

HDAC1: An Essential and Conserved Member of the Diverse Zn2+-Dependent HDAC Family Driven by Divergent Selection Pressure

 and
and 
Abstract
:1. Introduction
2. Results
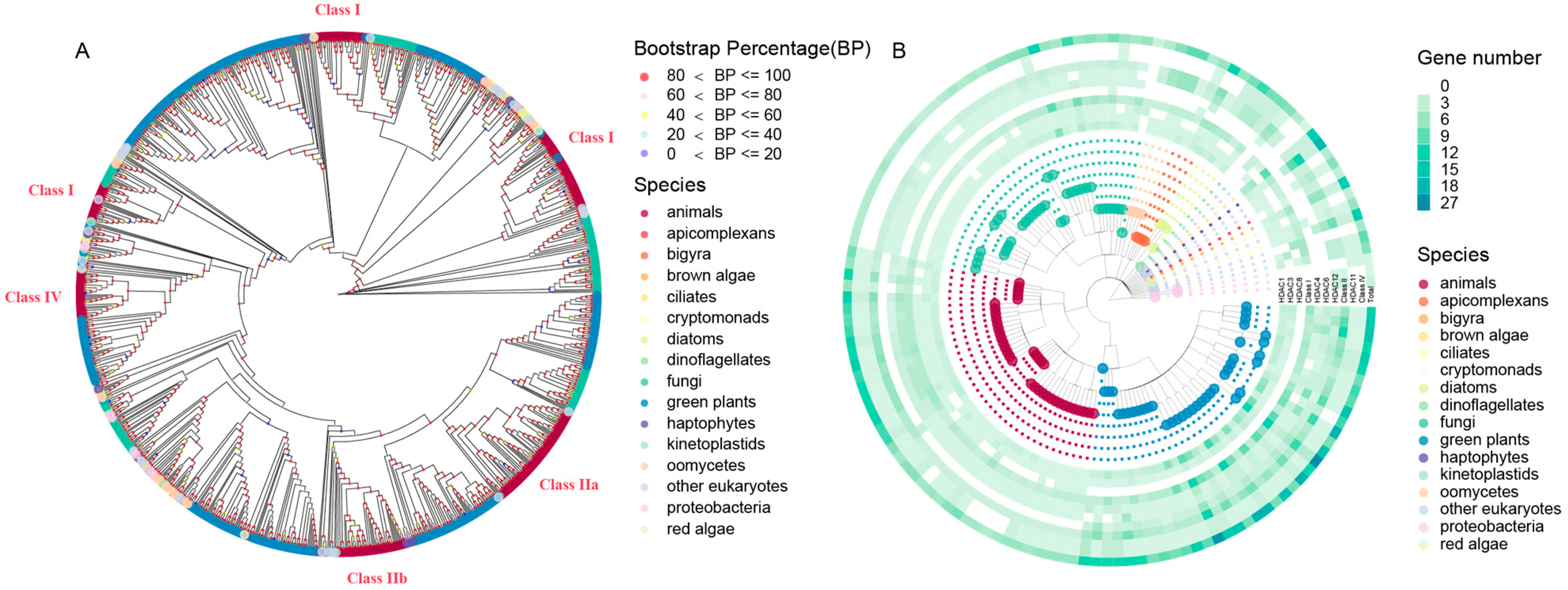
2.1. The Distribution, Classification, and Phylogenetic Analysis of HDACs
2.2. The Divergence of HDACs
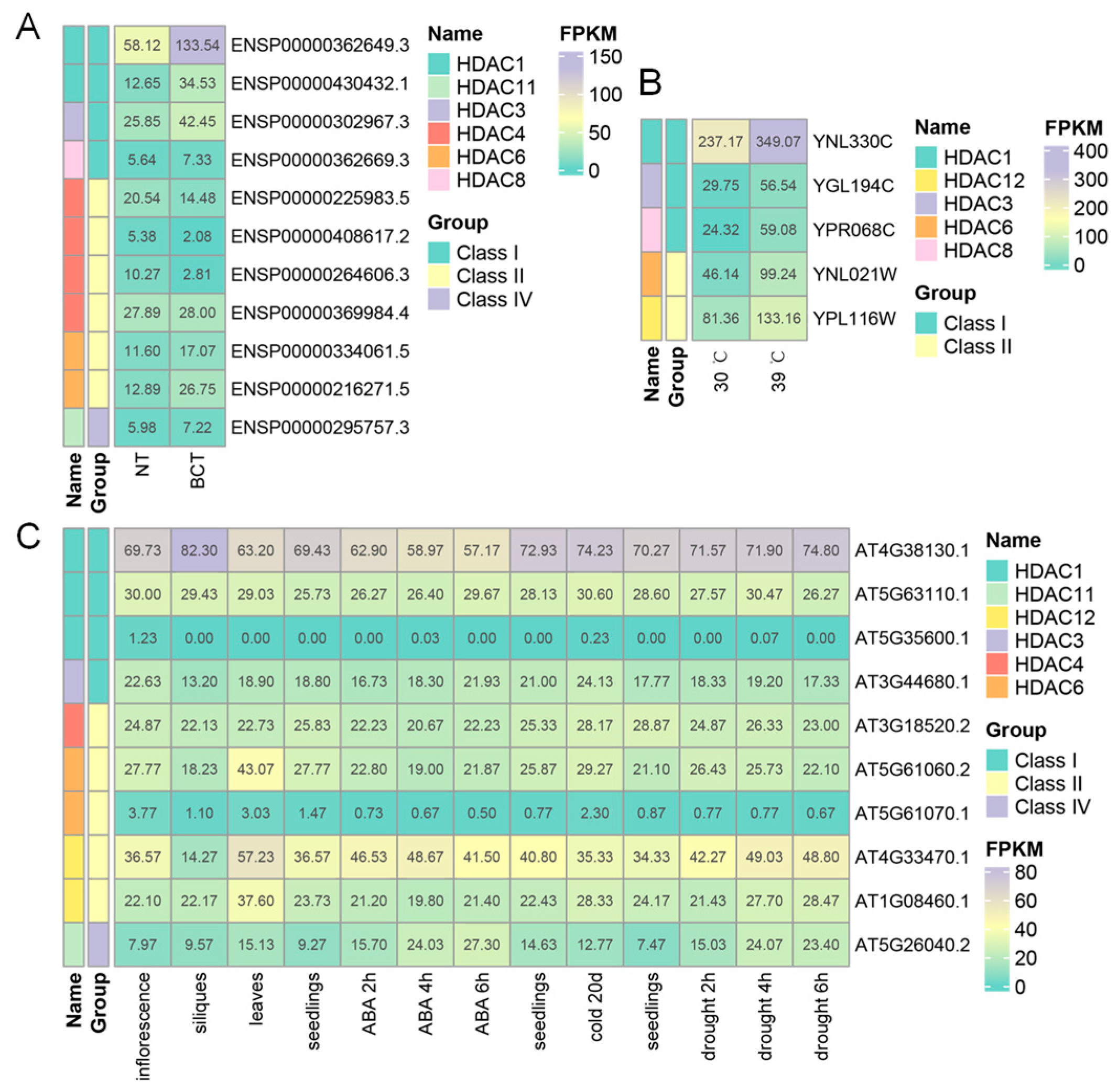
2.3. The Gene Duplication, Molecular Evolutionary, and Functional Divergence Analysis of HDACs
3. Discussion
4. Materials and Methods
4.1. HDAC Gene Related Data Collection and Analysis
4.2. Phylogenetic Analysis
4.3. Evolutionary Conservation Analysis
4.4. RNA-Seq Data Collection and Analysis
4.5. Analysis of HDAC1 Physical Interaction
4.6. Selection Pressure Analysis
4.7. Functional Diversification Analysis
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
References
- Lee, J.-H.; Bollschweiler, D.; Schäfer, T.; Huber, R. Structural basis for the regulation of nucleosome recognition and HDAC activity by histone deacetylase assemblies. Sci. Adv. 2021, 7, eabd4413. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Cao, R.; Niu, J.; Yang, S.; Ma, H.; Zhao, S.; Li, H. Molecular basis for hierarchical histone de-β-hydroxybutmlation by SIRT3. Cell Disco. 2019, 5, 35. [Google Scholar] [CrossRef] [PubMed]
- Porter, N.J.; Mahendran, A.; Breslow, R.; Christianson, D.W. Unusual zinc-binding mode of HDAC6-selective hydroxamate inhibitors. Proc. Natl. Acad. Sci. USA 2017, 114, 13459–13464. [Google Scholar] [CrossRef] [PubMed]
- Gaddelapati, S.C.; Albishi, N.M.; Dhandapani, R.K.; Palli, S.R. Juvenile hormone-induced histone deacetylase 3 suppresses apoptosis to maintain larval midgut in the yellow fever mosquito. Proc. Natl. Acad. Sci. USA 2022, 119. [Google Scholar] [CrossRef]
- Yruela, I.; Moreno-Yruela, C.; Olsen, C.A. Zn2+-Dependent Histone Deacetylases in Plants: Structure and Evolution. Trends Plant Sci. 2021, 26, 741–757. [Google Scholar] [CrossRef] [PubMed]
- Bernstein, B.E.; Tong, J.K.; Schreiber, S.L. Genomewide studies of histone deacetylase function in yeast. Proc. Natl. Acad. Sci. USA 2000, 97, 13708–13713. [Google Scholar] [CrossRef]
- Johnstone, R.W. Histone-deacetylase inhibitors: Novel drugs for the treatment of cancer. Nat. Rev. Drug Discov. 2002, 1, 287–299. [Google Scholar] [CrossRef] [PubMed]
- Bagnall, N.H.; Hines, B.M.; Lucke, A.J.; Gupta, P.K.; Reid, R.C.; Fairlie, D.P.; Kotze, A.C. Insecticidal activities of histone deacetylase inhibitors against a dipteran parasite of sheep, Lucilia cuprina. Int. J. Parasitol. Drugs Drug Resist. 2017, 7, 51–60. [Google Scholar] [CrossRef]
- Bondarev, A.D.; Attwood, M.M.; Jonsson, J.; Chubarev, V.N.; Tarasov, V.V.; Schiöth, H.B. Recent developments of HDAC inhibitors: Emerging indications and novel molecules. Br. J. Clin. Pharmacol. 2021, 87, 4577–4597. [Google Scholar] [CrossRef]
- Haberland, M.; Montgomery, R.L.; Olson, E.N. The many roles of histone deacetylases in development and physiology: Implications for disease and therapy. Nat. Rev. Genet. 2009, 10, 32–42. [Google Scholar] [CrossRef]
- Wang, X.; Wang, Y.; Liu, S.; Zhang, Y.; Xu, K.; Ji, L.; Kornberg, R.D.; Zhang, H. Class I histone deacetylase complex: Structure and functional correlates. Proc. Natl. Acad. Sci. USA 2023, 120, e2307598120. [Google Scholar] [CrossRef]
- Pandey, R.; Müller, A.; Napoli, C.A.; Selinger, D.A.; Pikaard, C.S.; Richards, E.J.; Bender, J.; Mount, D.W.; Jorgensen, R.A. Analysis of histone acetyltransferase and histone deacetylase families of Arabidopsis thaliana suggests functional diversification of chromatin modification among multicellular eukaryotes. Nucleic Acids Res. 2002, 30, 5036–5055. [Google Scholar] [CrossRef]
- Alinsug, M.V.; Yu, C.-W.; Wu, K. Phylogenetic analysis, subcellular localization, and expression patterns of RPD3/HDA1 family histone deacetylases in plants. BMC Plant Biol. 2009, 9, 37. [Google Scholar] [CrossRef] [PubMed]
- Bourque, S.; Jeandroz, S.; Grandperret, V.; Lehotai, N.; Aimé, S.; Soltis, D.; Miles, N.; Melkonian, M.; Deyholos, M.; Leebens-Mack, J.; et al. The Evolution of HD2 Proteins in Green Plants. Trends Plant Sci. 2016, 21, 1008–1016. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.-W.; Guo, L.-Y.; Han, M.; Shan, K. Diversity, evolution and expression profiles of histone acetyltransferases and deacetylases in oomycetes. BMC Genom. 2016, 17, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Ledent, V.; Vervoort, M. Comparative genomics of the class 4 histone deacetylase family indicates a complex evolutionary history. BMC Biol. 2006, 4, 24. [Google Scholar] [CrossRef]
- He, Y.; Petrie, M.V.; Zhang, H.; Peace, J.M.; Aparicio, O.M. Rpd3 regulates single-copy origins independently of the rDNA array by opposing Fkh1-mediated origin stimulation. Proc. Natl. Acad. Sci. USA 2022, 119, e2212134119. [Google Scholar] [CrossRef]
- Lee, S.H.; Farh, M.E.-A.; Lee, J.; Oh, Y.T.; Cho, E.; Park, J.; Son, H.; Jeon, J. A Histone Deacetylase, Magnaporthe oryzae RPD3, Regulates Reproduction and Pathogenic Development in the Rice Blast Fungus. Mbio 2021, 12, e0260021. [Google Scholar] [CrossRef]
- Gregoricchio, S.; Polit, L.; Esposito, M.; Berthelet, J.; Delestre, L.; Evanno, E.; Diop, M.B.; Gallais, I.; Aleth, H.; Poplineau, M.; et al. HDAC1 and PRC2 mediate combinatorial control in SPI1/PU.1-dependent gene repression in murine erythroleukaemia. Nucleic Acids Res. 2022, 50, 7938–7958. [Google Scholar] [CrossRef]
- Yang, Y.; Yang, C.; Li, T.; Yu, S.; Gan, T.; Hu, J.; Cui, J.; Zheng, X. The Deubiquitinase USP38 Promotes NHEJ Repair through Regulation of HDAC1 Activity and Regulates Cancer Cell Response to Genotoxic Insults. Cancer Res. 2020, 80, 719–731. [Google Scholar] [CrossRef]
- Pao, P.-C.; Patnaik, D.; Watson, L.A.; Gao, F.; Pan, L.; Wang, J.; Adaikkan, C.; Penney, J.; Cam, H.P.; Huang, W.-C.; et al. HDAC1 modulates OGG1-initiated oxidative DNA damage repair in the aging brain and Alzheimer’s disease. Nat. Commun. 2020, 11, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Zong, W.; Ren, D.; Huang, M.; Sun, K.; Feng, J.; Zhao, J.; Xiao, D.; Xie, W.; Liu, S.; Zhang, H.; et al. Strong photoperiod sensitivity is controlled by cooperation and competition among Hd1, Ghd7 and DTH8 in rice heading. New Phytol. 2020, 229, 1635–1649. [Google Scholar] [CrossRef] [PubMed]
- Verdin, E.; Dequiedt, F.; Kasler, H.G. Class II histone deacetylases: Versatile regulators. Trends Genet. 2003, 19, 286–293. [Google Scholar] [CrossRef] [PubMed]
- Nagarajan, S.; Rao, S.V.; Sutton, J.; Cheeseman, D.; Dunn, S.; Papachristou, E.K.; Prada, J.-E.G.; Couturier, D.-L.; Kumar, S.; Kishore, K.; et al. ARID1A influences HDAC1/BRD4 activity, intrinsic proliferative capacity and breast cancer treatment response. Nat. Genet. 2020, 52, 354. [Google Scholar] [CrossRef] [PubMed]
- Bahari-Javan, S.; Varbanov, H.; Halder, R.; Benito, E.; Kaurani, L.; Burkhardt, S.; Anderson-Schmidt, H.; Anghelescu, I.; Budde, M.; Stilling, R.M.; et al. HDAC1 links early life stress to schizophrenia-like phenotypes. Proc. Natl. Acad. Sci. USA 2017, 114, E6026. [Google Scholar] [CrossRef] [PubMed]
- Bradner, J.E.; Mak, R.; Tanguturi, S.K.; Mazitschek, R.; Haggarty, S.J.; Ross, K.; Chang, C.Y.; Bosco, J.; West, N.; Morse, E.; et al. Chemical genetic strategy identifies histone deacetylase 1 (HDAC1) and HDAC2 as therapeutic targets in sickle cell disease. Proc. Natl. Acad. Sci. USA 2010, 107, 12617–12622. [Google Scholar] [CrossRef]
- Bludau, A.; Neumann, I.D.; Menon, R. HDAC1-mediated regulation of GABA signaling within the lateral septum facilitates long-lasting social fear extinction in male mice. Transl. Psychiatry 2023, 13, 1–10. [Google Scholar] [CrossRef]
- Bantscheff, M.; Hopf, C.; Savitski, M.M.; Dittmann, A.; Grandi, P.; Michon, A.-M.; Schlegl, J.; Abraham, Y.; Becher, I.; Bergamini, G.; et al. Chemoproteomics profiling of HDAC inhibitors reveals selective targeting of HDAC complexes. Nat. Biotechnol. 2011, 29, 255–265. [Google Scholar] [CrossRef]
- Guo, Z.; Chu, C.; Lu, Y.; Zhang, X.; Xiao, Y.; Wu, M.; Gao, S.; Wong, C.C.L.; Zhan, X.; Wang, C. Structure of a SIN3–HDAC complex from budding yeast. Nat. Struct. Mol. Biol. 2023, 30, 753–760. [Google Scholar] [CrossRef]
- Wang, Z.A.; Millard, C.J.; Lin, C.-L.; Gurnett, J.E.; Wu, M.; Lee, K.; Fairall, L.; Schwabe, J.W.R.; Cole, P.A. Diverse nucleosome Site-Selectivity among histone deacetylase complexes. eLife 2020, 9, e57663. [Google Scholar] [CrossRef]
- Maglott, D.; Ostell, J.; Pruitt, K.D.; Tatusova, T. Entrez Gene: Gene-centered information at NCBI. Nucleic Acids Res. 2011, 39, D52–D57. [Google Scholar] [CrossRef] [PubMed]
- Camacho, C.; Coulouris, G.; Avagyan, V.; Ma, N.; Papadopoulos, J.; Bealer, K.; Madden, T.L. BLAST plus: Architecture and applications. BMC Bioinform. 2009, 10, 421. [Google Scholar] [CrossRef] [PubMed]
- Goodstein, D.M.; Shu, S.; Howson, R.; Neupane, R.; Hayes, R.D.; Fazo, J.; Mitros, T.; Dirks, W.; Hellsten, U.; Putnam, N.; et al. Phytozome: A comparative platform for green plant genomics. Nucleic Acids Res. 2012, 40, D1178–D1186. [Google Scholar] [CrossRef]
- Howe, K.L.; Achuthan, P.; Allen, J.; Allen, J.; Alvarez-Jarreta, J.; Amode, M.R.; Armean, I.M.; Azov, A.G.; Bennett, R.; Bhai, J.; et al. Ensembl 2021. Nucleic Acids Res. 2021, 49, D884–D891. [Google Scholar] [CrossRef] [PubMed]
- Yates, A.D.; Allen, J.; Amode, R.M.; Azov, A.G.; Barba, M.; Becerra, A.; Bhai, J.I.; Campbell, L.; Martinez, M.C.; Chakiachvili, M.; et al. Ensembl Genomes 2022: An expanding genome resource for non-vertebrates. Nucleic Acids Res. 2021, 50, D996–D1003. [Google Scholar] [CrossRef]
- Potter, S.C.; Luciani, A.; Eddy, S.R.; Park, Y.; López, R.; Finn, R.D. HMMER web server: 2018 update. Nucleic Acids Res. 2018, 46, W200–W204. [Google Scholar] [CrossRef]
- Chen, C.J.; Chen, H.; Zhang, Y.; Thomas, H.R.; Frank, M.H.; He, Y.H.; Xia, R. TBtools: An Integrative Toolkit Developed for Interactive Analyses of Big Biological Data. Mol. Plant 2020, 13, 1194–1202. [Google Scholar] [CrossRef]
- Wang, Y.; Tang, H.; DeBarry, J.D.; Tan, X.; Li, J.; Wang, X.; Lee, T.-H.; Jin, H.; Marler, B.; Guo, H.; et al. MCScanX: A toolkit for detection and evolutionary analysis of gene synteny and collinearity. Nucleic Acids Res. 2012, 40, e49. [Google Scholar] [CrossRef]
- Tamura, K.; Stecher, G.; Peterson, D.; Filipski, A.; Kumar, S. MEGA6: Molecular Evolutionary Genetics Analysis version 6. Mol. Biol. Evol. 2013, 30, 2725–2729. [Google Scholar] [CrossRef]
- Price, M.N.; Dehal, P.S.; Arkin, A.P. FastTree 2—Approximately Maximum-Likelihood Trees for Large Alignments. PLoS ONE 2010, 5, e9490. [Google Scholar] [CrossRef]
- Guindon, S.; Dufayard, J.-F.; Lefort, V.; Anisimova, M.; Hordijk, W.; Gascuel, O. New Algorithms and Methods to Estimate Maximum-Likelihood Phylogenies: Assessing the Performance of PhyML 3.0. Syst. Biol. 2010, 59, 307–321. [Google Scholar] [CrossRef]
- Darriba, D.; Taboada, G.L.; Doallo, R.; Posada, D. ProtTest 3: Fast selection of best-fit models of protein evolution. Bioinformatics 2011, 27, 1164–1165. [Google Scholar] [CrossRef]
- Brewer, M.J.; Butler, A.; Cooksley, S.L. The relative performance of AIC, AICC and BIC in the presence of unobserved heterogeneity. Methods Ecol. Evol. 2016, 7, 679–692. [Google Scholar] [CrossRef]
- Morariu, V.; Srinivasan, B.; Raykar, V.C.; Duraiswami, R.; Davis, L.S. Automatic online tuning for fast Gaussian summation. In Advances in Neural Information Processing Systems 21 (NIPS 2008), Proceedings of the Twenty-Second Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–11 December 2008; MIT Press: Cambridge, MA, USA, 2008. [Google Scholar]
- Lauffer, B.E.L.; Mintzer, R.; Fong, R.; Mukund, S.; Tam, C.; Zilberleyb, I.; Flicke, B.; Ritscher, A.; Fedorowicz, G.; Vallero, R.; et al. Histone Deacetylase (HDAC) Inhibitor Kinetic Rate Constants Correlate with Cellular Histone Acetylation but Not Transcription and Cell Viability. J. Biol. Chem. 2013, 288, 26926–26943. [Google Scholar] [CrossRef] [PubMed]
- Ashkenazy, H.; Abadi, S.; Martz, E.; Chay, O.; Mayrose, I.; Pupko, T.; Ben-Tal, N. ConSurf 2016: An improved methodology to estimate and visualize evolutionary conservation in macromolecules. Nucleic Acids Res. 2016, 44, W344–W350. [Google Scholar] [CrossRef]
- Yuan, S.; Chan, H.S.; Hu, Z. Using PyMOL as a platform for computational drug design. WIREs Comput. Mol. Sci. 2017, 7, e1298. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, F.; Yu, Y.; Feng, L.; Jia, J.; Liu, B.; Li, B.; Guo, H.; Zhai, J. A Comprehensive Online Database for Exploring ∼20,000 Public Arabidopsis RNA-Seq Libraries. Mol. Plant. 2020, 13, 1231–1233. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Jia, J.; Zhai, J. Plant Intron-Splicing Efficiency Database (PISE): Exploring splicing of ∼1,650,000 introns in Arabidopsis, maize, rice, and soybean from ~57,000 public RNA-seq libraries. Sci. China Life. Sci. 2023, 66, 602–611. [Google Scholar] [CrossRef]
- Wickham, H. ggplot2: Elegant Graphics for Data Analysis; Springer: New York, NY, USA, 2016. [Google Scholar]
- Yang, Z. PAML 4: Phylogenetic Analysis by Maximum Likelihood. Mol. Biol. Evol. 2007, 24, 1586–1591. [Google Scholar] [CrossRef]
- Gu, X.; Zou, Y.; Su, Z.; Huang, W.; Zhou, Z.; Arendsee, Z.; Zeng, Y. An Update of DIVERGE Software for Functional Divergence Analysis of Protein Family. Mol. Biol. Evol. 2013, 30, 1713–1719. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Foreground Branch | Model | p a | Parameter Estimates | Ln L | p | BEB b | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| (Frequency, f, and ω Values) | ||||||||||
| Class II | One-ratio model 0 (ω0 = ω1) | 128 | ω0 = ω1 = 0.1242 | −138,343.69 | 3.08 × 10−4 | NA | ||||
| Two-ratio model 2 (ω0, ω1) | 129 | ω0 = 0.1124; ω1 = 0.1541 | −138,337.18 | NA | ||||||
| Model 3 (discrete) | 132 | - | −134,286.29 | 2.15 × 10−4 | NA | |||||
| Clade model D (K = 3) | 133 | site class | 0 | 1 | 2 | −134,279.44 | NA | |||
| proportion | 0.1031 | 0.5918 | 0.3050 | |||||||
| branch type 0 | 0.0274 | 0.4668 | 0.0974 | |||||||
| branch type 1 | 0.0274 | 0.4668 | 0.1185 | |||||||
| Model A null (ω2 = 1) | 130 | 1 | −135,334.52 | 1 | NA | |||||
| Model A (0 < ω0 < 1) | 131 | site class | 0 | 1 | 2a | 2b | −135,334.52 | 7 **, 9 **, 10 **, 28 **, 50 **, 53 *, 56 **, 67 **, 84 *, 88 **, 96 **, 251 **, 324 **, 327 *, 328 **, 329 **, 332 **, 368 **, 376 **, 377 **, 379 *, 380 **, 381 **, 382 **, 383 **, 384 **, 385 **, 386 **, 393 **, 396*, 397 **, 398 * | ||
| proportion | 0.2656 | 0.2667 | 0.2334 | 0.2343 | ||||||
| background w | 0.0944 | 1.0000 | 0.0944 | 1.0000 | ||||||
| foreground w | 0.0944 | 1.0000 | 1.0000 | 1.0000 | ||||||
| HDAC Subfamily | Coefficient θI | θSE | Critical Amino Acid Site (Qk > 0.7) | p |
|---|---|---|---|---|
| Class I vs Class II | 0.3888 | 0.063 | 134, 137 **, 153 **, 159, 160, 178, 187 **, 188, 230 **, 232 *,234,239 * | 1.78 × 10−6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, J.-F.; Shi, L.-R.; Wang, K.-C.; Huang, L.-L.; Deng, Y.-S.; Chen, M.-X.; Wan, F.-H.; Zhou, Z.-S. HDAC1: An Essential and Conserved Member of the Diverse Zn2+-Dependent HDAC Family Driven by Divergent Selection Pressure. Int. J. Mol. Sci. 2023, 24, 17072. https://doi.org/10.3390/ijms242317072
Yang J-F, Shi L-R, Wang K-C, Huang L-L, Deng Y-S, Chen M-X, Wan F-H, Zhou Z-S. HDAC1: An Essential and Conserved Member of the Diverse Zn2+-Dependent HDAC Family Driven by Divergent Selection Pressure. International Journal of Molecular Sciences. 2023; 24(23):17072. https://doi.org/10.3390/ijms242317072
Chicago/Turabian StyleYang, Jing-Fang, Le-Rong Shi, Ke-Chen Wang, Li-Long Huang, Yun-Shuang Deng, Mo-Xian Chen, Fang-Hao Wan, and Zhong-Shi Zhou. 2023. "HDAC1: An Essential and Conserved Member of the Diverse Zn2+-Dependent HDAC Family Driven by Divergent Selection Pressure" International Journal of Molecular Sciences 24, no. 23: 17072. https://doi.org/10.3390/ijms242317072
APA StyleYang, J.-F., Shi, L.-R., Wang, K.-C., Huang, L.-L., Deng, Y.-S., Chen, M.-X., Wan, F.-H., & Zhou, Z.-S. (2023). HDAC1: An Essential and Conserved Member of the Diverse Zn2+-Dependent HDAC Family Driven by Divergent Selection Pressure. International Journal of Molecular Sciences, 24(23), 17072. https://doi.org/10.3390/ijms242317072