1. Introduction
In recent years, a number of mega-cities such as New York and Toronto have built-up detailed 3D city models to support the decision-making process for smart city applications. These 3D models are usually static snapshots of the environment and represent the status quo at the time of their data acquisition. However, cities are dynamic systems that continuously change over time. Accordingly, their virtual representations need to be regularly updated in a timely manner in order to allow for accurate analysis and simulation results that decisions are based upon. In this context, a framework for continuous city modeling by integrating multiple data sources was proposed by [
1].
A fundamental step to facilitate this task is to coherently register remotely sensed data taken at different epochs with existing 3D building models. Great research efforts have already been undertaken to address the related problem of image registration. [
2,
3], e.g., give comprehensive literature reviews of relevant methods. Fonseca
et al. [
4] conducted a comparative study of different registration techniques for multisensory remotely sensed imagery. Although most of the existing registration methods have shown promising success in controlled environments, registration is still a challenging task due to the diverse properties of remote sensing data related to resolution, spectral bands, accuracy, signal-to-noise ratio, scene complexity, occlusions,
etc. [
3]. These variables have a major influence on the effectiveness of the registration process, and lead to severe difficulties when attempting to generalize it. Still, though a universal method applicable to all registration tasks seems impossible, the majority of existing method consists of the following three steps [
2,
5]:
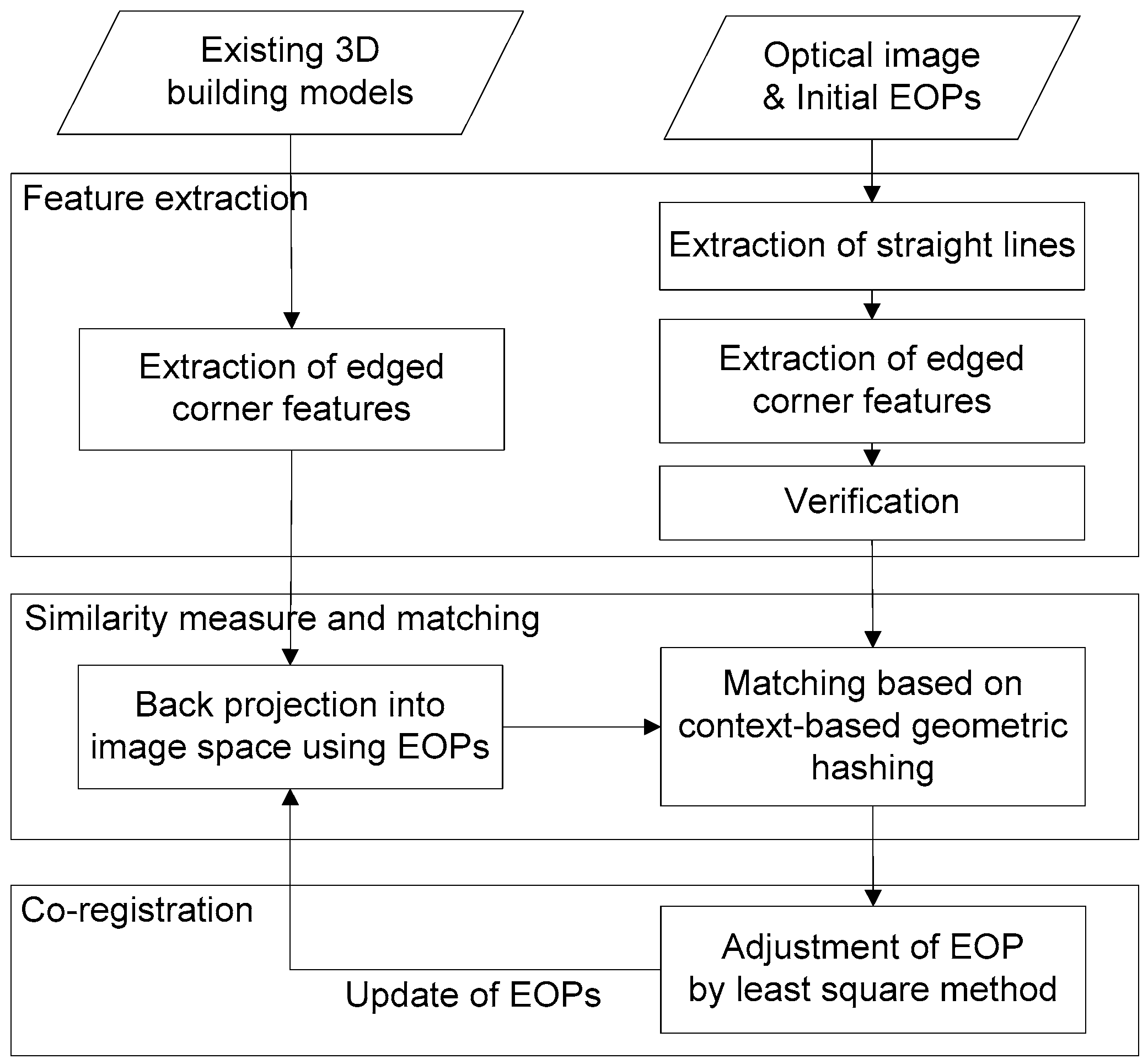
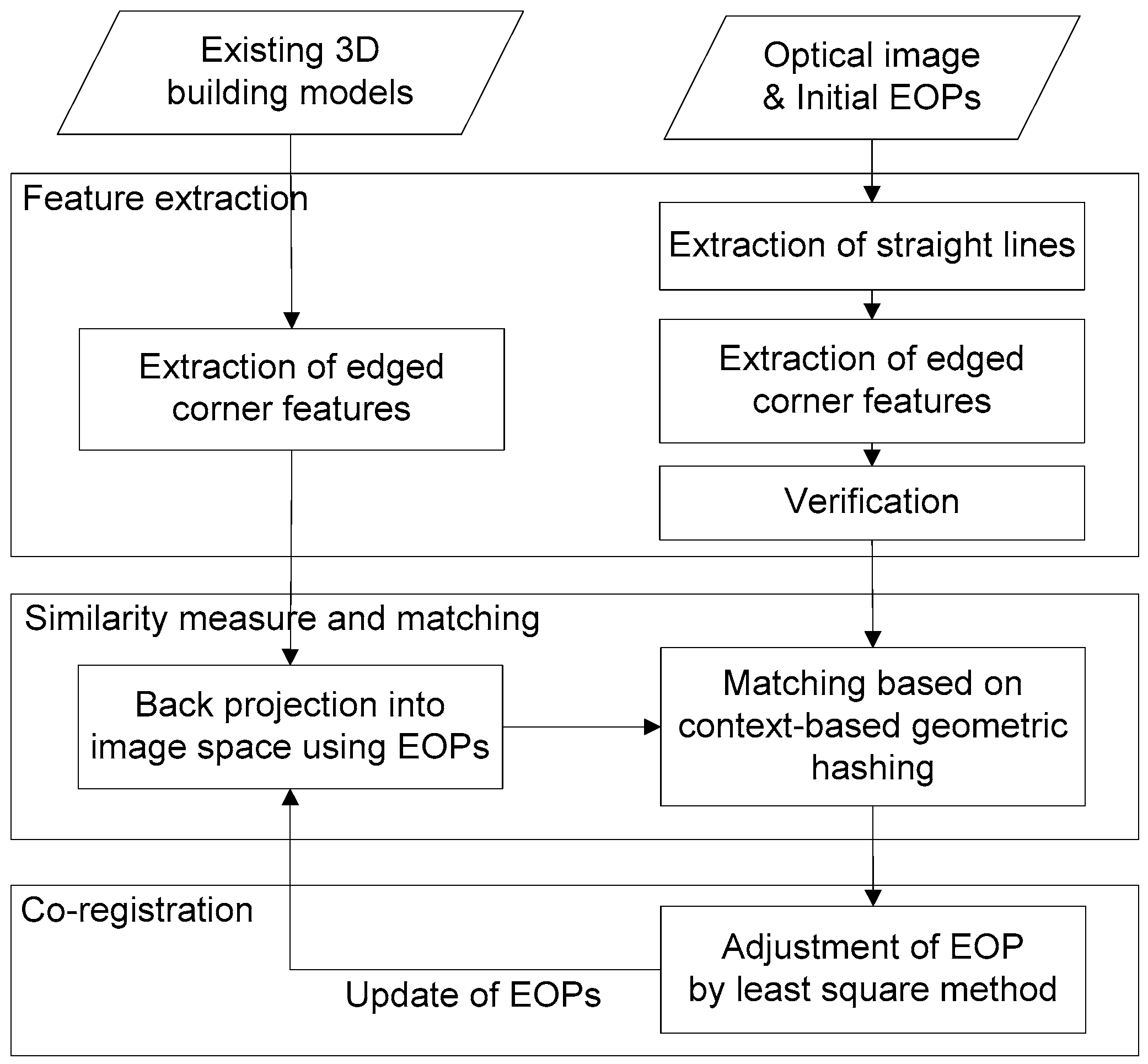
Feature extraction: Salient features such as closed-boundary regions, edges, contour lines, intersection points, corners, etc. are detected in two datasets, and used in the registration process. Special care has to be taken to ensure that these features are distinctive, well distributed and can be reliably observed in both datasets.
Similarity measure and matching: The correspondences between features that are extracted from two different datasets are then found by a matching process. A similarity measure that is based on the attributes of the features quantifies its correctness. To be effective, the measure should consider the specific feature characteristics in order to avoid possible ambiguities, and to be accurately evaluated.
Transformation: Based on the established correspondences, a transformation function is constructed that transforms one dataset to the other. The function depends on the assumed geometric discrepancies between both datasets, the mechanism of data acquisition, and required accuracy of the registration.
A successful registration strategy must consider the characteristics of the data sources, its later applications, and the required accuracy during the design and combination of the individual steps. Recent advancements of aerial image acquisition make direct geo-referencing for certain types of applications (coarse localization, and visualization) possible. If an engineering-level accuracy is needed, however, including continuous 3D city modeling, the exterior orientation parameters (EOPs) obtained through these techniques may need to be further adjusted. In indirect geo-referencing of aerial images, accurate EOPs are generally determined by bundle adjustment with ground control points. However, obtaining or surveying such points over a large-scale area is labor intensive, and time-consuming. An alternative method is to use other known points instead.
Nowadays, large-scale 3D city models have been generated for many major cities in the world, and are, e.g., available within the Google Earth platform. Thus, the corner points of 3D building models can be used for registration purposes. However, the quality of the existing models is often unknown and varies furthermore from building to building, which is the result from different reconstruction methods and data sources being applied. For example, LiDAR points are mostly measured within the roof faces and seldom at their edges, which often results in their boundaries and corner points to be geometrically inexact. Thus, the sole use of corner points from existing building data bases as local features can lead to matching ambiguities and therefore to errors in the registration.
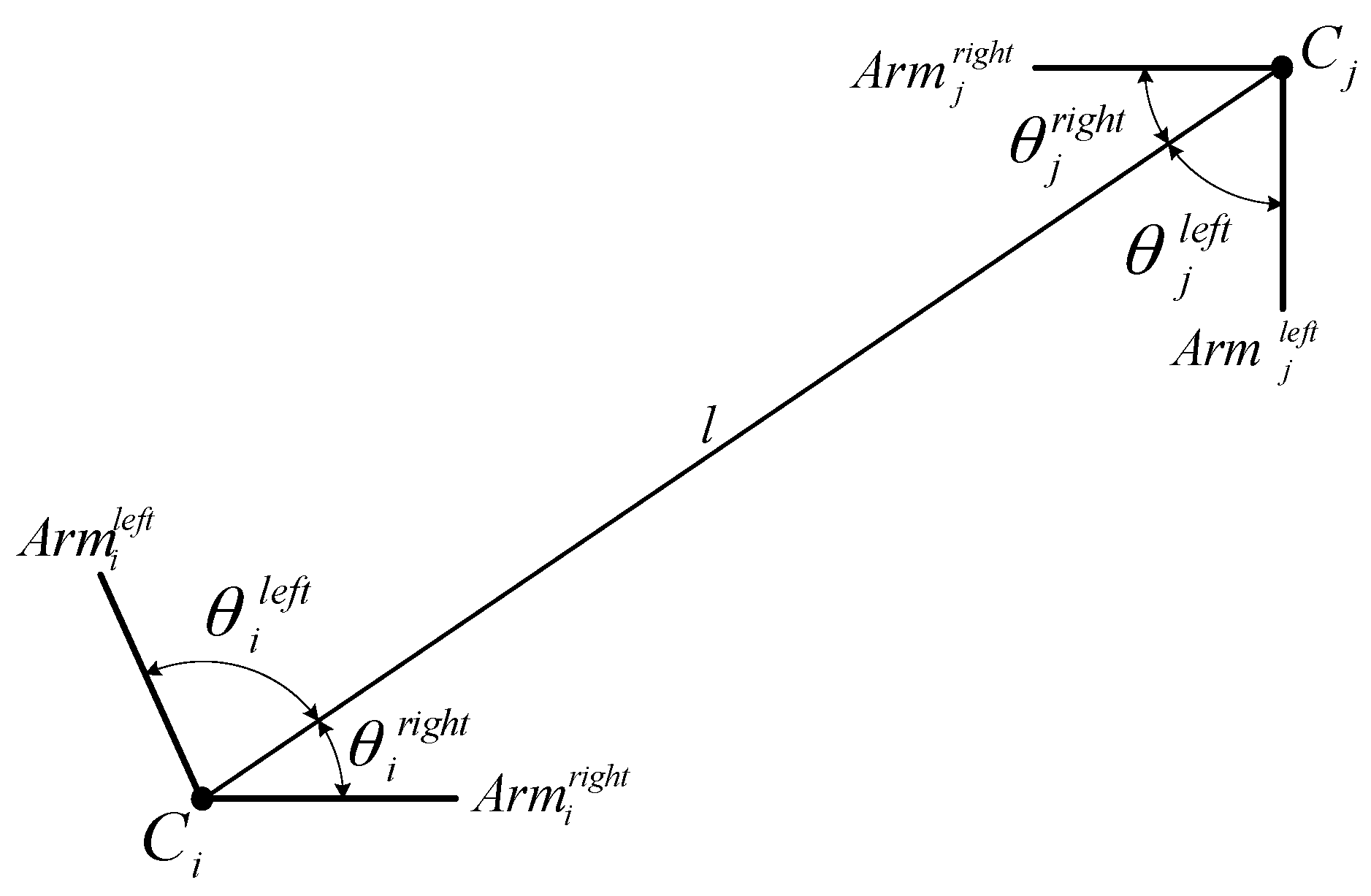
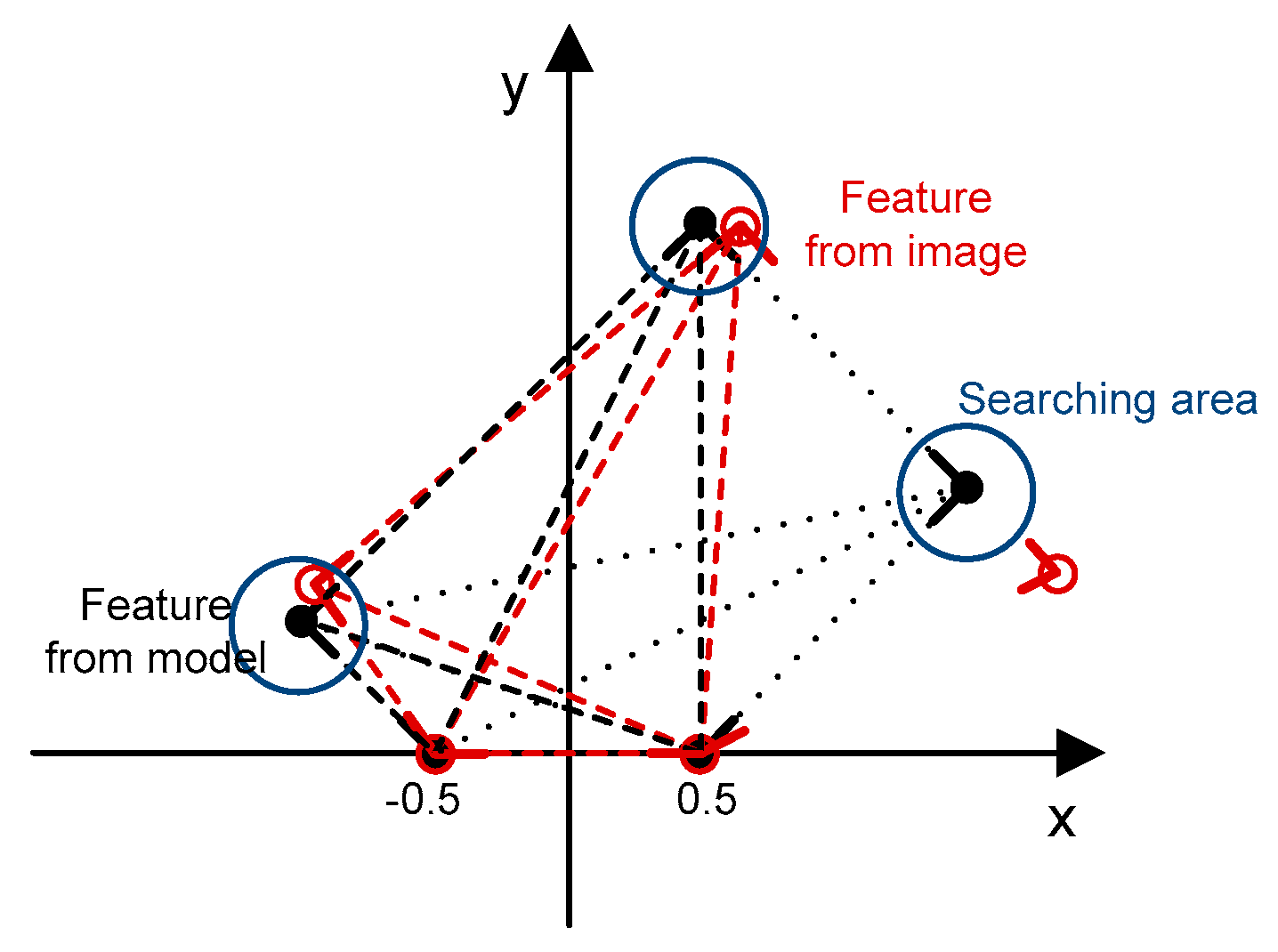
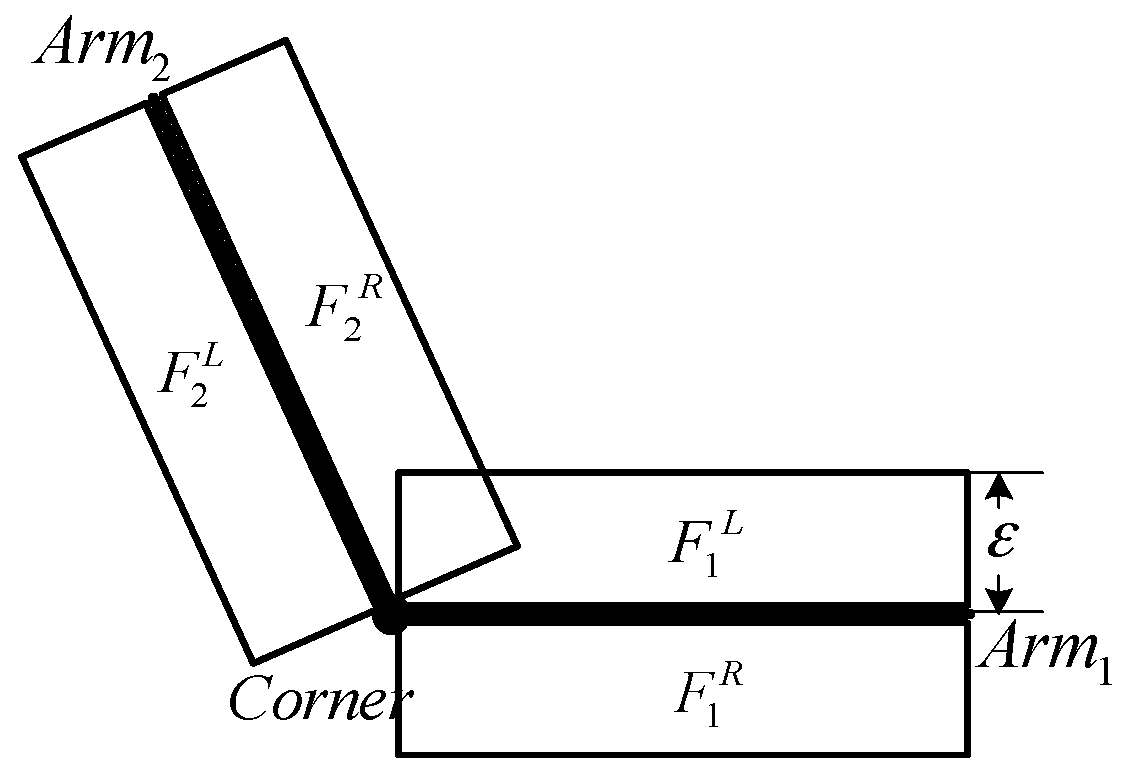
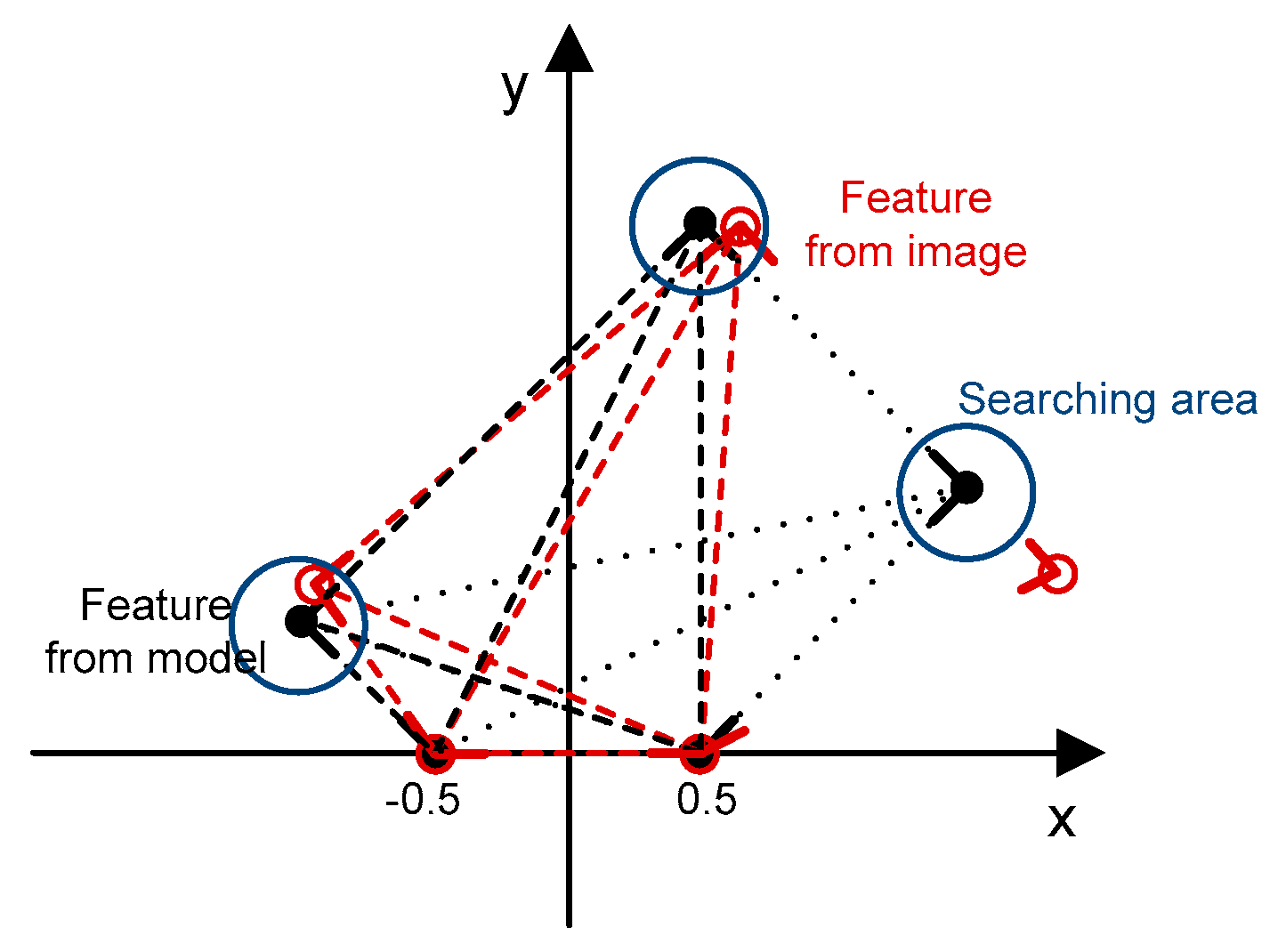
To address this issue for the registration of single images with existing 3D building models, we propose to use two types of matching cues: (1) edged corner features that represent the saliency of building corner points with associated edges; and (2) context features that represent the relations between the edged corner features within an individual roof. Our matching method is based on the Geometric Hashing method, which is a well-known indexing-based object recognition technique [
6], and it is combined with a scoring function that reinforces the context force. We have tested our approach on large urban areas with over 1000 building models in total.
Related Work
Registration is an essential process when multisensory datasets are used for various applications such as object recognition, environmental monitoring, change detection, and data fusion. In computer vision, remote sensing and photogrammetry, this includes registrations between same source taken from different viewpoints at different times (e.g., image to image), between datasets collected with different sensors (e.g., image and LiDAR), and between an existing model and remotely sensed raw data (e.g., map and image). Numerous registration methods have been proposed to solve the registration problems for given environments, and for different purposes [
2,
3,
4,
7]. Regardless of data types and applications, the registration process can be recognized as a feature extraction, and correspondence problem (or matching problem) between datasets. Brown [
2] categorized the existing matching methods into area-based, and feature-based methods according to their nature. Area-based matching methods use image intensity values extracted from image patches. They deal with images without attempting to detect salient objects. Correspondences between two image patches are determined with a moving kernel sliding across a specific size of image search window or across the entire other image by correlation-like methods [
8], Fourier methods [
9], mutual information methods [
10], and others. In contrast, feature-based methods use salient objects such as points, lines, and polygons to establish relations between two different datasets. In feature matching processes, correspondences are determined by considering the attributions of the used features. In model-to-image registration, most of the existing registration methods adopt a feature-based method because many 3D building models have no texture information.
In terms of features, point features such as line intersections, corners and centroids of regions can be easily extracted from both models and images. Thus, Wunsch
et al. [
11] applied the Iterative Closest Point (ICP) algorithm to register 3D CAD-models with images. The ICP algorithm iteratively revises the transformation with two sub-procedures. First, all closest point pair correspondences are computed. Then, the current registration is updated using the least square minimization of the displacement of matched point pair correspondences. In a similar way, Avbelj
et al. [
12] used point features to align 3D wire-frame building models with infrared video sequences using a subsequent closeness-based matching algorithm. Lamdan
et al. [
6] used a geometric hashing method to recognize 3D objects in occluded scenes from 2D grey scale images. However, Frueh
et al. [
13] pointed out that point features extracted from images cause false correspondences due to a large number of outliers.
As building models or man-made objects are mainly described by linear structures, many researchers have used lines or line segments instead of points as features. Hsu
et al. [
14] used line features to estimate the 3D pose of a video where the coarse pose was refined by aligning projected 3D models of line segments to oriented image gradient energy pyramids. Frueh
et al. [
13] proposed a model to image registration for texture mapping of 3D models with oblique aerial images. Correspondences between line segments are computed by a rating function, which consists of slope and proximity. Because an exhaustive search to find optimal pose parameters was conducted, the method is affected by the sampling size of the parameter space, and it is computationally expensive. Eugster
et al. [
15] also used line features for real-time geo-registration of video streams from unmanned aircraft systems (UAS). They applied relational matching, which does not only consider the agreement between an image feature and a model feature, but also takes the relations between features into account. Avbelj
et al. [
16] matched boundary lines of building models derived from DSM and hyper-spectral images using an accumulator. Iwaszczuk
et al. [
17] compared RANSAC and the accumulator approach to find correspondences between line segments. Their results showed that the accumulator approach achieves better results. Yang
et al. [
18] proposed a method to register UAV-borne sequent images and LiDAR data. They compared building outlines derived from LiDAR data with tensor gradient magnitudes and orientation in image to estimate key frame-image EOPs. Persad
et al. [
19] matched linear features between Pan-Tilt-Zoom (PTZ) video images with 3D wireframe models based on hypothesis-verification optimization framework. However, Tian
et al. [
20] pointed out several reasons that make the use of line or edge segments for registration a difficult problem. First, edges or lines are extracted incompletely, and inaccurately so that ideal edges might be broken into two or more small segments that are not connected to each other. Secondly, there is no strong disambiguating geometric constraint, whereas building models are reconstructed with certain regularities such as orthogonality, and parallelism.
Utilizing prior knowledge of building structures can reduce the matching ambiguities, and the search space. 3D object recognition method from single image based on the notion of perceptual grouping, which groups image lines based on proximity, parallelism and collinearity relations, was proposed in [
21]. Also, hidden lines of objects, which do not appear in the image, were eliminated through visibility analysis to reduce search space and to increase the robustness of matching process. In [
22], the work of [
21] was extended to increase the robustness of the matching by devising a rule-based grouping method. However, a shortcoming of the approach is that matching fails in cases of nadir images where building walls and footprints are invisible in the image. Similar method was used to match 3D building models to aerial images by [
23]. However, their implementation was only tested for a small number of buildings and it was limited to standard gable roof models. Also, a requirement of their approach was that each pixel must be within some range of an edge. 2D orthogonal corner (2DOC) was used in [
24] as a feature to recover the camera pose for texture mapping of 3D building model. The coarse camera parameters were determined by vertical vanishing points that correspond to vertical lines in the 3D models. Correspondences between image 2DOC and DSM 2DOC were determined using Hough transform, and generalized M-estimator sample consensus. However, they described their error source as too limited to correct 2DOCs matches, in particular, for residential areas. Instead of using 2DOC, Wang
et al. [
25] proposed three connected segments (3CS) as a feature, which is more distinctive, and repeatable. For putative feature matches, they applied a two level RANSAC method, which consists of a local, and a global RANSAC for robust matching.
3. Experimental Results
The proposed CGH-based registration method was tested on benchmark datasets over the downtown areas in Toronto (ON, Canada) and Vaihingen in Germany provided by the ISPRS Commission III, WG3/4 [
30].
Table 1 shows characteristics of reference building models, which were used to determine EOPs. For the Toronto datasets, two different types of reference building models were prepared by: (1) a manual digitization process conducted by human operators; and (2) using a state-of-the art algorithm [
31] from airborne LiDAR point clouds. These two building models were used to investigate their respective effects on the performance of our method (
Figure 7). For the Vaihingen datasets, LiDAR-driven building models were automatically generated by [
32] and adjusted as described in [
33] as shown in
Figure 8. A total of 16 check points for each dataset, which were evenly distributed throughout the images, were used to evaluate the accuracy of the EOPs.
For the Toronto dataset, various analyses were conducted to evaluate the performance of the proposed registration method in detail. From the aerial image, a total of 90,951 straight lines were extracted and 258,486 intersection points were derived by intersecting any two straight lines found within 20 pixels of proximity constraint. Out of these, 57,767 intersection points were selected as edged corner features following the removal of 15%, and 60% of intersection points using geometric constraint (
), and radiometric constraints (
, and
), respectively (
Table 2). The
and
were automatically determined by Otsu’s binarization method.
Figure 9 shows edged corner features extracted from the aerial image. As many of the intersection points are not likely to be corners, the majority of them were removed. The method correctly detected corners and arms in most cases even though some corners were visually difficult to detect due to their low contrasts.
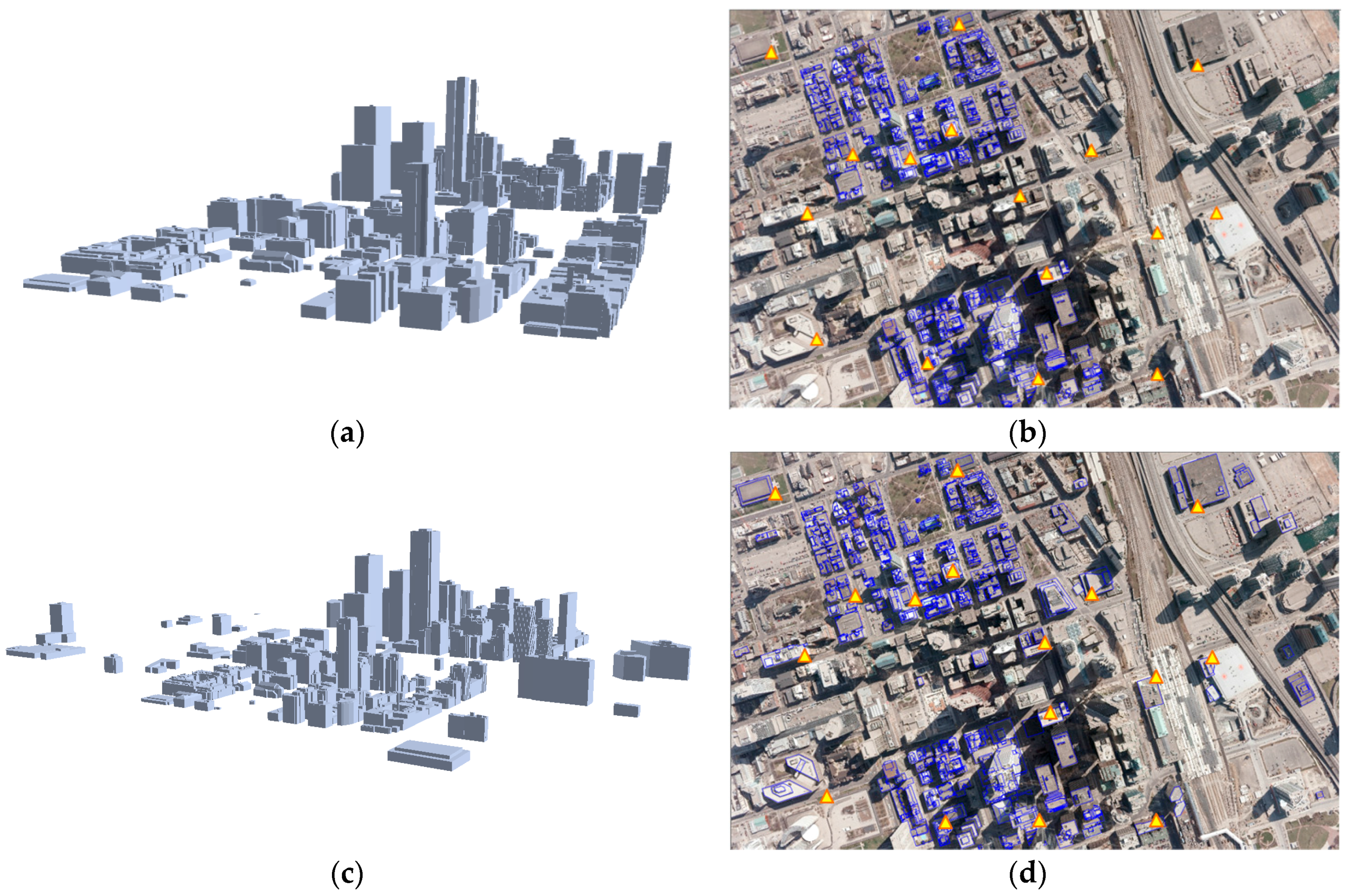
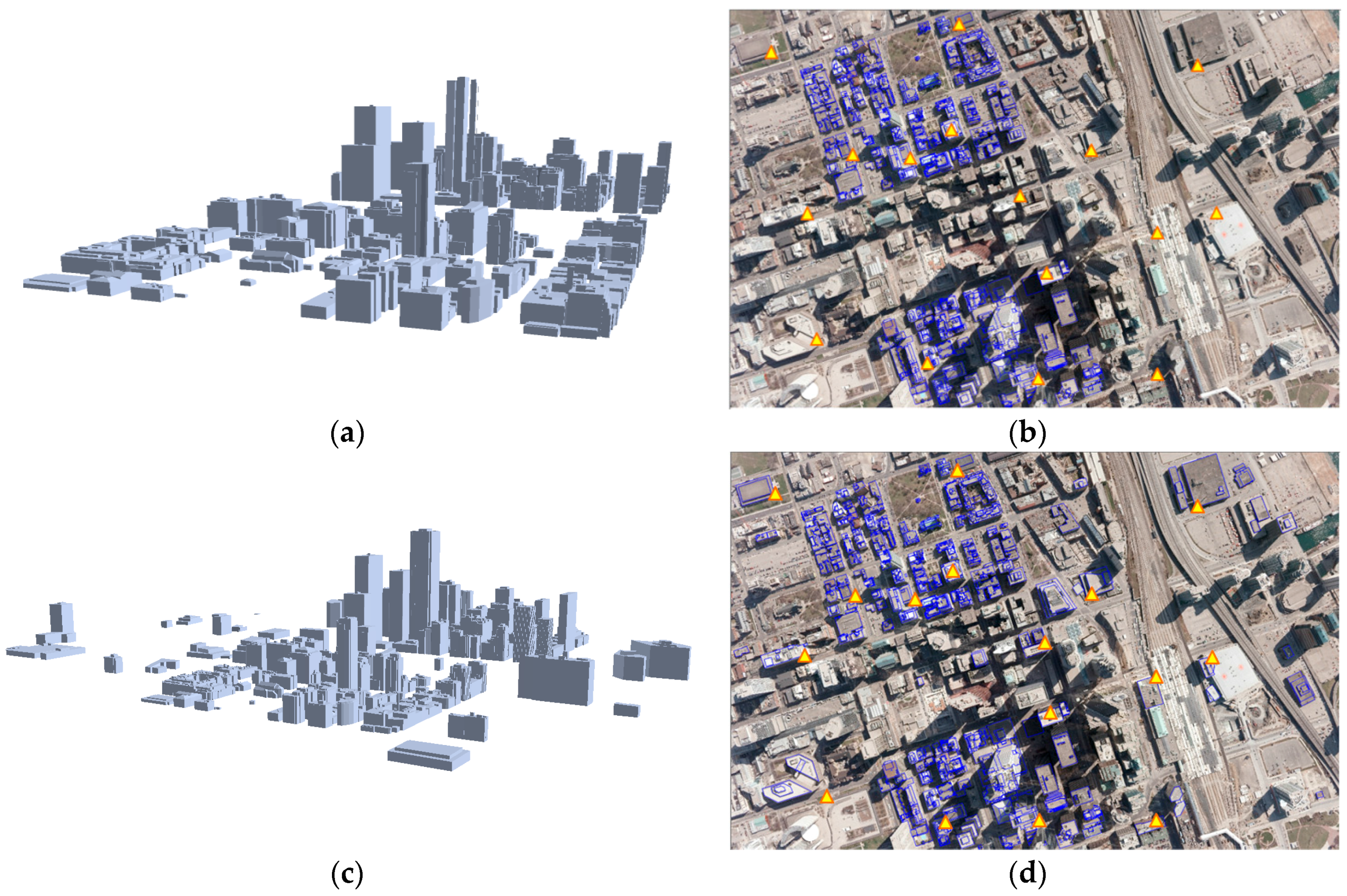
After the existing building models were back-projected onto the image using error-contained EOPs, edged corner features were extracted from the vertices of the building models in the image space (
Figure 10). It should be noted that two different datasets were used as the existing building models. Some edged corner features extracted from both existing building models were not observed in the image due to occlusions caused by neighbor building planes. Also, some edged corner features, in particular those extracted from LiDAR-driven building models, do not match with the edged corner features extracted from the image due to modeling errors caused by irregular point distribution, occlusions and the reconstruction mechanism. Thus, correspondences between edged corner features from the image and from the existing building models are likely to be partly established.
The proposed CGH method was applied to find correspondences between features derived from the image and from existing building models. When manually digitized building models are used as building models, a total of 693 edged corner features (7.8% of edged corner features extracted from the entire building models) were matched using the parameters given in
Table 3.
It is noted that only models whose vertices were greater than
were considered to find possible building matches. For LiDAR-driven building models, only 381 edged corner features (4.9% from the entire building models) were matched (
Table 2). It is noted that the number of matched edged corner features is influenced by the quality of the existing building models, and thresholds used,
in particular. As shown in
Table 2, more edged corner features are matched when manually digitized building models were used as the existing building models than when LiDAR-driven building models were used. If
is set as a small value, the number of matched edged corner features increases, but this increases the risk it may contain a large number of incorrect matched edged corner features. The effect on the
will be discussed in detail later.
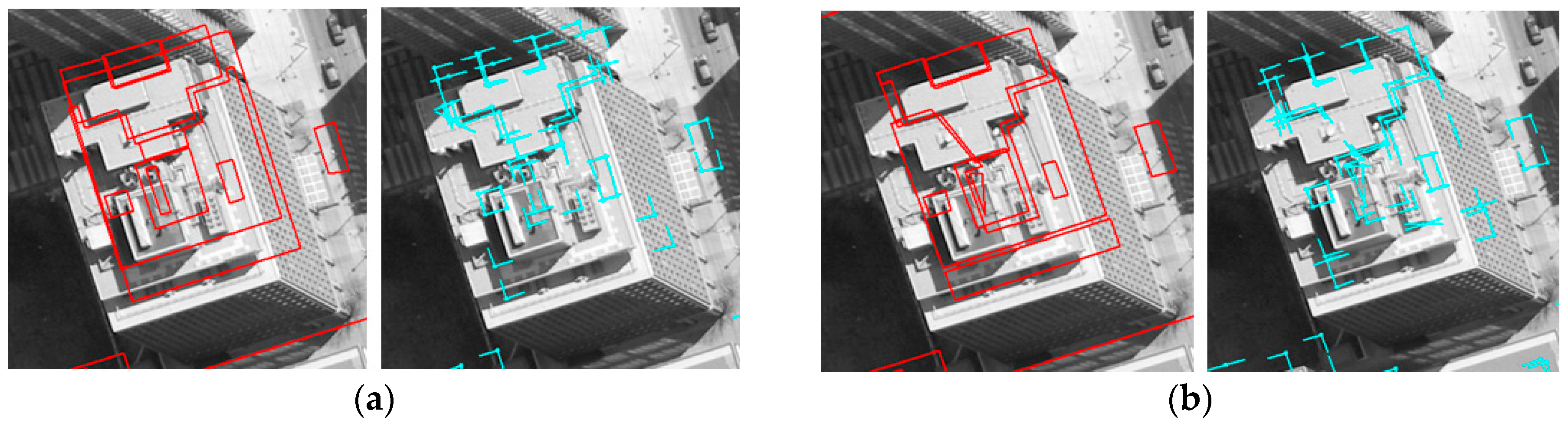
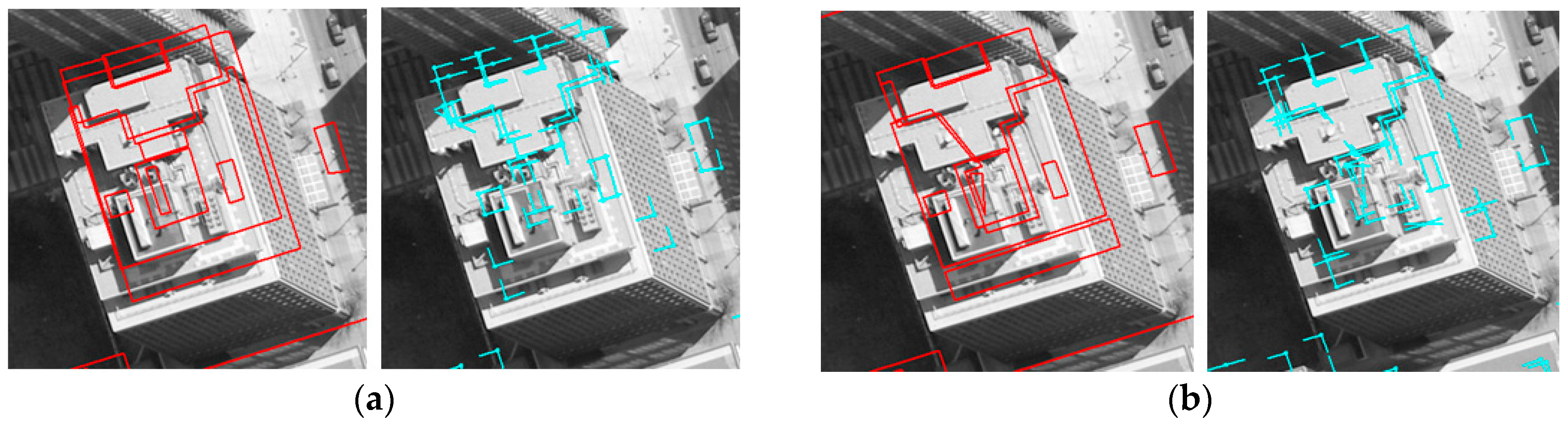
Based on matched edged corner features, EOPs for the image were calculated by applying the least square method based on co-linearity equations. For qualitative assessment, the existing models were back-projected to the image with refined EOPs. Each column of
Figure 11 and
Figure 12 shows back-projected building models with error-contained EOPs (a), matched edged corner features (b), and back-projected building models with refined EOPs (c). In the figures, boundaries of the existing building models are well matched to building boundaries in the image with refined EOPs.
In our quantitative evaluation, we assessed the root mean square error (RMSE) of check points back-projected onto the image space using refined EOPs (
Table 4). When reference building models were used as the existing building models, the results show that the average difference in
x and
y directions are −0.27 and 0.33 pixels, respectively, with RMSE of ±0.68 and ±0.71 pixels, respectively. The results with LiDAR-driven buildings models show that the average differences in
x and
y directions are −1.03 and 1.93 pixels, with RMSE of ±0.95 and ±0.89 pixels, respectively. Although LiDAR-driven building models are used, the accuracy of the EOPs is less than 2 pixels in image space (approximately 30 cm in ground sample distance (GSD)). Considering that the point space (resolution) of the input airborne LiDAR dataset is larger than 0.3 m, the refined EOPs provide a greater accuracy for engineering applications.
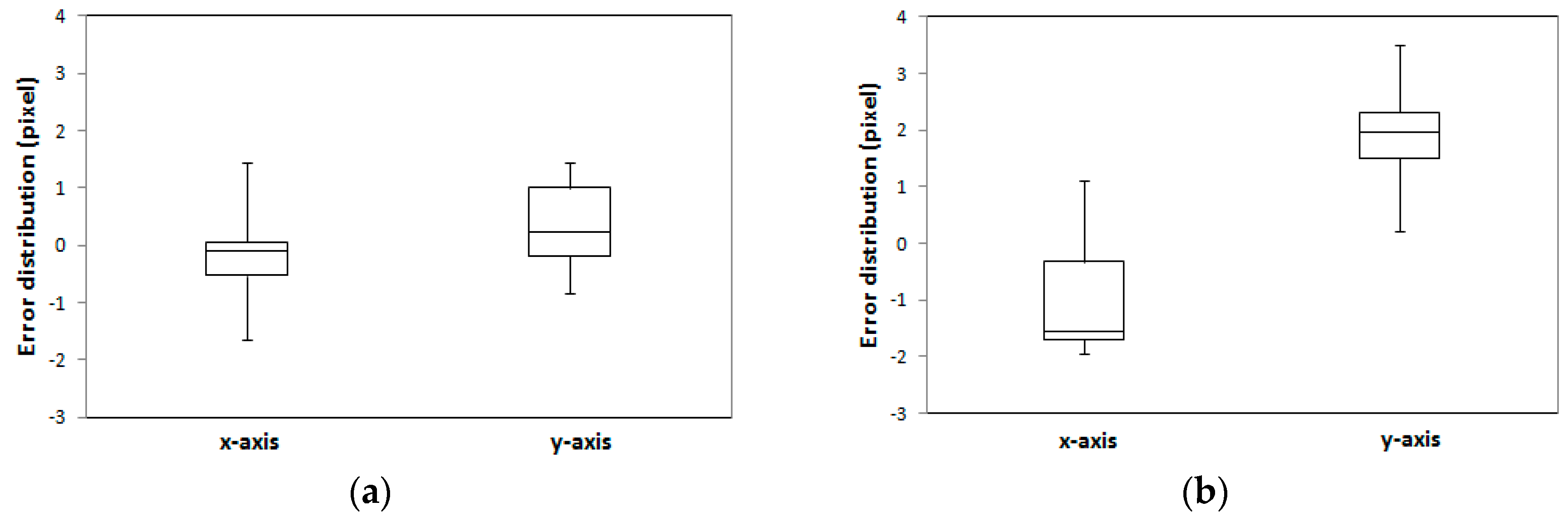
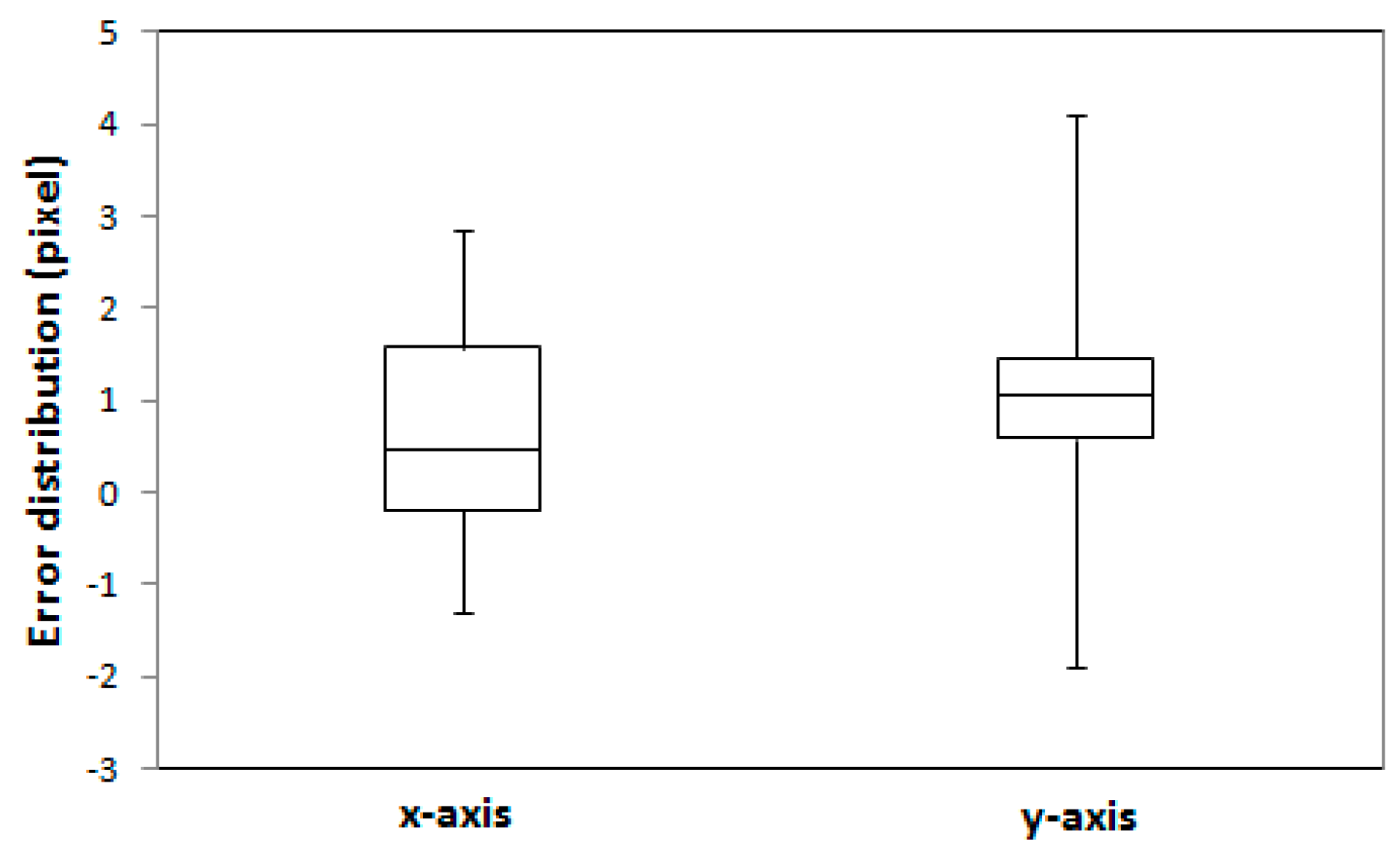
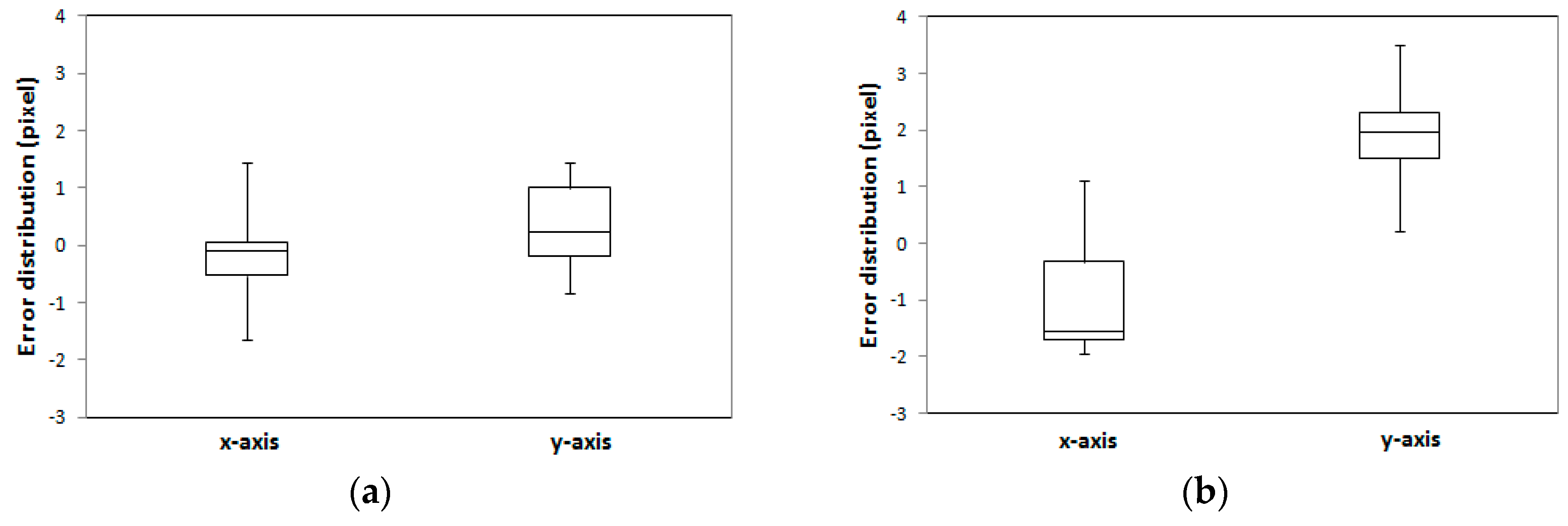
The error distribution of 16 check points is illustrated in
Figure 13. The error distributions showed that the interquartile range (IQR) for both manually digitized and LiDAR-driven building models were under 1.5 pixels. The maximum error value for LiDAR-driven models was however 1 pixel greater than for manually digitized models.
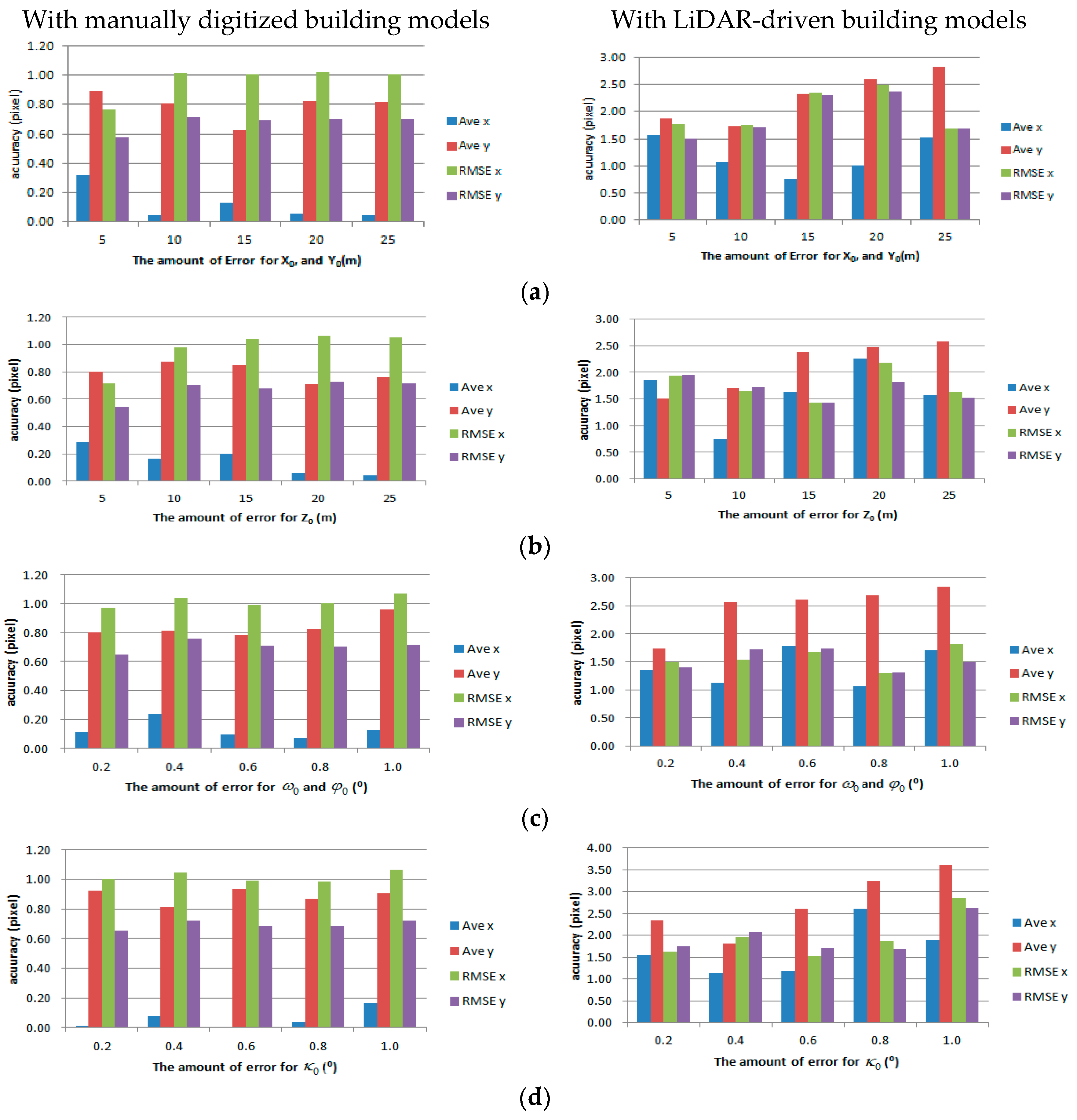
In this study, threshold,
has an effect on the accuracy of the EOPs. In order to evaluate the effect of
, we estimated the matched number of edged corner features, and calculated the average error and the RMSE of the check points with different values of
. As shown in
Table 5, the number of matched features is inversely proportional to the value of
, regardless of which existing building models are used. However, the effect of
on the accuracy is not the same for both building models. We observed
affects the matching accuracy of digitized building models less than it does for LiDAR-driven building models. Furthermore, the matching accuracy tends to get worse with very low or high
values. The latter can be explained by the low number of matched features, giving us insufficient data to accurately adjust the EOPs of the image. In the other case, if a low
value is selected, the number of matched features increases, but so does the number of incorrect matches if the building models are inaccurate. Thus, we can observe that LiDAR-driven building models, reconstructed with relatively lower accuracy compared to the manually digitized models, produced more sensitive results in the matching accuracy according to
. In contrast, the matching accuracy of the manually digitized building models remains high because of high model accuracy. In summary, a higher accuracy of the building models can lead to a higher EOP accuracy, while the value of
should be determined by balancing the ratio of correct matched features and incorrect matched features.
In order to evaluate the effect on context feature, we set weight parameter
w in score function (Equation (1)) as 1 and 0.5, respectively, and then compared the results. When
w = 1, the score function considers only the unary term without the effect of the contextual term so that the contextual force is ignored. As shown in
Table 6, the results show that registration with only unary terms causes considerably low accuracy in both cases. In particular, with LiDAR-driven models, the accuracy is heavily affected. These results indicate that the use of context features has a positive effect on resolving the matching ambiguity and thus improving the EOP accuracy by reinforcing contextual force.
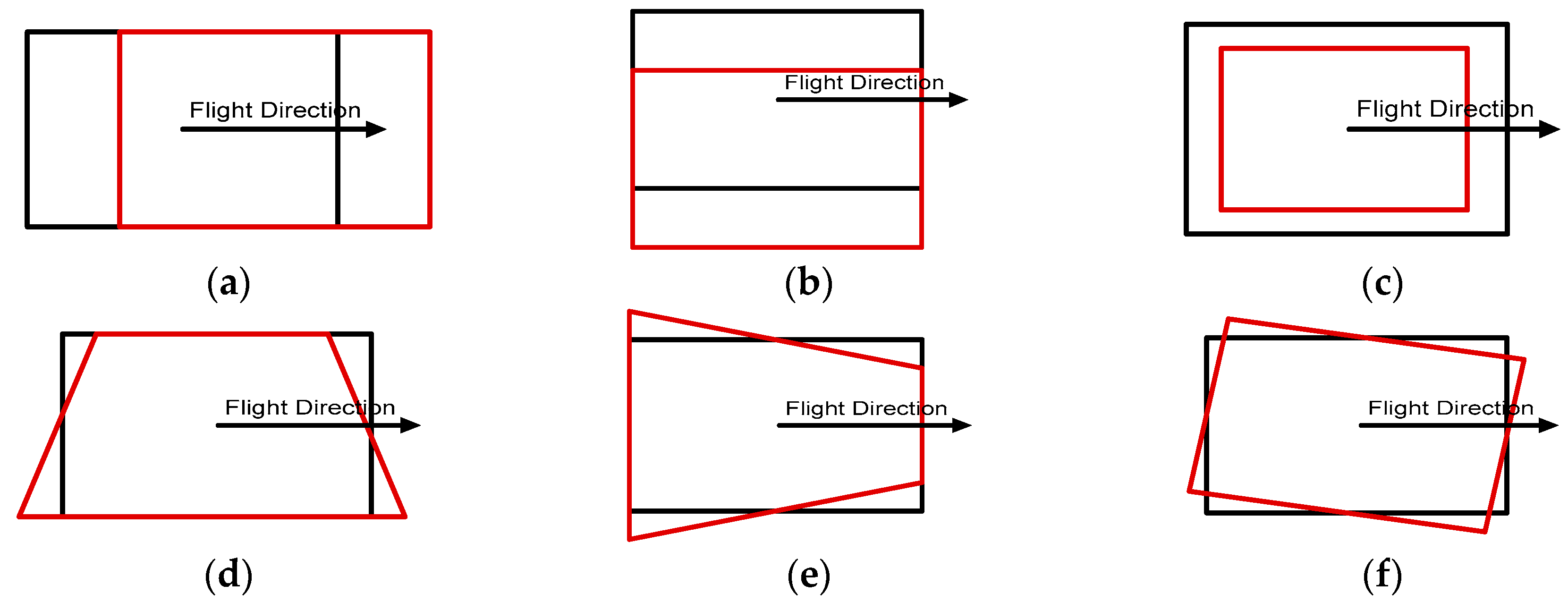
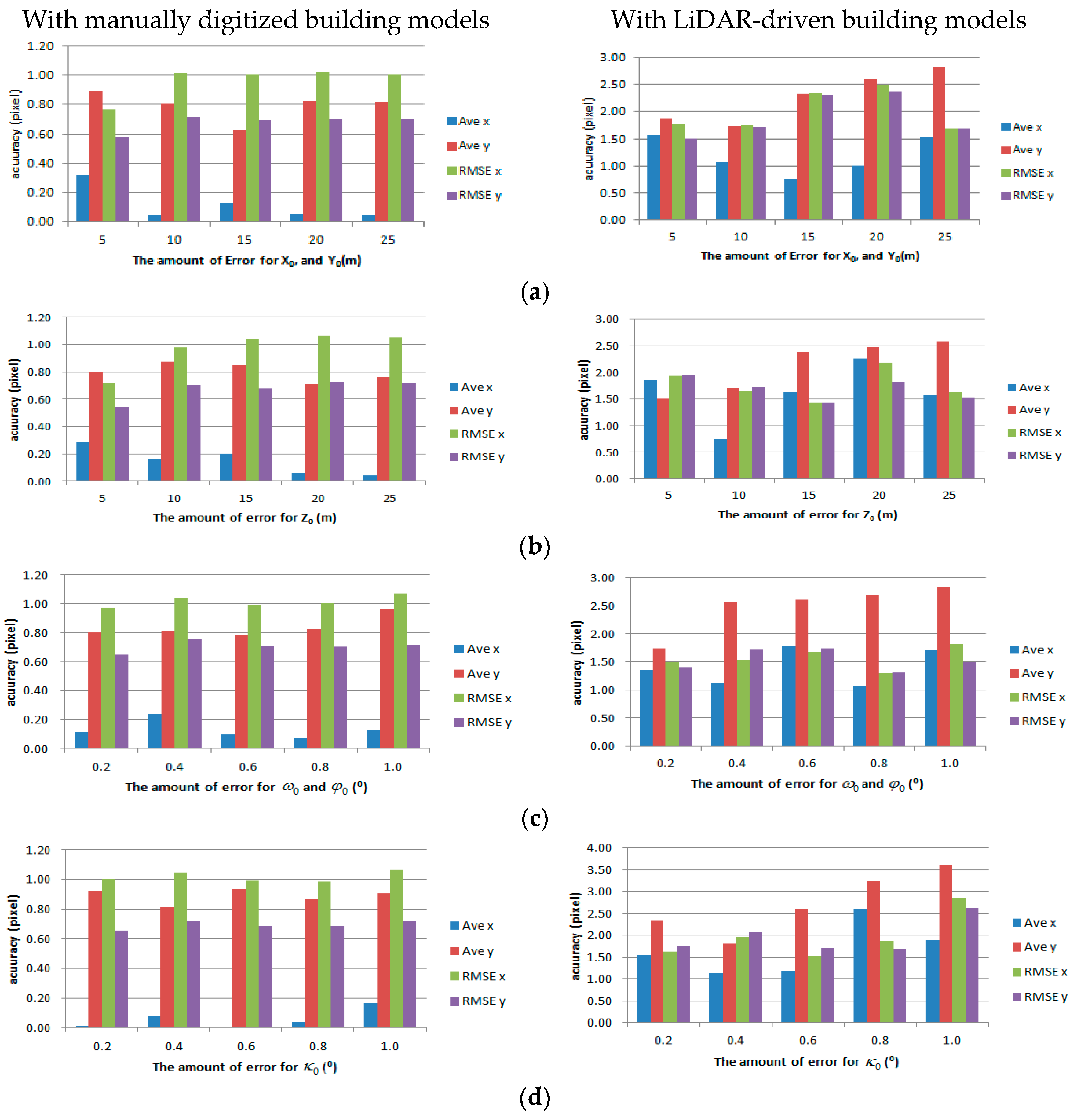
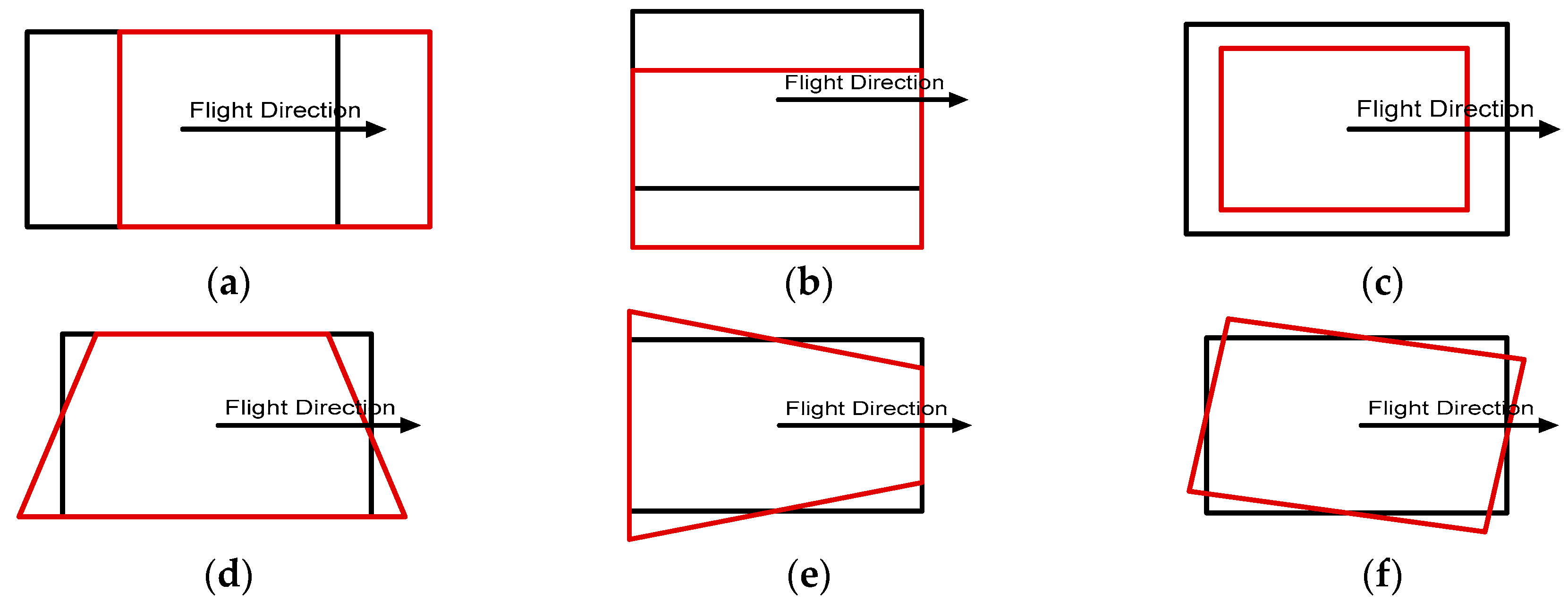
We also analyzed various impacts of errors in initial EOPs on the matching accuracy by adding different levels of errors to evaluate our proposed method. Each parameter of the EOPs leads to different behaviors from back-projected building models:
and
parameters are related to the translation of back-projected building models;
is related to scale;
and
cause shape distortion;
is related to rotation (
Figure 14). In order to assess the effects on translation and scale, errors ranging from 0 m to 25 m were added to three position parameters. To assess the shape distortion and rotation effects, errors ranging from 0° to 2.5° were added to three rotation parameters.
Figure 15 shows the accuracies of the refined EOPs with different level of errors for each EOP parameter. Regardless of errors in the initial EOPs, RMSE of under 2 pixels for manually digitized building models, and RMSE of under 3 pixels for LiDAR-driven building models were achieved. The results indicate that the accuracy of the refined EOPs was less affected by the amount of initial EOPs errors. This is due to the fact that the EOPs converge to the optimum solution iteratively.
In order to evaluate the robustness of the proposed registration method, the algorithm was applied to the Vaihingen dataset. A total of 31,072 edged corner features from the image and 11,812 edged corner features from the existing building models were extracted using the parameters set in
Table 3. A total of 379 edged corner features were matched by the CGH method where
was heuristically set as 0.7, and other parameters were set by
Table 3. The results of the extracted and matched features are summarized in
Table 7. Sixteen check points were evaluated for error-contained EOPs and refined EOPs. The accuracies of the check points with refined EOPs show that the average difference for
x and
y directions are 0.67 and 0.91 pixels with RMSE of ±1.25 and ±1.49 pixels respectively (
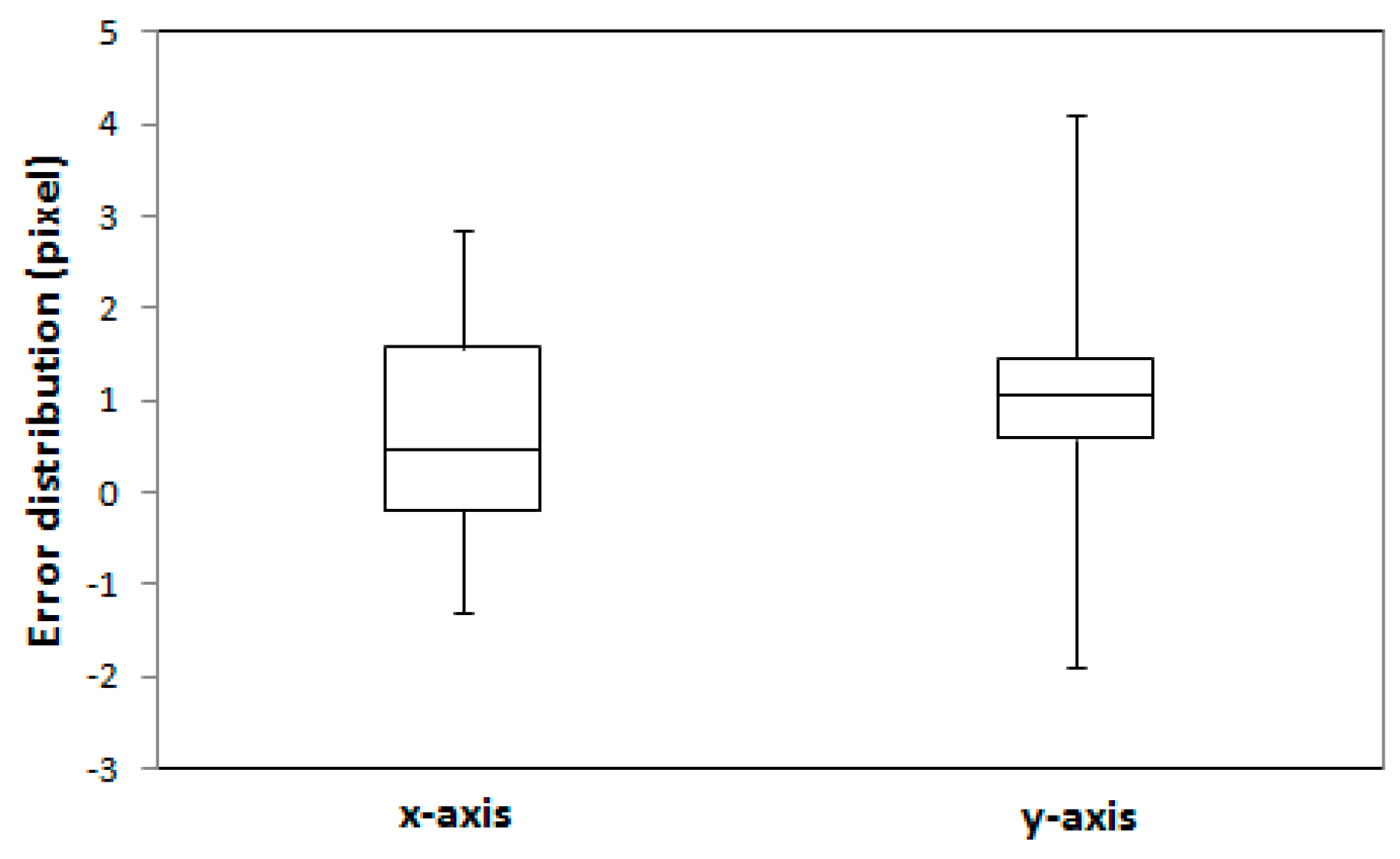
Table 8). A summary of the error distribution for the 16 check points is presented in
Figure 16. The results suggest that the proposed registration method can achieve accurate and robust matching results even though building models with different error types were used for the registration of a single image.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}