Cybernetics, Kunming, China, 12–15 July 2008; pp. 2852–2856.
- Lai, C.-L.; Chen, J.-H.; Hsu, J.-Y.; Chu, C.-H. Spoofing Face Detection based on Spatial and Temporal Features Analysis. In Proceedings of 2th IEEE Global Conference on Consumer Electronics (GCCE), Tokyo, Japan, 1–4 October 2013.
- Cootes, T. An Introduction to Active Shape Models. In Image Processing and Analysis; Oxford University Press: New York, NY, USA, 2000; Chapter 7; pp. 223–248. [Google Scholar]
- Specht, D.F. Probabilistic Neural Networks and the Polynomial Adaline as Complementary Techniques for Classification. IEEE Trans. Neural Netw. 1990, 1, 111–121. [Google Scholar] [CrossRef] [PubMed]
- Parzen, E. On Estimation of a Probability Density Function and Mode. Annu. Math. Stat. 1962, 33, 1065–1076. [Google Scholar] [CrossRef]
- Specht, D.F. Enhancements to Probabilistic Neural Networks. In Proceedings of the International Joint Conference on Neural Networks, Baltimore, MD, USA, 7–11 June 1992.
- Yang, J.-C.; Lai, C.-L.; Sheu, H.-T.; Chen, J.-J. An intelligent automated door control system based on a smart camera. Sensors 2013, 13, 5923–5936. [Google Scholar] [CrossRef] [PubMed]
- Parveen, S.; Mumtazah, S.A.S.; Hanafi, M.; Azizun, W.A.W. Face anti-spoofing methods. Curr. Sci. 2015, 108, 1491–1500. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Independent Variables | Glasses: if the subject wears glasses |
| Saturation of the left eye: the average saturation of the left eye’s image | |
| Chrominance of the left eye: the average chrominance of the left eye’s image (within the eye’s region) | |
| Saturation of the right eye: the average saturation of the right eye’s image | |
| Chrominance of the right eye: the average chrominance of the right eye’s image (within the eye’s region) | |
| Saturation of the left eyebrows: the average saturation of the left eyebrows’ image | |
| Chrominance of the left eyebrows: the average chrominance of the left eyebrows’ image (within the eyebrows’ region) | |
| Saturation of the right eyebrows: the average saturation of the right eyebrows’ image | |
| Chrominance of the right eyebrows: the average chrominance of the right eyebrows’ image (within the eyebrows’ region) | |
| Saturation of the nose: the average saturation of the nose image (within the region of the nose) | |
| Chrominance of the nose: the average chrominance of the nose image (within the region of the nose) | |
| Saturation of the mouth: the average saturation of the mouth image (within the region of the mouth) | |
| Chrominance of the mouth: the average chrominance of the mouth image (within the region of the mouth) | |
| Dependent Variable | Determined Result: if the image is authentic |
| FAR (single shot) | |
| FRR (single shot) | |
| A life face is easy to be confirmed by the previous algorithms, thus FRR can be ignored | |
| 10 | 8 | 83.05% |
| 10 | 7 | 95.42% |
| 10 | 6 | 99.12% |
| 15 | 12 | 83.40% |
| 15 | 11 | 94.41% |
| 15 | 10 | 98.52% |
| 15 | 9 | 99.69% |
| 15 | 8 | 99.95% |
| 0.6 | 16 | 82.46% |
| 0.6 | 18 | 57.85% |
| 0.7 | 16 | 98.31% |
| 0.7 | 18 | 91.55% |
| 0.8 | 16 | 99.98% |
| 0.8 | 18 | 99.69% |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lai, C.; Tai, C. A Smart Spoofing Face Detector by Display Features Analysis. Sensors 2016, 16, 1136. https://doi.org/10.3390/s16071136
Lai C, Tai C. A Smart Spoofing Face Detector by Display Features Analysis. Sensors. 2016; 16(7):1136. https://doi.org/10.3390/s16071136
Chicago/Turabian StyleLai, ChinLun, and ChiuYuan Tai. 2016. "A Smart Spoofing Face Detector by Display Features Analysis" Sensors 16, no. 7: 1136. https://doi.org/10.3390/s16071136
APA StyleLai, C., & Tai, C. (2016). A Smart Spoofing Face Detector by Display Features Analysis. Sensors, 16(7), 1136. https://doi.org/10.3390/s16071136