1. Introduction
Advancements in miniaturisation and the declined cost of hardware have made Wireless Sensor Networks (WSN) a realistic vision: networks of tiny computers can monitor environments using sensors and wireless communication [
1]. An efficient implementation of a practical WSN, however, is not a trivial task. Even on small scale WSNs, the amount of data that can be sampled by the sensor nodes is considerably more than what can be sustainably transmitted using current WSN radios with current battery technology [
2,
3,
4].
For many applications, the raw sensor data itself is not of interest. For example, in domestic fire detection [
5], carbon-dioxide readings do not necessarily need to reach a human operator. The presence of a fire, however, is the important information. In applications like this, processing data locally on the deployed sensor node with the goal of extracting the relevant information, for example the presence of a fire, eliminates the need for the transmission of raw data. This significantly reduces the amount of data that needs to be transmitted. From now on, we will call this online processing [
2].
Online processing comes in many forms, ranging from simple schemes to compress the data to complex event recognition algorithms that draw high-level conclusions [
2]. Especially, this last group of algorithms result in considerable reductions in communication by removing the need to transmit the raw sensor readings. Taking into account that the energy needed to transmit a few bytes of data already is significant [
3,
4], it is clear that online processing is a promising area of research for WSNs. One important example of the application of intelligent algorithms on WSNs is the use of classification algorithms to draw conclusions from raw sensor readings, e.g., classifying the samples for a given moment in time as “fire” or “no fire”.
Processing data using online classification algorithms is a challenging task [
2]. In order to get correct classifications, training data is needed first. Supervised learning can be applied in two ways: online learning and offline learning. For offline learning, the sensor nodes send their measurements to a central location where individual classifiers are trained for each sensor node. After the training phase, these classifiers are deployed on the sensor nodes.
Online supervised learning works the other way around: each node trains a classifier with its own local data. Instead of transmitting the data, the desired classification outputs or labels are sent to all of the sensor nodes. Each sensor node uses these outputs to update their own local classifier.
Considering that wireless communication requires a lot of energy [
4], the initial training process can deplete a significant part of the available energy of the sensor nodes. For example, if we were to apply online learning on a sensor network of
n sensor nodes over a period of
t seconds with a sample rate of
f Hz, the nodes would have to receive a total of
messages containing the desired classification output on their location. To train the sensor network for the dataset we use in this paper [
6], for a period of one week, the nodes have to receive a total of over 13 million messages under the assumption that the network topology allows all nodes to directly receive the messages without intermediate hops. More complex network topologies could require a multitude of this number of messages.
Training data needs to be representative for the relevant situations of what the classifier might encounter, which complicates training [
7]. For example, if sensor readings for a classification problem are influenced by environmental conditions, proper online training might require a network to run in training mode for a year in order to account for all seasonal effects. Another drawback of supervised learning is the possible need for human interaction. If a human needs to train the network by labelling the desired outputs, this requires expensive man-hours. Furthermore, due to variations in hardware and deployment locations, this complicated process needs to be repeated every time, and a sensor node needs to be replaced or installed in a new environment. As a consequence, the maintenance of a WSN using a classification algorithm for a long period of time is often highly impractical.
The use of classification algorithms on WSNs is not a new idea. For example, Ref. [
8] describes the detection of environmental events using Bayesian classifiers on WSNs. The work described in [
9] describes a scalable method for collaborative event detection on WSNs. Fault tolerant classification is the subject of [
10]. The feasibility of sound classification on WSNs is the subject of [
11]. All these papers have in common that they propose classification algorithms or applications for classification algorithms in the scope of WSNs.
Another application related to WSNs is the field of Body Area Networks (BAN). BANs are small networks of devices on or around a human body. Applications for BANs include gait analysis for rehabilitation purposes [
12,
13], activity monitoring [
14] and athlete coaching [
15]. For these applications, online classification is frequently applied. Ref. [
12], for example, applies a distributed Hidden Markov Model to detect the gait phases of a person walking. BANs have many similarities with WSNs, and could even be defined as small WSNs. A BAN is a network of small battery powered devices with sensors to observe an environment. However, there are some key differences to WSNs in general. A BAN is usually deployed in a very accessible area: around a human body. This means that battery replacement or recharging is not a major challenge. Furthermore, communication distance is limited to several meters, making communication more energy efficient. As such, the techniques suitable for a BAN are not necessarily applicable for WSNs.
Looking at the used classification approaches, we can state that many different approaches have been proposed over the years. Our work is based on the Naive Bayes classifier [
16], a well-known classification technique that has been used for sensor networks in other research (see e.g., [
5,
17,
18,
19]).
In this work, we introduce QUEST, which stands for QUantile Estimation after Supervised Training. QUEST is a versatile classification algorithm for WSNs. QUEST aims to combine some advantages of unsupervised learning with the accuracy of supervised learning. Advantages of unsupervised learning algorithms include that they need no human involvement, which saves valuable man-hours [
7]. Another advantage is the fact that there is no dependency on wireless communication, as learning is done based on local samples.
The mixture of supervised and unsupervised learning by itself also is not a new idea. For example, in [
20], it is applied for time series forecasting. Note that, for many applications, the clustering of data using unsupervised learning does not provide meaningful information without supervised labeling of the clusters. The contribution of this work is a scheme where unsupervised learning is not only used to create clusters that are used in an supervised learning settings, as in [
17], but the continuation of unsupervised learning in a deployed sensor node to adapt an existing classifier to the particular environment of the deployed sensor node.
The division of an input space into areas of interest using unsupervised learning is one of the key principles used in this paper. Some examples of the many algorithms in this area are Kohonen networks [
21], which are self organising feature maps, and the
algorithm (see [
22,
23]), which is a heuristic to estimate quantiles. However, there are numerous other published approaches (see e.g., [
24,
25]).
The remainder of this paper is organised as follows.
Section 2 describes the principles behind QUEST and the experiments used to show the efficiency of QUEST, and
Section 3 gives the results of these experiments. The conclusions of this work are presented in
Section 4.
2. Method
We have restructured the Method section In this section, we describe our proposed solution and the experiments performed to verify its efficiency. The working of the QUEST algorithm is described in
Section 2.1,
Section 2.2 describes the experiments performed on a real-life dataset and
Section 2.3 describes the experiments performed using simulated data.
2.1. Proposed Solution
This part was moved into the method section In this paper we introduce QUEST, a classification algorithm that combines supervised learning with unsupervised learning in a way that enables efficient deployment of a classification algorithm on a WSN. QUEST is based on the principles behind the Naive Bayes classification [
16].
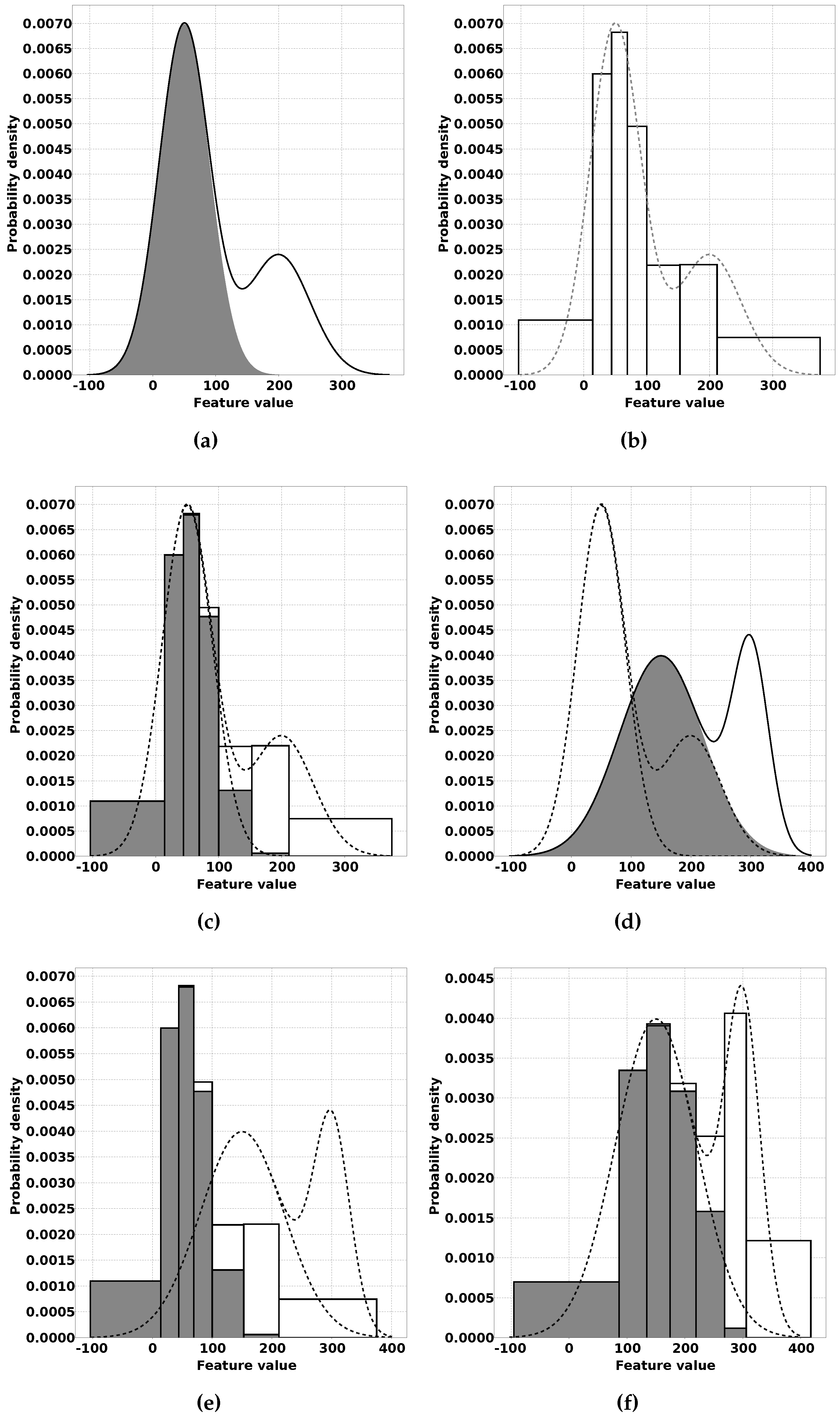
In the following section, we clarify our proposed solution using a simulated classification problem. The inputs are generated by drawing samples from a distribution consisting of two Gaussian distributions representing two possible classification outputs:
and
. An example of such a distribution is shown in
Figure 1a. This figure is a stacked area chart that shows a probability density function, where the gray area represents
and the white area represents
.
Naive Bayes classifiers process input values, which are raw sensor measurements or features derived from those measurements, and automatically assign a classification, or label, to those input values. An example of a derived feature can be a frequency component derived from a Fast Fourier Transform of the output of a vibration sensor. An example of the output of the Naive Bayes classifier can be fire or no fire, or “vehicle present in the detection range”.
To create an output, Naive Bayes classifiers use Bayesian statistics and Bayes’ theorem to find the probability
that a given observation
belongs to a class
c, where
is the value of feature
at time
t. This probability
is estimated using Equation (
1) [
16]:
In order to make a classification decision, the Naive Bayes algorithm calculates for each . The class with the highest probability is the final classification.
In this case, class c can, for example, be the class of samples where there is a fire, is the output of sensor on time t. The algorithm is called naive because of the assumption that all the inputs have an independent contribution to .
Accurately estimating the probabilities for Equation (
1) is important for the classification result. One approach is to model the inputs using standard data distributions, such as the Gaussian distribution [
7]. Another approach is to divide the input space into separate parts for which the probabilities are estimated based on supervised learning. For each part of the input space, the fraction of samples belonging to each class is determined empirically. These fractions are used to determine the probability that an input will fall in a certain interval given a classification
c.
In [
17], we already presented an approach to efficiently train a Naive Bayes classifier for WSN applications. This approach works in two steps. The first step is to divide the input space for each feature using unsupervised learning. The second step is to empirically estimate the distribution of each class of observations over these intervals. These distributions are what the Naive Bayes classifier uses to determine the classification output. The result of the second step for the example distribution is shown in
Figure 1c. Once again, in this figure, the gray areas represent output
and the white areas represent output
. Algorithm 1 gives a description of this process.
QUEST is developed with [
17] as a starting point. The first improvement came through the observation that where unsupervised learning provided a functional division of the input space for the Naive Bayes classifier, the actual goal was to divide the input space by estimated quantiles so that each interval between two neighbouring quantiles has the same probability density. The reason for this is that with equally populated intervals, the chance that an estimated probability for a class in an interval has a large error compared to the actual probability becomes smaller. For this, the
p-quantile is used. It is defined as the value below which
percent of the distribution lies (e.g., the median is the
quantile). In our example figures, we use a division of the input space in seven intervals for which the borders lie on
, where
is the
quantile (see
Figure 1b). Therefore, for QUEST, we have selected an unsupervised learning algorithm that aims to learn the correct quantile estimations.
Unsupervised quantile estimation can be done in several ways. The approach used in [
17], which is a modified version of the Kohonen network algorithm [
21], gives estimates roughly correlated with the quantiles. Other options are the regular Kohonen network algorithm or the
algorithm [
23].
With QUEST, we solve a problem that was left unsolved by [
17]. Where the approach of [
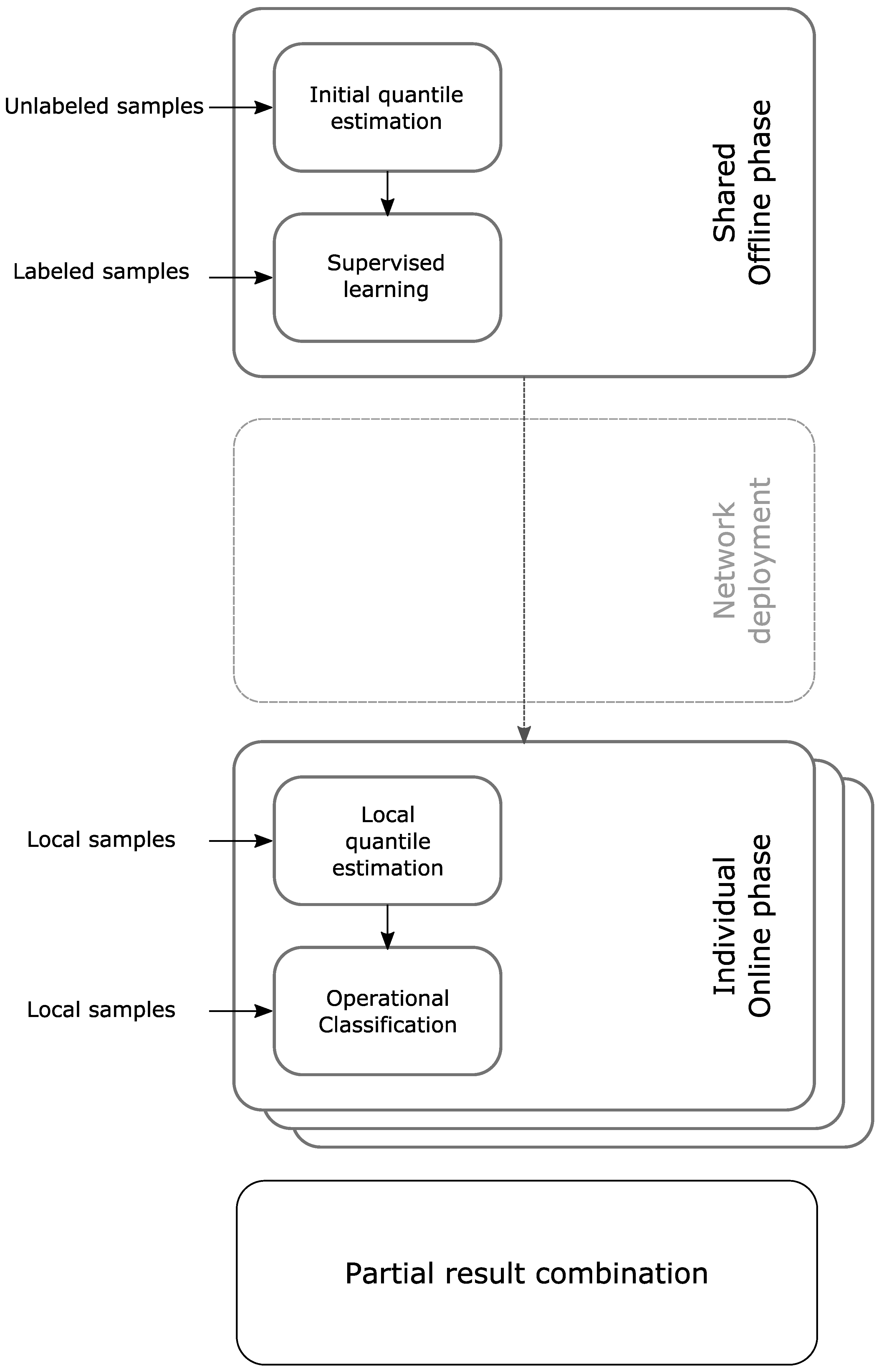
17] allows for memory efficient training of Naive Bayes classifiers, online or offline supervised training still requires a lot communication. In this paper, we propose a solution where unsupervised learning is not only applied before supervised learning, but also after supervised learning to adapt a trained classifier. In the first phase, which we call the offline phase, a single classifier is trained using the described process from [
17] but with an improved quantile estimation algorithm. The data this classifier is trained with should be carefully selected to be a good representation for the complete classification problem. This data can e.g. be generated in lab conditions where various conditions that can be encountered are created.
Figure 1a–c show this process on an example distribution created by two Gaussian distributions, one for each class. The results of the two steps of this algorithm are the knowledge needed to implement a Naive Bayes classifier trained for the example data. The classifier resulting from this data will be pre-loaded on all sensor nodes.
| Algorithm 1: Naive Bayes based on unsupervised clustering |
, possible classification outputs
desired classification output at time t
actual classification output at time t
the value of feature at time t
, observation at time t
the interval number sample x lies in for feature s
the estimated probability of given
the estimated overall probability of class
▹ Unsupervised phase
while ¬Unsupervised phase finished do
for to do
update with sample using unsupervised learning
end
end
▹ Supervised phase
while ¬Supervised phase finished do
for to do
update the statistics used to determine given and
update the statistics used to determine given
end
end
▹ Classification phase
while ¬Classification phase finished do
▹ See Equation (1)
end |
In the second phase, which we call the online phase, each node on a deployed network uses the unsupervised learning heuristic from step one to update the quantiles and thereby the division of the input space. Next to that, the classifier contributes to the classification output of the overall network. We expect that, at first, the network will not perform very well, since each node uses a classifier that was trained for a sensor node deployed under different circumstances. These different circumstances may have influence on the data distribution. For example, variations in temperature, distance to the observed phenomenon, hardware, etc. may have a negative impact on the classification performance. An example of a possible modified distribution is shown in
Figure 1d, where the original distribution is shown as dashed lines and the new distribution of the classes is shown as gray and white areas stacked on top of each other. The pre-loaded data for the classifier trained in the offline phase in this case does not match the data distribution for the new circumstances (see
Figure 1e).
To handle these variations, each node continues with the unsupervised learning. This leads to updates to the quantile estimations to match the sensor readings for the location on which the sensor node is deployed. By providing unlabelled samples, the intervals will gradually change to reflect the new conditions, resulting in the data shown in
Figure 1f.
Figure 2 gives an overview of the phases of QUEST and Algorithm 2 shows the working of QUEST in pseudocode. In the remainder of this section and
Section 3, we describe experiments and results to give more details about the way QUEST works.
| Algorithm 2: QUEST (QUantile Estimation after Supervised Training) updates the unsupervised clustering of the feature space after deployment |
▹ Offline unsupervised training phase
while ¬Unsupervised phase finished do
for to do
update with sample using unsupervised learning
end
end
▹ Offline Supervised training phase
while ¬Supervised phase finished do
for to do
update the statistics used to determine given and
update the statistics used to determine given
end
end
▹ End of offline phase, each node is now deployed with the trained classifier
▹ Online unsupervised training phase
while ¬Online unsupervised phase finished do
for to do
update local with sample using unsupervised learning
end
end
▹ Classification phase
while ¬Classification phase finished do
▹ see Equation (1)
end |
2.2. Experiments on Real Data
2.2.1. Real-Life Dataset
For experiments using a real-life dataset, we used the SITEX02 dataset [
6]. The SITEX02 dataset is a dataset that was fully made available online, which is fairly uncommon. As such, it is an excellent foundation for WSN experiments. This dataset provides seismic and acoustic sensor readings for experiments with different types of vehicles that drove through an area where a network was deployed. The sensor network was Sensoria Corporations WINS NG 2.0 build using 22 WINS NG sensor nodes (Version 2.0, Sensoria Corporation, San Diego, CA, USA) [
26]. The size of the target area is approximately 900 × 300 m
2. In this dataset, ground truth location information on the vehicles is provided based on GPS trackers placed on the vehicles. The exact details of the sensors were not provided in [
6] but are of limited importance for this work.
Two different type of vehicles were used in this dataset: the Dragon Wagon (DW) and the Assault Amphibian Vehicle (AAV). The dataset contains nine runs for the AAV vehicle through the target area and 11 runs for the DW vehicle. The seismic and acoustic sensor readings are both processed into features using Fast Fourier Transforms. Each sample stream was divided into 50 frequency bands for which the intensity was recorded once each second. The result is a dataset with 100 features, each with a sample rate of 1 Hz.
For this paper, we assigned the samples to one of the following classes: (1) DW within the detection radius; (2) AAV within the detection radius; and (3) no vehicle within the detection radius. For the detection radius, we have experimented with several values, namely 50 m, 75 m, 100 m and 125 m. These values influence the training of the classifier in two ways. First, a larger radius means that a node has to detect a vehicle over a longer distance, which is more complicated since acoustic and seismic signals fade over distance, resulting in a lower signal-to-noise ratio. On the other hand, a larger detection radius means that the dataset contains more samples with a vehicle in the detection radius, which means that the classification can be based on more information.
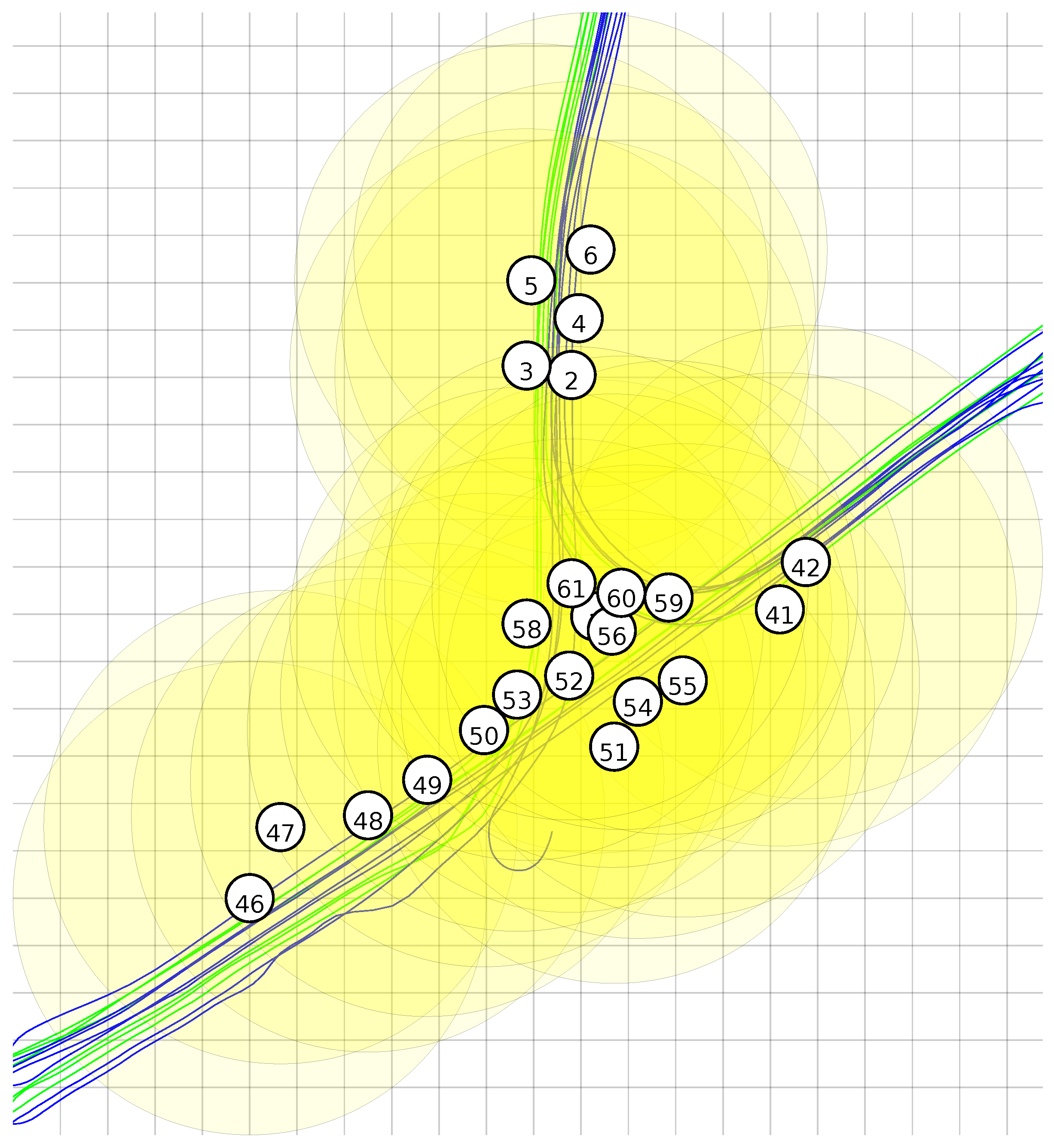
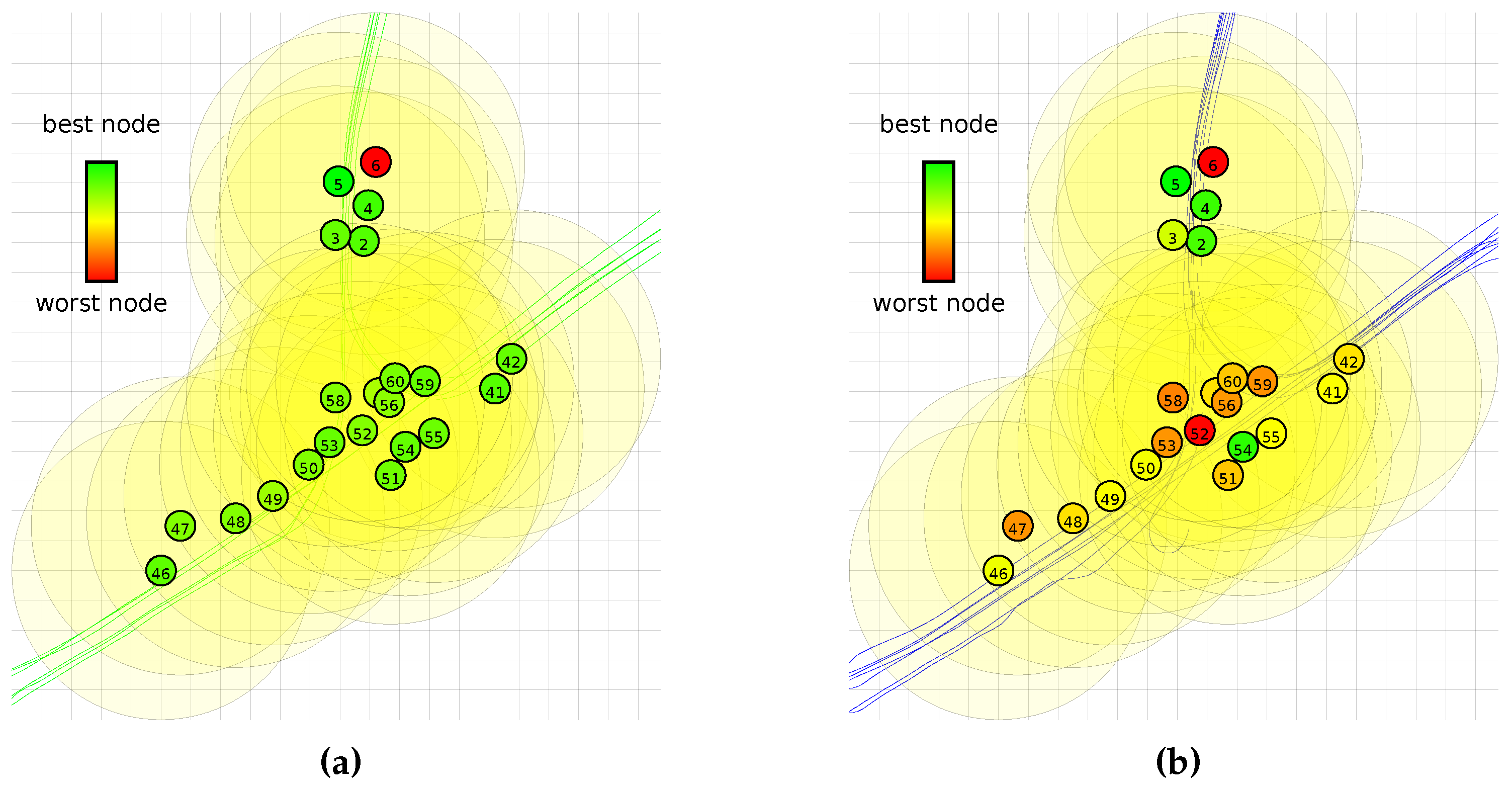
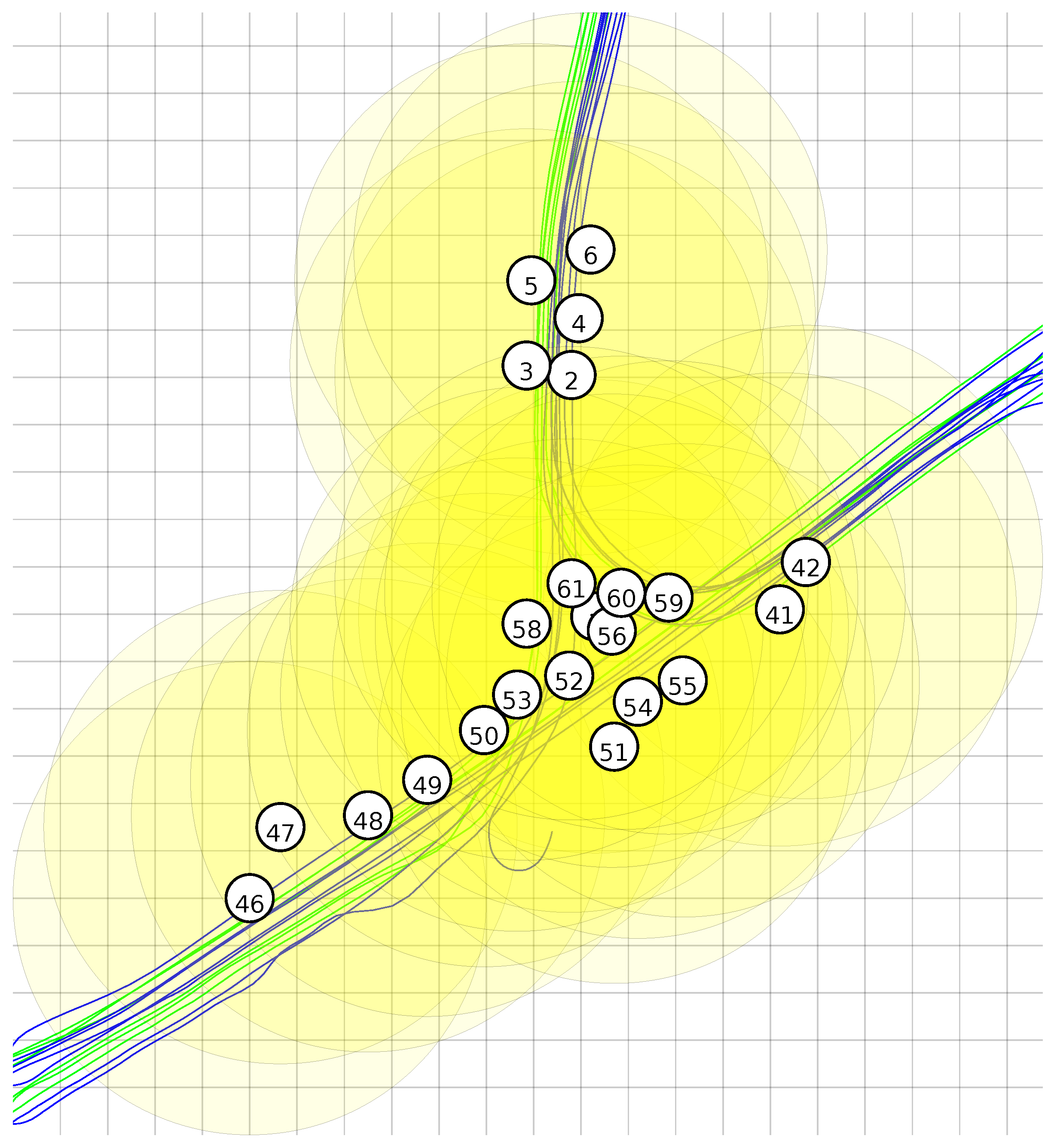
To label all the samples in the dataset, we used the recorded vehicle positions and the given node coordinates. The deployment of the nodes of the network can be seen in
Figure 3.
Figure 4 shows the node locations, vehicle traces and the detection range. It can be seen that a lot of overlap is present.
2.2.2. Fusion Model
A challenging aspect of the SITEX02 dataset is that the events are not global. If a vehicle is in the detection range of one node, it is not necessarily in the detection range of another node. Regular Naive Bayes classification fuses all input probabilities using multiplication. This approach is not suitable to combine the classification outputs of multiple nodes from the SITEX02 dataset. When a single node correctly determines that the probability of a vehicle being in its detection radius is zero, other nodes still need to be able to detect the presence of the vehicle. A multiplication by zero would prevent that.
In order to take the relation between detection areas into account, we created a fusion model. In this paper, we have chosen to use a simple model based on the distance between sensor nodes for this paper. In the selection of this approach, we did not try to achieve the best classification result possible, but merely aimed for a reasonable solution that allowed us to demonstrate the performance impact of QUEST compared to regular Naive Bayes.
For the fusion method, we have chosen a weighted sum where the influence of each node was determined using Equation (
2). In this equation,
is the fused classification score for node
n and classification class
C. For example,
can represent the local score of detecting a Dragon Wagon at time
t for node
i. The weight
of the contribution of node
i for the result of node
n is determined based on the distance
between the nodes
n and
i and the detection radius
r:
2.2.3. Feasibility Study Based on Correlation
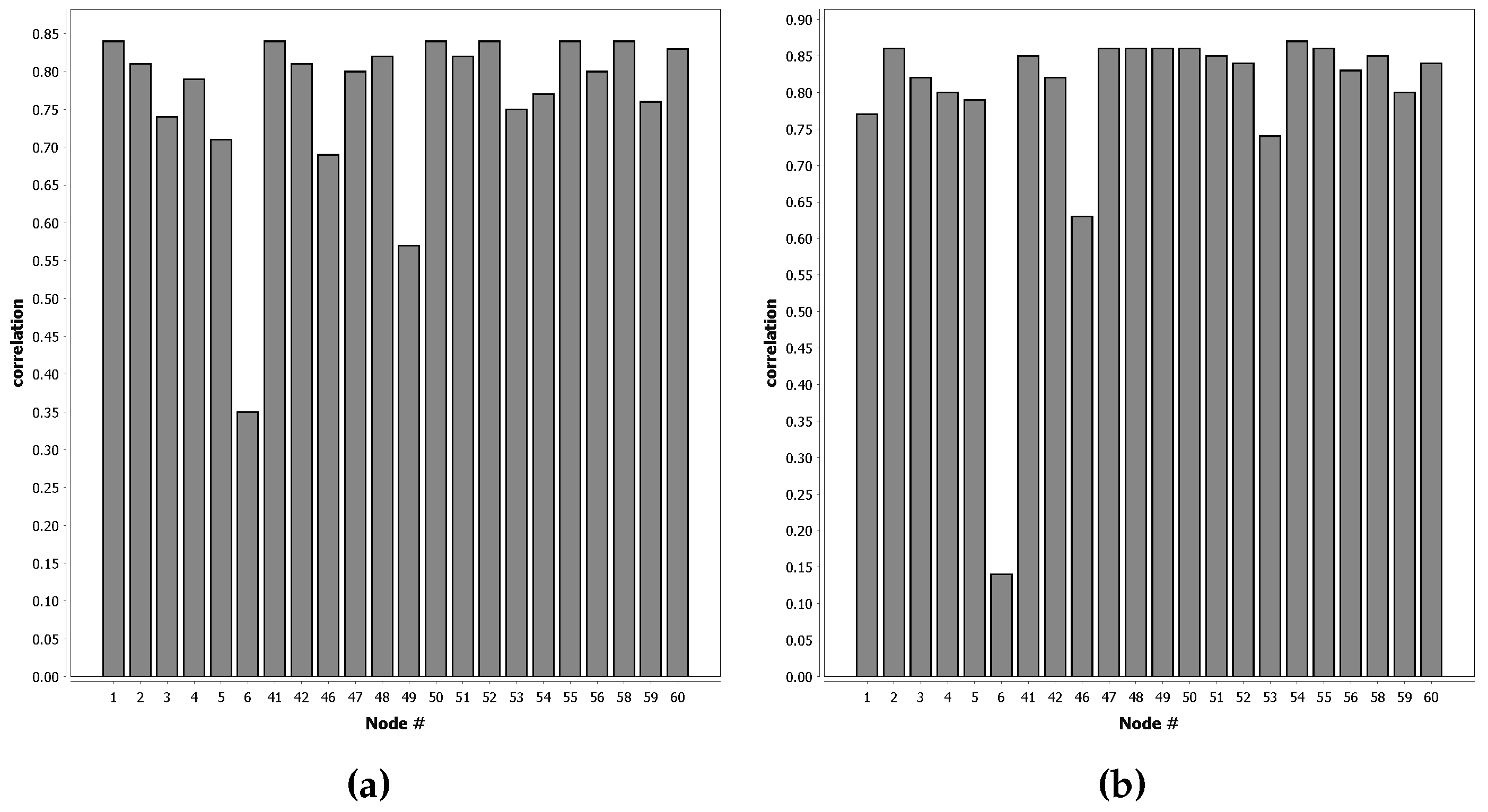
QUEST is based on the assumption that the probability distribution over the intervals determined for a single node is related to the distribution determined for all other nodes. For QUEST, we adapt quantile estimations in the online phase, the probability distribution of the classes over the intervals is not changed during the online phase. If that assumption is correct, we would expect to observe a high correlation between the class probabilities in corresponding intervals between classifiers for different sensor nodes that were trained using supervised learning.
We have verified the validity of this assumption by training classifiers for each sensor node of the SITEX02 dataset separately, using quantile estimation and supervised training. For these classifiers, we compared the probability distribution for each interval for each feature with the classifiers trained for other nodes. For each sensor in the dataset, we have determined the correlation between these values. The results of this experiment are shown in
Section 3.1.1.
2.2.4. Performance Compared to Regular Naive Bayes
In order to further demonstrate the validity of our approach, in a WSN application, we performed simulations to determine the accuracy of QUEST compared to regular Naive Bayes. We simulated a scenario where the nodes collaborate to determine whether the vehicles in the SITEX02 dataset are in the detection range of each individual node. This means that, for each instant for which there are measurements, each node makes a classification if there is a vehicle in its range, based on its own measurements and information given by the other nodes.
Baseline
Using the described fusion method, we compare the performance of our approach to the performance of a network completely trained with supervised learning. The performance of the network trained completely with supervised learning is called the baseline in the remainder of this paper. In this way, the baseline performance gives a measure of the accuracy that can be achieved using Naive Bayes classifiers on the given classification problem.
The baseline was trained using a randomly selected training set consisting of 10% of the available data. Using these trained classifiers and our fusion model, we assessed the performance of the classifiers using the distance to the Receiver Operating Characteristics (ROC) center line [
27,
28,
29,
30]. The distance to the ROC center line is a metric that gives a good indication of how well a classifier can discriminate between two classes regardless of a possible bias between the classes. This metric is preferable to, for example, accuracy, since, for heavily biased classification problems, a high accuracy can be reached without actually having a meaningful classifier. For example, when 99% of the samples are of class A, an accuracy of 99% can be achieved by always classifying samples as class A. We also used this method in previous work [
19].
Experiment
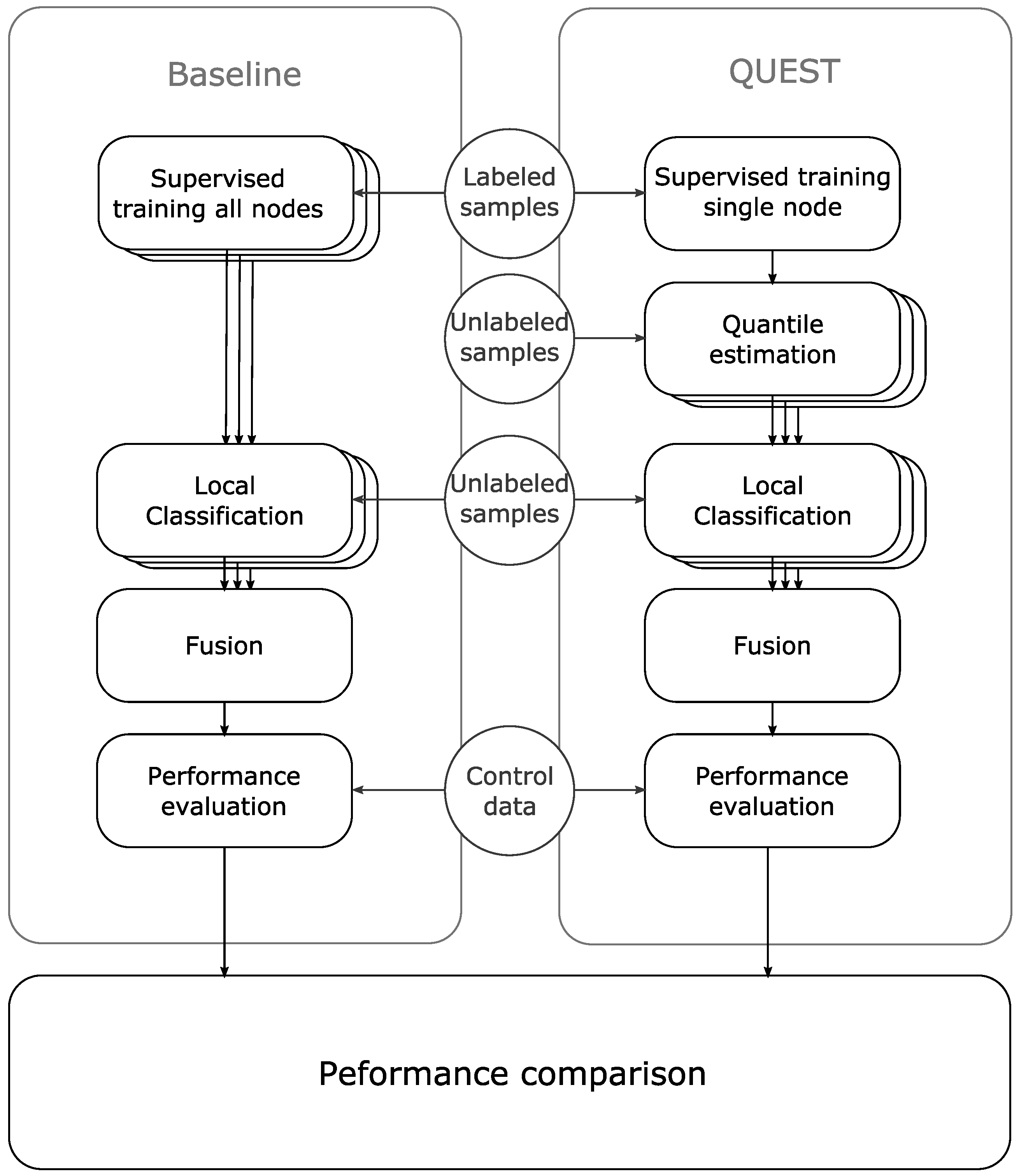
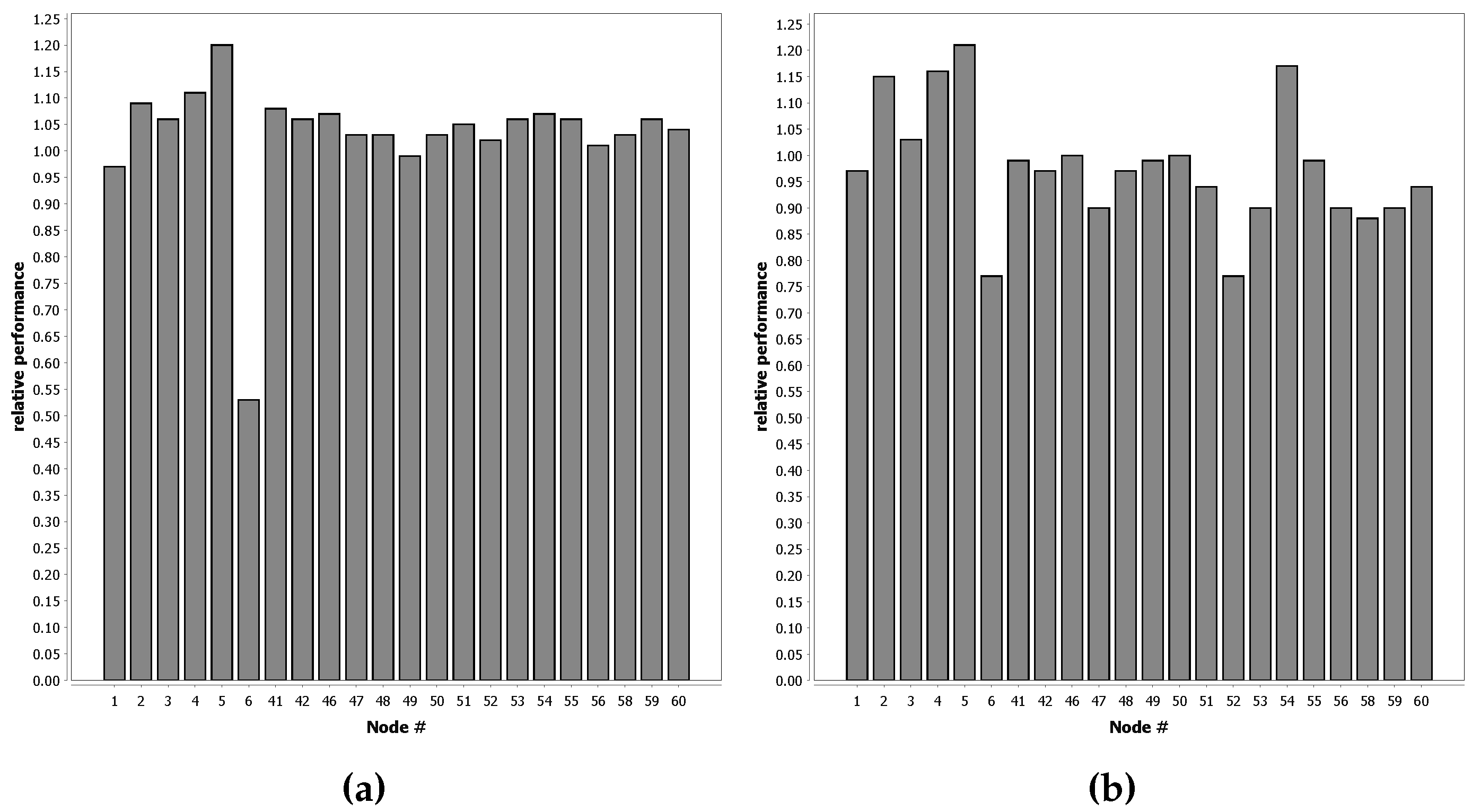
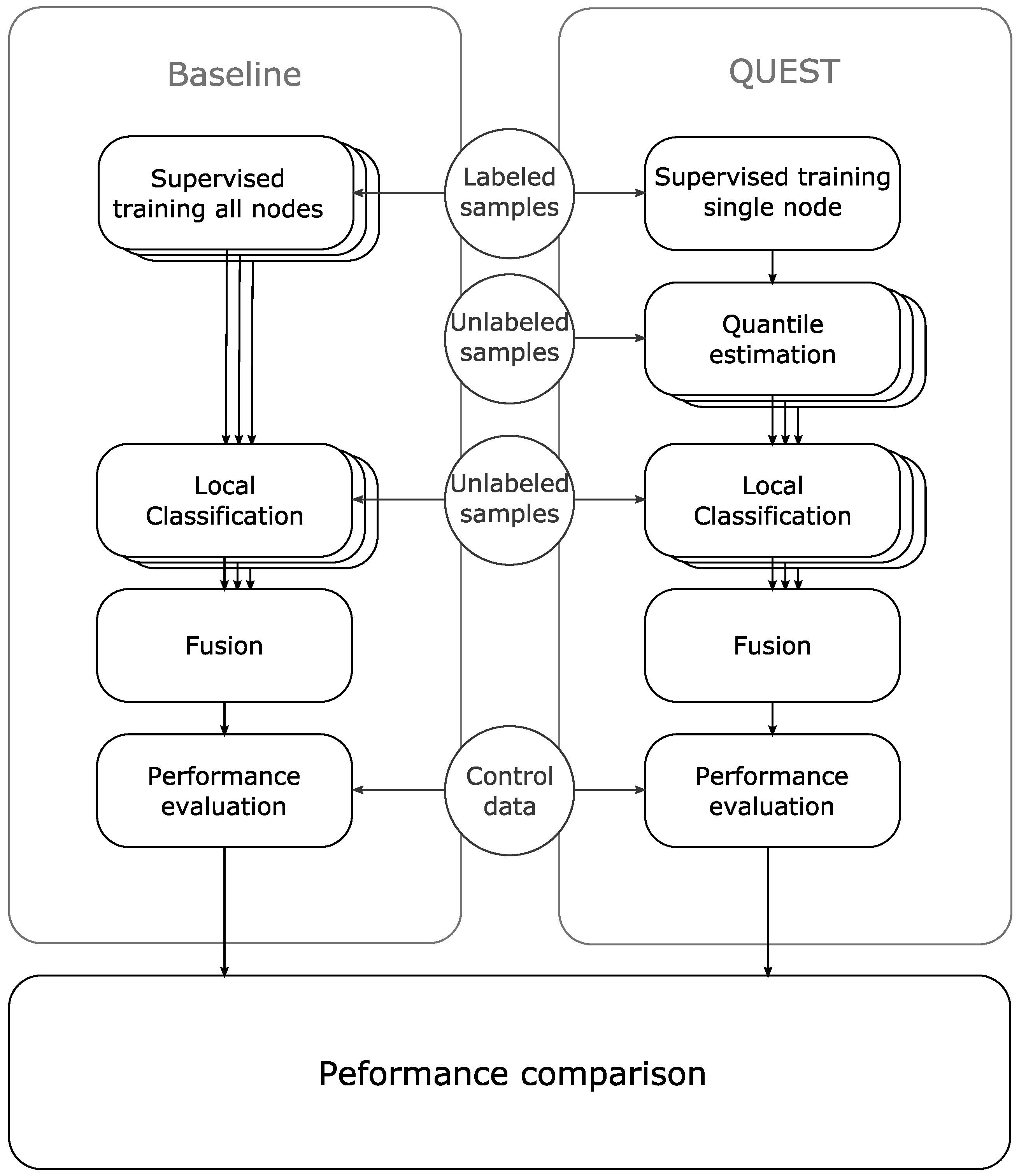
To compare our approach to the baseline, we conducted 22 experiments, one for each sensor node from the dataset. In each experiment, we used supervised learning to train a classifier for a single node, with a dataset of 10% of the available data for that node. Next, we used unsupervised learning to adapt 21 copies of this classifier. For each copy, we used a training set with 10% of the data from another single sensor node from the dataset. Finally, we compared the performance of the 21 classifiers for each experiment to the performance of the classifier for the baseline. We calculated the relative change in the distance to the ROC center line for each classifier. By averaging the result of the classifiers for each experiment, we demonstrate the relative performance to the baseline for each of the 22 experiments.
Figure 5 shows the procedure for one of the 22 experiments.
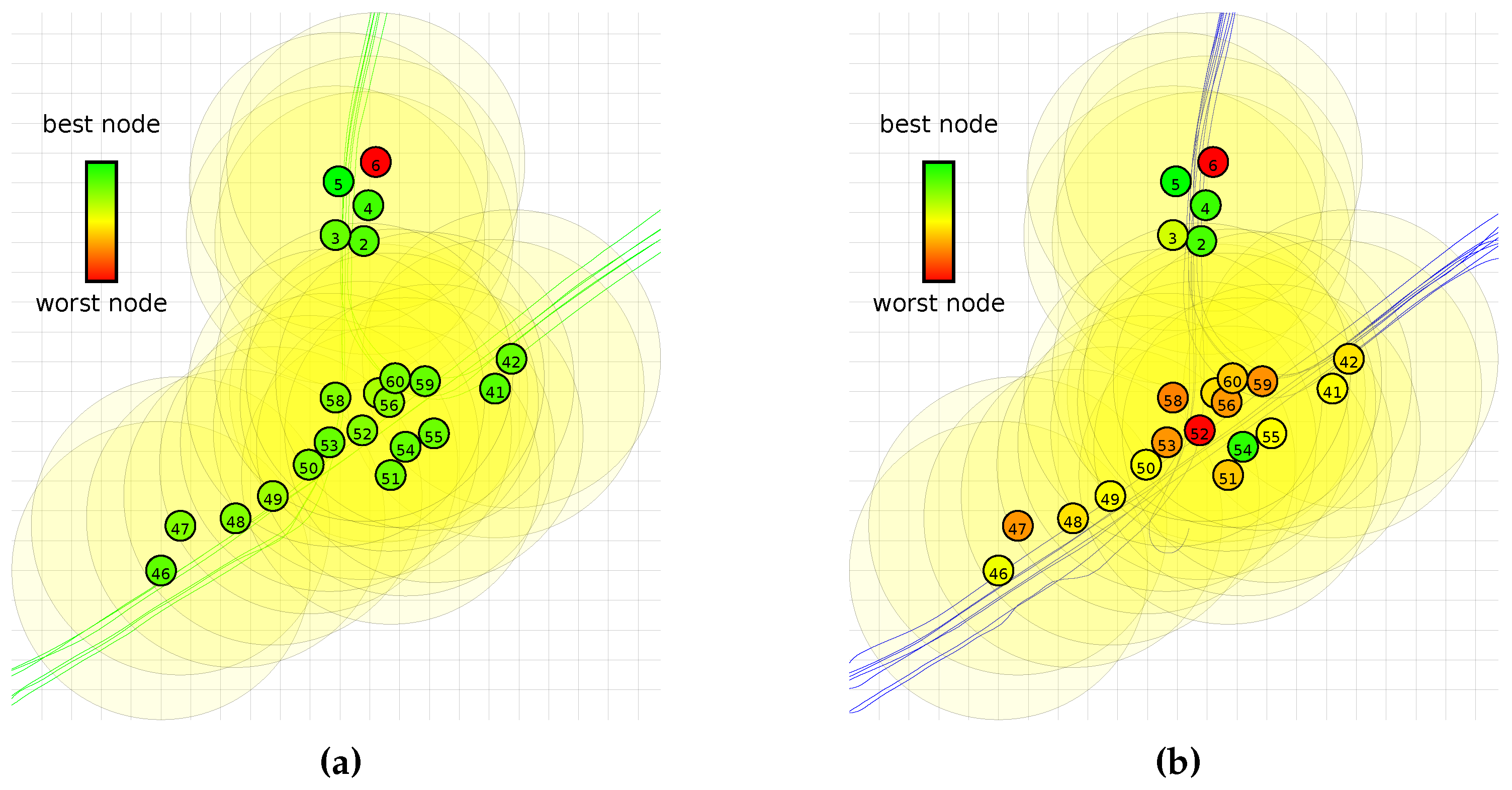
Furthermore, we have investigated if there is a clear relation between the location of a sensor node and how suitable it is to provide the supervised data from the offline phase. If the suitability is highly location-dependent, we expect that the best performing experiments are the result of an offline phase with sensor nodes that are in close proximity. If there is no clear relation between the performance of the experiment and the location of the sensor node and QUEST shows good performance, this is an indication that all nodes learned a similar classification strategy, which can be adapted by QUEST.
2.3. Experiments on Simulated Data
To be able to perform a detailed investigation of the properties of QUEST, we used simulated data. These experiments are described in this section. Simulated data has the advantage that it can be manipulated in order to conduct experiments using specific variations in parameters.
For the experiments using simulated data, we use samples drawn from a mixture of Gaussian distributions (Gaussian Mixture Model). We have conducted experiments using various numbers of features and output classes. Each sample consists of a value for each feature. Each feature value is drawn from a mixture of n Gaussian distributions where n is the number of classes. For each experiment, we simulated the offline phase using one mixture of Gaussian distributions and the online phase using a modified mixture. The modifications were based on a number of parameters that are described in this section.
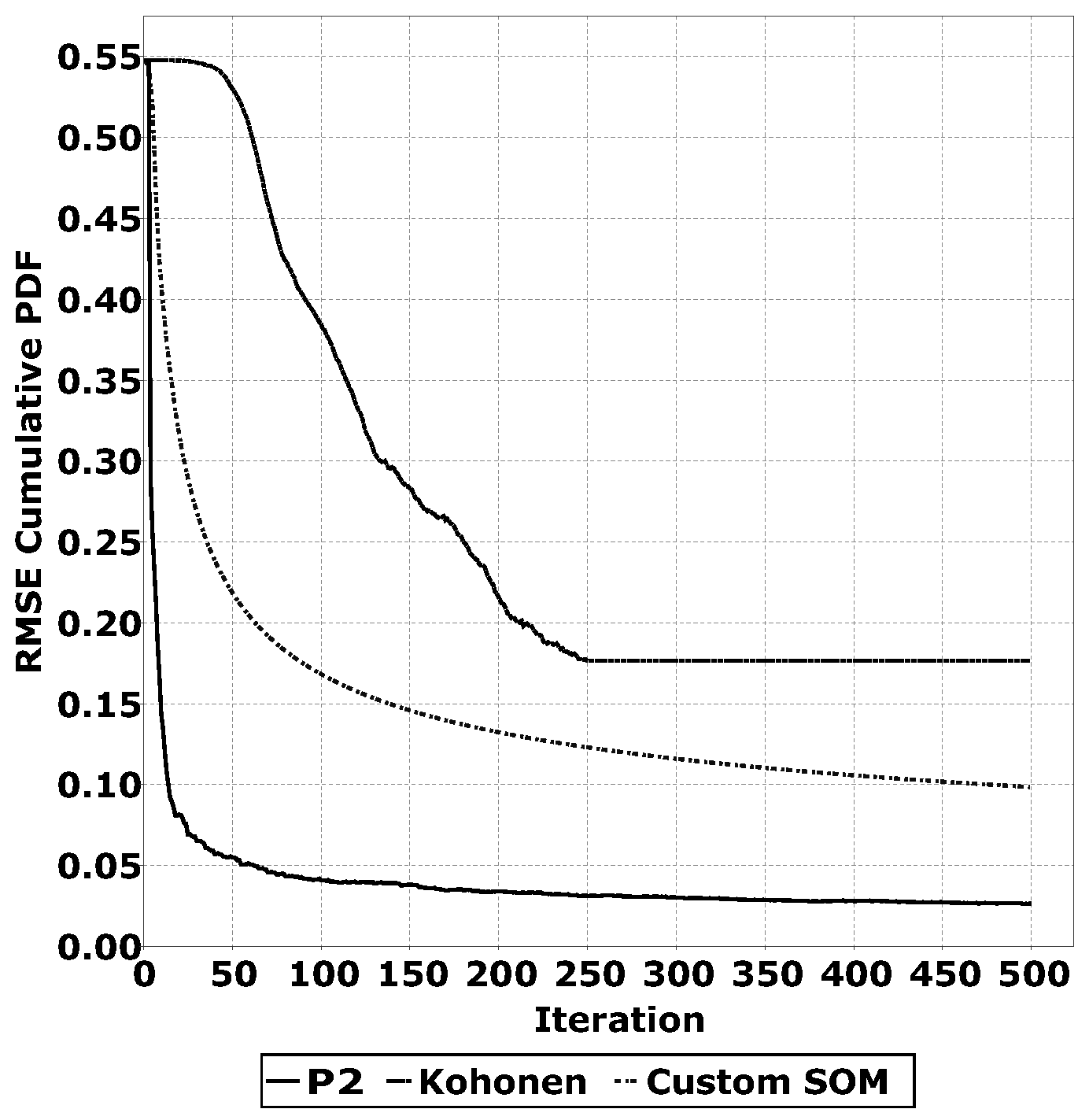
2.3.1. Comparing Quantile Estimation Heuristics
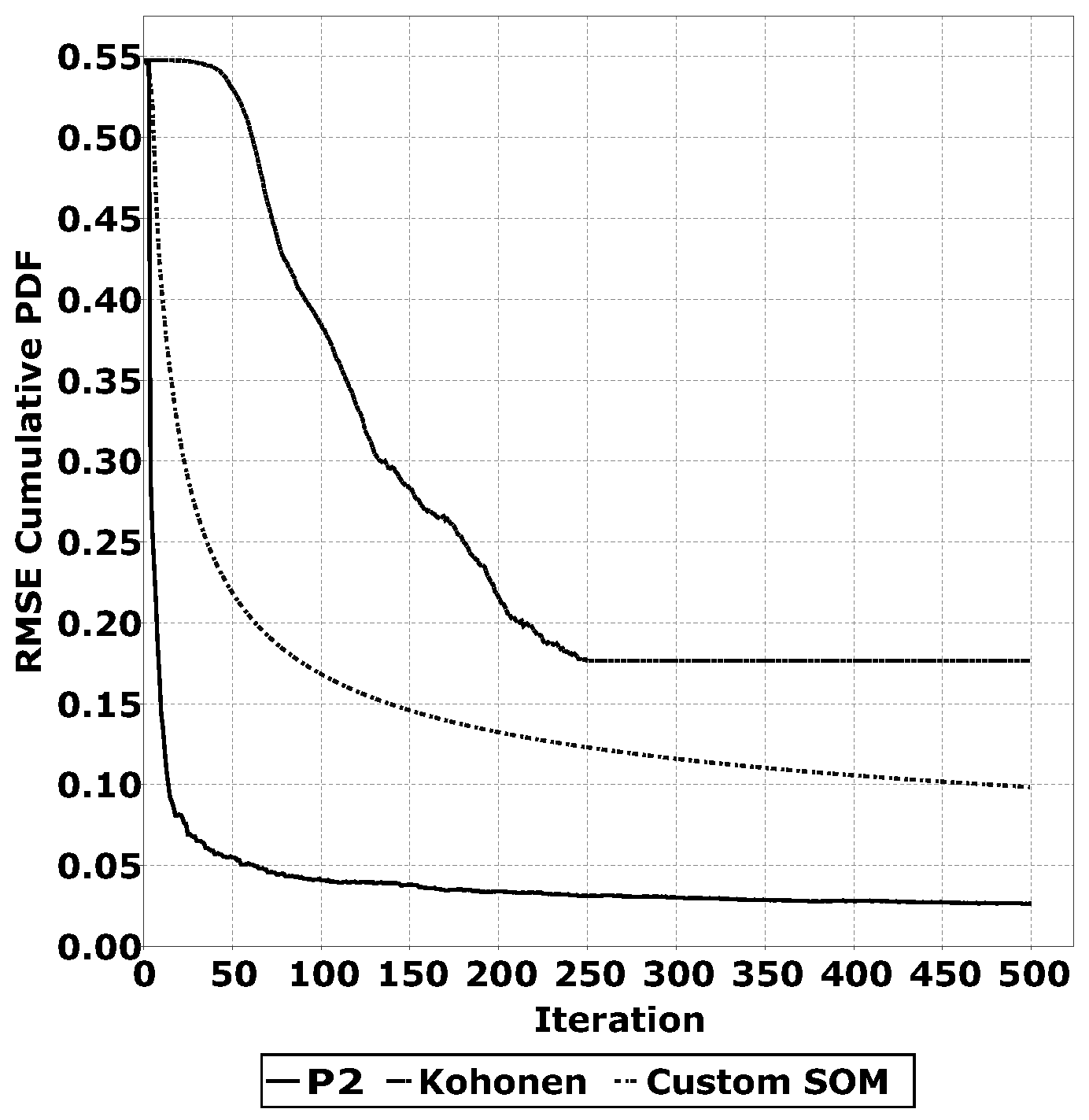
A key part of the QUEST algorithm is the quantile estimation heuristic. There are multiple algorithms that can perform this task. For the application on WSNs, low memory usage and low computational complexity are key aspects. Based on these factors, we have selected the
algorithm [
23], Kohonen networks [
21] and a custom Self Organising Map (SOM) used in [
17]. These three algorithms do not require the storage of a large number of samples in memory and do not require complex computations. The goal of these algorithms for QUEST is to accurately estimate the quantiles. To determine the accuracy of the quantile estimations, we have conducted experiments with a distribution with a known Cumulative Probability Density Function (CPDF). This implies that, for each estimated quantile, we know the desired CPDF value; for example, the 0.5 quantile has a desired CPDF value of 0.5. We have determined the Root Mean Square Error (RMSE) of the quantile estimations over multiple training iterations. We have repeated this experiment for multiple distributions and plotted the average RMSE over multiple unsupervised training iterations. The results of this experiment are shown in
Section 3.2.1.
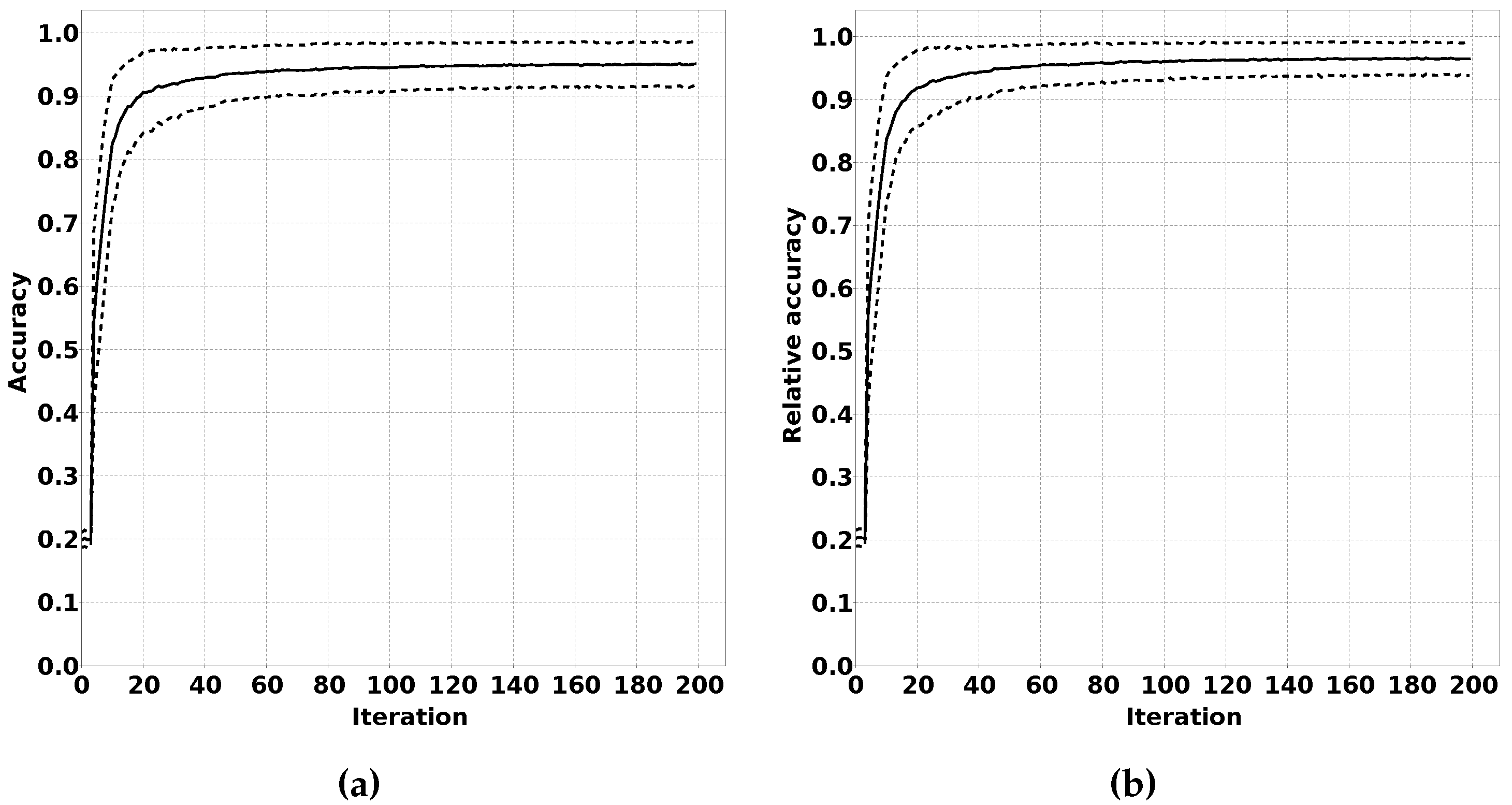
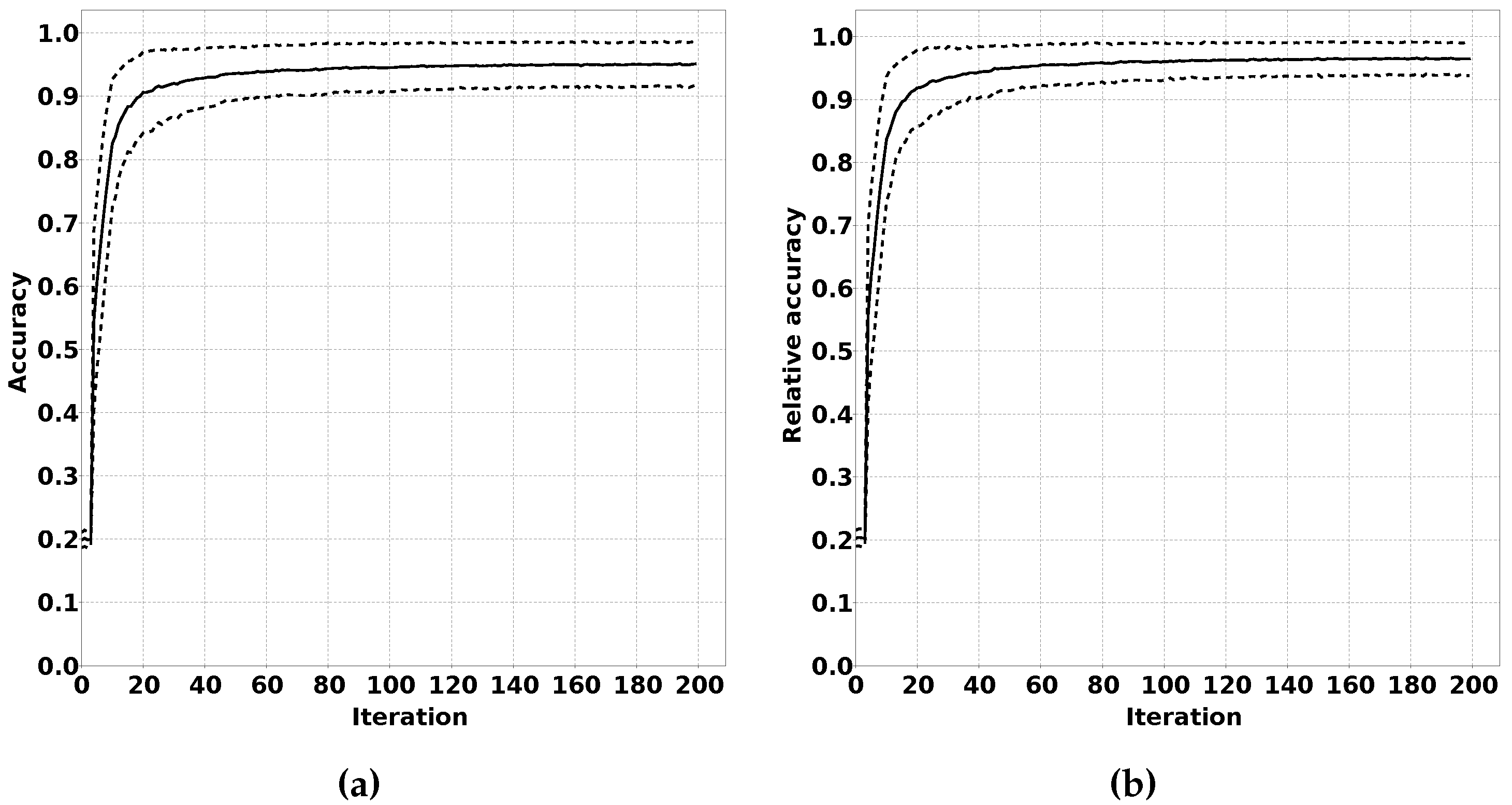
2.3.2. Accuracy Evolution over Training Iterations
We have rephrased these sentencesIn our proposed solution, we expect the classification output of sensor nodes to have a low accuracy at the beginning of the online phase. This low accuracy would be the result of the quantile estimations not matching the data distribution in the new environment. During the online phase, a sensor node should adapt their quantile estimations, thereby improving the classification accuracy.
To verify this effect, we have performed an experiment where we trained a classifier for an initial sample distribution. After this training phase, we changed the data distribution by using different means and standard deviations for the Gaussian distributions for each feature for each class. We ran experiments over a number of iterations. For each iteration, we generated a sample to train the quantile estimators and a number of samples to estimate the accuracy of the classifier after training. We expect that the accuracy of the classifier over the iterations increases until a certain threshold is reached. Repeating these experiments multiple times to calculate average accuracy and determining the relative accuracy compared to a classifier trained with supervised training for the new distribution gives valuable insight in the performance of QUEST. The described test procedure is summarised in Algorithm 3, and the results of this experiment are shown in
Section 3.2.2.
| Algorithm 3: Procedure used for the simulation of QUEST to evaluate the accuracy evolution over training iterations |
number of samples used for supervised learning
number of samples for initial unsupervised learning
number of samples used for accuracy determination
Train classifier c with n labeled samples from class distribution d
Train classifier c with n unlabelled samples from class distribution d
generate an initial random class distribution
generate a modified distribution from d
generate an untrained classifier
create a copy of classifier c
accuracy for classifier c for distribution d over n samples
the accuracy of the classifier for repeat r after iteration i
for 1 to repeats do
for 1 to iterations do
end
end
▹ Result |
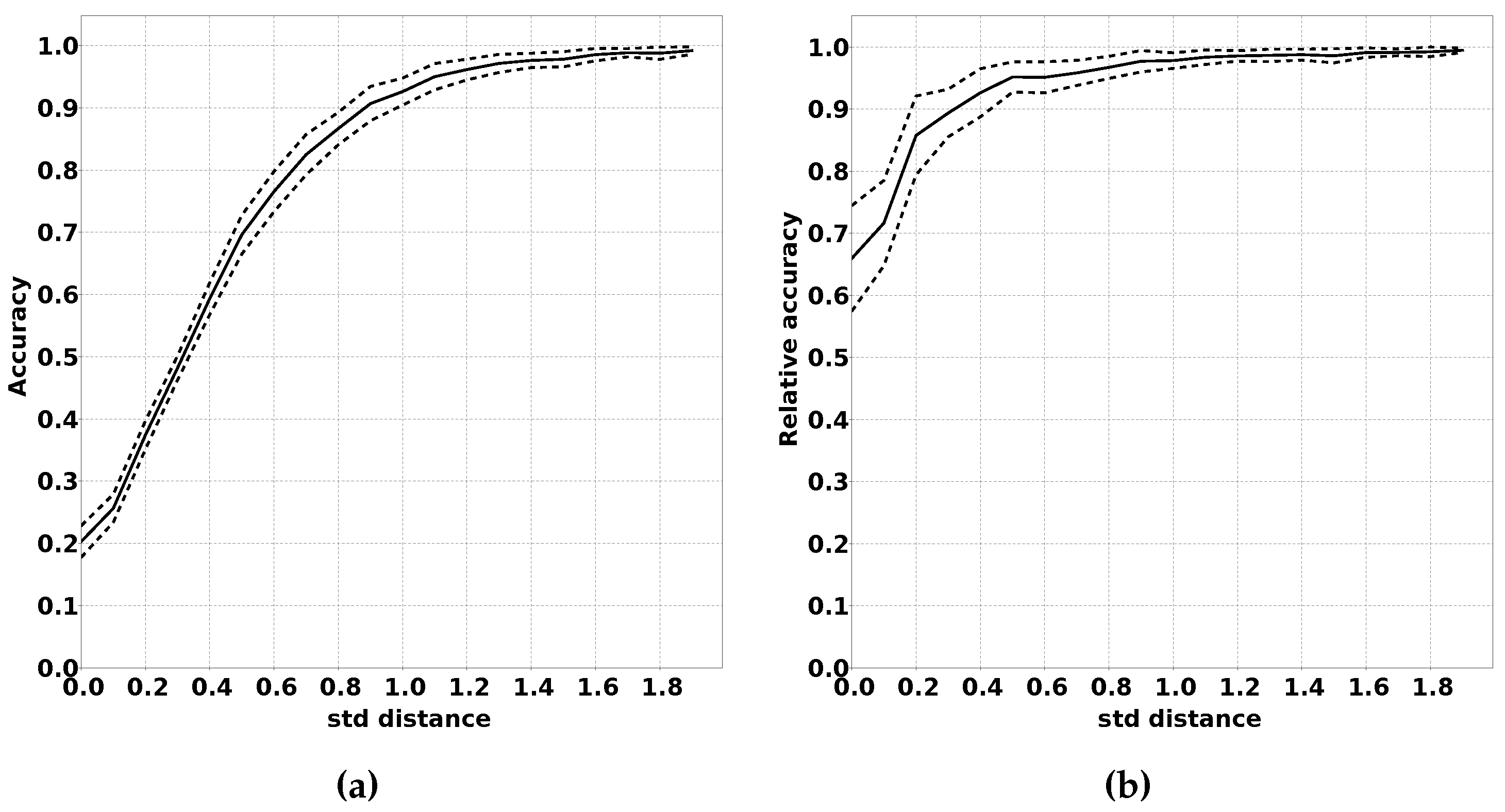
2.3.3. Impact of the Increased Overlap Between Classes
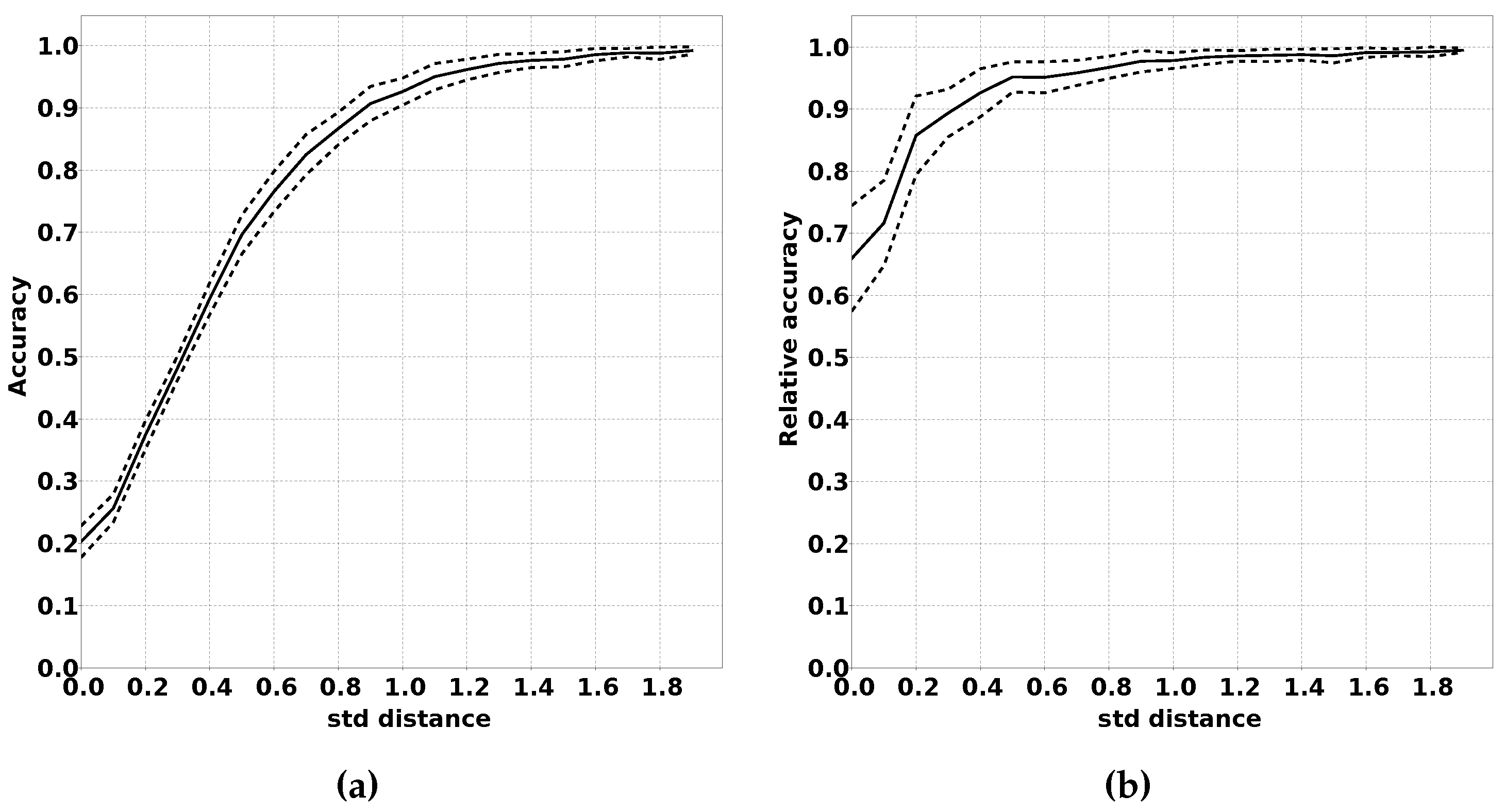
There are multiple ways in which the modified distribution can differ from the original distribution. One of the factors that can differ is the overlap between the class distribution. When there is more overlap between classes, the classification problem becomes more complex since it is harder to distinguish between the classes. We expect that the absolute accuracy of QUEST will drop with larger overlap, but that the drop in accuracy is comparable to classifiers using fully supervised training.
In order to demonstrate this effect, we have performed multiple experiments where we limited the distance between the means of the Gaussian distributions for the various classes. A larger distance between two classes means less overlap. We repeated each experiment for each distance a number of times and calculated the mean accuracy (both absolute and relative) compared to classifiers that were trained using supervised learning. As the unit of distance between classes we used the largest standard deviation of the two distributions between which the distance is measured. This metric was chosen since the amount of overlap between two Gaussian distributions has a high correlation with this metric, and this metric easily can be changed between experiments. The procedure for this experiment is summarised in Algorithm 4, and the results of this experiment are shown in
Section 3.2.3.
| Algorithm 4: Procedure used for the simulation of QUEST to evaluate the effect of increasing the distance between class distributions |
generate an initial random class distribution with δ as the maximum distance between class distributions in standard deviations
generate a modified distribution from d with δ as the maximum distance between class distributions in standard deviations
generate an untrained classifier
create a copy of classifier c
accuracy for classifier c for distribution d over n samples
the accuracy of the classifier for repeat r and distance δ
the accuracy of the original classifier for repeat r and distance δ
for to repeats do
while do
end
end
▹ Result
▹Supervised result for comparison |
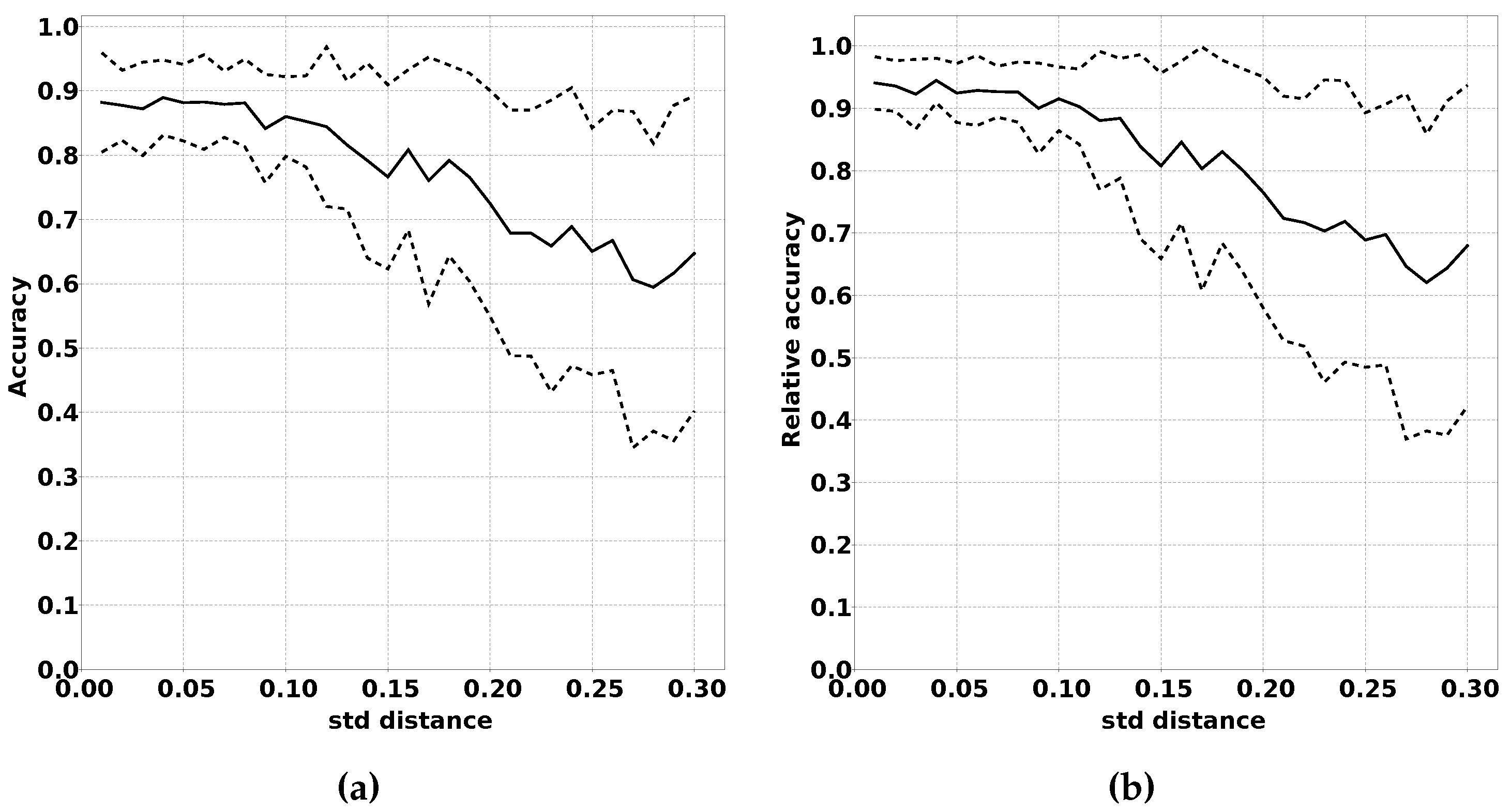
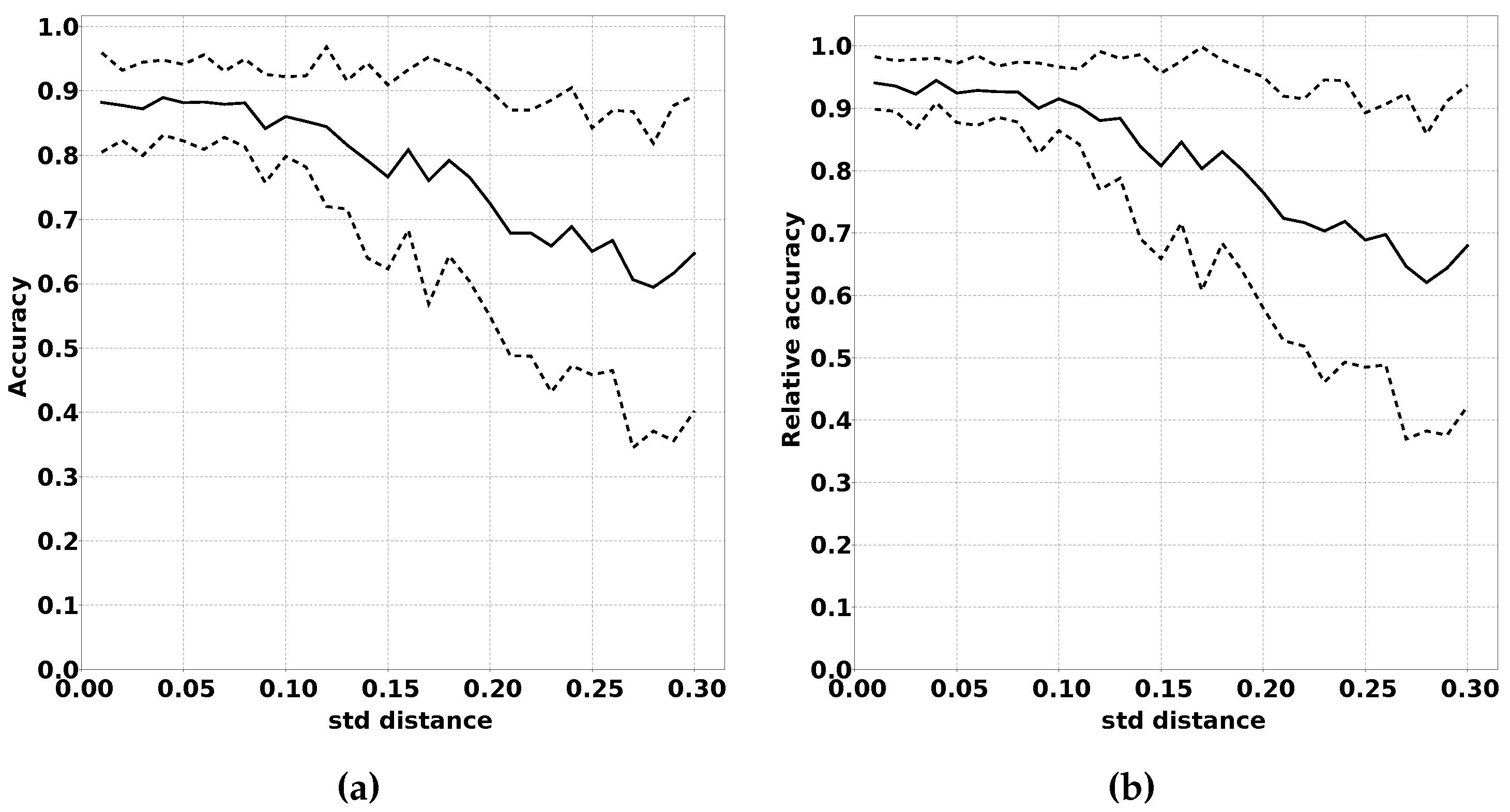
2.3.4. Impact of Changed Bias Between Classes
Another way in which the modified distribution can differ from the original distribution is the bias between the classes. We expect these variations to have a large negative impact on the performance of QUEST. Large variations in the frequency in which classes occur have a strong impact on the location of quantiles on which QUEST is based.
We have conducted experiments on this effect by running experiments with increasing variation in the distribution of samples over the classes. We expect that a larger variation in the distribution results in a decreased performance, both absolute as well as relative to classifiers trained using fully supervised learning. Algorithm 5 summarises this procedure in pseudocode, and the results of this experiment are shown in
Section 3.2.4.
| Algorithm 5: Procedure used for the simulation of QUEST to evaluate the effect of variations in the bias between classes |
generate an initial random class distribution with σ as standard deviation in the fractions with which classes occur
generate a modified distribution from d with σ as standard deviation in the fractions with which classes occur
generate an untrained classifier
create a copy of classifier c
accuracy for classifier c for distribution d over n samples
the accuracy of the classifier for repeat r and distance δ
the accuracy of the original classifier for repeat r and distance δ
for to repeats do
while do
end
end
▹ Result
▹ Supervised result for comparison |
4. Conclusions
The proof that the principle behind the QUEST algorithm works is clearly demonstrated in
Figure 10. This figure shows that a QUEST classifier can be modified for a new classification problem using unsupervised learning. In
Section 3.1.2, we demonstrate that QUEST also works on a real-life classification problem. QUEST is clearly able to adapt a general classifier trained for one situation to a new situation resulting from different circumstances.
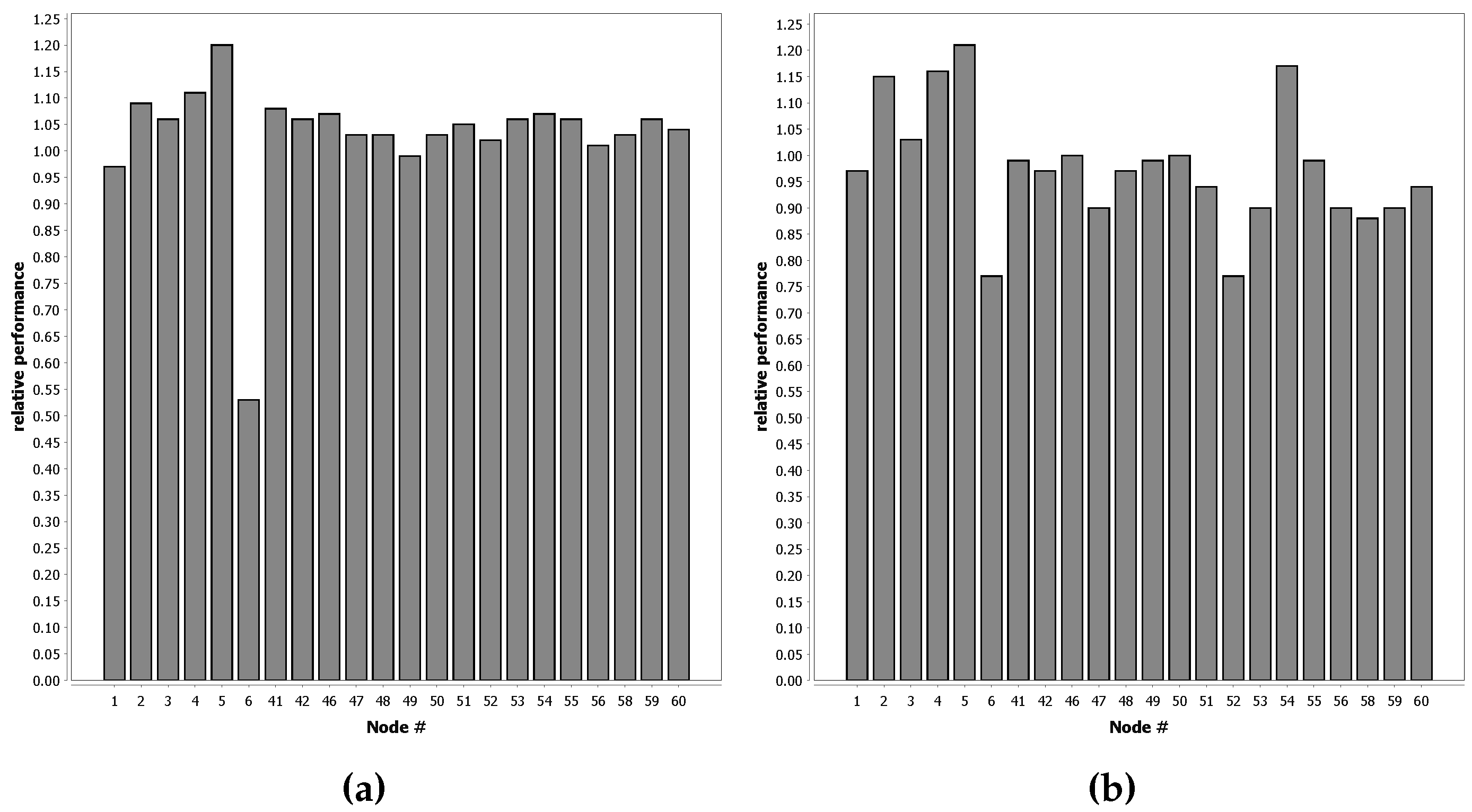
Figure 10b shows that the performance can closely match the optimal level in a simulated environment. Furthermore,
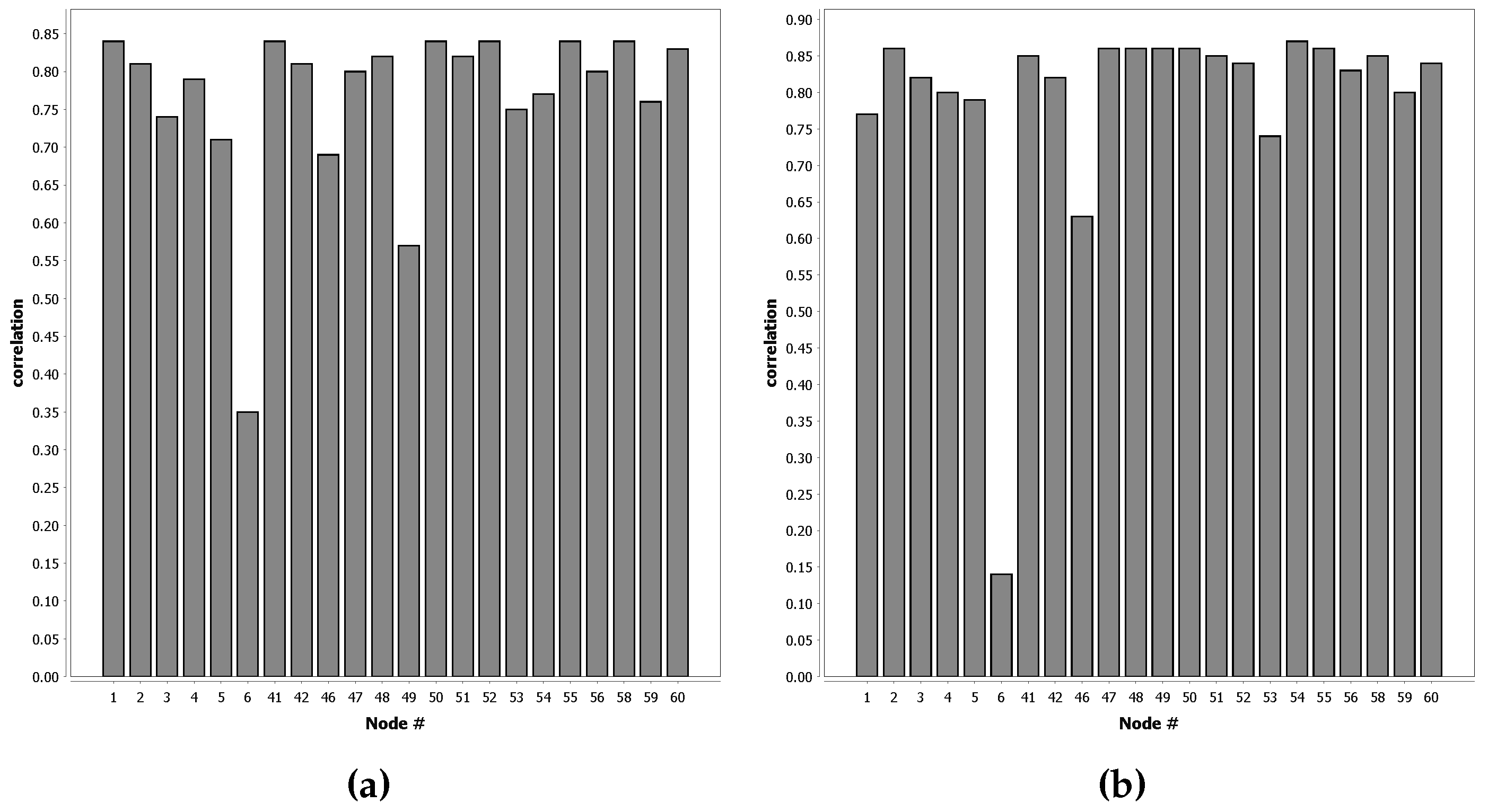
Figure 7 shows that QUEST classifiers can closely match the performance of supervised learning in real-life classification problems. In 90% of the tests shown in
Figure 7, the decrease in performance is less than 10% when compared to full supervised learning. For some nodes, the network performance is even better compared to the case that each node uses a classifier resulting from an offline phase on its own local supervised training data.
There is some reason for caution, however, as
Figure 7 shows that some nodes do not provide suitable data for the offline phase. The exact reason why some nodes work well and others do not is not directly clear from the results. Possible causes could be that nodes are deployed on a location where the distinction between classes in less clear. Another option is that node 6 malfunctions, either by providing erroneous sensor values or timestamps.
Figure 8 does not show a clear spatial relation for the nodes that work well and the ones that do not. In practice, however, this is not necessarily a problem. The offline phase can be run in a controlled environment, allowing the classifier for the offline phase to be better trained than the ones used in this dataset. If node 6 is indeed malfunctioning and removed from the results, more than 95% of the tests have less than a 10% performance penalty.
Another reason for caution is the effect changed bias between output classes has on the performance of the classifiers.
Figure 12a,b demonstrates the negative impact of a large change in class bias. It is our belief, however, that, for the majority of applications, these effects will be minimal. For fire detection, for example, the classification “fire detected” will probably remain a rare classification for which the sensor readings are positioned in the highest and lowest quantiles.
The results presented in this work demonstrate that the application of QUEST enables the deployment of a WSN that requires no on-site communication for training and minimal transmission of data during operation. As such, we believe that QUEST is a valuable contribution to the field of Wireless Sensor Networks.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}