1. Introduction
Protein aggregation is an active, multidisciplinary science, with researchers and practitioners working in broad disciplines, including biophysics, medicine, biomaterials, and pharmaceuticals. With diverse perspectives, it is not surprising that the papers on protein aggregation differ widely in their emphasis and methodologies: from fundamental research related to molecular mechanisms and aggregation pathways to searching for biomarkers, drug targets, even to imaging of plaques in the brain, dissolution of fibrils and amyloids
in vivo,
etc. The present article is only concerned with the fundamental investigations into the aggregation mechanisms of amyloid formation related to neurodegenerative disease. Many review articles have been written on the approaches based on molecular dynamical simulations [
1–
4], as well as kinetic studies [
5–
7]. In our examination, we will focus instead on the statistical mechanical approaches to equilibrium assembly processes and present some new results while summarizing past approaches.
Early applications of statistical mechanical methods to the studies of protein problems can best be represented by the treatment of helix-coil transitions in proteins by Zimm and Bragg in the 1950s [
8–
13]. They assumed that each peptide bond linking amino acid residues together can exist in two states: a helical or non-helical state, and characterized the linear chain of residues with a partition function, which is a sum of all possible combinations of states.
Analogous to a one-dimensional Ising model [
14], Zimm and Bragg expressed the partition function in terms of transfer matrices and solved the problem analytically in the large polymerization limit, and also for finite chains [
8]. Over the years, researchers have extended the original Ising-type models to study sheet-coil [
15–
21] and helix-sheet [
21–
23] transitions in proteins, as well as helix-coil [
24], sheet-coil [
25], and helix-sheet-coil [
23,
26] transitions in protein aggregates.
It is in a similar spirit that our statistical mechanical treatment of protein aggregation has been developed [
21], which is the main subject of this article. Our formalism of the aggregation processes was stimulated by other statistical mechanical studies. These works will be briefly reviewed in Section 3, along with conceptual developments of statistical mechanical techniques beyond those used in the Zimm-Bragg model. In Sections 4–6, canonical ensemble and grand canonical ensemble treatments of the aggregation processes will be separately presented, which is followed by a conclusion section. In Section 2, we first review some properties of amyloid proteins and aggregates.
2. Amyloid Aggregation
To see the complication of protein aggregation processes, we use
β-amyloid as an example. Under proper conditions, such as higher concentration, amyloid monomers can aggregate into dimers, trimers, tetramers, . . ., oligomers. These co-existing oligomers are in rapid kinetic equilibrium, making it difficult to determine their structures or numbers [
27]. Oligomers of the same size may exist in different conformations: some are partially ordered and some are disordered. As soluble oligomers grow larger they can become richer in
β-sheet structures, but overall they lack secondary structures. They may resemble micelles, which have a spherical or cylindrical shape [
28]. A
βoligomers seem to range in size, with a diameter ranging from 5–15 nm and molar mass ranging from 20–50 kDa up to 1 MDa [
29,
30]. Additionally, oligomers with ordered
β-sheet or
β-hairpin structures are believed to form protofibrils at a higher rate than their disordered counterparts [
3,
31–
33]. For example, Li
et al. [
3] showed in numerical simulations that a native chain has to unfold partially into an intermediate with beta-hairpin structure before ordered assembly can be formed. Since protein aggregation is thought to be a nucleation process, some of the ordered oligomers may act as paranuclei [
34]. Once formed, paranuclei can lead to the formation of protofibrils in down-hill fashion. The nucleation is illustrated in
Figure 1b,c. Since A
βoligomers may contain
β-sheet structure, they could be pathway intermediate [
28]. However, the same cannot be said about other oligomers, such as those comprised of prion proteins [
35]. Additionally, A
β(1-40) and A
β(1-42) monomers may self-associate to form off-pathway globular assemblies including amylospheroids [
34,
36] and
β-amyloid balls [
37] [formed by A
β(1-40) only]. Both of these structures can grow to be quite large.
Protofibrillar intermediates are heterogeneous, metastable aggregates already containing
β-sheet regions in the core [
38], but retaining some features that are similar to oligomers. The term “protofibril” has varying definitions throughout the literature, where for A
β the term could refer to structures ranging from 4–11 nm in diameter, up to 200 nm in length, and possibly even longer [
39,
40]. Protofibrils are considered to be on-pathway during fibrillogenisis, and they could grow larger via monomer addition or merging with other oligomers or protofibrils [
41,
42]. As protofibrils grow longer, the
β -sheet region grows larger. Eventually, a stable and tight
β -sheet network is formed in the core by the backbone H-bonds and the hydrophobic interactions of side chains [
38].
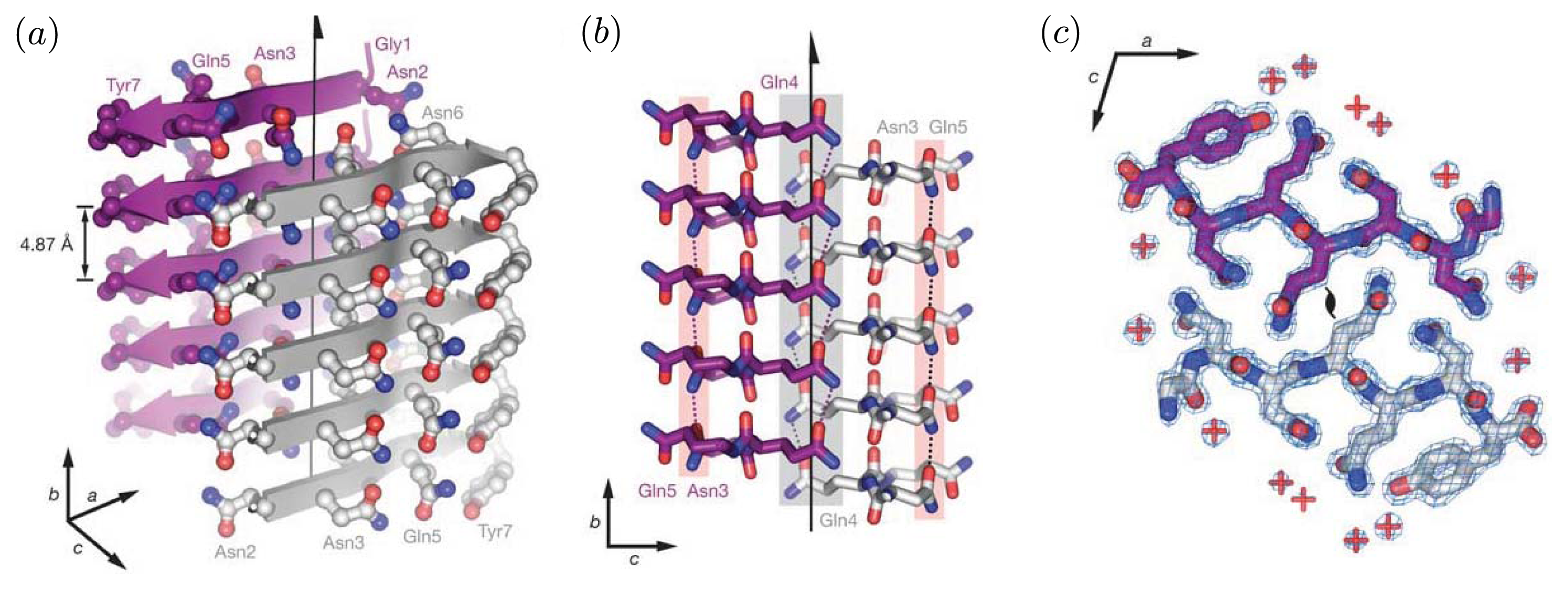
Figure 2 illustrates the cross-beta structure of fibrils comprised of the prion Sup35. These features are generally associated with protofibrils and fibrils [
38]. Another early intermediate thought to play a role in the formation of fibrils is the A
β protofilament, which can range in diameter from 2.5 nm up to about 6 nm [
43], and are 50–100 nm long [
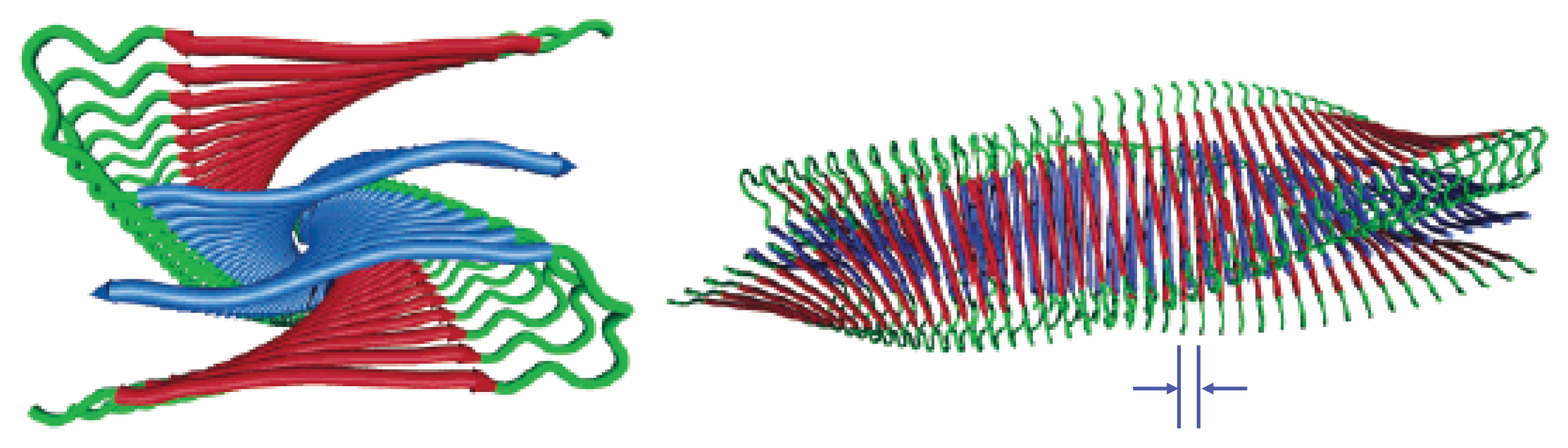
44]. Several protofilaments may then merge and form fibrils, which may exhibit a twisted, helical ribbon structure [
45] and contain highly-ordered
β-sheet regions. A cartoon illustration of an A
β protofilament is shown in
Figure 3. The fibrils may even be composed of several segments with distinct morphologies and varying levels of ordered structure [
46]. Additionally, mature fibrils have a diameter ranging from 7–12 nm, and may grower longer than 1
μm [
45]. Typically, fibrils are linear, non-branching structures. They contain very large amounts of
β-structure, and are generally insoluble. Fibrils can further assemble into bundles [
47], and may form plaques outside the neurons. The total assembly process from monomers to fibrils for a simple 1D model is illustrated in
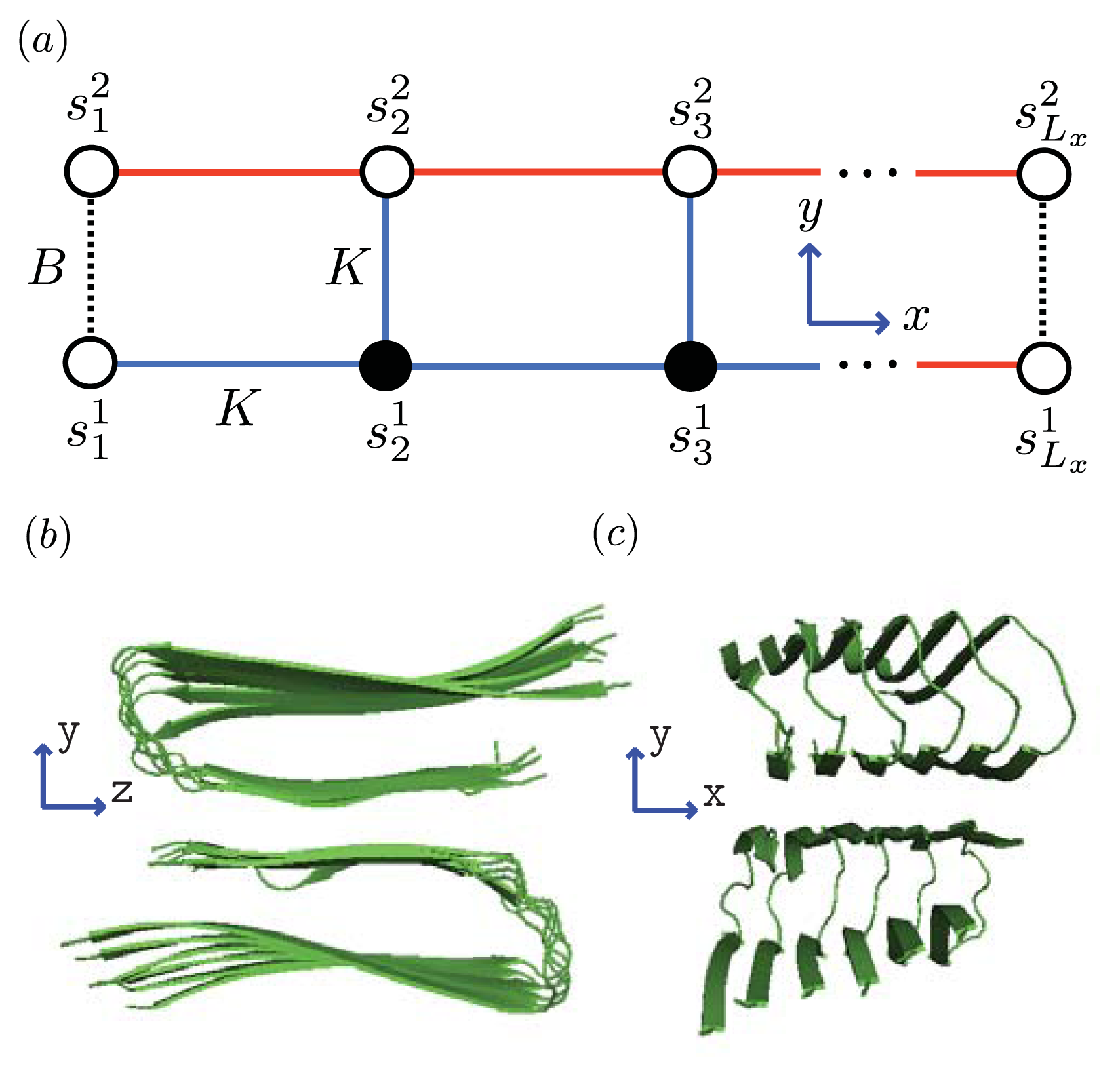
Figure 1a, and models for A
β(1-42) and A
β(1-40) fibrils are illustrated in
Figure 1b and 1c, respectively.
4. Equilibrium Protein Aggregation
In 1961, Oosawa and Kasai constructed a model for equilibrium protein aggregation using ideas from the helix-coil theory that were being developed at the same time. First, in the model the total number of proteins in the system is fixed and is denoted by
mtot. Next, the model assumes that a dimer is the smallest aggregate that may form. The chemical reaction for dimer formation represents the nucleation of an aggregate [
51,
52,
66] and can be quantified by an equilibrium constant denoted
Keq:
where A represents monomer, Ak represents the aggregate containing k proteins and is referred to as a k-mer.
The nucleation equilibrium constant is often denoted
Keq =
σs, for example, in Terzi’s model [
52]. The concentrations for monomers,
n1, and dimers,
n2, can also be written as:
Once a dimer is formed, then trimer, . . ., k-mer may form by successive addition of a protein to an aggregate. Any of these reactions can be described by the monomer addition mechanism, represented by:
where s is the equilibrium constant. Thus, if the equilibrium constant for monomer addition is s, we can write the equilibrium concentration for the k-mer as:
Since the total protein mass in the system is conserved, mtot can be written in terms of the concentrations of monomers and aggregates as:
Therefore, in the thermodynamic limit N → ∞ the expression can be written as:
where the sum converges when
sn1< 1. If
mtot is known,
Equation (17) can be solved for the monomer concentration
n1.
4.1. A Generalized Zimm-Bragg Model for Protein Aggregation
A more recent approach to equilibrium peptide assembly introduced by van Gestel and van der Schoot relates the concentrations of protein aggregates to equilibrium partition functions [
25]. The partition functions of aggregates are expressed in terms of ZB initiation and propagation parameters and a transfer matrix. The model describes 1D protein aggregation, where the protein monomer is dominated by coil, sheet, or helical conformations, discussed below, and may participate in short-ranged interactions with other proteins. Hence, the aggregates may exhibit various degrees of conformational order, where helix-coil [
24,
67], sheet-coil [
25,
68], or helix-sheet transitions [
21,
26] may occur.
This modeling approach is consistent with a recent set of experiments [
69], for example, that have shown that oligomers of A
β(1-40) and A
β(1-42) are dominated by antiparallel
β-sheet structures, while their fibrils are mainly characterized by parallel
β-sheet structures. Thus major conformational changes may take place somewhere between the oligomer and the fibril formations, and using Ising-like ZB models may be advantageous for studying conformational transitions involved in protein aggregation.
The isolated monomer in the ZB model for aggregation is assumed to be a natively unstructured protein. A “helix” protein is defined if
θhelix> θsheet and
θhelix> θcoil, where
θhelix can be defined by using
Equation (10), or a related equation for sheets. Similar definitions define “sheet” and “coil” proteins. The random coil does not have stable secondary structures. This toy model is suitable for understanding how proteins form fibrils in 1D, however, a word of caution is that, as mentioned above, amyloid formation can be sequence-dependent, for example, A
β(1-40) and A
β(1-42), have different pathways [
27].
All of the aggregate species in a system of volume
V are assumed to be in kinetic equilibrium with each other, where interest lies in studying the thermodynamic properties of these aggregates. The system of proteins and aggregates is also assumed to be well mixed, and containing a fixed amount of protein mass given by
Equation (16). If the system contains only low concentrations of proteins and aggregates, the solution properties of the aggregates can be calculated by employing a standard ideal gas approximation for the
k-mers, where the partition function for the system can be written as:
where Zk is the canonical partition function for the k-mer. The number distributions nk per unit volume define the number densities ρk ≡nk=V. The relative densities of k-mers can be derived by considering the total free energy density Δ, which may be written compactly for a system containing N number of proteins, as:
which contains an entropy of mixing term as well as the free energy of the aggregate of size
N. We can minimize
Equation (19) with respect to the total number density
ρT and subject to constraint given in
Equation (16),
i.e., conservation of mass, which yields for the number densities:
where
μ is the Lagrange multiplier, and is realized as the chemical potential of a protein,
ρ(
N) is just the
Nth moment of quasi-grand ensemble
. As in the 1D model by van Gestel
et al. [
24,
25], the state of an aggregate is directly coupled to the aggregate size distribution.
A generalized ZB model for protein aggregation can now be defined by an effective Hamiltonian. The effective Hamiltonian is used to find a transfer matrix by assuming the interactions between aggregates are described by a nearest-neighbor, Ising-like model, in which the protein could be in any of the two states: a sheet (or helix) or coil conformation. The interactions include the free energy
R < 0, which describes the inter-facial tension between adjacent sheet and coil proteins in an aggregate. The parameter
P > 0 represents the interaction between two neighboring proteins, where one of the proteins located at position
j along the chain is in a sheet conformation.
P for sheets is measured relative to the coil interaction energy, which was taken to be zero. Additionally, the free energy
K > 0 quantifies a polymerizing interaction between any two monomers along the 1D lattice that does not depend on their respective conformations. The effective Hamiltonian used by van Gestel and others has the following form for
N monomers [
25,
70]:
where r = (r1,r2,. . ., rN) and ri can take on values {1,−1} corresponding to the spin states {↑, ↓ } in the Ising model, and to {s, c} in a Zimm-Bragg model for sheet-coil aggregates. With periodic boundary conditions, the partition function for the two-state model can be written as:
where eβ(N−1)K ≡ kN−1 with β = 1/kBT, and the parameters are redefined as K ≡ K/kBT, R ≡ R/kBT, P ≡ P/kBT. The transfer matrix can be written as:
where
σ1 = exp(−2
R) and
s1 = exp(
P) are the initiation and propagation parameters for the aggregate system. We note that
Equation (23) and
Equation (3) yield the same characteristic equation, hence they predict the same thermodynamics results. The difference in the formulation of the folding model versus the aggregation model is that the helical regions of proteins, for example, may only elongate in one direction, while helical aggregates may grow longer at either side. While amyloid fibrils during fibril formation [
71,
72]. It may also be advantageous to study statistical mechanical models that can describe the interaction of molecules capable of binding to A
β structure in fibrils, which may inhibit oligomer formation in the early stages of aggregation [
73].
5. Partition Functions for Fibrils
Amyloid formation is generally believed to be dominated by 1D or quasi-1D chains of proteins, which may then bundle into protofibrils and fibrils. It is because of this fact that the transfer matrix formulation in statistical mechanics, if extended successfully, is a powerful technique for the studies of amyloid formation. We focus on this extension in this and the following sections.
5.1. Potts Model for 1D Filaments
To include helix, sheet, and coil conformations in a single model, a Potts model [
74] for 3-state proteins can be used [
26]. The spin variable,
r, may now assume values of
r = 0 for coil proteins,
r = 1 for helical proteins, and
r = 2 for sheet proteins. Interactions between proteins are assumed to be with nearest-neighbors only so that a dimensionless Potts model for the aggregate containing
N number of proteins can be written as:
where the Kronecker delta
δ(
x, y) equals one if
x =
y and zero otherwise.
Equation (24) is illustrated in
Figure 4. Like in
Equation (21), the initiation parameters are defined as
σ(
rj, rj+1) ≡ exp(−2
R(
rj, rj+1)) and
R(
rj, rj+1)
> 0 is the free energy of the interfacial tension between proteins at positions
j, j + 1 that are not in the same conformation [
24]. Thus, three types of interfaces between neighboring proteins in a generalized model are possible:
hc or
ch,
R(0
, 1) =
R(1
, 0) ≡
R1;
sc or
cs,
R(0
, 2) =
R(2
, 0) ≡
R2; and
sh or
hs R(1
, 2) =
R(2
, 1) ≡
R3. The notation can be simplified by letting
σ(1
, 0) =
σ(0
, 1) ≡
σ1,
σ(0
, 2) =
σ(2
, 0) ≡
σ2, and finally
σ(2
, 1) =
σ(1
, 2) ≡
σ3.
The propagation parameters s1 and s2 are associated with the free energies P1 and P2 that refer to the interaction between the ith protein that is helix or sheet, respectively, and the nearest neighbor protein at location i + 1. The coil protein interaction energy is assumed to be zero so that it may serve as a reference state. The transfer matrix can then be written as
and the partition function for
N > 2 proteins in the aggregate can be calculated by diagonalizing
Equation (25) and plugging into
Equation (2).
The Ising-like ZB model for sheet-coil (or helix-coil) transitions in aggregates,
Equation (21), can be recovered by writing the
q = 2 version of the effective Hamiltonian given in
Equation (24). By choosing internal states such that
ri = −1 is the coil state and
ri = +1 is the helix state, and by making the substitution
, the effective Hamiltonian and corresponding transfer matrix for 1D, two-state helix-coil is recovered [
24]. Next, the Hamiltonian for the 1D model given by
Equation (24) can be applied to describe the interactions between proteins in aggregates on quasi-1D lattices.
5.2. Simple Model for Fibrils
To describe the fibrils, which may contain several filaments that can be described by
Equation (24), various models could be used. For example, two identical filaments could align in register, and all of the proteins could be in the sheet conformation already, or all coil, or some combination of sheet, coil, and even helix proteins. A simple Hamiltonian for the all-sheet case can be written as [
25,
55,
68]:
where the free energy
B > 0 describes a lateral binding interaction between two sheet proteins on different filaments,
Ly refers to the the number of filaments, and
Lx is the length of each filament. Additionally, in our approach
K was the polymerizing interaction between two adjacent proteins in a fibril, and
P1 was free energy of an interaction between a sheet protein and one of its neighbors. Other effective Hamiltonians could also be written to describe the case where the filaments are not aligned in register with each other, as well as cases where the protein conformation may also play a role in the assembly of the filaments into full fibrils [
55,
68].
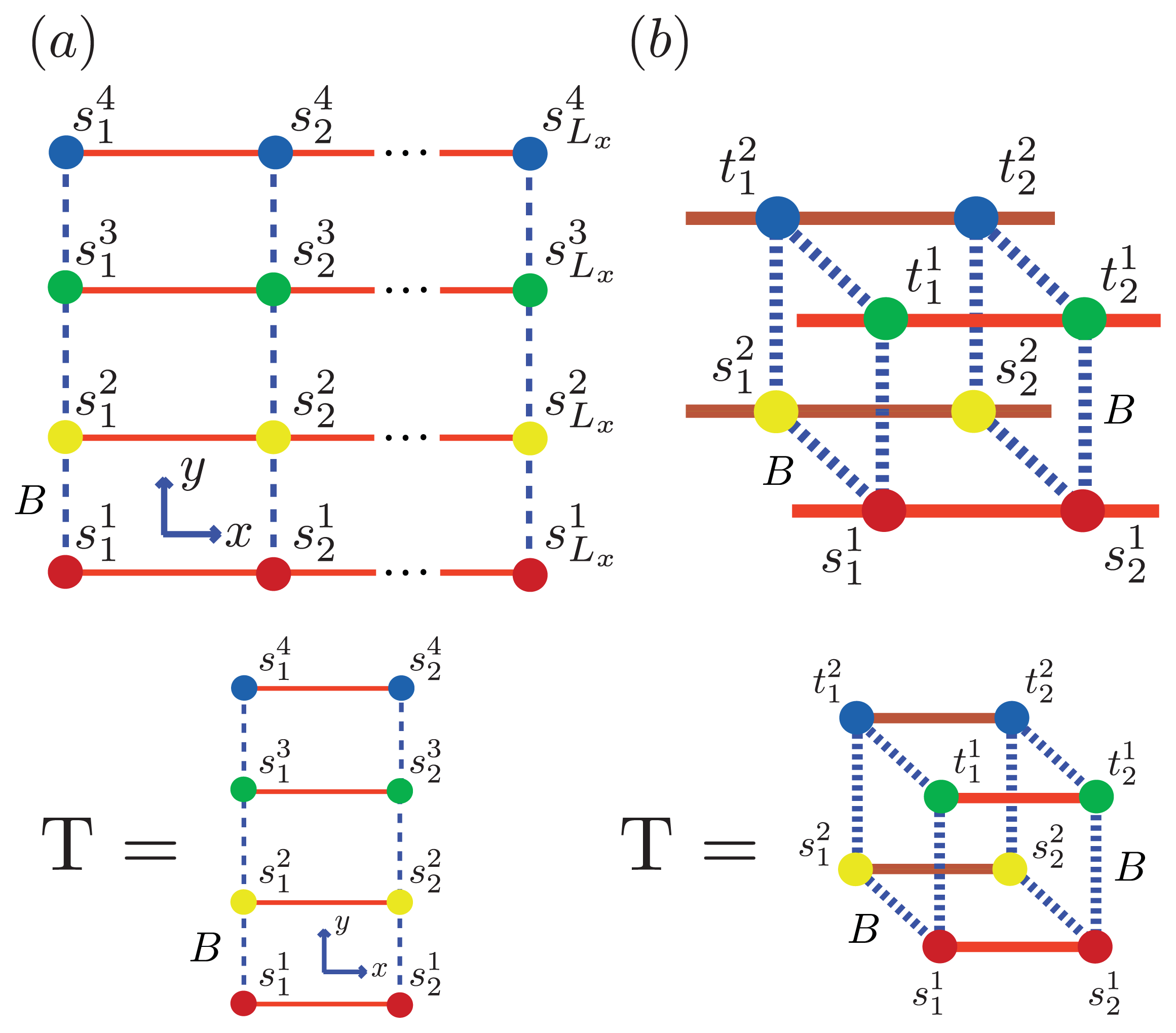
5.3. Quasi-1D Models for Aggregates
In addition to conformational changes in filaments and fibrils, another complication is that the kinetic pathways to the formation of fibrils seem to be sequence-dependent [
27]. The A
β(1–40) isoform solution is abundant in dimers, then trimers, tetramers, . . . , in decreasing order. However, the A
β(1–42) isoform is more abundant in hexamers and pentamers than in dimers and trimers [
4,
27]. These facts seem to be consistent with recent experiments [
38,
69,
75], which indicate that the A
β(1–40) dimer is particularly stable and contributes to protofibril formation. On the other hand, circular hexamers seem to play a role in the protofibril formation of A
β(1–42) [
4,
27].
We can model the equilibrium aggregates of A
β(1–40) and A
β(1–42) proteins by using finite strips of a two-dimensional
N ×
N square lattice. In
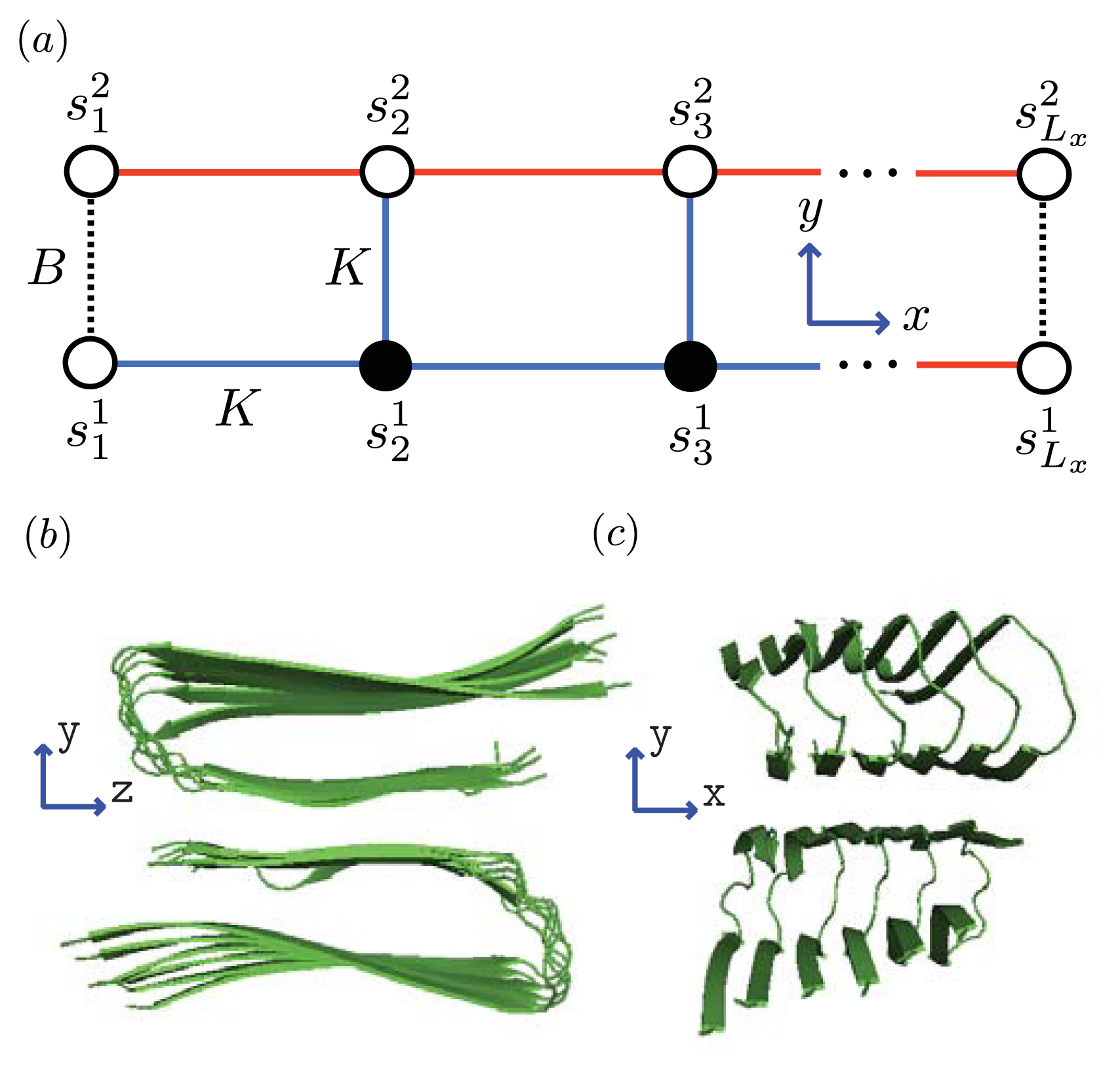
Figure 5 and
Figure 6a, two identical 1D lattices stacked in-register, that is, a strip lattice of width two, are used to represent an A
β(1–40) aggregate. For A
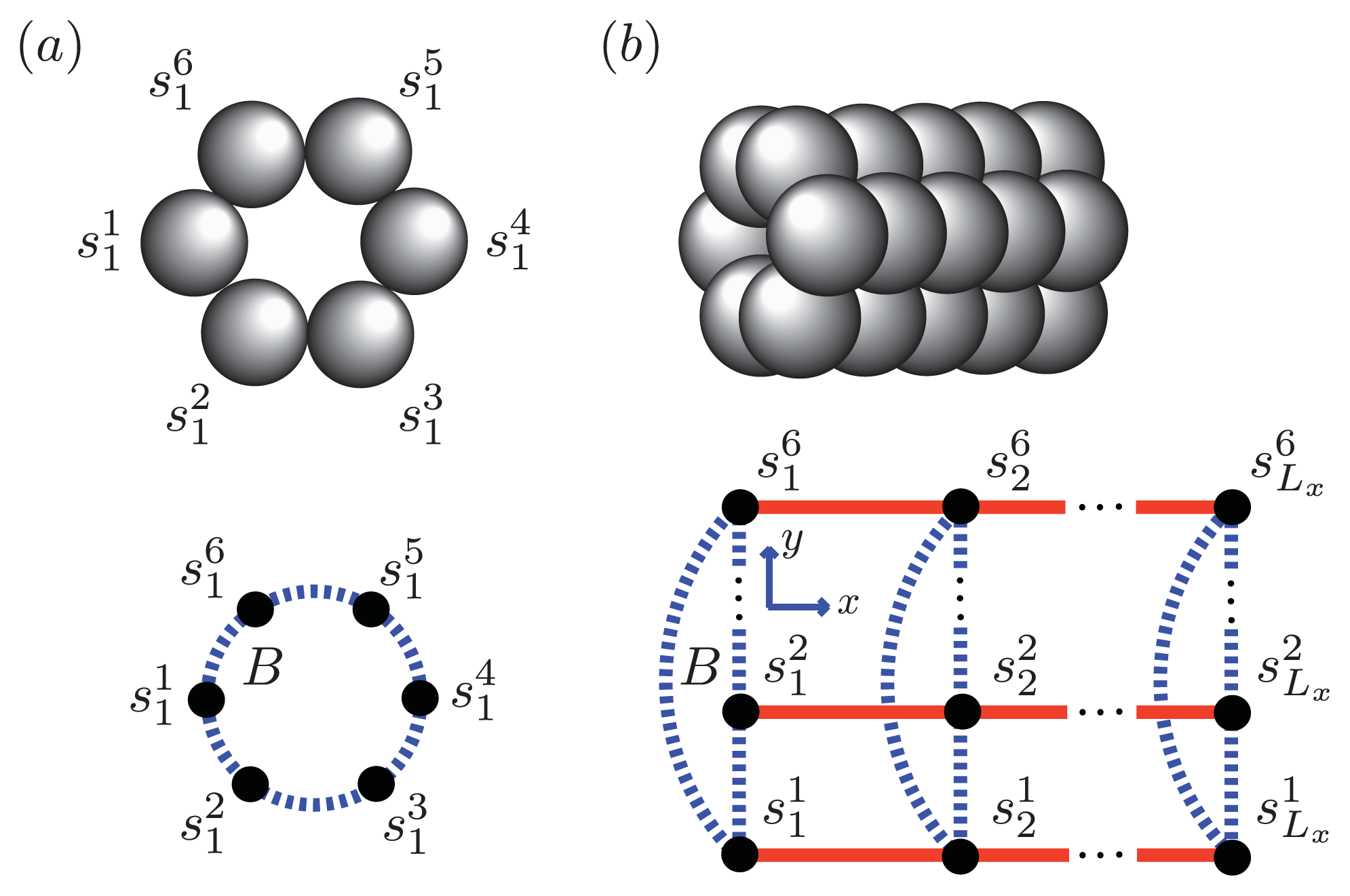
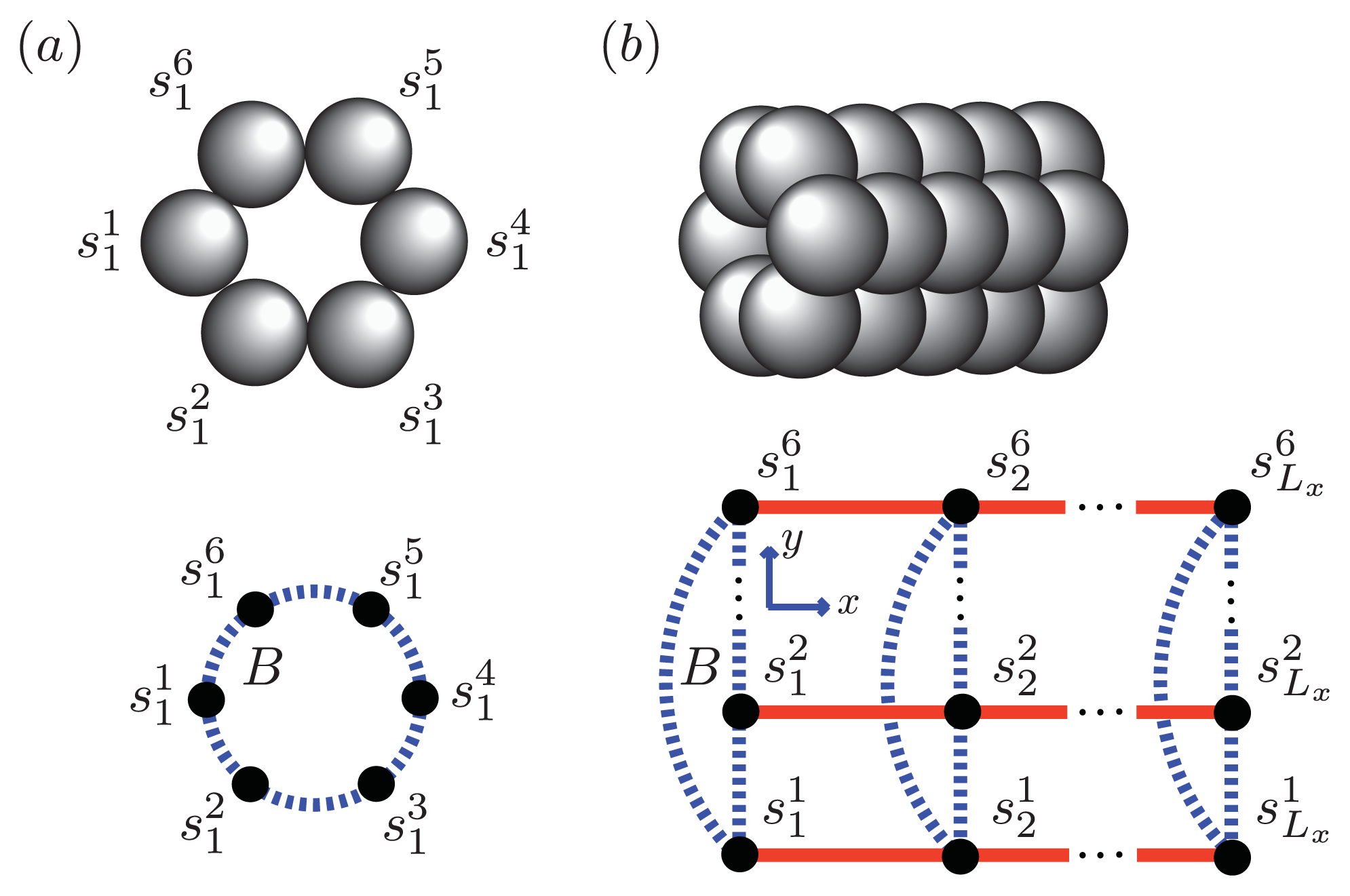
β(1–40), we assume that the smallest equilibrium aggregate is the critical nucleus, which in this case is taken to be the dimer, while the smallest aggregate for A
β(1–42) is the hexamer, as illustrated in
Figure 7 for a strip lattice of width six.
The position of a vertex within the strip is specified by coordinates (
i, j), where
i is the position along the
x-axis of length
Lx vertices and
j is the position along the
y-axis of width
Ly vertices. The total number of vertices is
NT =
LxLy. In
Figure 5a, strips of spin variables
in the
y-axis are referred to as
Ly-mer’s, where
for Ising-type models and 0, 1, or 2 for Potts models. The critical nucleus can be represented by a column of
Ly proteins on the strip lattice. The proteins in the nucleus could also participate in inter-protein interactions other than the polymerizing interaction
K in the
y-direction. These interactions can be described by using the sheet and helix interactions from the filament model, plus the free energy introduced above,
B > 0, that quantifies the inter-filament interactions between two sheet proteins.
The interactions between the proteins in these aggregates is modeled similarly to the 2-helix chain model for proteins proposed by Skolnick [
76] and others [
59,
63,
77,
78], which use Zimm-Bragg or Lifson-Roig (LR) parameters to quantify the inter-chain interactions between residues in independent chains. When the inter-chain interactions between two helical residues are made zero, for example, the partition function reduces to a direct product of Zimm-Bragg [
76] (or LR [
63,
77]) transfer matrices. Since the model for aggregates proposed here uses a strip of a finite 2D lattice, as illustrated in
Figure 6a, the two-protein case studied by Skolnick can be considered as a special case when considering protein folding instead of aggregation. The lessons learned from the folding models can guide us in constructing aggregation models.
As mentioned, the nucleus is the smallest equilibrium aggregate in our formulation. The next smallest aggregate occupies the first two columns of the strip lattice, and contain 2Ly number of proteins, then 4Ly number of proteins, and so on. The interactions between Ly-mers along the x-axis can be described by generalizing the effective Hamiltonian for the 1D aggregation model, that is, P1> 0 and P2> 0 represent the interaction between helical and sheet proteins, respectively, and their nearest-neighbors in the aggregate. The total effective Hamiltonian for aggregates on a strip lattice with boundary conditions can be written as:
where
Hfil is given by
Equation (24) upon substituting
and where
can assume the values of 0
, 1
, 2 for coil, helix, or sheet monomers, respectively. Additionally,
B is the lateral binding interaction between two proteins from different filaments. The third term involving
K are the polymerizing interactions between proteins in both the
x and
y directions on the quasi-1D lattice. We assumed any polymerizing interactions between proteins on a quasi-1D lattice were equal in magnitude in order to keep the number of parameters used in the model to a minumum. It is similar to the parameter
K in
Equation (21), which took into account the polymerizing interaction between two adjacent proteins on the 1D lattice. For the case
q = 2 and
Ly = 2 of
Equation (27), the Hamiltonian for sheet-coil protofibrils can be explicitly written as:
where 2D refers to aggregates on a strip lattice. The transfer matrix can then be written as:
where
b ≡ exp(
B). As mentioned, in the limit when the inter-filament interactions between two sheet proteins
B → 0, the transfer matrix given by
Equation (29) decomposes into a direct product of transfer matrices given by
Equation (23) for 1D filaments of length
N along the
x-axis [
25]. Moreover, the limit in which the sheet-coil interfacial interactions
R → 0 (or
σ1 → 1) yields independent strips parallel to the
y-axis. The 2
Ly × 2
Ly transfer matrix is also symmetric with respect to the sheet-coil interfacial interaction
R. This fact is analogous to the 1D case, where the transfer matrix was symmetric in
σ1,
σ2 and
σ3. The partition function for aggregates on the strip lattice can be calculated by plugging the eigenvalues,
σ2D,i, of
Equation (29) into
Equation (2) and specifying boundary conditions. The result is:
where, again,
ci are determined by boundary conditions and
k was defined in
Equation (22).
Using the ZB formalism, we can also model fibrils in the
x-,
y- and
z-directions using a quasi-1D lattice in 3D. For example, two or more filaments could join to form a protofibril or fibril, as illustrated in
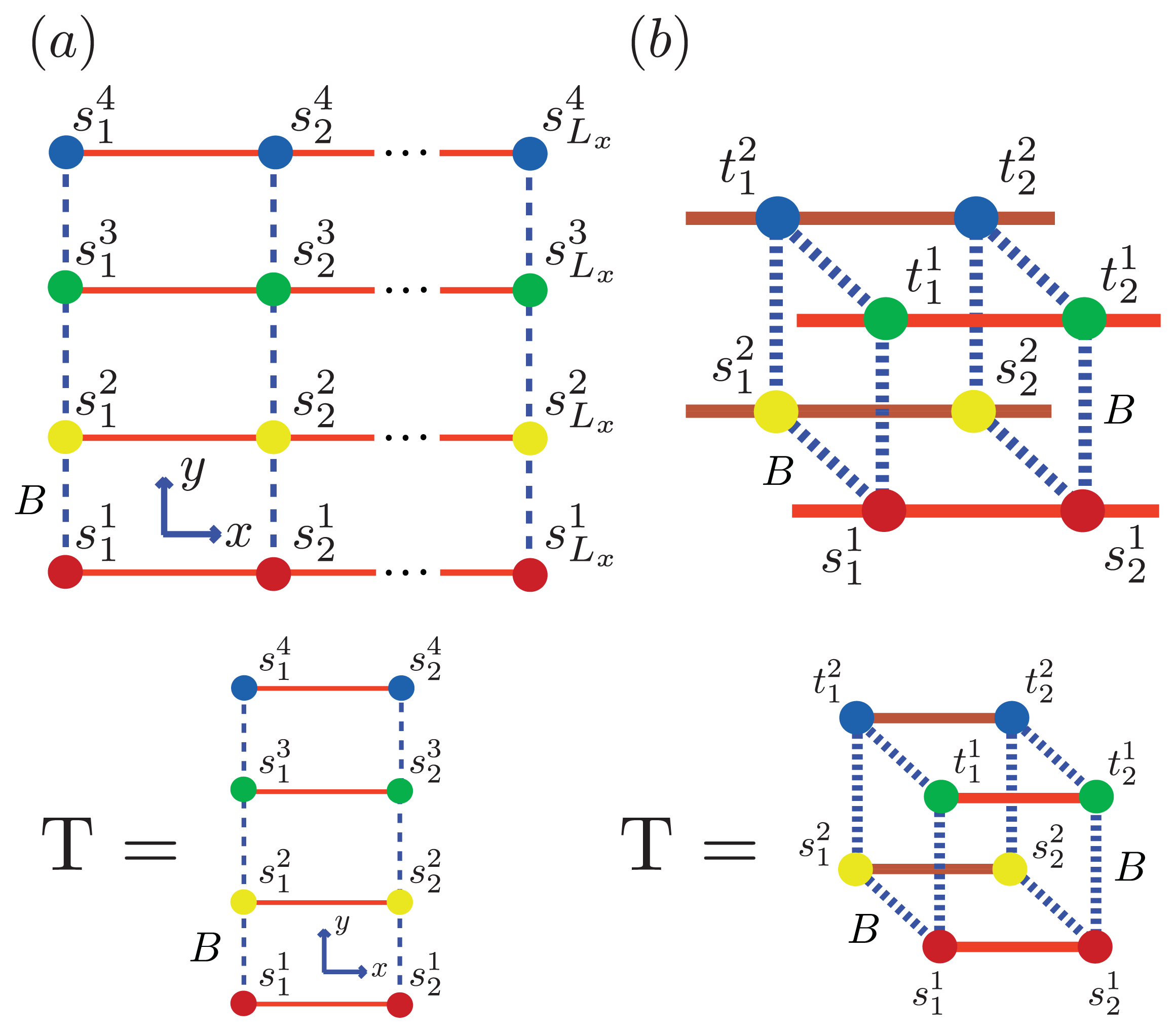
Figure 6 for two simple geometric configurations. For simplicity, we study the case where two 2D aggregates represented by strip lattices, as depicted in
Figure 6b, are the same geometrical shape and are stacked one on top the other, in-register. The spin variable associated with one of the aggregates is denoted by
s, while the spin variables associated to the second aggregate is denoted by
t. The effective Hamiltonian for the fibril model in
Figure 6b, referred to as the “cube” model, may be written using the strip model for aggregates as:
where we assume that the interaction between any two sheet proteins from adjacent aggregates is also quantified by the free energy B > 0. Additionally, the aggregates can now polymerize in any direction. To help keep the number of parameters used in the model to a minimum, we assume the polymerizing interactions between two adjacent proteins in the z-direction has the same strength as the polymerizing interactions, K, in the x and y directions. The corresponding transfer matrices for each model for fibrils are found just as they were for the 1D and strip models discussed earlier. The result is:
In general, the transfer matrix for the 2D model has dimension
qLy ×
qLy, while the 3D model has dimension
q2Ly ×
q2Ly, where we assumed that the two protofibrils composing the fibril contain
Ly number of filaments. The transfer matrices for both the 2D and 3D models are illustrated in
Figure 6a and
Figure 6b, respectively. Since the Potts model is used,
q is 2 for sheet-coil, helix-coil, or helix-sheet models, and 3 for the helix-sheet-coil model.
5.4. Dilute Thermodynamic Averages
To compare with experiments, some average properties of the dilute system of monomers and aggregates can be defined. The total number density for the strip or cube model for fibrils can be written as:
where
Z can be given by
Equation (30) or
(32) for 2D or 3D aggregates, respectively, and
L is the total number of proteins in aggregates. In the 2D case,
L =
LxLy. The average fraction that an aggregate is helix (
i = 1) or sheet (
i = 2) can be defined as:
where the
x-axis is the axis of propagation of the aggregate, and
θi can be calculated for any of the aggregate species discussed earlier by computing
Equation (9).
Equation (34) can be used as a fit function for CD spectral data points. The average degree of polymerization of an aggregate growing in the
x-direction can also be defined as:
and is directly related to the length of the fibrils. The expressions for 〈
θ1〉 and 〈
L〉 can be obtained for systems of
α-synuclein (
αS) and A
β(1–40) aggregates. The
α-synuclein fibril is modeled by placing the proteins in the aggregates onto the
Ly=4 strip lattice, as illustrated in
Figure 6a. Thus, the average length of these fibrils is then:
which can be used to fit the AFM measurements of the average lengths of the fibrils. This relation also holds for the average length of a fibril described by the cube lattice model as depicted in
Figure 6b for the A
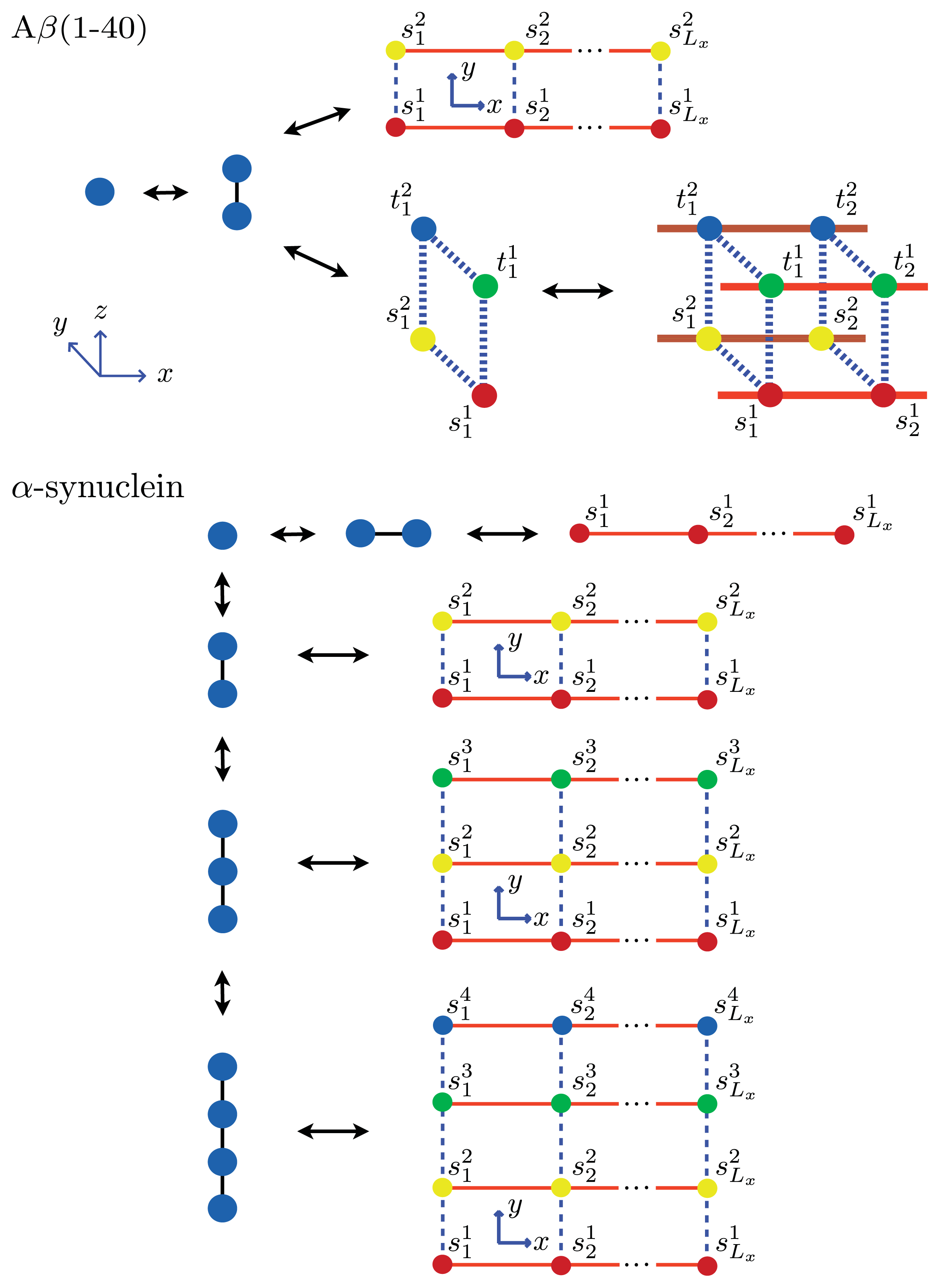
β(1–40) fibrils. As an example, we calculate these quantities explicitly for a system of equilibrium A
β(1–40) aggregates using a sheet-coil model. Specifically, for a system where 1D filaments,
Ly = 2 strip aggregates, or 3D cube aggregates could be present at equilibrium, we first define:
where the fugacity
z ≡ exp(
βμ) and in each sum
λk is the
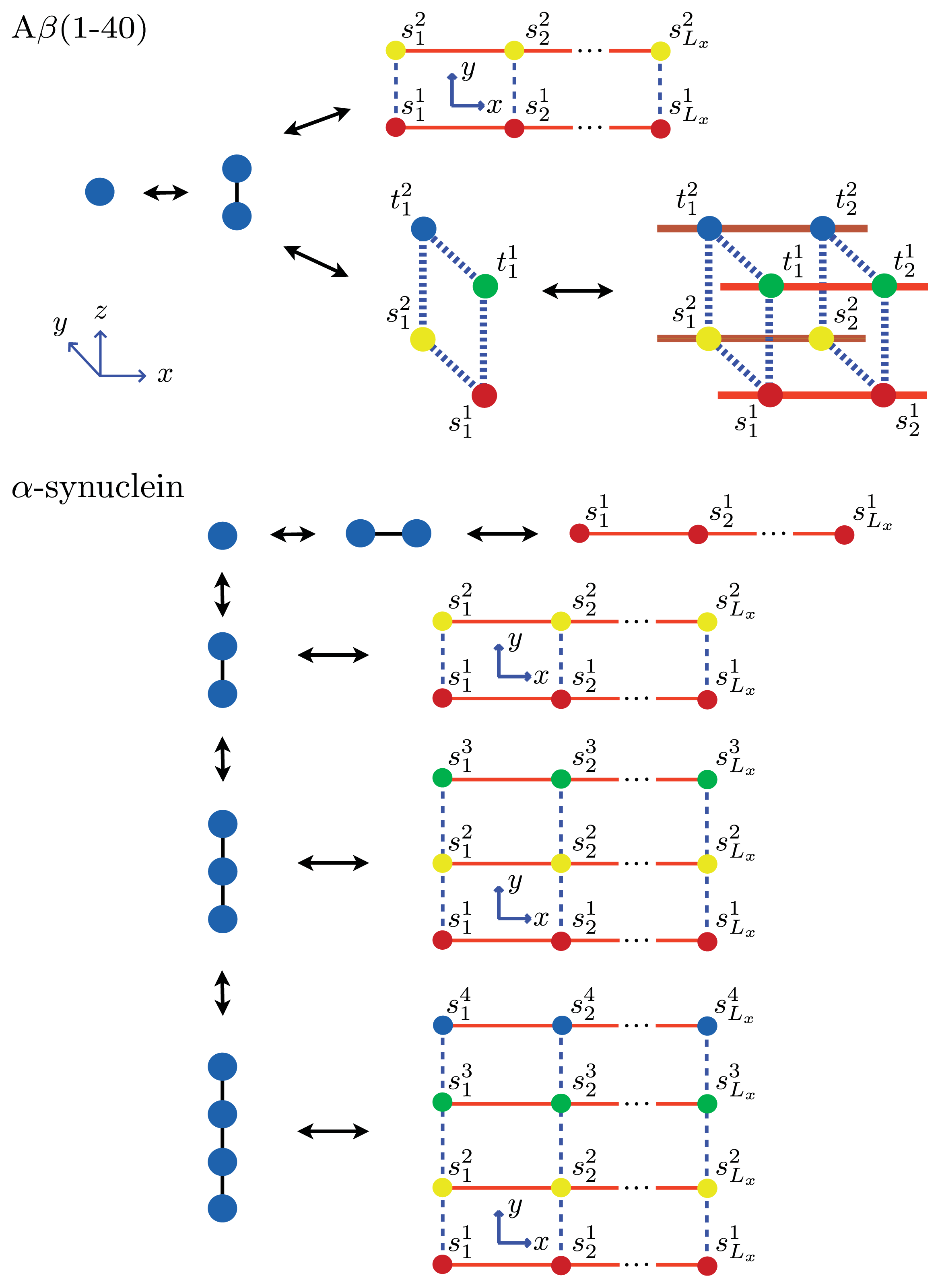
kth eigenvalue of the 1D, 2D, or 3D transfer matrix for filament, strip, or cube models, respectively. The A
β(1–40) aggregates considered here at equilibrium are illustrated in
Figure 8. Additionally,
xk is the
kth term of the expression 〈
i|
f〉, where |
i〉 and |
f〉 are the specified boundary conditions. The sums computed converge only if
kzλj< 1 for all
j. Details on boundary conditions for ZB-type models can be found in [
67]. By using
Equation (16),
φ =
mtot/V can also be written explicitly for A
β(1–40) aggregates as:
Now the average lengths of the aggregates can be computed. Next, the average fraction of the aggregates that are sheet, 〈
θ2〉, is calculated for the A
β(1–40) model. By plugging
Equation (6) for filament, strip, and cube aggregates into
Equation (34), 〈
θ2〉 can be written as:
where s2 is the sheet propagation parameter. The procedure for finding 〈θ2〉 is quite general, and works for all of the transfer matrices that we have considered in this model.
5.5. Comparison to Experiment
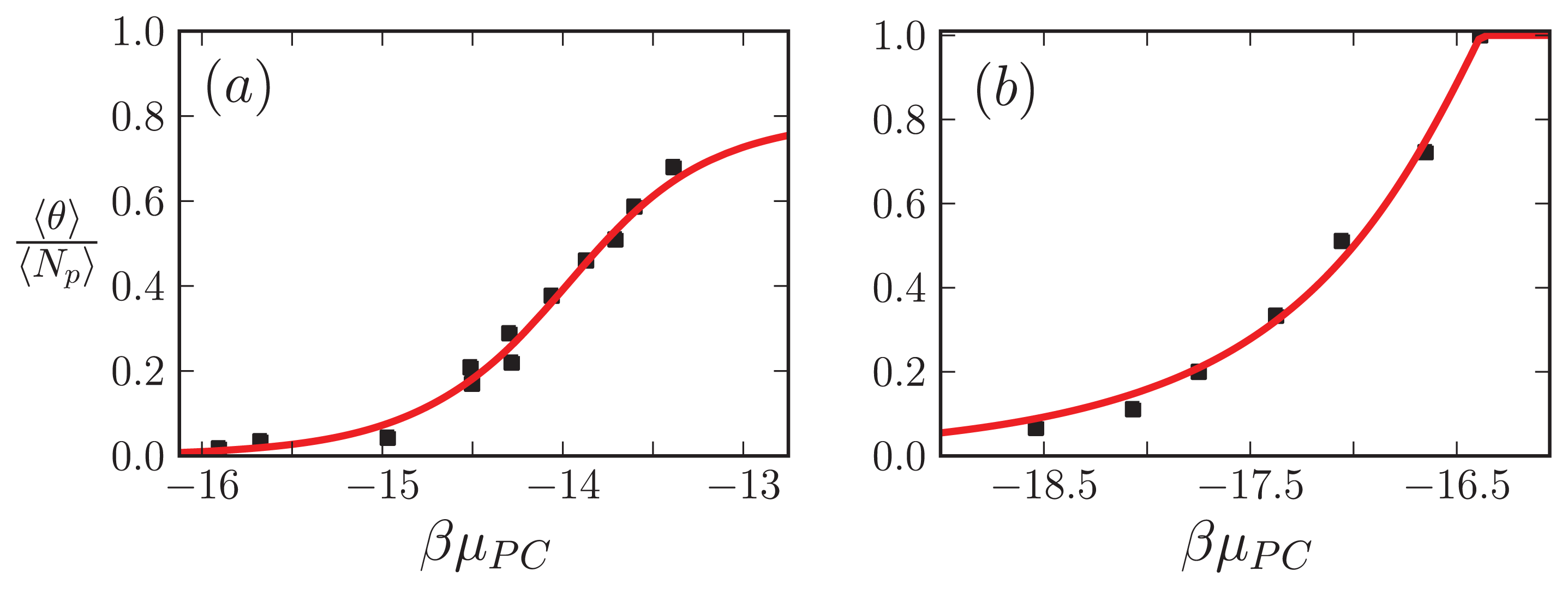
In this subsection, our ZB-like model predictions are compared to the experimental results for the CD spectra of A
β(1–40) fibrils [
52] and the AFM measurements of the lengths of
α-synuclein fibrils [
68]. The CD and the AFM measurements were made at various initial mass concentrations of each protein, when the fibrils had reached a steady state. For the fit of the CD data, we used as our fit function the total fractional amount of sheet structure in all of the aggregates, 〈
θ2〉
Aβ, given by
Equation (39). The proteins at the boundaries of aggregates could be coil or sheet for 1D, 2D, and 3D lattices. The fit and the values for
P2, the sheet interaction free energy,
K, the free energy describing the polymerization of the aggregate in any direction,
R2, the sheet-coil interfacial free energy, and
B, and lateral binding free energy for the
q = 2 sheet-coil model are given in
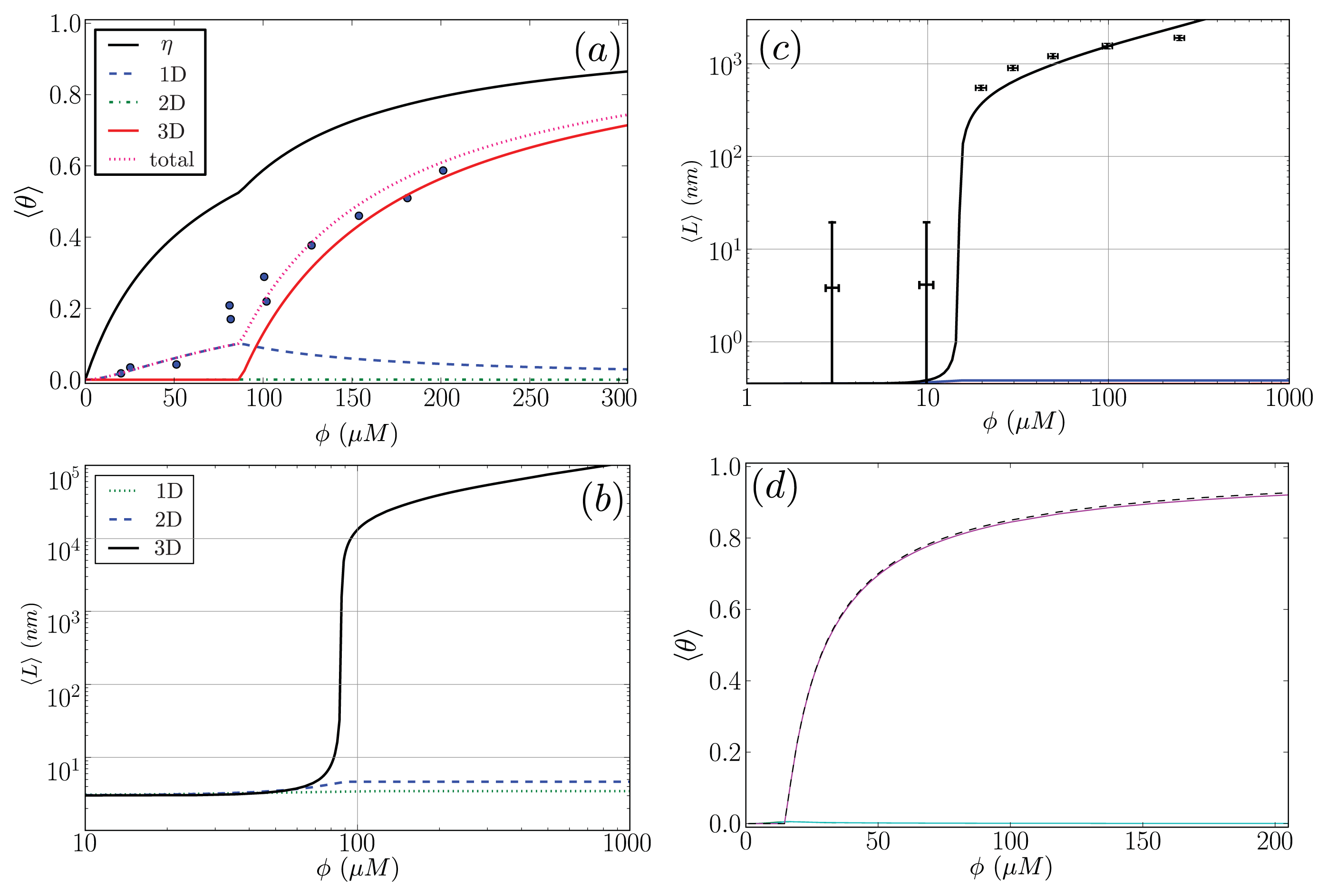
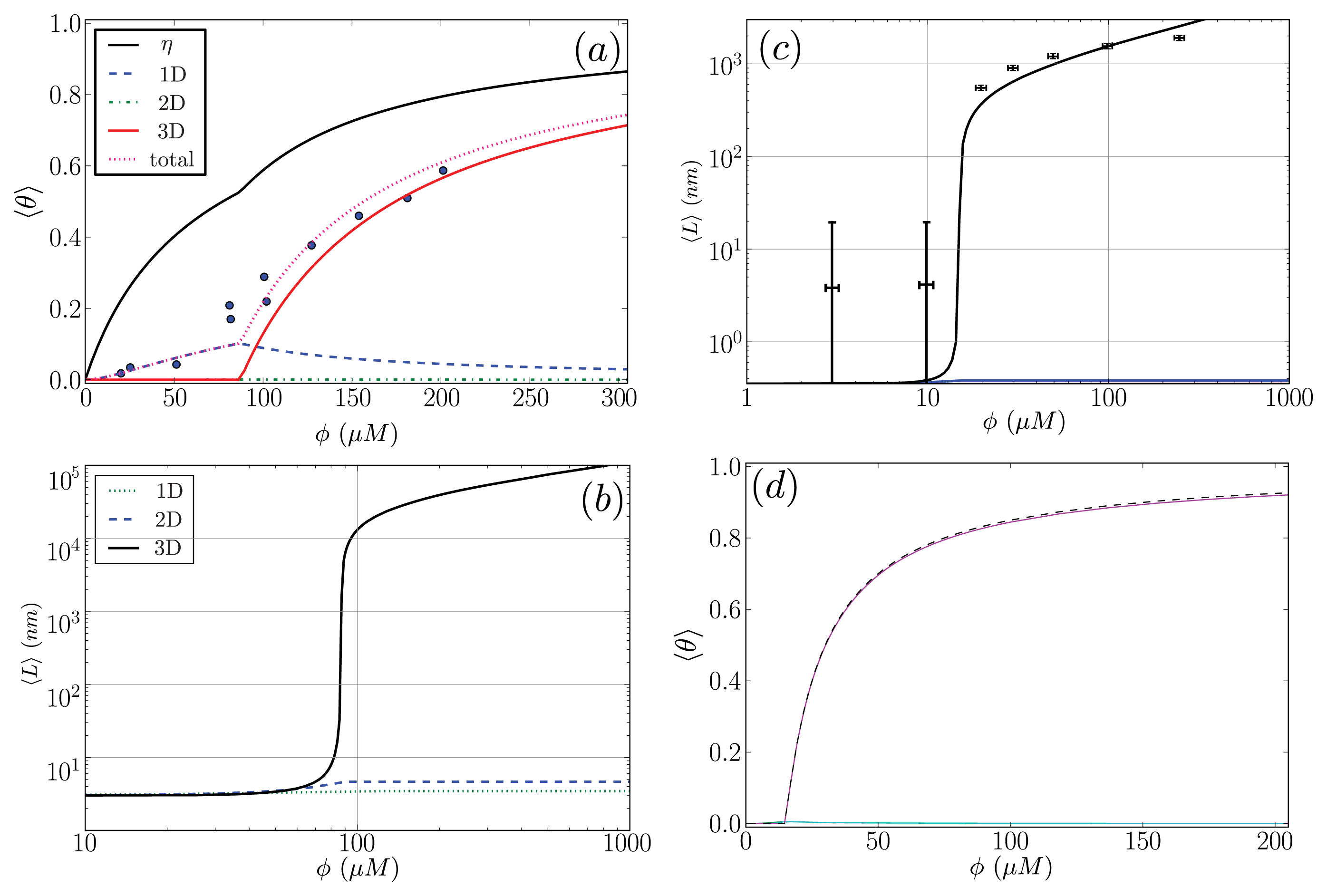
Figure 9a. The fit parameters are then used to predict the average length of the fibrils in the system, 〈
L〉, which illustrated in
Figure 9b.
For the
α-synuclein model, where
Ly = 1, 2, 3 and 4 strip aggregates could be present, we fit the
Ly = 4 contribution from
Equation (36) to the AFM average length data for the fibrils. The
α-synuclein aggregates at equilibrium are illustrated in
Figure 8. The fit is illustrated in
Figure 9c. The fit parameters are then used to predict the total fraction of aggregates that are sheet, which can be written for the
α-synuclein model as:
where each contribution in
Equation (40) can be calculated using transfer matrices derived from
Equation (27) for
Ly = 1, ..., 4.
Equation (40) is illustrated in
Figure 9d. The model predicts the average length data pretty well (Notice the log scales used in the plot. At the low coverage, the predicted points fall actually within the error bars), as we should have expected because the other variations of the Ising-ZB model fit the data well [
25,
68]. The resulting predictions for 〈
θ2〉
αS illustrate that the concentration at which the fibril concentration takes off is around 15 μM, again, as we should have expected [
68].
The fit of 〈
θ2〉
Aβ to the CD data predicts that the fibrils are held together tightly due to the relatively large value of the sheet-interaction between proteins in the aggregates,
P1, and to a lesser extent on the binding between filaments as quantified by
B. The fitted value for the sheet-coil interface free energy,
R2, indicates that the interfacial tension between sheet and coil regions in the aggregates is modest. However, the fibril concentrations do not really increase from zero until nearly 100 μM according to the model predictions, but
β-rich fibrils have been observed at lower concentrations as seen in
Figure 9a. The fit could be improved by considering other types of models for the A
β fibrils and as well as different boundary conditions.
The model predictions for the strip model of
α-synuclein fibrils seem to agree with the experimentally determined average lengths as illustrated in
Figure 9c where the boundary conditions were set so that the ends of fibrils could be sheet or coil proteins. Additionally, as illustrated in
Figure 9d, the model for synuclein fibrils predicts that the sheet-coil transition of proteins in fibrils largely drives the polymerization process, where
ρƒib/
φ and 〈
θ2〉
Ly=4 give nearly the same result for the concentrations used in the AFM experiments.
The fits of the AFM data done by van Raaij
et al. [
68] and Schmit
et al. [
53] needed only 2 parameters, compared to 3 in the present model. When compared with van Raaij’s fit of the AFM data, our model predicts that the probability that fibrils contain sheet structure is high once overcoming a sheet-coil free energy barrier
R2, whereas in van Raaij’s model prediction, the free energy barrier between adjacent sheet and coil proteins in the aggregates does not seem to be present. A finite contribution from
R2 means the fibrils will have longer stretches of sheet content when compared to cases when
R2 is closer to zero when there is little or no penalty between coil to sheet regions in the fibrils. Additionally, our model predicts that the inter-filament interactions,
B, are slightly weaker than the interactions between sheets along the axis of growth of the fibril, whereas van Raaij’s fit is the other way around: the inter-filament interactions are stronger than those between proteins along the fibril axis of growth.
When fitting the Aβ(1–40) CD data, our model predicts that the value of the polymerizing interaction between proteins on a quasi-ID lattice, K, is small and could be due to modeling uncertainty, thus the number of parameters needed to fit the CD data could be less. The fact that not all adjustable parameters were required to fit CD and AFM data suggests that the model Hamiltonians introduced throughout the paper may be simplified to describe only the relevant interactions quantified by the non-zero fit parameters. It may also imply that the fibrils are mainly held together by a few types of energetic interactions, for example, the inter-filament interaction B for Aβ(1–40) had a finite contribution in the Hamiltonian. Other interactions described by the Hamiltonians could be non-existent or very small. More detailed experimental results are needed to discern the correctness of the models in predicting the values of interaction energy parameters, which in turn describe the dominant interactions within the fibrils.
As mentioned, the data sets were fit using various boundary conditions, and the open boundary case (proteins could adopt either conformation at the boundaries) was found to be the best choice for fitting for the average lengths of the
α-synuclein fibrils. The CD fits could not be shown to be dependent on certain boundary conditions since there is currently no AFM measurements of the fibrils to compliment the CD data. This means we could fit the CD data using most choices for boundary conditions, including the case where all proteins at the ends of fibrils are in the coil conformation. However, for some choices of boundary conditions [
25,
67], the corresponding average length predictions yielded unreasonable lengths (not shown) for protein aggregates
in vivo.
6. Grand Canonical Approach
The models for fibrils discussed so far do not take into account interactions between protein and solvent, or some free energy that would be associated with nucleus formation. The ZB model for aggregation can be extended to take into account these phenomena by using a grand-canonical model. We summarize several main differences between canonical and grand-canonical approaches: (1) in the grand canonical model, aggregates of all sizes are included; (2) an aggregate phase and solution phase are in equilibrium; (3) chemical potentials can be used relating the solution phase as well as the aggregate phase [
26].
The solution phase is defined by specifying the chemical potential for protein monomers in the solution can be written [
79–
81] as:
where the subscript “
S” stands for solution,
μST and
μSR are the free energy contributions arising from the translational and rotational motion of monomers moving in solution, respectively, and
c is the concentration of monomers in solution. The aggregate phase is defined by specifying the chemical potential of the aggregates,
μagg, by assuming a crystalline approximation so that
μagg can be written as [
82]:
where “
P” stands for polymers of proteins.
μPC is the free energy contribution arising from the contact interactions between proteins in aggregates, which may vary for different monomer organizations in the aggregates. We assume this term also includes the conformational entropy of the backbone and side-chains. The term
μPV is the free energy arising from the proteins vibrating about their equilibrium positions, but not molecular internal vibrations within the proteins [
79,
82]. When the phases are at equilibrium, the chemical potentials for each phase are equal:
With the simple statistical mechanical model summarized in the sections to follow, we can relate the chemical potential contribution from the protein interactions in aggregates,
μPC, to the experimental concentration of protein in solution via
Equation (43).
As a first step in generalizing the canonical effective-Hamiltonian models presented earlier, the free energy A is introduced to quantify the entropic penalty needed to nucleate the aggregate, i.e., the first column of a strip lattice that contains protein aggregates. This free energy may also be viewed as a boundary between proteins and solvent. The aggregate phase then assumes strip or cube lattices may be occupied by aggregates and any other species, including solvent clusters.
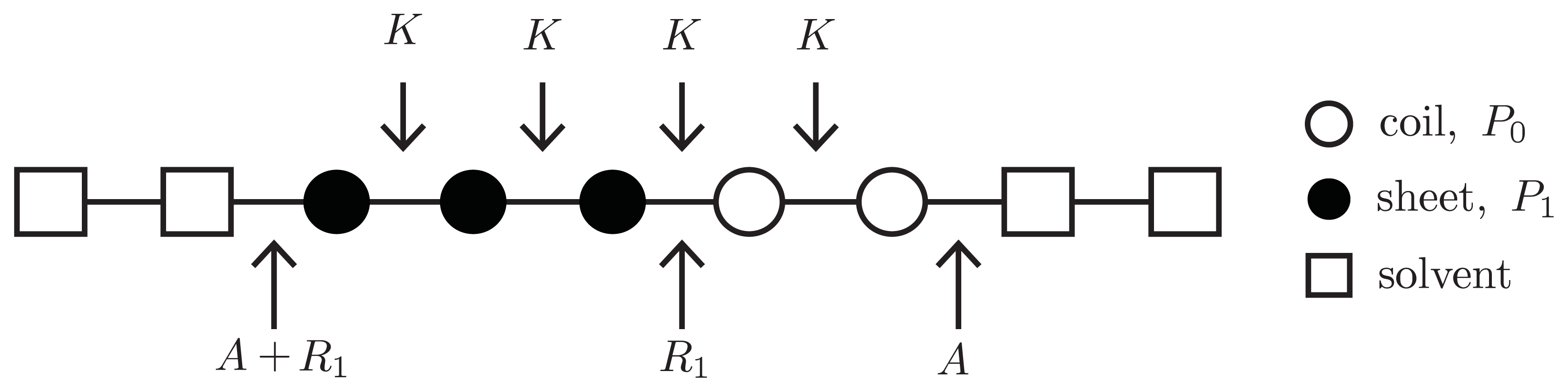
To write down an effective Hamiltonian that can include the free energy
A, the 1D or quasi-1D lattices used in constructing fibrils can be generalized to allow solvent clusters to occupy the lattice sites. For example, in
Figure 10, a square represents a solvent cluster, whereas circle represents protein. Both solvent and proteins can occupy sites along 1D or quasi-1D lattices. By introducing a lattice gas model into the aggregate phase, a Potts Hamiltonian for the 1D lattice that quantifies the interactions between helix, sheet, or coil proteins and solvent can be written as [
26]:
where the lattice-gas variable ni = 1 refers to a protein occupied lattice site, and ni = 0 a solvent occupied site. Additionally, “pp” in −βpp refers to “protein-protein” interactions and “ps” in
refers to “protein-solvent” interactions. The term χ(ni,ni+nc) = 1 − δ(ni, ni+nc) ensuring that there is solvent at site i and a protein at i + nc, or vice-versa.
Since the number of proteins on the lattice can fluctuate, this description of protein aggregation is described by using the grand canonical ensemble. The lattice-gas formalism,
i.e.,
Equation (44), is able to describe a variety of elongation mechanisms including merging and fracturing of aggregates of different sizes along the 1D lattice. The partition function can be written as:
where
βμPC is the dimensionless chemical potential arising from the contact and interfacial interactions between proteins in aggregates, and where the sum is performed over both spin and lattice-gas variables. Just like in the canonical models,
![Ijms 14 17420f13]()
may be solved for exactly by a transfer matrix
T. A simple example illustrating
T for the case
nc = 1 in a sheet-coil (
ti = −1 for coil,
ti = 1 for sheet) system can be written as:
where s1, σ1, and k were defined earlier and α ≡ exp(−2A) is a new Zimm-Bragg-like parameter. Additionally, the fugacity is now defined as z ≡ exp(βμPC).
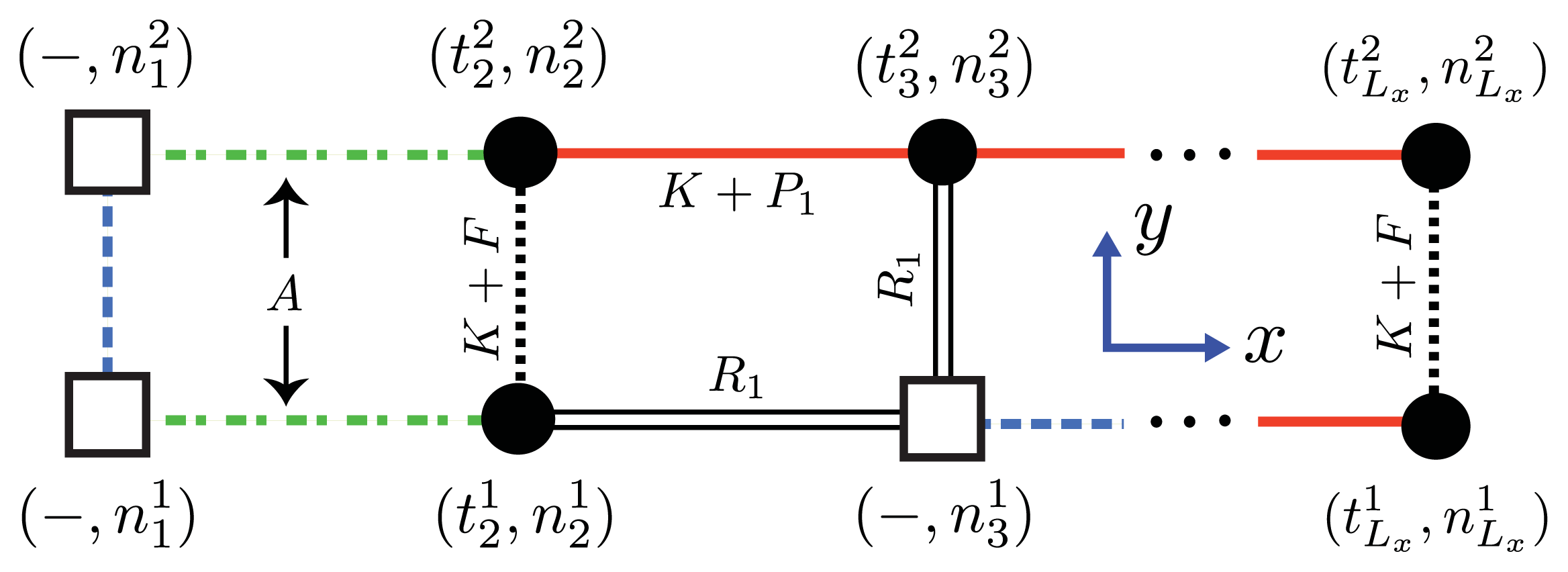
The inter-filament interactions between two 1D filaments are treated using the same methodology introduced in earlier sections. In general, the Hamiltonian for an
Lx ×
Ly strip lattice that includes inter-filament interactions can be written using the 1D Hamiltonian,
Equation (44), by changing the spin and lattice-gas variables
and
, respectively, as:
where
fil(
j) refers to the
jth filament. For A
β(1–40)
Ly = 2, as illustrated in
Figure 5b,c. The parameter
F quantifies the interaction energy between two sheet-linked proteins from adjacent filaments, and plays the same role as the free energy
B in earlier models for fibrils in this article. In our treatment
F > 0, the proto-fibrils and fibrils are more stable than single filaments.
Since nucleation cannot in reality occur in 1D, we consider a similar model for aggregates that positions the nucleus along the
y-axis, as shown in
Figure 6a and
Figure 11. From this point of view the orientations of proteins in the nucleus are perpendicular to the direction of propagation (
x-axis) of the fibrils, and the nucleus is now a multi-layer, 1D aggregate. The nuclei may assemble into proto-fibrils that grow longer on the quasi-1D lattice. An effective Hamiltonian for protein aggregation, including the quasi-1D nucleus, can be written:
where −
βHpp(
j) is given by
Equation (45) after substituting
and
. In the
y-direction we write analogous interactions, −
βHy, similar to those in the
x-direction. Also included in the
y-direction is the nucleus term containing the parameter
A, which has the same meaning of surface energy as before. The effective Hamiltonians given by
Equations (49) and
(50) are the most general forms of fibrils that we have considered so far.
For either description of fibrils (model A or B), the total number of proteins on a strip lattice is then
. The grand partition function can be written as:
where the sums over {
t}, {
n} are for all
i and
j, and A, B refers to the effective Hamiltonians given by
Equation (49) or
(50), respectively. For periodic boundary conditions,
Equation (53) can be solved as
where
is the partition function for the lattice-gas model (A or B). Just as in Subsection 3.1, in the thermodynamic limit
NT → ∞:
where
is the largest eigenvalue of
. In general, the dimension of the transfer matrix
is (q + 1)ncLy × (q + 1)ncLy and has (q + 1)ncLy number of eigenvalues, whereas the transfer matrix
is (q + 1)Ly × (q + 1)Ly and has (q + 1)Ly number of eigenvalues.
To compare with experiments, we can define quantities similar to
Equations (34) and
(36), and others. For example, in the grand canonical ensemble, the average number of proteins on the lattice, 〈
Np〉, referred to as the occupation of the lattice, the number of proteins in filaments, 〈
ψ〉, the average number of filaments, 〈
γ〉, and the average number of sheet segments, 〈
θ〉, can be written as:
respectively. Other quantities may also be defined including the average lengths of filaments, and the average length of sheet stretches in aggregates [
26,
83].
8. Conclusions
By focusing on the aggregation of proteins in forming oligomers, protofibrils, and fibrils, and their relations to neurodegenerative diseases, statistical mechanical approaches to protein aggregation have been developed. We have made a general summary of the field, presenting recent formulations of the ZB model based on the canonical, as well as the grand canonical, approaches to the amyloid formation processes. Some results are presented to show that these models can be used to interpret experimental observations as well as to provide phase diagrams [
26] showing the parameter dependence of the
β-sheet dominating regions.
More experimental data like the CD results of Terzi
et al. [
52] and the AFM measurements performed by van Raaij
et al. [
68] would help validate the ZB approach. For example, the ZB model for protein folding has been used to classify all the amino acids based on their propensity to fold from coil to helix [
12]. Similar classification schemes could potentially be devised for the many proteins that can aggregate to form fibrils if a much larger collection of experimental data (like the CD and AFM results) were available.
Of course, a statistical mechanical approach to protein aggregation has serious limitations. It can only be used to study the equilibrium properties of the systems, not the rates of the processes involved nor the transient behaviors, such as quasi-equilibrium or kinetic trapping. Furthermore, the available experimental data that we can compare our theories with are so far extremely limited. Therefore, statistical mechanical models are not a tool for predicting assembly pathways. However, statistical mechanics can be used to show that experimental observations are consistent with the predictions of a certain route of aggregation, that is, given a route of aggregation and the associated effective free energy, statistical mechanical models can predict equilibrium distributions of oligomers, protofibrils, fibrils, etc., which can then be compared to observed data.
The pathway prediction function is better achieved by using kinetic models [
7,
41,
42,
85,
86], or better still, by molecular dynamics simulations [
1,
2,
32,
33,
87,
88]. Unfortunately, the latter are highly restricted by the system size and length of time that molecular dynamics can be used to simulate. On the other hand, protein aggregation, as discussed earlier, is a complex process spanning many levels of structure and many chemical species. Thus, at present, the kinetic models or coarse-graining models may be better tools for the purpose of predicting pathways. Moreover, many more experimental data are available in the literature for non-equilibrium or kinetic studies. It would be interesting, for example, to develop a kinetic approach based on statistical mechanics, similar to a kinetic Ising model derived from an Ising model. The kinetic study of protein aggregation is a rich field of investigation and of great current interest. We hope to be able to report progress in the non-equilibrium studies of protein aggregation in future work.

 may be solved for exactly by a transfer matrix T. A simple example illustrating T for the case nc = 1 in a sheet-coil (ti = −1 for coil, ti = 1 for sheet) system can be written as:
may be solved for exactly by a transfer matrix T. A simple example illustrating T for the case nc = 1 in a sheet-coil (ti = −1 for coil, ti = 1 for sheet) system can be written as: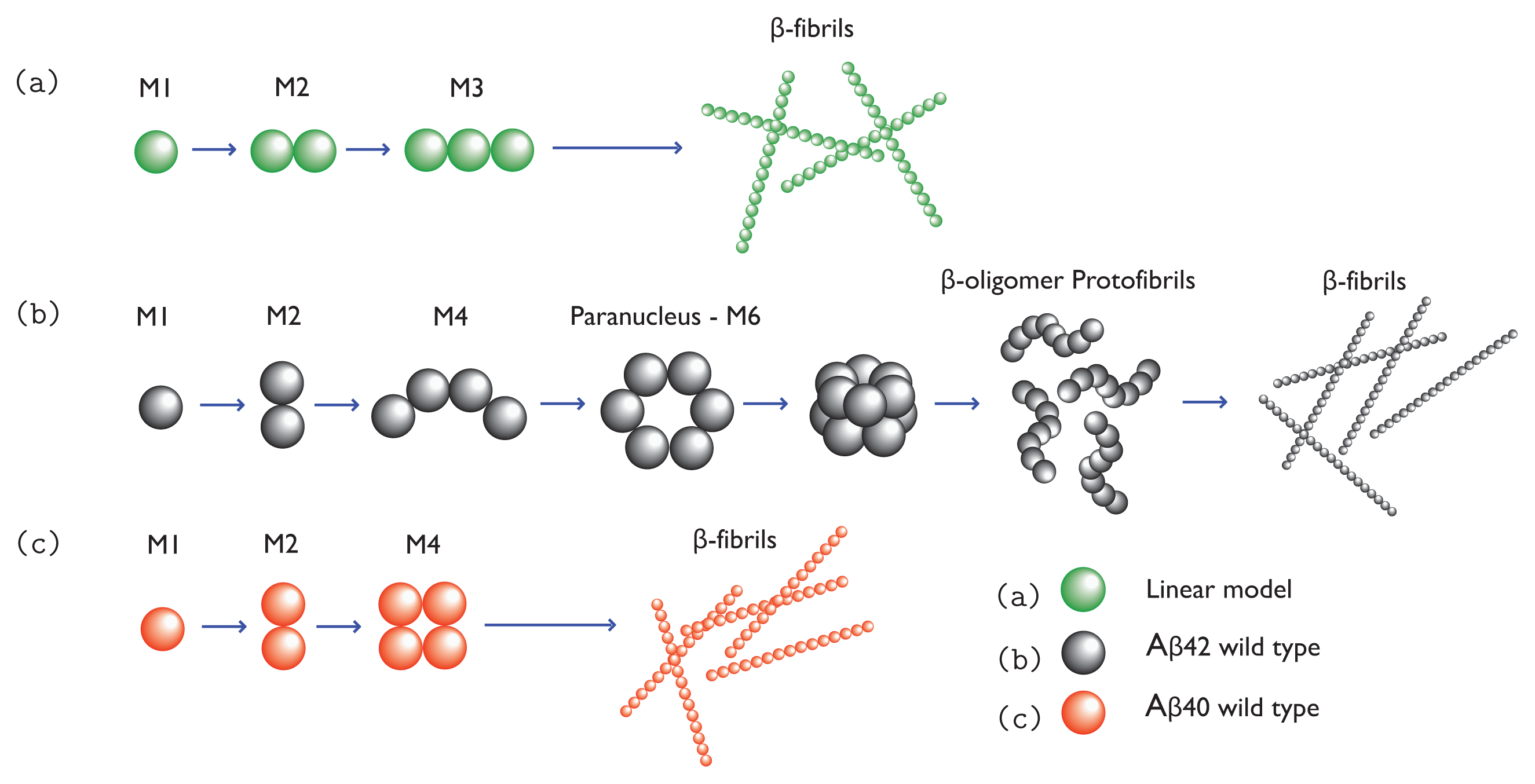


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}