1. Introduction
Electroencephalography (EEG) is a non-invasive method to record electrical activity of the brain using sensors distributed along the scalp. Signals detected by an EEG with no connection to a specific brain activity are called artifacts. These are usually classified as physiological and non-physiological artifacts. Physiological artifacts are generated by the patient and non-physiological artifacts can arise from outside of the body (i.e., equipment, environment, etc.).
In many cases the information that is hidden behind the physiological artifacts is relevant to a proper diagnosis. Think, for instance, about early detection of mental fatigue or in monitoring stress levels. Others health applications need EEG signals without artifacts contamination in order to reduce the misinterpretation of the EEG and limit the potential for adverse clinical consequences. In this case brain computer interfaces need to filter artifacts in real time [
1,
2]. Consequently, it is necessary, especially for long recordings, to develop methods to detect and correctly identify artifacts either for analyzing or removing them. This is the main goal of this paper.
There are some approaches for detecting and removing artifacts using EEG recordings. Statistical methods as SCADS (Statistical Control of Artifacts in Dense Array Studies) [
3] and FASTER (Fully Automated Statistical Thresholding for EEG Artifact Rejection) [
4] detect and remove artifacts to analyze event-related potentials. The packages EEGLAB [
5] and FieldTrip [
6] include some routines to detect EEG artifacts but some threshold values need to be defined. Reference [
7] is a practical example of how threshold values are used for detection of EEG artifacts in polysomnographic recordings.
DETECT [
8] is a toolbox for detecting and identifying artifacts based on the supervised classifier support vector machine (SVM). Note that other supervised methods do not carry out an identification process [
9,
10,
11,
12]. An advantage of DETECT over other methods is that the user is not required to manually define threshold values (with the exception of a certainty value applied to the classification outcome to reduce false positives). Moreover it captures the frequency and duration of artifacts. DETECT only finds artifacts included in the training process and the quality of this detection depends on the quality of the training data.
In [
13], the authors present a practical example of how a SVM classifier is used to detect artifacts arising from head-movements. Reference [
14] describes a novel application of one-class support vector machine novelty detection for detecting seizures in humans.
In this paper we first propose a new, simple, and effective unsupervised method (UMED) to characterize and detect events in multichannel signals. Then the proposed method is applied to detect artifacts in EEG recordings. We use the term “artifact detection” interchangeably with the term “event detection” although artifact is more closely associated with the EEG recordings.
Some advantages of the proposed method are the following: (i) it does not need to manually specify any threshold value; (ii) it allows the measurement of the frequency and duration of the events; (iii) as an unsupervised method it does not need training data; (iv) it can be applied to signals with
a priori unknown events; (v) it provides an optimal detection technique to characterize the events by finding an optimal window; (vi) it can be used in real-time; and (vii) it provides the number of independent components (NIC) required to remove artifacts by means of an independent component analysis (ICA) [
2,
15,
16].
This paper is organized as follows.
Section 2 presents some terms and theoretical background used to implement UMED. The proposed unsupervised method to characterize and detect events in multichannel signals is presented in
Section 3. In
Section 4, we test this method using an EEG recordin
g with artifacts. Finally in
Section 5 and
Section 6, a discussion and conclusions of the paper are respectively presented.
2. Background
2.1. Events and Multi-Channel Signals
In this section, we formally define the terms “event” and “multichannel signal”. Both are linked to the concept of temporal sequence. Temporal sequence refers to a sequence of happenings or events in a time interval. An event is something that happens at a time tE and it reflects some kind of change in a temporal evolution. An important characteristic of temporal sequences is the order in which events take place. Another important characteristic is the duration dE between tE and the next event.
A temporal sequence is normally represented by a series of nominal symbols from a particular alphabet. Every event is characterized by a symbol. In this way, an event with symbol E is described by two elements (E, tE). The three elements (E, tE, dE) represent a state. A temporal sequence P made of u events Ei for i = 1, …, u can be described by a u-tuple of states P = <(E1, tE1, dE1), (E2, tE2, dE2), …, (Eu, tEu, dEu)>.
In general, the number and temporal locations of events can be unknown within a temporal sequence. This means that events have to be recognized and located inside the sequence. It occurs, for example, in the monitoring of a physical system with Q sensors for a period of time [T1, T2]. In this case, every sensor represents a channel and simultaneously provides a signal describing part of the whole information. Signals of this type that are generated by multiple sensors are called multichannel (MC) signals. In other words, a MC signal refers to a set of signals that show cross-channel similarity or correlation. A MC signal with Q channels is represented by a vector X(t) = [CH1(t) CH2(t), …, CHQ(t)] where CHq(t) is the signal of the channel q for q = 1, 2, ..., Q. A MC signal X(t) with events can also be described, in compact form, as a temporal sequence P.
2.2. The Hierarchical Clustering, the Cophenetic Correlation Coefficient, and the S_Dbw Validity Index
In this section we briefly describe three concepts used in the implementation of the proposed algorithm: the hierarchical clustering (HC) algorithm [
17], the Cophenetic Correlation Coefficient (CCC) [
18], and the
S_Dbw Validity Index [
19].
The HC groups data over a variety of scales by creating a cluster tree or dendrogram. It follows this general procedure: (1) find the similarity or dissimilarity between every pair of objects in the data set; (2) group the objects into a binary, hierarchical cluster tree (linkage); (3) determine where to cut the hierarchical tree into clusters.
In a dendrogram, the cophenetic distance between two objects is represented by the height of the link at which those two objects are first joined. That height is the distance between the two subclusters that are merged by that link. The CCC for a cluster tree is defined as the linear correlation coefficient between the cophenetic distances obtained from the tree, and the similarities (or dissimilarities) used to construct the tree. The CCC is a measure of how faithfully a dendrogram maintains the original pairwise distances. The magnitude of CCC should be very close to 1 to achieve a high-quality solution of the HC algorithm.
Given a dataset, if
x(
Oi,
Oj) is the distance between the
ith and
jth object,
t(
Oi,
Oj) is their cophenetic distance,
is the average of the
x(
Oi,
Oj) and
is the average of the
t(
Oi,
Oj), then the CCC is given by Equation (1):
The S_Dbw validity index is used for measuring “goodness” of a clustering result. Its definition is based on cluster compactness and separation but it also takes into consideration the density of the clusters. Lower index value indicates better clustering schema.
Given a set of
k clusters
Gi (
i = 1, …,
k) of the dataset
DS, the
S_Dbw index is defined in the following way:
where
Scat is the intra-cluster variance that measures the average scattering of clusters and it is described by:
σ(
DS) is the variance of the dataset
DS and
σ(
Gi) is the variance of the cluster
Gi.
The inter-cluster density
Dens_bw is defined as follows:
where
μ is the center of the cluster
G, |
G| is the number of objects in
G, and the function
f(
xi,
μ) is defined by:
If G = Gi U Gj, then μ is the middle point of the line segment that is defined by the μi and μj clusters centers.
3. Method for the Characterization and Detection of Events in Multichannel Signals
In this section, we propose an unsupervised method (UMED) to characterize and detect the events of a MC signal of duration [T1, T2] whose events are a priori unknown. A small temporal window slides along the interval [T1, T2]. For each window displacement, it is obtained a feature vector of S variables which picks up the behavior of the MC signal. A feature vector unsupervised classification is carried out, which allows automatic characterization and detection of the events. The quality of this characterization (and the number of events detected) depends significantly on the size of the sliding window. This is why the algorithm searches for an optimal window size that provides the maximum compactness and separation of the content between the events.
The UMED detects and characterizes events by means of an optimal unsupervised classification. The S_dbw index and the HC algorithm are used to find the best window along with its unsupervised classification characterized by its optimal number of clusters.
Given a MC signal X for a period of time [T1, T2] with unknown events to be characterized and detected, the steps of UMED can be summarized as follows:
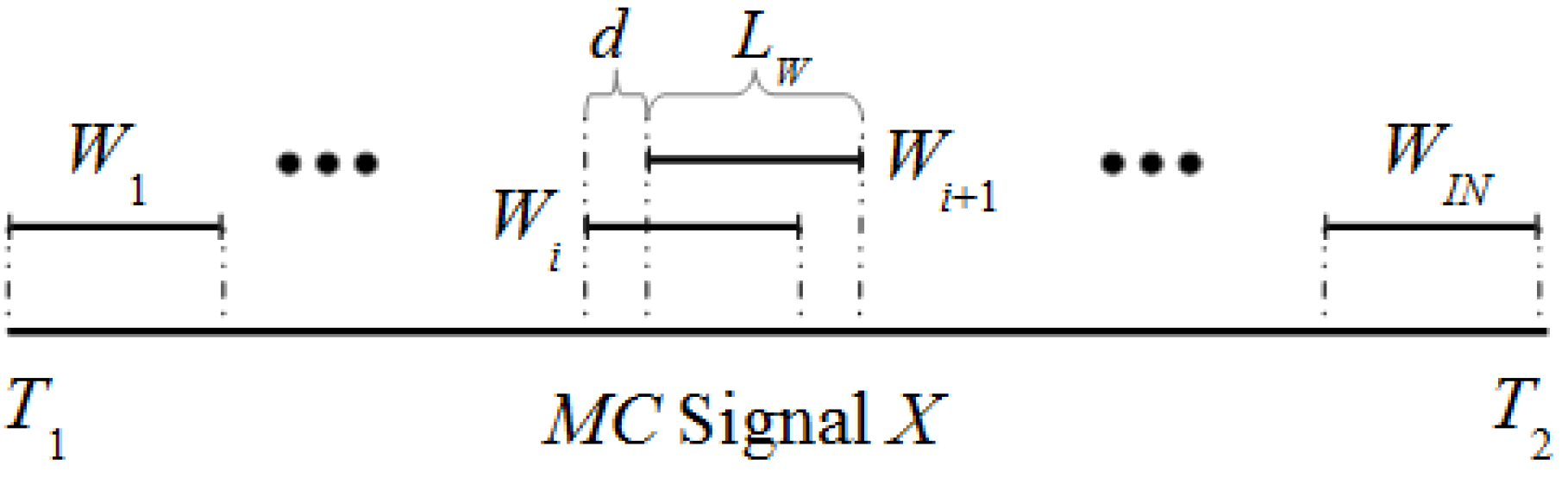
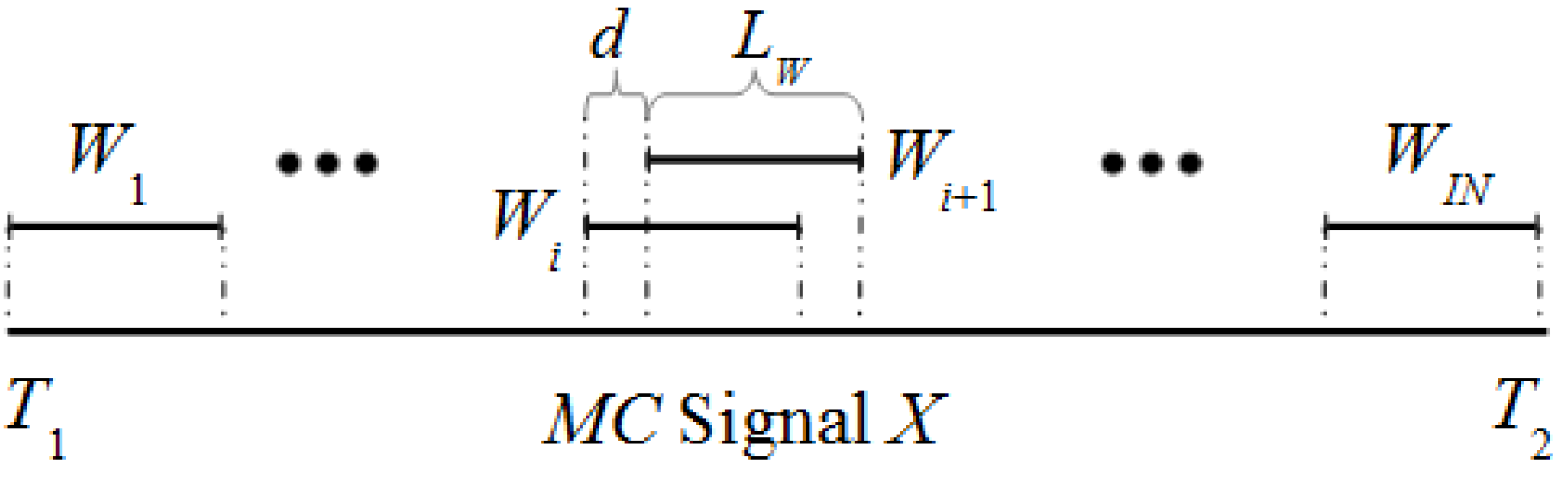
Step 1: Specification of windows. The algorithm uses a sliding window approach.
Figure 1 shows the details of the sliding window in a
MC signal
X along the interval [
T1,
T2]. If the window
Wi of size
Lw is defined by the interval [
t1,
t2] then the window
Wi+1 is defined by [
t1 +
d,
t2 +
d] with
d > 0. As first step, a set of
IN windows is selected for a specific
Lw and
d.
Step 2: Feature matrix (FV) calculation. In this step a matrix FV of IN rows is generated. Each row i of FV represents a Q-feature vector of the window Wi. So first we calculate for each channel q and window Wi a feature vector of size s. Then, these features vectors are concatenated to form a unique Q-feature vector Fvi (with S = Q × s features) for each Wi. At last, all the feature vectors Fvi (for i = 1, ..., IN) are saved in a matrix FV of size IN × S concatenating them vertically.
Two autoregressive coefficients are good candidates to form the feature vector for each channel
q and window
W. The coefficients
a1 and
a2 of an autoregressive model
AR(2) of a window
W(
r) for a single channel can be written as:
where
e(
r) is zero-mean white noise. The
ai coefficients can be estimated using Burg’s method [
20]. Normally the
Q-feature vector with a
AR(2) (of length
Q × 2) offers superior or equal performance to detect artifacts in EEG recordings than a
AR(
p) with
p > 2 [
8,
21], and it is computationally less intensive.
Step 3: Selection of a window size Lw using the CCC. In this step, first the CCC of the IN rows of the matrix FV is calculated. If CCC reaches approximately a particular threshold U, it is selected the value of Lw. This value is named Lw0 and its feature matrix FV0. In case CCC is much lower than U, we go back to the step 1 to choose a larger Lw, and then a new FV and CCC are tested.
The CCC threshold U is defined as 0.85. This value comes from experience and guarantees that the HC algorithm will find a significant classification. From a practical point of view, this threshold is used to reduce the grid search for the window length in step 4. For small window sizes (some dozens of samples) the CCC value can be <0.85. In this case the CCC is used to determine a minimum window size from which the step 4 will start. In step 4, the S_dbw takes the responsibility to calculate an optimum window size. A low value of S_dbw comes with a high CCC value. However, the CCC is not defined by compactness and separation of groups and it cannot be used to determine an optimal group number.
For each window size the processing time of CCC is low. So a possible strategy to determine Lw0 is to select a small group of window sizes and check if the CCC > 0.85 is respected from a particular window size.
Step 4: Selection of an optimal window size (LwH) and its unsupervised classification. In this step, first the size of the window is increased NL times by means of Lwm = Lw0 + m × DL for m = 0, ..., NL and the integer DL ≥ 1. Second, for each Lwm, it is calculated its feature matrix FVm. Third, the HC algorithm is applied NG times to classify the rows of each matrix FVm in different partitions i.e., in 2, 3, ..., NG + 1 groups. Fourth, for each partition, its S_Dbwmg index (with g = 2, ..., NG + 1) is calculated. The minimum value of the index, named MInm, determines the optimal number of groups Nom. The minimum value MInH between the Min’s determines the optimal window size LwH, the optimal feature matrix FVH and the optimal number of groups NoH.
The selected NL value allows to check a significant number of window sizes. The MC signal X has an initial period of time (IPT) where there are no events. If IPT is known, then LwNL has to be <IPT. If IPT is not known, then it is possible to add at the start of X a synthetic portion of signal without events. When the size LwH is near to LwNL a bigger value of NL is chosen (with the help of a synthetic IPT, if necessary) to ensure that LwH is well surrounded by other suboptimal sizes.
The selected NG value allows to check a significant number of partitions. In case the optimal number Nom is near to NG, a bigger value of NG is chosen to ensure that Nom is well surrounded by other suboptimal group numbers.
Step 5: Event Detection by means of the optimal unsupervised classification. It is accomplished the unsupervised classification for the predetermined number of groups NoH. The condition CCC > U and the selection of MInH allow the HC algorithm to find a high-quality classification with the best group compactness and separation taking into consideration the density of the clusters.
Once all the windows of size LwH have been classified into NoH clusters, the different events can be detected along the MC signal X. After this classification, we will use, preferably, the term interval instead of the window to stress the window time interval.
The events are characterized by the group numbers of the optimal classification. These are placed at the beginning and the end of each group of consecutive intervals [
Wi,
Wi+1, ...,
Wj] where (
1 ≤
i ≤
j ≤
IN) with the same group number. The beginning and the end can be defined using the next formula [
8]:
where
i is the number of the first intervals
Wi,
j is the number of the last interval
Wj,
d is the slide width, and
M = 6/7. The product
LW × 6/7 is more accurate than using the midpoint with
M = 1/2. Equation (4) uses only
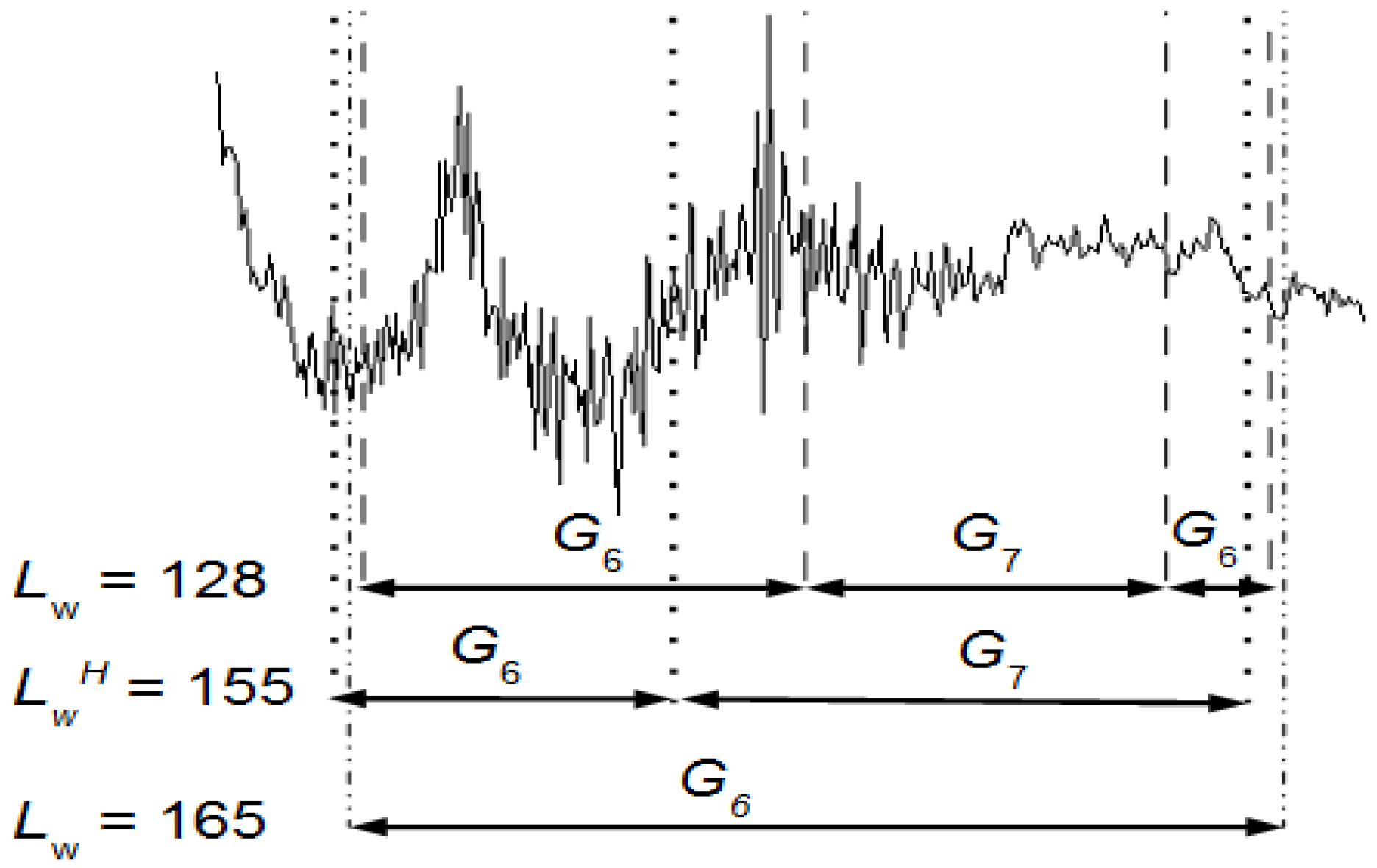
d samples per interval along the signal without overlapping. In this way, intervals between events are uniquely labeled regardless of whether events are placed in the intersection of two overlapping windows classified in a different way. Equation (4) is used to plot the events along the EEG signal. It finds the events’ temporal locations along the EEG signal and, thus, it is possible to study their behavior.
5. Discussion
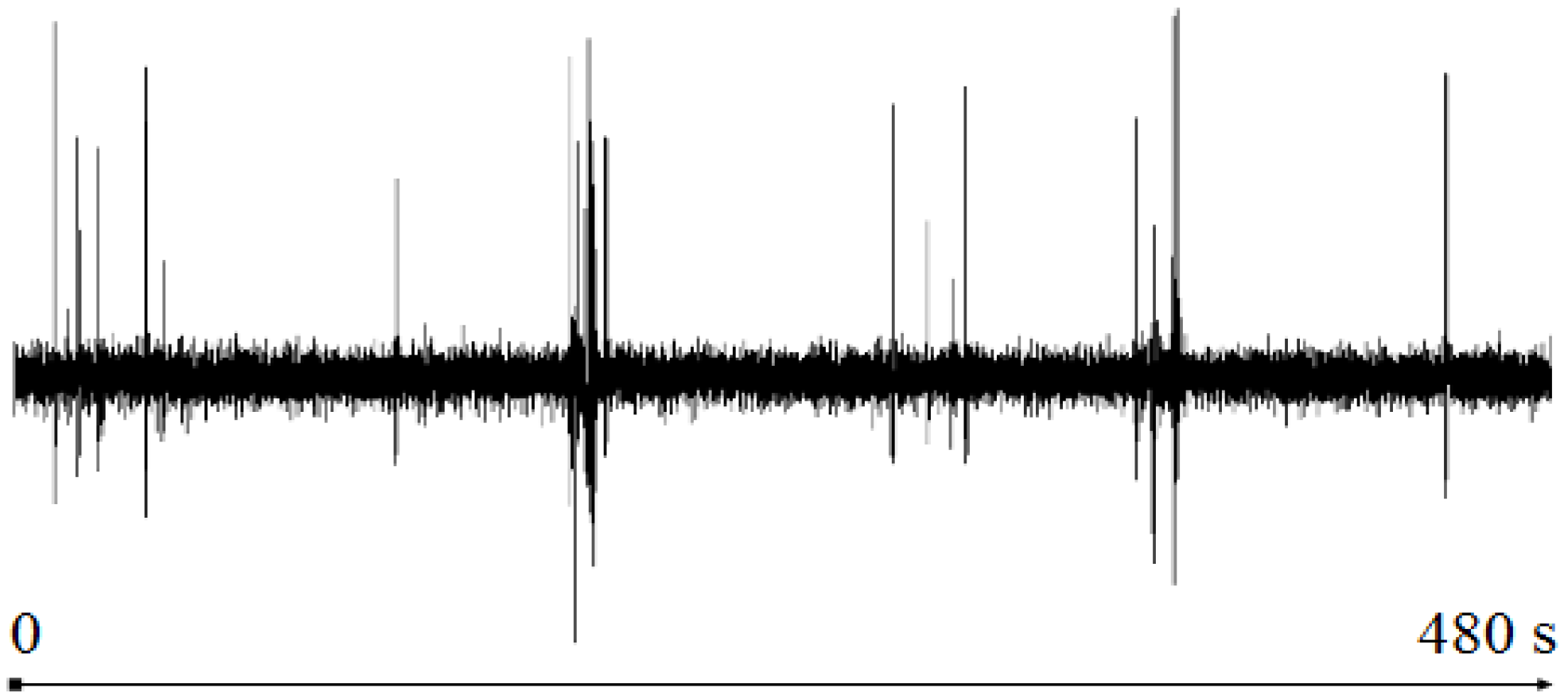
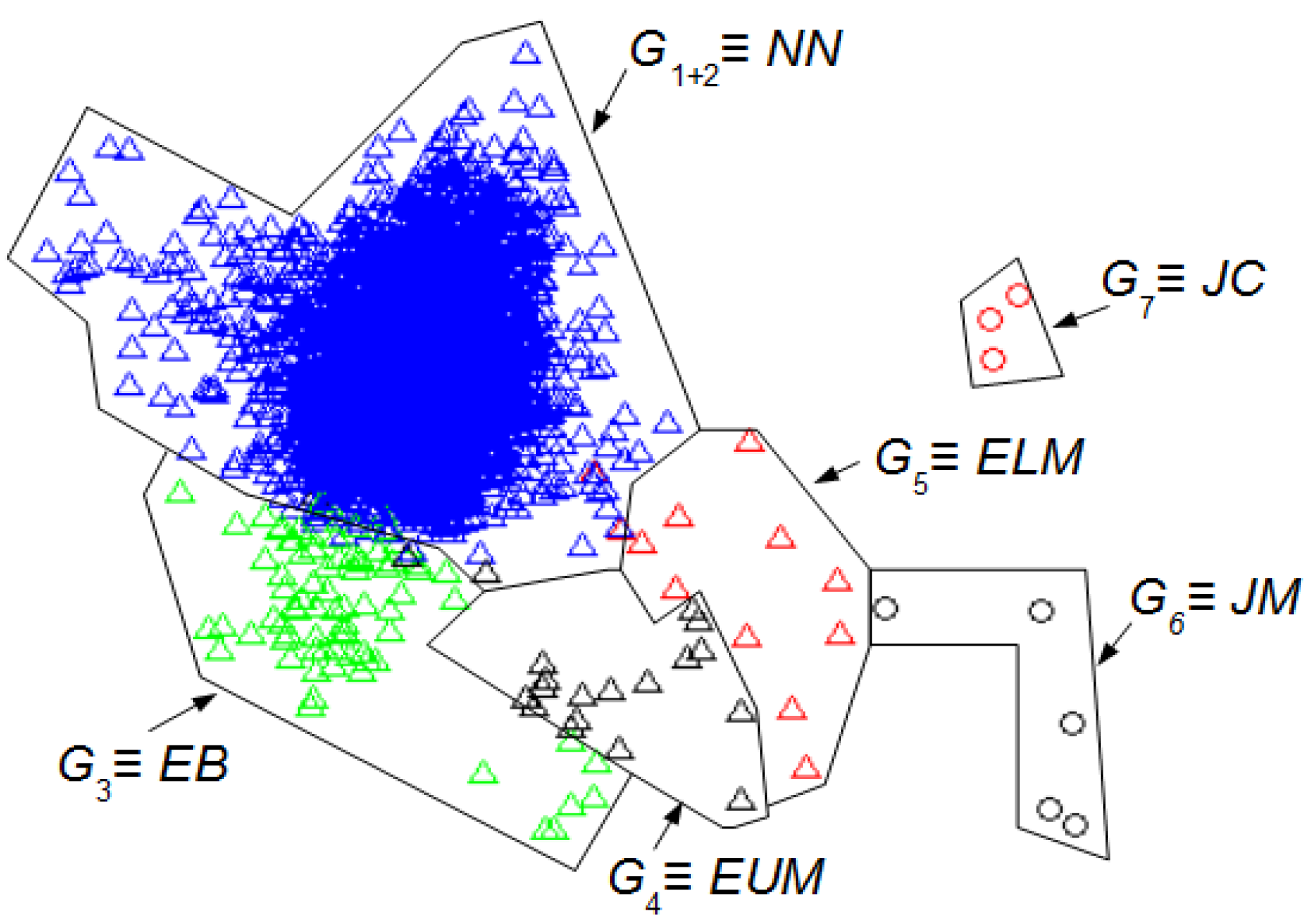
Artifacts can be either analyzed or filtered from an EEG recording. The UMED, as the SM approach, has been mainly developed to analyze artifacts, to study for instance the frequency and the duration of artifacts. The UMED also provides, in a unsupervised way, the number of different artifacts. For instance, in
Figure 6 and for
LwH, the number of artifacts is 2: JM and JC. The durations of JM and JC are 0.37 s and 0.62 s, respectively. Both appear once during the entire EEG recording.
In
Section 4 the proposed UMED has been evaluated by comparing its classification result with the one obtained with the SM using the same
Lw,
d and EEG recording. It has been used with the PCA and the NMI to contrast, visually and quantitatively, both classifications. This evaluation is significant because, in addition to the fact that two different methods UMED and SM obtain similar results, the SM method was validated comparing “user labelings” with “automated labelings”. The SM method was validated by measuring the agreement (in seconds) between expert and SM labeling in some EEG recordings. This agreement is, in the worst case, over 80%. The best case reaches about 98%. In this way, we have checked that UMED with the same
Lw,
d, and EEG recording provides a similar result to the one given by an expert. Therefore, UMED could also be considered as an unsupervised expert system.
Unlike SM, UMED determines an optimal window size LwH which allows an optimal classification based on the S_Dbw index. With this index and the HC algorithm, UMED characterizes clusters that have different density and can provided new clusters that SM could not have considered during the training process. The HC computes the distance between two data points and the distance between two clusters (linkage) using, respectively, the Euclidean and the average distance (the average distance between each element in one cluster to every element in the other cluster).
The quality of the SM outcome depends on the quality of the training process but, as UMED, it also depends on the size of the sliding window selected. As said in [
8]: “If the window size is too small, then the window may not contain sufficient information to model the feature. On the other hand, if the window is too large, SM will not be able to distinguish closely-spaced events, and temporal precision regarding the exact onset of an event is diminished”. This is also true for UMED. Unlike UMED, SM has no mathematical criteria to decide the sliding window size, except to check different sizes and compare the results with the opinion of an expert. This process seems slower and more tedious than the one of UMED.
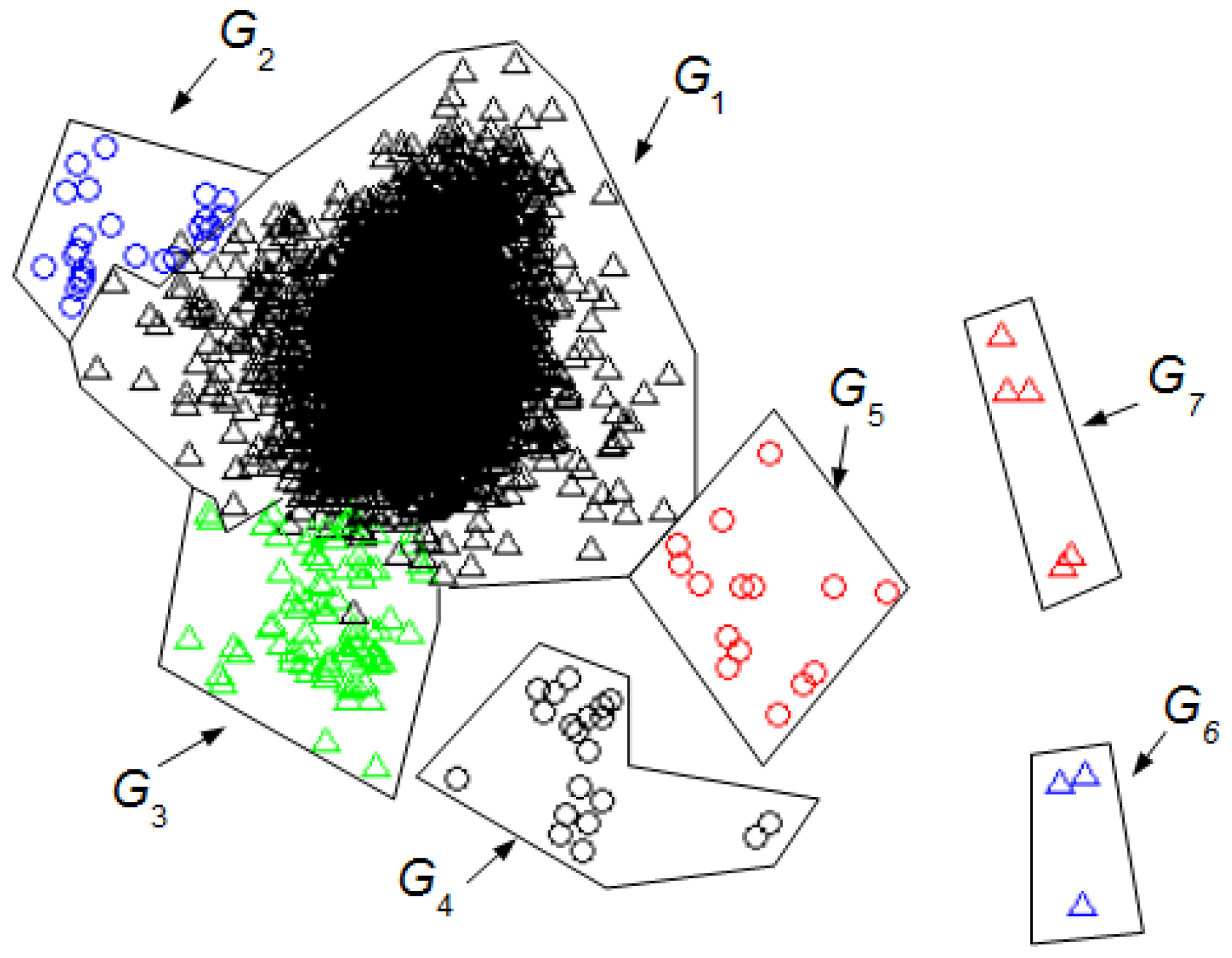
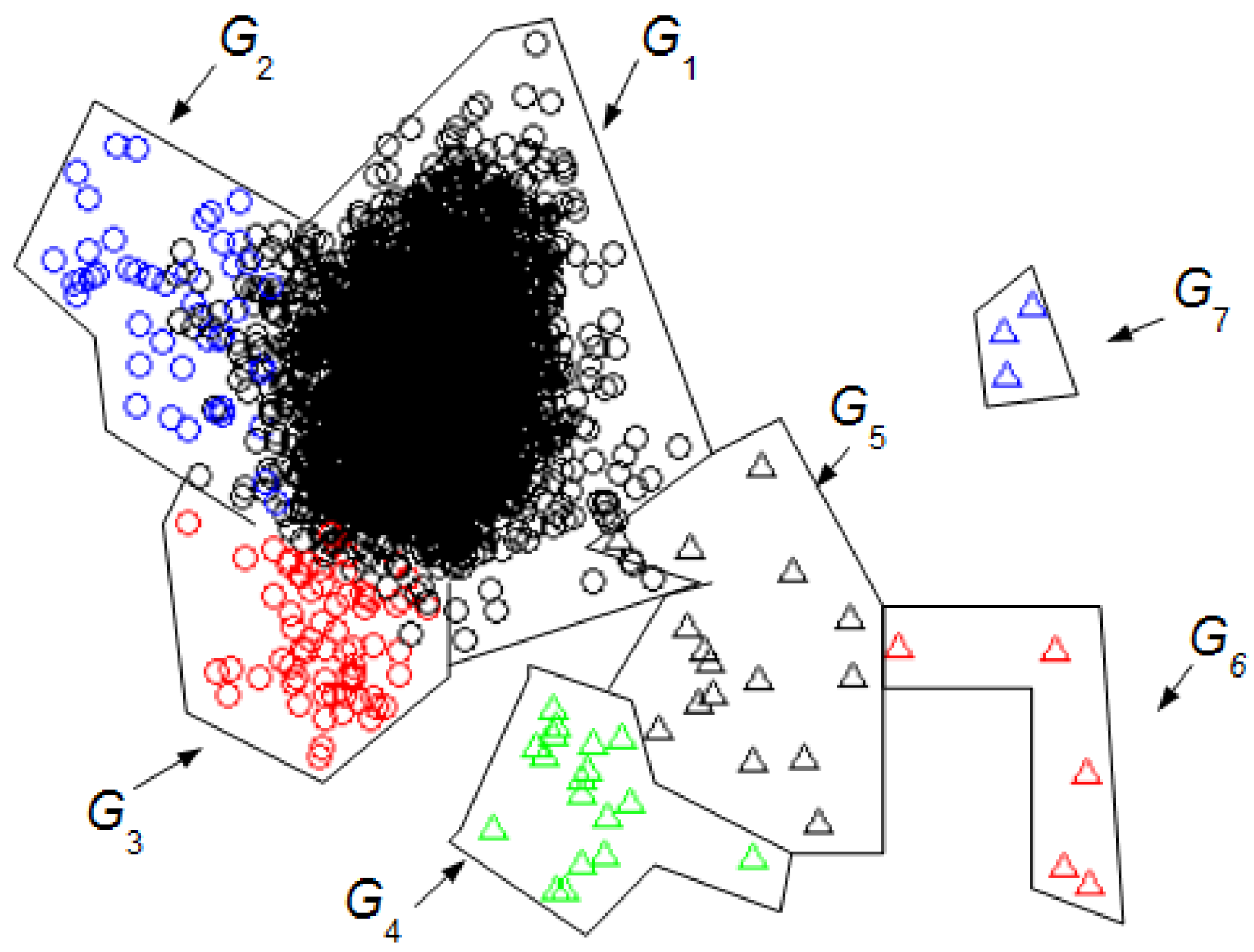
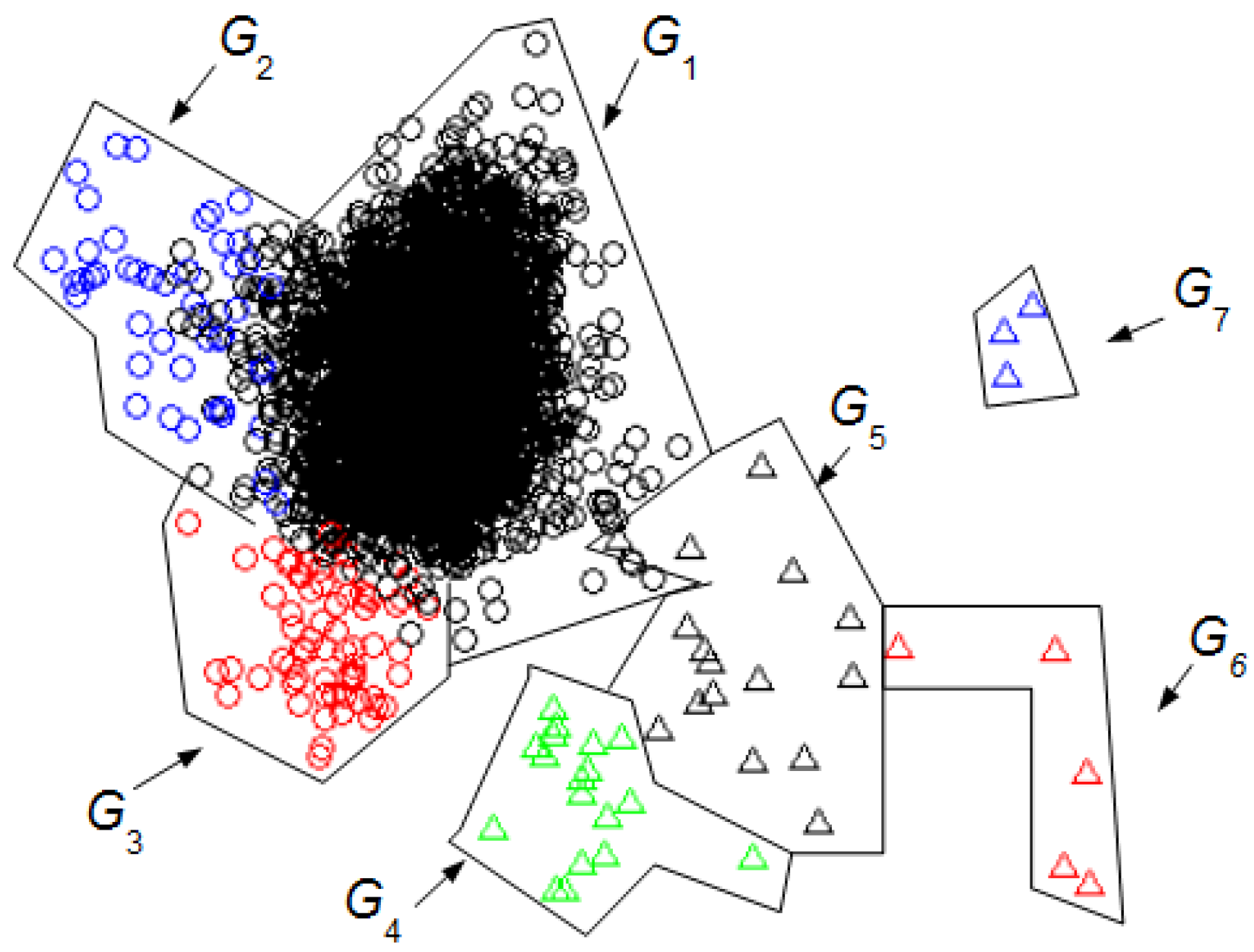
We can compare the
Figure 3 and
Figure 4 with
Figure 5 to identify the clusters obtained in
Figure 3 and
Figure 4. In this case, it is not necessary for an expert to identify the clusters found using UMED. In
Figure 4, by means of UMED, the groups
G3 and
G4 are clearly distinguished. On the contrary, in
Figure 5, SM does not differentiate well these groups because some Eye Up Movement (EUM) are considered as Eye Blink (EB). Some EUM do not follow the PCA representation (the lowest green triangles are in
G3 instead of
G4). Possibly, a better quality of the trials (used for the training process) would have improved the quality of the SM result. In
Figure 3, due to the use of
LwH, the compactness and separation of the clusters are better than in
Figure 4 and
Figure 5. Likewise, in
Figure 6, the intervals of Jaw Movement
G6 and Jaw Clench
G7 for
LwH are better defined.
The SM can be used in real time to detect artifacts in an EEG recording. The classifier has been trained with a balanced set of trials for each type of artifact. Both, the number of artifacts and their trials have to be selected by an expert. Their size Lw is the same for all. The SM classifier uses a sliding window with the same size Lw. In real time, each new interval is classified during the acquisition of the next interval.
The UMED can also work in real time primarily in two ways. The first one (UMED1) acts similarly to SM but now the training process of the SVM is different. The UMED automatically detects the number of artifacts and their trials from a significant EEG recording using an optimal window size LwH. Then, an expert only needs to identify one portion of consecutive intervals of each cluster and select a significant number of intervals per cluster. This number has to be adequate to get a balanced set of trials. Once the SVM has been trained with these trials (the result of UMED), it is ready to work in real-time. Similarly to SM, each new interval (from other EEG recording) is classified during the acquisition of the next interval.
The second way (UMED2) consists on using UMED as a supervised method without using a SVM. In this case the first step is to get a reference classification from a significant EEG recording similarly to UMED1. Unlike UMED1 that selects a set of intervals for a training process, UMED2 characterizes a dataset DS2 using the feature vectors of all the intervals (of size LwH). The UMED2 selects DS2 along with its optimal number of clusters NoH and its S_Dbw index named IndNo. An expert only needs to identify one portion of consecutive intervals of each cluster.
Then, UMED2 is ready to classify new sets of Nint intervals from other EEG recording. Each set of intervals is added to DS2. The optimal number of clusters is calculated using the S_Dbw index and then it is compared the S_Dbw index for NoH (named IndNo) and the one for NoH + 1 (named IndN1). If the value IndNo < IndN1 the solution is the unsupervised classification using HC for NoH groups. If IndNo > IndN1 it is compared IndN1 with IndN2 and so on until IndNi < IndNi+1. In general, the solution is the classification using HC for NoiH groups when IndNi < IndNi+1.
Usually with a significant DS2 (containing all the types of artifacts) each of the Nint intervals belongs to one of the NoH groups and IndNo < IndN1. The Nint intervals are classified at the same time and, after that, their feature vectors are removed from the reference dataset. However, if any of the Nint intervals are classified in a new cluster, then it can remain in the dataset. The new cluster will be a new type of artifact, but it is not identified. This is similar to a SVM that only identifies artifacts included in the training process. In real-time, every Nint intervals are classified during the acquisition of the next Nint intervals.
The SM method identifies the artifacts. The UMED method characterizes and detects the artifacts. The identification process is also possible by means of UMED1 and UMED2. Thanks to UMED the training process in UMED1 and UMED2 is simpler and faster than the one of SM. It is understood that UMED1 and UMED2 can also be used for offline applications.
The UMED does not reduce the feature vectors dimensionality by using for example PCA. The PCA is only used to visually contrast the SM and UMED outcomes. In addition to the loss of information, the use of PCA would be a disadvantage for UMED1 and UMED2.
Some real-time EEG applications use a small number of electrodes. The use of UMED is not limited by the number of channels. With a lower number, the computational effort decreases, though the quality of the result can change. Usually, with fewer channels, discrimination between artifacts decreases so different artifacts could be classified into the same group. If the goal is the correct identification of the artifacts, then, this rule applies: the more channels, the better the discrimination of artifacts.
Artifacts are superimposed on the real EEG signal. Once they have been detected, they can be directly removed by cutting the segments of the signal where there are overlaps. In this case there is a loss of information because those segments include a part of the real EEG signal. The UMED (that detects artifacts and the portions of signals without artifacts (PWA)), can also be used along with other algorithms, such as ICA [
15,
16], specialized to filter artifacts leaving the full EEG signal with useful information. The PWA can lose information after using ICA. By replacing the PWA after using ICA with the original PWA detected using UMED ensures the maximum of useful information along with the EEG signal without artifacts. UMED also provides the
NIC used in an ICA that corresponds to the number of clusters. For the full EEG signal of
Figure 1,
NIC = 7. For a specific EEG segment, this number will depend on the artifacts detected by UMED in that portion of signal. In
Figure 6,
NIC = 3.
There is a large number of recent research papers that present artifact de-noising of EEG signals. Reference [
24] presents an algorithm for removing peak and spike noise from EEG. This is based on filtering and thresholding the analytic signal envelope. Reference [
25] presents an unsupervised algorithm that uses modified multiscale sample entropy and Kurtosis to automatically identify the independent eye blink artefactual components and, subsequently, denoise these components using biorthogonal wavelet decomposition. This method neither requires manual identification for artefactual components nor an additional electrooculographic channel. The method
FORCe [
26] is an artifact removal method developed for use in brain-computer interfacing. It is based upon a combination of wavelet decomposition, independent component analysis, and thresholding. The method LAMIC [
27] does not outperform
FORCe but it is interesting because the artifact removal from the EEG has been performed by means of a clustering algorithm. The EEMD-ICA approach [
28] removes artifacts preserving more information than other classical ICA methods.
The UMED has been used to study physiological artifacts without the presence of electrical interferences. Modern acquisition systems allow for reducing that kind of interference. However, for a specific application, it could be interesting to check the UMED behavior in the presence of non-physiological artifacts. Usually, the UMED will create new clusters if the electrical artifacts are strong and located in specific portions of the signal. In case the electrical interference is weak along the full EEG signal, there would be no new clusters related to that non-physiological artifact and the UMED performance would not change. When the electrical interferences are not the subject of study, the best choice is to avoid them or filter them during the acquisition process. That is imperative when the interference is strong and distributed continuously along the full EEG signal
The UMED method has been presented using an EEG recording. The artifacts are very well-differentiated from the cognitive EEG part without artifacts. This cognitive part is only related to the thinking and its high variability is concentrated in a unique cluster that is the biggest. This cluster is not affected using different subjects since the
AR coefficients are scale- and location-invariant [
8,
21]. Normally, there is also a unique cluster per artifact from multiple subjects. It may happen that a type of artifact, from a subject with very different morphology, could be grouped in a different cluster. In this case, we could find more than a cluster per artifact, although the distinction between the different artifacts remains. This possibility can diminish as the number of subjects increases.
The AR(2) coefficients are good candidates as feature vectors because they allow differentiation between artifacts in the EEG signal and are also scale- and location-invariant. Furthermore, with AR(2), the cognitive part without artifacts is well differentiated and is grouped in a single cluster.
The
AR coefficients are useful to detect artifacts but they cannot detect cognitive events. In theory, once an EEG recording has been cleaned of artifacts, the UMED could be used along with other type of feature vectors that contain spatio-temporal information to detect cognitive events. The UMED outcome for these feature vectors could be evaluated by using a non-invasive optical technique as Near-infrared spectroscopy (NIRS) [
29,
30,
31,
32].







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}