1. Introduction
Building extraction from remotely sensed data is being used for many different applications, e.g., disaster monitoring, real estate, national security and public service centres for solving the human welfare matters, especially at the time of an accident, disaster or combat situation. However, the automatic extraction of buildings from remotely sensed data is one of the challenging tasks faced by the computer vision and remote sensing communities. This task is challenging due to many reasons such as complexity in the building structures, surrounding environment (highly-dense vegetation, occluded building and hilly scene), poor acquisition of data and registration error between data sources.
There are mainly two different sources of input data, i.e., the photogrammetric imagery and Light Detection And Ranging (LiDAR) data, available for building extraction. Generally, a photogrammetric image has three colour channels and may have an additional infrared channel, whereas LiDAR data mainly contain height information. Both sources have their own limitations such as photogrammetry imagery does not work well in certain weather conditions, whereas the LiDAR data have low point-density that causes small buildings to be undetected in dense vegetation regions. Both data sources require large number of manual settings to distinguish buildings from trees. In addition, the LiDAR data are prone to height error when representing transparent building roofs as the LiDAR points could be reflected from different levels of transparent roofs and objects under the transparent roofs.
Based on the input data to the building extraction methods, Lee et al. [
1] categorised the building extraction methods into three different classes. The first class contains methods that use 2D or 3D information from photogrammetric imagery to extract building [
2]. However, the 2D derived information, e.g., edges and textures, is inadequate to extract building completely and misclassification is very common, especially in very high resolution images. This problem is further compounded by the presence of shadows cast on the objects [
3]. The 3D information, e.g., depth derived by multiple images, is inaccurate due to the mismatch between different capturing view angles [
4].
The second class of methods uses LiDAR data only. Compared with photogrammetry imagery, LiDAR data provide more accurate height information [
5,
6,
7]. By applying a height threshold, the LiDAR data are classified into ground and non-ground groups. Next, the ground LiDAR points are used to generate the building mask [
8]. However, the transparent buildings contain ground points along with non-ground point, and therefore, these buildings are easily missed in building mask process [
9]. This class also includes methods which use the filters such as recursive terrain fragmentation filter and morphological filter in order to group LiDAR data into off-terrain and on-terrain points [
10,
11]. However, the low LiDAR point density affects the building extraction accuracy of these methods. Alternatively, the LiDAR points are interpolated to preserve the sharp edges of buildings [
12,
13], but the manually generated LiDAR points might lead to false building extraction.
In the third class, instead of using data from only one system, the integration of the LiDAR and photogrammetric imagery data provides much better results in building extraction [
5,
7,
14,
15]. This is because each of these two types of data contains useful information about the terrain and the objects that the other type lacks. Different information derived from the photogrammetric imagery is merged with LiDAR height information, for example, some methods merge the Normalized Difference Vegetation Index (NDVI) with LiDAR height information to extract buildings [
16,
17], whereas other methods merge various types of information, e.g., textures, NDVI and edges, derived from photogrammetric imagery with LiDAR height information to extract buildings [
5,
7]. However, the methods in the third class still have limitations, e.g., (1) limited robustness in extracting buildings with fully or partially transparent roof as well as buildings which are partially occluded or small [
7,
9], and (2) not fully automatic as parameters are empirically tuned based on the set of the training areas [
15] and therefore are ineffective in other environments.
This paper proposes a new Gradient-based Building Extraction (GBE) method (i.e., belongs to the third class), which is more robust in extracting buildings of a greater range of sizes, including the smaller buildings. In addition, the proposed GBE method can extract the transparent buildings as it does not use the building mask derived from the ground LiDAR points which would mark transparent portions of a building as ground objects. In the proposed method, the initial building cue, i.e., the prominent orientations of buildings, are first determined by analysing straight edges/lines extracted from the photogrammetric imagery. For each prominent orientation, a grid is set and the non-ground points are sampled based on the maximum height of the points within each cell in the grid. By calculating the maximum height of the LIDAR points, LiDAR points representing rooftop are extracted and this helps in extracting the transparent buildings. Next, the gradient is calculated in two orthogonal directions i.e., X and Y axes of the grid. The pixels whose gradient values are constant in direction are marked as pixels of building planes or regions. Instead of using a large area threshold to remove the small trees detected as buildings, the proposed method uses surrounding colour information of candidate building and matches it with that of the candidate. The candidate building is removed if more than 50% of its pixels are matched with the surrounding colour information. In cases where the candidate building is not matched up to predefined threshold, then only the matched pixels of the candidate building are removed. The LiDAR point variance and density analysis is also applied to remove vegetation. In addition, a shadow-based analysis is employed to eliminate the trees covered by the shadow of buildings.
The remainder of this paper is organised as follows:
Section 2 provides an overview of the current state-of-the-art building extraction methods which are compatible to our proposed method. The limitations of these current methods and the main contributions of this research will also be presented in this section. Our proposed GBE method will be presented in
Section 3. The experimental setup and the detail of the benchmark data sets will be described in
Section 4.
Section 5 presents the qualitative and quantitative results of the GBE method compared with four of the best current methods. Finally,
Section 6 concludes the paper.
2. Related Work
In the past five years, the extraction of buildings from complex environments is trending towards using the combination of both photogrammetric imagery and LiDAR data. The methods using both types of data can generally be grouped into either the classification or rule-based segmentation approaches. Comparatively, the rule-based building extraction methods are more commonly used due to their simplicity and effectiveness for large range of environments. Our proposed method also belongs to this approach.
Generally, rule-based building extraction methods work as follows. First, the pre-processing stage provides the initial building cue. Second, this building cue is processed in main stage to extract the candidate building regions. Finally, the extracted building regions are verified in post-processing stage. Some methods only use the LiDAR data for searching of the initial building cue at pre-processing stage and it is further processed in the main process using the spectral features derived from the photogrammetric imagery [
7,
18]. In Cao et al. [
19], the initial building cue is generated from the photogrammetric imagery using the Gabor and Morphological filters of a certain window size (a.k.a. structure element). Next, the building cue is further processed in the main process using the LiDAR data. The methods using the photogrammetric imagery and LiDAR data in every stage yield better results than the methods using either of them in each stage. Earlier, both types of data were only employed at the pre-processing stage to segment the sites into building and other groups [
20], but later they are employed in every stage to extract buildings [
21,
22]. In Chen et al. [
21], the region-based segmentation is employed on the photogrammetric imagery and LiDAR data to find the initial building cue. The initial building cue is then further processed using the rule-based segmentation to extract buildings. Sohn and Dowman [
22] employed a classification algorithm to find the initial building cue from the photogrammetric imagery, LiDAR data and their derived data i.e., NDVI, Digital Surface Model (DSM) and Digital Terrain Model (DTM). The initial building cue is then further processed using the model-driven and data-driven approaches to extract rectilinear building edges. The trend of using derived data is followed by many methods [
3,
5,
23,
24,
25]. In the post-processing stage, these methods employed the variance analysis and morphological filter to verify the buildings.
The derived information from photogrammetric imagery can be highly affected by the shadows casted on buildings [
3]. Thus, some shadow indexes have been introduced to overcome this problem. These shadow indexes use the Hue, Saturation and Intensity (HSI) model where the saturation and intensity channels are used to detect the shadows [
26]. In [
26], the Ostu method is applied on the HSI derived indexes, i.e., difference index (
S −
I), ratio index (
S/
I) and normalization difference (
S −
I/
S +
I) where
S is saturation and
I is intensity, for detecting shadows. However, these indexes also incorrectly detect the dark blue and dark green regions of other non-shadow objects as shadows. This problem can be reduced by applying a threshold on the Ostu method [
27], and by modifying the index formulae to measure Hue, Intensity (brightness) and Saturation [
28]. Recently, three indexes, i.e., Morphological Shadow Index (MSI), Morphological Building Index (MBI) and Geometrical Index (GI) are proposed. These are collectively applied to eliminate the shadows and to extract buildings from the high resolution satellite imagery [
29].
2.1. Limitations of Rule-Based Building Extraction Methods
In rule-based building extraction methods, LiDAR points with different heights on transparent buildings are used in building extraction process and as a result, (1) these LiDAR points are classified as tree points or (2) these points are classified as ground points and produce a ground region in a mask [
9]. In addition, the transparent buildings have similar colour information of ground and thereby transparent buildings are undetected by applying image analysis as well.
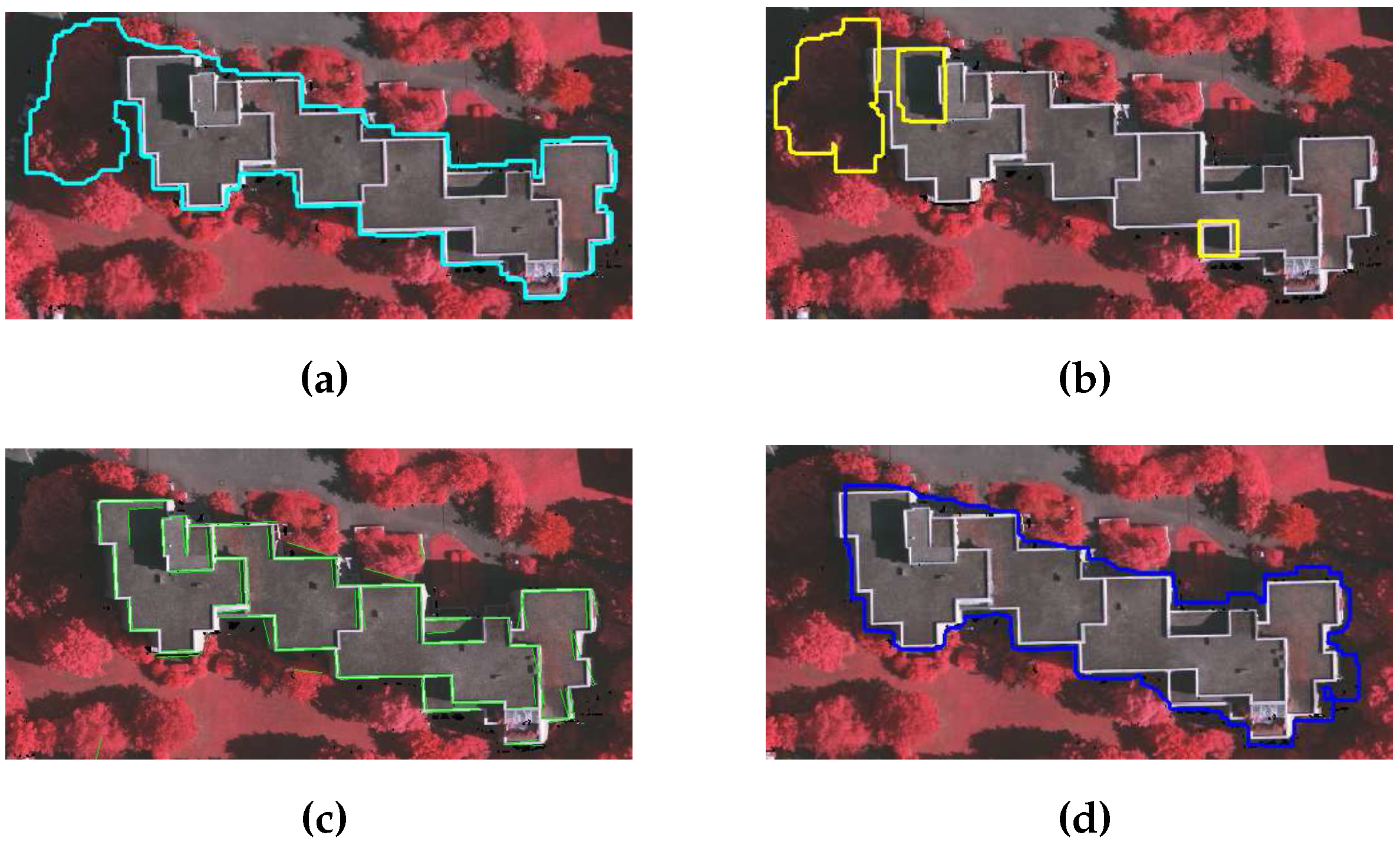
Furthermore, the rule-based building extraction methods use empirically defined threshold of filter size to remove small regions as a remaining portions of trees. However, some sites contain small buildings and are removed by applying the large filter size threshold. In addition, colour derived indexes such as NDVI and texture are sensitive to shadow [
5]. For example in
Figure 1, the shadowed portions of trees, which are indicated by yellow arrows, have low texture index value and are extracted as building portions if a texture threshold is applied (e.g., 0.8 [
5]). This example confirms the low discriminative power of the texture index.
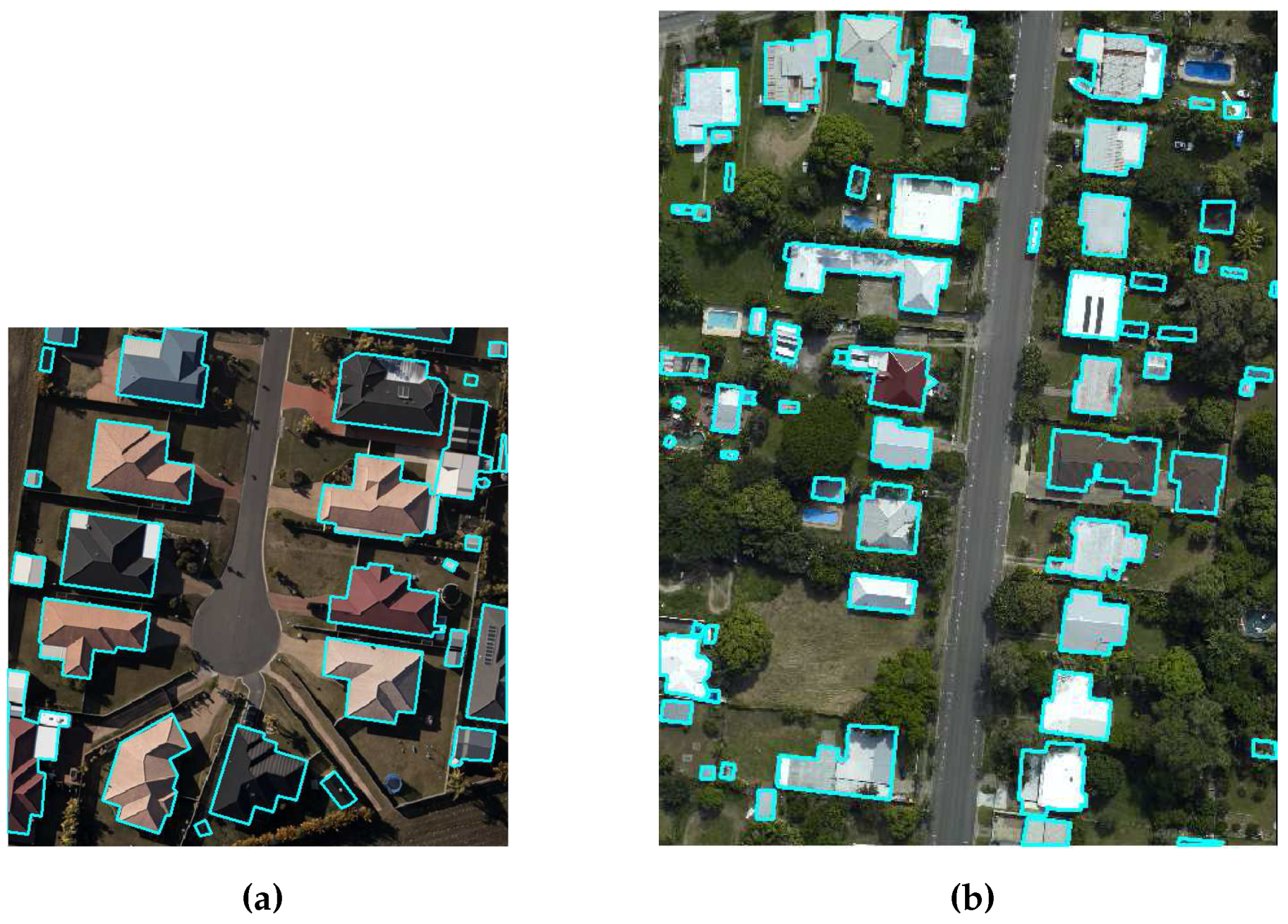
As for NDVI, it needs proper selection of colour channels of photogrammetric image [
30]. For example, two channels, i.e., red and infrared channel, are selected manually to generate the NDVI index that can separate the green colour trees from buildings. If the red colour trees are present in the site, then the red channel is replaced with the green channel to separate the red colour trees from buildings. The provided data sets, i.e., Australian and German data sets [
31], do not have a infrared channel. Therefore, a pseudo-NDVI is used as an alternative index. It is calculated by following the process in [
7,
24], where the red, green, and blue (RGB) channels are interpreted as Infrared, Green and Blue (IGB) channels respectively. The pseudo-NDVI results show different index values for locations with red and green trees, and therefore, it is very hard to tune a NDVI threshold. This phenomena is also verified in
Figure 2, where trees in red and green colour shown different NDVI index values with respect to the surrounding buildings. Like the thresholds of colour derived indexes, and size filter, many other parameters of rule-based building extraction methods are also empirically tuned based on the set of training sites. Therefore, the robustness of the rule-based building extraction methods is limited to the environments present in the training sites.
2.2. Contributions of the Research
In this paper, we propose a novel Gradient-based Building Extraction method which uses the photogrammetric imagery and LiDAR data to utilise the benefits of both data. This research addresses two main problems, i.e., misclassification of small and transparent buildings, and sensitivity of rule-based parameters. To address the first problem, we propose a new method which does not use ground LiDAR points in generating the building mask, and therefore, the non-ground points on the transparent buildings are further processed in building extraction. In addition, the proposed method reduces the misclassification of non-ground LiDAR points of different heights as rooftop non-ground LiDAR points. Therefore, the rooftop non-ground LiDAR points are used to represent buildings with transparent roof. As mentioned in the
Section 2.1, the large number of empirically tuned parameters reduce the robustness of rule-based building extraction methods. We propose a novel local colour matching analysis and shadow elimination procedure, where parameters are automatically set based on the local information of a given data and based on general conditions, e.g., darker region is a shadow region. These analyses replace the NDVI and texture. As a result, the introduced concepts not only are more adaptive in eliminating the vegetation from the sites, but also help in reducing the number of empirically set parameters required by the proposed building extraction method.
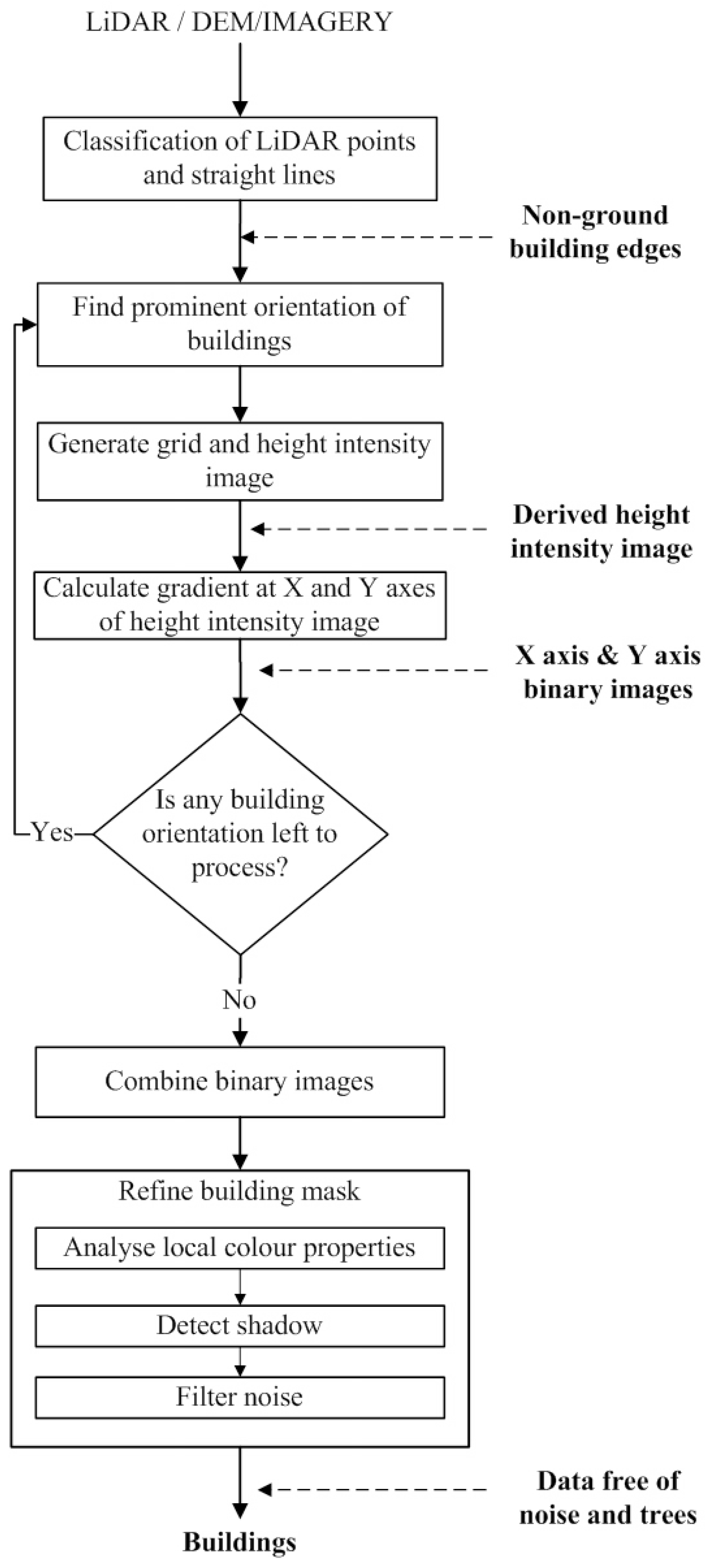
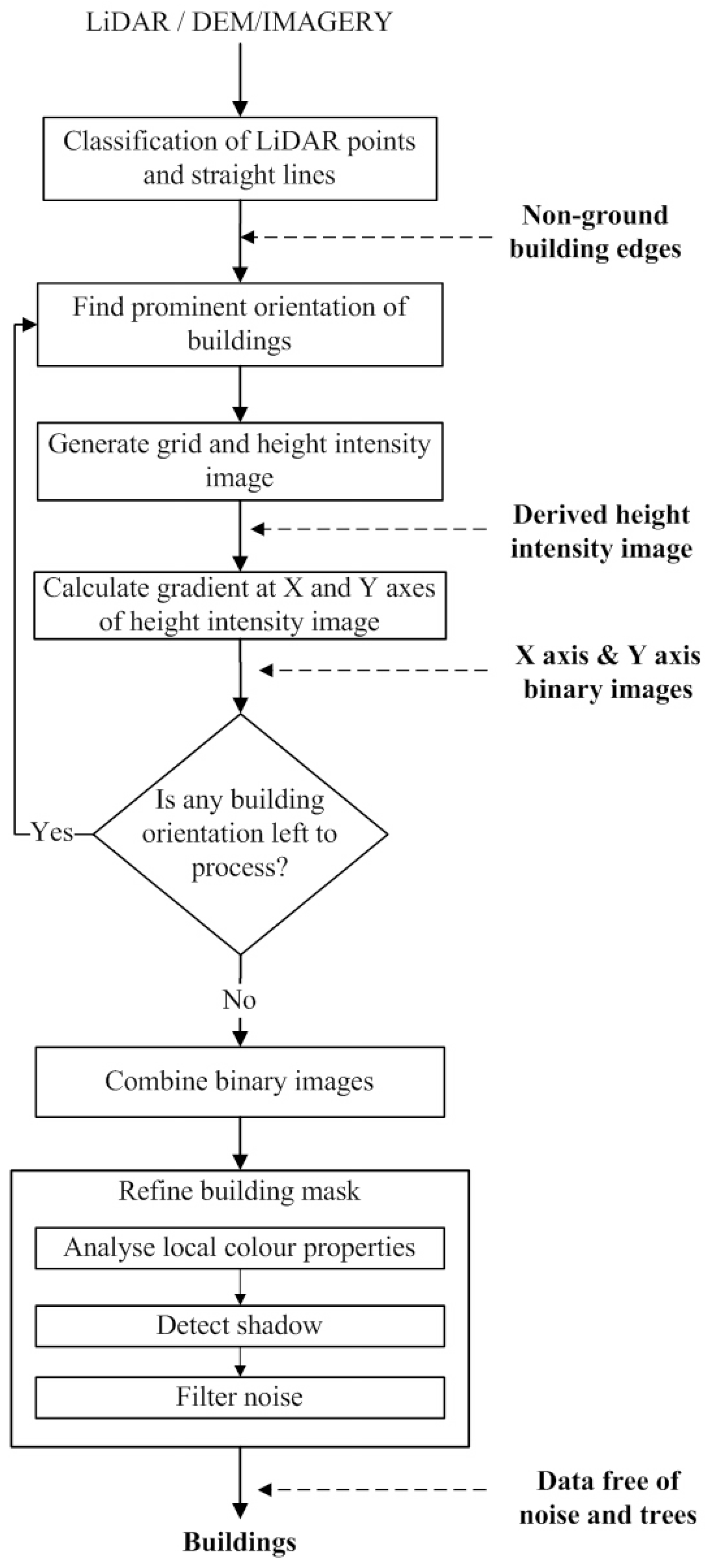
3. The Proposed Gradient-Based Building Extraction Method
Figure 3 shows the flow diagram of the proposed GBE method. The inputs to the GBE method are the photogrammetric imagery and the LiDAR data of a given site. The LiDAR data are first divided into ground and non-ground points and then straight lines (i.e., principal orientations of buildings) are extracted from the photogrammetric imagery. The non-ground points help in separating non-ground lines from the ground lines. The principal orientations of buildings, i.e., initial building cue, are estimated using the non-ground lines. For each principal orientation
i, the non-ground points are employed to generate an intensity image. The binary building mask
in direction
i is derived through a gradient analysis on the intensity image. Then, the masks
,
, where
n is the number of principal directions, are combined for a refinement process to remove trees. In the refinement process, the variance and density analysis is employed on the non-ground building points to eliminate trees, whereas, the local colour matching and shadow elimination analyses are employed on the imagery pixels to eliminate the remaining regions of trees. Some of the remaining tree pixels can be removed by using the morphological filter. Finally, the building boundaries are extracted around each building.
3.1. Classification of LiDAR Points and Straight Lines
A DEM, i.e., bare earth height information, is derived from the LiDAR data with the help of a commercial software i.e., [
32]. The bare-earth height information is subtracted from the LiDAR data to generate LiDAR points that are free of the terrain height. Later, the LiDAR points are grouped into ground and non-ground LiDAR points using a height threshold. An 1 m height threshold has been used to group the LiDAR points by many researchers [
9,
15,
30]. Therefore, the 1 m height threshold is also used in the proposed GBE method to group the LiDAR points into ground and non-ground LiDAR points.
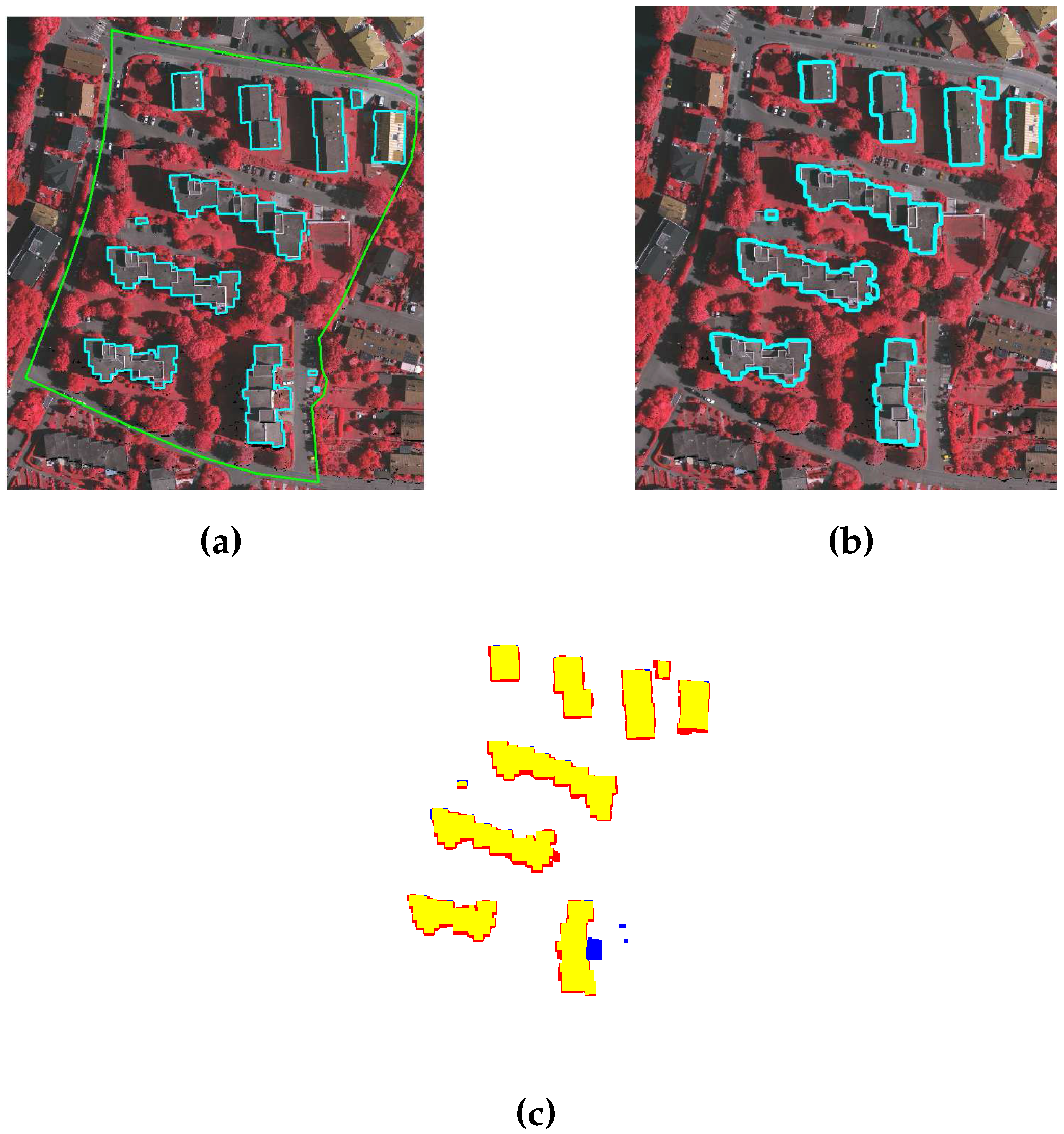
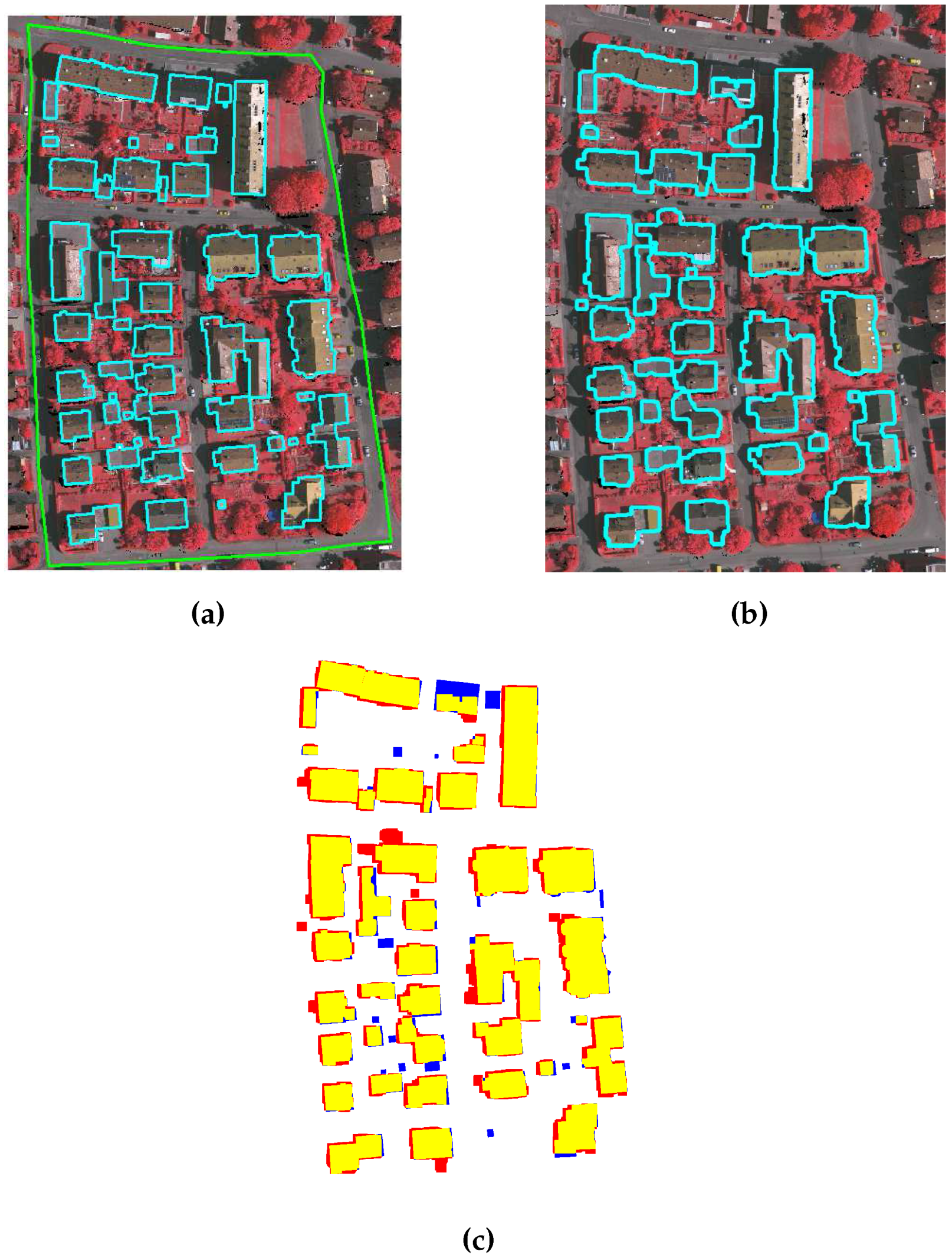
Figure 4a shows the ground and non-ground points for a sample scene.
In addition, the straight lines are extracted from the photogrammetric imagery following the procedure in [
5,
33]. First, Canny Edge detector and Gaussian function are employed to extract straight lines from the photogrammetric imagery. Then, considering that buildings are at least 3 m in length [
7], a 3 m length threshold is applied to extract the straight lines which are longer than 3 m. Finally, the non-ground LiDAR points are used to separate the non-ground straight lines from the ground straight lines. The non-ground straight lines represent buildings’ edges and ridges. The extracted straight lines from the sample scene are shown in
Figure 4b, where that the ground lines and the non-ground lines are highlighted in yellow and red colours, respectively.
3.2. Finding Prominent Orientation of Buildings
Finding prominent orientation of buildings is a complicated task. The extracted straight lines are used to estimate the prominent building orientations as follows. The angles of these lines are estimated between 0° and 180°. Then, these lines are grouped into 16 bins at
= 11.25° per bin size. This angle threshold is based on the assumption that buildings in a given scene are not randomly oriented. They are mainly oriented at around 0° (parallel), 90° (perpendicular), 45° (diagonally), 22.5° or 11.25° to one another. Then, mean angle
i of each group is calculated to find the prominent direction of each group. Thus, approximately 16 prominent directions can be obtained and will be arranged in descending order according to size of the angle groups. Since, we are considering buildings of rectilinear shapes, each pair of bins which are perpendicular to each other will generate one prominent building orientation. For example, as shown in
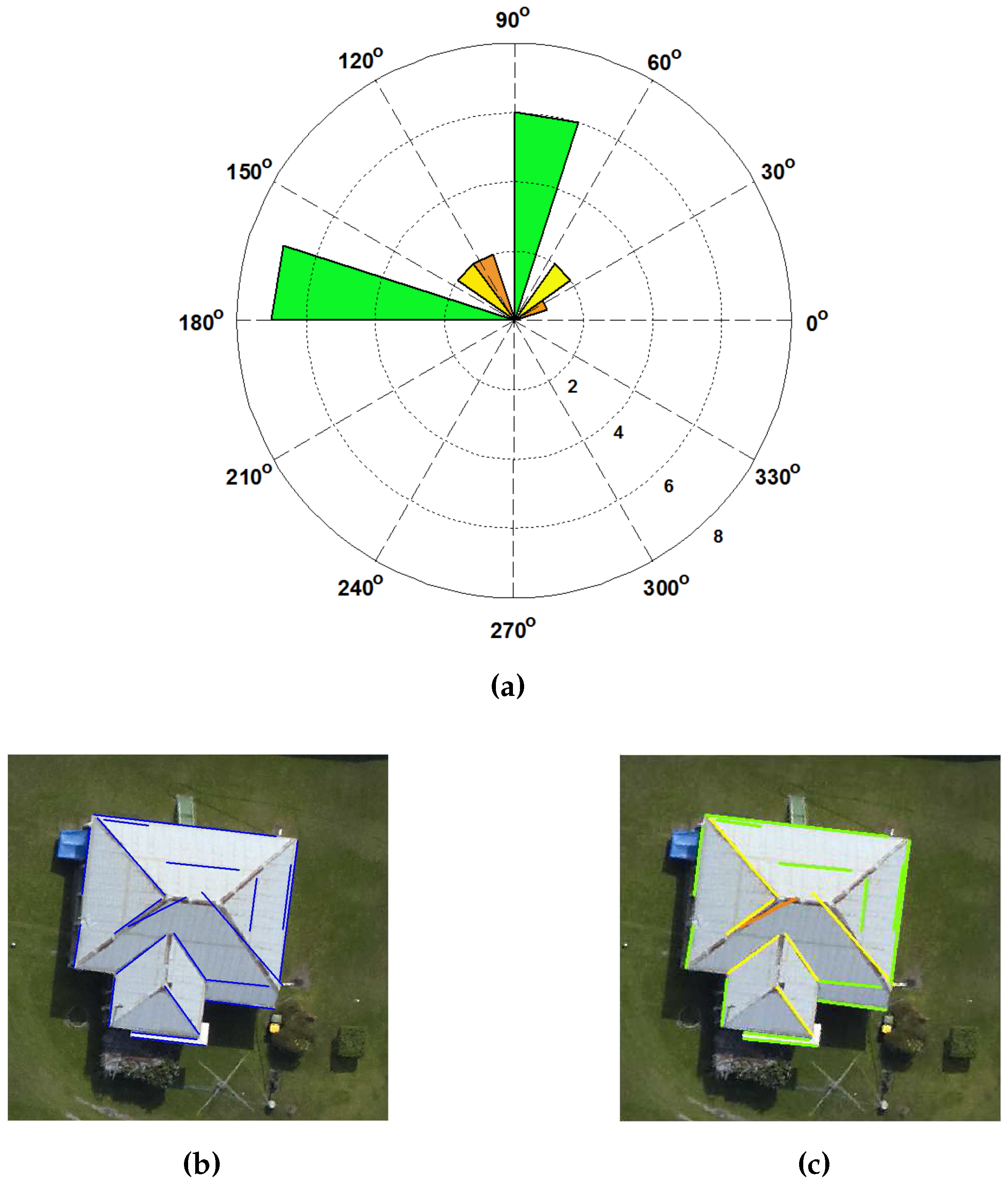
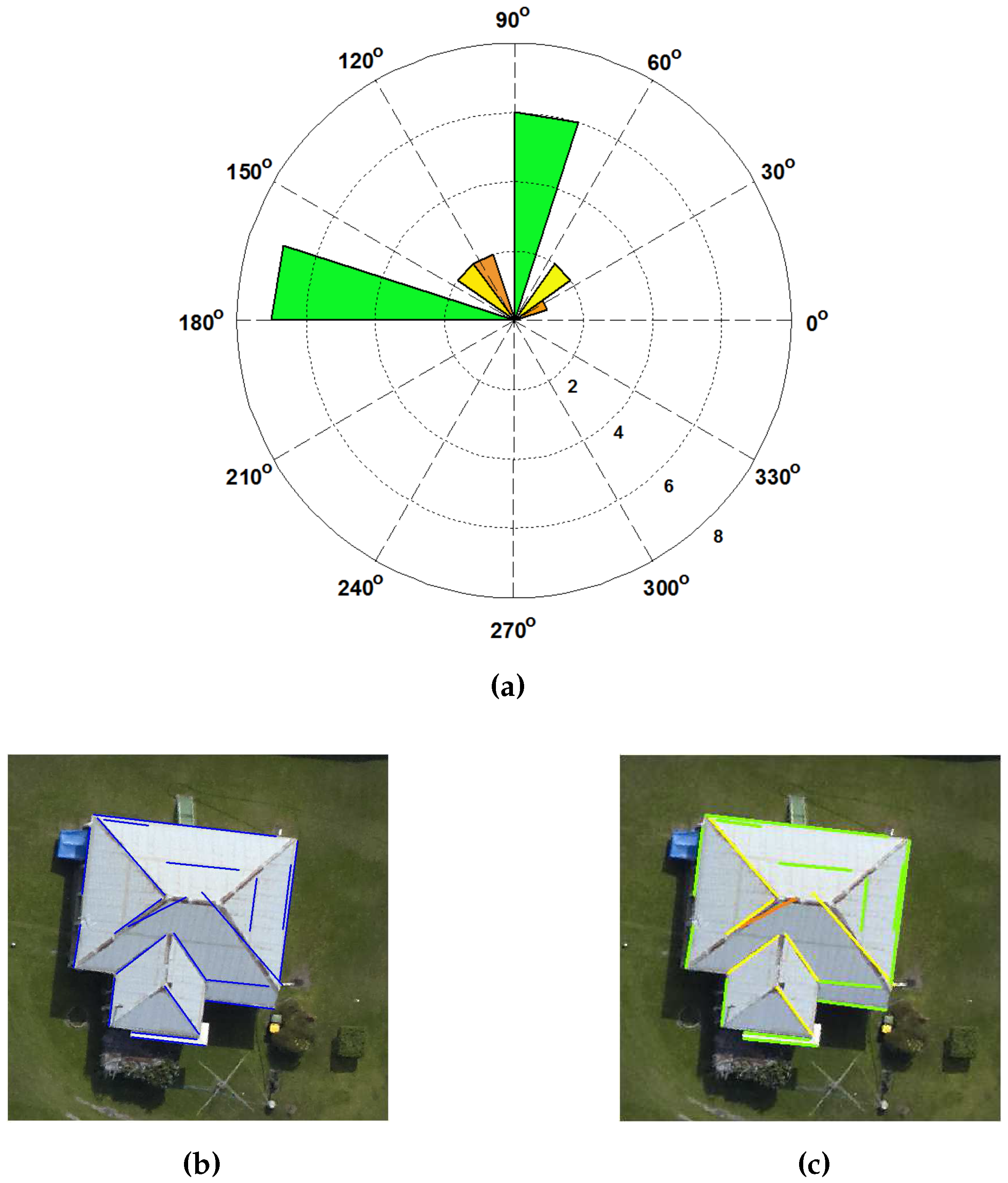
Figure 5a, there are pairs of orthogonal orientations.
We illustrate the calculation of the prominent building edges with an example shown in
Figure 5b. There is a building which contains 20 edges at its building boundary and ridges. The threshold
is applied to divide the building edges into 16 groups based on the edge angle. An angular histogram of building edges, as shown in
Figure 5a, is then generated. The three prominent building angles,
i = [81°, 26° and 39°], are obtained. A green colour class, i.e.,
i = 81°, contains 13 building edges. The other seven building edges are grouped into yellow colour class (i.e.,
i = 26°) and orange colour class (i.e.,
i = 39°) respectively. The fourth quadrant of the angular histogram represents the perpendicular building edges of each group in a first quadrant. The building edges of each group are also plotted on an image, as shown in
Figure 5c.
3.3. Generating Grid and Height Intensity Image
For each estimated principal orientation, a height intensity image is created using a prominent orientation of building and a grid of resolution
= 2
d, where
d represents maximum point-to-point distance in the LiDAR data. If the value of
d is not available, it can be estimated using input point-density.
Figure 6a shows the cell size and the direction of a grid. Then the conversion of 3D LiDAR information into intensity image is performed and
m, i.e., the maximum of the LiDAR height values in the cell, is assigned as
, i.e., pixel of the height intensity image. Here, notation
is the coordinate of height intensity image. Thus, the height intensity images at three prominent directions of lines, as shown in
Figure 7, are generated.
The advantage of using maximum is that it helps to reduce the height error of non-ground LiDAR point of transparent building, therefore, the transparent buildings can be extracted. Like maximum, mean can also be used to reduce the height error but mean cannot extract rooftop LiDAR points at multistorey transparent roof or transparent window buildings. The multistorey glass buildings would result in LiDAR points reflected from different floors close to transparent glass windows. The mean calculation extracts floor from the middle of the buildings as a roof. Therefore, the maximum of the LiDAR points in a cell is used to generate the gradient based height intensity image.
We illustrate the advantage of using maximum with an example shown in
Figure 6b. There is a transparent building which contains LiDAR points at different heights. Therefore, if an incorrect LiDAR point is selected to represent a cell, then the transparent building will not be extracted. For example, Awrangjeb and Fraser [
15] assigned the point closest to a cell center to cell. However, the center LiDAR point may not be reflected from rooftop of transparent building. Therefore, we assign the maximum of cell’s LiDAR points to cell that extract rooftop LiDAR point in a cell and also reduces the height error of non-ground LiDAR points among the cells. As a result, the transparent building will be extracted.
3.4. Gradient Calculation
Gradient is calculated using a differential function, which measures the slope magnitude in a direction of the greatest change. In the proposed method, gradient represents the slope and tangent of intensity changes among the pixels in each grid cell. The rate of change in intensity of a grid is measured in both
X and
Y directions of a grid. The building roofs generally have a constant rate of change in the intensity image, whereas trees have a random rate of change in intensity. A height tolerance threshold of 0.2 m is exploited to extract buildings. The regions with a rate of change in intensity less than 0.2 m are detected as building planes and are marked as building regions in gradient-based building mask. The constant rate of change in intensity on building planes is only observed when the grid is in the direction of building, otherwise a random rate of change in intensity on building planes is obtained. This phenomenon is also observed in
Figure 8. Thus, the gradient calculation is vital to extract the transparent or opaque buildings of various sizes. There is a possibility that a site has multiple buildings at different orientations, and therefore, masks at every orientation are added to extract all buildings in a site.
3.5. Refine the Building Mask Using LiDAR Points
The gradient-based building mask may contain tree regions if dense trees, especially with flat tops, are present in a given area. In the proposed GBE method, the variance and density analysis [
30] is used to remove the dense tree regions. The variance analysis is adopted based on the principle that LiDAR points representing trees have relatively higher variance as compared to those representing building roofs [
34]. In order to calculate the variance, a window that is shifted over the non-ground LiDAR points of the gradient-based mask. In our method, the window size is equal to the twice of LiDAR point spacing
, thereby, a window will contain at least one LiDAR point. A threshold of 0.2 m variance is set to eliminate the tree LiDAR points from non-ground LiDAR points.
After applying the variance analysis, the density of the non-ground LiDAR points on tree is reduced as compared to building roofs which is also shown in
Figure 9b. Therefore a window, i.e., cell size window, is shifted over the non-ground LiDAR points to analyse the LiDAR points density. The non-ground LiDAR points in a window are removed if they are less than half of the possible non-ground LiDAR points in a window. For example, if the non-ground LiDAR points density is 4 points/
after variance analysis and is less than half of the actual non-ground LiDAR points i.e., 10 LiDAR points/
, then these LiDAR points will be removed. In
Figure 9c, the LiDAR points of considerably high LiDAR point density regions are assigned as non-ground points of buildings. Finally, the remaining non-ground LiDAR points of buildings are used to update the gradient-based building mask. By using the density analysis followed by variance analysis, the LiDAR points on trees are either removed or reduced.
3.6. Refining Building Using Imagery
Dense vegetation may not be eliminated solely using the LiDAR data. Therefore, some existing methods [
5,
7] use additional information from the photogrammetric imagery, e.g., NDVI and texture, to eliminate vegetation. However, manual settings are required to derive such information from the photogrammetric imagery. For example, two channels, i.e., red and infrared, are selected manually to generate the NDVI data that can separate the green colour trees from buildings. If the infrared channel is absence, then a NDVI is estimated from the R, G and B channels. If the red colour trees are present in the site, then the red channel is replaced with the green channel to separate the red colour trees from buildings. Similarly, a window size has to be known beforehand to produce the texture information. In addition, thresholds are used in the NDVI and texture analysis to separate the trees from buildings. These thresholds are empirically tuned based on the characteristics of the training sets and their effectiveness to a given input may not be guaranteed.
The proposed method adopts a local adaptive approach, i.e., local colour matching analysis, to eliminate trees. This approach matches colour properties of objects with their surroundings and eliminates the matched objects. The unmatched objects are further processed by the shadow analysis. If objects are covered by shadow of buildings and have no straight lines, then those objects are also removed. Finally, a morphological filter is used to remove noise.
3.6.1. Local Colour Matching Analysis
As mentioned earlier, a local colour matching analysis matches the buildings with their surroundings using colour information from the photogrammetric image. In terms of definition, the updated gradient-based building mask
contains
B number of buildings which are matched with the objects present in their surrounding area
A. The size of area
A around the building is equal to half of the size of that building. It is also shown in
Figure 10a, where the building regions inside the blue boundaries are matched with their surrounded region (i.e., area
A between the red and blue boundaries). The mean
of colour information of objects’ pixels present in the surrounding area
A is measured. The extracted tree pixels from the gradient process are used to set a colour range threshold
. The colour range threshold is defined as:
where the r, g and b are red, green and blue colour channels, respectively. Later, the number of matched pixels of the building are calculated by:
Finally, the building is removed if the value of
is more than half of that building pixels. In other words, the buildings are removed if more than half of their pixels matched with
. Later, the matched pixels of buildings are also removed to eliminate the trees that are connected to buildings. Using the building pixels, the building boundaries are drawn on the photogrammetric image. Generally, the implementation of the proposed local colour matching analysis is as follows:
Input the photogrammetric image and updated gradient-based building mask .
Extract B buildings from the .
Extract area A around the each of the B buildings.
Calculate the mean of colour information in area A for building i, where i∈B.
Calculate
the colour range threshold using Equation (
1).
Calculate the number of matched Pixels of the building
according to Equation (
2).
Eliminate the building if more than half of its pixels match with the .
Eliminate the matched pixels of building as well.
Repeat Steps 4 to 8 until all the buildings are processed.
3.6.2. Shadow Analysis
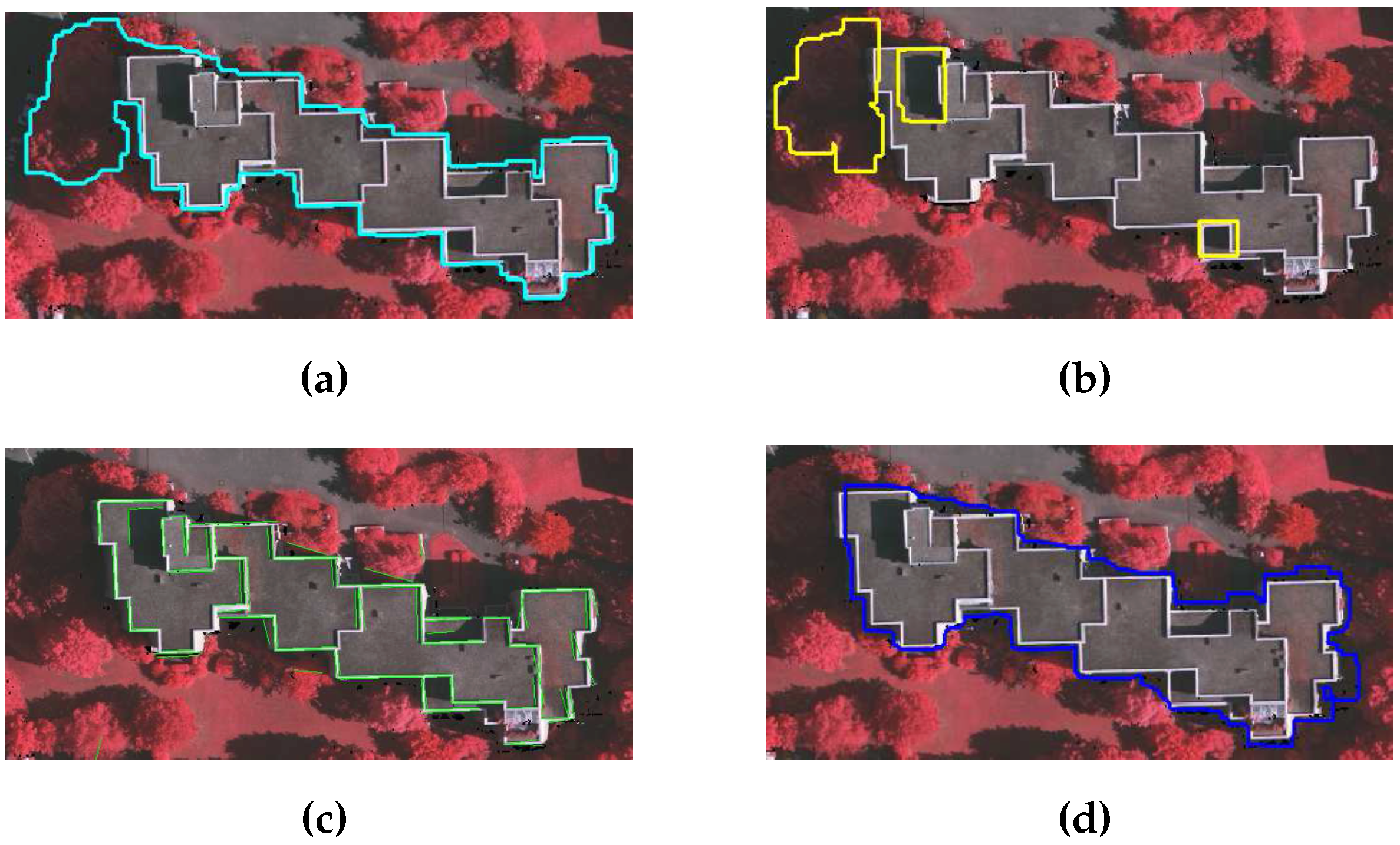
Dense trees covered by the shadows of buildings are not eliminated by the local colour matching analysis. This is also shown in
Figure 11a, where the shadowed region is extracted as a part of the building. Therefore, a two-step shadow analysis is also defined in our proposed method as follows:
Step 1 (Detect shadow region): The
image of the input photogrammetric image is derived, where
I is intensity and its range is [0, 1]. The lower value of
I, e.g.,
= 0.25, indicates shadow region. Therefore, pixels having
I less than
are grouped as shadow regions which are also shown in
Figure 11b.
Step 2 (Eliminate shadow region): The shorter trees and buildings may be covered by the shadows of the taller buildings. Interestingly, the shadowed buildings may have some long straight lines (i.e., extracted during initial steps by Canny edge detector), whereas shadowed trees have no long straight lines. This is also shown in
Figure 11c, where the shadowed buildings have some straight lines and shadowed trees have no straight lines. Therefore, the straight lines are used to distinguish the shadowed trees from shadowed building. The shadowed tree pixels are eliminated and the building pixels are used to update the building regions. Finally, the building regions are masked into a refined mask.
3.6.3. Morphological Filter
Morphological filter uses non-linear operations, e.g., opening function or dilation followed by erosion, to eliminate objects smaller than a predefined structure element (). The refined mask still has some smaller portion of trees. Therefore, the of size 1 is used to eliminate all objects below the 1 . The refined mask, i.e., the updated gradient-based building mask, contains only the buildings. Using the refined mask, the buildings boundaries are outlined on a given photogrammetric imagery.
6. Conclusions
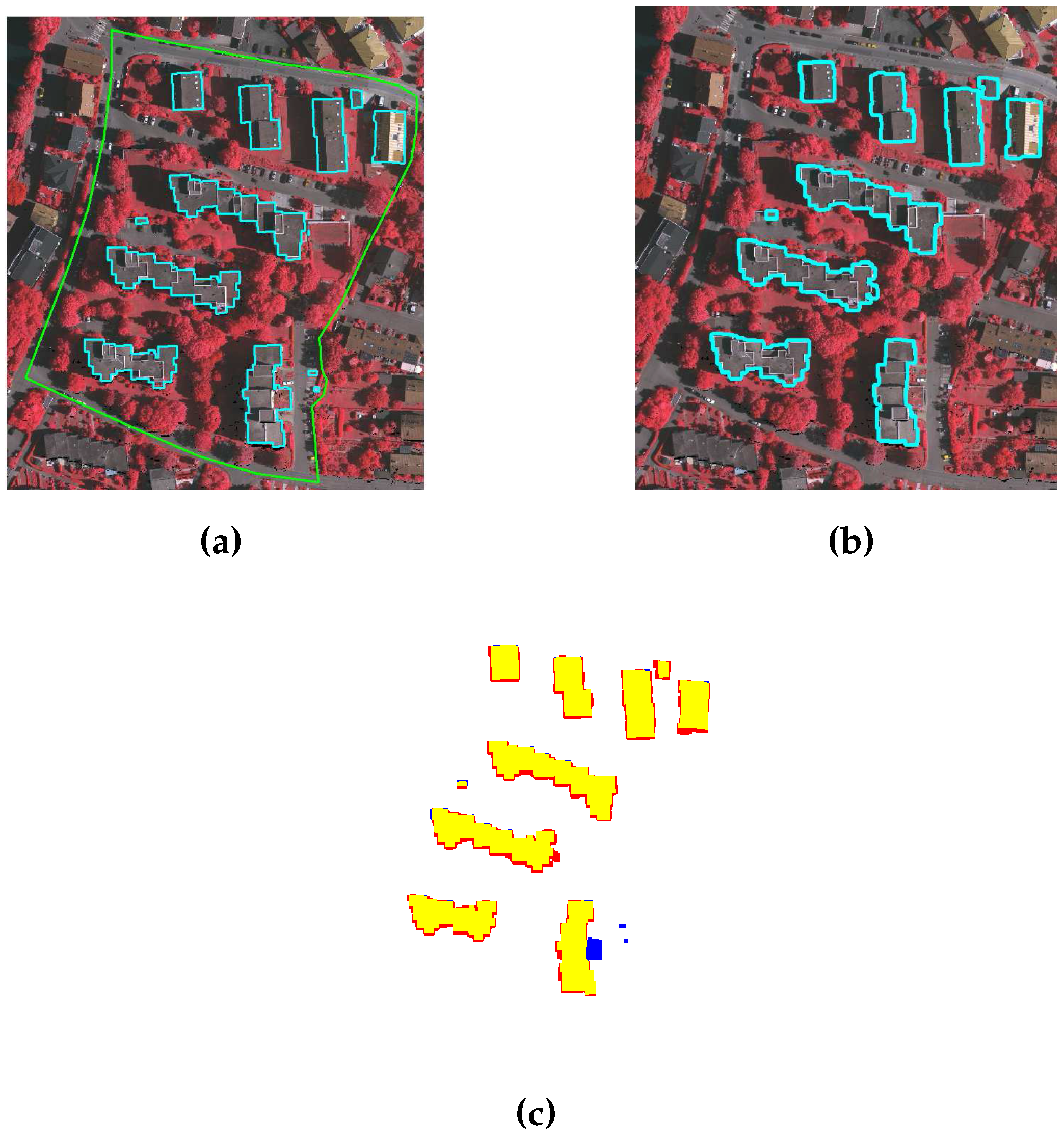
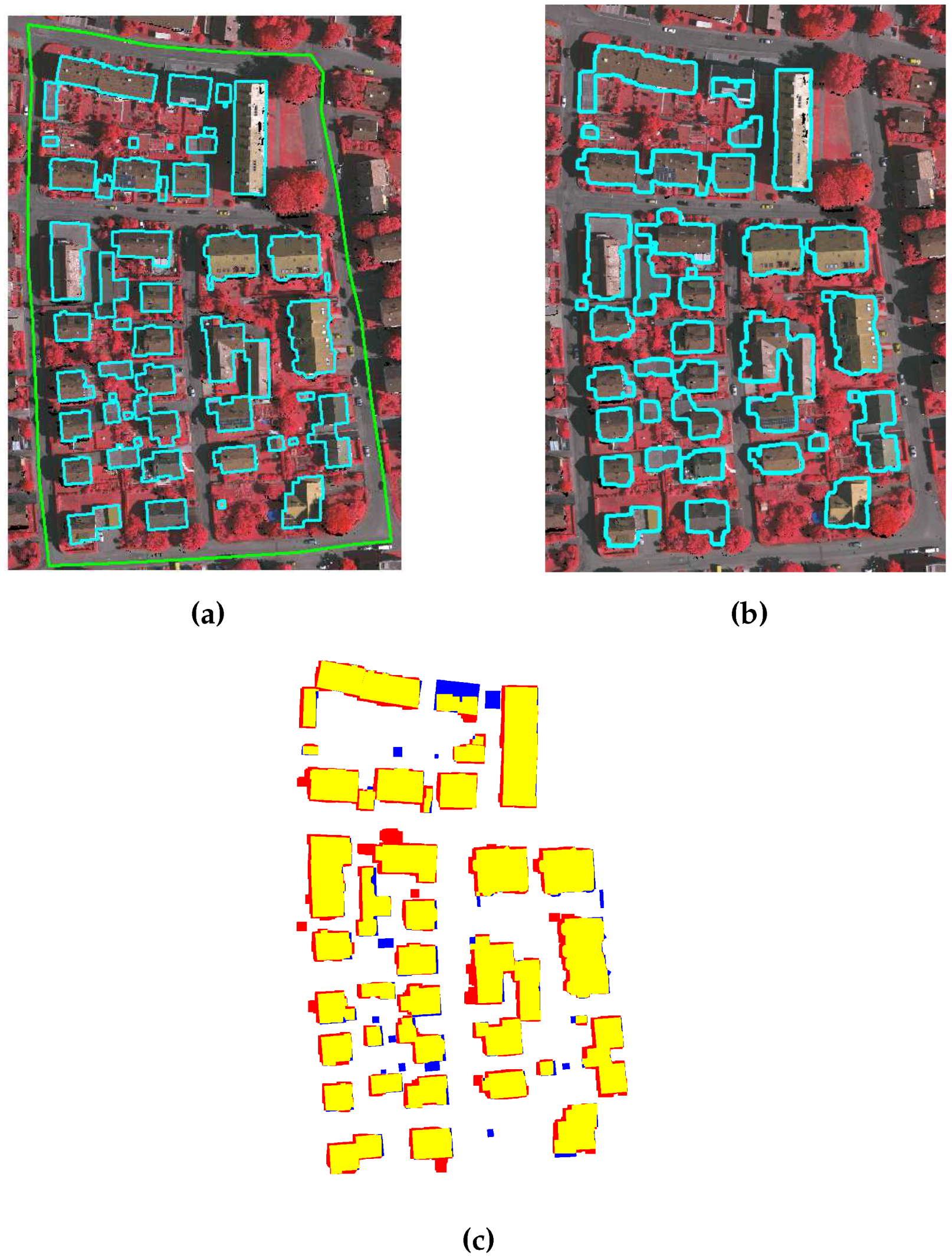
In this paper, a new gradient-based building extraction method is proposed. This gradient-based method is more robust in extracting of bigger range of sizes as well as transparent buildings. The proposed method uses LiDAR points in a direction of the extracted building lines from photogrammetric image to extract buildings. In addition, the local colour matching and shadow analysis are introduced, where some parameters are automatically set based on local information from a given image. This analysis replaces many empirically set parameters of the existing building extraction methods, and as a result, the proposed method uses fewer empirically set parameters. One of the introduced parameters, i.e., shadow threshold, is set based on a general observation, whereas a building match threshold is set empirically and it is more stable at different parameter values. The proposed method is compared with state-of-the-art methods for building extraction. Our experimental results show that our proposed method is more effective in extracting all kinds of building, i.e., small size buildings and buildings with transparent roof. Among the compared methods for ISPRS data set, KNTUmod is the only method which is consistent in generating the good results. Compared with the quantitative analysis of KNTUmod, the GBE method’s average completeness is 6.01% higher in pixel-based and 2.1% higher in object-based evaluation. The performance of our proposed method is further verified on CRCSI data sets and its results are compared with one of the most recent methods i.e., MON2. Compared with quantitative analysis of MON2, the GBE method’s average completeness is 12.9% higher in object-based evaluation and its average correctness is also 0.25% higher in pixel-based evaluation. Furthermore, our proposed parameters are more robust. Based on the stability test, the proposed parameters are comparatively more stable and have achieved the lowest standard deviation of quality i.e., 0.004 and 0.215 for VA02 and AV areas, respectively.
The proposed method mainly depends on LiDAR data to extract building planes. Therefore, the proposed method is unable to extract the planes which are smaller than the LiDAR point spacing. In addition, the proposed method is designed to extract buildings with flat and slope roofs. As a result, buildings with curved roofs, e.g., rainbow roofs, barrel roofs, bow roofs and dome roofs, will not be extracted by the proposed method. Our future work is to develop a more robust surface modelling procedure that can extract all kinds of curved roof.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}