1. Introduction
Personal risk detection [
1] has been defined as the timely identification of when someone is in a dangerous situation, such as a health crisis or car accident or other events that may endanger a person’s physical integrity. To structure this problem, Barrera-Animas et al. [
1] suggested that people usually behave according to the same behavioral and physiological patterns or small variations of them. A risk-prone situation should produce sudden and significant deviations in these user patterns, and the changes can be captured by a group of sensors, such as an accelerometer, gyroscope and heart rate monitor, which are normally found in current wearable devices. The problem posed in [
1] is an anomaly detection problem, where the aim is to distinguish an unusual condition (possibly a risk-prone situation) from a normal behavior. One-class classification mechanisms have proven effective in this context. Indeed, Barrera-Animas et al. reported in [
1] that a one-class support vector machine (ocSVM) achieved the best performance and best average ranking compared with other classifiers in tests.
Techniques for combining one-class classifiers aim to improve the classification performance provided by single classifiers. Additionally, a promising approach for enhancing an ensemble involves training one or several classifiers of the ensemble with different features of the dataset, where the most common techniques are random feature selection methods, such as the random subspace method (RSM, which is also called attribute bagging) and random partitions, subspace clustering, projection methods, bagging and rotation forest [
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13].
In this regard, Tax and Duin [
2] and Nanni [
4] used feature selection in order to train every single classifier in an ensemble. The results obtained in both studies demonstrated that combining features is more effective than combining different classifiers and, in general, produces better results than the individual classifier counterpart.
Juszczak and Duin [
3], Biggio et al. [
5] and Medina-Pérez et al. [
13] aimed to improve the accuracy of classification by employing ensembles based on several instances of the same base classifiers. The techniques used in [
3,
5] for feature subspace partition included fixed combining rules, RSM and bagging. Juszczak and Duin successfully minimized the number of classifiers considered for the ensemble, whereas Biggio et al. and Medina-Pérez et al. obtained improvements in both the classification accuracy and robustness when they compared their ensemble approaches with state-of-the-art classifiers.
Alternatively, Cheplygina and Tax [
6] proposed applying pruning to an RSM of one-class classifiers; they demonstrated that the performance could be noisy using RSM, and pruning inaccurate classifiers from the ensemble was more effective than using all of the available classifiers. Recently, Krawczyk in [
8] proposed a technique for producing efficient one-class classifier ensembles by combining a pruning algorithm with a weighted fusion module that controls the influence of the selected classifiers on the final ensemble decision. The experimental results demonstrated that in most cases, this method outperformed the state-of-the-art pruning algorithms for selecting one-class classifiers from an ensemble.
Therefore, one-class classifier ensembles combined with classifier pruning and random feature selection have the ability to outperform state-of-the-art one-class single classifiers in most cases. In general, the ensembles exhibit robustness and diversity, which allow them to obtain better classification accuracy.
Table 1 presents a summary and a brief comparison of the methods used by the studies reviewed in this work. As can be noted, a wide range of applications has been considered, where ensembles of one-class classifiers were applied satisfactorily, but none were used in our area under study: personal risk detection.
The aim of this study is to improve the accuracy of the detection results reported by Barrera-Animas et al. [
1]. To accomplish this, a new algorithm is proposed and its applicability to the personal risk detection problem demonstrated. The proposed algorithm called One-Class K-means with Randomly-projected features Algorithm (OCKRA) is an ensemble of one-class classifiers, built over multiple projections of the dataset according to random subsets of features. OCKRA comprises 100 classifiers, each of which is built upon 10 centers computed by k-means++ [
14] with Euclidean distance. In the training phase, each individual classifier applies k-means [
15] to a random projection of the dataset and stores the centroids of the clusters. In the classification phase, to determine whether a query object is a risk-prone situation or a normal behavior, each classifier compares it with all of the centroids in order to determine the cluster to which the object is most likely to belong. Each classifier returns a similarity value according to the distance of the query object relative to its closest cluster centroid. The ensemble returns the average similarity computed by individual classifiers.
To evaluate the performance of OCKRA and to compare it with other classifiers, the Personal RIsk DEtection (PRIDE) dataset described in [
1] was used. PRIDE is built based on 23 test subjects where the user data were collected in ordinary life activities, as well as specific scenarios under stressful conditions. Data were captured for the users by employing a set of sensors embedded in a wearable band. The classifiers were trained based only on the daily behavior of the users. Then, the performance of the classifiers was tested while detecting anomalies that were not included in the training process for the classifiers.
OCKRA was compared with the following classifiers: ocSVM [
16], the Parzen window classifier using Euclidean distance [
17] and two versions of the Parzen window classifier based on k-means. In the first version, k-means classifies new objects based only on the closest center of the cluster [
2], whereas in the second, k-means classifies new objects using all of the centers of the clusters [
18]. On average, results showed that OCKRA outperformed the other algorithms for at least 0.53% of the area under the curve (AUC). This number is small, but it is significant because a user will have a higher probability of being assisted in time if they encounter a risk-prone situation. Experimental results are encouraging because the classifier achieved an AUC greater than 90% for more than 57% of the users.
The main contribution of the present study is a new algorithm based on an ensemble designed for one-class classification, which is suitable for personal risk detection. During the design process, it was necessary to consider that OCKRA should run on a mobile personal device, such as a smartphone, with limited resources in terms of the CPU and memory. These restrictions affect the ensemble parameters, i.e., a small value for k (the number of clusters) and the number of classifier instances, while maintaining good classification accuracy. In addition, the final design had to be capable of efficiently integrating any new learning object into the ensemble’s knowledge base without the need to retrain every single classifier.
Before introducing the new algorithm in
Section 3, the dataset used for the experiments is described in the following.
2. PRIDE Dataset
The PRIDE dataset was described in [
1], and it is based on ordinary daily activities as well as specific scenarios under stressful situations. The PRIDE dataset was built based on 23 test subjects during a data collection period of one week for 24 h each day to obtain the normal conditions dataset (NCDS). A Microsoft Band v1
© and a mobile application developed by the authors using the available SDK were used to collect the data. All of the captured stream data were transferred to a private cloud under our control.
Next, to build the anomaly conditions dataset (ACDS), the same 23 test subjects participated in another process to acquire data under particular conditions, where five scenarios to simulate abnormal or stressful conditions were designed, which included the following activities: rushing 100 m as fast as possible, going up and down the stairs in a multi-floor building as fast as possible, a two-minute boxing practice session, falling back and forth and holding one’s breath for as long as possible. Each activity aimed to simulate a dangerous or abnormal condition in the real world, e.g., running away from a dangerous situation, leaving a building due to an evacuation alert, fighting an aggressor during a quarrel, swooning and experiencing breathing problems, such as dyspnea. The session required building the anomaly dataset for each test subject lasting for about two hours, and it demanded major physical effort.
In order to obtain reliable data that could help to distinguish abnormal from normal conditions, the daily collection of behavior and vital signs data was not restricted to a laboratory environment; on the contrary, test subjects felt comfortable wearing the band [
19], and they were not deprived of their privacy [
20]. Furthermore, the ACDS data collection process was monitored without interfering with the test subjects in terms of their freedom to perform activities.
The daily log obtained from a test subject included all of the observations that occurred from 00:00 h to 23:59 h. Data were collected for a test subject during a period of seven days, but there were gaps in the log of at least 40 min usually for three times per day due to the battery recharging process. Moreover, the data were collected during ordinary daily tasks, so the test subjects usually paused the data collection process for personal reasons on several occasions, e.g., to perform an aquatic activity.
To perform a more comprehensive study [
21], test subjects with diverse characteristics in terms of gender, age, height and sedentary lifestyle were considered. The test subjects comprised eight female and 15 male volunteers aged between 21 and 52 years, with heights from 1.56 to 1.86 m, weights from 42 to 101 kg, exercising rates of 0 to 10 h a week and the time spent sitting during working hours or leisure ranging from 20 to 84 h a week. The elderly comprise a very important group in society, but were not included in the data collection process due to the demanding nature of the method employed.
PRIDE is freely available for downloading through the Syncplicity©cloud solution by sending a request to the corresponding author. For the interested reader, Annex 1 shows the mean value, , and the sample standard deviation, s, for all of the test subject features, as well as the number of observations from the PRIDE dataset. All of the procedures performed in this study involving human participants were conducted in accordance with the national law of the Protection of Personal Data in Possession of Particulars. Informed consent was obtained from all of the individual participants in the study.
Next, a brief description of the mobile application developed, as well as the band’s built-in sensors is given.
2.1. Mobile Application and Sensor Network Description
To capture data from the test subjects, a Microsoft Band [
22,
23] was used because of two main reasons: the number and nature of sensors included in the band; and the availability of an SDK that allowed us to develop an application according to our needs. The application was developed for the Android platform, and it was connected to the band via Bluetooth. The application acquired the sensor data in real time and stored all of the measurements in a CSV file on the mobile phone. The file was transferred to a secure FTP server under our control, which was performed by the test subject once or twice each day by using the upload file to server option on the application.
Accelerometer and gyroscope data were acquired at an interval of 125 ms (the sensor operating frequency was set to 8 Hz) in order to maintain a reasonable file size (about 175 MB) after 24 h and a battery life of almost 9 h. The battery could be recharged to 80% of its full capacity within approximately 40 min. For comparison, if a sensor operating frequency of 31 Hz or 62 Hz were used, the size of the file would have increased to 650 MB and 870 MB, respectively, and the battery life would have degraded to 8 h and 6 h, respectively. However, the frequency of operation could be set directly to 8, 31 or 62 Hz at any time from the application. Distance, heart rate, pedometer and calorie measurements were logged using a readout interval of 1 s, and UV and skin temperature data were collected every 60 s and 30 s, respectively, or whenever the value changed. GPS data were not available using the SDK, so it should be noted that the distance was derived using a proprietary Microsoft algorithm, which considered the number of steps taken by the user (pedometer), the user’s stride length and their height. Height and other types of general user information were provided when setting up the application and during synchronization with the band for the first time. The algorithm was patented by Microsoft (Adaptive Lifestyle Metric Estimation. Microsoft Internal Number 341468. U.S. Patent 20150345985-A1).
Table 2 describes the sensors in the band, as well as the frequencies at which their data could be retrieved. Using the sensor operating frequencies shown in the table, the test subject data could reach approximately 1,670,160 records per day (around 175 MB), and the battery life was about 9 h.
2.2. PRIDE Pre-Processing for Online Personal Risk Detection
Before using PRIDE and performing any experiments, the data had to be prepared in order to derive a feature vector for every test subject, which was refreshed every second. The following steps summarize the dataset pre-processing procedure.
For each test subject in the PRIDE dataset, the records were arranged by day.
The feature vector was computed using a window size of one second. The frequency of our sensors varied significantly, so three rules were applied to compute the feature vector for a given window: (1) if the readout interval was less than one second, the feature vector was assigned both the average and sample standard deviation for all of the sensor measurements; (2) if it was equal to one second, then the feature vector was assigned directly the sensor value; and (3) if it was greater than one second, the feature vector was assigned the last sensor value.
Specifically, a feature vector for a given window contained the following:
Means and standard deviations for the gyroscope and accelerometer measurements;
Absolute values obtained by the heart rate, skin temperature, pace, speed and UV sensors;
The incremental changes (Δ-value) in the absolute values for the total steps, total distance and calories burnt; a Δ-value was computed as the difference between the current and previous values.
Thus, a 26-dimensional feature vector was obtained, and its values were refreshed every second. The structure of this vector is shown in
Table 3 and
Table 4. Both the NCDS and ACDS were pre-processed using this method.
Next, each of the test subject logs was divided into five folds to use them in a five-fold cross-validation. In the cross-validation, four folds of the normal behavior by test subjects were used for training, and one fold was joined with the anomaly dataset log to test the classifiers. This procedure was repeated five times by alternating the test subject fold that was retained for testing. Thus, five training datasets and five testing datasets were obtained.
In our datasets (the pre-processed PRIDE dataset), every object was stored as a row in a CSV file, which followed the structure of the feature vector described previously. The last column of every row contained one of two labels: “typical” or “atypical”. The label “typical” indicated that the object represented normal test subject behavior, and the label “atypical” indicated that the object represented an anomalous state. This label was never used for training the classifier, and it was only used for testing purposes.
Next, the new algorithm will be described in detail as an ensemble of one-class classifiers for personal risk detection.
3. Proposed Algorithm
This study introduces a new algorithm called OCKRA, which is based on the hypothesis that a risk-prone situation produces sudden and significant deviations from standard user patterns. These patterns are computed based on the data sensed by the Microsoft Band, as described in
Section 2.1.
The proposed algorithm is an ensemble of one-class classifiers, based on multiple projections of the dataset according to random subsets of features. Random subsets of features are used to ensure that there is high diversity [
6,
7,
8] among the classifiers, in the same manner as some other well-known ensembles, e.g., random forest [
24]. OCKRA first applies k-means++ [
14] to each subset of features to obtain a collection of cluster centroids. Next, to classify a new sample observation, OCKRA returns an average similarity measurement, which is computed by the ensemble of all of the individual classifiers. While combining multiple k-means, each one computed on a random projection of the dataset, has already been explored for clustering [
15], the novel aspect of our method is that OCKRA is designed for one-class classification problems instead of several-class problems. In particular, OCKRA operates in the context of personal risk detection based on wearable sensors, where processing is performed by devices with limited resources, such as smartphones. In the following, a formal description of the ensemble training and classification phases is given.
3.1. Training OCKRA
OCKRA is an ensemble of one-class classifiers, each of which is based on k-means++ (Algorithm 1). As described by Breiman in [
24], the number of individual classifiers was set at 100, which yielded good experimental results, but determining the best number of classifiers with respect to detection performance remains an open question. In order to introduce diversity among each of the elements of the ensemble, a different set of features was used in order to train each individual classifier. To train the ensemble, the process starts with an initial training dataset
T of size
, where
m is the number of samples and
n is the number of features. Random feature selection with replacement was used (Step 4). In this step,
n random numbers between one and
n are generated using a uniform probability distribution. After removing any duplicates, the remaining elements represent the index of the features that will be considered during the construction of individual classifiers. According to our experience, this procedure extracts 63% of the
n original features on average.
Next, for each classifier, the algorithm projects the training dataset T (Step 5) over the randomly-selected features in order to obtain the projected dataset . This dataset has a size of , where is the number of randomly-selected features. Next, the algorithm computes the centers of the k clusters obtained using k-means++ (Step 7). The distance function is set to Euclidean (which is standard in previous studies) and k = 10. k needs to be small since OCKRA must work online using smartphones, so it should consume low RAM memory and CPU resources while maintaining good classification accuracy. Again, determining the optimum value of k with respect to the consumption of resources and detection performance remains an open question. The algorithm uses the centers of the clusters obtained by k-means++ to build one-class classifiers, which return the likelihood that a new object belongs to its nearest cluster given a distance threshold. To compute the distance threshold (Step 6) and because of the massive amount of available data for each user, the process uses a subset of created by using only the data points separated by 60 s between them, which reduces the data required for processing from m samples to approximately . The distance threshold is computed by averaging the distance between all of these points. It was decided to use the average distance after experimenting with different thresholds, such as the maximum and minimum distance between points, because it performed better in different contexts.
The training phase returns a set comprising the parameters of each individual classifier, which consists of a triplet containing the randomly-selected features, the computed centroids of each cluster and the distance threshold.
| Algorithm 1 OCKRA training phase. |
- 1:
function OCKRA_Train(T) ▷T: training dataset. - 2:
- 3:
for do - 4:
RandomFeatures - 5:
Project - 6:
AvgDistances - 7:
ApplyKMeansAndComputeCentres - 8:
- 9:
end for - 10:
return - 11:
end function
|
3.2. Classification Using OCKRA
In order to classify a new object, the algorithm takes a one-dimensional table O containing the object, which is a vector of size (Algorithm 2). The following steps need to be performed for each classifier parameter triplet obtained from the training phase. First, OCKRA projects O onto the randomly-selected feature space (Step 5) obtained by training, thereby resulting in a projected object contained in . After projection, the first step for classification by OCKRA involves selecting the nearest cluster to , which is achieved by selecting the centroid with the smallest Euclidean distance to the object in (Step 6).
The last step of classification with OCKRA involves transforming the distance between the projected object and its nearest cluster centroid onto a similarity value in the interval (Step 7). A value of zero indicates a risk-prone behavior, whereas a value of one indicates that the object resembles the normal behavior of users. If the distance value is less than , the algorithm computes a high similarity value (>0.6), which indicates that the object is likely to belong to the cluster of its nearest center. When the distance is more than three times , the algorithm yields a low similarity value (<0.02), which indicates that the object does not belong to any cluster. It is worth noting that there is an inverse relationship between the similarity score and the distance from the object to the nearest cluster.
In order to reach a consensus among all of the members of the ensemble, OCKRA averages the similarity measurements of all of its classifiers (Step 9).
The ensemble returns a similarity value where zero indicates a potentially risky situation and one represents normal behavior, so the accuracy of our classifier relies on a threshold for determining what is anomalous and what is not. A threshold value closer to one will detect most of the risk-prone situations, but it may annoy the user by confusing normal behavior with risk. By contrast, if the threshold is closer to zero, the user would be notified less often, but the system is likely to miss many actual risky situations. Hence, the setting of the threshold value depends on the specific needs of the user (e.g., detecting risky situations for a healthy athlete is not the same as that for an elderly person in a retirement home).
| Algorithm 2 OCKRA classification phase. |
- 1:
function OCKRA_Classify() - 2:
▷O: table that contains object to be classified; OCKRAParameters: set returned by Algorithm 1 - 3:
- 4:
for each do - 5:
Project - 6:
EuclideanDistance - 7:
- 8:
end for - 9:
- 10:
return s - 11:
end function
|
4. Results and Discussion
By using the method described in [
1], the performance of OCKRA was tested based on a five-fold cross-validation, as described in
Section 2.2, during the pre-processing step with the PRIDE dataset.
Users want to be protected by an ideal classifier, which can correctly discriminate every possible abnormal behavior from that of a normal user. Therefore, the aim is to build classifiers that maximize true positive classifications (i.e., true abnormal conditions) while minimizing false positive ones (i.e., false abnormal or dangerous situations). Therefore, the classifiers were evaluated using the following performance indicators.
Precision-recall (P-R) curves: Precision refers to the fraction of retrieved instances that are relevant, and recall (also known as sensitivity) is the fraction of relevant instances that are retrieved. In our case, a relevant instance is characterized by a true anomaly. In addition, recall is equivalent to the true positive detection rate (TPR). A P-R curve was built for each user independently, as well as a single P-R curve based on the mean and standard deviation for all of the users.
ROC curves: The performance indicators were computed based on the receiver operating characteristic (ROC) curves, built according to Fawcett [
25]. A similar approach to that used for constructing the P-R curves was employed. A ROC curve was built for each user independently and also a single ROC curve based on the mean and standard deviation of the total population. Sensitivity is crucial in a personal risk detection context, where it is preferable to receive several false alerts (false abnormal or dangerous situation), rather than missing one true one (false ordinary or normal condition); hence, it is important to maximize recall even at the cost of experimenting with a certain false alarm rate.
AUC: The AUC of the TPR versus the false positive detection rate (FPR), which indicates the general performance of the classifier for all FPR rates.
OCKRA was compared with the following classifiers.
ocSVM: The implementation of ocSVM [
16] included in LibSVM [
26] with the default parameter values (
and
) and using the radial basis function kernel.
Parzen: Parzen window classifier using the Euclidean distance [
17]. For every training dataset, the classifier computes the width of the Parzen window by averaging the distances between objects sampled every 60 s (this procedure saved approximately seven days when computing the distances per test subject using an Intel Core i7-4600M CPU at 2.90 GHz).
k-means1: A version of the Parzen window classifier based on k-means [
2]. k-means1 classifies new objects based only on the closest center of the cluster.
k-means2: A version of the Parzen window classifier based on k-means [
18]. k-means2 classifies new objects using all of the centers of the clusters.
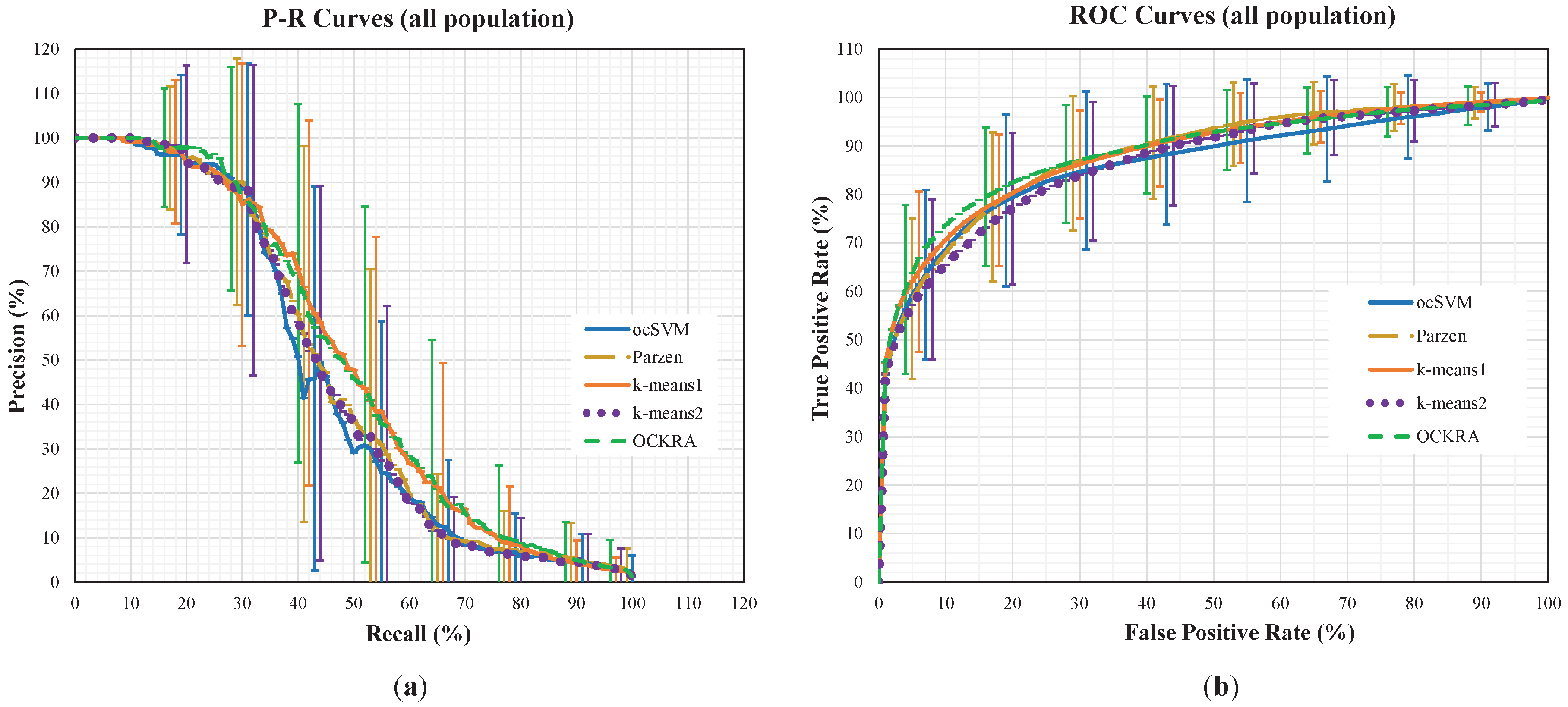
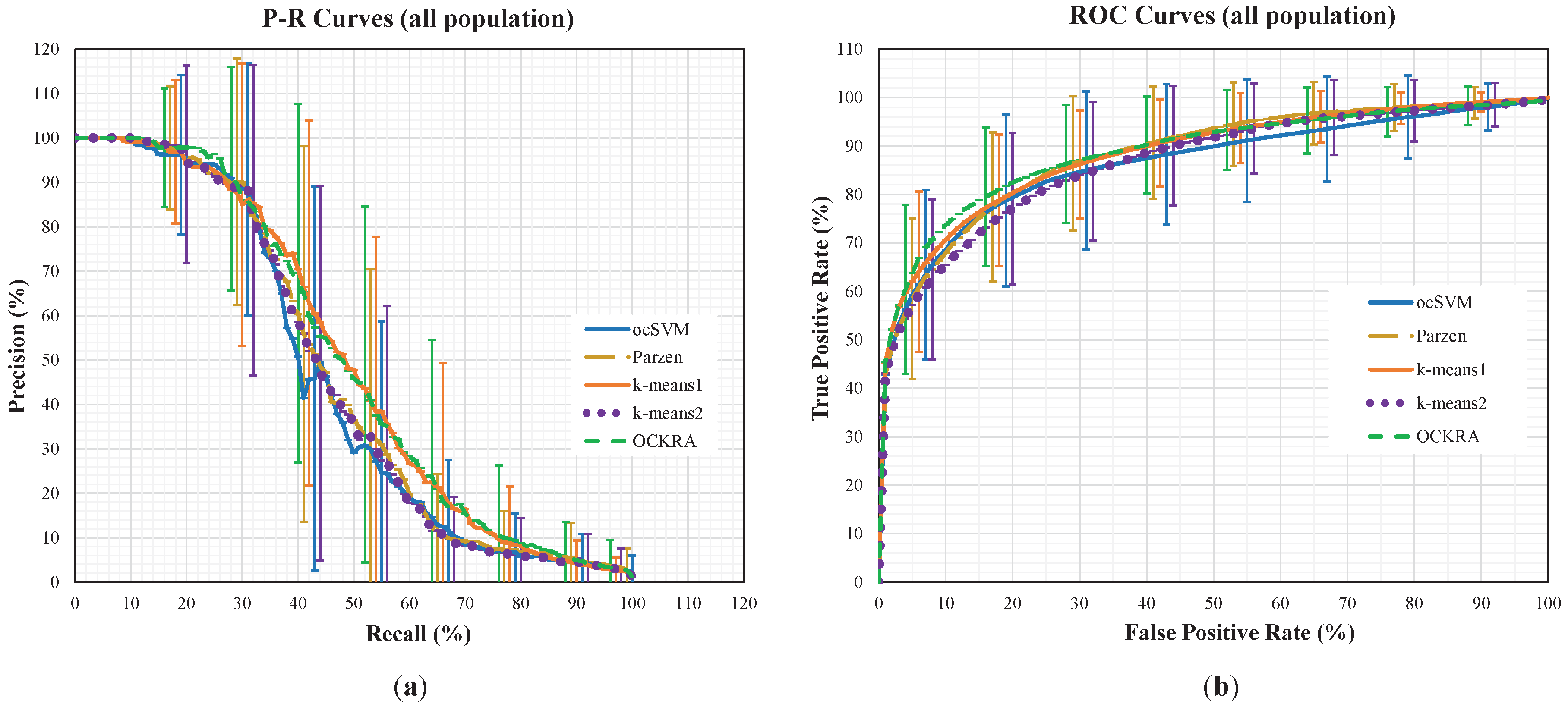
Figure 1 shows the average P-R and ROC curves for all of the population, where the standard deviations are shown as vertical lines for each algorithm at different intervals. For the interested reader, the individual P-R and ROC curves can be accessed as
Supplementary Material. The P-R curves in
Figure 1 show that OCKRA and k-means1 outperformed Parzen and k-means2, and there was no significant difference between OCKRA and k-means1. The ROC curves in
Figure 1 confirm the results of the P-R curves, but it can be noticed that OCKRA obtained better FPR rates between 5% and 30%.
In order to quantify the differences among the algorithms, the average of the AUC results was computed for all of the test subjects.
Table 5 shows that OCKRA outperformed the other algorithms for at least 0.53% of the AUC on average. This number is small, but it has a significant impact because it means that a user will have a higher probability of assistance in a risk-prone situation. Parzen achieved the second best result in terms of AUC, but it is less suitable for running on a smartphone because it is two orders of magnitude more expensive than OCKRA (i.e., Parzen requires the full dataset to classify a new object, whereas OCKRA requires only 1000 centers of the clusters). In summary, our classifier achieved an AUC above 90% for approximately 57% of the users, which is an encouraging result.
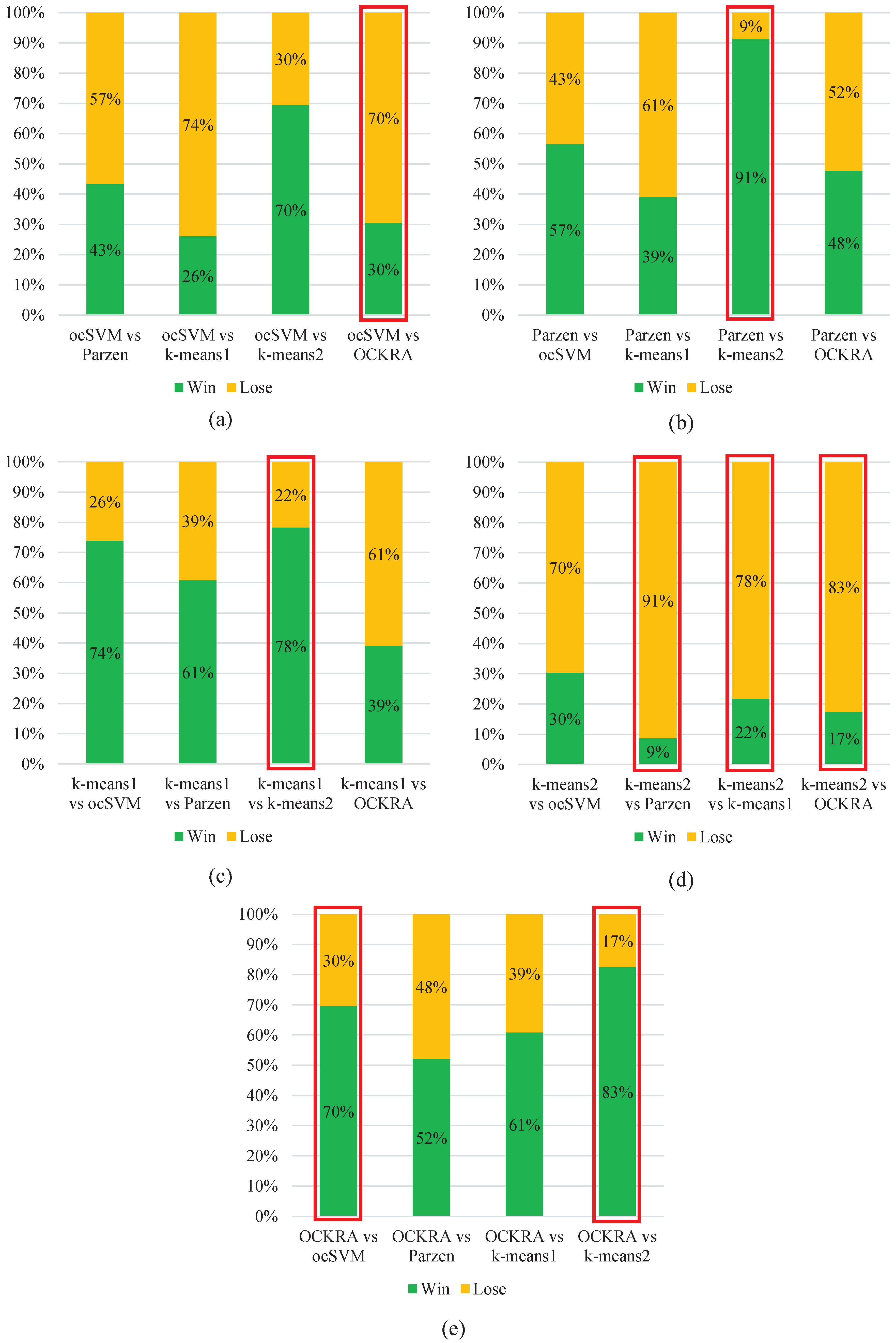
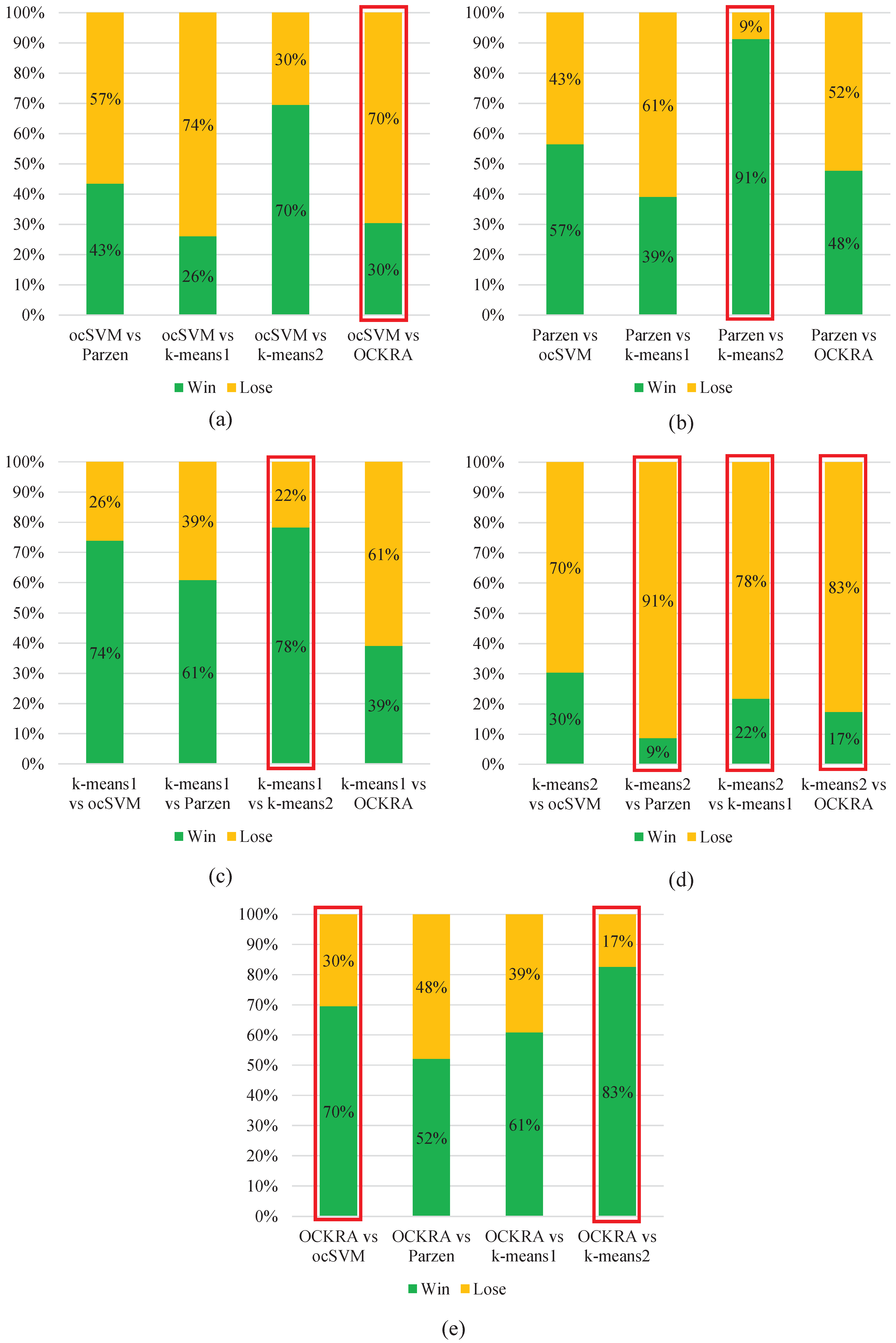
Figure 2 shows pairwise comparisons of the algorithms, which demonstrates that OCKRA outperformed the other algorithms for most of the test subjects. Furthermore, OCKRA was the only algorithm to obtain significantly higher accuracy than ocSVM according to Wilcoxon’s signed-rank test at a significance level of
.
The methodology used in this study to train and test the classifier is based on subject-dependent tests; thus, the results just presented represent the potential performance of OCKRA in a production stage. By running the Kruskal–Wallis test, it has been proven that all users’ datasets are statistically different, i.e., they are not drawn from the same population; hence, using a subject-independent approach is not feasible.
5. Conclusions and Further Work
This study introduces a new algorithm, called OCKRA, that stands for One-Class K-means with Randomly-projected features Algorithm. OCKRA is an ensemble of one-class classifiers built over multiple projections of the dataset according to random subsets of features; OCKRA comprises 100 classifiers, each of which is built upon 10 centers computed by k-means++ with Euclidean distance.
Combining one-class classifiers has been demonstrated to outperform the classification performance obtained by single classifiers; additionally, the ensemble can be enhanced by training one or several of its classifiers with different features of the dataset [
2,
3,
4,
5,
6,
7,
8]. Several studies have reported a wide range of applications where these techniques have been applied satisfactorily; however, none is oriented toward our area under study: personal risk detection.
Barrera-Animas et al. [
1] argued that it is possible to use PRIDE, a dataset with information drawn from a number of test subjects wearing a sensor network device, to develop a personal risk detection mechanism. They showed that abnormal behavior can be automatically detected by a one-class classifier. In addition, they showed that one-class support vector machine (ocSVM) achieved the best performance and best average ranking compared with other classifiers. The present study aims to improve on the best results reported therein; i.e., to improve the anomaly detection accuracy in the context of PRIDE.
The results obtained in this study supersede those reported in [
1]; therefore, OCKRA stands so far as the state-of-the-art in the context of personal risk detection. Additionally, experimental results show that OCKRA is the only algorithm that achieved significant statistical improvement over ocSVM, as shown in
Figure 2.
In [
1], ocSVM was compared with the following classifiers: the Parzen window classifier (PWC) using the Mahalanobis distance and two versions of PWC based on k-means with the Mahalanobis distance. The present study compared OCKRA with ocSVM [
16], PWC, but this time using Euclidean distance [
17], and two versions of PWC based on k-means also based on Euclidean distance [
2,
18]. It should be noted that all versions of PWC used in this study outperform their counterpart in [
1]. In summary, the authors have knowledge of eight different classifiers tested on the same one-class dataset.
It remains an open question, beyond the scope of this paper, to compare OCKRA with other one-class algorithms in a different context; that is, using a different dataset. Furthermore, as discussed in [
1], it is difficult to find open-access datasets posing a one-class detection problem.
A publicly-available one-class dataset that could be a good candidate for comparison purposes is WUIL (the Windows-Users and -Intruder simulations Logs) [
27]. However, preliminary tests on WUIL have led to the conclusion that classifiers based on the Mahalanobis distance perform better on WUIL than those based on Euclidean distance, whereas in the context of PRIDE, our results show exactly the opposite. Due to the scarcity of datasets posing a one-class classification problem, a common practice in the research community is to transform a “multi-class” dataset into a “one-class” dataset. However, the authors have so far refrained from adopting this procedure since modifying the problem domain amounts to creating a new domain that often departs from the original nature of the problem.
The main contribution of this study is the introduction of OCKRA, a new algorithm which is an ensemble specially designed for one-class classification, which is highly suitable for personal risk detection based on wearable sensors.
Results showed that OCKRA outperformed the other algorithms for at least 0.53% of the AUC on average. This number is small, but it has a significant impact because it means that a user will have a higher probability of being assisted in time if they encounter a risk-prone situation. The classifier achieved an AUC above 90% for more than 57% of the users, which is an encouraging result because it supports the hypothesis that abnormal behavior can be detected automatically.
A promising approach to consider in future work is to combine the proposed ensemble with other classifiers that take into account temporal relationships among consecutive events. In addition, another approach will be explored that updates the ensemble knowledge continuously whenever it misclassifies normal behavior as abnormal (i.e., when it generates a false alarm).
Furthermore, due to the high amount of raw data collected by users, the possibility of implementing mechanisms based on information fusion [
28] will be considered, with the aims of both decreasing the amount of data stored/transmitted and improving the classification process.



 ,
, 

{kind=link}
{kind=link}