
Real-Time Lane Region Detection Using a Combination of Geometrical and Image Features


Abstract
:1. Introduction
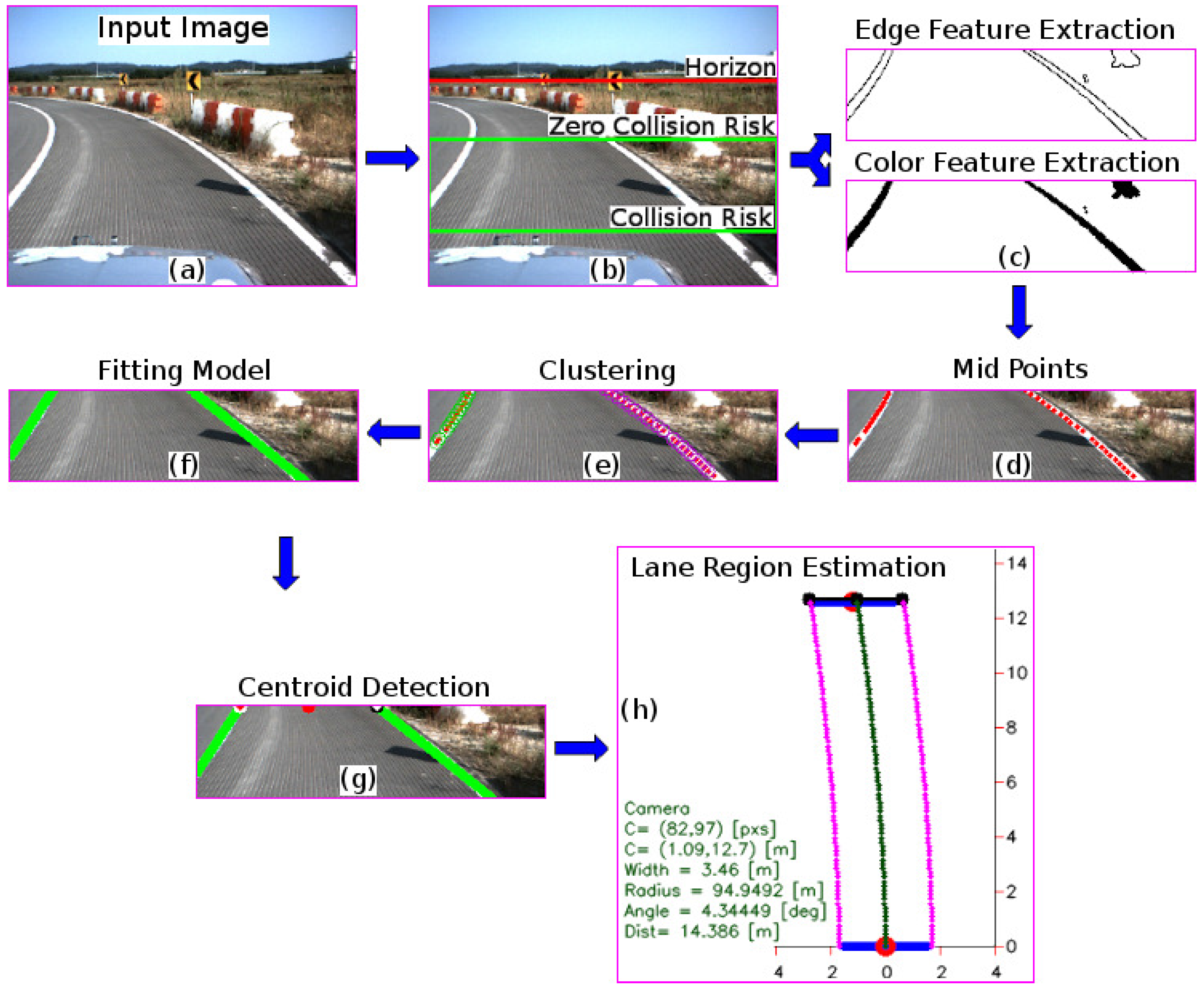
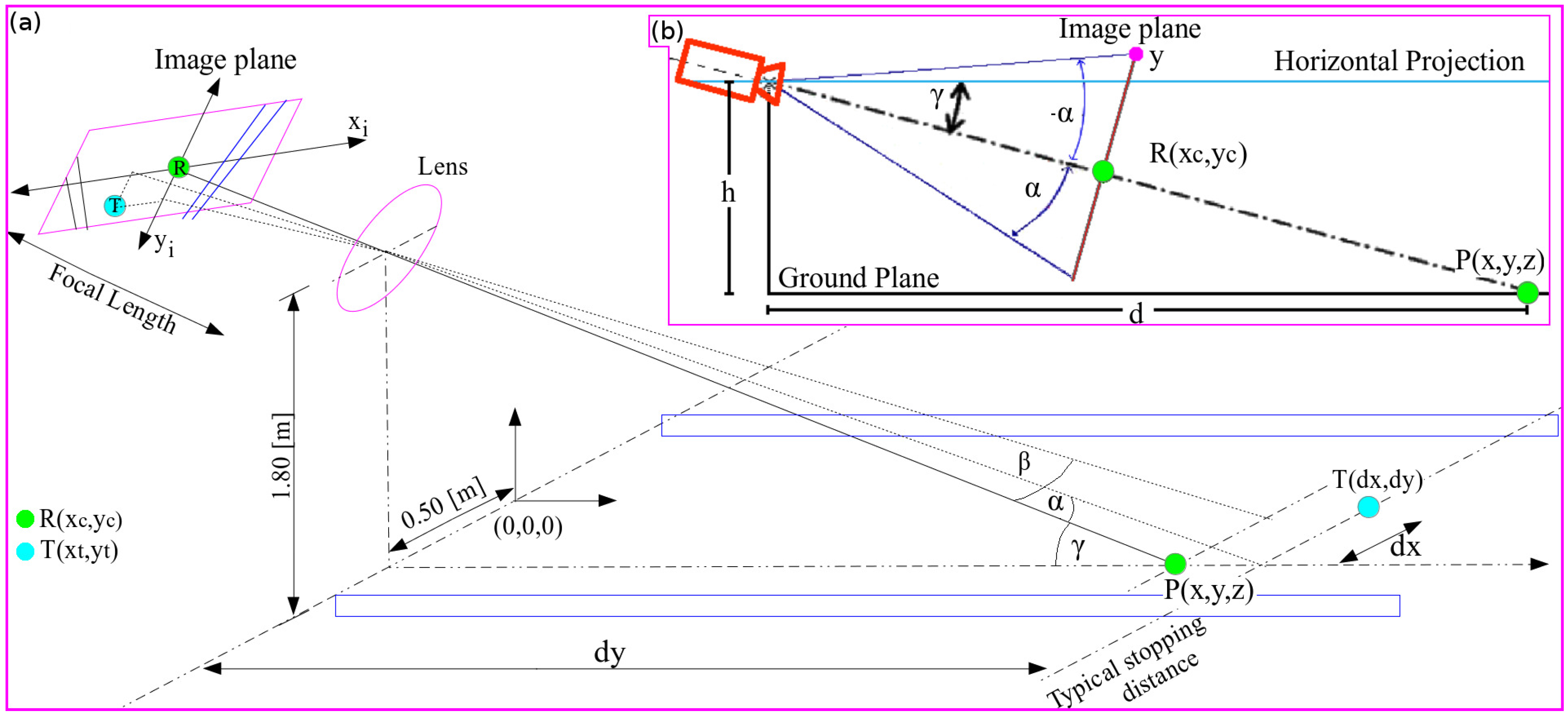
2. System Overview
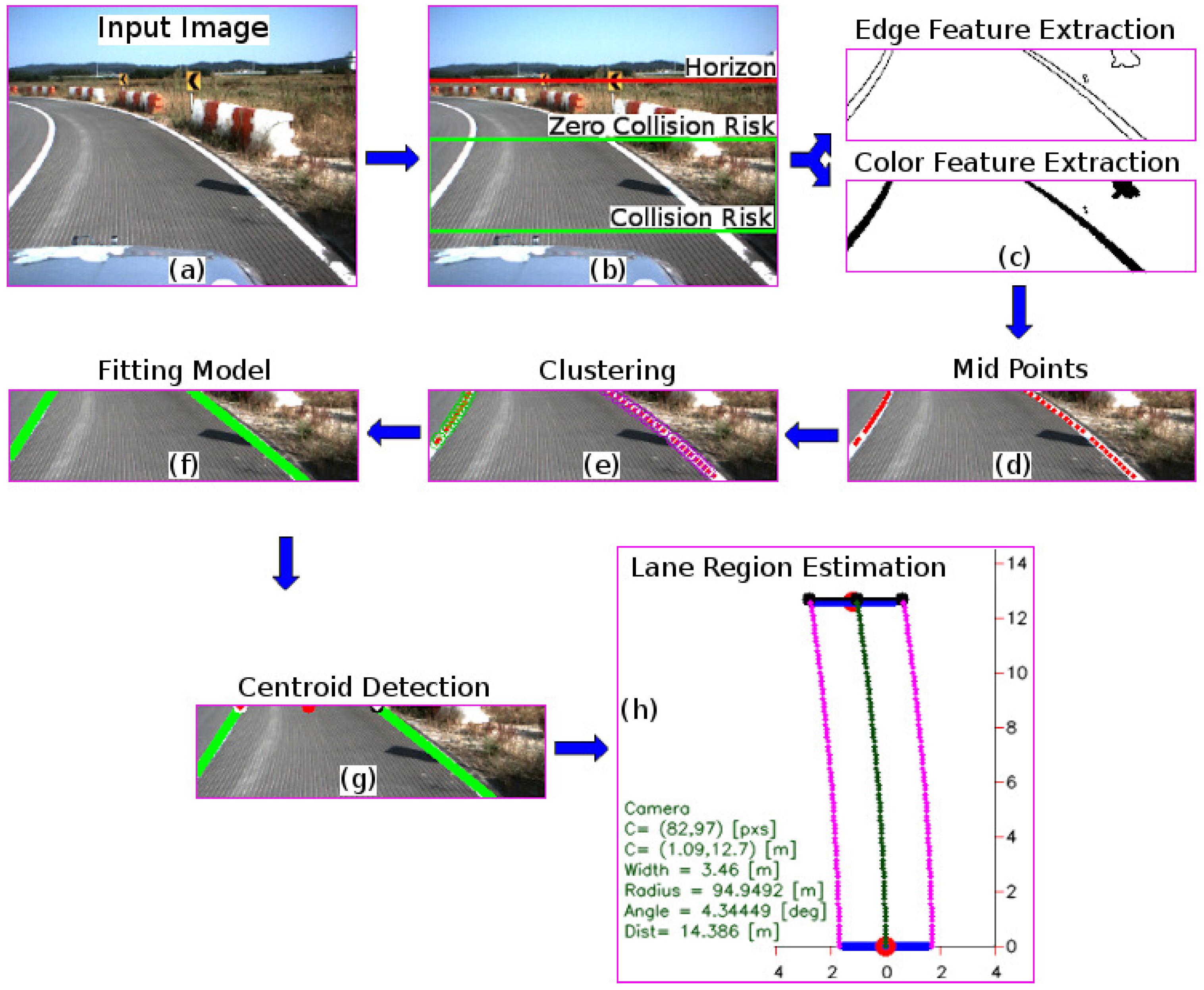
3. Proposed Method
3.1. Lane Marking Estimation
3.2. Lane Region Detection
4. Experiments
4.1. Lane Marking Evaluation
- Stopping lane markings: this type of marker does not affect the performance, since the distance between the starting and ending of the edge point is larger than the distance constraints.
- Channelizing lane markings: the midpoints are extracted from the region that belongs to the distance constraints. Using the set of extracted points and the clustering strategy, the lane markings are extracted; see columns 1 and 2 in Figure 9. In the first two columns, three clusters were detected, each one belonging to each lane marking.
- Crosswalk markings: similarly to the stopping lane marker, these markers do not affect the algorithm due to the distance constraints. Columns 4 and 5 in Figure 9 show the performance. It should be noted that the lane markings were detected due to the presence of broken markings before the crosswalk region as well as the reflection of the sun within the curb region; see the input image in Figure 9 row 1.
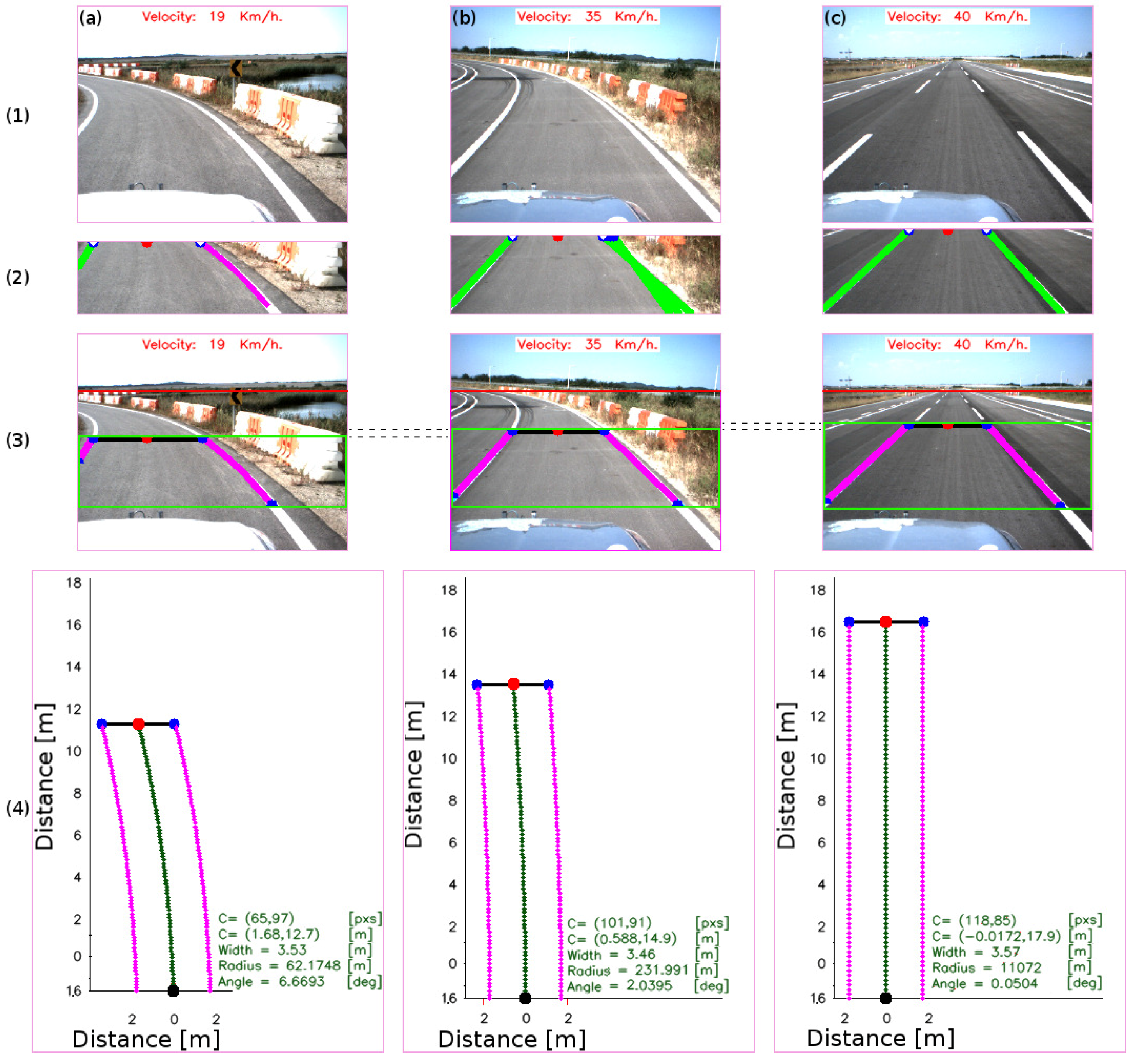
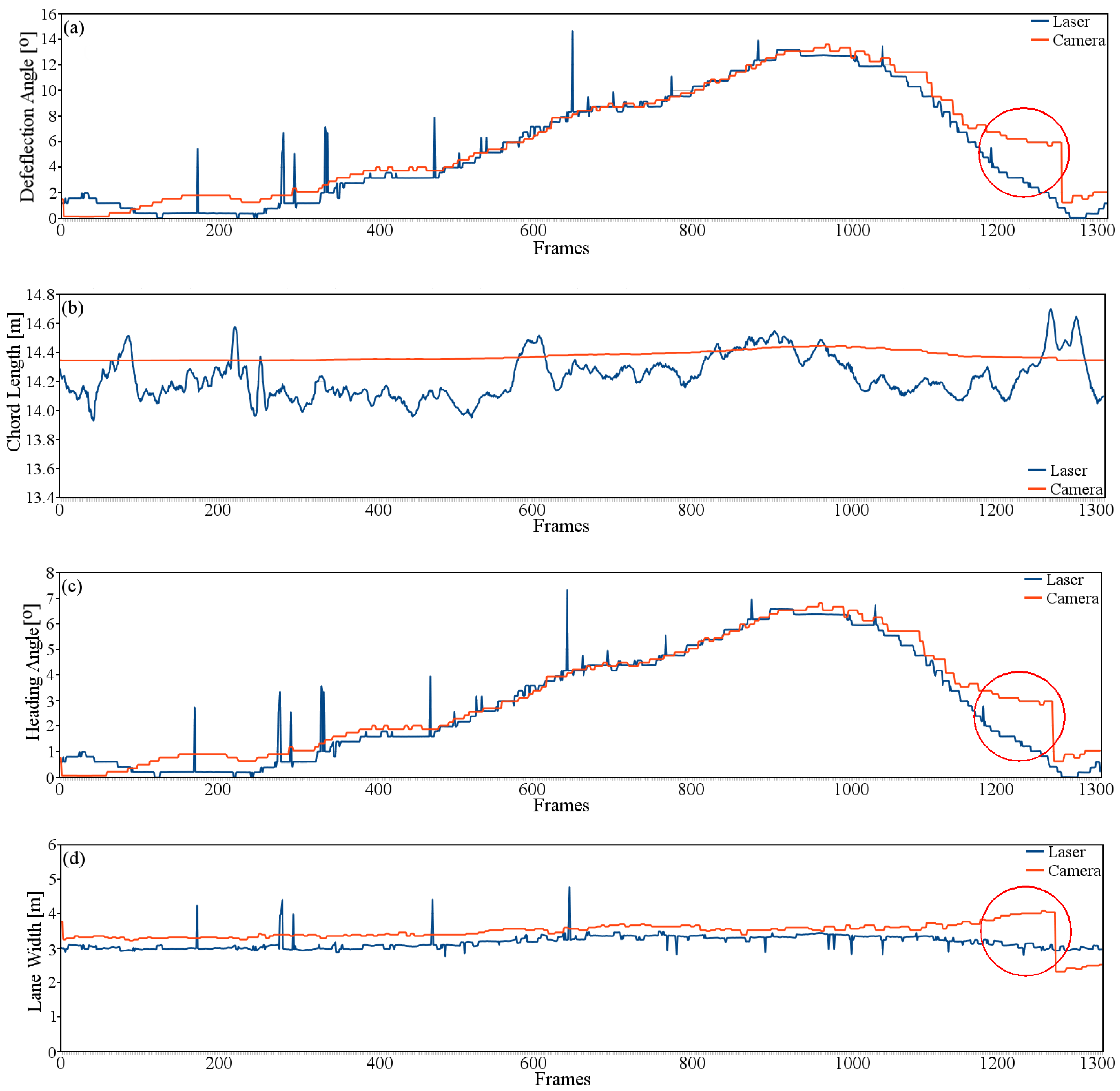
4.2. Lane Region Evaluation
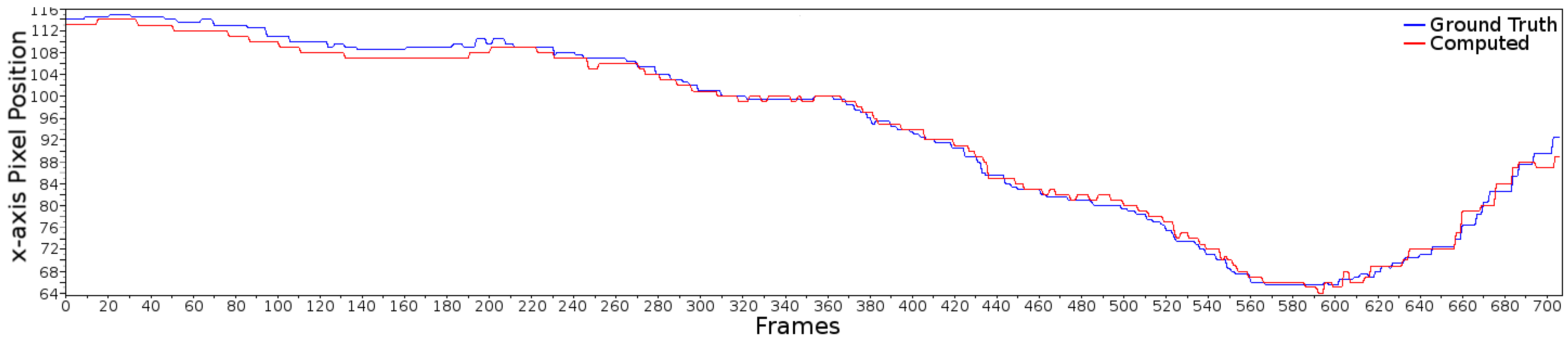
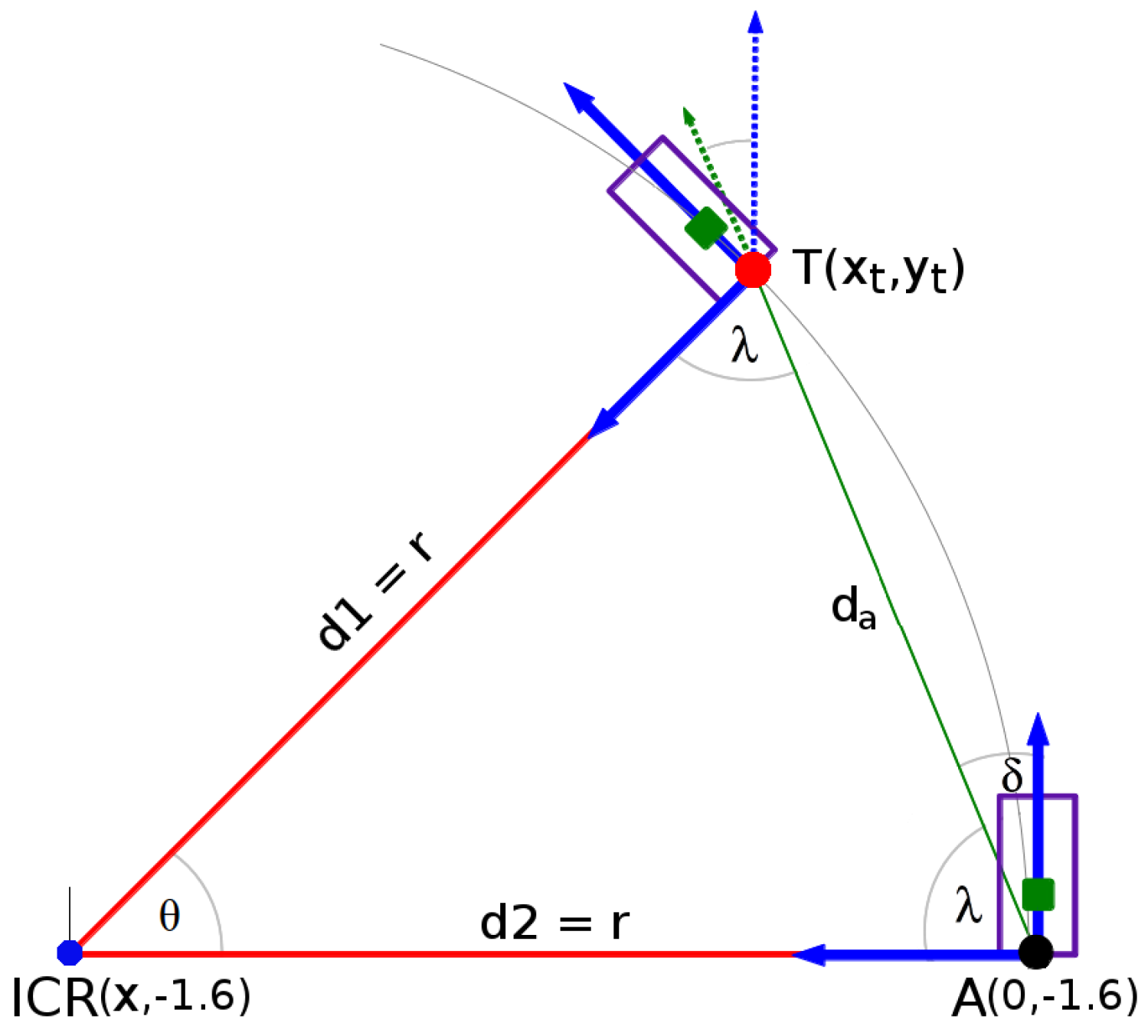
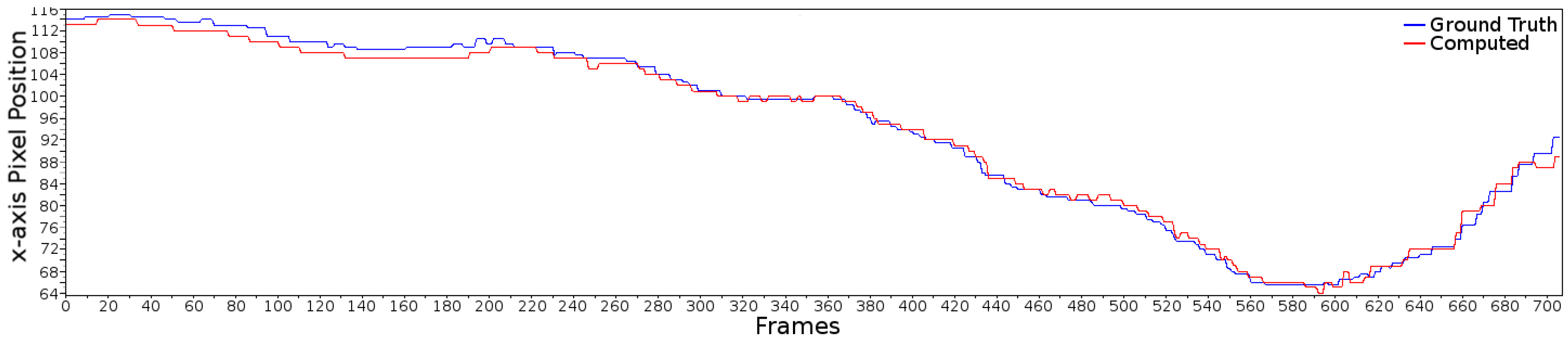
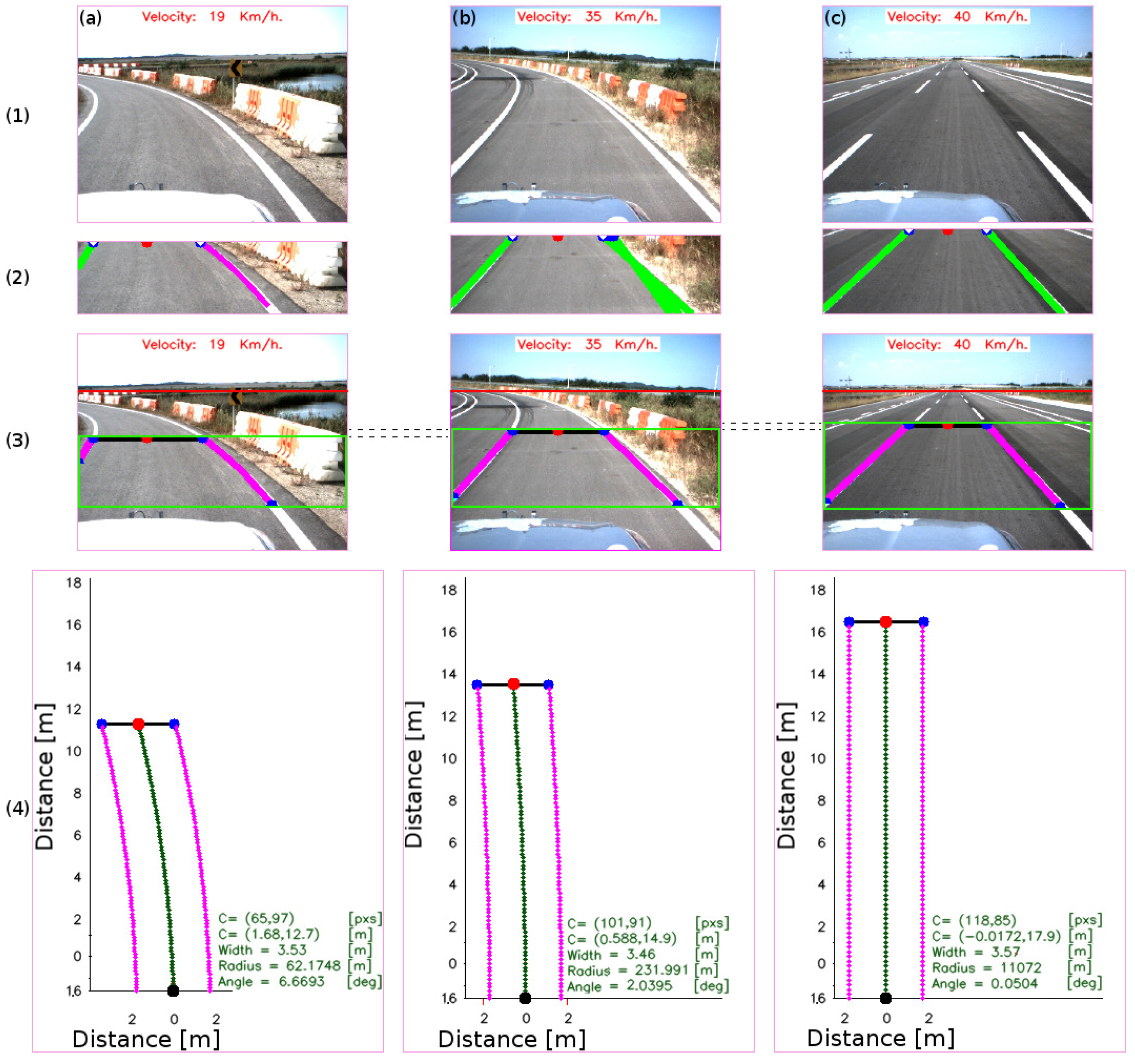
4.2.1. Centroid of the Lane
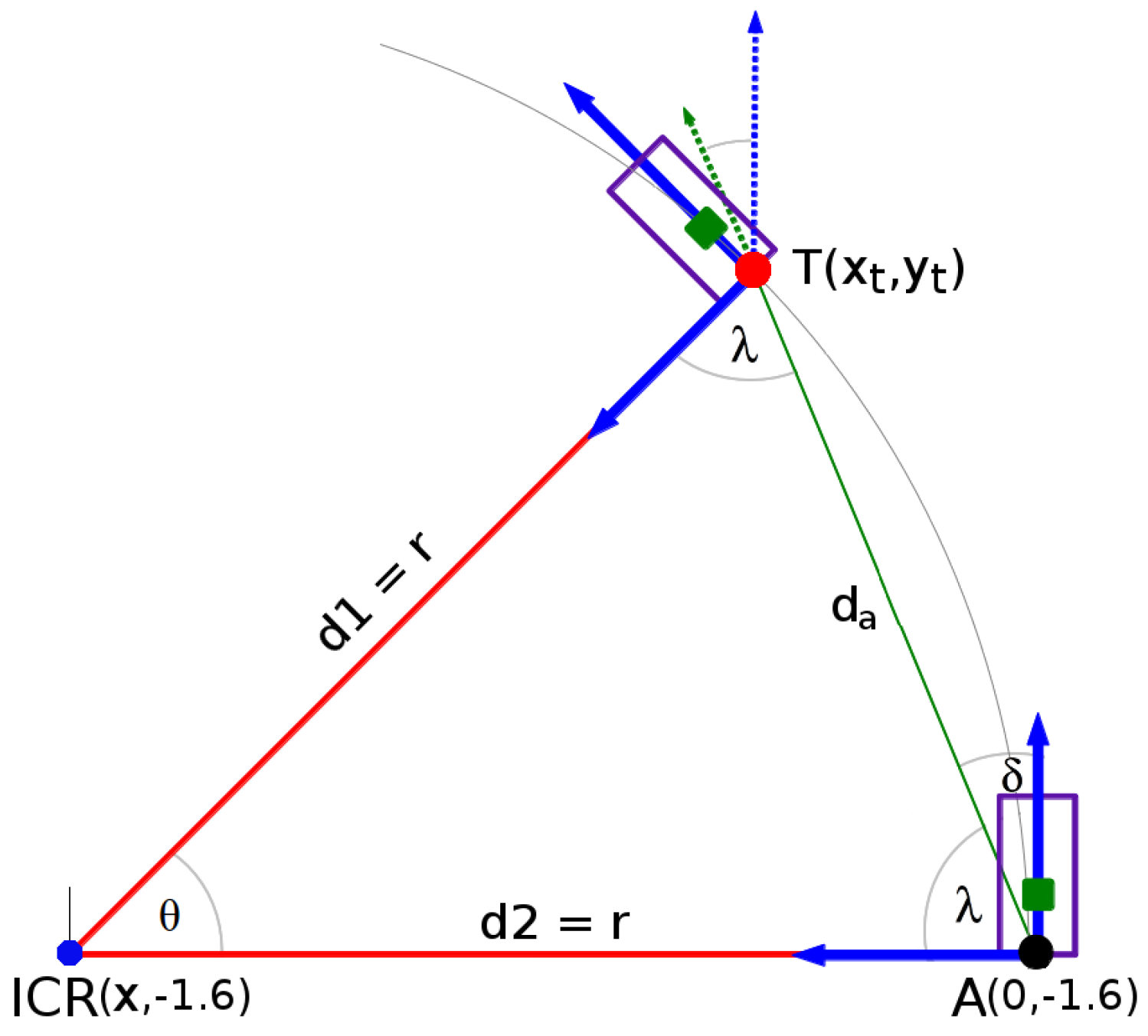
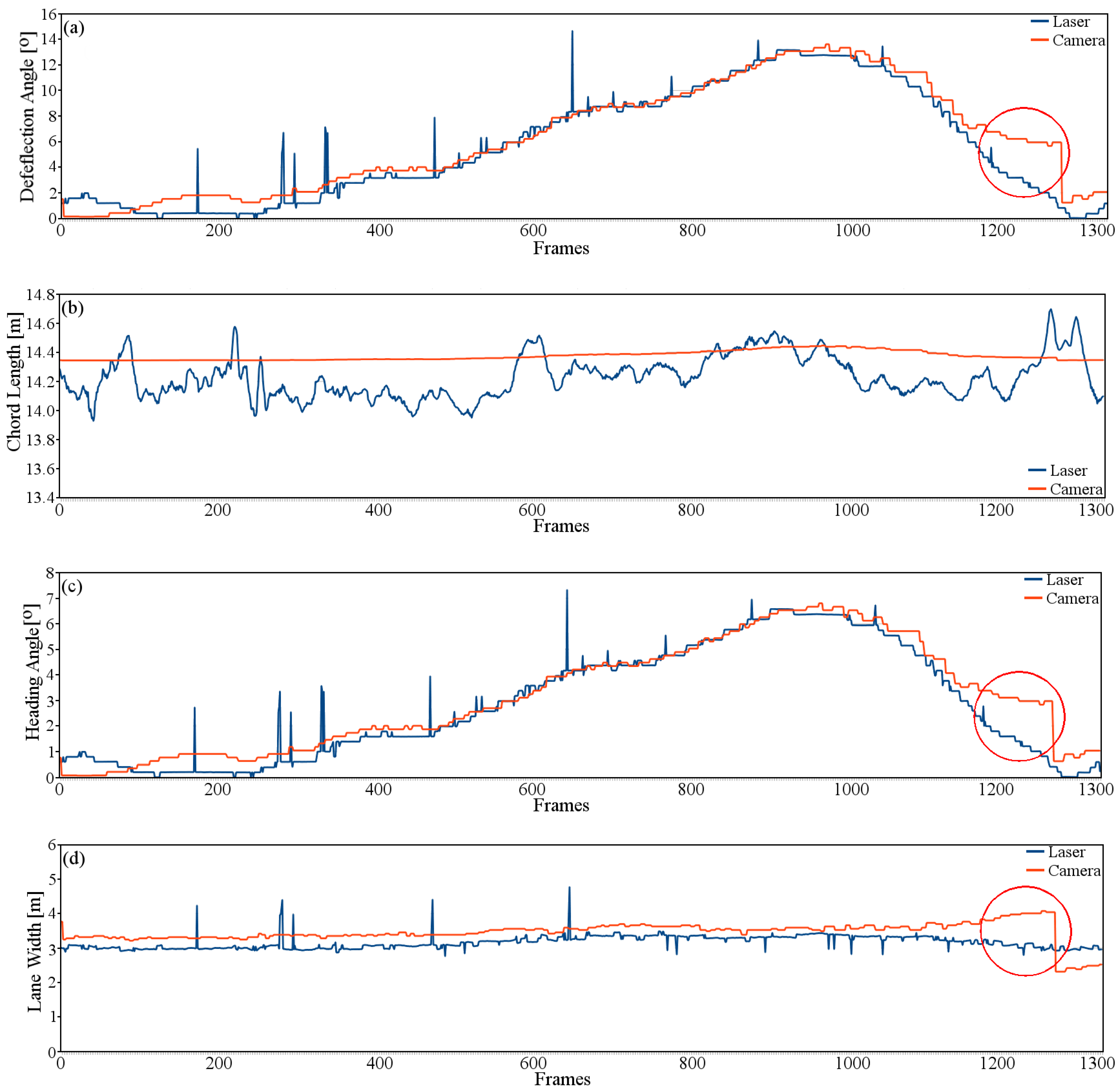
4.2.2. Road Geometry Parameters
4.3. Comparative Analysis
5. Conclusions
- To introduce an automated method for extracting the region of interest based on the relationship between the vehicle speed and the typical stopping distance within the image. As a result, the image is sectioned into three regions: information above the horizon, a zero collision risk, and a collision risk region.
- To propose a real-time lane marking detection strategy combining edge and color features, which uses the probability that the extracted features define a lane marking, as well as a hierarchical fitting model. As a result, the method is able to detect lane markings with an accuracy of 96.84% at an average processing time of 28.30 ms, for a speed range of [5–45] km/h. Similarly, the algorithm solves the problem given by traffic marking signal types such as channelizing lines, stop lines, crosswalks, and arrows.
- To estimate the lane region and the vehicle heading angle by using the road geometry model and the lane centroid information.
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Sun, T.Y.; Tsai, S.J.; Chan, V. HSI color model based lane-marking detection. In Proceedings of the 2006 IEEE Intelligent Transportation Systems Conference, Toronto, ON, Canada, 17–20 September 2006; pp. 1168–1172.
- Tran, T.T.; Bae, C.S.; Kim, Y.N.; Cho, H.M.; Cho, S.B. An Adaptive Method for Lane Marking Detection Based on HSI Color Model. In Proceedings of the 6th International Conference on Intelligent Computing Advanced Intelligent Computing Theories and Applications, Changsha, China, 18–21 August 2010; pp. 304–311.
- Du, X.; Tan, K.K. Comprehensive and Practical Vision System for Self-Driving Vehicle Lane-Level Localization. IEEE Trans. Image Process. 2016, 25, 2075–2088. [Google Scholar] [CrossRef] [PubMed]
- Mammeri, A.; Boukerche, A.; Tang, Z. A real-time lane marking localization, tracking and communication system. Comput. Commun. 2016, 73, 132–143. [Google Scholar] [CrossRef]
- Jung, S.; Youn, J.; Sull, S. Efficient Lane Detection Based on Spatiotemporal Images. IEEE Trans. Intell. Transp. Syst. 2016, 17, 289–295. [Google Scholar] [CrossRef]
- James, A.P.; Al-Jumeily, D.; Thampi, S.M.; John, N.; Anusha, B.; Kutty, K. A reliable method for detecting road regions from a single image based on color distribution and vanishing point location. Procedia Comput. Sci. 2015, 58, 2–9. [Google Scholar]
- Cáceres, H.D.; Filonenko, A.; Seo, D.; Jo, K.H. Laser scanner based heading angle and distance estimation. In Proceedings of the 2015 IEEE International Conference on Industrial Technology, Seville, Spain, 17–19 March 2015; pp. 1718–1722.
- Cáceres, H.D.; Seo, D.; Jo, K.H. Robust lane marking detection based on multi-feature fusion. In Proceedings of the 9th International Conference on Human System Interaction (HSI), Portsmouth, UK, 6–8 July 2016; pp. 423–428.
- Aly, M. Real time detection of lane markers in urban streets. In Proceedings of the 2008 IEEE Intelligent Vehicles Symposium, Eindhoven, The Netherlands, 4–6 June 2008; pp. 7–12.
- Li, Q.; Zheng, N.; Cheng, H. Springrobot: A prototype autonomous vehicle and its algorithms for lane detection. IEEE Trans. Intell. Transp. Syst. 2004, 5, 300–308. [Google Scholar] [CrossRef]
- Otsu, N. A Threshold Selection Method from Gray-Level Histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar] [CrossRef]
- Du, X.; Tan, K.K. Vision-based approach towards lane line detection and vehicle localization. Mach. Vis. Appl. 2016, 27, 175–191. [Google Scholar] [CrossRef]
- Lu, M.C.; Hsu, C.C.; Lu, Y.Y. Image-Based System for Measuring Objects on an Oblique Plane and Its Applications in 2-D Localization. IEEE Sens. J. 2012, 12, 2249–2261. [Google Scholar] [CrossRef]
- Lu, M.C.; Hsu, C.C.; Lu, Y.Y. Distance and angle measurement of distant objects on an oblique plane based on pixel variation of CCD image. In Proceedings of the 2010 IEEE Instrumentation and Measurement Technology Conference, Austin, TX, USA, 3–6 May 2010; pp. 318–322.
- Pauly, N.; Rafla, N.I. An automated embedded computer vision system for object measurement. In Proceedings of the 2013 IEEE 56th International Midwest Symposium on Circuits and Systems, Columbus, OH, USA, 4–7 August 2013; pp. 1108–1111.
- Fernandes, J.C.A.; Neves, J.A.B.C. Angle Invariance for Distance Measurements Using a Single Camera. In Proceedings of the 2006 IEEE International Symposium on Industrial Electronics, Montreal, QC, Canada, 9–13 July 2006; pp. 676–680.
- Hernández, D.C.; Filonenko, A.; Seo, D.; Jo, K.H. Lane marking recognition based on laser scanning. In Proceedings of the 2015 IEEE 24th International Symposium on Industrial Electronics, Búzios, Brazil, 3–5 June 2015; pp. 962–965.
- Hernández, D.C.; Filonenko, A.; Seo, D.; Jo, K.H. Crosswalk detection based on laser scanning from moving vehicle. In Proceedings of the 2015 IEEE 13th International Conference on Industrial Informatics, Cambridge, UK, 22–24 July 2015; pp. 1515–1519.
- Tran, T.T.; Cho, H.M.; Cho, S.B. A robust method for detecting lane boundary in challenging scenes. Inf. Technol. 2011, 10, 2300–2307. [Google Scholar] [CrossRef]
- Wolcott, R.; Eustice, R. Visual localization within LIDAR maps for automated urban driving. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 14–18 September 2014; pp. 176–183.
- Guan, H.; Li, J.; Yu, Y.; Chapman, M.; Wang, C. Automated Road Information Extraction From Mobile Laser Scanning Data. IEEE Trans. Intell. Transp. Syst. 2015, 16, 194–205. [Google Scholar] [CrossRef]
- Guan, H.; Li, J.; Yu, Y.; Wang, C.; Chapman, M.; Yang, B. Using mobile laser scanning data for automated extraction of road markings. ISPRS J. Photogramm. Remote Sens. 2014, 87, 93–107. [Google Scholar] [CrossRef]
- Guo, J.; Wei, Z.; Miao, D. Lane Detection Method Based on Improved RANSAC Algorithm. In Proceedings of the 2015 IEEE Twelfth International Symposium on Autonomous Decentralized Systems, Taichung, Taiwan, 25–27 March 2015; pp. 285–288.
- Zhang, Y.Q.; Ding, Y.; Xiao, J.S.; Liu, J.; Guo, Z. Visibility enhancement using an image filtering approach. EURASIP J. Adv. Signal Process. 2012, 2012, 220. [Google Scholar] [CrossRef]
- Huang, S.C.; Chen, B.H.; Cheng, Y.J. An Efficient Visibility Enhancement Algorithm for Road Scenes Captured by Intelligent Transportation Systems. IEEE Trans. Intell. Transp. Syst. 2014, 15, 2321–2332. [Google Scholar] [CrossRef]
- Lantieri, C.; Lamperti, R.; Simone, A.D.G. Mobile Laser Scanning System for Assessment of the Rainwater Runoff and Drainage Conditions on Road Pavements. Int. J. Pavement Res. Technol. 2015, 8, 1–9. [Google Scholar]
- Sallis, P.; Dannheim, C.; Icking, C.; Maeder, M. Air Pollution and Fog Detection through Vehicular Sensors. In Proceedings of the 2014 8th Asia Modelling Symposium, Taiwan, 23–25 September 2014; pp. 181–186.
- Hybrid Lane Detection Results Using Camera and Laser Sensors. Available online: http://islab.ulsan.ac.kr/supplementary/lane_detection/lane_detection_result_camera_laser.avi (accessed on 15 November 2016).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Types a | Frames | TP | FP | FN | TN | St [%] | Sp [%] | A [%] | FPs | FNs |
|---|---|---|---|---|---|---|---|---|---|---|
| Total | 3781 | 5891 | 148 | 234 | 5851 | 96.17 | 97.53 | 96.84 | 0.92 | 1.46 |
| Single | 3781 | 3781 | 148 | 138 | 7961 | 96.45 | 98.17 | 97.22 | 0.92 | 0.86 |
| Double | 1055 | 2014 | 0 | 96 | 2683 | 95.45 | 100 | 97.99 | 0 | 2.15 |
| Average | Standard Deviation | Maximum Value | |
|---|---|---|---|
| Line | 4.34 | 3.25 | 14.88 |
| Curve | 3.81 | 0.336 | 4.39 |
| Deflection Angle [] | Chord Length [m] | Vehicle Heading Angle [] | Lane Width [m] | |
|---|---|---|---|---|
| RMSE | 1.28 | 0.20 | 0.63 | 0.40 |
| Authors a | Frame No. | DR [%] | FDR [%] | PT [ms] | DA [m] |
|---|---|---|---|---|---|
| Proposed method | 3781 | 96.17 | 2.47 | 28.30 | 0.77 |
| Mammeri et al. [4] | 912 | 100.00 | 3.60 | ≫32.31 ** | ≫0.90 |
| Du et al. [13] | 350 | 98.50 | 2.20 | 120.04 | 3.33 |
| Jung et al. [5] | N/D | 98.31 | N/D | 116.82 | 3.24 |
| Guo et al. [24] | 2132 | 94.79 | 7.77 | 40.00 | 1.10 |
| Distance | ROI a | Color | Edge | Mid-Points | Clustering | Fitting | Heading | Total |
|---|---|---|---|---|---|---|---|---|
| 0.0407 | 0.0807 | 5.8629 | 6.2400 | 0.7989 | 11.788 | 2.4640 | 1.0269 | 28.3021 |
| Total | Standard Deviation | Max. Time |
|---|---|---|
| 28.3021 | 7.003 | 48.99 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cáceres Hernández, D.; Kurnianggoro, L.; Filonenko, A.; Jo, K.H. Real-Time Lane Region Detection Using a Combination of Geometrical and Image Features. Sensors 2016, 16, 1935. https://doi.org/10.3390/s16111935
Cáceres Hernández D, Kurnianggoro L, Filonenko A, Jo KH. Real-Time Lane Region Detection Using a Combination of Geometrical and Image Features. Sensors. 2016; 16(11):1935. https://doi.org/10.3390/s16111935
Chicago/Turabian StyleCáceres Hernández, Danilo, Laksono Kurnianggoro, Alexander Filonenko, and Kang Hyun Jo. 2016. "Real-Time Lane Region Detection Using a Combination of Geometrical and Image Features" Sensors 16, no. 11: 1935. https://doi.org/10.3390/s16111935
APA StyleCáceres Hernández, D., Kurnianggoro, L., Filonenko, A., & Jo, K. H. (2016). Real-Time Lane Region Detection Using a Combination of Geometrical and Image Features. Sensors, 16(11), 1935. https://doi.org/10.3390/s16111935