1. Introduction
Wireless sensor networks (WSNs) are currently deployed for many applications, such as environmental monitoring, civil structure maintenance, military surveillance, and so on. In most of these kinds of applications, sensor nodes in the network are set to periodically report their sensed data (
i.e., readings) to a sink node (or remote base station) through intermediate nodes’ relay. Under such circumstances, energy efficiency becomes one of the dominating issues of this data gathering process. Many solutions have been proposed based on various aspects, which include, among others, topology control (e.g., [
1]), sleep scheduling (e.g., [
2]), mobile data collectors (e.g., [
3]), and data aggregation (e.g., [
4,
5,
6,
7]). The first three approaches focus on the energy efficiency of data gathering protocols or strategies, while the last one aims at reducing the required number of data packets to be sent to the sink node by eliminating data redundancy [
8], hence it complements the others.
Generally speaking, depending on the information that is needed at the sink node, existing data aggregation research falls into two categories: “functional” and “recoverable” [
9]. The first one corresponds to cases where only some values of statistical function of the network sensed data (e.g., AVG, MAX, SUM) are required by the sink node. Alternatively, the second one is for applications where the sink node needs the set of entire network sensed data. Compressed data gathering (CDG), based on the theory of compressed sensing (CS, [
10]) and network coding (NC, [
11]), has recently been proposed as a promising “recoverable” scheme, it enables the sink node acquire the complete network sensed data in an energy-efficient manner, as well as balance the energy consumption among sensor nodes.
First of all, we make some definitions on the problem to be discussed. Given a WSN of
N sensor nodes, each having a piece of reading
at each data gathering epoch, we denote
as the network sensed data. In a typical CDG scheme, the sink node will reconstruct
by collecting only
weighted sums of
from the network rather than all
N original readings (in CS theory, these
M weighted sums
are formed by
, where the
M-by-
N matrix
Φ is the measurement matrix (or called projection matrix), and each
is the corresponding measurement (or projection) result of
; unless otherwise specified, “projection” and “measurement” are interchangeable hereunder). Such a reconstruction process is guaranteed and performed based on an observation fact that, in most network deployment cases,
has a property called
K-sparse (
) under certain orthogonal transform domains (e.g., discrete wavelet transform, discrete cosine transform [
10,
12]).
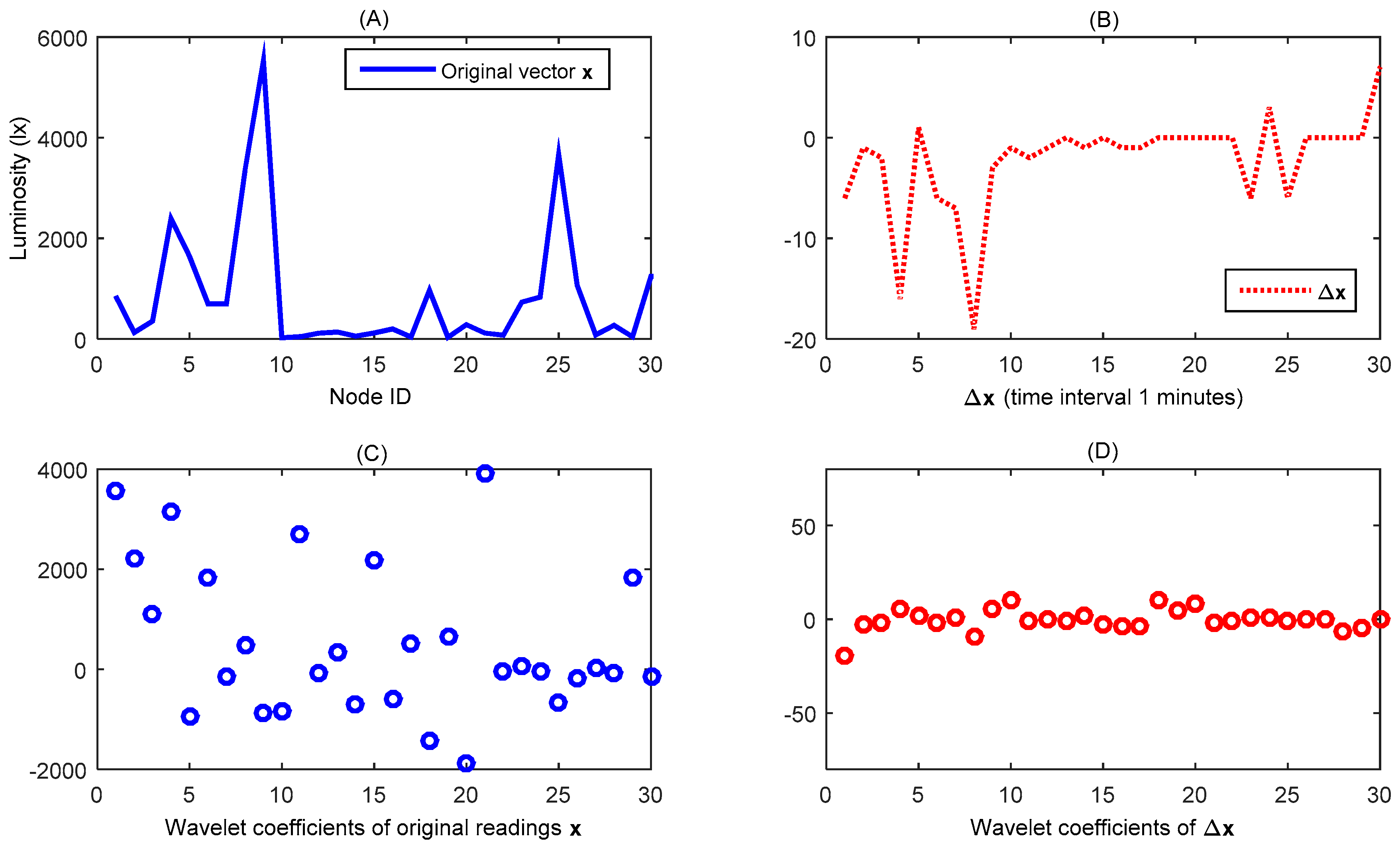
In most previous CDG studies, classical CS theory is directly adopted without concern for the the WSN specialty, which inevitably incurs several shortcomings. For example, when processing a signal, CS theory conventionally supposes that the sparsity (
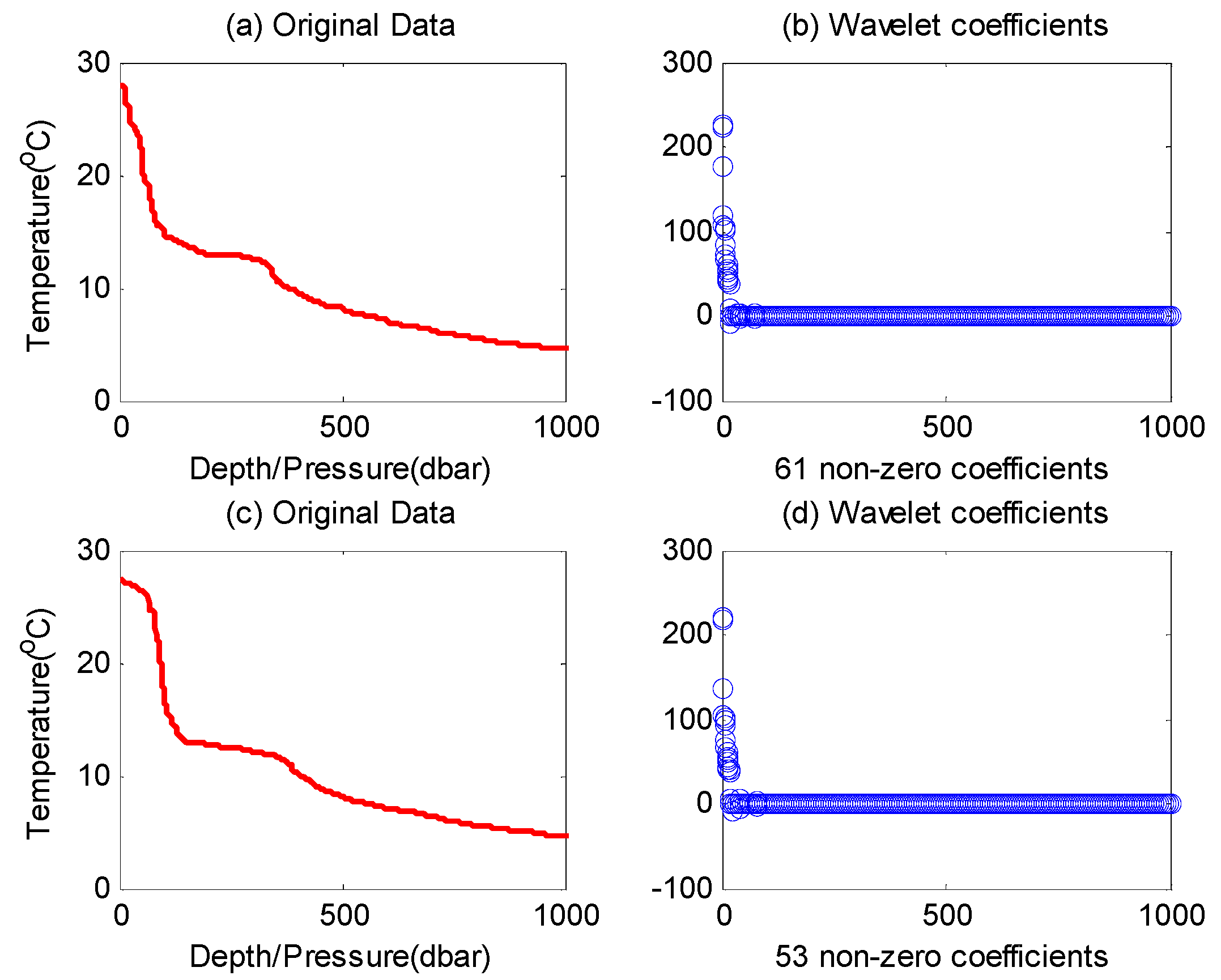
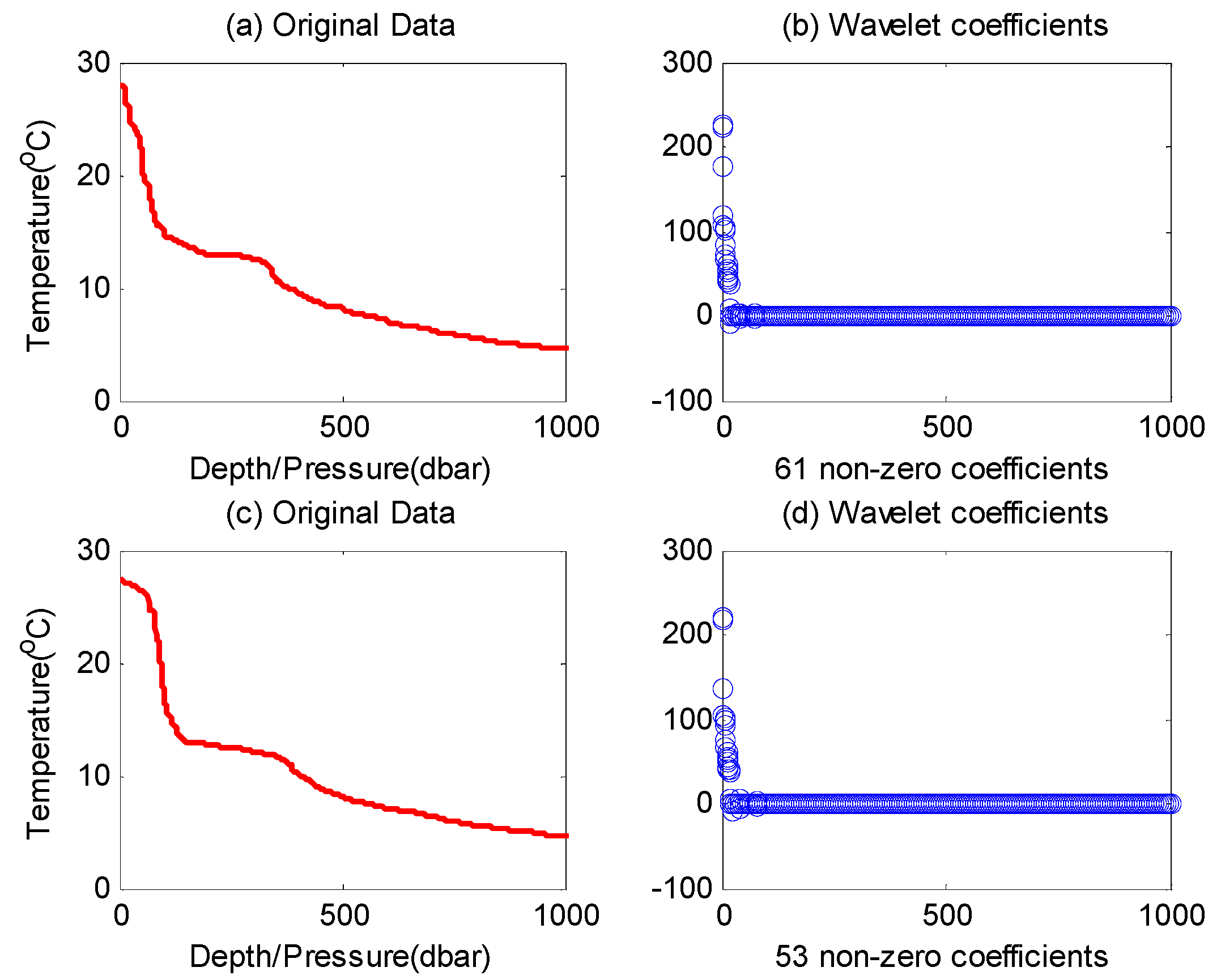
i.e., sparse degree) of this signal is fixed, while in a more general network deployment environment, the sparsity of the data observed by the network may change frequently. As shown in
Figure 1, two 1000-reading datasets of ocean temperature data (OTD) are plotted with red lines. These datasets were collected from the Pacific Ocean on 29 March 2014 (
Figure 1a) and 2 April 2014 (
Figure 1c), respectively [
13].
By comparing these two figures, we can see that the sparsity is changing; specifically, there are 61 larger coefficients after transformation of the first dataset (61-sparse signal), and only 53 in the second (53-sparse signal). There are also some other practical shortcomings, which will be elaborated in
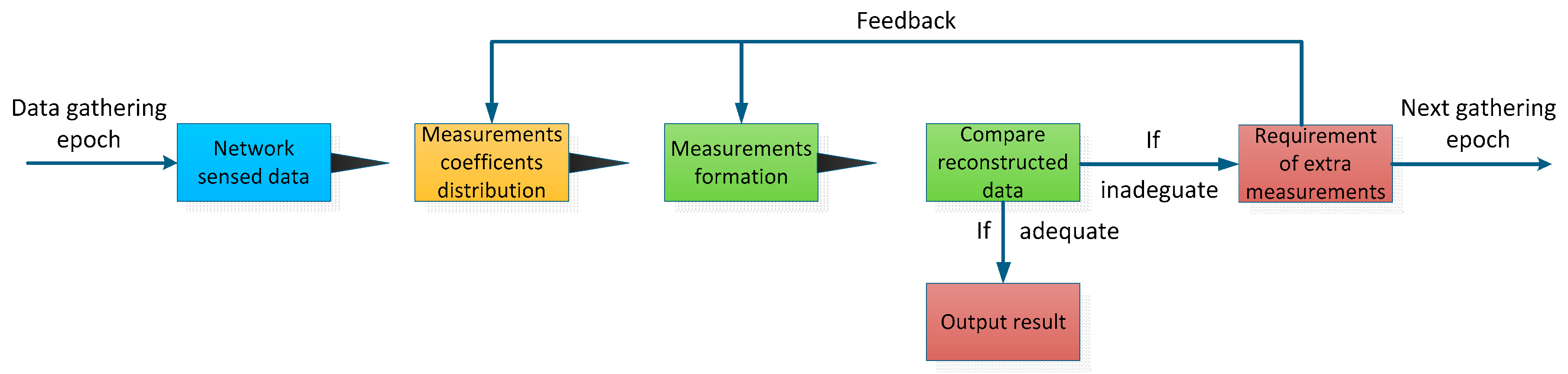
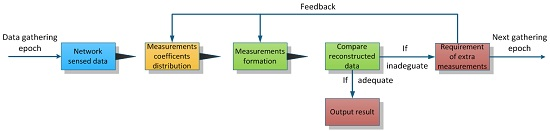
Section 3. To address these challenges, we propose an adaptive CDG scheme in this paper. During each data gathering epoch, we evaluate the current network sensed data at the sink node and adjust the measurement-formation process according to this evaluation. By doing so, it forms a kind of feedback-control process, and the required number of measurements is tuned adaptively according to the real-time variation of data to be gathered.
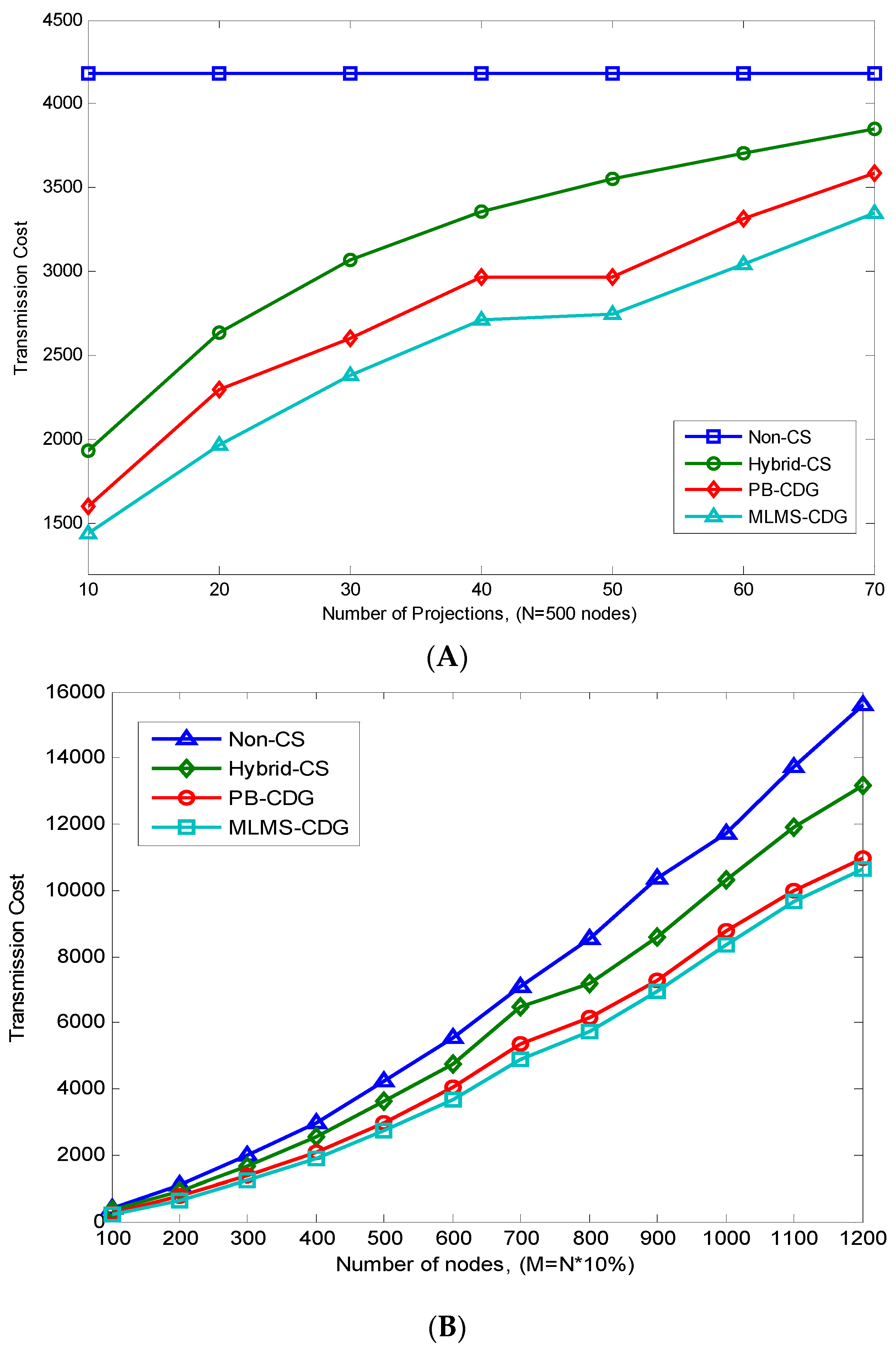
From another point of view, despite CDG’s ability to reduce the global communication cost, multiple studies show that the effectiveness of CDG is still affected by the strategy of the measurements’ formation process [
9,
12,
14]. Several optimization schemes, such as Hybrid-CDG [
9], are proposed to form all of the measurement results through a single routing tree in each data gathering epoch. To further reduce the energy consumption of such process, different from Hybrid-CDG, we supply a measurement-formation algorithm in this paper, where each measurement-formation path is treated individually in a data gathering epoch. Similar idea was also adopted by PB-CDG [
14], yet the novelty of our approach lies in the path-generation procedure and the underlying method of measurement coefficients’ distribution, which omits the massive coordination among sensor nodes in the network.
The remainder of this paper is organized as follows: in
Section 2 we first give a comprehensive overview on the typical CDG scheme mentioned above. Then, we propose our explicit motivation and main resolve method in
Section 3. Next, we illustrate our data gathering approach in detail in
Section 4 and
Section 5. Simulation and practical experiment results are presented in
Section 6. At last, we address the conclusions in
Section 7.
2. Related Work of Compressed Data Gathering
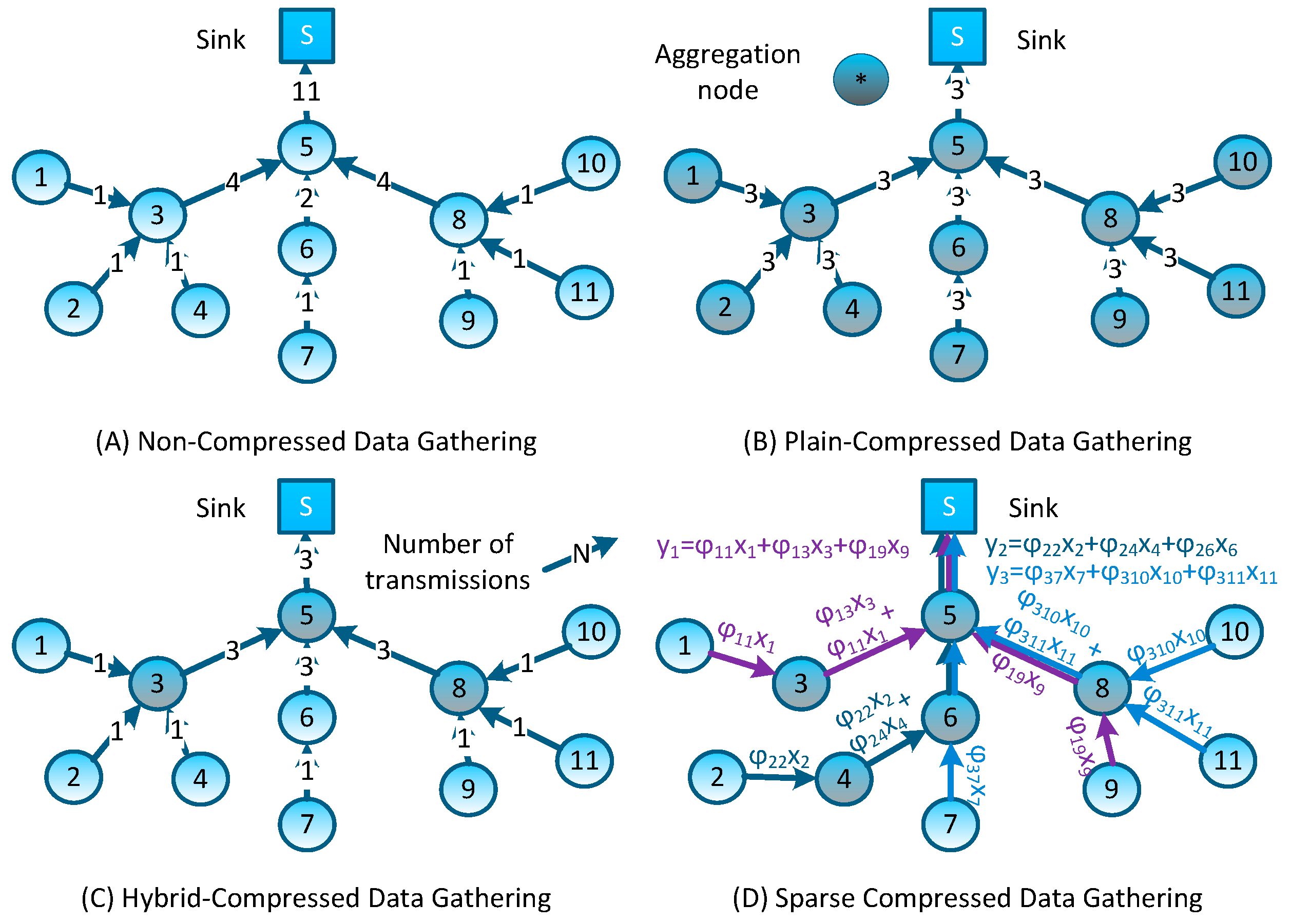
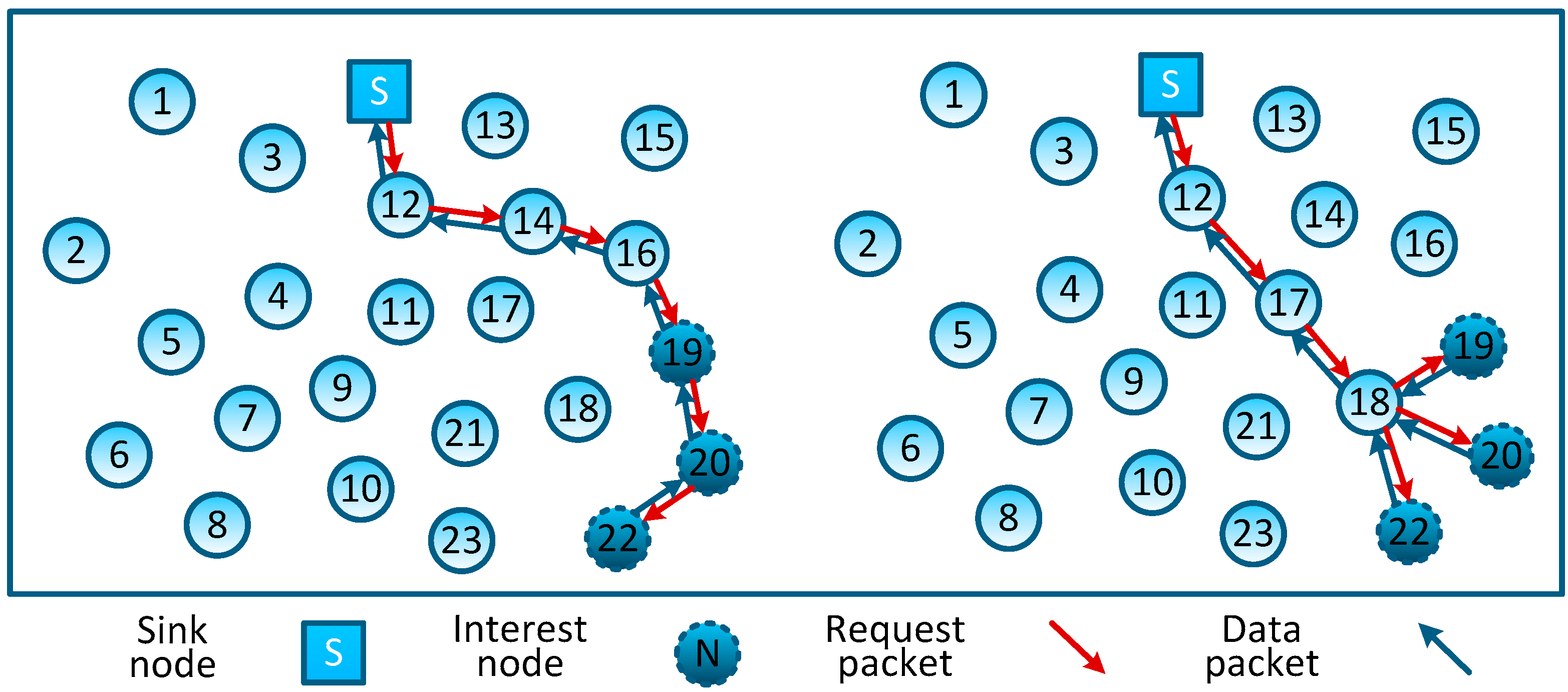
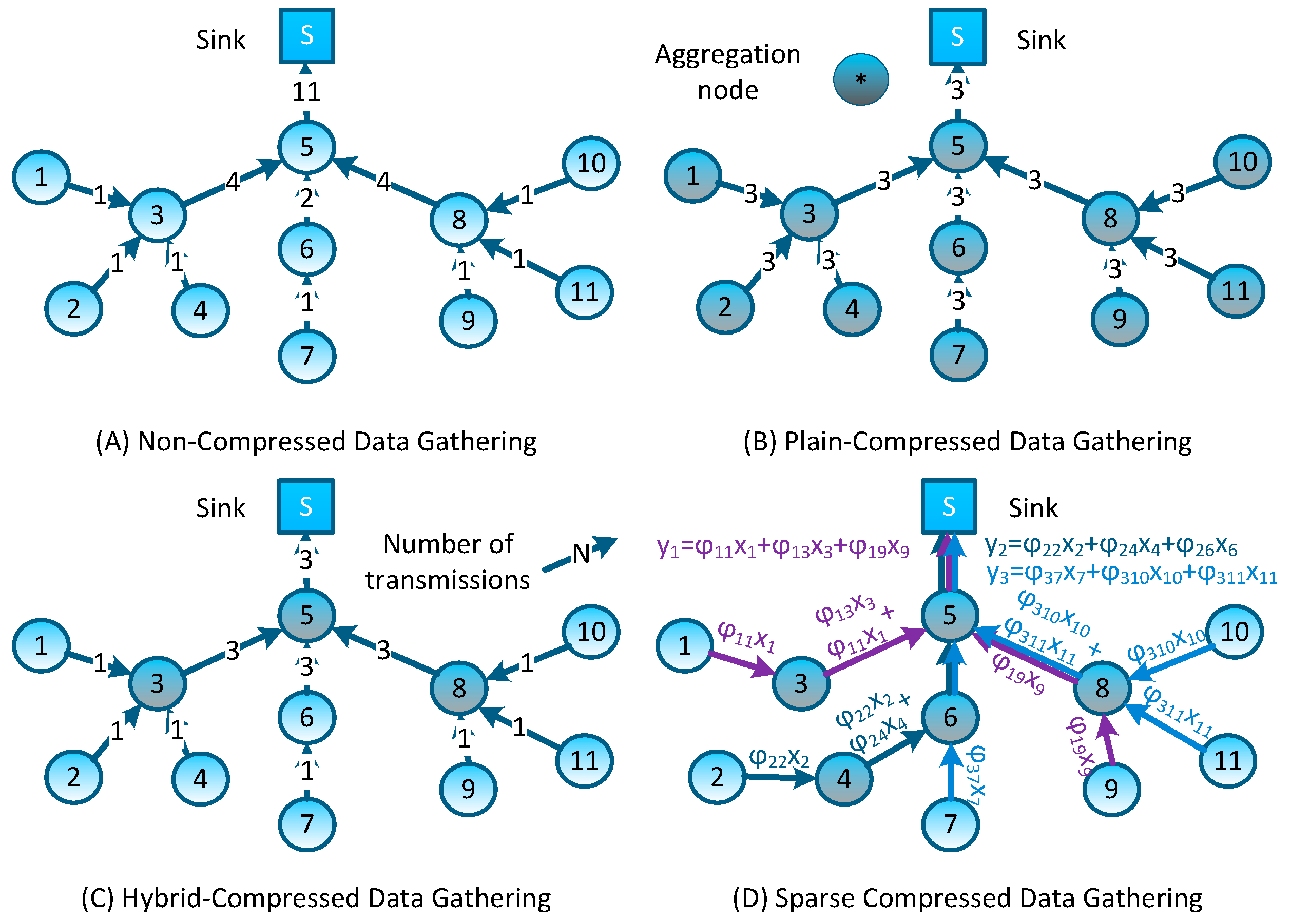
In non-aggregation data gathering schemes, data packets generated by sensor nodes are directly forwarded to the sink node through a certain topology organization (e.g., the tree-type topology as shown in
Figure 2A). These data gathering schemes do not exploit the correlation of network sensed data, resulting in the network forwarding a larger number of original packets; what’s more, in addition to sending their own detected data, nodes that are closer to the sink node tend to relay a number of packets from remote nodes (e.g., in
Figure 2A, node #5 forwards 11 packets while each leaf node only forwards one packet). Such an imbalance of energy consumption will inevitably lead to the quick failure of the whole network. Thus, the lifetime of nodes which are closer to the sink node forms a bottleneck in these data-gathering schemes.
Plain-CDG, as shown in
Figure 2B, is the earliest and the most rudimental data gathering scheme which exploits the CS and NC theory. During each data gathering epoch, every node needs to forward a fixed number of packets (denoted as
M) to form
M weighted sums
(we let
M = 3 in
Figure 2B, and
, where
is the reading of node #
j and
is its coefficient of this measurement). Note that each weighted sum corresponds to one measurement of network sensed data, and after receiving these measurement results, the sink node can reconstruct the network sensed data by adopting an appropriate CS reconstruction algorithm. Comparing to the Non-CDG schemes, Plain-CDG can reduce the number of transmissions, and balance the transmission load among sensor nodes.
The authors in [
9] proposed a scheme based on Plain-CDG, called Hybrid-CDG (shown in
Figure 2C), to further reduce the number of transmissions. In the Hybrid-CDG scheme, nodes whose degrees are equal to or less than
M will employ the Non-CDG to forward their readings and the others will employ the Plain-CDG scheme to generate
M measurement packets. By comparing
Figure 2C to
Figure 2B, it is easy to find that the Hybrid-CDG scheme indeed reduces the redundancy transmission of the Plain-CDG (e.g., the leaf node #1 forwards three packets in Plain-CDG while only one packet in Hybrid-CDG). More efficient data gathering schemes using random sparse measurements were first introduced in [
15] and developed in [
14] as follows: at the beginning of each epoch,
M projection nodes are selected randomly to collect
M measurements (
i.e., each projection node collects one measurement), meanwhile, each projection node is assigned or generates a sparse vector
by itself. Then, projection node #
i is obliged to inform all nodes whose coefficient
to report their contributions (
) back. After receiving all segments of a measurement (
), the projection node sends the result to the sink node through the shortest routing path. An example of such measurement-formation process is illustrated in
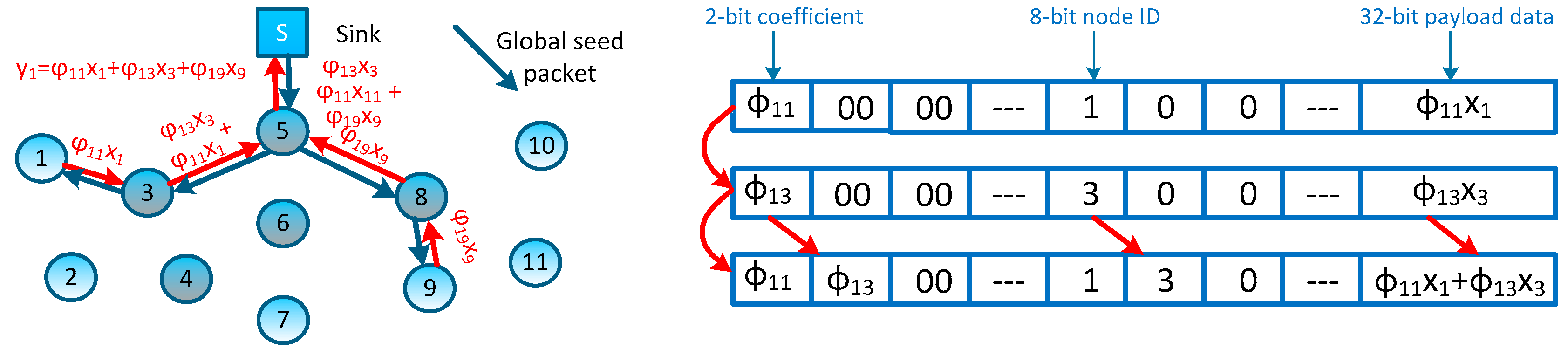
Figure 2D. To form the measurement result
, as the projection node, node #5 has randomly generated a sparse coefficient vector
, then, for these non-zero coefficients (
,
and
), it sends transmission requests to nodes #1, #3 and #9; these nodes reply to the requests by sending their contributions back (e.g., node #3 will reply
). Note that, similar to other CDG schemes, those packets can be merged into one single packet on their measurement formation path (e.g., packets can be merged on nodes #3 and #5 for forming measurement
—this packet-merging process can be regarded as a network coding process [
16]). Similarly, other measurements are formed in the network and forwarded to the sink node. It is easy to see that these sparse measurement-based CDG schemes would outperform prior dense schemes, because the formation of each measurement only involves several nodes, and the rest of the nodes can still stay in an idle/sleeping mode to reduce energy consumption.
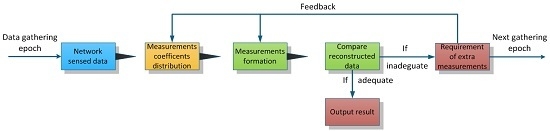
4. Measurement Formation Process
According to the description in
Section 2, CDG schemes require a certain number of measurements of network sensed data, and these measurement results are generated and aggregated on measurement-formation paths (
i.e., trees). As each measurement is a linear combination of multiple contributions, each of which is generated by multiplying the reading of an interested node and its corresponding measurement coefficient, an underlying question surfaces that how the measurement coefficients are generated and distributed. For the example proposed in
Figure 2D, before responding to the requirement of the formation of the measurement
, interested nodes #1, #3 and #9 should receive their coefficients first. One may think that the sink node can pack and broadcast each measurement coefficient vector
to the network during each data gathering epoch, and every node in the network can directly acquire its measurement coefficient vector by monitoring these packets. However, for a WSN which has dozens of sensor nodes deployed in a large harsh field, such a process will incur a very heavy overhead of the time slice. What’s worst, such broadcasting requires the synchronization among nodes in the network, thus it is impractical, especially for those WSNs applying sleeping mechanisms.
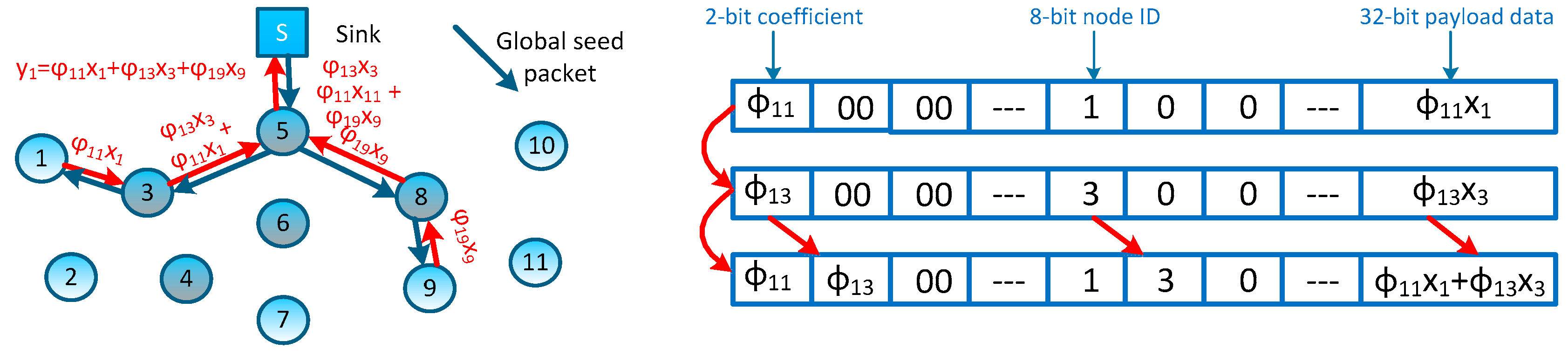
Considering the tree-type and sink-rooted measurement-formation path which covers all interested nodes, we propose to generate the measurement coefficients during constructing these paths. We achieve this object by associating a pseudo-random generator, which is an algorithm publicly known by both the sink node and sensor nodes in the network. In each measurement-coefficient-generating procedure, the sink node first produces a global seed corresponding to this measurement (in fact, the sink node’s running time would be a greater candidate for this global seed). Once the interested nodes in the network receive this global seed, it can generate its own measurement coefficient by adding the node ID. The sink node can generate a sparse coefficient vector
, where each element
is randomly generated by using the group seed: (global seed
, node ID
j). Thus, coefficients in
obey an independent and identical distribution (i.i.d.) and the sink node can programme the measurement-formation path according to
. For the measurement
proposed in
Figure 2D, such measurement-formation process is depicted in
Figure 5, and two contribution packets can be merged on node #3. Now, there’s still an issue remaining,
i.e., how to energy efficiently build an optimal measurement-formation path which covers all interested nodes. In other words, how to ensure that all interested nodes in the network can receive the global seeds efficiently, and meanwhile how to minimize the total transmission cost. In the following sections, we would like to present our measurement-formation method.
4.1. Construction of the Measurement-Formation Path (Tree)
According to the perspective of graph theory, this measurement-formation process comes down to constructing a sink-rooted path which covers all interested nodes. To improve the efficiency of measurement formation, the total length of this tree should be minimized. Thus, the construction of such optimal tree is a typical Steiner minimum tree problem [
17]. Unfortunately, it has been proved to be a kind of NP-complete problem [
18]. To solve this problem, a heuristic method based on the All-Pair-Shortest-Paths (APSP) [
14] algorithm has been proposed for CDG applications. However, APSP tries to form a line-shape measurement-formation path which does not consider the wireless transmission characteristics of WSNs. For example, the total lengths of both the left and right trees in
Figure 6 are 6, but if we consider the eavesdropping characteristics of the wireless channels used in WSNs, the actual transmission overheads of the left and right trees are 6 and 4, respectively. From this example, we can find that the overhead of the construction of this tree depends on the number of non-leaf nodes, namely the number of relay nodes. Thus, this is a Maximum Leaf Nodes-Minimum Steiner Nodes (MLMS) problem,
i.e., we need to build a sink-rooted minimum Steiner tree (denoted by
T) that covers all interested nodes (denoted by
I). Note that not all interested nodes are located on the leaf nodes, some can also act as non-leaf nodes. MLMS tree has the requirement to minimize the number of introduced non-interested nodes (or called Steiner nodes), and maximum number of leaf nodes. In the next subsection, we will present the mathematical model of this problem, and after that, a global approximation algorithm is designed to solve this problem. Note that, classical converge-cast protocols can be a good candidate for data aggregation schemes as well as those CDG applications which do not consider the measurement coefficients generation/distribution (these CDG applications assume that nodes in network have already been assigned the measurement coefficients). Through this local gradient-routing mechanism, measurement results can be safely reported to the sink node. We proposed our MLMS tree-shape method based on an overall consideration of path generation, coefficients generation/distribution and the measurement results’ formation, and the measurement-formation path is created at the time of the global seed distribution.
4.2. Mathematical Model of MLMS Problem
We describe the WSN as a connected graph
, where
V is the set of nodes;
E is the set of undirected edges connecting any two nodes that can directly communicate with each other.
is the set of
M measurement-formation routing trees.
is the set of interested nodes of
ith measurement, and
(
) is the set of Steiner nodes,
is a binary variable indicating whether there is an edge between node
i and node
j for tree
t, when (
i,
j) is the edge of the optimal Steiner tree
t,
, otherwise,
. Then the objective and constraints of our MLMS construction problem can be formulated as below:
Constraint (2) limits each interested node that can only connect with one Steiner node. By using Constraint (3), the degree of each Steiner node is limited to no less than 2. Constraint (4) ensures that the result we obtained is a spanning tree. Constraint (5) is a restriction on the number of interested nodes for the spanning tree.
4.3. Scalable Algorithm for MLMS Construction
Notice that all interested nodes
Iv within the communication range of node
v can be considered to come from the same group, and based on this circumstance, we can perform a greedy iterative algorithm to reduce the complexity of MLMS construction problem. Without loss of generality, node
v can perform the iteration operation on behalf of other nodes in such a group. During each iteration, we first select the node that connects the most interested nodes or groups; combine this node and its associated nodes or groups to form a new group; and we repeat this process until find out all groups. Next, in order to make group leader nodes and the remaining interested nodes be connected with the sink node, an optimal Steiner tree approximation algorithm is required. Since this problem is NP-complete, we proposed an alternative algorithm which is built upon the minimum spanning tree (MST) algorithm. The scope to run the MST is the closure that takes the sink node as a fulcrum and contains all the remaining interested nodes. Then, we perform the Graham scan algorithm to obtain a convex hull of all remaining groups. At last, we perform the MST algorithm to connect these nodes in convex hull. Detailed description of this algorithm is shown in Algorithm 2. It is easy to see that for each measurement formation tree, maximum iterations times for group formation is
ρ/2; and for the node-sparse graph, the proposed algorithm has a complexity of
, and for the edge-sparse graph is
, where
d is the average degree of the nodes in network,
n is the number of edges and
ρ is the number of interested nodes.
| Algorithm 2: Construction of the Measurement-Formation Path |
| Input: Sparse measurement coefficients vectors each with n i.i.d. elements; nodes’ maximum communication range Rcomm; |
| Output: Set of measurement formation a trees , |
| 1 For each measurement |
| 2 Calculate the set of interested nodes . |
| 3 Calculate the set of neighbor nodes . |
| 4 Do |
| 5 Calculate the number of edges incident from to (denoted as ). |
| 6 If |
| 7 Remove all adjacent nodes of node v from where and |
| 8 Add node v into Ini |
| 9 Renew Ne and Ini |
| 10 Ifend |
| 11 While (). |
| 12 Calculate the convex hull (denoted as ) of set by using Graham scan method |
| 13 Construct the MST which takes the sink as a root and connects all Cl nodes |
| 14 where recorded the edge information of such MST |
| 15 Forend |
| 16 Return |
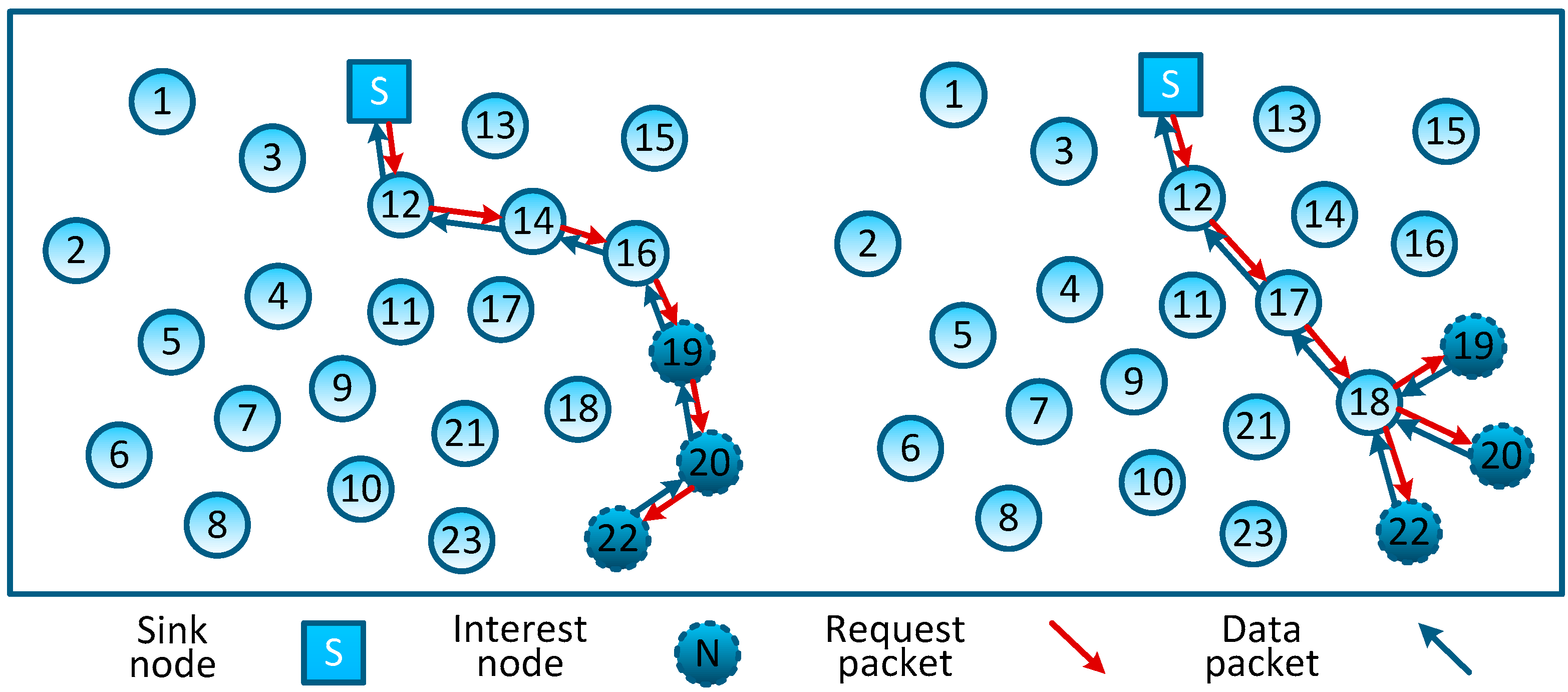
4.4. MLMS Tree Construction and Maintenance
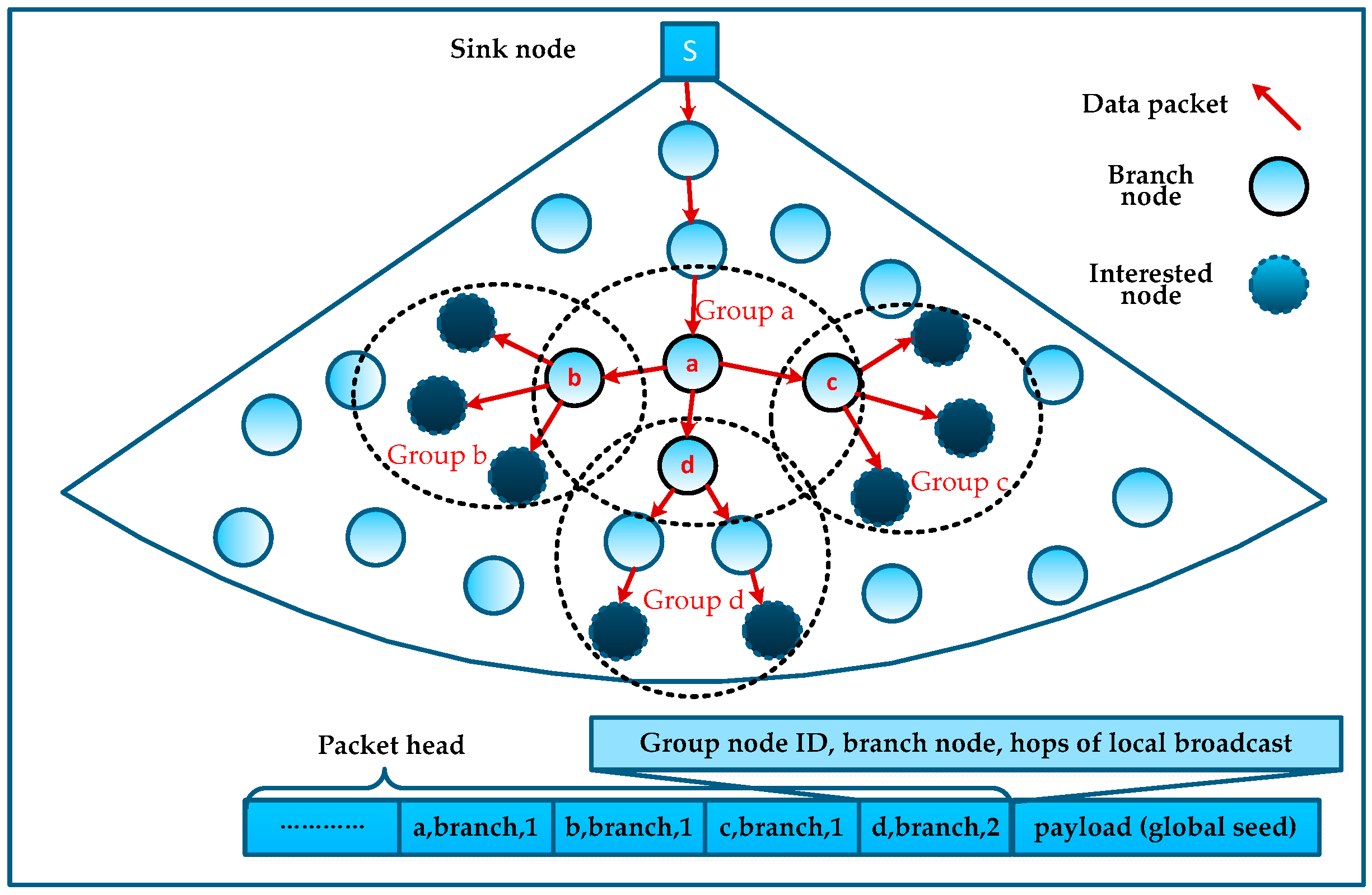
In order to avoid a large number of control packets caused by constructing MLMS trees, after calculating the approximate minimum cost MLMS path
T, we let the sink node pack the information of
T with the global seed into several packets. Through the nodes’ relay of these packets the MLMS tree is constructed orderly (as shown in
Figure 7), but for a large-scale network (meaning there are many interested nodes in each measurement and the path from the sink node to the interested nodes may be extremely deep), the complete path information will take up a lot of space in the packet head. Due to the length limitation of packets transmitted in the WSN, the sink node needs to compress and encode the information of
T.
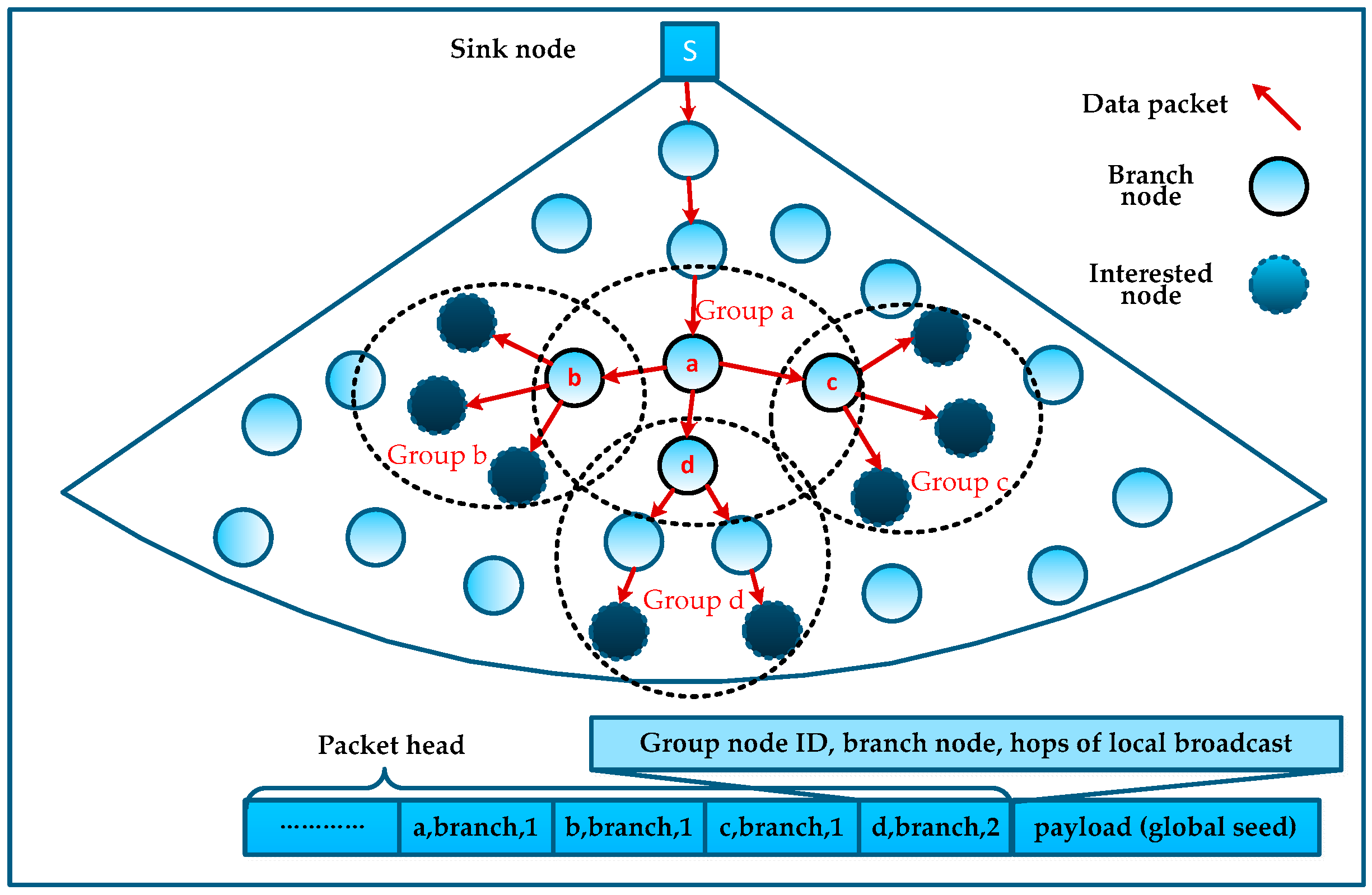
Noticing that Algorithm 2 divides the neighboring interested nodes into a group, we can use the effect of wireless communication to locally broadcast such packets at each branch node and thus all its neighbors can overhear them. Thus, in the branches of the MLMS path, we only need to encode the branch node information and add the local broadcast hops to the packet header, rather than the information of all interested nodes. In this way, we can compress the path information to reduce the number of control packets.
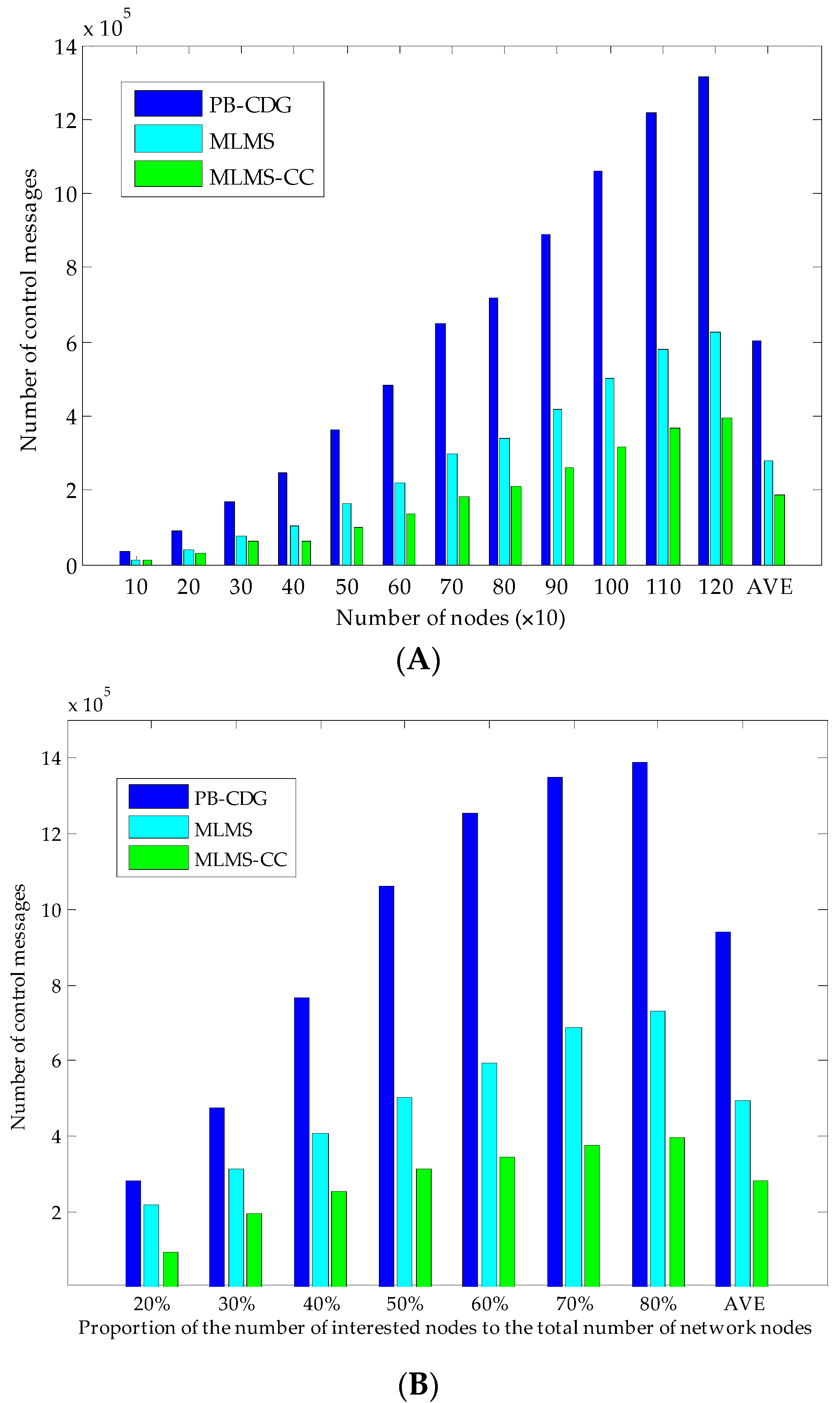
As shown in
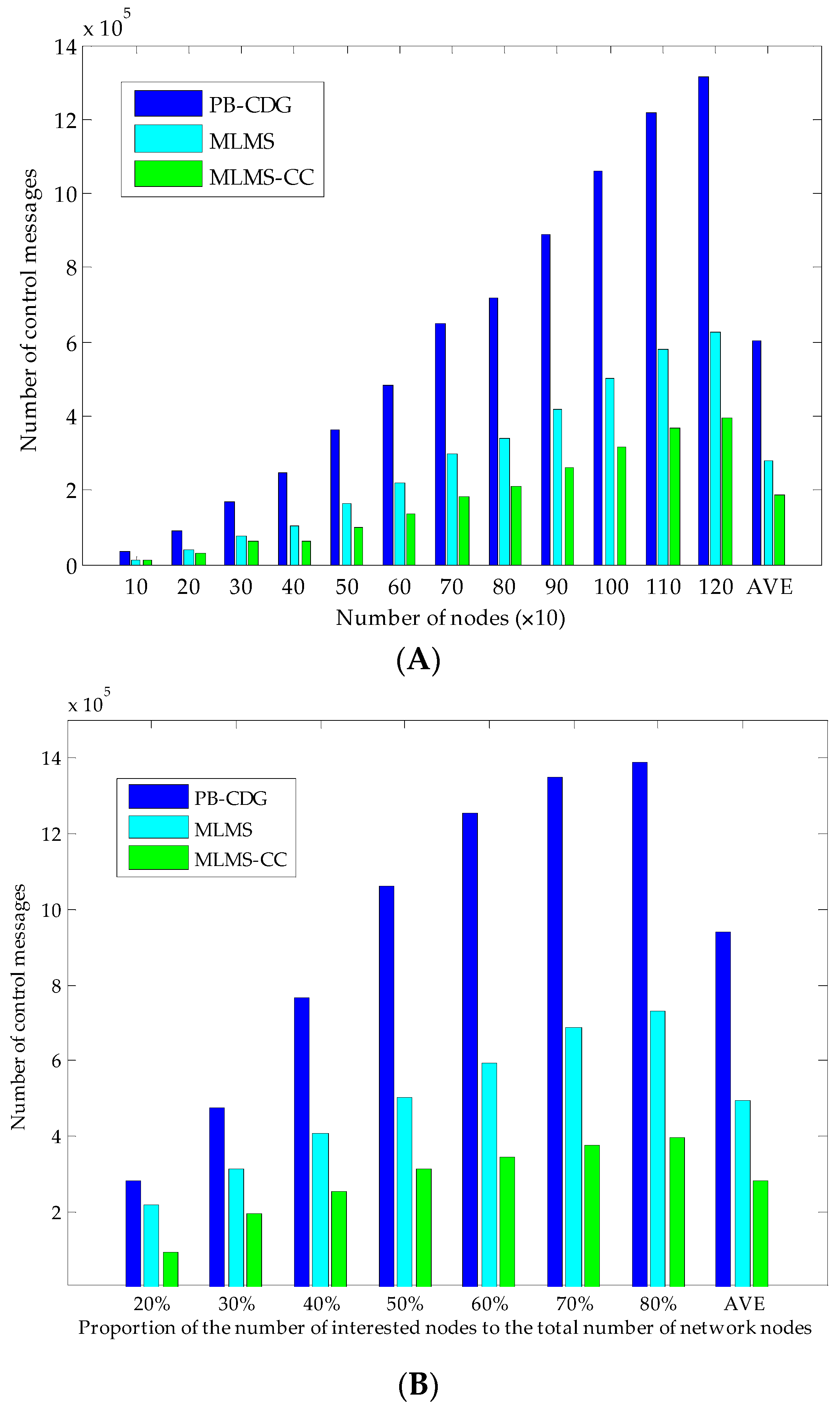
Figure 7, all interested nodes and branch nodes are in four groups a, b, c and d, and we can guarantee that all interested nodes can receive the corresponding global seed simply by coding the information of branch nodes into the packet header, and the MLMS path can be constructed in disseminating such packets. Obviously, this mechanism is affected by the density of the interested nodes (
i.e., the proportion of the number of interested nodes to the total number of network nodes), and we will evaluate it in
Section 6.
4.5. Maintenance of MLMS Measurement-Formation Path
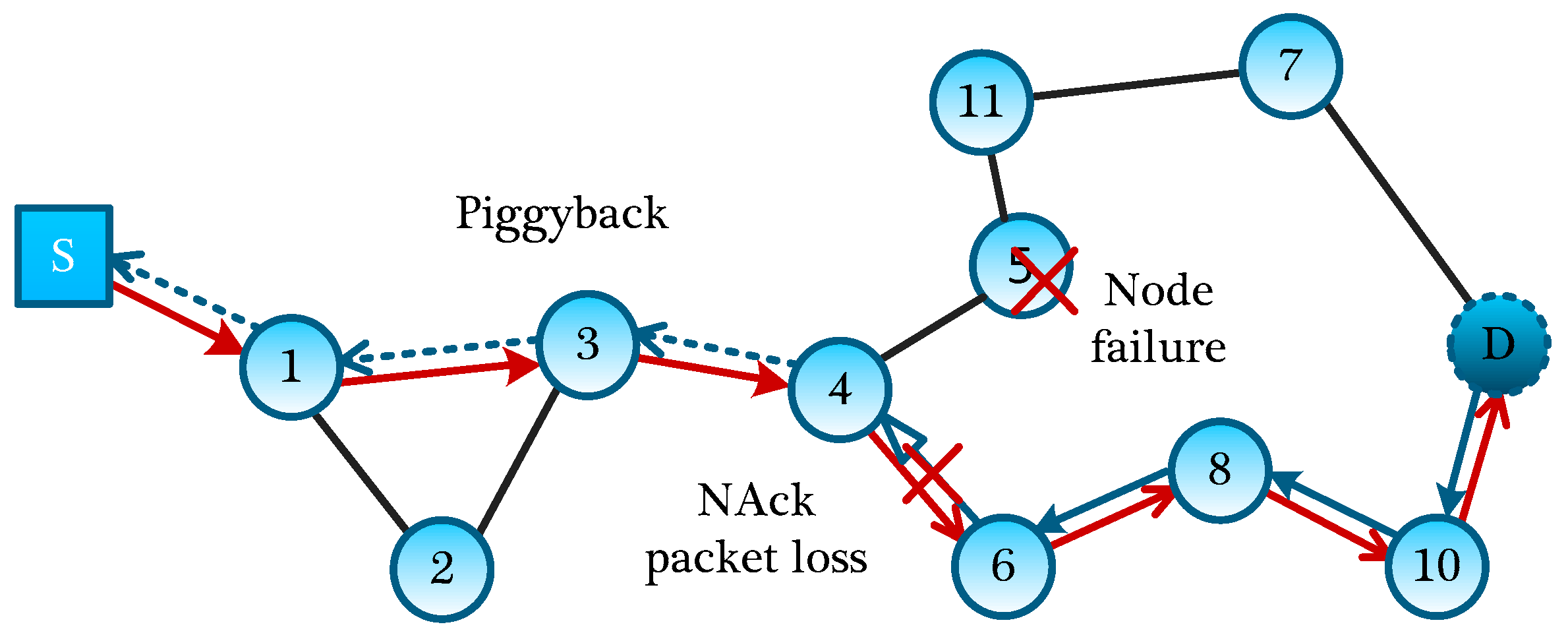
WSNs are always deployed in a harsh environment, where unreliable wireless links and failure of certain nodes are prevalent, which potentially leads to the failure of creating and maintaining the MLMS path. In fact, the failure of any intermediate node compromises the delivery of all data aggregated and sent by the previous nodes in the path. Hence, some improvements to the scheme should be implemented. We will discuss this problem from two aspects: the nodes failure and the packets loss.
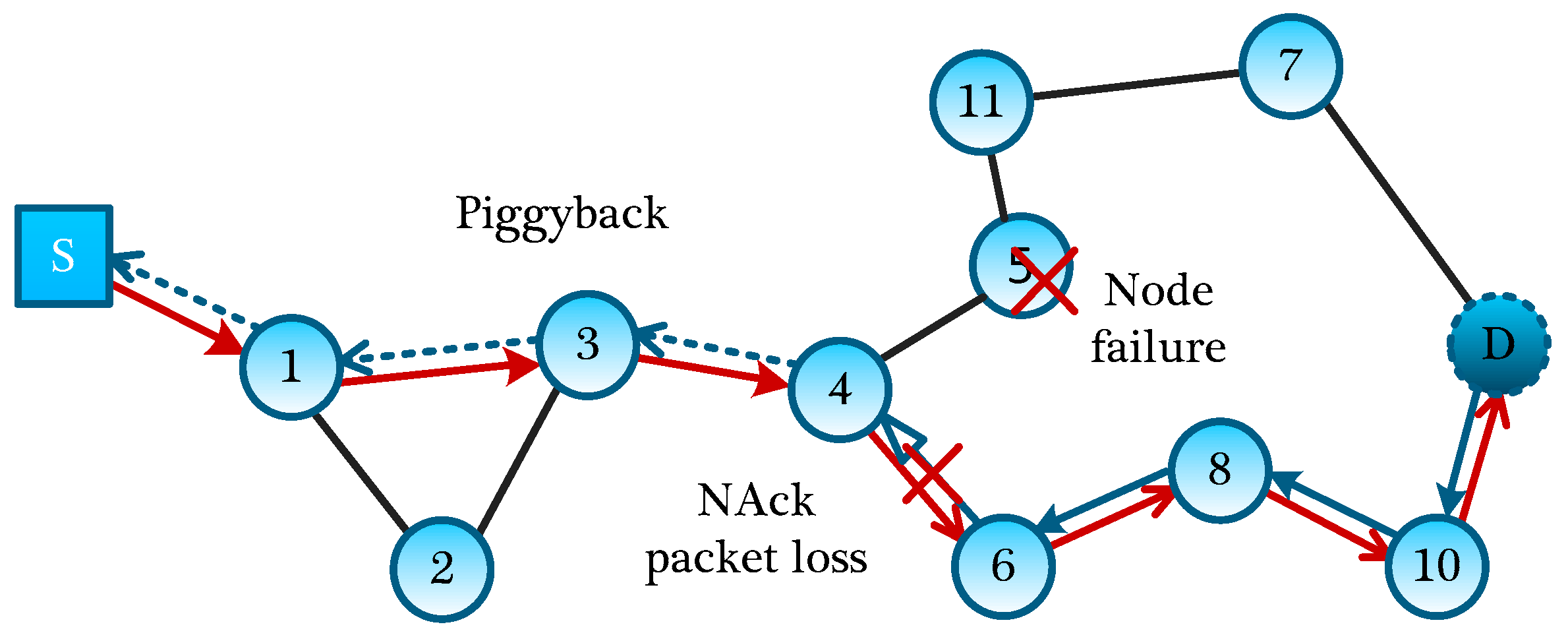
Because the failures of other nodes will not affect the current MLMS measurement formation process, we mainly deal with the node failure on the MLMS path. If a node has failed, a new routing path should be established in a timely fashion, and the information of this failed node should be reported to the sink node to guide the building of another MLMS path. Then, two kinds of node failures on a MLMS path will be discussed below, including the group head node failure and the ordinary node failure. If a group head node at the end of MLMS path has failed, a new head node needs to be selected to continue to transmit packets of nodes in the group. Through dividing the remaining nodes into several small groups, we can choose the node which has the second-highest number of neighbor nodes to act as a new group head. If a node on the path fails to operate, its upstream node will choose the next neighbor nodes, which is similar to the GPSR protocol [
19], and continue to transmit the packet, since all routing information (heading to interested nodes) is encoded into the packet head. As shown in
Figure 8, when node #5 has failed, and its upstream node #4 encounters this situation, according to the working nodes in the neighbors, it will automatically select a next-hop node (e.g., node #6). But at this time, the routing path is probably not the optimal path, and if necessary, the optimal MLMS path should be recalculated.
For the node-failure message return, we need to respectively deal with node failures in different measurement-formation periods. In the distribution of the global seed, we can use the Piggyback method, which allowing the sender to add the ID of the failure node to the fixed position of seed-distribution packet. As node #4 sends packets to node #6, because node #3 can eavesdrop on the packet, it writes the ID of failure node #8 into a corresponding fixed position of its next packet to be sent, and in turn, until the failure information of node #5 reversely backtracking to the Sink through the normal data channel.
Therefore, without increasing any control packet, by adopting the eavesdropping property, information about failed nodes is quickly reported to the Sink, while for the information return of the failed nodes in the process of measurement-formation, we can directly write the ID of the failed node to the fixed position of the measurement-formation packet. With the return of measurement-formation packets, the sink node can directly obtain the information of failing nodes.
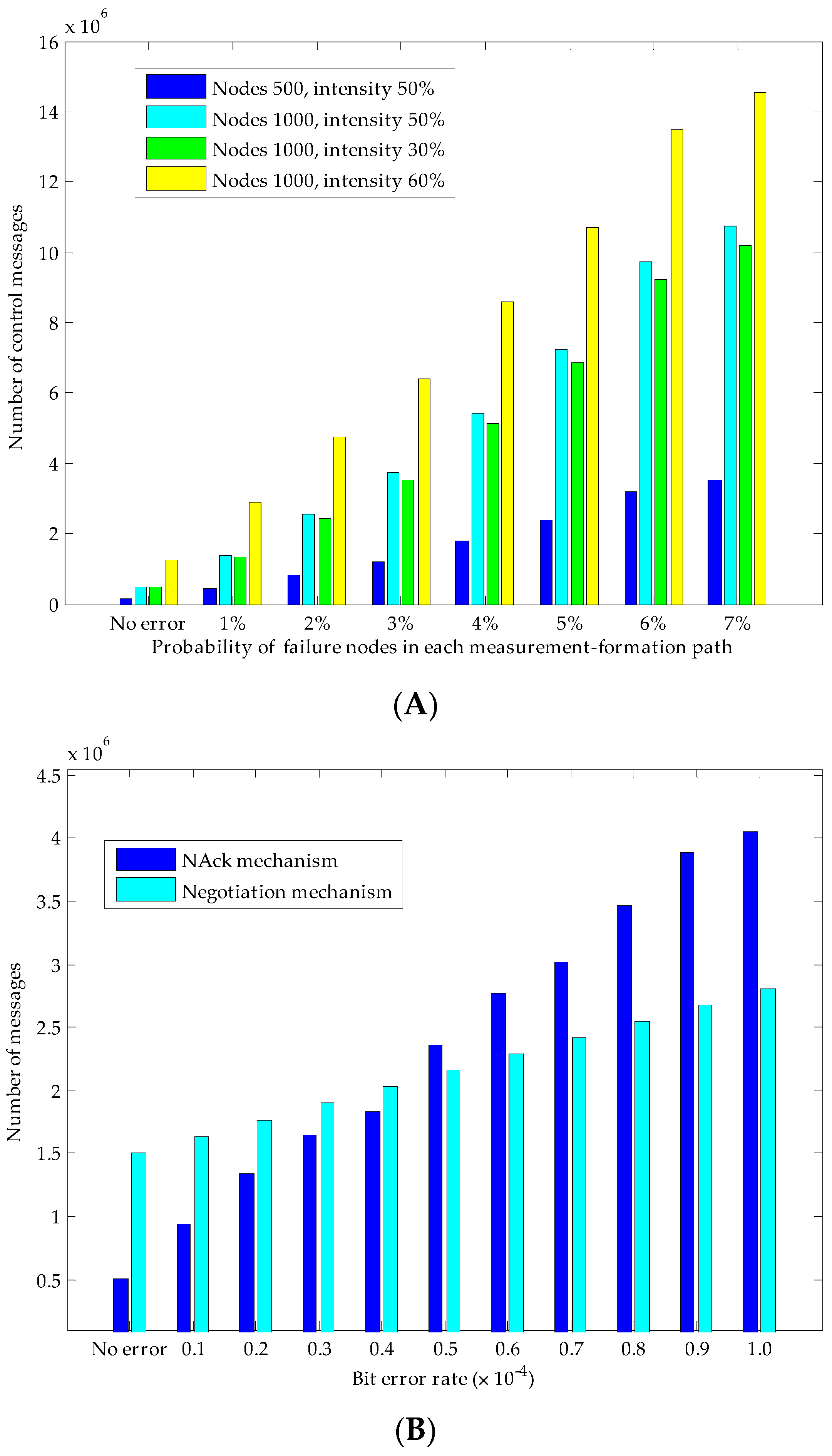
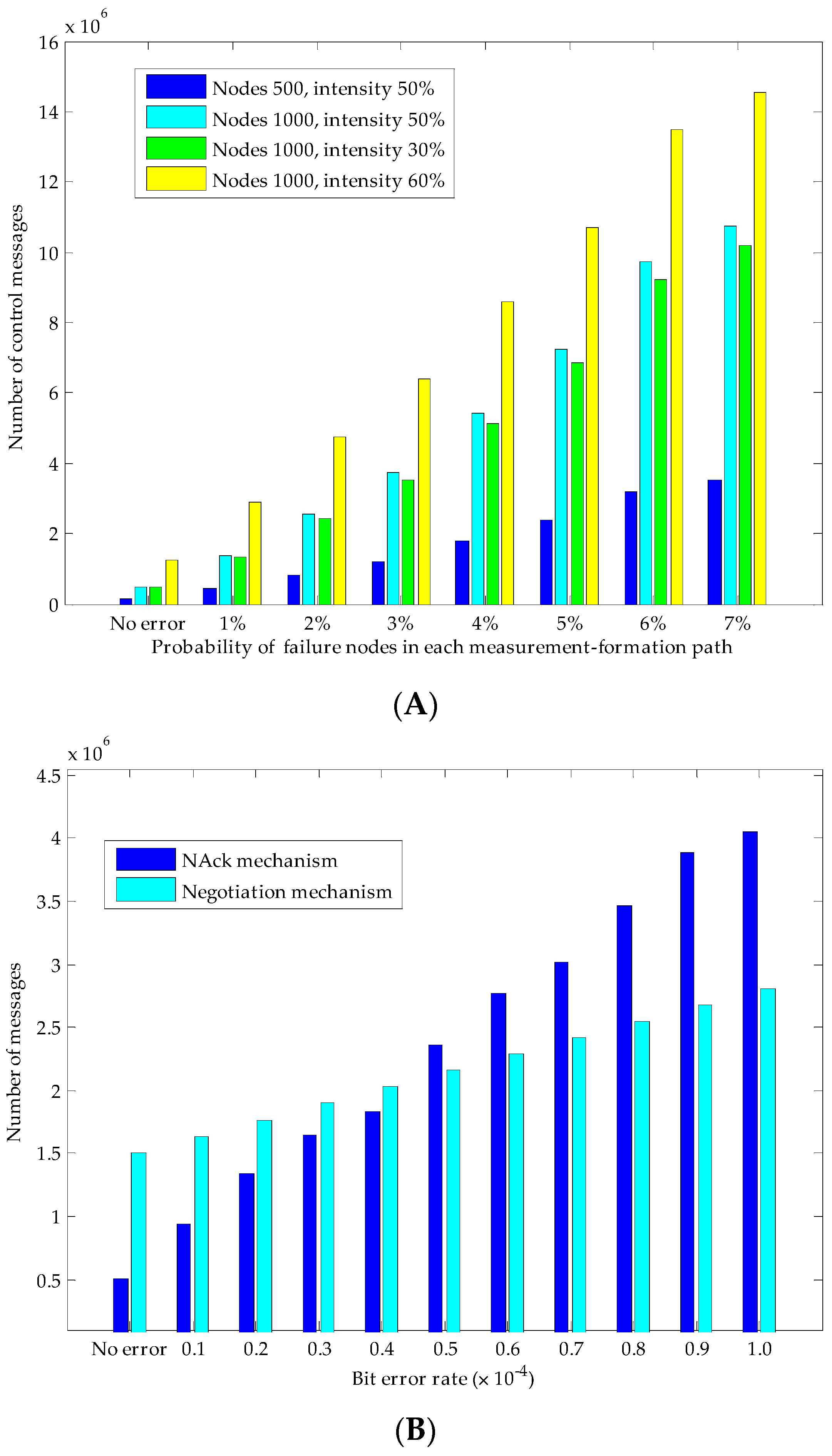
For each measurement formation process, both in the global seed distribution period and the establishment of measurement result, it will inevitably experience packet losses, and if the packet losses occur without a recovery mechanism, failure of this measurement formation will be induced, definitely. If a node in MLMS path discoveries that several packets in a sequence are not received within an acceptable TTL time, it will ask the upstream node for these packets along the reverse path. If the upstream node does not keep these packets, this process will continue until reaching the interested nodes. As shown in
Figure 8, if node #4 fails to receive the packet from #6, node #4 will request this packet from its upstream node #6; if node #6 does not keep it, node #6 will request its upstream node #8 for this packet, and such process will be repeated until the packet is found. Of course, in order to further improve the reliability and recover the lost packets timely, we can set nodes around the MLMS paths to buffer the packets they have eavesdropped on; when certain packets are lost, they can be recovered quickly and accurately through multicast inquiry messages to the neighbor nodes. What’s more, a consultation method can also be used to further improve the reliability of packet transmission (for example, three-handshake negotiation). The disadvantages of these two methods are the large overhead of transmitting control messages, and we will evaluate it in
Section 6.
5. Adaptive Termination Rule of the Measurement-Formation
As we mentioned before, after choosing a reconstruction algorithm (such as BP, or MP), the sink node can reconstruct the
K-sparse original signal with the probability close to 1 as long as it receives a certain number of measurement results (theoretically,
O(
KlogN)). However, as shown in
Section 3, this bound cannot be applied to our method directly, because it requires prior knowledge of the sparsity information of the network sensed data. By using the conclusion from “sequential compress sensing [
20]”, an adaptive termination condition of measurement procedure was proposed in literature [
21]. Specifically, assume that we can obtain measurement result of a
K-sparse signal
x (
x ∈ ℝ
N,
K is unknown) step by step (each step gets one measurement result and we denote the measurement on step
i as
); if the reconstruction result on step
M is
and
, then
is the result which we need (
i.e.,
) with probability 1.
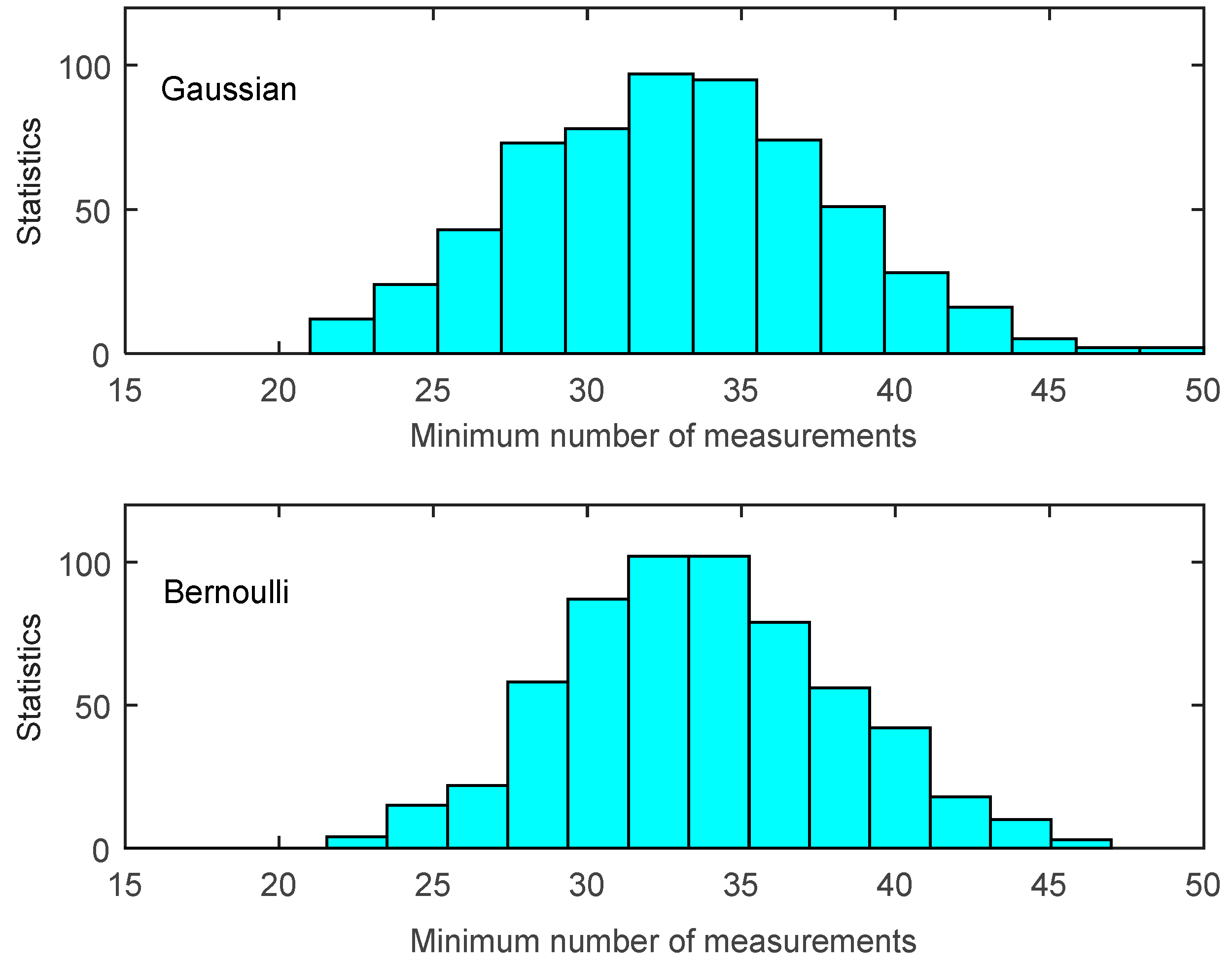
Although this termination rule is very concise, it still has some limitations when applied it to CDG for WSNs. Because this rule is based on the dense measurement method (each measurement coefficients vector
obey Gaussian distribution), as shown in
Section 2, each measurement formation will concern every node in the network, which will lead to more energy consumption than the sparse measurement method. On the other hand, coefficients in the measurement vector of this termination rule are continuous; thus, it is very difficult to generate on cheap WSN sensor nodes. Therefore, we need to find a termination rule for the sparse measurement method in this study. The difference emerging from the dense Gaussian measurement method is that the probability of being nonsingular for each submatrix of the measurement coefficient matrix is no longer 0. In order to meet our specific demands, we modified the termination rule in [
20] to obtain agreement for a certain number of consecutive measurements (denoted as Δ
M) (as shown in Proposition 1). Note that, we assume that the sink node can obtain and reconstruct the sparse Bernoulli measurement results step by step, and
x represents the
N-dimensional data vector which is desired by the sink node in each data-gathering epoch.
Lemma 1. Let v be an n-dimensional sparse Bernoulli vector () and . Let W be a deterministic w-dimensional subspace of , then .
Proof. Given W being a w-dimensional subspace, there exist w coordinates that determine all the other n-w coordinates of an arbitrary vector . Thus, if we condition on the coordinates of v, there is at most one case to make in the other n-w coordinates. Hence the probability of is at most .
Proposition 1. Suppose that the sink node has got measurement results in previous steps, and at step M, if the sink node have got the measurement result from the network, it can get a reconstruction result of network sensed data (denote as ) from these received measurement results; if , is the reconstruction result which we need with probability no less than .
Proof. We prove this proposition by using argumentum ad absurdum. We denote the measurement coefficient vector at Step i as , and the measurement result of Step i as . Assume that, and is not the correct reconstruction result of x, then is valid. Because we have obtained the solution result at the Step , equation comes into existence. Thus, according to the assumption that , it is easy to obtain . By following this idea, for measurement coefficient vectors generated from Step to Step M, we can also get equations. Let V be a vector space which is spanned from the non-zero vector , and if this equation set is correct, entire measurement coefficient vectors must exactly belong to the orthogonal complement of V (denoted as where ). For a 1-dimensional nonzero linear transformation , its orthogonal complement is an ()-dimensional subspace of . Hence, from Lemma 1, it can be seen that the probability of an imprecise solution being calculated and kept is greater than , as desired.
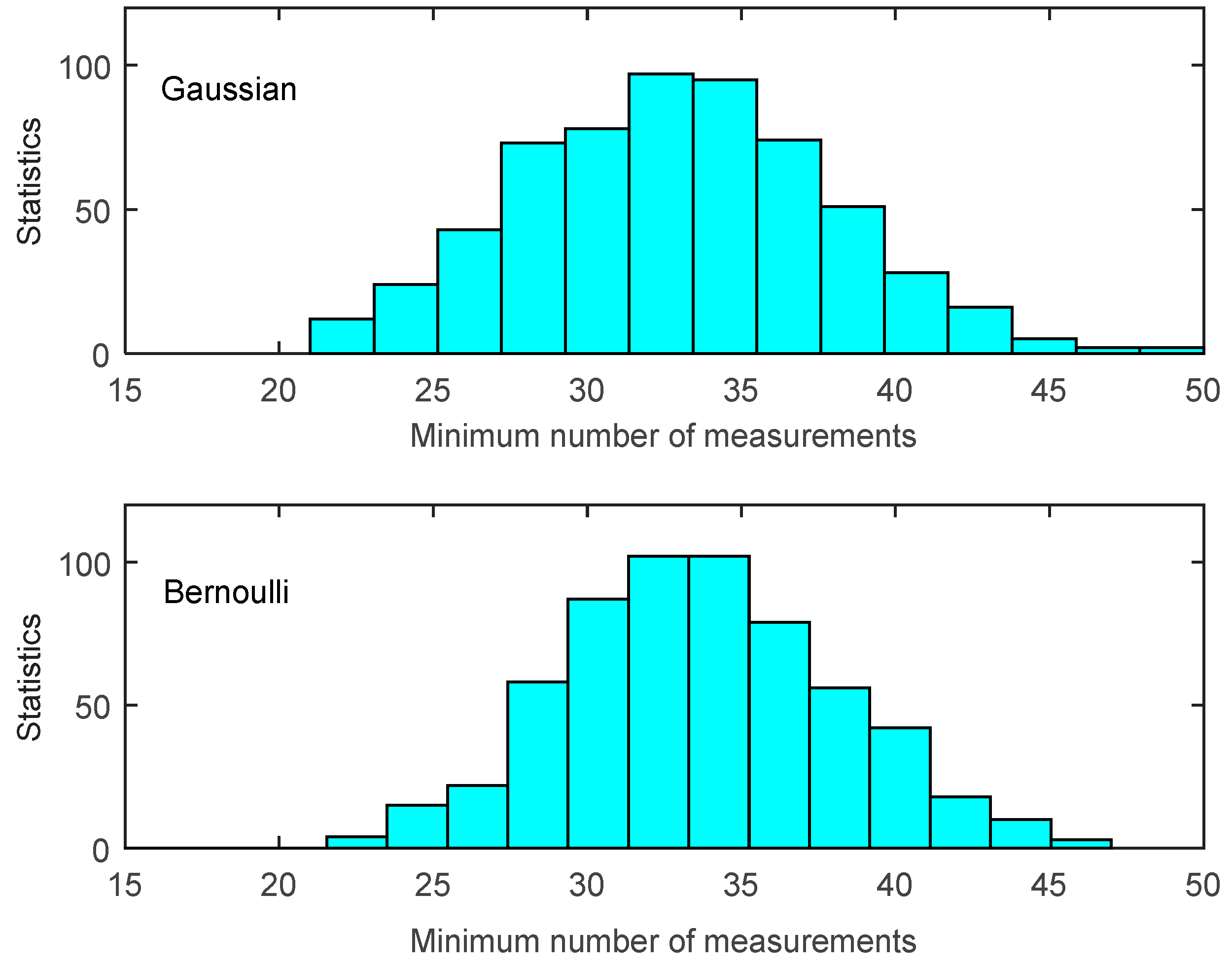
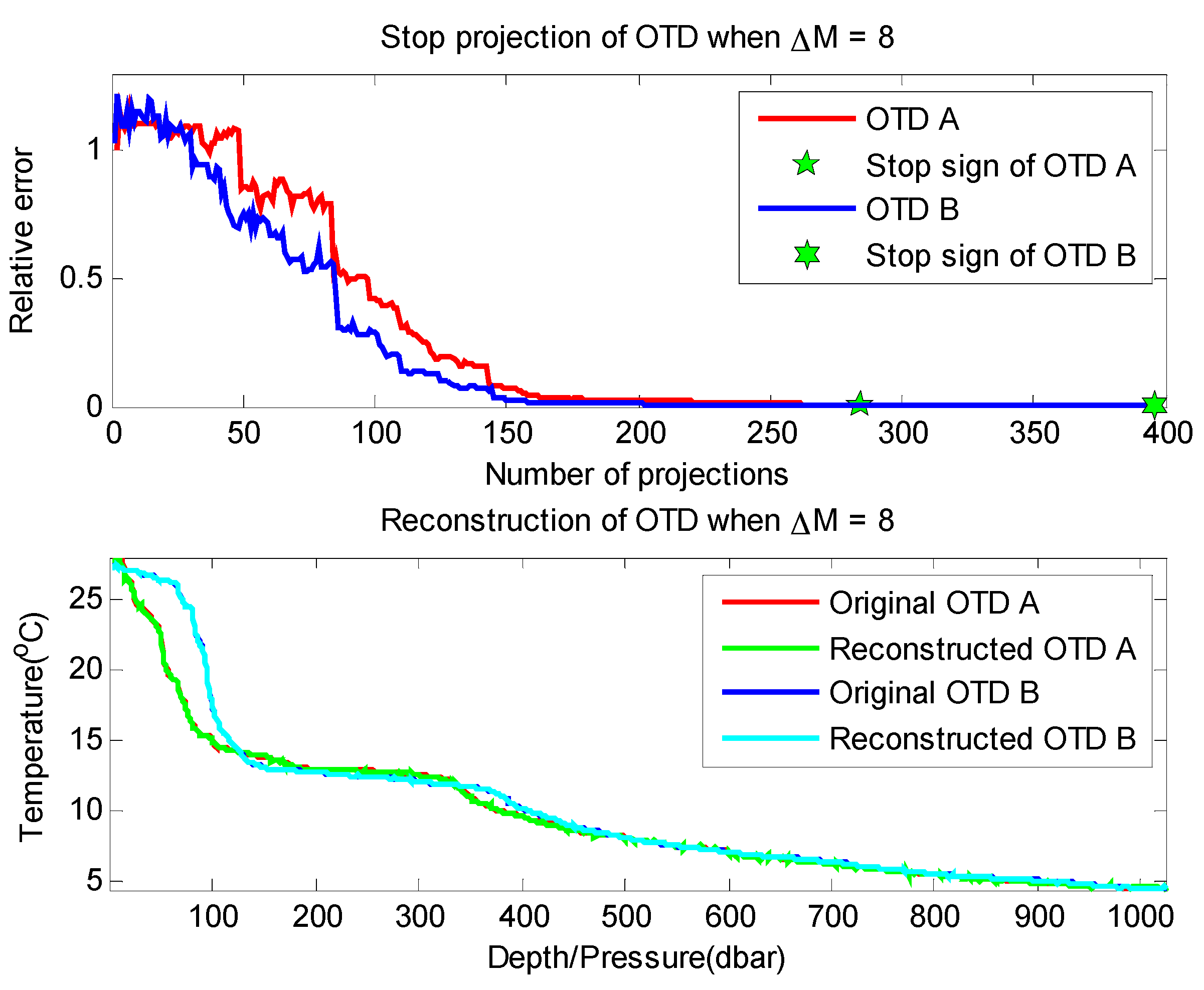
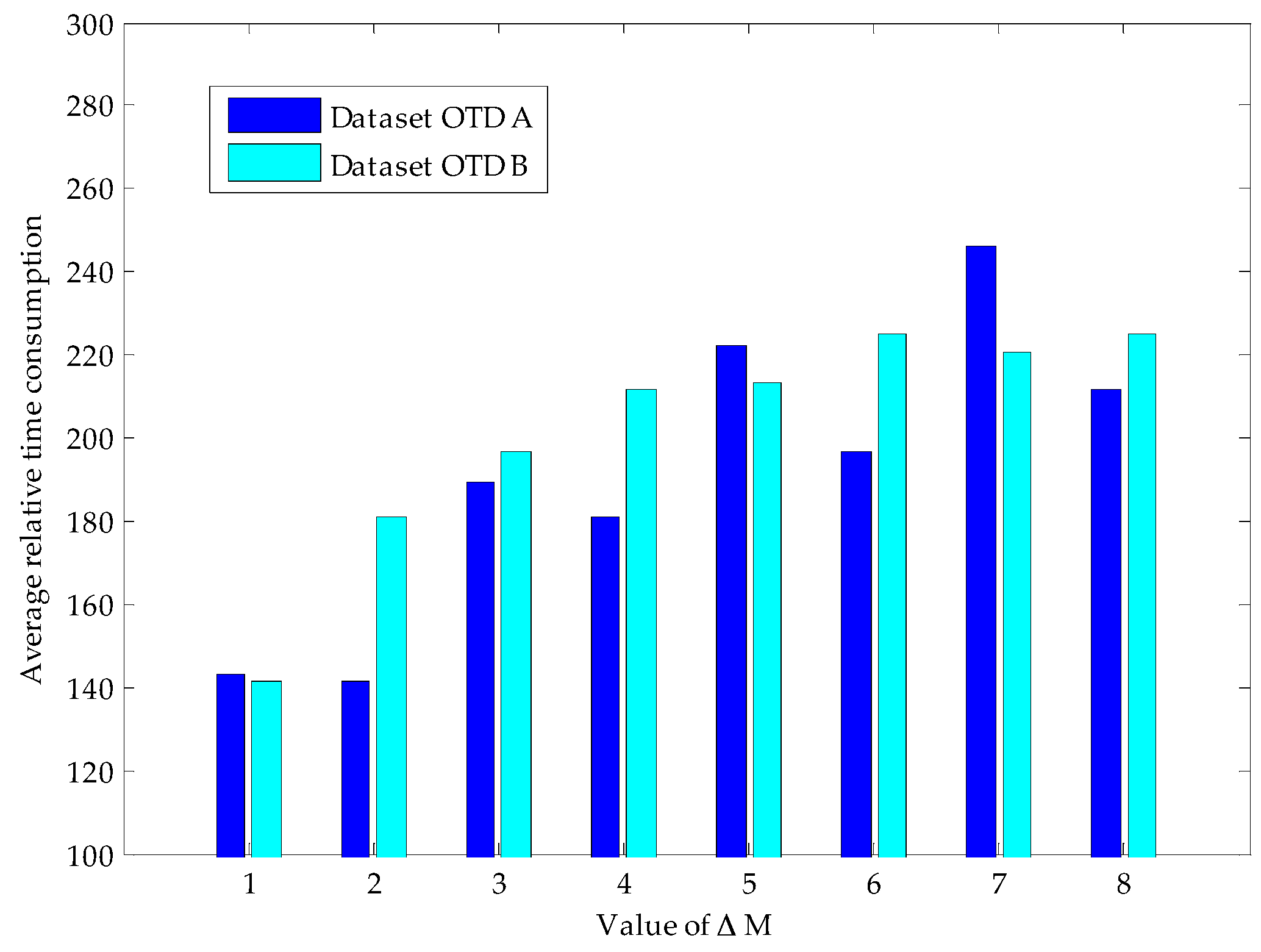
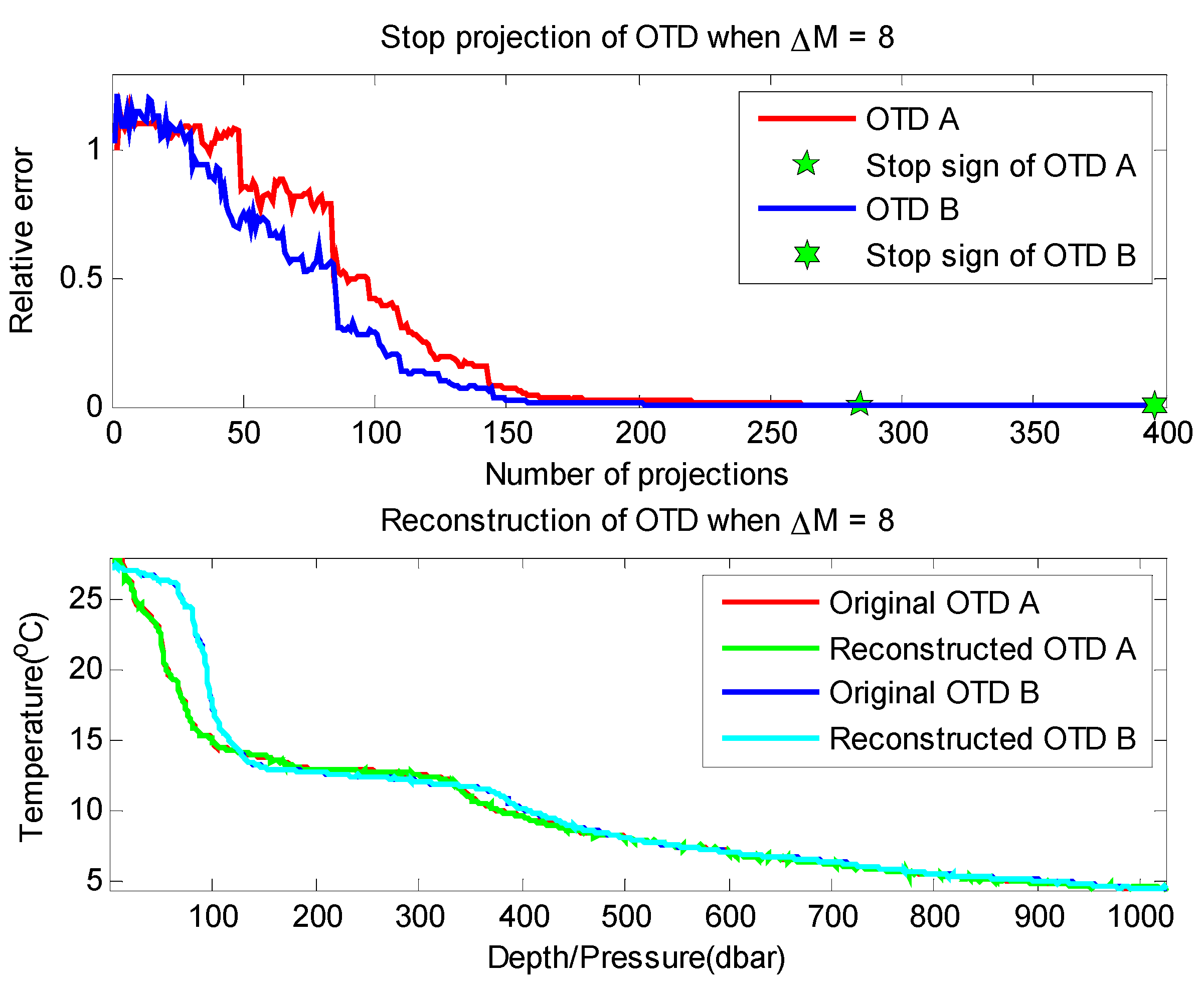
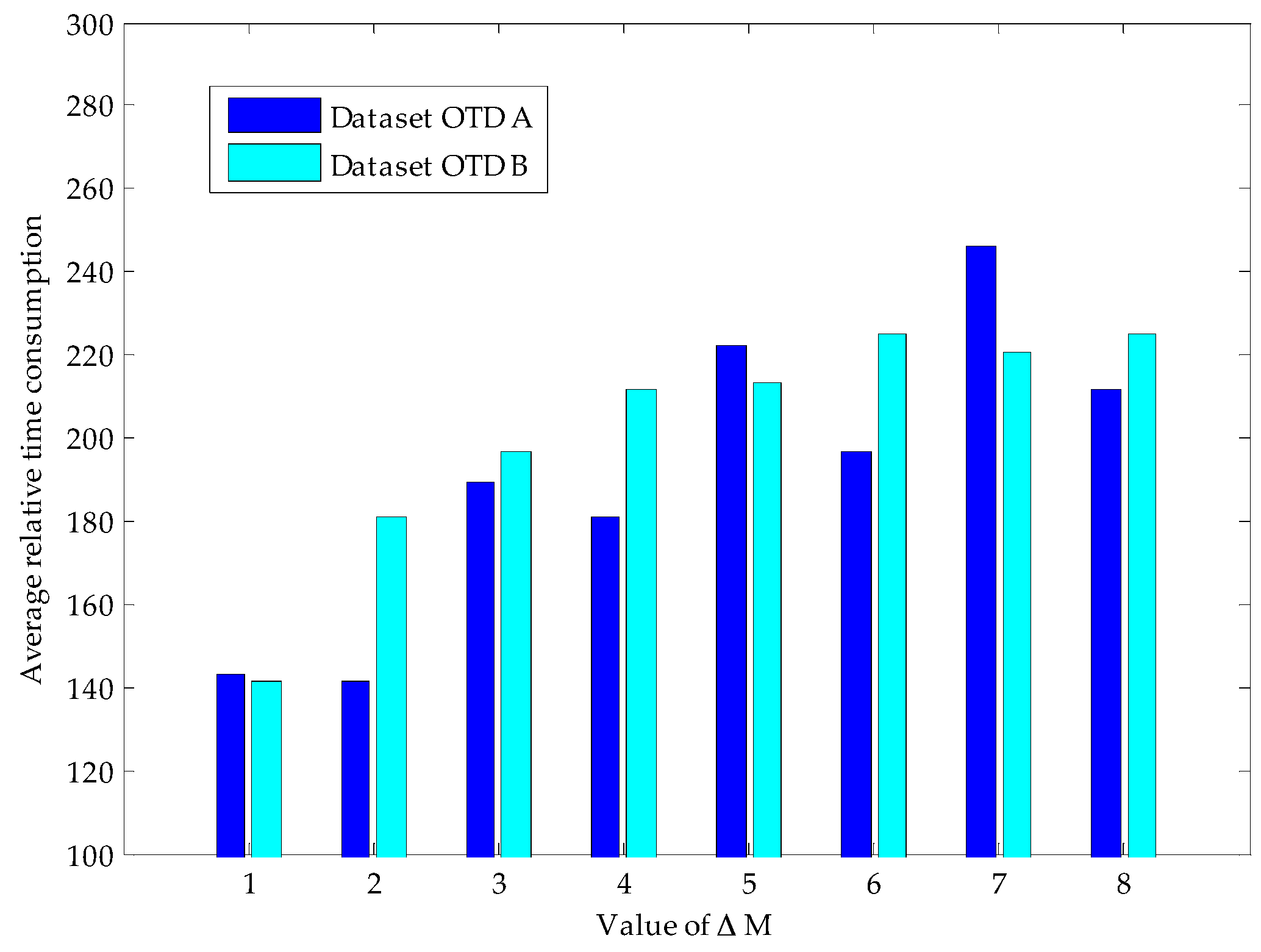
Proposition 1 provides us a termination rule of sparse Bernoulli measurement formation by comparing several construction results. In our experiments, signals are generated with the same signal length and sparse degree as shown in
Figure 3. We test the signal reconstruction under the termination rule proposed in Proposition 1 with different Δ
M values, and the experiment results are shown in
Table 1. We can see that Proposition 1 presents a very efficient terminating condition in the reconstruction of sparse Bernoulli measurement method. The larger the quantity (Δ
M) is adopted, the lower error reconstruction generates (
i.e., 128 errors happen under Δ
M = 1, while only 2 under Δ
M = 2). Thus, our data gathering process can adapt to the various requirements of network applications by adjusting the value of Δ
M.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}