
Development and Application of a Senolytic Predictor for Discovery of Novel Senolytic Compounds and Herbs

 ,
,
Abstract
1. Introduction
2. Results
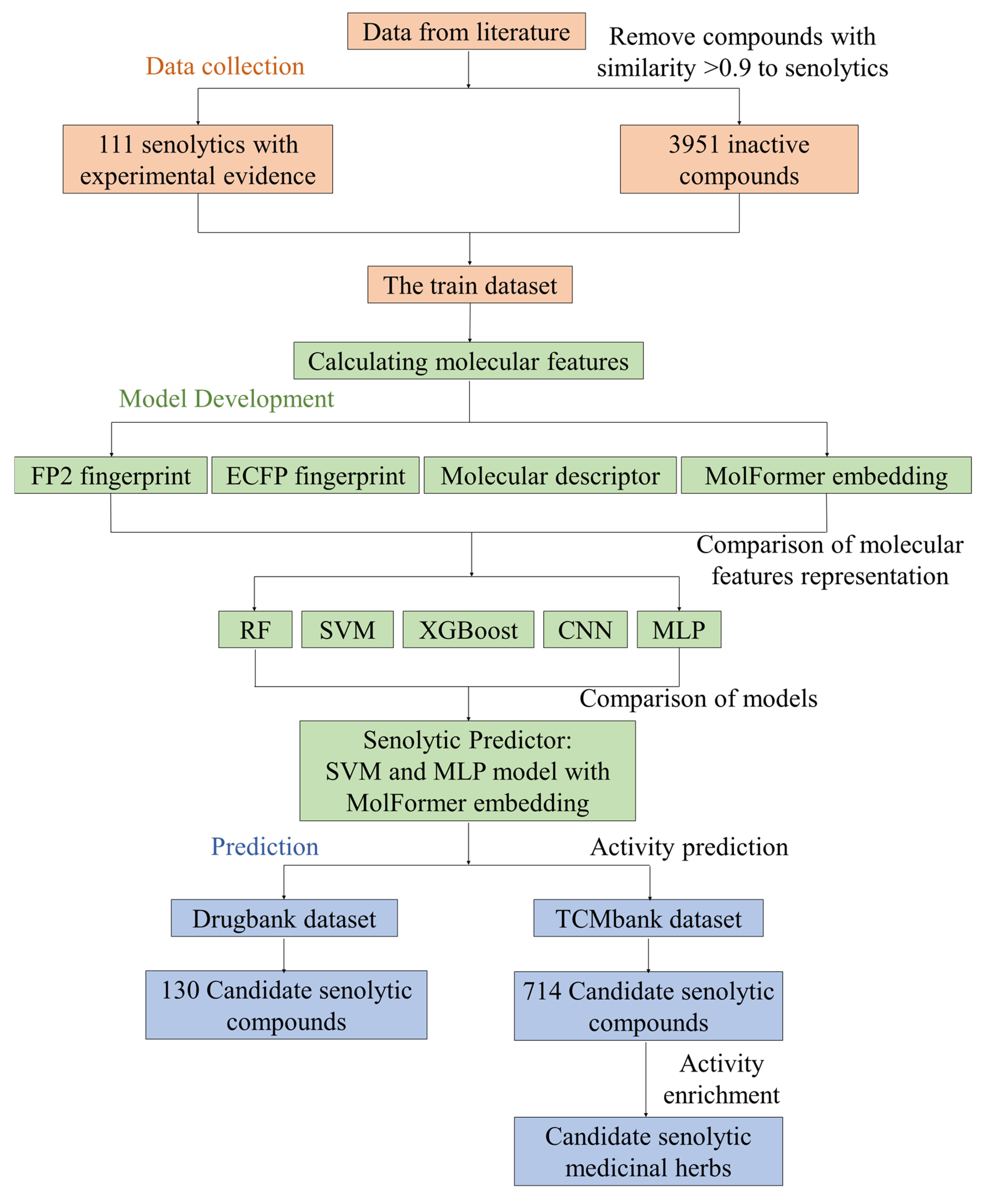
2.1. Workflow for Developing Senolytic Predictor
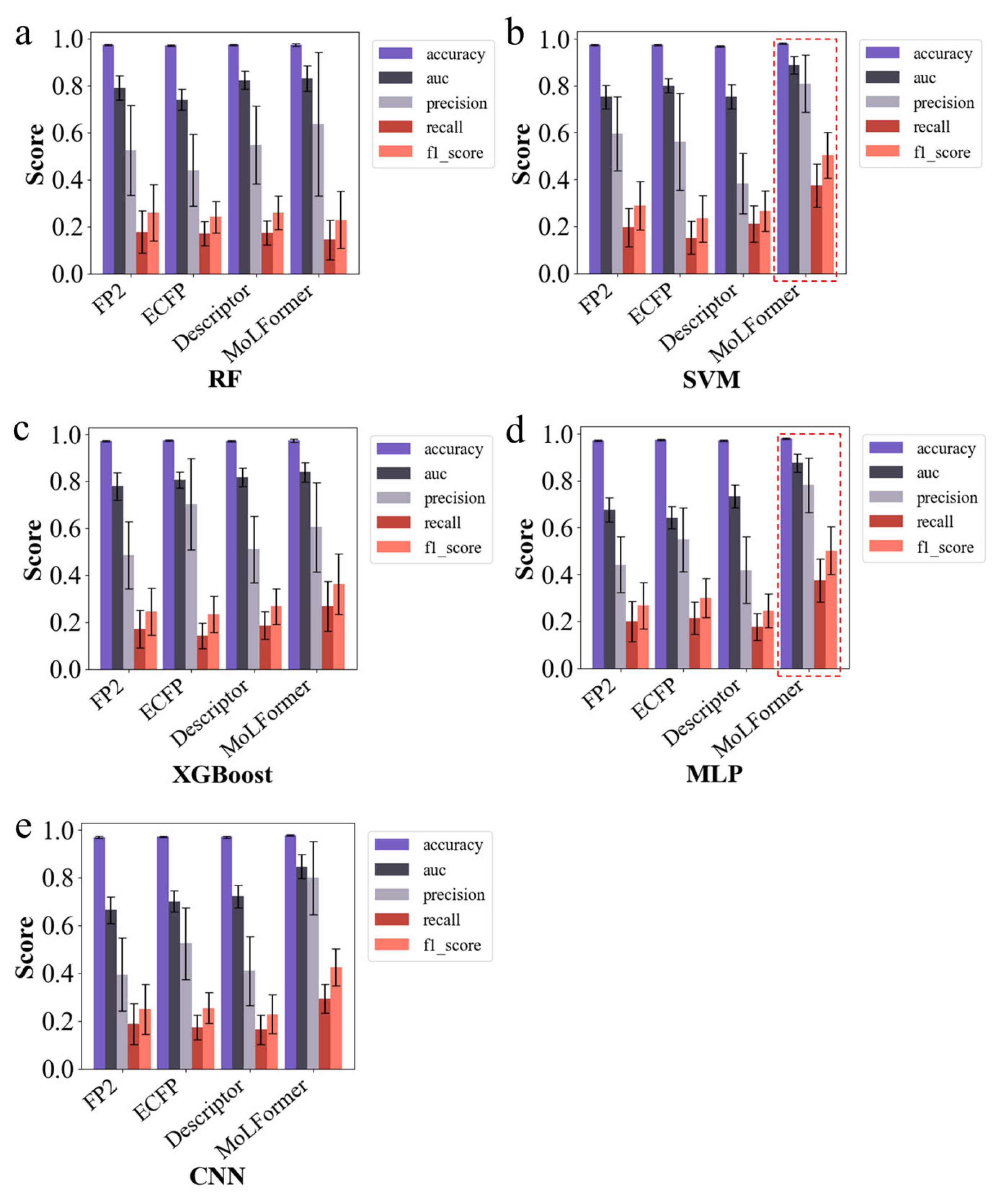
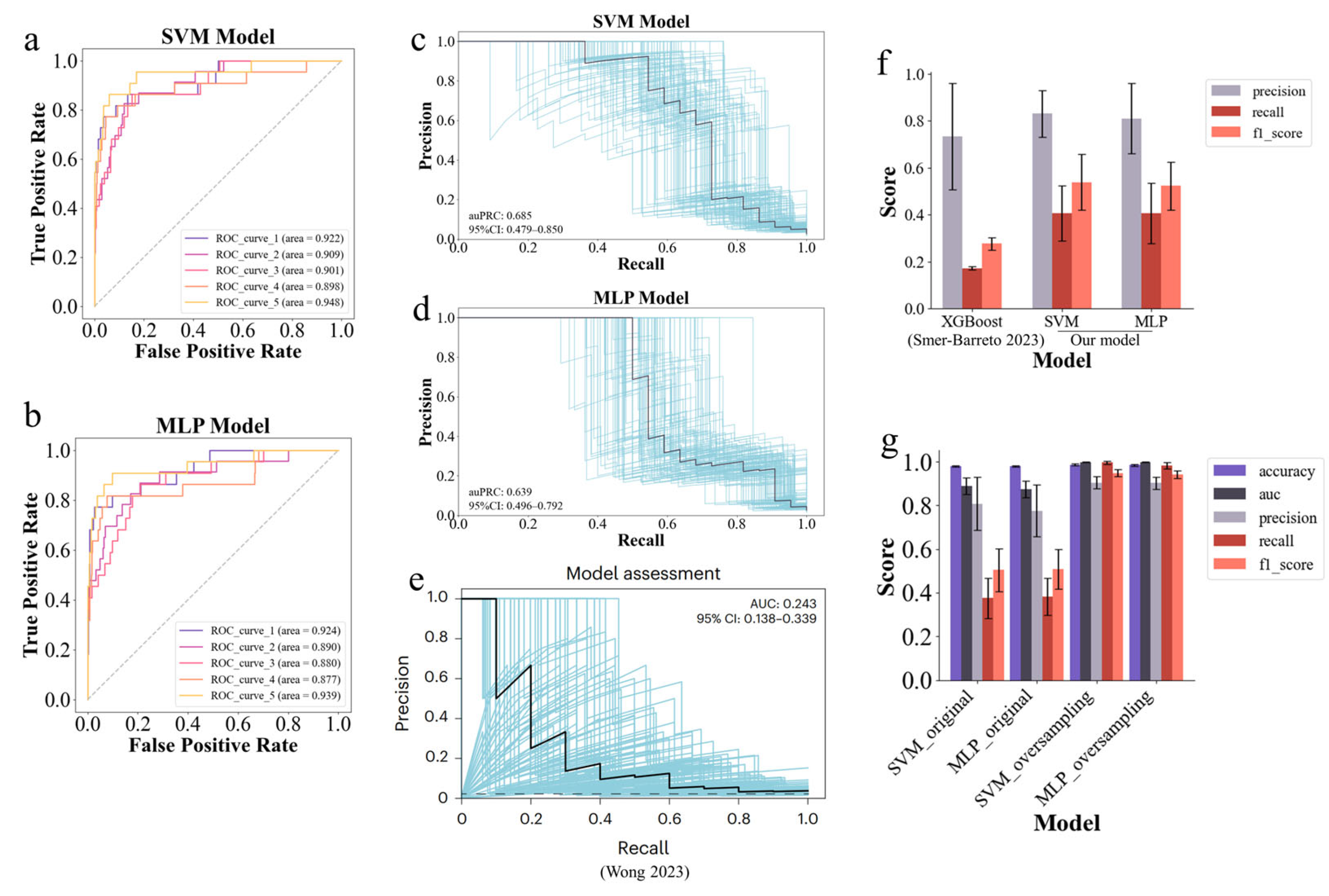
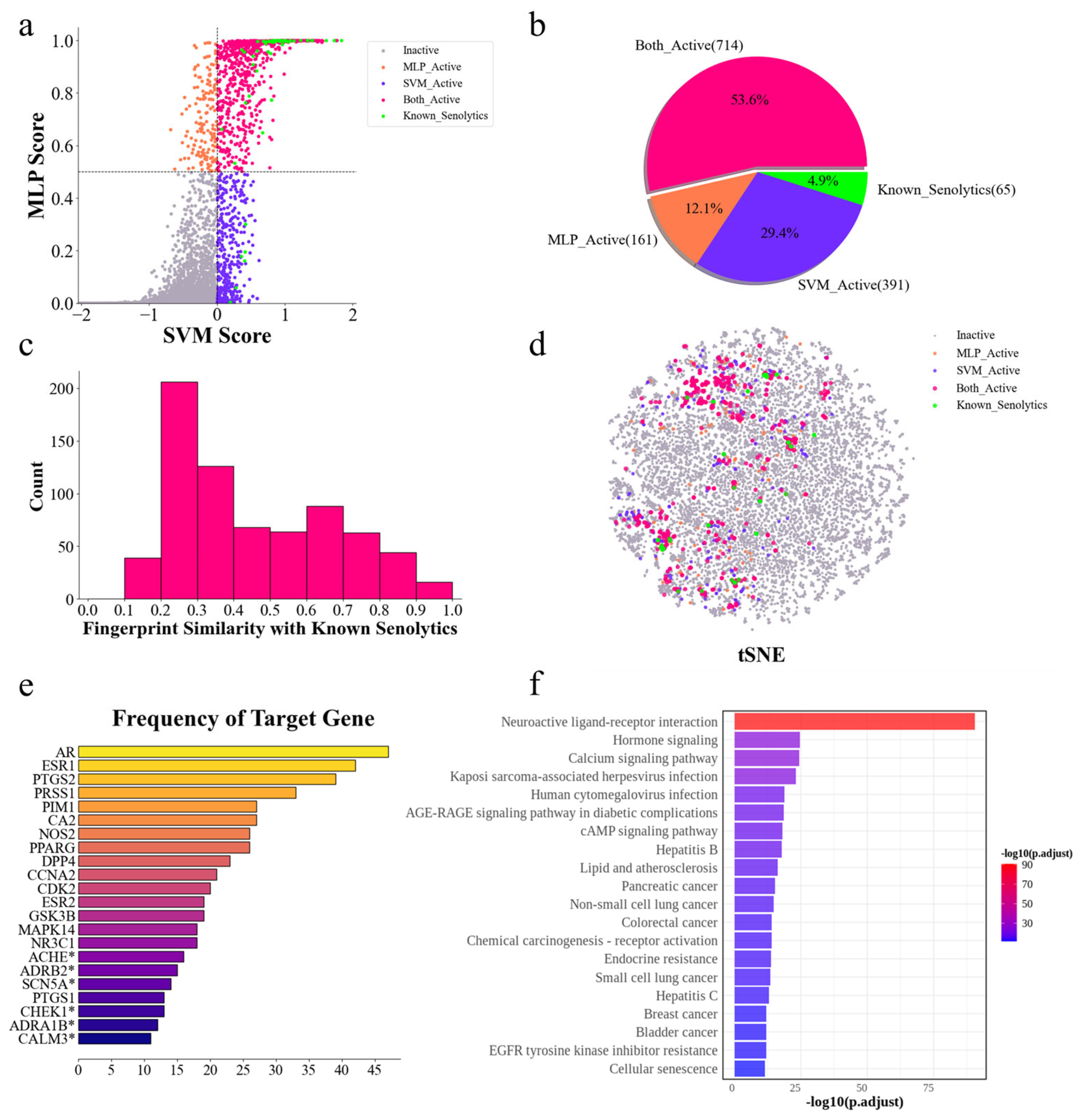
2.2. SVM and MLP Models with MoLFormer Molecular Embeddings Perform Best
2.3. Enhanced Senolytic Predictor Through Optimized Machine Learning Models and Oversampling Strategies
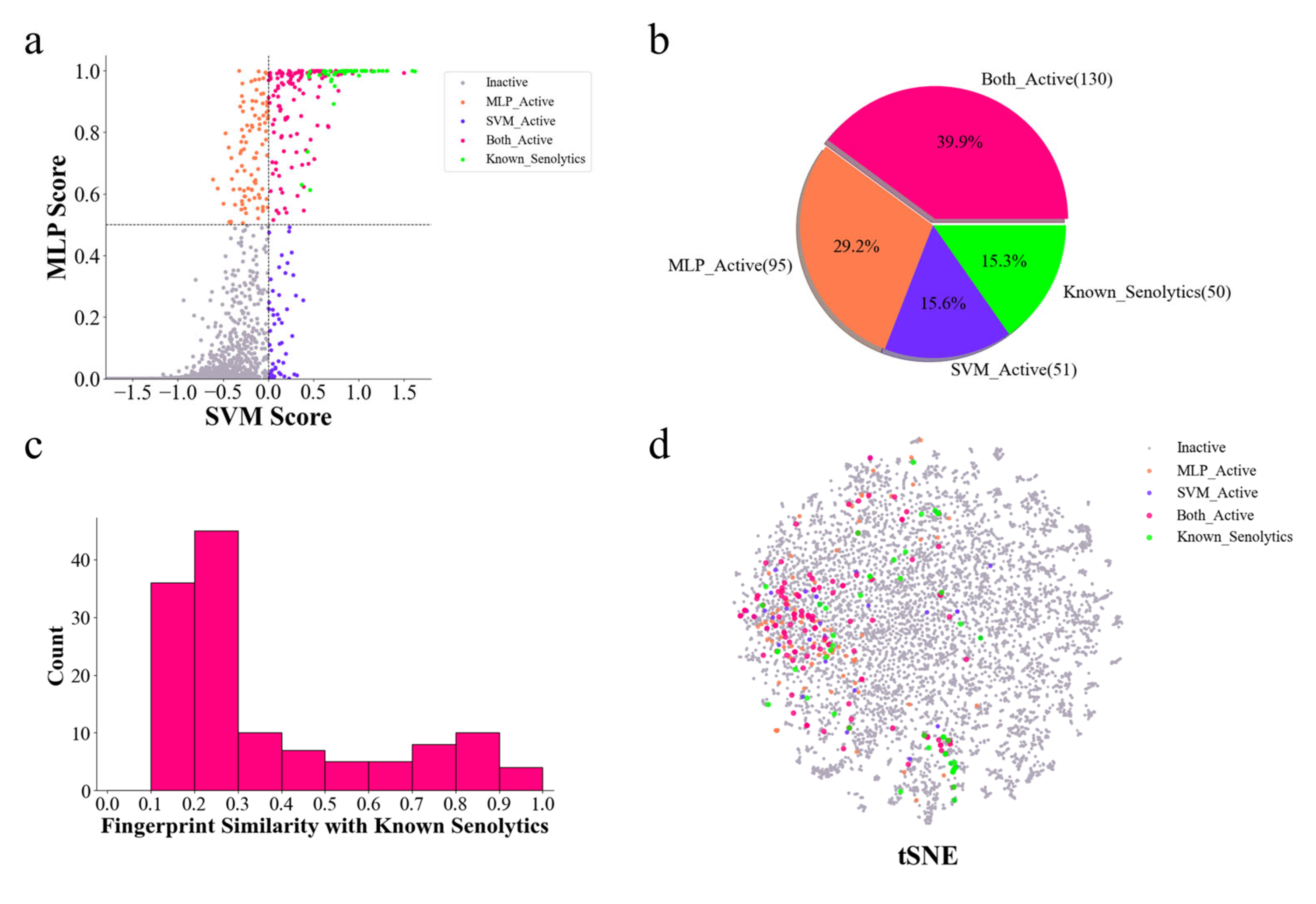
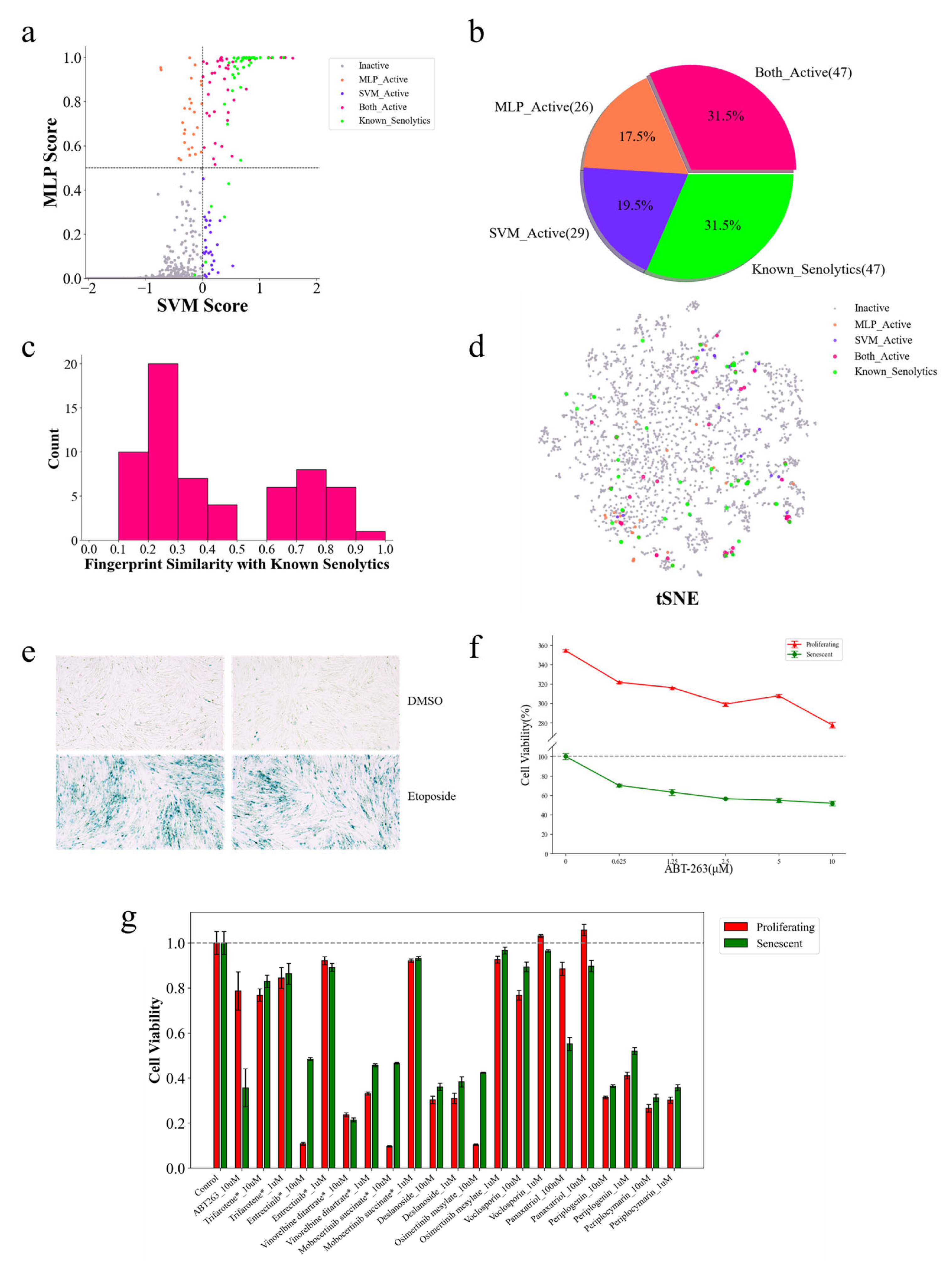
2.4. Discovery of New Senolytics Through DrugBank Dataset Prediction
2.5. Identification of Structurally Novel Senolytic Candidates from the TCMbank Database
2.6. Identification of Potential Senolytic Medicinal Herbs
2.7. Target Analysis and Pathway Enrichment Reveal Potential Mechanisms of Senolytic Activity
2.8. Cellular Assay for Senolytic Activity of Candidate Compounds
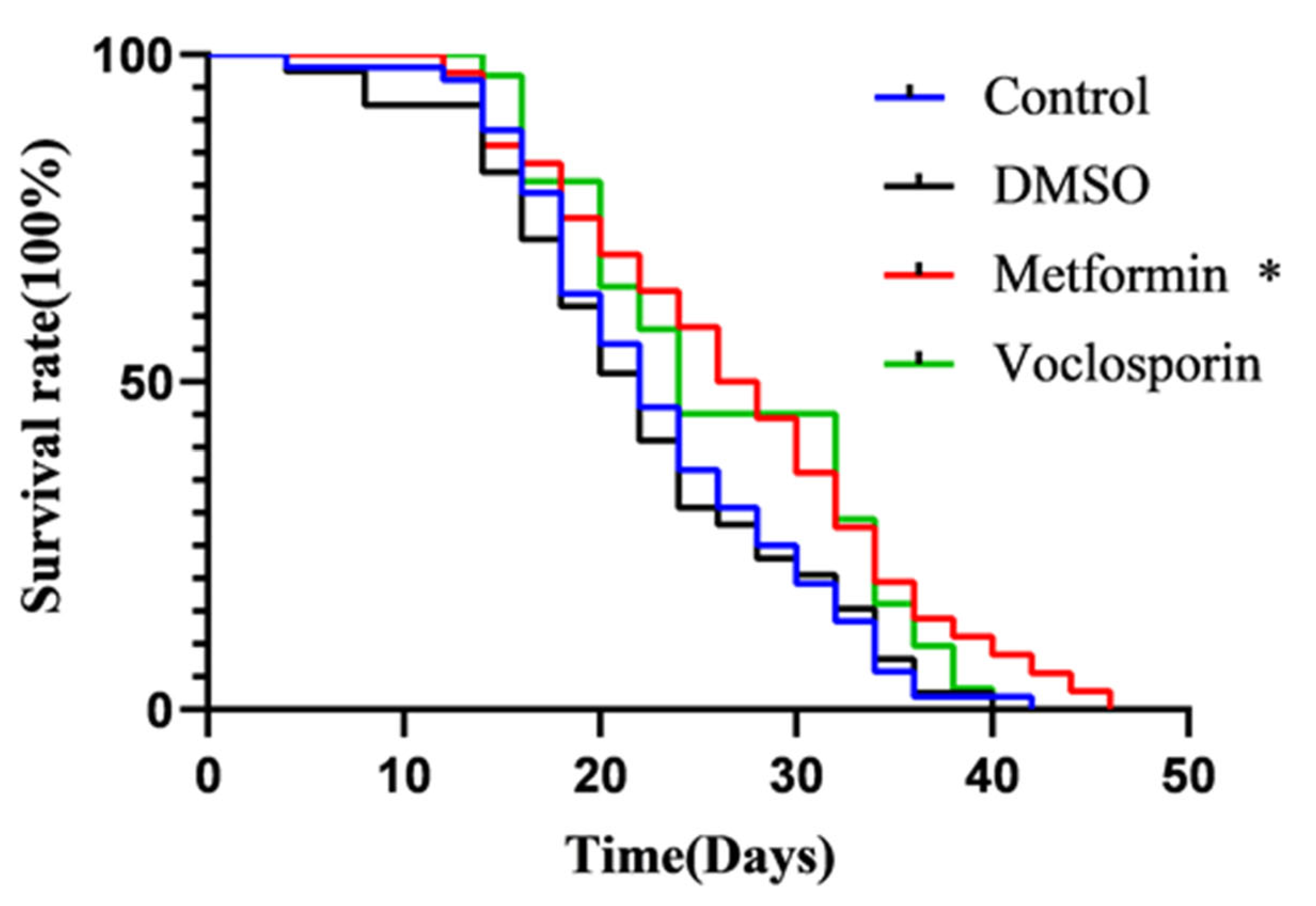
2.9. The C. elegans Lifespan Assay Reveals the Anti-Aging Effects of the Candidate Compound Voclosporin
3. Discussion
4. Methods
4.1. Construction of Senolytic and Screening Datasets for Machine Learning
4.2. Selection of Machine Learning Models and Molecular Features
4.3. Optimization of the SVM and MLP Models to Build Senolytic Predictor
4.4. Positive Sample Oversampling with the MolFormer Model
4.5. Evaluation Metrics for Model Performance
4.6. t-SNE and Molecular Similarity Comparison
4.7. Enrichment Analysis of the TCMbank Prediction Results
4.8. Analysis of the Applicability Domain of Models
4.9. Cell Line and Senescence Induction
4.10. SA-β-Gal Staining
4.11. Cell Viability Assay
4.12. C. elegans Strains and Maintenance
4.13. C. elegans Lifespan Measurement
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- López-Otín, C.; Blasco, M.A.; Partridge, L.; Serrano, M.; Kroemer, G. The hallmarks of aging. Cell 2013, 153, 1194–1217. [Google Scholar] [CrossRef] [PubMed]
- López-Otín, C.; Blasco, M.A.; Partridge, L.; Serrano, M.; Kroemer, G. Hallmarks of aging: An expanding universe. Cell 2023, 186, 243–278. [Google Scholar] [CrossRef] [PubMed]
- Gorgoulis, V.; Adams, P.D.; Alimonti, A.; Bennett, D.C.; Bischof, O.; Bishop, C.; Campisi, J.; Collado, M.; Evangelou, K.; Ferbeyre, G.; et al. Cellular senescence: Defining a path forward. Cell 2019, 179, 813–827. [Google Scholar] [CrossRef] [PubMed]
- Coppé, J.-P.; Desprez, P.-Y.; Krtolica, A.; Campisi, J. The senescence-associated secretory phenotype: The dark side of tumor suppression. Annu. Rev. Pathol. 2010, 5, 99–118. [Google Scholar] [CrossRef]
- Herbig, U.; Ferreira, M.; Condel, L.; Carey, D.; Sedivy, J.M. Cellular senescence in aging primates. Science 2006, 311, 1257. [Google Scholar] [CrossRef]
- Farr, J.N.; Xu, M.; Weivoda, M.M.; Monroe, D.G.; Fraser, D.G.; Onken, J.L.; Negley, B.A.; Sfeir, J.G.; Ogrodnik, M.B.; Hachfeld, C.M.; et al. Targeting cellular senescence prevents age-related bone loss in mice. Nat. Med. 2017, 23, 1072–1079. [Google Scholar] [CrossRef]
- Musi, N.; Valentine, J.M.; Sickora, K.R.; Baeuerle, E.; Thompson, C.S.; Shen, Q.; Orr, M.E. Tau protein aggregation is associated with cellular senescence in the brain. Aging Cell 2018, 17, e12840. [Google Scholar] [CrossRef]
- Roos, C.M.; Zhang, B.; Palmer, A.K.; Ogrodnik, M.B.; Pirtskhalava, T.; Thalji, N.M.; Hagler, M.; Jurk, D.; Smith, L.A.; Casaclang-Verzosa, G.; et al. Chronic senolytic treatment alleviates established vasomotor dysfunction in aged or atherosclerotic mice. Aging Cell 2016, 15, 973–977. [Google Scholar] [CrossRef]
- Palmer, A.K.; Xu, M.; Zhu, Y.; Pirtskhalava, T.; Weivoda, M.M.; Hachfeld, C.M.; Prata, L.G.; van Dijk, T.H.; Verkade, E.; Casaclang-Verzosa, G.; et al. Targeting senescent cells alleviates obesity-induced metabolic dysfunction. Aging Cell 2019, 18, e12950. [Google Scholar] [CrossRef]
- Schafer, M.J.; White, T.A.; Iijima, K.; Haak, A.J.; Ligresti, G.; Atkinson, E.J.; Oberg, A.L.; Birch, J.; Salmonowicz, H.; Zhu, Y.; et al. Cellular senescence mediates fibrotic pulmonary disease. Nat. Commun. 2017, 8, 14532. [Google Scholar] [CrossRef]
- Krishnamurthy, J.; Torrice, C.; Ramsey, M.R.; Kovalev, G.I.; Al-Regaiey, K.; Su, L.; Sharpless, N.E. Ink4a/Arf expression is a biomarker of aging. J. Clin. Investig. 2004, 114, 1299–1307. [Google Scholar] [CrossRef] [PubMed]
- Baker, D.J.; Wijshake, T.; Tchkonia, T.; LeBrasseur, N.K.; Childs, B.G.; van de Sluis, B.; Kirkland, J.L.; van Deursen, J.M. Clearance of p16Ink4a-positive senescent cells delays ageing-associated disorders. Nature 2011, 479, 232–236. [Google Scholar] [CrossRef] [PubMed]
- Xu, M.; Bradley, E.W.; Weivoda, M.M.; Hwang, S.M.; Pirtskhalava, T.; Decklever, T.; Curran, G.L.; Ogrodnik, M.; Jurk, D.; Johnson, K.O.; et al. Transplanted Senescent Cells Induce an Osteoarthritis-Like Condition in Mice. J. Gerontol. Biol. Sci. Med. Sci. 2017, 72, 780–785. [Google Scholar] [CrossRef] [PubMed]
- Xu, M.; Pirtskhalava, T.; Farr, J.N.; Weigand, B.M.; Palmer, A.K.; Weivoda, M.M.; Inman, C.L.; Ogrodnik, M.B.; Hachfeld, C.M.; Fraser, D.G.; et al. Senolytics improve physical function and increase lifespan in old age. Nat. Med. 2018, 24, 1246–1256. [Google Scholar] [CrossRef]
- Di Micco, R.; Krizhanovsky, V.; Baker, D.; d’Adda di Fagagna, F. Cellular senescence in ageing: From mechanisms to therapeutic opportunities. Nat. Rev. Mol. Cell Biol. 2021, 22, 75–95. [Google Scholar] [CrossRef]
- Zhu, Y.; Tchkonia, T.; Pirtskhalava, T.; Gower, A.C.; Ding, H.; Giorgadze, N.; Palmer, A.K.; Ikeno, Y.; Hubbard, G.B.; Lenburg, M.; et al. The Achilles’ heel of senescent cells: From transcriptome to senolytic drugs. Aging Cell 2015, 14, 644–658. [Google Scholar] [CrossRef]
- Power, H.; Valtchev, P.; Dehghani, F.; Schindeler, A. Strategies for senolytic drug discovery. Aging Cell 2023, 22, e13948. [Google Scholar] [CrossRef]
- Rudin, C.M.; Hann, C.L.; Garon, E.B.; Ribeiro de Oliveira, M.; Bonomi, P.D.; Camidge, D.R.; Chu, Q.; Giaccone, G.; Khaira, D.; Ramalingam, S.S.; et al. Phase II study of single-agent navitoclax (ABT-263) and biomarker correlates in patients with relapsed small cell lung cancer. Clin. Cancer Res. 2012, 18, 3163–3169. [Google Scholar] [CrossRef]
- Ziff, O.J.; Kotecha, D. Digoxin: The good and the bad. Trends Cardiovasc. Med. 2016, 26, 585–595. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Y.; Doornebal, E.J.; Pirtskhalava, T.; Giorgadze, N.; Wentworth, M.; Fuhrmann-Stroissnigg, H.; Niedernhofer, L.J.; Robbins, P.D.; Tchkonia, T.; Kirkland, J.L. New agents that target senescent cells: The flavone, fisetin, and the BCL-XL inhibitors, A1331852 and A1155463. Aging 2017, 9, 955–963. [Google Scholar] [CrossRef]
- Deryabin, P.I.; Shatrova, A.N.; Borodkina, A.V. Apoptosis resistance of senescent cells is an intrinsic barrier for senolysis induced by cardiac glycosides. Cell Mol. Life Sci. 2021, 78, 7757–7776. [Google Scholar] [CrossRef] [PubMed]
- Chaib, S.; Tchkonia, T.; Kirkland, J.L. Cellular senescence and senolytics: The path to the clinic. Nat. Med. 2022, 28, 1556–1568. [Google Scholar] [CrossRef] [PubMed]
- Deng, J.; Yang, Z.; Ojima, I.; Samaras, D.; Wang, F. Artificial intelligence in drug discovery: Applications and techniques. Brief Bioinform. 2022, 23, bbab430. [Google Scholar] [CrossRef] [PubMed]
- Moffat, J.G.; Vincent, F.; Lee, J.A.; Eder, J.; Prunotto, M. Opportunities and challenges in phenotypic drug discovery: An industry perspective. Nat. Rev. Drug Discov. 2017, 16, 531–543. [Google Scholar] [CrossRef]
- Hughes, R.E.; Elliott, R.J.R.; Dawson, J.C.; Carragher, N.O. High-content phenotypic and pathway profiling to advance drug discovery in diseases of unmet need. Cell Chem. Biol. 2021, 28, 338–355. [Google Scholar] [CrossRef]
- Wong, F.; Omori, S.; Donghia, N.M.; Zheng, E.J.; Collins, J.J. Discovering small-molecule senolytics with deep neural networks. Nat. Aging 2023, 3, 734–750. [Google Scholar] [CrossRef]
- Smer-Barreto, V.; Quintanilla, A.; Elliott, R.J.R.; Dawson, J.C.; Sun, J.; Campa, V.M.; Lorente-Macías, Á.; Unciti- Broceta, A.; Carragher, N.O.; Acosta, J.C.; et al. Discovery of senolytics using machine learning. Nat. Commun. 2023, 14, 3445. [Google Scholar] [CrossRef]
- Xu, Q.; Fu, Q.; Li, Z.; Liu, H.; Wang, Y.; Lin, X.; He, R.; Zhang, X.; Ju, Z.; Campisi, J.; et al. The flavonoid procyanidin C1 has senotherapeutic activity and increases lifespan in mice. Nat. Metab. 2021, 3, 1706–1726. [Google Scholar] [CrossRef]
- Moaddel, R.; Rossi, M.; Rodriguez, S.; Munk, R.; Khadeer, M.; Abdelmohsen, K.; Gorospe, M.; Ferrucci, L. Identification of gingerenone A as a novel senolytic compound. PLoS ONE 2022, 17, e0266135. [Google Scholar] [CrossRef]
- Cho, H.J.; Yang, E.J.; Park, J.T.; Kim, J.R.; Kim, E.C.; Jung, K.J.; Park, S.C.; Lee, Y.S. Identification of SYK inhibitor, R406 as a novel senolytic agent. Aging 2020, 12, 8221–8240. [Google Scholar] [CrossRef]
- Cherif, H.; Bisson, D.G.; Jarzem, P.; Weber, M.; Ouellet, J.A.; Haglund, L. Curcumin and o-Vanillin Exhibit Evidence of Senolytic Activity in Human IVD Cells In Vitro. J. Clin. Med. 2019, 8, 433. [Google Scholar] [CrossRef] [PubMed]
- Troiani, M.; Colucci, M.; D’Ambrosio, M.; Guccini, I.; Pasquini, E.; Varesi, A.; Valdata, A.; Mosole, S.; Revandkar, A.; Attanasio, G.; et al. Single-cell transcriptomics identifies Mcl-1 as a target for senolytic therapy in cancer. Nat. Commun. 2022, 13, 2177. [Google Scholar] [CrossRef] [PubMed]
- Limbad, C.; Doi, R.; McGirr, J.; Ciotlos, S.; Perez, K.; Clayton, Z.S.; Daya, R.; Seals, D.R.; Campisi, J.; Melov, S. Senolysis induced by 25-hydroxycholesterol targets CRYAB in multiple cell types. iScience 2022, 25, 103848. [Google Scholar] [CrossRef] [PubMed]
- Wakita, M.; Takahashi, A.; Sano, O.; Loo, T.M.; Imai, Y.; Narukawa, M.; Iwata, H.; Matsudaira, T.; Kawamoto, S.; Ohtani, N.; et al. A BET family protein degrader provokes senolysis by targeting NHEJ and autophagy in senescent cells. Nat. Commun. 2020, 11, 1935. [Google Scholar] [CrossRef]
- Cherif, H.; Bisson, D.G.; Mannarino, M.; Rabau, O.; Ouellet, J.A.; Haglund, L. Senotherapeutic drugs for human intervertebral disc degeneration and low back pain. eLife 2020, 9, e54693. [Google Scholar] [CrossRef]
- He, Y.; Li, W.; Lv, D.; Zhang, X.; Zhang, X.; Ortiz, Y.T.; Budamagunta, V.; Campisi, J.; Zheng, G.; Zhou, D. Inhibition of USP7 activity selectively eliminates senescent cells in part via restoration of p53 activity. Aging Cell 2020, 19, e13117. [Google Scholar] [CrossRef]
- Yang, D.; Tian, X.; Ye, Y.; Liang, Y.; Zhao, J.; Wu, T.; Lu, N. Identification of GL-V9 as a novel senolytic agent against senescent breast cancer cells. Life Sci. 2021, 272, 119196. [Google Scholar] [CrossRef]
- Hubackova, S.; Davidova, E.; Rohlenova, K.; Stursa, J.; Werner, L.; Andera, L.; Dong, L.; Terp, M.G.; Hodny, Z.; Ditzel, H.J.; et al. Selective elimination of senescent cells by mitochondrial targeting is regulated by ANT2. Cell Death Differ. 2019, 26, 276–290. [Google Scholar] [CrossRef]
- Nogueira-Recalde, U.; Lorenzo-Gómez, I.; Blanco, F.J.; Loza, M.I.; Grassi, D.; Shirinsky, V.; Shirinsky, I.; Lotz, M.; Robbins, P.D.; Domínguez, E.; et al. Fibrates as drugs with senolytic and autophagic activity for osteoarthritis therapy. EBioMedicine 2019, 45, 588–605. [Google Scholar] [CrossRef]
- Cho, H.J.; Hwang, J.A.; Yang, E.J.; Kim, E.C.; Kim, J.R.; Kim, S.Y.; Kim, Y.Z.; Park, S.C.; Lee, Y.S. Nintedanib induces senolytic effect via STAT3 inhibition. Cell Death Dis. 2022, 13, 760. [Google Scholar] [CrossRef]
- Liao, C.M.; Wulfmeyer, V.C.; Chen, R.; Erlangga, Z.; Sinning, J.; von Mässenhausen, A.; Sörensen-Zender, I.; Beer, K.; von Vietinghoff, S.; Haller, H.; et al. Induction of ferroptosis selectively eliminates senescent tubular cells. Am. J. Transplant. 2022, 22, 2158–2168. [Google Scholar] [CrossRef] [PubMed]
- Pramotton, F.M.; Abukar, A.; Hudson, C.; Dunbar, J.; Potterton, A.; Tonnicchia, S.; Taddei, A.; Mazza, E.; Giampietro, C. DYRK1B inhibition exerts senolytic effects on endothelial cells and rescues endothelial dysfunctions. Mech. Ageing Dev. 2023, 213, 111836. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Zhang, Q.; Chu, Z.; Chen, L.; Chen, J.; Yang, Y.; Tang, H.; Cheng, G.; Ma, A.; Zhang, Y.; et al. Oridonin acts as a novel senolytic by targeting glutathione S-transferases to activate the ROS-p38 signaling axis in senescent cells. Chem. Commun. 2022, 58, 13250–13253. [Google Scholar] [CrossRef] [PubMed]
- Al-Mansour, F.; Alraddadi, A.; He, B.; Saleh, A.; Poblocka, M.; Alzahrani, W.; Cowley, S.; Macip, S. Characterization of the HDAC/PI3K inhibitor CUDC-907 as a novel senolytic. Aging 2023, 15, 2373–2394. [Google Scholar] [CrossRef]
- Zhang, Y.; Gao, D.; Yuan, Y.; Zheng, R.; Sun, M.; Jia, S.; Liu, J. Cycloastragenol: A Novel Senolytic Agent That Induces Senescent Cell Apoptosis and Restores Physical Function in TBI-Aged Mice. Int. J. Mol. Sci. 2023, 24, 6554. [Google Scholar] [CrossRef]
- Takaya, K.; Asou, T.; Kishi, K. Identification of resibufogenin, a component of toad venom, as a novel senolytic compound in vitro and for potential skin rejuvenation in male mice. Biogerontology 2023, 24, 889–900. [Google Scholar] [CrossRef]
- Admasu, T.D.; Kim, K.; Rae, M.; Avelar, R.; Gonciarz, R.L.; Rebbaa, A.; Pedro de Magalhães, J.; Renslo, A.R.; Stolzing, A.; Sharma, A. Selective ablation of primary and paracrine senescent cells by targeting iron dyshomeostasis. Cell Rep. 2023, 42, 112058. [Google Scholar] [CrossRef]
- Raffaele, M.; Kovacovicova, K.; Biagini, T.; Lo Re, O.; Frohlich, J.; Giallongo, S.; Nhan, J.D.; Giannone, A.G.; Cabibi, D.; Ivanov, M.; et al. Nociceptin/orphanin FQ opioid receptor (NOP) selective ligand MCOPPB links anxiolytic and senolytic effects. Geroscience 2022, 44, 463–483. [Google Scholar] [CrossRef]
- Wang, H.; Yuan, S.; Zheng, Q.; Zhang, S.; Zhang, Q.; Ji, S.; Wang, W.; Cao, Y.; Guo, Y.; Yang, X.; et al. Dual Inhibition of CDK4/6 and XPO1 Induces Senescence with Acquired Vulnerability to CRBN-Based PROTAC Drugs. Gastroenterology 2024, 166, 1130–1144. [Google Scholar] [CrossRef]
- Kusumoto, D.; Seki, T.; Sawada, H.; Kunitomi, A.; Katsuki, T.; Kimura, M.; Ito, S.; Komuro, J.; Hashimoto, H.; Fukuda, K.; et al. Anti-senescent drug screening by deep learning-based morphology senescence scoring. Nat. Commun. 2021, 12, 257. [Google Scholar] [CrossRef]
- Wang, Y.; Chang, J.; Liu, X.; Zhang, X.; Zhang, S.; Zhang, X.; Zhou, D.; Zheng, G. Discovery of piperlongumine as a potential novel lead for the development of senolytic agents. Aging 2016, 8, 2915–2926. [Google Scholar] [CrossRef] [PubMed]
- Chang, J.; Wang, Y.; Shao, L.; Laberge, R.M.; Demaria, M.; Campisi, J.; Janakiraman, K.; Sharpless, N.E.; Ding, S.; Feng, W.; et al. Clearance of senescent cells by ABT263 rejuvenates aged hematopoietic stem cells in mice. Nat. Med. 2016, 22, 78–83. [Google Scholar] [CrossRef] [PubMed]
- Yosef, R.; Pilpel, N.; Tokarsky-Amiel, R.; Biran, A.; Ovadya, Y.; Cohen, S.; Vadai, E.; Dassa, L.; Shahar, E.; Condiotti, R.; et al. Directed elimination of senescent cells by inhibition of BCL-W and BCL-XL. Nat. Commun. 2016, 7, 11190. [Google Scholar] [CrossRef] [PubMed]
- Guerrero, A.; Herranz, N.; Sun, B.; Wagner, V.; Gallage, S.; Guiho, R.; Wolter, K.; Pombo, J.; Irvine, E.E.; Innes, A.J.; et al. Cardiac glycosides are broad-spectrum senolytics. Nat. Metab. 2019, 1, 1074–1088. [Google Scholar] [CrossRef]
- Triana-Martínez, F.; Picallos-Rabina, P.; Da Silva-Álvarez, S.; Pietrocola, F.; Llanos, S.; Rodilla, V.; Soprano, E.; Pedrosa, P.; Ferreirós, A.; Barradas, M.; et al. Identification and characterization of Cardiac Glycosides as senolytic compounds. Nat. Commun. 2019, 10, 4731. [Google Scholar] [CrossRef]
- Liu, H.; Xu, Q.; Wufuer, H.; Li, Z.; Sun, R.; Jiang, Z.; Dou, X.; Fu, Q.; Campisi, J.; Sun, Y. Rutin is a potent senomorphic agent to target senescent cells and can improve chemotherapeutic efficacy. Aging Cell 2024, 23, e13921. [Google Scholar] [CrossRef]
- Carracedo-Reboredo, P.; Liñares-Blanco, J.; Rodríguez-Fernández, N.; Cedrón, F.; Novoa, F.J.; Carballal, A.; Maojo, V.; Pazos, A.; Fernandez-Lozano, C. A review on machine learning approaches and trends in drug discovery. Comput. Struct Biotechnol. J. 2021, 19, 4538–4558. [Google Scholar] [CrossRef]
- Ross, J.; Belgodere, B.; Chenthamarakshan, V.; Padhi, I.; Mroueh, Y.; Das, P. Large-scale chemical language representations capture molecular structure and properties. Nat. Mach. Intell. 2022, 4, 1256–1264. [Google Scholar] [CrossRef]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Foody, G.M. Challenges in the real world use of classification accuracy metrics: From recall and precision to the Matthews correlation coefficient. PLoS ONE 2023, 18, e0291908. [Google Scholar] [CrossRef]
- Fort, S.; Hu, H.; Lakshminarayanan, B. Deep ensembles: A loss landscape perspective. arXiv 2020, arXiv:1912.02757. [Google Scholar] [CrossRef]
- Wishart, D.S.; Feunang, Y.D.; Guo, A.C.; Lo, E.J.; Marcu, A.; Grant, J.R.; Sajed, T.; Johnson, D.; Li, C.; Sayeeda, Z.; et al. DrugBank 5.0: A major update to the DrugBank database for 2018. Nucleic Acids Res. 2018, 46, D1074–D1082. [Google Scholar] [CrossRef] [PubMed]
- Lv, Q.; Chen, G.; He, H.; Yang, Z.; Zhao, L.; Zhang, K.; Chen, C.Y. TCMBank-the largest TCM database provides deep learning-based Chinese-Western medicine exclusion prediction. Signal Transduct. Target. Ther. 2023, 8, 127. [Google Scholar] [CrossRef] [PubMed]
- Zeng, X.X.; Gao, D.D.; Zhang, F. Cortex Mori Radicis[Morus Alba, L. (Moraceae)] extract alleviates senescence via PI3K/Akt signaling in COPD fibroblasts. Phytomedicine 2024, 135, 156004. [Google Scholar] [CrossRef]
- Yu, X.; Miao, Z.; Zhang, L.; Zhu, L.; Sheng, H. Extraction, purification, structure characteristics, biological activities and pharmaceutical application of Bupleuri Radix Polysaccharide: A review. Int. J. Biol. Macromol. 2023, 237, 124146. [Google Scholar] [CrossRef]
- Dagouassat, M.; Gagliolo, J.M.; Chrusciel, S.; Bourin, M.C.; Duprez, C.; Caramelle, P.; Boyer, L.; Hue, S.; Stern, J.B.; Validire, P.; et al. The cyclooxygenase-2-prostaglandin E2 pathway maintains senescence of chronic obstructive pulmonary disease fibroblasts. Am. J. Respir. Crit. Care Med. 2013, 187, 703–714. [Google Scholar] [CrossRef]
- Gao, A.Y.; Diaz Espinosa, A.M.; Gianì, F.; Pham, T.X.; Carver, C.M.; Aravamudhan, A.; Bartman, C.M.; Ligresti, G.; Caporarello, N.; Schafer, M.J.; et al. Pim-1 kinase is a positive feedback regulator of the senescent lung fibroblast inflammatory secretome. Am. J. Physiol. Lung Cell Mol. Physiol. 2022, 323, L685–L697. [Google Scholar] [CrossRef]
- Kanehisa, M.; Goto, S. KEGG: Kyoto encyclopedia of genes and genomes. Nucleic Acids Res. 2000, 28, 27–30. [Google Scholar] [CrossRef]
- Zhu, Y.; Tchkonia, T.; Fuhrmann-Stroissnigg, H.; Dai, H.M.; Ling, Y.Y.; Stout, M.B.; Pirtskhalava, T.; Giorgadze, N.; Johnson, K.O.; Giles, C.B.; et al. Identification of a novel senolytic agent, navitoclax, targeting the Bcl-2 family of anti-apoptotic factors. Aging Cell 2016, 15, 428–435. [Google Scholar] [CrossRef]
- Heo, Y.A. Voclosporin: First Approval. Drugs 2021, 81, 605–610. [Google Scholar] [CrossRef]
- Zhan, X.; Wu, H.; Wu, H.; Wang, R.; Luo, C.; Gao, B.; Chen, Z.; Li, Q. Metabolites from Bufo gargarizans (Cantor, 1842): A review of traditional uses, pharmacological activity, toxicity and quality control. J. Ethnopharmacol. 2020, 246, 112178. [Google Scholar] [CrossRef] [PubMed]
- Ran, H.L.; Huang, S.Z.; Wang, H.; Yang, L.; Gai, C.J.; Duan, R.J.; Dai, H.F.; Guan, Y.L.; Mei, W.L. Cytotoxic steroids from the stems of Strophanthus divaricatus. Phytochemistry 2023, 210, 113668. [Google Scholar] [CrossRef] [PubMed]
- Younkin, G.C.; Alani, M.L.; Páez-Capador, A.; Fischer, H.D.; Mirzaei, M.; Hastings, A.P.; Agrawal, A.A.; Jander, G. Cardiac glycosides protect wormseed wallflower (Erysimum cheiranthoides) against some, but not all, glucosinolate-adapted herbivores. New Phytol. 2024, 242, 2719–2733. [Google Scholar] [CrossRef] [PubMed]
- Tian, D.M.; Cheng, H.Y.; Jiang, M.M.; Shen, W.Z.; Tang, J.S.; Yao, X.S. Cardiac Glycosides from the Seeds of Thevetia peruviana. J. Nat. Prod. 2016, 79, 38–50. [Google Scholar] [CrossRef]
- Biswas, A.; Dey, S.; Huang, S.; Deng, Y.; Birhanie, Z.M.; Zhang, J.; Akhter, D.; Liu, L.; Li, D. A Comprehensive Review of C. capsularis and C. olitorius: A Source of Nutrition, Essential Phytoconstituents and Pharmacological Activities. Antioxidants 2022, 11, 1358. [Google Scholar] [CrossRef]
- Wang, Y.; Ai, Q.; Gu, M.; Guan, H.; Yang, W.; Zhang, M.; Mao, J.; Lin, Z.; Liu, Q.; Liu, J. Comprehensive overview of different medicinal parts from Morus alba L.: Chemical compositions and pharmacological activities. Front. Pharmacol. 2024, 15, 1364948. [Google Scholar] [CrossRef]
- Bender, B.J.; Gahbauer, S.; Luttens, A.; Lyu, J.; Webb, C.M.; Stein, R.M.; Fink, E.A.; Balius, T.E.; Carlsson, J.; Irwin, J.J.; et al. A practical guide to large-scale docking. Nat. Protoc. 2021, 16, 4799–4832, Erratum in Nat. Protoc. 2022, 17, 177. [Google Scholar] [CrossRef]
- Kuang, B.; Geng, N.; Yi, M.; Zeng, Q.; Fan, M.; Xian, M.; Deng, L.; Chen, C.; Pan, Y.; Kuang, L.; et al. Panaxatriol exerts anti-senescence effects and alleviates osteoarthritis and cartilage repair fibrosis by targeting UFL1. J. Adv. Res. 2024, 21. [Google Scholar] [CrossRef]
- Wu, Q.; Chen, P.; Tu, G.; Li, M.; Pan, B.; Guo, Y.; Zhai, J.; Fu, H. Synthesis and evaluation of panaxatriol derivatives as Na+, K+-ATPase inhibitors. Bioorg. Med. Chem. Lett. 2018, 28, 2885–2889. [Google Scholar] [CrossRef]
- Kale, A.; Shelke, V.; Lei, Y.; Gaikwad, A.B.; Anders, H.J. Voclosporin: Unique Chemistry, Pharmacology and Toxicity Profile, and Possible Options for Implementation into the Management of Lupus nephritis. Cells 2023, 12, 2440. [Google Scholar] [CrossRef]
- Tsubaki, M.; Tomii, K.; Sese, J. Compound-protein interaction prediction with end-to-end learning of neural networks for graphs and sequences. Bioinformatics 2019, 35, 309–318. [Google Scholar] [CrossRef] [PubMed]
- Hicks, S.A.; Strümke, I.; Thambawita, V.; Hammou, M.; Riegler, M.A.P.; Parasa, S. On evaluation metrics for medical applications of artificial intelligence. Sci. Rep. 2022, 12, 5979. [Google Scholar] [CrossRef] [PubMed]
- Yacouby, R.; Axman, D. Probabilistic extension of precision, recall, and f1 score for more thorough evaluation of classification models. In Proceedings of the First Workshop on Evaluation and Comparison of NLP Systems, Virtual, 20 November 2020; pp. 79–91. [Google Scholar]
- Huang, J.; Ling, C.X. Using AUC and accuracy in evaluating learning algorithms. IEEE Trans. Knowl. Data Eng. 2005, 17, 299–310. [Google Scholar] [CrossRef]
- McDermott, M.; Zhang, H.; Hansen, L.; Angelotti, G.; Gallifant, J. A closer look at auroc and auprc under class imbalance. Adv. Neural Inf. Process. Syst. 2024, 37, 44102–44163. [Google Scholar]
- Dragos, H.; Gilles, M.; Alexandre, V. Predicting the predictability: A unified approach to the applicability domain problem of QSAR models. J. Chem. Inf. Model. 2009, 49, 1762–1776. [Google Scholar] [CrossRef]
- Golbraikh, A.; Shen, M.; Xiao, Z.; Xiao, Y.D.; Lee, K.H.; Tropsha, A. Rational selection of training and test sets for the development of validated QSAR models. J. Comput. Aided Mol. Des. 2003, 17, 241–253. [Google Scholar] [CrossRef]
- Clay, K.J.; Petrascheck, M. Design and Analysis of Pharmacological Studies in Aging. Methods Mol. Biol. 2020, 2144, 77–89. [Google Scholar]
- Stokes, J.M.; Yang, K.; Swanson, K.; Jin, W.; Cubillos-Ruiz, A.; Donghia, N.M.; MacNair, C.R.; French, S.; Carfrae, L.A.; Bloom-Ackermann, Z.; et al. A Deep Learning Approach to Antibiotic Discovery. Cell 2020, 181, 475–483. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Match_degree 1 | Match_id 2 | SVM Score | SVM Prediction | MLP Score | MLP Prediction | Target |
|---|---|---|---|---|---|---|---|
| Cymarin | 0.793 | Strophanthin K | 1.501 | 1 | 0.993 | 1 | / |
| Metildigoxin | 0.889 | Digoxin | 1.140 | 1 | 0.999 | 1 | / |
| Amrubicin | 0.575 | Idarubicin | 1.057 | 1 | 1.000 | 1 | TOP2A |
| Alisporivir * | 0.783 | Cyclosporin A | 0.972 | 1 | 1.000 | 1 | CAMLG |
| Reidispongiolide A * | 0.196 | Alvespimycin | 0.929 | 1 | 0.991 | 1 | ACTA1 |
| NIM811 * | 0.924 | Cyclosporin A | 0.865 | 1 | 1.000 | 1 | / |
| Acetyldigitoxin | 0.846 | Digitoxin | 0.816 | 1 | 0.996 | 1 | ATP1A1 |
| Aclarubicin | 0.339 | Idarubicin | 0.804 | 1 | 0.990 | 1 | TOP2A, TOP2B |
| Acetyldigoxin | 0.846 | Digoxin | 0.767 | 1 | 0.986 | 1 | / |
| Quisinostat | 0.245 | CUDC-907 | 0.748 | 1 | 1.000 | 1 | / |
| Name | Match_degree 1 | Match_id 2 | SVM Score | SVM Prediction | MLP Score | MLP Prediction |
|---|---|---|---|---|---|---|
| Sesguoiaflavone | 0.705 | Ginkgetin | 1.766 | 1 | 1.000 | 1 |
| Bufotalidin | 0.656 | Strophanthidin | 1.757 | 1 | 1.000 | 1 |
| Helveticoside | 0.789 | Convallotoxin | 1.553 | 1 | 0.999 | 1 |
| cis-Miyabenol a | 0.274 | Procyanidin C1 | 1.541 | 1 | 1.000 | 1 |
| Bipindoside | 0.756 | Ouabain | 1.545 | 1 | 0.993 | 1 |
| Cymarin | 0.793 | Strophanthin K | 1.501 | 1 | 1.000 | 1 |
| Malayoside | 0.878 | Peruvoside | 1.493 | 1 | 1.000 | 1 |
| Helveticosol | 0.688 | Digitoxin | 1.485 | 1 | 0.995 | 1 |
| Cymarol | 0.750 | Periplocin | 1.472 | 1 | 0.997 | 1 |
| Gnetuhainin m | 0.333 | Procyanidin C1 | 1.460 | 1 | 1.000 | 1 |
| Herb_name | Family | Genus | Compound | P_adj 1 |
|---|---|---|---|---|
| Bufo bufo gargarizans, Bufo melanostictus | Bufonidae | Bufo | 23 | 2.92 × 10−19 |
| Erysimum cheiranthoides | Brassicaceae | Erysimum | 9 | 8.75 × 10−11 |
| Strophanthus divaricatus | Apocynaceae | Strophanthus | 10 | 2.10 × 10−10 |
| Thevetia neriifolia | Apocynaceae | Thevetia | 10 | 3.20 × 10−8 |
| Corchorus capsularis | Malvaceae | Corchorus | 6 | 3.20 × 10−8 |
| Morus alba L. | Moraceae | Morus | 22 | 3.20 × 10−8 |
| Strophanthus kombe | Apocynaceae | Strophanthus | 7 | 3.83 × 10−8 |
| Tabernaemontana corymbosa | Apocynaceae | Tabernaemontana | 7 | 1.09 × 10−7 |
| Corchorus olitorius | Malvaceae | Corchorus | 5 | 2.84 × 10−7 |
| Cerbera manghas | Apocynaceae | Cerbera | 6 | 9.56 × 10−7 |
| Cerbera odollam | Apocynaceae | Cerbera | 5 | 2.12 × 10−6 |
| Erysimum diffusum | Brassicaceae | Erysimum | 4 | 2.55 × 10−6 |
| Rosa chinensis | Rosaceae | Rosa | 16 | 2.60 × 10−6 |
| Antiaris toxicaria | Moraceae | Antiaris | 5 | 7.31 × 10−6 |
| Adonis mongolica | Ranunculaceae | Adonis | 4 | 1.01 × 10−5 |
| Bupleurum smithii | Apiaceae | Bupleurum | 5 | 1.96 × 10−5 |
| Nerium indicum | Apocynaceae | Nerium | 11 | 2.52 × 10−5 |
| Gnetum gnemon | Gnetaceae | Gnetum | 5 | 4.31 × 10−5 |
| Adonis vernalis | Ranunculaceae | Adonis | 4 | 5.44 × 10−5 |
| Bupleurum yinchowense | Apiaceae | Bupleurum | 3 | 0.000102922 |
| NAME | Structure | SVM Score | SVM Prediction | MLP Score | MLP Prediction | Life Expectancy (Day) | Life Extension Rate(%) | p Value 1 |
|---|---|---|---|---|---|---|---|---|
| Voclosporin |  | 0.746 | 1 | 0.999 | 1 | 26.39 ± 1.53 | 19.1 | 0.060 |
| Simeprevir | 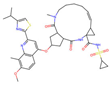 | −0.654 | 0 | 0.002 | 0 | 19.52 ± 0.86 | −11.9 | 0.054 |
| Belinostat | 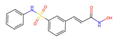 | −0.544 | 0 | 0.024 | 0 | 22.77 ± 0.62 | 2.8 | 0.760 |
| Paritaprevir | 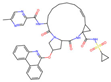 | −0.743 | 0 | 0.0 | 0 | 22.53 ± 1.96 | 1.7 | 0.870 |
| Tenapanor | 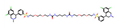 | −0.074 | 0 | 0.098 | 0 | 23.37 ± 1.58 | 5.5 | 0.338 |
| Control | / | / | / | / | / | 23.15 ± 0.15 | / | |
| DMSO | / | / | / | / | / | 22.15 ± 0.17 | / | |
| Metformin | 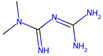 | / | / | / | / | 25.78 ± 2.40 | 11.3 | 0.039 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Zhao, K.; Yang, G.; Lv, H.; Zhang, R.; Li, S.; Chen, Z.; Xu, M.; Yang, N.; Dai, S. Development and Application of a Senolytic Predictor for Discovery of Novel Senolytic Compounds and Herbs. Molecules 2025, 30, 2653. https://doi.org/10.3390/molecules30122653
Li J, Zhao K, Yang G, Lv H, Zhang R, Li S, Chen Z, Xu M, Yang N, Dai S. Development and Application of a Senolytic Predictor for Discovery of Novel Senolytic Compounds and Herbs. Molecules. 2025; 30(12):2653. https://doi.org/10.3390/molecules30122653
Chicago/Turabian StyleLi, Jinjun, Kai Zhao, Guotai Yang, Haohao Lv, Renxin Zhang, Shuhan Li, Zhiyuan Chen, Min Xu, Naixue Yang, and Shaoxing Dai. 2025. "Development and Application of a Senolytic Predictor for Discovery of Novel Senolytic Compounds and Herbs" Molecules 30, no. 12: 2653. https://doi.org/10.3390/molecules30122653
APA StyleLi, J., Zhao, K., Yang, G., Lv, H., Zhang, R., Li, S., Chen, Z., Xu, M., Yang, N., & Dai, S. (2025). Development and Application of a Senolytic Predictor for Discovery of Novel Senolytic Compounds and Herbs. Molecules, 30(12), 2653. https://doi.org/10.3390/molecules30122653