
Geographic Patterns of Vascular Plant Diversity and Endemism Using Different Taxonomic and Spatial Units

 , , , ,
, , , , {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Materials and Methods
2.1. Floristic Database
2.2. Specimen-Based Analyses
2.3. Species Distribution Model-Based Analyses
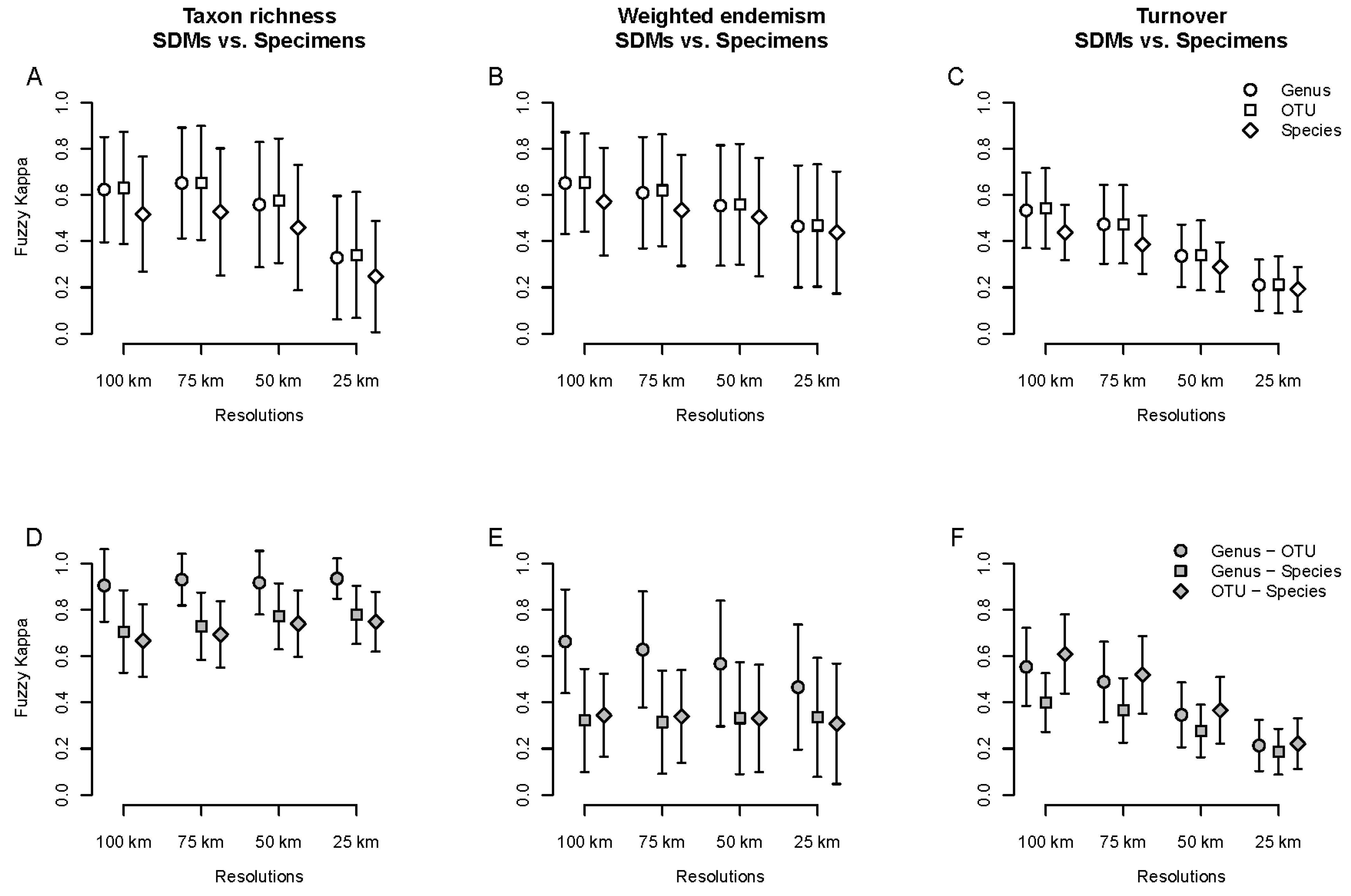
2.4. Comparisons
2.4.1. Specimen-Based Analyses
2.4.2. Species Distribution Models (SDMs)
3. Results
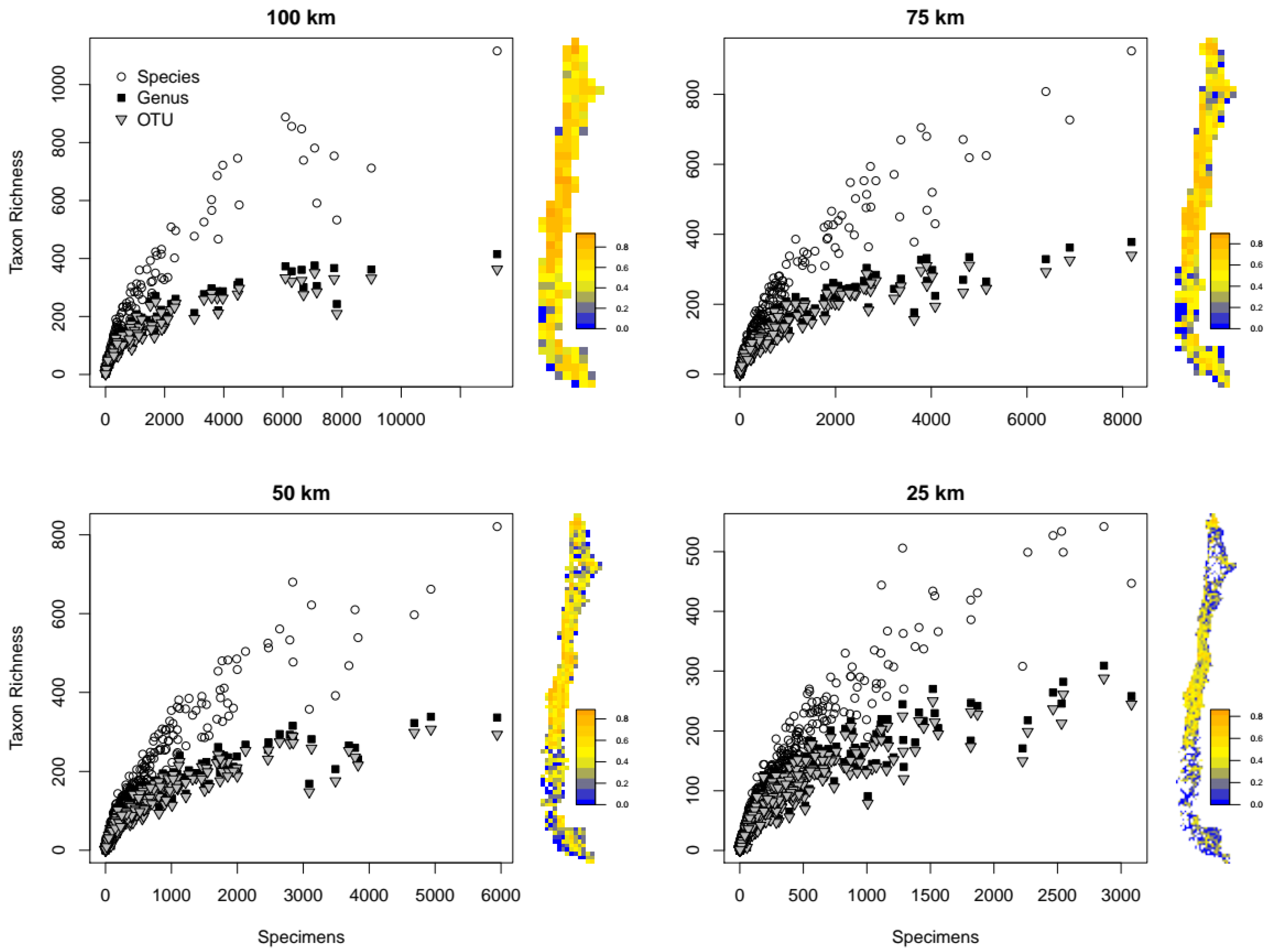
3.1. Redundancy and Grid Effects
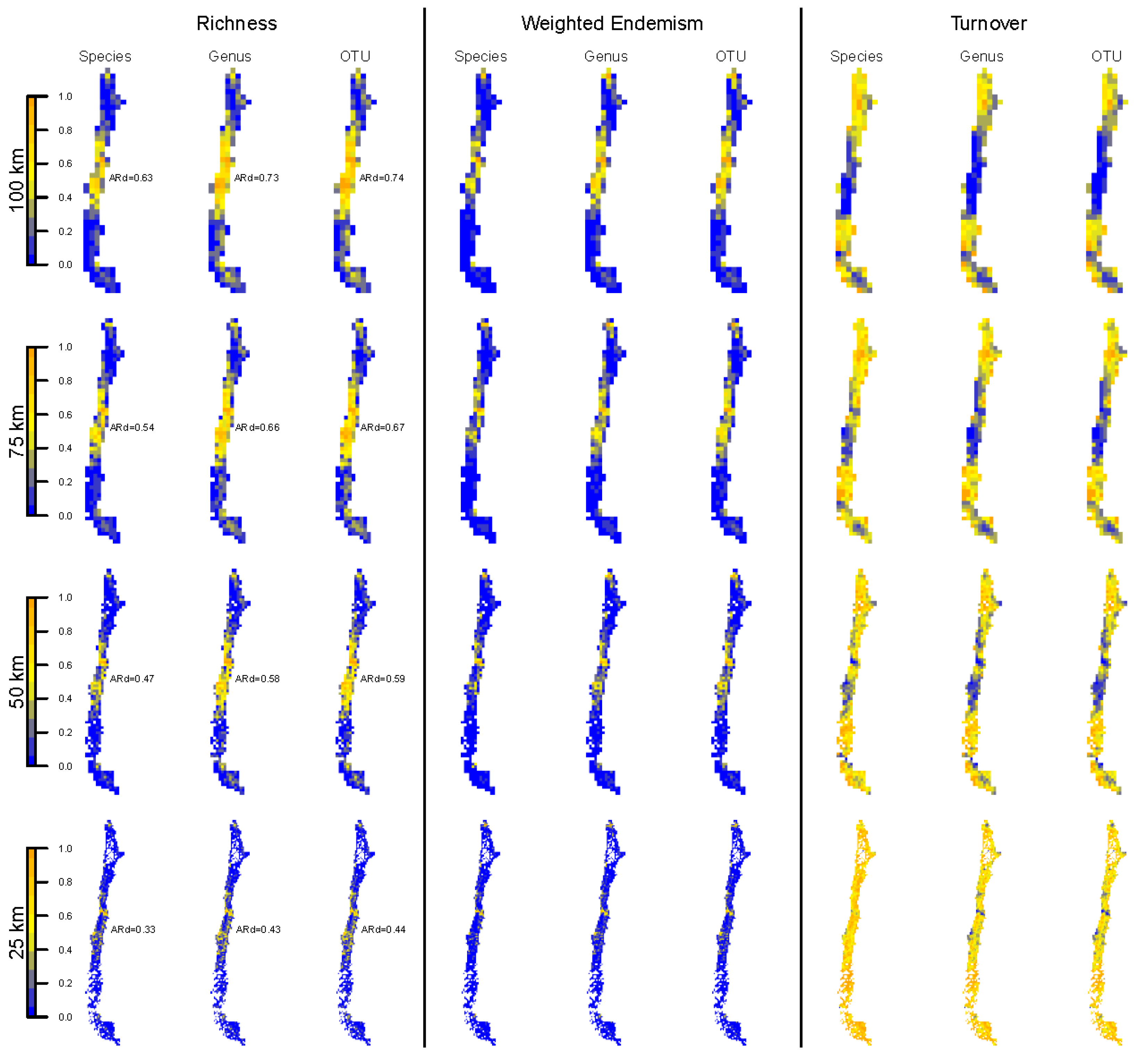
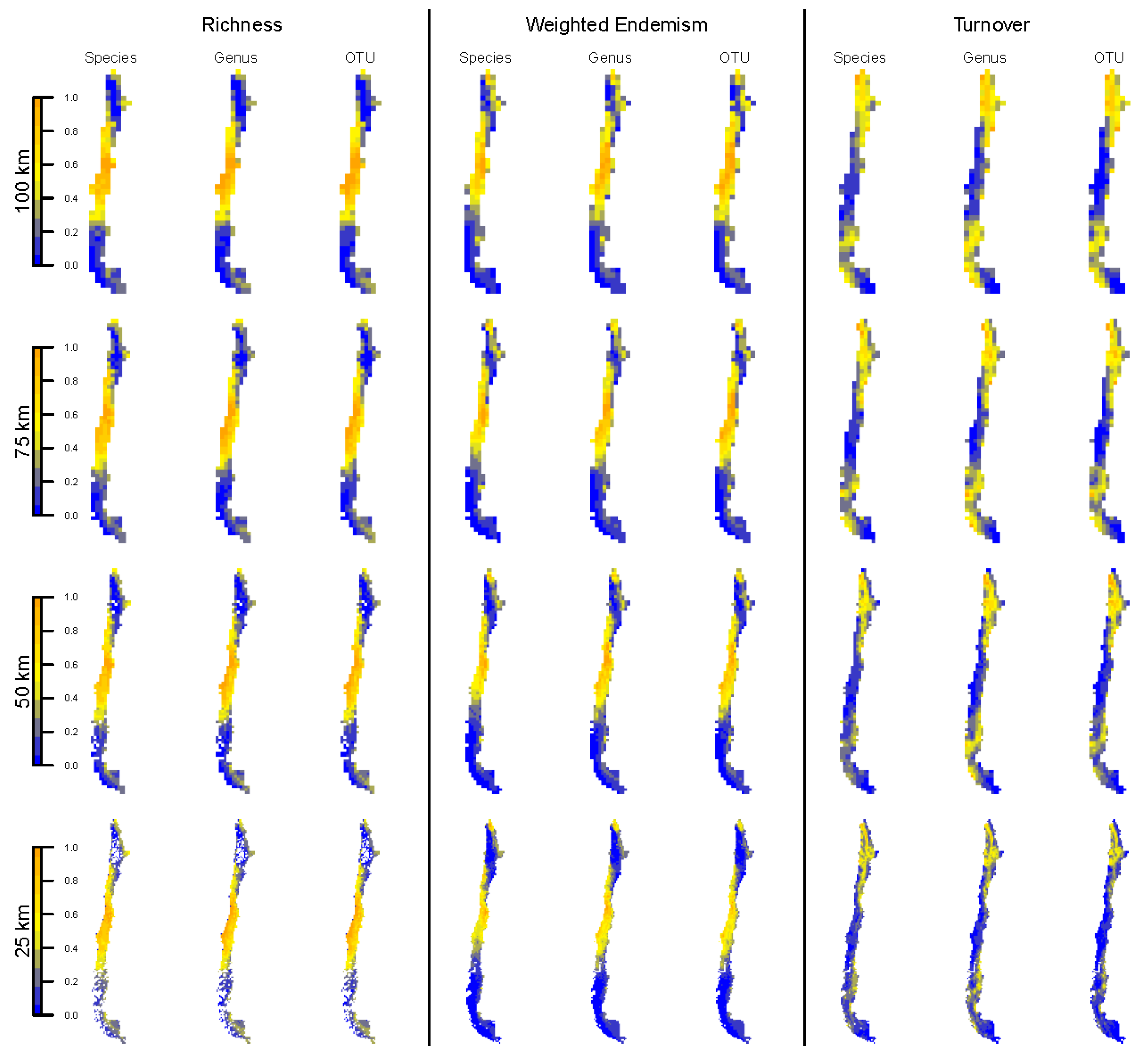
3.2. Spatial Patterns of Biodiversity—Specimen-Based Analyses
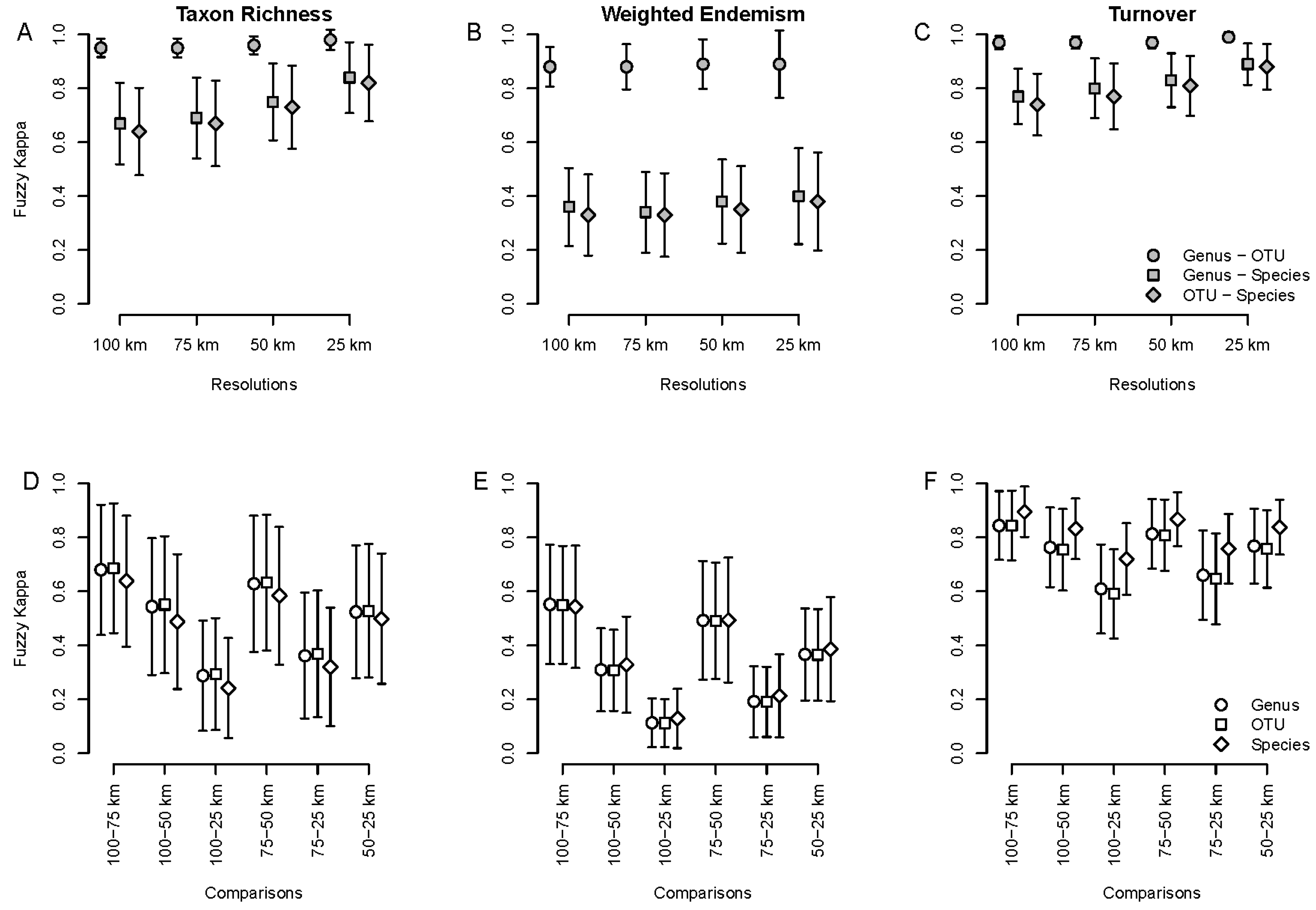
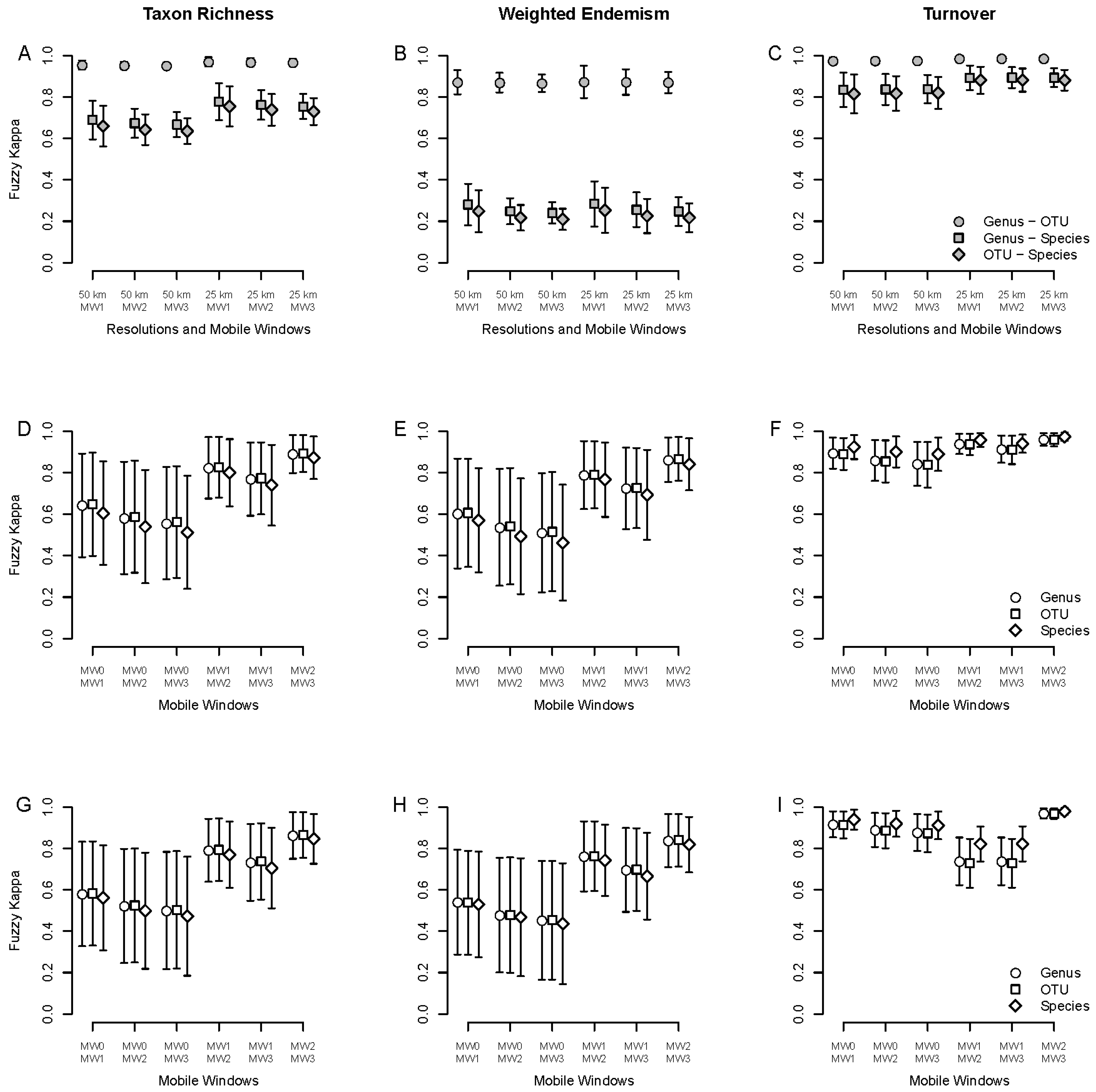
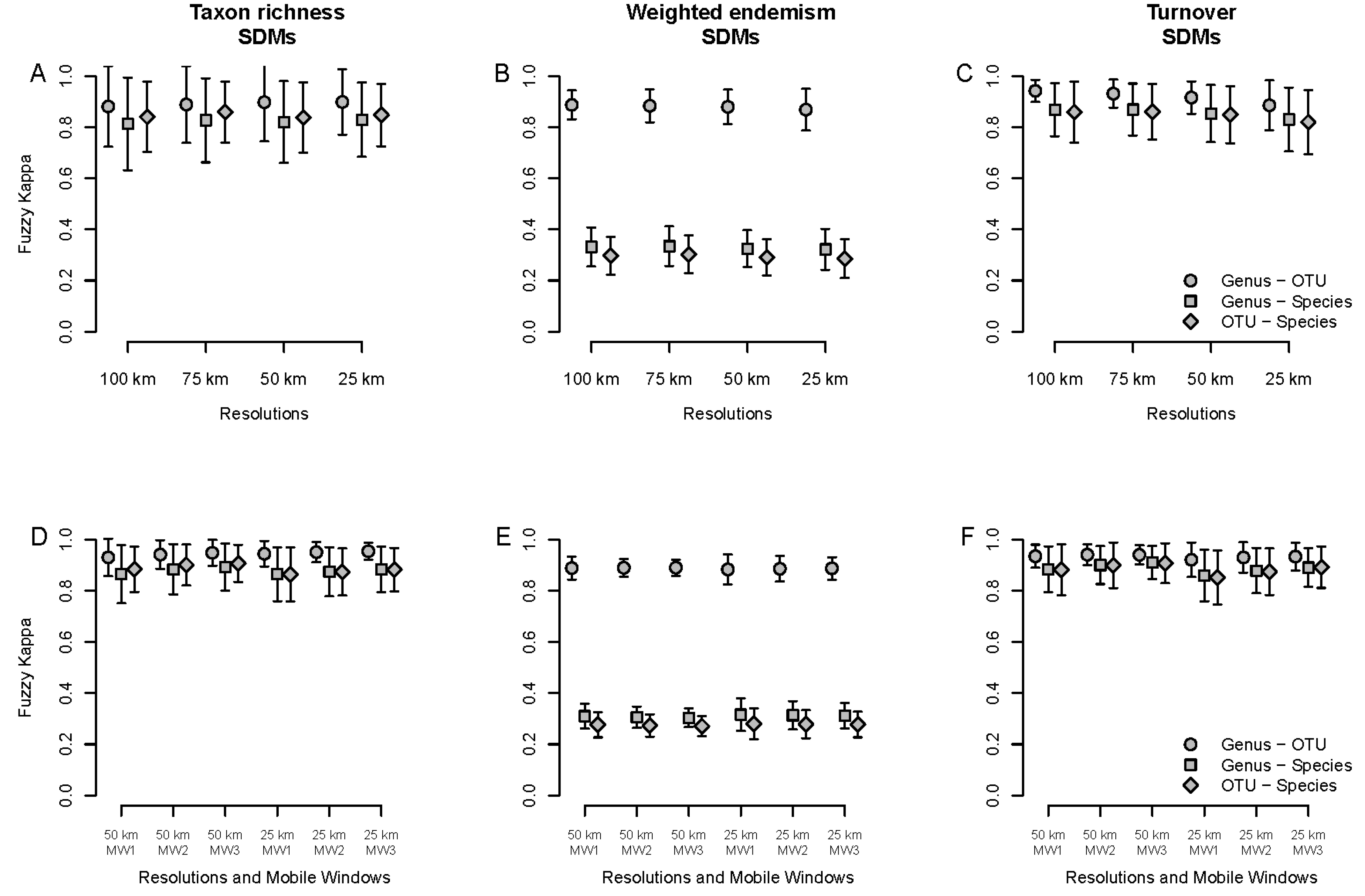
3.3. Spatial Patterns—Mobile Windows
3.4. Spatial Patterns—SDM-Based Analyses
3.5. Spatial Patterns of Species Richness—Mobile Windows of SDMs
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ferrier, S. Mapping Spatial Pattern in Biodiversity for Regional Conservation Planning: Where to from Here? Syst. Biol. 2002, 51, 331–363. [Google Scholar] [CrossRef] [PubMed]
- Foley, J.A.; DeFries, R.; Asner, G.P.; Barford, C.; Bonan, G.; Carpenter, S.R.; Chapin, F.S.; Coe, M.T.; Daily, G.C.; Gibbs, H.K.; et al. Global Consequences of Land Use. Science 2005, 309, 570–574. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Thomas, C.D.; Cameron, A.; Green, R.E.; Bakkenes, M.; Beaumont, L.J.; Collingham, Y.C.; Erasmus, B.F.N.; de Siqueira, M.F.; Grainger, A.; Hannah, L.; et al. Extinction Risk from Climate Change. Nature 2004, 427, 145–148. [Google Scholar] [CrossRef]
- Cardoso, P.; Erwin, T.L.; Borges, P.A.V.; New, T.R. The Seven Impediments in Invertebrate Conservation and How to Overcome Them. Biol. Cons. 2011, 144, 2647–2655. [Google Scholar] [CrossRef] [Green Version]
- Mutke, J.; Weigend, M. Mesoscale Patterns of Plant Diversity in Andean South America Based on Combined Checklist and GBIF Data. Ber. R. Tüx. Ges. 2017, 29, 83–97. [Google Scholar]
- Forest, F.; Grenyer, R.; Rouget, M.; Davies, T.J.; Cowling, R.M.; Faith, D.P.; Balmford, A.; Manning, J.C.; Procheş, Ş.; van der Bank, M.; et al. Preserving the Evolutionary Potential of Floras in Biodiversity Hotspots. Nature 2007, 445, 757–760. [Google Scholar] [CrossRef] [PubMed]
- Baldwin, B.G.; Thornhill, A.H.; Freyman, W.A.; Ackerly, D.D.; Kling, M.M.; Morueta-Holme, N.; Mishler, B.D. Species Richness and Endemism in the Native Flora of California. Am. J. Bot. 2017, 104, 487–501. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ulloa Ulloa, C.; Acevedo-Rodríguez, P.; Beck, S.; Belgrano, M.J.; Bernal, R.; Berry, P.E.; Brako, L.; Celis, M.; Davidse, G.; Forzza, R.C.; et al. An Integrated Assessment of the Vascular Plant Species of the Americas. Science 2017, 358, 1614–1617. [Google Scholar] [CrossRef] [Green Version]
- Erickson, D.L.; Jones, F.A.; Swenson, N.G.; Pei, N.; Bourg, N.A.; Chen, W.; Davies, S.J.; Ge, X.; Hao, Z.; Howe, R.W.; et al. Comparative Evolutionary Diversity and Phylogenetic Structure across Multiple Forest Dynamics Plots: A Mega-Phylogeny Approach. Front. Genet 2014, 5, 358. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.-X.; Zhang, M.-L. Spatial Patterns of Species Diversity and Phylogenetic Structure of Plant Communities in the Tianshan Mountains, Arid Central Asia. Front. Plant Sci. 2017, 8, 2134. [Google Scholar] [CrossRef]
- Gaston, K.J.; Williams, P.H. Mapping the World’s Species-The Higher Taxon Approach. Biodivers. Lett. 1993, 1, 2. [Google Scholar] [CrossRef]
- Williams, P.H.; Gaston, K.J. Measuring More of Biodiversity: Can Higher-Taxon Richness Predict Wholesale Species Richness? Biol. Cons. 1994, 67, 211–217. [Google Scholar] [CrossRef]
- Balmford, A.; Green, M.J.B.; Murray, M.G. Using Higher-Taxon Richness as a Surrogate for Species Richness: I. Regional Tests. Proc. Roy. Soc. B 1996, 263, 1267–1274. [Google Scholar] [CrossRef]
- Viveiros Grelle, C.E. Is Higher-Taxon Analysis an Useful Surrogate of Species Richness in Studies of Neotropical Mammal Diversity? Biol. Cons. 2002, 108, 101–106. [Google Scholar] [CrossRef]
- Cardoso, P.; Silva, I.; de Oliveira, N.G.; Serrano, A.R.M. Higher Taxa Surrogates of Spider (Araneae) Diversity and Their Efficiency in Conservation. Biol. Cons. 2004, 117, 453–459. [Google Scholar] [CrossRef]
- Von Konrat, M.; Renner, M.; Söderström, L.; Hagborg, A.; Mutke, J. Early Land Plants Today: Liverwort Species Diversity and the Relationship with Higher Taxonomy and Higher Plants. Fieldiana. Bot. 2008, 2008, 91–104. [Google Scholar] [CrossRef]
- Foord, S.H.; Dippenaar-Schoeman, A.S.; Stam, E.M. Surrogates of Spider Diversity, Leveraging the Conservation of a Poorly Known Group in the Savanna Biome of South Africa. Biol. Cons. 2013, 161, 203–212. [Google Scholar] [CrossRef]
- Pérez-Fuertes, O.; García-Tejero, S.; Pérez Hidalgo, N.; Mateo-Tomás, P.; Cuesta-Segura, A.D.; Olea, P.P. Testing the Effectiveness of Surrogates for Assessing Biological Diversity of Arthropods in Cereal Agricultural Landscapes. Ecol. Indic. 2016, 67, 297–305. [Google Scholar] [CrossRef]
- Pik, A.J.; Oliver, I.; Beattie, A.J. Taxonomic Sufficiency in Ecological Studies of Terrestrial Invertebrates. Aust. J. Ecol. 1999, 24, 555–562. [Google Scholar] [CrossRef]
- Prinzing, A.; Klotz, S.; Stadler, J.; Brandl, R. Woody Plants in Kenya: Expanding the Higher-Taxon Approach. Biol. Cons. 2003, 110, 307–314. [Google Scholar] [CrossRef]
- Mandelik, Y.; Dayan, T.; Chikatunov, V.; Kravchenko, V. Reliability of a Higher-Taxon Approach to Richness, Rarity, and Composition Assessments at the Local Scale. Cons. Biol. 2007, 21, 1506–1515. [Google Scholar] [CrossRef] [PubMed]
- Groc, S.; Delabie, J.H.C.; Longino, J.T.; Orivel, J.; Majer, J.D.; Vasconcelos, H.L.; Dejean, A. A New Method Based on Taxonomic Sufficiency to Simplify Studies on Neotropical Ant Assemblages. Biol. Conserv. 2010, 143, 2832–2839. [Google Scholar] [CrossRef]
- Andersen, A.N. Measuring More of Biodiversity: Genus Richness as a Surrogate for Species Richness in Australian Ant Faunas. Biol. Cons. 1995, 73, 39–43. [Google Scholar] [CrossRef]
- Rosser, N.; Eggleton, P. Can Higher Taxa Be Used as a Surrogate for Species-Level Data in Biodiversity Surveys of Litter/Soil Insects? J. Insect. Conserv. 2012, 16, 87–92. [Google Scholar] [CrossRef]
- Gaston, K.J. Biodiversity: Higher Taxon Richness. Prog. Phys. Geogr. 2000, 24, 117–127. [Google Scholar] [CrossRef] [Green Version]
- Balmford, A.; Jayasuriya, A.H.M.; Green, M.J.B. Using Higher-Taxon Richness as a Surrogate for Species Richness: II. Local Applications. Proc. R. Soc. Lond. B 1996, 263, 1571–1575. [Google Scholar] [CrossRef]
- Guisan, A.; Zimmermann, N.E. Predictive Habitat Distribution Models in Ecology. Ecol. Model. 2000, 135, 147–186. [Google Scholar] [CrossRef]
- Guisan, A.; Thuiller, W.; Zimmermann, N.E. Habitat Suitability and Distribution Models: With Applications in R.; Cambridge University Press: Cambridge, UK, 2017; ISBN 978-0-521-75836-9. [Google Scholar]
- Breiner, F.T.; Guisan, A.; Bergamini, A.; Nobis, M.P. Overcoming Limitations of Modelling Rare Species by Using Ensembles of Small Models. Meth. Ecol. Evol. 2015, 6, 1210–1218. [Google Scholar] [CrossRef]
- Hernández, P.A.; Graham, C.H.; Master, L.L.; Albert, D.L. The Effect of Sample Size and Species Characteristics on Performance of Different Species Distribution Modeling Methods. Ecography 2006, 29, 773–785. [Google Scholar] [CrossRef]
- Stockwell, D.R.B.; Peterson, A.T. Effects of Sample Size on Accuracy of Species Distribution Models. Ecol. Model. 2002, 148, 1–13. [Google Scholar] [CrossRef]
- Scherson, R.A.; Thornhill, A.H.; Urbina-Casanova, R.; Freyman, W.A.; Pliscoff, P.A.; Mishler, B.D. Spatial Phylogenetics of the Vascular Flora of Chile. Mol. Phylogenet. Evol. 2017, 112, 88–95. [Google Scholar] [CrossRef] [PubMed]
- Scherson, R.A.; Fuentes-Castillo, T.; Urbina-Casanova, R.; Pliscoff, P. Phylogeny-Based Measures of Biodiversity When Data Is Scarce: Examples with the Vascular Flora of Chile and California. In Phylogenetic Diversity: Applications and Challenges in Biodiversity Science; Scherson, R.A., Faith, D.P., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 131–144. ISBN 978-3-319-93145-6. [Google Scholar]
- Thornhill, A.H.; Mishler, B.D.; Knerr, N.J.; González-Orozco, C.E.; Costion, C.M.; Crayn, D.M.; Laffan, S.W.; Miller, J.T. Continental-Scale Spatial Phylogenetics of Australian Angiosperms Provides Insights into Ecology, Evolution and Conservation. J. Biogeogr. 2016, 43, 2085–2098. [Google Scholar] [CrossRef]
- Thornhill, A.H.; Baldwin, B.G.; Freyman, W.A.; Nosratinia, S.; Kling, M.M.; Morueta-Holme, N.; Madsen, T.P.; Ackerly, D.D.; Mishler, B.D. Spatial Phylogenetics of the Native California Flora. BMC Biol. 2017, 15, 96. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pio, D.V.; Broennimann, O.; Barraclough, T.G.; Reeves, G.; Rebelo, A.G.; Thuiller, W.; Guisan, A.; Salamin, N. Spatial Predictions of Phylogenetic Diversity in Conservation Decision Making. Cons. Biol. 2011, 25, 1229–1239. [Google Scholar] [CrossRef]
- Pio, D.V.; Engler, R.; Linder, H.P.; Monadjem, A.; Cotterill, F.P.D.; Taylor, P.J.; Schoeman, M.C.; Price, B.W.; Villet, M.H.; Eick, G.; et al. Climate Change Effects on Animal and Plant Phylogenetic Diversity in Southern Africa. Glob. Chang. Biol. 2014, 20, 1538–1549. [Google Scholar] [CrossRef]
- Mishler, B.D.; Knerr, N.; González-Orozco, C.E.; Thornhill, A.H.; Laffan, S.W.; Miller, J.T. Phylogenetic Measures of Biodiversity and Neo- and Paleo-Endemism in Australian Acacia. Nat. Commun. 2014, 5, 4473. [Google Scholar] [CrossRef]
- Schmithüsen, J. Die Räumliche Ordnung Der Chilenischen Vegetation. Bonn. Geogr. Abh. 1956, 17, 1–86. [Google Scholar]
- Myers, N.; Mittermeier, R.A.; Mittermeier, C.G.; da Fonseca, G.A.B.; Kent, J. Biodiversity Hotspots for Conservation Priorities. Nature 2000, 403, 853–858. [Google Scholar] [CrossRef]
- Bannister, J.R.; Vidal, O.J.; Teneb, E.; Sandoval, V. Latitudinal Patterns and Regionalization of Plant Diversity along a 4270-km Gradient in Continental Chile. Aust. Ecol. 2012, 37, 500–509. [Google Scholar] [CrossRef]
- Zuloaga, F.O.; Morrone, O.; Belgrano, M.J. Catálogo de Las Plantas Vasculares Del Cono Sur (Argentina, Sur de Brasil, Chile, Paraguay y Uruguay). Monogr. Syst. Bot. Mo. Bot. Gard. 2008, 107, 1–3348. [Google Scholar]
- Echeverria, C.; Coomes, D.; Salas, J.; Rey-Benayas, J.M.; Lara, A.; Newton, A. Rapid Deforestation and Fragmentation of Chilean Temperate Forests. Biol. Cons. 2006, 130, 481–494. [Google Scholar] [CrossRef]
- Urbina-Casanova, R.; Luebert, F.; Pliscoff, P.; Scherson, R.A. Assessing Floristic Representativeness in the Protected Areas National System of Chile: Are Vegetation Types a Good Surrogate for Plant Species? Environ. Cons. 2016, 43, 199–207. [Google Scholar] [CrossRef] [Green Version]
- Simonetti, J.A. On the Size of the Chilean Flora (a Speculation). J. Medit. Ecol. 1999, 1, 129–132. [Google Scholar]
- Garcillán, P.P.; Ezcurra, E.; Riemann, H. Distribution and Species Richness of Woody Dryland Legumes in Baja California, Mexico. J. Veg. Sci. 2003, 14, 475–486. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2017. [Google Scholar]
- Crisp, M.D.; Laffan, S.; Linder, H.P.; Monro, A. Endemism in the Australian Flora. J. Biogeogr. 2001, 28, 183–198. [Google Scholar] [CrossRef]
- Laffan, S.W.; Rosauer, D.F.; Di Virgilio, G.; Miller, J.T.; González-Orozco, C.E.; Knerr, N.; Thornhill, A.H.; Mishler, B.D. Range-Weighted Metrics of Species and Phylogenetic Turnover Can Better Resolve Biogeographic Transition Zones. Meth. Ecol. Evol. 2016, 7, 580–588. [Google Scholar] [CrossRef]
- Koleff, P.; Gaston, K.J.; Lennon, J.J. Measuring Beta Diversity for Presence-Absence Data. J. Anim. Ecol. 2003, 72, 367–382. [Google Scholar] [CrossRef] [Green Version]
- Tuomisto, H. A Diversity of Beta Diversities: Straightening up a Concept Gone Awry. Part 1. Defining Beta Diversity as a Function of Alpha and Gamma Diversity. Ecography 2010, 33, 2–22. [Google Scholar] [CrossRef]
- Guerin, G.R.; Ruokolainen, L.; Lowe, A.J. A Georeferenced Implementation of Weighted Endemism. Meth. Ecol. Evol. 2015, 6, 845–852. [Google Scholar] [CrossRef]
- Oksanen, J.; Blanchet, F.G.; Friendly, M.; Kindt, R.; Legendre, P.; McGlinn, D.; Minchin, P.R.; O’Hara, R.B.; Simpson, G.L.; Solymos, P.; et al. Vegan: Community Ecology Package. 2018. Available online: http://cc.oulu.fi/~jarioksa/ (accessed on 27 September 2020).
- Hijmans, R.J. Raster: Geographic Data Analysis and Modeling. R Package Version 2.8-19. Available online: https://CRAN.R-project.org/package=raster (accessed on 27 September 2020).
- Phillips, S.J.; Anderson, R.P.; Schapire, R.E. Maximum Entropy Modeling of Species Geographic Distributions. Ecol. Model. 2006, 190, 231–259. [Google Scholar] [CrossRef] [Green Version]
- Pliscoff, P.; Luebert, F.; Hilger, H.H.; Guisan, A. Effects of Alternative Sets of Climatic Predictors on Species Distribution Models and Associated Estimates of Extinction Risk: A Test with Plants in an Arid Environment. Ecol. Model. 2014, 288, 166–177. [Google Scholar] [CrossRef]
- Di Cola, V.; Broennimann, O.; Petitpierre, B.; Breiner, F.T.; D’Amen, M.; Randin, C.; Engler, R.; Pottier, J.; Pio, D.; Dubuis, A.; et al. Ecospat: An R Package to Support Spatial Analyses and Modeling of Species Niches and Distributions. Ecography 2017, 40, 774–787. [Google Scholar] [CrossRef]
- Pearson, R.G.; Raxworthy, C.J.; Nakamura, M.; Peterson, A.T. Predicting Species Distributions from Small Numbers of Occurrence Records: A Test Case Using Cryptic Geckos in Madagascar. J. Biogeogr. 2007, 34, 102–117. [Google Scholar] [CrossRef]
- Visser, H.; de Nijs, T. The Map Comparison Kit. Environ. Model. Softw. 2006, 21, 346–358. [Google Scholar] [CrossRef]
- Laffan, S.W. Phylogeny-Based Measurements at Global and Regional Scales. In Phylogenetic Diversity: Applications and Challenges in Biodiversity Science; Scherson, R.A., Faith, D.P., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 111–129. ISBN 978-3-319-93145-6. [Google Scholar]
- Rahbek, C. The Role of Spatial Scale and the Perception of Large-Scale Species-Richness Patterns. Ecol. Lett. 2005, 8, 224–239. [Google Scholar] [CrossRef]
- Laffan, S.W.; Crisp, M.D. Assessing Endemism at Multiple Spatial Scales, with an Example from the Australian Vascular Flora. J. Biogeogr. 2003, 30, 511–520. [Google Scholar] [CrossRef]
- Barton, P.S.; Cunningham, S.A.; Manning, A.D.; Gibb, H.; Lindenmayer, D.B.; Didham, R.K. The Spatial Scaling of Beta Diversity. Glob. Ecol. Biogeogr. 2013, 22, 639–647. [Google Scholar] [CrossRef] [Green Version]
- Adler, P.B.; White, E.P.; Lauenroth, W.K.; Kaufman, D.M.; Rassweiler, A.; Rusak, J.A. Evidence for a General Species–Time–Area Relationship. Ecology 2005, 86, 2032–2039. [Google Scholar] [CrossRef] [Green Version]
- McGlinn, D.J.; Palmer, M.W. Modeling the Sampling Effect in the Species–Time–Area Relationship. Ecology 2009, 90, 836–846. [Google Scholar] [CrossRef] [Green Version]
- Daru, B.H.; Farooq, H.; Antonelli, A.; Faurby, S. Endemism Patterns Are Scale Dependent. Nat. Commun. 2020, 11, 2115. [Google Scholar] [CrossRef]
- Nelson, J.K.; Brewer, C.A. Evaluating Data Stability in Aggregation Structures across Spatial Scales: Revisiting the Modifiable Areal Unit Problem. Cartogr. Geogr. Inf. Sci. 2017, 44, 35–50. [Google Scholar] [CrossRef]
- Openshaw, S. The Modifiable Areal Unit Problem. Concepts Tech. Modern Cartogr. 1983, 38, 1–41. [Google Scholar]
- O’Sullivan, D.; Unwin, D.J. Geographic Information Analysis, 2nd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2010; ISBN 978-0-471-21176-1. [Google Scholar]
- Alroy, J. Limits to Species Richness in Terrestrial Communities. Ecol. Lett. 2018, 21, 1781–1789. [Google Scholar] [CrossRef] [PubMed]
- Medail, F.; Quezel, P. Hot-Spots Analysis for Conservation of Plant Biodiversity in the Mediterranean Basin. Ann. Mo. Bot. Gard. 1997, 84, 112–127. [Google Scholar] [CrossRef]
- Gaston, K.J.; Spicer, J.I. Biodiversity: An Introduction, 2nd ed.; Blackwell Science: Oxford, UK, 2004; ISBN 978-1-4051-1857-6. [Google Scholar]
- Luebert, F.; Pliscoff, P. Sinopsis Bioclimática y Vegetacional de Chile, 2nd ed.; Editorial Universitaria: Santiago, Chile, 2017. [Google Scholar]
- Jost, L. Partitioning Diversity into Independent Alpha and Beta Components. Ecology 2007, 88, 2427–2439. [Google Scholar] [CrossRef] [Green Version]
- Tuomisto, H. A Diversity of Beta Diversities: Straightening up a Concept Gone Awry. Part 2. Quantifying Beta Diversity and Related Phenomena. Ecography 2010, 33, 23–45. [Google Scholar] [CrossRef]
- Qian, H.; Ricklefs, R.E. A Latitudinal Gradient in Large-Scale Beta Diversity for Vascular Plants in North America. Ecol. Lett. 2007, 10, 737–744. [Google Scholar] [CrossRef]
- Harrison, S.; Ross, S.J.; Lawton, J.H. Beta Diversity on Geographic Gradients in Britain. J. Anim. Ecol. 1992, 61, 151–158. [Google Scholar] [CrossRef]
- Gaston, K.J.; Blackburn, T.M. Mapping Biodiversity Using Surrogates for Species Richness: Macro-Scales and New World Birds. Proc. R. Soc. Lond. B 1995, 262, 335–341. [Google Scholar] [CrossRef]
- La Ferla, B.; Taplin, J.; Ockwell, D.; Lovett, J.C. Continental Scale Patterns of Biodiversity: Can Higher Taxa Accurately Predict African Plant Distributions? Bot. J. Linn. Soc. 2002, 138, 225–235. [Google Scholar] [CrossRef]
- Rosser, N. Shortcuts in Biodiversity Research: What Determines the Performance of Higher Taxa as Surrogates for Species? Ecol. Evol. 2017, 7, 2595–2603. [Google Scholar] [CrossRef]
- Neeson, T.M.; Rijn, I.V.; Mandelik, Y. How Taxonomic Diversity, Community Structure, and Sample Size Determine the Reliability of Higher Taxon Surrogates. Ecol. Appl. 2013, 23, 1216–1225. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Moreira-Muñoz, A. Plant Geography of Chile; Springer: Dordrecht, The Netherlands, 2011. [Google Scholar]
- Arroyo, M.T.K.; Riveros, M.; Peñaloza, A.; Cavieres, L.A.; Faggi, A.M. Phytogeographic Relationships and Regional Richness Patterns of the Cool Temperate Rainforest Flora of Southern South America. In High-Latitude Rainforest and Associated Ecosystems of the West Coast of the Americas; Lawford, R.G., Alaback, P., Fuentes, E., Eds.; Springer: New York, NY, USA, 1996; pp. 134–172. [Google Scholar]
- Stevens, G.C. The Latitudinal Gradient in Geographical Range: How so Many Species Coexist in the Tropics. Am. Nat. 1989, 133, 240–256. [Google Scholar] [CrossRef]
- Pineda, E.; Lobo, J.M. Assessing the Accuracy of Species Distribution Models to Predict Amphibian Species Richness Patterns. J. Anim. Ecol. 2009, 78, 182–190. [Google Scholar] [CrossRef]
- Raes, N.; Roos, M.C.; Slik, J.W.F.; Loon, E.E.V.; Steege, H.t. Botanical Richness and Endemicity Patterns of Borneo Derived from Species Distribution Models. Ecography 2009, 32, 180–192. [Google Scholar] [CrossRef] [Green Version]
- Calabrese, J.M.; Certain, G.; Kraan, C.; Dormann, C.F. Stacking Species Distribution Models and Adjusting Bias by Linking Them to Macroecological Models. Glob. Ecol. Biogeogr. 2014, 23, 99–112. [Google Scholar] [CrossRef]
- Pouteau, R.; Bayle, É.; Blanchard, É.; Birnbaum, P.; Cassan, J.-J.; Hequet, V.; Ibanez, T.; Vandrot, H. Accounting for the Indirect Area Effect in Stacked Species Distribution Models to Map Species Richness in a Montane Biodiversity Hotspot. Divers. Distrib. 2015, 21, 1329–1338. [Google Scholar] [CrossRef]
- Zhang, M.-G.; Slik, J.W.F.; Ma, K.-P. Using Species Distribution Modeling to Delineate the Botanical Richness Patterns and Phytogeographical Regions of China. Sci. Rep. 2016, 6, 22400. [Google Scholar] [CrossRef] [Green Version]
- Kadmon, R.; Farber, O.; Danin, A. Effect of Roadside Bias on the Accuracy of Predictive Maps Produced by Bioclimatic Models. Ecol. Appl. 2004, 14, 401–413. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luebert, F.; Fuentes-Castillo, T.; Pliscoff, P.; García, N.; Román, M.J.; Vera, D.; Scherson, R.A. Geographic Patterns of Vascular Plant Diversity and Endemism Using Different Taxonomic and Spatial Units. Diversity 2022, 14, 271. https://doi.org/10.3390/d14040271
Luebert F, Fuentes-Castillo T, Pliscoff P, García N, Román MJ, Vera D, Scherson RA. Geographic Patterns of Vascular Plant Diversity and Endemism Using Different Taxonomic and Spatial Units. Diversity. 2022; 14(4):271. https://doi.org/10.3390/d14040271
Chicago/Turabian StyleLuebert, Federico, Taryn Fuentes-Castillo, Patricio Pliscoff, Nicolás García, María José Román, Diego Vera, and Rosa A. Scherson. 2022. "Geographic Patterns of Vascular Plant Diversity and Endemism Using Different Taxonomic and Spatial Units" Diversity 14, no. 4: 271. https://doi.org/10.3390/d14040271
APA StyleLuebert, F., Fuentes-Castillo, T., Pliscoff, P., García, N., Román, M. J., Vera, D., & Scherson, R. A. (2022). Geographic Patterns of Vascular Plant Diversity and Endemism Using Different Taxonomic and Spatial Units. Diversity, 14(4), 271. https://doi.org/10.3390/d14040271