

Towards Machine Learning in Heterogeneous Catalysis—A Case Study of 2,4-Dinitrotoluene Hydrogenation

 ,
,  , and
, and
Abstract

1. Introduction
2. Results and Discussion
2.1. Future Selection Analysis
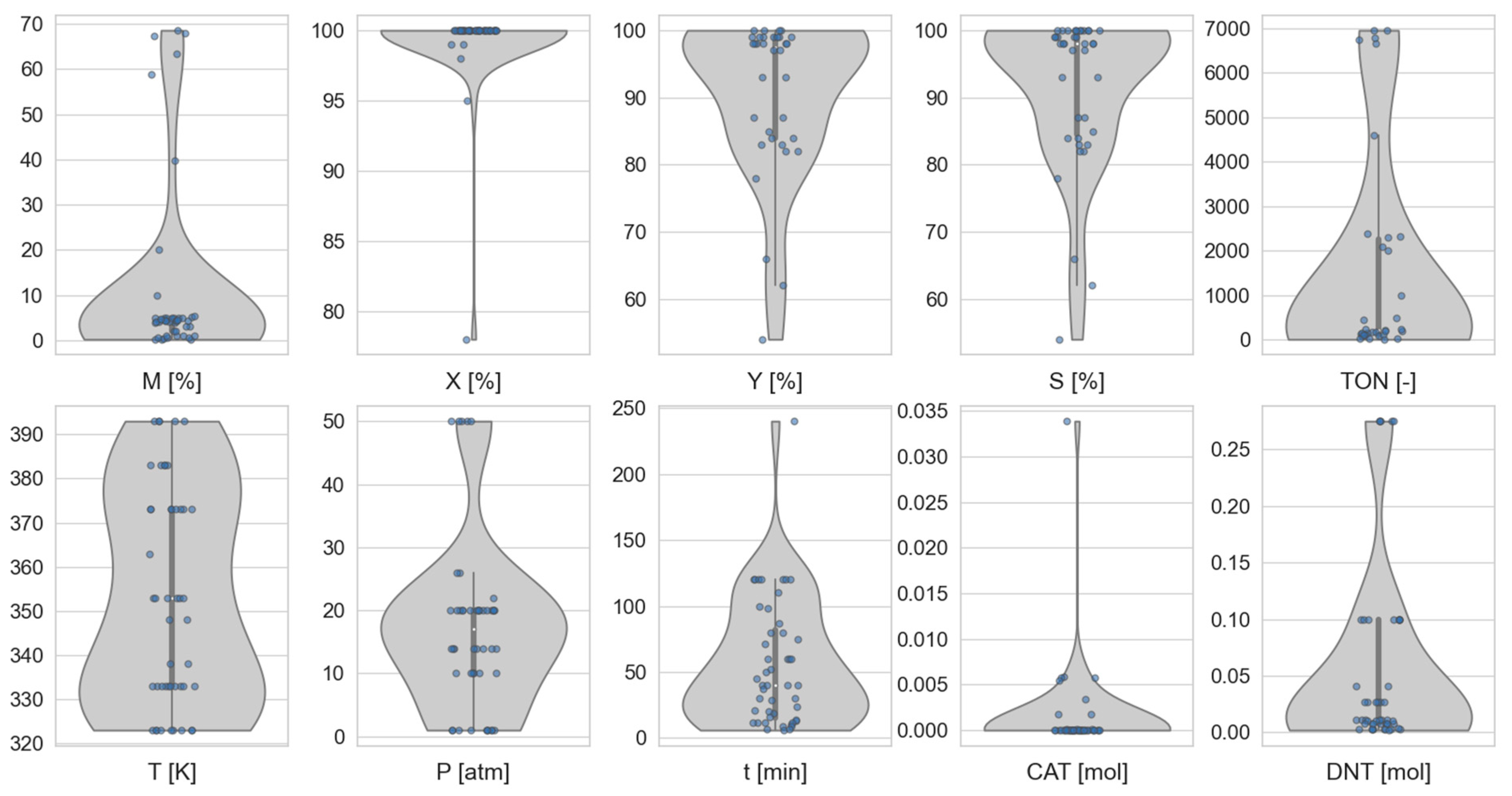
2.2. Data Distributions
2.3. Correlation Analysis
- Level of Measurement: The two variables should be measured at the interval or ratio level.
- Linear Relationship: There should exist a linear relationship between the two variables.
- Normality: Both variables should be roughly normally distributed.
- Related Pairs: Each observation in the dataset should have a pair of values.
- No Outliers: There should be no extreme outliers in the dataset [36].
2.4. Assessment of DNT Hydrogenation Database
3. Materials and Methods
3.1. Catalyst Library
3.2. Exploratory Data Analysis
- Univariate analysis (exploring characteristics of a single variable);
- Bi/multivariate analysis (comparative analysis of multiple variables; if we compare the correlation of two variables, it is called bivariate analysis).
3.3. Data Visualization
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Catalyst Market Size, Share|Analysis, Demand|Growth 2023–2028. Available online: https://www.expertmarketresearch.com/reports/catalyst-market (accessed on 14 March 2023).
- Horváth, I.T. Introduction: Sustainable Chemistry. Chem. Rev. 2018, 118, 369–371. [Google Scholar] [CrossRef]
- Heath, D.E.; Cooper, S.L. Polyurethanes. In Biomaterials Science. An Introduction to Materials in Medicine, 3rd ed.; Academic Press: Cambridge, MA, USA, 2013; pp. 79–82. [Google Scholar] [CrossRef]
- Nitro Aromatic Hydrogenation Catalyst—Search|ScienceDirect.com. Available online: https://www.sciencedirect.com/search?qs=nitro aromatic hydrogenation catalyst (accessed on 14 March 2023).
- Zhang, J.; Wang, L.; Shao, Y.; Wang, Y.; Gates, B.C.; Xiao, F.-S. A Pd@Zeolite Catalyst for Nitroarene Hydrogenation with High Product Selectivity by Sterically Controlled Adsorption in the Zeolite Micropores. Angew. Chem. 2017, 129, 9879–9883. [Google Scholar] [CrossRef]
- Wen, H.; Yao, K.; Zhang, Y.; Zhou, Z.; Kirschning, A. Catalytic transfer hydrogenation of aromatic nitro compounds in presence of polymer-supported nano-amorphous Ni–B catalyst. Catal. Commun. 2009, 10, 1207–1211. [Google Scholar] [CrossRef]
- Xie, M.; Zhang, F.; Long, Y.; Ma, J. Pt nanoparticles supported on carbon coated magnetic microparticles: An efficient recyclable catalyst for hydrogenation of aromatic nitro-compounds. RSC Adv. 2013, 3, 10329–10334. [Google Scholar] [CrossRef]
- Huang, L.; Lv, Y.; Wu, S.; Liu, P.; Xiong, W.; Hao, F.; Luo, H. Activated carbon supported bimetallic catalysts with combined catalytic effects for aromatic nitro compounds hydrogenation under mild conditions. Appl. Catal. A Gen. 2019, 577, 76–85. [Google Scholar] [CrossRef]
- Chen, Y.; Qiu, J.; Wang, X.; Xiu, J. Preparation and application of highly dispersed gold nanoparticles supported on silica for catalytic hydrogenation of aromatic nitro compounds. J. Catal. 2006, 242, 227–230. [Google Scholar] [CrossRef]
- Cárdenas-Lizana, F.; Gómez-Quero, S.; Keane, M.A. Ultra-selective gas phase catalytic hydrogenation of aromatic nitro compounds over Au/Al2O3. Catal. Commun. 2008, 9, 475–481. [Google Scholar] [CrossRef]
- Yun, R.; Hong, L.; Ma, W.; Jia, W.; Liu, S.; Zheng, B. Fe/Fe2O3@N-dopped Porous Carbon: A High-Performance Catalyst for Selective Hydrogenation of Nitro Compounds. ChemCatChem 2019, 11, 724–728. [Google Scholar] [CrossRef]
- Yue, S.; Wang, X.; Li, S.; Sheng, Y.; Zou, X.; Lu, X.; Zhang, C. Highly selective hydrogenation of halogenated nitroarenes over Ru/CN nanocomposites by in situ pyrolysis. New J. Chem. 2020, 44, 11861–11869. [Google Scholar] [CrossRef]
- Li, W.; Artz, J.; Broicher, C.; Junge, K.; Hartmann, H.; Besmehn, A.; Palkovits, R.; Beller, M. Superior activity and selectivity of heterogenized cobalt catalysts for hydrogenation of nitroarenes. Catal. Sci. Technol. 2019, 9, 157–162. [Google Scholar] [CrossRef]
- Huang, L.; Lv, Y.; Liu, S.; Cui, H.; Zhao, Z.; Zhao, H.; Liu, P.; Xiong, W.; Hao, F.; Luo, H. Non-Noble Metal Ni Nanoparticles Supported on Highly Dispersed TiO2-Modified Activated Carbon as an Efficient and Recyclable Catalyst for the Hydrogenation of Halogenated Aromatic Nitro Compounds under Mild Conditions. Ind. Eng. Chem. Res. 2020, 59, 1422–1435. [Google Scholar] [CrossRef]
- Dai, Y.; Li, X.; Wang, L.; Xu, X. Highly efficient hydrogenation reduction of aromatic nitro compounds using MOF derivative Co–N/C catalyst. New J. Chem. 2021, 45, 22908–22914. [Google Scholar] [CrossRef]
- Lara, P.; Philippot, K. The hydrogenation of nitroarenes mediated by platinum nanoparticles: An overview. Catal. Sci. Technol. 2014, 4, 2445–2465. [Google Scholar] [CrossRef]
- Blaser, H.U.; Steiner, H.; Studer, M. Selective Catalytic Hydrogenation of Functionalized Nitroarenes: An Update. ChemCatChem. 2009, 1, 210–221. [Google Scholar] [CrossRef]
- Yao, J.; Wang, L.; Xie, D.; Jiang, L.; Li, J.; Fang, X. Nanocarbon-based catalysts for selective nitroaromatic hydrogenation: A mini review. Front. Chem. 2022, 10, 1000680. [Google Scholar] [CrossRef]
- Jakab-Nácsa, A.; Sikora, E.; Prekob, Á.; Vanyorek, L.; Szőri, M.; Boros, R.Z.; Nehéz, K.; Szabó, M.; Farkas, L.; Viskolcz, B. Comparison of Catalysts with MIRA21 Model in Heterogeneous Catalytic Hydrogenation of Aromatic Nitro Compounds. Catalysts 2022, 12, 467. [Google Scholar] [CrossRef]
- Jakab-Nácsa, A.; Hajdu, V.; Vanyorek, L.; Farkas, L.; Viskolcz, B. Overview of Catalysts with MIRA21 Model in Heterogeneous Catalytic Hydrogenation of 2,4-Dinitrotoluene. Catalysts 2023, 13, 387. [Google Scholar] [CrossRef]
- Baum, Z.J.; Yu, X.; Ayala, P.Y.; Zhao, Y.; Watkins, S.P.; Zhou, Q. Artificial Intelligence in Chemistry: Current Trends and Future Directions. J. Chem. Inf. Model. 2021, 61, 3197–3212. [Google Scholar] [CrossRef]
- Mendes, P.S.F.; Siradze, S.; Pirro, L.; Thybaut, J.W. Open Data in Catalysis: From Today’s Big Picture to the Future of Small Data. ChemCatChem. 2021, 13, 836–850. [Google Scholar] [CrossRef]
- Lafuente, D.; Cohen, B.; Fiorini, G.; García, A.A.; Bringas, M.; Morzan, E.; Onna, D. A Gentle Introduction to Machine Learning for Chemists: An Undergraduate Workshop Using Python Notebooks for Visualization, Data Processing, Analysis, and Modeling. J. Chem. Educ. 2021, 98, 2892–2898. [Google Scholar] [CrossRef]
- Mowbray, M.; Vallerio, M.; Perez-Galvan, C.; Zhang, D.; Del Rio Chanona, A.; Navarro-Brull, F.J. Industrial data science—A review of machine learning applications for chemical and process industries. React. Chem. Eng. 2022, 7, 1471–1509. [Google Scholar] [CrossRef]
- Yang, W.; Fidelis, T.T.; Sun, W.H. Machine Learning in Catalysis, from Proposal to Practicing. ACS Omega 2020, 5, 83–88. [Google Scholar] [CrossRef] [PubMed]
- A Practical Introductory Guide to Exploratory Data Analysis|datos.gob.es. Available online: https://datos.gob.es/en/documentacion/practical-introductory-guide-exploratory-data-analysis (accessed on 17 April 2023).
- Zavyalova, U.; Holena, M.; Schlögl, R.; Baerns, M. Statistical analysis of past catalytic data on oxidative methane coupling for new insights into the composition of high-performance catalysts. ChemCatChem 2011, 3, 1935–1947. [Google Scholar] [CrossRef]
- Ras, E.J.; McKay, B.; Rothenberg, G. Understanding catalytic biomass conversion through data mining. Top. Catal. 2010, 53, 1202–1208. [Google Scholar] [CrossRef]
- Schmack, R.; Friedrich, A.; Kondratenko, E.V.; Polte, J.; Werwatz, A.; Kraehnert, R. A meta-analysis of catalytic literature data reveals property-performance correlations for the OCM reaction. Nat. Commun. 2019, 10, 441. [Google Scholar] [CrossRef]
- Yang, Q.; Skrypnik, A.; Matvienko, A.; Lund, H.; Holena, M.; Kondratenko, E.V. Revealing property-performance relationships for efficient CO2 hydrogenation to higher hydrocarbons over Fe-based catalysts: Statistical analysis of literature data and its experimental validation. Appl. Catal. B Environ. 2021, 282, 119554. [Google Scholar] [CrossRef]
- Fedorov, A.; Linke, D. Data analysis of CO2 hydrogenation catalysts for hydrocarbon production. J. CO2 Util. 2022, 61, 102034. [Google Scholar] [CrossRef]
- Goldsmith, B.R.; Esterhuizen, J.; Liu, J.X.; Bartel, C.J.; Sutton, C. Machine learning for heterogeneous catalyst design and discovery. AIChE J. 2018, 64, 2311–2323. [Google Scholar] [CrossRef]
- Keith, J.A.; Vassilev-Galindo, V.; Cheng, B.; Chmiela, S.; Gastegger, M.; Müller, K.-R.; Tkatchenko, A. Combining Machine Learning and Computational Chemistry for Predictive Insights into Chemical Systems. Chem. Rev. 2021, 121, 9816–9872. [Google Scholar] [CrossRef]
- Rodríguez-Pérez, R.; Bajorath, J. Feature importance correlation from machine learning indicates functional relationships between proteins and similar compound binding characteristics. Sci. Rep. 2021, 11, 14245. [Google Scholar] [CrossRef]
- Peter, X.-K.; Song, K. Correlated Data Analysis: Modeling, Analytics, and Applications; Springer: New York, NY, USA, 2007. [Google Scholar] [CrossRef]
- Kim, Y.; Kim, T.H.; Ergün, T. The instability of the Pearson correlation coefficient in the presence of coincidental outliers. Financ. Res. Lett. 2015, 13, 243–257. [Google Scholar] [CrossRef]
- Zar, J.H. Spearman Rank Correlation: Overview. In Wiley StatsRef: Statistics Reference Online; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2014. [Google Scholar] [CrossRef]
- Myers, J.L.; Well, A.D. Research Design & Statistical Analysis. In Research Design & Statistical Analysis; Psychology Press: New York, NY, USA, 2003. [Google Scholar] [CrossRef]
- Chen, X.; Shen, K.; Ding, D.; Chen, J.; Fan, T.; Wu, R.; Li, Y. Solvent-Driven Selectivity Control to Either Anilines or Dicyclohexylamines in Hydrogenation of Nitroarenes over a Bifunctional Pd/MIL-101 Catalyst. ACS Catal. 2018, 8, 10641–10648. [Google Scholar] [CrossRef]
- Neri, G.; Musolino, M.G.; Milone, C.; Pietropaolo, D.; Galvagno, S. Particle size effect in the catalytic hydrogenation of 2,4-dinitrotoluene over Pd/C catalysts. Appl. Catal. A Gen. 2001, 208, 307–316. [Google Scholar] [CrossRef]
- Hajdu, V.; Varga, M.; Muránszky, G.; Karacs, G.; Kristály, F.; Fiser, B.; Viskolcz, B.; Vanyorek, L. Development of magnetic, ferrite supported palladium catalysts for 2,4-dinitrotoluene hydrogenation. Mater. Today Chem. 2021, 20, 100470. [Google Scholar] [CrossRef]
- Yu, Z.; Liao, S.; Xu, Y.; Yang, B.; Yu, D. Hydrogenation of nitroaromatics by polymer-anchored bimetallic palladium-ruthenium and palladium-platinum catalysts under mild conditions. J. Mol. Catal. A Chem. 1997, 120, 247–255. [Google Scholar] [CrossRef]
- Yan, S.; Fan, H.; Liang, C.; Li, Z.; Yu, Z. Preparation and characterization of Ni-La-B amorphous alloy catalyst for low-pressure dinitrotoluene hydrogenation. Cuihua Xuebao/Chin. J. Catal. 2012, 33, 1374–1382. [Google Scholar] [CrossRef]
- Hajdu, V.; Muránszky, G.; Hashimoto, M.; Kristály, F.; Szőri, M.; Fiser, B.; Kónya, Z.; Viskolcz, B.; Vanyorek, L. Combustion method combined with sonochemical step for synthesis of maghemite-supported catalysts for the hydrogenation of 2,4-dinitrotoluene. Catal. Commun. 2021, 159, 106342. [Google Scholar] [CrossRef]
- Ren, X.; Li, J.; Wang, S.; Zhang, D.; Wang, Y. Preparation and catalytic performance of ZrO2-supported Pt single-atom and cluster catalyst for hydrogenation of 2,4-dinitrotoluene to 2,4-toluenediamine. J. Chem. Technol. Biotechnol. 2020, 95, 1675–1682. [Google Scholar] [CrossRef]
- Hajdu, V.; Jakab-Nácsa, A.; Muránszky, G.; Kocserha, I.; Fiser, B.; Ferenczi, T.; Nagy, M.; Viskolcz, B.; Vanyorek, L. Precious-metal-decorated chromium(Iv) oxide nanowires as efficient catalysts for 2,4-toluenediamine synthesis. Int. J. Mol. Sci. 2021, 22, 5945. [Google Scholar] [CrossRef]
- Auer, E.; Gross, M.; Panster, P.; Takemoto, K. Supported indium catalysts—A novel catalytic system for the synthesis of toluenediamine. Catal. Today 2001, 65, 31–37. [Google Scholar] [CrossRef]
- Kut, O.M.; Yücelen, F.; Gut, G. Selective liquid-phase hydrogenation of 2,6-dinitrotoluene with platinum catalysts. J. Chem. Technol. Biotechnol. 1987, 39, 107–114. [Google Scholar] [CrossRef]
- Zhao, F.; Fujita, S.I.; Sun, J.; Ikushima, Y.; Arai, M. Hydrogeation of nitro compounds with supported platinum catalyst in supercritical carbon dioxide. Catal. Today 2004, 98, 523–528. [Google Scholar] [CrossRef]
- Mathew, S.P.; Rajasekharam, M.V.; Chaudhari, R.V. Hydrogenation of p-isobutyl acetophenone using a Ru/Al2O3 catalyst: Reaction kinetics and modelling of a semi-batch slurry reactor. Catal. Today 1999, 49, 49–56. [Google Scholar] [CrossRef]
- Hajdu, V.; Sikora, E.; Kristály, F.; Muránszky, G.; Fiser, B.; Viskolcz, B.; Nagy, M.; Vanyorek, L. Palladium Decorated, Amine Functionalized Ni-, Cd- and Co-Ferrite Nanospheres as Novel and Effective Catalysts for 2,4-Dinitrotoluene Hydrogenation. Int. J. Mol. Sci. 2022, 23, 13197. [Google Scholar] [CrossRef] [PubMed]
- Dell’Anna, M.M.; Gagliardi, M.; Mastrorilli, P.; Suranna, G.P.; Nobile, C.F. Hydrogenation reactions catalysed by a supported palladium complex. J. Mol. Catal. A Chem. 2000, 158, 515–520. [Google Scholar] [CrossRef]
- Suh, D.J.; Tae-Jin, P.; Son-Ki, I. Effect of surface oxygen groups of carbon supports on the characteristics of Pd/C catalysts. Carbon 1993, 31, 427–435. [Google Scholar] [CrossRef]
- Zhang, X.; Niu, F. Liquid-phase hydrogenation to 2,4-tolylenediamine over supported HY catalysts. Adv. Mater. Res. 2012, 512–515, 2381–2385. [Google Scholar] [CrossRef]
- Li Vigni, M.; Durante, C.; Cocchi, M. Exploratory Data Analysis. Data Handl. Sci. Technol. 2013, 28, 55–126. [Google Scholar] [CrossRef]
- Asuero, A.G.; Sayago, A.; González, A.G. The Correlation Coefficient: An Overview. Crit. Rev. Anal. Chem. 2007, 36, 41–59. [Google Scholar] [CrossRef]
- Desouky, M.; Tariq, Z.; Aljawad, M.S.; Alhoori, H.; Mahmoud, M.; Abdulraheem, A. Machine Learning-Based Propped Fracture Conductivity Correlations of Several Shale Formations. ACS Omega 2021, 6, 18782–18792. [Google Scholar] [CrossRef]
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef] [PubMed]
- Waskom, M. seaborn: Statistical data visualization. J. Open Source Softw. 2021, 6, 3021. [Google Scholar] [CrossRef]
- Hunter, J.D. Matplotlib: A 2D graphics environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- McKinney, W. Python for Data Analysis: Data Wrangling with Pandas, NumPy, and IPython; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2017. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Catalyst Composition | Catalyst Performance | Reaction Conditions | Catalyst Properties | Sustainability Parameters |
|---|---|---|---|---|
| Active metal content | Maximum conversion | Temperature | Catalyst particle size | Reactivation |
| Type of active metal content | Product yield | Pressure | Catalyst surface area | Stability |
| Number of active metals | Product selectivity | Time | Catalyst carrier | |
| Catalyst carrier | Turnover number | Molar amount of catalyst | ||
| Molar amount of 2,4-dinitrotoluene | ||||
| Solvent |
| Notation | Name | Unit | Definition | |
|---|---|---|---|---|
| M | Catalyst composition | w/w% | Weight percentage of active component in the catalyst | |
| Catalyst performance | X | Maximum conversion | mol% | Maximum desired product conversion achieved on a given catalyst |
| Y | Product yield | mol% | Product yield for maximum conversion | |
| S | Product selectivity | mol% | Product selectivity for maximum conversion | |
| TON | Turnover number | - | Number of moles of product formed per 1 mol active metal when the maximum conversion reached | |
| Reaction conditions | T | Temperature | K | Reaction temperature for maximum conversion |
| P | Pressure | atm | Reaction pressure for maximum conversion | |
| t | Time | min | Time required to reach maximum conversion | |
| CAT | Molar amount of initial catalyst | mol | The molar amount of the active metal involved in the reaction—in the case of several metals, the sum of molar numbers | |
| DNT | Molar amount of starting substance | mol | The initial amount of starting substance involved in the reaction—2,4-dinitrotoluene |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jakab-Nácsa, A.; Garami, A.; Fiser, B.; Farkas, L.; Viskolcz, B. Towards Machine Learning in Heterogeneous Catalysis—A Case Study of 2,4-Dinitrotoluene Hydrogenation. Int. J. Mol. Sci. 2023, 24, 11461. https://doi.org/10.3390/ijms241411461
Jakab-Nácsa A, Garami A, Fiser B, Farkas L, Viskolcz B. Towards Machine Learning in Heterogeneous Catalysis—A Case Study of 2,4-Dinitrotoluene Hydrogenation. International Journal of Molecular Sciences. 2023; 24(14):11461. https://doi.org/10.3390/ijms241411461
Chicago/Turabian StyleJakab-Nácsa, Alexandra, Attila Garami, Béla Fiser, László Farkas, and Béla Viskolcz. 2023. "Towards Machine Learning in Heterogeneous Catalysis—A Case Study of 2,4-Dinitrotoluene Hydrogenation" International Journal of Molecular Sciences 24, no. 14: 11461. https://doi.org/10.3390/ijms241411461
APA StyleJakab-Nácsa, A., Garami, A., Fiser, B., Farkas, L., & Viskolcz, B. (2023). Towards Machine Learning in Heterogeneous Catalysis—A Case Study of 2,4-Dinitrotoluene Hydrogenation. International Journal of Molecular Sciences, 24(14), 11461. https://doi.org/10.3390/ijms241411461