
Towards the Interpretability of Machine Learning Predictions for Medical Applications Targeting Personalised Therapies: A Cancer Case Survey



 ,
, 
 , ,
, ,  ,
,
Abstract
1. Introduction
2. What Kind of ML Is important in Medicine/Cancer Prediction and Treatment
2.1. Factor One: Output Interpretability
2.2. Factor Two: Linking to Original Cases to Produce Outputs
2.3. Factor Three: Data Hungriness
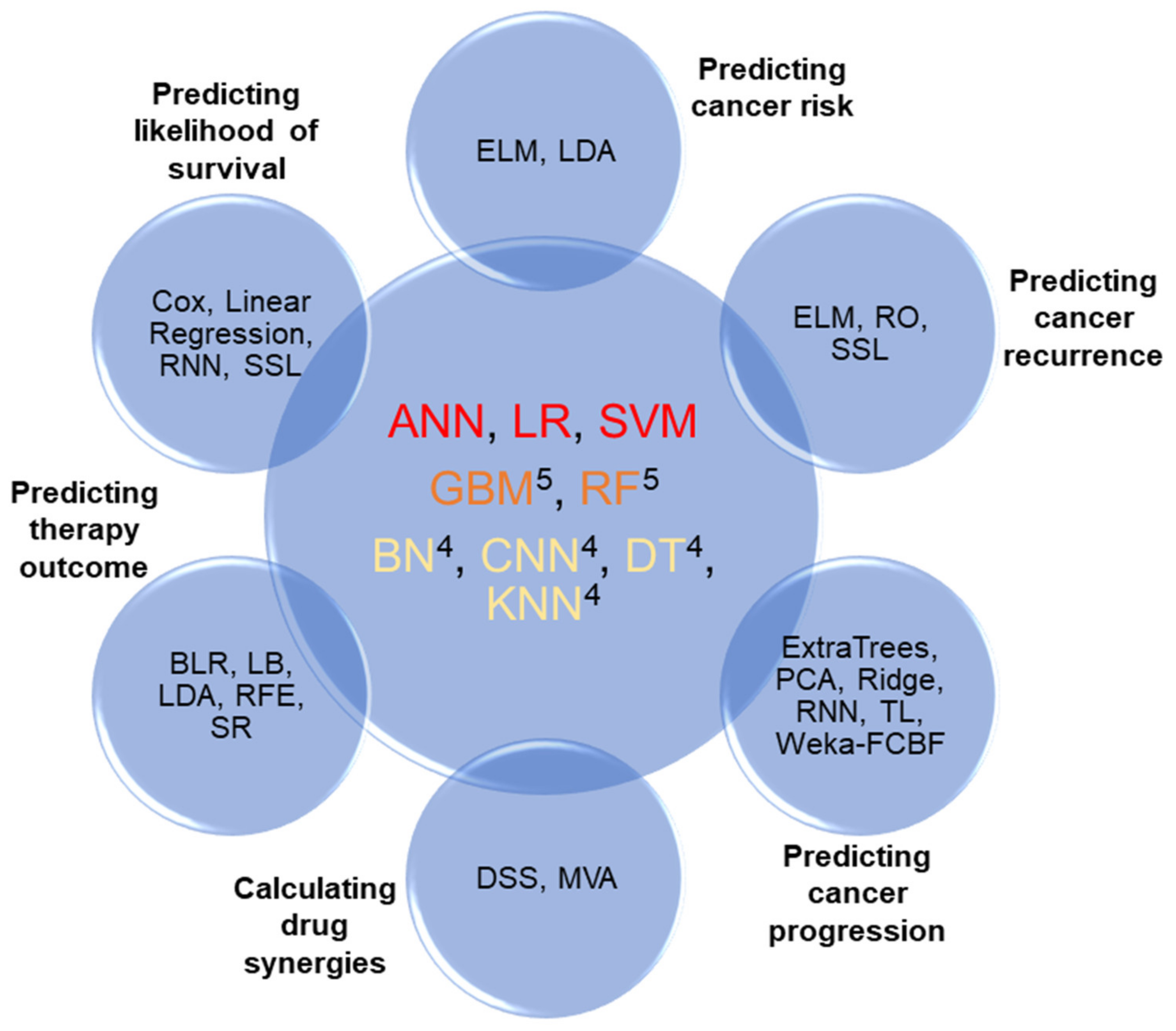
3. Application of ML Approaches in Cancer Cases
3.1. Predict the Possibility of Cancer
3.2. Predict Cancer Recurrence
3.3. Predicting Cancer Progression
3.4. Calculating Drug Doses or Drug Combinations
3.5. Predict Treatment Outcome
3.6. Predicting Survival Likelihood
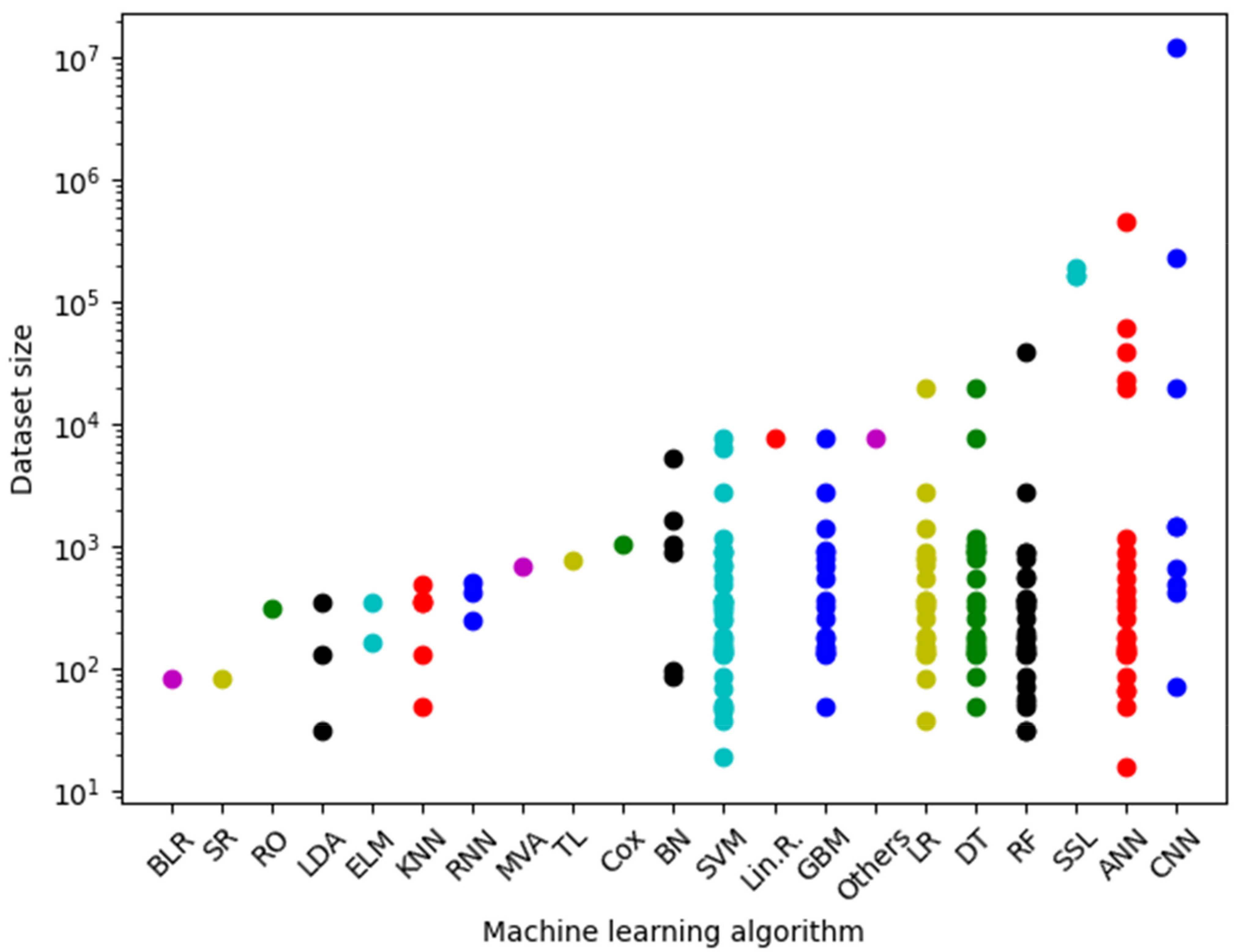
4. Software and Datasets
4.1. Software Tools
4.2. HPC Infrastructures
4.3. Datasets
5. Conclusions and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| 1CM | One-carbo metabolism |
| AI | Artificial Intelligence |
| ANN | Artificial Neural Network |
| AUC | Area Under the Curve |
| BC | Breast Cancer |
| BioBIM | InterInstitutional Multidisciplinary Biobank |
| BMI | Body Mass Index |
| BN | Bayesian Network |
| CCF | Cancer Cell Fraction |
| CNN | Convolutional Neural Network |
| CRC | Colorectal Cancer |
| DCNN | Dilated Convolutional Neural Network |
| DL | Deep Learning |
| DSS | Decision Support System |
| DT | Decision Tree |
| ELM | Extreme Learning Machine |
| EMR | Electronic Medical Record |
| ENLR | Elastic Net Logistic Regression |
| FOLFIRI | 5-FU leucovorin and irinotecan |
| FOLFOX | 5-FU leucovorin and oxaliplatin |
| FT | Fourier Transform |
| GBM | Gradient Boosting Machine |
| GEO | Gene Expression Omnibus |
| GOSS | Genetic Ontology Similarity Score |
| GPU | Graphics Processing Unit |
| HDF5 | Hierarchical Data Format 5 |
| HNSCC | Head and Neck Squamous Cell Carcinoma |
| HPC | High Performance Computing |
| ICBC | Iranian Centre for Breast Cancer |
| IMRT | Intensity Modulated Radiotherapy |
| KNN | K-Nearest Neighbours |
| LDA | Linear Discriminant Analysis |
| LPP | Locality Preserving Projection |
| LR | Logistic Regression |
| LSTM | Long Short-Term Memory |
| ML | Machine Learning |
| MVA | Multivariate analysis |
| NCBI | National Center for Biotechnology Information |
| NCSS | Number Cruncher Statistical Systems |
| NMSC | Non-Melanoma Skin Cancer |
| PCA | Principal Component Analysis |
| RECIST | Response Evaluation Criteria In Solid Tumors |
| REVOLVER | Repeated EVOLution in cancER |
| RF | Random Forest |
| RMSE | Root Mean Square Error |
| RNN | Recurrent Neural Network |
| RO | Random Optimization |
| ROC | Receiver Operating Characteristic |
| SAP | Single Amino Acid Polymorphism |
| SEABED | Segmentation and Biomarker Enrichment of Differential Treatment Response |
| SEER | Surveillance Epidemiology and End Results |
| SIFT | Sorting Intolerant From Tolerant |
| SKCM | Skin Cutaneous Melanoma |
| SNP | Single Nucleotide Polymorphism |
| SSL | Semi-Supervised Learning |
| SVC-W | Support Vector Classification with Weight |
| SVM | Support Vector Machine |
| SVM-L1 | Support Vector Machine with L1 Regularization |
| TCGA | The Cancer Genome Atlas |
| TGF-β | Transforming Growth Factor beta |
| TL | Transfer Learning |
| WEKA-FCBF | Waikato Environment of Knowledge Analysis—Fast Correlation Based Filter |
| WHO | World Health Organization |
| XAI | Explainable Artificial Intelligence |
| YARN | Yet Another Resource Negotiator |
References
- Cronin, K.A.; Lake, A.J.; Scott, S.; Sherman, R.L.; Noone, A.M.; Howlader, N.; Henley, S.J.; Anderson, R.N.; Firth, A.U.; Ma, J.; et al. Annual report to the nation on the status of cancer, part I: National cancer statistics. Cancer 2018, 124, 2785–2800. [Google Scholar] [CrossRef]
- Culp, M.B.B.; Soerjomataram, I.; Efstathiou, J.A.; Bray, F.; Jemal, A. Recent global patterns in prostate cancer incidence and mortality rates. Eur. Urol. 2020, 77, 38–52. [Google Scholar] [CrossRef]
- Ferlay, J.; Soerjomataram, I.; Dikshit, R.; Eser, S.; Mathers, C.; Rebelo, M.; Parkin, D.M.; Forman, D.; Bray, F. Cancer incidence and mortality worldwide: Sources, methods and major patterns in GLOBOCAN 2012. Int. J. Cancer 2015, 136, E359–E386. [Google Scholar] [CrossRef]
- Chiavenna, S.; Jaworski, J.P.; Vendrell, A. State of the art in anti-cancer mAbs. J. Biomed. Sci. 2017, 24. [Google Scholar] [CrossRef]
- Loud, J.T.; Murphy, J. Cancer screening and early detection in the 21st century. Semin. Oncol. Nurs. 2017, 33, 121–128. [Google Scholar] [CrossRef]
- Coleman, C. Early detection and screening for breast cancer. Semin. Oncol. Nurs. 2017, 33, 141–155. [Google Scholar] [CrossRef]
- Araghi, M.; Soerjomataram, I.; Jenkins, M.; Brierley, J.; Morris, E.; Bray, F.; Arnold, M. Global trends in colorectal cancer mortality: Projections to the year 2035. Int. J. Cancer 2019, 144, 2992–3000. [Google Scholar] [CrossRef] [PubMed]
- Dekker, E.; Tanis, P.J.; Vleugels, J.L.A.; Kasi, P.M.; Wallace, M.B. Colorectal cancer. Lancet 2019, 394, 1467–1480. [Google Scholar] [CrossRef]
- Arnold, M.; Sierra, M.S.; Laversanne, M.; Soerjomataram, I.; Jemal, A.; Bray, F. Global patterns and trends in colorectal cancer incidence and mortality. Gut 2017, 66, 683–691. [Google Scholar] [CrossRef] [PubMed]
- Kuipers, E.J.; Grady, W.M.; Lieberman, D.; Seufferlein, T.; Sung, J.J.; Boelens, P.G.; Van De Velde, C.J.H.; Watanabe, T. Colorectal cancer. Nat. Rev. Dis. Prim. 2015, 1. [Google Scholar] [CrossRef] [PubMed]
- Weinberg, B.A.; Marshall, J.L.; Salem, M.E. The growing challenge of young adults with colorectal cancer. Oncology 2017, 31, 381–389. [Google Scholar]
- García-Figueiras, R.; Baleato-González, S.; Padhani, A.R.; Luna-Alcalá, A.; Marhuenda, A.; Vilanova, J.C.; Osorio-Vázquez, I.; Martínez-de-Alegría, A.; Gómez-Caamaño, A. Advanced imaging techniques in evaluation of colorectal cancer. Radiographics 2018, 38, 740–765. [Google Scholar] [CrossRef] [PubMed]
- Valle, L.; Vilar, E.; Tavtigian, S.V.; Stoffel, E.M. Genetic predisposition to colorectal cancer: Syndromes, genes, classification of genetic variants and implications for precision medicine. J. Pathol. 2019, 247, 574–588. [Google Scholar] [CrossRef]
- Huang, D.; Sun, W.; Zhou, Y.; Li, P.; Chen, F.; Chen, H.; Xia, D.; Xu, E.; Lai, M.; Wu, Y.; et al. Mutations of key driver genes in colorectal cancer progression and metastasis. Cancer Metastasis Rev. 2018, 37, 173–187. [Google Scholar] [CrossRef] [PubMed]
- Oh, M.; McBride, A.; Yun, S.; Bhattacharjee, S.; Slack, M.; Martin, J.R.; Jeter, J.; Abraham, I. BRCA1 and BRCA2 gene mutations and colorectal cancer risk: Systematic review and meta-analysis. J. Natl. Cancer Inst. 2018, 110, 1178–1189. [Google Scholar] [CrossRef]
- Ruiz-López, L.; Blancas, I.; Garrido, J.M.; Mut-Salud, N.; Moya-Jódar, M.; Osuna, A.; Rodríguez-Serrano, F. The role of exosomes on colorectal cancer: A review. J. Gastroenterol. Hepatol. 2018, 33, 792–799. [Google Scholar] [CrossRef]
- Yiu, A.J.; Yiu, C.Y. Biomarkers in colorectal cancer. Anticancer Res. 2016, 36, 1093–1102. [Google Scholar]
- Lech, G.; Słotwiński, R.; Słodkowski, M.; Krasnodębski, I.W. Colorectal cancer tumour markers and biomarkers: Recent therapeutic advances. World J. Gastroenterol. 2016, 22, 1745–1755. [Google Scholar] [CrossRef] [PubMed]
- Ding, D.; Han, S.; Zhang, H.; He, Y.; Li, Y. Predictive biomarkers of colorectal cancer. Comput. Biol. Chem. 2019, 83. [Google Scholar] [CrossRef] [PubMed]
- Kather, J.N.; Halama, N.; Jaeger, D. Genomics and emerging biomarkers for immunotherapy of colorectal cancer. Semin. Cancer Biol. 2018, 52, 189–197. [Google Scholar] [CrossRef] [PubMed]
- Jain, K.K. Personalised medicine for cancer: From drug development into clinical practice. Expert Opin. Pharmacother. 2005, 6, 1463–1476. [Google Scholar] [CrossRef]
- Jackson, S.E.; Chester, J.D. Personalised cancer medicine. Int. J. Cancer 2015, 137, 262–266. [Google Scholar] [CrossRef]
- Usher-Smith, J.A.; Silarova, B.; Lophatananon, A.; Duschinsky, R.; Campbell, J.; Warcaba, J.; Muir, K. Responses to provision of personalised cancer risk information: A qualitative interview study with members of the public. BMC Public Health 2017, 17. [Google Scholar] [CrossRef]
- Olin, R.L. Delivering intensive therapies to older adults with hematologic malignancies: Strategies to personalize care. Blood 2019, 134, 2013–2021. [Google Scholar] [CrossRef] [PubMed]
- Upton, A.; Trelles, O.; Cornejo-García, J.A.; Perkins, J.R. Review: High-performance computing to detect epistasis in genome scale data sets. Brief. Bioinform. 2016, 17, 368–379. [Google Scholar] [CrossRef] [PubMed]
- Schmidt, B.; Hildebrandt, A. Next-generation sequencing: Big data meets high performance computing. Drug Discov. Today 2017, 22, 712–717. [Google Scholar] [CrossRef] [PubMed]
- Chen, S.; He, Z.; Han, X.; He, X.; Li, R.; Zhu, H.; Zhao, D.; Dai, C.; Zhang, Y.; Lu, Z.; et al. How big data and high-performance computing drive brain science. Genom. Proteom. Bioinf. 2019, 17, 381–392. [Google Scholar] [CrossRef]
- Wang, H.; Ma, Y.; Pratx, G.; Xing, L. Toward real-time Monte Carlo simulation using a commercial cloud computing infrastructure. Phys. Med. Biol. 2011, 56, N175–N181. [Google Scholar] [CrossRef]
- Garg, V.; Arora, S.; Gupta, C. Cloud computing approaches to accelerate drug discovery value chain. Comb. Chem. High Throughput Screen. 2011, 14, 861–871. [Google Scholar] [CrossRef]
- Nobile, M.S.; Cazzaniga, P.; Tangherloni, A.; Besozzi, D. Graphics processing units in bioinformatics, computational biology and systems biology. Brief. Bioinf. 2017, 18, 870–885. [Google Scholar] [CrossRef]
- Dilsizian, S.E.; Siegel, E.L. Artificial intelligence in medicine and cardiac imaging: Harnessing big data and advanced computing to provide personalized medical diagnosis and treatment. Curr. Cardiol. Rep. 2014, 16. [Google Scholar] [CrossRef]
- Pérez-Sianes, J.; Pérez-Sánchez, H.; Díaz, F. Virtual Screening Meets Deep Learning. Curr. Comput. Aided. Drug Des. 2019, 15, 6–28. [Google Scholar] [CrossRef]
- Kourou, K.; Exarchos, T.P.; Exarchos, K.P.; Karamouzis, M.V.; Fotiadis, D.I. Machine learning applications in cancer prognosis and prediction. Comput. Struct. Biotechnol. J. 2015, 13, 8–17. [Google Scholar] [CrossRef]
- Lipton, Z.C. The Mythos of Model Interpretability. arXiv 2018, arXiv:1301.3781. [Google Scholar] [CrossRef]
- Jacovi, A.; Sar Shalom, O.; Goldberg, Y. Understanding convolutional neural networks for text classification. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 56–65. [Google Scholar]
- Swartout, W.; Paris, C.; Moore, J. Explanations in knowledge systems: Design for explainable expert systems. IEEE Exp. 1991, 6, 54–58. [Google Scholar] [CrossRef]
- Johnson, W.L. Agents that learn to explain themselves. In Proceedings of the 12th National Conference on Artificial Intelligence (AAAI’ 94), Seattle, WA, USA, 31 July– 4 August 1994; pp. 1257–1263. [Google Scholar]
- Lacave, C.; Díez, F.J. A review of explanation methods for Bayesian networks. Knowl. Eng. Rev. 2002, 17, 107–127. [Google Scholar] [CrossRef]
- Holzinger, A.; Langs, G.; Denk, H.; Zatloukal, K.; Müller, H. Causability and explainability of artificial intelligence in medicine. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2019, 9, e1312. [Google Scholar] [CrossRef] [PubMed]
- Holzinger, A.; Dehmer, M.; Jurisica, I. Knowledge discovery and interactive data mining in bioinformatics—State-of-the-art, future challenges and research directions. BMC Bioinf. 2014, 15, I1. [Google Scholar] [CrossRef] [PubMed]
- Lee, S.; Holzinger, A. Knowledge discovery from complex high dimensional data. In Solving Large Scale Learning Tasks. Challenges and Algorithms, Lecture Notes in Artificial Intelligence; Michaelis, S., Piatkowski, N., Eds.; Springer: Heidelberg, Germany, 2016; pp. 148–167. [Google Scholar]
- Gunning, D. Explainable artificial intelligence (XAI). AI Mag. 2019, 40, 44–58. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Schlegl, T.; Seeböck, P.; Waldstein, S.M.; Schmidt-Erfurth, U.; Langs, G. Unsupervised anomaly detection with generative adversarial networks to guide marker discovery. In Proceedings of the International Conference on Information Processing in Medical Imaging, Boone, NC, USA, 25–30 June 2017; pp. 146–157. [Google Scholar]
- Bærøe, K.; Miyata-Sturm, A.; Henden, E. How to achieve trustworthy artificial intelligence for health. Bull. World Health Organ. 2020, 98, 257–262. [Google Scholar] [CrossRef]
- Sundararajan, M.; Taly, A.; Yan, Q. Axiomatic attribution for deep networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 3319–3328. [Google Scholar]
- Oakden-Rayner, L.; Palmer, L.J. Artificial intelligence in medicine: Validation and study design: Opportunities, applications and risks. In Artificial Intelligence in Medical Imaging; Springer: Cham, Switzerland, 2019; pp. 83–104. [Google Scholar]
- Hermon, R.; Williams, P.A. Big data in healthcare: What is it used for? In Proceedings of the Australian Ehealth Informatics and Security Conference, Perth, Australia, 1–3 December 2014; pp. 40–49. [Google Scholar]
- Archenaa, J.; Anita, E.M. A survey of big data analytics in healthcare and government. Procedia Comput. Sci. 2015, 50, 408–413. [Google Scholar] [CrossRef]
- Ristevski, B.; Chen, M. Big Data Analytics in Medicine and Healthcare. J. Integr. Bioinform. 2018, 15, 20170030. [Google Scholar] [CrossRef] [PubMed]
- Sun, H.; Liu, Z.; Wang, G.; Lian, W.; Ma, J. Intelligent analysis of medical big data based on deep learning. IEEE Access 2019, 7, 142022–142037. [Google Scholar] [CrossRef]
- Hassan, A.K.; Hassan, Y.F.; Kholief, M.H. A deep classification system for medical big data analysis. J. Med. Imag. Health Inf. 2018, 8, 250–256. [Google Scholar]
- Chen, S.; Wu, S. Identifying lung cancer risk factors in the elderly using deep neural networks: Quantitative analysis of web-based survey data. J. Med. Internet Res. 2020, 22, e17695. [Google Scholar] [CrossRef]
- Kaminker, J.S.; Zhang, Y.; Watanabe, C.; Zhang, Z. CanPredict: A computational tool for predicting cancer-associated missense mutations. Nucleic Acids Res. 2007, 35. [Google Scholar] [CrossRef] [PubMed]
- Capriotti, E.; Altman, R.B. A new disease-specific machine learning approach for the prediction of cancer-causing missense variants. Genomics 2011, 98, 310–317. [Google Scholar] [CrossRef]
- Celli, F.; Cumbo, F.; Weitschek, E. Classification of large DNA methylation datasets for identifying cancer drivers. Big Data Res. 2018, 13, 21–28. [Google Scholar] [CrossRef]
- Myte, R.; Gylling, B.; Häggström, J.; Schneede, J.; Magne Ueland, P.; Hallmans, G.; Johansson, I.; Palmqvist, R.; Van Guelpen, B. Untangling the role of one-carbon metabolism in colorectal cancer risk: A comprehensive Bayesian network analysis. Sci. Rep. 2017, 7. [Google Scholar] [CrossRef]
- Ayer, T.; Alagoz, O.; Chhatwal, J.; Shavlik, J.W.; Kahn, C.E.; Burnside, E.S. Breast cancer risk estimation with artificial neural networks revisited: Discrimination and calibration. Cancer 2010, 116, 3310–3321. [Google Scholar] [CrossRef]
- Heidari, M.; Khuzani, A.Z.; Hollingsworth, A.B.; Danala, G.; Mirniaharikandehei, S.; Qiu, Y.; Liu, H.; Zheng, B. Prediction of breast cancer risk using a machine learning approach embedded with a locality preserving projection algorithm. Phys. Med. Biol. 2018, 63. [Google Scholar] [CrossRef]
- Behravan, H.; Hartikainen, J.M.; Tengström, M.; Pylkäs, K.; Winqvist, R.; Kosma, V.-M.; Mannermaa, A. Machine learning identifies interacting genetic variants contributing to breast cancer risk: A case study in Finnish cases and controls. Sci. Rep. 2018, 8. [Google Scholar] [CrossRef] [PubMed]
- Taninaga, J.; Nishiyama, Y.; Fujibayashi, K.; Gunji, T.; Sasabe, N.; Iijima, K.; Naito, T. Prediction of future gastric cancer risk using a machine learning algorithm and comprehensive medical check-up data: A case-control study. Sci. Rep. 2019, 9. [Google Scholar] [CrossRef] [PubMed]
- Roffman, D.; Hart, G.; Girardi, M.; Ko, C.J.; Deng, J. Predicting non-melanoma skin cancer via a multi-parameterized artificial neural network. Sci. Rep. 2018, 8. [Google Scholar] [CrossRef] [PubMed]
- Martínez-Más, J.; Bueno-Crespo, A.; Khazendar, S.; Remezal-Solano, M.; Martínez-Cendán, J.P.; Jassim, S.; Du, H.; Assam, H.A.; Bourne, T.; Timmerman, D. Evaluation of machine learning methods with Fourier Transform features for classifying ovarian tumors based on ultrasound images. PLoS ONE 2019, 14, e0219388. [Google Scholar] [CrossRef]
- Martínez-Más, J.; Bueno-Crespo, A.; Martínez-España, R.; Remezal-Solano, M.; Ortiz-González, A.; Ortiz-Reina, S.; Martínez-Cendán, J.P. Classifying Papanicolaou cervical smears through a cell merger approach by deep learning technique. Exp. Syst. Appl. 2020, 160, 113707. [Google Scholar] [CrossRef]
- Lu, W.; Fu, D.; Kong, X.; Huang, Z.; Hwang, M.; Zhu, Y.; Chen, L.; Jiang, K.; Li, X.; Wu, Y.; et al. FOLFOX treatment response prediction in metastatic or recurrent colorectal cancer patients via machine learning algorithms. Cancer Med. 2020, 9, 1419–1429. [Google Scholar] [CrossRef]
- Xu, Y.; Ju, L.; Tong, J.; Zhou, C.M.; Yang, J.J. Machine Learning Algorithms for Predicting the Recurrence of Stage IV Colorectal Cancer After Tumor Resection. Sci. Rep. 2020, 10, 1–9. [Google Scholar] [CrossRef]
- Kim, J.; Shin, H. Breast cancer survivability prediction using labeled, unlabeled, and pseudo-labeled patient data. J. Am. Med. Inf. Assoc. 2013, 20, 613–618. [Google Scholar] [CrossRef]
- Ahmad, L.; Eshlaghy, A.; Poorebrahimi, A.; Ebrahimi, M.; AR, R. Using three machine learning techniques for predicting breast cancer recurrence. J. Health Med. Inf. 2013, 4. [Google Scholar] [CrossRef]
- Ferroni, P.; Zanzotto, F.M.; Riondino, S.; Scarpato, N.; Guadagni, F.; Roselli, M. Breast cancer prognosis using a machine learning approach. Cancers 2019, 11, 328. [Google Scholar] [CrossRef]
- Park, C.; Ahn, J.; Kim, H.; Park, S. Integrative gene network construction to analyze cancer recurrence using semi-supervised learning. PLoS ONE 2014, 9. [Google Scholar] [CrossRef] [PubMed]
- Exarchos, K.P.; Goletsis, Y.; Fotiadis, D.I. Multiparametric decision support system for the prediction of oral cancer reoccurrence. IEEE Trans. Inf. Technol. Biomed. 2012, 16, 1127–1134. [Google Scholar] [CrossRef] [PubMed]
- Tseng, C.J.; Lu, C.J.; Chang, C.C.; Chen, G. Den Application of machine learning to predict the recurrence-proneness for cervical cancer. Neural Comput. Appl. 2014, 24, 1311–1316. [Google Scholar] [CrossRef]
- Dercle, L.; Lu, L.; Schwartz, L.H.; Qian, M.; Tejpar, S.; Eggleton, P.; Zhao, B.; Piessevaux, H. Radiomics response signature for identification of metastatic colorectal cancer sensitive to therapies targeting EGFR pathway. J. Natl. Cancer Inst. 2020, 112, 902–912. [Google Scholar] [CrossRef] [PubMed]
- Yates, L.R.; Gerstung, M.; Knappskog, S.; Desmedt, C.; Gundem, G.; Van Loo, P.; Aas, T.; Alexandrov, L.B.; Larsimont, D. Subclonal diversification of primary breast cancer revealed by multiregion sequencing. Nat. Med. 2015, 21, 751–759. [Google Scholar] [CrossRef]
- Gerlinger, M.; Horswell, S.; Larkin, J.; Rowan, A.J.; Salm, M.P.; Varela, I.; Fisher, R.; McGranahan, N.; Matthews, N.; Santos, C.R.; et al. Genomic architecture and evolution of clear cell renal cell carcinomas defined by multiregion sequencing. Nat. Genet. 2014, 46, 225–233. [Google Scholar] [CrossRef]
- Caravagna, G.; Giarratano, Y.; Ramazzotti, D.; Tomlinson, I.; Graham, T.A.; Sanguinetti, G.; Sottoriva, A. Detecting repeated cancer evolution from multi-region tumor sequencing data. Nat. Methods 2018, 15, 707–714. [Google Scholar] [CrossRef]
- Auslander, N.; Wolf, Y.I.; Koonin, E.V. In silico learning of tumor evolution through mutational time series. Proc. Natl. Acad. Sci. USA 2019, 116, 9501–9510. [Google Scholar] [CrossRef] [PubMed]
- Albertazzi, E.; Cajone, F.; Leone, B.E.; Naguib, R.N.; Lakshmi, M.S.; Sherbet, G.V. Expression of metastasis-associated genes h-mts1 (S100A4) and nm23 in carcinoma of breast is related to disease progression. DNA Cell Biol. 1998, 17, 335–342. [Google Scholar] [CrossRef]
- Grey, S.R.; Dlay, S.S.; Leone, B.E.; Cajone, F.; Sherbet, G. V Prediction of nodal spread of breast cancer by using artificial neural network-based analyses of S100A4, nm23 and steroid receptor expression. Clin. Exp. Metastasis 2003, 20, 507–514. [Google Scholar] [CrossRef] [PubMed]
- Ishii, H.; Saitoh, M.; Sakamoto, K.; Sakamoto, K.; Saigusa, D.; Kasai, H.; Ashizawa, K.; Miyazawa, K.; Takeda, S.; Masuyama, K.; et al. Lipidome-based rapid diagnosis with machine learning for detection of TGF-β signalling activated area in head and neck cancer. Br. J. Cancer 2020, 122, 995–1004. [Google Scholar] [CrossRef] [PubMed]
- Bhalla, S.; Kaur, H.; Dhall, A.; Raghava, G.P.S. Prediction and analysis of skin cancer progression using genomics profiles of patients. Sci. Rep. 2019, 9. [Google Scholar] [CrossRef]
- Shiraishi, S.; Tan, J.; Olsen, L.A.; Moore, K.L. Knowledge-based prediction of plan quality metrics in intracranial stereotactic radiosurgery. Med. Phys. 2015, 42, 908. [Google Scholar] [CrossRef] [PubMed]
- Shiraishi, S.; Moore, K.L. Knowledge-based prediction of three-dimensional dose distributions for external beam radiotherapy. Med. Phys. 2016, 43, 378–387. [Google Scholar] [CrossRef]
- Nguyen, D.; Long, T.; Jia, X.; Lu, W.; Gu, X.; Iqbal, Z.; Jiang, S. A feasibility study for predicting optimal radiation therapy dose distributions of prostate cancer patients from patient anatomy using deep learning. Sci. Rep. 2019, 9. [Google Scholar] [CrossRef]
- Musen, M.A.; Tu, S.W.; Das, A.K.; Shahar, Y. EON: A component-based approach to automation of protocol-directed therapy. Emerg. Infect. Dis. 1996, 3, 367–388. [Google Scholar] [CrossRef]
- Celebi, R.; Movva, R.; Alpsoy, S.; Dumontier, M. In-silico prediction of synergistic anti-cancer drug combinations using multi-omics data. Sci. Rep. 2019, 9. [Google Scholar] [CrossRef]
- Keshava, N.; Toh, T.S.; Yuan, H.; Yang, B.; Menden, M.P.; Wang, D. Defining subpopulations of differential drug response to reveal novel target populations. NPJ Syst. Biol. Appl. 2019, 5. [Google Scholar] [CrossRef] [PubMed]
- O’Neil, J.; Benita, Y.; Feldman, I.; Chenard, M.; Roberts, B.; Liu, Y.; Li, J.; Kral, A.; Lejnine, S.; Loboda, A.; et al. An unbiased oncology compound screen to identify novel combination strategies. Mol. Cancer Ther. 2016, 15, 1155–1162. [Google Scholar] [CrossRef] [PubMed]
- Preuer, K.; Lewis, R.P.I.; Hochreiter, S.; Bender, A.; Bulusu, K.C.; Klambauer, G. DeepSynergy: Predicting anti-cancer drug synergy with Deep Learning. Bioinformatics 2018, 34, 1538–1546. [Google Scholar] [CrossRef] [PubMed]
- McIntosh, C.; Purdie, T.G. Contextual atlas regression forests: Multiple-atlas-based automated dose prediction in radiation therapy. IEEE Trans. Med. Imag. 2016, 35, 1000–1012. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Weinstein, J.N.; Kohn, K.W.; Grever, M.R.; Viswanadhan, V.N.; Rubinstein, L.V.; Monks, A.P.; Scudiero, D.A. Neural computing in cancer drug development: Predicting mechanism of action. Science 1992, 258, 447–451. [Google Scholar] [CrossRef]
- Skrede, O.J.; De Raedt, S.; Kleppe, A.; Hveem, T.S.; Liestøl, K.; Maddison, J.; Askautrud, H.A.; Pradhan, M.; Nesheim, J.A.; Albregtsen, F.; et al. Deep learning for prediction of colorectal cancer outcome: A discovery and validation study. Lancet 2020, 395, 350–360. [Google Scholar] [CrossRef]
- Tsuji, S.; Midorikawa, Y.; Takahashi, T.; Yagi, K.; Takayama, T.; Yoshida, K.; Sugiyama, Y.; Aburatani, H. Potential responders to FOLFOX therapy for colorectal cancer by Random Forests analysis. Br. J. Cancer 2012, 106, 126–132. [Google Scholar] [CrossRef]
- Steele, S.R.; Bilchik, A.; Johnson, E.K.; Nissan, A.; Peoples, G.E.; Berhardt, J.S.; Kalina, P.; Petersen, B.; Brücher, B.; Protic, M.; et al. Time-dependent estimates of recurrence and survival in colon cancer: Clinical decision support system tool development for adjuvant therapy and oncological outcome assessment. Am. Surg. 2014, 80, 441–453. [Google Scholar] [CrossRef] [PubMed]
- Menden, M.P.; Iorio, F.; Garnett, M.; McDermott, U.; Benes, C.H.; Ballester, P.J.; Saez-Rodriguez, J. Machine learning prediction of cancer cell sensitivity to drugs based on genomic and chemical properties. PLoS ONE 2013, 8. [Google Scholar] [CrossRef]
- Lin, H.; Qiu, X.; Zhang, B.; Zhang, J. Identification of the predictive genes for the response of colorectal cancer patients to FOLFOX therapy. Oncol. Targets Ther. 2018, 11, 5943–5955. [Google Scholar] [CrossRef]
- Gan, Z.; Zou, Q.; Lin, Y.; Xu, Z.; Huang, Z.; Chen, Z.; Lv, Y. Identification of a 13-gene-based classifier as a potential biomarker to predict the effects of fluorouracil-based chemotherapy in colorectal cancer. Oncol. Lett. 2019, 17, 5057–5063. [Google Scholar] [CrossRef] [PubMed]
- Land, W.H.; Margolis, D.; Gottlieb, R.; Yang, J.Y.; Krupinski, E.A. Improving CT prediction of treatment response in patients with metastatic colorectal carcinoma using statistical learning. Int. J. Comput. Biol. Drug Des. 2010, 3, 15–18. [Google Scholar] [CrossRef] [PubMed]
- Del Rio, M.; Molina, F.; Bascoul-Mollevi, C.; Copois, V.; Bibeau, F.; Chalbos, P.; Bareil, C.; Kramar, A.; Salvetat, N.; Fraslon, C.; et al. Gene expression signature in advanced colorectal cancer patients select drugs and response for the use of leucovorin, fluorouracil, and irinotecan. J. Clin. Oncol. 2007, 25, 773–780. [Google Scholar] [CrossRef] [PubMed]
- Hess, K.R.; Anderson, K.; Symmans, W.F.; Valero, V.; Ibrahim, N.; Mejia, J.A.; Booser, D.; Theriault, R.L.; Buzdar, A.U.; Dempsey, P.J.; et al. Pharmacogenomic predictor of sensitivity to preoperative chemotherapy with paclitaxel and fluorouracil, doxorubicin, and cyclophosphamide in breast cancer. J. Clin. Oncol. 2006, 24, 4236–4244. [Google Scholar] [CrossRef] [PubMed]
- Thuerigen, O.; Schneeweiss, A.; Toedt, G.; Warnat, P.; Hahn, M.; Kramer, H.; Brors, B.; Rudlowski, C.; Benner, A.; Schuetz, F.; et al. Gene expression signature predicting pathologic complete response with gemcitabine, epirubicin, and docetaxel in primary breast cancer. J. Clin. Oncol. 2006, 24, 1839–1845. [Google Scholar] [CrossRef] [PubMed]
- Harris, L.N.; You, F.; Schnitt, S.J.; Witkiewicz, A.; Lu, X.; Sgroi, D.; Ryan, P.D.; Come, S.E.; Burstein, H.J.; Lesnikoski, B.A.; et al. Predictors of resistance to preoperative trastuzumab and vinorelbine for HER2-positive early breast cancer. Clin. Cancer Res. 2007, 13, 1198–1207. [Google Scholar] [CrossRef] [PubMed]
- Mitra, A.P.; Skinner, E.C.; Miranda, G.; Daneshmand, S. A precystectomy decision model to predict pathological upstaging and oncological outcomes in clinical stage T2 bladder cancer. BJU Int. 2013, 111, 240–248. [Google Scholar] [CrossRef]
- Talby, L.; Chambost, H.; Roubaud, M.-C.; N’Guyen, C.; Milili, M.; Loriod, B.; Fossat, C.; Picard, C.; Gabert, J.; Chiappetta, P.; et al. The chemosensitivity to therapy of childhood early B acute lymphoblastic leukemia could be determined by the combined expression of CD34, SPI-B and BCR genes. Leuk. Res. 2006, 30, 665–676. [Google Scholar] [CrossRef]
- Huang, C.C.; Gadd, S.; Breslow, N.; Cutcliffe, C.; Sredni, S.T.; Helenowski, I.B.; Dome, J.S.; Grundy, P.E.; Green, D.M.; Fritsch, M.K.; et al. Predicting relapse in favorable histology wilms tumor using gene expression analysis: A report from the renal tumor committee of the children’s oncology group. Clin. Cancer Res. 2009, 15, 1770–1778. [Google Scholar] [CrossRef]
- Dressman, H.K.; Berchuck, A.; Chan, G.; Zhai, J.; Bild, A.; Sayer, R.; Cragun, J.; Clarke, J.; Whitaker, R.S.; Li, L.H.; et al. An integrated genomic-based approach to individualized treatment of patients with advanced-stage ovarian cancer. J. Clin. Oncol. 2007, 25, 517–525. [Google Scholar] [CrossRef]
- Duong, C.; Greenawalt, D.M.; Kowalczyk, A.; Ciavarella, M.L.; Raskutti, G.; Murray, W.K.; Phillips, W.A.; Thomas, R.J.S. Pretreatment gene expression profiles can be used to predict response to neoadjuvant chemoradiotherapy in esophageal cancer. Ann. Surg. Oncol. 2007, 14, 3602–3609. [Google Scholar] [CrossRef] [PubMed]
- Belderbos, J.; Heemsbergen, W.; Hoogeman, M.; Pengel, K.; Rossi, M.; Lebesque, J. Acute esophageal toxicity in non-small cell lung cancer patients after high dose conformal radiotherapy. Radiother. Oncol. 2005, 75, 157–164. [Google Scholar] [CrossRef] [PubMed]
- Bots, W.T.C.; van den Bosch, S.; Zwijnenburg, E.M.; Dijkema, T.; van den Broek, G.B.; Weijs, W.L.J.; Verhoef, L.C.G.; Kaanders, J.H.A.M. Reirradiation of head and neck cancer: Long-term disease control and toxicity. Head Neck 2017, 39, 1122–1130. [Google Scholar] [CrossRef] [PubMed]
- Carvalho, S.; Troost, E.G.C.; Bons, J.; Menheere, P.; Lambin, P.; Oberije, C. Prognostic value of blood-biomarkers related to hypoxia, inflammation, immune response and tumour load in non-small cell lung cancer—A survival model with external validationPrognostic value of blood-biomarkers in NSCLC. Radiother. Oncol. 2016, 119, 487–494. [Google Scholar] [CrossRef]
- Janssens, G.O.; Rademakers, S.E.; Terhaard, C.H.; Doornaert, P.A.; Bijl, H.P.; Van Ende, P.D.; Chin, A.; Marres, H.A.; De Bree, R.; Van Der Kogel, A.J.; et al. Accelerated radiotherapy with carbogen and nicotinamide for laryngeal cancer: Results of a phase III randomized trial. J. Clin. Oncol. 2012, 30, 1777–1783. [Google Scholar] [CrossRef] [PubMed]
- Jochems, A.; Deist, T.M.; El Naqa, I.; Kessler, M.; Mayo, C.; Reeves, J.; Jolly, S.; Matuszak, M.; Ten Haken, R.; van Soest, J.; et al. Developing and validating a survival prediction model for NSCLC patients through distributed learning across 3 countries. Int. J. Radiat. Oncol. Biol. Phys. 2017, 99, 344–352. [Google Scholar] [CrossRef] [PubMed]
- Kwint, M.; Uijterlinde, W.I.; Nijkamp, J.; Chen, C.; de Bois, J.; Sonke, J.J.; van Herk, M.; van den Heuvel, M.M.; Belderbos, J. Acute esophagus toxicity in lung cancer patients after Intensity Modulated Radiotherapy and concurrent chemotherapy. Int. J. Radiat. Oncol. Biol. Phys. 2012, 84, 223–228. [Google Scholar] [CrossRef] [PubMed]
- Lustberg, T.; Bailey, M.; Thwaites, D.I.; Miller, A.; Carolan, M.; Holloway, L.; Velazquez, E.R.; Hoebers, F.; Dekker, A. Implementation of a rapid learning platform: Predicting 2-year survival in laryngeal carcinoma patients in a clinical setting. Oncotarget 2016, 7, 37288–37296. [Google Scholar] [CrossRef] [PubMed]
- Oberije, C.; De Ruysscher, D.; Houben, R.; Van De Heuvel, M.; Uyterlinde, W.; Deasy, J.O.; Belderbos, J.; Dingemans, A.M.C.; Rimner, A.; Din, S.; et al. A validated prediction model for overall survival from stage III non-small cell lung cancer: Toward survival prediction for individual patients. Int. J. Radiat. Oncol. Biol. Phys. 2015, 92, 935–944. [Google Scholar] [CrossRef]
- Olling, K.; Nyeng, D.W.; Wee, L. Predicting acute odynophagia during lung cancer radiotherapy using observations derived from patient-centred nursing care. Tech. Innov. Patient Support Radiat. Oncol. 2018, 5, 16–20. [Google Scholar] [CrossRef]
- Wijsman, R.; Dankers, F.J.W.M.; Troost, E.G.C.; Hoffmann, A.L.; van der Heijden, E.H.F.M.; de Geus-Oei, L.-F.; Bussink, J. Multivariable normal-tissue complication modeling of acute esophageal toxicity in advanced stage non-small cell lung cancer patients treated with intensity-modulated (chemo-)radiotherapy. Radiother. Oncol. 2015, 117, 49–54. [Google Scholar] [CrossRef] [PubMed]
- Wijsman, R.; Dankers, F.J.W.M.; Troost, E.G.C.; Hoffmann, A.L.; van der Heijden, E.H.F.M.; de Geus-Oei, L.F.; Bussink, J. Inclusion of incidental radiation dose to the cardiac atria and ventricles does not improve the prediction of radiation pneumonitis in advanced-stage non-small cell lung cancer patients treated with intensity modulated radiation therapy. Int. J. Radiat. Oncol. Biol. Phys. 2017, 99, 434–441. [Google Scholar] [CrossRef]
- Deist, T.M.; Dankers, F.J.W.M.; Valdes, G.; Wijsman, R.; Hsu, I.C.; Oberije, C.; Lustberg, T.; van Soest, J.; Hoebers, F.; Jochems, A.; et al. Machine learning algorithms for outcome prediction in (chemo)radiotherapy: An empirical comparison of classifiers. Med. Phys. 2018, 45, 3449–3459. [Google Scholar] [CrossRef] [PubMed]
- Van de Vijver, M.J.; Yudong, D.H.; van’t Veer, L.J.; Dai, H.; Hart, A.A.M.; Voskuil, D.W.; Schreiber, G.J.; Peterse, J.L.; Roberts, C. A gene-expression signature as a predictor of survival in breast cancer. N. Engl. J. Med. 2002, 347, 1999–2009. [Google Scholar] [CrossRef] [PubMed]
- Xu, X.; Zhang, Y.; Zou, L.; Wang, M.; Li, A. A gene signature for breast cancer prognosis using support vector machine. In Proceedings of the 5th International Conference on Biomedical Engineering and Informatics—BMEI 2012, Chongqing, China, 16–18 October 2012; pp. 928–931. [Google Scholar]
- Van’t Veer, L.J.; Dai, H.; Van de Vijver, M.J.; He, Y.D.; Hart, A.A.M.; Mao, M.; Peterse, H.L.; Van Der Kooy, K.; Marton, M.J.; Witteveen, A.T.; et al. Gene expression profiling predicts clinical outcome of breast cancer. Nature 2002, 415, 530–536. [Google Scholar] [CrossRef]
- Gevaert, O.; De Smet, F.; Timmerman, D.; Moreau, Y.; De Moor, B. Predicting the prognosis of breast cancer by integrating clinical and microarray data with Bayesian networks. Bioinformatics 2006, 22, e184–e190. [Google Scholar] [CrossRef]
- Park, K.; Ali, A.; Kim, D.; An, Y.; Kim, M.; Shin, H. Robust predictive model for evaluating breast cancer survivability. Eng. Appl. Artif. Intell. 2013, 26, 2194–2205. [Google Scholar] [CrossRef]
- Delen, D.; Walker, G.; Kadam, A. Predicting breast cancer survivability: A comparison of three data mining methods. Artif. Intell. Med. 2005, 34, 113–127. [Google Scholar] [CrossRef]
- Rosado, P.; Lequerica-Fernandez, P.; Villallain, L.; Peña, I.; Sánchez-Lasheras, F.; De Vicente, J.C. Survival model in oral squamous cell carcinoma based on clinicopathological parameters, molecular markers and support vector machines. Expert Syst. Appl. 2013, 40, 4770–4776. [Google Scholar] [CrossRef]
- Chen, Y.-C.; Ke, W.-C.; Chiu, H.-W. Risk classification of cancer survival using ANN with gene expression data from multiple laboratories. Comput. Biol. Med. 2014, 48, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Lynch, C.M.; Abdollahi, B.; Fuqua, J.D.; de Carlo, A.R.; Bartholomai, J.A.; Balgemann, R.N.; van Berkel, V.H.; Frieboes, H.B. Prediction of lung cancer patient survival via supervised machine learning classification techniques. Int. J. Med. Inform. 2017, 108, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Bychkov, D.; Linder, N.; Turkki, R.; Nordling, S.; Kovanen, P.E.; Verrill, C.; Walliander, M.; Lundin, M.; Haglund, C.; Lundin, J. Deep learning based tissue analysis predicts outcome in colorectal cancer. Sci. Rep. 2018, 8, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Zadeh Shirazi, A.; Fornaciari, E.; Bagherian, N.S.; Ebert, L.M.; Koszyca, B.; Gomez, G.A. DeepSurvNet: Deep survival convolutional network for brain cancer survival rate classification based on histopathological images. Med. Biol. Eng. Comput. 2020. [Google Scholar] [CrossRef] [PubMed]
- Zupan, B.; Demšar, J.; Kattan, M.W.; Beck, J.R.; Bratko, I. Machine learning for survival analysis: A case study on recurrence of prostate cancer. Artif. Intell. Med. 2000, 20, 59–75. [Google Scholar] [CrossRef]
- Kim, W.; Kim, K.S.; Lee, J.E.; Noh, D.Y.; Kim, S.W.; Jung, Y.S.; Park, M.Y.; Park, R.W. Development of novel breast cancer recurrence prediction model using support vector machine. J. Breast Cancer 2012, 15, 230–238. [Google Scholar] [CrossRef]
- McGranahan, N.; Swanton, C. Clonal heterogeneity and tumor evolution: Past, present, and the future. Cell 2017, 168, 613–628. [Google Scholar] [CrossRef]
- Greaves, M.; Maley, C.C. Clonal evolution in cancer. Nature 2012, 481, 306–313. [Google Scholar] [CrossRef]
- Hall, A.; Massagué, J. Cell regulation. Curr. Opin. Cell Biol. 2008, 20, 117–118. [Google Scholar] [CrossRef]
- Greenberg, E.S.; Chong, K.K.; Huynh, K.T.; Tanaka, R.; Hoon, D.S.B. Epigenetic biomarkers in skin cancer. Cancer Lett. 2012, 342, 170–177. [Google Scholar] [CrossRef]
- Mazar, J.; Khaitan, D.; DeBlasio, D.; Zhong, C.; Govindarajan, S.S.; Kopanathi, S.; Zhang, S.; Ray, A.; Perera, R.J. Epigenetic regulation of MicroRNA genes and the role of miR-34b in cell invasion and motility in human melanoma. PLoS ONE 2011, 6, e24922. [Google Scholar] [CrossRef]
- Mokhtari, R.B.; Homayouni, T.S.; Baluch, N.; Morgatskaya, E.; Kumar, S.; Das, B.; Yeger, H. Combination therapy in combating cancer. Oncotarget 2017, 8, 38022–38043. [Google Scholar] [CrossRef] [PubMed]
- Menden, M.P.; Wang, D.; Guan, Y.; Mason, M.J.; Szalai, B.; Bulusu, K.C.; Yu, T.; Kang, J.; Jeon, M.; Wolfinger, R.; et al. A cancer pharmacogenomic screen powering crowd-sourced advancement of drug combination prediction. bioRxiv 2017. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Kearney, V.; Chan, J.W.; Valdes, G.; Solberg, T.D.; Yom, S.S. The application of artificial intelligence in the IMRT planning process for head and neck cancer. Oral Oncol. 2018, 87, 111–116. [Google Scholar] [CrossRef]
- Zhu, W.; Xie, L.; Han, J.; Guo, X. The application of deep learning in cancer prognosis prediction. Cancers 2020, 12, 603. [Google Scholar] [CrossRef] [PubMed]
- Cox, D.R. Regression models and life-tables. J. R. Stat. Soc. Ser. B 1972, 34, 187–220. [Google Scholar] [CrossRef]
- Weinstein, J.N.; Collison, E.A.; Mills, G.B.; Shaw, K.R.M.; Ozenberger, B.A.; Ellrott, K.; Shmulevich, I.; Sander, C.; Stuart, J.M. The cancer genome atlas pan-cancer analysis project. Nat. Genet. 2013, 45, 1113–1120. [Google Scholar] [CrossRef]
- SEER. SEER Research Data 1975–2017—Surveillance, Epidemiology, and End Results (SEER) Program. 2019. Available online: www.seer.cancer.gov (accessed on 29 March 2021).
- Hutter, C.; Zenklusen, J.C. The Cancer Genome Atlas: Creating lasting value beyond its data. Cell 2018, 173, 283–285. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Cancer Type | AI Approach | Datasets | Software | Training Data Set Size | Data Types | Exp? | Reference |
|---|---|---|---|---|---|---|---|
| Lung | CNN 1 | BRFSS | Caffe | 235,673 | Text | Yes | [53] |
| Any | RF 2 | COSMIC, dbSNP | R, HMMER, Dojo | 200, 800 | Text | No | [54] |
| Any | SVM 3 | Cosmic, SwissVar, Swiss-Prot | Libsvm | 6326 | Text | No | [55] |
| Breast, Thyroid, Kidney | RF | TCGA:BRCA, TCGA:THCA, TCGA:KIRP | Java, Weka, YARN, MLlib | 897, 571, 321 | Text | No | [56] |
| DT 4 | TCGA:BRCA | unknown | 897 | Text | No | ||
| SVM | TCGA:BRCA | unknown | 897 | Text | No | ||
| BN | TCGA:BRCA | unknown | 897 | Text | No | ||
| CRC | BN | NSHDS | R, Visualizations with Cytoscape | 1676 | Text | Yes | [57] |
| Breast | ANN 5 | Private | Matlab | 62,219 | Images, Text | No | [58] |
| CNN, SVM | unknown | R | 500 | Images, Text | No | [59] | |
| CNN, KNN 6 | unknown | R | 500 | Images, Text | No | ||
| GBM 7, SVM | KBCP, OBCS | XGBoost, Sklearn, esyN, Matplotlib, Python | 696, 923 | Text | Yes | [60] | |
| Gastric | GBM | Private | XGBoost | 1431 | Text | No | [61] |
| LR 8 | Private | unknown | 1431 | Text | No | ||
| Skin | ANN | NHIS | unknown | 462,630 | Text | No | [62] |
| Ovarian | KNN, LDA 9, SVM, ELM 10 | IOTA tumor images database | Matlab | 348 | Images | No | [63] |
| Cervical | CNN | Private | Caffe | 20,000 | Images | No | [64] |
| Cancer Type | AI Approach | Datasets | Software | Training Data Set Size | Data Types | Exp? | Reference |
|---|---|---|---|---|---|---|---|
| CRC | KNN, SVM, GBM, ANN, DT, RF | GEO, ArrayExpress | R | 50 | Text | Yes | [65] |
| LR, DT, GBM | BioStudies database | Python, R | 800 | Text | Yes | [66] | |
| Breast | SVM, ANN, Regression | unknown | SPSS, R | 733 | Text | No | [67] |
| SVM, ANN, DT | ICBC | Weka | 1189 | Text | No | [68] | |
| SVM, RO 1 | BioBIM | Java | 318 | Text | Yes | [69] | |
| Breast | SSL 2 | GEO, I2D | C++ | 194,988 | Text | Yes | [70] |
| CRC | |||||||
| Oral | BN, ANN, SVM, DT, RF | unknown | unknown | 86 | Text, Images | Yes | [71] |
| Cervical | SVM, DT, ELM | Chung Shan Medical University Hospital Tumor Registry | unknown | 168 | Text | Yes | [72] |
| Cancer Type | AI Approach | Datasets | Software | Training Dataset Size | Data Types | Exp? | Reference |
|---|---|---|---|---|---|---|---|
| Lung | RF | Multicenter Clinical Trials | Matlab2016, SPSS23 | 72, 32, 31 | Images | No | [73] |
| Lung | TL 1 | TRACERx, [74,75] | ClonEvol | 768 | CCF, binary data | Yes | [76] |
| Breast | |||||||
| Renal | |||||||
| CRC | |||||||
| Lung | RNN | TCGA | Matlab | 506, 253 | Numbers | No | [77] |
| CRC | |||||||
| Breast | ANN | [78] | unknown | 16 | Numbers | No | [79] |
| Head and Neck | LR | GSE57441, GSE9844 | GraphPad Prism | 330 | Mass spectra | No | [80] |
| Skin | Weka-FCBF 2, SVM, PCA 3, ExtraTrees, KNN, RF, LR, Ridge | TCGA | caret, scikit, OmicsMarkeR, Rtsne, scatterplot3d | 371, 354, 371 | Numbers | No | [81] |
| Cancer Type | AI Approach | Datasets | Software | Training Dataset Size | Data Types | Exp? | Reference |
|---|---|---|---|---|---|---|---|
| Prostate | ANN | UCSD #140520 study | unknown | 66 | Text, Images | unknown | [82] |
| ANN | UCSD #140520 study | unknown | 66 | Text, Images | No | [83] | |
| CNN | unknown | Keras, Tensorflow | 72 | Images | No | [84] | |
| Breast | DSS 1 | Local database | unknown | unknown | DB-stored medical records | Yes | [85] |
| Any | LR, SVM, RF, GBM | AstraZeneca, DREAM consortium | sklearn, xgboost | 2790 | Numbers | Yes | [86] |
| MVA 2 on Undirected Graphs | GDSC, CCLE, CTRP | R, Matplotlib, Graphviz | 700 | CSV, Text | Yes | [87] | |
| ANN | [88] | TensorFlow | 23,062 | Compounds, Cell lines | Yes | [89] | |
| RF | Princess Margaret Cancer Centre | unknown | 383 | Images | No | [90] | |
| CNN | PASCAL VOC 2012 | TensorFlow | 1464 | Images | No | [91] | |
| CNN | PASCAL VOC 2012 | Caffe, TensorFlow | 1464 | Images | No | [92] | |
| ANN | NCI database | unknown | 141 | Text | Yes | [93] |
| Cancer Type | AI Approach | Datasets | Software | Training Dataset Size | Data Types | Exp? | Reference |
|---|---|---|---|---|---|---|---|
| CRC | CNN | Akershus University Hospital, Aker University Hospital, Gloucester Colorectal Cancer Study, VICTOR trial | TensorFlow | 12×106 | Images | No | [94] |
| RF | Teikyo University Hospital, Gifo University Hospital | unknown | 54 | Medical Records | No | [95] | |
| RF, SVM, ANN, DT, KNN, GBM | GSE19860, GSE28702, GSE72970 | caret, class, e1071, gbm, tree, randomForest, RSNNS | 50 | Raw data | No | [65] | |
| LR, DT, GBM | BioStudies database | Scikit-learn, R | 800 | Excel | No | [66] | |
| BN | ACTUR database | NCSS | 5301 | DB-stored medical records | Yes | [96] | |
| RF, ANN | Genomics of Drug Sensitivity in Cancer portal | Encog, randomForest | 38,930 | Raw data | No | [97] | |
| SVM | GSE19860, GSE28702, GSE72970 | e1071 | 144 | Raw data | No | [98] | |
| RF | GSE52735, GSE62080, GSE69657 | limma, glmnet, Boruta, randomForest, pROC | 58 | Raw data | No | [99] | |
| SVM, LR | unknown | Orange | 38 | unknown | No | [100] | |
| SVM | Val d’Aurelle Regional Cancer Center | MAS 5.0 | 5 to 19 | Numbers | No | [101] | |
| Breast | Diagonal LDA, KNN | Nellie B. Connally Breast Center, M.D. Anderson Cancer Center, Instituto Nacional de Enfermedades Neoplásicas de Lima | dCHIP | 133 | Text, Numbers | No | [102] |
| SVM, Recursive Feature Elimination | University of Heidelberg | e1071, ROC | 52, 48 | Numbers | No | [103] | |
| LR | unknown | unknown | 84 | Numbers | No | [104] | |
| Bladder | DT | University of Southern California | SPSS | 948 | Numbers | No | [105] |
| Blood | LDA | FRALLE93 protocol | unknown | 32 | Numbers | No | [106] |
| Renal | SVM | National Wilms Tumor Study-5 | e1071 | 250 | Numbers | No | [107] |
| Ovary | Binary LR, Stochastic Regression | Duke University Medical Center, H. Lee Moffitt Cancer Center and Research Institute | Bioconductor | 83 | Numbers | No | [108] |
| Esophageal | SVM | unknown | unknown | 46 | Text, Numbers | No | [109] |
| Lung | DT, RF, ANN, SVM, LR, GBM | [110,111,112,113,114,115,116], Morin (forthcoming), [117,118,119,120] | caret | 156, 137, 363, 179, 327, 139, 922, 257, 548, 131, 149, 188 | Text | Yes | [121] |
| Head and Neck | |||||||
| Meningioma | |||||||
| Laryngeal |
| Cancer Type | AI Approach | Datasets | Software | Training Dataset Size | Data Types | Exp? | Reference |
|---|---|---|---|---|---|---|---|
| Breast | SVM | [122] | unknown | 295 | Numbers | No | [123] |
| BN | [124] | unknown | 97 | Numbers | Yes | [125] | |
| SSL | SEER database | unknown | 162,500 | DB-stored medical records | No | [126] | |
| SSL Co-training | SEER database | unknown | 162,500 | DB-stored medical records | No | [67] | |
| ANN, LR, DT | SEER database | unknown | 200,000 | DB-stored medical records | Yes | [127] | |
| Oral | SVM | unknown | unknown | 69 | unknown | No | [128] |
| Any | ANN | unknown | unknown | 440 | unknown | No | [129] |
| Lung | Linear Regression, DT, SVM, GBM, Custom1 | SEER database | R | 7830 | DB-stored medical records | Yes | [130] |
| CRC | CNN, RNN | Helsinki University Central Hospital | Keras | 420 | Images | Yes | [131] |
| Brain | CNN | TCGA, South Australian public hospital system | Keras, Tensorflow | 679 | Images | Yes | [132] |
| Prostate | DT, BN, Cox | The Methodist Hospital | S-PLUS | 1050 | Text | Yes | [133] |
| Task | Ref. | Code Availability 1 |
|---|---|---|
| Predict cancer risk | [60] | https://github.com/hambeh/breast-cancer-risk-prediction |
| [56] | https://github.com/fcproj/BIGBIOCL | |
| Predict progression | [77] | https://github.com/noamaus/LSTM-Mutational-series |
| [81] | https://webs.iiitd.edu.in/raghava/cancerspp/ | |
| Predictrecurrence | [134] | http://ami.ajou.ac.kr/bcr/ |
| Estimate drug synergy | [85] | https://protege.stanford.edu/ |
| [86] | https://github.com/rcelebi/dream-drugcombohttps://www.synapse.org/#!Synapse:syn5605365/wiki/394725 | |
| [87] | https://github.com/szen95/SEABED | |
| [89] | http://www.bioinf.jku.at/software/DeepSynergy/ | |
| [91] | https://github.com/tensorflow/models/tree/master/research/deeplab | |
| [92] | http://liangchiehchen.com/projects/DeepLab.html | |
| Predict therapy outcome | [121] | https://github.com/timodeist/classifier_selection_code |
| Predict survival | [126] | http://embio.yonsei.ac.kr/Park/ssl.php |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Banegas-Luna, A.J.; Peña-García, J.; Iftene, A.; Guadagni, F.; Ferroni, P.; Scarpato, N.; Zanzotto, F.M.; Bueno-Crespo, A.; Pérez-Sánchez, H. Towards the Interpretability of Machine Learning Predictions for Medical Applications Targeting Personalised Therapies: A Cancer Case Survey. Int. J. Mol. Sci. 2021, 22, 4394. https://doi.org/10.3390/ijms22094394
Banegas-Luna AJ, Peña-García J, Iftene A, Guadagni F, Ferroni P, Scarpato N, Zanzotto FM, Bueno-Crespo A, Pérez-Sánchez H. Towards the Interpretability of Machine Learning Predictions for Medical Applications Targeting Personalised Therapies: A Cancer Case Survey. International Journal of Molecular Sciences. 2021; 22(9):4394. https://doi.org/10.3390/ijms22094394
Chicago/Turabian StyleBanegas-Luna, Antonio Jesús, Jorge Peña-García, Adrian Iftene, Fiorella Guadagni, Patrizia Ferroni, Noemi Scarpato, Fabio Massimo Zanzotto, Andrés Bueno-Crespo, and Horacio Pérez-Sánchez. 2021. "Towards the Interpretability of Machine Learning Predictions for Medical Applications Targeting Personalised Therapies: A Cancer Case Survey" International Journal of Molecular Sciences 22, no. 9: 4394. https://doi.org/10.3390/ijms22094394
APA StyleBanegas-Luna, A. J., Peña-García, J., Iftene, A., Guadagni, F., Ferroni, P., Scarpato, N., Zanzotto, F. M., Bueno-Crespo, A., & Pérez-Sánchez, H. (2021). Towards the Interpretability of Machine Learning Predictions for Medical Applications Targeting Personalised Therapies: A Cancer Case Survey. International Journal of Molecular Sciences, 22(9), 4394. https://doi.org/10.3390/ijms22094394