
A Robust Method for Ego-Motion Estimation in Urban Environment Using Stereo Camera


Abstract
:1. Introduction
1.1. Related Work
1.2. Overview of the Approach
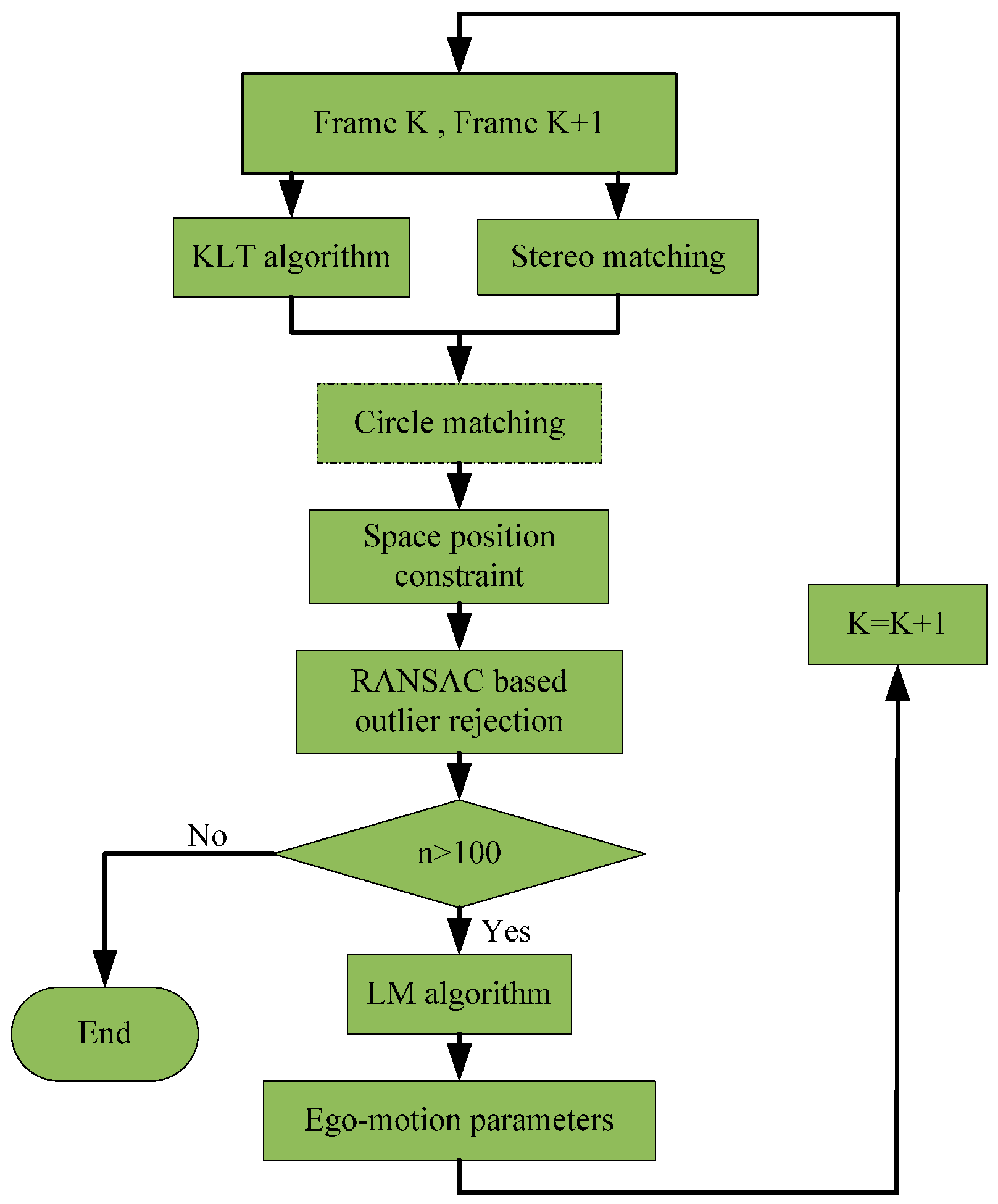
2. Proposed Method
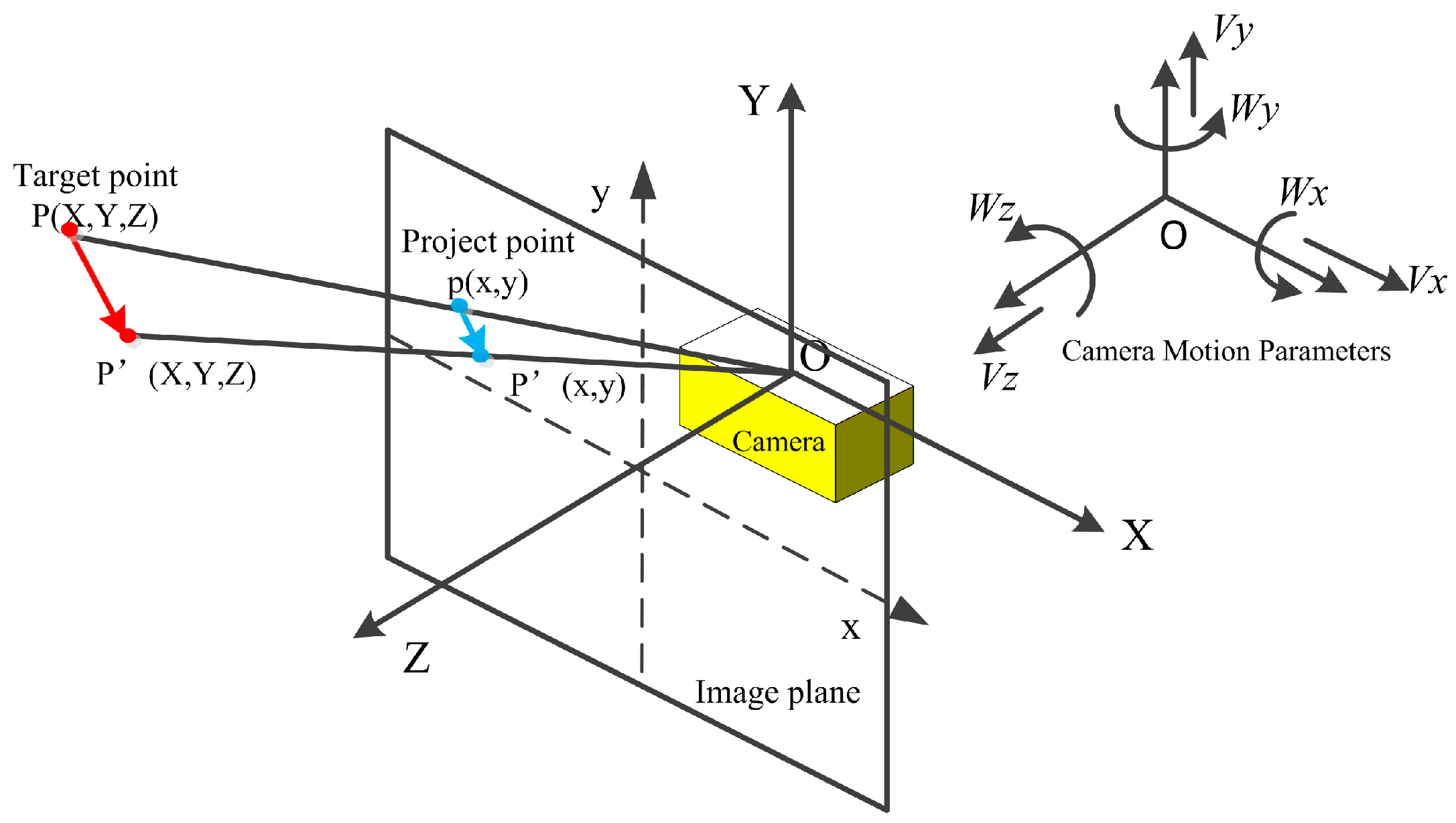
2.1. 3-Dimensional Motion Model and Objective Function
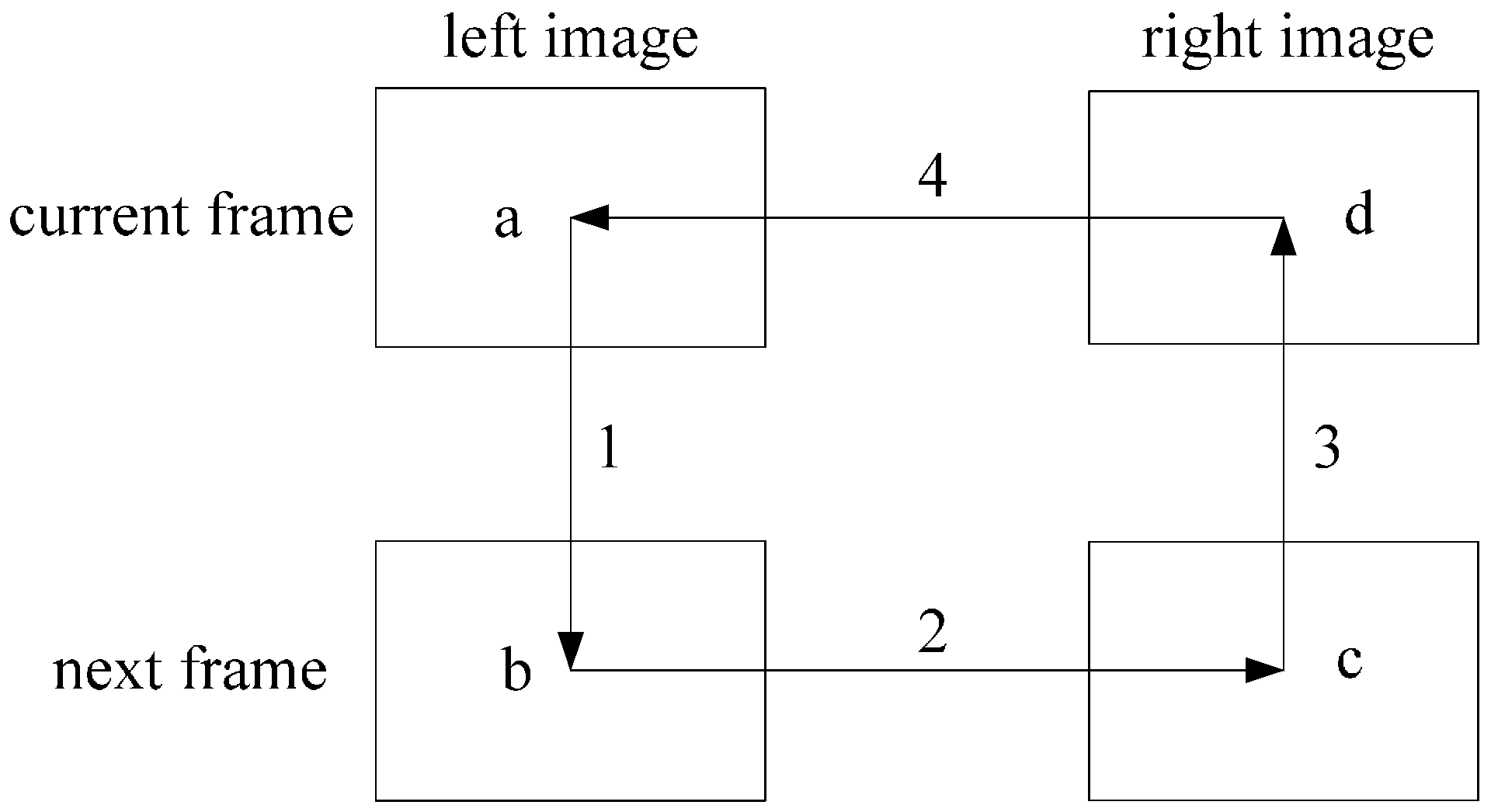
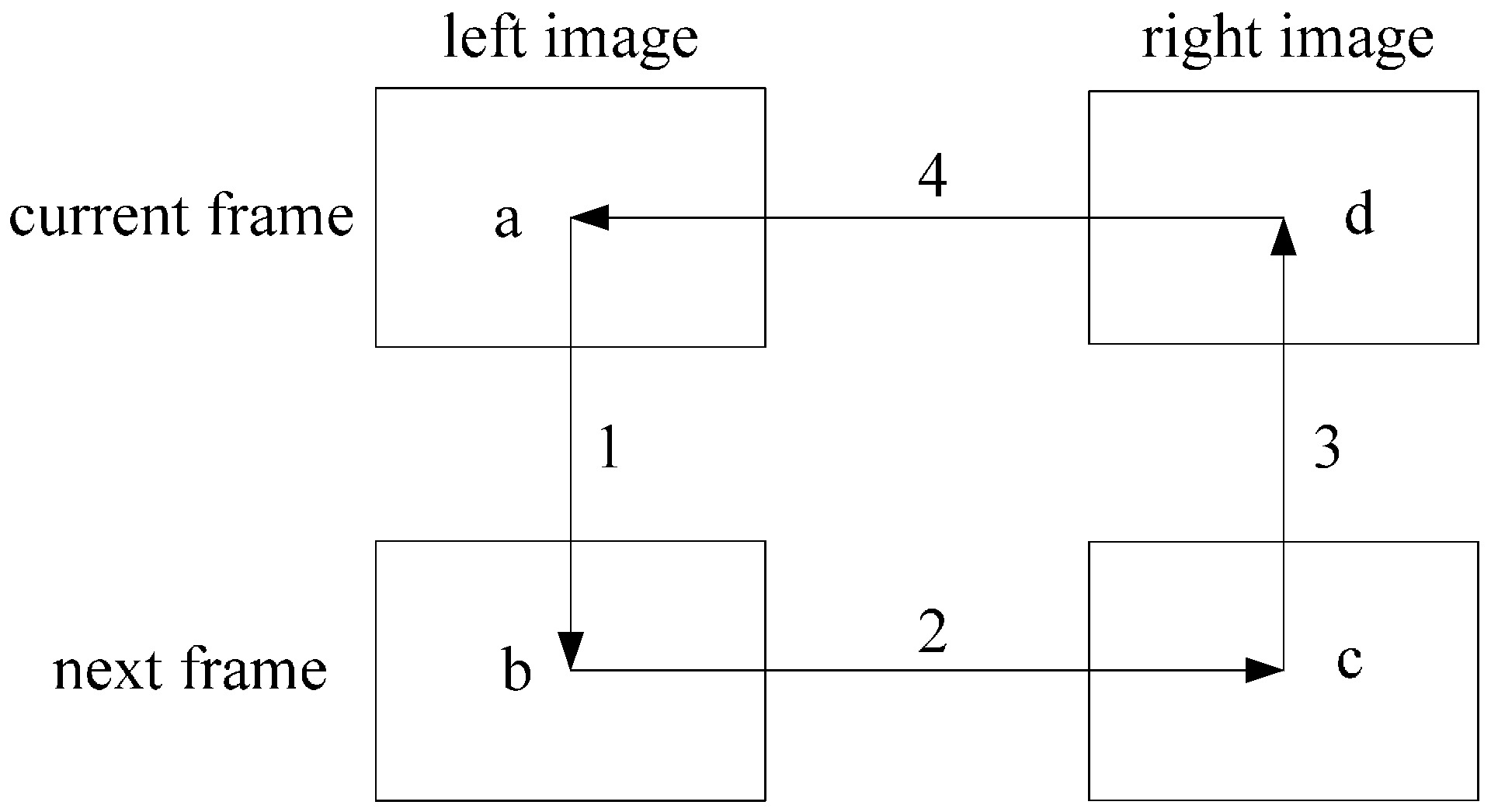
2.2. KLT Algorithm and Circle Matching
2.3. Space Position Constraint
2.4. RANSAC Based Outlier Rejection
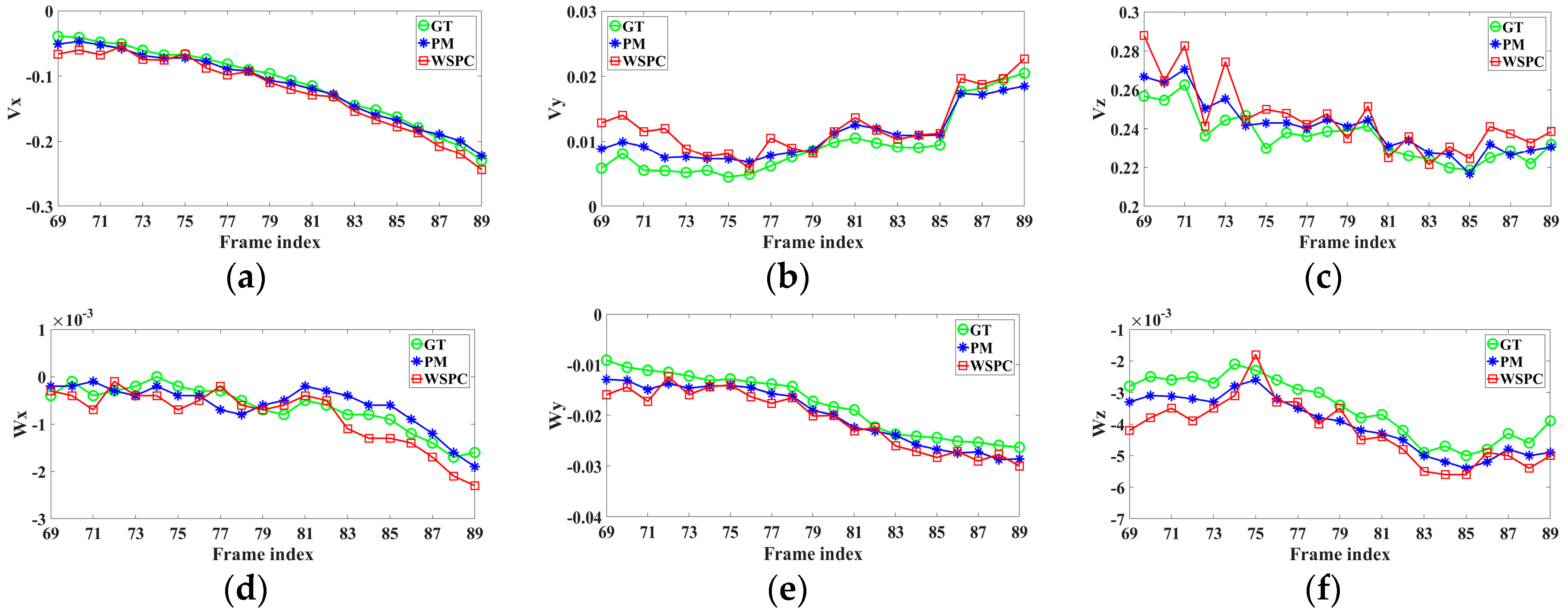
3. Experiments and Results
4. Evaluation and Comparison
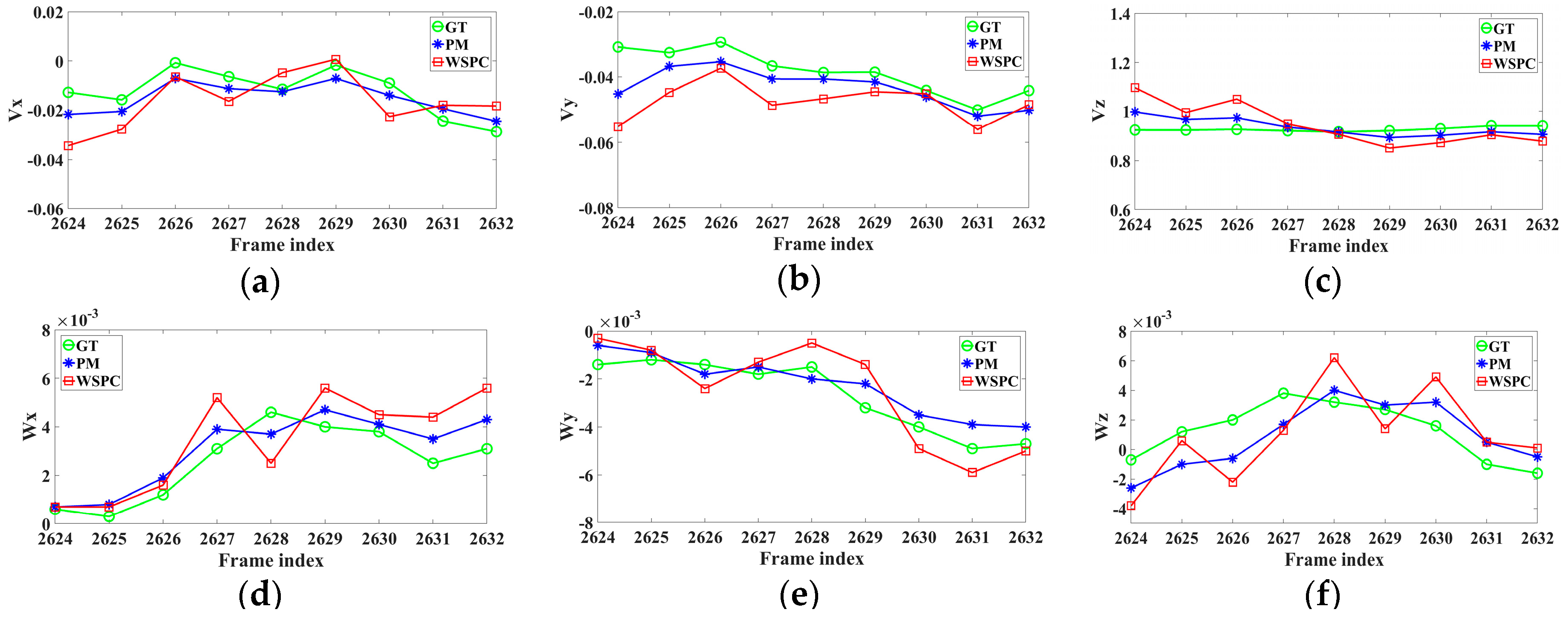
4.1. Robustness
4.2. Absolute Trajectory Error
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Ligorio, G.; Sabatini, A.M. Extended Kalman filter-based methods for pose estimation using visual, inertial and magnetic sensors: Comparative analysis and performance evaluation. Sensors 2013, 13, 1919–1941. [Google Scholar] [CrossRef] [PubMed]
- Scaramuzza, D.; Fraundorfer, F. Visual odometry (part I: The first 30 years and fundamentals). IEEE Robot. Autom. Mag. 2011, 18, 80–92. [Google Scholar] [CrossRef]
- Nister, D.; Naroditsky, O.; Bergen, J. Visual odometry. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004; pp. 652–659.
- Ke, Q.; Kanade, T. Transforming camera geometry to a virtual downward-looking camera: Robust ego-motion estimation and ground-layer detection. In Proceedings of the 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’03), Madison, WI, USA, 18–20 June 2003; pp. 390–397.
- Matthies, L.; Shafer, S. Error modeling in stereo navigation. IEEE J. Robot. Automat. 1987, 3, 239–248. [Google Scholar] [CrossRef]
- Milella, A.; Siegwart, R. Stereo-based ego-motion estimation using pixel tracking and iterative closest point. In Proceedings of the 4th IEEE International Conference on Computer Vision Systems, New York, NY, USA, 4–7 January 2006.
- Ni, K.; Dellaert, F. Stereo Tracking and Three-Point/One-Point Algorithms-A Robust Approach in Visual Odometry. In Proceedings of the 2006 International Conference on Image Processing, Atlanta, GA, USA, 8–11 October 2006; pp. 2777–2780.
- Kong, X.; Wu, W.; Zhang, L.; Wang, Y. Tightly-coupled stereo visual-inertial navigation using point and line features. Sensors 2015, 15, 12816–12833. [Google Scholar] [CrossRef] [PubMed]
- Comport, A.I.; Malis, E.; Rives, P. Real-time quadrifocal visual odometry. Int. J. Robot. Res. 2010, 29, 245–266. [Google Scholar] [CrossRef]
- Geiger, A.; Ziegler, J.; Stiller, C. Stereoscan: Dense 3D reconstruction in real-time. In Proceedings of the IEEE Intelligent Vehicles Symposium, Baden-Baden, Germany, 5–9 June 2011; pp. 963–968.
- Talukder, A.; Matthies, L. Real-time detection of moving objects from moving vehicles using dense stereo and optical flow. In Proceedings of the 2004 IEEE/RSJ International Conference on Intelligent Robots and Systems, Sendai, Japan, 28 September–2 October 2004; pp. 3718–3725.
- Kitt, B.; Ranft, B.; Lategahn, H. Detection and tracking of independently moving objects in urban environments. In Proceedings of the 13th International IEEE Conference on Intelligent Transportation Systems (ITSC), Funchal, Portugal, 19–22 September 2010; pp. 1396–1401.
- Kreso, I.; Segvic, S. Improving the Egomotion Estimation by Correcting the Calibration Bias. In Proceedings of the 10th International Conference on Computer Vision Theory and Applications, Berlin, Germany, 11–14 March 2015; pp. 347–356.
- Fanfani, M.; Bellavia, F.; Colombo, C. Accurate keyframe selection and keypoint tracking for robust visual odometry. Mach. Vis. Appl. 2016, 27, 833–844. [Google Scholar] [CrossRef]
- Pire, T.; Fischer, T.; Civera, J.; Cristoforis, P.; Berlles, J. Stereo Parallel Tracking and Mapping for robot localization. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 1373–1378.
- Musleh, B.; Martin, D.; De, L.; Armingol, J.M. Visual ego motion estimation in urban environments based on U-V. In Proceedings of the 2012 Intelligent Vehicles Symposium, Alcala de Henares, Spain, 3–7 June 2012; pp. 444–449.
- Min, Q.; Huang, Y. Motion Detection Using Binocular Image Flow in Dynamic Scenes. EURASIP J. Adv. Signal Process. 2016, 49. [Google Scholar] [CrossRef]
- He, H.; Li, Y.; Guan, Y.; Tan, J. Wearable Ego-Motion Tracking for Blind Navigation in Indoor Environments. IEEE Trans. Autom. Sci. Eng. 2015, 12, 1181–1190. [Google Scholar] [CrossRef]
- Shi, J.B.; Tomasi, C. Good features to track. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 21–23 June 1994; pp. 593–600.
- Huang, Y.; Fu, S.; Thompson, C. Stereovision-based objects segmentation for automotive applications. EURASIP J. Adv. Signal Process. 2005, 14, 2322–2329. [Google Scholar] [CrossRef]
- Yousif, K.; Bab-Hadiashar, A.; Hoseinnezhad, R. An overview to visual odometry and visual SLAM: Applications to mobile robotics. Intell. Ind. Syst. 2015, 1, 289–311. [Google Scholar] [CrossRef]
- Marquardt, D.W. An algorithm for least-squares estimation of nonlinear parameters. J. Soc. Ind. Appl. Math. 1963, 11, 431–441. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361.
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vilamoura, Portugal, 7–12 October 2012; pp. 573–580.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Frame 2624 | Frame 2625 | Frame 2628 | Frame 2632 | |
|---|---|---|---|---|
| green points | 282 | 200 | 168 | 104 |
| proportion of the inliers | 91.49% | 93.50% | 95.24% | 95.19% |
| PM | WSPC | |
|---|---|---|
| ATE | 3.46% | 8.51% |
| ARE | 0.0028 deg/m | 0.0037 deg/m |
| Frame 69 | Frame 70 | Frame 79 | Frame 89 | |
|---|---|---|---|---|
| green points | 1037 | 732 | 372 | 128 |
| proportion of the inliers | 92.57% | 94.54% | 95.16% | 94.53% |
| PM | WSPC | |
|---|---|---|
| ATE | 3.25% | 5.49% |
| ARE | 0.0089 deg/m | 0.0151 deg/m |
| Sequence | VISO2-S [10] | S-PTAM [15] | Our Method |
|---|---|---|---|
| 00 | 29.54 | 7.66 | 13.47 |
| 01 | 66.39 | 203.37 | 227.51 |
| 02 | 34.41 | 19.81 | 11.35 |
| 03 | 1.72 | 10.13 | 1.08 |
| 04 | 0.83 | 1.03 | 0.96 |
| 05 | 21.62 | 2.72 | 1.73 |
| 06 | 11.21 | 4.10 | 3.04 |
| 07 | 4.36 | 1.78 | 5.84 |
| 08 | 47.84 | 4.93 | 9.48 |
| 09 | 89.65 | 7.15 | 5.89 |
| 10 | 49.71 | 1.96 | 3.16 |
| mean | 32.48 | 24.06 | 25.77 |
| mean(w/o 01) | 29.09 | 6.13 | 5.60 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ci, W.; Huang, Y. A Robust Method for Ego-Motion Estimation in Urban Environment Using Stereo Camera. Sensors 2016, 16, 1704. https://doi.org/10.3390/s16101704
Ci W, Huang Y. A Robust Method for Ego-Motion Estimation in Urban Environment Using Stereo Camera. Sensors. 2016; 16(10):1704. https://doi.org/10.3390/s16101704
Chicago/Turabian StyleCi, Wenyan, and Yingping Huang. 2016. "A Robust Method for Ego-Motion Estimation in Urban Environment Using Stereo Camera" Sensors 16, no. 10: 1704. https://doi.org/10.3390/s16101704
APA StyleCi, W., & Huang, Y. (2016). A Robust Method for Ego-Motion Estimation in Urban Environment Using Stereo Camera. Sensors, 16(10), 1704. https://doi.org/10.3390/s16101704