1. Introduction
Within the automotive industry, the advanced driver assistance system (ADAS) technology, in existence for many years, is now adding enhanced automated function that provides the driver and passengers with a higher level of safety and comfort relative to current ADASs.
An ADAS includes a variety of functions, e.g., automated cruise control, adaptive light control, parking assistance, collision avoidance, rear view, blind spot detection, driver drowsiness alert, global positioning system (GPS) navigation, lane departure warning, and intelligent speed control. Several of these technologies have been researched and are now implemented and integrated within many automobiles from a variety of manufacturers. In many cases, the results are an improved driving experience and better road safety. With an ADAS installed, a driver constantly receives visual images of the road and surroundings. The primary purpose of the road markings is to alert the driver or pedestrian relative to potential hazards and provide guidance, rules, or directions to drivers and pedestrians. In order to integrate the road marking recognition and reaction process within an ADAS, it is necessary to provide an automated visual recognition system for all road markings and implement timely responses to these markings, either by providing advice to the driver or, unilaterally, controlling the car to take the appropriate action.
Automatic recognition of road markings is a challenging problem to solve and integrate into an automotive vision system. Unlike traffic signs, road markings exist on road surfaces and they can be easily damaged. For example, directional arrows, numbers, and word messages are more likely to be damaged than traffic signs because the paint on the marking is eroded by vehicular traffic over time. A human brain is quite skilled at analyzing this information and can respond in a timely manner with an appropriate series of actions. However, in order to recognize damaged or indistinguishable road markings with a high degree of accuracy, a computer vision system must support very small response times and a high sensitivity to the field of vision. In the next Section, we provide detailed explanations of previous work in this research area.
2. Related Works
The problem of automated recognition of road markings has been studied by many researchers. Previous researchers used various image processing techniques to recognize road markings and signs [
1,
2,
3,
4]. For example, Foucher et al. [
5] presented a method of detection and recognition of lane, crosswalks, arrows, and several related road markings, all painted on the road. They propose a road marking recognition method that consists of two steps: (1) extraction of marking elements; and (2) identification of connected components based on single pattern or repetitive rectangular patterns.
The template matching method was also used to implement road marking recognition. In [
6], the maximally stable extremal regions (MSERs) were used to detect a region of interest (ROI) of road marking. In order to classify road markings, a histogram of oriented gradient (HOG) features and template matching methods was used. This method was proposed to detect and classify text and symbols; the results show a false positive rate of 0.9% and a true positive rate of 90.1%. Another template matching-based method was proposed in [
7] for the recognition of road markings. Through the augmented transition network (ATN), the lanes are detected. Next, these lanes are used to establish the ROI that determines the boundaries in which the road markings, such as arrows, are located. Detected lanes that are valid are mostly used as a guide to detect markings. Ding et al. [
8] presented a method for detection and identification of road markings. The researchers use HOG features and a support vector machine (SVM) to identify and classify five road markings. The method presented by Greenhalgh et al. [
9] also used HOG features and a SVM for recognition of symbol-based road markings.
Text-based road-signs are recognized by an optical character recognition (OCR) method [
1,
10,
11]. The system can recognize any random text word that might appear. In [
12], a method was proposed that uses a Fourier descriptor and k-nearest neighbor (KNN) algorithm for recognition of road markings. In the fields of speed limit sign recognition, lane detection and traffic-sign detection and recognition, researchers have proposed techniques using an artificial neural network. One road-sign recognition algorithm is based on a neural network that uses color and shape information with back propagation, for the recognition of Japanese road signs [
13]. In addition, the researchers used template matching and neural networks to recognize the road markings. The back propagation method is used as the learning method in a hierarchical neural network. The results show that the accuracy of the template matching algorithm remained lower than the accuracy of the neural network algorithm. Another approach to road-sign recognition is an earlier solution that uses artificial neural networks for the Bengali textual information box [
14]; the results show a recognition accuracy of 91.48%.
While research of road-sign recognition using neural networks has been quite active, few research studies of road marking recognition using neural networks are available in the literature. One of the earliest methods for the recognition of arrow-marking was proposed by Baghdassarian et al. [
15]. This research generated arrow-marking candidates through image binarization, and used a neural network with a chain code comparison for arrow classification. Another proposal uses a neural network to recognize road markings [
16]. The researchers used the back propagation method as the learning method in a hierarchical neural network. They performed their experiments over six types of white road markings (turn left, turn right, turn left straight, turn right straight, straight, and crosswalk) and five orange road markings (30 km, 40 km, 50 km, 60 km, and U-turn ban). The experimental results showed that the average accuracy of recognition of white road markings was about 71.5%, while the average accuracy of recognition of orange markings was about 46%. Another research study proposed a method for detection and recognition of text and road marking [
17]; this study extracts the shape-based feature vector from the candidates of road marking, and a neural network is used for classification of road marking. This approach shows a successful recognition rate of approximately 85% for arrows and 81% for the 19 dictionary words/text patterns. In [
18], another machine learning-based method is proposed to detect and classify road markings. In this case, a binarized normed gradient (BING) and a principal component analysis (PCA) network with a SVM classifier were used for object detection and classification, respectively. In [
19], the researchers used HOG features and a total error rate (TER)-based classifier for road marking classification; this resulted in an overall classification accuracy of 99.2%.
The arrow-road markings on a road surface typically become illegible or unidentifiable as the car tires erode the paint on the marking. Although this makes it difficult to correctly recognize the arrow-road marking, and represents an important problem but there is little research activity in the recognition of this type of damage to arrow-road markings. We propose to fill this research void and introduce a method that uses a convolutional neural network (CNN) to recognize six types of road markings of arrows, including damaged arrow-markings on the road surface. Recently, deep learning-based methods such as deep neural networks and CNNs have shown encouraging results in the field of computer vision and pattern recognition. Convolution can allow image-recognition networks to function in a manner similar to biological systems and produce more accurate results [
20]. In recent works, a CNN has also been used for detection and classification of traffic signs [
21], lane detection [
22], and lane position estimation [
23]. However, there is no previous research documenting studies of arrow-road marking recognition based on a CNN.
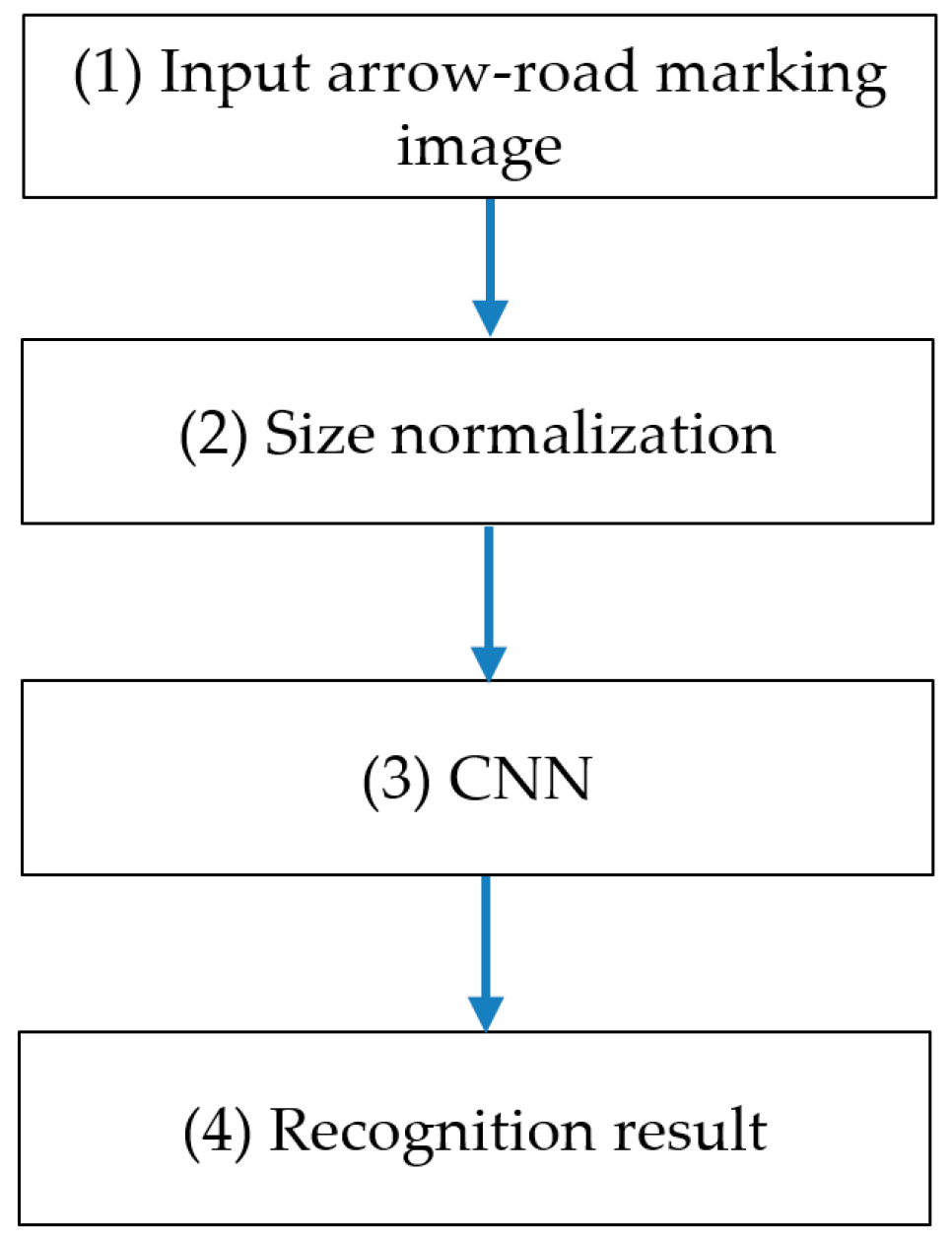
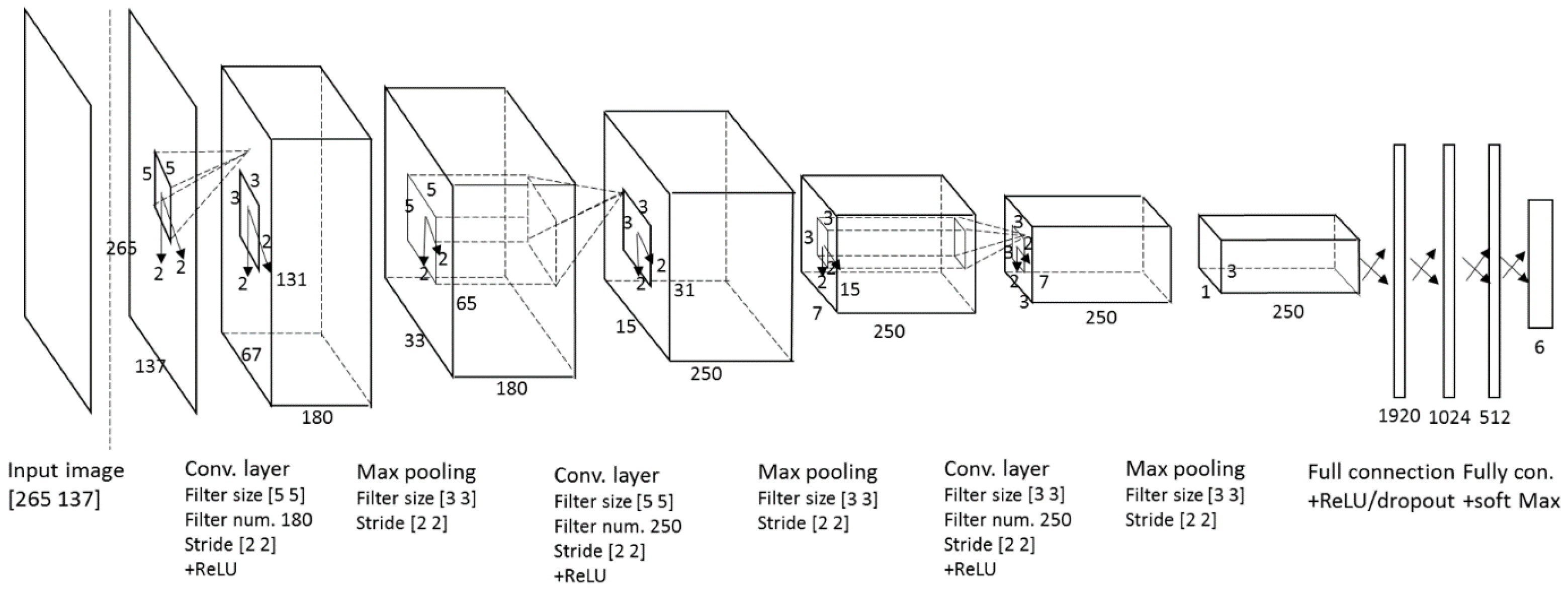
Hence, we propose a method based on a CNN to recognize damaged arrow-road markings painted on the road. The CNN-based method is a new CNN application for the recognition of the painted arrow-road marking. Our system will also provide useful results that are not affected by partial occlusions, perspective distortion, or shadow or lighting changes. We expect that this method will provide good results in conditions of poor visibility and other conditions that may inhibit collecting good-to-excellent images of the environment. Compared to the state of the art, our research is innovative in the following three ways.
- -
We propose a CNN-based method to recognize painted arrow-road markings. This method is new as it is not reported in the state of the art. Our method results in high accuracy of recognition and it is robust to the image quality of arrow-road marking.
- -
Our method is capable of recognizing severely damaged arrow-road markings. It also demonstrates good recognition accuracy in a variety of lighting conditions, such as shadowed, dark and dim arrow-road marking images that are not easily recognized.
- -
We used six datasets (Road marking dataset, KITTI dataset, Málaga dataset 2009, Málaga urban dataset, Naver street view dataset, and Road/Lane detection evaluation 2013 dataset) for CNN training and testing. These datasets were obtained from different countries, each with a diverse environment. The arrow-road markings of each dataset have different sizes and different image qualities. Through the intensive training of a CNN using these datasets, our method demonstrates robust performance that is independent of the nature of the datasets.
The comparisons of previous and proposed research related to road marking recognition are presented in
Table 1.
The remainder of this paper is organized as follows. In
Section 3, our proposed system and methodology are introduced. The experimental setup and results are presented in
Section 4.
Section 5 includes both our conclusions and discussions on some ideas for future work.
5. Conclusions
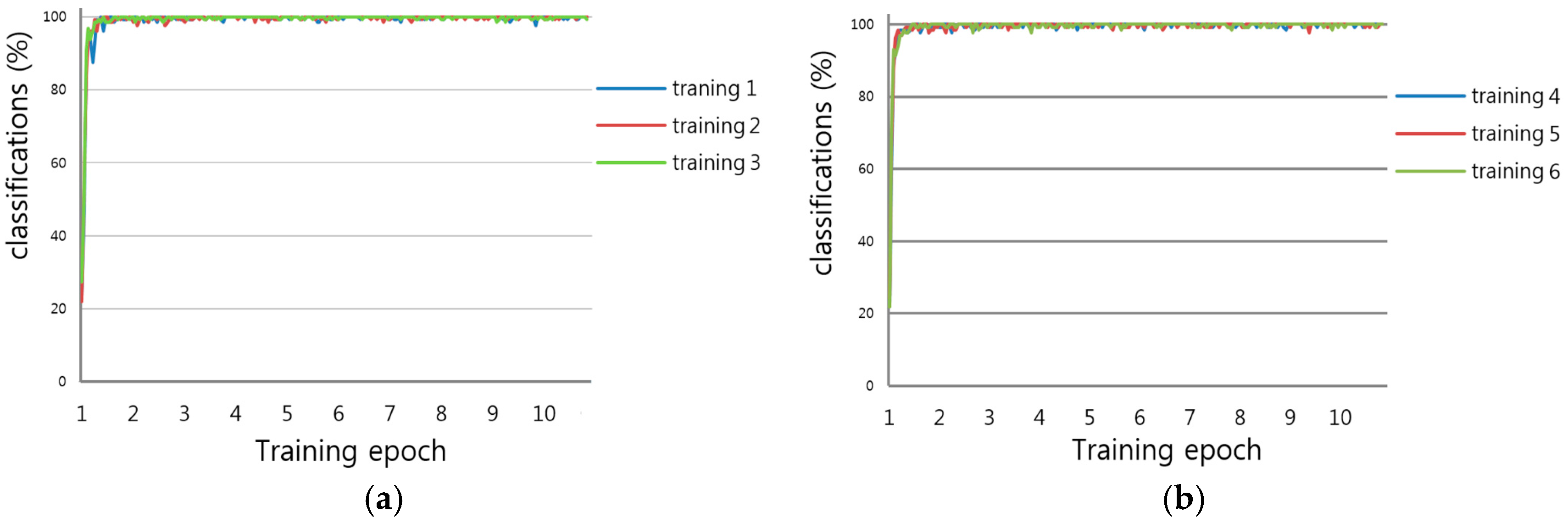
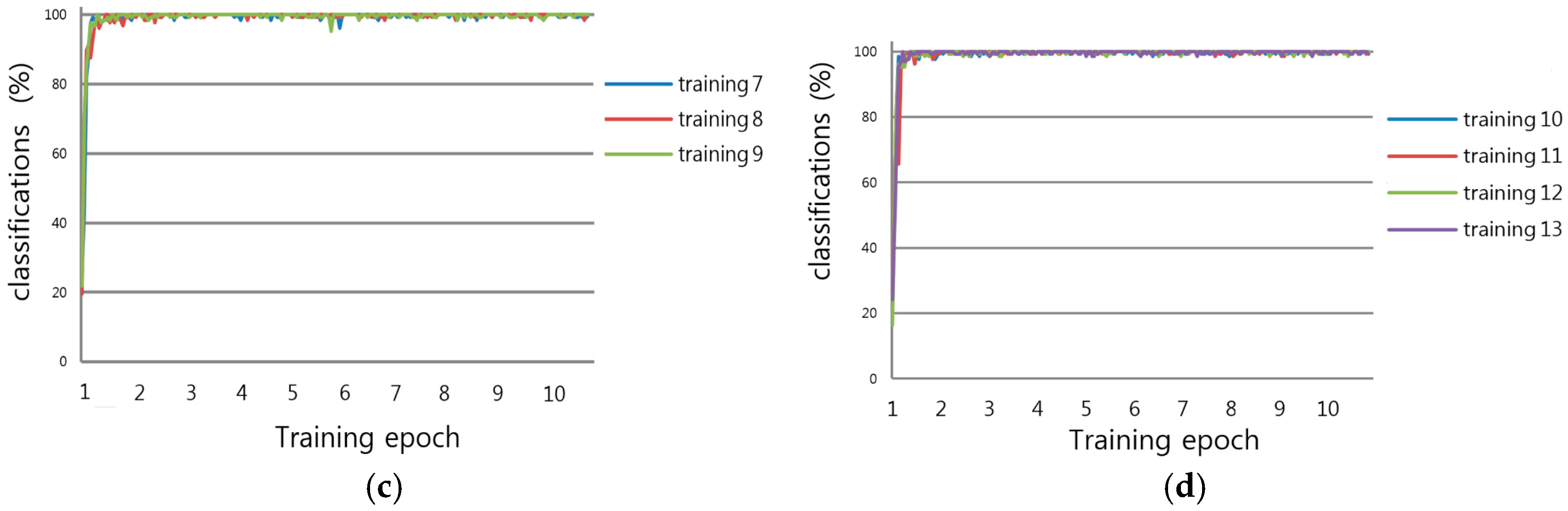
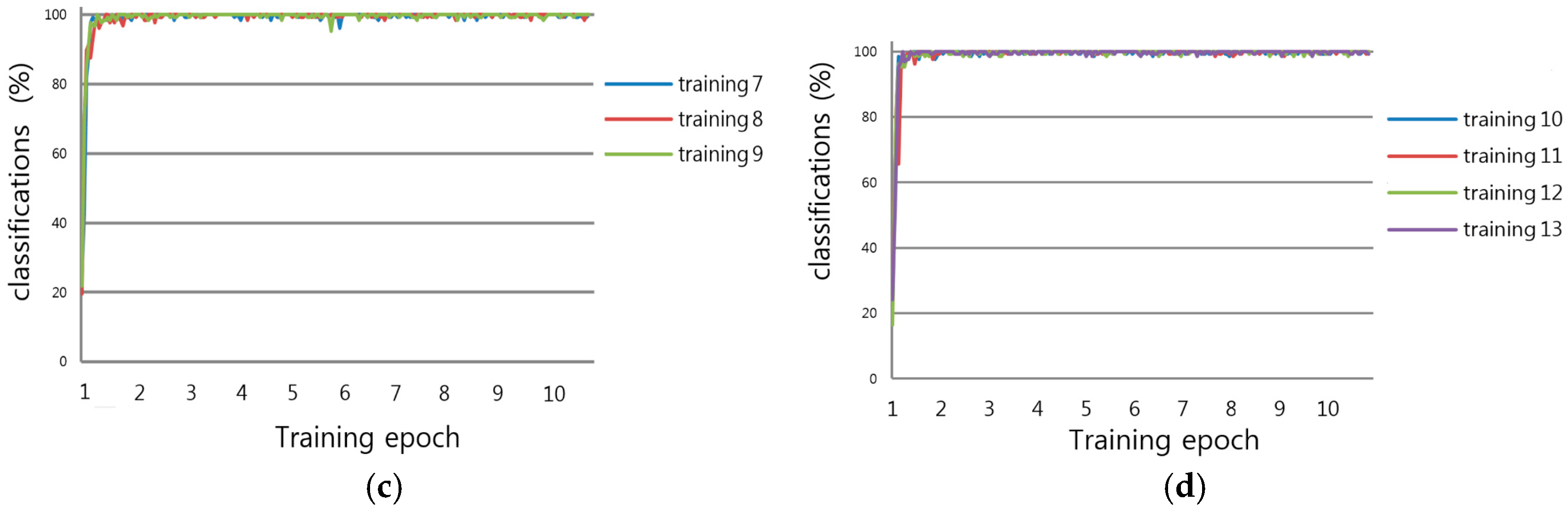
In this research, we proposed a method to recognize damaged arrow markings residing on a road. We deployed a CNN and collected training and testing data from various types of datasets. We trained the CNN to recognize arrow markings in the presence of varying illumination, and shadow and damage conditions. A simple CNN was designed and then trained using various “raw” datasets, i.e., the datasets were not preprocessed for noise removal, contrast normalization, or brightness correction. The experimental results demonstrate that the accuracy of recognizing arrow markings by the proposed method was consistently higher and more reliable, relative to the previous method.
In the future, we plan to implement and integrate our method on an actual automobile, and measure the performance while driving the car. We will then compare the accuracy of our method with the accuracies of other known CNN implementations.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}