1. Introduction
The species–area relationship (SAR) is one of the most general ecological patterns, depicting the changing process of species richness as the sampling area increases. Notably, the SAR is a fundamental pattern in ecology, containing complex ecological processes closely related to the formation, migration, spread, and extinction of species [
1,
2]. Increasing attention is given to exploration of ways in which to use the SAR for conservation purposes, including selection of biodiversity hotspots, determination of the optimal size and shape of natural areas, and the prediction of species extinction [
3,
4].
Since the concept of SAR was first proposed, ecologists have developed a significant amount of fundamental theoretical research and practical application of SAR [
5,
6,
7]. Note that the first SAR model put forward by Arrhenius was depicted by a power function [
8], but many mathematical variants of SAR have been continuously proposed to account for diverse shapes of SAR in practical applications [
9,
10]. Over 30 models have been applied to SARs [
11]. Although the mathematical and biological mechanisms behind the SAR have been preliminarily studied, the applicability of the SAR model is controversial. There is currently no consensus about the exact form of the species–area relationship, and its shape has remained largely unexplained [
12]. The best known and most commonly applied curves are the exponential curve and the power curve. However, there is no clear biological foundation to give preference to these particular models [
13] and the best-fitting model for a particular species–area curve can only be determined empirically [
7].
We can use linear regressions to fit SARs with a linear model, or a linearized version of the curvilinear model, but not when fitting a non-linear SAR model in the arithmetic space. The use of free and open-source R software is currently prevalent in the analysis of ecological data, with the possibility of performing non-linear fits. There is a wide assortment of R packages for non-linear fits with effective methods to generate reliable initial parameters that provide the individual or multiple SAR model fitting functions, such as ‘mmsar’ and the ‘sars’ [
14,
15]. However, these packages only use one algorithm for SAR model fitting. The difference in applicability of different algorithms is unknown. Due to the lack of a procedure for effective initial parameters estimation, it is impractical to use these packages to fit SAR models. The packages are problematic because the algorithm may converge, but the resulting model fit can be far from optimal. In this study, we numerically evaluated the applicability of the three classic algorithms in SAR model fitting and provide insight for the choice of algorithms when fitting new SAR models.
2. Methods
The SAR model fitting can be recognized as a nonlinear least squares (NLS) problem. We take the classic SAR model as an example, where stands for the area size and is the key parameter. Assume that the observed data points are denoted by , if we assign a value to then we can obtain + , where stands for the observed number of species in the sampling area size of , . is the deviations between the theoretical number of species and the true number of species. As a result, we can simply use the NLS method to fit the SAR model and find the , that minimizes the sum of . Mathematically speaking, the NLS method minimizes the function defined as with respect to the parameter , where = . The factor in the definition of has no effect on and it is introduced only for convenience of calculation.
All nonlinear optimization algorithms are an iterative process when fitting a model. The initial parameters,
, are first established and then the algorithm produces a series of
converging to optimal
. Although there are many nonlinear optimization algorithms that can fit non-linear functions, this study focuses primarily on three effective classic methods: The Gauss–Newton method, the Levenberg–Marquardt method, and the Nelder–Mead method. These algorithms were selected because they have strong stability and have a wide variety of applications. Furthermore, many modified versions have been derived [
16].
2.1. The Gauss–Newton Method
According to Taylor’s expansion we can obtain
, where
is similar to
is a vector. If we find
satisfies
then we can obtain
, in this case we can say that
is a descent direction for
. However, the Gauss–Newton method is based on the first derivatives of the vector function
, according to Taylor’s expansion: For small
,
,
is the Jacobian, which contains the first partial derivatives of the function components,
. (
).
According to
, we can obtain
, the following equations are derived:
and
. We can see that
is independent of
, and it is symmetric and if
has full rank, then
is also positively defined. In such a case,
has a unique minimizer, which can be found by
According to , is a descent direction for , because , where is positively defined.
The algorithm iteration process is as follows:
- (1)
Set the initial parameter manually.
- (2)
Find the descent direction by solving , then update by .
- (3)
Update continuously until is close to .
2.2. The Levenberg–Marquardt Method
The Levenberg–Marquardt algorithm, originally suggested by Levenberg and later by Marquardt [
17,
18], is the most widely used optimization algorithm. It outperforms the gradient descent and other conjugate gradient algorithms in a wide variety of problems [
19]. This method is also based on the first derivative of each component of the vector function
. Same as the Gauss–Newton method, for small
,
. However, unlike the Gauss–Newton method, this method adds a damping term
, where
is a number that is different for each iteration. We can obtain
=
=
. It is easy to obtain
, if
, then
. So, we can obtain
( stands for the identity matrix).
Since is approximately equal to when is sufficiently small, algorithm fails to converge when is too large. If the iteration is succeeded, perhaps the step size of this iteration can be expanded, thereby reducing the number of steps needed before approximates . The Levenberg–Marquardt method evaluates the quality of the iteration by (the ratio between the actual and predicted decrease in function ). If , it means that is too large, is not approximately equal to , should be reduced. If it means that is approximately equal to . So is very important and the choice of the initial -value should be related to the size of the elements in , for example by letting , where is chosen by the user. During the iteration, the size of is controlled by , and if , accept the and update by . Otherwise, adjust and recalculate , until is close to .
The algorithm iteration process is as follows:
- (1)
Set the initial parameter .
- (2)
Find the descent direction by solving .
- (3)
Decide whether to accept according to φ.
- (4)
Iterate until is close to .
2.3. The Nelder–Mead Method
Since its publication in 1965 (Nelder and Mead, 1965), the Nelder–Mead “simplex” algorithm has become one of the most widely used methods for nonlinear unconstrained optimization, which is especially popular in the fields of chemistry, chemical engineering, and medicine [
20]. Unlike the Gauss-Newton and the Levenberg–Marquardt methods, this algorithm can iterate directly without derivative information. Taking the
as an example, the algorithm iteration process is as follows:
(1) Take the initial parameter as a vertex of the simplex and generate 2 additional parameters around the initial parameters, since the power model has two parameters.
(2) Construct the initial simplex with these parameters and determine the parameters , , of the worst, second worst, and the best vertex, respectively, in the simplex by , .
(3) Find the centroid of the best side, which is opposite to the worst vertex , .
(4) Construct the new simplex by replacing the worst vertex though reflection, expansion, or contraction with respect to the best side. If the new simplex is constructed successfully, repeat the above steps to continue the iteration. If this fails, shrink the simplex towards the best vertex , in this case and replacing all parameters except .
Reflection: Find the reflection vertex where is reflected by , . If , then .
Expansion: If , find the expansion point by . If , then , otherwise .
Contraction: If , find the contraction point through the following calculation:
If , , if then .
If , , if then .
Shrink: Find two new vertices by in case any of the above conditions are not met.
In most cases,
,
. The algorithm terminates, when the simplex
is sufficiently small (some or all vertices
are close enough), or if the number of iterations or the number of function evaluations exceeds some specified maximum allowable number [
21,
22].
2.4. Data Simulation
Presently numerous functions have been proposed for modelling SARs, varying in complexity from two to four parameters, in the general form they produce, theoretical background, origin, and justification [
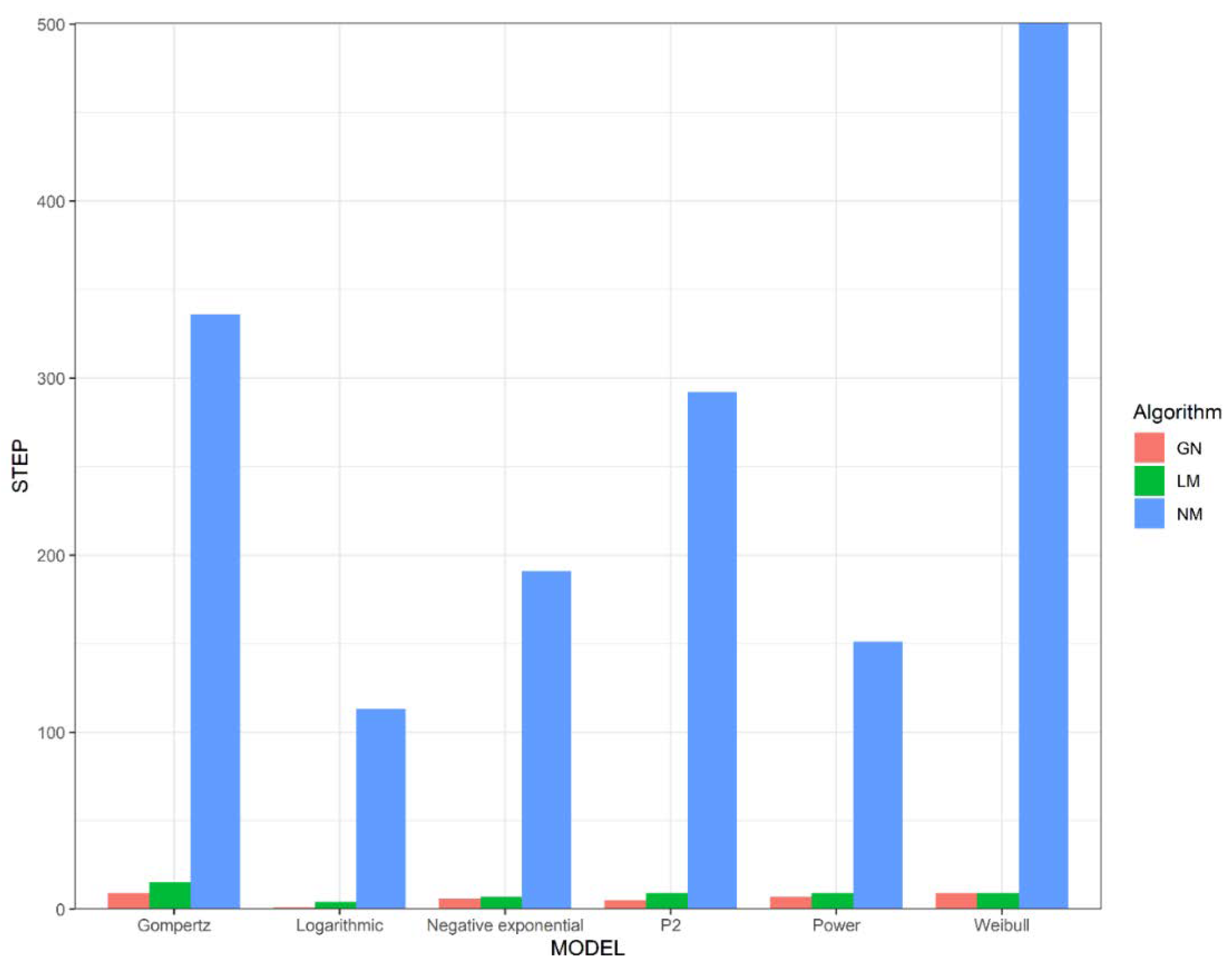
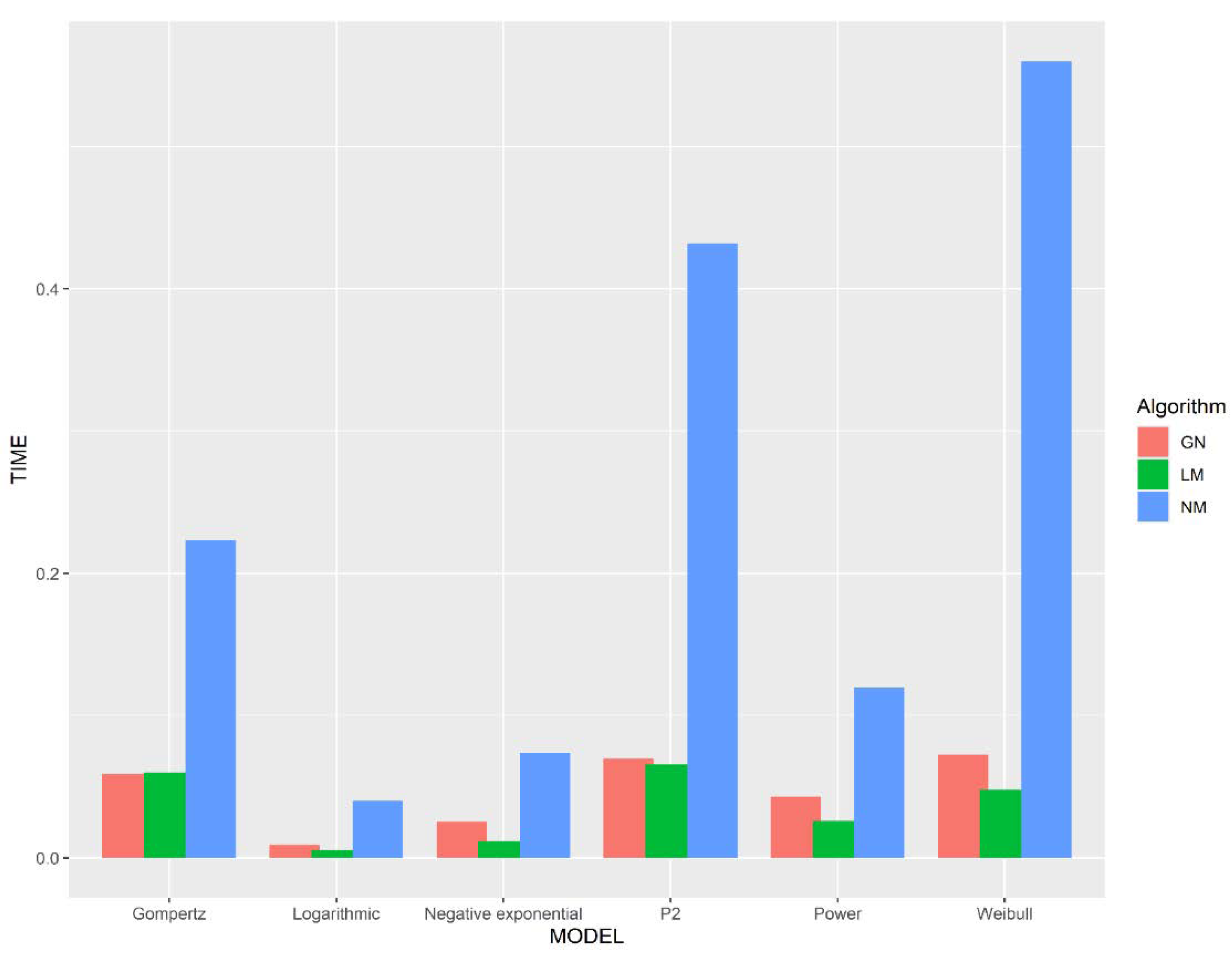
23]. We chose six representative models: Power, Gompertz, Negative exponential, Logarithmic models, Weibull, and Persistence function 2. We used the nls function, the optim function, and the nls.Lm function of the minpack.lm package of R software to implement the above algorithms to fit the SAR model. Their applicability is evaluated from three aspects: the number of iterations, the time consumption, and the sensitivity to the initial parameter setting.
In order to investigate the difference in the number of iteration steps and time consumption of different algorithms when fitting the same nonlinear SAR model, we gave the Gauss–Newton method, the Levenberg–Marquardt method, and the Nelder–Mead method the same initial parameters
and then processed the same data. To highlight the differences in time consumption and the number of iterations between these algorithms, we simulated species area data for each model by manually setting the model parameters
and adding “white noise” items (
Table 1). The noise is a random number constructed by R within a certain range. In this way, we generated a dataset in which each data point is distributed around the curve, and we can approximate that
. We ran forty thousand simulations for each model and then counted the number of iterations and time that were required for different algorithms to iterate from
to
when processing the simulated data.
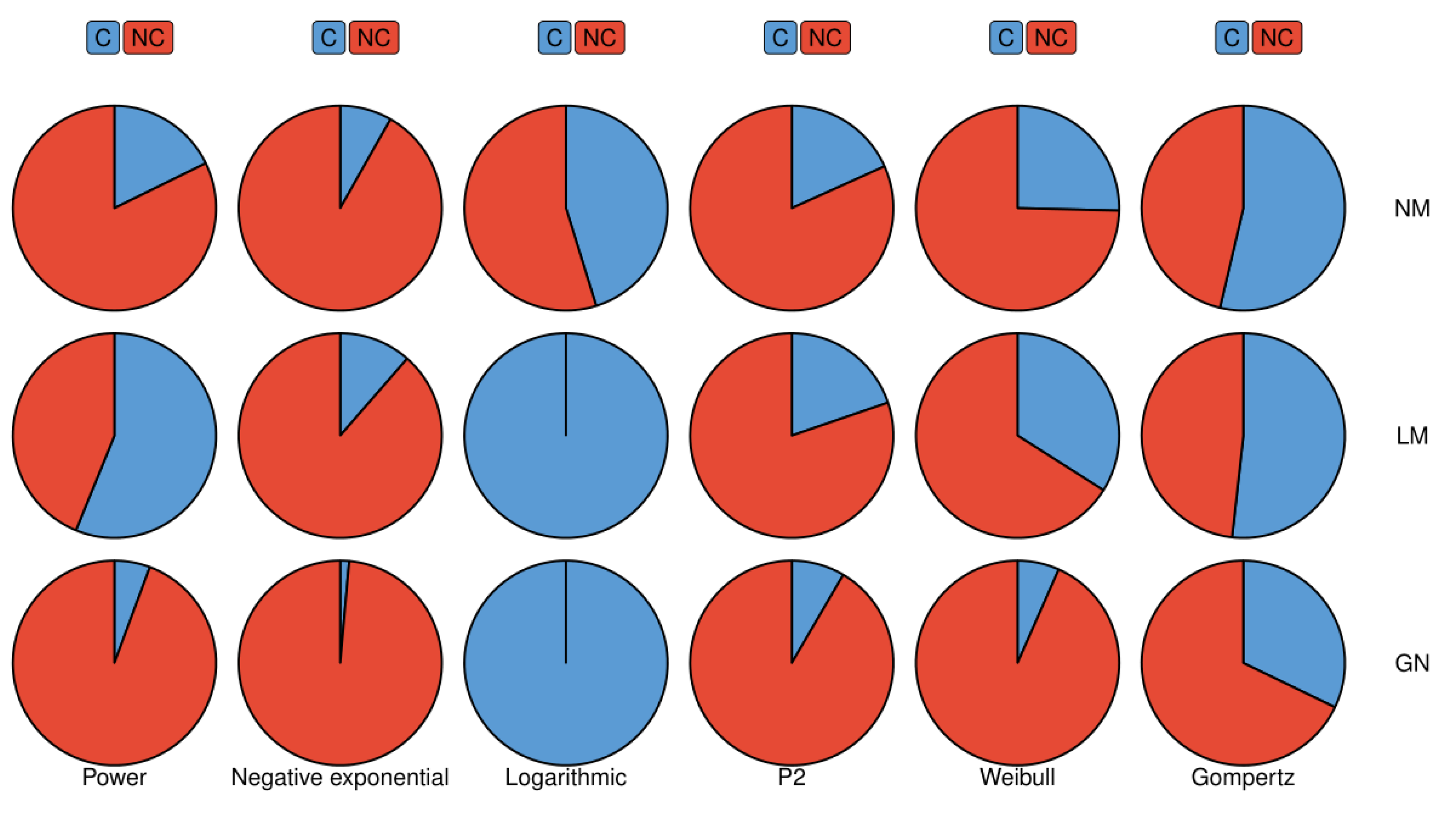
When we study the sensitivity of different algorithms to initial parameter setting, we only need to process general data to show their differences. We used six real species regional data sets from published papers [
24,
25], including mammal, bird, plant, and insect data. We set a range for each parameter, taking the initial parameters in this range can ensure the algorithm will converge in most cases and will also reflect the difference in sensitivity of different algorithms to the initial parameters. The more times the algorithm converges the less sensitive the algorithm is to initial parameters. We tested all real data sets with all models in
Table 1.
4. Discussion
Many ecologists have applied these algorithms to SAR study [
26,
27,
28]. These algorithms are based on different principles and therefore vary considerably in SAR model fitting. Both the Gauss–Newton’s method and the Levenberg–Marquardt method use the Taylor’s series expansion
to approximate the nonlinear regression model
, and then the regression coefficients
are approximated to the optimal coefficient
through several iterations to minimize the sum of the squares of
. The Levenberg–Marquardt method adds a damping term and evaluates whether
is a good approximation of
before each iteration. The Levenberg–Marquardt method can be seen as a combination of the gradient descent method and the Gauss–Newton method [
29]. The introduction of the damping factor
makes the Levenberg–Marquardt method more flexible. If
is close to one, Equation (3) can be approximated as
. In such cases, the Levenberg–Marquardt is converted to the gradient descent method. If
is close to 0, Equation (3) can be approximately transformed into Equation (3), and the Levenberg–Marquardt method is converted to the Gauss–Newton method. The gradient descent method reduces the sum of the squares of the residuals of
by updating the parameters in the steepest descent direction. At the beginning of the iteration, the Levenberg–Marquardt method is converted to the gradient descent method and, at the final stage of the iteration process, the Levenberg–Marquardt method is converted to the Gauss–Newton method [
29]. Such a strategy can quickly reduce the
in the early stage of the iteration, while still maintaining a fast convergence rate in the final stage. Therefore, even though the Levenberg–Marquardt method requires the evaluation of the similarity of
and
in each iteration, there is not much difference in the number of iterations and running time between the Levenberg–Marquardt and the Gauss–Newton method.
Unlike the Gauss–Newton method and the Levenberg–Marquardt method, the Nelder–Mead method can take an enormous number of iterations with almost no reduction in , despite being nowhere near , so this method requires more iterative steps to obtain to the . Although the Nelder–Mead method requires more iteration steps, this method consumes less time per iteration than the other algorithms. This is because both the Gauss–Newton method and the Levenberg–Marquardt method require the derivation of each parameter of the model to be fitted. Assuming that the model to be fitted has parameters, both algorithms require function evaluations per iteration, which undoubtedly requires a lot of time. In contrast, the Nelder–Mead method only requires one or two function evaluations per iteration, which is very important in applications for which each function evaluation is time consuming.
Finally, the sensitivity of these algorithms to the initial parameters is very different, especially between the Gauss–Newton method and the Levenberg–Marquardt method. This difference in sensitivity is driven by the replacement of the Hessian
with
in the Gauss–Newton method. Although this change omits a lot of calculations, it also adds instability to the algorithm, because the matrix
is only positive semi-definite, which may be singular matrices and ill-conditioned. Poor stability of
will result in non-convergence of the algorithm, but the Levenberg–Marquardt method introduces the damping parameter
, ensuring that the matrix J has full rank. The matrix (
is positive define, which means
is a descent direction. After each iteration, the Levenberg–Marquardt method evaluates whether the Taylor expansion
approximates the residual function
and prevents the algorithm from converging due to a large
. The damping parameter
is adjusted according to the quantized result until it reaches the threshold. In contrast, the Nelder–Mead method relies on the initial parameters to generate the initial simplex according to an adjustable strategy, and then converges to the optimal parameters through the deformation of the simplex, so the selection of initial parameters and the strategy of generating simplex will affect the convergence of the algorithm. If the initial simplex is too small, it leads to local search, so the Nelder–Mead method is likely to get stuck. Rigorous analysis of the Nelder–Mead method is a very difficult mathematical problem. A detailed study carried out by Lagarias [
20] contains several convergence results in one and two dimensions for strictly convex functions with bounded level sets.








{kind=link}
{kind=link}
{kind=link}