
Human Pose Estimation from Monocular Images: A Comprehensive Survey


 , ,
, ,
Abstract
:1. Introduction
1.1. Related Works
1.2. Contributions
- The first comprehensive survey of human pose estimation on monocular images including more than 300 references. These works includes top conferences and journals, which are milestone works on this topic. Table 1 gives a preview of included references, and its structure follows the composition of this paper. This survey considers several modules: features, human body models, and methodologies—as shown in Figure 1. We collect 26 publicly available data sets for the evaluation of human pose estimation algorithms. Furthermore, various evaluation measurements are included so that researchers can compare and choose an appropriate one for the evaluation of the proposed algorithm.
- The first survey that includes recent advancements on human pose estimation based on deep learning algorithms. Although deep learning algorithms bring huge success to many computer vision problems, there are no human pose estimation reviews that discuss these works. In this survey, about 20 papers of this category are included. This is not a very large number compared to other problems, but this is a inclusive survey considering the relatively few works addressing this problem.
2. Features
2.1. Low-Level Features
2.2. Mid-Level Features
2.3. High-Level Features
2.4. Motion Features
3. Human Body Models
3.1. Kinematic Model
3.2. Planar Model
3.3. Volumetric Model
3.4. Human Pose Priors
4. Methodologies
4.1. Discriminative Methods and Generative Methods
4.1.1. Discriminative Methods
- Learning-based methods
- (a)
- Mapping based methods. One extremely popular model for learning these types of maps isSupport Vector Machine. Support Vector Machines (SVMs) [120,121,122] are discriminant classifiers that train hyperplanes for discrimination between classes. The most decisive examples in training are picked as support vectors. Similarly, in Relevance Vector Machines (RVMs), which are a Bayesian kernel method, the most decisive training examples are picked as relevance vectors [32,123,124,125]. Non-linear mapping models are also utilized, for example, Gaussian Processes [26].More complex mapping mechanisms can be modeled with a Mixture of Experts (MoE) model, a Bayesian mixtures of experts (BME) model, and other models. For example, the authors of [262] exploit a learned MoE model which represents the conditionals [126,127,128] to infer a distribution of 3D poses conditioned on 2D poses. BME [129,130] could model the multi-model distribution of the 3D human pose space conditioned on the feature space, since the image-to-pose relation is hardly linear.Mapping-based methods can also be further categorized into direct mapping methods and 2D-to-3D boosting methods. One class of learning approaches uses direct mapping from image features [32,60,131,132,133,162,263], and another class of approaches maps the image features to 2D parts and then uses modeling or learning approaches to map 2D parts to 3D poses [78,134,135,136,137].
- (b)
- Space learning-based methods. Both topology space and subspace are utilized to learn mapping. For example, in a topology space-based method, arbitrary non-rigid deformations of a 3D mesh surface could be learned as manifold [24,34,142,143,144,145,146,147].On the other hand, subspace could also be learned to constrain the solution space. For example, an embedding can be learned by placing images in similar poses nearby, avoiding the estimation of body joint positions [148,149]. Dimensional reduction technologies can also be used to remove redundant information [150]. Locality-constrained Linear Coding (LLC) algorithms [151,152] can also be performed to learn the nonlinear mapping in order to reconstruct 3D human poses.
- (c)
- Bag-of-words based methods. The bag-of-words pipeline is the most popular computer vision algorithm solution before the deep learning algorithm. The main idea of the bag-of-words pipeline is to first extract the most representative features as a vocabulary, and then denote each training data based on image evidence and the vocabulary in a statistical way: the occurrence of each word in the image is counted, all occurrences of words in the vocabulary form a histogram, and this histogram is taken as the final representation of the input image. This representation process is shown in Figure 12. This feature representation is then fed to a classifier or a regression model to complete the task [130].By selecting the most representative features as the vocabulary, followed by a histogram representation based on the vocabulary, an image can be represented with a vector of a fixed length equal to the size of the vocabulary. In this way, the image is represented with a statistical occurrence of the most salient features and is compressed to the size of the vocabulary.
- (d)
- Deep learning-based methods. Deep learning is an end-to-end learning method that automatically learns the key information in images. Convolutional Neural Networks (CNN) [156,157,264,265] are popular deep learning models which have multi-layers, with each layer composed of multiple convolutions and some other hybrid architectures (refer to Figure 13 for an example of CNN architecture). Deep learning-based human pose estimation mainly has three categories: (1) combined part detection with the accurate localization of human body parts through deep learning networks [66,153,154]; (2) learning features through deep convolutional neural networks and learning human body kinematics through graphical modelling [155,156]; (3) learning both features and body part locations through deep learning networks [90,157,158,159].The regression methods [162] based on deep learning have various extensions, such as a mixture of Neural Networks (NNs) [160] which uses a two-layer feedforward network and linear output neurons as a model for local NN regression. The authors of [155] also propose a combined architecture that involves a deep convolutional network and a Markov Random Field (MRF) model. The authors of [163] present a CNN that involves training an Regions with CNN features (R-CNN) detector with loss functions. The authors of [164] adopt an iterative error feedback that changes an initial solution by feeding back error predictions.
- Exemplar-Based MethodsThe exemplar-based approaches estimate the pose of an unknown visual input image [118] based on a discrete set of specific poses with their corresponding representations [160]. Randomized trees [165] and random forests [166,167] are fast and robust classification techniques that can handle this type of problem [266].Random Forest is an ensemble classifier that consists of several randomized decision trees [142,267] and has a nonterminal node containing a decision function to predict the correspondences by regressing from images to terminal nodes, like mesh vertices [9] (Figure 14 shows an example). Enhanced random forests were used by [268], which employed two-layered random forests as joint regressors, with the first layer acting as a discriminative body part classifier and the second one predicting joint locations according to the results of the first layer.Another type of approach is based on Hough forests. Hough forests are combinations of decision forests, and the leaf nodes in each tree are either a classification node or a regression node. The set of leaf nodes can be regarded as a discriminative codebook. The authors iof [269] directly regressed an offset to several joint locations at each pixel. Improved versions include an optimized objective, like a parts objective (“PARTS”) based on discrete information gain [9], while other works report the generalization problem of the specified objective [270,271]. Furthermore, sparse representation (SR) is used to extract the most significant training samples, and later on, all estimations are carried out based on these samples [168,169,170,171].
4.1.2. Generative Methods
4.1.3. Combined Methods of Discriminative and Generative Methods
4.2. Bottom-Up Methods and Top-Down Methods
4.2.1. Bottom-Up Methods
- Pixel- or superpixel-based methods. Pixel information can also be used to boost pose estimation accuracy [186]. For example, pixel information is used as input to an iterative parsing process, which learns better features tuned to a particular image [182].The pixels or superpixels of an image can also be used to formulate a segmentation function and be integrated into pose estimation. For example, they can be used to formulate the energy function of segmentation algorithms and integrate object segmentation with a joint optimization [187,191,193].Pixel-based methods can also be combined with other methods. For example, the authors of [192] extend the per-pixel classification method with graph-cut optimization, which is an energy minimization framework. Furthermore, results from segmentation can be utilized to enhance pixel-level estimation. The authors of [188] propose an approach that progressively reduces the search space for body parts by employing “grabcut” initialized on detected regions to further prune the search space [189,190]. Part-based and pixel-based approaches can also be combined in a single optimization framework [208].The superpixels are also useful in restricting the joint positions in the human body model [283]. In superpixel-based methods, body part matching and foreground estimation obtained by superpixel labeling could be optimized, for example, with a branch-and-bound (BB) algorithm [97,183,184,185]. Additionally, the authors of [284] compare the quality of segmentation derived from appearance models generated by several approaches.
- Part-based methods. Part-based methods solve pose estimation problems through learning body part appearance and position models. In part-based methods, body part candidates are first detected from image evidence, and then detected body parts are assembled to fit image observations and a body plan [206]. As an iconic work, a flexible mixture of parts model was introduced in [80], which extends the deformable parts model (DPM) [41] for articulated 2D body pose estimation. It was further improved using a compositional and/or graph grammar model [285].One key issue in part-based methods is to decide how to fuse responses of each single body part into a whole, and this is related to how the human body is modeled. We organize the following based on the characteristics of the human body models, and further divide part-based methods.
- (a)
- Pictorial Structures. Pictorial structures [36,77,79,189,194,196,197,286] are a kind of graphical kinematic model over detection methods, with the nodes of the graph representing object parts, and edges between parts encoding pairwise geometric relationships.Different deformations of the classic Pictorial Structures models have been developed, such as Adaptive Pictorial Structures (APS) [79], Multi-person Pictorial Structures (MPS) [195], Poselet Conditioned Pictorial Structures [198], the Fields of Parts (FOP) [199], and others.The tree structure is one of the most successfully applied pictorial structures. The model decomposes a tree structure into unary appearance terms and pairwise potentials between pairs of physically-connected parts, as shown in Figure 16a. With sliding windows methods, trained body part templates (HOG templates are visualized in Figure 6b) are compared with image features. Responses from all body parts are passed through the tree structure (as shown in Figure 16b), and a final score is calculated at the root of the tree.
- (b)
- Enhanced Kinematic Models. Enhanced kinematic models often have better appearance, and are more expressive in describing pose constraints. For example, a variety of modes are included to enhance the representation abilities of the kinematic model, such as the Multimodal decomposable model (MODEC) model [88], which has a left and right mode and half- and full-bodied modes.There have also been many studies conducted on improving kinematic models with cascaded structures. For example, the authors of [36] propose a coarse-to-fine cascade of pictorial structure models. The states of cascade framework could be pruned and computed [201]. By resorting to multiple trees, the framework estimates parameters for all models, requiring only a linear increase in computation over learning or inference than a single tractable sub-model [200]. The authors of [84] propose a new hierarchical spatial model that can capture an exponential number of poses with a compact mixture representation on each part. Using latent nodes, it represents a high-order spatial relationship among parts with exact inference.Furthermore, instead of pre-defining a kinematic model, a latent tree model [287] can recover a tree-structured graphical model which best approximates the distributions of a set of observations. In addition, by modifying regression methods, pose estimation accuracy can be improved. For example, the authors of [187] introduce part-dependent body joint regressors to classify the body parts and predict joint locations.The local scores of children in tree-structured models could be correctly traversed to their parents, while in case occlusion, the score may traverse to the wrong parent, resulting in missing parts and inaccurate detection, turning the tree structure into a graph [288]. Enhanced tree-structured models are also proposed to deal with this problem. The occlusion rectification method based on regression could detect occlusion by encoding the kinematic configurations in a tree. Since non-adjacent parts are independent, the occluded parts could be estimated [289]. The problems of foreshortening and part scale variation can be addressed by defining a body part with body joints instead of body limbs [206,258,290].None-tree methods have recently been proposed to facilitate stronger structure constraints, and can be optimized using convex programming or belief propagation [130]. It is believed that loopy graphical models are necessary when combined parts are used to handle large variance in appearance [87]. Loopy Graphical Models [202,203] begin by sending messages from the leaf nodes to the root, and then from the root node to the rest. Articulated grammar models are another example of non-tree models. The authors of [285] present a framework using the articulated grammar model to integrate a background model into the grammar to improve localization performance.
4.2.2. Top-Down Methods
4.2.3. Combined Bottom-Up and Top-Down Methods
- Combined detection- and recognition-based methods. Motivated by extensive literature on both detection [33,35,51,58,59,200] and recognition [32,52,236,260,292,293,294], many works explore the possibility of combing these two types of methods together to enhance estimation accuracy [37,204]. For example, by combining the graphical kinematic models with detection methods, the detection and 3D poses could be obtained simultaneously [60,205,206,207]. On the other hand, the authors of [295] introduce a method of monocular 3D pose estimation from video using action detection on top of a 2D deformable part.
- Combined pixel-based and part-based methods. Concurrent optimizing object matching and segmentation enables more robust results, since the two closely-related pixel-based and part-based methods support each other [46,193,208]. For example, pixel-wise body-part labels can be obtained by combining part-based and pixel-based approaches in a single optimization framework [208].The authors of Bray et al. [205] use graph cuts to optimize pose parameters to perform integrated segmentation and 3D pose estimation of a human body. Global minima of energies can be found by graph cut [209], and the graph cut computation is made significantly faster by using the dynamic graph cut algorithm [210].
4.3. Motion-Based Methods
5. Datasets, Error Measurements, and Toolkits
5.1. Datasets
5.2. Error Measurements
5.3. Toolkits
6. Discussion
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Cheng, S.Y.; Trivedi, M.M. Human Posture Estimation Using Voxel Data for “Smart” Airbag Systems: Issues and Framework. In Proceedings of the IEEE Intelligent Vehicles Symposium, Parma, Italy, 14–17 June 2004; pp. 84–89.
- Dinh, D.L.; Lim, M.J.; Thang, N.D.; Lee, S.; Kim, T.S. Real-Time 3D Human Pose Recovery from a Single Depth Image Using Principal Direction Analysis. Appl. Intell. 2014, 41, 473–486. [Google Scholar] [CrossRef]
- Hirota, M.; Nakajima, Y.; Saito, M.; Uchiyama, M. Human Body Detection Technology by Thermoelectric Infrared Imaging Sensor. In Proceedings of the International Technical Conference on the Enhanced Safety of Vehicles, Nagoya, Japan, 19–22 May 2003; pp. 1–10.
- Buys, K.; Cagniart, C.; Baksheev, A.; De Laet, T.; De Schutter, J.; Pantofaru, C. An Adaptable System for RGB-D Based Human Body Detection and Pose Estimation. J. Vis. Commun. Image Represent. 2014, 25, 39–52. [Google Scholar] [CrossRef]
- Meet Kinect for Windows. Available online: http://www.microsoft.com/en-us/kinectforwindows (accessed on 11 November 2016).
- Leap Motion. Available online: http://www.leapmotion.com (accessed on 11 November 2016).
- GestureTek. Available online: http://www.gesturetek.com (accessed on 11 November 2016).
- Oleinikov, G.; Miller, G.; Little, J.J.; Fels, S. Task-based Control of Articulated Human Pose Detection for Openvl. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Colorado Springs, CO, USA, 24–26 March 2014; pp. 682–689.
- Shotton, J.; Sharp, T.; Kipman, A.; Fitzgibbon, A.; Finocchio, M.; Blake, A.; Cook, M.; Moore, R. Real-Time Human Pose Recognition in Parts from Single Depth Images. Commun. ACM 2013, 56, 116–124. [Google Scholar] [CrossRef]
- Gong, W.; Brauer, J.; Arens, M.; Gonzalez, J. Modeling vs. Learning Approaches for Monocular 3D Human Pose Estimation. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Barcelona, Spain, 6–13 November 2011; pp. 1287–1294.
- Cedras, C.; Shah, M. Motion-Based Recognition: A Survey. Image Visi. Comput. 1995, 13, 129–155. [Google Scholar] [CrossRef]
- Koschan, A.; Kang, S.; Paik, J.; Abidi, B.; Abidi, M. Color Active Shape Models for Tracking Non-rigid Objects. Pattern Recognit. Lett. 2003, 24, 1751–1765. [Google Scholar] [CrossRef]
- Baumberg, A.M. Learning Deformable Models for Tracking Human Motion. Ph.D. Thesis, The University of Leeds, Leeds, UK, 1995. [Google Scholar]
- Krotosky, S.J.; Trivedi, M.M. Occupant Posture Analysis Using Reflectance and Stereo Image for “Smart” Airbag Deployment. In Proceedings of the IEEE Intelligent Vehicles Symposium, Parma, Italy, 14–17 June 2004; pp. 698–703.
- Moeslund, T.B.; Hilton, A.; Krüger, V. A Survey of Advances in Vision-Based Human Motion Capture and Analysis. Comput. Vis. Image Underst. 2006, 104, 90–126. [Google Scholar] [CrossRef]
- Poppe, R. Vision-Based Human Motion Analysis: An Overview. Comput. Vis. Image Underst. 2007, 108, 4–18. [Google Scholar] [CrossRef]
- Li, Y.; Sun, Z. Vision-Based Human Pose Estimation for Pervasive Computing. In Proceedings of the ACM Workshop on Ambient Media Computing, Beijing, China, 23 October 2009; pp. 49–56.
- Liu, Z.; Zhu, J.; Bu, J.; Chen, C. A Survey of Human Pose Estimation: The Body Parts Parsing based Methods. J. Vis. Commun. Image Represent. 2015, 32, 10–19. [Google Scholar] [CrossRef]
- Lepetit, V.; Fua, P. Monocular Model-Based 3D Tracking of Rigid Objects: A Survey. Found. Trends Comput. Graph. Vis. 2005, 1, 1–89. [Google Scholar] [CrossRef]
- Perez-Sala, X.; Escalera, S.; Angulo, C.; Gonzalez, J. A Survey on Model Based Approaches for 2D and 3D Visual Human Pose Recovery. Sensors 2014, 14, 4189–4210. [Google Scholar] [CrossRef] [PubMed]
- Hu, W.; Tan, T.; Wang, L.; Maybank, S. A Survey on Visual Surveillance of Object Motion and Behaviors. IEEE Trans. Syst. Man Cybern. C Appl. Rev. 2004, 34, 334–352. [Google Scholar] [CrossRef]
- Lepetit, V.; Fua, P. Monocular Model-Based 3D Tracking of Rigid Objects. Found. Trends. Comput. Graph. Vis. 2005, 1, 1–89. [Google Scholar] [CrossRef]
- Yao, A.; Gall, J.; Fanelli, G.; Van Gool, L.J. Does Human Action Recognition Benefit from Pose Estimation? In Proceedings of the British Machine Vision Conference, Dundee, UK, 29 August–2 September 2011; pp. 67.1–67.11.
- Yao, A.; Gall, J.; Van Gool, L. Coupled Action Recognition and Pose Estimation from Multiple Views. Int. J. Comput. Vis. 2012, 100, 16–37. [Google Scholar] [CrossRef]
- Nie, X.; Xiong, C.; Zhu, S.C. Joint Action Recognition and Pose Estimation from Video. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Boston, WA, USA, 7–12 June 2015; pp. 1293–1301.
- Gong, W.; Gonzalez, J.; Roca, F.X. Human action recognition based on estimated weak poses. EURASIP J. Adv. Signal Process. 2012, 2012, 1–14. [Google Scholar] [CrossRef]
- Poppe, R. A Survey on Vision-Based Human Action Recognition. Image Vis. Comput. 2010, 28, 976–990. [Google Scholar] [CrossRef]
- Weinland, D.; Ronfard, R.; Boyer, E. A Survey of Vision-based Methods for Action Representation, Segmentation and Recognition. Comput. Vis. Image Underst. 2011, 115, 224–241. [Google Scholar] [CrossRef]
- Aggarwal, J.K.; Ryoo, M.S. Human Activity Analysis: A Review. ACM Comput. Surv. 2011, 43, 16. [Google Scholar] [CrossRef]
- Chen, L.; Wei, H.; Ferryman, J. A Survey of Human Motion Analysis Using Depth Imagery. Pattern Recognit. Lett. 2013, 34, 1995–2006. [Google Scholar] [CrossRef]
- Inferring Body Pose without Tracking Body Parts. Available online: http://ieeexplore.ieee.org/document/854946/ (accessed on 10 November 2016).
- Agarwal, A.; Triggs, B. Recovering 3D Human Pose from Monocular Images. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 44–58. [Google Scholar] [CrossRef] [PubMed]
- Gavrila, D.M. A Bayesian, Exemplar-Based Approach to Hierarchical Shape Matching. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1408–1421. [Google Scholar] [CrossRef] [PubMed]
- Elgammal, A.; Lee, C.S. Inferring 3D Body Pose from Silhouettes Using Activity Manifold Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004; pp. 681–688.
- Viola, P.; Jones, M.J.; Snow, D. Detecting Pedestrians Using Patterns of Motion and Appearance. Int. J. Comput. Vis. 2005, 63, 153–161. [Google Scholar] [CrossRef]
- Sapp, B.; Toshev, A.; Taskar, B. Cascaded Models for Articulated Pose Estimation. In Proceedings of the European Conference on Computer Vision, Crete, Greece, 5–11 September 2010; pp. 406–420.
- Dimitrijevic, M.; Lepetit, V.; Fua, P. Human Body Pose Detection Using Bayesian Spatio-Temporal Templates. Comput. Vis. Image Underst. 2006, 104, 127–139. [Google Scholar] [CrossRef]
- Weinrich, C.; Volkhardt, M.; Gross, H.M. Appearance-based 3D Upper-Body Pose Estimation and Person Re-Identification on Mobile Robots. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics, Manchester, UK, 13–16 October 2013; pp. 4384–4390.
- Wren, C.R.; Azarbayejani, A.; Darrell, T.; Pentland, A.P. Pfinder: Real-Time Tracking of the Human Body. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 780–785. [Google Scholar] [CrossRef]
- Kakadiaris, I.A.; Metaxas, D. 3D Human Body Model Acquisition from Multiple Views. In Proceedings of the IEEE International Conference on Computer Vision, Cambridge, MA, USA, 20–23 June 1995; pp. 618–623.
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object Detection with Discriminatively Trained Part-Based Models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed]
- Zahn, C.T.; Roskies, R.Z. Fourier Descriptors for Plane Closed Curves. IEEE Trans. Comput. 1972, 100, 269–281. [Google Scholar] [CrossRef]
- Belongie, S.; Malik, J.; Puzicha, J. Shape Matching and Object Recognition Using Shape Contexts. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 509–522. [Google Scholar] [CrossRef]
- Mori, G.; Belongie, S.; Malik, J. Efficient Shape Matching Using Shape Contexts. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1832–1837. [Google Scholar] [CrossRef] [PubMed]
- Ek, C.H.; Torr, P.H.; Lawrence, N.D. Gaussian Process Latent Variable Models for Human Pose Estimation. In Machine Learning for Multimodal Interaction; Springer: Heidelberg, Germany, 2007; pp. 132–143. [Google Scholar]
- Jiang, H. Human Pose Estimation Using Consistent Max Covering. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1911–1918. [Google Scholar] [CrossRef] [PubMed]
- Zolfaghari, M.; Jourabloo, A.; Gozlou, S.G.; Pedrood, B.; Manzuri-Shalmani, M.T. 3D Human Pose Estimation from Image Using Couple Sparse Coding. Mach. Vis. Appl. 2014, 25, 1489–1499. [Google Scholar] [CrossRef]
- Arkin, E.M.; Chew, L.P.; Huttenlocher, D.P.; Kedem, K.; Mitchell, J.S. An Efficiently Computable Metric for Comparing Polygonal Shapes. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 13, 209–216. [Google Scholar] [CrossRef]
- Gorelick, L.; Galun, M.; Sharon, E.; Basri, R.; Brandt, A. Shape Representation and Classification Using the Poisson Equation. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1991–2005. [Google Scholar] [CrossRef] [PubMed]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; pp. 886–893.
- Zhu, Q.; Yeh, M.C.; Cheng, K.T.; Avidan, S. Fast Human Detection Using a Cascade of Histograms of Oriented Gradients. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; pp. 1491–1498.
- Shakhnarovich, G.; Viola, P.; Darrell, T. Fast Pose Estimation with Parameter-Sensitive Hashing. In Proceedings of the IEEE International Conference on Computer Vision, Madison, WI, USA, 16–22 June 2003; pp. 750–757.
- Nayak, S.; Sarkar, S.; Loeding, B. Distribution-Based Dimensionality Reduction Applied to Articulated Motion Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 795–810. [Google Scholar] [CrossRef] [PubMed]
- Lowe, D.G. Object Recognition from Local Scale-Invariant Features. In Proceedings of the IEEE International Conference on Computer Vision, Corfu, Greece, 20–25 September 1999; pp. 1150–1157.
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Agarwal, A.; Triggs, B. A Local Basis Representation for Estimating Human Pose from Cluttered Images. In Proceedings of the Asian Conference on Computer Vision, Hyderabad, India, 13–16 January 2006; pp. 50–59.
- Scovanner, P.; Ali, S.; Shah, M. A 3-Dimensional Sift Descriptor and Its Application to Action Recognition. In Proceedings of the International Conference on Multimedia, Augsburg, Bavaria, Germany, 23–28 September 2007; pp. 357–360.
- Wu, Y.; Lin, J.; Huang, T.S. Analyzing and Capturing Articulated Hand Motion in Image Sequences. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1910–1922. [Google Scholar] [PubMed]
- Sabzmeydani, P.; Mori, G. Detecting Pedestrians by Learning Shapelet Features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 18–23 June 2007; pp. 1–8.
- Ionescu, C.; Li, F.; Sminchisescu, C. Latent Structured Models for Human Pose Estimation. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2220–2227.
- Serre, T.; Wolf, L.; Poggio, T. Object Recognition with Features Inspired by Visual Cortex. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; pp. 994–1000.
- Agarwal, A.; Triggs, B. Hyperfeatures–Multilevel Local Coding for Visual Recognition. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 30–43.
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; pp. 2169–2178.
- Kanaujia, A.; Sminchisescu, C.; Metaxas, D. Semi-Supervised Hierarchical Models for 3D Human Pose Reconstruction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 18–23 June 2007; pp. 1–8.
- Li, S.; Chan, A.B. 3D Human Pose Estimation from Monocular Images with Deep Cnvolutional Neural Network. In Proceedings of the Asian Conference on Computer Vision, Singapore, 1–5 November 2014; pp. 332–347.
- Li, S.; Liu, Z.Q.; Chan, A. Heterogeneous Multi-Task Learning for Human Pose Estimation with Deep Convolutional Neural Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 482–489.
- Pfister, T.; Charles, J.; Zisserman, A. Flowing Convnets for Human Pose Estimation in Videos. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1913–1921.
- Roberts, T.J.; McKenna, S.J.; Ricketts, I.W. Human Pose Estimation Using Learnt Probabilistic Region Similarities and Partial Configurations. In Proceedings of the European Conference on Computer Vision, Prague, Czech Republic, 11–14 May 2004; pp. 291–303.
- Bourdev, L.; Maji, S.; Brox, T.; Malik, J. Detecting People Using Mutually Consistent Poselet Activations. In Proceedings of the European Conference on Computer Vision, Crete, Greece, 5–11 September 2010; pp. 168–181.
- Gkioxari, G.; Hariharan, B.; Girshick, R.; Malik, J. Using k-Poselets for Detecting People and Localizing Their Keypoints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3582–3589.
- Zuffi, S.; Freifeld, O.; Black, M.J. From Pictorial Structures to Deformable Structures. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3546–3553.
- Lu, Y.; Jiang, H. Human Movement Summarization and Depiction from Videos. In Proceedings of the IEEE International Conference on Multimedia and Expo, San Jose, CA, USA, 15–19 July 2013; pp. 1–6.
- Sminchisescu, C.; Triggs, B. Covariance Scaled Sampling for Monocular 3D Body Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; pp. I-447–I-454.
- Johnson, S.; Everingham, M. Clustered Pose and Nonlinear Appearance Models for Human Pose Estimation. In Proceedings of the British Machine Vision Conference, Aberystwyth, Wales, UK, 30 August–2 September 2010; pp. 12.1–12.11.
- Felzenszwalb, P.; McAllester, D.; Ramanan, D. A Discriminatively Trained, Multiscale, Deformable Part Model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 24–26 June 2008; pp. 1–8.
- Felzenszwalb, P.F.; Huttenlocher, D.P. Pictorial Structures for Object Recognition. Int. J. Comput. Vis. 2005, 61, 55–79. [Google Scholar] [CrossRef]
- Andriluka, M.; Roth, S.; Schiele, B. Pictorial Structures Revisited: People Detection and Articulated Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1014–1021.
- Andriluka, M.; Roth, S.; Schiele, B. Monocular 3D Pose Estimation and Tracking by Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 623–630.
- Sapp, B.; Jordan, C.; Taskar, B. Adaptive Pose Priors for Pictorial Structures. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 422–429.
- Yang, Y.; Ramanan, D. Articulated Pose Estimation with Flexible Mixtures-of-Parts. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1385–1392.
- Chen, X.; Yuille, A.L. Parsing Occluded People by Flexible Compositions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3945–3954.
- Wang, Y.; Mori, G. Multiple Tree Models for Occlusion and Spatial Constraints in Human Pose Estimation. In Proceedings of the European Conference on Computer Vision, Marseille, France, 12–18 October 2008; pp. 710–724.
- Johnson, S.; Everingham, M. Learning Effective Human Pose Estimation from Inaccurate Annotation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1465–1472.
- Tian, Y.; Zitnick, C.L.; Narasimhan, S.G. Exploring the Spatial Hierarchy of Mixture Models for Human Pose Estimation. In Proceedings of the European Conference on Computer Vision, Firenze, Italy, 7–13 October 2012; pp. 256–269.
- Duan, K.; Batra, D.; Crandall, D.J. A Multi-Layer Composite Model for Human Pose Estimation. In Proceedings of the British Machine Vision Conference, Surrey, UK, 3–7 September 2012; pp. 116.1–116.11.
- Sun, M.; Savarese, S. Articulated Part-Based Model for Joint Object Detection and Pose Estimation. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 723–730.
- Wang, Y.; Tran, D.; Liao, Z. Learning Hierarchical Poselets for Human Parsing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1705–1712.
- Sapp, B.; Taskar, B. Modec: Multimodal Decomposable Models for Human Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3674–3681.
- Xiao, Y.; Lu, H.; Li, S. Posterior Constraints for Double-Counting Problem in Clustered Pose Estimation. In Proceedings of the IEEE International Conference on Image Processing, Orlando, FL, USA, 30 September–3 October 2012; pp. 5–8.
- Chen, X.; Yuille, A.L. Articulated Pose Estimation by a Graphical Model with Image Dependent Pairwise Relations. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 1736–1744.
- Lehrmann, A.; Gehler, P.; Nowozin, S. A Non-parametric Bayesian Network Prior of Human Pose. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1281–1288.
- Tashiro, K.; Kawamura, T.; Sei, Y.; Nakagawa, H.; Tahara, Y.; Ohsuga, A. Refinement of Ontology-Constrained Human Pose Classification. In Proceedings of the IEEE International Conference on Semantic Computing, Newport Beach, CA, USA, 16–18 June 2014; pp. 60–67.
- Cootes, T.F.; Taylor, C.J.; Cooper, D.H.; Graham, J. Active Shape Models-Their Training and Application. Comput. Vis. Image Underst. 1995, 61, 38–59. [Google Scholar] [CrossRef]
- Freifeld, O.; Weiss, A.; Zuffi, S.; Black, M.J. Contour People: A Parameterized Model of 2D Articulated Human Shape. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 639–646.
- Baumberg, A.; Hogg, D. Learning Flexible Models from Image Sequences. In Proceedings of the European Conference on Computer Vision, Stockholm, Sweden, 2–6 May 1994; pp. 297–308.
- Urtasun, R.; Fua, P. 3D Human Body Tracking Using Deterministic Temporal Motion Models. In Proceedings of the European Conference on Computer Vision, Prague, Czech Republic, 11–14 May 2004; pp. 92–106.
- Jiang, H. Finding Human Poses in Videos Using Concurrent Matching and Segmentation. In Proceedings of the Asian Conference on Computer Vision, Queenstown, New Zealand, 8–12 November 2010; pp. 228–243.
- Sidenbladh, H.; De la Torre, F.; Black, M.J. A Framework for Modeling the Appearance of 3D Articulated Figures. In Proceedings of the IEEE International Conference on Automatic Face and Gesture Recognition, Grenoble, France, 28–30 March 2000; pp. 368–375.
- Anguelov, D.; Srinivasan, P.; Koller, D.; Thrun, S.; Rodgers, J.; Davis, J. SCAPE: Shape Completion and Animation of People. ACM Trans. Graph. 2005, 24, 408–416. [Google Scholar] [CrossRef]
- Peng, G.; Weiss, A.; Balan, A.O.; Black, M.J. Estimating Human Shape and Pose from a Single Image. In Proceedings of the IEEE International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 1381–1388.
- Bălan, A.O.; Sigal, L.; Black, M.J.; Davis, J.E.; Haussecker, H.W. Detailed Human Shape and Pose from Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 18–23 June 2007; pp. 1–8.
- Ge, S.; Fan, G. Articulated Non-Rigid Point Set Registration for Human Pose Estimation from 3D Sensors. Sensors 2015, 15, 15218–15245. [Google Scholar] [CrossRef] [PubMed]
- Ge, S.; Fan, G. Non-rigid Articulated Point Set Registration for Human Pose Estimation. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Waikoloa Beach, HI, USA, 6–9 January 2015; pp. 94–101.
- Zuffi, S.; Black, M.J. The Stitched Puppet: A Graphical Model of 3D Human Shape and Pose. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3537–3546.
- Balan, A.O.; Black, M.J.; Haussecker, H.; Sigal, L. Shining a Light on Human Pose: On Shadows, Shading and the Estimation of Pose and Shape. In Proceedings of the IEEE International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8.
- De Aguiar, E.; Theobalt, C.; Stoll, C.; Seidel, H.P. Marker-Less Deformable Mesh Tracking for Human Shape and Motion Capture. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 18–23 June 2007; pp. 1–8.
- Sminchisescu, C.; Triggs, B. Estimating Articulated Human Motion with Covariance Scaled Sampling. Int. J. Robot. Res. 2003, 22, 371–391. [Google Scholar] [CrossRef]
- Demirdjian, D.; Ko, T.; Darrell, T. Constraining Human Body Tracking. In Proceedings of the IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; pp. 1071–1078.
- Jaeggli, T.; Koller-Meier, E.; Van Gool, L. Learning Generative Models for Monocular Body Pose Estimation. In Proceedings of the Asian Conference on Computer Vision, Tokyo, Japan, 18–22 November 2007; pp. 608–617.
- Wang, J.M.; Fleet, D.J.; Hertzmann, A. Multifactor Gaussian Process Models for Style-Content Separation. In Proceedings of the International Conference on Machine Learning, Las Vegas, NV, USA, 25–28 June 2007; pp. 975–982.
- Urtasun, R.; Fleet, D.J.; Hertzmann, A.; Fua, P. Priors for People Tracking from Small Training Sets. In Proceedings of the IEEE International Conference on Computer Vision, Beijing, China, 17–20 October 2005; pp. 403–410.
- Brubaker, M.A.; Fleet, D.J.; Hertzmann, A. Physics-Based Person Tracking Using Simplified Lower-Body Dynamics. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 18–23 June 2007; pp. 1–8.
- Metaxas, D.; Terzopoulos, D. Shape and Nonrigid Motion Estimation through Physics-Based Synthesis. IEEE Trans. Pattern Anal. Mach. Intell. 1993, 15, 580–591. [Google Scholar] [CrossRef]
- Parameswaran, V.; Chellappa, R. View Independent Human Body Pose Estimation from a Single Perspective Image. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004; pp. 16–22.
- Pons-Moll, G.; Rosenhahn, B. Model-Based Pose Estimation. In Visual Analysis of Humans; Springer: Heidelberg, Germany, 2011; pp. 139–170. [Google Scholar]
- Güdükbay, U.; Demir, I.; Dedeoğlu, Y. Motion Capture and Human Pose Reconstruction from a Single-View Video Sequence. Digit. Signal Process. 2013, 23, 1441–1450. [Google Scholar] [CrossRef]
- Zhang, W.; Shang, L.; Chan, A.B. A Robust Likelihood Function for 3D Human Pose Tracking. IEEE Trans. Image Process. 2014, 23, 5374–5389. [Google Scholar] [CrossRef] [PubMed]
- Babagholami Mohamadabadi, B.; Jourabloo, A.; Zarghami, A.; Kasaei, S. A Bayesian Framework for Sparse Representation Based 3D Human Pose Estimation. IEEE Signal Process. Lett. 2014, 21, 297–300. [Google Scholar] [CrossRef]
- Zhu, Y.; Dariush, B.; Fujimura, K. Controlled Human Pose Estimation from Depth Image Streams. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 24–26 June 2008; pp. 1–8.
- Ronfard, R.; Schmid, C.; Triggs, B. Learning to Parse Pictures of People. In Proceedings of the European Conference on Computer Vision, Copenhagen, Denmark, 28–31 May 2002; pp. 700–714.
- Okada, R.; Soatto, S. Relevant Feature Selection for Human Pose Estimation and Localization in Cluttered Images. In Proceedings of the European Conference on Computer Vision, Marseille, France, 12–18 October 2008; pp. 434–445.
- Zhang, W.; Shen, J.; Liu, G.; Yu, Y. A Latent Clothing Attribute Approach for Human Pose Estimation. In Proceedings of the Asian Conference on Computer Vision, Singapore, 1–5 November 2014; pp. 146–161.
- Metric Regression Forests for Human Pose Estimation. Available online: www.bmva.org/bmvc/2013/Papers/paper0004/paper0004.pdf (accessed on 10 November 2016).
- Sedai, S.; Bennamoun, M.; Huynh, D. Evaluating Shape and Appearance Descriptors for 3D Human Pose Estimation. In Proceedings of the IEEE Conference on Industrial Electronics and Applications, Beijing, China, 21–23 June 2011; pp. 293–298.
- Sedai, S.; Bennamoun, M.; Huynh, D. Context-Based Appearance Descriptor for 3D Human Pose Estimation from Monocular Images. In Proceedings of the International Conference on Digital Image Computing: Techniques and Applications, Melbourne, Australia, 1–3 December 2009; pp. 484–491.
- Agarwal, A.; Triggs, B. Learning to Track 3D Human Motion from Silhouettes. In Proceedings of the International Conference on Machine Learning, Banff, AB, Canada, 4–8 July 2004; pp. 9–16.
- Agarwal, A.; Triggs, B. 3D Human Pose from Silhouettes by Relevance Vector Regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004; pp. 882–888.
- Sminchisescu, C.; Kanaujia, A.; Li, Z.; Metaxas, D. Discriminative Density Propagation for 3D Human Motion Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; pp. 390–397.
- Jordan, M.I.; Jacobs, R.A. Hierarchical Mixtures of Experts and the EM Algorithm. Neural Comput. 1994, 6, 181–214. [Google Scholar] [CrossRef]
- Ning, H.; Xu, W.; Gong, Y.; Huang, T. Discriminative Learning of Visual Words for 3D Human Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 24–26 June 2008; pp. 1–8.
- Ionescu, C.; Bo, L.; Sminchisescu, C. Structural SVM for Visual Localization and Continuous State Estimation. In Proceedings of the IEEE International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 1157–1164.
- Bo, L.; Sminchisescu, C. Structured Output-Associative Regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 2403–2410.
- Rosales, R.; Athitsos, V.; Sigal, L.; Sclaroff, S. 3D Hand Pose Reconstruction Using Specialized Mappings. In Proceedings of the IEEE International Conference on Computer Vision, Vancouver, BC, Canada, 7–14 July 2001; pp. 378–385.
- Barbulescu, A.; Gong, W.; Gonzalez, J.; Moeslund, T.B.; Xavier Roca, F. 3D Human Pose Estimation Using 2D Body Part Detectors. In Proceedings of the International Conference on Pattern Recognition, Tsukuba, Japan, 11–15 November 2012; pp. 2484–2487.
- Cour, T.; Sapp, B.; Jordan, C.; Taskar, B. Learning from Ambiguously Labeled Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 919–926.
- Simo-Serra, E.; Quattoni, A.; Torras, C.; Moreno-Noguer, F. A Joint Model for 2D and 3D Pose Estimation from a Single Image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3634–3641.
- Akhter, I.; Black, M.J. Pose-Conditioned Joint Angle Limits for 3D Human Pose Reconstruction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1446–1455.
- Yang, Y.; Saleemi, I.; Shah, M. Discovering Motion Primitives for Unsupervised Grouping and One-Shot Learning of Human Actions, Gestures, and Expressions. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1635–1648. [Google Scholar] [CrossRef] [PubMed]
- Olshausen, B.A.; Field, D.J. Sparse Coding with an Overcomplete Basis Set: A Strategy Employed by V1. Vis. Res. 1997, 37, 3311–3325. [Google Scholar] [CrossRef]
- Gong, S.; Xiang, T.; Hongeng, S. Learning Human Pose in Crowd. In Proceedings of the ACM International Workshop on Multimodal Pervasive Video Analysis, Firenze, Italy, 29 October 2010; pp. 47–52.
- Cour, T.; Jordan, C.; Miltsakaki, E.; Taskar, B. Movie/Script: Alignment and Parsing of Video and Text Transcription. In Proceedings of the European Conference on Computer Vision, Marseille, France, 12–18 October 2008; pp. 158–171.
- Taylor, J.; Shotton, J.; Sharp, T.; Fitzgibbon, A. The Vitruvian Manifold: Inferring Dense Correspondences for One-Shot Human Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 103–110.
- Baak, A.; Müller, M.; Bharaj, G.; Seidel, H.P.; Theobalt, C. A Data-Driven Approach for Real-Time Full Body Pose Reconstruction from a Depth Camera. In Consumer Depth Cameras for Computer Vision; Springer: London, UK, 2013; pp. 71–98. [Google Scholar]
- Freifeld, O.; Black, M.J. Lie Bodies: A Manifold Representation of 3D Human Shape. In Proceedings of the European Conference on Computer Vision, Firenze, Italy, 7–13 October 2012; pp. 1–14.
- Christoudias, C.M.; Darrell, T. On Modelling Nonlinear Shape-and-Texture Appearance Manifolds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; pp. 1067–1074.
- Morariu, V.I.; Camps, O.I. Modeling Correspondences for Multi-Camera Tracking Using Nonlinear Manifold Learning and Target Dynamics. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; pp. 545–552.
- Gall, J.; Yao, A.; Van Gool, L. 2D Action Recognition Serves 3D Human Pose Estimation. In Proceedings of the European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010; pp. 425–438.
- Gupta, A.; Chen, T.; Chen, F.; Kimber, D.; Davis, L.S. Context and Observation Driven Latent Variable Model for Human Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 24–26 June 2008; pp. 1–8.
- Mori, G.; Pantofaru, C.; Kothari, N.; Leung, T.; Toderici, G.; Toshev, A.; Yang, W. Pose Embeddings: A Deep Architecture for Learning to Match Human Poses. arXiv, 2015; arXiv:1507.00302. [Google Scholar]
- Sminchisescu, C.; Jepson, A. Generative Modeling for Continuous Non-Linearly Embedded Visual Inference. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 759–766.
- Wang, J.; Yang, J.; Yu, K.; Lv, F.; Huang, T.; Gong, Y. Locality-Constrained Linear Coding for Image Classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3360–3367.
- Sun, L.; Song, M.; Tao, D.; Bu, J.; Chen, C. Motionlet LLC Coding for Discriminative Human Pose Estimation. Multimed. Tools Appl. 2014, 73, 327–344. [Google Scholar] [CrossRef]
- Ouyang, W.; Chu, X.; Wang, X. Multi-Source Deep Learning for Human Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2329–2336.
- Gkioxari, G.; Girshick, R.; Malik, J. Contextual Action Recognition with R* Cnn. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1080–1088.
- Tompson, J.J.; Jain, A.; LeCun, Y.; Bregler, C. Joint Training of a Convolutional Network and a Graphical Model for Human Pose Estimation. In Proceedings of the Advances in Neural Information Processing Systems, Beijing, China, 21–26 June 2014; pp. 1799–1807.
- Jain, A.; Tompson, J.; Andriluka, M.; Taylor, G.W.; Bregler, C. Learning Human Pose Estimation Features with Convolutional Networks. arXiv, 2014; arXiv:1312.7302. [Google Scholar]
- Toshev, A.; Szegedy, C. Deeppose: Human Pose Estimation via Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1653–1660.
- Pfister, T.; Simonyan, K.; Charles, J.; Zisserman, A. Deep Convolutional Neural Networks for Efficient Pose Estimation in Gesture Videos. In Proceedings of the Asian Conference on Computer Vision, Singapore, 1–5 November 2014; pp. 538–552.
- Fan, X.; Zheng, K.; Lin, Y.; Wang, S. Combining Local Appearance and Holistic View: Dual-Source Deep Neural Networks for Human Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1347–1355.
- Flitti, F.; Bennamoun, M.; Huynh, D.Q.; Owens, R.A. Probabilistic Human Pose Recovery from 2D Images. In Proceedings of the IEEE International Conference on Image Processing, Hong Kong, China, 12–15 September 2010; pp. 1517–1520.
- Daubney, B.; Xie, X. Entropy Driven Hierarchical Search for 3D Human Pose Estimation. In Proceedings of the British Machine Vision Conference, Dundee, UK, 29 August–2 September 2011; pp. 1–11.
- Hara, K.; Chellappa, R. Computationally Efficient Regression on a Dependency Graph for Human Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3390–3397.
- Gkioxari, G.; Hariharan, B.; Girshick, R.; Malik, J. R-CNNs for Pose Estimation and Action Detection. arXiv, 2014; arXiv:1406.5212. [Google Scholar]
- Carreira, J.; Agrawal, P.; Fragkiadaki, K.; Malik, J. Human Pose Estimation with Iterative Error Feedback. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4733–4742.
- Amit, Y.; Geman, D. Shape Quantization and Recognition with Randomized Trees. Neural Comput. 1997, 9, 1545–1588. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Chang, J.Y.; Nam, S.W. Fast Random-Forest-Based Human Pose Estimation Using a Multi-Scale and Cascade Approach. ETRI J. 2013, 35, 949–959. [Google Scholar] [CrossRef]
- Chen, C.; Yang, Y.; Nie, F.; Odobez, J.M. 3D human pose recovery from image by efficient visual feature selection. Comput. Vis. Image Underst. 2011, 115, 290–299. [Google Scholar] [CrossRef]
- Wright, J.; Yang, A.Y.; Ganesh, A.; Sastry, S.S.; Ma, Y. Robust Face Recognition via Sparse Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 210–227. [Google Scholar] [CrossRef] [PubMed]
- Huang, J.B.; Yang, M.H. Estimating Human Pose from Occluded Images. In Proceedings of the Asian Conference on Computer Vision, Xi’an, China, 23–27 September 2009; pp. 48–60.
- Huang, J.B.; Yang, M.H. Fast Sparse Representation with Prototypes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3618–3625.
- Orrite-Urunuela, C.; Herrero-Jaraba, J.E.; Rogez, G. 2D Silhouette and 3D Skeletal Models for Human Detection and Tracking. In Proceedings of the International Conference on Pattern Recognition, Cambridge, UK, 23–26 August 2004; pp. 244–247.
- Sigal, L.; Balan, A.; Black, M.J. Combined Discriminative and Generative Articulated Pose and Non-Rigid Shape Estimation. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007; pp. 1337–1344.
- Agarwal, A.; Triggs, B. Monocular Human Motion Capture with a Mixture of Regressors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; p. 72.
- Sidenbladh, H.; Black, M.J.; Fleet, D.J. Stochastic Tracking of 3D Human Figures Using 2D Image Motion. In Proceedings of the European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010; pp. 702–718.
- Lee, C.S.; Elgammal, A. Modeling View and Posture Manifolds for Tracking. In Proceedings of the IEEE International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8.
- Integrating Bottom-up/Top-down for Object Recognition by Data Driven Markov Chain Monte Carlo. Available online: http://ieeexplore.ieee.org/document/855894/ (accessed on 23 November 2016).
- Kuo, P.; Makris, D.; Nebel, J.C. Integration of Bottom-up/Top-down Approaches for 2D Pose Estimation Using Probabilistic Gaussian Modelling. Comput. Vis. Image Underst. 2011, 115, 242–255. [Google Scholar] [CrossRef]
- Kanaujia, A. Coupling Top-down and Bottom-up Methods for 3D Human Pose and Shape Estimation from Monocular Image Sequences. arXiv, 2014; arXiv:1410.0117. [Google Scholar]
- Rosales, R.; Sclaroff, S. Combining Generative and Discriminative Models in a Framework for Articulated Pose Estimation. Int. J. Comput. Vis. 2006, 67, 251–276. [Google Scholar]
- Torres, F.; Kropatsch, W.G. Top-down 3D Tracking and Pose Estimation of a Die Using Check-Points. In Proceedings of the Computer Vision Winter Workshop, Hernstein, Austria, 4–6 February 2013.
- Ramanan, D. Learning to Parse Images of Articulated Bodies. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 4–7 December 2006; pp. 1129–1136.
- Tian, T.P.; Sclaroff, S. Fast Globally Optimal 2D Human Detection with Loopy Graph Models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 81–88.
- Sun, M.; Telaprolu, M.; Lee, H.; Savarese, S. An Efficient Branch-and-Bound Algorithm for Optimal Human Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1616–1623.
- Nakariyakul, S. A Comparative Study of Suboptimal Branch and Bound Algorithms. Inf. Sci. 2014, 278, 545–554. [Google Scholar] [CrossRef]
- Wang, C.; Wang, Y.; Yuille, A. An Approach to Pose-based Action Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 915–922.
- Eichner, M.; Ferrari, V.; Zurich, S. Better Appearance Models for Pictorial Structures. In Proceedings of the British Machine Vision Conference, London, UK, 7–10 September 2009; pp. 1–11.
- Ferrari, V.; Marin-Jimenez, M.; Zisserman, A. Progressive Search Space Reduction for Human Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 24–26 June 2008; pp. 1–8.
- Ferrari, V.; Marin-Jimenez, M.; Zisserman, A. Pose Search: Retrieving People Using Their Pose. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1–8.
- Ferrari, V.; Marín-Jiménez, M.; Zisserman, A. 2D Human Pose Estimation in TV Shows. In Statistical and Geometrical Approaches to Visual Motion Analysis; Springer: Heidelberg, Germany, 2009; pp. 128–147. [Google Scholar]
- Wang, H.; Koller, D. Multi-Level Inference by Relaxed Dual Decomposition for Human Pose Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 2433–2440.
- Hernández-Vela, A.; Zlateva, N.; Marinov, A.; Reyes, M.; Radeva, P.; Dimov, D.; Escalera, S. Graph Cuts Optimization for Multi-Limb Human Segmentation in Depth Maps. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 726–732.
- Lu, H.; Shao, X.; Xiao, Y. Pose Estimation with Segmentation Consistency. IEEE Trans. Image Process. 2013, 22, 4040–4048. [Google Scholar] [PubMed]
- Andriluka, M.; Roth, S.; Schiele, B. People-Tracking-by-Detection and People-Detection-by-Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 24–26 June 2008; pp. 1–8.
- Eichner, M.; Ferrari, V. We Are Family: Joint Pose Estimation of Multiple Persons. In Proceedings of the European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010; pp. 228–242.
- Belagiannis, V.; Amin, S.; Andriluka, M.; Schiele, B.; Navab, N.; Ilic, S. 3D Pictorial Structures for Multiple Human Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1669–1676.
- Penmetsa, S.; Minhuj, F.; Singh, A.; Omkar, S. Autonomous UAV for Suspicious Action Detection Using Pictorial Human Pose Estimation and Classification. Electron. Lett. Comput. Vis. Image Anal. 2014, 13, 18–32. [Google Scholar]
- Pishchulin, L.; Andriluka, M.; Gehler, P.; Schiele, B. Poselet Conditioned Pictorial Structures. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 588–595.
- Kiefel, M.; Gehler, P.V. Human Pose Estimation with Fields of Parts. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 331–346.
- Weiss, D.; Sapp, B.; Taskar, B. Sidestepping Intractable Inference with Structured Ensemble Cascades. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 6–9 December 2010; pp. 2415–2423.
- Bo, Y.; Jiang, H. Scale and Rotation Invariant Approach to Tracking Human Body Part Regions in Videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013; pp. 1041–1047.
- Sapp, B.; Weiss, D.; Taskar, B. Parsing Human Motion with Stretchable Models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1281–1288.
- Cherian, A.; Mairal, J.; Alahari, K.; Schmid, C. Mixing Body-Part Sequences for Human Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2353–2360.
- Bissacco, A.; Yang, M.; Soatto, S. Detecting Humans via Their Pose. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 4–7 December 2006; pp. 169–176.
- Bray, M.; Kohli, P.; Torr, P.H. Posecut: Simultaneous Segmentation and 3D Pose Estimation of Humans Using Dynamic Graph-Cuts. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 642–655.
- Rogez, G.; Rihan, J.; Ramalingam, S.; Orrite, C.; Torr, P.H. Randomized Trees for Human Pose Detection. In Proceedings of the Computer Vision and Pattern Recognition, Anchorage, AK, USA, 24–26 June 2008; pp. 1–8.
- Kohli, P.; Rihan, J.; Bray, M.; Torr, P.H. Simultaneous Segmentation and Pose Estimation of Humans Using Dynamic Graph Cuts. Int. J. Comput. Vis. 2008, 79, 285–298. [Google Scholar] [CrossRef]
- Ladicky, L.; Torr, P.; Zisserman, A. Human Pose Estimation Using a Joint Pixel-Wise and Part-Wise Formulation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3578–3585.
- Kolmogorov, V.; Zabin, R. What Energy Functions Can be Minimized via Graph Cuts? IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 147–159. [Google Scholar] [CrossRef] [PubMed]
- Kohli, P.; Torr, P.H. Efficiently Solving Dynamic Markov Random Fields Using Graph Cuts. In Proceedings of the IEEE International Conference on Computer Vision, Beijing, China, 17–20 October 2005; pp. 922–929.
- Ju, S.X.; Black, M.J.; Yacoob, Y. Cardboard People: A Parameterized Model of Articulated Image Motion. In Proceedings of the International Conference on Automatic Face and Gesture Recognition, Killington, VT, USA, 14–16 October 1996; pp. 38–44.
- Datta, A.; Sheikh, Y.; Kanade, T. Linear Motion Estimation for Systems of Articulated Planes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 24–26 June 2008; pp. 1–8.
- Bregler, C.; Malik, J. Tracking People with Twists and Exponential Maps. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Santa Barbara, CA, USA, 23–25 June 1998; pp. 8–15.
- Rehg, J.M.; Kanade, T. Model-Based Tracking of Self-Occluding Articulated Objects. In Proceedings of the International Conference on Computer Vision, Cambridge, MA, USA, 20–23 June 1995; pp. 612–617.
- Ghosh, S.; Loper, M.; Sudderth, E.B.; Black, M.J. From Deformations to Parts: Motion-Based Segmentation of 3D Objects. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 1997–2005.
- Lee, M.W.; Cohen, I. Human Upper Body Pose Estimation in Static Images. In Proceedings of the European Conference on Computer Vision, Prague, Czech Republic, 11–14 May 2004; pp. 126–138.
- Attractive People: Assembling Loose-Limbed Models Using Non-Parametric Belief Propagation. Available online: http://machinelearning.wustl.edu/mlpapers/paper_files/NIPS2003_VM07.pdf (accessed on 23 November 2016).
- Sigal, L.; Isard, M.; Haussecker, H.; Black, M.J. Loose-Limbed People: Estimating 3D Human Pose and Motion Using Non-Parametric Belief Propagation. Int. J. Comput. Vis. 2012, 98, 15–48. [Google Scholar] [CrossRef]
- Urtasun, R.; Fleet, D.J.; Lawrence, N.D. Modeling Human Locomotion with Topologically Constrained Latent Variable Models. In Human Motion—Understanding, Modeling, Capture and Animation; Springer: Heidelberg, Germany, 2007; pp. 104–118. [Google Scholar]
- Hou, S.; Galata, A.; Caillette, F.; Thacker, N.; Bromiley, P. Real-time Body Tracking Using a Gaussian Process Latent Variable Model. In Proceedings of the IEEE International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8.
- Tian, T.P.; Li, R.; Sclaroff, S. Articulated Pose Estimation in a Learned Smooth Space of Feasible Solutions. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, San Diego, CA, USA, 21–23 September 2005.
- Tian, Y.; Sigal, L.; Badino, H.; De la Torre, F.; Liu, Y. Latent Gaussian Mixture Regression for Human Pose Estimation. In Proceedings of the Asian Conference on Computer Vision, Queenstown, New Zealand, 8–12 November 2010; pp. 679–690.
- Urtasun, R.; Fleet, D.J.; Fua, P. 3D People Rracking with Gaussian Process Dynamical Models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; pp. 238–245.
- Grauman, K.; Shakhnarovich, G.; Darrell, T. Inferring 3D Structure with a Statistical Image-Based Shape Model. In Proceedings of the IEEE International Conference on Computer Vision, Madison, WI, USA, 16–22 June 2003; pp. 641–647.
- Kehl, R.; Bray, M.; Van Gool, L. Full Body Tracking from Multiple Views Using Stochastic Sampling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; pp. 129–136.
- Sminchisescu, C.; Telea, A. Human Pose Estimation from Silhouettes-A Consistent Approach Using Distance Level Sets. In Proceedings of the International Conference in Central Europe on Computer Graphics, Visualization and Computer Vision, Bory, Czech Republic, 4–8 February 2002.
- Wang, L.; Tan, T.; Ning, H.; Hu, W. Silhouette Analysis-Based Gait Recognition for Human Identification. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 1505–1518. [Google Scholar] [CrossRef]
- Wu, J.; Geyer, C.; Rehg, J.M. Real-Time Human Detection Using Contour Cues. In Proceedings of the IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 860–867.
- Yang, Y.; Ramanan, D. Articulated Human Detection with Flexible Mixtures of Parts. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2878–2890. [Google Scholar] [CrossRef] [PubMed]
- Wu, B.; Nevatia, R. Detection of Multiple, Partially Occluded Humans in a Single Image by Bayesian Combination of Edgelet Part Detectors. In Proceedings of the IEEE International Conference on Computer Vision, Beijing, China, 17–20 October 2005; pp. 90–97.
- Hara, K.; Kurokawa, T. Human Pose Estimation Using Patch-Based Candidate Generation and Model-Based Verification. In Proceedings of the IEEE International Conference on Automatic Face and Gesture Recognition, Santa Barbara, CA, USA, 21–25 March 2011; pp. 687–693.
- Lallemand, J.; Szczot, M.; Ilic, S. Human Pose Estimation in Stereo Images. In Proceedings of the International Conference on Articulated Motion and Deformable Objects, Palma de Mallorca, Spain, 16–18 July 2014; pp. 10–19.
- Slama, R.; Wannous, H.; Daoudi, M. Extremal Human Curves: A New Human Body Shape and Pose Descriptor. In Proceedings of the IEEE International Conference and Workshops on Automatic Face and Gesture Recognition, Shanghai, China, 22–26 April, 2013; pp. 1–6.
- Dalal, N.; Triggs, B.; Schmid, C. Human Detection Using Oriented Histograms of Flow and Appearance. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 428–441.
- Scene Constraints-aided Tracking of Human Body. Available online: http://ieeexplore.ieee.org/document/855813/ (accessed on 23 November 2016).
- Yang, M.H.; Bissacco, A. Fast Human Pose Estimation Using Appearance and Motion via Multi-Dimensional Boosting Regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 1–8.
- Sedai, S.; Bennamoun, M.; Huynh, D.Q.; Crawley, P. Localized Fusion of Shape and Appearance Features for 3D Human Pose Estimation. In Proceedings of the British Machine Vision Conference, Aberystwyth, UK, 31 August–3 September 2010; pp. 1–10.
- Sedai, S.; Bennamoun, M.; Huynh, D.Q. Discriminative Fusion of Shape and Appearance Features for Human Pose Estimation. Pattern Recognit. 2013, 46, 3223–3237. [Google Scholar] [CrossRef]
- Sidenbladh, H.; Black, M.J. Learning Image Statistics for Bayesian Tracking. In Proceedings of the IEEE International Conference on Computer Vision, Vancouver, BC, Canada, 7–14 July 2001; pp. 709–716.
- Ramakrishna, V.; Kanade, T.; Sheikh, Y. Tracking Human Pose by Tracking Symmetric Parts. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3728–3735.
- Komodakis, N.; Paragios, N.; Tziritas, G. MRF Energy Minimization and Beyond via Dual Decomposition. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 531–552. [Google Scholar] [CrossRef] [PubMed]
- Gall, J.; Stoll, C.; De Aguiar, E.; Theobalt, C.; Rosenhahn, B.; Seidel, H.P. Motion Capture Using Joint Skeleton Tracking and Surface Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1746–1753.
- Allen, B.; Curless, B.; Popović, Z. Articulated Body Deformation from Range Scan Data. ACM Trans. Graph. 2002, 21, 612–619. [Google Scholar] [CrossRef]
- Park, S.I.; Hodgins, J.K. Capturing and Animating Skin Deformation in Human Motion. ACM Trans. Graph. 2006, 25, 881–889. [Google Scholar] [CrossRef]
- Sand, P.; McMillan, L.; Popović, J. Continuous Capture of Skin Deformation. ACM Trans. Graph. 2003, 22, 578–586. [Google Scholar] [CrossRef]
- Blinn, J.F. Models of Light Reflection for Computer Synthesized Pictures. ACM SIGGRAPH Comput. Graph. 1977, 11, 192–198. [Google Scholar] [CrossRef]
- Cheung, G.K.; Baker, S.; Hodgins, J.; Kanade, T. Markerless Human Motion Transfer. In Proceedings of the International Symposium on 3D Data Processing, Visualization and Transmission, Thessaloniki, Greece, 6–9 September 2004; pp. 373–378.
- Rius, I.; Gonzàlez, J.; Varona, J.; Roca, F.X. Action-Specific Motion Prior for Efficient Bayesian 3D Human Body Tracking. Pattern Recognit. 2009, 42, 2907–2921. [Google Scholar] [CrossRef]
- Moeslund, T.B.; Granum, E. A Survey of Computer Vision-based Human Motion Capture. Comput. Vis. Image Underst. 2001, 81, 231–268. [Google Scholar] [CrossRef]
- Wei, X.; Chai, J. Videomocap: Modeling Physically Realistic Human Motion from Monocular Video Sequences. ACM Trans. Graph. 2010, 29, 42. [Google Scholar] [CrossRef]
- Liu, Y.; Stoll, C.; Gall, J.; Seidel, H.P.; Theobalt, C. Markerless Motion Capture of Interacting Characters Using Multi-view Image Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1249–1256.
- Wang, Y.K.; Cheng, K.Y. 3D Human Pose Estimation by an Annealed Two-Stage Inference Method. In Proceedings of the International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 535–538.
- Bowden, R.; Mitchell, T.A.; Sarhadi, M. Non-linear Statistical Models for the 3D Reconstruction of Human Pose and Motion from Monocular Image Sequences. Image Vis. Comput. 2000, 18, 729–737. [Google Scholar] [CrossRef]
- Bo, L.; Sminchisescu, C. Twin Gaussian Processes for Structured Prediction. Int. J. Comput. Vis. 2010, 87, 28–52. [Google Scholar] [CrossRef]
- Lee, C.S.; Elgammal, A. Coupled Visual and Kinematic Manifold Models for Tracking. Int. J. Comput. Vis. 2010, 87, 118–139. [Google Scholar] [CrossRef]
- Sminchisescu, C.; Bo, L.; Ionescu, C.; Kanaujia, A. Feature-Based Pose Estimation. In Visual Analysis of Humans; Springer: London, UK, 2011; pp. 225–251. [Google Scholar]
- Memisevic, R.; Sigal, L.; Fleet, D.J. Shared Kernel Information Embedding for Discriminative Inference. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 778–790. [Google Scholar] [CrossRef] [PubMed]
- Urtasun, R.; Darrell, T. Sparse Probabilistic Regression for Activity-Independent Human Pose Inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 24–26 June 2008; pp. 1–8.
- Zhao, X.; Ning, H.; Liu, Y.; Huang, T. Discriminative Estimation of 3D Human Pose Using Gaussian Processes. In Proceedings of the International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; pp. 1–4.
- Mori, G.; Malik, J. Recovering 3D Human Body Configurations Using Shape Contexts. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1052–1062. [Google Scholar] [CrossRef] [PubMed]
- Toyama, K.; Blake, A. Probabilistic Tracking with Exemplars in a Metric Space. Int. J. Comput. Vis. 2002, 48, 9–19. [Google Scholar] [CrossRef]
- Sigal, L.; Black, M.J. Predicting 3D People from 2D Pictures. In Proceedings of the International Conference on Articulated Motion and Deformable Objects, Port d’Andratx, Mallorca, Spain, 11–14 July 2006; pp. 185–195.
- Roth, S.; Sigal, L.; Black, M. Gibbs Likelihoods for Bayesian Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004; pp. 886–893.
- Pinto, N.; Cox, D.D.; DiCarlo, J.J. Why is Real-World Visual Object Recognition Hard? PLoS Comput. Biol. 2008, 4, e27. [Google Scholar] [CrossRef] [PubMed]
- Jain, A.; Tompson, J.; LeCun, Y.; Bregler, C. Modeep: A Deep Learning Framework Using Motion Features for Human Pose Estimation. In Proceedings of the Asian Conference on Computer Vision, Singapore, 1–5 November 2014; pp. 302–315.
- Lepetit, V.; Fua, P. Keypoint Recognition Using Randomized Trees. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1465–1479. [Google Scholar] [CrossRef] [PubMed]
- Belagiannis, V.; Amann, C.; Navab, N.; Ilic, S. Holistic Human Pose Estimation with Regression Forests. In Proceedings of the International Conference on Articulated Motion and Deformable Objects, Palma de Mallorca, Spain, 16–18 July 2014; pp. 20–30.
- Dantone, M.; Gall, J.; Leistner, C.; Van Gool, L. Human Pose Estimation Using Body Parts Dependent Joint Regressors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3041–3048.
- Girshick, R.; Shotton, J.; Kohli, P.; Criminisi, A.; Fitzgibbon, A. Efficient Regression of General-Activity Human Poses from Depth Images. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 415–422.
- Buntine, W.; Niblett, T. A Further Comparison of Splitting Rules for Decision-Tree Induction. Mach. Learn. 1992, 8, 75–85. [Google Scholar] [CrossRef]
- Improved Information Gain Estimates for Decision Tree Induction. In Proceedings of the International Conference on Machine Learning, Edinburgh, UK, 26 June–1 July 2012; pp. 297–304.
- Baak, A.; Müller, M.; Bharaj, G.; Seidel, H.P.; Theobalt, C. A Data-Driven Approach for Real-Time Full Body Pose Reconstruction from a Depth Camera. In Consumer Depth Cameras for Computer Vision; Springer: Heidelberg, Germany, 2013; pp. 71–98. [Google Scholar]
- Ganapathi, V.; Plagemann, C.; Koller, D.; Thrun, S. Real Time Motion Capture Using a Single Time-of-Flight Camera. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 755–762.
- Bregler, C.; Malik, J.; Pullen, K. Twist Based Acquisition and Tracking of Animal and Human Kinematics. Int. J. Comput. Vis. 2004, 56, 179–194. [Google Scholar] [CrossRef]
- Brubaker, M.A.; Fleet, D.J.; Hertzmann, A. Physics-Based Person Tracking Using the Anthropomorphic Walker. Int. J. Comput. Vis. 2010, 87, 140–155. [Google Scholar] [CrossRef]
- Ganapathi, V.; Plagemann, C.; Koller, D.; Thrun, S. Real-Time Human Pose Tracking from Range Data. In Proceedings of the European Conference on Computer Vision, Firenze, Italy, 7–13 October 2012; pp. 738–751.
- Pons-Moll, G.; Leal-Taixé, L.; Truong, T.; Rosenhahn, B. Efficient and Robust Shape Matching for Model Based Human Motion Capture. In Proceedings of the Joint Pattern Recognition Symposium, Frankfurt/Main, Germany, 31 August–2 September 2011; pp. 416–425.
- Stoll, C.; Hasler, N.; Gall, J.; Seidel, H.P.; Theobalt, C. Fast Articulated Motion Tracking Using a Sums of Gaussians Body Model. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 951–958.
- Deutscher, J.; Reid, I. Articulated Body Motion Capture by Stochastic Search. Int. J. Comput. Vis. 2005, 61, 185–205. [Google Scholar] [CrossRef]
- Gall, J.; Rosenhahn, B.; Brox, T.; Seidel, H.P. Optimization and Filtering for Human Motion Capture. Int. J. Comput. Vis. 2010, 87, 75–92. [Google Scholar] [CrossRef]
- Pons-Moll, G.; Baak, A.; Gall, J.; Leal-Taix, L.; Mueller, M.; Seidel, H.P.; Rosenhahn, B. Outdoor Human Motion Capture Using Inverse Kinematics and von Mises-Fisher Sampling. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 1243–1250.
- Wei, X.K.; Chai, J. Modeling 3D Human Poses from Uncalibrated Monocular Images. In Proceedings of the IEEE International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 1873–1880.
- Mori, G. Guiding Model Search Using Segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Beijing, China, 17–20 October 2005; pp. 1417–1423.
- Hao, W.; Fanhui, M.; Baofu, F. Iterative Human Pose Estimation Based on a New Part Appearance Model. Appl. Math. 2014, 8, 311–317. [Google Scholar] [CrossRef]
- Rothrock, B.; Park, S.; Zhu, S.C. Integrating Grammar and Segmentation for Human Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3214–3221.
- Eichner, M.; Ferrari, V. Human Pose Co-Estimation and Applications. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2282–2288. [Google Scholar] [CrossRef] [PubMed]
- Wang, F.; Li, Y. Beyond Physical Connections: Tree Models in Human Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 596–603.
- Radwan, I.; Dhall, A.; Goecke, R. Monocular Image 3D Human Pose Estimation under Self-Occlusion. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1888–1895.
- Sigal, L.; Black, M.J. Measure Locally, Reason Globally: Occlusion-Sensitive Articulated Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; pp. 2041–2048.
- Lee, M.W.; Nevatia, R. Human Pose Tracking Using Multi-Level Structured Models. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 368–381.
- Brox, T.; Rosenhahn, B.; Weickert, J. Three-Dimensional Shape Knowledge for Joint Image Segmentation and Pose Estimation. In Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2005; pp. 109–116. [Google Scholar]
- Rogez, G.; Orrite-Uruñuela, C.; Martínez-del Rincón, J. A Spatio-Temporal 2D-Models Framework for Human Pose Recovery in Monocular Sequences. Pattern Recognit. 2008, 41, 2926–2944. [Google Scholar] [CrossRef]
- Hernández, N.; Talavera, I.; Dago, A.; Biscay, R.J.; Ferreira, M.M.C.; Porro, D. Relevance Vector Machines for Multivariate Calibration Purposes. J. Chemom. 2008, 22, 686–694. [Google Scholar] [CrossRef]
- Yacoob, Y.; Black, M.J. Parameterized Modeling and Recognition of Activities. In Proceedings of the International Conference on Computer Vision, Bombay, India, 4–7 January 1998; pp. 120–127.
- Yu, T.H.; Kim, T.K.; Cipolla, R. Unconstrained Monocular 3D Human Pose Estimation by Action Detection and Cross-Modality Regression Forest. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3642–3649.
- Cheung, G.K.; Baker, S.; Kanade, T. Shape-from-Silhouette of Articulated Objects and Its Use for Human Body Kinematics Estimation and Motion Capture. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Madison, WI, USA, 16–22 June 2003; pp. 77–84.
- Wang, Y.; Tran, D.; Liao, Z.; Forsyth, D. Discriminative Hierarchical Part-Based Models for Human Parsing and Action Recognition. J. Mach. Learn. Res. 2012, 13, 3075–3102. [Google Scholar]
- Hahn, M.; Krüger, L.; Wöhler, C.; Gross, H.M. Tracking of Human Body Parts Using the Multiocular Contracting Curve Density Algorithm. In Proceedings of the International Conference on 3-D Digital Imaging and Modeling, Montreal, QC, Canada, 21–23 August 2007; pp. 257–264.
- Balan, A.O.; Black, M.J. An adaptive appearance model approach for model-based articulated object tracking. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; pp. 758–765.
- Fragkiadaki, K.; Hu, H.; Shi, J. Pose from Flow and Flow from Pose. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2059–2066.
- Tian, J.; Li, L.; Liu, W. Multi-Scale Human Pose Tracking in 2D Monocular Images. J. Comput. Commun. 2014, 2, 78. [Google Scholar] [CrossRef]
- Guo, F.; Qian, G. Monocular 3D Tracking of Articulated Human Motion in Silhouette and Pose Manifolds. J. Image Video Process. 2008, 2008, 4. [Google Scholar] [CrossRef]
- Rasmussen, C.E. Gaussian Processes for Machine Learning; MIT Press: London, UK, 2006. [Google Scholar]
- Urtasun, R.; Fleet, D.J.; Fua, P. Monocular 3D Tracking of the Golf Swing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; pp. 932–938.
- Agarwal, A.; Triggs, B. Tracking Articulated Motion Using a Mixture of Autoregressive Models. In Proceedings of the European Conference on Computer Vision, Prague, Czech Republic, 11–14 May 2004; pp. 54–65.
- Souvenir, R.; Hajja, A.; Spurlock, S. Gamesourcing to Acquire Labeled Human Pose Estimation Data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 1–6.
- Leeds Sports Pose. Available online: http://www.comp.leeds.ac.uk/mat4saj/lsp.html (accessed on 11 November 2016).
- We are family Stickmen. Available online: http://calvin.inf.ed.ac.uk/datasets/we-are-family-stickmen/ (accessed on 11 November 2016).
- PASCAL Stickmen. Available online: http://groups.inf.ed.ac.uk/calvin/ethz_pascal_stickmen/ (accessed on 11 November 2016).
- PEAR. Available online: http://www.visionlab.sjtu.edu.cn/pear/dataset.html (accessed on 11 November 2016).
- KTH Multiview Football Dataset I. Available online: http://www.csc.kth.se/cvap/cvg/?page=software (accessed on 11 November 2016).
- KTH Multiview Football Dataset II. Available online: http://www.csc.kth.se/cvap/cvg/?page=footballdataset2 (accessed on 11 November 2016).
- FLIC (Frames Labeled In Cinema). Available online: http://bensapp.github.io/flic-dataset.html (accessed on 11 November 2016).
- FLIC-full. Available online: http://bensapp.github.io/flic-dataset.html (accessed on 11 November 2016).
- FLIC-plus Dataset. Available online: http://www.cims.nyu.edu/~tompson/flic_plus.htm (accessed on 11 November 2016).
- Learning to Parse Images of Articulated Bodies. Available online: http://www.ics.uci.edu/~dramanan/papers/parse/index.html (accessed on 11 November 2016).
- MPII Human Pose Dataset. Available online: http://human-pose.mpi-inf.mpg.de (accessed on 11 November 2016).
- Mixing Body-Part Sequences for Human Pose Estimation. Available online: http://lear.inrialpes.fr/research/posesinthewild/ (accessed on 11 November 2016).
- Multiple Human Pose Estimation. Available online: http://campar.in.tum.de/Chair/MultiHumanPose (accessed on 11 November 2016).
- Human 3.6H (H36M). Available online: http://vision.imar.ro/human3.6m/description.php (accessed on 11 November 2016).
- ChaLearn Looking at People 2015: Human Pose Recovery. Available online: https://competitions.codalab.org/competitions/2231 (accessed on 11 November 2016).
- CMU-Mocap Dataset. Available online: http://mocap.cs.cmu.edu/ (accessed on 11 November 2016).
- Utrecht Multi-Person Motion Benchmark. Available online: http://www.projects.science.uu.nl/umpm/ (accessed on 11 November 2016).
- HumanEva-I Dataset. Available online: http://humaneva.is.tue.mpg.de/ (accessed on 11 November 2016).
- TUM Kitchen Dataset. Available online: https://ias.cs.tum.edu/software/kitchen-activity-data (accessed on 11 November 2016).
- Buffy Pose Classes (BPC). Available online: http://www.robots.ox.ac.uk/~vgg/data/buffy_pose_classes/index.html (accessed on 11 November 2016).
- Buffy Stickmen V3.01. Available online: http://www.robots.ox.ac.uk/~vgg/data/stickmen/index.html (accessed on 11 November 2016).
- Video Pose. Available online: http://bensapp.github.io/videopose-dataset.html (accessed on 11 November 2016).
- Eichner, M.; Marin-Jimenez, M.; Zisserman, A.; Ferrari, V. 2D Articulated Human Pose Estimation and Retrieval in (Almost) Unconstrained Still Images. Int. J. Comput. Vis. 2012, 99, 190–214. [Google Scholar] [CrossRef]
- OpenVL: Developer-Friendly Computer Vision. Available online: http://www.openvl.org.uk/projects.php?id=OpenVL (accessed on 11 November 2016).

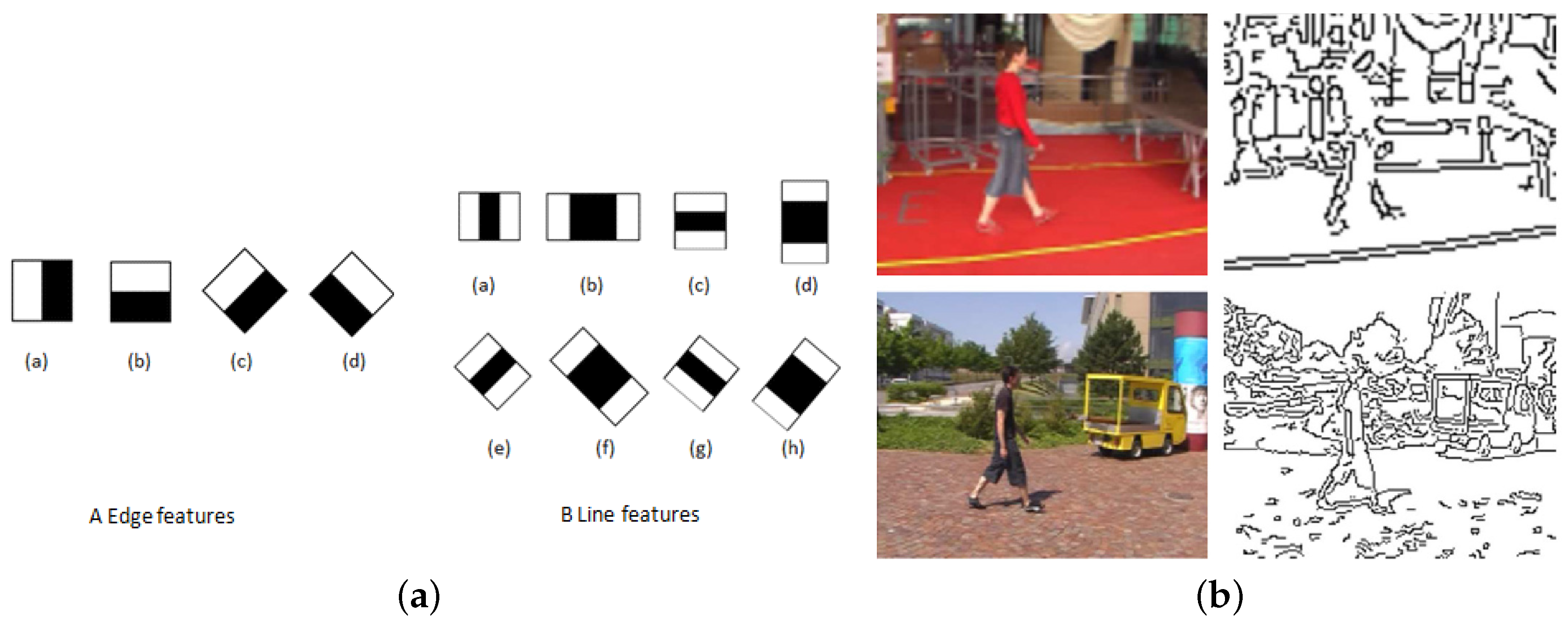


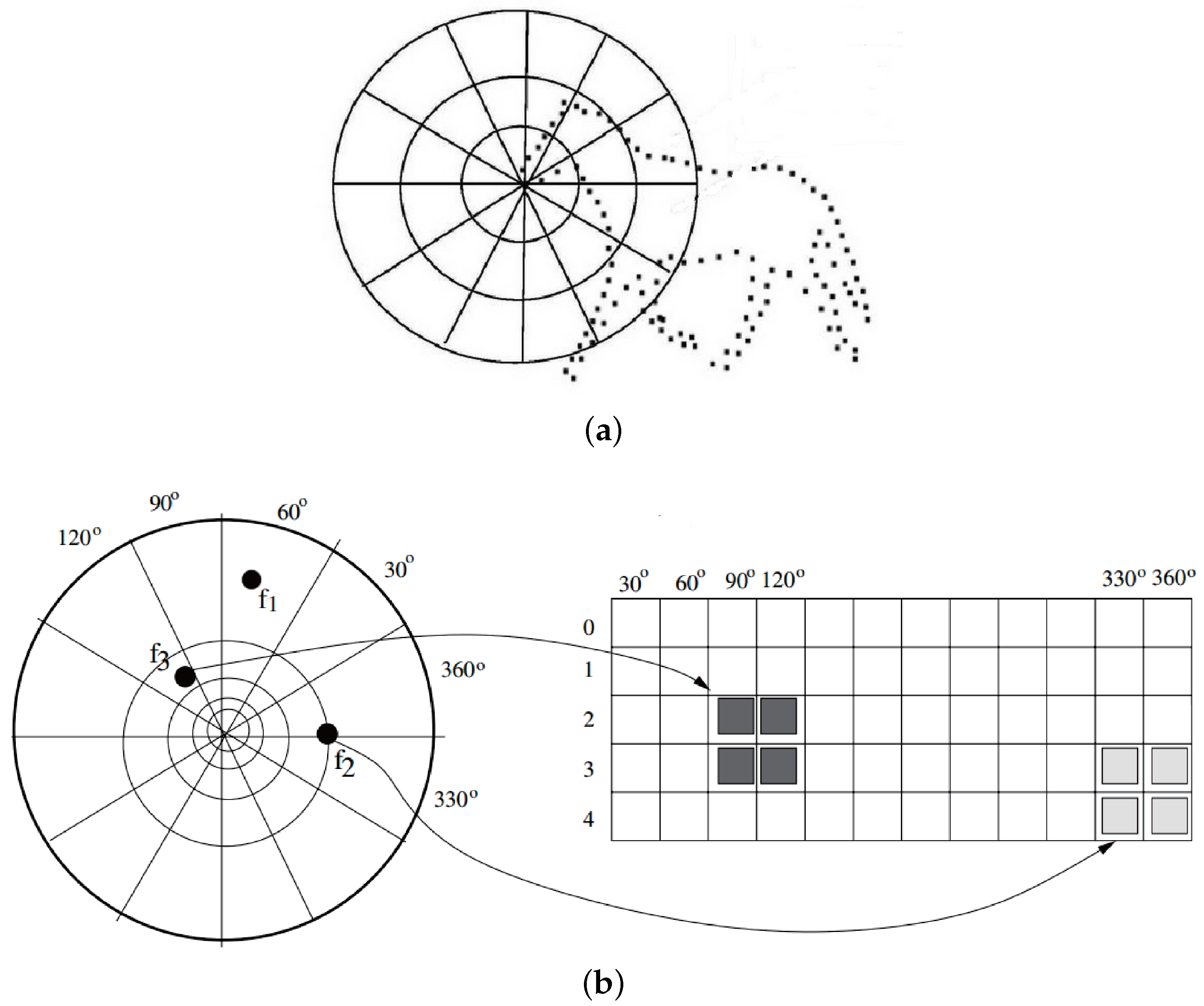
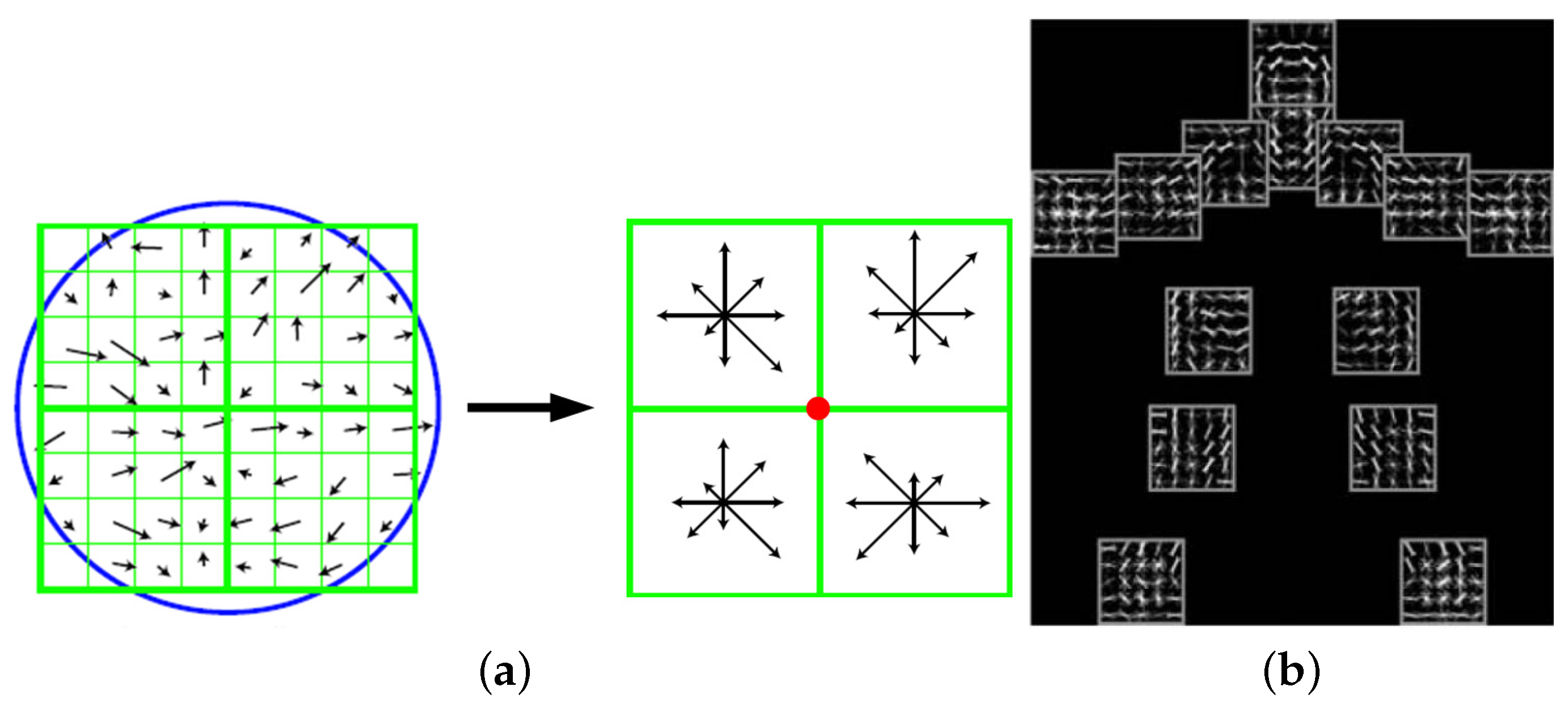
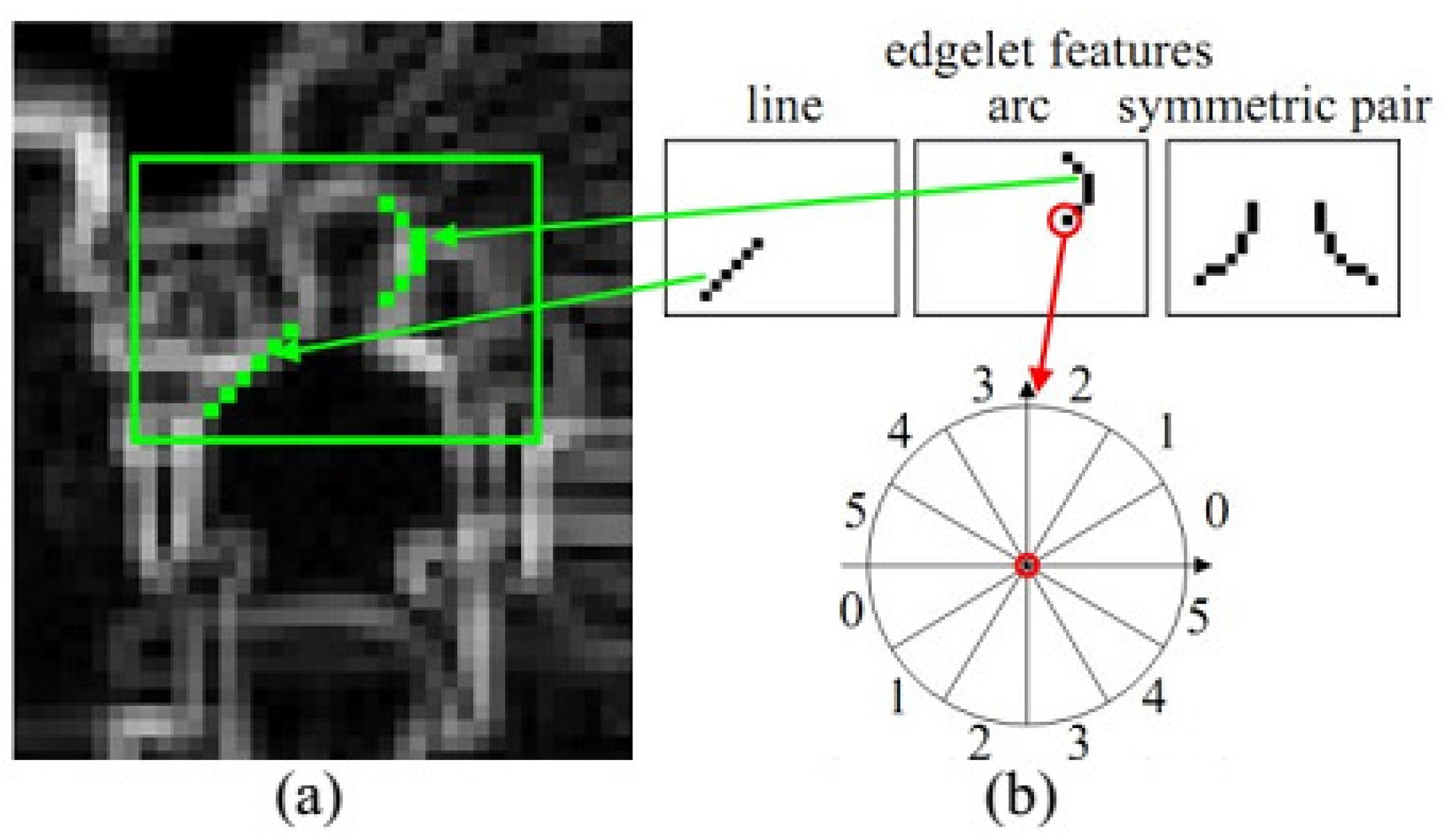



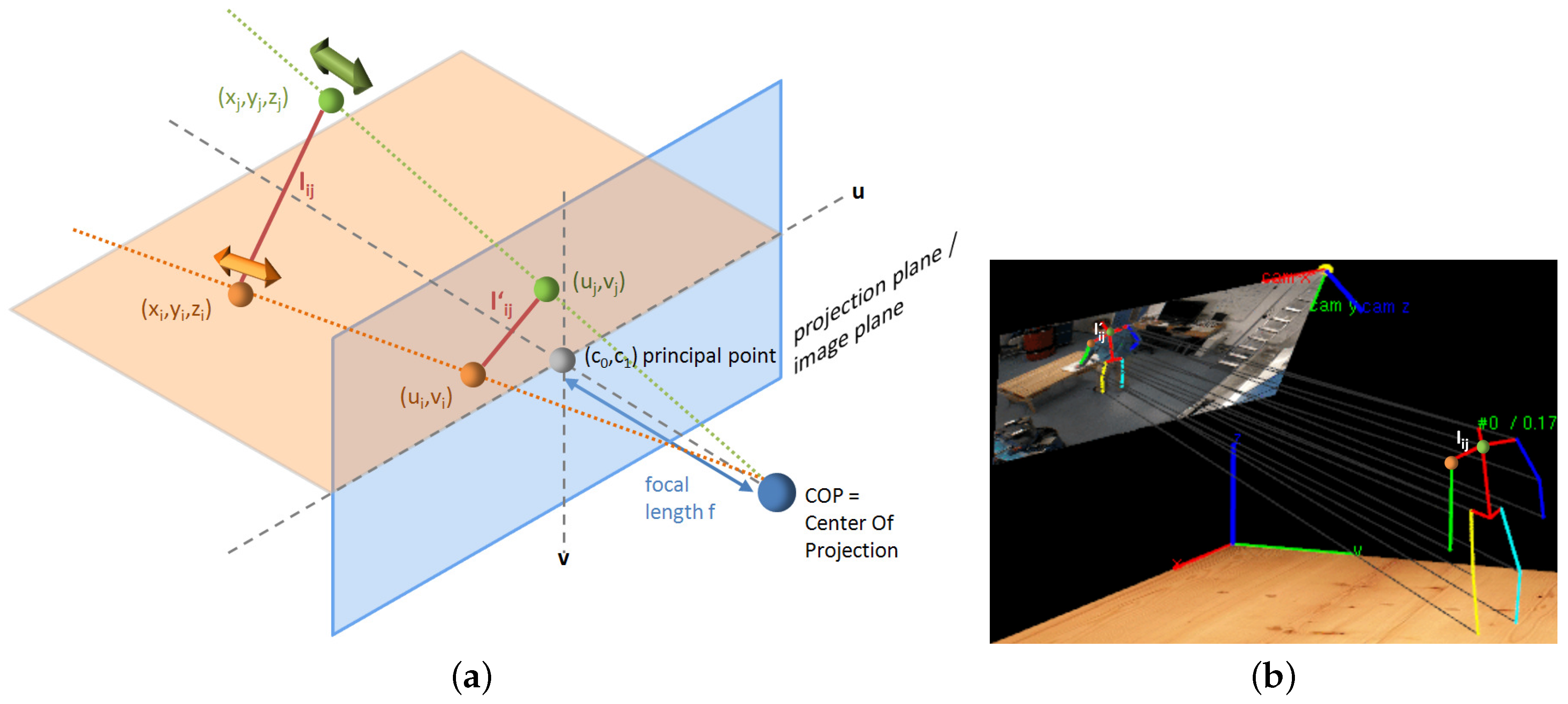
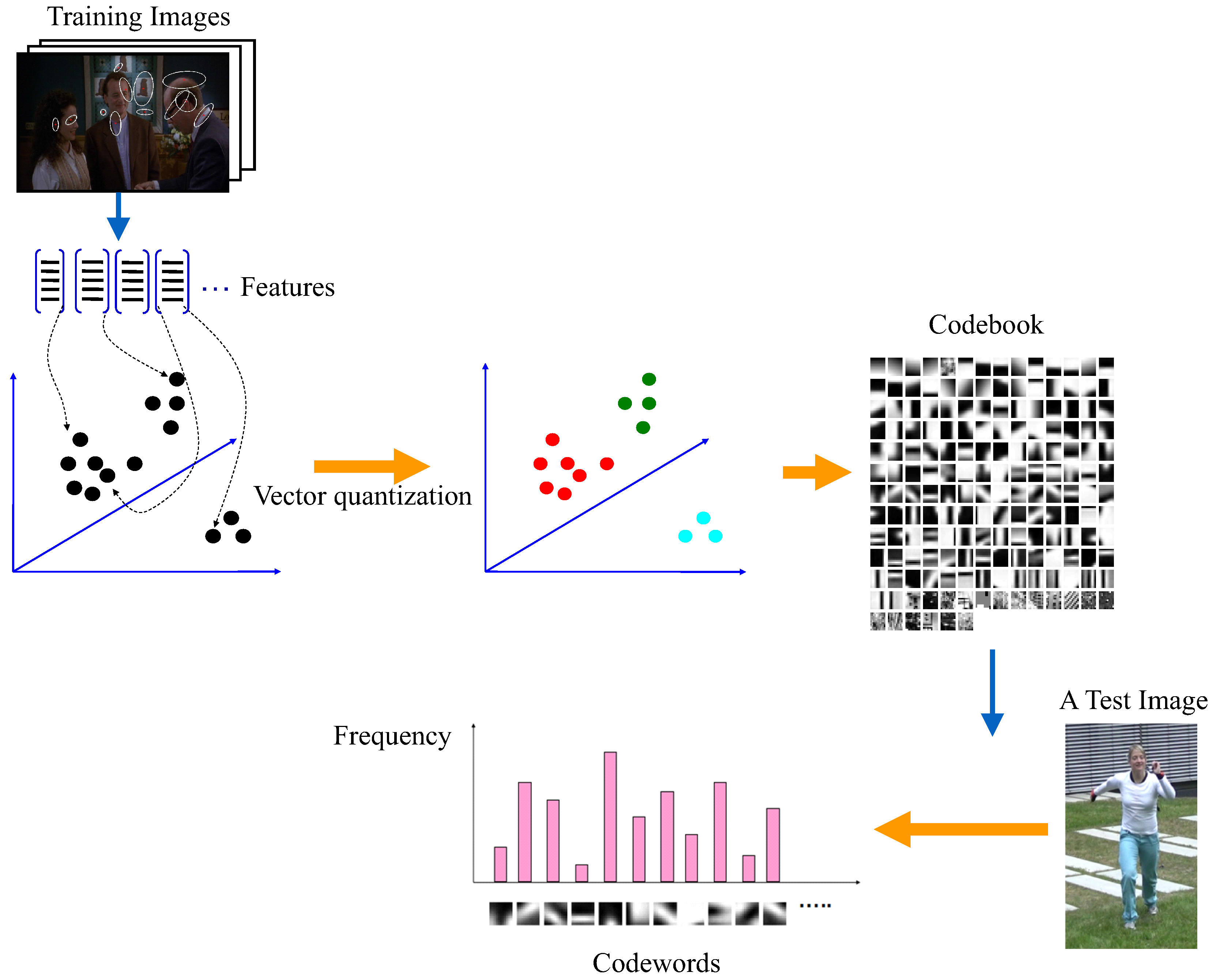
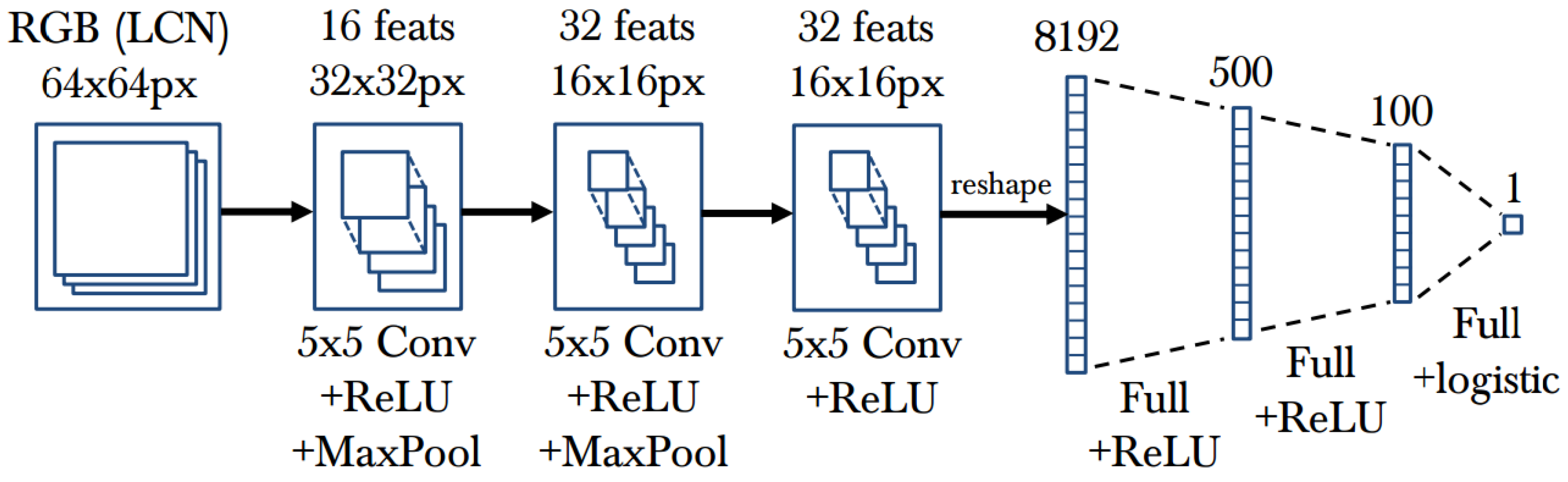


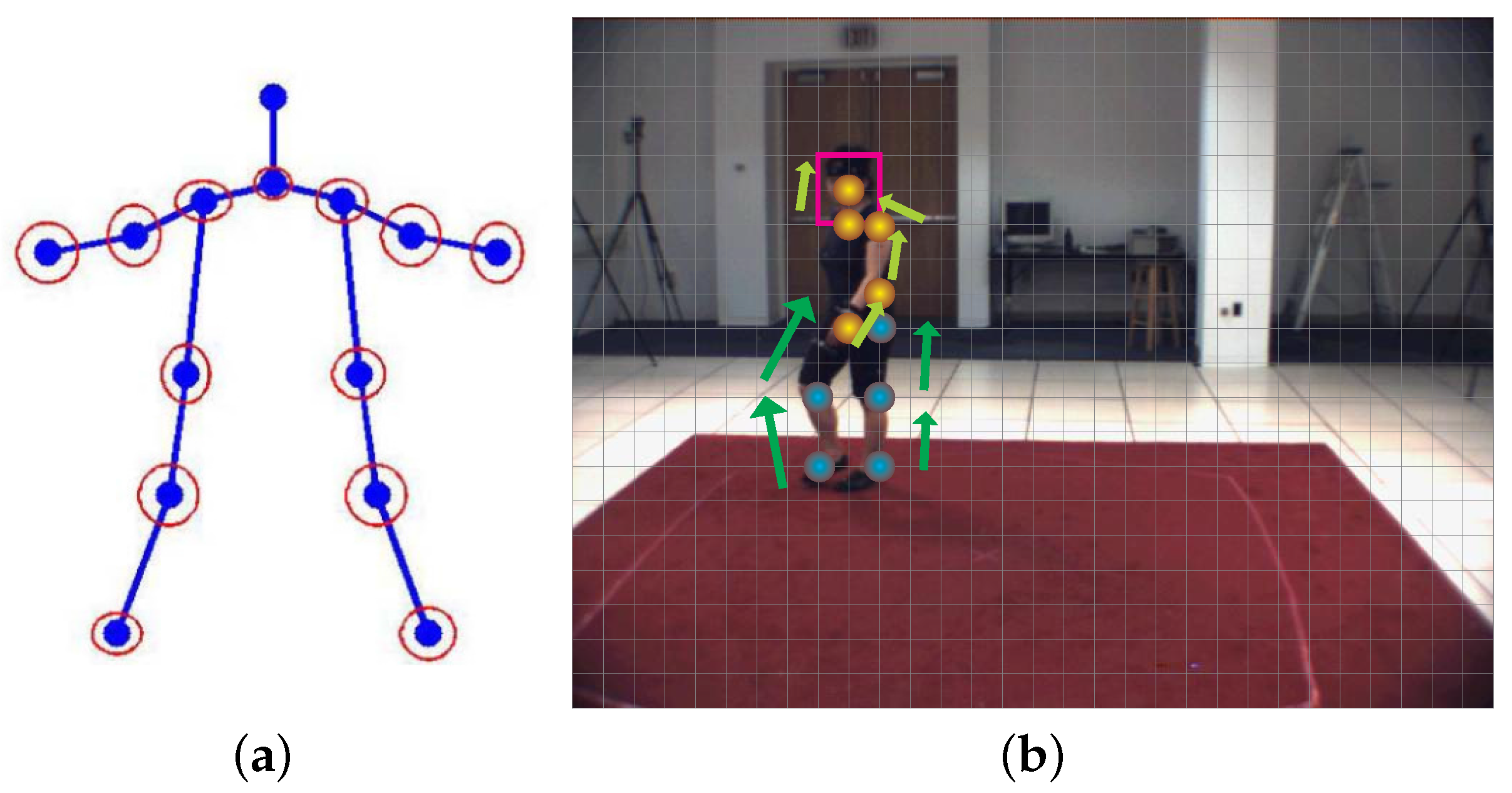

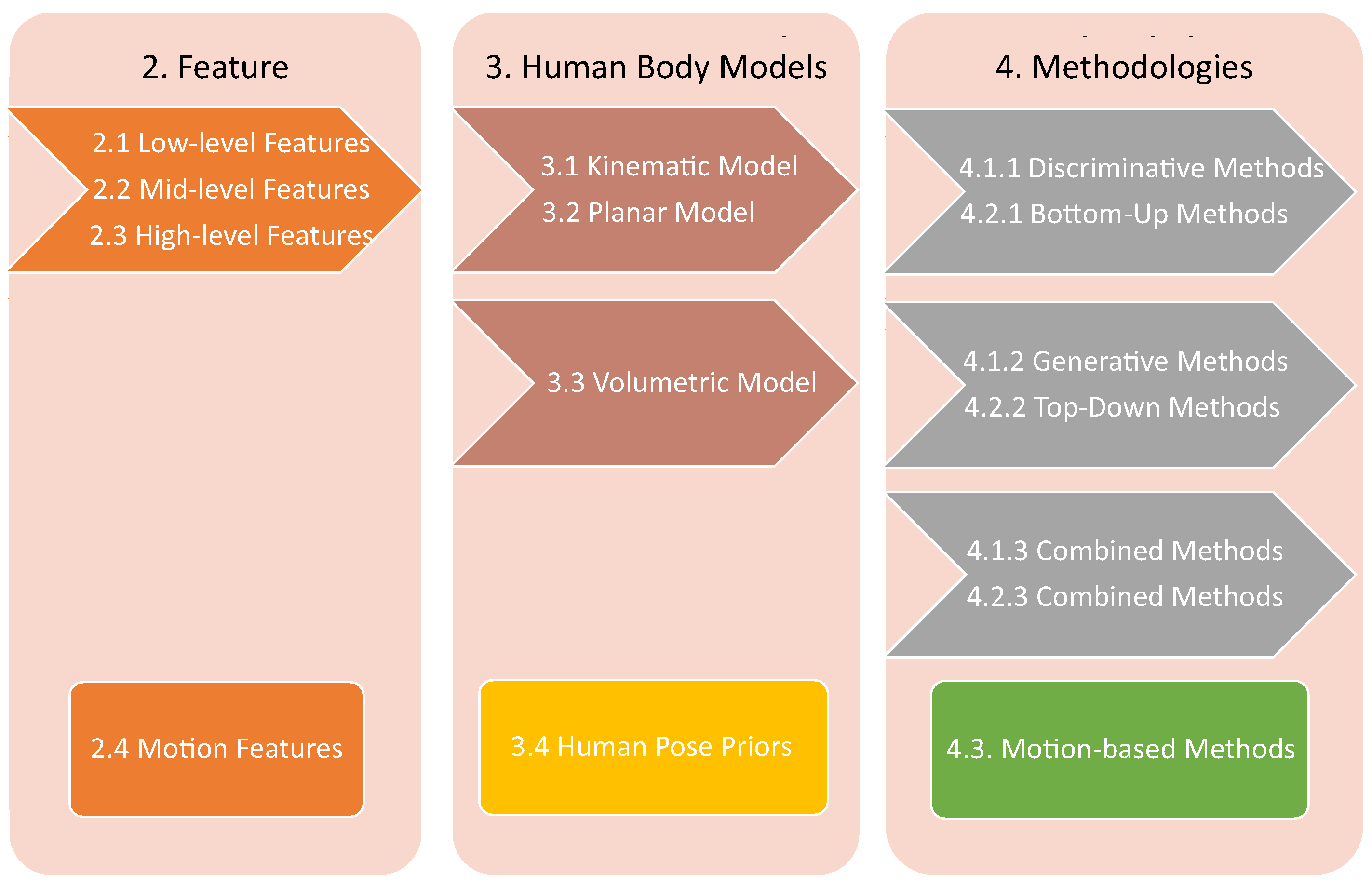{kind=link}
{kind=link}
{kind=link}
{kind=link}
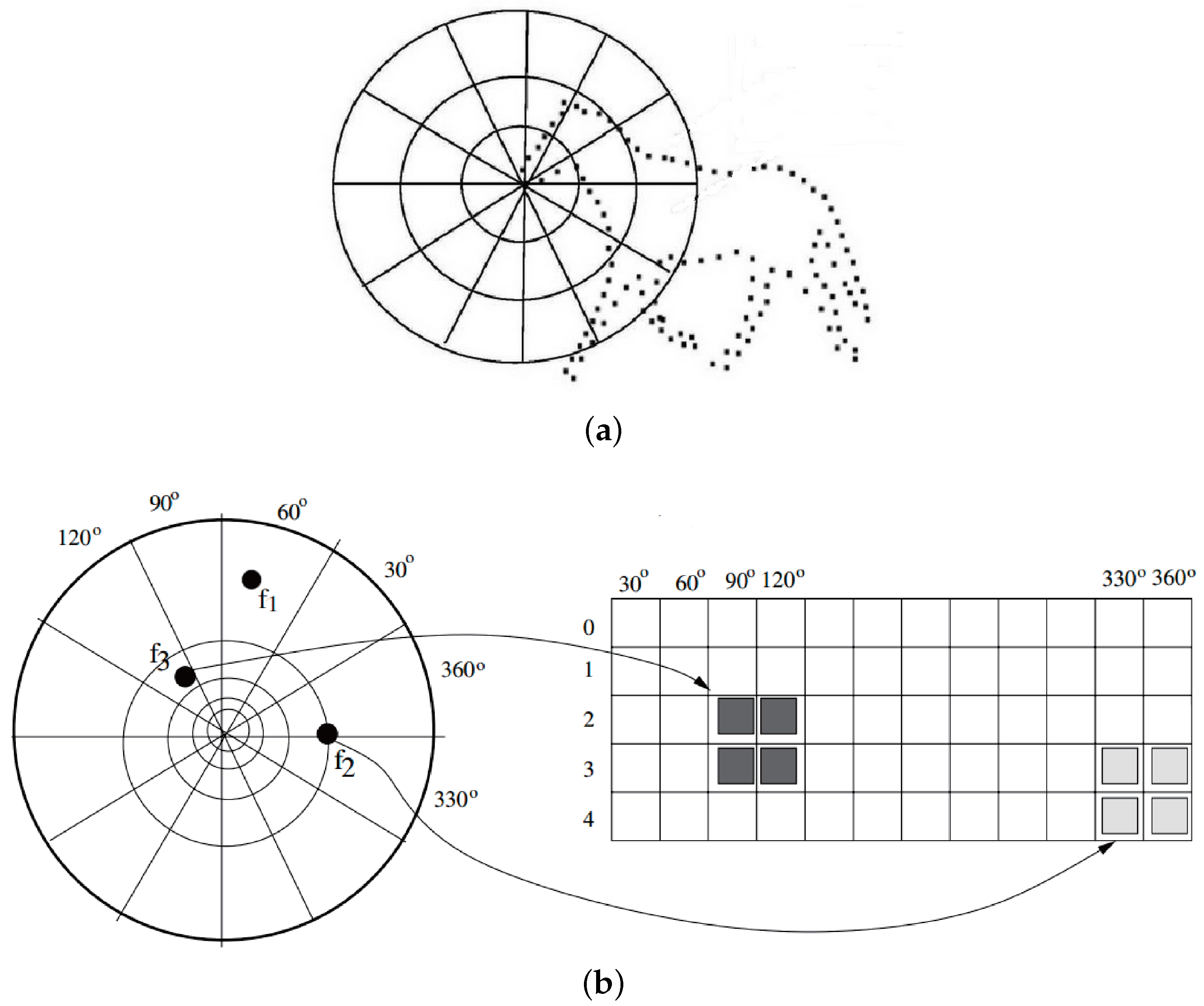{kind=link}
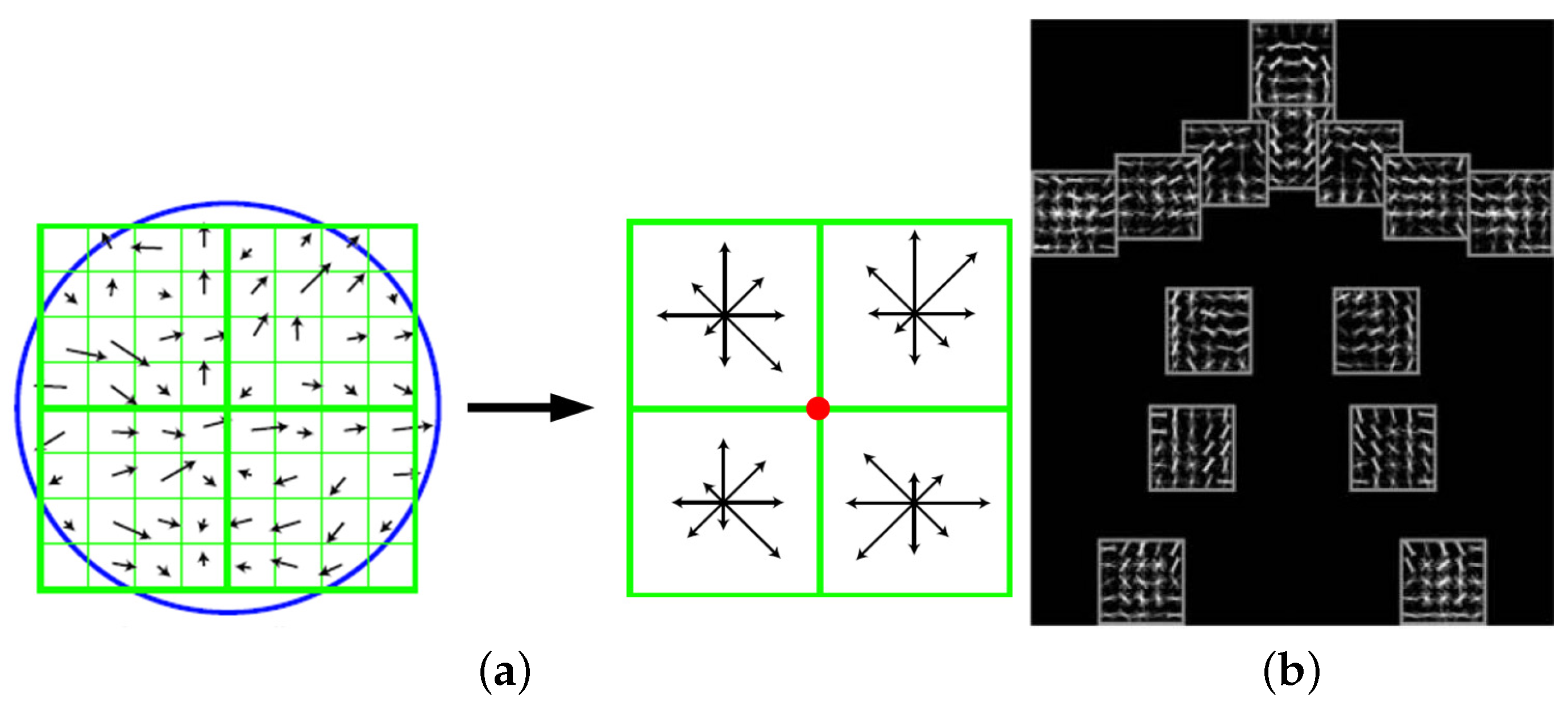{kind=link}
{kind=link}
{kind=link}
{kind=link}
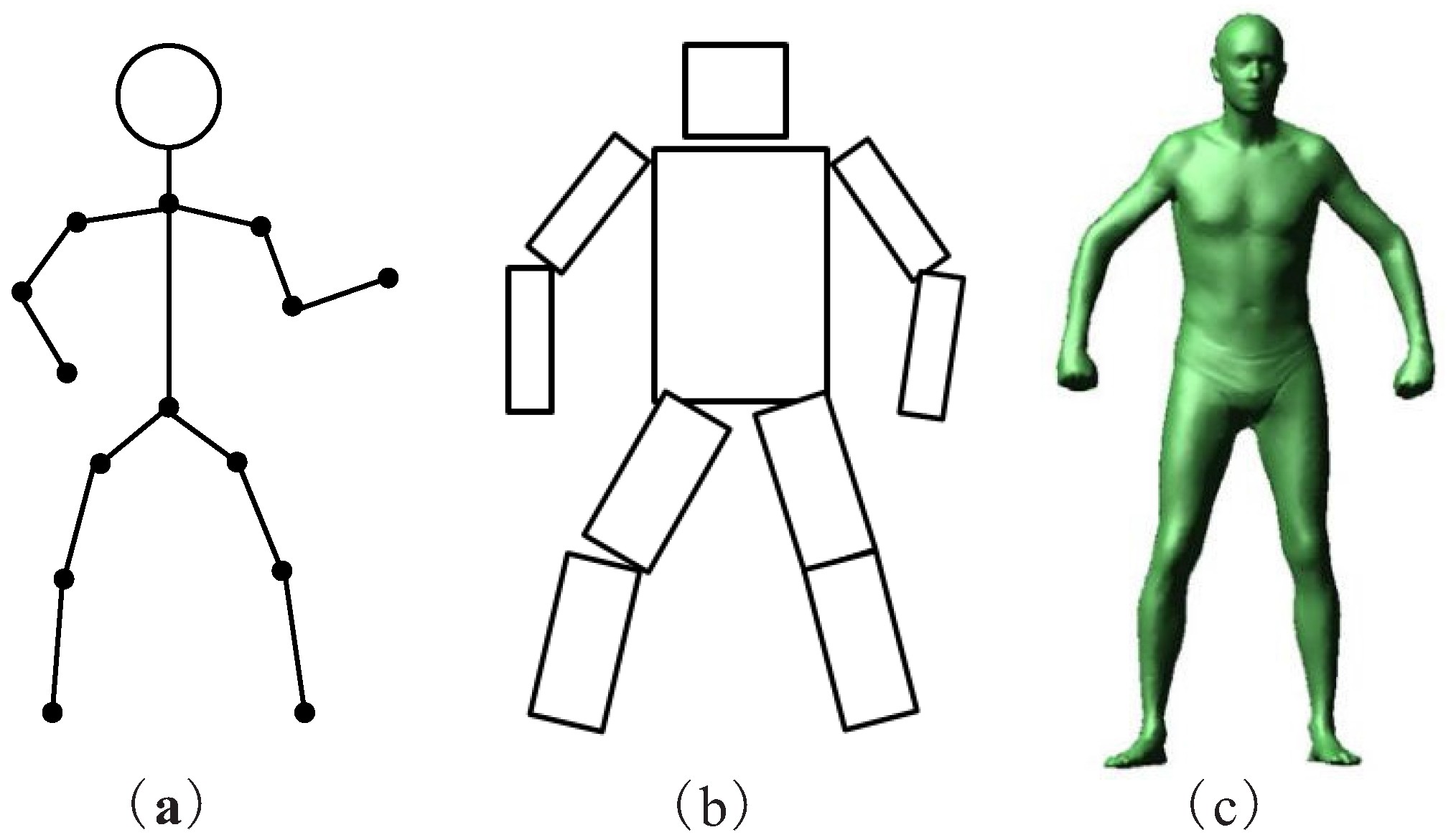{kind=link}
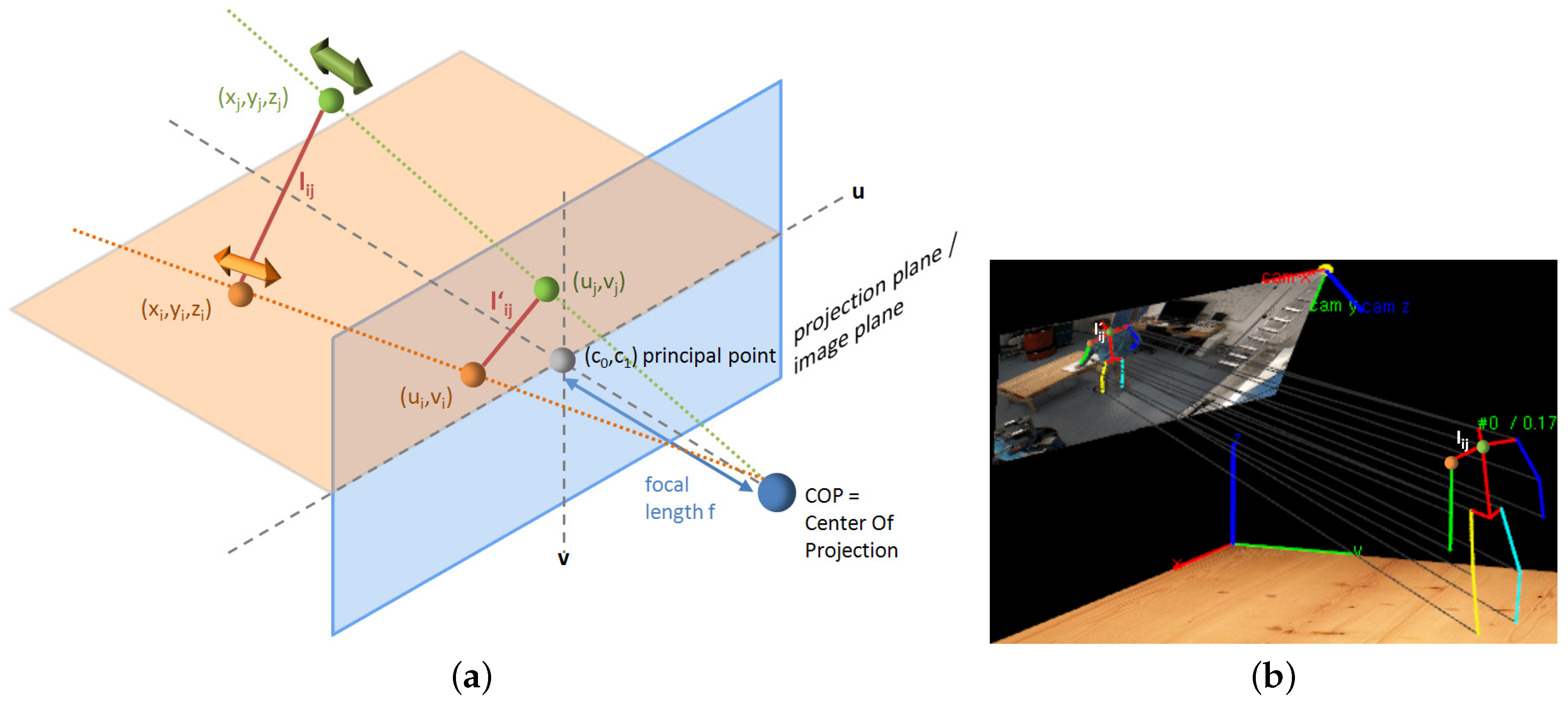{kind=link}
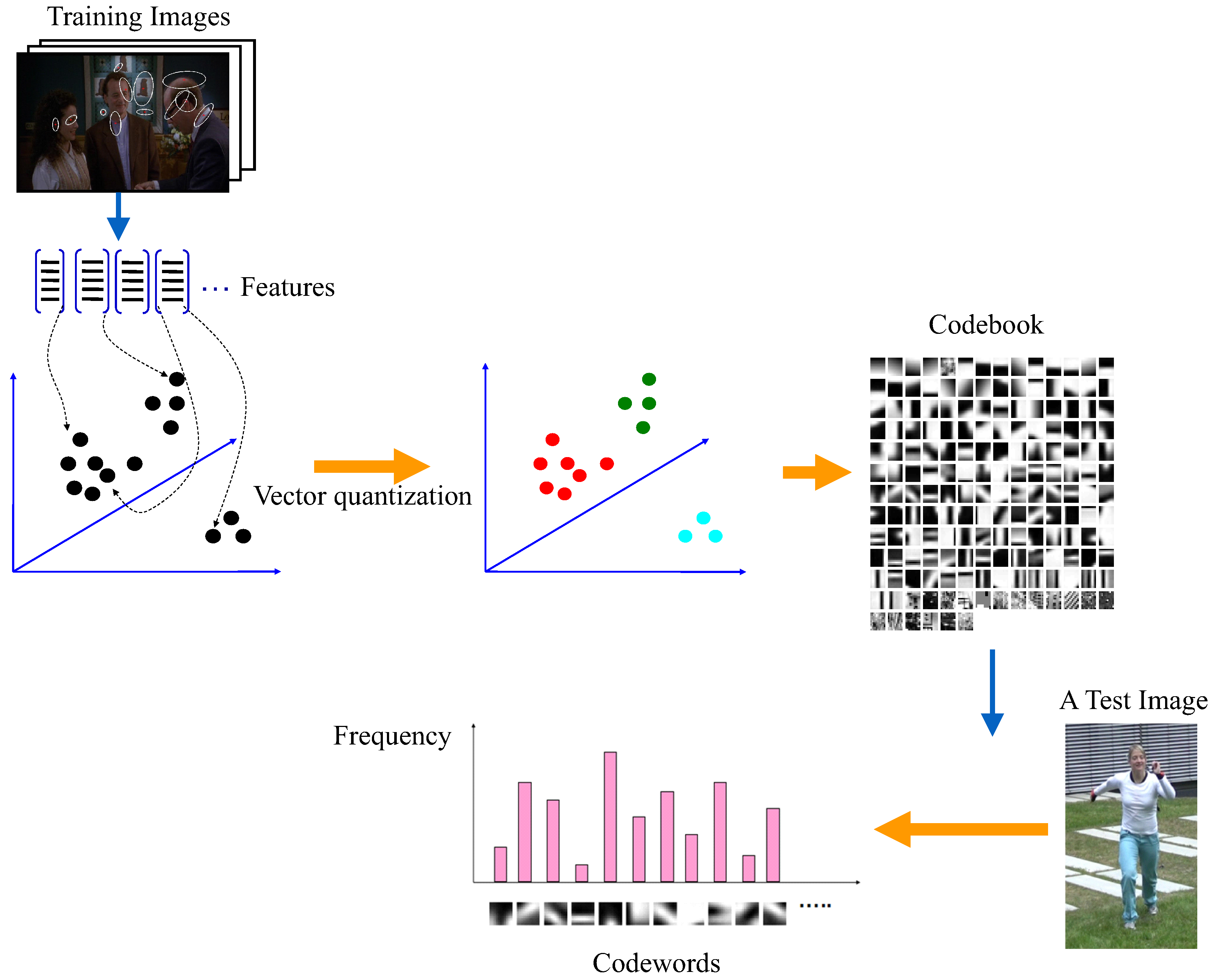{kind=link}
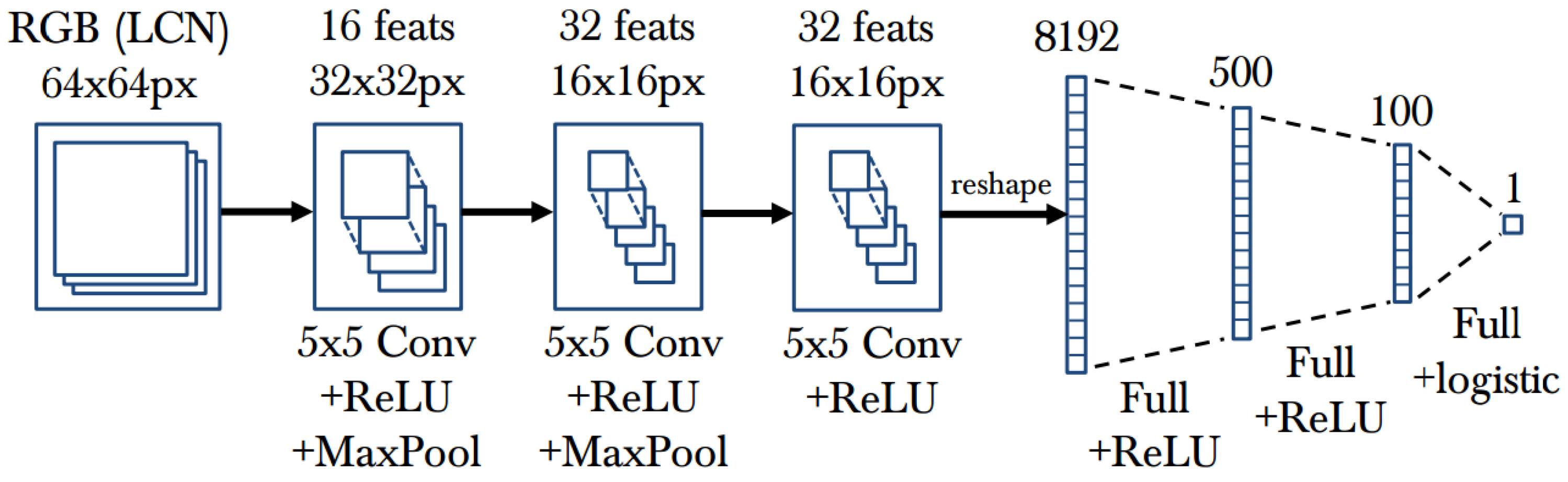{kind=link}
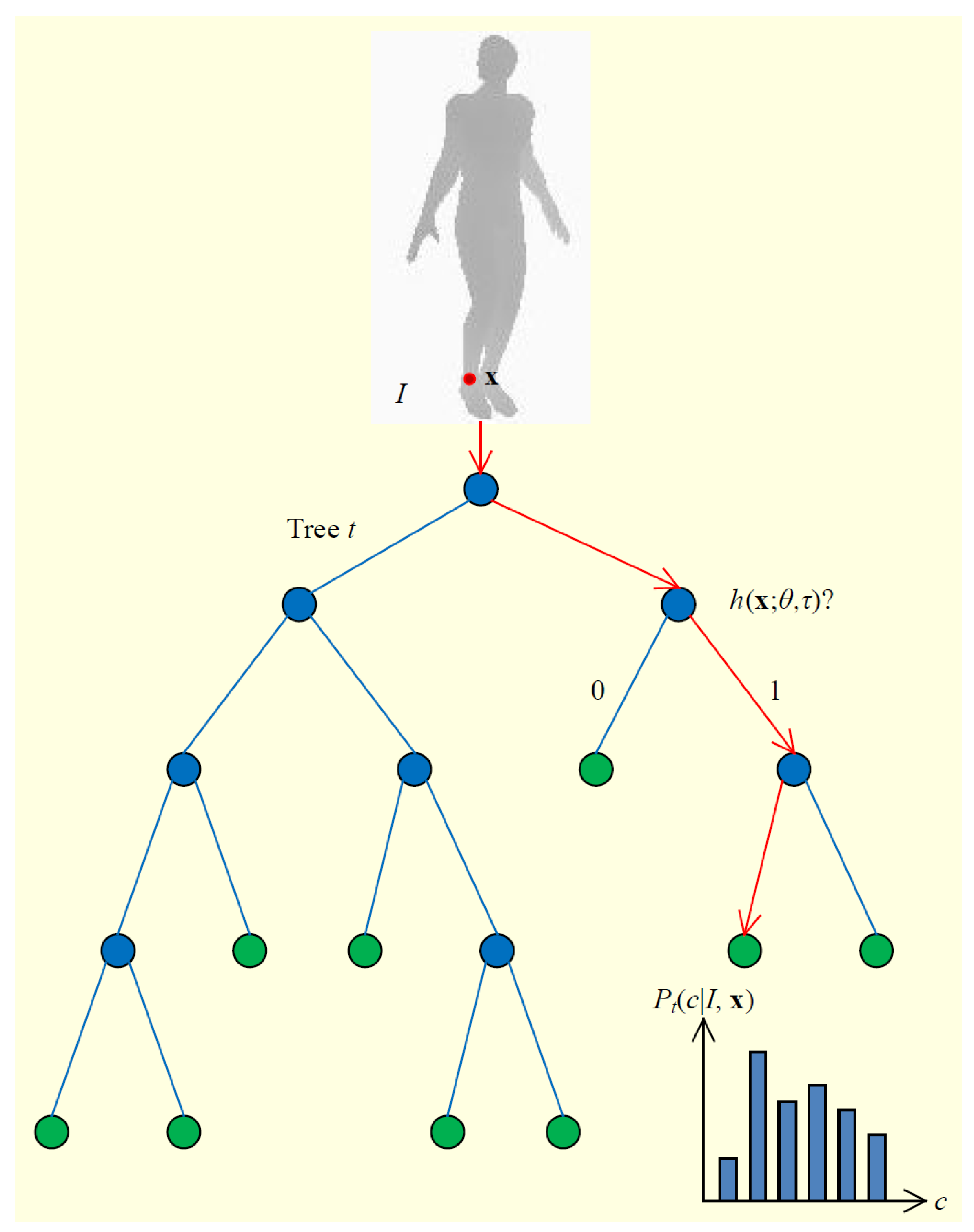{kind=link}
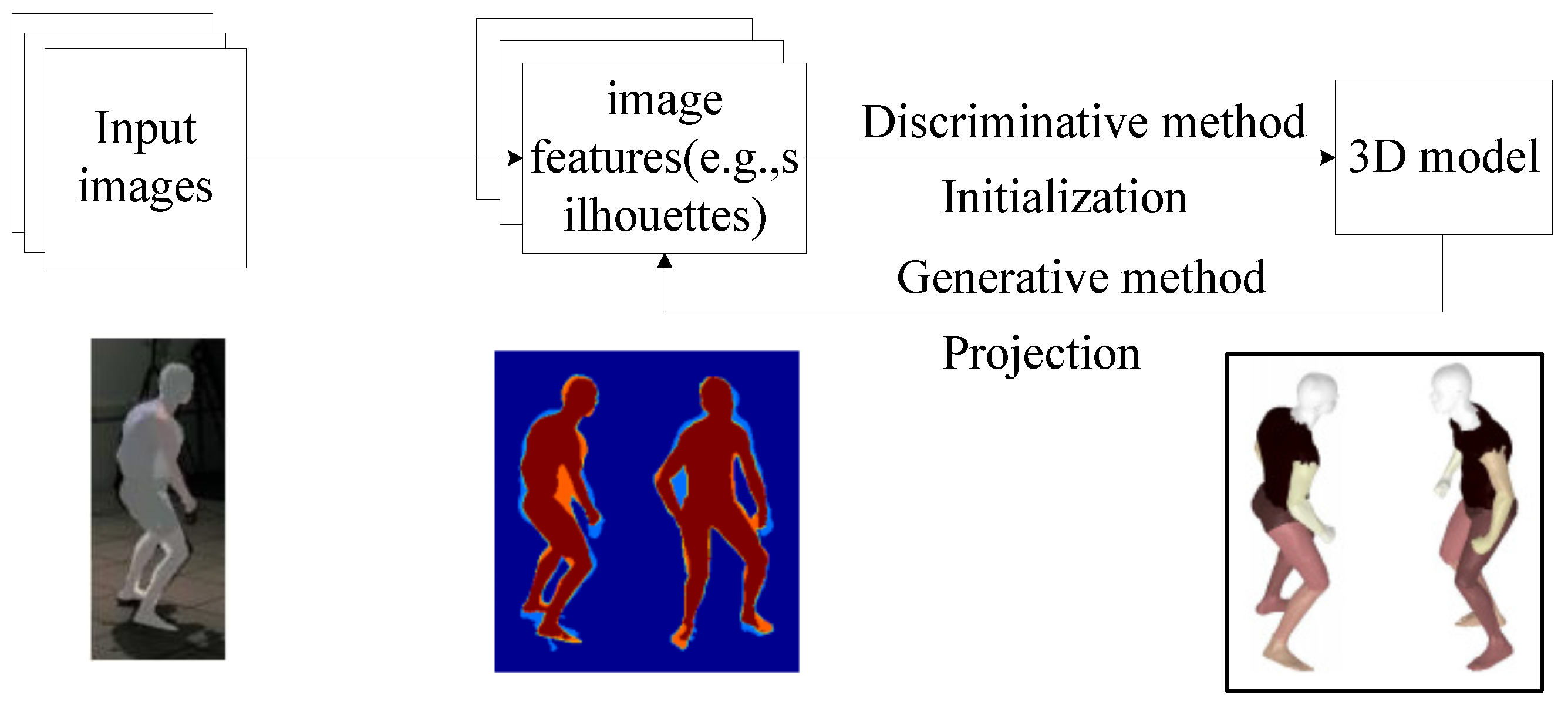{kind=link}
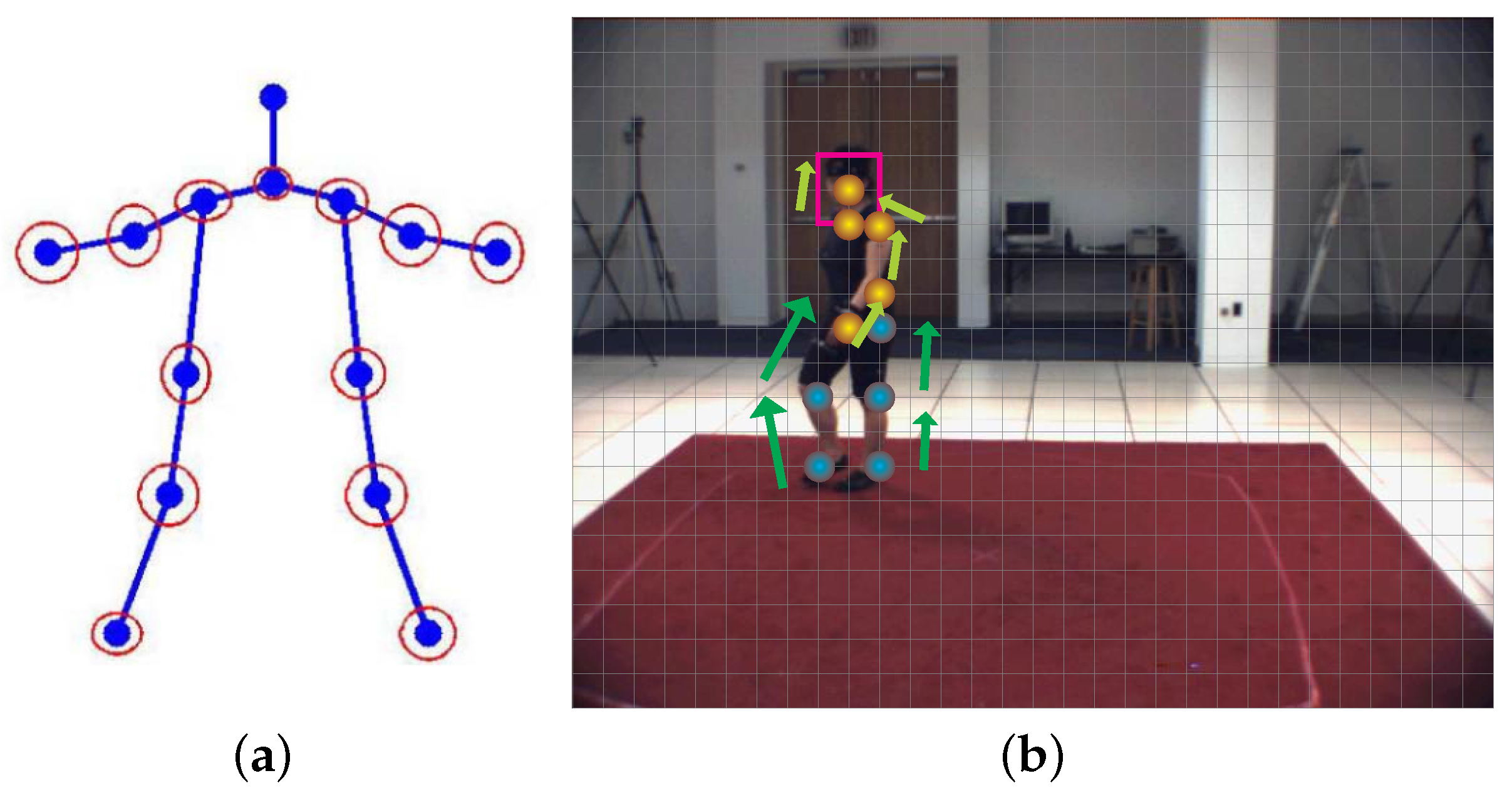{kind=link}
| Components | Categories | Sub-Categories | |
|---|---|---|---|
| Features | Low-level Features | (1) Shape: silhouettes [31,32,33,34], contours [35,36], edges [37,38] | |
| (2) Color: [36,39,40] | |||
| (3) Textures: [41] | |||
| Mid-level Features | (1) Local features: like Fourier descriptor [42], shape contexts [43,44,45,46,47], geometric signature [48], Poisson features [49], histogram of oriented gradients (HOG) [50,51,52], relational edge distribution [53], Scale Invariant Feature Transform (SIFT) [54,55] and SIFT-like features [56,57], edgelet features [58], and shapelet features [59] | ||
| (2) Global Features: like object foreground map [46], max-covering [46], dense grid features [50,56,60] | |||
| (3) Multilevel hierarchical encodings: like Hierarchical Model and X (HMAX) [61], hyperfeatures [62] , spatial pyramid [63], vocabulary tree and Multilevel Spatial Blocks (MSB) [64] | |||
| (4) Automatic extracted features: like from a convolutional neural network (CNN) [65,66,67] | |||
| High-level Features | (1) Context [8] | ||
| (2) Combined body parts [68,69,70] | |||
| Motion Features | (1) Optical flow related: dense optical flow [71], robust optical flow [72] | ||
| (2) Combined motion features: like combined edge energy and motion boundaries [73] | |||
| Human Body Models | Kinematic Models | (1) Predefined model: pictorial structure models (PSM) [71,74], tree-structured models [41,75,76,77,78,79,80,81], improved tree-structured models [36,82,83,84,85,86,87,88,89] | |
| (2) Learned graph structure: learned pairwise body part relations [90], learned tree structure based on Bayesian Networks [91,92] | |||
| Planar | Planar model: Active Shape Model (ASM) [93,94,95,96], cardboard [97] | ||
| Volumetric Models | (1) Cylindrical model: [98] | ||
| (2) Meshes: Shape Completion and Animation of People (SCAPE) [99,100,101,102,103], enhanced SCAPE model [104], 3D models with shading [105], and others [94,99,106] | |||
| Prior Models | Motion prior model: motion priors from motion capture data [107,108,109,110], joint limits [111], random forests (RFs) and principal direction analysis [2], physics-based models with dynamics [112,113] | ||
| Methods | Generative | Generative methods [22,114,115,116,117,118,119] | |
| Discrimi-native Methods | Learning-based Methods | (1) Mapping-based methods: Support Vector Machines (SVMs) [120,121,122], Relevance Vector Machines (RVMs) [32,123,124,125], Mixture of Experts (MoE) [126,127,128], Bayesian Mixtures of Experts (BME) [129,130], direct mapping [32,60,120,121,122,123,124,125,131,132,133], 2D to 3D pose boosting [78,134,135,136,137]; supervised and unsupervised [64,138] and semi-supervised methods [139,140,141] | |
| (2) Space Learning: manifold learning [24,34,142,143,144,145,146,147], subspace learning [148,149], dimensional reduction [150], and others [56,64,151,152] | |||
| (3) Bag-of-words: [130] | |||
| (4) Deep learning: part detection with the accurate localization of human body parts through deep learning networks [66,153,154], features learned through deep learning and modeling the human body with kinematic graphical models [155,156], learning both with deep learning [90,157,158,159], and enhanced deep learning algorithms [160,161,162,163,164] | |||
| Examplar | Randomized trees [165], Random Forests [166,167], and sparse representation [168,169,170,171] | ||
| Combined Methods | Combined Methods of discriminative and generative methods: [147,172,173,174,175,176,177,178,179,180] | ||
| Top-Down Methods | Top-Down Methods: [181] | ||
| Bottom-Up Methods | Pixel-based | Boosting pose estimation accuracy iteratively [97,182,183,184,185,186], pose estimation combined with segmentation [187,188,189,190,191,192,193] | |
| Part-based Methods | (1) Pictorial Structures: Pictorial Structures [36,77,79,189,194,195,196,197] and its deformations [79,195,198,199] | ||
| (2) Enhanced Kinematic Models: better appearance [187], more modes [88], cascaded models [36,84,200,201], and loopy-graph models [87,202,203] | |||
| Combined Methods | First | Combined methods of detection- and recognition-based methods: [37,60,204,205,206,207] | |
| Second | Combined methods of pixel-based and part-based methods: [46,193,205,208,209,210] | ||
| Motion-based Methods | Motion model [211,212], kinematic constraints from motion [213,214,215], sampling based tracking [177,216,217,218], Gaussian Process Latent Variable Model (GPLVM) [45,219,220,221,222], Gaussian Process Dynamical Models (GPDMs) [223] | ||
| Data Set | Content | Image No. | |
|---|---|---|---|
| Type | Name | ||
| Still Images | PASCAL VOC 2009 | Phoning, Riding Horse, Running, Walking | 7054 |
| Gamesourcing [306] | 300 images each from PARSE, BUFFY, LEEDS | 48 | |
| Leeds Sports Pose Dataset [307] | Athletics, Badminton, Baseball, Gymnastics, Parkour, Soccer, Tennis, Volleyball | 2000 | |
| “We are family” stickmen [308] | |||
| PASCAL VOC 2012 | Ten actions, including jumping, phoning, playing instrument, etc. | 11,530 | |
| PASCAL Stickmen [309] | 549 | ||
| PEAR [310] | Five subjects performing seven predefined | ||
| KTH Multiview Football Dataset I [311] | 2D dataset | 5907 | |
| KTH Multiview Football Dataset II [312] | 3D dataset | 2400 | |
| FLIC (Frames Labeled In Cinema) [313] | Images in 30 movies | 5003 | |
| FLIC-full [314] | Images in 30 movies | 20,928 | |
| FLIC-plus [315] | |||
| PARSE [316] | Mostly playing sports | 305 | |
| MPII Human Pose Dataset [317] | hockey ice, rope skipping, trampoline, rock climbing, cricket batting, etc. | 25,000 | |
| Poses in the Wild [318] | 900 | ||
| Multi Human Pose [319] | |||
| Human 3.6H (H36M) [320] | Seventeen scenarios, including discussion, smoking, taking photo, talking on the phone, etc. | 3.6 million | |
| ChaLearn Looking at People 2015: Human Pose Recovery [321] | 8000 | ||
| Image Sequences | CMU-Mocap [322] | Jumping Jacks, Climbing a ladder, Walking | |
| Utrecht Multi-Person Motion [323] | Multi-person motion image sequences | ||
| HumanEva-I [324] | Walk, Jog, Gestures, ThrowCatch, Box | 74,267 | |
| HumanEva-II | |||
| TUM Kitchen [325] | >20,000 | ||
| Buffy Pose Classes (BPC) [326] | Episodes 2 to 6 of the 5th season the TV show “Buffy the vampire slayer” (BTVS) | 748 | |
| Buffy Stickmen V3.01 [327] | Five episodes of the fifth season of BTVS | ||
| H3D database | With 3D joint positions | 1240 | |
| Video Pose [328] | Forty-four short clips from Buffy the Vampire Slayer, Friends, and LOST | 1286 | |
| Video Pose 2.0 dataset | 900 | ||
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gong, W.; Zhang, X.; Gonzàlez, J.; Sobral, A.; Bouwmans, T.; Tu, C.; Zahzah, E.-h. Human Pose Estimation from Monocular Images: A Comprehensive Survey. Sensors 2016, 16, 1966. https://doi.org/10.3390/s16121966
Gong W, Zhang X, Gonzàlez J, Sobral A, Bouwmans T, Tu C, Zahzah E-h. Human Pose Estimation from Monocular Images: A Comprehensive Survey. Sensors. 2016; 16(12):1966. https://doi.org/10.3390/s16121966
Chicago/Turabian StyleGong, Wenjuan, Xuena Zhang, Jordi Gonzàlez, Andrews Sobral, Thierry Bouwmans, Changhe Tu, and El-hadi Zahzah. 2016. "Human Pose Estimation from Monocular Images: A Comprehensive Survey" Sensors 16, no. 12: 1966. https://doi.org/10.3390/s16121966
APA StyleGong, W., Zhang, X., Gonzàlez, J., Sobral, A., Bouwmans, T., Tu, C., & Zahzah, E.-h. (2016). Human Pose Estimation from Monocular Images: A Comprehensive Survey. Sensors, 16(12), 1966. https://doi.org/10.3390/s16121966