
Software-Assisted Pattern Recognition of Persistent Organic Pollutants in Contaminated Human and Animal Food


Abstract
1. Introduction
2. Results
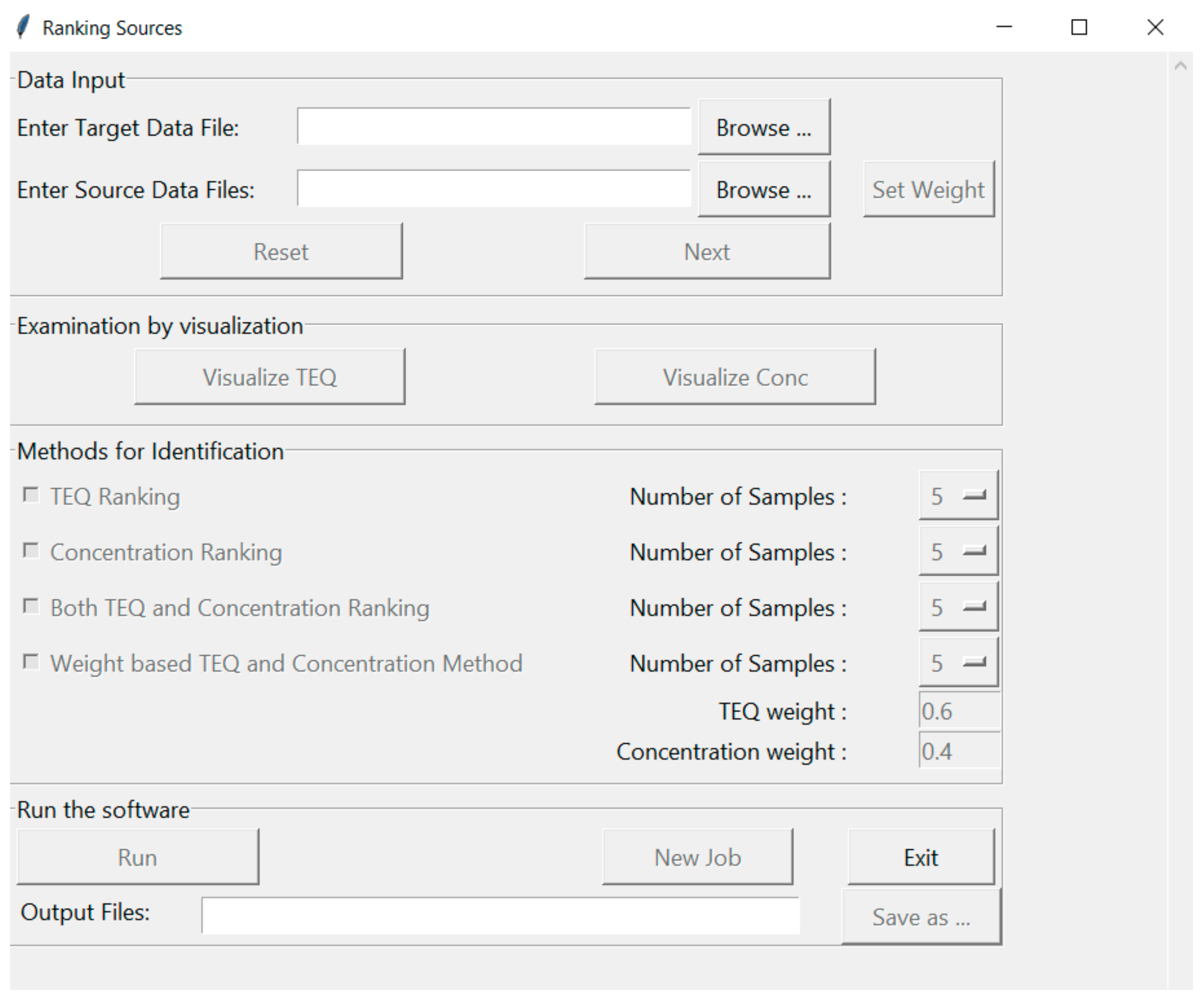
2.1. Software Details and Interface
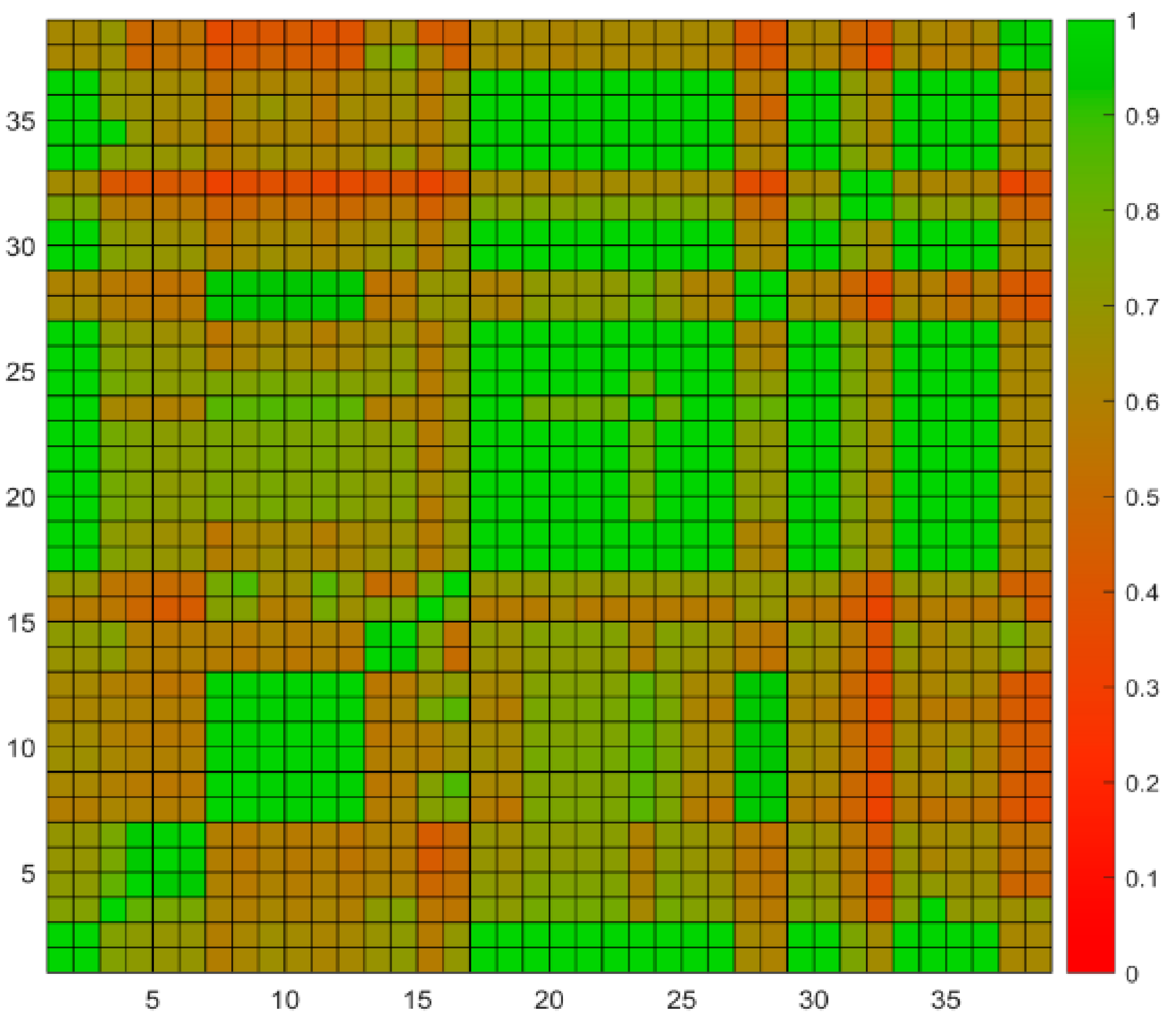
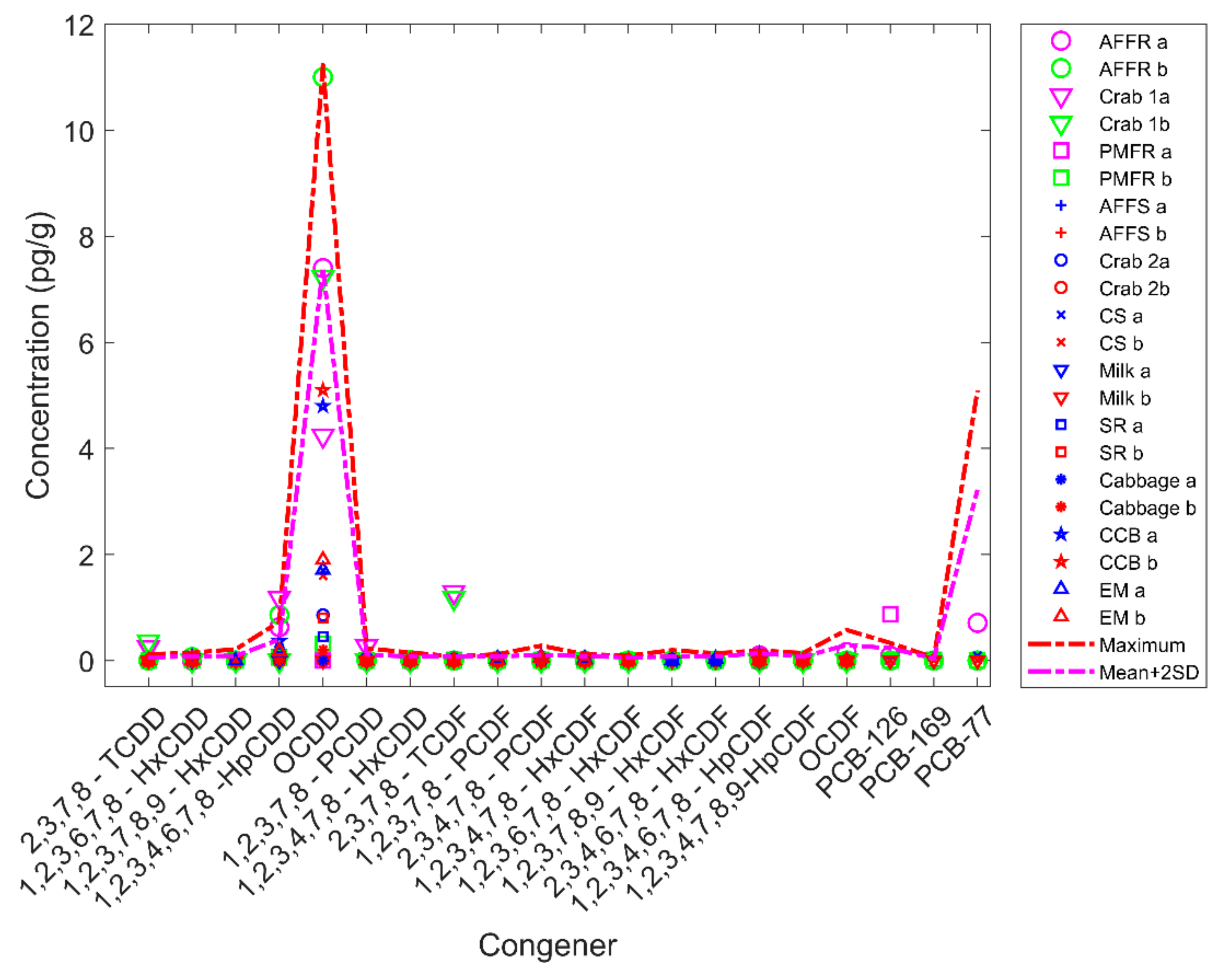
2.2. Performance Test
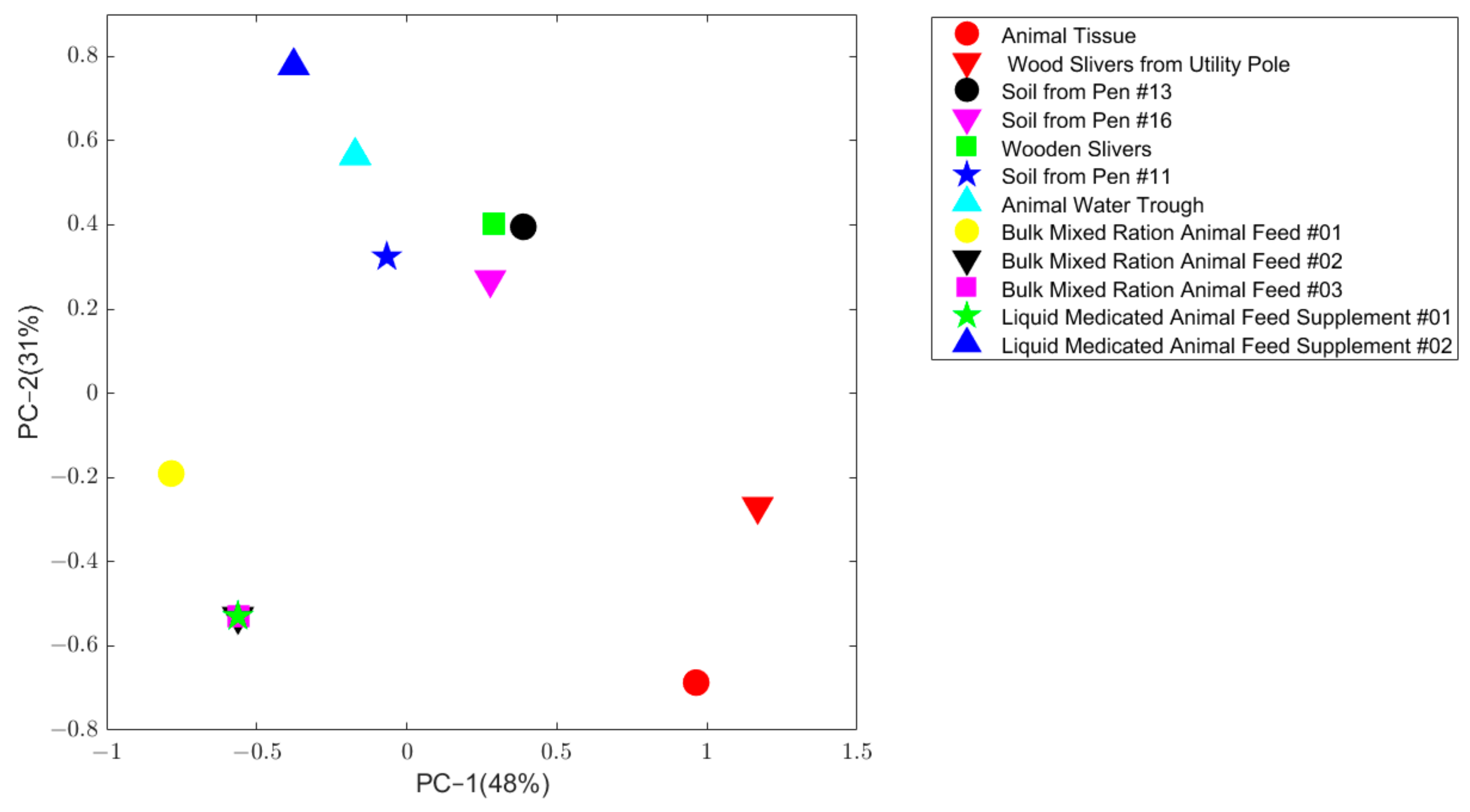
2.2.1. Potential Source Sample Test Case
2.2.2. Potential Source Sample Test Results
3. Discussion
4. Materials and Methods
4.1. Study Design
4.2. Similarity Calculation
4.2.1. Normalized Concentration/TEQ
4.2.2. Calculate Similarity
4.2.3. Ranking Potential Source Samples
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Disclaimer
Sample Availability
References
- Ashraf, M.A. Persistent organic pollutants (POPs): A global issue, a global challenge. Environ. Sci. Pollut. Res. 2017, 24, 4223–4227. [Google Scholar] [CrossRef]
- Gaur, N.; Narasimhulu, K.; Y, P. Recent advances in the bio-remediation of persistent organic pollutants and its effect on environment. J. Clean. Prod. 2018, 198, 1602–1631. [Google Scholar] [CrossRef]
- El-Shahawi, M.; Hamza, A.; Bashammakh, A.; Al-Saggaf, W. An overview on the accumulation, distribution, transformations, toxicity and analytical methods for the monitoring of persistent organic pollutants. Talanta 2010, 80, 1587–1597. [Google Scholar] [CrossRef]
- Jones, K.C.; De Voogt, P. Persistent organic pollutants (POPs): State of the science. Environ. Pollut. 1999, 100, 209–221. [Google Scholar] [CrossRef]
- Beyer, A.; Mackay, D.; Matthies, M.; Wania, F.; Webster, E. Assessing Long-Range Transport Potential of Persistent Organic Pollutants. Environ. Sci. Technol. 2000, 34, 699–703. [Google Scholar] [CrossRef]
- Kelly, B.C.; Ikonomou, M.G.; Blair, J.D.; Morin, A.E.; Gobas, F.A.P.C. Food Web-Specific Biomagnification of Persistent Organic Pollutants. Science 2007, 317, 236–239. [Google Scholar] [CrossRef]
- Guo, W.; Pan, B.; Sakkiah, S.; Yavas, G.; Ge, W.; Zou, W.; Tong, W.; Hong, H. Persistent Organic Pollutants in Food: Contamination Sources, Health Effects and Detection Methods. Int. J. Environ. Res. Public Health 2019, 16, 4361. [Google Scholar] [CrossRef]
- Alharbi, O.M.; Basheer, A.A.; Khattab, R.A.; Ali, I. Health and environmental effects of persistent organic pollutants. J. Mol. Liq. 2018, 263, 442–453. [Google Scholar] [CrossRef]
- Vorkamp, K.; Rigét, F.F. A review of new and current-use contaminants in the Arctic environment: Evidence of long-range transport and indications of bioaccumulation. Chemosphere 2014, 111, 379–395. [Google Scholar] [CrossRef]
- Li, Q.Q.; Loganath, A.; Chong, Y.S.; Tan, J.; Obbard, J.P. Persistent Organic Pollutants and Adverse Health Effects in Humans. J. Toxicol. Environ. Health Part A 2006, 69, 1987–2005. [Google Scholar] [CrossRef]
- Tang, H.P.-O. Recent development in analysis of persistent organic pollutants under the Stockholm Convention. TrAC Trends Anal. Chem. 2013, 45, 48–66. [Google Scholar] [CrossRef]
- Xu, W.; Wang, X.; Cai, Z. Analytical chemistry of the persistent organic pollutants identified in the Stockholm Convention: A review. Anal. Chim. Acta 2013, 790, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Vallack, H.W.; Bakker, D.J.; Brandt, I.; Brostrom-Lunden, E.; Brouwer, A.; Bull, K.R.; Gough, C.; Guardans, R.; Holoubek, I.; Jansson, B.; et al. Controlling Persistent Organic Pollutants-What Next? Environ. Toxicol. Pharmacol. 1998, 6, 143–175. [Google Scholar] [CrossRef]
- UNEP. Stockholm Convention on Persistent Organic Pollutants; Secretariat of the Stockholm Convention Report: Geneva, Switzerland, 2001; p. 43. [Google Scholar]
- UNECE. Protocol to the 1979 Convention on Long-Range Transboundary Air Pollution on Persistent Organic Pollutants. UNECE: Aarhus, Denmark. 1998. Available online: http://www.unece.org/env/lrtap/pops_h1.html (accessed on 18 December 2020).
- EC. Commission Regulation (EU) No 253/2011 of 15 March 2011 Amending Regulation (EC) No 1907/2006 of the European Parliament and of the Council on the Registration, Evaluation, Authorisation and Restriction of Chemicals (REACH) as Re-gards Annex XIII. Off. J. Eur. Union. 2011, 69, 7–12. [Google Scholar]
- EP&C. Regulation (EC) No 1107/2009 of the European Parliament and of the Council of 21 October 2009 Concerning the Placing of Plant Protection Products on the Market and Repealing Council Directives 79/117/EEC and 91/414/EEC (91/414/EEC). Off. J. Eur. Union. 2009, 309, 1–50. [Google Scholar]
- U.S. EPA. Category for Persistent, Bioaccumulative, and Toxic New Chemical Substances. Fed. Regist. 1999, 64, 20194–60204. [Google Scholar]
- Yoshimura, T. Yusho in Japan. Ind. Health 2003, 41, 139–148. [Google Scholar] [CrossRef]
- Hsu, S.-T.; Ma, C.-I.; Hsu, S.K.-H.; Wu, S.-S.; Hsu, N.H.-M.; Yeh, C.-C. Discovery and epidemiology of PCB poisoning in Taiwan. Am. J. Ind. Med. 1984, 5, 71–79. [Google Scholar] [CrossRef]
- Bernard, A.; Broeckaert, F.; De Poorter, G.; De Cock, A.; Hermans, C.; Saegerman, C.; Houins, G. The Belgian PCB/Dioxin Incident: Analysis of the Food Chain Contamination and Health Risk Evaluation. Environ. Res. 2002, 88, 1–18. [Google Scholar] [CrossRef]
- Pratt, I.; Anderson, W.A.; Crowley, D.; Daly, S.F.; Evans, R.I.; Fernandes, A.R.; Fitzgerald, M.; Geary, M.; Keane, D.P.; Malisch, R.; et al. Polychlorinated dibenzo-p-dioxins (PCDDs), polychlorinated dibenzofurans (PCDFs) and polychlorinated biphenyls (PCBs) in breast milk of first-time Irish mothers: Impact of the 2008 dioxin incident in Ireland. Chemosphere 2012, 88, 865–872. [Google Scholar] [CrossRef]
- Van Leeuwen, F.; Feeley, M.; Schrenk, D.; Larsen, J.C.; Farland, W.; Younes, M. Dioxins: WHO’s tolerable daily intake (TDI) revisited. Chemosphere 2000, 40, 1095–1101. [Google Scholar] [CrossRef]
- European Commission. Commission Regulation (EC) No 1881/2006 of 19 December 2006 setting maximum levels for certain contaminants in foodstuffs. Off. J. Eur. Union 2006, 364, 324–365. [Google Scholar]
- EC. Commission Regulation (EU) 2020/685 of 20 May 2020 Amending Regulation (EC) No 1881/2006 as Regards Maximum Levels of Perchlorate in Certain Foods. Off. J. Eur. Union. 2020, 160, 3–5. [Google Scholar]
- Hoogenboom, R.L.; Zeilmaker, M.; Van Eijkeren, J.; Kan, K.; Mengelers, M.; Luykx, D.; Traag, W. Kaolinic clay derived PCDD/Fs in the feed chain from a sorting process for potatoes. Chemosphere 2010, 78, 99–105. [Google Scholar] [CrossRef]
- Hoogenboom, R.; Malisch, R.; van Leeuwen, S.P.J.; Vanderperren, H.; Hove, H.; Fernandes, A.; Schächtele, A.; Rose, M. Congener Patterns of Polychlorinated Dibenzo-P-Dioxins, Dibenzofurans and Biphenyls as a Useful Aid to Source Identification During a Con-tamination Incident in the Food Chain. Sci. Total Environ. 2020, 746, 141098. [Google Scholar] [CrossRef]
- Johansson, A.-K.; Sellström, U.; Lindberg, P.; Bignert, A.; de Wit, C.A. Polybrominated Diphenyl Ether Congener Patterns, Hexabromocyclododecane, and Brominated Biphenyl 153 in Eggs of Peregrine Falcons (Falco Peregrinus) Breeding in Sweden. Environ. Toxicol. Chem. 2009, 28, 9–17. [Google Scholar] [CrossRef]
- Kim, K.S.; Hirai, Y.; Kato, M.; Urano, K.; Masunaga, S. Detailed PCB congener patterns in incinerator flue gas and commercial PCB formulations (Kanechlor). Chemosphere 2004, 55, 539–553. [Google Scholar] [CrossRef]
- Santillo, D.; Fernandes, A.; Stringer, R.; Alcock, R.; Rose, M.; White, S.; Jones, K.C.; Johnston, P. Butter as an indicator of regional persistent organic pollutant contamination: Further development of the approach using polychlorinated dioxins and furans (PCDD/Fs), and dioxin-like polychlorinated biphenyls (PCBs). Food Addit. Contam. 2003, 20, 281–290. [Google Scholar] [CrossRef]
- Gerig, B.S.; Chaloner, D.T.; Janetski, D.J.; Rediske, R.R.; O’Keefe, J.H.; Moerke, A.H.; Lamberti, G.A. Congener Patterns of Persistent Organic Pollutants Establish the Extent of Contaminant Biotransport by Pacific Salmon in the Great Lakes. Environ. Sci. Technol. 2015, 50, 554–563. [Google Scholar] [CrossRef]
- Wu, M.-H.; Pei, J.-C.; Zheng, M.; Tang, L.; Bao, Y.-Y.; Xu, B.-T.; Sun, R.; Sun, Y.-F.; Xu, G.; Lei, J. Polybrominated diphenyl ethers (PBDEs) in soil and outdoor dust from a multi-functional area of Shanghai: Levels, compositional profiles and interrelationships. Chemosphere 2015, 118, 87–95. [Google Scholar] [CrossRef]
- Pozo, K.; Harner, T.; Rudolph, A.; Oyola, G.; Estellano, V.H.; Ahumada-Rudolph, R.; Garrido, M.; Pozo, K.; Mabilia, R.; Focardi, S. Survey of Persistent Organic Pol-lutants (POPs) and Polycyclic Aromatic Hydrocarbons (PAHs) in the Atmosphere of Rural, Urban and Industrial Areas of Concepción, Chile, Using Passive Air Samplers. Atmos. Pollut. Res. 2012, 3, 426–434. [Google Scholar] [CrossRef]
- Jin, R.; Fu, J.; Zheng, M.; Yang, L.; Habib, A.; Li, C.; Liu, G. Polychlorinated Naphthalene Congener Profiles in Common Veg-etation on the Tibetan Plateau as Biomonitors of Their Sources and Transportation. Environ. Sci. Technol. 2020, 54, 2314–2322. [Google Scholar] [CrossRef]
- Antignac, J.P.; Marchand, P.; Gade, C.; Matayron, G.; Qannari el, M.; Le Bizec, B.; André, F. Studying Variations in the PCDD/PCDF Profile across Various Food Products Using Multivariate Statistical Analysis. Anal Bioanal Chem. 2006, 384, 271–279. [Google Scholar] [CrossRef] [PubMed]
- Alava, J.J.; Keller, J.M.; Wyneken, J.; Crowder, L.; Scott, G.; Kucklick, J.R. Geographical variation of persistent organic pollutants in eggs of threatened loggerhead sea turtles (Caretta caretta) from southeastern United States. Environ. Toxicol. Chem. 2011, 30, 1677–1688. [Google Scholar] [CrossRef] [PubMed]
- Guo, W.; Archer, J.C.; Moore, M.; Bruce, J.; McLain, M.; Shojaee, S.; Zou, W.; Benjamin, L.A.; Adeuya, A.; Fairchild, R.; et al. QUICK: Quality and Usability Investigation and Control Kit for Mass Spectrometric Data from Detection of Persistent Organic Pollutants. Int. J. Environ. Res. Public Health 2019, 16, 4203. [Google Scholar] [CrossRef]
- Dioxin FY2013 Survey: Dioxins and Dioxin-Like Compounds in the U.S. Domestic Meat and Poultry Supply. Available online: https://www.fsis.usda.gov/wps/portal/fsis/topics/data-collection-and-reports/chemistry/dioxin-related-activites (accessed on 18 December 2020).
- Berg, M.V.D.; Birnbaum, L.S.; Denison, M.; De Vito, M.; Farland, W.; Feeley, M.; Fiedler, H.; Hakansson, H.; Hanberg, A.; Haws, L.; et al. The 2005 World Health Organization Reevaluation of Human and Mammalian Toxic Equivalency Factors for Dioxins and Dioxin-Like Compounds. Toxicol. Sci. 2006, 93, 223–241. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ranking | Potential Source Sample | Similarity Score |
|---|---|---|
| 1 | Wood Slivers from Utility Pole | 0.63 |
| 2 | Soil from Pen #13 | 0.58 |
| 3 | Soil from Pen #16 | 0.56 |
| 4 | Wooden Slivers | 0.54 |
| 5 | Animal Water Trough | 0.50 |
| 6 | Bulk Mixed Ration Animal Feed #02 | 0.50 |
| 7 | Bulk Mixed Ration Animal Feed #03 | 0.50 |
| 8 | Liquid Medicated Animal Feed Supplement #01 | 0.50 |
| 9 | Liquid Medicated Animal Feed Supplement #02 | 0.50 |
| 10 | Soil from Pen #11 | 0.49 |
| 11 | Bulk Mixed Ration Animal Feed #01 | 0.43 |
| Sample Number | Sample Matrix |
|---|---|
| Sample 1 | Animal Feed ferrous sulfate duplicate |
| Sample 2 | Animal Feed ferrous sulfate original |
| Sample 3 | Animal feed finisher ration duplicate |
| Sample 4 | Animal feed finisher ration original |
| Sample 5 | Animal feed starter ration duplicate |
| Sample 6 | Animal feed starter ration original |
| Sample 7 | Bluefish 1 duplicate |
| Sample 8 | Bluefish 1 original |
| Sample 9 | Bluefish 2 duplicate |
| Sample 10 | Bluefish 2 original |
| Sample 11 | Bluefish 3 duplicate |
| Sample 12 | Bluefish 3 original |
| Sample 13 | Complete turkey ration duplicate |
| Sample 14 | Complete turkey ration original |
| Sample 15 | Crab 1 duplicate |
| Sample 16 | Crab 1 original |
| Sample 17 | Crab 2 duplicate |
| Sample 18 | Crab 2 original |
| Sample 19 | Cream Substitute duplicate |
| Sample 20 | Cream Substitute original |
| Sample 21 | Milk duplicate |
| Sample 22 | Milk original |
| Sample 23 | Poultry Mixed feed ration duplicate |
| Sample 24 | Poultry Mixed feed ration original |
| Sample 25 | Sweet rolls duplicate |
| Sample 26 | Sweet rolls original |
| Sample 27 | Trout duplicate |
| Sample 28 | Trout original |
| Sample 29 | Cabbage duplicate |
| Sample 30 | Cabbage original |
| Sample 31 | Chocolate candy bar 1 duplicate |
| Sample 32 | Chocolate candy bar 1 original |
| Sample 33 | Chocolate candy bar 2 duplicate |
| Sample 34 | Chocolate candy bar 2 original |
| Sample 35 | English muffins duplicate |
| Sample 36 | English muffins original |
| Sample 37 | Frankfurters duplicate |
| Sample 38 | Frankfurters original |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, W.; Archer, J.; Moore, M.; Shojaee, S.; Zou, W.; Ge, W.; Benjamin, L.; Adeuya, A.; Fairchild, R.; Hong, H. Software-Assisted Pattern Recognition of Persistent Organic Pollutants in Contaminated Human and Animal Food. Molecules 2021, 26, 685. https://doi.org/10.3390/molecules26030685
Guo W, Archer J, Moore M, Shojaee S, Zou W, Ge W, Benjamin L, Adeuya A, Fairchild R, Hong H. Software-Assisted Pattern Recognition of Persistent Organic Pollutants in Contaminated Human and Animal Food. Molecules. 2021; 26(3):685. https://doi.org/10.3390/molecules26030685
Chicago/Turabian StyleGuo, Wenjing, Jeffrey Archer, Morgan Moore, Sina Shojaee, Wen Zou, Weigong Ge, Linda Benjamin, Anthony Adeuya, Russell Fairchild, and Huixiao Hong. 2021. "Software-Assisted Pattern Recognition of Persistent Organic Pollutants in Contaminated Human and Animal Food" Molecules 26, no. 3: 685. https://doi.org/10.3390/molecules26030685
APA StyleGuo, W., Archer, J., Moore, M., Shojaee, S., Zou, W., Ge, W., Benjamin, L., Adeuya, A., Fairchild, R., & Hong, H. (2021). Software-Assisted Pattern Recognition of Persistent Organic Pollutants in Contaminated Human and Animal Food. Molecules, 26(3), 685. https://doi.org/10.3390/molecules26030685