1. Introduction
The global climate changes and the uneven weather conditions in different spatial-temporal scales are causes for severe problems like droughts and floods [
1]. As droughts and floods become more frequent in the changing climate, accurate rainfall forecasting becomes more important for planning in agriculture and other relevant activities. Although several modern algorithms and models have been used to forecast rainfall, the very short-term rainfall is still one of the most difficult tasks in hydrology due to the high spatial and temporal variability in the complex physical process [
2].
Regional rainfall forecasting constrains the spatial variable to local or a particular region, making the prediction processing relatively controllable comparing with the globe weather prediction. However, the regional rainfall forecasting is still a problem controlled by many variables. This study aims to utilize machine learning methods to solve the problem. The problem of regional rainfall forecasting can be briefly described as follows: Given a number of historical weather data including rainfall information in a particular place or a region, one tries to devise a computational model that can predict and tell the rainfall status either categorically or quantitatively in the period of time in the future. That is, it can be either a classification problem or a regression problem from the perspective of prediction.
There are two main categories of approaches for solving the problem. The first category models the underlying physical principles of the complex atmospheric processing. Although it is thought feasible, it is limited by the complex climatic system in various spatial and temporal dimensions over short time frames of days to a few weeks. The second category is based on data mining models. Depending on the disciplines, this category has two branches: statistical models and machine learning models. Both subcategories of methods are fed with a large volume of the historical meteorological data including precipitation information. It does not require a thorough understanding of the climatic laws but it does need the data modeling for data mining and pattern recognition [
3]. Statistical methods attempt to mine rainfall patterns and learn the knowledge from statistical perspectives. Those mostly utilized statistical methods for rainfall forecasting include Markov model [
4,
5,
6,
7,
8,
9], Logistic model [
10,
11,
12,
13], Exponential Smoothing [
14,
15,
16], Auto Regressive Integrated Moving Average (ARIMA) [
17,
18,
19,
20], Generalized Estimating Equation [
21,
22,
23,
24], Vector Auto Regression (VAR) [
25,
26,
27,
28], Vector Error Correction Model (VECM) [
29,
30,
31], and so forth. In the recent decade, with the advent of artificial intelligence and machine learning technologies, the machine learning based methods have emerged as an important direction for data-driven rainfall forecasting, which has drawn broad attention from researchers. There are a number of published research that have used machine learning algorithms to solve problems in hydrology. These modern machine learning algorithms include K-Nearest Neighbors (KNN), Support Vector Machine (SVM), Deep Neural Network (DNN), Wide Neural Network (WNN), Deep and Wide Neural Network (DWNN), Reservoir Computing (RC), Long Short Term Memory (LSTM), and so forth. As the statistical methods are not the focus of this paper, we put most effort into machine learning based methods.
However, most related literature focused on the particular method design and development and many papers have some common drawbacks: (1) being specific and limited by particular techniques such as neural networks or support vector machine and (2) lacking the quantitative comparison and investigation over other existing machine learning models on the same computing context [
32,
33,
34,
35,
36]. Our study can make up the niche by providing quantitative analysis and comparative investigation over a variety of existing machine learning algorithms using the same computing framework and the same dataset. Moreover, we have implemented a generic computing framework that can integrate various machine learning algorithms as the prediction engines for forecasting regional precipitations over different catchments in Upstate New York. Bolstered by the established framework, we are able to quantitatively analyze and compare the performance of these machine learning algorithms for rainfall forecasting on the same context. These algorithms were utilized to forecast rainfall in Rochester and multiple other locations for the next hour based on previously observed precipitation data from Upstate New York.
From the aspect of the dataset, we focus on the regional rainfall forecasting in Upstate New York, a geographic region consisting of the portion of New York State lying north of the New York City metropolitan area. Upstate New York historically had sufficient precipitation until recently, with intense drought occurring over the recent years [
37]. Our study can benefit the rainfall forecasting for agriculture and economy-related activities in Upstate New York over different catchments.
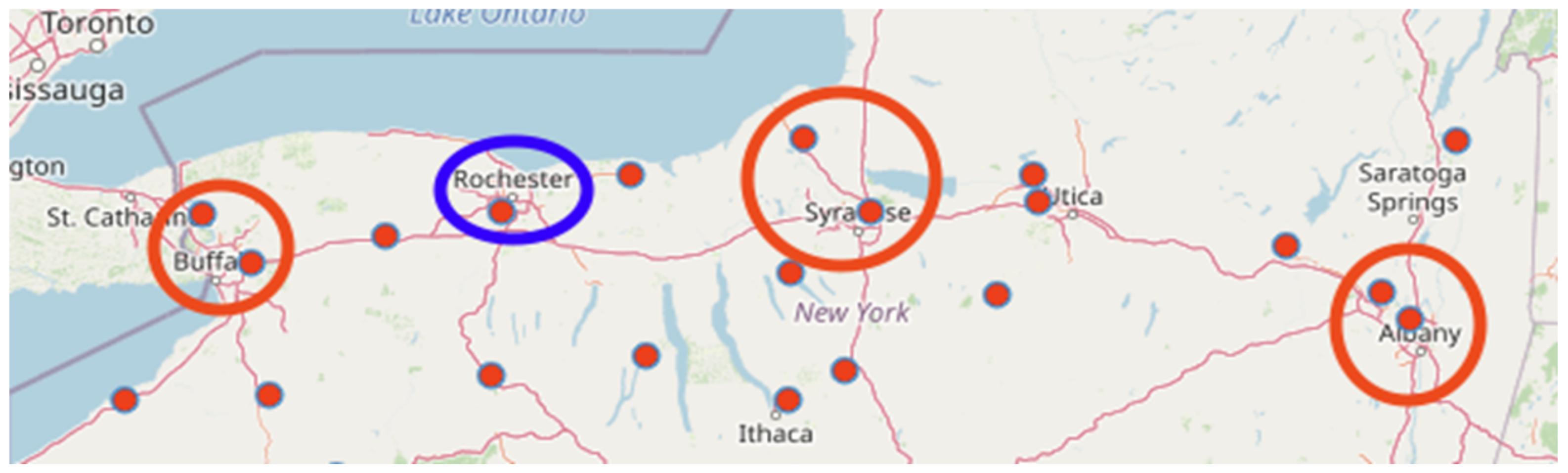
Figure 1 shows the map of weather stations on which the rainfall datasets were collected.
In summary, the contributions of this study are generalized as following thrusts. (1) We proposed a generic computing framework that can integrate a variety of machine learning models as engine options for regional rainfall forecasting in Upstate New York. It can provide a practical open-source framework for modeling rainfall forecasting and benefit the agriculture and related activities in Upstate New York. (2) Relying on the proposed prediction framework, we are able to quantitatively analyze, compare, and evaluate a variety of machine learning algorithms based on the same computing framework and the same datasets. It is superior to the existing literature in depth (quantitative comparison) and width (more algorithms involved). Meanwhile, (3) we integrate the most used normalization methods Z-score and Minmax to investigate the impact of normalization methods on those machine learning algorithms, which is unique over other similar literature.
The remaining sections are organized in the following way. In
Section 2 we introduce the related work to this study. After that, in
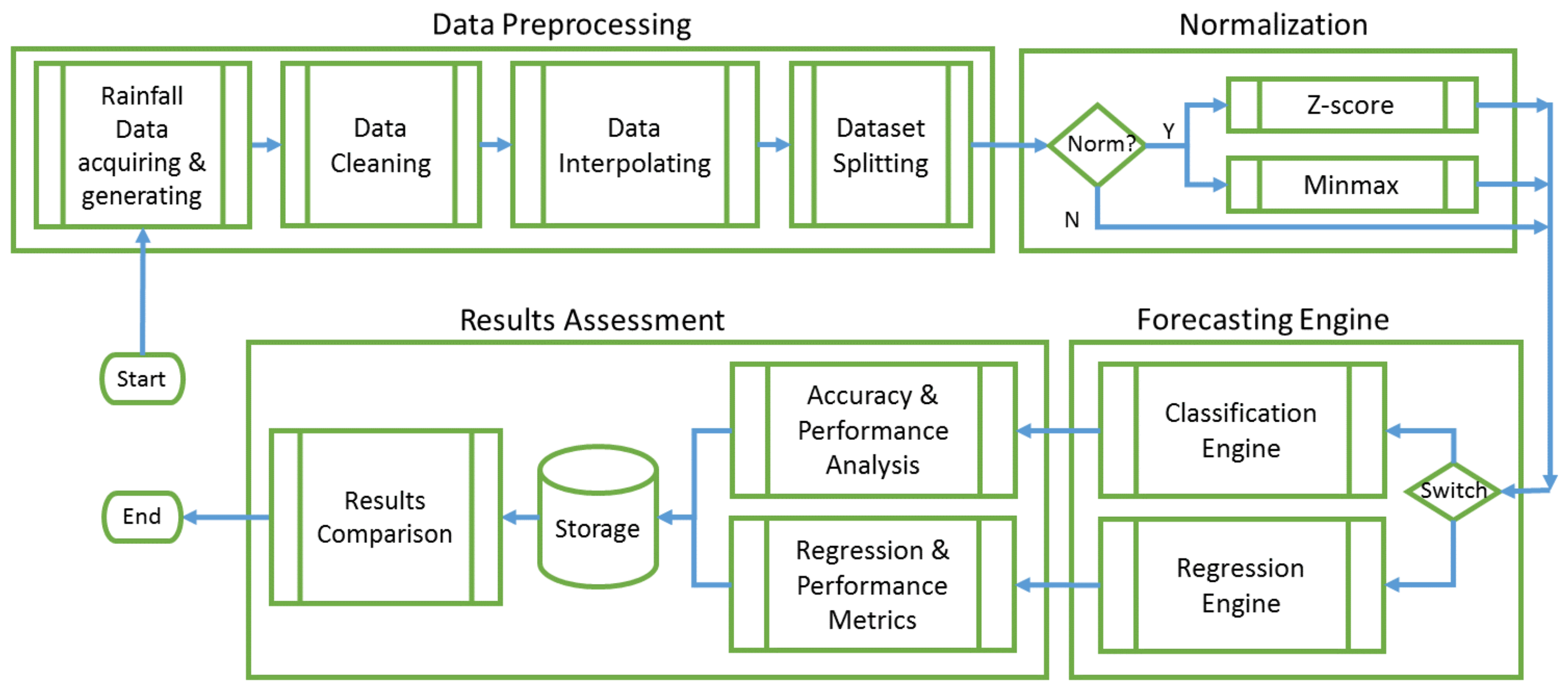
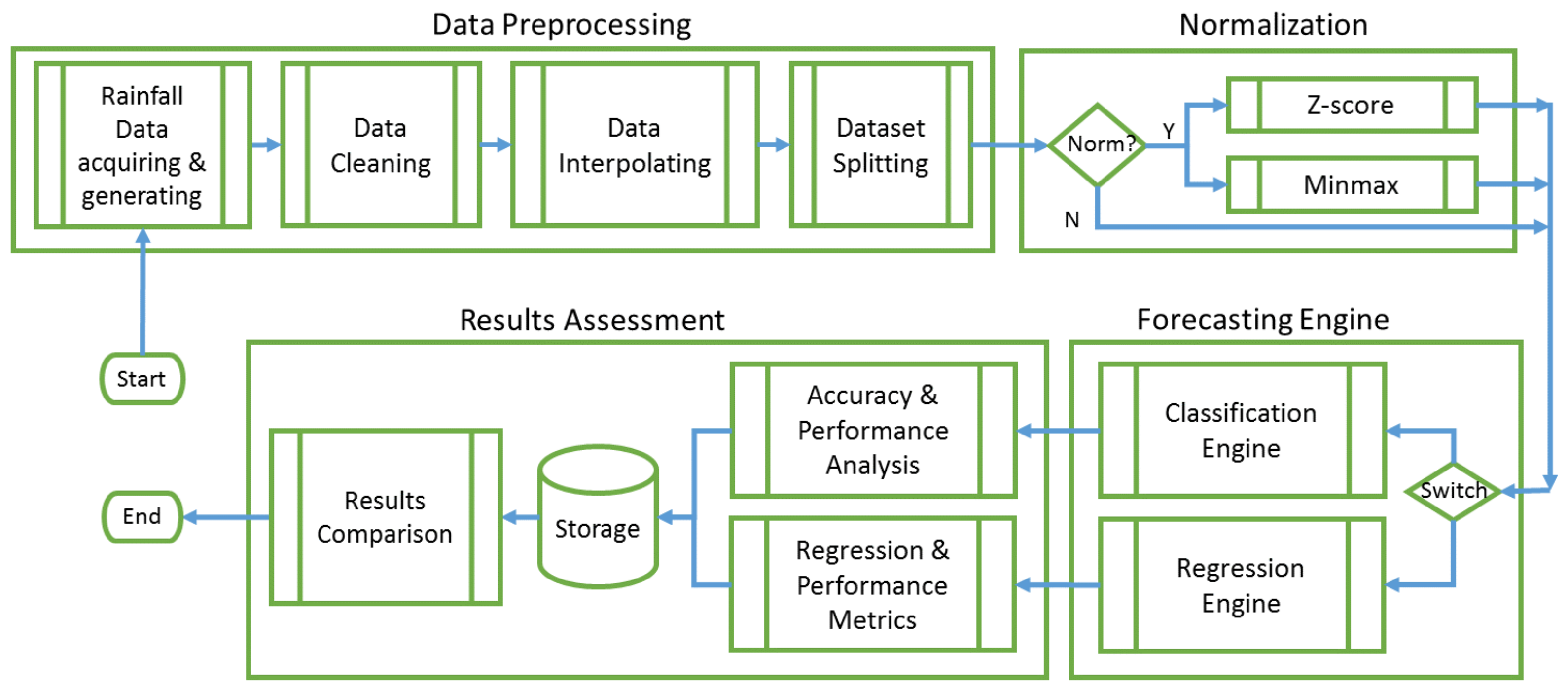
Section 3.1 we depict the prototype of the generic computing framework in which a variety of machine learning models are integrated for regional rainfall forecasting. There are also other two important components in
Section 3. In
Section 3.2 we show the datasets and how they are prepared for the models, and in
Section 3.3 we depict those machine learning models and related algorithms that are bagged into the framework. Subsequently, in
Section 4 we show the experimental performances of those bagged models in the computing framework for classification and regression. At last, in
Section 5 we give the further discussion about the results and conclude the paper.
2. Related Work
As one of the machine learning models, the K-nearest neighbors model has shown a promising performance in climate prediction [
38,
39,
40,
41]. For example, Jan et al. applied KNN for climate prediction by using the historical weather data of a region such as rain, wind speed, dew point, and temperature [
42]. However, until the recent years starting from 2017, the KNN related methods for rainfall forecasting have drawn more attention from researchers. Huang et al. developed a KNN-based algorithm to offer robustness in the irregular class distribution of the precipitation dataset and made a sound performance in precipitation forecast [
43]. However, they did not show the comparison with other advanced machine learning algorithms such as deep learning, limiting its application on the rainfall forecasting. Yang et al. developed an Ensemble–KNN forecasting method based on historical samples to avoid uncertainties caused by modeling inaccuracies [
44]. Hu et al. proposed a model that combined empirical mode decomposition (EMD) and the K-nearest neighbors model to improve the performance of forecasting annual average rainfall [
45]. A KNN-based hybrid model was used to improve the performance in monthly rainfall forecasting [
46].
Like multi-layer perceptrons and radial basis function networks, support vector machines can be used for pattern classification and nonlinear regression. SVM has been found to be a significant technique to solve many classification problems in the last couple of years. Hasan et al. exhibited a robust rainfall prediction technique using Support Vector Regression (SVR) [
47]. Support Vector Machine based approaches also have illustrated quite the capability for rainfall forecasting. Support vector regression combined with Singular Spectrum Analysis (SSA) has shown its efficiency for monthly rainfall forecasting in two reservoir watersheds [
48]. Yu et al. conducted a comparative study and revealed that a single-mode SVM-based forecasting model can have a better performance than multiple-mode forecasting models [
49]. Tao et al. adopted a hybrid method that combined SVM and an optimization algorithm to improve the accuracy of regional rainfall forecasting in India [
50].
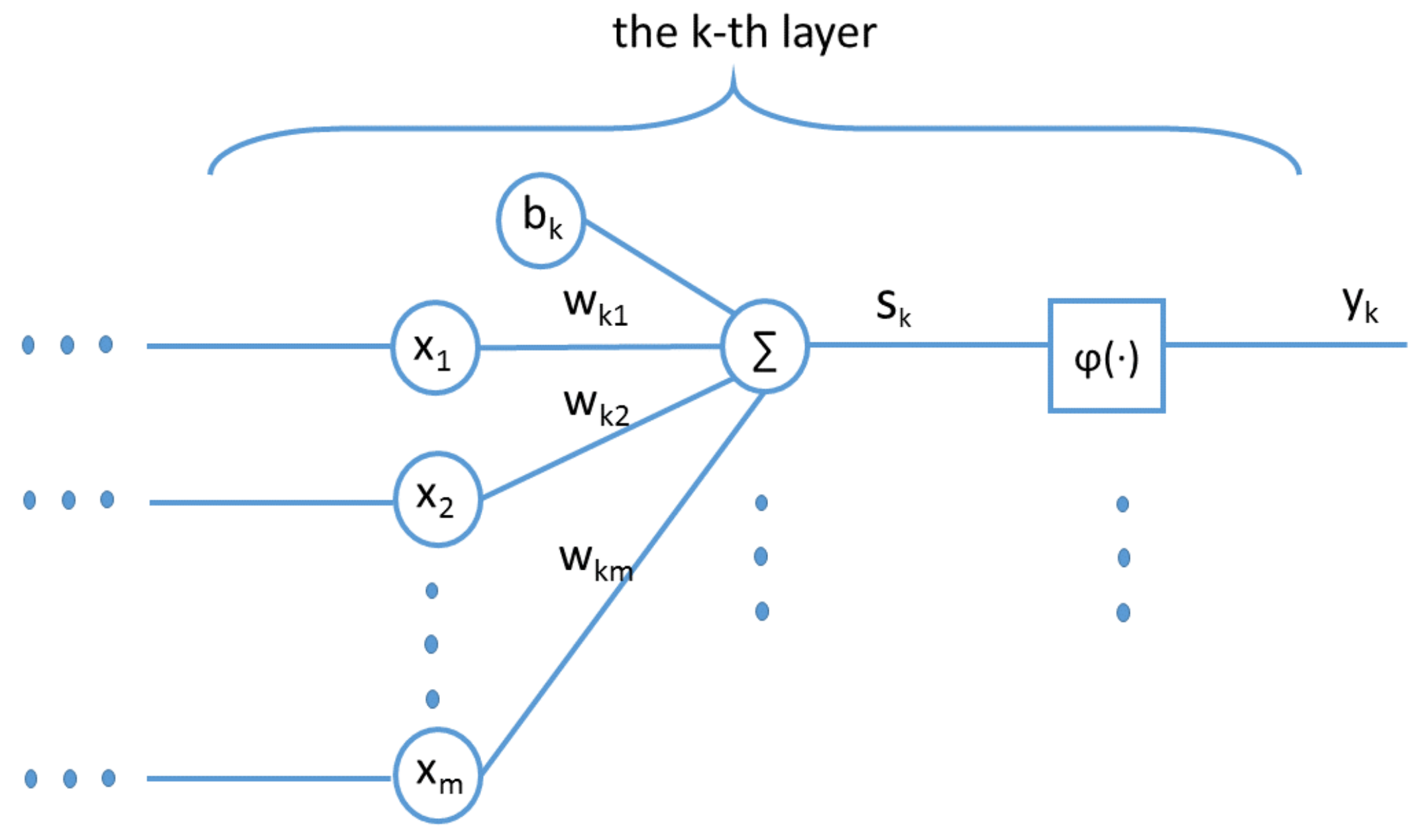
As a type of Artificial Neural Networks (ANN), DNN can emulate the process of the human nervous system and have proven to be very powerful in dealing with complicated problems, such as computer vision and pattern recognition. Moreover, DNN are computationally robust even when input data contains lots of uncertainty such as errors and incompleteness. Such examples are very common in rainfall data.
A pioneer two-dimensional ANN model [
51] was used to simulate complex geophysical processes and forecast the rainfall. Howevr, it was limited by many aspects including insufficient neural network configurations and a mathematical rainfall simulation model that was used to generate the input data. More applications of NN models were developed later. Koizumi utilized an ANN model for radar, satellite, and weather-station data together to provide better performance than the persistence forecast, the linear regression forecasts, and the numerical model precipitation prediction [
52]. By comparing several short-time rainfall prediction models including linear stochastic auto-regressive moving-average (ARMA) models, artificial neural networks (ANN), and the non-parametric nearest-neighbors method, a significant improvement on those ANN-based models were demonstrated in real-time flood forecasting [
53,
54]. Luk et al. developed several types of Artificial Neural Networks and revealed that rainfall time series have very short-term memory characteristics [
3]. The performance of three Artificial Neural Network (ANN) approaches were evaluated in the forecasting of the monthly rainfall anomalies for Southwestern Colombia [
55]. The combination of ANN approaches had demonstrated the ability to provide useful prediction information for the decision-making. A similar case study conducted by Hossain et al. uncovered that the non-linear model ANN can beat multiple linear models in rainfall forecasting in western Australia [
56]. Similarly, Jaddi and Abudullah utilized optimization techniques [
57] to choose and optimize the weights in neural networks [
58]. Hung et al. applied ANN model for real time rainfall forecasting and flood management in Bangkok, Thailand [
59].
Cheng et al. proposed Wide & Deep Neural Network (WDNN or DWNN) model for recommender systems originally, where it contains two components: wide neural network and deep neural network [
60]. The wide neural network (WNN) was designed to effectively memorize the feature interactions through a wide set of cross-product feature transformations. The deep neural network (DNN) was used to better generalize hidden features through low-dimensional dense embeddings learned from the sparse matrix [
60]. DWNN has been used in various applications, such as clinical regression prediction for Alzheimer patients [
61]. In the latest publication, Bajpai and Bansal analyzed and evaluated three deep learning approaches, one dimensional Convolutional Neutral Network, Multi-layer Perceptron, and Wide Deep Neural Networks for the prediction of regional summer monsoon rainfall in India and found that DWNN can achieve the best performance over the rest two deep learning methods [
62].
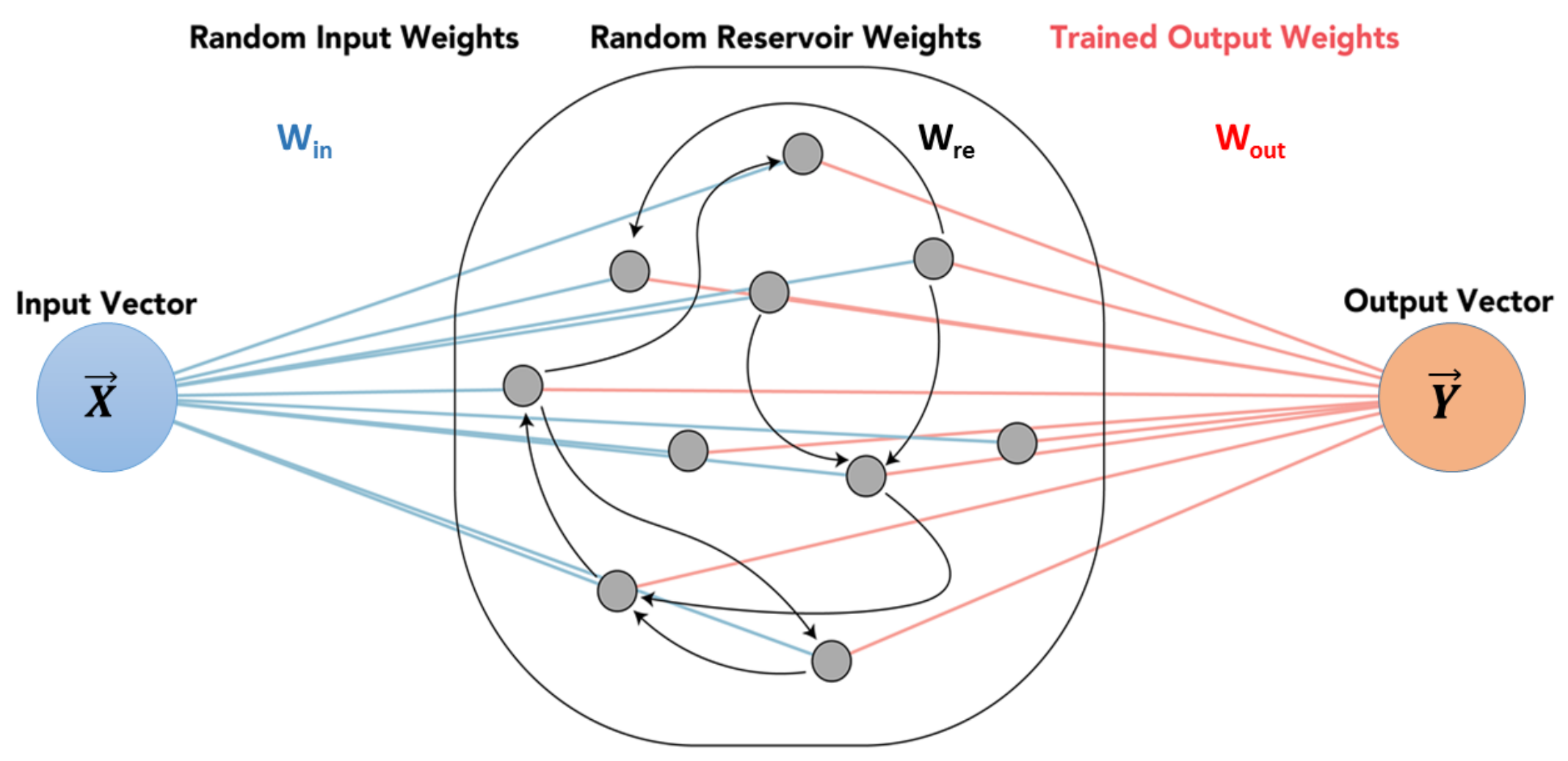
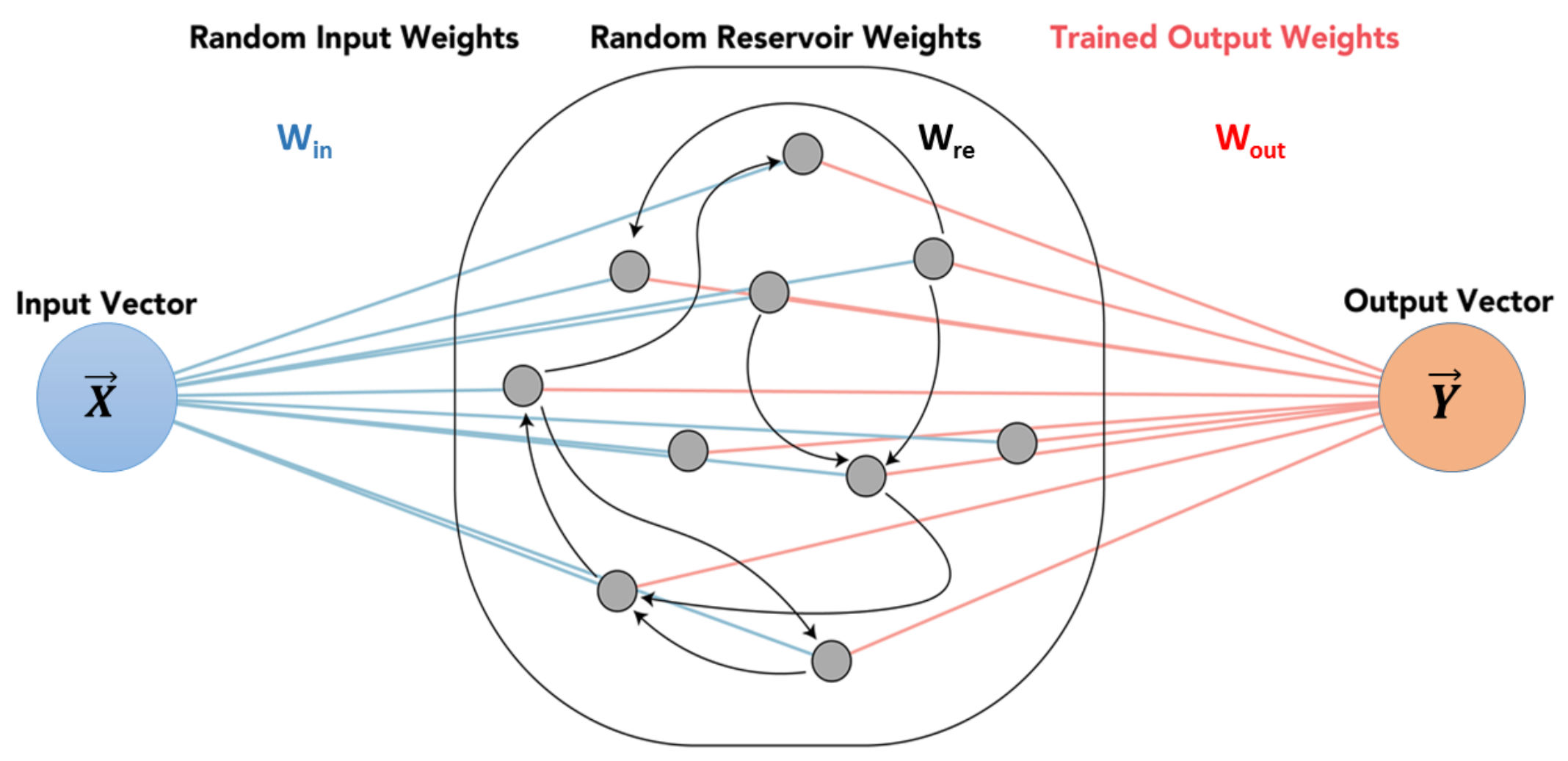
The Reservoir Computing framework has been known for over a decade as a state-of-the-art paradigm for the design of RNN [
63]. Among the models of RC instances, the echo state network (ESN) represents a type of the most widely known schemes with a strong theoretical support and various applications [
64]. Yen et al. used the ESN and the DeepESN algorithms to analyze the meteorological hourly data in Taiwan and showed that DeepESN was better than that by using the ESN and other neuronal network algorithms [
65]. Backpropagation algorithms and Reservoir Computing in Recurrent Neural Networks were adopted to predict the complex spatio-temporal dynamics [
66]. An ESN-based method was proposed by Ouyang and Lu to better forecast the monthly rainfall while a SVM regressor was used as a reference for the comparison [
67]. Coulibaly utilized Reservoir Computing approach to forecast the Great Lakes water level and achieved the better forecasting performance over other two neural networks including recurrent neural network [
68]. A similar approach was used by De Vos to investigate the effectiveness of neural networks in rainfall-runoff modeling [
69]. Bezerra et al. took advantage of the characteristic of dynamic behavior modeling in RC and combined RC with trend information extracted from the series for short-term streamflow forecasting, achieving better generalization performance than linear time series models [
70].
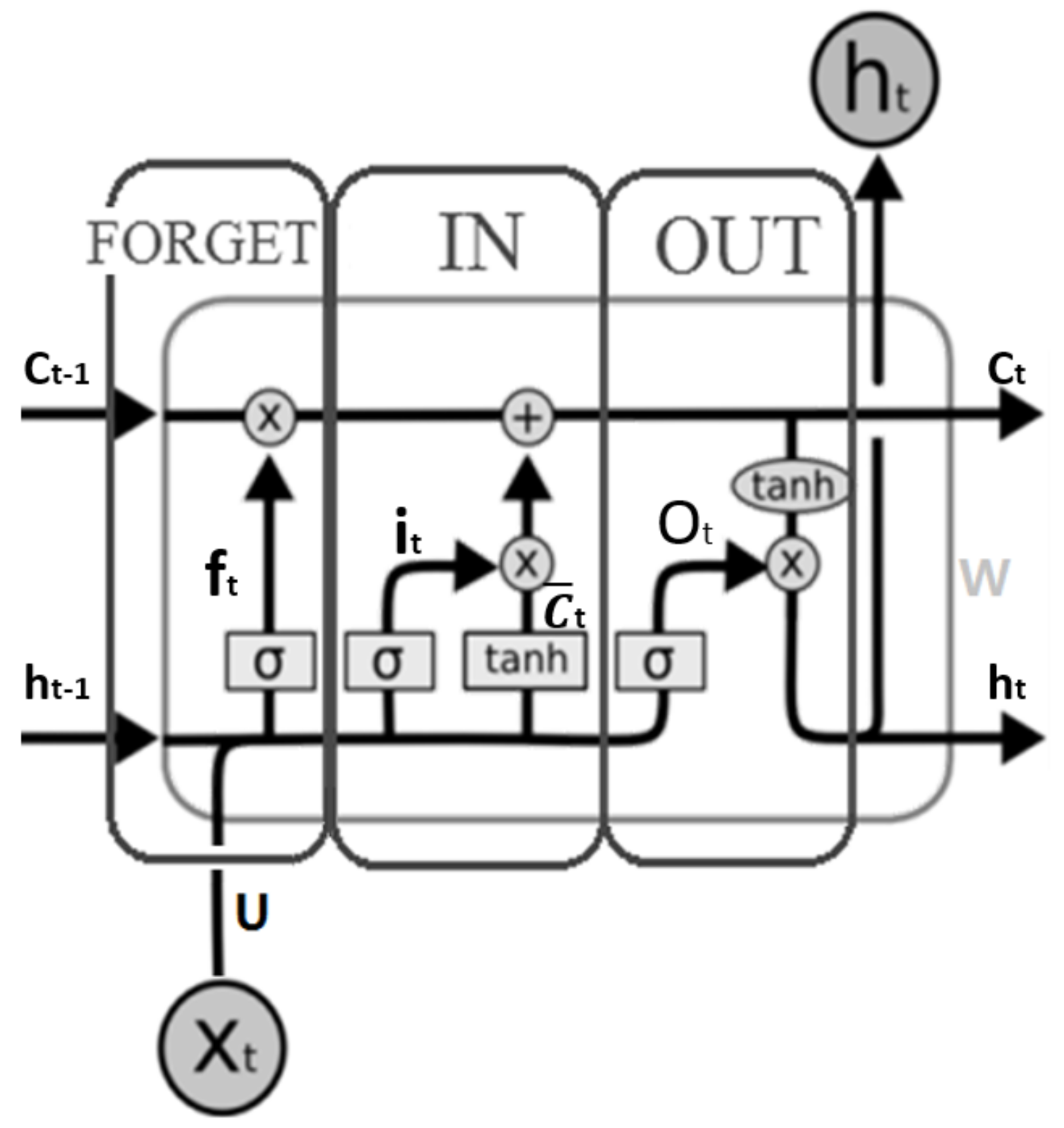
As a type of recurrent neural network (RNN), Long Short-Term Memory neural networks (LSTM) have been studied by many researchers in recent literature. Liu et al. used LSTM to simulate rainfall–runoff relationships for catchments with different climate conditions [
71]. The LSTM model then was coupled with a KNN algorithm as an updating method to further boost the performance of LSTM method. LSTM-KNN model was validated by comparing the single LSTM and the recurrent neural network (RNN). Chhetri et al. studied LSTM, Bidirectional LSTM (BLSTM), and Gated Recurrent Unit (GRU), another variant of RNN [
72]. LSTM recorded the best Mean Square Error (MSE) score which outperformed the other six different existing models including Linear Regression, Multi-Layer Perceptron (MLP), Convolutional Neural Network (CNN), GRU, and BLSTM. They further modified the model by combining LSTM and GRU to carry out monthly rainfall prediction over a region in the capital of Bhutan.
As an emerging technology, deep learning based methods have embarked as a trend for weather forecasting or rainfall forecasting in recent years [
65,
73,
74,
75]. Klemmer et al. utilized Generative Adversarial Networks (GAN) to generate the spatio-temporal weather patterns for the extreme weather event [
76]. Hossain et al. employed a deep neural network with Stacked Denoising Auto-Encoders (SDAE) to predict air temperature from historical dataset including pressure, humidity, and temperature data gathered in Northwestern Nevada [
77]. Karevan and Suykens developed a 2-layer spatio-temporal stacked LSTM model in an application [
78] for regional weather forecasting in 5 cities including Brussels, Antwerp, Liege, Amsterdam, and Eindhoven. A deep LSTM network on the Spark platform was developed by Mittal and Sangwan for weather prediction using historical datasets collected from Brazil weather stations [
79]. Qiu et al. elaborated a multi-task model based on convolutional neural network (CNN) to automatically extract features and predict the short-term rainfall from sequential dataset measured from observation sites [
80]. Hewage et al. proposed a data-driven model using the combination of long short-term memory (LSTM) and temporal convolutional networks (TCN) for weather forecasting over a given period of time [
31].
However, as we discussed in
Section 1, most literature were specific and limited to only particular techniques such as deep learning, neural networks, or support vector machine and lacked the quantitative comparison and investigation over a wide range of existing machine learning models. Our study can make up this niche by developing a generic framework based on machine learning models and quantitatively comparing a variety of models through the same computing framework and datasets.
In addition, we also investigated the impact of normalization on machine learning algorithms, as normalization has shown its important impact as part of data representation for feature extraction [
81]. The purpose of normalization is to convert numeric values in the dataset to the ranges of values in a common scale without erasing differences or losing significant information. Normalization is also required for some algorithms to model the data correctly [
82,
83]. Normalization issues have drawn broad attention from researchers in machine learning [
84,
85,
86,
87]. For example, batch normalization becomes a technique widely adopted in machine learning modeling [
82,
88,
89]. One of its fundamental impacts is that normalization makes the optimization landscape significantly smoother and it further induces a more predictive and stable behavior of the gradients and results in a faster training [
90]. Some experiments were conducted to contrast the performance between normalization and non-normalization [
91,
92]. However, they involved only a few machine learning algorithms. Our study can make up this niche by integrating the normalization methods to a variety of machine learning models in a generic framework to test the impacts of non-normalization and normalization and the difference between the commonly used normalization methods Z-score and Minmax.
4. Results Assessment
4.2. Classification
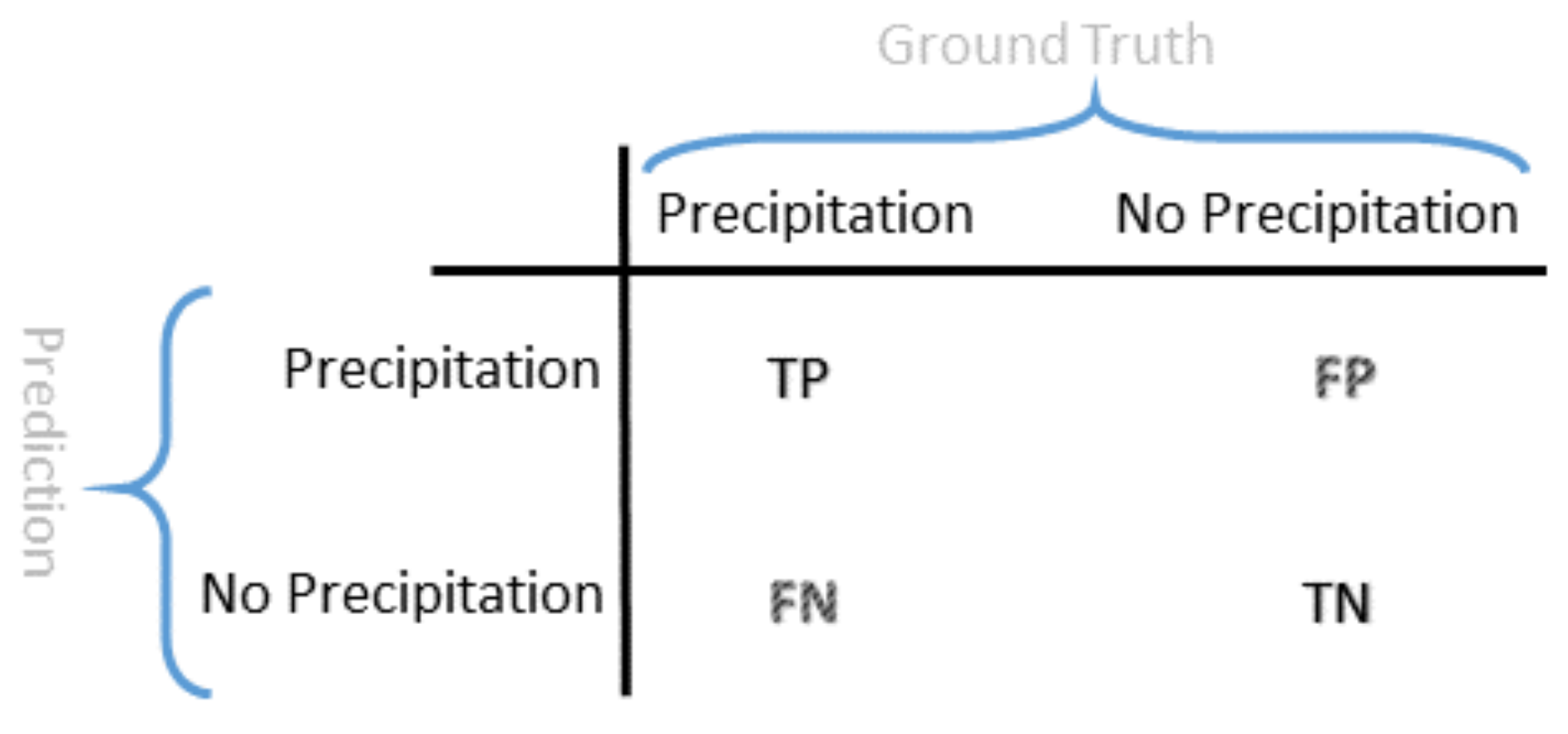
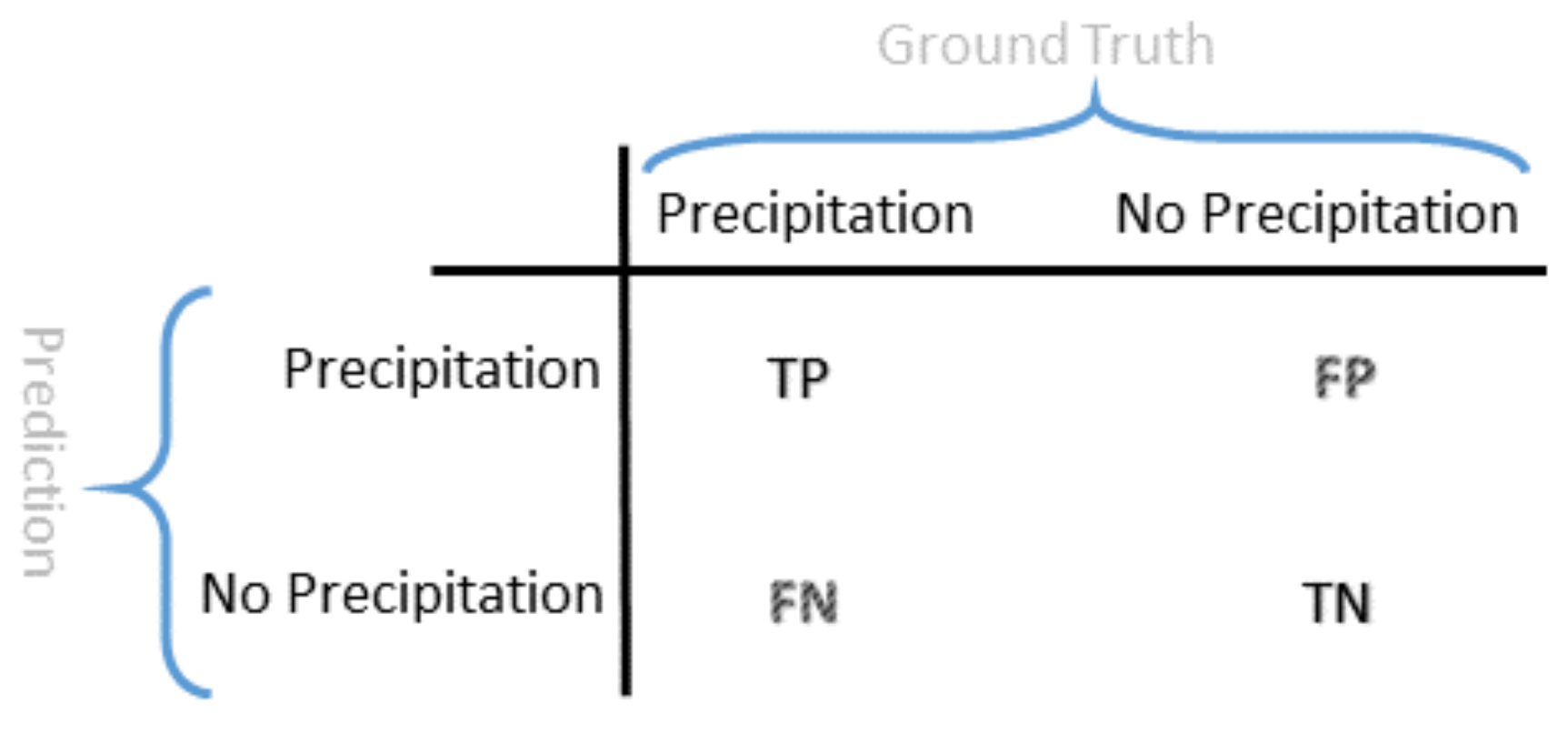
Accuracy is the metric to measure the classifier’s performance. It is expressed in Equation (
19):
where
TP is true positive,
TN is true negative,
FP is false positive, and
FN is false negative according to the confusion matrix shown in
Figure 8.
KNN: Six datasets were crossed with the 3 different random seeds for a total of 18 forms of data. These 18 forms were iterated through a KNN Classifier 25 times to find the best n_neighbor value. After 450 iterations the best accuracy was 96.09% which was obtained from the Rochester, Buffalo, Syracuse, and Albany dataset, normalized by Z-score, a random state of 0, and 9 n_neighbors.
SVM: There were 72 unique Support Vector Machine Classifiers by training against the cross of 6 premade datasets, 4 kernels, and the same 3 random states as before. The best accuracy for SVM, and ultimately the best accuracy for all classifiers, was 96.22% obtained from the ROC + BUF + SYR + ALB, normalized with Z-score, using 0 as random state and the rbf kernel.
DNN: 126 DNN Classifiers were tested and used by training against the cross of the 6 premade datasets, 7 different amounts of hidden layers, and the 3 random states used from before. The 7 different hidden layers were: 2, 3, 4, 5, 10, 20, and 30 layers. Each of the hidden layers had the number of inputs equal to the number of features which for the ROC datasets was 9 and for the ROC + BUF + SYR + ALB there were 36 inputs at each hidden layer. The best accuracy for DNN was 94.81% obtained from the ROC dataset only, normalized with Z-score, using 42 as random state and with 10 hidden layers.
WNN: There were 18 unique WNN Classifiers by training against the cross of the 6 premade datasets and the 3 random states used from before. The best accuracy for WNN was 95.91% obtained from the ROC + BUF + SYR + ALB, normalized with Z-score, using 0 as random state.
DWNN: There were 126 unique DWNN Classifiers by training against the cross of the 6 premade datasets, 7 different amounts of hidden layers for the deep aspect, and the 3 random states used from before. The 7 different hidden layers were: 2, 3, 4, 5, 10, 20, and 30 layers. Each of the hidden layers had the number of inputs equal to the number of features which for the ROC datasets was 9 and for the ROC + BUF + SYR + ALB there were 36 inputs at each hidden layer. The best accuracy for DWNN was 95.74% obtained from the ROC + BUF + SYR + ALB, normalized with Z-score, using None as random state and with 10 hidden layers.
RCC: Reservoir Computing Classifier was investigated because, in a previous investigation of daily values, RCC had the highest accuracy. For RCC, six datasets were crossed with the same 3 random states as before and crossed again with 6 different sizes of the reservoir; 50, 100, 200, 400, 600, 1000. The result of these crosses was 108 unique data forms to train with. The best accuracy was 95.81% which was obtained from the Rochester only dataset, normalized by Z-score, a random state of 42, and a reservoir size of 1000.
LSTM: There were 12 unique LSTM Classifiers by training against the cross of the 6 premade datasets, and 2 different sequence lengths. Random states were not used for LSTM as it depends on chronologically consecutive rows of data. The two sequence lengths considered were 3 previous rows of data and 7 previous rows of data. The best accuracy for LSTM was 94.82% obtained from the ROC + BUF + SYR + ALB, normalized with Minmax, using a sequence length of 3.
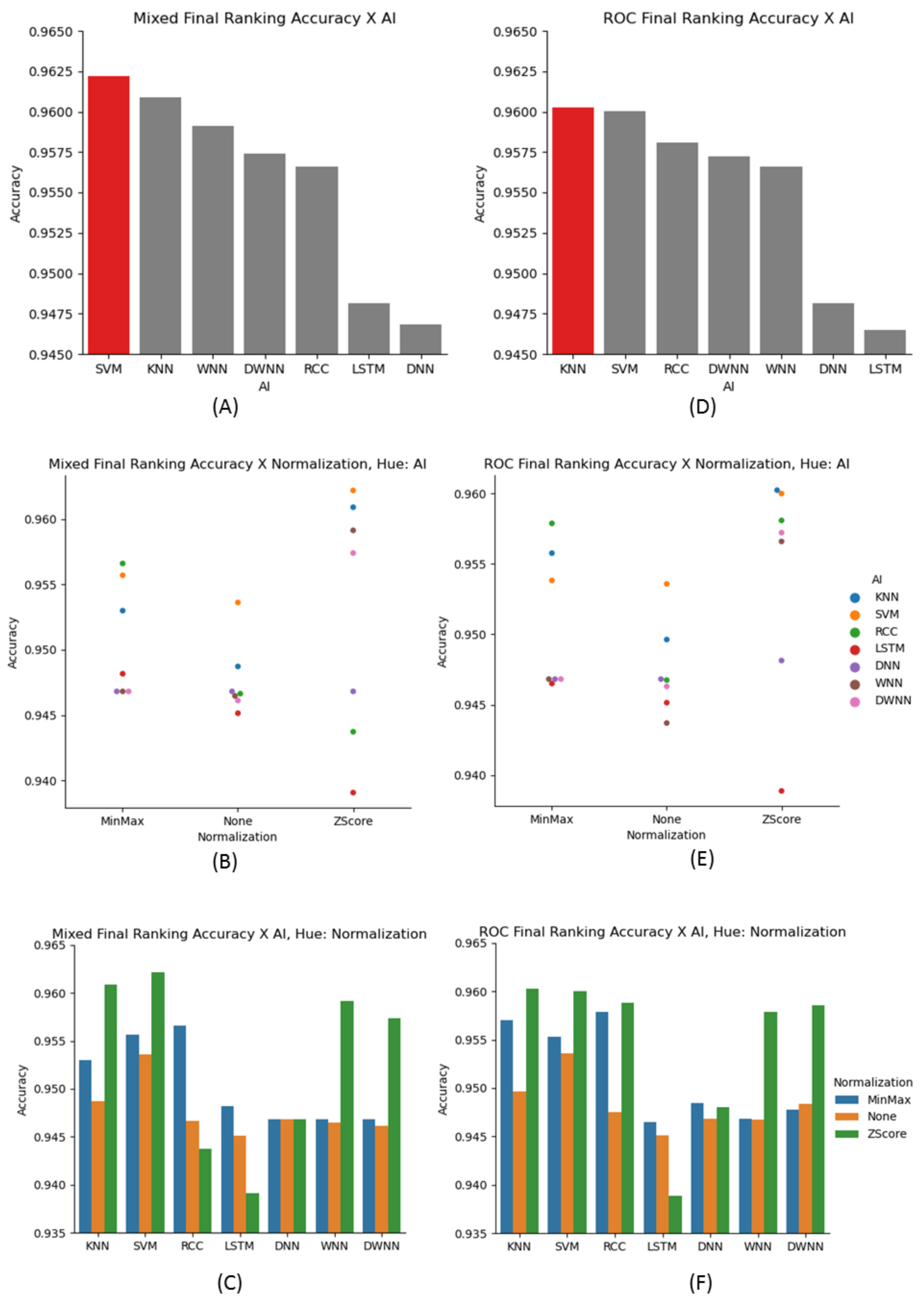
Overall: Both SVM and KNN classifiers performed the best.
Figure 9A,D show all of the best accuracies for each of the classification methods used in the mixed and ROC datasets. The plotting for this ranking was zoomed into the accuracy range of 94.5–96.5% to better show the differences between the methods. A further examination of the ranking with the normalization data is shown in
Figure 9C,F. In almost every case except for LSTM, the best normalization method was Z-score. It can also be seen that in many cases the non-normalized version of the data performed measurably worse than its Z-score counterpart. The groups of (B,E) and (C,F) are derived from the same results. However,
Figure 9B,E show another way to highlight the performance in regards to normalization.
5. Discussion and Conclusions
Rainfall forecasting plays an important role in our daily lives, especially agriculture and related activities. In this study, we have designed and implemented a generic computational framework based on learning models for regional rainfall forecasting to solve both classification and regression problems. The machine learning models, including some state-of-the-art algorithms, are integrated into the generic framework. They are K-Nearest Neighbors (KNN), Support Vector Machine (SVM), Deep Neural Network (DNN), Wide Neural Network (WNN), Deep and Wide Neural Network (DWNN), Reservoir Computing (RC), Long Short-Term Memory (LSTM) and two LSTM variants LSTM bi-directional and Gated Recurrent Unit (GRU). We used the classification models to forecast if precipitation will occur in next hour and we used the regression models to predict the regression value of the rainfall in the next hour. Also, we adopted two commonly used normalization methods Minmax and Z-score to compare their performance with those of non-normalized models. The results show that (1) SVM and KNN with Z-score normalization have been listed as the top 2 classification models in the generic machine learning framework and (2) DWNN and KNN models with Z-score normalization have achieved the best rank according to the regression metrics of on the large dataset but KNN beats all others in MSE, RMSE, and Pcc. The results in the small ROC dataset were basically consistent with those in the mixed dataset. However, considering the volume of data size, the results on the larger mixed dataset seem more convincing.
According to the results in regression, DWNN was listed as the top model according to
although its performance was very close to that of KNN in the mixed dataset. The result is aligned with the recent literature where DWNN was found superior over other two deep learning methods [
62]. Also, it seems a bit surprising that the KNN model was ranked as top 2 for both classification and regression in larger datasets. As a traditional machine learning method, KNN has not drawn as much attention as other trending machine learning methods such as neural networks or deep learning.
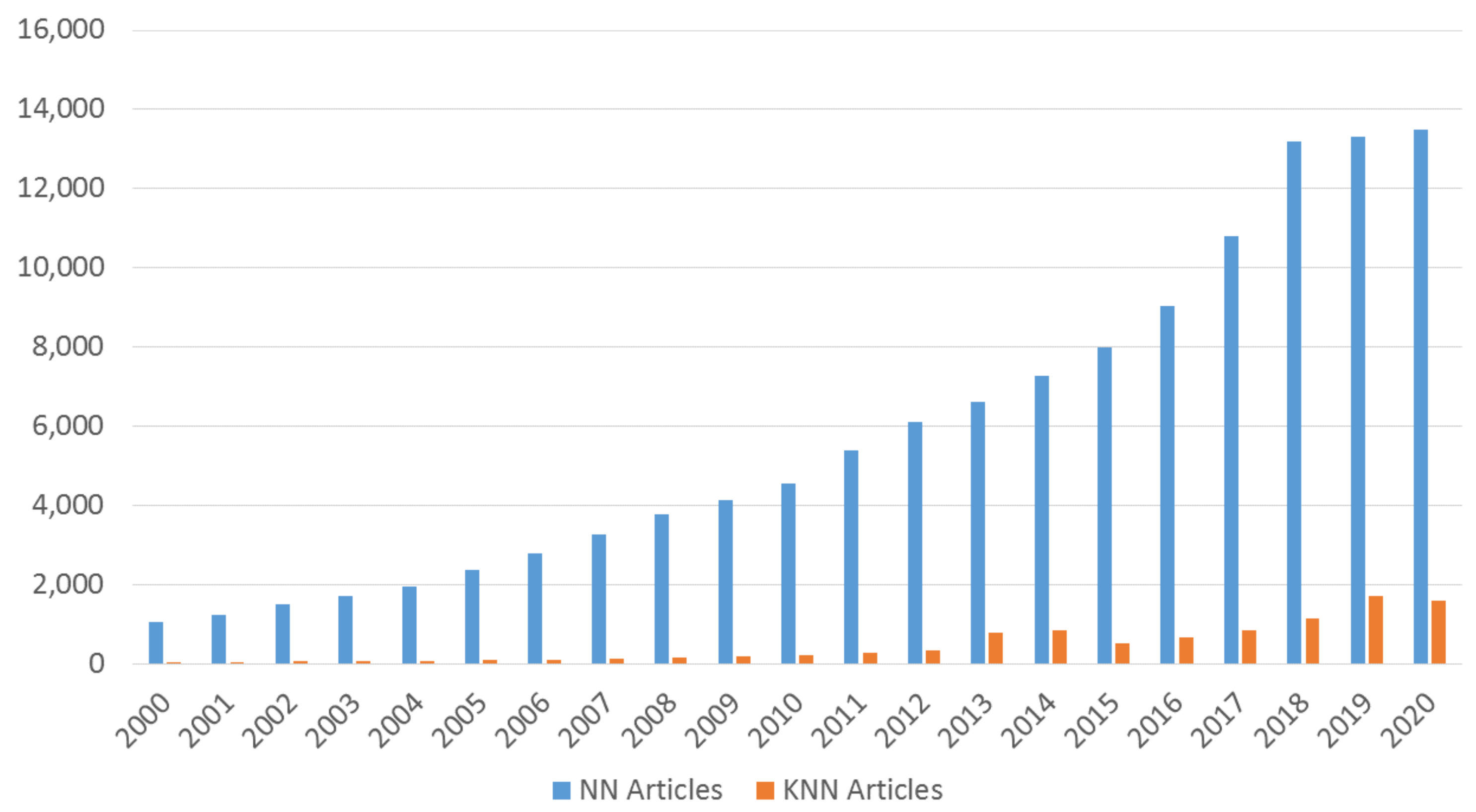
Figure 11 shows the number of articles as a comparison in terms of the keyword search
KNN rainfall forecasting and
Neural Network rainfall forecasting respectively in the order of year from Google Scholar. Note that we used the number of publications indexed from Google Scholar as the indicator for the researcher’s interests including peer review sources and non-peer review sources [
97] such as thesis, preprint, etc. Our results are also aligned with the recent literature where KNN-based methods were found effective in rainfall forecasting [
43,
44].
Time series prediction models such as LSTM, GRU, and LSTM-bidirection have not shown satisfactory performance in rainfall forecasting. The overall results showed that LSTM models with relatively short sequence steps (short-term memory) have the better performance than those with longer sequence steps. It might be the very short-term memory characteristics in the short-term hourly rainfall forecasting that affect the performance of the longer sequences. In contrast, the linear based models such as DWNN, linear models, and WNN have much better performance than complicated models such as DNN, SVR, and LSTM. The reason behind the ranking may be that the weather data, unlike other data, contains many uncertain outliers, errors, and missing values that may fuel lots of distractions to the precise models such as neural networks and time series models. Therefore, rainfall forecasting may require more robust models to find the knowledge from those weather datasets. Fortunately, we have found that the SVM and KNN models are qualified for classification and DWNN and KNN are good for regression. However, SVM’s performance in regression was far behind others and DWNN’s performance in classification was not as good as its performance in regression. In contrast, surprisingly, the KNN model that has been long underestimated is robust enough to be qualified for both classification and regression.
Certainly, this study also has some limitations. First, our focus was a generic computing framework that can accommodate a variety of forecasting engines rather than optimizing an individual algorithm inside a specific method. Although the parameters of those bagged machine learning methods have been carefully configured to get the best performance, they are out-of-the-box configurations. Also, limited by the computing resources, our datasets were only from the 11-year weather data in Upstate New York since 2010. Therefore, in the future, we will extend this study on two thrusts: First, refining and enhancing the computing framework to provide more functions such as data preprocessing algorithms [
98,
99] that can aid to improve the feature selection and reduce the noise to better learn weather features; Second, expanding the datasets with more historically weather data and more regions. We believe that this study and its expansion can advance the method design in this area and benefit the modeling of rainfall forecasting in Upstate New York.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}