Abstract
We present a novel derivation of the multipole interaction (energies, forces and fields) in spherical harmonics, which results in an expression that is able to exactly reproduce the results of earlier Cartesian formulations. Our method follows the derivations of Smith (W. Smith, CCP5 Newsletter 1998, 46, 18.) and Lin (D. Lin, J. Chem. Phys. 2015, 143, 114115), who evaluate the Ewald sum for multipoles in Cartesian form, and then shows how the resulting expressions can be converted into spherical harmonics, where the conversion is performed by establishing a relation between an inner product on the space of symmetric traceless Cartesian tensors, and an inner product on the space of harmonic polynomials on the unit sphere. We also introduce a diagrammatic method for keeping track of the terms in the multipole interaction expression, such that the total electrostatic energy can be viewed as a ‘sum over diagrams’, and where the conversion to spherical harmonics is represented by ‘braiding’ subsets of Cartesian components together. For multipoles of maximum rank n, our algorithm is found to have scaling of vs. for our most optimised Cartesian implementation.
1. Introduction
Point-charge electrostatic models have been a mainstay of molecular simulation for years. Increasing in sophistication, many authors have also implemented dipole interactions, such that the electrostatics on each nuclear site is modelled by the combination of a dipole and a charge, which requires that the simulation code be capable of calculating both charge–dipole and dipole–dipole interactions in addition to the usual charge–charge interactions required for point charge models. This presented particular problems for treatment of long-range interactions, as typically handled by an Ewald sum, or related schemes, as such algorithms were initially developed for the case of point charge models, and thus needed to be modified in order to account for dipole interactions. Fortunately, the problem of adapting Ewald sums for dipoles has largely been solved, and, Smith [1] in particular has provided a formulation which is well organised and easy to follow.
In recent years, some groups have moved even beyond the dipole level, exploring the use of yet higher terms in the multipole expansion of the charge distribution, where the terms in the next three ranks are referred to by names quadrupole, octopole and hexadecapole. Again though, the problem is faced—how to implement these terms in a simulation code, and how to modify an Ewald sum, or similar algorithm, such that it can properly handle the higher order multipoles interactions.
There is currently a strong need for such methods, given that there now exist reliable convenient methods to partition the charge distribution from electronic-structure calculations into atomic multipoles residing on each nuclear site, with the most notable method being the Distributed Multipole Analysis (DMA) approach of Stone and coworkers [2,3,4]. DMA provides a particularly appealing route for the construction of accurate empirical models, because researchers should now be able take the values of atomic multipoles as output from a DMA analysis as input for their models. However, doing this depends, of course, on the ability to write code which can calculate the required multipole interactions, and this is far from trivial.
Progress has been made, with popular molecular-dynamics packages, such as DL-POLY [5] and TINKER [6] having functionality to evaluate potential-energy surfaces with multipole interactions. So, in a sense, this is a solved problem, but it is still worth exploring, given the complexity of the current approaches, if there are any ways to simplify the mathematical and computational approaches for computing multipole interactions.
Smith’s method can, in principle, be used up to arbitrary rank, and his original paper even includes the terms up to quadrupole. However, there is a noticeable increase in complexity and computational cost incurred by going up to higher ranks, such that the quadrupole terms are both more difficult to both derive and to calculate than the dipole terms, and, it seems like it would be a significant undertaking to extend this approach to yet higher ranks.
However, it was recently shown by Lin [7] that we do not have to derive the higher multipole terms “by hand”, as it were. Instead, it is possible to derive a more general formula which more or less automatically generates the expression for any degree multipole, without resorting to increasingly tedious algebra.
It is true that past formulations by Smith and others [8,9] are extendable to arbitrarily higher rank multipoles, but Lin’s work is, to our best knowledge, the first to give such a direct closed form expression for the interaction between multipoles of any rank. However, even Lin’s extension to Smith’s approach suffers from a drawback, which is that they both choose to evaluate the multipole interaction in Cartesians. Furthermore, this is a problem because, as it turns out, the Cartesian representation of multipoles is highly redundant. This is due to the presence of symmetries in the Cartesian representation, resulting in the use of far more numbers than is strictly required to represent each multipole, making it hard to calculate the multipole interactions in the minimal number of operations.
Bearing this in mind, it is possible to make many optimisations in the Cartesian implementation, such that these redundancies have relatively minimal impact. Most notably, it is possible to take advantage of the fact that the traces of the Cartesian tensors do not contribute to the total energies/forces of the multipole interaction, and so remove them, an approach that has been used with success by both Lin and Huang [10,11]. It is also possible to write the required sums in such a way that the redundancy from the remaining tensor symmetries is reduced.
However, to increase computational efficiency even further, what is really needed is an expression in which the multipoles are described by a completely non redundant basis. Furthermore, it has long been known that this is provided by moving from a Cartesian representation to spherical harmonics.
It could be argued that a Cartesian-multipole representation is more compatible with existing molecular dynamics codes, given they are normally mostly written in Cartesians. Furthermore, it is certainly true that most people prefer thinking in terms of Cartesians, than the somewhat complex spherical harmonics. However, the spherical harmonics approach ultimately proves to be faster, and more elegant, and so is arguably worth the extra effort for codes which make heavy use of multipoles.
Writing the interaction in terms of spherical harmonics is usually regarded as a formidable task, requiring mastery of the mathematics of manipulating these objects, and intimate knowledge of the spherical harmonics’ properties. Furthermore, the complexity is further multiplied when it comes to modifying the treatment of long-range interactions, such as when handled by Ewald sums. Even so, a derivation of the Ewald sum for multipoles has been given by Leslie [12], who described his implementation of multipoles in the DL-MULTI software package, which can be interfaced with DL-POLY [5] molecular dynamics software package. Leslie gave the expression for the Ewald sum form of the multipole interaction in terms of Stone’s S functions. These functions, which are derived in ref. [13], act give the interaction tensor components between two multipoles on different sites, each described in their local reference frames, where the necessary orientational information is described by Wigner rotation matrices, and where the S function also contains a spherical harmonic, which acts to mediate the interaction between.
Another derivation has recently been given by Simmonett et al. [14] who proposed a method for converting the Ewald sum into the spherical harmonic formulation of Stone, which required the aid of symbolic algebra package to derive. Furthermore, the resulting expression requires the calculation of hard to interpret ‘contamination terms’ in the tensorial interactions between the multipoles, which arise from the modification of the multipole interaction due to the Gaussian screening functions that are present in the real-space part of the Ewald sum. Although the above derivations appear complete and satisfactory, they do depend on fairly technical knowledge, which is presumably why many in the community have been slow to implement such approaches.
In the present contribution, we aim to rectify this situation by providing a surprisingly straightforward derivation of the multipole interaction in spherical harmonics which, unusually, does not require any detailed technical knowledge of the theory of spherical harmonics. Our method provides a direct connection between the Cartesian and spherical harmonic representations, such that it becomes straightforward to transform between the two representations, and our final expressions lend themselves to being easily implemented in Ewald sum type methods. Now, we seek to provide a comprehensive account of the full development of this Cartesian formulation, so this will necessarily involve some presentation of relatively well-known, pervious material in the theory and (spherical-harmonics) presentation and treatment of multipoles. Still, in the present contribution, we wish to provide a full, and self-contained development of a Cartesian formulation, in addition to an intuitive associated graphical representation.
We do not claim that the resulting expressions are superior to previous derivations, such as that given by Leslie and Simmonett et al.; we are full of admiration for their work. However, the approach presented here is significantly different to standard derivations, which makes it interesting in itself, and our resulting expressions are also in a different form, though they must be completely equivalent in their predictions, to those obtained with other methods. We also think our approach will be of interest in showing how the Smith and Lin method for Cartesian multipoles can be transformed into a spherical harmonic equivalent, while preserving the essential structure of their solution.
It would, of course, be of enormous interest to find a reasonably direct way of connecting our expressions for the multipole interaction in spherical harmonics to those produced by other derivations. However, this appears far from trivial, given we have taken what seems to be such a radically different approach to that used by other authors.
Our approach is also very much inspired by the work of Applequist [15,16], who published two papers detailing some quite beautiful theorems on the deep connection between homogeneous polynomials and Cartesian tensors, and also on the properties of the Maxwell Cartesian spherical harmonics, which are the natural Cartesian analogues of the spherical harmonics, both of which we will have cause to use in the course of this work.
Our approach is summarised as follows. We first essentially follow the approaches of Smith and Lin to give the multipole interactions in terms of Cartesians. We then proceed to show how this interaction can be converted into spherical harmonic form. This is done with the aid of three key ideas. (i) the use of a diagrammatic representation of the interaction between multipole sites, which greatly clarifies the math, as it turns out the complete interaction can be calculated in a ‘sum over diagrams’ type sense. (ii) the use of spherical harmonics to construct an orthogonal basis for the traceless multipole tensors, such that the Cartesian to spherical harmonic conversion can be achieved by way of Stone’s tables of spherical harmonics, as given in reference [13]. (iii) the recognition that the multipole interaction can be written in terms of so-called tensor inner products, which we will show are proportional to inner products involving spherical harmonics, allowing us to convert the entire multipole interaction into spherical-harmonic form.
2. Results
2.1. The Multipole Expansion
Consider a cluster of charges, with charges , at positions , where the is used to signify that the displacements are typically quite small (at least, they are closer to than any test sites probing the fields from the distribution). We then define the rank-n Cartesian multipole tensors (n = 0,1,…), , of the distribution, with respect to , according to
where is a tensor product, with Cartesian components , in which each Greek index is one of , and there being factors of type in the product. Furthermore, where, for n = 0, the tensor becomes unity: (see Section 4.1).
Note: In Equation (1), and throughout, we are following Smith in subsuming the inverse factorial in the definition of each multipole, but we warn that other authors use different conventions, and it is important to check which convention is being used when comparing different works.
The rank 0 multipole, , which is a scalar, is just the sum of the charge. The rank 1 multipole multipole is referred to as the dipole moment, and is a vector with components , , . The rank 2 multipole, is called the quadrupole, and has 9 components: , , , etc., and the rank 3 multipole with 27 components is called the hexadecapole, and so on.
It is clear from their definition in Equation (1). that each multipole tensor is symmetric under any permutation of its indices; e.g., for the rank-3 multipole tensor, . Furthermore, it can be shown that the same is true in any axis frame. This permutation symmetry means that the multipole tensors belong to a class that are referred to as symmetric tensors, and we will have frequent cause to make use of this symmetry throughout this work.
The multipoles are useful because the electrostatic properties of the cluster can often be written in terms of a rapidly converging series over multipole moments of increasing rank, rather than having to sum over the individual charges themselves. To see this, let us place the charge distribution in a background non-uniform electrostatic potential, . Then, the electrostatic energy, , of the cluster due to is given by
Now, using the inner product notation , where indicates an inner product over tensors and (see Section 4.1)
the Taylor series expansion of can be written as
where with components (again, see Section 4.1).
Now, defining the rank n symmetric electrostatic field tensors from
Furthermore, substituting Equation (4) into Equation (2) and using Equation (1), we can rewrite the energy expression as
Similarly, it can be shown from the elementary theory of multipoles, and from using another Taylor series expansion, that the electrostatic potential at , from a charge cluster around the origin, with multipoles is given by
where we have set to simplify the formulae.
Thus, assuming the above series converges, and we wish to calculate the electrostatic potential from the charge cluster, we are justified in ignoring the fine details of the charge distribution and just working with its multipoles up to a maximum rank, where these multipoles are calculated from the multipole expansion of the charge distribution in Equation (1), and where we imagine the multipoles are placed on the multipole expansion site, in this case at the origin.
2.2. Traceless Tensors and the Detracing Operator
The trace of a rank 2 tensor is given by the sum of its diagonal elements,
In general, and following Applequist [15] (Section 2.3), we will define the trace of a rank n symmetric Cartesian tensor as
where the trace tensor, , is a symmetric tensor of rank n − 2.
Tensors for which = will be referred to as traceless. In fact, we have already encountered two such tensors: (i) the tensor, defined in Equation (5) above, and (ii) the tensor which occurs in Equation (7).
To show that the tensor is traceless, we combine Equations (5) and (9) to obtain
where we have used the fact that the electrostatic potential in free space is a solution to Laplace’s eqn, . Thus, is traceless, and, given that is just the potential from a unit charge, a similar argument shows that is also traceless.
As an aside, it may be argued that in real systems the Laplacian is not zero, because any real atomic site will experience a non-zero charge-density from the inter-atomic and inter-molecular charge-clouds from the other electrons. However, the standard multipole expansion for the interatomic electrostatic energy does not account for such effects, and they will henceforth be assumed to be zero.
The addition of any two rank n traceless tensors, or the multiplication of a traceless tensor by a scalar will result in another traceless tensor. Thus, the traceless tensors of rank n form a vector subspace of rank n tensors. As such we ought to be able to find a projection operator which projects out the non-traceless part of any rank n symmetric tensor. For example, we might (correctly) guess that the rank 2 tensor has the traceless projection . Furthermore, we will now show how to find this projection in general.
Before we begin, it is convenient to introduce tensors, , with components , and where by convention (see Section 4.1).
We will now make use of a theorem due to Hobson, [17] which has been extensively discussed by Applequist, ref [15,16] that the projection of the tensors onto the subspace of traceless tensors is given by
where is the so-called detracing projection operator onto the subspace of traceless tensors, and where is the traceless tensor resulting from the projection of into that traceless subspace. Furthermore, where that is traceless follows immediately from the traceless nature of .
Applequist refers to as the Maxwell Cartesian spherical harmonics, given that these gradients were investigated by James Clerk Maxwell [18], and given that, although they are not orthogonal, they behave in many senses like the Cartesian analogue of the spherical harmonic polynomials, of which more later.
For the moment we can think of the operator as being defined by Equation (11), and so our job is to show that defined this way is indeed the detracing projection operator.
Firstly, we need a way to express the action of on a general degree n tensor. Applequist has provided a closed-form expression for the matrix representation of [15], but here we will show a perhaps easier method, which is to infer these coefficients from Equation (11).
This is perhaps easiest shown by way of example. From Equation (11), and calculating the repeated derivatives of , we find that
where the term in brackets corresponds to a sum over all distinct permutations of the indices.
We can now define the action of the operator on a general tensor, , through substituting components of for those of , which gives
We will now show that the are traceless. Starting from a result from Applequist [15] (Section 3.3) that it always possible to find vectors such that any degree n tensor can be expressed as a linear combination in , viz
We then apply the operator to both sides of the above to give
and given that every is traceless we have that must also be traceless, which was to be shown.
To show that is a proection operator onto the subspace of traceless tensors we first note that every term in in Equations (12)–(15) is of the form
where C is some constant and where it is easy to show that there must be m Kronecker deltas if the term is to be dimensionally correct. That each term must be in this form can be shown from induction on the repeated directional derivatives of .
Looking again at Equations (12)–(15), we also see that, for each degree n, there is always a first term with m = 0, i.e., containing no factors of , or Kronecker deltas, which is given by . Again, this can be shown from induction.
Now, consider what happens when we make the substitution from to in expression 22, which gives
where the sum involves taking m traces of . Then if is a traceless tensor, the above must be equal to zero for every term except the m = 0 term, which is equal to . Furthermore, it follows that .
In general, we have that is not traceless, but given that, for any , we have already shown that is traceless, we also have that , and so . It follows that is the detracing projection operator, which projects onto the entire subspace of traceless tensors.
2.3. The Multipole Interaction in Terms of Traceless Tensors
In this section, we will show how the multipole interaction can be written in terms of traceless tensors.
We begin with an observation that If is a rank n tensor and is a traceless tensor of the same rank, then the inner product .
To see this, write , where is the traceless part of , and is the non-traceless remainder, then , because is completely outside the traceless subspace as a result of this decomposition, by construction, and the result follows.
We will now show that the traces of the multipole tensors make no contribution to the energies forces and torques, and so can be set to zero if desired.
Given that is traceless, we can use the above theorem to show that the inner product in Equation (6) can be written as either , and similarly, the inner product in Equation (7) can also be written using either or , without making any difference to the result.
We have shown that the energy of a multipole in a background field is independent of its trace, and the field from a multipole, as given by Equation (7) is also independent of the multipole traces. Thus, the energies of any set of interacting multipoles are also independent of their traces, and the same is true for all the forces and torques being that they involve gradients of the energy.
Finally, we will show that the electrostatic potential from a multipole distribution at a given point in space can be written in terms of the traceless tensors and . Substitution of Equation (11) into Equation (7) gives
Furthermore, given the claim at the start of this section, we could use the substitutions in the above.
2.4. The Multipole Interaction Generating Formula
The gradients play a central role in the theory of multipoles, as should already be evident from the last section. However, as shown by Smith, the Ewald sum analogue of the multipole interaction requires the calculation of more general gradients, in which spherically symmetric functions, here written as , are substituted for the terms in equalities like Equation (7). That is, instead of calculating the gradients, we will now be interested in finding gradients , with the knowledge that, should we wish to find results for the non-Ewald regular multipole expansion then we can simply set in the final expressions.
In particular, the Ewald sum analogue to the normal multipole formulae requires using the kernel , where erfc(x) is the complimentary error function, which corresponds to the interaction of a unit charge with a negative Gaussian ‘screening’ density, where the screening density is of the form (suitably normalised).
To simplify these gradient calculations, Smith defines the radial functions, , where the zeroth term is given by , and with the higher order terms defined according to
from which it follows that if , then , , and, in general, , where is the double factorial.
As might be expected, the expressions are somewhat more complicated when the kernel is used, but the repeated derivatives for these functions can be readily evaluated in terms of Gaussian functions.
It is instructive to calculate the first few terms in the directional gradients of the functions. Begin by recalling that for a general spherically symmetric function, , we have that . It then follows that
from which the first two directional derivatives evaluate to
and
where the terms in brackets are the results for the particular choice of , and where we note that these terms can be written in terms of the Maxwell Cartesian spherical harmonics we encountered in Equation (11).
It is of course possible to continue calculating higher-order terms in this fashion, but the main point we want to make here is that the first two directional derivatives of above contain terms in , for some value of ; in general, as a consequence of the chain rule, it can be shown that gradient terms in every order can be expressed as a series in , where the th derivative requires calculated functions up to the th term.
Returning to the multipole problem, suppose that there are two multipole sites, and , at locations and respectively, each of which carry a set of multipoles of different ranks, where the multipoles are placed at the site locations. Then the electrostatic energy of this pair is due to each multipole on site interacting with every multipole on site , which can be determined by first evaluating the field at from the multipoles at according to Equation (7), and then calculating the energy of the multipoles on in the presence of that field according to Equation (5). Labelling this energy , we obtain
where is the inter-site vector, , are the directional derivatives with respect to and where we have used the more general form containing the kernel.
Similarly to how we found that every order term in the repeated derivatives of contain a series in , it is not difficult to see that the same must be true for the interaction energy, , and, following Smith, we can make this clear by collecting terms in to write
where the functions can be thought of as coefficients in .
Evaluating these functions would seem to require calculating and summing over the terms ‘by hand’, as it were, which would involve much tedious algebra. However, a closed form solution has been given by Lin [7], (cf. equation 4.3 in Lin’s paper) and we simply state without proof that it is given by
where (see Section 4.1); the multipoles are all assumed to be traceless; the notation indicates a d-fold contraction over the tensor indices of and (again, see Section 4.1); is the number of contractions in the bracket containing ; is the number of contractions in the bracket containing ; is the number of contractions acting in the centre, between the two brackets, which we have expressed as an inner product; and where are integer combinatorial coefficients, given by
We also have that the sum in Equation (31) is over all , where ; , i.e., the sum is over all possible terms having contractions.
We will refer to Equation (31) as the multipole interaction generating formula, as it generates all the terms in the multipole-multipole expansion of the electrostatic energy. Its derivation is not too difficult, if a little tedious, and essentially involves expanding out the repeated derivatives of the functions, and using combinatorics to find the number of symmetrically equivalent terms.
The functions up to rank 3 are given in Section 4.1, from which it is readily apparent that the total number of dots, i.e., the number of contractions, in each term of the th function is equal to , which is also apparent from the structure of Equation (31).
Claim 1.
The traces of both the tensors and the tensors make no contribution to the multipole interaction generating formula.
Sketch of Proof: For the multipoles, this follows straightforwardly from the trace condition that all multipole tensors must be traceless. Furthermore, that the same applies to the tensors follows from the fact that their indices are completely contracted with the traceless tensors, and then using a similar argument to that used in Section 1 for the traceless multipoles. Q.E.D.
We have shown that it is possible to detrace the tensors in the sum of Equation (31). However, we will generally prefer to work with the tensors in their simpler, untraced, form, unless we have cause otherwise.
One of the real advantages of the Smith and Lin method for deriving the multipole interactions is that it provides a clean separation between the functions, which depend on the traceless tensor components, and the spherically symmetric kernel dependent part, which are described by the functions. This suggests that the Smith and Lin approach may provide a useful starting point for converting the multipole interaction into spherical harmonics, and later on, we shall show how this can be done.
2.5. The Diagrammatic Representation
It is possible to construct a diagrammatic representation of the multipole interaction generating formula of Equation (31), where one such diagram is shown in Figure 1. The figure shows one term in the formula for , corresponding to . The rules being that each node represents a different tensor, where its rank is given by the number of spokes radiating from the node in question; the number of spokes shared between two nodes is equal to the degree of the contraction acting between the corresponding tensors; and the sign of the diagram is taken to be negative when there are an odd number of bonds connecting the multipole with its tensor.

Figure 1.
A term in the multipole interaction generating formula for , corresponding to , where the nodes from left to right represent (black circle), (red circle), (green circle) and (black circle).
Theorem 1.
The complete expression for the th term involves the sum over all -bond diagrams, where the spokes on each multipole tensor are treated as distinct, and where no tensor is allowed to bond to itself.
Proof.
The total number of bonds is equal to the total number of contractions which is given by , which is the range of the sum in Equation (31). Assume that the spokes on each multipole are distinct, such that it is possible to label the spokes on both multipoles. Then the integer coefficients of Equation (32) are seen to be the number of unique ways of arranging the spokes on both the and multipoles for the topology described by contractions . Furthermore, the negative sign mentioned above is a consequence of the factor in Equation (32). Q.E.D. □
We also stated that no tensor may bond to itself. Given that a self-bond corresponds to taking the partial trace of a tensor, this rule follows directly from the fact that the traces of the and tensors make no contribution to the multipole interaction generating formula, as established in the last section.
The diagrammatic representation is by no means essential for following the math in this work, but it does provide a useful mnemonic for keeping track of the various terms in the multipole interaction. Furthermore, it will be interesting to see whether such a simple picture can still be constructed when we come to convert these expressions into spherical harmonics.
2.6. Forces, Fields, Angular Derivatives and Torques
We are generally interested in more than just calculating the total energy, and for completeness, this section will detail how to calculate the forces, multipole fields, angular derivatives and torques, all of which are commonly required when implementing multipole interactions into molecular-simulation code.
We begin with the forces. Let be the force on multipole site due to its interaction with multipoles site , where the total force on is given by .
The force is found through taking the gradient of Equation (30) and evaluates to
where we have used Equation (26) to find the gradient of the function, and where the functions are found from taking the gradient of Equation (31), and are given by
The functions up to rank 3 are listed in Section 4.2.
A diagrammatic representation of one force term is shown in Figure 2, which corresponds to taking the gradient of the interaction from Figure 1. Comparing Figure 1 and Figure 2, it can be seen that taking the gradient results in breaking one of the bonds connecting either the or multipole with its tensor. This leaves the multipole with a bare (or unbonded) spoke, which means that, taken as a whole, we have a diagrammatic representation of a rank 1 vector.
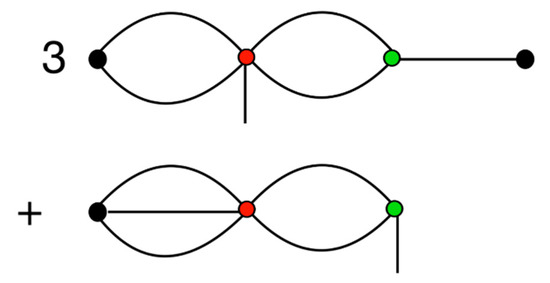
Figure 2.
A force term obtained from taking the gradient of the term in Figure 1, which equates to .
We have already provided an expression for the total energy of the system, but an arguably more elegant expression for the energy is in terms of multipole field tensors, according to
where is the rank n field tensor on site , which is defined from
Equation (35), which is written in terms of multipole fields has the distinct advantage that it allows for an automatic decomposition of the total energy into contributions from the different multipole ranks, i.e., charge, dipole, quadrupole etc. Furthermore, another reason why we may want to calculate the fields is that it greatly simplifies calculation of angular derivatives and torques, to be given in the next section.
The fields can be calculated by finding the derivative of the energy with respect to each multipole. Looking at just one pair of multipole sites, the field on multipole site due to the multipoles on site is given by
where, taking the derivative of Equation (31) with respect to the multipoles we obtain
where SYMM indicates that the resulting tensor elements are to be symmetrised over all index permutations, and for their traces to be removed.
This final step is necessary to ensure that the field tensors have the same symmetries as their corresponding multipoles, given that per their definition, the field tensors must be unchanged with respect to any permutation of their indices. Furthermore, the removal of the traces is because the field traces make no contribution to the energy, and so it makes sense that these are set to zero.
A diagrammatic representation of the field calculation is shown in Figure 3, in which the rank 5 field on and the rank 3 field on , corresponding to the multipole interaction in Figure 1, are shown. Both diagrams can be thought of as cutting a multipole free from Figure 1, which corresponds to taking the derivative with respect to that multipole.
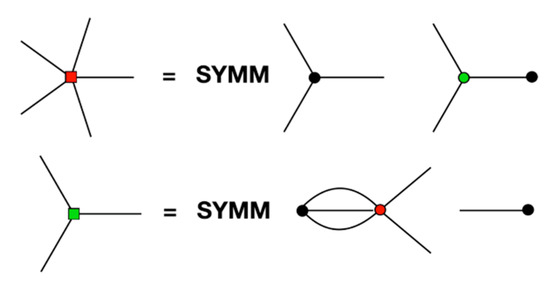
Figure 3.
Representation of the multipole field terms for the interaction in Figure 1. The spokes radiating from coloured squares represent multipole fields tensors, of rank given by their number of spokes. The star with the central red square represents the rank-5 field tensor on the i site, and the star with the central green square represents the rank-3 field tensor on the j site.
In order that we may calculate the angular derivatives of the energy, let be orthogonal rotation matrices which transform vector components from the reference frame to the laboratory frame (see Section 4.1). Furthermore, suppose that , where are (three) Euler angles (e.g., see ref. [19]) and we wish to find the energy derivatives with respect to these angles. Taking the Euler angle as an example, use the chain rule to obtain the contribution from the rank n multipole as
where we have used Equation (78) from Section 4.1 to relate the components of the multipole tensor to their components in the reference frame, and where the factor of in the above derives from the index permutation symmetry of and , such that it can be shown that each of the n terms involving derivatives of the rotation matrices are identical, and so can be added together.
The torques may be evaluated from the energy derivatives with respect to rotations about each axis. First consider an infinitesimal rotation by about the axis. If a vector has the value after the rotation, then we have , which has components
where is the Levi-Civita symbol, , , and otherwise.
It will prove useful to recast Equation (40) in terms of a rotation matrix. We have , where is given by
The components of the torque, , are obtained from substitution of the above into Equation (39) to give
where we have used , and , both of which can be deduced from Equation (41).
A diagrammatic representation of the torque for one multipole is given in Figure 4.
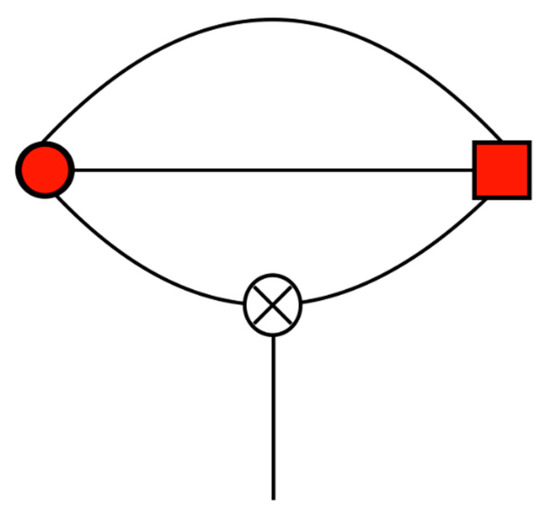
Figure 4.
The (negative of) the torque on a rank-3 multipole. The red circle represents the multipole, the red square is its rank-3 field, and the circle with the cross represents a rank-1 vector cross product.
2.7. Polynomials and Symmetric Tensors
This section explores the deep connection between homogeneous polynomials and symmetric tensors, covering similar ground to the treatment by Applequist [15].
We begin with introducing some useful notation. Suppose that is a symmetric Cartesian tensor component where the index contains occurrences of , occurrences of and occurrences of . Defining , it will be useful to introduce what Applequist refers to as compressed tensor notation, in which we write
where, in total, there is a multinomial of permutations of the indices belonging to a particular .
Now suppose that is a homogeneous polynomial of degree n, such that , where is a scalar. For example, a degree 3 homogenous polynomial is given by .
To express in general form, we use compressed notation to write , and we will label the monomial coefficient in the component as . The bar is used to signify that the are monomial coefficients, although we will shortly see that the can also be interpreted as tensor components.
In terms of the polynomial coefficients , we can express any degree n homogeneous polynomial as
where the sum is over all values of for which , and where we have also introduced the symmetric Cartesian tensor, .
To clarify the above, it may help to take an example. The second order polynomial, , can be written as either
or
where we have used the permutation symmetry of .
Equating terms in the polynomial, we have , and , and similarly for other terms. In general, is related to by
where the inverse multinomial coefficients are required due to the permutation symmetry of the indices.
We can also form inner products, , which can be evaluated as
Given that encodes all the information in the polynomial coefficients, i.e., there is a one to one mapping between the polynomial coefficients and the tensor components, we can think of as being the symmetric tensor form of .
Technically, is a so-called covariant tensor, which transforms under rotations in the opposite sense to . To see why, consider a rotation of the coordinate system
where is the orthogonal tensor rotation matrix, (See Section 4.1.)
This shows that we can find from either transforming the components of by the usual orthogonal rotation , or, we can do it by transforming the components of by the inverse rotation .
The tensor may also be obtained from the polynomial itself by way of a linear operator, , according to
which may be seen by applying the above gradient operator to Equation (44). Note that because we are taking n derivatives of a degree-n homogeneous polynomial that the LHS above is independent of .
Furthermore, we have that the inverse to Equation (50) is given by
We now introduce the so-called harmonic polynomials, , which are a subset of the polynomials which have a vanishing Laplacian, . As an example, one such polynomial is given by , for which it may be confirmed that .
The harmonic polynomials are of particular interest, as their corresponding symmetric tensors, given by , are traceless, due to the vanishing Laplacian condition on , i.e.,
Thus, the linear operator, , together with its inverse in Equation (51), establishes an isomorphism between the vector spaces of harmonic polynomials of degree n, and symmetric traceless tensors of rank n.
The harmonic polynomials, or equivalently the rank n traceless tensors are spanned by 2n + 1 linearly independent vectors. To see this, first consider the components, , of a rank n symmetric Cartesian tensor for which it is a simple matter to show that there are possible values of for which . Furthermore, the trace condition imposes constraints. To see this, take the trace tensor, from Equation (9), which is a degree n − 2 symmetric tensor, having components , where clearly, each component is independent, and as such the trace tensor is described by linearly independent vectors, all of which must be independently equal to zero in order that be traceless. This leaves us with degrees of freedom for both the rank n traceless tensors and the degree n harmonic polynomials.
2.8. Spherical Harmonics as a Basis for Traceless Symmetric Tensors
The discussion at the end of the last section referred to the fact that symmetric traceless tensors can in principle be spanned by a minimal set of 2n + 1 linearly independent vectors. It would obviously be advantageous to work in a representation in which just this number of components are used, and in this section we shall show how this can be done using spherical harmonics, which provide a natural orthonormal basis for traceless tensors.
We begin by defining what we will refer to as the spherical inner product, , not to be confused by our tensor inner product, , which is given by
where the superscripts and label two homogeneous polynomials of order m and n, respectively, and we have switched to spherical coordinates. (Also note, here we are using real polynomials, but either one of , or in the integral would need to be replaced by its complex conjugate in the full complex case, in order that be a true inner product.)
We now state a theorem which will allow us to convert between the tensor inner product of traceless tensors and the spherical inner product of harmonic polynomials.
A Theorem on the Equivalence of Two Inner Products
Suppose that is a degree n harmonic polynomial, and is its traceless tensor equivalent, then the spherical inner product, , and the tensor inner product, , are in a constant ratio for each rank, according to
The above theorem may seem like it would be easy to derive through standard algebraic methods, but in fact, it is surprisingly hard to obtain and our derivation ended up being quite technical. Thus, we will leave the mathematical details to Section 4.4 through Section 4.6; Section 4.5, we show that the two inner products are proportional, whilst in Section 4.6 we derive the proportionality constant. We should also note that similar expressions to Equation (54) have been developed by Ehrentraut and Muschik, [20] (especially Section 4 in this reference) although using a quite different approach to the one taken here.
From the theory of spherical harmonics, a complete orthogonal basis (with respect to the spherical inner product) for degree harmonic polynomials is provided by the spherical harmonics (technically, the regular solid harmonics), which comprise a set of 2n + 1 real harmonic polynomials orthogonal over the unit sphere, such that, writing the spherical harmonic polynomials as , we have that
where is the norm of , and similarly for .
A note on the nomenclature. Strictly speaking, a spherical harmonic can be used to describe any harmonic polynomial confined to the unit sphere. However, here we will use the term spherical harmonic polynomial to refer specifically to the set of polynomials, which are orthogonal over the unit sphere.
By application of Equation (50), we can also define the traceless tensor form of the spherical harmonics, which we will call , from
which, using Equation (51), has an inverse given by
The spherical harmonic polynomials up to rank 3 are given in Table 1, adapted from Stone [13].

Table 1.
Spherical harmonics in Cartesians up to rank 3. Adapted from Stone, and normalised such that , where are the tensor forms of the polynomials (see text for details). Here, we are using a simplified labelling scheme, in which the spherical harmonics, , are identified by their degree, , and an index, , within each degree, where the index runs from , and the ordering within each degree is (for our purposes) arbitrary.
Given the orthogonality of the spherical harmonic polynomials from Equation (55) and given the inner product equivalence from Equation (54), we also have that, under suitable normalisation,
A note on the normalisation: Here, we are choosing the normalisation such that Equation (58) above holds, i.e., . So that the are consistent with the according to Equation (56), we have, by way of Equation (54), that the polynomials should be normalised according to .
Thus the provide an orthogonal basis for the traceless symmetric rank n tensors, and as such, we can express any symmetric traceless rank n tensor as a linear sum in , according to
and taking the inner product of both sides of Equation (59) above with respect to shows that , the components of in the spherical harmonic basis are given by
where we use the convention that spherical harmonic components are to be indexed by modern roman lower case letters, as opposed to Greek for the Cartesian indices.
Conversion of traceless tensors from Cartesians to spherical harmonics according to Equation (60) is perhaps most easily done through consulting tables of spherical harmonics polynomials, such as those given by Stone [13]. Furthermore, for convenience, the spherical harmonic polynomials up to rank 3 are listed in Table 1, which is adapted from Stone.
As an example, from Table 1 (Section 4.7), we have that the spherical harmonic , which gives, , and given that , we have that , and so on.
The spherical harmonic representation comes in particularly useful for calculating inner products; for, we can use the orthogonality of spherical harmonics to write
Thus, it can be seen that calculating an inner product in spherical harmonics requires the minimal 2n + 1 operations for that rank, which is an enormous saving over the multiplications required for naively multiplying all of the matrix Cartesian components together [21,22].
We have seen how the coefficients allow for transformation of Cartesians into spherical harmonics. There is also an inverse transformation, given by , which are the components of projected onto the spherical harmonic basis, and which can be used to transform the components in the spherical harmonic basis back to Cartesians.
Furthermore, once again, Stone has provided tables which give a very convenient way for carrying out these transformations; Table 2, which is also adapted from Stone, provides the relevant information.
Table 2.
Cartesians in terms of spherical harmonics, up to rank 3. Adapted from Stone, such that the transformation is the inverse of Table 1.
As an example, from Table 2, we have that , from which it follows that, if we have spherical harmonic components , then .
We conclude this section with a discussion of what Applequist [15] has called the detracing operator.
Suppose that is an in-general non-traceless symmetric tensor. Given that the spherical harmonics form a complete orthonormal basis for the subspace of traceless rank n tensors, the detracing operator can be written in spherical harmonics as
One application of is in particular worth noting. Applying the above expression for , and using Equation (57) to make the substitution gives via Equation (60) that
where are the traceless projections of the tensors (see Equation (11)), and where we have used , which holds because only the traceless component of can contribute to the inner product with the traceless .
Thus, the spherical harmonic components of the Maxwell Cartesian spherical harmonics are just the spherical harmonic polynomials themselves.
3. Discussion
3.1. The Multipole Interaction in Spherical Harmonics
In this section, we will aim to convert the various expressions so far developed in Cartesians into their spherical harmonic equivalents.
In the last section, we showed how to convert inner products into spherical harmonics. Furthermore, in this regard, it is unfortunate the multipole interaction generating formula of Equation (31) cannot be expressed entirely in terms of such products, involving as it does problematic contractions of the form .
However, even when dealing with such contractions, there is a way of still using the inner product method, which we shall now describe. We introduce what we will refer to as the split-component representation of a symmetric tensor, using the notation , where is the full rank of the tensor, , of which is but one representation. Taking , as an illustrative example, we write the symmetric traceless multipole tensor, , which has Cartesian components
where transforms as a symmetric traceless Cartesian tensor with respect to (i) its before-comma components, (ii) its after-comma components, and (iii) in all its components as a whole. In this representation, an example contraction can now be written as
which behaves like an inner product with respect to the after-comma components, and, as such, can be readily evaluated in spherical harmonics.
We proceed by separately transforming the before-comma and after-comma components of into spherical harmonics, and, using transformations of the sort described by Equation (60), we have that
where is used to transform , and is used to transform . (As discussed in the last section, these transformations are easiest done by way of tables of spherical harmonics, suitably implemented into code.)
Also, and referring to the discussion of the detracing operator of Equation (62), the tensor components are transformed as , and so the desired contraction can now be written in spherical harmonics as
Notes:
- (i)
- The concept of a split component representation can be made quite general. If we wished to, we could use a mixed Cartesian-spherical harmonic representation, such as , or we could choose to use more than one; for instance, is a valid split of . However, no matter how we choose the split, or the base, it is still referring to the same underlying tensor, and, if necessary, one can always recover all the original components from the by taking the appropriate inverse transformations.
- (ii)
- The rank-1 spherical harmonics are just x, y and z (see Table 1, in Section 4.7), from which it follows that a rank 1 tensor has spherical harmonic components , the same as in Cartesians. Furthermore, in general, we have that .
- (iii)
- The split component representation is symmetric with regards to any permutation of its components, e.g., , and , and so on.
- (iv)
- The transformations can all be done by way of the table method explained in the last section. That is, we do not have to carry out tedious matrix multiplications, but can instead just use Table 1 suitably implemented into code to convert the Cartesians into spherical harmonic components.
At this stage it will prove useful to return to the diagrammatic representation.
Figure 5’s top illustrates the equivalence between different representations of the tensors in spherical harmonics and Cartesian coordinates. The example given is of a traceless symmetric rank 4 tensor, which can be represented as either , or , or , or , or , where the Cartesian coordinates are, as usual, represented by spokes, and where the transformation to spherical harmonics is depicted by braiding any number of spokes together. Of course, this is just a visual metaphor, but it is intended to convey how the transformation into spherical harmonics intertwines (through taking linear combinations of) multiple Cartesian indices into one spherical harmonic index.
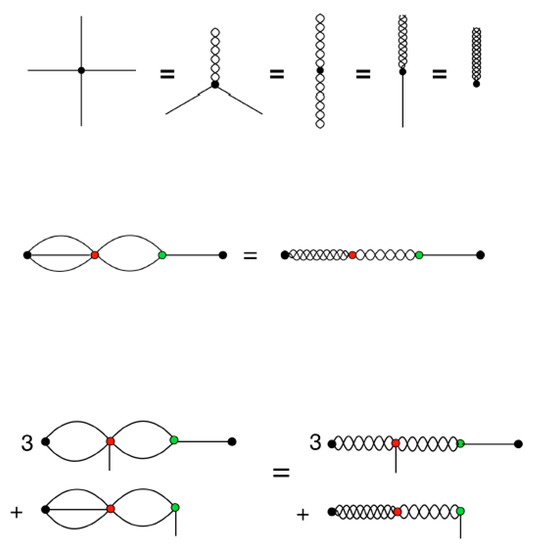
Figure 5.
Equivalence of Cartesian and spherical harmonic representations. Top line: Four equivalent ways of representing a rank-4 symmetric traceless tensor. Middle line: two equivalent ways of representing the tensor product from Figure 1. Bottom: two equivalent ways of representing the gradient of this tensor product. The unbraided spokes represent Cartesian vectors, and the braided spokes are spherical harmonics.
The next line, in Figure 5’s middle, shows how energy term, , depicted in Figure 1, can be converted to spherical harmonics, through performing the braidings , , and , and then calculating the contractions according to
Furthermore, the final diagrammatic equation, in Figure 5’s bottom, shows how to convert the gradient of the above term into spherical harmonics, which requires the additional braiding .
The methods developed here can be used to transform any contraction, and thus, we are now in a position to transform the entire multipole interaction, energies and forces and fields, into spherical harmonics. We begin with the multipole interaction generating formula of Equation (31), which in spherical harmonics is given by
The spherical harmonic analogue to Equation (34), which gives the gradient terms necessary for the force calculations (per Equation (31)) is given by
and the spherical harmonic analogue to Equation (38), which gives the derivatives necessary for the multipole fields (per Equation (37)) is given by
This last expression needs some explanation. Each term in the sum has a tensor representation of type , but given that the sum is over , the quantity in square brackets will result in a sum in different split component representations, e.g., for rank 4, the sum will have the form , where the representations do not in general refer to symmetric tensors. However, once the full sum has been evaluated, it can be symmetrised by converting the result back into Cartesians, before averaging over all permutations of the Cartesian indices.
The electrostatic potential at , from a multipole expansion at the origin can be found from the above by taking the rank 0 multipole derivative and then using Equation (37) to obtain
where the last term can be derived from the first, or obtained from taking the rank 0 multipole derivative of Equation (38), and where we note that it reduces to Equation (22) for the kernel
Finally, the spherical harmonic analogue for Equation (42), giving the total torque on a multipole site is given by
Equations (69)–(73) then comprise our final expressions for the multipole interaction in spherical harmonics, in a form suitable for implementation into the Ewald sum. Here, we should admit that we have not given spherical harmonic equivalents for rotation of the multipoles, or for calculation of the angular derivatives (Equation (39)). We currently prefer to keep these in Cartesians for simplicity, but given that both these calculations can be performed outside the main ij particle loop, there is no significant computational cost to their calculation.
3.2. Implementation
It may be a cause for worry that implementing the expressions in the last section is technically very difficult, or computationally costly; however, neither of these things is true.
As far as the implementation goes, it is true that, due to the amount of ‘book-keeping’ required, implementing the multipole interaction in either Cartesians or spherical harmonics is a moderately difficult coding task, but implementing Equations (69)–(73), does not need to be any more difficult than implementing the same sums in Cartesians.
As for computational cost, note that, contrary to a perennial myth, implementation of the multipole interaction in spherical harmonics does not require the calculation of any expensive trigonometric functions. All of the necessary coordinate transformations can be done using Table 1, suitably implemented into code, obviating the need for any explicit matrix multiplication or calculation of trigonometric functions (see Section 4.7). It is true that the spherical harmonic transformations may need to be evaluated afresh each step of a simulation, but the required transformations can be done exclusively outside the main ij particle loop, which almost always takes up the vast majority of time in a calculation. These transformations can be done in a time that’s linear with the number of particles, and which, in any case require no operations more complex than the multiplication of real numbers. Furthermore, the final expressions in spherical harmonics require fewer operations than their Cartesian equivalents to calculate, thus providing an overall saving in computational time.
Implementation is greatly aided by the use of tests to verify the results at each stage.
We begin with the energies, where numerical differentiation can be used to check that the multipole interactions are giving the right energies for each rank.
Suppose we are confident that the multipole interactions are accurate to rank n. Then, it can be checked that the rank n + 1 multipoles are also giving the right results by comparing the analytic energies for rank n + 1 multipoles against numerical results found from numerical differentiation of the rank n multipoles.
One way of doing this is, given rank-n multipole , we construct a fictitious diatom of bond-length , in which the first site holds a multipole , and the second site holds a multipole . Then, as , a multipole expansion of the diatom as a whole will give a pure rank n + 1 multipole moment. We can now check to see how the energy of this diatom in the field of other rank n multipoles compares to the energy of the system when replacing it by an analytic multipole of rank n + 1, where the analytic multipole is assigned the rank n + 1 multipole moments of the diatom.
If is made small enough, it should be possible to obtain exact agreement up to numerical precision. Furthermore, in this way, it is possible to boot-strap our way to checking multipoles of arbitrary rank. We begin with charges, which can be added together to make numerical dipoles. Furthermore, once the analytic dipoles are confirmed, pairs of analytic dipoles can be added to together to make numerical quadrupoles, and so on.
We have implemented our expressions for the energies, fields, forces and torques in spherical harmonics into an Ewald sum code, going up to rank 3 in the multipole expansion. The analytic forces’ torques and angular derivatives were checked by comparison to numerical derivatives.
The reciprocal space and self-interaction parts of the Ewald sum are given in Section 4.7, and given that both these terms involve simple to convert inner products over the multipoles, it is absolutely straightforward to convert the Cartesian multipole form of these expressions as given by Smith [1] into their spherical harmonic equivalents.
We tested our code on a system of 32 molecules each containing 26 nuclei and interacting under periodic boundary conditions, and found about a 22% speed-up upon converting the full Ewald sum to spherical harmonics for multipoles up to rank 3, where the Cartesian form had already been heavily optimised to remove all obviously redundant operations. This is a not insignificant saving, and the difference would only be expected to grow with increasing rank.
We have made a copy of our code available on the Internet [21]. It includes all the gradient tests mentioned in this section, and also includes the aforementioned multipole consistency test, in which numerical rank n + 1 multipoles are created from displacing rank n multipoles.
3.3. Scaling
The implementation of site multipole expansions does not alter the fundamental scaling with respect to the number of particles over that of a calculation involving just point charges, but there is a scaling with respect to the maximum multipole rank used in the expansion, and it is to this we now turn.
To obtain an estimate of this scaling, we will try enumerating the number of multiplications involved in calculating the functions from Equation (31) up to a given rank.
Recall that the inner product of two rank-n tensors requires a minimum of multiplications in Cartesians (accounting for permutation symmetry), and 2n + 1 multiplications in spherical harmonics. Then, the inner product of Equation (31), which has left-bracket contractions, right-bracket contractions, and between-bracket contractions requires
multiplications in Cartesians and
multiplications in spherical harmonics, where the terms in the above two expressions arise from the fact that if , then the corresponding tensor is equal to unity and no multiplication is required (and similarly for ).
To obtain the total number of multiplications involved in calculating the functions for multipoles up to a given rank, we wrote a simple code to sum the values
where is the total number of multiplications, and where we are only summing over terms with multipole ranks .
Finally, to obtain the scaling, we fit the curves up to a maximum rank of , with the form , where , are fitting coefficients, with being the scaling power.
The result of this exercise was that we found for Cartesians and in spherical harmonics. Thus, the spherical harmonics are expected to have better scaling than the Cartesian case ( 3.3 for spherical harmonics vs. 3.8 for Cartesians.)
It is hard to imagine many users would want to go beyond n = 8, but repeating the above in the range n = 1…16 gives a scaling of 3.6 for spherical harmonics vs. 4.3 for Cartesians.
This analysis is admittedly quite crude. It does not consider the cost of calculating the forces, the fields, or the cost of array look-ups. It also ignores the fact that at least some of the inner products occur more than once in the calculation of the functions, and so only need to be evaluated once and stored for later use. In light of this, it is worth discussing how our actual implementations perform.
To this end, we ran a 32-molecule test case with each molecule having 26 atoms, for both periodic and non-periodic boundary conditions, and for both spherical harmonics and Cartesian implementations of the multipole interactions, where the periodic simulations employed a full Ewald sum.
We recognise that some groups will be interested in calculations using much larger system sizes, but our code is optimised for crystal-structure prediction using relatively small numbers of molecules, as it often makes sense to look for crystal structures with relatively small simulation cells. Here, we also mention that, unlike many codes, our code allows for arbitrary cut-off radii, [22] where the cut-off sphere is allowed to be larger than can fit in the simulation cell, which means that we can converge energies for even small unit cells, and in this case we employed a real space cut-off of 16 .
For the periodic calculation we obtained scalings of = 3.7 for spherical harmonics, and = 4.5 for Cartesians, and for the non-periodic calculation we obtained s = 2.7 for spherical harmonics and = 3.3 for Cartesians; results that are not too dissimilar from our relatively crude theoretical predictions.
4. Materials and Methods
We discuss in this section, by way of technical sub-sections, the underlying intellectual and mathematical infrastructure underpinning the above-discussed novel contributions of the present work outlined in Section 2 and discussed further in Section 3, before summarising and concluding the article in Section 5 below.
4.1. Some Mathematical Properties of Cartesian Tensors and Notation
Let be a Cartesian vector in R3, which has Cartesian components , where is one of , or , and is a unit vector in the direction. If , , is an orthogonal axis set, then , where if , and otherwise. Thus, we can write , where the sum is over the three directional indices, , and .
Now suppose we also have a reference set of axes, given by , and , where , then is the orthogonal 3 × 3 rotation matrix, which takes the reference-frame components to the components in the laboratory frame via
Now, let be a tensor of rank n, which has Cartesian components , where the number of indices is equal to its rank, and where the tensor components transform according to
where there are occurrences of the rotation matrix in the above, and where we have defined the orthogonal tensor rotation matrix , with components
We will generally use the superscript notation (n) to indicate the rank of each tensor, except in a small number of cases where the rank can be inferred from counting its indices. To distinguish different tensors of the same kind and rank, we will often also use the superscript to give labels to the tensors, e.g., if we have two rank-n tensors we wish to label a and b, then we will use the notation and , which have components and .
Almost all of the tensors used in this work are symmetric with respect to the permutation of their indices, e.g., , and we will refer to such tensors as symmetric.
We now turn to a discussion of tensor contractions. We will only give a brief overview, but we note that Applequist has written extensively on this topic, and the interested reader should consult his work [15].
Suppose that and are two such symmetric tensors. We introduce the notation to indicate a contraction over indices of two such tensors, e.g.,
is a contraction over 2 indices, and
is a contraction over 3 indices.
Furthermore, in general, the contraction results in a symmetric tensor of rank i + j − 2n.
For small numbers of contractions, we can use the alternative notation that a contraction is indicated by vertical dots, where the number of dots is equal to the degree of the contraction, e.g., , , and .
Now consider the contraction , where , and are traceless rank (n) tensors, and the result, , is a scalar. It is easy to show that this contraction forms an inner product on the vector space of all rank-d tensors. Thus, we will use the notation
To prove that the above is a genuine inner product, we first use the fact that symmetric rank-n tensors form a vector space, that is, the addition of any two rank-n symmetric tensors results in another rank-n symmetric tensor, and the multiplication of any symmetric rank-n tensor by a scalar also results in another rank-n symmetric tensor. Then, we can show that on this vector space, (i) is always a scalar. (ii) for any scalar, : (linearity), (iii) (symmetry), and (iv) . (positive defiteness). Which are the four conditions required for to be an inner product.
It remains to be shown that the inner product is the same in any axis frame, such that it operates on the tensors, and not just their components.
Firstly, working in the lab-axis frame, if are any rank 1 Cartesian vectors, then . From which it follows that if we have axes defined by orthogonal unit vectors and , where one is rotated with respected to the other, then , where are the components of the rotation matrix which transforms between the two frames.
Now, suppose we expand out the inner product of two rank 2 tensors and , where the latter’s components are calculated in the frame, then, writing for the components in this frame we have
which is the same as if both tensors components were calculated in the same frame. Thus, is the same no matter the frame each tensor’s components are calculated in, and the same goes for all tensor inner products in general.
Finally, it is useful to define the tensors
with components , where the number of s is equal to its rank. It can be readily seen that , which implies that .
Similarly, we define the tensors
where , and again, we have that , which implies that .
4.2. The Functions up to Rank 3
The following lists the functions defined from Equation (31) (and surrounding text) up to multipoles of rank 3. These formulae agree with those derived by Smith, [1] who calculated terms up to rank 3, except that here we list only those terms which occur for traceless multipole tensors.
4.3. The Functions up to Rank 3
The following lists the functions given by Equation (34), up to rank 3 in the multipoles. These formulae agree with those derived by Smith, [1] who calculated terms up to rank 3, except that here we list only those terms which occur for traceless multipole tensors.
4.4. The General Decomposition for Homogeneous Polynomials
This sub-section introduces a standard decomposition for polynomials into mutually orthogonal rotationally invariant subspaces. The results will be used below in Section 4.5, in which we explain how to convert between the tensor and spherical inner products.
A result from the theory of spherical harmonics (e.g., see chapter 2 of ref. [23]): Any degree n homogeneous polynomial, , has a unique decomposition given by
where is the mth harmonic polynomial, and where, as usual, the degree of the polynomial is placed in brackets, so that describes a polynomial of degree n−2m. Furthermore, where, the in Equation (77) is the smallest integer less than or equal to , e.g., and .
The decomposition of Equation (100) is unique, because each term in the sum resides in a subspace which is mutually orthogonal under the spherical inner product.
To show this, use the result from the theory of spherical harmonics (e.g., chapter 2 of ref. [23]) that for any two harmonic polynomials of degree and , the spherical inner product is zero, unless . Thus, if , and , then the spherical inner product, is zero unless .
The decomposition of Equation (100) is also complete, because the dimension of the th subspace is , and summing over all subspaces gives a dimension of (which can be proved by induction), which is the full dimension of the vector space of degree n homogeneous polynomials. (For example, if , then , and the total dimension is .)
Now consider a polynomial in the mth subspace, and so of the form , and what happens when that polynomial is rotated.
We can rotate the polynomial through calculating , where is an orthogonal rotation matrix, and where the result of which is . However, given that the rotation of any harmonic polynomial is still a harmonic polynomial of the same degree, we have that must still belong to the same subspace as . Thus, any polynomial which belongs to the mth subspace is guaranteed to remain in that subspace after any rotation.
Furthermore, it can be shown (e.g., chapter 2 of ref. [23]) that each subspace is irreducible, in the sense that it cannot be further divided into rotationally invariant orthogonal subspaces. (Spherical harmonic polynomials of degree n form a 2n + 1 dimensional basis for the irreducible representation of SO(3), the group of all rotations in three dimensions. See also, for example, chapter 8 in ref. [24]).
We can also define associated projection operators, , such that the mth projection operator projects a homogeneous polynomial into the mth subspace, according to.
It was shown in Equation (44) that a degree-n polynomial can be written in the form
which allows us to define the associated tensor operators, , according to
where Equation (103) must define uniquely the , because the polynomial is uniquely defined, and there is a one to one correspondence between polynomials and their equivalent tensors.
One iteration of Equation (103) gives
Consider the case , for which we have , given that are projection operators. In this case, equating Equations (103) and (104) then implies that , and so is also a projection operator.
Conversely, for , we have that , because are orthogonal projectional operators, in which case, Equation (104) must equal zero, which can only be possible for all , if , again for ; from which we conclude that the are orthogonal projection operators.
It can be seen from Equation (101) that the operator projects polynomials into the space of harmonic polynomials of the same degree, with for any . Given that the tensor equivalent to a harmonic polynomial is traceless, the corresponding operator must project tensors into the space of traceless tensors, i.e., we have that , the detracing operator.
4.5. Conversion between the Tensor and Spherical Inner Products
This sub-section gives the conversion between the spherical inner product , defined in Equation (53), and the tensor inner product, , where is the tensor equivalent to , and similarly for and .
We begin by recalling from Equation (44) that any degree homogeneous polynomial can be written as
Substituting the above into the spherical inner product gives
which can be rewritten as
where the self-adjoint tensor operator is defined from its action on a degree n Cartesian tensor, , according to
where has matrix elements
The components of are easiest expressed in compressed notation, in which they are given by
where , and if , and are all even, and otherwise, and where the integral above was solved using the methods for integrating polynomials over the unit sphere in ref. [25].
Although Equation (110) defines completely the matrix elements of , it is not in a very useful form. In the remainder of this section we will show how can be put in a more useful form by writing it as a spectral sum in the projection operators, , defined in Section 4.5.
Let be a rotation operator, parameterised in terms of Euler angles say, which acts to rotate the system, where acting on a polynomial rotates the polynomial by Euler angles , i.e., , where rotation of can be achieved using orthogonal rotation matrices as described in Section 4.1. We also define the action of on tensors, such that if is the tensor equivalent of the polynomial , then is the tensor equivalent of the polynomial .
We will now establish that both and , and and always commute, i.e., and . Furthermore, this will allow us to show that must be a linear combination of .
We first show that . Recall from Section 4.4 that no rotation can move a polynomial, , in the mth subspace out of its subspace, which implies that , or .
Now, given that any polynomial in the mth subspace (with associated projection operator ) is equivalent to a tensor in its mth subspace (with associated projection operator ), it also follows that no rotation of a tensor in its mth subspace can move that tensor out of the mth subspace. (If it could, we could transform a polynomial in the mth subspace into its corresponding tensor, rotate that tensor out of the mth subspace, and then transform back, which would mean that the mth subspace is not rotationally invariant.)
Thus, we also have that , or , which was to be shown.
We will now show that . First note that because the spherical inner product is the integral of the product of two polynomials over the unit sphere, we have that rotating both polynomials by the same Euler angles must leave the inner product unchanged. We thus have that
From Equation (107), the LHS above can be rewritten as . Further, we also have that the RHS above can be rewritten as
where the last part of Equation (112) above comes from applying the inverse rotation, , to both sides of the inner product. We thus have that
which implies that , or , which was to be shown.
We will now show that since and , it follows that must be a linear combination of .
Suppose that is an eigenvector of with eigenvalue . Given that , we have that
It follows that is also an eigenvector of , also with eigenvalue . Thus, must belong to a degenerate subspace of spanned by all eigenvectors of with eigenvalue . Furthermore, this subspace is rotationally invariant, i.e., for any vector in that subspace also belongs to that subspace. However, we have seen that the orthogonal irreducible rotationally invariant subspaces on the vector space of tensors are described by projection operators , so each one of the mutually orthogonal degenerate eigenspaces of is one of the m spaces associated with the projection operators.
Now, given that any symmetric matrix can be expressed as a linear sum: , where is the projection into the ith degenerate eigenspace, with associated eigenvalue , we have that can be written in the form
with the to be determined.
As a check, we can take the commutator of both sides of Equation (115) above with respect to , which gives
as expected.
Finally, substitution of Equation (116) above into Equation (107) gives
where we have now included the index in given that it is possible these scalars also have a dependence on n, and where we have used
However, Equation (117) must hold separately for each value of m, for the mth term on the LHS can only depend on the mth term on the RHS. So we have that
which, apart from the to be determined in the next sub-section (i.e., 4.6) for the m = 0 case, is our final form for the conversion between inner products.
4.6. Proportionality Constants for Conversion between the Tensor and Spherical Inner Products for the Case of Traceless Tensors and Harmonic Functions
In Section 4.5, we developed a general expression (Equation (119)) for the conversion between the spherical and tensor inner products. We will only need the m = 0 case for this present work, for which the projection operator is the detracing operator, , and the associated operator describes a projection onto the space of harmonic polynomials. Thus, for m = 0, Equation (119) can be written as
where are traceless tensors, and are their associated harmonic polynomials.
In the present sub-section, it will be shown that the rank-dependent proportionality constants are given by
Note that as the multipole interaction formulae are written in terms of traceless tensors, only the m = 0 case is required for this present work. However, the general approach described here should be extensible to results for higher orders.
Our ‘plan of attack’ is to fix its value by choosing the simplest rank n harmonic polynomials we can think of, which are arguably provided by the so-called zonal spherical harmonics, , where is the nth Legendre polynomial, and where . We also have that the zonal spherical harmonics are symmetric about the z axis, which should make them particularly simple to work with.
Again, aiming for simplicity, we will set both and to the same zonal spherical harmonic.
Now, using the properties of Legendre polynomials, we have that the LHS of Equation (120) is given by
where we have used the standard formula for Legendre polynomials that the integral of over to is given by .
We next turn to calculating the equivalent inner product on the RHS of Equation (120). Let be the zonal spherical harmonics in Cartesian tensor form, which using Equation (50) are given by . Given the z symmetry of the zonal harmonics, we have that the must be proportional to , where . (No other choice would have the right symmetry.)
Taking the inner product of a rank n tensor, e.g., , with returns the component, i.e., , and we will now state two such inner products (to be proved at the end of this section), which will come in useful for the following.
Using the last two identities above fixes the proportionality constant between and to give
We can then write
where we have (i) used Equation (126) to exchange for , (ii) used the fact that is inside the traceless subspace to allow us to exchange for , and (iii) used Equation (124) above.
Finally, substituting Equations (127) and (123) into Equation (120) fixes , which is Equation (121).
As promised, we will now provide the proofs of Equations (124) and (125).
To prove Equation (124), we use the identity
which can be proved by algebraic differentiation using the standard identity for the derivative of a Legendre polynomial: .
Thus, we have that
To prove Equation (125), we use the standard generating function for Legendre polynomials
Substituting and , where , and recognising that, under these substitutions, the LHS above is now equivalent to , we have
However, the LHS above can also be Taylor-expanded as
where we have made use of the expression for the Maxwell Cartesian spherical harmonics from Equation (11).
Comparing Equations (131) and (132), we deduce that
Now, setting and means the LHS becomes equal to , and RHS is given by , which gives the required identity.
4.7. Ewald-Sum Terms
For completeness, the full Ewald sum is given by (following Smith [1]).
where the terms are given by Equation (31) for Cartesians, and by Equation (69) for spherical harmonics, and where the kernel is used, where is a width parameter, which controls the Gaussian width of the Ewald screening charges, and where the higher order functions generated by Equation (25).
The in Equation (134) are reciprocal-lattice vectors: for an orthogonal unit cell of dimensions .
where is the tensor product
The in Equation (134) are so-called self terms, given by
Note: A recent paper by Stamm et al. [26] provides a mathematically rigorous derivation of the self terms as given by Smith.
Both Equations (135) and (136) are in the form of inner products, and so can be readily expressed in either Cartesians or in spherical harmonics using Equation (61).
5. Conclusions
We have presented a non-technical—indeed, almost trivial—derivation of the multipole interaction in spherical harmonics, in a form suitable for use with Ewald-sum methods.
We began by summarising one derivation of the multipole interaction in Cartesians, most of which is not new to us, but goes back to the work of Smith and earlier, and continues up to Lin’s derivation of what we refer to as the multipole interaction generating formula.
We then introduced a diagrammatic method for visualising the multipole interactions, in where it was shown that the entire multipole interaction can be represented as a ‘sum over diagrams’, which arguably makes for a much more appealing representation of the interaction than thinking in terms of mathematical formulae alone.
Here, we admit that the results in this work could have been obtained without the aid of diagrams, but given that the diagrams show so clearly the structure of the interaction, we think they provide a valuable insight into what our various algebraic manipulations are actually doing.
Using what we believe to be a novel approach, the remainder of this work showed how the multipole interaction can be converted from Cartesians into spherical harmonics. This involved what was perhaps the key part of this paper, which was (i) the recognition that the multipole interaction in Cartesians involve expressions that can be written as inner products over tensors, (ii) showing that these tensor inner products are proportional to an inner product over the vector space of harmonic polynomials on the unit sphere, (iii) using this relation to convert the Cartesian tensor inner products to spherical inner products involving spherical harmonic polynomials.
The key expression here is Equation (54), which gives the proportionality relation between tensor and spherical inner products. Deriving this relation turns out to be a surprisingly non-trivial problem, but once it has been shown, it becomes a relatively straightforward task to convert the entire multipole interaction from Cartesians into spherical harmonics.
Our method relies on the use of existing tables of spherical harmonics to Cartesian transformations, which have already been given by Stone, and whose properties have been analysed extensively by Stone and others.
Another novelty of our method is that our ‘end-result’ formulae are not pure functions of the spherical harmonic multipoles, like seen in other approaches. Instead, our formulae are functions of split tensor components, which may have several indices, all of which are separately represented in spherical harmonics. However, what really distinguishes our approach from others is that our approach involves fully transforming the between-tensor contractions (bonds in the diagrams) into their spherical harmonic form, while respecting the underlying structure of the contractions; this structure which is particularly evident from the diagrammatic form.
It is surprising to us that such a straightforward conversion method appears to have been overlooked in the literature. It is not clear to us if this method will prove to give superior efficiency when compared to standard approaches, but it is faster than the Cartesian scheme, and it appears to us that our method is comparatively more straightforward and easier to implement than previous approaches. Furthermore, it is our hope that this work will prove a ‘less-painful’ route for the implementation of spherical-harmonic multipole expansions in computational-chemistry codes.
Author Contributions
Conceptualisation, C.J.B.; methodology, C.J.B.; software, C.J.B.; validation, C.J.B.; resources, N.J.E.; writing—original draft preparation, C.J.B.; writing—review and editing, N.J.E.; supervision, N.J.E.; project administration, N.J.E.; funding acquisition, N.J.E. All authors have read and agreed to the published version of the manuscript.
Funding
This research and APC was funded by Enterprise Ireland, grant number CF 2017 0777-P.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Smith, W. Point Multipoles in the Ewald Summation (Revisited). CCP5 Newsl. 1998, 46, 18. [Google Scholar]
- Stone, A.J. Distributed Multipole Analysis, or How to Describe a Molecular Charge Distribution. Chem. Phys. Lett. 1981, 83, 233. [Google Scholar] [CrossRef]
- Stone, A.J. Distributed Multipole Analysis. Methods and Applications. Mol. Phys. 1985, 56, 1047. [Google Scholar] [CrossRef]
- Stone, A.J. Distributed Multipole Analysis: Stability for Large Basis Sets. JCTC 2005, 1, 1128. [Google Scholar] [CrossRef] [PubMed]
- Todorov, I.T.; Smith, W. The DL_POLY_4 User Manual. Available online: ftp://ftp.dl.ac.uk/ccp5/DL_POLY/DL_POLY_4.0/DOCUMENTS/USRMAN4.pdf (accessed on 26 December 2019).
- Al, J.P.E. Tinker Software Package. Available online: https://dasher.wustl.edu/tinker/ (accessed on 26 December 2019).
- Lin, D. Generalized and Efficient Algorithm for Computing Multipole Energies and Gradients Based on Cartesian Tensors. J. Chem. Phys. 2015, 143, 114115. [Google Scholar] [CrossRef] [PubMed]
- Sagui, C.; Pedersen, L.G.; Darden, T.A. Towards an accurate representation of electrostatics in classical force fields: Efficient implementation of multipolar interactions in biomolecular simulations. J. Chem. Phys. 2004, 120, 73. [Google Scholar] [CrossRef] [PubMed]
- Boateng, H.A.; Todorov, I.T. Arbitrary order permanent Cartesian multipolar electrostatic interactions. J. Chem. Phys. 2015, 142, 034117. [Google Scholar] [CrossRef] [PubMed]
- Huang, H.; Shanker, B. Maxwell Cartesian Harmonics and the Static Fast Multipole Method. IEEE Antennas Propag. Soc. Int. Symp. 2006, 4099. [Google Scholar] [CrossRef]
- Huang, H.; Luo, L.-S.; Li, R.; Chen, J.; Zhang, H. Improve the Efficiency of the Cartesian Tensor Based Fast Multipole Method for Coulomb Interaction Using the Traces. J. Comput. Phys. 2018, 371, 122–136. [Google Scholar] [CrossRef]
- Leslie, M. Dl_Multi—A Molecular Dynamics Program to Use Distributed Multipole Electrostatic Models to Simulate the Dynamics of Organic Crystals. Mol. Phys. 2010, 106, 1567. [Google Scholar] [CrossRef]
- Stone, A.J. The Theory of Intermolecular Forces; Oxford University Press: Oxford, UK, 2016. [Google Scholar]
- Simmonett, A.C.; Pickard, F.C., IV; Schaefer, H.F., III; Brooks, B.R. An efficient algorithm for multipole energies and derivatives based on spherical harmonics and extensions to particle mesh Ewald. J. Chem. Phys. 2014, 140, 184101. [Google Scholar] [CrossRef] [PubMed]
- Applequist, J. Traceless Cartesian Tensor Forms for Spherical Harmonic Functions: New Theorems and Applications to Electrostatics of Dielectric Media. J. Phys. A Math. Gen. 1989, 22, 4303. [Google Scholar] [CrossRef]
- Applequist, J. Maxwell Cartesian Spherical Harmonics in Multipole Potentials and Atomic Orbitals. Theor. Chem. Acc. 2001, 107, 103. [Google Scholar] [CrossRef]
- Hobson, E.W. The Theory of Spherical and Ellipsoidal Harmonics; Springer: Vienna, Austria, 1931. [Google Scholar]
- Maxwell, J.C. A Treatise on Electricity and Magnetism; Macmillan and Co.: New York, NY, USA, 1873. [Google Scholar]
- Allen, M.P.; Tildesley, D.J. Computer Simulation of Liquids; Oxford Science Publications: New York, NY, USA, 1987. [Google Scholar]
- Ehrentraut, T.H.; Muschik, W. On Symmetric irreducible tensors in d-dimensions. ARI 1998, 51, 149. [Google Scholar] [CrossRef]
- Burnham, C.J. XMULTI. Available online: https://github.com/christianjburnham/xmulti (accessed on 26 December 2019).
- Burnham, C.J.; English, N.J. Crystal Structure Prediction via Basin-Hopping Global Optimization Employing Tiny Periodic Simulation Cells, with Application to Water−Ice. JCTC 2019, 15, 3889. [Google Scholar] [CrossRef] [PubMed]
- Atkinson, K.; Han, W. Spherical Harmonics and Approximations on the Unit Sphere: An Introduction; Springer: Berlin, Germany, 2012. [Google Scholar]
- Vvedesnky, D. Group Theory (Course). Available online: http://www.cmth.ph.ic.ac.uk/people/d.vvedensky/courses.html (accessed on 26 December 2019).
- Folland, G.B. How to integrate a polynomial over a sphere. Am. Math. Mon. 2001, 108, 446. [Google Scholar] [CrossRef]
- Stamm, B.; Lagardère, L.; Polack, E.; Maday, Y.; Piquemal, J.-P. A coherent derivation of the Ewald summation for arbitrary orders of multipoles: The self-terms. J. Chem. Phys. 2018, 149, 124103. [Google Scholar] [CrossRef] [PubMed]





© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).