
A Practical Application of Machine Learning for the Development of Metallole-Based Fluorescent Materials

 , , , and
, , , and
Abstract
1. Introduction
2. Results and Discussion
2.1. Evaluation of the Classification Model
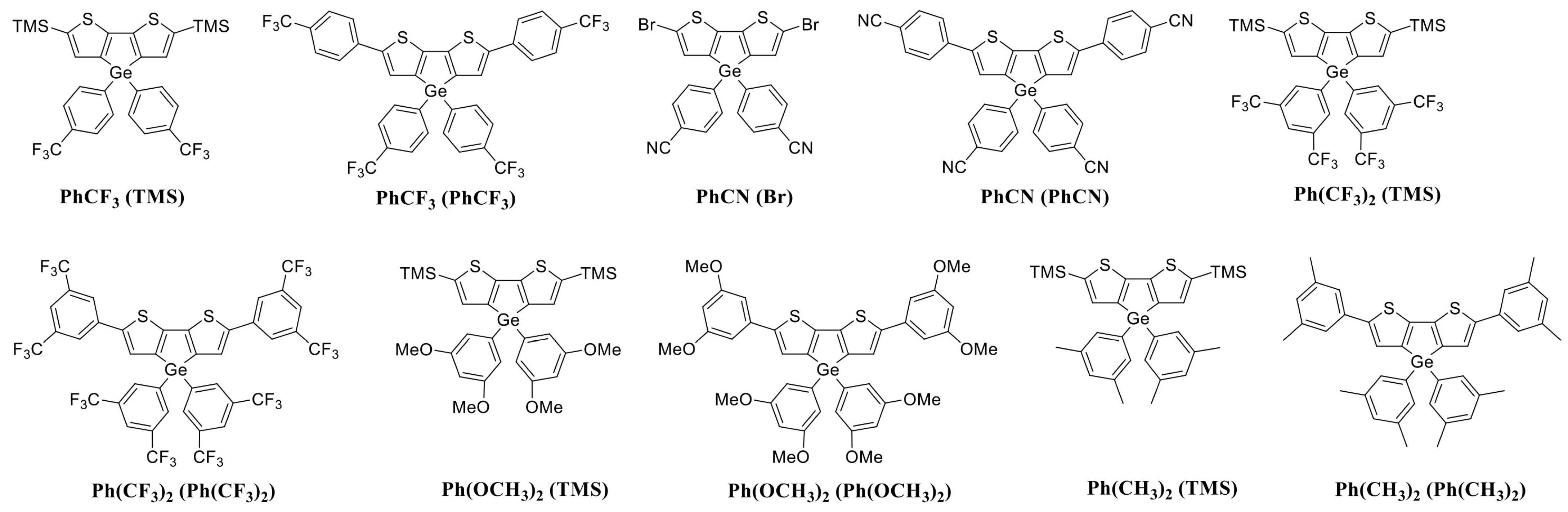
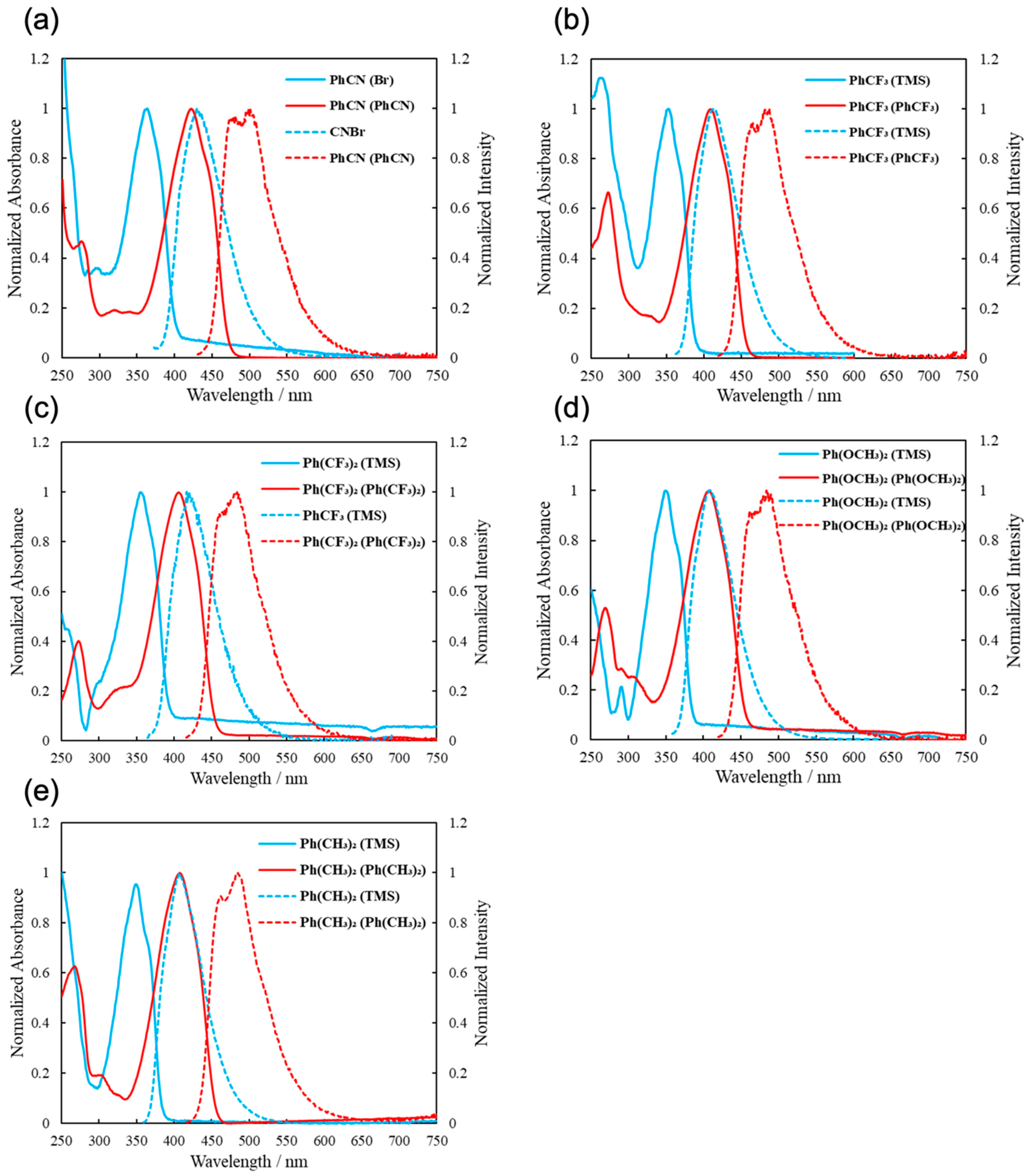
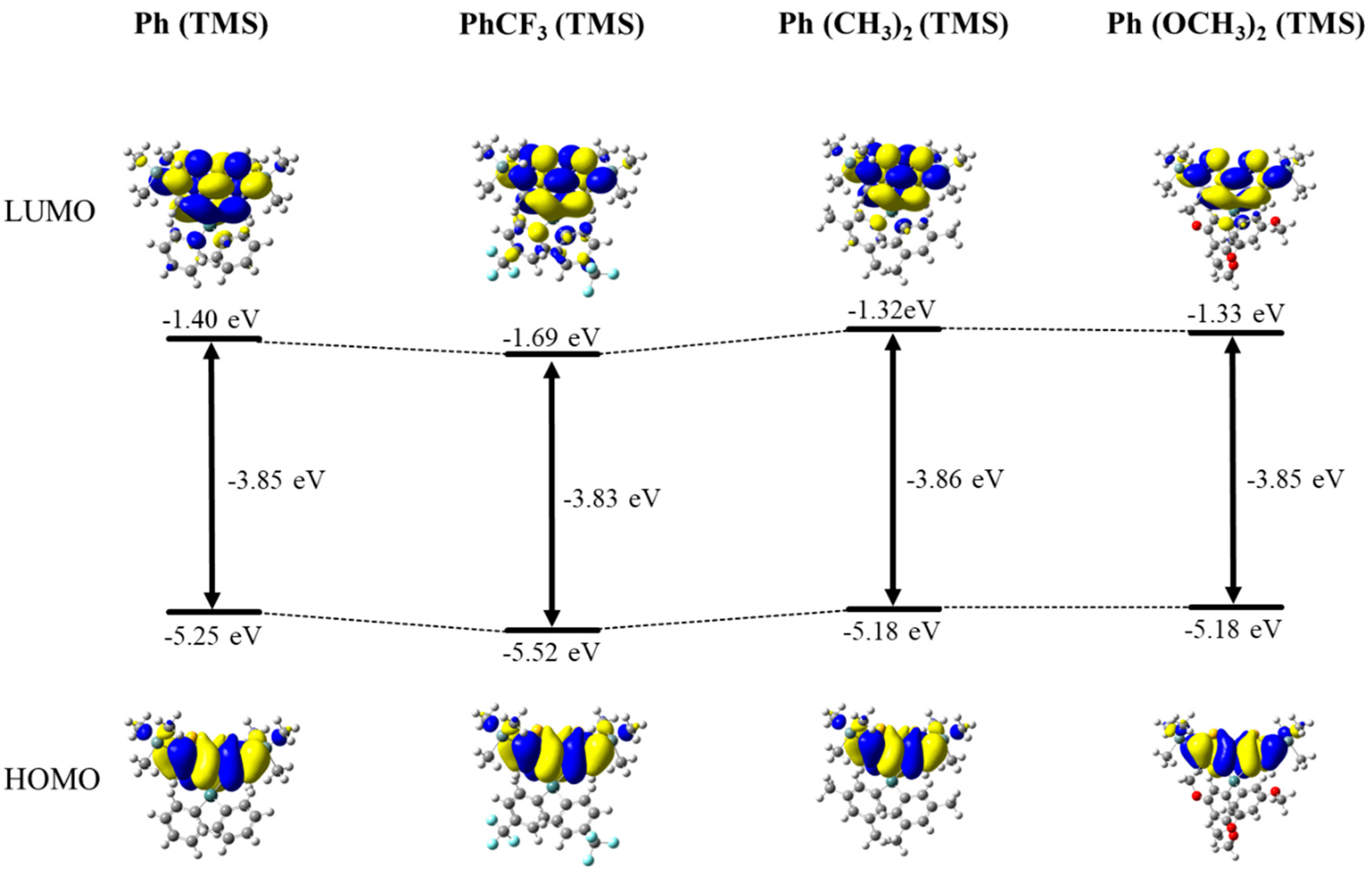
2.2. Spectroscopy of New Molecules
2.3. Comparison of Observed and Predicted Quantum Yields
2.4. Revision of the Model with Extending Dataset
3. Materials and Methods
3.1. Computational Details
3.1.1. Building Initial Models
3.1.2. Model Revision
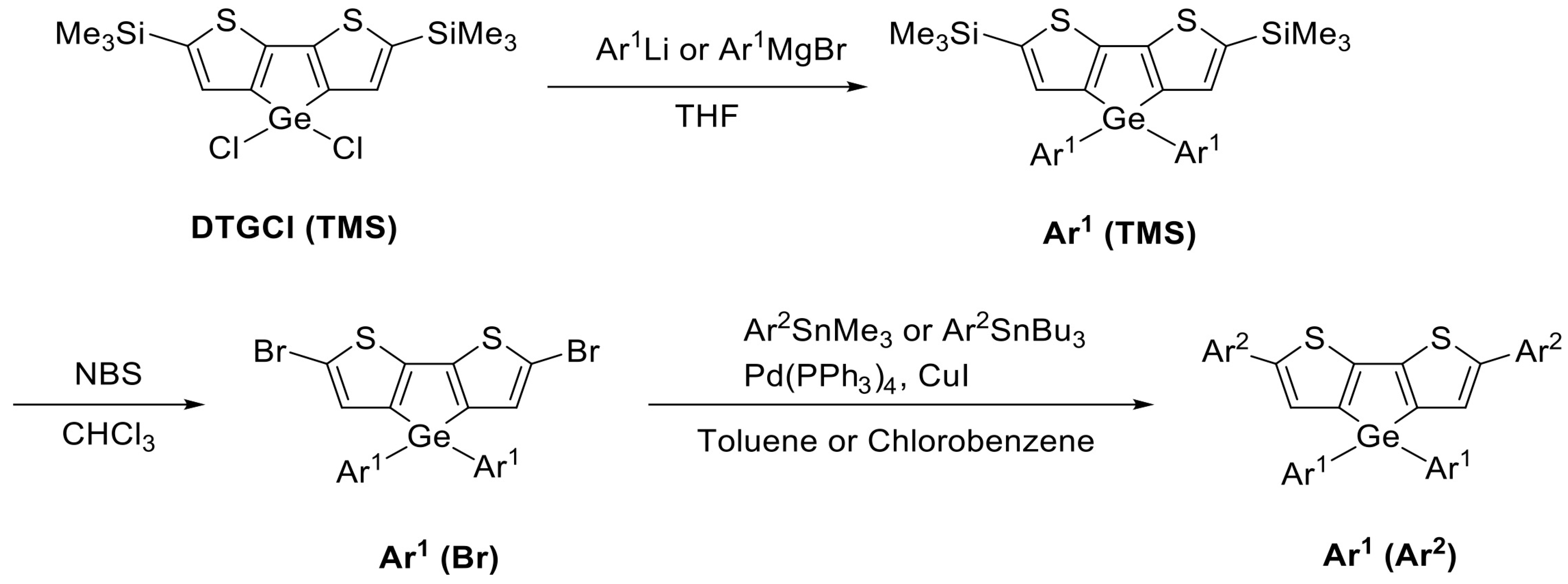
3.2. Synthesis
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CV | Cross validation |
| DTG | Dithienogermole |
| DTS | Dithienosilole |
| LGBM | Light Gradient Boosting Machine |
| RF | Random Forest |
References
- Yamaguchi, S.; Tamao, K. Silole-Containing σ- and π-Conjugated Compounds. J. Chem. Soc. Dalton Trans. 1998, 22, 3693–3702. [Google Scholar] [CrossRef]
- Ohshita, J. Conjugated Oligomers and Polymers Containing Dithienosilole Units. Macromol. Chem. Phys. 2009, 210, 1360–1370. [Google Scholar] [CrossRef]
- Ohshita, J. Group 14 Metalloles Condensed with Heteroaromatic Systems. Org. Photonics Photovolt. 2016, 4, 52–59. [Google Scholar] [CrossRef]
- Caselli, M.; Vanossi, D.; Buffagni, M.; Imperato, M.; Pigani, L.; Mucci, A.; Parenti, F. Optoelectronic Properties of A-π-D-π-A Thiophene-Based Materials with a Dithienosilole Core: An Experimental and Theoretical Study. ChemPlusChem 2019, 84, 1314–1323. [Google Scholar] [CrossRef] [PubMed]
- Tsurusaki, A.; Kobayashi, A.; Kyushin, S. Synthesis, Structures, and Electronic Properties of Dithienosiloles Bearing Bulky Aryl Groups: Conjugation between a π-Electron System and “Perpendicular” Aryl Groups. Asian J. Org. Chem. 2017, 6, 737–745. [Google Scholar] [CrossRef]
- Nakamura, M.; Shigeoka, K.; Adachi, Y.; Ooyama, Y.; Watase, S.; Ohshita, J. Preparation of Dithienogermole-Containing Polysilsesquioxane Films for Sensing Nitroaromatics. Chem. Lett. 2017, 46, 438–441. [Google Scholar] [CrossRef]
- Hirano, K.; Ikeda, T.; Fujii, N.; Hirao, T.; Nakamura, M.; Adachi, Y.; Ohshita, J.; Haino, T. Helical Assembly of a Dithienogermole Exhibiting Switchable Circularly Polarized Luminescence. Chem. Commun. 2019, 55, 10607–10610. [Google Scholar] [CrossRef]
- Rasmussen, S.C.; Evenson, S.J.; McCausland, C.B. Fluorescent Thiophene-Based Materials and Their Outlook for Emissive Applications. Chem. Commun. 2015, 51, 4528–4543. [Google Scholar] [CrossRef]
- Nketia-Yawson, B.; Jung, A.R.; Noh, Y.; Ryu, G.S.; Tabi, G.D.; Lee, K.K.; Kim, B.; Noh, Y.Y. Highly Sensitive Flexible NH3 Sensors Based on Printed Organic Transistors with Fluorinated Conjugated Polymers. ACS Appl. Mater. Interfaces 2017, 9, 7322–7330. [Google Scholar] [CrossRef]
- Morimoto, A.; Hayashi, Y.; Maeda, T.; Yagi, S. NIR Fluorescence of A–D–A Type Functional Dyes Modulated by Terminal Lewis Basic Groups. Dye. Pigment. 2021, 184, 108768. [Google Scholar] [CrossRef]
- Zheng, Y.; Sun, S.; Liu, J.; Zhao, Q.; Zhang, H.; Zhang, J.; Zhou, P.; Xiong, Z.; He, C.-S.; Lai, B. Application of Machine Learning for Material Prediction and Design in the Environmental Remediation. Chin. Chem. Lett. 2024, in press. [Google Scholar] [CrossRef]
- Ju, C.-W.; Bai, H.; Li, B.; Liu, R. Machine Learning Enables Highly Accurate Predictions of Photophysical Properties of Organic Fluorescent Materials: Emission Wavelengths and Quantum Yields. J. Chem. Inf. Model. 2021, 61, 1053–1065. [Google Scholar] [CrossRef] [PubMed]
- Guo, H.; Lu, Y.; Lei, Z.; Bao, H.; Zhang, M.; Wang, Z.; Guan, C.; Tang, B.; Liu, Z.; Wang, L. Machine Learning-Guided Realization of Full-Color High-Quantum-Yield Carbon Quantum Dots. Nat. Commun. 2024, 15, 4843. [Google Scholar] [CrossRef]
- Zhao, Y.; Chen, K.; Yu, B.; Wan, Q.; Wang, Y.; Tang, F.; Li, X. Development of Organic Aggregation-Induced Emission Fluorescent Materials Based on Machine Learning Models and Experimental Validation. J. Mol. Struct. 2024, 1317, 139126. [Google Scholar] [CrossRef]
- Geramita, K.; McBee, J.; Tilley, T.D. 2,7-Substituted Hexafluoroheterofluorenes as Potential Building Blocks for Electron Transporting Materials. J. Org. Chem. 2009, 74, 820–829. [Google Scholar] [CrossRef]
- Chi, W.; Chen, J.; Liu, W.; Wang, C.; Qi, Q.; Qiao, Q.; Tan, T.M.; Xiong, K.; Liu, X.; Kang, K.; et al. A General Descriptor Δ E Enables the Quantitative Development of Luminescent Materials Based on Photoinduced Electron Transfer. J. Am. Chem. Soc. 2020, 142, 6777–6785. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Landrum, G. RDKit documentation: Open-Source Cheminformatics. Release 2019, 9, 1. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. Lightgbm: A Highly Efficient Gradient Boosting Decision Tree. Adv. Neural Inf. Process Syst. 2017, 30, 3146–3154. [Google Scholar]
- Kaneko, H. Structure Generator Based on R-Group (SGRG). Available online: https://github.com/hkaneko1985/structure_generator_based_on_r_group (accessed on 3 April 2025).
- Zhao, Y.; Liu, Y.; Tian, C.; Liu, Z.; Wu, K.; Zhang, C.; Han, X. Construction of Antibacterial Photothermal PCL/AgNPs/BP Nanofibers for Infected Wound Healing. Mater. Des. 2023, 226, 111670. [Google Scholar] [CrossRef]
- Weininger, D. SMILES, a Chemical Language and Information System. 1. Introduction to Methodology and Encoding Rules. J. Chem. Inf. Comput. Sci. 1988, 28, 31–36. [Google Scholar] [CrossRef]
- Dimitrov, S.; Dimitrova, G.; Pavlov, T.; Dimitrova, N.; Patlewicz, G.; Niemela, J.; Mekenyan, O. A Stepwise Approach for Defining the Applicability Domain of SAR and QSAR Models. J. Chem. Inf. Model. 2005, 45, 839–849. [Google Scholar] [CrossRef]
- Sushko, I.; Novotarskyi, S.; Körner, R.; Pandey, A.K.; Cherkasov, A.; Li, J.; Gramatica, P.; Hansen, K.; Schroeter, T.; Müller, K.-R.; et al. Applicability Domains for Classification Problems: Benchmarking of Distance to Models for Ames Mutagenicity Set. J. Chem. Inf. Model. 2010, 50, 2094–2111. [Google Scholar] [CrossRef]
- Kaneko, H.; Funatsu, K. A Soft Sensor Method Based on Values Predicted from Multiple Intervals of Time Difference for Improvement and Estimation of Prediction Accuracy. Chemom. Intell. Lab. Syst. 2011, 109, 197–206. [Google Scholar] [CrossRef]
- Goldberger, J.; Roweis, S.; Hinton, G.; Salakhutdinov, R. Neighbourhood Components Analysis. In Advances in Neural Information Processing Systems 17; Bottou, L., Saul, L., Weiss, Y., Eds.; MIT Press: Cambridge, MA, USA, 2005; pp. 513–520. [Google Scholar]
- Ohshita, J.; Nakamura, M.; Ooyama, Y. Preparation and Reactions of Dichlorodithienogermoles. Organometallics 2015, 34, 5609–5614. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classification Model | Accuracy (CV) | Number of Selected Descriptors | |
|---|---|---|---|
| Before Selection | After Selection | ||
| RF-2D | 0.75 | 0.81 | 14 |
| RF-3D+ | 0.77 | 0.82 | 11 |
| LGBM-2D | 0.76 | 0.83 | 9 |
| LGBM-3D+ | 0.76 | 0.83 | 10 |
| Prediction Model | Accuracy (CV) | Precision (CV) |
|---|---|---|
| RF-3D+ | 0.82 | 0.78 |
| CPM | 0.78 | 0.85 |
| Compound | Predicted QY | Compound | Predicted QY |
|---|---|---|---|
| PhCF3 (TMS) | 1 | Ph (CF3)2 (Ph (CF3)2) | 1 |
| PhCF3 (PhCF3) | 1 | Ph (OCH3)2 (TMS) | 1 |
| PhCN (Br) | 0 | Ph (OCH3)2 (Ph (OCH3)2) | 0 |
| PhCN (PhCN) | 0 | Ph (CH3)2 (TMS) | 1 |
| Ph(CF3)2 (TMS) | 1 | Ph (CH3)2 (Ph (CH3)2) | 0 |
| Compound | λabs | λem |
|---|---|---|
| PhCF3 (TMS) | 353 | 414 |
| PhCF3 (PhCF3) | 409 | 487 |
| PhCN (Br) | 363 | 430 |
| PhCN (PhCN) | 421 | 499 |
| Ph(CF3)2 (TMS) | 355 | 417 |
| Ph(CF3)2 (Ph (CF3)2) | 406 | 484 |
| Ph(OCH3)2 (TMS) | 349 | 409 |
| Ph(OCH3)2 (Ph (OCH3)2) | 407 | 484 |
| Ph(CH3)2 (TMS) | 349 | 407 |
| Ph(CH3)2 (Ph (CH3)2) | 407 | 485 |
| Compound | Observed | Predicted | ||
|---|---|---|---|---|
| τ | Φf | QY | QY | |
| PhCF3 (TMS) | 4.25 | 70 | 1 | 1 |
| PhCF3 (PhCF3) | 1.26 | 40 | 0 | 1 |
| PhCN (Br) | 1.13 | <2 | 0 | 0 |
| PhCN (PhCN) | 0.81 | 18 | 0 | 0 |
| Ph(CF3)2 (TMS) | 4.62 | 46 | 0 | 1 |
| Ph(CF3)2 (Ph (CF3)2) | 1.35 | 28 | 0 | 1 |
| Ph(OCH3)2 (TMS) | 3.88 | 58 | 1 | 1 |
| Ph(OCH3)2 (Ph (OCH3)2) | 1.42 | 29 | 0 | 0 |
| Ph(CH3)2 (TMS) | 3.42 | 71 | 1 | 1 |
| Ph(CH3)2 (Ph (CH3)2) | 1.18 | 42 | 0 | 0 |
| Classification Model | Rev-RF | Rev-LGBM | CPM | |
|---|---|---|---|---|
| Accuracy | Train | 0.97 | 0.98 | 0.93 |
| Test | 0.86 | 0.84 | 0.84 | |
| Precision | Train | 0.94 | 0.96 | 1.00 |
| Test | 0.81 | 0.86 | 0.89 | |
| Molecular Index | Observed | Predicted QY | |||
|---|---|---|---|---|---|
| Φf | QY | CPM | Rev-RF | Rev-LGBM | |
| 1 | 70 | 1 | 0 | 1 | 1 |
| 2 | 84 | 1 | 1 | 1 | 1 |
| 3 | 0 | 0 | 0 | 0 | 0 |
| 4 | 2 | 0 | 0 | 0 | 0 |
| 5 | 7 | 0 | 0 | 0 | 0 |
| 6 | 20 | 0 | 0 | 0 | 0 |
| 7 | 13 | 0 | 0 | 0 | 0 |
| 8 | 62 | 1 | 0 | 1 | 1 |
| 9 | 71 | 1 | 1 | 1 | 1 |
| 10 | 9 | 0 | 0 | 0 | 0 |
| 11 | 5 | 0 | 0 | 0 | 0 |
| 12 | 17 | 0 | 0 | 0 | 0 |
| 13 | 25 | 0 | 0 | 0 | 0 |
| 14 | 54 | 1 | 0 | 1 | 0 |
| 15 | 35 | 0 | 0 | 0 | 0 |
| 16 | 25 | 0 | 0 | 1 | 0 |
| 17 | 67 | 1 | 0 | 0 | 0 |
| 18 | 8 | 0 | 0 | 0 | 0 |
| 19 | 22 | 0 | 0 | 0 | 0 |
| 20 | 10 | 0 | 0 | 0 | 0 |
| 21 | 18 | 0 | 0 | 0 | 0 |
| Accuracy | 0.81 | 0.90 | 0.90 | ||
| Precision | 1.00 | 0.83 | 1.00 | ||
| Ar (Ar1 = Ar2) | Ar1 (TMS)/% | Ar1 (Br)/% | Ar1 (Ar2)/% |
|---|---|---|---|
| PhCF3 | 26 | 91 | 28 |
| PhCN | 34 | 87 | 21 |
| Ph(CF3)2 | 46 | 70 | 16 |
| Ph(OCH3)2 | 33 | 73 | 17 |
| Ph(CH3)2 | 74 | 75 | 19 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kanematsu, Y.; Ohta, A.; Nagai, S.; Adachi, Y.; Kaneko, H.; Ishimoto, T.; Kurita, T.; Ohshita, J. A Practical Application of Machine Learning for the Development of Metallole-Based Fluorescent Materials. Molecules 2025, 30, 1686. https://doi.org/10.3390/molecules30081686
Kanematsu Y, Ohta A, Nagai S, Adachi Y, Kaneko H, Ishimoto T, Kurita T, Ohshita J. A Practical Application of Machine Learning for the Development of Metallole-Based Fluorescent Materials. Molecules. 2025; 30(8):1686. https://doi.org/10.3390/molecules30081686
Chicago/Turabian StyleKanematsu, Yusuke, Akiyoshi Ohta, Shunya Nagai, Yohei Adachi, Hiromasa Kaneko, Takayoshi Ishimoto, Takio Kurita, and Joji Ohshita. 2025. "A Practical Application of Machine Learning for the Development of Metallole-Based Fluorescent Materials" Molecules 30, no. 8: 1686. https://doi.org/10.3390/molecules30081686
APA StyleKanematsu, Y., Ohta, A., Nagai, S., Adachi, Y., Kaneko, H., Ishimoto, T., Kurita, T., & Ohshita, J. (2025). A Practical Application of Machine Learning for the Development of Metallole-Based Fluorescent Materials. Molecules, 30(8), 1686. https://doi.org/10.3390/molecules30081686